Cursor 2.4.21 更新 – 添加子 agent,图像生成,agent 下的 ask 工具使用
期盼了好久是 subagent 终于是加上了,实测还是比较好用的,跟 cc 基本一致



可以直接使用 cursor 进行生成图片到本地,写前端更方便配图了,具体是什么模型还不清楚

撇清责任用的更新 hh

agent 模式下模型可用 ask 工具,之前一直到切换到 plan 或者 debug 才能用

xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
期盼了好久是 subagent 终于是加上了,实测还是比较好用的,跟 cc 基本一致
可以直接使用 cursor 进行生成图片到本地,写前端更方便配图了,具体是什么模型还不清楚
撇清责任用的更新 hh
agent 模式下模型可用 ask 工具,之前一直到切换到 plan 或者 debug 才能用
编者按: 我们今天为大家带来的这篇文章,作者的核心观点是:相较于依赖复杂且高成本的动态 MCP 工具加载机制,以 Skills 为核心的能力摘要与自维护模式,在当前阶段反而更加高效、稳定且可控。 文章系统梳理了延迟工具加载(deferred tool loading)的工程现实与限制,指出即便工具可以延后注入,对话级别的工具集合仍然是静态的,且发现机制高度依赖正则匹配,收益并不如预期。作者进一步深入分析了 MCP 在上下文占用、API 稳定性、缓存失效与推理轨迹丢失等方面带来的隐性成本,并结合 Sentry MCP、Playwright 等实践案例,说明为何将 MCP 转换为 Skills,反而能让 Agent 更好地发挥既有工具的能力。文章最后还探讨了 MCP 是否可能完全转化为 Skills 的可行性,并坦率指出当前协议与生态在稳定性与摘要机制上的不足。 作者 | Armin Ronacher (作者为 Flask、Jinja2 等开源项目的创建者) 编译 | 岳扬 我正把所有的 MCP 都迁移到 Skills 上,包括之前还在使用的最后一个:Sentry MCP(译者注:Sentry 是流行的应用监控与错误追踪平台)。早前我就已经完全弃用 Playwright(译者注:由 Microsoft 开发的现代 Web 自动化测试和浏览器自动化框架),转向使用 Playwright Skill。 过去一个月左右,关于使用“动态工具配置(dynamic tool loadouts)[1]”来推迟工具定义的加载的讨论一直不少。Anthropic 也在探索通过代码来串联 MCP 调用的思路,这一点我也尝试过[2]。 我想分享一下自己在这方面的最新心得,以及为什么 Anthropic 提出的“延迟工具加载方案(deferred tool loading)”并未改变我对 MCP 的看法。或许这些内容对他人会有所帮助。 当 Agent 通过强化学习或其他方式接触到工具定义时,它会被鼓励在遇到适合使用该工具的场景时,通过特殊的 token 输出工具调用。实际上,工具定义只能出现在系统提示词(system prompt)中特定的工具定义 token 之间。从历史经验来看,这意味着我们无法在对话状态的中途动态发出新的工具定义。因此,唯一的现实选择是在对话开始时就将工具加载好。 在智能体应用场景中,我们当然可以随时压缩对话状态,或更改系统消息中的工具定义。但这样做的后果是,我们会丢失推理轨迹(reasoning traces)以及缓存(cache)。以 Anthropic 为例,这将大幅增加对话成本:基本上就是从头开始,相比于缓存读取,需要支付完整的 token 费用,外加缓存写入成本。 Anthropic 最近的一项创新是“延迟工具加载”(deferred tool loading)。我们仍然需要提前在系统提示词(system message)中声明工具,但这些工具不会在系统提示词发出时就注入到对话中,而是会稍后才出现。不过据我所知,这些工具定义在整个对话过程中仍必须是静态的 —— 也就是说,哪些工具可能存在,是在对话开始时就确定好的。 Anthropic 发现这些工具的方式,纯粹是通过正则表达式(regex)搜索实现的。 尽管带延迟加载的 MCP 感觉上应该表现更优,实际上却需要在 LLM API 端做不少工程化工作。而 Skills 系统完全不需要这些,至少从我的经验来看,其表现依然更胜一筹。 Skills 实质上只是对现有能力及其说明文件位置的简短摘要。这些信息会被主动加载到上下文中。 因此,智能体能在系统上下文里(或上下文的其他位置)知晓自己具备哪些能力,并获知如何使用这些能力的“手册链接”。 关键在于,Skills 并不会真正把工具定义加载到上下文中。 可用工具保持不变:bash 以及智能体已有的其他工具。Skills 所能提供的,只是如何更高效使用这些工具的技巧和方法。 由于 Skills 主要教的是如何使用其他命令行工具和类似实用程序,因此组合与协调这些工具的基本方式其实并未改变。让 Claude 系列模型成为优秀工具调用者的强化学习机制,恰好能帮助处理这些新发现的工具。 这自然引出了一个问题:既然 Skills 效果这么好,我能不能把 MCP 完全移出上下文,转而像 Anthropic 提议的那样,通过 CLI 来调用它?答案是:可以,但效果并不好。Peter Steinberger 的 mcporter[3] 就是其中一种方案。简单来说,它会读取 .mcp.json 文件,并将背后的 MCP 暴露为可调用的工具: 确实,它看起来非常像一个 LLM 可以调用的命令行工具。但问题在于,LLM 根本不知道有哪些工具可用 —— 现在你得专门教它。于是你可能会想:那为什么不创建一些 Skills,来教 LLM 了解这些 MCP 呢?对我而言,这里的问题在于:MCP 服务器根本没有维持 API 稳定性的意愿。它们越来越倾向于将工具定义精简到极致,只为节省 token。 这种做法有其道理,但对 Skills 模式来说却适得其反。举个例子,Sentry MCP 服务器曾彻底将查询语法切换为自然语言。这对 Agent 来说是一次重大改进,但我之前关于如何使用它的建议反而成了障碍,而且我没能第一时间发现问题。 这其实和 Anthropic 的“延迟工具加载方案”非常相似:上下文中完全没有任何关于该工具的信息,我们必须手动创建一份摘要。我们过去对 MCP 工具采用的预加载(eager loading)方式,如今陷入了一个尴尬的局面:描述既太长,不便预加载;又太短,无法真正教会 Agent 如何使用它们。 因此,至少从我的经验来看,你最终还是得为通过 mcporter 或类似方式暴露出来的 MCP 工具,手动维护这些 Skills 摘要。 这让我得出了目前的结论:我倾向于选择最省事的方式,也就是让 Agent 自己以“Skills”的形式编写所需的工具。 这样做不仅耗时不多,最大的好处还在于工具基本处于我的掌控之中。每当它出问题或需要新增功能时,我就让 Agent 去调整它。Sentry MCP 就是个很好的例子 —— 我认为它可能是目前设计得最好的 MCP 之一,但我已经不再使用它了。一方面是因为一旦在上下文中立即加载它,就会直接消耗约 8k 个 token;另一方面,我也一直没能通过 mcporter 让它正常工作。现在我让 Claude 为我维护一个对应的 Skill。没错,这个 Skill 可能有不少 bug,也需要不断更新,但由于是 Agent 自己维护的,整体效果反而更好。 当然,这一切很可能在未来发生变化。但就目前而言,手动维护的 Skills,以及让 Agent 自行编写工具,已成为我的首选方式。我推测,基于 MCP 的动态工具加载终将成为主流,但要实现这一点,可能还需要一系列协议层面的改进,以便引入类似 Skills 的摘要机制,以及为工具内置使用手册。 我也认为,MCP 如果能具备更强的协议稳定性,将大有裨益。目前 MCP 服务器随意更改工具描述的做法,与那些已经固化下来的调用方式(materialized calls)以及在 README 和技能文件中编写的外部工具说明很难兼容。 END 本期互动内容 🍻 ❓抛开现有方案,你理想中的AI工具调用范式应该长什么样?用一句话描述你最核心的需求。 文中链接 [1]https://www.anthropic.com/engineering/advanced-tool-use [2]https://lucumr.pocoo.org/2025/7/3/tools/ [3]https://github.com/steipete/mcporter 原文链接:01 什么是工具(Tool)?
02 与 Skills 的对比
03 MCP 能否转换为 Skills?
npx mcporter call 'linear.create_comment(issueId: "ENG-123", body: "Looks good!")'04 最省事的路线
本文为《2025 年度盘点与趋势洞察》系列内容之一,由 InfoQ 技术编辑组策划。本系列覆盖大模型、Agent、具身智能、AI Native 开发范式、AI 工具链与开发、AI+ 传统行业等方向,通过长期跟踪、与业内专家深度访谈等方式,对重点领域进行关键技术进展、核心事件和产业趋势的洞察盘点。内容将在 InfoQ 媒体矩阵陆续放出,欢迎大家持续关注。 我们采访了百度智能云平台产品事业部算法架构师、千帆策略部负责人吴健民,他指出,Agentic 模型训练最大卡点不是模型,是真实环境复刻,外部接口、数据库、登录依赖等真实链路的稳定访问,技术实现门槛极高。在当前,通用全能的 Agentic 模型现阶段不可能实现,业务场景、工具、环境差异过大,通用模型泛化性有限,针对垂直场景的模型定制和持续学习或是破局关键。 在多模态模型发展方面,吴健民指出,视觉生成主流为 模型框架从 Diffusion Model 发展到 Flow Matching,效果、稳定性碾压前代方案,视觉理解模型仍以 ViT Encoder 嫁接语言模型的主流方案,模型能力迭代的主要聚焦在垂直方向的数据合成。虽然工业和学术界有很多尝试,当前未真正实现多模态理解和生成的统一建模,目前分开独立优化效果依旧优于融合建模。 下面是详细对话内容,以飨读者。 InfoQ:如何让大模型更好支持 Agent 应用?技术有哪些瓶颈? 吴健民:目前我们的研发目标,是让模型能够在各类 垂直 Agent 场景中更好地发挥作用。其中,最核心、发展也最快的场景是 Coding Agent,包括通用编程以及面向网页开发或特定垂直领域的 Agent 应用。现阶段,我们的工作重点之一就是更具体地聚焦在网页开发相关的 Agent 能力上。 在这一过程中,有一个重要的问题需要回答:SOTA 的通用模型是否能在各种垂直 Agent 场景下都能达到工业级的效果。就目前来看,具备这种能力的通用模型还没有出现。 原因在于,不同 垂直 Agent 所处的场景设定、可使用的工具集合以及运行环境差异极大,而当前的通用模型尚不足以在如此多样的场景中实现稳定泛化。因此,围绕具体应用场景定制模型,反而更容易形成优势。 此外,不同场景对效果的评估标准也存在显著差异,即 Reward 的定义并不通用。如果一个场景能够清晰地定义 Reward,并且该 Reward 判断能够高效自动地完成,那么针对这一场景通过强化学习在通用基座模型上定制训练的 Agentic 模型,往往可以显著超过现有通用模型。 第二个难点在于环境的复杂性。以代码场景为例,其运行环境不仅涉及代码本身,还包括外部接口调用、工具使用、数据库依赖,以及登录、扫码等一系列真实应用中的外部依赖。在训练过程中,这些依赖都必须能够被高并发、稳定地访问,这对技术实现提出了很高要求。 第三个挑战在于强化学习系统本身。当前业内已形成共识,即要实现模型在特定场景中的持续迭代,必须依赖一套在该场景下运行顺畅、具备高效率和高吞吐能力的强化学习系统。由于强化学习系统本身的架构复杂性,也出现了不少 RLaaS 的平台产品,把算法复杂性封装在平台内,业务仅需要聚焦在业务场景定义,Reward 评估方案制定和迭代。这也是百度千帆平台 26 年的重点业务方向。 InfoQ:那现在有没有比较通用、效果较好的强化学习框架? 吴健民:目前开源社区中已有不少强化学习框架,例如 OpenRLHF、TRL 以及 VeRL 等,它们基本覆盖了强化学习流程中的主要环节。但在工业级应用中,这些框架仍然不够成熟,特别是涉及多轮工具调用的 Agentic 场景,往往需要进行深度定制和打磨。 打磨方向主要在两个方面:首先是模型规模支持,严肃应用往往依赖参数量较大的 SOTA 模型,例如百度文心或 DeepSeek 开源的模型,强化框架能否高效支撑这类大模型至关重要;其次是 Agent 训练能力,早期的强化学习多集中于单步任务,例如数学推理,而代码类、客服、DeepReasearch 等 Agent 更依赖多轮工具调用的复杂交互,这就要求强化训练框架能够配合一整套稳定、高效的脚手架系统。 此外,工业级 Agentic 模型的 研发对整体技术栈的要求极高,包括沙盒环境以及高性能、高并发的调度运行能力;若涉及联网搜索,还需要稳定的高并发搜索 API 支持。因此,具备云计算或搜索基础能力的团队往往更具优势。 InfoQ:要在基座模型上增强 Agentic 能力,需要哪些技术支持? 吴健民:这一问题的核心仍然在于强化学习如何在基座模型之上更好地服务于具体场景。强化训练的本质并不是创造全新的能力,而是激发和稳定模型在特定场景中的既有能力。因此,首要前提是基座模型本身在目标场景上具备优势。这种优势通常来源于预训练阶段的数据分布。例如,搜索相关数据占比更高的模型,在代码类 Agent 场景中往往更具潜力,不同场景基座模型的选择,通常观察基座模型在对应场景的 Pass@k 指标,即推理多次能得到正确答案的比例。Pass@k 指标高的模型,有更大空间通过强化学习训练激发并稳定模型在对应场景的表现。 另一个关键依赖是训练效率。强化学习的过程本质上更接近一种搜索机制:模型通过大量尝试生成不同路径,Reward 对每次尝试进行优劣评估,并将表现较好的路径通过强化训练反馈到模型参数中。在这一过程中,生成尝试路径(Rollout)通常占据 80%—90% 的时间成本。因此,是否能够以高吞吐方式高效完成 Rollout,是强化训练成败的关键。这个过程的关键是“训推一体”的技术,实现训推计算资源的高效利用以及训练精度差异的对齐。 InfoQ:另外,现在强化学习的 scaling 在业内似乎未形成共识? 吴健民:的确不像预训练 scaling 一样普遍的共识。过去,强化训练通常只占总体训练很小的一部分,被视为对预训练模型的微调,给预训练模型的蛋糕上放一个樱桃。而现在,强化训练的样本规模已经可以扩展到百万级,系统性地提升了模型推理和复杂问题解决能力。 要实现大规模多场景的强化训练,前提是结果评估能够准确自动完成,且最好能有稠密的评估奖励反馈。在代码或数学等评估相对确定的场景中,这一点相对容易实现,模型在代码和数学解题方向能力也得到显著提升。但在通用问答或复杂垂直场景中,由于缺乏统一、自动化的评估方案,规模扩展变得困难。这也是模型尚未在更通用场景实现泛化的重要原因。 尽管如此,业内普遍认为强化训练依然具有显著的 scaling 效果,问题的焦点转化到可泛化到评估奖励方案设计上。从依赖人工反馈的小规模 RHF,到基于规则甚至更通用奖励方案的 RLVR 强化训练,随着规模扩大,模型效果确实在持续提升,这一点在实际应用中也得到了验证。 InfoQ:通用 Agent 与专用 Agent 之间的能力差距,该如何弥补? 吴健民:当前主要存在两种思路。一种是追求在所有方向上都表现出超过人类的全能模型或 Agent,这本质上指向 AGI。业内对实现 AGI 需要的时间判断差异很大,而我们认为这一目标仍然相当遥远。另一种更现实的路径,是在特定专业场景中不断提升模型和 Agent 能力,能够在局部任务上超过人类水平,这在相当长一段时间内仍将是主流方向。 我们负责研发的全球领先的可商用自我演化超级智能体百度伐谋,为可以准确定义评估验证方案的 NP-hard 问题,提供高效的最优解演化方案,实现超过人类水平的效果。 InfoQ:长上下文能力对 Agent 的支持非常重要,应当如何建设? 吴健民:模型支持的上下文长度与 Agent 能力之间存在直接关系。上下文决定了模型能够记忆和理解的信息规模,而在复杂任务中,Agent 需要不断与环境交互,每一次反馈都会进入上下文,成为下一步决策的依据。因此,交互轮次越多,对模型长上下文理解能力的要求就越高。 在此基础上,业界也在探索通过 Agent 脚手架本身“放大记忆”的方案。类似人类并不会记住所有信息,而是通过笔记、字典或工具进行辅助,Agent 也可以通过工具使用来弥补上下文长度的限制。例如,在审核数百页合同的场景中,即便无法一次性将全文放入上下文,Agent 仍可以借助工具调用逐页查看、回溯关联内容,从而完成整体审核任务。从这个角度看,通过工具增强记忆能力,也是实现长上下文处理的一种有效路径,体现了 Agent 开发中 Progressive Disclosure 的原则。 InfoQ:在一些偏注意力机制的底层架构方面,业内是否做了调整? 吴健民:这个涉及模型网络结构本身的问题了。无论通过何种工具把上下文扩展得更长,模型本身的上下文理解能力始终存在上限。比如目前常见的 128K 或 256K 甚至 1M 上下文,长上下文能力的关键是模型能否准确理解高效处理,这依赖高效的注意力机制设计和实现。 模型利用上下文,在生成下一个 token 时,一个重要的观察是:并非全部上文 token 都对预估当前 token 同等重要,真正起作用的往往只是其中一小部分。基于这一特性,注意力机制可以采用稀疏化策略,不必对全部 128K 的 token 做同等精细的计算,可以采用比如 DeepSeek DSA 方案,先租略进行一次快速扫描,再对相关性高的部分 token 进行精细注意力计算。另一个思路是把上文 token 进行分块,先筛选相关的块,再对相关块内 token 进行精细注意力计算。结合两个方案的优势,也是一个实现的思路。 InfoQ:2025 年 MoE 架构被广泛采用,是否意味着更强模型的整体方向已经基本确定? 吴健民:MoE 架构被广泛应用到搜索、推荐等不同预估场景。大模型提到的 MoE,实际上是稀疏 MoE。其实从去年年初开始,这项技术就在业内受到较多关注。它要解决的核心问题仍然是 Scaling Law:随着模型参数规模不断增大,训练和推理成本也在持续上升,是否能在保持参数规模扩展的同时,控制实际训推计算的成本。 MoE 给出的答案是肯定的。通过这种方式,可以在继续增大模型总参数的同时,让训练和推理所实际使用的参数规模保持次线性增长。具体而言,在 Transformer 架构中,MoE 将原本的全连接层拆分为多个对等的小模块,即“专家”,在每次前向推理只激活其中一部分,从而显著降低计算成本。稀疏 MoE 已逐渐成为业内的主流选择,稀疏比耶做到了 5% 甚至更低的水平,成为推动模型规模继续扩展的一种现实可行方案。 InfoQ:从单一模态发展到多模态并引入 Agent,在底层架构上发生了哪些变化? 吴健民:一个最显著的变化,是在原有语言模型基础上引入视觉能力,这也是从去年开始 VLM 大量出现的主要方向。实际工作中,核心仍然在语言模型本身:通常是在语言模型训练到一定阶段后,引入视觉编码器,并用图文对其数据与语言模型联合训练,对齐文本和视觉 token,使模型能够理解视觉信号。这种 “桥接”或“嫁接”的方案,逐步成为当前的主流方案。 在多模态领域,一个长期目标是希望视觉模型也能像语言模型一样有很好的Scaling Law,但这一问题至今仍未解决。视觉信号本身的信息密度比较低,它更像是自然世界的直接映射,并不一定承载明确的知识结构。相比而言,互联网上存在的海量文本数据,是人类产生的对世界知识的总结压缩,信息密度很高。这使得仅依赖视觉输入进行大规模训练,难以达到语言模型那样的效果。 因此,现有方案高度依赖图文对齐数据,即为图片配备高质量、细粒度的文本描述,通过充分对齐文本与图片,来提升模型的理解能力。但这类数据难以规模化获取,不易全面覆盖实际的图片分布,目前行业可用的规模大致在 3–5T token,量级上存在明显差距,也限制了多模态模型的进一步 scale。 InfoQ:2025 年文生图、图生图模型更新频繁,突破点主要在哪里? 吴健民:这属于视觉生成方向。从 Sora 开始,这一领域受到了广泛关注,也出现了不少高质量的开源项目,支持生成效果不断提升。但像 Sora 2 或 Nano Banan 等业内 SOTA 的生成模型,其具体实现细节并未完全公开。 从算法角度看,视觉生成方案本身仍在快速演进,从早期的 Stable Diffusion 到当前的 Flow Matching,建模方法和训练效率都得到了显著优化。不过,从能力定位上看,视觉生成模型更偏向专精模型,主要解决“生成”的问题,也有观点认为,生成模型可能进一步发展为所谓的“世界模型”,即在理解物理规律的基础上生成符合现实约束的内容,进而通向 AGI 的实现。 InfoQ:在此基础上,未来一段时间,尤其是 2026 年,大家主要会沿着哪些方向继续演进? 吴健民:一个非常重要的方向,多模态生成与理解的统一建模。很多公司都在尝试通过统一的多模态建模方式,让生成能力和理解能力形成协同效应,而不再是彼此割裂。这意味着模型既不是单纯为生成而设计,也不是只服务于理解任务。外界对 GPT-5 等模型也曾寄予类似期待,尽管目前看相关路径尚未完全跑通,但可以确定的是,这一方向仍在持续探索之中。 InfoQ:在专家视角下,生成与理解真正实现统一,应当达到什么样的效果? 吴健民:最终评价标准仍然是结果导向。如果通过统一训练得到的模型,在生成和理解两个维度上的表现,都优于分别独立训练的模型,那么这种统一才是有意义的。举例来说,如果一个生成 - 理解统一模型在生成质量上能够超过当前生成领域的 SOTA 模型,那么就可以认为内生的理解能力确实提升了生成效果。但就目前来看,分开针对生成和理解进行优化,独立效果仍然更好。 InfoQ:也就是说,目前融合后的效果还不如单独优化? 吴健民:是的,至少在现阶段仍是如此。 InfoQ:但很多团队似乎还是在把各种能力揉合进一个模型里。 吴健民:确实存在这种趋势,但并非所有团队都选择同一条路径。不同团队对通用人工智能实现方式的理解并不一致。 一种思路是将多种能力融合到单一模型中,希望模型像人一样具备听、说、读、写等多种模态能力,这是一种全模态模型的路线。 另一种思路则是强调模型学会使用工具。人类智能的显著提升,本质上源于工具使用能力的不断演进,从最原始的简单工具到今天的计算机系统,工具极大放大了人的能力。Agent 的发展,本质上正是沿着“工具使用”这一路径展开的,不同理解会带来不同的技术路线和实现方式,当前没有看到哪条路一定能走通。 InfoQ:2025 年“世界模型”这个概念被频繁提及,从语言模型到动态模型再到世界模型,这条演进逻辑是怎样的? 吴健民:“世界模型”这一说法本身就存在多种理解。最早在 Sora 第一代发布时,其自称为世界模型,核心目标是通过建模来理解物理世界的运行规律,尤其是借助视觉输入,让模型学习空间关系和物理约束,例如生成的视频必须符合基本物理常识。这一路线随后发展得很快,重点在于提升模型的空间感知推理和物理一致性。 但也存在另一种理解路径。例如 Meta 前段时间发布的 CWM 模型,强调的是代码能力和工具调用能力,同样定义为世界模型。在这种视角下,只要模型能够高效使用现实世界中的各种工具,就可以被视为对“世界”的一种建模。 InfoQ:展望明年,大模型能力提升的核心突破点可能来自哪些技术路线? 吴健民:明年的变化大概率会延续 2025 年已经显现的趋势。2025 年一个非常明显的方向是 Agentic Model,即模型具备稳定、准确的工具调用能力。代码场景已经率先验证了这一点,明年这一能力很可能扩展到更多应用场景,模型将不再只调用编程相关工具,而是能够使用更广泛的现实世界 API,这是一个较为明确的发展趋势。 InfoQ:那面对复杂环境,大模型将如何应对? 吴健民:通用场景的环境通常非常复杂,模型需要对接的 API 接口、数据库、人际交互界面等系统差异较大。针对后者,目前较为可行的方案,仍然是让模型在特定场景的 Agent 脚手架中学会熟练使用该场景所涉及的工具。尽管应用场景很多,但每个场景对应的工具集合通常是相对有限的。模型通过场景反馈不断优化工具使用方式,就可以逐步适应复杂环境。代码 Agent 场景正是一个典型例子,模型通常只需要掌握十几种工具调用方式,随着打磨程度提升,其在该场景下的表现也会持续改善。“没有模型可以支持所有 Agent 场景”
多模态模型架构层逐渐收敛
2026 方向:生成与理解的统一建模
Agentic 模型是今年必答题
以下内容来源于DataforAI社区,作者Data for AI 大模型并没有直接带来 AI 应用的成熟。真正决定 AI 能否规模化落地的,正在从模型本身,转移到数据、上下文与基础设施。 与此同时,数据基础设施也正经历一轮深刻演进:从传统的数据湖仓,到多模态数据管理;从 SQL 查询引擎,到面向 AI 的数据解析与治理能力。这些变化,正在重新定义我们构建 AI 应用的方式。 1 月 24 日(周六)下午 ,Data for AI 社区 将携手 ALC Beijing (Apache Local Community Beijing) 举办 Data for AI Meetup Beijing,邀请来自产业、开源社区与学术界的一线实践者,围绕 AI 时代的数据基础设施演进 展开深入交流。 本次 Meetup 汇聚了来自 字节跳动火山引擎 / Daft 社区、OceanBase社区、北京大学、Datastrato / Apache Gravitino 社区、Zilliz / Milvus 社区的技术专家,深度剖析 AI 时代数据基础设施的技术演进路径。 多模态数据处理引擎实践: Daft 在 AI 数据预处理与训练加载中的工程经验 AI 原生元数据平台: Apache Gravitino 1.1.0 的关键能力与治理实践 Agent 数据基座设计: 记忆、检索与数据统一的工程解法 Data-centric AI 方法论: 面向大模型的数据准备与质量体系 混合检索实践: 向量 + 全文检索在真实业务中的优化路径 开源探索: Skill 驱动的上下文工程平台化可能性 圆桌讨论: 下一代面向 AI 应用的数据基础设施如何设计与落地 AI 训练对数据处理提出了全新挑战。火山引擎 AI 数据湖服务架构师 琚克俭 将分享 Daft 在多模态数据处理上的工程实践,聚焦图像、视频、文本等异构数据在统一处理、预处理与训练加载阶段的性能与架构挑战。 这一分享直面当前 AI 工程的核心痛点:传统数据引擎已难以支撑多模态 AI 工作负载,而 Daft 通过全新的架构设计,在数据预处理和训练加载环节实现了显著的性能提升。 Datastrato VP of Engineering 史少锋 将深度解析 Apache Gravitino 1.1.0 的核心升级,包括 Lance REST 支持、Generic Lakehouse Catalog、Iceberg 安全增强等关键特性。 当 AI 团队需要在多个集群间管理训练数据、推理数据和模型元数据时,传统的元数据工具往往各自为政。Apache Gravitino 1.1.0 通过统一的元数据治理架构,让跨引擎、跨存储的数据协同变得标准化、可管理,大幅降低 AI 工程中的数据协同成本。 OceanBase 技术专家 汤庆 将深度解析当下最热的「上下文工程」话题。他指出,企业级 Agent 面临三大核心挑战:如何让 Agent 拥有可靠的「记忆」(记忆管理)、如何让 Agent「理解」复杂文档(知识检索),以及如何统一处理向量、文本、结构化数据(数据统一)。 这三款 AI 产品的协同设计给出了答案:PowerMem 基于艾宾浩斯遗忘曲线构建智能记忆系统并支持多智能体隔离,PowerRAG 提供多引擎 OCR 与向量 + 全文的混合检索能力,seekdb 则作为 AI 原生数据库统一管理多模态数据并兼容 MySQL 生态。这套方案的核心价值在于:用数据架构的确定性,对抗 Agent 行为的不确定性。 北京大学助理教授 张文涛 将从学术与工程结合的视角,系统阐述 AI 从「模型为中心」到「数据为中心」的范式转变。当大模型能力趋同,数据质量正在成为决定模型性能的关键变量。 张文涛团队主导开发的 DataFlow 数据准备系统已在大模型预训练、企业知识库构建等场景得到验证。本次分享将深入解析 LLM 数据工程的完整流程:如何获取数据(爬取、解析、合成、标注),如何处理数据(过滤、改写、配比),以及如何评估数据质量。这套开源工具链与方法论,正在为 AI 开发者降低数据工程的门槛。 Zilliz 资深解决方案架构师 刘汉卿 将系统回顾从 Prompt Engineering 到 Context Engineering 的演进路径。随着 RAG 技术从单一向量检索发展到 GraphRAG 与全文检索的混合查询阶段,检索系统已经从「找到相似内容」进化到「理解查询意图并精准召回」。 在这个演进过程中,一个关键趋势是:用向量计算代替多轮LLM推理,通过检索层的优化来提升 AI 应用的性能与稳定性。刘汉卿将结合企业知识库、推荐系统、智能助理等场景,分享混合查询的工作流搭建经验,以及在金融、医疗、法律、教育等行业的实际落地案例。 独立开源开发者 袁怿(Sam Yuan)将从前瞻视角探讨 2026 年上下文工程的技术趋势。如果说 2025 是 Agent 元年,那么随着上下文工程的快速演进,一个关键问题正在浮现:上下文能力是否应该从「各自实现」走向「横向平台化」? 袁怿将上下文工程拆解为三个维度:工具调用(空间维度)、RAG(信息密度维度)与 Memory(时间维度)。他将以最近进入 AAIF 的 Skill 机制为切入点,对比 Skill 与传统 Function Call 的本质差异,并结合他在开源社区贡献的 StructuredContextLanguage 项目,展示以渐进式加载为代表的平台化思路——让 AgentOS 像操作系统管理进程一样,统一管理上下文资源。 从多模态数据处理到 AI 原生元数据平台,从上下文工程到混合检索系统——本次 Meetup 的所有分享指向同一个命题:在 Agent 时代,数据不再只是「被调用的资源」,而正在成为被理解、被约束、被治理的核心能力。 越来越多团队在实践中遇到相似挑战:Agent 需要访问的数据分散在不同系统中,权限、语义与上下文边界不清;模型可以生成「看似合理」的请求,却难以保证结果的安全性与一致性。这些问题往往无法通过 Prompt 或单点优化解决。 我们特邀到前 Apple 数据与机器学习平台负责人 谭涛(Kwaai AI Lab 顾问)、Datastrato 创始人 CEO 堵俊平、北京大学助理教授 张文涛 三位圆桌嘉宾,围绕三个核心问题展开讨论: 这些讨论并不立马给出最终答案,而是帮助我们勾勒下一代面向 AI 应用的数据基础设施轮廓——一个更开放、更可治理、也更适合 Agent 时代的技术底座。 时间: 2026 年 1 月 24 日(周六)13:10 – 18:00 地点: 北京 · 原点学堂(东升大厦 A 座 10 层)(不提供线上直播) 立即报名: 👉 访问链接:https://www.huodongxing.com/event/3843480320400 ⚠ 名额有限,需审核通过(请详实填写报名信息,并通过主理人的微信添加请求,确认审核状态) 这是一场面向 AI & Data 工程实践者的技术深度交流。 无论你是正在构建企业级 Agent 系统的架构师, 还是关注 Data-centric AI 的研发工程师, 都能在这里找到有价值的技术洞察和落地经验。 Community Over Code,期待与你在北京相聚。 阅读更多 Voice Agent 学习笔记:了解最懂 AI 语音的头脑都在思考什么当 AI 遇见数据:一场面向工程实践的技术交流

📍 本次 Meetup 核心看点
多模态数据处理的新范式
元数据治理进入 AI 原生时代
上下文工程:Agent 落地的数据基座
面向大模型时代的 Data-centric AI 基础设施
从向量检索到混合查询:Context Engineering 实践
上下文工程的平台化探索
圆桌论坛:下一代面向 AI 应用的 Data Infra 的设计和落地
活动信息



allowed-tools 配置不能限制工具的使用。agent 字段只有配合 context: fork 才会生效context: fork:Skill 在主 agent 上下文执行,继承主 agent 全部工具,agent 和 allowed-tools 字段被忽略context: fork:Skill 在独立子代理执行,agent 字段生效,限制工具集为该 agent 类型的固有工具agent 优先于 allowed-tools:当同时指定时,agent 类型决定工具集,allowed-tools 无法扩展name: test-agent-tools
description: 测试 agent 字段和 allowed-tools 的优先级关系
version: 1.0.0
agent: Bash
allowed-tools: Bash, Read
user-invocable: true agent 字段被忽略,Skill 在主 agent 上下文执行,继承全部工具name: test-agent-tools description: 测试 agent 字段和 allowed-tools 的优先级关系 version: 1.0.0 agent: Bash allowed-tools: Bash, Read user-invocable: true context: fork agent: Bash 生效,限制工具集为 Bash agent 的工具| 配置 | Bash | Read | Write |
|---|---|---|---|
无 context: fork | |||
有 context: fork |
科技云报道原创。
面对越来越激烈的商业竞争,企业是否还困在机械重复的流程里打转?系统一更新,自动化脚本就失效;遇到企业流程规则调整,系统需要重新配置;投入越多人力维护,效率提升却越乏力?
RPA一直以来都是企业降本增效的“得力干将”,用精准执行终结了无数重复性劳动,成为数字化升级的标志性技术。如今,随着Agent的崛起,自动化技术正迎来关键变局。
Ovations Technologies首席技术官Deon van Niekerk表示:“真正的生产力革命,必然是认知决策与精准执行的协同共振。”
Agent与RPA的深度融合,形成了“Agent懂业务、RPA懂执行”的清晰分工:Agent将非结构化数据转化为明确指令,RPA在企业系统中完成稳定可控的批量操作,通过清晰分工实现了从单点任务自动化到多场景价值交付的跨越,正推动企业业务从“智变”迈向“质变”。

RPA+Agent,1+1>2
自动化技术的演进,始终围绕着“解放人力”的核心诉求。从早期的脚本自动化,到RPA的可视化流程搭建,再到当下Agent驱动多场景提效,每一次迭代都源于企业对效率提升的迫切需求。
随着智能化时代来临,企业对自动化的需求早已超越“替代重复劳动”,以业务为核心,结合流程的精准执行,成为企业释放数字生产力的关键。
当RPA成为行业标配,单纯的效率提升已无法为企业构建竞争壁垒,企业需要通过RPA的持续进化打造不可复制的优势。
随着RPA的发展,其对业务的价值已从“效率提升工具”进化为“业务赋能者”,通过与AI的技术融合,为支撑业务创新、实现可持续发展提供重要支撑。
当RPA遇上Agent,“手脚”和“大脑”的互补融合便成为企业提高自动化效率的最佳路径。Agent负责“看懂”和“想清楚”,RPA负责“做对、做完、可复盘”,两者协同打通智能时代的自动化全链路。

Agent作为智慧“大脑”的角色,基于AI的自主决策能力,擅长复杂场景的智能决策。
Agent具备强大的认知与决策能力,能够理解自然语言意图,处理合同、邮件等非结构化数据,并根据实时情况自主规划任务流程。
即使面对系统报错或界面变化等异常情况,Agent也能可通过推理进行动态调整,显著提升了自动化的稳定性与适应性。
而RPA则是麻利的“手脚”,其优势集中于标准化流程的高效自动化,是企业降本增效、规范合规的“工具型”解决方案。
RPA专为规则明确、重复性高的结构化流程设计,模拟人类在计算机上的操作(如数据录入、表单填写、系统对账等),实现流程全自动化执行。
其部署周期短,前期投入低,通过零代码/低代码部署,企业无需改造现有IT系统,能够快速适配财务发票审核、HR人力流程、电商订单处理等标准化场景,且无需专业技术团队深度参与,中小企业也能快速应用,大幅减少人为操作错误,同时降低人力成本,是企业降本增效的有力工具。
RPA+Agent的进化本质上是RPA从“工具属性”向“伙伴属性”的转变。它不再是人类的“执行助手”,而是能理解业务逻辑、适配动态场景、协同解决复杂问题的“智能同事”。
这种“Agent 做决策、RPA 做执行”的协同模式,正在实现企业向业务智能化方向全面进阶。
聚焦场景释放价值
IDC报告显示,2025年,RPA与AI的深度融合正成为重塑企业运营效率的核心引擎。研究显示,中国RPA+AI解决方案市场规模在2023年已达24.7亿元人民币,并预计在2026年突破70亿元大关。
Gartner将AI与RPA的融合模式定义为“组合式自动化”(Composable Automation),其核心是像搭积木一样动态编排数字员工,快速响应市场变化。
这种模式下,企业可以根据业务需求,灵活组合Agent、RPA、数据分析等能力,构建个性化的自动化解决方案,无需从零开发。
从RPA向RPA+Agent发展,不仅是自动化工具的技术迭代,更是智能生产力从“流程执行层”向“决策协同层”的跨越,标志着人机协同进入到全新阶段。而艺赛旗的实践,正是这一方向的典型代表。
去年10月,艺赛旗企业级自动化平台再度升级,通过AI Center、Agent+RPA一体化、智能组件三大技术能力,完成了从“流程自动化”到“智能体自主协同”的跃迁,既保留了RPA的稳定高效,又赋予了自动化“主动决策、灵活协作”的智能属性,帮助企业在降本提效的同时,构建更具适应性的数字化业务体系。
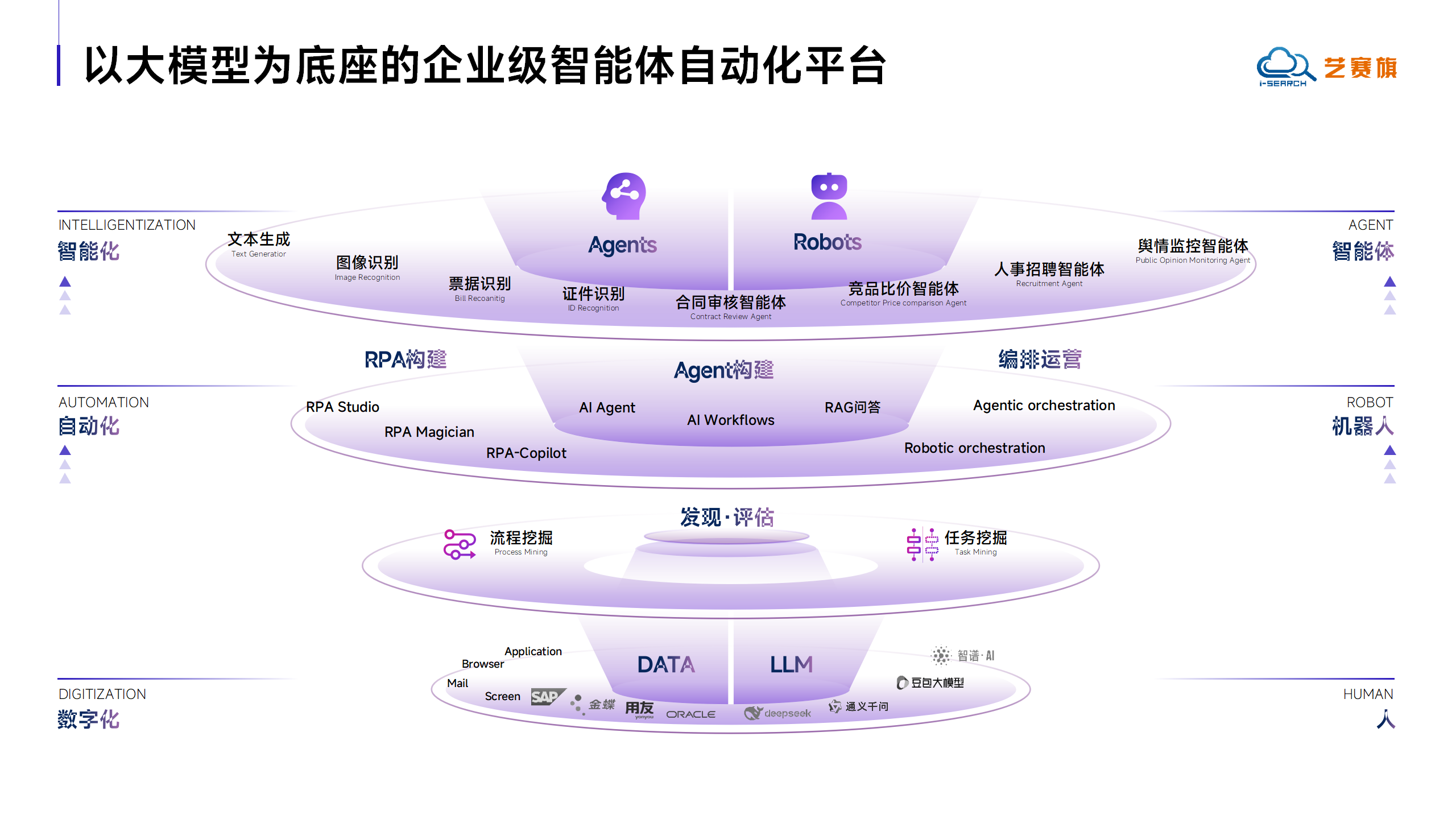
作为本次升级的核心模块,AI Center实现了智能体与业务流程的全自定义适配,技术能力覆盖零代码和低代码双模式智能体构建。
零代码构建支持企业用户通过可视化界面,自主配置智能体调用的内部工具、数据接口,无需技术背景即可快速搭建能解决复杂业务任务的智能体。
低代码开发提供拖拽式操作界面,支持主流大语言模型(如GPT、通义千问等)的即连即用,大幅降低智能体的开发门槛。
这一模块让自动化从“被动执行指令”升级为“主动理解意图、自主决策任务”,例如智能体可自动识别财务报表中的异常数据,并主动调用RPA流程完成溯源与修正。
而Agent+RPA一体化则实现了智能体与流程的无缝协同。通过iS-RPA设计器与AI Center的深度技术融合,构建了“智能体调度流程+流程调用智能体”的双向协作机制。
一方面,智能体可根据业务场景的动态需求,自主调用预设的RPA流程库(如合同审核流程、发票验真流程),实现业务逻辑的智能化编排,避免人工干预流程衔接。
另一方面,在RPA执行过程中,若遇到非标准化任务(如客户邮件的情感分析、非结构化数据的提取),可直接调度智能体完成决策,让自动化流程从“机械执行”转向“灵活应变”。
这一方式打破了智能体与自动化流程的技术边界,不仅是功能的整合,更是范式的进化,让每个业务流程都具备“思考+执行”的双重能力。
例如采购流程中,智能体可先分析需求优先级,再调度RPA完成供应商比价与下单。
为进一步降低自动化开发门槛,艺赛旗引入全新的智能组件体系,以大语言模型的理解与推理能力为核心,实现自然语言驱动开发。
通过自然语言指令,系统可自动识别网页元素、完成表格抓取、数据提取、表单填写等操作,替代以往RPA的“录屏式配置”,大幅降低网页操作的开发成本。
非技术人员仅需通过文字描述业务需求,即可完成自动化流程的搭建,真正实现“会表达就能会开发”。
智能协同 突破边界
从RPA的机械执行到RPA+Agent的智能协同,自动化技术的每一次迭代,都在突破企业业务自动化的边界,实现从“流程自动化”到“业务智能”的核心跃迁。
RPA作为数字化时代的重要生产力工具,正以前所未有的速度改变着企业的运营模式。
从基础的流程自动化到智能化的深度融合,RPA不断进化,为企业带来了效率提升、成本降低、风险可控等诸多优势。
展望未来,随着技术的持续创新与应用场景的不断拓展,RPA必将在企业数字化、智能化的进程中扮演更为重要的角色,通过让自动化体系深度融入业务核心环节,成为企业提升核心竞争力、应对市场变化的关键支撑,为企业发展注入源源不断的创新动力。
【关于科技云报道】
专注于原创的企业级内容行家——科技云报道。成立于2015年,是前沿企业级IT领域Top10媒体。获工信部权威认可,可信云、数博会、国家网安周与全球云计算等大型活动的官方指定传播媒体之一。深入原创报道云计算、人工智能、大模型、网络安全、大数据、区块链等企业级科技领域。
此前,我曾在《[教程] 如何使用 AI 智能规划你的专属行程?》一文中分享过基于 MCP 智能生成旅游攻略的方案。当时的解决方案主要依赖 “厚重” 的提示词(Prompt)来驱动 Agent。这种方式虽然可行,但存在一个显著弊端:大量的 Context(上下文)窗口被提示词本身占用,导致实际处理任务的上下文空间被浪费,且 Token 消耗巨大。
为了解决上述问题,在深入研究了 SKILL 机制后,我调整了技术思路,采用了 SKILL + MCP 的组合架构。通过将复杂的指令逻辑封装为 SKILL,减轻了 Prompt 的负担,从而释放了更多的上下文空间给实际业务数据。
经过测试,在新架构下生成一篇简单的旅游攻略,Token 消耗成功控制在了 169.7k 左右,相比纯 Prompt 驱动方案有了显著优化。
目前该方案的 SKILL 实现已上传至 GitHub,欢迎参考: SKILL 地址: QianJue-CN/TravePlanHelper
当然,目前的 SKILL 实现尚不完善,对于上下文的精细控制和 Token 消耗的极致优化也仅仅是一个开始。本文旨在抛砖引玉,分享一次技术探索的尝试,希望能得到各位佬友的指正与认可。
杭州 - 千岛湖周末情侣游攻略.pdf
Agent时代,为什么多模态数据湖是必选项?




















Agent时代,为什么多模态数据湖是必选项?
 「2025 年,注定被铭记为 AI 工业时代的黎明。」
「2025 年,注定被铭记为 AI 工业时代的黎明。」回望这一年,吴恩达教授曾这样感慨。
这一年,大量企业你追我赶,投身于 AI 应用及 Agent 建设。然而,许多企业或许尚未意识到:如果 AI 竞速只停在应用层,可能连这场竞争的「起跑线」都尚未站上。
AI 时代,数智化表面是模型的狂欢,底层是基建的深耕。
唯有能支撑 AI 应用规模化落地的数据基座,才能构筑企业真正的竞争力。
近来, AI 行业普遍认为我们正在进入所谓的「AI 下半场」,而此时行业面临的一大关键问题是「究竟应该让 AI 去做什么?又该如何衡量真正的进展?」
而这个问题的答案也基本已有共识:要想在这下半场脱颖而出,我们需要及时转变思维方式,应当用 AI 的思维,把该做的事情重新做一遍。
与上一阶段不同,这一阶段的企业数据,不再等待人来解读,而是被模型直接「消费」。
以音频数据应用为例,AI 时代,音频数据不应只是一份录音数据存档,还应成为可查询和交互的信息源,比如应该支持查找「录音中的人是客户 A ,上周在另一业务有投诉记录」这类关联信息。这种跨模态的关联性,是实现模型复杂推理的基础。
推及其他行业:
在智能驾驶中,道路视频、点云与传感器数据需要被实时送入智能体,支撑感知、规划与异常检索;
在游戏行业,需要将对话、行为与世界观等多模态数据沉淀为长期记忆,用于沉浸式 NPC 与自动化资产生成;
在传媒行业,需要使用视频、音频与用户互动数据来驱动内容生成与精准分发;
在电商领域,商品图文与交易数据直接喂给模型,实现智能选品与个性化推荐。
因此,对多种模态数据的处理与使用的能力,正在影响各行业商业竞争的形态与上限。
接下来的风口要踏在哪里?我们关注到了火山引擎近期发布的《AI 时代企业数据基建升级路线图》。
它在开篇写到:AI 时代,数据基建已经成为决定企业竞争高度的战略资产。
笔者深以为然。
企业要发展可以处理多模态数据的底层基建。因为 AI 时代最深的红利,并不在于「拥有」SOTA 的模型,而在于能否持续「驾驭」并「滋养」它。更进一步,可以说构建多模态数据湖已经成为企业参与这场 Agent 竞赛的必选项。

传统数据湖与多模态数据湖对比,图像由 AI 生成。
Agent 时代,这是你不能错过的风口
智能的涌现扎根于坚实、鲜活且可进化的数据土壤。
尤其在 Agent 时代的到来之际,企业竞速也正由数据基建分野:领先者正将沉睡的非结构化数据转化为可用的竞争力,而落后者由于非结构化数据资产仍处于休眠状态,而只得徘徊在 Agent 应用的起点。
当行业的聚光灯都投向大模型或智能体本身时,真正的竞争已转入水下,即底层的、支撑多模态数据的数据工程。
唤醒数据,化「沉睡库存」为核心资产
IDC 预测,2025 年企业超过 80% 的数据将是非结构化的。
这些长期堆积的视频、音频、图像和传感器数据,曾被视为「数字负债」。然而,多模态与大模型技术的成熟,正让它们焕发前所未有的价值。
以制造业为例,以往无人问津的历史故障录像,经大模型解析与标注,即可成为「智能知识库」。新员工用自然语言提问,便能精准调取同类故障的处理记录 —— 沉寂数据瞬间转化为实战生产力。
本质上,AI 时代的数据基建,正通过向量化等处理能力,让非结构化数据真正「活」起来,使其从被动存储的负担,变为可随时调用、持续学习的战略资源。
唤醒这 80% 的数据,是在 Agent 时代构建竞争力的工程前提。
让数据资产驱动业务,启动飞轮
强大的数据基建能构建数据、模型与业务深度耦合的闭环,真正「让模型自主成长」,为 Agent 赋予更多智能。
一个优秀的数据架构,需在企业数据平台、MaaS(模型即服务)平台、Agent 开发工具与应用之间建立高效的数据流通管道,否则数据会停留于「孤岛」,智能难以落地。
典型的例子是传统智能客服:尽管不断采集用户的语音、文本、截图与操作轨迹,却因模型与业务间数据不通,导致客服模型始终重复犯错、体验停滞,陷入「千人一面」的困境。
我们发现,火山引擎通过多模态数据湖与 AgentKit、火山方舟等产品的联动,已验证了数据、模型、业务打通的可行性。在零售行业中,完善的多模态数据湖不仅能分析销售报表,还可实时捕捉顾客行为、评论与画像。这些鲜活数据持续回流,使企业 AI 能力能随业务不断演进。
这种「业务滋养模型、模型反哺业务」的闭环,使企业 AI 能力可伴随业务持续进化,这正因为此,多模态数据湖成为了 Agent 时代构建智能护城河的必选项。
让业务拥有锚点,获得未来的确定性
新一代数据基建通过统一的数据与计算底座,以同一平台支撑多模态数据,并持续适配技术演进。
以某安防企业为例,传统数据管理体系下,如果从视频监控扩展至智能识别,往往需为不同算法供应商重建独立的计算平台与数据库,导致内部数据不互通、烟囱林立。巨大的管理和技术成本,会拖累企业创新动力。
而统一的多模态数据湖体系,能以统一元数据管理结构化和非结构化数据,提供面向 AI 的灵活数据集能力,支持数据快速探查与调用。通过标准化存储与可扩展接口,系统能在上层屏蔽底层模型的频繁迭代,使数据始终以对模型友好的形态稳定输入。
这意味着,当该企业未来业务从「视频监控」拓展至「自动巡检」、「人流预测」等领域时,可低成本接入新算法模块,无需颠覆底层架构。
「基建不动,技术常新」,在追求敏捷响应速度的 Agent 时代,这种具备工程确定性的多模态基座正在成为架构的必选项。
升级三部曲:积累,重构,融合
火山的这份「数据基建升级路线图」之所以值得展开聊聊,是因为它在行业内率先为企业提供了一套从「拥有模型」到「驾驭智能」的数据基建进化蓝图。在 Agent 时代,它为企业提供一套实现多模态数据湖的清晰演进路径。
这个蓝图可作为重要的参考框架,企业可结合业务特点与发展阶段,衍生出适合自身的基建升级路径,进而在 Agent 时代构筑自己的核心竞争力。

具体而言,火山引擎将企业数据基建的演进分为了三步渐进式过程。
异构算力与分布式引擎阶段
这一阶段的核心是突破算力瓶颈。为应对大规模数据处理与大模型训练的需求,传统仅依赖 CPU 的架构已难以满足 AI 时代对存储与计算的高实时性要求。企业需转向为 AI 任务量身打造的 CPU+GPU 异构架构,实现灵活调度。
这一阶段的核心目标是:数据「进得来,跑得快」,并原生支持 AI 服务。在异构算力的支撑下,企业能在技术快速迭代中平衡性能与成本,真正让算力服务于业务与模型增长。整体来说,这一阶段可为多模态数据湖这一必选项提供坚实的物理支撑。
模型即引擎与多模态重构阶段
在算力基础就绪后,需进一步推动数据基建与 AI 的深度融合。本阶段的关键在于将预训练大模型嵌入数据流水线,实现文本、图像、音频等多模态数据向统一语义向量与高价值知识标签的自动转换。
Agent 时代,数据价值不在于「存量」,而在于能被 AI 调用的「流量」。通过向量化处理,企业的多模态资产第一次真正实现通用「可读、可感、可交互」。该过程直接发生于数据基建层,从源头确保企业数据对大模型友好,使其可随时被检索、推理与学习,赋能全感官业务洞察。
因此,这一阶段可使多模态数据湖成为 Agent 识别与推理的逻辑重心,进一步确立了其作为基建必选项的地位。
全域数据治理与平台融合阶段
目标是在管理层面对数据资产进行统一管控,推动全域数据的治理、价值激活与安全合规。
这意味着 AI 能力可深度融入每一条业务流程,激活分散在不同系统与形态中的数据资产,并将其持续转化为增长动能。统一的数据治理体系不仅能显著降低安全与合规风险,还可大幅提升数据复用效率,助力企业将技术优势系统化、可持续地转化为长期竞争力。
这一阶段标志着多模态数据湖从单一的技术底座演变为全域的智能中枢,完成了其作为 Agent 时代必选项的最后拼图。
Agent 时代数据基建的选型指南
国内云厂商都在积极拥抱 Agent 时代的技术升级,从各大厂商的进度来看,对多模态数据的「存、算、管」重视度在持续提升。其中,我们观察到火山引擎「多模态数据湖」在行业内的进展最快,能够提供数据统一入湖与治理能力,在算子体系、性能优化、异构算力调度以及与大模型生态的无缝协同方面形成了更完整的一体化方案。
同时通过观察行业内其他厂商面向多模态数据的方案方向,我们也在思考:AI 和 Agent 时代的企业需要的数据基建,到底应该是什么样的?
综合起来,我们认为企业应将以下特质列为 AI 数据基建的必选项。
从「存储中心」到「价值中心」
在 AI 浪潮下,企业首先撞上的,是数据体系的根本性变革。
一方面,数据规模动辄 PB 级,非结构化格式复杂,处理流程高度碎片化,还要同时承载 CPU + GPU 混合负载与复杂作业调度;另一方面,大量数据分散存储、难以统一检索,无法被模型高效消费,数据准备周期越来越长,成本却持续上升。
真正有价值的数据,是能被快速获取、被模型理解、能转化为 Token 并直接参与推理与训练的数据。而那些无法被向量化、无法进入模型工作流的数据,正在从资产变成沉重的存储负担。
AI 时代的数据底座,是从「存储中心」转向「价值中心」的底座。
业务优先,回归实用主义
在技术变革快速的当下,除去技术复杂性之外,企业更大的挑战是:数据基建与业务脱节。
当前很多企业同时面临多模态数据分散、训练与生产割裂、血缘与版本缺失、质量评估与数据反馈闭环不足的问题。结果是数据冗余高、问题排查难、准备周期长,而业务决策却越来越依赖实时与精准。
在这种背景下,盲目堆算力、追求极限性能,反而成了负担。AI 时代最昂贵的基建,是那些无法转化为业务价值的闲置能力。
衡量一套数据基建是否先进,在于它是否能以最低成本、最快速度完成从数据输入到业务决策的闭环,并持续驱动数据飞轮运转。
开放解耦,对冲未来不确定性
随着模型与技术路线持续快速更迭,企业面临的另一项长期风险正在显现:如果数据基建随模型变化不断重构,系统将永远处于迁移与动荡之中。
在多模态数据规模持续膨胀、合规与安全要求不断提高的背景下,这种反复重构的代价几乎不可承受。
因此,解耦与开放的能力决定了成为企业的「生存能力」。通过模块化、可替换的数据与 AI 基础设施,企业才能在模型更替、技术跃迁时实现平滑升级,既保持系统稳定,又持续吸收新能力,将技术不确定性转化为长期竞争力。
在 AI 时代,模型会不断过时,真正具有长期价值的,只有数据资产与承载它的基础设施弹性。

这使得多模态数据管理必须从「存得全、存得久」升级为「取得快、读得懂」的针对业务模式的系统性工程。
我们观察到火山引擎多模态数据湖有一个非常有意思的理念。
其提出了「乐高式」可组合底座的观点,与其他云厂商的解决方案大相径庭。这种方式支撑企业以乐高积木般灵活、高效的方式,自主构建上层应用与智能体。
在这种框架下,企业可以根据现有的技术情况,选择渐进式的解决方案,同时可以模块化设计数据与智能架构,结合自身业务来进行组合式的升级,方案完全「量身定做」。

从行业视角看,这一设计理念呼应了企业长期的 AI 战略 —— 让数据基础设施具备持续演进的能力,使企业在快速迭代的技术环境中,始终拥有自主调整与进化的空间。
目前火山的多模态数据湖,已经在智驾、游戏、传媒等多个行业落地。
在某智驾企业的模型训练中,该方案可在 150–200 毫秒内完成 12 亿级别数据的「以图搜图」,性能提升 20 倍以上;
某游戏企业在 AI NPC 模型训练过程中,音视频数据加工效率提升 50%;
应用于某头部传媒企业的媒资平台后,其内容生产与运营效率提升 90%。
这些实践表明了采用多模态数据湖的必要性,同时也揭示出:AI 和 Agent 时代,用好多模态数据,可以激发出推动企业智能化跃迁的潜能。千行百业,都值得以此为起点,探索数据基建的更多可能,拥抱智能时代的风口。
结语
当下,企业正站在一场深刻技术变革的洪流之中。
AI 落地的前提,是多模态数据处理走向标准化与智能化。对坚定投身于 AI 浪潮的企业来说,在见证大模型所带来的能力飞跃的同时,更应关注到多模态数据管理作为基础设施的必要性。
构建能够支撑未来十年 AI 发展的数据基座,是这场变革中最应锚定的重心。
对企业而言,多模态数据湖的意义远不止步于一套数据架构。它是承载 AI 应用持续演进的土壤,是企业在技术红利窗口期建立确定性的基础。
是的,正如我们已经在文中多次强调的那样:多模态数据湖已经不再只是可有可无的优化项,而是企业进入智能赛道的必选项。
它赋予企业的,是在 Agent 时代中「以静制动」的底气,也是在变革中持续进化的能力。
前文见:[开源] AI 网关 AxonHub 发布 v0.7.0 ,支持模型管理以及批量映射
本次是个大版本,攒了挺多功能,所以发布时间稍晚,欢迎大家试用反馈,觉得有用的话,欢迎点个 。
主要大功能如下:
![[开源] AI 网关 AxonHub 发布 v0.8.0 ,迈向 Agent 的第一步1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/12/20260112164128_6964b3b8a8307.png!mark)
备份恢复
![[开源] AI 网关 AxonHub 发布 v0.8.0 ,迈向 Agent 的第一步2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/12/20260112164130_6964b3bab45f0.png!mark)
Prompt 注入
![[开源] AI 网关 AxonHub 发布 v0.8.0 ,迈向 Agent 的第一步3](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/12/20260112164133_6964b3bd76460.png!mark)
自动禁用配置
![[开源] AI 网关 AxonHub 发布 v0.8.0 ,迈向 Agent 的第一步4](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/12/20260112164135_6964b3bf91933.png!mark)
其他大量细节优化和修复
这个版本变更很大,为了尽快发布,很多细节还没完善,欢迎大家反馈。
然后标题也起的很大(抄的 DeepSeek v3.1 发布),其实 prompt 管理等相关 agent 功能是早就计划的内容了,从 0.4 开始就准备做,一直到 v0.8 才是真的落地,中间对于网关代理的基础功能做了很多完善优化,感谢大家的反馈。
接下来会在继续完善网关基础功能的前提下,加入更多 agent 相关的能力,其实这也是这个项目的启动初衷;当然功能越多,服务越重,有很多需要考虑的,比如是不是大部分佬友不需要 agent 能力,是不是应该新开一个项目,或者是构建的时候拆分,欢迎大家提出反馈,
引言:唐杰、杨植麟、林俊旸、姚顺雨聚会:AI 发展的共识和差异;“死了么”APP 爆火,开发者:用户数翻了 50 倍,尚不准备改名;消息称微软本月将启动新一轮大裁员,规模达 1.1 万至 2.2 万人;字节实习生全面涨薪,最高涨幅达 150%;马斯克:X 平台将于七天内开源其算法;消息称约翰・特努斯成库克头号苹果接班人,曾主导 iPhone Air 项目;OpenAI 预留 500 亿美元员工股权激励池;王腾官宣创业:核心成员来自小米、华为,薪资福利基本看齐大厂;京东将推出全年龄段人群 AI 玩具…… 在近日的 AGI-Next 前沿峰会上,唐杰、杨植麟、林俊旸、姚顺雨等行业标杆人物,与张钹院士共同勾勒出大模型发展的新图景,围绕技术突破、行业分化、范式变革与中国 AI 的未来展开了一场思想碰撞。 在技术发展的核心议题上,各位领军者达成了“突破现有瓶颈、迈向多元智能”的共识。智谱创始人唐杰直言,中国开源大模型虽成果斐然,但与美国闭源大模型的差距可能仍在拉大,行业需保持清醒认知。他提出,大模型的下一阶段应借鉴人脑认知过程,重点突破三大能力:多模态“感统”能力,实现视觉、声音、触感等多源信息的统一感知;构建全人类“第四级记忆”,解决模型记忆与持续学习不足的问题;探索反思与自我认知,挖掘大模型自主意识的可能性。2026 年,智谱将聚焦架构创新、多模态感统等方向,推动 AI 进入长任务场景并实现具身智能,同时预判今年将成为 AI for Science 的爆发年。 月之暗面 Kimi 创始人杨植麟则从 Agentic 时代的技术架构切入,强调提升 token efficiency 与实现 long context 的双重重要性。他认为,前者能以更少 token 达到同等效果,后者可突破传统架构局限,支撑复杂 Agent 任务,二者结合方能实现更高水平的代理智能。更具启发性的是,他提出智能具有“非同质化”属性,未来的技术升级不仅是算力的堆砌,更关乎“品味”——即对 AI 价值观与形态的深层理解,这种差异性将催生出更多新颖应用场景。面对 AGI 潜在风险,杨植麟秉持开放态度,认为 AGI 是提升人类文明上限的关键工具,应在风险可控的前提下持续迭代突破。 通义 Qwen 技术负责人林俊旸则将目光投向物理世界,提出打造 Multimodal Foundation Agent 的愿景。他认为行业发展“殊途同归”,全模态模型与具身推理是核心方向,Agent 将从数字世界走向物理世界。林俊旸描绘了具体的落地场景:数字特工可实现 GUI 操作与 API 调用,物理特工则能完成斟茶倒水等实体交互动作,这种从虚拟到现实的延伸,为 AI 应用开辟了广阔空间。 作为压轴嘉宾,张钹院士从旁观者视角给出了深刻洞见。他指出,大模型当前擅长跨领域泛化,但落地应用需实现跨任务泛化,重点解决分布外、长尾场景的泛化难题,具体应推进多模态、具身交互、结构化知识对齐等六大方向。在人机关系上,他大胆质疑“机器必须与人类对齐”的传统认知,认为人类存在固有缺陷,无需让 AI 完全复刻;而 AI 治理的核心,不应是约束机器,而是规范研究者与使用者的行为。值得关注的是,张院士一改以往态度,鼓励最优秀的学生投身创业,认为人工智能时代的企业家应承担起将知识、伦理与应用转化为通用工具的使命。 圆桌对话环节,嘉宾们围绕行业分化、范式变革、Agent 战略与中国 AI 的胜算四大议题展开深度探讨。腾讯首席科学家姚顺雨从跨中美视角指出,To C 与 To B 场景的模型需求已分道扬镳:To C 用户对强智能需求有限,To B 领域则呈现“智能即生产力”的鲜明特征,模型强弱分化将愈发明显。在范式变革方面,姚顺雨提出自主学习已实际发生,只是尚未形成颠覆性感知;唐杰则预判 2026 年将出现新范式,单纯依靠扩算力、扩数据的 Scaling 模式已难以为继,创新是唯一出路。 关于中国 AI 的全球竞争力,嘉宾们既正视差距也保持信心。姚顺雨认为中国团队在快速复现与局部优化上具备优势,但缺乏敢于探索未知的“冒险家”;林俊旸坦言美国在算力投入上领先 1-2 个数量级,中国团队领先概率约为 20%,但“穷则思变”可能催生创新机会;唐杰则强调,凭借敢冒险的年轻一代、良好的发展环境与持续深耕的定力,中国 AI 有望在长期竞争中实现突破。 2026 年 1 月,郑州月境技术 3 人 95 后团队开发的 8 元付费 APP “死了么” 爆火,苹果付费软件排行榜登顶,用户数较此前翻 50 倍仍在上涨。据悉,该 APP 专为独居人群设计,2 日未签到即自动向紧急联系人发邮件,因名字有传播力、需求旺盛等爆火,团队表示暂不改名,计划上线短信提醒、留言等功能。 该软件不需注册登录,首次使用只需填写本人姓名与紧急联系人邮箱即可。每天打开应用轻轻一点完成签到,后台自动监测状态。系统有一个异常未签到自动通知的功能,如果用户连续 2 天没有在应用内签到,系统将于次日自动发送邮件告诉对方。 其背后公司名为月境(郑州)技术服务有限公司,2025 年 3 月份才成立,注册资本 10 万元。创始人之一小郭对媒体介绍,团队有 3 人,一位是朋友,一位是网友,都是 95 后。这款 APP 耗时 1 个月完成,开发成本约 1500 元。 据报道,“死了么”在 2025 年中旬上线,不过期间团队未花过多精力打理,在一个月前才做了一次更新。上线后很长一段时间里用户量很少,团队也不擅长营销,直到最近突然爆火,用户数达到之前的 50 倍,目前热度还在上涨。不过由于用户规模数能直接推导出团队收益,小郭表示,目前不便透露具体用户规模。 1 月 7 日消息,据报道,微软公司计划于 2026 年 1 月启动新一轮裁员。预计全球范围内裁员规模将达到 1.1 万至 2.2 万人,约占其全球约 22 万名员工总数的 5% 至 10%。此次裁员预计将在 1 月第三周实施。有员工透露,微软 Azure 云团队、Xbox 游戏部门以及全球销售部门将是裁员的重点领域。截至目前,微软尚未证实该计划。微软在 2025 年尽管全年营收与利润保持稳健态势,该公司仍通过多轮裁员削减了超过 1.5 万个岗位。 与此同时,微软正加大对人工智能系统的投入力度。仅在 2026 财年第一季度,其资本支出就高达 349 亿美元(现汇率约合 2441.36 亿元人民币)。该公司预计全年总支出将突破 800 亿美元(现汇率约合 5596.24 亿元人民币),超过 2025 财年水平。这笔资金的大部分将用于数据中心、芯片及人工智能工具的建设与研发。分析师认为,受此战略调整影响,微软正将资金从人力成本转向长期技术资产投资。因此,中层管理人员及传统产品团队将面临更高的裁员风险。 1 月 5 日,有消息称字节跳动实习生全面涨薪,覆盖技术、产品、运营等多个岗位,薪资标准自 2026 年 1 月 1 日起正式生效。其中,技术类实习生日薪调整至 500 元,较此前上涨 25%。产品类岗位从每日 200 元提升至 500 元,较此前上涨 150%。此外,运营、设计、市场、职能、销售等其他岗位也均有不同程度涨薪,调整后日薪区间涵盖 100 余元至 400 余元。 需要注意的是,此次公布的涨薪标准主要适用于北上广深杭等一线城市。同时,具体薪资仍会根据岗位类型、所在业务线等因素有所区别,并非完全统一。通过查询招聘软件发现,目前北京地区的产品实习生日薪已调整为 500 元,运营、营销类实习生日薪则为 350 元/天。 据了解,字节跳动 2025 年 12 月发布面向全球员工的内部邮件,宣布继续加大人才投入,提高薪酬竞争力、提升期权激励力度。具体包括以下措施:增加奖金(含绩效期权)投入,2025 全年绩效评估周期相比上个周期提升 35%;大幅增加调薪投入,较上个周期提升 1.5 倍;提高所有职级薪酬总包的下限(起薪)和上限(天花板)。该公司表示,此举系为确保员工薪酬竞争力和激励回报在全球各个市场都“领先于头部水平”。 社交媒体平台 X 创始人埃隆・马斯克于周六表示,该平台将在七天内面向公众开源其新版算法,这一算法包含用于决定向用户推荐哪些帖文及广告的相关代码。“这项举措将每四周推行一次,同时会附上详尽的开发者说明文档,助力大家了解算法的具体更新内容。”身为 X 平台所有者的马斯克在该平台发布的一则帖子中如此表示。 1 月 9 日消息,报道称伴随着现任首席执行官蒂姆・库克年满 65 岁,且其本人有意减轻工作负荷,苹果公司已加速接班人计划,而约翰・特努斯再次被认为是接班热门人选。媒体援引博文介绍,现年 65 岁的库克向高层坦言感到疲惫,希望减轻工作负担。若库克决定卸任 CEO 一职,极有可能转任苹果董事会主席。在众多候选人中,现任硬件工程主管约翰・特努斯尽管行事低调,但已跃升为头号热门人选。特努斯现年 50 岁,这一年龄恰好与库克 2011 年接替乔布斯时的年龄相同。 知情人士透露,特努斯之所以脱颖而出,源于其在产品定义与商业利益间“穿针引线”的精准把控力。据内部人士回忆,2018 年前后,苹果为了提升摄影与增强现实(AR)体验,曾考虑在 iPhone 上引入一种微型激光(LiDAR)组件。然而,该组件高达 40 美元的单项成本将严重压缩利润。特努斯当时果断建议:仅在价格更高的 Pro 机型上搭载该组件。他认为,购买 Pro 系列的忠实用户更愿为新技术买单,而普通用户对此并不敏感。这一决策不仅保住了利润,也确立了产品分级策略。 针对外界关于其缺乏创新能力的质疑,Ternus 的支持者指出,他实际上深度参与了近年来多个关键产品的研发。值得注意的是,备受瞩目的 iPhone Air 以及即将面世的折叠屏 iPhone 均由他牵头主导。这些项目显示,Ternus 不仅具备卓越的执行力,在推动产品形态创新方面同样拥有实际战绩。此外在管理风格方面,特努斯被认为与库克高度相似。他于 2001 年加入苹果,以注重细节和深谙庞大的供应链网络著称。 1 月 8 日消息,据外媒报道,人工智能公司 OpenAI 去年秋季设立了一项规模达约 500 亿美元的员工股票激励池,相当于公司当时估值的约 10% 股份,该估值基于 2025 年 10 月约 5000 亿美元 的公司估值水平。报道指出,此前 OpenAI 已向员工授予约 800 亿美元的已归属股权,本次新增的股票激励池与既有部分合计约占公司总股份的 26%。 在过去一年中,OpenAI 的估值经历了快速增长。2025 年年中公司通过一笔员工股份二级市场交易达到约 5000 亿美元估值,高于前一次由 SoftBank 等领投的 3000 亿美元融资轮。二级股权交易不仅为员工提供了变现渠道,同时也被视为衡量市场对 OpenAI 增长前景信心的一个指标。 这一大规模股权激励池反映了 OpenAI 在全球 AI 竞争中对人才吸引与保留的高度重视。在人工智能研发与产品商业化日益加剧的背景下,顶尖 AI 研究人员和工程师成为市场追逐的稀缺资源,竞争对手包括 Meta、Google 等科技巨头均提供了丰厚的股权激励条件。在行业快速发展与人才争夺日益激烈的背景下,OpenAI 的股权策略旨在通过高比例激励计划锁定核心技术人才,同时支持公司未来产品和业务长期增长。 1 月 8 日,王腾在社交平台公布最近情况。王腾称,从小米离开后开始筹备创业,最近新公司已经成立,公司取名为“今日宜休”,目标是通过研发睡眠健康相关的产品,让大家能拥有更好的精力状态。王腾表示,目前已经组了一个初创团队,核心成员主要来自小米、华为等头部科技大厂。 王腾还放出招聘广告,重点招聘软硬件产品经理、 健康/AI 算法工程师、脑科学睡眠健康专家等岗位。王腾还解释为何选择睡眠健康、精力管理方向:1. 首先睡眠、精力已经成为每个人都关心的健康问题。2. 社会对睡眠的价值理解有待提升。3. 新时代下 AI 大模型发展迅速,让很多产品的体验能大幅提升。公开信息显示,北京今日宜休科技有限责任公司成立于 2026 年 1 月 6 日,由王腾持股 55%并担任法定代表人,注册资本是 100 万人民币,注册地址是北京市海淀区。 此前报道,去年 9 月 8 日,小米发布内容通报,原小米中国区市场部总经理、REDMI 品牌总经理王腾因泄密被小米公司辞退。11 月份,王腾发文称告别手机行业。他表示前段时间因为自己的问题离开小米,最近也有一些公司发来邀约,但综合竞业限制和个人兴趣的考虑,想跟手机行业说声再见了,愿还在这个行业的朋友们继续加油,期待更精彩的产品出现。王腾还透露 11 月开始准备尝试些新的赛道,大的方向是科技+健康领域,具体还在筹备中,“迎接新的挑战,正是闯的年纪。” 1 月 8 日消息,据媒体报道,京东成立“变色龙业务部”,全面承接 JoyAI App、JoyInside、数字人等核心 AI 产品的打造与商业化。报道称,全新的第二批 AI 玩具已在筹备中,此次新品将推出面向全年龄段人群的 AI 玩具,将于 1 月中旬全面上线。 值得一提的是,在 2025 世界人工智能大会(WAIC)期间,京东正式宣布旗下大模型品牌升级为 JoyAI,以及京东在大模型方向的技术进展和 JoyAI 应用全景图,同时也发布了全新的附身智能品牌 JoyInside。据当时介绍,JoyAI 大模型拥有从 3B 到 750B 全尺寸模型家族,且通过动态分层蒸馏、跨领域数据治理等创新技术,大模型推理效率平均提升了 30%,训练成本降低 70%。 此外,谈到 JoyInside,截至 2025 年 7 月,已有众擎、云深处、商汤元萝卜、火火兔、Fuzozo 等数十家企业已正式接入,覆盖人形机器人、四足机器人、儿童玩具、AI 潮玩等多类载体。另据京东官方披露,截止 2025 年 12 月,已有超 4.5 万家品牌接入数字人服务,数字人直播成本约为真人直播的 1/10,平均转化率提升约 30%。在 2025 年“双 11”期间,采用数字人直播的商家数量同比增长近 6 倍,全年累计带动商品交易总额(GMV)达数百亿元。 1 月 5 日,北京 AI 硬件创企 Looki 正式完成超 2000 万美元(约合人民币 1.4 亿元)A 轮融资,本轮由蚂蚁集团领投,美团龙珠、华登国际、中关村资本跟投,老股东 BAI 资本连续两轮超额追投,阿尔法公社、同歌创投持续加码。在完成本轮融资后,Looki 计划加快人才建设、模型迭代、产品研发及供应链整合,围绕 AI 原生硬件推进下一代交互设备的探索。 Looki 成立于 2024 年 5 月,截至目前已连续完成 4 轮融资。该公司由两位卡内基梅隆大学(CMU)的校友联合创办,CEO 孙洋曾任美团智能硬件负责人、Momenta 高级研发总监,是 Google Assistant 早期创始成员之一。CTO 刘博聪曾任美团自动驾驶算法负责人、Pony.ai 创始成员。团队成员来自清华大学、北京大学、多伦多大学、伊利诺伊大学、伦敦政经等知名院校,曾就职于 Google、Amazon、Qualcomm、字节跳动等公司,在 AI 算法、AI 产品、硬件工程等方面具备丰富经验。 在 Looki 发布的一段产品介绍视频中,CEO 孙洋称,Luki L1 自去年 8 月上线以来,已被不少用户当作“记录生活节奏”的常用设备使用。Luki 还具备“主动 AI”能力,如根据饮食、坐姿时间、行为节奏提出健康建议,例如“你今天已经喝了两杯咖啡,要不要换成水?”或者“你已经在桌前坐了一小时,要不要走一走?”等。 1 月 8 日智谱上市当天,清华大学计算机系教授、智谱创立发起人兼首席科学家唐杰发布内部信,宣布很快将推出新一代模型 GLM-5。内部信还介绍了 2026 年智谱聚焦的三个技术方向,包括全新的模型架构设计,更通用的 RL(强化学习)范式以及对模型持续学习与自主进化的探索。它们均围绕基础模型能力提升展开。 继沐曦股份、壁仞科技之后,上海又一家 AI 芯片企业成功上市。1 月 8 日,上海芯片企业天数智芯登陆港交所,在 1 个月的时间内,上海已先后有“港股国产 GPU 第一股”的壁仞科技和科创板上市首日涨幅近 7 倍的沐曦股份,加上已完成 IPO 辅导冲刺科创板的燧原科技,上海 GPU“四小龙”齐聚资本市场。 媒体从上海市经信委获悉,2025 年 1-11 月,上海市集成电路产业营收规模 3912 亿元,同比增长 23.72%,2025 年全年产业规模预计超 4600 亿元,同比增长 24%,五年间产业规模翻了一番多,超额完成“十四五”发展目标。集聚超 1200 家集成电路企业,汇聚全国约 40%的产业人才、近 50%的产业创新资源。 天数智芯战略与公共关系部副总裁余雪松表示,作为国内首家开展通用 GPU 自主研发的企业,公司已完成从核心技术攻关到商业化落地的全链路贯通。“我们的研发团队有 480 人,平均拥有 20 年以上行业经验,超三分之一研发人员具备 10 年以上芯片设计与软件开发经验。包含架构、通用 GPU IP 及芯片设计、基础软件、软硬件协同等各领域的专家。”余雪松说。上海市经信委相关工作人员表示,除了上海 GPU 芯片“四小龙”(壁仞、沐曦、天数、燧原),光计算、近存计算等创新路线 AI 芯片企业也相继涌现,支撑国内大模型等新质生产力发展。 1 月 6 日消息,在 2026 消费电子展(CES)上,英伟达宣布推出 Alpamayo 系列开放式 AI 模型、模拟工具和数据集,旨在解决自动驾驶安全挑战。对此,马斯克回应称:“好吧,这正是特斯拉在做的。他们会发现,达到 99%很容易,但要解决分布的长尾问题却非常困难。” 据悉,Alpamayo 平台的核心是 Alpamayo 1 模型,这是一款拥有 100 亿参数、基于思维链技术的视觉-语言-行动(VLA)模型。该模型可让自动驾驶汽车具备类人思维能力,即便在未经任何训练和标注的情况下,也能解决复杂的场景问题,例如在交通信号灯失灵的路口规划通行路线。 英伟达还强调,Alpamayo 模型并非直接在车内运行,而是作为大规模教师模型,供开发者微调并提取到其完整自动驾驶技术栈的骨干中。黄仁勋在声明中表示:“首款搭载英伟达技术的汽车将于第一季度在美国上路。” 1 月 5 日消息,曾经靠海洋球滑梯、免费尼古丁袋等五花八门的福利留住员工的硅谷热门科技初创公司,如今又出新招——要求员工进门脱鞋。根据观察,在年轻人占主导的办公场所,“无鞋办公”政策正悄然兴起。雇主们认为,员工穿着毛绒袜、拖鞋踩在地毯上,能打造出更轻松无压的工作氛围。然而矛盾的是,这些公司中不少仍推行“996”工作制,要求员工从早 9 点工作到晚 9 点,每周连轴转 6 天。 斯坦福大学经济学家、职场文化专家尼克·布鲁姆表示,无鞋办公政策的流行,在一定程度上是“睡衣经济”的延伸——随着远程办公者被要求重返办公室,他们也把居家办公的习惯带到了办公室。但这一趋势也与硅谷高压的工作文化一脉相承。布鲁姆说:“如果你每天要在公司待 12 个小时,那不如直接穿拖鞋上班,毕竟在家也没机会穿。” 1 月 8 日,就 Meta 收购人工智能平台 Manus 一事,中国商务部新闻发言人何亚东表示,中国政府一贯支持企业依法依规开展互利共赢的跨国经营与国际技术合作。何亚东在当日举行的例行新闻发布会上回应称,需要说明的是,企业从事对外投资、技术出口、数据出境、跨境并购等活动,须符合中国法律法规,履行法定程序。商务部将会同相关部门对此项收购与出口管制、技术进出口、对外投资等相关法律法规的一致性开展评估调查。 在北京时间 1 月 6 日凌晨举办的 CES 2026 主题演讲中,英伟达首席执行官黄仁勋发表主题演讲,介绍了新一代“Rubin”计算架构,并将其定义为当前 AI 硬件领域的“最先进技术”,该架构已进入全面量产阶段。Rubin 架构以天文学家薇拉·鲁宾的名字命名,由六款协同工作的独立芯片组成。该系统的核心是 Rubin GPU,同时配备了专为“智能体推理”(Agentic Reasoning)设计的全新 Vera CPU。 在性能表现方面,Rubin 架构相较于前代产品实现了显著跨越。根据英伟达官方测试数据,Rubin 在 AI 模型训练任务上的运行速度是 Blackwell 架构的 3.5 倍;在推理任务中,其速度更是达到了前代的 5 倍,峰值运算能力高达 50 Petaflops。此外,新平台的能效表现同样优异,其每瓦推理算力提升了 8 倍。这一性能飞跃将为日益复杂的 AI 模型提供强大的算力支撑。 同时,黄仁勋也介绍并推出了全新的 Alpamayo 1,是其视觉-语言-动作模型(VLA),结合因果链推理与轨迹规划,主要增强复杂驾驶场景中的决策能力。 智元机器人在 CES 国际消费电子展首日正式发布首个大语言模型驱动的开源仿真平台——Genie Sim 3.0。基于 NVIDIA Isaac Sim,Genie Sim 3.0 融合三维重建与视觉生成,打造数字孪生级的高保真环境;首创大语言模型驱动的场景泛化技术,让万级场景的生成只需几分钟;同步开源包含真实机器人作业场景的上万小时仿真数据集;并构建了覆盖 10 万+场景的多维度智能评估体系,为模型能力绘制全景画像。 1 月 8 日消息,OpenAI 正式宣布推出 ChatGPT Health,该模式集成于 ChatGPT 中,号称是一个“专门用于与 ChatGPT 进行健康相关对话的独立空间”,预计将在未来几周内陆续向用户开放。OpenAI 称,目前平台每周有超过 2.3 亿人询问有关健康的问题,因此该公司推出了 ChatGPT Health 模式,旨在让用户更系统、更安全地讨论自身的健康问题。 据介绍,在 ChatGPT Health 模式下,系统会将用户的对话与其他普通聊天记录进行隔离,避免用户的健康背景在日常对话中被无意提及。如果用户在普通聊天中开始讨论健康问题,系统也会引导其切换到 Health 模式进行交流。同时,在 Health 模式下,AI 仍然可以参考用户在其他场景中的部分信息。ChatGPT Health 还将支持与个人信息及健康类应用的数据整合,包括 Apple Health(苹果健康)、Function 和 MyFitnessPal 等。OpenAI 强调,Health 模式中的对话内容不会被用于训练模型。 不过,ChatGPT 这样的“大模型”本质上是通过预测最可能的回答来生成内容,而不是基于对“真实与否”的判断,因此并不保证生成的医疗见解一定正确,OpenAI 也在其服务条款中明确指出,ChatGPT 仅供参考,不能够用于任何健康状况诊断 / 治疗。 1 月 8 日消息,雷鸟在 CES 2026 中正式推出了全球首款支持 eSIM 功能的 AR 智能眼镜 X3 Pro Project eSIM,但并未公布价格和上市时间。据介绍,该产品采用双目全彩光机,可获得“等效 43 英寸的 3D 空间视觉观感”,同时产品搭载高通骁龙 AR 1 计算平台,内置 RayNeo AR 应用虚拟机,支持微信、抖音、B 站等多款应用。此外,该产品搭载 eSIM 通信模块,使得 AR 眼镜首次真正具备脱离手机的能力,产品无需通过手机或 Wi-Fi,即可独立完成包括通话、实时 AI 对话、实时翻译、在线流媒体播放等功能。 1 月 8 日,据摩尔线程消息,近日,摩尔线程正式发布开源大模型分布式训练仿真工具 SimuMax 的 1.1 版本。该版本在完整继承 v1.0 高精度仿真能力的基础上,实现了从单一工具到一体化全栈工作流平台的重要升级,为大模型训练的仿真与调优提供系统化支持。本次更新聚焦三大核心创新:用户友好的可视化配置界面、智能并行策略搜索,以及融合计算与通信效率建模的 System-Config 生成流水线。新版本同时提升了对主流训练框架 Megatron-LM 的兼容性,并增强了对混合并行训练中复杂通信行为的建模精度,使仿真环境更贴近真实生产场景。 1 月 7 日,微创机器人依托神经元 MicroGenius 多模态自主手术大模型,成功完成了全球首例“大模型自主手术”动物实验。这一突破性成果不仅填补了全球大模型自主手术在体动物实验的技术空白,更推动全球 AI 产业在医疗领域的深度升级与跨界融合。 1 月 6 日,波士顿动力与谷歌 DeepMind 宣布建立新的人工智能合作伙伴关系,目标将 Gemini Robotics 人工智能基础模型与波士顿动力的新型 Atlas 人形机器人集成。 1 月 6 日,高通与谷歌宣布深化长达十年的汽车领域合作,双方将整合骁龙数字底盘解决方案与谷歌汽车软件及云服务能力,加速软件定义汽车落地,推动 AI 赋能的智能出行体验规模化普及。 1 月 5 日,腾讯 AI 工作台 ima.copilot 迎来更新:正式上线“生成 PPT”功能。用户只需进入“任务模式”,即可调用个人知识库中的素材,一键生成幻灯片。 1 月 5 日,智元机器人已与 MiniMax 达成合作,MiniMax 将为智元机器人提供文本到语音全流程 AI 技术支持。针对智元机器人的产品定位与功能特性,MiniMax 为其量身打造专属人设体系,优化用户与机器人的语音交互体验。同时,基于人设体系构建定制化提示词策略,为用户生成专属音色,实现千人千面的个性化音色合成,满足多样化语音交互需求。此外,MiniMax 还基于自研音乐生成模型,助力智元机器人拓展娱乐场景玩法。行业热点
唐杰、杨植麟、林俊旸、姚顺雨聚会:AI 发展的共识和差异
“死了么”APP 爆火,开发者:用户数翻了 50 倍,尚不准备改名
消息称微软本月将启动新一轮大裁员,规模达 1.1 万至 2.2 万人
字节实习生全面涨薪,最高涨幅达 150%
马斯克:X 平台将于七天内开源其算法
消息称约翰・特努斯成库克头号苹果接班人,曾主导 iPhone Air 项目
OpenAI 预留 500 亿美元员工股权激励池
王腾官宣创业:核心成员来自小米、华为,薪资福利基本看齐大厂

京东将推出全年龄段人群 AI 玩具
蚂蚁美团联手投了一家 AI 硬件创企,前美团硬件负责人带队
智谱上市,唐杰内部信要求全面回归基础模型研究
上海又一 GPU“四小龙”上市!
马斯克回应英伟达自动驾驶 AI 模型:特斯拉正在做,达到 99%很容易
硅谷科技初创公司兴起“脱鞋办公”潮
中国商务部回应 Meta 收购 Manus
大模型一周大事
重磅发布
黄仁勋官宣英伟达已投产 Vera Rubin:训练 AI 速度是 Blackwell 架构 3.5 倍
智元发布开源仿真平台 Genie Sim 3.0
OpenAI 推出 ChatGPT Health 模式,为“健康 / 医疗”类型对话设立专属空间
雷鸟 CES 2026 推出全球首款 eSIM 功能 AR 智能眼镜 X3 Pro Project eSIM
摩尔线程正式发布开源大模型分布式训练仿真工具 SimuMax 的 1.1 版本
企业应用
在人工智能技术以指数级速度迭代的当下,技术知识的半衰期显著缩短,传统的教育体系往往难以跟上工业界的步伐。Datawhale 作为成立于 2018 年的专注于 AI 领域的开源组织,其 “For the Learner” 的核心价值观不仅是一种口号,更是一种应对技术变革的系统性方法论。该组织通过汇聚具备开源与探索精神的理想主义者,构建了一个去中心化、高响应速度的知识生产与传播网络。
对于渴望成为大模型(Large Language Model, LLM)应用开发工程师或智能体(Agent)开发者的学习者而言,Datawhale 提供了一个独特的生态位:它既不完全等同于学术界的纯理论研究,也不同于商业公司的封闭技术栈。Datawhale 的项目矩阵通常呈现出 “元认知” 的特性 —— 不仅教授如何使用工具,更深入工具背后的原理与设计哲学。通过对 Datawhale 开源仓库的全面梳理,我们可以清晰地通过其项目演进看到 AI 工程化范式的转移:从早期的模型训练(Training-centric),过渡到以提示工程(Prompt Engineering)为核心的应用开发,最终演进至 2024-2025 年爆发的智能体(Agentic)系统构建。
本报告旨在为学习者规划一条详尽的进阶路径,该路径严格基于 Datawhale 的开源项目构建,旨在培养具备 “全栈 AI 思维” 的工程师。一个合格的大模型 / Agent 应用开发工程师,其能力图谱已发生根本性重构:
本报告将摒弃版本过旧或简单的搬运类项目,聚焦于 Datawhale 生态中具备系统性、原创性及前沿性的核心仓库,规划出一条长达数千小时的深度学习路线。
任何复杂的 Agent 系统,其原子单元皆为单次的大模型调用。因此,理解如何与模型高效沟通,即 “提示工程”,是所有后续开发的基石。Datawhale 在此领域提供了两套互补的 “教材”,分别侧重于交互逻辑与工程落地。
llm-cookbook该项目是吴恩达(Andrew Ng)与 OpenAI 合作推出的系列课程的中文版。Datawhale 团队不仅进行了翻译,更针对中英文模型在理解 Prompt 时的细微差异进行了大量的 “本地化” 调优。这使得该项目成为了解 LLM 思维方式的最佳起点。
在这一模块中,学习者将深入探究控制大模型输出质量的底层逻辑。这并非简单的 “说话技巧”,而是一种编程思维。
从单一 Prompt 进阶到系统构建,项目涵盖了 Building Systems with the ChatGPT API 的核心内容。
messages 列表来构建对话历史(History),以及如何处理上下文窗口限制,为后续理解 Agent 的 Memory 模块打下基础。虽然 Datawhale 有更复杂的 Agent 教程,但 llm-cookbook 中关于 LangChain 的章节提供了最纯粹的原理解读。
llm-universe如果说 llm-cookbook 是注重理论的 “计算机科学导论”,那么 llm-universe 就是注重实操的 “软件工程实验课”。该项目致力于帮助小白开发者从零开始构建一个完整的、可部署的个人知识库助手。
在实际的国内开发环境中,开发者往往面临 OpenAI 访问受限或成本过高的问题。llm-universe 的一个核心贡献是提供了一套统一的接口设计模式,涵盖了百度文心(Ernie)、讯飞星火(Spark)、智谱 AI(ZhipuAI)等主流国产大模型。
LLM 基类,将不同厂商的 SDK(如 zhipuai、dashscope)封装为统一的_call 接口。这种能力对于企业级应用中实现 “模型热切换” 至关重要,也是构建模型无关(Model-Agnostic)Agent 框架的前提。RAG 是目前解决大模型知识截止和私有数据访问最成熟的技术方案。本项目通过由浅入深的实战,剖析了 RAG 的每一个环节。
为了完成工程闭环,项目引入了 Streamlit 框架。学习者不再停留于 Jupyter Notebook 的黑底白字,而是能够快速构建具备侧边栏配置、聊天气泡界面的 Web 应用。这对于展示 Agent Demo、进行用户测试(User Testing)具有重要意义。
在掌握了 API 调用与基础应用开发后,真正的专家级工程师必须具备 “打开黑盒” 的能力。理解 Transformer 架构、训练过程及微调(Fine-tuning)原理,是优化复杂 Prompt、调试模型异常表现以及进行私有化部署的前提。
hugging-llm此项目被称为 “蝴蝶书”,意在阐述微小的代码变动可能引发的模型行为的巨大蝴蝶效应。它连接了深度学习理论与 Hugging Face 开源生态。
学习者将通过该项目,梳理 NLP 从 RNN/LSTM 到 Transformer 的范式转移。
Hugging Face 已成为 AI 领域的 GitHub。本项目手把手教导如何利用 transformers 库加载开源模型。
<|endoftext|>)的处理。不同模型的 Tokenizer 实现差异(如 SentencePiece vs Byte-Pair Encoding)直接影响 Prompt 的 Token 计算与上下文窗口利用率。happy-llm该项目从更加底层的视角,剖析了大模型全生命周期的训练过程。
<Instruction, Input, Output> 格式的数据集,将预训练模型转化为 Chat 模型。这对于开发者想要在特定垂直领域(如医疗、法律)微调模型以获得更好表现极具指导意义。Reinforcement Learning from Human Feedback(RLHF)是大模型安全性的核心。虽然大多数应用开发者不需要亲自进行 RLHF,但理解其原理(奖励模型 Reward Model、PPO 算法)有助于理解模型为何会拒绝某些请求,以及如何通过 Prompt 设计规避过度的防御机制。
2024 年与 2025 年被普遍认为是 “Agent 元年”。大模型的能力焦点从单纯的文本生成(Chatbot)转移到了具备自主感知、规划、工具使用能力的智能体(Agent)。Datawhale 的 hello-agents 项目是目前开源社区中最系统、最前沿的 Agent 学习资料,是本报告的核心推荐内容。
hello-agents该项目立意高远,旨在培养 “AI Native” 的 Agent 开发者。它不仅介绍了如何使用工具,更从第一性原理出发,探讨 Agent 的本质。
学习者首先需要建立对 Agent 的科学认知。
在这一部分,hello-agents 展现了极高的教学价值:它拒绝直接使用封装好的框架,而是引导学习者用原生 Python 复现经典论文。
hello-agents 第七章 8在掌握了原理后,Datawhale 鼓励学习者造一个属于自己的轮子。这一章指导学习者构建名为 HelloAgents 的轻量级框架。
Agent 基类、ToolRegistry(工具注册表)、Memory(记忆模块)等核心组件。当单一 Agent 受限于上下文窗口或能力瓶颈无法解决复杂问题时,多智能体系统(Multi-Agent Systems, MAS)应运而生。Datawhale 通过 handy-multi-agent 和 hello-agents 的高级章节,深入探索了这一前沿领域。
handy-multi-agent该项目基于 CAMEL(Communicative Agents for “Mind” Exploration of Large Scale Language Model Society)框架,重点展示了 Agent 社会的构建。
CAMEL 框架的核心创新在于 “角色扮演”。
除了自研框架和 CAMEL,hello-agents 还深入剖析了工业界主流框架。
微软推出的 AutoGen 是目前最火的框架之一。
LangGraph 代表了 Agent 编排的另一方向 —— 基于图(Graph)。
wow-agent作为一个更轻量级的选择,wow-agent 提供了一个跨平台的视角。其中的 Zigent 模块展示了极简主义的 Agent 设计。学习者可以对比其与庞大的 LangChain/AutoGen 的差异,理解在资源受限或需要快速原型开发时如何取舍。
在掌握了单个和多个 Agent 的构建后,最后阶段将聚焦于数据的深度利用与生态互联,这是构建具备商业价值应用的关键。
wow-rag基础的 RAG(如 llm-universe 中所述)往往面临检索精度不足、多跳推理困难的问题。wow-rag 聚焦于 Advanced RAG 技术。
项目触及了最前沿的 GraphRAG 技术。利用知识图谱(Knowledge Graph)捕捉实体间的关系,解决 “跨文档推理” 难题。学习者将了解如何将非结构化文本转化为图谱,并利用图算法增强检索上下文。
easy-vectordb为了支持上述 RAG 系统,对向量数据库的深入理解不可或缺。该项目专注于向量数据库的原理与实践,填补了数据库层面的认知空白,是构建大规模知识库 Agent 的基石。
hello-agents 第 13-16 章 8学习的终点是创造。本部分提供了多个企业级复杂度的案例,涵盖了当前最热门的应用方向。
最后,学习者需完成一个完整的开源项目。hello-agents 提供了详细的指南,包括选题(如代码审查 Agent、数据分析师)、项目结构规范(src, tests, docs)、以及如何撰写 requirements.txt 和 README.md。这不仅是技术的总结,更是开源礼仪与工程规范的实战。
| 阶段 | 核心项目 | 学习重点 | 预计耗时 | 产出物 |
|---|---|---|---|---|
| P1: 基础 | llm-cookbook | Prompt Engineering, API, LangChain Basic | 20h | 翻译助手,摘要工具 |
| P2: 应用 | llm-universe | RAG, VectorDB, Streamlit UI | 30h | 个人知识库助手 (Web 版) |
| P3: 原理 | hugging-llm | Transformer, Tokenizer, Open Source Models | 25h | 本地模型推理 Demo |
| P4: 智能体 | hello-agents (Part 1-2) | ReAct, Plan-and-Solve, HelloAgents 框架 | 40h | 手写 Agent 框架,命令行工具 |
| P5: 协作 | handy-multi-agent | CAMEL, Role-Playing, Agent Society | 30h | 多智能体辩论系统 |
| P6: 进阶 | hello-agents (Part 3-5) + wow-rag | MCP, GraphRAG, Deep Research, Simulation | 50h+ | 毕业设计开源项目 |
Datawhale 的开源项目群构建了一座宏大的 “AI 工程学院”。从掌握 Prompt 这一原子能力,到构建复杂的 Agent 社会,这条路径既漫长又充满挑战。
愿这份基于 Datawhale 生态的详尽报告,能成为你在大模型与智能体开发之路上最坚实的导航图。
附录:引用项目清单
llm-cookbook: GitHub - datawhalechina/llm-cookbook: 面向开发者的 LLM 入门教程,吴恩达大模型系列课程中文版llm-universe: GitHub - datawhalechina/llm-universe: 本项目是一个面向小白开发者的大模型应用开发教程,在线阅读地址:https://datawhalechina.github.io/llm-universe/hugging-llm: GitHub - datawhalechina/hugging-llm: HuggingLLM, Hugging Future.happy-llm: GitHub - datawhalechina/happy-llm: 📚 从零开始的大语言模型原理与实践教程hello-agents: GitHub - datawhalechina/hello-agents: 📚 《从零开始构建智能体》—— 从零开始的智能体原理与实践教程handy-multi-agent: GitHub - datawhalechina/handy-multi-agent: This is a multi agent tutorial based on the CAMEL framework, aimed at understanding how to build an Agent Society from the ground up!wow-agent: GitHub - datawhalechina/wow-agent: A simple and trans-platform agent framework and tutorialwow-rag: GitHub - datawhalechina/wow-rag: A simple and trans-platform rag framework and tutorialeasy-vectordb: GitHub - datawhalechina/easy-vectordb: 📚 从零开始的向量数据库原理与实践教程,在线阅读地址:https://datawhalechina.github.io/easy-vectordb/2025 年的硅谷 AI 圈,最激烈的战场已不止于模型参数和榜单上,另一场残酷的战争也在暗中同步升级。 当大模型一路卷到极限,算力、参数规模、基准测试分数开始出现明显的边际递减,真正被重新定价的,是“人”。 过去几年,硅谷 AI 的主叙事是“谁能训练出更大的模型、刷出更高的分数”。 但进入 2025 年,模型能力仍然重要,却不再是唯一的决定因素;大家的关注重心逐渐从“模型参数与评测分数”,转向“谁能够将模型纳入产品与系统核心,并持续推动其在真实业务场景中发挥作用”。 这一变化,非常直观地体现在一连串人员流动中: 一边是科技巨头高调宣布重金抢人、疯狂扩招 Agent、系统、基础设施方向的研究与工程负责人;另一边,他们又在内部对原有 AI 研究体系进行重组,让多位中高层研究负责人选择离开舞台中央。 在一系列重大人事变动中,Meta 今年的变化尤为瞩目:比如前两天豪掷 20 亿美元买下智能体公司 Manus,顺手也把 Manus 创始人肖弘“纳入囊中”。另外据《华尔街日报》7 月报道,Meta 采用“爆炸式 offer”战术:签约金最高达 1 亿美元,决策窗口短至几小时。 而作为 Meta 的前首席 AI 科学家兼 FAIR 创始人的 Yann LeCun,却在 11 月官宣离职创业,聚焦高级机器智能研究项目(Advanced Machine Intelligence,AMI)。 OpenAI CEO 奥特曼直言,今年他见到了职业生涯中“最残酷的人才市场”,Meta 向他的 OpenAI 团队挖人,还抛出炸裂的报价:“签约金 1 亿美元起步,年薪还远高于此”。 从 Meta 到 OpenAI,从谷歌到苹果,从“首席科学家”到“研究负责人”...... 这些名字的变动,正在折射出一件重要的事情——美国科技巨头的 AI 研发重心,正在整体迁移。 不过研究的价值也从未失效,模型训练依然是产业生长的底座。但 AI 行业更看重的,已逐渐变成了把模型转化为可执行系统、并在真实场景中持续创造价值的能力。 还有值得一提的是,这场混战中,大量华人工程师在站上了关键岗位。 为什么今年看起来“裁员”和“抢人”同时发生? 看似矛盾现象的背后,其实是行业对 AI 发展路径的认知正在发生转向:通用人工智能(AGI)的乌托邦式愿景逐渐褪色,特定领域、可落地的超级智能(ASI)成为新共识。 对此,Anthropic 高管 Jack Clark 曾警告“巨变在即,AI 将把世界撕裂为两个平行宇宙”。 更直接的变化在于,AI 正在从“技术突破期”快速切换到“工程兑现期”。裁员与抢人,正是这一阶段转换在人才市场上的投射。 核心矛盾的起点,是大语言模型(LLM)正式迈入平台期。过去数年,“更大参数、更多数据、更高算力”的线性增长逻辑,支撑着 AI 行业的技术狂热与估值飙升。 但到 2025 年,这条路径的边际收益明显下降。顶尖模型的能力天花板逐渐显现,再叠加算力成本的指数级攀升,企业突然发现,“把模型做得更强”的投入产出比已大幅下滑。 这一点在 OpenAI 身上体现得尤为明显,其年营收约 130 亿美元,却要烧掉 90 亿美元维持运营,2028 年亏损甚至可能膨胀至营收的四分之三,算力成本压力倒逼企业必须转向商业价值兑现。 当技术探索的空间收窄,企业关注的重心自然转向三件事:能不能用、能不能卖、能不能规模化。 这一转向,直接改变了 AI 人才的价值排序。 在技术突破期,中高层研究人才的核心价值在于定义方向、探索未知、构建长期技术壁垒;但进入工程兑现期,企业的战略重心变成“把已有的模型能力转化为稳定的系统、可落地的产品和持续的现金流”。 不是 AI 人才变多了,而是“被需要的 AI 能力类型变了”。 2025 年硅谷 AI 人才流动潮中,Meta 是最具冲击力的变量之一:一边以天价薪酬全球争抢工程与产品型人才,一边持续流失 AI 体系核心的研究型高层。 田渊栋被裁、Joelle Pineau 离职、Yann LeCun 话语权旁落,这些并非孤立事件,而是 Meta AI 战略根本转向的集中体现——从“基础研究与产品并行”,彻底转向“以产品为核心的集权化研发体系”。 基础研究不再天然拥有战略优先级,唯有能直接服务产品主线、影响竞争胜负的研究,才能留在权力中心。 这一转向最直观的标志,是 FAIR 实验室的衰落。 2013 年,扎克伯格与 Yann LeCun 共同创立这个以“推动 AI 前沿、造福人类”为使命的基础研究高地,代表着 Meta 对长期 AI 研究的耐心押注——彼时逻辑清晰:基础研究定义能力上限,产品负责兑现价值。 但生成式 AI 浪潮打破了平衡,算力、数据与资本成为核心变量后,组织价值评判标准彻底转向“可转化性”:研究的重要性,不再取决于是否推进认知边界,而在于能否快速落地为产品能力。负责产品落地的 GenAI 团队逐渐成为主线,FAIR 则从“战略源头”退为“技术后方”。 Llama 系列的演进加速了这一趋势。Llama 3 的开源成功让 Meta 成为大厂开源阵营核心玩家,也让管理层明确目标:AI 不仅要领先,更必须渗透进 Meta 所有产品形态。 在此导向下,Llama 4 的规划重点被强拉至多模态能力与应用整合,推理能力、思维链等基础研究被归为“可延后”选项。直到 DeepSeek 与 OpenAI o1 实现推理突破,Meta 才意识到基础能力缺口无法用产品工程弥补,即便抽调 FAIR 团队临时“救火”,路线已难以逆转。 Meta 在 10 月裁掉 600 人,不少 FAIR 老人黯然离场,包括顶级研究员田渊栋。 值得注意的是,这些离开或被边缘化的顶尖研究者并未退场,反而带着对主流 AI 路径的明确判断,分流成截然不同的创业赛道。 最具前沿探索性的,是 Yann LeCun 押注的“世界模型”路线。 作为 FAIR 创始人、图灵奖得主,他始终是主流 LLM 路线的尖锐异议者,长期质疑“堆参数、喂数据”的范式,认为当前模型仅停留在统计拟合,并未真正理解世界。 离开 Meta 后,他创办 Advanced Machine Intelligence Labs(AMI),核心目标是通过建模世界运行规律,构建具备持久记忆、推理与规划能力的系统——这一路线不追逐短期性能指标,而是试图从根源重塑智能实现方式。 另一批研究者选择向现实业务靠拢,Joelle Pineau 是典型代表。 2025 年 5 月,这位 FAIR 体系的核心组织者、Llama 早期技术路线的深度参与者离职,加盟 Cohere 出任首席 AI 官。她长期主导强化学习与对话系统研究,此次转向清晰指向“可控、可部署、能被企业真正使用的 AI”。 而正以“主权模型”重新定位的 Cohere,也借 Pineau 的加入,补齐了研究深度与工程落地之间的关键短板。 还有一条路径,流向了全栈实验室化的创业公司,“PyTorch 之父” Soumith Chintala 是其中的代表。 2025 年 11 月,结束 11 年 Meta 生涯的他加入 OpenAI 前 CTO Mira Murati 创办的 Thinking Machines Lab(TML)。这位曾构建全球 AI 研究基础设施的人直言,离职的原因是希望跳出“极度成功的舒适区”,探索下一代 AI 系统形态。 在 OpenAI 核心研究员持续外流的背景下,TML 正逐渐成为新的承接平台。它以“让强 AI 更可理解、可定制”为方向,集结多位来自大厂的核心成员,凭借高额融资与“开放科学”的研究取向,逐渐成长为能够独立承担前沿探索的“平行实验室”。 答案从 2025 年硅谷科技巨头们的招聘与收编动态就能读出来,这场激烈的人才抢夺赛主要围绕三类核心能力展开:agent、多模态与实时交互、推理和 AI Infra。 首先是 Agent 与可执行系统方向,即能把模型变成“能干活”的系统。 这类人才的能力,不只限于模型训练本身,而是把模型嵌入到可执行、可操作的系统里——包括多步任务规划、工具调用、页面 / 应用直接操作等能力。 其二,多模态在 2025 年不再停留在“能生成图片 / 文字”这种静态功能,而更强调实时感知、持续交互和环境理解。 极具代表性案例,就是 Meta 在 6 月份不仅斥资约 140 亿美元投资并收编 Scale AI,还将其创始人兼 CEO 亚历山大·王(Alexandr Wang) 招致麾下。 亚历山大·王是一位 97 年出生的美籍华人小伙,从 MIT 辍学,后创立了一家做 AI 数据与评测基础设施的公司 Scale AI,为大型科技公司训练最新 AI 模型。 小扎还让这位年轻人和前 GitHub CEO Nat Friedmany 一起领导新成立的 “超级智能实验室(Meta Superintelligence Labs,MSL)”。 这个 MSL 很不简单,据 OpenAI CEO 奥特曼爆料,Meta 给该团队新员工提供签字奖金可达 1 亿美元(约合人民币 7 亿元)! 至于此消息为啥为从奥特曼口中说出,或许是因为小扎从 OpenAI 猛猛“偷家”吧——扎克伯格在他的备忘录中提到了 11 人,其中至少有 6 人是华人,7 人来自 OpenAI。 据 Business Insider 消息,MSI 首发团队成员中,余家辉、赵晟佳、毕树超、Huiwen Chang、Ji Lin、任泓宇、等 6 人都曾在 OpenAI 担任关键模型、关键团队的负责人。 这些人中,有的人曾参与过 Agent 型、多步推理或执行研究,有人则是在多模态、语音 / 视觉理解、后训练 / 交互系统方面有深厚积累的复合型研究人员。 另外,马斯克的 xAI 虽然暂时没有没有统一公开名单,但关于 xAI 的战略规划,曾多次提到多模态能力(尤其与超算中心、NVIDIA 推理能力结合),这类战略需要大量精通多模态模型与分布式系统的工程师来实现。 其三,关于推理和 AI Infra,主要是为了让模型跑得起、跑得稳、跑得便宜。 这里的“推理与 AI Infra”包含两个层面: 推理系统设计与优化:如何让大型模型在实际场景中高速、低成本地响应; 基础设施与可服务化能力:从数据管线、模型发布、调度、监控到弹性伸缩。 这类人才既要懂深度学习,又要懂系统工程、服务架构、调度策略,在 2025 年极度抢手。 比如,英伟达通过与 AI 芯片初创公司 Groq 的顶尖工程师达成协议,引入其联合创始人 Jonathan Ross 及执行团队。 这批人才曾在谷歌等大厂负责高性能、低延迟的 AI 推理芯片架构设计,而优化推理能力正是 Infra 人才的核心一环。 而谷歌这边,也在忙着抢夺 AI 软件工程师,其中高达 20% 的新增 hires 是“回流员工”(boomerang workers),这类岗位几乎全部聚焦于将内部 AI 研发转写入产品 / 系统层,包括推理效率提升、API 服务化框架、企业级部署架构等。 可见,推理效率和基础设施能力已成为 AI 竞争的重要战场,过去仅靠堆算力已无法满足企业级需求。 总而言之,这些都是硅谷 AI 战场上现在被重金争抢的关键能力,远远超出过去单纯“模型参数”和“benchmark 比拼”。 2025 年,顶级 AI 人才并没有离场,只是大家从论文和 Demo,更多地走向了系统、平台与现实世界。而 2025 年的硅谷,也正是在这场无声的人才迁徙中,完成了一次新的方向校准。 参考链接: https://www.ft.com/content/3584197e-a99a-4a06-9386-dc65cf603f45?utm_source为什么 2025 年的硅谷,裁员和抢人同时发生?
谁在离开舞台中央?长期研究型高层的集体“降权”
谁在被疯狂争抢?华人工程师站上关键岗位
可以使用自己的大模型去审查已经有的代码库主要有以下功能(第一次做代码相关的 Agent,佬们请指导
![[开源自荐] 代码考古学家1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/01/20260101155109_6956276d4b663.png!mark)