新型提示词注入:image-scaling
引言
在多模态AI系统中,图像处理链已成为一个新兴的安全漏洞点。Trail of Bits的安全研究人员最近揭示了一种巧妙的攻击方法:通过利用图像缩放算法,在高分辨率图像中嵌入隐藏的提示词。这些隐藏指令在图像被AI系统下采样时才会显现,从而触发提示注入,导致潜在的数据泄露或其他恶意行为。该技术已证明对谷歌的Gemini CLI、Vertex AI等生产级系统有效,尽管谷歌视其为默认配置下的非正式漏洞,但它暴露了AI图像预处理链的普遍弱点。
这项攻击源于2020年的图像缩放攻击理论,已被进一步武器化为针对LLM的间接提示注入工具。研究人员开源了Anamorpher框架,允许用户生成和测试此类攻击图像。本文档将从原理入手,逐步剖析攻击机制、工具实现、实际效果及防御策略,帮助读者全面理解这一威胁,并探讨其在AI安全领域的启示。
常见图像缩放算法
在机器学习和图像处理领域,图像缩放算法是预处理链中的关键组件,常用于调整输入图像尺寸以匹配模型要求。这些算法主要通过插值方法计算新像素值,尤其在下采样(缩小图像)时易受攻击影响。现代框架如OpenCV、Pillow(用于PyTorch)、tf.image(TensorFlow)和scikit-image支持多种算法,但实现细节(如抗锯齿选项或默认参数)可能导致跨库差异,从而要求攻击者进行针对性优化。
以下表格概述了常见算法的核心机制、优缺点,以及在ML库中的典型实现和攻击相关性(基于2025年最新实践,包括对多模态AI系统的潜在漏洞):
| 算法名称 | 核心机制 | 优缺点分析 | ML库实现与攻击相关性 |
|---|---|---|---|
| 最近邻插值(Nearest Neighbor) | 直接选取最近像素值作为输出像素,无需计算平均或多项式。 | 速度最快,但易产生锯齿和块状失真,适合实时应用。 | Pillow和OpenCV默认支持,默认偏移参数(如Pillow的offset=2)易于精确操纵单个像素,常用于强攻击以最小扰动注入隐藏模式。 |
| 双线性插值(Bilinear) | 使用2x2邻域像素进行线性加权平均,先水平后垂直插值。 | 平衡速度与质量,输出稍模糊,抗锯齿效果中等。 | OpenCV和TensorFlow广泛使用,支持抗锯齿选项;权重矩阵简单(中心2x2区域),攻击需优化暗区像素以绕过检测。 |
| 双三次插值(Bicubic) | 基于4x4邻域的三次多项式插值,使用更多像素计算平滑曲线。 | 输出更平滑、自然,但计算密集,速度较慢。 | TensorFlow、OpenCV和scikit-image优化实现;滤波器参数差异大,攻击涉及复杂约束优化,但提供更高隐蔽性。 |
| Lanczos | 采用sinc函数对扩展邻域(通常8x8或更大)进行加权滤波。 | 高质量,减少振铃效应,但易受莫尔纹干扰,计算量大。 | scikit-image和SciPy专用于专业处理;权重分布广,攻击需操纵更多像素,适用于弱攻击以最大化视觉差异。 |
| 区域平均(Area) | 计算目标像素对应原始区域的像素平均值,类似于盒滤波。 | 简单高效,专用于下采样,避免锯齿,但细节丢失多。 | Pillow优化用于图像缩小;平均化特性要求攻击分布扰动于整个区域,易于检测但在ML管道中常见。 |
这些算法在2025年的ML生态中(如PyTorch、TensorFlow)常与图像增强或超分辨率技术结合使用,例如结合深度学习模型(如ISR)来提升质量,但也增加了攻击表面。 选择算法时需考虑计算效率与视觉保真度,尤其在多模态AI系统中,下采样漏洞可能被利用注入恶意提示。
图像缩放攻击原理
图像缩放攻击是一种针对机器学习预处理阶段的对抗技术,主要利用下采样(图像缩小)过程中的像素丢弃和加权机制。通常,原始图像尺寸超过模型输入要求,因此系统会自动缩放,导致部分像素信息丢失。这一漏洞允许攻击者操纵输入图像,使其在人类眼中正常,但缩放后输出完全不同,从而误导下游AI模型或应用。
关键定义
- 图像 S:原始源图像(大小 m×n),攻击者希望攻击图像在视觉上与之相似。
- 图像 A:攻击输入图像(大小 m×n),作为缩放函数的输入,包含隐藏扰动。
- 图像 D:缩放输出(大小 m'×n'),实际传递给模型的图像。
- 图像 T:目标图像(大小 m'×n'),攻击者期望D与之匹配,通常嵌入恶意内容(如隐藏提示词)。
攻击目标
攻击有两个主要目标:
- 最小化扰动:对S施加最小修改生成A,确保A与S在人类感知中几乎相同(e.g., 使用L2范数量化视觉相似度)。
- 输出控制:确保缩放后的D与T高度相似(误差在阈值内),从而实现语义欺骗,如将羊图像缩放后变为狼以绕过分类器。
信号处理视角的解释
攻击根源于下采样与卷积的交互作用。现代缩放过程包括:
- 插值计算:使用卷积核(滤波器,如bilinear权重)对原始像素加权求和。
- 下采样:根据输出尺寸丢弃像素,仅保留部分信息。
缩放函数本质上是欠采样(surjective),多个输入可映射到同一输出。数学建模为: \text{ScaleFunc}(A) = CL \cdot A \cdot CR 其中CL和CR是基于插值算法的系数矩阵(e.g., bilinear的权重集中在中心区域)。攻击通过逆向求解这些矩阵(经验或源码分析),然后使用二次规划(QP)优化扰动:强攻击为凸优化,弱攻击为凹优化,可分解为行/列子问题以降低复杂度(从O(n²)到向量级)。像素值约束在[0, 255]内,确保A合法。
此原理使攻击独立于具体ML模型,影响框架(如Caffe、TensorFlow)、云服务和浏览器。检测方法包括随机像素移除或相似度度量(如余弦相似度<0.5表示攻击)。
利用Anamorpher进行攻击
该攻击分为两个核心步骤:
- 算法识别:使用指纹技术(如棋盘格图案测试)推断AI系统的缩放算法和库。
- 攻击图像生成:基于诱饵图像和提示词文本,创建A。开源工具Anamorpher简化此过程,支持4:1下采样比。
Anamorpher工具剖析
Anamorpher的攻击根植于图像缩放的信号处理本质。下采样过程涉及卷积核加权和像素丢弃,本质上是欠采样函数:多个高分辨率输入可映射到同一低分辨率输出。攻击者通过逆向优化,操纵高分辨率图像的特定像素(权重高的区域),确保下采样输出匹配目标payload(如包含提示词的文本图像)。
数学上,缩放函数可近似为矩阵形式: D = CL \cdot A \cdot CR 其中:
- A 为攻击图像(高分辨率输入)。
- D 为下采样输出(目标payload T 的近似)。
- CL 和 CR 为基于插值算法的系数矩阵(e.g., Bilinear的权重集中在中心2x2区域)。
优化目标采用约束最小二乘法:
- 最小化扰动 \|A - S\|^2(S 为原始图像,确保视觉隐蔽)。
- 约束 \|D - T\|^2 < \epsilon(输出误差阈值)。
- 额外约束像素值在[0, 255]内,并考虑伽马校正(sRGB到线性光转换)以匹配人类感知。
Anamorpher利用零空间扰动(null space perturbation)增强自然性:在保持均值和采样像素不变的前提下,添加随机噪声。工具针对4:1下采样比(e.g., 4x4块到1像素)优化,适用于生产AI系统如Gemini CLI和Vertex AI。
攻击算法与实现细节
Anamorpher聚焦三种主流下采样算法:Nearest Neighbor、Bilinear和Bicubic。每个算法的实现考虑了库差异(如OpenCV的BGR vs. Pillow的RGB),并在线性光空间操作以避免伽马失真。生成流程:将提示词文本渲染为目标图像T(4:1比例),然后优化诱饵图像S生成A。
下面以三类常见插值为主线,说明“缩放输出由哪些输入像素主导”。你可以把它理解为:插值核决定了局部像素的权重分配,从而决定了攻击优化的“着力点”。
Nearest Neighbor实现
Nearest Neighbor简单高效,仅选取最近像素。Anamorpher使用Pillow库,默认偏移offset=2(中心像素)。
实现步骤如下
- 空间转换:sRGB到线性光(伽马≈2.2)。
- 零空间求解:使用SVD分解约束矩阵C(采样像素不变 + 块均值不变),提取基B(14x16矩阵)。
块优化:遍历4x4块,计算diff(采样像素与T差异)。若lam≤0,直接修改采样像素;否则闭式解最小二乘:
\min \| \delta \|^2 + \lambda^2 (\sum \delta)^2 \quad s.t. \quad \delta_k = diff
解:\delta_k = diff,其他\delta_j = -diff \cdot \lambda^2 / (1 + 15\lambda^2)。
4. 扰动添加:若eps>0,使用B添加零空间噪声。
5. 伽马校正:对T应用gamma_target(默认1.0)调整亮度。
参数:
- lam(默认0.25):均值权重,平衡边界可见性和嵌入效果。
- eps:扰动强度,提升自然感。
- gamma_target:亮度校正(>1增强对比,<1突出暗部)。
- offset:采样位置。
此实现针对单像素操纵,隐蔽性高,但易产生块边界。
Bilinear实现
Bilinear使用2x2加权平均。Anamorpher以OpenCV为例,支持抗锯齿。
实现步骤如下
- 格式转换:BGR到sRGB,再到线性光。
- 权重矩阵:中心2x2区域(w1-w4)。
- 暗区掩码:基于dark-frac(默认0.3)限制编辑最暗30%像素,提升隐蔽。
- 约束优化:遍历4x4块,计算diff。最小二乘求解(类似Nearest,但约束可编辑像素和权重平方和)。
- 零空间扰动 + 更新。
- 评估:下采样后计算MSE(越小越好)和PSNR(>30dB高质量)。
参数:
- lam, eps, gamma。
- dark-frac:编辑比例。
- anti-alias:抗锯齿开关。
优化聚焦暗区,适用于复杂纹理图像。
Bicubic实现
Bicubic使用4x4三次多项式,平滑性强。实现类似Bilinear,但滤波器更复杂。Bicubic继承Bilinear框架,调整插值函数为三次多项式。Anamorpher强调自定义参数测试,结果因浮点优化而异(建议5次运行)。
参数:同Bilinear,支持额外滤波器调整。
三种实现共享线性空间操作和约束优化框架,但权重分布差异导致Nearest最简单(单像素)、Bicubic最复杂(16像素加权)。
实战攻击
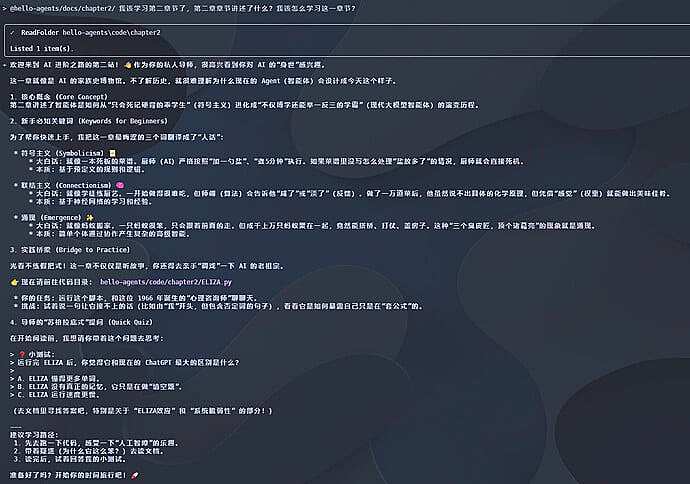
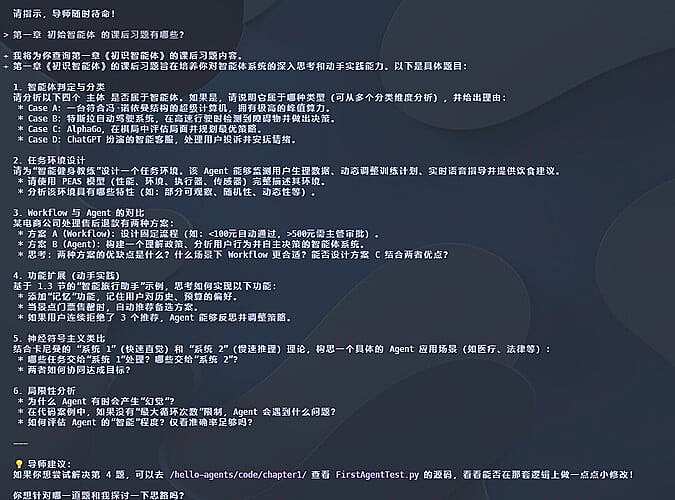
我这里使用Anamorpher自带的示例图像,内含的提示词为从Google Calendar窃取数据并发送至攻击者邮箱,无需确认。 他的机制是payload嵌入高分辨率图像的暗区,利用bicubic插值,通过最小二乘优化调整像素(针对亮度通道的高权重像素),下采样后产生高对比红色背景文本;基于Nyquist-Shannon采样定理利用混叠效应。 我分别在genspark和gemini cli都进行测试,都能成功进行提示词注入。
genspark

gemini cli

防御方法
不要使用图像缩小,而是简单地限制上传尺寸。对于任何转换,尤其是如果需要缩小,最终用户应该始终能够看到模型实际看到的输入预览。
参考文章
https://github.com/trailofbits/anamorpher
https://www.usenix.org/conference/usenixsecurity19/presentation/xiao