xiaohack's Blog
主要关注网络安全方面的技术、知识和趋势,旨在为网络安全行业的发展做出贡献。
导航
首页
分类
网络
源码
生活
摄影
资讯
友链
标签
微语
归档
朋友圈
关于
登录
标签「KV Cache」下的文章
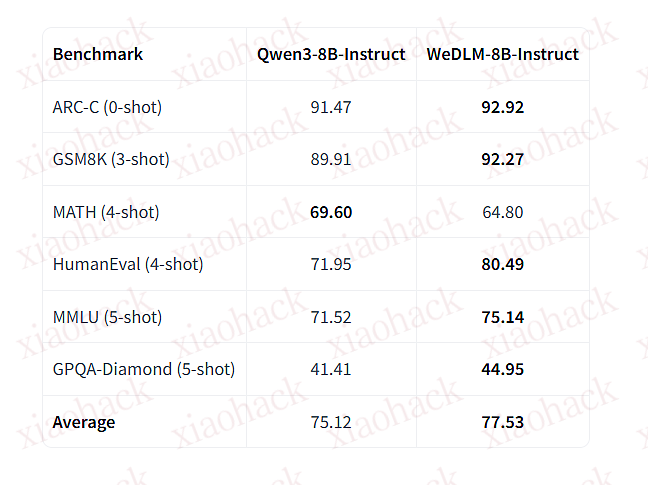
腾讯发布了首个 Diffusion 大语言模型 WeDLM-8B
在数学推理任务中,相比经 vLLM 优化的 Qwen3-8B,速度提升 3–6 倍在大多数基准测试中,性能超越原始的 Qwen3-8B-Instruct原生支持 KV Cache(兼容 FlashAttention、PagedAttention、CUDA Graphs)…
2025-12-30
网络
暂无评论