腾讯发布了首个 Diffusion 大语言模型 WeDLM-8B
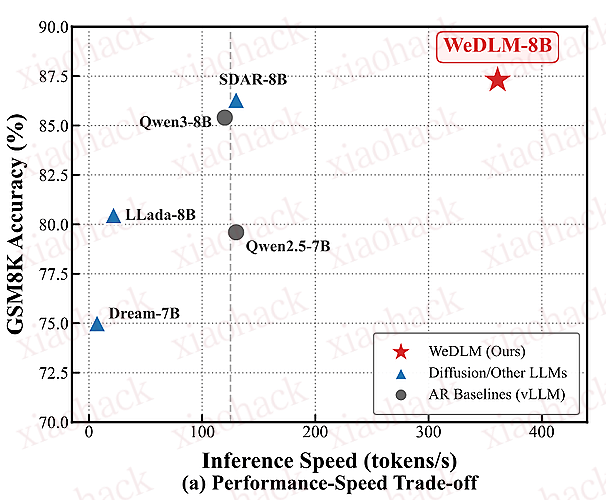
在数学推理任务中,相比经 vLLM 优化的 Qwen3-8B,速度提升 3–6 倍
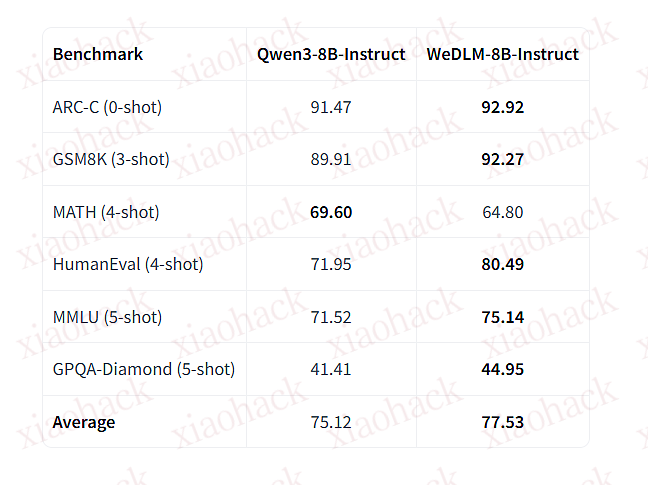
在大多数基准测试中,性能超越原始的 Qwen3-8B-Instruct
原生支持 KV Cache(兼容 FlashAttention、PagedAttention、CUDA Graphs)
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
在数学推理任务中,相比经 vLLM 优化的 Qwen3-8B,速度提升 3–6 倍
在大多数基准测试中,性能超越原始的 Qwen3-8B-Instruct
原生支持 KV Cache(兼容 FlashAttention、PagedAttention、CUDA Graphs)