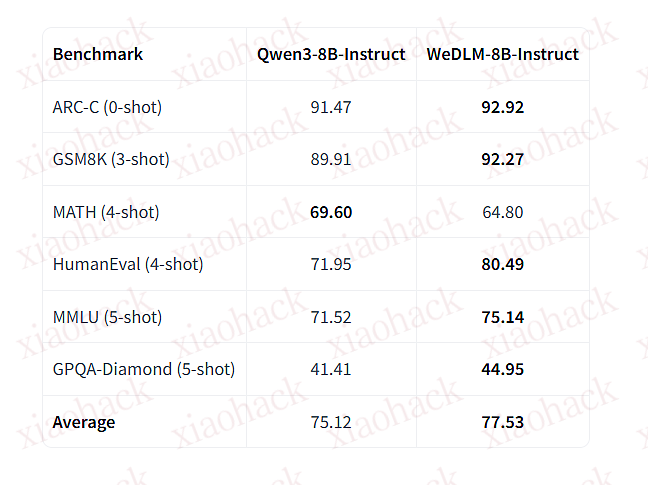
vLLM 推理 GPU 选型指南:显存、KV Cache 与性能瓶颈全解析
为 vLLM 推理有效规划 GPU 规模并进行合理配置,首先需要清晰理解大语言模型处理的两个基本阶段——Prefill(预填充)和 Decode(解码),以及这两个阶段对硬件提出的不同需求。 本指南深入剖析了 vLLM 运行时行为的内部机制,阐明了内存需求、量化和张量并行等核心概念,并提供了将 GPU 选型与实际工作负载相匹配的实用策略。通过探究这些因素之间的相互作用,您将能够准确预判性能瓶颈,并在 GPU 基础设施上部署大型语言模型时,做出明智且具有成本效益的决策。 预填充阶段("读取"阶段) 这是任何请求的第一步。vLLM 接收整个输入提示(用户查询 + 系统提示 + 任何 RAG 上下文),并以高度并行的方式一次性处理所有内容。 解码阶段("写入"阶段) 预填充完成后,vLLM 进入自回归循环以生成输出。 预填充阶段与解码阶段的对比 了解哪个阶段在您的工作负载中占主导地位,对于选择合适的硬件至关重要。 运行时的 KV Cache 在推理过程中,vLLM 高度依赖 KV Cache,用来避免重复计算已经完成的工作。 在 Transformer 中,每个 token 都会在注意力层内被转换为 Key(K) 和 Value(V) 向量。 如果没有缓存机制,模型在生成第 t+1 个 token 时,就必须重新处理整个历史序列(token 0 … t)。 解决方案:KV Cache KV Cache 的作用正是把这些已经计算过的 K / V 向量保存下来并重复利用。 这种机制将注意力计算: 性能提升的代价是 显存占用。 每生成一个新 token,KV Cache 中都会追加新的条目。运行时,KV Cache 的使用量会随着以下因素动态增长: 这正是为什么人们经常说,使用同一个模型的两个工作负载,可能对硬件的需求却天差地别。 例如:一个 70B 模型 本身也许能放进单张 GPU,但如果在长对话中 KV Cache 持续膨胀,服务器仍然可能因为 显存耗尽(OOM)而直接崩溃。 因此,在生产环境中,理解并管理内存行为是部署 LLM 的核心能力之一,这一点在我们卓普云官网博客中的《LLM 微调与部署指南》中也有详细说明。 理解 vLLM 的运行时行为后,下一步是确定模型能否在给定 GPU 上运行,以及它能支持怎样的并发级别或上下文长度。 本节将提供所需的数学公式与决策树,用于计算静态内存需求、估算 KV 缓存增长,并系统性地排查和确定适配问题。 在计算模型大小之前,首先必须理解我们要把模型放进的“容器”是什么。不同的 GPU 在可行性与性能上都有各自明确的硬性限制。 以下是当前主流推理 GPU 的物理显存上限,也是模型部署时不可突破的硬限制。 vLLM 推理与训练的 GPU 对比: 即使模型本身能够装入显存,GPU 架构差异仍会显著影响 vLLM 的实际性能。需要重点关注以下指标: 在 vLLM 能够对外提供推理服务之前,模型必须先将全部权重加载进 GPU 显存(VRAM)。 权重大小完全取决于模型的参数数量以及所选择的数值精度。 模型所需的显存容量(GB)可以使用以下公式进行估算: 显存(GB)≈ 参数量(十亿) × 每个参数所占字节数 下表展示了 Llama 3.1 70B(700 亿参数)模型在不同量化精度下的显存占用情况: 精度选择是决定模型是否可部署的最关键因素。 将一个 70B 模型从 FP16 量化为 INT4,可将静态显存占用减少 75%,使其从“单节点无法运行”变为“可在单张 A100 上运行”。 因此,在 DigitalOcean GPU 服务器等云环境中,量化是实现高性价比部署的必要手段。 如果说模型权重决定模型是否能够启动,那么 KV Cache 决定模型是否能够扩展。 KV Cache 往往被严重低估,这也是推理负载下最常见的 OOM 原因之一。 要准确评估部署规模,必须根据预期的上下文长度与并发请求数,估算 KV Cache 的显存消耗。 在大多数实际业务场景中,精确公式并不适合即时计算。 因此通常采用“每 token 显存系数”的方法进行估算,该方式足以支撑初步容量判断。 简化 KV Cache 公式: KV Cache 总显存(MB) = Token 总数 × 显存系数 其中:Token 总数 = 上下文长度 × 并发请求数 标准显存系数如下表所示: 我们假设,某用户计划运行: 计算 Token 总数:32,000 × 10 = 320,000 tokens 套用标准系数(0.35):320,000 × 0.35 MB = 112,000 MB ≈ 112 GB FP8 选项验证:若启用 FP8 量化缓存,显存占用将降至一半:约 56 GB 精确计算工具与公式 针对边界场景或深度验证,请使用专业公式或在线计算器: Tensor Parallelism(TP)是一种将模型权重矩阵拆分到多张 GPU 上的技术。 它可以让 vLLM 将多张 GPU 视为一张“逻辑大卡”,共享显存资源。 为什么要使用张量并行?张量并行的主要目标是可行性,而非性能优化。 通常在以下场景中启用: 1、模型权重超限:模型体量超过单卡物理承载极限(例如:24GB 显存的 GPU 无法加载 Llama 3 70B 模型) 2、KV 缓存空间耗尽:模型权重虽可加载,但未预留任何 KV 缓存空间,导致无法处理长上下文或高并发请求 虽然张量并行(TP)能极大释放显存,但它也引入了通信开销。在每一层计算完成后,所有 GPU 必须同步它们的部分计算结果。 若需部署多 GPU 环境,可考虑使用 DigitalOcean Kubernetes 来编排 vLLM 服务。 在进入高级配置前,让我们将前几节的数学计算应用到实际场景中。这有助于验证我们对“适配性”的理解,并揭示纯计算中常被忽略的实际约束。 隐藏的显存开销 一个常见的错误是计算 \` 权重 + 缓存 = 总显存需求\`,并假设可以达到 100% 的利用率。实际情况并非如此。 场景 A:轻松适配(标准聊天) 计算: 结论:适配极佳。此配置可应对大规模负载(例如,60 个并发用户,每人 3k 上下文)。 结果:高吞吐量,低成本。 场景 B:“权重超标”(大模型,单GPU) 权重:700 亿参数 x 2 字节 = 140 GB 结论:完全无法适配。模型权重(140 GB)已超过 GPU 物理容量(80 GB)。 要想解决这个问题,必须使用张量并行(2x GPU) 或量化技术(见第 3 节)。 场景 C:“缓存陷阱”(模型能加载,但无法运行) 计算: 结论:有风险 / 适配性差。模型可以加载,但几乎没有可用的工作空间。 如果现在有 10 个并发用户,每人仅能分配到约 3.4k 上下文。一旦有用户粘贴长文档(4k Token),系统就会因显存不足而崩溃。 这个场景给我们一个启发,即权重能放下,不代表工作负载能运行。 此场景通常需要增加 GPU 或选择更小的模型。 场景 D:解决方案(张量并行) 让我们通过增加第二张 GPU 来解决场景 C 中的“缓存陷阱”。这展示了张量并行(TP)如何整合内存资源。 计算: 结论:可用于生产环境。通过增加第二张 GPU,我们从“仅有风险性的 6 GB”缓存空间,提升到了“充裕的 82 GB”。 对于 10 个并发用户情况,现在每人可获得约46k 上下文。显存不足的风险已消除,该部署可以轻松应对 RAG 或长文档处理。 正如前文资源配置场景所示,VRAM 是 LLM 推理的主要瓶颈。量化是一种通过降低数字表示精度的技术,用微小的精度损失换取内存效率和速度的大幅提升。 关键在于区分 vLLM 中使用的两种量化类型,因为它们针对不同的约束条件。 类型一:模型权重量化("静态"优化方案) 这涉及在加载预训练模型之前,对其庞大、静态的权重矩阵进行压缩。 类型二:KV缓存量化("动态"优化方案) 这涉及在序列生成过程中,对存储在内存中的中间键(Key)和值(Value)状态进行压缩。 vLLM GPU精度格式 并非所有量化格式都是相同的。选择取决于可用的硬件架构以及模型大小与精度之间的期望平衡。 策略性应用与权衡 决定何时应用量化需要在实际约束与工作负载敏感性之间取得平衡。量化虽强大,但涉及在部署规划时必须考虑的根本性权衡。 关键考量因素:精度与硬件 在确定具体场景前,请考虑以下两个基础约束: 何时应推荐使用量化 基于上述权衡,量化适用于广泛的现实场景,并且在企业环境中经常是默认选择: 何时应避免使用量化 量化并非普遍适用。有些工作负载对精度损失高度敏感,应尽可能保持在 FP16/BF16 精度: 至此,我们已经探讨了 vLLM 的运行时行为(第 1 节)、内存基础原理(第 2 节)以及量化策略(第 3 节)。 本节将这些概念连接成一个可重复的决策框架。它将引导你从理论走向实践,提供一个结构化的工作流程,用于评估可行性、选择硬件并制定部署计划。 第一步:资源配置需求问卷 要准确配置 vLLM 部署,必须从工作负载描述中提取具体的技术细节。像“快速推理”这样的抽象目标是不够的。使用以下五个问题来收集必要的数据: 第二步:选择模型大小与精度 需求明确后,确定能满足质量要求的最小的模型和最高的精度。 指导原则: 代码/推理:使用 FP16 或 FP8(避免 INT4)。 第三步:硬件可行性检查 使用第 2 节的数学方法进行适配性验证。 工作负载适配(带宽): 标准聊天:需要高算力(L40S)。 第四步:推荐GPU策略 可行性确认后,选择具体的 GPU 型号。可参考以下“速查表”应对常见场景。DigitalOcean 平台可提供以下表格中所有型号的 GPU(其中 B300 GPU 将在 2026 年初上线,可联系卓普云 AI Droplet 进行预约测试)。 第五步:使用指标进行验证 纸上计算并非完美。 1. 运行LLM推理需要多少GPU显存? GPU 显存需求取决于模型大小、精度、上下文长度和并发量。一个粗略的经验法则是:仅就权重而言,FP16 模型每 10 亿参数约需要 2GB。因此,一个 70B 的模型,FP16 权重需要 140GB,但使用 INT4 量化后仅需 35GB。此外,还必须考虑 KV 缓存的内存占用,它会随上下文长度和并发用户数增长。例如,对于一个 70B 模型,32k 上下文长度和 10 个并发用户,FP16 缓存约需 112GB,而 FP8 缓存约需 56GB。 2. vLLM 中张量并行与流水线并行有何区别? 张量并行:将模型权重矩阵在同一层内切分到多个 GPU 上,允许多个 GPU 同时处理同一计算。这整合了显存资源,但需要在每层计算后进行同步,从而引入通信开销。 流水线并行:将模型各层按顺序分配到不同 GPU 上,每个 GPU 处理不同的层。 TP 通常用于单个 GPU 无法容纳整个模型时,而 PP 更常见于训练场景。对于推理任务,当模型超出单 GPU 容量时,TP 是标准的处理方法。 3. 在 vLLM 部署中,何时应使用量化技术? 在以下情况推荐使用量化:模型无法在可用显存中加载时;需要支持更高并发或更长上下文窗口时;或者成本优化是优先考虑事项时。FP8 量化是现代硬件(H100, L40S, MI300X)的理想选择,精度损失极小。INT4 量化是在较小 GPU 上运行大模型的必要手段,但在代码生成、数学及科学计算等对精度敏感的任务中应避免使用。对于聊天和 RAG 类工作负载,量化通常是默认选择。 4. 如何计算KV缓存的内存需求? 可以使用每 token 乘数法进行快速估算:将总 token 数(上下文长度 × 并发量)乘以模型特定的系数。对于小型模型(7B-14B),FP16 缓存系数约为 0.15 MB/token,FP8 约为 0.075 MB/token。对于大型模型(70B-80B),FP16 缓存系数约为 0.35 MB/token,FP8 约为 0.175 MB/token。如需精确计算,可使用公式:总 KV 缓存 = (2 × 层数 × 模型维度 × 序列长度 × 批次大小 × 精度字节数) / (1024³),或使用在线工具如 LMCache KV Calculator。 5. 我可以在 DigitalOcean GPU Droplets 上运行 vLLM 吗? 可以,vLLM 可以部署在 DigitalOcean GPU Droplets 上。DigitalOcean 提供的搭载 NVIDIA GPU 的 Droplets 能够满足 vLLM 的运行要求。部署时,请确保所选 GPU 的显存足以支撑您的模型大小和工作负载。对于追求成本效益的部署,可以考虑使用量化模型(INT4 或 FP8)以便在较小的 GPU 实例上运行更大的模型。DigitalOcean 的 GPU Droplets 提供 NVLink 连接,这在多 GPU 使用张量并行时对保证效率至关重要。 基于对模型大小、精度、GPU 架构、KV 缓存及批处理等因素如何影响性能的基础理解,在接下来的教程中,我们将把这些概念应用到实际的 vLLM 工作负载中。 针对每个用例,我们将围绕三个核心问题来确定最优配置方案: 用例一:交互式聊天与智能助手 用例二:高吞吐量批处理 用例三:RAG 与长上下文推理 为 vLLM 合理配置 GPU 资源,需要深入理解模型大小、精度、上下文长度和并发量之间的根本性权衡。预填充阶段和解码阶段对硬件有不同的需求:预填充阶段需要高内存带宽,而解码阶段则需要高计算吞吐量。量化技术是在现有硬件上运行大型模型的核心调节手段,而张量并行则能突破单 GPU 的限制,实现横向扩展。 成功部署的关键在于将您的工作负载特性与正确的硬件配置相匹配。交互式聊天应用优先考虑算力以实现快速 Token 生成,而 RAG 和长上下文工作负载则需要巨大的显存容量和高内存带宽。遵循本指南概述的资源配置框架,您可以系统地评估可行性、选择合适的硬件,并为生产环境中的工作负载优化您的 vLLM 部署。 准备好在 GPU 基础设施上部署 vLLM 了吗?你可以通过以下资源快速开始: 通过在 DigitalOcean GPU Droplets 上实际部署 vLLM,获得第一手使用体验。你可以在 DigitalOcean 官方文档中学习如何搭建运行环境,并对 vLLM 进行性能优化配置。你也可以通过以下 DigitalOcean 发布在卓普云官网的教程与实践总结,学习更多经验: 如需更多技术指南与最佳实践,欢迎访问 DigitalOcean 英文官网,或咨询 DigitalOcean 中国区独家战略合作伙伴卓普云(aidroplet.com)。vLLM 运行时行为剖析:预填充阶段 vs 解码阶段

将阶段与工作负载及硬件关联
运行时阶段 主要操作 主要硬件约束 主要用例场景 预填充阶段 并行处理长输入。 内存带宽(TB/s)(对快速 TTFT 至关重要) • RAG• 长文档摘要 • 大规模少样本提示 解码阶段 顺序生成输出。 计算能力(TFLOPS)(对快速 Token 生成至关重要) • 交互式聊天与客服 • 实时代码生成 • 多轮智能体工作流 工作机制
带来的收益
代价:动态内存增长

资源配置基础:模型、精度与硬件如何决定适配性
GPU 硬件特性与约束
常见数据中心 GPU 的显存容量
模型权重占用(静态显存)
静态权重计算公式
KV Cache 需求(动态显存)
“现场经验法则”(快速估算)
示例
最终配置方案:
总KV缓存 (GB) = (2 × 模型层数 × 模型维度 × 序列长度 × 批大小 × 精度字节数) / 1024³何时需要使用 Tensor Parallelism(张量并行)
数值实测:资源配置场景分析




量化:“压缩”模型的艺术
精度 / 格式 每个参数占用字节数 精度影响 最佳硬件支持 推荐使用场景 FP16 / BF16 (基准) 2 无(参考标准) 所有现代 GPU 黄金标准。在 VRAM 容量允许时优先使用。 FP8 (8 位浮点数) 1 可忽略 H100, H200, L40S, MI300X 现代默认选择。在新硬件上速度与质量的最佳平衡。KV 缓存理想选择。 AWQ / GPTQ (INT4 变体) \~0.5 低/中 A100, L40S, 消费级显卡 “极致压缩”选项。在较旧或较小 GPU 上运行大模型的必备技术。解码速度优异。 通用 INT8 1 中 旧款 GPU (V100, T4) 传统方案。在新硬件上通常被 FP8 取代,或在追求极限压缩时被 AWQ 取代。 
整合实践:从需求到部署方案
原因:决定 KV 缓存大小(进而决定 OOM 风险)。
原因:KV 缓存需求会成倍增加。
原因:决定您是需要高带宽(H100)还是仅需足够容量(L40S)。
原因:决定您是否可以使用量化(INT4/FP8)来节省成本。
原因:帮助在优化极致速度(H100)与性价比(L40S)之间做出抉择。
聊天/助理:使用 INT4 或 FP8。
如果不能:进行量化(第二步)或增加 GPU(张量并行)。
如果不能:降低并发数、缩短上下文长度,或启用 FP8 KV 缓存。
长文本 RAG/摘要:需要高带宽(H100/A100)。常见问题解答
vLLM GPU推理的实际应用场景
小结
接下来你还可以
在 DigitalOcean GPU Droplets 上部署
体验 DigitalOcean 产品