写在前面,本人目前处于求职中,如有合适内推岗位,请加:lpshiyue 感谢。同时还望大家一键三连,赚点奶粉钱。本系列已完结,完整版阅读课联系本人
高可用不是简单的冗余堆砌,而是无状态化、水平扩展与故障转移三者协同的艺术品
在掌握了系统压测方法论,能够准确评估系统容量边界后,我们面临一个更根本的挑战:如何让系统在真实流量冲击和故障发生时保持稳定?高可用架构设计正是解决这一挑战的核心手段。本文将深入解析无状态化、水平扩展与故障转移三大支柱技术的协同设计,帮助构建真正弹性可靠的系统架构。
1 高可用的本质:从故障避免到故障容忍的哲学转变
1.1 高可用性的核心价值重估
传统观念中,高可用意味着尽可能避免故障,而在分布式系统环境下,这一理念已转变为快速发现和恢复故障。根据Gartner的统计,企业IT系统平均每分钟的宕机成本超过5600美元,对于大型电商平台,这个数字可能达到数万美元。
高可用设计的哲学转变体现在三个层面:
- 从完美预防到快速恢复:接受故障必然性,专注于最小化MTTR(平均修复时间)
- 从单体坚固到分布式韧性:通过系统设计而非组件质量保证可用性
- 从人工干预到自动化愈合:建立系统自愈能力,减少人工依赖
这种转变使我们需要重新定义高可用的成功标准:不是追求100%无故障,而是确保故障发生时业务影响可控、恢复过程自动。
1.2 可用性等级的理性定位
不同业务场景对可用性有不同要求,理性定位是避免过度设计的第一步:
99.9%可用性(年停机时间≤8.76小时)适合内部管理系统
99.95%可用性(年停机时间≤4.38小时)适合一般业务系统
99.99%可用性(年停机时间≤52.6分钟)适合核心业务系统
99.999%可用性(年停机时间≤5.26分钟)适合金融交易系统
确立合理的可用性目标后,我们才能有针对性地选择技术方案,在成本与可靠性间找到平衡点。
2 无状态化:弹性架构的基石
2.1 无状态设计的本质与价值
无状态化不是简单去除会话数据,而是将状态与计算分离,使应用实例变得可替代。这种分离是水平扩展和故障转移的基础。
有状态架构的典型问题:
// 问题示例:会话绑定导致扩展困难
@RestController
public class StatefulController {
// 会话状态存储在内存中
private Map<String, UserSession> userSessions = new ConcurrentHashMap<>();
@GetMapping("/userinfo")
public String getUserInfo(HttpSession session) {
UserSession userSession = (UserSession) session.getAttribute("currentUser");
// 此实例绑定特定用户会话,无法随意替换
return userSession.getUserInfo();
}
}
状态内嵌导致实例不可替换
无状态化改造方案:
@Configuration
@EnableRedisHttpSession // 启用Redis会话存储
public class StatelessConfig {
// 会话外部化配置
}
@RestController
public class StatelessUserController {
@GetMapping("/userinfo")
public String getUserInfo(@RequestHeader("Authorization") String token) {
// 从Redis获取用户信息,不依赖本地状态
String userJson = redisTemplate.opsForValue().get("session:" + token);
User user = JsonUtil.fromJson(userJson, User.class);
return user.toString();
}
}
状态外置使实例可任意替换
2.2 无状态化的多层次实践
无状态化需要在不同层级实施协同策略:
应用层无状态:会话数据外部化到专用存储(Redis Cluster)
服务层无状态:API设计保证请求自包含,不依赖服务实例内存状态
任务层无状态:计算任务参数和结果完全自包含,支持任意重调度
无状态设计的业务适配策略:
- 完全无状态:适合查询类、计算型业务(商品查询、价格计算)
- 外部状态:适合需要会话保持但无需实例绑定的业务(用户登录状态)
- 轻量状态:适合短暂业务流程,状态生命周期与请求周期一致
2.3 无状态架构的代价与应对
无状态化不是银弹,需要认识其代价并制定应对策略:
性能代价:状态外部化增加网络开销,需要通过缓存、批处理优化
一致性挑战:分布式状态需要处理并发更新,采用乐观锁或版本控制
复杂度增加:需要引入额外组件(Redis、ZooKeeper),增加运维复杂度
合理的无状态化是有选择的无状态,而非盲目去除所有状态。核心是确保实例可替换性,而非完全消除状态。
3 水平扩展:流量压力的分布式化解
3.1 水平扩展的本质与架构前提
水平扩展通过增加实例数量而非提升单机性能来应对流量增长,其有效性直接依赖于无状态化程度。
水平扩展的架构前提:
- 无状态设计:实例间无数据依赖,可任意增减
- 负载均衡:流量按策略分发到多个实例
- 服务发现:动态感知实例上下线,实时更新路由
- 健康检查:自动隔离故障实例,保证流量只会到达健康节点
3.2 分层扩展策略
系统不同层级需要采用不同的水平扩展策略:
接入层扩展:通过DNS轮询、全局负载均衡实现流量入口扩展
# Nginx上游服务配置示例
upstream backend_servers {
server 10.0.1.10:8080 max_fails=3 fail_timeout=30s;
server 10.0.1.11:8080 max_fails=3 fail_timeout=30s;
server 10.0.1.12:8080 backup; # 备份节点
least_conn; # 最少连接负载均衡
}
接入层通过集群化实现扩展
应用层扩展:无状态服务实例水平扩展,结合自动伸缩策略
# Kubernetes HPA配置示例
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: frontend-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: frontend
minReplicas: 3
maxReplicas: 100
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
应用层根据负载自动伸缩
数据层扩展:通过分片、读写分离等技术实现数据访问扩展
-- 数据库分片示例:用户数据按ID分片
-- 分片1:用户ID以0-4结尾
CREATE TABLE users_1 (
id BIGINT PRIMARY KEY,
name VARCHAR(100),
-- 其他字段
);
-- 分片2:用户ID以5-9结尾
CREATE TABLE users_2 (
id BIGINT PRIMARY KEY,
name VARCHAR(100),
-- 其他字段
);
数据层通过分片实现水平扩展
3.3 水平扩展的粒度控制
科学的水平扩展需要精细化粒度控制,避免过度或不足扩展:
单元化扩展:按业务单元而非整体系统进行扩展,如用户服务独立于订单服务扩展
弹性伸缩:基于预测和实时指标动态调整实例数量,平衡性能与成本
分级扩展:核心服务与非核心服务差异化扩展策略,确保关键业务资源
4 故障转移:从被动应对到主动容错
4.1 故障检测:快速发现的艺术
有效的故障转移始于精准的故障检测,需要在及时性与准确性间找到平衡:
多层次健康检查策略:
# Kubernetes就绪与存活探针配置
apiVersion: v1
kind: Pod
metadata:
name: web-application
spec:
containers:
- name: web
image: nginx:latest
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
timeoutSeconds: 3
failureThreshold: 1
通过探针机制实现精准故障检测
智能故障判定:结合多个指标(响应时间、错误率、资源使用率)综合判断,避免单指标误判。
4.2 故障隔离:防止雪崩的屏障
故障转移不仅是将流量从故障实例移走,更重要的是隔离故障影响:
熔断器模式:在连续失败达到阈值时自动熔断,避免重试风暴
@Component
public class ProductService {
@CircuitBreaker(name = "productService",
fallbackMethod = "getProductFallback")
public Product getProduct(Long productId) {
return remoteProductService.getProduct(productId);
}
public Product getProductFallback(Long productId, Exception ex) {
return cacheService.getBasicProduct(productId);
}
}
熔断器防止故障扩散
隔离策略:
- 线程池隔离:不同服务使用独立线程池,避免资源竞争
- 信号量隔离:控制并发调用数,防止资源耗尽
- 超时控制:设置合理超时时间,避免长时间阻塞
- 限流降级:流量超过阈值时自动降级,保护系统不被冲垮
4.3 流量切换:无缝转移的技术实现
故障转移的核心是流量重路由,需要在不同层级实现协同:
负载均衡器切换:健康检查失败时自动从路由表中移除故障节点
upstream backend {
server 10.0.1.10:8080 max_fails=3 fail_timeout=30s;
server 10.0.1.11:8080 max_fails=3 fail_timeout=30s;
server 10.0.1.12:8080 backup;
# 故障转移配置
proxy_next_upstream error timeout http_500 http_502 http_503;
}
负载均衡器实现自动故障转移
服务网格流量管理:基于Istio等服务网格实现细粒度流量控制
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: product-service
spec:
host: product-service
trafficPolicy:
outlierDetection:
consecutiveErrors: 5
interval: 10s
baseEjectionTime: 30s
maxEjectionPercent: 50
服务网格提供高级故障检测与转移能力
5 三大支柱的协同设计
5.1 协同工作的架构模式
无状态化、水平扩展与故障转移不是孤立技术,而是相互依赖的有机整体:
无状态化赋能水平扩展:只有无状态设计,才能实现真正的无缝水平扩展
水平扩展增强故障转移:多实例为故障转移提供目标节点,使转移成为可能
故障转移保障水平扩展:在扩展过程中,故障转移确保个别实例故障不影响整体
协同架构示例:
用户请求 → 负载均衡器(故障检测/转移)
↓
无状态应用集群(水平扩展)
↓
集中式状态存储(Redis集群)
↓
数据存储层(分片/主从)
5.2 协同设计的反模式与陷阱
伪无状态陷阱:表面无状态但实际存在隐性状态依赖(如本地缓存、文件存储)
不平衡扩展:计算层扩展但数据层成为瓶颈,或相反
过度转移:过于敏感的故障检测导致频繁转移,反而影响稳定性
单点转移:故障转移机制本身存在单点故障
5.3 协同效能的度量体系
三大支柱的协同效果需要可度量的指标验证:
无状态化程度指标:
- 实例启动时间(应小于30秒)
- 请求路由一致性(任意实例处理结果相同)
- 状态外部化比例(超过90%状态外部化)
水平扩展效能指标:
- 线性扩展比(实例增加与性能提升比例)
- 扩展速度(从触发到完成扩展的时间)
- 资源利用率(避免过度或不足扩展)
故障转移质量指标:
- 故障检测时间(秒级检测)
- 转移恢复时间(分钟级恢复)
- 转移成功率(超过99%的转移成功)
6 实战案例:电商平台高可用架构演进
6.1 单体架构的高可用改造
初始状态:单体应用,会话绑定,数据库单点
改造步骤:
- 无状态化改造:用户会话外置到Redis集群
- 水平扩展准备:应用容器化,配置负载均衡
- 故障转移基础:数据库主从分离,读写分离
- 渐进式迁移:先读流量,后写流量;先非核心功能,后核心功能
改造效果:可用性从99.9%提升至99.95%,扩展时间从小时级降至分钟级
6.2 微服务架构的高可用深化
架构特点:服务拆分,分布式依赖,复杂调用链
深化措施:
- 精细化无状态:API网关无状态化,业务服务按需无状态
- 弹性扩展策略:基于业务优先级差异化扩展策略
- 智能故障转移:基于调用链分析的精准故障定位和隔离
深化效果:可用性提升至99.99%,故障恢复时间从30分钟降至5分钟以内
总结
高可用架构的本质是通过无状态化、水平扩展、故障转移三大支柱的协同设计,构建能够容忍故障、快速恢复的弹性系统。
核心洞察:
- 无状态化是基础:只有解耦状态与计算,才能实现真正的弹性
- 水平扩展是手段:通过分布式架构将集中式风险分解为可管理单元
- 故障转移是保障:在故障发生时快速隔离和恢复,最小化业务影响
- 协同设计是关键:三大支柱必须统一设计,相互配合,而非孤立优化
成功的高可用架构不是追求零故障,而是确保在故障发生时:
- 系统能够快速检测并定位问题
- 故障影响被有效隔离,防止扩散
- 业务流量被无缝转移到健康实例
- 系统能够自动恢复,减少人工干预
在云原生时代,随着Kubernetes、服务网格等技术的成熟,高可用能力已经日益平台化、标准化。然而,技术选型只是起点,真正的挑战在于根据业务特点合理运用这些能力,构建既可靠又经济的高可用体系。
📚 下篇预告
《CDN与边缘缓存策略——静态、动态与签名鉴权的组合拳》—— 我们将深入探讨:
- 🌐 缓存层次体系:浏览器缓存、边缘缓存、中心缓存的协同分工
- ⚡ 动态内容加速:边缘计算、智能路由与协议优化技术
- 🔐 安全缓存挑战:签名URL、权限验证与敏感内容保护
- 📊 缓存效能优化:命中率提升、失效策略与成本平衡
- 🚀 边缘架构演进:从内容分发到边缘计算的范式转变
点击关注,构建高效安全的全球内容分发体系!
今日行动建议:
- 评估现有应用的无状态化程度,制定状态外部化改造路线
- 设计水平扩展的容量规划与自动伸缩策略
- 建立多层级的故障检测与转移机制,定期进行故障演练
- 制定三大支柱协同效能的度量体系,持续优化高可用能力












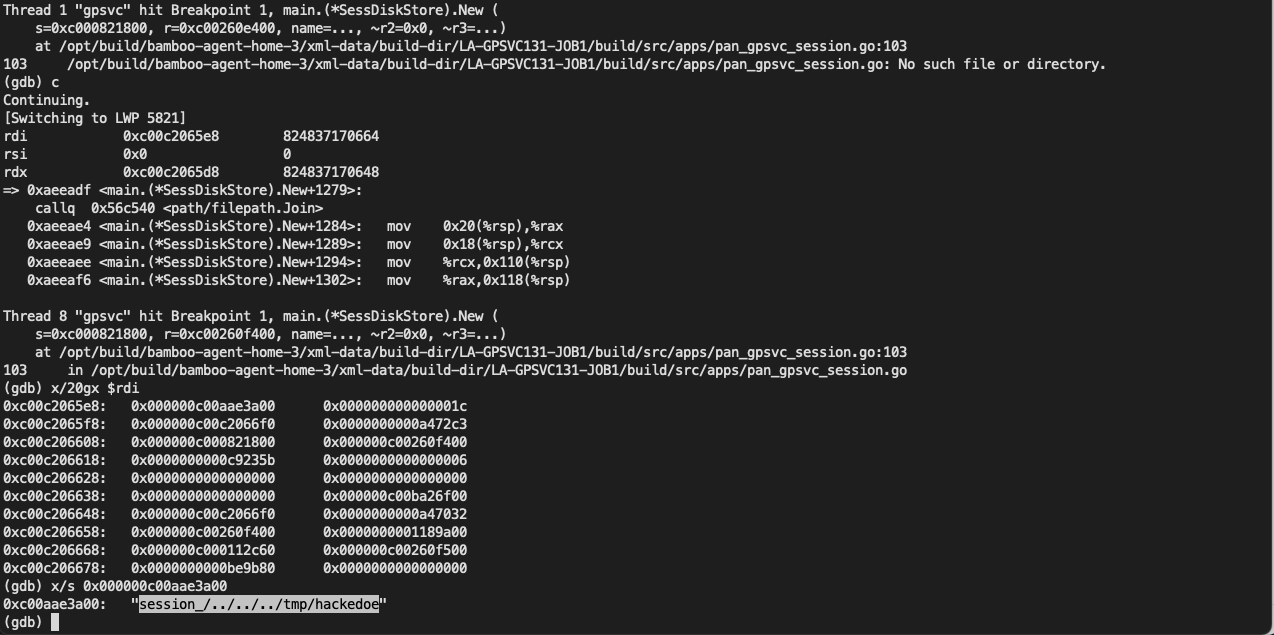

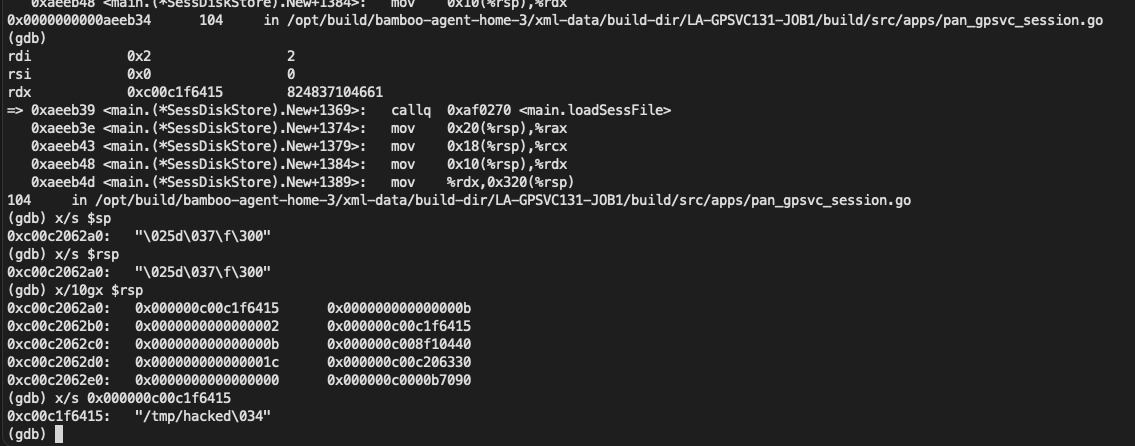
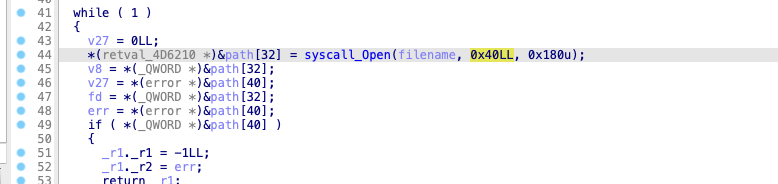
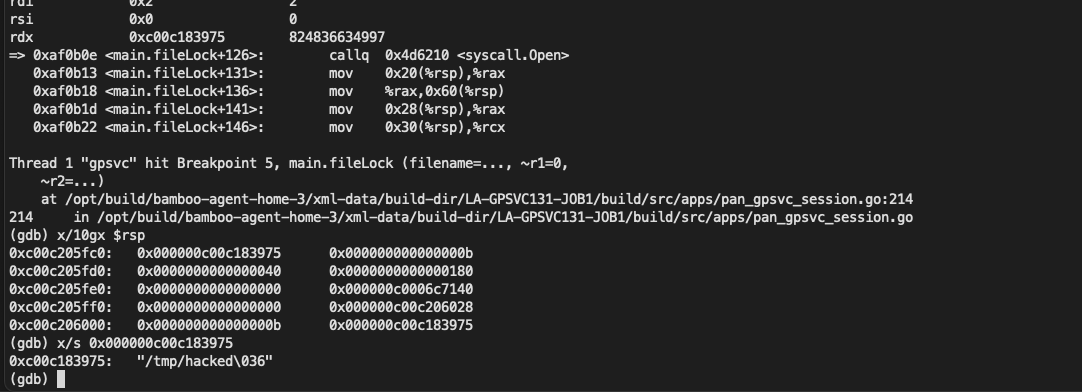






 今天跟大家分享一个etcd的内存大量占用的问题,这是前段时间在我们开源软件Easegress中遇到的问题,问题是比较简单的,但是我还想把前因后果说一下,包括,为什么要用etcd,使用etcd的用户场景,包括etcd的一些导致内存占用比较大的设计,以及最后一些建议。希望这篇文章不仅仅只是让你看到了一个简单的内存问题,还能让你有更多的收获。当然,也欢迎您关注我们的开源软件,给我们一些鼓励。
今天跟大家分享一个etcd的内存大量占用的问题,这是前段时间在我们开源软件Easegress中遇到的问题,问题是比较简单的,但是我还想把前因后果说一下,包括,为什么要用etcd,使用etcd的用户场景,包括etcd的一些导致内存占用比较大的设计,以及最后一些建议。希望这篇文章不仅仅只是让你看到了一个简单的内存问题,还能让你有更多的收获。当然,也欢迎您关注我们的开源软件,给我们一些鼓励。