分享一个我自用的 “穿着铠甲的 MCP” 工具
一、工具简介
Vortex(能将一切纳入 “怀中” 的漩涡)是一个穿着铠甲的 MCP 工具,使用 Rust 构建,高性能、低资源开销,为你 “年迈” 的电脑省点力气(哈哈~~~)。
其实吧,我们都知道,MCP 工具领域大多都是用 node 或 python 实现的,毕竟简单,代码好写,至于性能的,毕竟只是自己本地跑,也无伤大雅的,这也是为什么这么多的 MCP 工具都喜欢用 node 或 python 了(咳咳~~,话说,这个怎么几个人用 Java 写 MCP 呢?这个分发起来真是头疼啊~,总不能带个 JVM 遍地跑,哈哈,当然虽说现在 native 技术还不错,但毕竟不是与生俱来的 “能力”,我是不太想踩这个坑)。
最终我还是选择了 Rust,因为我非常喜欢这门语言(我不是专业户),她那简洁且极其优美的语法让整个代码看起来无比的舒服,且极具艺术与观赏性,好了,吹完了,你们有意见的可以发话怼我了 !
不过,有一说一哈,Rust 绝对的类型安全(不考虑 Unsafe Rust)确实是其它很多语言难以企及的,TS 中 any、Python 中的 Any,Go 中的 any(interface {} 别名)、C# 中的 object 和 dynamic、Java 中的 Object、C 中的 void* 等等,这那个不是需要你极具猜想力的盲盒?运行时的类型断言的代码相比大家都写过,这起码你还能知道类型,要是不知道具体类型的,直接反射搞起来~~~ (也还行~~~ 哦,对了,还有神奇的 NullPointerException)。
不知道各位道友啥感受,反正我自己受不了这种能够 “包容万物” 的 Object 和 any,看代码都费劲(我每次掉头发都是因为我在想:这个 Object 中到底放的是啥呢? 嗯~~~顺着代码调用链多找几个源文件就明白了,同时也半小时过去了…)。
当然了,其它这些语言好学呀,这点 Rust 确实…
这个世界从来不是非黑即白、非利即弊的,学习它们的思想,在适合的地方用好它们就行了,但是,“信仰” 咱得有!
好了,就说这么多吧,下面开始分享工具及其用法,至于源码,后面看心情了~~~
事先声明毕竟是我个人自用工具,工具中有一些工具具有危险性,使用与否全凭自愿哈。
二、工具安装
这里我只提供 MacOS 和 Windows 的版本,暂时没有 Linux 的版本(使用 Linux 开发的道友们对不住了哈~)
夸克网盘链接(附件大小限制,纯属无奈之举):
我用夸克网盘给你分享了「Vortex MCP」,点击链接或复制整段内容,打开「夸克 APP」即可获取。
/~52113A8qbo~:/
链接:https://pan.quark.cn/s/e59c8a3ba6ff

1、vortex-mcp
MacOS:
Apple M 系列芯片的选择 vortex-mcp.mac.arm64.zip 下载;Intel 芯片的用户应该不多了吧?如果有,评论区留言,我再更新(我太懒了~)。
Windows:
直接选择 vortex-mcp.win.x86.zip 下载。
2、vortex-companion
这是 MCP 工具的一个伴侣 App,主要用于危险命令的同意授权、用户提问以及 scp 文件上传下载的进度显示,完全可选,不强绑定,但是非常的推荐(基于 Tauri 的,也非常省资源)。
MacOS:
Apple M 系列芯片的选择 Vortex MCP Companion_0.1.0_universal.dmg 下载;Intel 芯片的用户同上,评论区留言。
Windows:
直接选择 Vortex MCP Companion_0.1.0_x64-setup.exe 下载。
安装很简单,解压后就双击,然后下一步下一步就行了。
三、工具使用
vortex-mcp 工具支持的环境变量:
| 环境变量 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| 核心配置 | |||
VORTEX_NAME | 字符串 | - | 你的聊天工具名称(可选) |
| 数据库连接 | |||
VORTEX_DATABASES | 字符串列表(分号分隔) | - | 数据库连接字符串,格式:<driver>://<user>:<pass>@<host>:<port>/<database>?name=<connection_name>支持驱动: mysql, postgres, sqlite |
| SSH 服务器 | |||
VORTEX_SSH_SERVERS | 字符串列表(分号分隔) | - | SSH 服务器连接字符串,格式: 密码认证: ssh://user:password@host:port?name=<connection_name>密钥认证: ssh://user@host:port?name=<connection_name>&private_key=/path/to/key |
| Redis 实例 | |||
VORTEX_REDIS | 字符串列表(分号分隔) | - | Redis 连接字符串,格式:redis://[:password]@host:port/db?name=<connection_name> |
| API 密钥 | |||
VORTEX_WEB_SEARCH_API_KEY | 字符串 | - | Tavily API 密钥(用于 Web 搜索 / 爬取),自行获取 |
VORTEX_DOCS_API_KEY | 字符串 | - | Context7 API 密钥(用于文档查询)自行获取 |
| Shell Guard 安全设置 | |||
VORTEX_SHELL_GUARD_ENABLED | 布尔值 | true | 启用 / 禁用危险命令检测 |
VORTEX_SHELL_GUARD_MAX_FILES | 整数 | 100 | 触发确认提示的文件数量阈值 |
VORTEX_SHELL_GUARD_MAX_TOTAL_SIZE_MB | 整数 | 100 | 触发确认提示的总文件大小阈值(MB) |
VORTEX_SHELL_GUARD_TIMEOUT_SECS | 整数 | 10 | 影响分析超时时间(秒) |
| 确认超时设置 | |||
VORTEX_DANGEROUS_CONFIRM_TIMEOUT_SECS | 整数 | 25 | 危险命令确认超时时间 |
VORTEX_OVERWRITE_CONFIRM_TIMEOUT_SECS | 整数 | 25 | 文件覆盖确认超时时间 |
VORTEX_ASK_USER_TIMEOUT_SECS | 整数 | 90 | 提问用户交互超时时间 |
MCP 配置:
{ "mcpServers": { "vortex": { "command": "vortex-mcp", "args": ["--enable-fs"], // 这个参数可选 "env": { "GITHUB_TOKEN": "ghp_your-token", // 这个可选,如果你要用 gh 命令的话,最好设置上 "VORTEX_SSH_SERVERS": "ssh://root:123456@192.168.100.66?name=我的66服务器;ssh://root:123456@192.168.100.88?name=我的88服务器", "VORTEX_DATABASES": "postgres://postgres:123456@192.168.100.66:5432/postgres?name=我的66数据库;postgres://postgres:123456@192.168.100.88:5432/postgres?name=我的88数据库", "VORTEX_WEB_SEARCH_API_KEY": "tvly-dev-your-key", "VORTEX_DOCS_API_KEY": "ctx7sk-your-key" } } } } 小提示上面的环境变量都是可选的,你不配置对应的环境变量,就不会出现对应的工具,工具是按需加载的。
数据库 / 服务器密码 / 名称中的特殊字符如果有特殊字符,要使用 URL 编码,一切都是按照 URL 规范来的。
四、效果展示
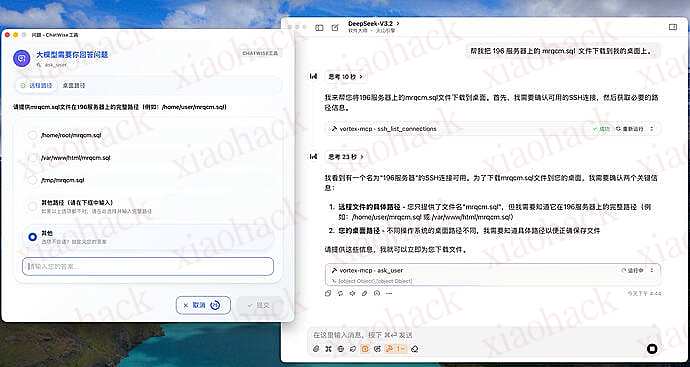
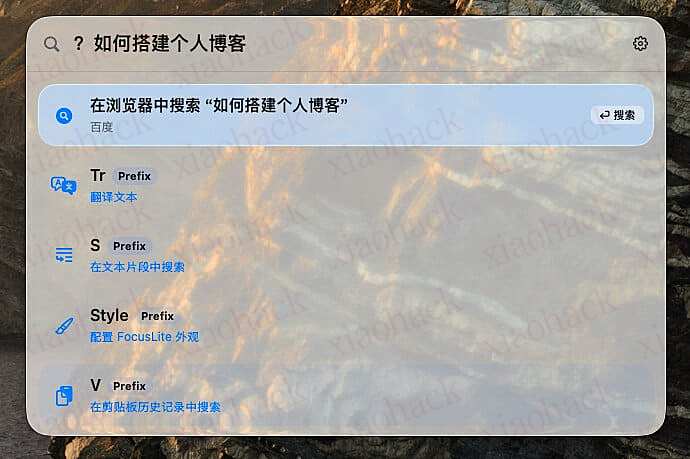
询问用户问题:
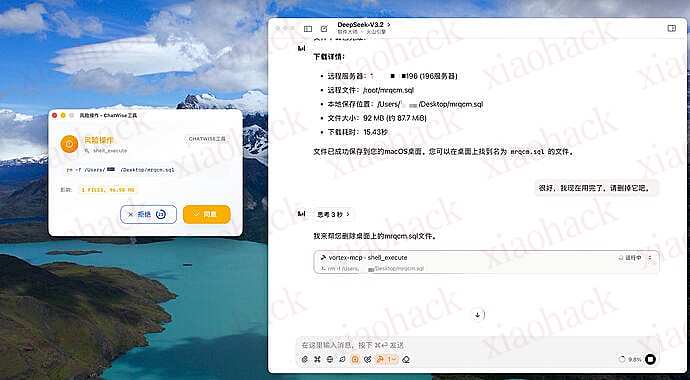
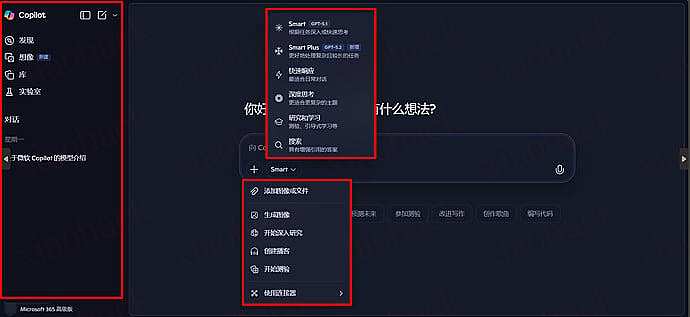
下载服务器文件:

确认危险命令:

























![[开源自荐] 极简但好用的提示词管理器2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/21/20260121212314_6970d342ea9c3.png!mark)
![[开源自荐] 极简但好用的提示词管理器3](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/21/20260121212317_6970d345292ef.png!mark)
![[开源自荐] 极简但好用的提示词管理器5](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/21/20260121212323_6970d34b57d87.png!mark)
![[开源自荐] 极简但好用的提示词管理器4](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/21/20260121212320_6970d3486fe0b.png!mark)


























































