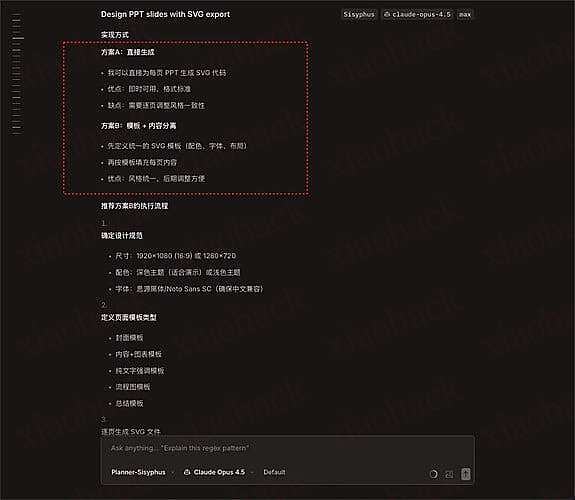
js 代码
// 这里的 main 函数会接收当前的配置(config),修改后返回
function main(config) {
// 1. 定义我们需要的节点分组和对应的正则
// 格式:[组名, 正则表达式, 图标(可选)]
const regionFilters = [
['🇭🇰 香港节点', /(HK|Hong|Kong|香港|🇭🇰)/i],
['🇯🇵 日本节点', /(JP|Japan|日本|🇯🇵)/i],
['🇺🇸 美国节点', /(US|America|美国|🇺🇸)/i],
['🇸🇬 新加坡节点', /(SG|Singapore|新加坡|🇸🇬)/i],
['🇹🇼 台湾节点', /(TW|Taiwan|台湾|🇹🇼)/i],
['🇰🇷 韩国节点', /(KR|Korea|韩国|🇰🇷)/i]
];
// 辅助函数:检查是否是垃圾节点(剩余流量、官网等)
const isBadProxy = (name) => {
return /剩余|到期|重置|官网|客户端|备用|过期|错误|流量|时间/i.test(name);
};
// 2. 准备分组的节点容器
const groups = {
'🇭🇰 香港节点': [],
'🇯🇵 日本节点': [],
'🇺🇸 美国节点': [],
'🇸🇬 新加坡节点': [],
'🇹🇼 台湾节点': [],
'🇰🇷 韩国节点': [],
'🌍 其他地区': [],
'♻️ 自动选择': [] // 所有可用节点
};
// 3. 遍历现有节点,进行分类
const proxies = config.proxies || [];
proxies.forEach(proxy => {
const name = proxy.name;
// 过滤垃圾节点
if (isBadProxy(name)) return;
// 加入“自动选择”全集
groups['♻️ 自动选择'].push(name);
let matched = false;
// 尝试匹配特定地区
for (const [groupName, regex] of regionFilters) {
if (regex.test(name)) {
groups[groupName].push(name);
matched = true;
break; // 一个节点只归入一个主地区
}
}
// 如果没匹配到任何主要国家,放入“其他地区”
if (!matched) {
groups['🌍 其他地区'].push(name);
}
});
// 4. 定义新的策略组结构
const newProxyGroups = [
{
name: '🚀 节点选择',
type: 'select',
proxies: [
'♻️ 自动选择',
'🇭🇰 香港节点',
'🇯🇵 日本节点',
'🇺🇸 美国节点',
'🇸🇬 新加坡节点',
'🇹🇼 台湾节点',
'🇰🇷 韩国节点',
'🌍 其他地区',
'DIRECT'
]
},
{
name: '♻️ 自动选择',
type: 'url-test',
url: 'http://www.gstatic.com/generate_204',
interval: 300,
tolerance: 50,
proxies: groups['♻️ 自动选择'].length > 0 ? groups['♻️ 自动选择'] : ['DIRECT']
},
// 生成各个地区的 url-test 组
...regionFilters.map(([name]) => ({
name: name,
type: 'url-test',
url: 'http://www.gstatic.com/generate_204',
interval: 300,
tolerance: 50,
// 如果该地区没节点,回退到 DIRECT 防止报错
proxies: groups[name].length > 0 ? groups[name] : ['DIRECT']
})),
{
name: '🌍 其他地区',
type: 'select', // 其他地区用手动选择比较好,因为可能包含不同国家
proxies: groups['🌍 其他地区'].length > 0 ? groups['🌍 其他地区'] : ['DIRECT']
},
{
name: '📲 电报消息',
type: 'select',
proxies: ['🚀 节点选择', '🇸🇬 新加坡节点', '🇭🇰 香港节点', '🇺🇸 美国节点']
},
{
name: '🤖 OpenAI',
type: 'select',
proxies: ['🇺🇸 美国节点', '🇯🇵 日本节点', '🇸🇬 新加坡节点', '🚀 节点选择']
},
{
name: '🐟 漏网之鱼',
type: 'select',
proxies: ['🚀 节点选择', 'DIRECT']
}
];
// 5. 定义规则集 (Rule Providers)
const ruleProviders = {
reject: {
type: 'http',
behavior: 'domain',
url: 'https://cdn.jsdelivr.net/gh/Loyalsoldier/clash-rules@release/reject.txt',
path: './ruleset/reject.yaml',
interval: 86400
},
icloud: {
type: 'http',
behavior: 'domain',
url: 'https://cdn.jsdelivr.net/gh/Loyalsoldier/clash-rules@release/icloud.txt',
path: './ruleset/icloud.yaml',
interval: 86400
},
apple: {
type: 'http',
behavior: 'domain',
url: 'https://cdn.jsdelivr.net/gh/Loyalsoldier/clash-rules@release/apple.txt',
path: './ruleset/apple.yaml',
interval: 86400
},
google: {
type: 'http',
behavior: 'domain',
url: 'https://cdn.jsdelivr.net/gh/Loyalsoldier/clash-rules@release/google.txt',
path: './ruleset/google.yaml',
interval: 86400
},
proxy: {
type: 'http',
behavior: 'domain',
url: 'https://cdn.jsdelivr.net/gh/Loyalsoldier/clash-rules@release/proxy.txt',
path: './ruleset/proxy.yaml',
interval: 86400
},
direct: {
type: 'http',
behavior: 'domain',
url: 'https://cdn.jsdelivr.net/gh/Loyalsoldier/clash-rules@release/direct.txt',
path: './ruleset/direct.yaml',
interval: 86400
},
private: {
type: 'http',
behavior: 'domain',
url: 'https://cdn.jsdelivr.net/gh/Loyalsoldier/clash-rules@release/private.txt',
path: './ruleset/private.yaml',
interval: 86400
},
telegramcidr: {
type: 'http',
behavior: 'ipcidr',
url: 'https://cdn.jsdelivr.net/gh/Loyalsoldier/clash-rules@release/telegramcidr.txt',
path: './ruleset/telegramcidr.yaml',
interval: 86400
},
cncidr: {
type: 'http',
behavior: 'ipcidr',
url: 'https://cdn.jsdelivr.net/gh/Loyalsoldier/clash-rules@release/cncidr.txt',
path: './ruleset/cncidr.yaml',
interval: 86400
},
lancidr: {
type: 'http',
behavior: 'ipcidr',
url: 'https://cdn.jsdelivr.net/gh/Loyalsoldier/clash-rules@release/lancidr.txt',
path: './ruleset/lancidr.yaml',
interval: 86400
},
applications: {
type: 'http',
behavior: 'classical',
url: 'https://cdn.jsdelivr.net/gh/Loyalsoldier/clash-rules@release/applications.txt',
path: './ruleset/applications.yaml',
interval: 86400
}
};
// 6. 定义规则 (Rules)
const rules = [
'DOMAIN-KEYWORD,augment,🇺🇸 美国节点',
'RULE-SET,google,🇺🇸 美国节点',
'DOMAIN-KEYWORD,google,🇺🇸 美国节点',
'DOMAIN-KEYWORD,antigravity,🇺🇸 美国节点',
'DOMAIN-SUFFIX,goog,🇺🇸 美国节点',
'RULE-SET,applications,DIRECT',
'DOMAIN,clash.razord.top,DIRECT',
'RULE-SET,private,DIRECT',
'RULE-SET,reject,REJECT',
'RULE-SET,icloud,DIRECT',
'RULE-SET,apple,DIRECT',
'RULE-SET,proxy,🚀 节点选择',
'DOMAIN-KEYWORD,github,🚀 节点选择',
'RULE-SET,direct,DIRECT',
'RULE-SET,telegramcidr,📲 电报消息',
'GEOIP,LAN,DIRECT',
'GEOIP,CN,DIRECT',
'RULE-SET,lancidr,DIRECT',
'RULE-SET,cncidr,DIRECT',
'MATCH,🐟 漏网之鱼'
];
// 7. 写入配置
config['proxy-groups'] = newProxyGroups;
config['rule-providers'] = ruleProviders;
config['rules'] = rules;
// 返回修改后的配置
return config;
}