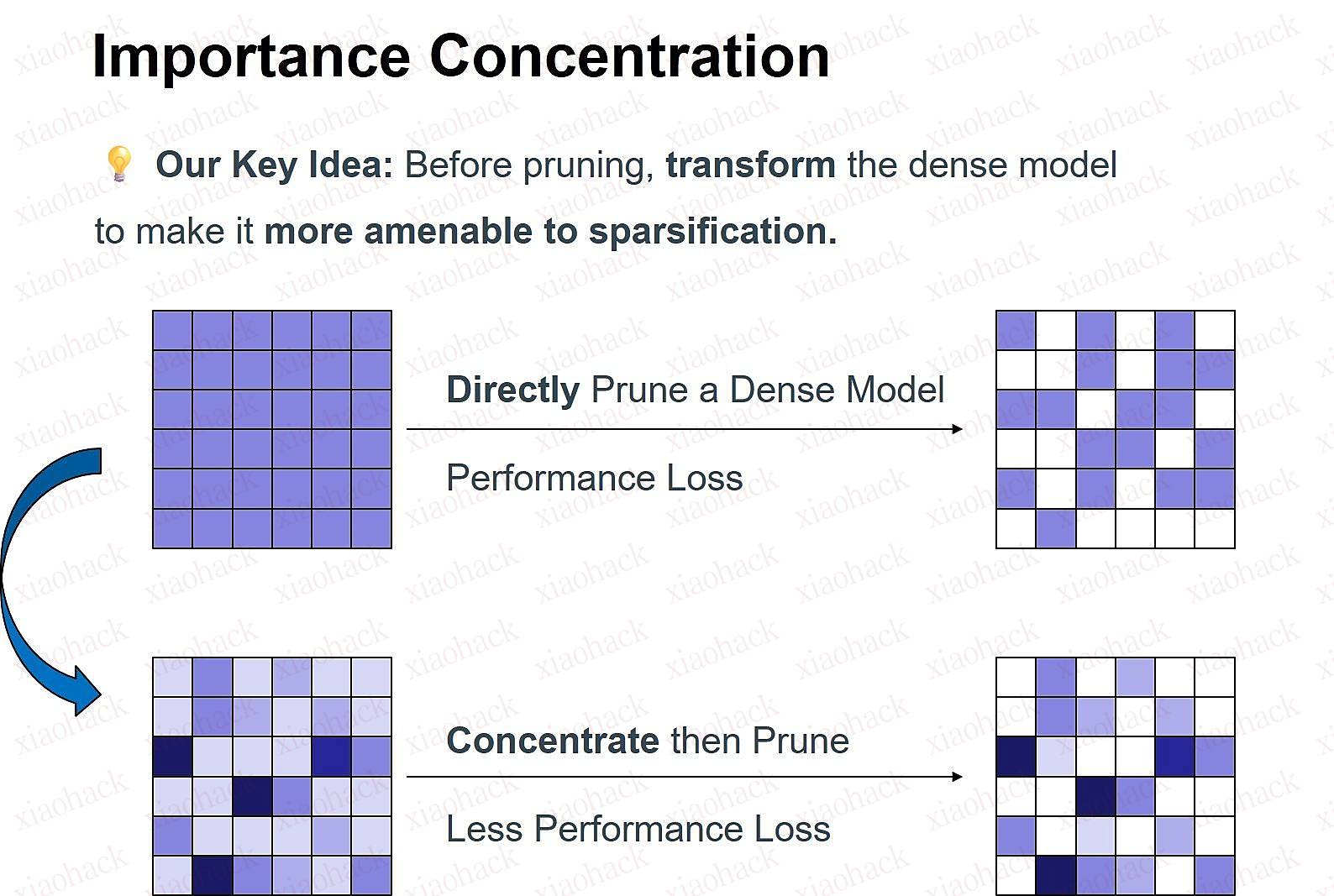
SGLang 团队是业界专注于大模型推理系统优化的技术团队,提供并维护大模型推理的开源框架SGLang。近期,美团M17团队与SGLang团队一起合作,共同实现了LongCat-Flash模型在SGLang上的优化,并产出了一篇技术博客《LongCat-Flash: Deploying Meituan’s Agentic Model with SGLang》,文章发表后,得到了很多技术同学的认可,因此我们将原文翻译出来,并添加了一些背景知识,希望更多同学能够从LongCat-Flash的系统优化中获益。(阅读全文)
基于这一理念,我们与复旦大学计算与智能创新学院 周扬帆教授团队 展开联合研究,设计并实现了 KuiTest —— 一套基于 大众通识 的 无规则(Rule-free)UI 功能测试系统。KuiTest 能够像人一样,理解按钮、图标等交互组件的含义,预测点击后的合理结果,并据此自动校验实际界面反馈是否符合预期,从而在无需手工脚本的情况下完成功能测试。该工作已在美团 App 的多个业务中落地应用,并产出论文《KuiTest: Leveraging Knowledge in the Wild as GUI Testing Oracle for Mobile Apps》,已被国际顶级软件工程会议 ICSE 2025(CCF-A 类会议)的 Software In Practice Track(软件工程应用实践)收录。
[2] SoM(Set-of-Mark)策略:Yang J, Zhang H, Li F, et al. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v [J]. arXiv preprint arXiv: 2310.11441, 2023.
[3] CLIP(Contrastive Language–Image Pre-training)模型:Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision [C]//International conference on machine learning. PMLR, 2021: 8748-8763.
Anthropic 提醒用户:“Cowork 是一个研究预览版,由于其 agentic 的特性以及可访问互联网,存在独特风险。”官方建议用户警惕“可能表明存在提示注入的可疑行为”。然而,由于该功能面向的是普通大众而非仅限技术用户,PromptArmor 表示认同 Simon Willison 的观点:“要求普通、非程序员用户去警惕‘可能表明提示注入的可疑行为’,这是不公平的!”
此前,Every 团队提前获得权限,Dan Shipper、Kieran Klaassen 直播测试了该产品并分享了使用体验。期间,Anthropic Claude Cowork 项目核心成员 Felix Rieseberg 参与解读了产品设计思路。Felix 介绍,Cowork 是一个快速上线、先交给大家看怎么应用的产品,只用了 1.5 周就完成了开发,Felix 表示未来将以用户反馈为核心快速迭代。此外,工程师 Boris Cherny 还在 X 上透露,该产品的全部代码都是由 Claude Code 编写的。
Kieran:这又回到一个老问题了。比如 Boris 就非常擅长把 Claude Code 做成一种让用户在使用过程中逐渐发现“自己到底想要什么”的工具。那你们在 Cowork 里有没有类似的策略?比如给我们一些“积木式”的东西?能不能加自己的插件或 Skills?Claude Code 很酷的一个地方在于它特别好 hack、特别可塑,你们面向非程序员的 Cowork 是不是也有类似理念?
Felix:对,非常强调可组合性。你刚才提到 Boris 推动 Claude Code 早发布、快迭代、看用户怎么用,其实特别巧,我们之所以能这么快上线,很大程度上也是 Boris 在推动我说,“你应该早点给大家看看,看他们会怎么用”。(注:Boris Cherny 是 Claude Code 核心创作者)
至于可组合这一点,过去几周、甚至最近两个月里,我自己感受最深的,是我越来越依赖 Skills。以前我可能会去写 MCP 工具,或者为 Claude 专门做一套很定制化的东西,现在我更多是直接写 Skills。
举个例子,我最近在给自己做一个马拉松训练计划。我写了一个小程序,从不同平台抓取我的运动数据;然后在一个 Skill 里写清楚:如果你要帮我做训练计划,请按这些原则来。现在,只要你在 Claude AI 里装过的 Skill,都会自动加载到 Cowork 里。而且我觉得这只会越来越重要,尤其是模型越来越聪明,比如 Opus 4.5 版本,对 Skills 的遵循能力真的非常强。
所以目前来说,Skills 大概是我们最主要、也最“可 hack”的入口。
统一的“泛化入口”趋势
Dan:太棒了。你刚才提到未来会有更少的 UI 形态。这是不是也意味着,围绕“聊天是不是 AI 的最终形态”这个争论,你其实是在押注自然语言会长期存在?也就是说,我们最终不会有越来越多复杂的 UI,而是更少的界面,人只需要和一个 Agent,或者一个能调度其他 Agent 的 Agent 对话?你们现在推动的方向,某种程度上是不是就类似今天 Claude Code 所展现出来的那种形态?
Claude Cowork 的核心定位是为非技术用户提供 Claude Code 级别的 AI 协作能力,其最显著的突破在于重构了 AI 使用逻辑,从传统“发提示词→等回复”的一问一答模式,升级为“异步协作”模式。
与普通 Claude 聊天相比,Claude Cowork 专为“长时间工作”设计,具备持续推进任务直至完成的能力。直播中展示的典型案例包括:审计过去一个月的日历并分析与目标的匹配度、抓取 PostHog 数据统计按钮点击量、分析 Every 咨询业务的竞品、整理下载文件夹、校对 Google Docs 文案等。这些任务均需 AI 持续“浏览”、推理,部分任务耗时可达一小时左右,远超普通 AI 聊天的响应速度。
另外在体验细节上,产品仍有诸多优化空间:一是 UI 打磨不足,任务列表仅按时间排序,缺乏视觉区分度,部分内容存在“懒加载”导致展示不及时;二是权限管理不够直观,普通用户难以清晰判断 AI 是在本地还是云端运行,文件夹访问权限需手动配置易造成困惑;三是“询问用户”功能存在逻辑缺陷,可能在用户未响应时自动跳过问题,且选项数量和字符数存在限制;四是对复杂应用(如 Google Docs)的适配尚不完善,相关操作容易失败。
针对不同用户,测评团队给出了针对性使用建议:非技术用户可将其视为“升级版聊天功能”,用日常任务直接尝试,逐步适应异步协作模式;重度用户可尝试通过 Skills 定制个性化功能,探索组合使用的可能性。他们表示,所有用户均需保持好奇心,忽略“三个月前 AI 做不到”的固有认知,在每一次产品更新后重新尝试核心需求,毕竟 AI 能力每隔几个月就会发生巨大迭代。
最终,测评团队给出的评分结论为:“理念绿牌,当前执行黄牌”。理念层面,产品开创性地将 Claude Code 级别的异步协作能力开放给非技术用户,推动了 AI 协作范式的转变,具备极高的探索价值;执行层面,因 UI 粗糙、部分功能逻辑不完善等问题,当前体验仍有较大优化空间。
当 AI 的能力边界不断拓展,从“聊天对话”延伸至购物付款等“办事时代”,新的问题也随之浮现:AI 操作是否获得用户明确授权?资金交易过程是否足够安全?更换设备或应用后,服务体验能否保持连贯?
ACT 协议的诞生正是为破解这些问题而来。支付宝为其搭建了 “委托授权域”“商业交互域”“支付服务域”“信任服务域” 四大核心基础设施标准,实现 AI 操作全流程可追溯、可验证,让人更放心;支持自动化交易流程,减少不必要的人工干预,提升服务效率;统一多平台服务标准,避免体验的割裂。
与传统付款模式不同,在 ACT 协议的规则框架下,AI 仅承担下单操作的执行角色,付款环节始终由用户主导或自主授权。在保障资金安全的前提下,为用户大幅节省时间成本。而对商家而言,未来接入 AI 原生应用时,只需按照协议标准配置统一接口,即可对接全渠道入口,无需单独进行复杂的 API 开发,大幅降低对接成本。
目前,ACT 协议可使用在 AI 代买、企业自动化采购等多元场景,并提供两种付款模式:一是即时付款,用户与 AI 实时对话,基于推荐列表自主决策,确认后完成付款授权与身份验证,适用于 AI 点外卖、日常购物等高频场景;二是委托授权,用户可提前设定时间窗口、金额上限、商家范围等条件,即便离线无指令,AI 也能自动监测商品动态并完成下单结算,适用于机票、酒店预订等场景。
该协议最大限度遵循兼容性、隐私性、开放性三大原则,全面适配现有商业与支付系统,并将伴随 AI 行业技术发展持续优化。支付宝同时表示,正积极推动更多支付服务商、商家与平台、AI 开发者、智能终端生态厂商加入,共同完善协议内容,共建 AI 商业信任新生态。
随着 AI 原生应用能力的持续升级,“AI 代办” 服务日渐普及,支付作为其中特殊且关键的环节,正成为全球科技企业的布局焦点。此前,OpenAI 联合 Stripe 推出协议以支持 ChatGPT 结账功能;近期,谷歌也发布 AI 购物全流程通用商务协议(Universal Commerce Protocol,简称 UCP),将实现用户在 Gemini 内直接下单。
据 Apple 介绍,Apple Pay 在上线之初就以提供简单、安全、私密的支付体验为目标,安全与隐私毫无疑问是重中之重。当用户将银行卡与 Apple Pay 绑定使用时,Apple 并不会在云端服务器存储用户的实体卡号信息,而是会以经过加密的专属设备账号存储在设备的安全元件中;若将同一张银行卡绑定到不同设备上,不同设备上的 Apple Pay 支付卡也将获得不同的账号号码。
能够得到全球范围内如此多家银行与网络的合作支持,为 Apple Pay 提供功能适配,就已经能够说明这项功能的安全性有多完善了。据 Apple 服务业务高级副总裁 Eddy Cue 日前公布的数据显示,Apple Pay 仅在 2025 一年就阻止了超过 10 亿美元的欺诈性交易。
众所周知,在过去十年里,Apple Pay 支持添加的大陆地区发行卡种仅限有银联标识的信用卡和借记卡,其它卡种如 Visa 和 Mastercard 等则不支持添加;如果想要添加这些外币卡种,则只能添加港澳台地区或海外发行的相关卡片。
现在,这一限制终于迎来解除,Visa 成为首个在中国大陆地区支持本地接入的国际卡组织,由大陆地区银行机构发行的 Visa 银行卡已在 1 月 15 日正式支持接入 Apple Pay 中,前往港澳台地区或出境旅游将更为便利。
我们从 Apple 方面了解到,即日起已经支持添加 Visa 卡片至 Apple Pay 的银行有:
中国工商银行 (Visa 信用卡)
中国银行 (Visa 信用卡)
中国农业银行 (Visa 信用卡)
交通银行 (Visa 信用卡)
招商银行 (Visa 信用卡)
中信银行 (Visa 信用卡)
平安银行 (Visa 信用卡)
兴业银行 (Visa 信用卡)
中信银行 (Visa 借记卡)
在未来几个月内,上海浦东发展银行、中国建设银行、中国民生银行、中国光大银行等更多银行发行的 Visa 信用卡也将陆续支持添加至 Apple Pay 中。据了解,大陆地区发行的 Mastercard 万事达卡,也同样将在未来数月内支持接入 Apple Pay 支付使用。
虽然目前在国内使用 Visa 或 Mastercard 的商铺相对而言不多,但除了使用 iPhone 和 Apple Watch 在线下实体刷卡以外,我们还能在 iPhone 或 iPad 上通过支持的 app 使用 Apple Pay 付款。此外,在 iPhone、iPad 和 Mac 的 Safari 浏览器中,只要线上商家支持,都可以选择使用 Apple Pay 交易结算,享受安全便捷的支付体验。
据介绍,在全球范围内支持通过 Visa 交易的商户,都可以使用添加进 Apple Pay 的国内 Visa 银行卡刷卡交易。对于国内发行的双币银行卡——即同时配备银联和 Visa 标识的同一张卡片——现在在添加至 Apple Pay 时,可以选择添加银联或 Visa 卡片,或者同时加入两种不同标识的两张卡片。
当然,目前 Apple Pay 添加 Visa 银行卡的功能才刚上线,难免可能会在部分银行的适配、卡片识别或商户受理范围等细节上出现差异或问题,实际体验仍有待进一步观察与完善。
有了开头就是好事,也期待 Apple Pay 能在不久的未来继续扩展更多银行和组织的相关卡片支持,以及增加更多新的使用功能,为用户带来更多便利及安全体验。
前面提到 DLSS 的全称是 Deep Learning Super Sampling(深度学习的超采样),9 月上线的《赛博朋克 2077》 2.0 版本更新中所搭载的 DLSS 3.5,则将这项超采样能力扩展到了提高分辨率、帧率之外——让深度学习参与光线追踪最终呈现效果的生成环节。
光线重建的核心理念在于,将光线追踪光照处理流程中的人工设计组件,改为效率更高、由深度学习驱动的 AI 模型。在大量训练素材的积累下,光线重建就像经验丰富的画家,不仅有更优质的工具,对游戏内的环境和世界也有更独特、更专业的看法和理解;他知道如何融合不同的颜色、纹理和运动,他熟知如何尽可能保留细腻的光照效果,并能善用各种手法来呈现各种光照效果。
1 月 15 日,联发科发布天玑 9500s 与天玑 8500 芯片。两款芯片在硬件层面对生成式推理与多模态模型作出深度优化,原生支持全球主流大语言模型(LLM / MLLM)及 Stable Diffusion 图像生成模型,并引入 AI 超清晰长焦算法、天玑 AI 语义分割引擎与 AI 反光炫光消除技术。同时,芯片支持端侧 AI 实况照片美化与照片编辑,以及基于端侧 AI 算力的通话、会议和文件内容 AI 摘要功能。
按照 K. Anders Ericsson 提出的「10000 小时定律」,要将一项技能练至世界级水平,需要投入 1 万小时。而对比上述两个例子,我最初认为自己两年来投入了不少时间在排球上,但实际上,这 350 小时与 1 万小时相比只是九牛一毛。虽然我的目标并非达到世界级水平,但若仅从 10000 小时的标准来看,这个时间显然远远不够。
大家一想到 AI,就会想到两个东西,一个是 ChatGPT,另外一个是 Claude Code。它们就是做 To C 和 To B 的典范。
对于 To C 来说,大部分人大部分时候不需要用到那么强的智能,可能今天的 ChatGPT 和去年相比,研究分析的能力变强了,但是大部分人大部分时候感受不到,更多把它当作搜索引擎的加强版,很多时候也不知道该怎么去用,才能把它的智能激发出来。
但对于 To B 来说,很明显的一点是智能越高,代表生产力越高,也就越值钱。所以,大部分时候很多人就是愿意用最强的模型。一个模型是200美元/月,第二强或者差一些的模型是50美元/月、20美元/月,我们今天发现很多美国的人愿意花溢价用最好的模型。可能他的年薪是20万美元,每天要做10个任务,一个非常强的模型可能10个任务中八九个做对了,差的是做对五六个,问题是你不知道这五六个是哪五六个的情况下,需要花额外精力去监控这个事情。
Benjamin Brundage是安全公司Synthient的22岁创始人,这家初创公司帮助企业检测代理网络并了解这些网络如何被滥用。Brundage在准备期末考试期间进行了大量关于Kimwolf的研究,他在2025年10月下旬告诉KrebsOnSecurity,他怀疑Kimwolf是Aisuru僵尸网络的一个新的基于Android的变种。Aisuru在去年秋天曾被错误地指责为多起破纪录DDoS攻击的元凶。