国内税真的太重了
最近在整退税,查看了一下每个月都差不多交 1500+个税,12 月份甚至 3200 ,拿个两三万的工资生活在一线城市,加上平时出门吃饭,开车加油生活各处都有隐形税,如此高的生活成本税务成本,根本剩不下几个钱,何谈提振内需消费
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
最近在整退税,查看了一下每个月都差不多交 1500+个税,12 月份甚至 3200 ,拿个两三万的工资生活在一线城市,加上平时出门吃饭,开车加油生活各处都有隐形税,如此高的生活成本税务成本,根本剩不下几个钱,何谈提振内需消费
开始同事对接了阿里百炼,发现 qps 少的吓人,并且无工作流,需要自己实现。对于中小企业开发团队不友好。
后面提出来 Coze 。直到前两天阿里销售过来聊提到 AgentScope ,不清楚长期用和这个开源“AgentScope”有没有一些建议,和已经使用过的友友们的心得。
如今虽然云服务越来越普及,但不少企业特别是金融、医疗、政务等对数据管控要求严格的行业,依然更倾向于选择本地托管服务器。这种模式让企业能在自有或可控的物理环境中部署服务器,既享受专业数据中心的设施优势,又保留对数据的完全控制权。 本地托管的核心优势在于数据自主可控。服务器放在企业指定的机房或数据中心,数据完全在企业管控范围内,不需要经过第三方传输或存储。对于涉及商业机密、用户隐私或合规要求的业务来说,这种物理隔离带来的安全感是远程托管难以替代的。在极云科技的本地托管方案中,我们还为客户提供独立的机柜空间、专属门禁和监控系统,进一步强化物理安全。 网络性能也是重要考量。本地部署意味着数据不需要经过公网传输,访问延迟更低,带宽质量更稳定。对于需要频繁进行内部数据交换、或者运行实时性要求高的应用(比如高频交易、实时渲染)来说,这点尤为关键。极云科技为本地托管客户提供可定制的网络架构,支持万兆互联和混合云专线接入。 当然本地托管也有些现实挑战需要面对。前期需要投入服务器硬件和配套设备,建设或租用符合标准的机房空间,配备专业的运维团队。不过从长远来看,对于数据量大、业务稳定的企业,本地托管的总体成本可能会更低。极云科技提供的托管方案支持客户自带设备,也提供硬件租赁选项,帮助企业平衡初期投入和长期收益。 维护管理确实需要专业能力。从电力保障、环境控制到系统更新、安全防护,每个环节都需要专业技术支持。极云科技的本地托管服务包含7×24小时现场运维,客户既可以完全自主管理,也可以选择由我们的专业团队负责日常维护,灵活度很高。 总的来说,本地托管特别适合对数据主权、网络性能和业务连续性要求高的场景。它让企业在享受专业机房环境的同时,保持对关键数据和系统的完全掌控。 如果你正在评估服务器部署方案,欢迎了解极云科技的本地托管服务。我们在全国多个核心城市拥有高标准数据中心,提供从机柜租用、网络连接到运维支持的全套解决方案,为你的关键业务提供稳定可靠的运行环境。
先说说我的背景:前端出身,但后端、数据库、运维、产品、UI 都摸过一些。典型的啥都会一点、啥都不精通。以前做项目经常是懂个大概,知道该用什么技术栈,遇到深坑就得花大把时间查资料、踩坑。工作里时间又被各种会议和杂事碎片化,很难在某个方向钻得特别深。
但最近半年感觉明显不一样了。
AI 接入工作流之后(主要是 Claude 、GPT 以及一些基于 AI 的工具),从需求分析、原型设计、代码骨架到测试用例、部署脚本,甚至运营文案,整个流程的效率提升太明显了。我开始能真正把各个环节串起来,独立且快速交付完整产品。
举几个最近做的项目:
项目 A - 前后端 + iOS App
一个完整的产品,从需求到上线都是我一个人负责。前端页面、后端接口、数据库设计、iOS 客户端的视图和交互,全套搞定。AI 帮我生成了大量接口模板、基础组件和错误处理逻辑,省了很多重复劳动,一共花费 2 个周(不包含上架)。
项目 B - 公司官网 + 后台管理系统(一天 MVP )
这个比较夸张,从零到可用的 MVP 真的只花了一天。就一个公司简介发起需求分析,原型设计、前端页面、CRUD 后台、部署脚本、基本 SEO 、测试框架,大部分是靠工具快速搭起来的。我主要做的是业务逻辑和上线前的检查。
项目 C - 黄酒智能配方小程序
这个涉及大模型调用,需要设计 prompt 、做结果过滤、处理异常、防刷、数据存储等。AI 在 prompt 模板和错误处理上帮了很多,我负责把业务逻辑、稳定性和安全性补全,一共花费 2 天(不包含上线)。
说这些主要是想表达:按我的经验来看,以前这些项目,要么组个 3-5 人的小团队干几周,要么一个人单干得憋几个月,但是现在在 AI 的加持下,两周不到,我自己一个人就能完成并交付,放到以前,是我自己不敢想象的。特别是开发 ios App ,去年我下半年我还在找人做项目,现在自己一个人就能完成了。
几点实际感受:
1. 效率放大了,但判断力变得更重要
AI 能搞定大量模板化工作:样式框架、接口示例、测试用例、CI 配置。但"做对"还是要靠人——业务边界在哪、数据一致性怎么保证、安全策略怎么设计、性能怎么权衡,这些 AI 给不出最终答案。
2. 广度的价值被放大,但深度仍然是护城河
我现在能独立做的事情多了,覆盖面变宽了。但感觉项目变大变复杂的话,还是会遇到真正的硬骨头(分布式一致性、复杂性能调优、安全攻防),还是要靠深度积累才能搞定。
3. 把 AI 工作流当成体系来积累
我现在积累的不只是 prompt 模板,更多是一套可复用的 skill (技能配置)、rules (规则集)、command (指令库)。比如针对不同场景的专用技能包、代码审查规则、部署流程指令等。把这些结构化地沉淀下来,每次新项目都能直接调用,效率提升很明显。
4. 沟通和产品感更值钱了
代码实现成本下降后,真正能拉开差距的,是产品理解、系统设计、跟团队和用户沟通的能力。能把模糊需求变成清晰的可交付产品,这个很难被完全自动化。
当然也有些担心:
想听听大家的看法:
顺便说一句,如果有团队在找能快速把想法做成 MVP 的人(前端/后端/小程序/大模型接入都能搞),可以站内私信聊聊。我也想听听市场上实际的需求是什么样的,作为下一步职业规划的参考。
非常期待大家的经验分享——尤其是那些已经在团队里落地 AI 工作流的朋友。
比如拿起手机准备点外卖,结果回个微信就忘了
想用手机开空调,解锁时在小红书界面,就不自觉刷起来了
vLLM 是一款专为大语言模型推理加速而设计的框架,实现了 KV 缓存内存几乎零浪费,解决了内存管理瓶颈问题。 更多 vLLM 中文文档及教程可访问 →https://go.hyper.ai/Wa62f 源码 examples/offline_inference/tpu.py
from vllm import LLM, SamplingParams
prompts = [
"A robot may not injure a human being",
"It is only with the heart that one can see rightly;",
"The greatest glory in living lies not in never falling,",
]
answers = [
" or, through inaction, allow a human being to come to harm.",
" what is essential is invisible to the eye.",
" but in rising every time we fall.",
]
N = 1
# Currently, top-p sampling is disabled. `top_p` should be 1.0.
# 当前,TOP-P 采样被禁用。 `top_p` 应为 1.0。
sampling_params = SamplingParams(temperature=0, top_p=1.0, n=N, max_tokens=16)
# Set `enforce_eager=True` to avoid ahead-of-time compilation.
# In real workloads, `enforace_eager` should be `False`.
# 设置 `enforce_eager = true`,避免提前汇编。
# 在实际的工作负载中,`enforace_eager` 应该是 False'。
llm = LLM(model="Qwen/Qwen2-1.5B-Instruct",
max_num_batched_tokens=64,
max_num_seqs=4)
outputs = llm.generate(prompts, sampling_params)
for output, answer in zip(outputs, answers):
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
assert generated_text.startswith(answer)
在数字化转型浪潮中,企业应用系统的安全性和用户体验同样重要。传统的账号密码登录方式已无法满足高安全场景需求,而生物识别技术以其唯一性和便捷性成为安全认证的新标准。葡萄城旗下活字格低代码平台与HAC移动应用的深度整合(1.21.0+版本),为企业提供了开箱即用的生物识别认证解决方案。本文将全面解析该技术的实现原理、应用场景和最佳实践,帮助开发者快速构建既安全又人性化的认证体系。 构建应用 构建认证逻辑: 发布并使用: 活字格与HAC的生物识别集成方案,通过技术透明化实现安全与体验的完美平衡。开发者无需深入掌握生物特征算法,即可快速构建符合金融级安全标准的认证流程。建议企业在以下场景优先采用:引言
一、生物识别认证的技术优势与行业趋势
典型案例:某金融机构在贷款审批流程中接入活字格生物认证后,欺诈案件发生率下降92%,客户满意度提升35个百分点
二、技术架构解析
2.1 分层认证体系
graph TD
A[生物识别认证] --> B[强生物识别]
A --> C[弱生物识别]
A --> D[设备密码认证]
B -->|华为/三星等| E(指纹/3D面部)
C -->|中端机型| F(2D面部)
D --> G(数字/图形密码)2.2 安全实现机制
三、开发实战指南
3.1 环境准备
3.2 认证流程实现


四、行业应用场景
4.1 高价值操作授权
4.2 移动办公场景
结论
注意事项:由于Android设备碎片化问题,上线前需完成至少20款主流机型的兼容性测试。葡萄城技术团队提供认证质量评估工具包,可联系售前支持获取。
我们是谁
要做什么
职位需求
优势
缺点
去年加入的小伙伴也来自 V2 ,十分感谢 V2 提供的平台。
非远程职位。
今年其它职位也会陆续开放
邮箱:c3V5YUBraXJhLWxlYXJuaW5nLmNvbQ==
在代理 IP 行业里,“动态住宅 IP”几乎成了高频词。做跨境电商的、做社媒矩阵的、做数据采集的、跑广告投放的,基本都会接触到它。但很多人只是“听说好用”,却没有真正理解它为什么好用。 动态住宅 IP 本质上是来自真实家庭宽带网络的 IP 地址,并且可以按照设定规则自动更换。 很多人误以为“只要用了代理就安全”。这是典型误区。 跨境电商多账号运营 如果你只是偶尔操作一个账号,差别可能不明显。但一旦进入规模化、多账号、多地区运营阶段,网络环境会成为核心变量。
如果你打算长期做线上业务,而不是短期套利,那么你一定要把动态住宅 IP 的底层逻辑弄清楚。因为它影响的不是某一次操作,而是整个账号体系的安全性和稳定性。一、什么是动态住宅 IP?先把概念讲清楚
这里有三个关键词:真实、住宅、动态。真实,意味着 IP 来源于普通家庭网络,而不是数据中心机房。住宅,意味着它归属于运营商分配给家庭用户的地址段。动态,意味着它可以定期或按请求轮换。为什么这三点重要?
因为平台的风控系统,会对 IP 进行画像。数据中心 IP 通常集中在固定 ASN 段,很容易被识别为代理或服务器行为。而住宅 IP 在统计模型中更接近普通用户上网行为。
换句话说,平台不是只看你做了什么,还看你“像不像一个正常人”。二、动态住宅 IP 的核心特点
动态住宅 IP 的最大优势就是来源真实。平台在识别访问风险时,会结合 IP 类型、历史访问行为、地理位置稳定性等数据进行综合判断。
真实住宅 IP 在风控模型中权重更低,更接近普通用户行为轨迹。这在注册账号、登录验证、广告审核时尤其重要。
动态机制是降低风险的关键。
如果你长时间使用同一个 IP,尤其是在高频请求场景下,很容易被标记为异常流量。动态住宅 IP 可以按时间、按会话、按请求自动切换出口地址,降低单一 IP 暴露风险。
对于数据采集、价格监控、SERP 抓取等场景,这一点几乎是刚需。
优质服务商通常覆盖多个国家和地区,可以根据业务需求选择目标国家出口。
比如你在做美国站电商,就使用美国住宅 IP;做东南亚市场,就切换对应国家节点。网络环境与目标市场匹配,账号行为更自然。
在验证码验证、登录风控、广告账户审核等环节,住宅 IP 的通过率通常明显高于数据中心 IP。
这不是玄学,而是统计概率问题。平台更愿意信任“像家庭用户”的流量。三、动态住宅 IP 和数据中心 IP 的本质差异
数据中心 IP 的问题在于集中度高、特征明显、可批量识别。一旦某个 IP 段被风控系统标记,整段地址都可能被限制。
住宅 IP 则分散在真实家庭网络中,不具备明显机房特征。从风险建模角度看,它更接近自然流量。
当然,住宅 IP 也不是万能的。如果频繁违规操作,再好的 IP 也救不了账号。但在合规前提下,它能显著降低误伤概率。四、动态住宅 IP 的典型应用场景
多个账号使用不同住宅 IP,可以有效降低账号关联风险。尤其在同类产品矩阵布局时,网络隔离非常重要。
社媒矩阵运营
在批量登录和发布内容时,真实住宅环境更接近普通用户行为,降低被限流或封号概率。
数据采集与爬虫项目
高频抓取容易触发网站反爬机制。动态轮换 IP 能分散请求压力,减少封锁风险。
广告投放与本地化测试
使用目标国家住宅 IP,可以更真实地模拟当地用户浏览环境,提高测试准确性。五、动态住宅 IP 到底值不值得投入
动态住宅 IP 的真正价值不在于“隐藏”,而在于提供一个更接近真实用户的访问环境。它不能保证百分百安全,但可以显著降低因 IP 异常带来的风险。风控是概率游戏,你能做的,是把风险压到最低。当越来越多团队把动态住宅 IP 当作基础设施,而不是临时工具时,他们的业务稳定性往往也更高。如果你是打算长期做项目,而不是短期试水,那么把网络环境搭好,是最基本的一步。
OpenAI大致介绍了他们如何扩展 PostgreSQL 以处理 ChatGPT 及其 API 平台(服务于全球数亿用户)上每秒数百万次的查询。这项工作突显了 PostgreSQL 单主实例(不引入额外的分布式解决方案)在面对写入密集型工作负载时所能达到的极限,同时也强调了构建全球可用的低延迟服务所需的设计权衡和运营保障措施。 在过去的一年中,PostgreSQL 的负载增长了十倍以上。为此,OpenAI 与 Azure 合作优化了其在Azure Database for PostgreSQL上的部署,在保持单一主实例不变的情况下,使系统能够为 8 亿 ChatGPT 用户提供服务,而且还留有足够的余量。优化工作涵盖了应用层和数据库层,包括扩展实例大小、优化查询模式和通过额外的只读副本进行扩展。应用层调优减少了冗余写入,并将新的写入密集型工作负载导向像Azure Cosmos DB这样的分片系统,而将 PostgreSQL 用于需要强一致性的关系型工作负载。 PostgreSQL 主实例由分布在不同地理位置的近 50 个 Azure Database for PostgreSQL 只读副本提供支持。读取操作分散在各个副本上,p99 延迟保持在低两位数毫秒级上,而写入操作则集中处理,并采取措施限制不必要的负载。延迟写入和应用层优化进一步减轻了主实例的压力,即使在全球流量激增的情况下也能保持一致的性能。 PostgreSQL 级联复制(图片来源:OpenAI博客文章) 随着流量的增长,运营挑战也随之出现。缓存未命中风暴、由ORM生成的多表连接模式以及服务范围的重试循环均被认定为常见的故障模式。为了解决这些问题,OpenAI 将部分计算移至应用层,对空闲和长时间运行的事务执行更严格的超时限制,并优化查询结构以减少对自动清理过程的干扰。 降低写入压力是一个关键策略。在高更新负载场景下,版本更迭和清理成本会导致 PostgreSQLMVCC模型的 CPU 和存储开销增加。为了缓解这种情况,OpenAI 将可分片的工作负载迁移到分布式系统上,限制回填和大批量更新的速度,并严格遵守运营策略以避免级联过载。 在LinkedIn上的一篇博文中,微软公司副总裁Shireesh Thota指出: 每个数据库都需要经过不同的优化和适当的微调才能适用于大规模工作负载。 连接池和工作负载隔离同样至关重要。PostgreSQL 的连接限制由 PgBouncer 以事务池的模式管理,这既可以降低连接建立延迟,又可以防止客户端连接激增。关键和非关键工作负载也做了隔离处理,从而在需求高峰期间避免了噪声邻居效应。 运行多个 PgBouncer pod 的 Kubernetes 部署(图片来源:OpenAI博客文章) 可扩展性限制也源于读取复制。随着副本数量的增加,主实例必须将WAL日志流式传输到每个副本,这会增加 CPU 和网络开销。OpenAI 正在尝试级联复制,由中间副本向下游转发 WAL 日志,这样既能减轻主实例的负载,又能支持未来的增长。这些策略使 PostgreSQL 能够跨地理位置不同的区域支撑极大规模的读密集型 AI 工作负载,同时通过分片系统处理写密集型操作以保持稳定性和性能。 OpenAI 表示,他们将继续评估提升 PostgreSQL 可扩展性的方法,包括分片 PostgreSQL 部署和其他可选的分布式系统,以平衡强一致性保证与日益增长的全球流量和随着平台增长而日益多样化的工作负载。 原文链接: https://www.infoq.com/news/2026/02/openai-runs-chatgpt-postgres/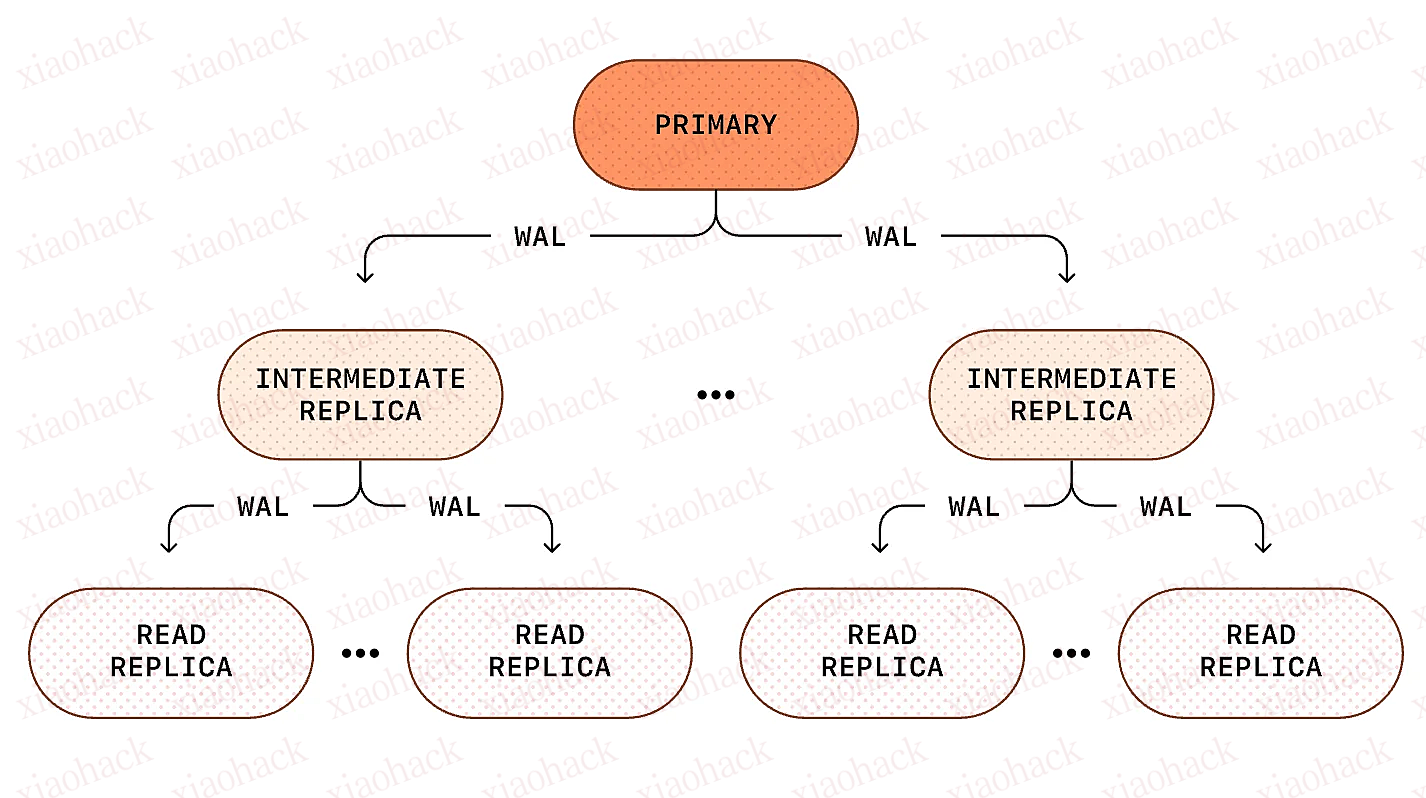

案卷作为烟草行政执法全过程的核心载体,精准反映监管质效,敏锐识别风险隐患,是优化资源配置的关键抓手。在实际运行中,面对案卷信息量大、类型多样、涉及环节多的特点,传统管理模式受限于数据分散、统计滞后、分析维度有限等问题,决策过程较多依赖过往经验,难以实现快速、全面、准确地把握整体态势。 针对上述痛点,北京中烟创新科技有限公司(简称:中烟创新)研发了烟草行政处罚案卷制作与评查平台上线|新技术、新产品、新模式、新服务,为案卷全生命周期的标准化管理奠定了坚实基础。该平台聚焦于执法文书的规范生成、审核流程的电子化流转以及案卷质量的自动化评查,有效保障了执法程序的规范性与案卷归档的完整性。在案卷管理逐步规范、数据资产持续积累的基础上,中烟创新进一步向数据智能应用延伸,推出“烟草案卷全域画像分析系统”。 作为烟草行政处罚案卷制作与评查平台的价值延伸与决策辅助工具,以标准化沉淀的案卷数据为输入,通过构建全域可视、风险预警、过程追溯与决策支撑于一体的智能分析体系,实现对案卷数据的深度挖掘与态势感知,推动案卷管理从流程驱动向数据驱动转型,为行业精准监管与科学决策提供系统化工具支撑。 自动汇总、智能分析,助力精准决策烟草案卷全域画像分析系统以“全域画像、智能分析、辅助决策、闭环管理”为核心思路,围绕这一思路,系统致力于打破信息壁垒,将分散于不同业务系统、不同格式的案卷相关数据进行系统性整合,通过清洗、转换与标准化处理,构建起统一、规范、可共享、可扩展的数据资源池,为后续各项分析应用奠定坚实的数据基础。在此基础上,系统将大量重复性、规则性的统计、核对工作交由自动化模型完成,依托预置的业务规则与机器学习算法,自动实现案件特征挖掘、流程效率分析、文书质量校验以及风险识别预警等复杂任务,将管理人员从繁琐的数据处理中解放出来,使其能够将更多精力聚焦于更高价值的判断与决策。 秉持“务实、高效、可靠”的原则,以业务需求为驱动,避免陷入技术空想。立足好用、实用、管用,做到基层可用、管理层可信、决策层可依,实现与业务的常态化融合。最终落脚点是为各级管理者提供客观、准确、及时的决策依据。通过可视化的数据看板、多维度的分析报告、前瞻性的风险预警以及横向的对标分析,系统用数据事实替代主观经验判断,有效支撑监管策略优化、执法流程改进、人员力量调配、培训资源投放等关键决策,推动管理模式从经验驱动向数据驱动的实质性转变。 案卷质量、流程效率、风险态势全方位监测全域分析模块作为系统总览,集中展示案件总量、涉案类型分布、涉案物品结构、文书风险概况、区域分布等关键指标。通过图表化、可视化方式,直观呈现整体运行态势,帮助管理人员快速把握总体情况,有效避免了信息碎片化和片面化认知,为管理者把握宏观方向、制定总体策略提供了第一手的数据依据。 文书是案卷质量的核心体现,系统自动对文书内容进行校验与分析,识别日期逻辑、签名验证、案发地点、金额计算等常见问题,统计风险提示次数与出错率,形成文书质量榜单与问题清单。通过常态化监测,可针对性开展培训与整改,推动文书制作更加规范、严谨,降低程序性风险,提升行政执法规范化水平。系统内置了基于法律法规和业务规范的校验规则库,能够对每一份上传文书的正文内容进行自动扫描与分析。校验范围覆盖日期逻辑一致性、签名盖章完整性、关键信息填写的规范性、涉案金额的计算准确性、引用法条的时效性与准确性等常见易错点。 全程跟踪办案效率,风险提前预警系统会为每个单位、每位执法人员生成文书质量画像,统计其风险提示次数、常见错误类型、文书平均出错率等指标。并据此形成“红黑榜”或“问题清单”,对文书质量优秀的单位/个人进行正向激励,对问题频发的进行预警提示。通过持续、自动化的文书质量监测,管理者可以清晰掌握文书质量的整体水平、变化趋势以及薄弱环节。基于这些数据,可以更有针对性地组织业务培训,精准指导存在问题的单位和个人,有效降低因文书不规范引发的行政复议、诉讼等程序性风险,显著提升行政执法的公信力。 系统对案件从受理到结案进行全流程跟踪,重点监测案件办理天数、超期情况、阶段流转效率等指标,自动识别办理时长异常、周期波动较大的单位与区域,辅助管理者优化流程、合理配置人员力量,缩短整体办案周期,提升监管响应速度。系统按重大风险、一般风险、综合风险等维度,对各单位、各区域风险提示数量、提示率、变化趋势进行持续跟踪,自动标注风险偏高、波动异常的主体与环节,实现风险早发现、早提醒、早处置。相较于传统事后检查、集中整改模式,风险预警模式更具前瞻性和主动性,有助于将问题化解在萌芽阶段。 画像看清结构,对标找到差距全域画像是系统的核心亮点,为每一类、每一组乃至每一件案件形成多维度标签,形成可量化、可对比、可挖掘的案卷画像体系。通过画像,管理者不再只是看到“案件数量”,而是能清晰理解 “案件结构、风险特征、变化规律”,为精准监管提供依据。系统支持区域之间、单位之间、中队之间的横向对标,围绕案件办理质量、风险提示率、文书规范度、办理时效等关键指标进行排名与对比,自动识别标杆单位与待提升对象,形成“学先进、找差距、补短板、强弱项” 的良性机制,推动整体监管能力稳步提升。关键指标排名与对比:系统围绕案件办理质量、流程效率、监管效果(如涉案金额、案件查办数量)等核心KPI,自动生成排名榜单和对比分析图表。标杆识别与差距分析:管理者可以一目了然地识别出各项指标上的标杆单位和待提升对象。 系统还能自动进行差距分析,例如,计算某单位与标杆单位在“案件平均办理天数”上的差距,为制定改进目标提供量化依据。经验分享与针对性帮扶:通过对标分析,可以引导各单位主动学习标杆单位的先进经验和做法,管理者可以据此精准定位短板弱项,组织针对性帮扶,推动经验共享与协同提升,将数据对比切实转化为整体效能提升的发展动能。 用数据驱动,赋能管理决策创新烟草案卷全域画像分析系统不是简单的工具升级,而是管理模式、工作方式、决策逻辑的整体优化,其价值集中体现在四个方面:系统实现案卷相关数据自动汇聚、统一口径、自动统计,替代大量人工汇总、制表、核对工作,大幅降低基层事务性负担,让工作人员把更多精力投入到案件办理、市场检查、风险排查等核心业务中,提升整体工作效率。通过对办理时效、文书质量、风险提示等关键指标的实时监测,管理者可随时掌握工作进展,及时发现流程堵点、管理弱点、执行偏差,实现从“阶段性检查” 向 “常态化管控” 转变,管理更加精细、过程更加可控。系统通过自动分析与预警,将以往靠人工抽查、经验判断的模式,转变为数据驱动、全覆盖、常态化的风险识别模式,有效降低文书不规范、流程不合规、办理超期等问题,提升行政执法的规范性与公信力。 以往决策更多依赖个人经验、直观感受和局部信息,容易出现判断偏差。系统上线后,决策依据转变为全域数据、客观指标、趋势规律: 决策从凭经验转向靠数据,从定性判断转向定量支撑,更加科学、稳健、精准。从实际应用效果来看,案卷分析效率明显提升,文书与流程问题发现更及时,区域与单位间对比更清晰,监管资源调配更合理,整体管理质效得到切实改善,真正实现了用数据说话、用数据管理、用数据决策、用数据创新。 烟草案卷全域画像分析系统不仅让沉淀的数据得以释放价值,更让每一份案卷背后蕴含的监管信息转化为可感知、可度量、可改进的管理资源。中烟创新也将继续深耕业务场景,以技术之力赋能管理之变,助力烟草行业在数字化转型的浪潮中行稳致远,为构建更加规范、高效、智慧的监管体系注入源源不断的创新动能。
当你把 AI 编程用到极致,它看起来就不再像“写代码”,而更像“带团队”。 Steve Yegge 说自己刚关掉了机器上的 320 个 Claude Code 实例,每个实例差不多 1GB 内存。 这种多智能体会同时在线:有人在写、有人在改、有人在合并;有人会突然宣告“搞定了”,也有人会互相等待、互相打断,把局面搅成一团。规模一上来,你会立刻体会到他为什么说:“这就让单个开发者遇到了以往只有团队才会遇到的问题。” 如今,AI 辅助编程早已超越自动补全:大模型不只是写函数、补几行代码,它开始能改动整套代码库、协调长时间运行的任务、在多个系统间协作。但当这些能力越强,越该告别的反而是“人工管理智能体”——你需要的不是更勤快地盯着它们,而是一套能让它们在规模化运行下依然可控、可收敛的机制。 于是他做了 Beads(共享记忆系统),又做了 Gas Town(多智能体编排系统:https://github.com/steveyegge/gastown)。320 个实例一跑,拼的是系统“能不能管住、能不能记住”。以后,智能体慢慢变得像角色扮演游戏、策略游戏乃至即时战略游戏。 他甚至相信:“可能到今年年底,人们就会像玩游戏那样开发软件。” 而更激进的,是他对未来软件生死的判断。在这期播客里,他给出了一个“未来软件生存公式”: “要想在 AI 的冲击下生存下来,就必须像 Beads、Dolt、MongoDB、Temporal、Kubernetes、Kafka、Cassandra 这类基础设施那样成为 AI 的优先选项。” 因为大模型是“懒”的。它会选择最节能、最省 token、路径最短的方案。“只要能让大模型知晓你的工具,那项目活下来就不成问题。” 换句话说,未来的软件不仅要服务人类用户,还要进入大模型的“默认工具箱”。谁能帮模型省 token、少绕路、跑得稳,谁就被优先调用;剩下的,要么被绕过,要么被吞掉。 以下是这期播客的完整翻译: 主持人:你的到来让我深感兴奋。我之前就说过,我一直是你的忠实读者,也很期待能跟你面谈。首先请向观众们介绍一下自己吧,他们可能不像我那么熟悉你的作品。你在自己眼中是个什么样的人,又是怎样一步步成长到如今的? Steve Yegge:好的,之前从来没人问过这个问题,那我就简单概括一下吧。首先我肯定算是个行业老手吧,我从事软件行业很久很久了。我从 17 岁就开始编程,前几天已经 57 岁了。40 年匆匆而过,我也亲眼见证了很多很多变革。 我最早是在亚马逊供职时开始写博客的,当时是希望能说服公司里那个坐拥 800 名工程师的团队能接受我的一些观点,因为我发现他们的不少想法是错的。之后我开始加入自己的吐槽,没想到博客居然火了起来。反正慢慢的写博客就成了我的习惯,特别是在小酌一杯之后。不过九年前我就戒酒了,希望我能把这个好习惯坚持到底。 主持人:在我眼中,你一直是引领软件行业前沿变革的先驱之一。那咱们不妨先来回顾整个变革历程,我也很好奇你当时是怎么思考的。记得你 2024 年就发表过一篇博文,其中提到了一种当时刚刚出现的模式。你称之为 CHOP,即聊天导向型编程。你也是在那时候刚刚开始接触大模型吗?还是说之前就已经萌生出相关想法了? Steve Yegge:让我真正感到震惊的应该是 ChatGPT 3.5,因为它居然能写出相当不错的 Emacs Lisp 函数。虽然还只是单条函数,没办法再做进一步扩展,但我还是觉得非常震撼。 所以我也说不好,反正我当时提出的聊天导向型编程让自己成了那个超前的疯子——刚开始没人听,后来几乎人人都在用。光是 Claude Code 的用户群体,现在可能就占开发者总数的 10%、15%,甚至有 20%了吧?我在 2024 年尝试推广聊天导向编程时,大多数人还在关注“补全接受率”呢。你对这个指标还有印象吧? 主持人:有的,好像直到现在 VS Code 也在监控这条。 Steve Yegge:没错,现在也还有开发者在使用代码补全功能。也正是在那个时候,我感觉自己好像能够预见未来了。我干这行有 40 年了,这 40 年间我一直在追求效率、努力让自己行动更快,所以我自然就对能进一步提效的要素拥有敏锐度。 当然,这其中也有不少障碍。首先就是 AI 经常出错之类,但我感觉这就像是很多游戏里最初级的载具一样,虽然还远不够完善,但至少比走路快。而且它未来一定会越来越快,不需要怀疑。 所以 Gas Town 负责把 Claude Code 引入编程回路,于是 Claude Code 就把对话引入了编程回路,对话又把问题引入编程回路。总之这就是 AI 渗透编程的过程,我们不断把更多 AI 功能引入进来,形成有可能解决一切问题的方案。当然,很多人也在对此发起抵制。Hacker News 论坛上就有不少反对的声音。 主持人:我先提个好奇的点,刚刚你说 GPT 3.5 是第一个让你感觉大开眼界的版本,因为突然之间就出现了比走路更快的“初级载具”。那在整个过程中,还有其他让你印象深刻的转折点吗? Steve Yegge:也有。下一个转折点是 GPT 4.0。我们之前构建的编程智能体只有聊天功能,需要手动执行复制、粘贴之类的操作。这就带来了新的麻烦:一旦文件达到 800 行左右,经过修改就很难再完美复现。Nano Banana 哪怕到了现在也是一样,在编辑大量代码时经常会犯迷糊。 而 GPT 4.0 的转折性意义在于,它能在完成修改和编辑之后,完美复现高达千行的文件。这一点意义重大,因为世界上大多数源代码文件都不足千行。也就是说 GPT 已经能够编辑大部分文件并进行简单修改,而且这是在 2024 年年中就迅速实现了的。 下一个让我印象深刻的版本是 Sonnet 3.7,更具体地讲就是 Claude Code。我发过一条短短的推文说“我天,Claude Code 可真行!”,浏览量高达 30 万。 接下来的重大版本是 Opus 4.5,正是它促成了 Gas Town 的发布。如果没有 Opus 4.5,就不会有 Gas Town。不知道你还记不记得,当初 Anthropic 模型的更新周期大概是 4 个月,而到 2025 年初间隔就缩短到大约 2 个月。可能我们很快就能迎来 Opus 5 了。 所以我想提醒那些仍然在唱衰 AI 的朋友,你们的视野大约只局限于过去三个月,也就是只关注三个月前上一代模型的情况。这有点像没学过微积分的人,他们只能看到导数,却看不到斜率。 所以我从 ChatGPT 3.5 开始就一直在关注整个过程的加速发展,而且在软件行业这种加速发展已经持续了 40 年。Opus 4.5 的诞生可谓一石激起千层浪,让人们意识到它的智能水平已经相当够用了。 主持人:没错,其实我的经历也差不多。我是从 Sonnet 3.5 开始,突然意识到哪怕他们再也不发布新的模型,当下的版本也足够支撑起大量构建工具、永远改变整个软件工程世界。 Steve Yegge:确实如此。当然,它们仍有不小的局限性。3.5 和 3.7 版本都还不够完善,能够处理的数据量是有限的,强迫开发者把内容拆分成相应的大小才能使用。可如今 4.5 版本出现了,数据处理量的上限进一步提升,而且后续还将不断增长。 很明显我们正身处一个全新的世界。比如 Redis 和 antirez 的缔造者前阵子就正式发帖,表示在深度使用 Opus 4.5 和 Claude Code 之后,“我们手动编写代码已经毫无意义了”。这就是整个软件行业必须面对的现实。 主持人:是的,我想接下来会有很多更有趣、更新鲜的东西需要我们去适应。但我们不妨先着眼于当下,比如你刚刚提到目前的难点在于如何协调大量智能体,无论是并行工作还是串行工作。这个问题在多任务协同的情况下显得尤其突出。你在这方面也做过一些项目,那咱们就从 Beads 开始。短短三个月它就取得了很大进展,无论是人气还是很多概念的普及。那咱们还是来聊聊 Beads,这是什么呀?它在智能体集群的世界中又发挥着怎样的基础性作用? Steve Yegge:不知道你有没有关注,Anthropic 日前发布了一项更新,推出了 Tasks,并表示它的灵感就来自 Beads。我觉得他们做得非常好,也完全理解他们为什么不直接使用 Beads。 简单来讲,Beads 类似一款任务跟踪器,也可以说是一种智能体待办事项清单。它有三项非常有趣的特性。首先它是以图的形式存在,也就是任务图,类似于工作图、实施计划、GitCharts 乃至其他成熟的知识工作管理方式。它会把工作内容记录并拆分成字节,这些字节又会随着认知能力的提升而扩展。 Beads 这种把工作拆分成图的方式跟我们长久以来的实践相一致,只不过还多了另外两个要素。首先是引入了 SQL。毕竟图和数据库从来都不算完美,但 40 年的发展还是让它们至少还算完备。图的本质就是一大堆顶点和边。此外我们还引入了 SQL,因为有了 SQL 就有全面的数据库功能。 主持人:是的,可以用非常接近 SQLite 的方式来跟踪思维过程。 Steve Yegge:确实。有了 SQL,再加上 Beads 带来的顶点和边,事情就有了飞跃。我们在 Beads 的设计中就有用到 Claude,所以这里包含了大量 AI 认为非常重要的信息,而且它们会经常使用这些信息。例如它会记录 Beads 开启时谁做了什么。AI 非常看重这些信息,这能帮助进行取证、了解工作如何展开,并体现出工作执行过程中的各个层面。所有关闭的 Beads 代表已经完成的工作,打开的 Beads 则代表剩余的工作。Beads 本身会跟踪相应的点下面积及相关信息。 而让 Beads 如此神奇的第三大要素就是 Git,它负责提供一份记录所有工作的 Git 账本。它把工作拆分成易于访问的小块,各个小块之间可以相互引用。它采用图结构,可以通过数据库进行查询,而且所有数据都存储在 Git 账本之内,这就保证内容永远不会丢失。历史记录始终存在,因此在出现问题时也随时可以重建。 不仅如此,大家还可以查看这些账本,并确定智能体随时间推移的表现如何。我们甚至可以在账本上看到自己的工作内容,这就像一分便携式的简历。真的很棒,Beads 确实是个非常有趣的成果。 主持人:是的,其中有很多部分都值得深入探讨。那咱们先从概念层面入手,专注于讨论 Beads,暂时不谈 Gas Town。身为开发者,当大家将 Beads 配合自己的智能体使用,那在认知层面会发生怎样的转变? Steve Yegge:如果是已经在使用智能体,那应该是已经在使用待办事项清单和 Markdown 文件了。此外还有什么呢?也许会使用 wiki 和数据库吧。但这些方案的问题在于,它们缺少 Git。 Markdown 最大的问题是没有能直接在数据库中查询的图结构。大模型每次查找时,都必须读取并解析 Markdown 文件才能获取相应的图结构。另外 Markdown 文件还会逐渐陈旧,这些都是问题。 但如果是认真用过智能体的朋友,在尝试了 Beads 之后都会有很深的感触。几乎每天都有世界各地的开发者主动跟我联系,类似“我开始使用 Beads,它简直是打开了新世界的大门,我也说不清是为什么。” 简单来讲,Beads 就像是大模型的“猫薄荷”,像一种记忆宝典。 一旦体会到 Beads 的好处,开发者们就想一直用下去。大模型总是顾头不顾尾的,只专注于你交给它的最新任务,哪怕之前的任务因此受到了巨大的影响,它也根本不会在乎。而且大模型连自己之前做过的事也不承认、或者说记不住。 但有了 Beads,这种情况就不会再发生了。因为它在面对问题时会提交一条 Bead,让开发者看到 Bead 是怎么跟智能体编排联系起来的。Beads 的累积其实就是工作的累积,开发者还可以根据需要添加规范,比如在 Bead 当中添加字段、注释、设计等等。 总之,只要任务描述得足够清楚,就可以把它交给智能体加以执行,再由另一智能体进行代码审查,并在通过所有测试之后提交完成。大家就这样把 Beads 作为智能体编排的基础。 它就像一整套内存,一套共享记忆体系。因为通过 Git 进行联合,它也像一套分布式数据库,可供用户在 AWS、GCP、Azure 乃至任何其他超大规模云平台的智能体上使用。这些智能体可以通过 Beads 相互沟通,不再需要依赖集中托管服务。所有操作都将通过 Git 仓库进行,非常神奇。 主持人:没错,确实很神奇。我还没看过 Beads 的实现,但通过 Git 进行操作确实是个好想法。那你们是把 Beads 存储在类似 SQLite 上面了?还是说就直接存储在文件系统当中、或者使用专有接口?能不能具体介绍一下,你们是怎样把 Beads 整合到 Git 当中,让它既是任务图、又存储在 SQL 中,同时还支持 Git 的?是以 SQLite 文件的形式吗? Steve Yegge:是的,而且这种设计其实是个败笔,因为我的背景调查没有做好。我最早想要的就是 Git 加 Clade 再加 SQL,所以选择了最粗暴的方式把这几样硬塞在了一起。JSON 文件中的每行代表一个 issue,经常引发合并冲突;再把它通过 xls 插入到数据库中,这需要建立相应的守护进程,数据也可能过时。总之这是套非常糟糕的双层架构。 好在这些问题都将在下个版本中得到解决,大概就是未来几天的事。如果当初好好做背调,我就会意识到自己需要的是 Git 数据库。而在认真整理了所有需求之后,我发现已经有人解决了这个问题——我在亚马逊的老朋友 Tim Shen 搞了个 Dolt 项目,而我之前竟然完全没听说过。好在接下来 Beads 将转向 Dolt,一切问题也将迎刃而解。 主持人:确实。SQLite 倒是很多人在用,但 Git 跟 SQLite 经常会引发合并冲突。所以选择 Git 原生数据库真的很重要。 Steve Yegge:没错,这样三路合并的问题解决了,bad sync 的问题解决了,守护进程的问题也解决了,一举三得。而且我们仍然可以导出 Git 代码,仍然可以进行联合。Dolt 的联合方式跟 Beads 完全一样,就好像大家在立项之初就分别想到一块去了。但他们确实做得更好,已经为此投入了十年时间。 Dolt 还能嵌入 Go 语言,所以跟 Beads 天然绝配——只需要一行代码就能搞定。用户甚至感受不到任何变化,只是越来越好用。Dolt 还支持很多其他功能,比如字段级合并解析,还有新的历史记录与新的视图维度——比如键值存储等,这些都是我们以往没能实现的成果。 总之 Beads 就是个数据平面。之前有位贡献者添加了一条键值存储并引起我的好奇,我认真研究了它的运作原理,意识到这完全说得通。如果让智能体们靠这个实现记忆—— 主持人:没错,可以通过这种方式分享信息,并提供可靠的信息查找途径。 Steve Yegge:对吧?Bead 虽然跟 GitHub issue 或者 Jira 之类的工具相比还算轻量,但仍然有点“重”。现在转为键值对,那就真的轻量化了。所以我想不妨试试,何况 Dolt 对于键值存储的支持也非常好。 我对 Bead 的发展态势非常满意。之前的代码库很差劲,是用氛围编程实现的,所以必须持续运行 CodeView 来检查。我的审查进度已经落后大概一个月了,所以现在的代码肯定就是一堆垃圾。它只是通过了测试,而且有人在用而已。不过再有几周甚至一周,我就能把一切都清理干净。我们会以 Dolt 为基础发布新版本,届时呈现在大家面前的 Beads 将成为一件精美的作品。 主持人:现在咱们退一步。你刚刚聊到关于 Beads 的很多具体细节,包括代码编写方式正在发生改变。那就在深入探讨 Gas Town 之前先说说这些改变,毕竟 Gas Town 的复杂程度还要再高好几个数量级。 你提到“如果一条 Bead 的规范足够完善,就可以把它外包出去,交给其他人维护”。那在我们现在的智能体环境下,你是如何看待规范的?你和其他人参与了哪些环节?你是如何管理这些环节,又是怎样看待这些问题的? Steve Yegge:是啊,我真希望能再多认真想想。这对 Ralph Loops 来说是个根本性问题,我也跟 Geoff Huntley 就此聊过很多。就 Ralph Loops 来讲,我们需要详尽定义验收标准,否则就可能搞出一大堆错误来。 所以 Gas Town 的做法,或者说我的做法,就是:除非像 Dolt 相关部分之类非常非常重要的东西,否则我们只需要先实现一个近似版本。我们在主线上会投入所有努力,至于其他东西则可以逐步迭代。我们先搞个能发布的版本,然后慢慢修复其中的 bug。大概就是这样。 主持人:好的。那你是怎么看待规范的?比如在使用 Beads 的工作流中,什么时候人为干预,什么时候可以允许它自主运行? Steve Yegge:我的工作流往往更强调迭代,所以很少花时间制定大量规范。但这确实是个很有意思的问题,毕竟这事非常花时间。Gas Town 引擎的功能非常强大,基本上所有时间都花在两种模式上面,也就是最大化或者最小化——当然,这里指的都是上下文窗口。 上周我跟 Anthropic 那边的同事进行了一次非常有趣的讨论。我接触过 Anthropic 一些非常优秀的团队,他们对 Gas Town 很感兴趣,认为它暴露出模型中的许多 bug。Gas Town 提出了很多变通方案,类似于对工人们做入职培训,确保他们在工厂里更好地完成工作。 在交流过程中,他们说 Anthropic 内部存在一种有趣的分歧。有些人希望尽量减少上下文的使用,比如尽可能把任务的体量收窄、做拆分,一次只设定一个临时性任务。因为虽然现在的上下文窗口虽然越来越大,但随着 token 数量的增加,运行成本也会迅速增长。而且小体量任务的运行性能也会更好。总之他们非常关注性能和成本问题。 另外一类人则倾向于最大化路线,也就是尽量增加上下文的容量。他们会在上下文窗口里塞满大量丰富的信息和指令。 大模型就是最大化一派的成果。大模型不仅明白用户想要什么,还能理解为什么要做这件事,所以它的决策、特别是在战略决策方面的表现就非常出色。 于是他们问道,“那 Steve,你更支持哪一派?”我觉得这事真的很有意思,因为 Gas Town 中也包含“polecats”的概念,负责处理那些明确定义的临时性工作,用完即弃。它们负责的就是小规模工作,一次只作一件事,把任务拆解开来,逐个完成、逐个产出。这就像工厂在以流水线形式生产代码。 但还有很多工作跟设计有关,需要我们进行深入思考,也需要跟大模型进行沟通。这往往要求我们为模型提供大量背景信息,提醒模型这是个非常棘手的问题。每当我在处理代码时遇到最困难的部分,都会提醒模型“注意这是个难题,不只是常规的修复,而需要弄清楚整个问题出在哪里,还有它怎样跟系统融合对接。”就是说我需要为模型提供丰富的背景信息。 所以我准备了一系列文档,内容也是逐渐深入,然后展示给大模型。Anthropic 团队的成员比较支持这种工作流,而“polecats”也有自己独特的价值和意义。我认为这意味着两种工作流都很重要。而且作为工程师,我们自己也需要在这两种工作流间来回切换。 但随着时间推移,我们肯定会迈向那种需要大量思考的工作,即大模型会负责所有编程工作,而一切复杂的设计工作则归人类处理。这也是我在自己上一篇博文中提出的判断。 主持人:关于这事我也有自己的感受。但在深入探讨之前,我想再补充一点。你刚刚描述的那种面对高强度问题前,启动所有相关上下文的情况,我之前也认真讨论过。如果把大模型的本质理解为虚拟机,看作是由自然语言驱动或者代码驱动的计算机,那么这种驱力的核心就是数据。 我们真正要做的,是为有待解决的问题编写引导加载程序。那么,我们该如何获取准确的上下文和数据,从而找到真正相关的信息?我很好奇你自己是怎样管理的,或者说你在 Gas Town 内部是如何管理这些的?对于不同类型的任务,其对应的启动加载程序又是怎样的? Steve Yegge:在 Gas Town 之前,我是用 Beads 实现工作流自动化。我猜很多人用的都是这种方法,哪怕是不用 Beads 的时候也有其他可行的替代方案——关键在于了解它们的各自专长,然后充分加以利用。这些方案最擅长的就是建立待办事项清单,处理繁琐的流程、建立验收标准并逐项检查。 所以在启动阶段,我希望处理那些在关闭阶段没做好的工作。比如说查找分支、暂存区、未合并的工作等等。Beads 就是这样,它在启动时会清理沙箱、清理环境等等。总之这些指令都被我整合成了提示词。 对很多工程师来说,现在的新挑战就是管理好自己的提示词库,并根据需要随时调用。Gas Town 的初衷其实是,如果能有一些预设的提示词并在特定角色上线时自动起效,结果会怎样。而这一切都基于这样一个假设:当 Claude Code 能够真正自我运行,会发生怎样的改变? 当然,启动和关闭都很重要。所以我写了一条名叫“飞机降落”的提示词。我有个同事就提起过这条提示词,他从没用过 Gas Town,之前只用 Beads。他觉得“飞机降落”非常实用。我用这条提示词也有六个礼拜了……天哪,怎么感觉像过了六个月。 主持人:现在技术变化太快了,时间也被同步压缩了。 Steve Yegge:现在时间真的太紧了。好在“飞机降落”真的好用,智能体不光能成功完成任务,还会列出长长的清单加一大堆生动的表情符号,帮助项目快速就绪。 主持人:Anthropic 的模型特别喜欢搞拟人,GPT 则更加戏剧化。我明白你的意思。 Steve Yegge:只是 GPT 模型不擅编程,但也无所谓,它真的很好玩。 主持人:这又是另一个话题了。我发现 GPT 5.2 在生成特定类型的代码和提示词方面非常有效,只是速度慢得令人发指。 Steve Yegge:我听说 Gemini 3 在 UI 编程方面很强,可能已经不逊于 Claude 了。 主持人:UI 编程一直是 GPT 的弱项,它表现太差了,实在是太差了。 Steve Yegge:是啊,也许不同的大模型最终会发展出各自的专长吧。Claude 更重视验收标准,“飞机降落”就是利用了这一点——有点像利用了它的强迫症习性,通过相应的条件确保它把事件做对。因为哪怕缺少上下文信息、上下文窗口也几乎被占满,当严肃程度达到“飞机降落”级别时,Claude 也会查阅操作说明并开始逐项核对,最终完成任务。这也算是一种调试思路吧,总之“飞机降落”确实让 Claude 更加可靠、尽量不遗漏事项。大模型确实掌握着海量的常识,但却容易分心。“飞机降落”就是用来提醒它们保持专注的。 这些都是我们在开发过程中需要磨练的技能,准备就绪之后才能真正投入到像 Gas Town 这样的复杂项目当中。我们得特别擅长把上下文信息融入到大模型当中,观察整个分类和处理过程。在亲自动手操作一段时间之后,大家就能信心满满地同时处理多个这样的项目了。 主持人:那我们不妨以此为契机来聊聊 Gas Town。那就从头说起吧。很多朋友应该还没读过你的论述或者网上的相关讨论,所以 Gas Town 是什么?其中包含哪些内容? Steve Yegge:我们可以从多个不同角度来看待 Gas Town。按最简单的理解,它属于一种编排器,跟长久以来的 Devin 等等都差不多。大家都希望能让多个编程智能体以团队形式运行,或者在特定任务上并行运行再匹配一些跟踪层,基本就是这个意思。 还有 Geoffrey Huntley 打造的 Ralph Wiggum Loop 和 Loom Loops,再就是 Claude Flow,那款带路由功能的高级工具。Gas Town 也属于这一类,以编排器的形式帮助用户运行多个编程智能体,而且现在跟 Claude Code 的联系非常紧密。Claude Code 的能力边界经常被触及,用户对智能体的要求很高,因此经常会出错。所以直到足够强大的 Opus 4.5,才能够可靠运行 Gas Town——而且哪怕如此,崩溃情况也不少见。 总之 Gas Town 的理念非常简单。我来解释一下,随着大家对大模型的信任度不断提高,开发者也开始意识到自己正越来越依赖智能体。这里讲的信任,是指能够更好地预测大模型接下来会做什么,这也是信任的基本前提。当然,这种可预测性需要通过实践来获取。而且目前这一切只发生在开发人员身上,而不久之后全体知识工作者都会面临同样的挑战。 有趣的是,信任度越高,用户的耐心就越低。因为大家习惯了认为只要把任务指派给一批智能体,它们就应该可以顺利完成——毕竟之前它们已经成功过好多次了。甚至连测试都想要交给智能体。这样之后每次遇到新任务,我们就习惯性地再添加一个智能体,最终由此形成新的开发常态。 主持人:我明白你的意思。那现在如果让我来评估,我自己大概可以同时使用六到七个智能体的阶段。比如我经常会同时管理三到五个智能体,有时候还会更多。后续我还有一些关于局限性的问题,咱们慢慢推进。那咱们回到话题,信任度越高、耐心却反而降低。 Steve Yegge:没错,现在大家运行的智能体越来越多,这就让单个开发者遇到了以往只有团队才会遇到的问题。智能体之间还会相互干扰,导致我们忘记哪个智能体在做什么。智能体之间还会设置网关,彼此等待和配合,情况由此变得愈发复杂。当规模达到一定程度,即使我们使用 Beads,也没办法在脑袋里追踪所有信息——这简直就是一团乱麻。 这就是 Gas Town 灵感的来源:“如果把它们都放进类似工作树的层次结构当中,再给它们明确命名,结果会如何呢?Beads 已经实现了巨大突破,但为什么不把整个想象空间都填充起来呢?” 还有个关键,大模型特别擅长处理自己在训练期间接触过的内容。而且训练时接触的越多,大模型就越擅长、越喜欢用。比如说从上世纪 70 年代就存在的邮件系统,对大模型来说就最最熟悉,也更倾向于使用。因此只要把智能体跟 ID、收件箱之类的设计结合起来,智能体间就能相互发送邮件——事实也确实如此。 于是很快,我们就有了这样一个由合作智能体构成的“城镇”,它们通过邮件彼此沟通。我会给它们设定头衔,比如你是镇长、你是 polecats 之类。我还会按《白雪公主和七个小矮人》给它们设定名字。这样观察下来,它们的运作方式就特别有意思——我就见过“镇长”指派其他智能体回归岗位、处理工作的情况。 它们的表现有时候甚至会超越我的预期。有一次我记得自己有大概 30 条 beads 有待处理,结果突然不见了,在惊慌中我意识到它们应该是都被成功修复并关闭了。哇,这种感觉真的非常神奇,是种以往从来不曾有过的体验。 Gas Town 就这样横空出世,打破了人为管理智能体的蒙昧时代。 而这又衍生出一种新的模式:只要给智能体定下了运行规则,接下来就要放心让它们自主运作。这其实有点反直觉,我发现大多数人都会一直盯着智能体,害怕它们会犯错,然后每次出问题都大惊小怪。 连我自己也是这样,大概持续了六个月吧。我尝试观察每个智能体,想要及时发现它们犯的错。 而一旦想通了这个道理,我们就会意识到智能体就像普通工程师那样,是肯定要犯错的。犯错并不值得大惊小怪,真正要关注的是那些宣称完成了任务的智能体。因为宣称完成跟真实可用之间还有距离,还需要我们人为引导。当然,如果实际完成了更好,我们可以跟智能体继续讨论接下来该做些什么。 在后续交流中,我们可以跟智能体进行精彩的设计讨论,比如“如果放弃数据库、尝试其他方案,结果会如何?”当这个智能体开始思考和实验之后,我们再挑选另一个智能体,给它指定新的难题。这就是我自己目前对 Gas Town 的使用方式,给每个智能体都安排难题。而且让人意外的是,十个难题里有八个都可以顺利完成,不过余下两个就被直接丢弃了。这点也比较烦人,我经常会意识到自己面对的某些问题之前是考虑或者遇到过的,但往往找不到之前的设计流程了,还得从头再来。 主持人:这就引出了我关心的一个核心问题,我自己也一直在努力解决。当然,我的困扰肯定没到 Gas Town 那种复杂程度,但未来应该会持续恶化,那就是怎样在管理大量智能体时保持心态上的平衡? Steve Yegge:我明白,整个使用体验确实让人相当沮丧,我有时候也会忍不住朝它怒吼。比如“我都跟你们说过无数次了,别提交 PR。我们只是做维护的,提示词里不是写了吗?!”但智能体还是在那里擅自提交 PR。但后来我意识到,这其实都是我自己的错,而且是有解决办法的。Claude 直接提供预用的钩子,只要在这里设置不提交 PR,问题就不会再出现了。 所以大家要意识到,目前是技术发展得太快了,我们必须努力保持住非常平和的心态。毕竟智能体已经在做事了,而且效果也是越来越好,只不过我们内心的预期和目标在随之提高。总之这代表着一个全新的世界、全新的时代,不能再用老眼光来看待。 但我也很理解你的感受。现在我感觉自己就像工厂厂长,带的还是一支新组建的团队,感觉“员工”们都很懵懂。它们很聪明,但彼此间的配合总是磕磕绊绊。 主持人:这又让我想到了新的问题,就是我们编写软件的方式本身到底靠不靠谱。回顾一下编程智能体成熟前、也就是两年之前的情况,传统软件编写主要就是达成两个目标。首先是生成一个可执行工件,这也是最基本的要求。其次,构建关于所开发系统的心理模型,或者说为待解决的业务问题构建心理模型。如今代码编写开始由智能体接管,但这两点似乎仍然存在——你对于代码编写有自己的心理模型吗? Steve Yegge:肯定有啊。你有没有跟那种特别特别优秀的产品经理共事过?就是那种技术非常精湛、曾经编写过大量代码,只是后来转为产品经理的同事? 主持人:有过一次。 Steve Yegge:有过一次,这就够了。你说得没错,这样的人才简直是无价之宝。实际上哪怕是像谷歌这样拥有极强技术积累的大厂,这类人才的比例相对很高,但也肯定达不到 100%。面对那些真正优秀的同事,大家几乎可以跟他们讨论任何架构细节。他们了解各种技术概念、知道怎么做性能调优,还有各种任务的执行时长等等。 他们会讨论类似“导出时间太长了,咱们试试用缓存吧”的问题。优秀的人就是这样,Uber 的技术主管也是如此。你之前有跟 Uber 或者其他硬碰硬的技术主管共事过吗?那你应该能体会,这些优秀的人才会整合所有团队的整体视角。这种情况下,我们自己扮演的就是工程领导的角色,比如产品经理、技术项目经理、高级工程主管等等。总之,任何希望深入了解机器运作原理的人,都得做好担任这类角色的准备。 其实这才是最重要的。通常情况下,重要的不是用什么语言来编写,也不是语法、链接器或者其他细节。最重要的是它能做到什么、功能规范是什么等等。我们现在之所以能够快速构建软件,就是因为前人解决了功能规范这项艰巨的任务。 主持人:这也是我想问的核心问题,“你到底是怎么做到的?” Steve Yegge:我需要记住 Beads 和 Gas Town 的所有细节,包括大家引入的所有集成点。我经常跟大模型讨论,比如“不好意思,我们的插件系统是怎么运行的?另外某项功能又是怎么运行的?我还真记不住了。” 上次检查的时候我确实有参与、也亲自批准了,但现在我早已忘记了具体运作方式。所以我必须回头重构构建一遍,这就是持续起效的纪律体系,也是不能丢掉的重要习惯。我们必须定期审查自己从未见过的代码,必须不断审查并提出问题。只有在细节上从各个角度都已经充分考量,我们才能像那些最出色的技术主管那样断言“行了,所有细节都已经涵盖到位,我们不再需要进行任何代码审查了。” 产品也是一样。我们必须了解产品的每一个细节。如果既不了解、也不使用,那为什么要编写这些代码?所以,我们必须积极精简代码,淘汰那些没有发挥应有作用的功能。如果做不到这些,技术债就会像山一样高。 我再澄清一下。很多人会说“不理解是因为没看过代码,看过代码肯定就理解了”。但这是种非常初级的心态,只有经验不足的人才会这样理解。领导过团队、参与过大型项目的朋友不会这么想。我曾经在海军的核潜艇上服过役,我们开发的软件项目在复杂度上也是不遑多让。别忘了,核潜艇可是有足足六层楼高、好几个足球场那么长,而无形的软件项目跟那差不多。所以很多人对软件的理解还太青涩。 主持人:我完全同意——再次强调,代码细节现在已经成为无关紧要的因素。我也经常会发现在交流过程中,不同的人对于软件的理解简直不在同一个世界。过去这十几、二十年里,我们对服务器的看法发生了根本性转变,服务器从“上帝”变成了“宠物”,最后变成“牛马”。我们不用再去操心什么时候开启和关闭服务器。代码的情况也差不多,它的神圣性光环正在快速褪去,逐渐也将变成“牛马”,这就是未来的世界。 让我好奇的是,我连自己当下正在做的工作的心理模型都很难跟上,真的还有余力领导一整个智能体团队吗?我得跟进 N 名同事,这些同事每人都有 N 个智能体在替他们工作。这个问题会迅速扩大,所以你在这方面有没有用到过什么有效的工作?Gas Town 是怎样以更容易理解的方式展现这些内容的? Steve Yegge:2008 年时我曾接受过一次采访,同样参加采访的大概有十位颇有声名的从业者,其中一位就是 Peter Norvig。除此之外还有 James Gosling、Guido van Rossum 等等,我们都受邀回答同样一组问题。 对于其中一个问题,我觉得 Peter Norvig 给出了历史最佳级别的回答。题面大概是:优秀程序员应当拥有怎样的特质?其他人都滔滔不绝讲了一大堆,而 Norvig 回应说“能够把整个问题都记在脑子里。”就这么简单,而且直接扼住了问题的咽喉。 事实上,成功团队与失败团队的区别就在于,前者能够把更大的问题容纳在脑海当中。而大模型正好擅长处理这种跨职能沟通与协调,帮助降低相关成本。当然,大模型的介入会让产出速度加快,所以问题本身也会进一步加剧——这就是项目管理中的所谓杰文斯导论。 我曾有位技术能力不太强的上司,但他非常擅长调度副手、顾问和资深首席工程师,也信任这些人来指导决策并领导团队。有了这份识人之能,再辅以他自己的领导魅力,使得整个体系非常高效。我觉得像亚马逊这样的巨头也直接采用了这样的模式,由此形成一种行政-技术双重管理架构。其中既有经理,也有技术顾问或者技术负责人。我认为整个行业都在朝着这个方向发展,让每个人都能获得技术顾问的协助。 我之前写过一篇博客,讲的是我有两个朋友因为同事交付晚了两个小时就冲对方大喊大叫。这俩朋友每人都管理着 20 个智能体。他们意识到,原来有智能体当帮手可以把工作效率提升这么多。当然,他们需要想办法以透明、主动和公开的方式分享自己的工作成果,这又是新的问题了。总之开发的世界变化实在太快,工作方式和瓶颈都在迅速更迭。 结果就是,这俩朋友跟同事闹得很凶。因为对方说“我用这两个小时实现了这项功能……”朋友们问“为什么,实现它干什么?”对方回答之后,朋友们说“那是两小时前的情况,你脑子有病吗?这两小时之间我们又做了六个决定,结果你还在处理之前的问题。”这就是新的现实,无论喜不喜欢都必须适应。 Beads 和 Gas Town 为这场软件开发狂飙又添了一股助力。再就是 Opus 5、Opus 5.5 等未来将要出现的模型新版本,也许可以让编排器运行更加流畅,甚至让智能体产出质量达到更值得信任和使用的程度。我有感觉,其实我们离那一天已经不远了。 主持人:我也有种感觉,所以特别想跟你聊聊这个话题。因为我采访过很多使用编程工具的从业者,包括我自己。大家关注的仍然是单兵作战的效果,那我们该怎么用好大模型、特别是智能体,优化开发者单兵的编程效率?而在此之外,团队使用环境下的瓶颈又完全不同。现在我们该怎么保证我们的技术水平也能与时俱进? Steve Yegge:好的。正如我刚刚所说,双重管理架构已经影响到每一个人。我们既是经理、又是主管,掌控着一整个软件工程团队的运作。由此开始,我们的软技能、人文素养、教育背景、认知观念乃至人际交往能力都会变得非常重要。 比方说我们编写了 30 万行代码,现在想把它移交给另一支团队。对方可能会说“我们看不懂你的代码。”因为代码量太过庞大,任何内容都得像谈判一样反复确认和协调。这肯定会让团队乃至整个公司感到异常苦恼。 这时候沟通能力越强,解决问题的思路就越是清晰。就是说我们必须以行政角度、成员管理的角度审视这一切。开发者必须学着搞清楚谁需要什么、谁在做什么,谁天生具备哪些技能、谁又天生不具备等等。当然,这些技能也是可以培养、发展和学习的。 所有知识型工作未来都将以这种方式运作,这时候我们就从纯粹的人进化成了“半人马”——是不是还挺形象的?头脑是人,但肌肉是马。你知道“半人马”这个比喻是谁提出来的吗? 主持人:我也不记得它的起源。但我在网上看到过,有人说这是 Bobby Fischer 发明的,最早用来描述 AI 辅助国际象棋。可问题是最终“半人马”是怎么构成的?AI 当头、人类当身体,还是说人当头、AI 当身体? Steve Yegge:这个概念火了之后,会有人跳出来唱反调,说“无聊”或者“混合体”之类的话。但实事求是地讲,每个人都会拥有自己的 AI 好友、AI 助手,它会渗透进我们的生活。你尝试过 Claude Cowork 吗? 主持人:我还没试过 Cowork,但我已经试用过 Claude Code 和 Codex。我能明白这里的潜力和未来的想象空间。 Steve Yegge:Claude Cowork 其实就是面向更广泛人群的 Claude Code。那些唱衰的朋友,今年之内肯定会经历一番思想观念的大颠覆。有些人会从中收获快乐,也有很多人会因此放弃知识型工作。但肯定有一部分人就是不喜欢什么“半人马”式的组合,就不愿意跟 AI 一起工作。 主持人:所以我一直在思考这样一个问题。我们现在已经能用 AI 工具解决很多问题,但本质都是要用更快的速度以同样的质量处理任务。而这只是精简角度的切入方式,换个角度来看,我们也许会迎来另外一种未来:用 AI 助手以远高于以往的质量完成同一项工作。 Steve Yegge:我有个朋友,他是世界上最优秀的工程师之一,在亚马逊和谷歌这样的大厂开发出过无数产品。他坚持认为,使用大模型能够显著提高产品质量。这是因为他的用法跟大多数人不一样。大模型给了我们更多选择,而他从中选择了质量更高的产出。 具体来讲,他的做法是审查所有智能体的成果,由此建立起一套结对编程的实践。这样肯定效果更好,把人和 AI 的优势融合了起来,实现了既优化吞吐效率、又提升质量的效果。对于像 Dolt 这样的项目,我会把质量诉求拉到最高,进行一轮又一轮代码审查,之后再把成果交给 Dolt 团队再审查一遍。这就是我的看法,质量是种选择,就这么简单。 主持人:我认为这里还有另一个值得讨论的重点。作为一个在开发领域摸爬滚打多年、比大多数听众都更深刻理解软件本质的从业者,你会在什么样的情况下强调质量提升? 具体来讲,你怎样判断什么样的时机最合适,什么时候质量比产出效率更重要?在做出判断后,你个人又会优先调整哪些参数? Steve Yegge:对我来说,这样的判断并不难做。毕竟作为得到无数开发者认可和依赖的项目,Beads 现在已经不容有失了,所以质量保障自然非常重要。我会对 Beads 做非常充分的测试,测试代码量甚至远多于项目本体,而且未来也肯定是这样的路子。集成测试也差不多。验证和确认都很重要,而这两点就是我最需要关注的问题。 另外还需要注意一点,也是我们面临的一大新挑战:AI 解决了旧的瓶颈问题,但新的瓶颈已经出现。其一是合并问题,其二是共享设计以及如何保持设计更新的问题。我们之前也提到,合并问题尤其棘手。因此 Gas Town 才专门设立了所谓“精炼厂”,尝试指定专门负责合并的人员来处理合并方面的难点。 而且有趣的是,我把 Gas Town 给 Anthropic 他们展示过,他们觉得 Gas Town 成功规避了他们模型中的一堆 bug。 也就是说,AI 的层次结构将会扁平化。我们不再需要那么多角色,因为其中半数角色只是权宜之计,未来的智能体可以更好地“各司其职”。在 AI 能意识到自己的职责之后,整个体系会非常简单。我认为最终会形成非常扁平的层次结构,或者只有两层、最多三层。因为从组织角度来看,我们应当充分利用这种优势。当然,对于规模特别大的项目,智能体可能也会选择更复杂的层次结构,我认为这就是未来的整体发展方向。 我认为这就是大家今年之内必须学习的技能,也必须重视由此带来的成效。总体来讲,AI 给资深员工带来的收益会比初级员工更多,因为前者更能理解什么叫做“好”。没错,现在我们还处于 AI 不知道什么叫“好”的阶段,所以资深员工仍有一定优势。 再次强调,对于资深工程师来说,验证和确认往往更为简单,一眼就能判断。但如果身处全新领域、面对全新的编程语言和应用场景,那这样的判断就比较困难了。而我会尽量避免在这类场景和开发需求中大量使用智能体。 主持人:那你有没有尝试用 Gas Town 为普通用户开发过什么成果? Steve Yegge:我一直忙着开发 Gas Town,所以腾不出手来做其他方面的尝试,比如在 UI 编程方面表现如何。我知道 Gas Town 还有很多 bug,但它的普及速度太快了,用户们宁愿无视我的警告也要大量使用。所以我得把时间都用在完善 Gas Town 上,暂时没空探索其他方向。 Gas Town 经常出毛病,甚至偶尔会失控。前几天我就关闭了机器上的 320 个 Claude Code 实例,每个实例大约占用 1 GB 内存。当前整个体系还很不稳定,但已经让我们看到了新时代的曙光,这绝对值得大家兴奋莫名。 至于要不要为普通用户开发成果,我还不太清楚。目前我的全部注意力都集中在 Gas Town 身上,思考它的长远发展方向、存在的意义等等。这是我眼下最重要、最需要解决的议题。 主持人:这有点像构建治理框架,它的制定根基是不会动摇的,外界的意见只会起到一定的引导作用。 Steve Yegge:是的,我能做的就是降低参与讨论的门槛。在 Gas Town 之前,我只是个软件开发博主,认为未来的 AI 会越来越强、人们会运行大量智能体之类。但 Gas Town 诞生之后,我用 Nano Banana 为项目生成了一整套角色形象,甚至还有项目主题曲。大模型真的牛,在艺术创作方面强得让人意外。 于是在一夜之间,似乎每个人都可以参与到对话中来。很多用户之前还觉得我的观点纯粹是放屁,但现在变成了“有点激进”。没办法,每个人都得承认 AI 正在自我构建,这种自我构建让智能体集群真的很可能成为现实。 很多人觉得这样的趋势让人感到不安,觉得自己好像成了蜂群意识中的一分子。这就像《安德的游戏》照进了现实,有些人接受不了也很正常。 主持人:这个过程让我想起另一件事,就是编译器的诞生过程。为语言编写编译器的首要目标之一,就是要求它能够自我编译。从这个角度看,Gas Town 就像一套引导式智能体编排框架。 Steve Yegge:确实是这样,这个比喻很贴切。当初我给朋友们介绍 Gas Town 时,他们首先想到的就是编译器,而当时 Gas Town 还没有真正能够自我构建呢。这种感觉也很神奇,就像是打通了一条时空隧道,直接通向一个全新的软件宇宙。 接下来我们开始建立基础设施,类似于现实中的城镇。通过一次次迭代和突破,Gas Town 终于实现了自给自足,而 Beads 就是其中的活动信息流。当 Bead 关闭,则代表一个事件。 身份也不需要独立出来,身份也是一种 Bead,代表数据计划。但就在我觉得一切都说得通的时候,项目出问题了,就是跑不通。 时间来到 12 月 28 号,突然之前 Gas Town 中的“镇长”开始大量返回报告:这项功能已完成、那项功能已完成……我当时就懵了。怎么回事?我什么都没动,但各项任务突然就开始跑通,整个体系运行起来了。这套“编译器”,开始成功进行自我编译。我当时真的特别兴奋,毕竟距离新年还有两天,于是我决定赶紧让它上线。这就是 Gas Town 的来历,我最终让它成功实现了自托管。 主持人:我很好奇,你觉得编译器这个比喻还适用于哪些其他场景?我个人经常用它来描述大模型,我觉得大模型类似某种形式的虚拟机。总之我们可以用提示词向大模型表达意图,之后它会不断迭代,直到找出相应的正确产出。那你还能想到其他合适的比喻吗?不一定非得是编译器。 Steve Yegge:说真的,我觉得 Beads 和 Gas Town 构成的这套系统,就代表着我从业以来想要完成的终极目标。类似于极其复杂的 Wyvern 属性体系,也有点像 JavaScript 中的瞬态属性。 比如在游戏中喝下一瓶药水,它会在一段时间内持续增加生命值。但如果退出游戏,这个效果应该马上中止。这就是永久属性和瞬态属性的概念。事实证明编排也是如此,除了固定任务之外,还有各种维护性质的零散任务,再加上内置的资产继承等机制。总之这是一套非常复杂的模式。 这就需要一套事件系统,就跟游戏中的事件系统一样。它的基本框架类似于操作系统,但随着加进各种界面,游戏的样貌也逐渐展现。前几天我在 X 上看到一篇同人帖,说是 Gas Town 彻底乱套了,工兵角色开始跟镇长争着当老大。虽然这只是虚构,但也并非完全不可能发生,某种程度上相当真实。 我觉得我们确实会发展到这样的程度:智能体慢慢变得像角色扮演游戏、策略游戏乃至即时战略游戏。我觉得我们离那天已经不远了。所以,我想就应该更进一步、做更积极的探索。 这肯定是件非常了不起的大事件。可能到今年年底,人们就会像玩游戏那样开发软件。以往很多高度复杂的软件需要一整支工程团队、甚至是大厂那样的组织形式才能完成,而普通人根本不可能具备这样的经验和资源。而未来软件开发将迎来爆发式增长,而且会遍地开花。正如 YouTube 让每个人都能发视频,社交媒体和手机让每个人都能发帖,大模型未来能让每个人都能开发软件。 主持人:虽然可能有点跑题,那你觉得这样的趋势会对行业产生怎样的影响? Steve Yegge:刚刚提到,我有两个朋友因为工作节奏太快跟同事吵起来了,这也让我担心后续还会发生什么样的情况。我也跟其他业内人士聊过,他们在工作中使用 Codex、Claude Code 或者 Gemini 等 CLI 工具的效率远超同事,也因此在绩效考核中占据了绝对优势。这肯定会动摇招聘乃至整个传统面试流程,进而影响到软件开发的方方面面。 由此所有瓶颈都开始转移。有些业务团队明显适应不了,因为他们还没准备好,工程团队已经把他们想要的东西交付过来了。也有一些业务团队因为无法容忍长期等待工程师的交付,所以开始自行开发软件,毕竟有了 AI 助手这些都是可以实现的。 所以就像亚马逊那边的“双披萨团队”,把一群想要解决问题的专家聚在一起,共同出谋划策。其中可能只有一位工程师就够了。展望未来,可能所有工作都开始向“零工经济”转型。比如项目中的产品经理只需要参与一个礼拜,或者偶尔引入一名用户体验设计师。既然都是临时的,那租赁肯定比长期招聘要划算。 这样公司内部的经济模式就很像 Airbnb 了——好吧,这个例子可能不太恰当。或者说,更像 Uber 吧。零工经济和员工租赁开始成为主流。谷歌早就这么做了,SRE 有自己的特定办公时间。总之随着氛围编程的普及,每个人都可以为同一款大体量产品贡献力量,共同参与构建。这将是一种更加动态、灵活的工作模式,人们可以根据需要随时提供助力。 回到你之前的问题,我认为传统的规划方式已经过时了。未来成功的企业会实时开发产品,开发出鲜活的软件成果。目前我们看到的很多,就是未来软件开发形态的雏形。 测试环境当然也会存在,我们可以启动多个类似的环境来尝试不同的方案,然后放弃掉其中跑不通的方案。整个效率将大大提升,而且规范也不再必要。未来真正需要共享的只有理念,也就是开发软件的理由。 这将彻底颠覆企业的运营方式,信息孤岛将被彻底打破。以往,很多官僚出于自身利益而操纵体系,比如努力保住自己的职位、或者逃避工作内容等等。但他们终将被揪出来并剔除出去。而且我认为,这样的机制会奖励那些真正擅长跟 AI 合作、跟其他人合作的从业者,奖励那些能够在庞大且混乱的环境中推动事物发展的人们。当然,这只是我自己的看法,你觉得呢? 主持人:我已经看到类似的情况开始发生了,而且瓶颈确实正在转移。接下来的问题是,我们该如何攻克新的瓶颈,或者如何改造这些卡点。你提到了规划,规划一直是巨大的瓶颈,还包括架构和决策等等。当然,我们之前也提到过那些特别出色的技术主管,以往只有优秀到这个程度才能快速掌握系统的状态信息。这就是新的瓶颈,因为大多数工程师都掌握不了这项技能。我甚至怀疑很多面试官都不行。或者说,他们也不打算培养自己的这方面能力。有些人觉得没啥意思,不如自己亲自动力。比如他们宁愿自己解决问题,也不愿意验证别人的解决方案。 但这段旅程真的很奇妙,对吧?我现在管理着一支智能体团队,编写的代码量比我之前全职作工程师时还要多。 Steve Yegge:是啊,当所有齿轮都完美啮合、顺畅运行,程序员就能充分体会到创造的乐趣。整个工作就像是一场游戏,不停地获得多巴胺的刺激。这就像在玩电子游戏一样,简直让人上瘾。人们会像玩游戏那样沉迷其中,一开发就是好多个小时。 我们离这个目标越来越近了,因为传统的编程就挺让人上瘾的。我们喜欢全神贯注,不愿浪费时间去折腾什么愚蠢的 JS 库之类。现在最好的时机终于来了。 主持人:我认识很多这样的开发者。我自己昨天在机场里也差不多,其实 Wi-Fi 信号很不好,我也本来想去趟洗手间、买点吃的之类。但我不愿意动,因为我刚启动了一批智能体,想看看它们会做什么,想要持续关注。 Steve Yegge:没错,我觉得编程智能体用起来就像在玩二十一点或者老虎机。只要开始信任大模型,我们就会不断启动新的智能体,并最终习惯这种总有智能体在运行的新常态。 就像那种能挂机的游戏。随时可以看看自动完成的日常任务做得怎么样了,随时去领取奖励。这种智能体加编排器的组合会变得像让人上瘾的电子游戏。这对我来说真的很值得期待。想想看,如果所有知识工作都能被拆分成一个个小块,并把这些小块跟世界上的每个人匹配起来,让大家都能参与其中、开发自己的软件,并从中获得乐趣。 这就是技术的大众化普及,我个人对此非常期待,但也有人对此感到害怕。无论如何,人们会越来越被自己所能创造出的事物所震撼,我对未来非常乐观。 主持人:其实以此为收尾就很好了,但在结束之前,能不能再补充一点咱们可能漏掉的内容? Steve Yegge:我想分享自己的一项发现,这也是专门为咱们这期节目准备的独家猛料。 主持人:好啊,这可是首次公开哦。 Steve Yegge:我觉得我找到了判断软件产品能不能在 AI 时代活下去的万能公式。 应该有很多朋友在关注这个问题吧。很多公司都在担忧,觉得 AI 正在吞噬软件、吞噬工作岗位、甚至吞噬整个行业。Stack Overflow 已经受到了冲击,家庭作业辅导软件 Chegg 也消失了。还有客服中心,集成开发环境(IDE)等等。 那我们要怎么判断一款软件能不能在 AI 时代生存下去呢?我觉得可以用热力学来尝试解释。谁的软件有利于节省 token,AI 就倾向于使用谁的产品,这样项目就能生存下去。计算器也好、数据库、存储系统、账本、事务处理系统、路由器、网络、基础设施等等都是如此。任何需要大量计算和数学运算的项目,只要是大模型自身就能完成的,那就必然灭亡。 主持人:明白了,就是说只要 AI 学会了使用工具和写代码,那就有着无穷的可能性。 Steve Yegge:没错,它们确实会这么做。它们会编写代码,也会使用工具。所以它们会进行大量的矩阵乘法运算。但 AI 都很懒惰,总是选择最短路径。因此,你会遇到一些障碍。所以最重要的就是怎么让自己的工具或产品进入 AI 的视野,这样 AI 才有足够的动力来了解并使用。 大家可能听说过一款叫 Serena 的产品,这是一款开源软件,利用 LSP 服务器加 IDE 来节约大量 token 只要把大模型接入 Serena,它就会优先使用 Serena 来替代 Grep。由于代码库中的所有代码都经过预先索引,所以无需 Grep 就能快速找到目标位置。事实证明,它确实可以节约大量 token。 所以对大模型来讲,这是一种更节能的运行状态,也必然成为一种更优选。 主持人:但好像这个观点没法用思想实验来证明吧? Steve Yegge:确实证明不了。但无论如何,浪费又低效的方案终会被放弃,大模型会选择更有效率的选项。目前编写代码的效率更高,后续如果出现了效率更高的工具,大模型也会选择使用。比方说只要能在底层解决问题,那 CPU 的计算周期要比 GPU 周期成本更低。 说实施,我认为 NPU 甚至人工神经元的成本更低。而且人类实际上更擅长某些任务,把这些任务交给人做成本更低。就像《黑客帝国》里那样,导演说人类的大脑被当作计算单元来使用,这个预言其实还挺准的。 总之,要想在 AI 的冲击下生存下来,就必须像 Beads、Dolt、MongoDB、Temporal、Kubernetes、Kafka、Cassandra 这类基础设施那样成为 AI 的优先选项。 只要能让大模型知晓你的工具,那项目活下来就不成问题。大模型可以使用这类工具降低热量损耗、节省任务处理所需要的 token。你觉得我的观点有道理吗,你认同吗? 主持人:我比较认可,咱们拭目以待。我觉得这个观点很有意思,我认为问题不仅在于节约能量,还在于访问权限。正因为如此,大家才在竞相构建某种形式的记录系统,积累宝贵的历史数据。 Steve Yegge:关于这个问题,我觉得同样可以用热力学系统的特性来解释。任何任务,最终都可以用 token 消耗量的角度来审视。比如说 RAG 系统就是为此而生,后续还将有更多同类系统不断涌现,并成为大模型倾向选择的优先选项。 Karpathy 还有不少 AI 研究者都相信,未来的 AI 能够解决一切问题。如果判断准确,那么两年之后我们的手机里就用不着安装一大堆 APP 了。只要一个 Claude 足矣,它无所不能而且用起来特别上瘾。只要 Claude 能做到,其他软件就没有存在的意义了。只有它涵盖不了的部分,比如设计精良的游戏、无法访问的数据存储,或者已经拥有强大使用惯性的老牌产品,才有可能继续生存。 这会是一种前所未有的新体验,而且 AI 会变得越来越根深蒂固,让人们建立起更强的依赖性。 主持人:我觉得这种趋势已经开始了。 Steve Yegge:是的,现在的 AI 甚至连时间都还看不懂,但未来的 AI 也许根本不需要去读时间。这个世界变得太快了,一切皆有可能。 主持人:很有趣,因为你在对话中描述了一个复杂的未来——一半是美好的乌托邦,另一半又反乌托邦。 Steve Yegge:我打算再看看 Arthur C. Clarke 的书,他其实准确预言了很多事情。只是他在科幻作品中提到的是外星人,而现实中是 AI。全人类正面对一个十字路口,未来可能通往光明、也可能通往黑暗。我完全相信这一点,而有些人正排队朝着黑暗那个方向前进。 想象一下,这将建立起全球统一的支付通道。有了它,世界上发生的任何事件都能提取交易信息。于是统一的工作通道、统一的运行通道和统一的社会体系都将由此产生。 但这又会让万事万物都笼罩在监控之下。我个人对此有点担心,总之 AI 将成为这个十字路口上的推动因素,很多人也肯定会站出来做出大规模反抗。总之,全社会都会以前所未有的方式在 AI 问题上站队。 原文链接:从补全到编排:软件工程正在被永久改写
当多智能体开始协作:需要一套新的数据平面与记忆系统
写代码不再是难点:难的是把问题说清、把上下文喂对
智能体越多越乱:个人开始遭遇团队级复杂度
写代码交给 AI,理解系统交给人
管理 320 个实例:编排系统的真实压力测试
未来软件生存公式:谁被大模型选中,谁就活下来
辣鸡绕城高速,两车道,出个车祸直接堵个四五公里,花钱受堵车气。
那些个走应急车道的,真想给你们拍下来,杭州交通还是太松,罚的还是太轻
今天又迟到了,难受~ 不过今天天气还不错,天很蓝,风很柔,是春天呀

minimax-m2.5:cloud glm-5:cloud qwen3.5:cloud
http://119.196.217.110:11434/v1/models
{
"object": "list",
"data": [
{
"id": "lfm2.5-thinking:latest",
"object": "model",
"created": 1772258608,
"owned_by": "library"
},
{
"id": "qwen3.5:397b-cloud",
"object": "model",
"created": 1771237111,
"owned_by": "library"
},
{
"id": "qwen3.5:cloud",
"object": "model",
"created": 1771236790,
"owned_by": "library"
},
{
"id": "minimax-m2.5:cloud",
"object": "model",
"created": 1770924063,
"owned_by": "library"
},
{
"id": "glm-5:cloud",
"object": "model",
"created": 1770840481,
"owned_by": "library"
},
{
"id": "deepseek-v3.1:671b-cloud",
"object": "model",
"created": 1770157871,
"owned_by": "library"
},
{
"id": "huihui_ai/deepseek-r1-abliterated:14b",
"object": "model",
"created": 1762497440,
"owned_by": "huihui_ai"
},
{
"id": "fluffy/l3-8b-stheno-v3.2:latest",
"object": "model",
"created": 1762496544,
"owned_by": "fluffy"
},
{
"id": "gpt-oss:20b",
"object": "model",
"created": 1762488549,
"owned_by": "library"
}
]
}
提示:安全性未知,请勿输入敏感信息。
之前一直想入一台 appletv ,但又有消息说会发新款,迟迟没下手,3 月有没有可能出新款?
各位今天捐了多少军费?
周五转到电力和绿电 ETF 一部分,今天对冲完居然还红了 20 块,看样子可以吃碗猪脚饭了。
之前潮的睡觉都难受,出汗蒸发不掉,空调除湿又太冷了。
一晚上储水盒都快满了。上海这几天太潮了
音视频软件开发工具包(Software Development Kit, SDK)是为开发者提供的一系列应用程序接口和工具,用于在音视频应用中实现多媒体内容的采集、编码、传输、解码和播放等功能。作为一种中间件技术,音视频SDK通过封装底层复杂的技术细节,为开发者提供了高效、便捷的开发方式,从而显著降低了音视频应用的开发门槛。目前市场上的音视频SDK种类繁多,不同厂商提供的产品在功能特性上存在显著差异。例如,KSYMediaPlayer SDK以其全平台兼容性和低延迟播放能力著称,广泛应用于直播和点播场景;而金山云播放内核则通过支持多种音视频格式和编码方式,在跨终端应用中表现出色。此外,部分SDK还集成了人工智能算法,如智能美颜、语音识别等功能,进一步丰富了其应用场景和技术价值。
音视频SDK的发展历程可以追溯到早期互联网音视频技术的初步探索阶段。在这一阶段,由于网络带宽和硬件性能的限制,SDK的功能相对简单,主要集中在基本的音视频采集和播放能力上。随着移动互联网的普及以及4G/5G网络的快速发展,音视频SDK逐渐向多元化和复杂化方向演进。特别是在直播、在线教育和视频会议等场景的需求驱动下,现代音视频SDK不仅支持高清视频编码和实时传输,还集成了多种增强功能,如动态码率调整、噪声抑制和实时通信等。技术突破方面,H.264/HEVC等高效视频编码标准的引入显著提升了视频压缩效率,而WebRTC等实时通信框架的推广则为低延迟互动提供了坚实的技术基础。市场驱动因素则主要体现在用户对高质量音视频体验的需求不断增长,以及企业对降本增效的追求。
当前关于音视频SDK开发的研究已取得了一系列重要成果,尤其是在编解码技术优化、传输协议改进以及实时通信能力提升等方面。例如,研究表明通过优化H.264编码算法,可以在较低码率下实现更高的视频质量,同时降低带宽消耗。此外,基于AES加密和SSL/TLS协议的数据安全保护机制也为音视频SDK的安全性提供了有力保障[8]。然而,现有研究仍存在一些不足之处。首先,在新技术融合方面,尽管人工智能和5G等技术为音视频SDK带来了新的发展机遇,但如何将其有效整合到现有框架中仍是一个亟待解决的问题。其次,跨平台兼容性问题依然突出,尤其是在不同操作系统和设备型号之间,接口差异和硬件适配问题可能导致开发成本增加和用户体验下降。最后,针对复杂网络环境下的性能优化研究相对有限,现有解决方案在处理高并发、低带宽场景时仍面临一定挑战。
开源仓库: https://github.com/golutra/golutra
视频演示地址: https://www.bilibili.com/video/BV1qcfhBFEpP/?vd_source=99a6a5e6529f563261503f851a93c005#reply294036475536
正在规划中的下一步计划包括:
接入或者重构 OpenClaw 为真正的“总指挥层”,手机端远程操控 ,自动 Agent 构建能力,Agent 接入永久记忆层
欢迎大佬们提出 bug ,给出建议
最近几年时间,国内新能源汽车在市场层面和技术层面的表现,大家已经看到了,很多燃油车企面对新能源汽车,能够做到最大的反应就是降价了。不仅仅在国内市场,国产新能源汽车在海外市场,也成为了很多车企的“梦魇”,像北美、欧洲等一些国家和地区,对国产新能源汽车设置了非常苛刻的准入门槛,要么设置最低价,要么100%关税,就怕国产新能源车进去之后,直接将其本土车企的市场份额给“冲散”了……
但是这种“掩耳盗铃”的方式,并没有办法解决现实问题,技术和产品方面的代际差已经明显存在了,尤其是在美国一些车企中,还存在一些“美奸”,到处说中国产新能源汽车的好,让很多当地消费者蠢蠢欲动。福特汽车的CEO吉姆·法利就是典型的代表,这位车企CEO,从我们国内空运小米SU7,开得不亦乐乎,甚至说出了开完再也不想开自己燃油车的“暴论”,被美国媒体一通喷,而且对理想增程、比亚迪磷酸铁锂电池也表达了非常高的评价。可以说,这位福特CEO是国产新能源汽车的铁粉,对美国汽车产业和国内新能源汽车产业的差距了解得非常清楚。
最近就有消息称,吉姆·法利正在与特朗普政府高级官员就一项潜在框架进行了会谈,该框架允许中国车企在美国本土生产汽车。而吉姆·法利的核心目标,就是游说川普方面能够同意,福特可以和比亚迪等中国新能源车企建立合资公司,以合资品牌身份在美国生产和销售新能源汽车。对于国产新能源汽车来说,这样的方式,也算是在一定程度上绕开了美国对国产新能源汽车的关税壁垒,国产新能源就有希望再次进入美国市场,然后给美国消费者开开眼了。
实际上,吉姆·法利对福特和比亚迪的合作,一直都是有“预谋”的,尤其是对比亚迪的磷酸铁锂电池非常感兴趣。之前吉姆·法利就曾表达过观点,由于磷酸铁锂电池的技术专利,基本上都掌握在比亚迪等国内企业手里,所以包括福特在内的美国车企,只能使用成本更高、循环次数少、安全性存疑的三元锂电池,所以福特的电动车在成本这一块,一直下不来。
当然这样的合资方式,我们实在太熟悉了,在过去三四十年里,全球知名的汽车品牌,很多都和国内车企建立了合资品牌,这些海外品牌得以在国内市场销售,而且福特方面的诉求,其实和我们当年很多车企的想法一样,试图通过市场换技术。大家都知道,比亚迪在新能源汽车领域的技术积累是相当强势和厚重的,包括易三方、易四方、兆瓦闪充、DM5.0等等,这些技术对于很多海外车企来说,就是“天方夜谭”般的存在,所以这种需求是存在的。
不过我们也很担心,虽然现在有这样的传闻,说福特正在游说川普方面,试图和比亚迪在美国建立合资品牌,生产和销售新能源汽车,但是其中的阻碍肯定还是很大的,包括在价格层面,比亚迪垂直整合的能力在美国市场未必能施展开来。而且美国很多车企对国产新能源汽车的敌意很大,之前加拿大对国内电动车开放每年4.9万辆的配额,就已经把通用等美国车企给吓坏了,甚至抛出了产业威胁论!更加重要的是,可能美国方面也会担心,一旦这个口子一开,美国那些落后的汽车产能,冲击太大!
所以就算有上面的传闻,大家也不必抱太大的希望,这其中的艰难和阻碍可能还是非常多的,但是这总归是一个思路,毕竟美国市场也是很大的市场,如果能够进入这个市场,并且占据一定的市场份额,对于其在全球市场的业务开展,还是很有示范效应的。
原文来源:https://zhuanlan.zhihu.com/p/2011382920556848899