jim 维护被我抓住了吧 🤣
请看图,还是第一次碰到网站维护,留个纪念。
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
请看图,还是第一次碰到网站维护,留个纪念。
从首页点了很多个帖子都提示了这个“未找到该帖子内容,请确认帖子 ID 是否正确 🤔”

在硬件战略的棋局上,OpenAI 落下了一枚重磅且出人意料的棋子。他们正式推出了 GPT-5.3-Codex-Spark 模型,而这项发布最大的核心爆点不在于模型本身,而在于其运行的底座——这是 OpenAI 首款放弃传统英伟达 GPU,转而部署在 Cerebras 晶圆级芯片(Wafer Scale Engine 3 加速器)上的生产级 AI 模型。 目前,基于 Cerebras 平台的 Codex‑Spark 已向 ChatGPT Pro 用户开放研究预览版。借由底层硬件的切换与系统级优化,该模型的运行速度达到了惊人的每秒 1000 个 Token。据 OpenAI 官方宣称,这一速度比早期版本快约 15 倍,能够为开发者带来极致流畅的实时交互式编码体验。 为了实现真正的“实时交互式编码”,OpenAI 在 GPT-5.3-Codex-Spark 上进行了极其残酷的取舍。该模型被明确设定为优化低延迟与交互式编码工作流,战略性放弃了聚焦深度推理或通用任务。在 SWE-Bench Pro 和 Terminal-Bench 2.0 两项基准测试中,其性能仅介于 GPT-5.1-Codex-mini 与 GPT-5.3-Codex 之间,但耗时大幅缩减。 除了硬件加持,OpenAI 在软件栈底层的“狂飙”同样值得关注:引入持久化 WebSocket 连接、简化流式传输、重写推理栈关键代码。这套组合拳将客户端与服务器的单次往返开销暴降 80%,首 Token 生成时间(TTFT)腰斩 50%。 尽管 OpenAI 宣称了极其华丽的提速数据,但这场“狂飙”在开发者社区却引发了剧烈的两极分化与质疑。 一方面,极客社区的声音显得格外犀利。Reddit 用户 Tystros 明确表达了对“降智提速”的抵触:“如果完成任务需要一小时但结果更好,我愿意等一小时”;而另一派用户(如 stobak)则认为,超快模型能大幅削减反复试错迭代带来的隐性累积成本。 更致命的打假来自 X 平台的研究者 Nicholas Van Landschoot。他毫不客气地戳破了“提速 15 倍”的公关泡沫——在实际基准测试中,真实性能提升仅接近 1.37 倍。所谓的 15 倍,只是 OpenAI 玩了一个偷换概念的把戏:他们拿新模型去对比了旧版 Codex 中一个刻意延长推理时间以提升准确性的特殊配置(x-high)。 👇 欢迎关注我的公众号 在 AI 爆发的深水区,我们一起探索真正能穿越周期的技术价值。 欢迎关注【睿见新世界】
一、 逃离英伟达围城:Cerebras 迎来的高光时刻
【笔者观点】
OpenAI 这一步棋极其“反常识”,却充满紧迫的战略威慑力。 当全行业仍在为英伟达的 H/B 系列算力卡抢破头时,奥特曼悄然将最吃吞吐量的生产级大模型搬到了 Cerebras 的晶圆级芯片上。这绝不仅仅是一次简单的硬件采购多元化,而是吹响了“推理侧去英伟达化”的号角。算力霸权的铜墙铁壁,正在被垂直场景(低延迟、高吞吐)的极速定制芯片硬生生撕开一道裂口。这也向全行业传递了一个明确的信号:大模型竞赛的下半场,推理成本与延迟的战争,GPU 已经不再是唯一解。二、 速度与深度的博弈:重构代码生成的交互范式
【笔者观点】
很多人陷入了“唯跑分论”的陷阱,认为牺牲模型的深度推理能力去换取速度是得不偿失的退步,这其实是一种极其短视的误判。 在真实的工程一线,开发者很多时候需要的不是一个思考一小时才能给出完美方案的“架构师”,而是一个能在一秒内完成 10 次语法修改、界面重构的“结对编程副手”。当首 Token 延迟压缩到人类近乎无感的毫秒级,人机协作的模式将从传统的“一问一答”彻底演变为“神经反射式”的共生。在特定场景下,极致的速度本身,就是一种颠覆性的智能。三、 公关数字的泡沫与开发者的真实倒戈
【笔者观点】
永远不要对硅谷的公关修辞照单全收。 1.37 倍的真实提升与 15 倍的宣传口径之间,折射出的是 AI 巨头在技术瓶颈期急于制造里程碑的焦虑。更危险的信号在于用户口碑的撕裂:天下武功唯快不破的前提,是你的方向得对。如果模型生成的代码充满了逻辑漏洞,那 1000 Token/秒的速度不过是在“加速制造工业垃圾”。OpenAI 必须清醒地认识到,Cerebras 带来的速度狂欢,只是一剂缓解交互阵痛的“局部止痛药”,它无法掩盖大模型在复杂推理上进化的停滞。GPU 依然是核心,而在速度与智能的钢丝绳上,稍有不慎,就会跌入虚假繁荣的深渊。
微信搜索 【睿见新世界】 或扫描下方二维码,获取每周硬核技术推文:
你在任何聊天窗口给它发一条消息,它就能帮你操作电脑——执行命令、读写文件、浏览网页、操控桌面应用、管理定时任务,甚至语音对话。 和常见的 AI 聊天机器人不同,OpenClaw 运行在你自己的电脑上,不依赖云端服务器。它支持 WhatsApp、Telegram、Discord、Slack、Signal、iMessage 等海外主流平台,也通过插件支持飞书、企业微信、qq等国内渠道。除了消息平台,还有 macOS / iOS / Android 原生应用,以及终端命令行和 Web 控制台。 简单说:20+ 种入口,一个本地 AI 大脑,一套工具集。 OpenClaw 历经 Warelay → Clawdis → Clawdbot → OpenClaw 四次更名,我们看看每次更名时的架构变化。 项目名 关键选择:用 Baileys(开源 WhatsApp 协议库)而非商业 API 收发 WhatsApp。好处是免费且不依赖第三方服务,代价是 Baileys 要求每台机器只能维持一个 WhatsApp 会话。 这是变化最剧烈的阶段——三件大事同时发生: 引入 Pi SDK:Pi 是一个外部 agent 框架,提供了"消息 → prompt → 调大模型 → 解析工具调用 → 执行 → 循环"的核心 agent 循环(架构详见后文 Pi Agent Runtime 一节)。OpenClaw 从此不再是"收到消息调一次 API",而是一个真正的 AI agent。 2 周内接入 5 个渠道:Telegram、Discord、Signal、iMessage、WhatsApp——每个平台的消息格式、API 风格、群组概念都不同。多渠道的差异催生了 Adapter 模式和 Channel Dock(统一注册中心),每个渠道只实现它需要的接口子集(详见后文通道适配器一节)。 Gateway 诞生:从一个 CLI 命令行工具变为常驻后台服务,所有客户端通过 WebSocket 统一接入,内含消息路由、队列、会话管理、Cron 调度、Hook 系统和 Plugin 注册。 核心思路是让新功能通过插件生长,核心代码库不再膨胀。为此落地了三层扩展机制: 社区开发插件时,导出一个 Node.js 生态的模块格式分裂(ESM vs CJS)是插件加载的主要障碍。OpenClaw 用 jiti(运行时 TypeScript 编译加载器)统一处理:插件不需要预编译,写完直接安装即可运行。目前 40+ 个扩展(飞书、LINE、Matrix、Twitch、语音通话……)都以插件形式存在。 让 AI 拥有跨会话的长期记忆。文本切片后转为向量,存入本地 SQLite,用 sqlite-vec 扩展做余弦相似度检索。搜索采用混合策略——向量语义匹配 + BM25 关键词匹配——兼顾"意思相近"和"关键词命中"。所有数据留在本地磁盘,也可通过 MCP 桥接对接外部知识库。 插件解决了渠道和工具的扩展,但 AI 的行为模式怎么共享?ClawHub(clawhub.ai)是公开的技能注册中心。技能本质是注入 system prompt 的声明文件,描述 AI 在特定场景下该怎么做(比如"操控 macOS 桌面"、"生成代码后自动运行测试")。 项目的 VISION.md 明确要求:新技能应先发布到 ClawHub,不要默认加入核心仓库。 OpenClaw 的 agent 能力不是从零自研——它站在 Pi SDK 的肩膀上。Pi 是一个 7 包 monorepo,从底向上分三层: pi-ai(LLM 抽象层) 把 16+ 家模型供应商统一成一个 pi-agent-core(Agent 运行时) 提供核心循环:用户消息进入 → 流式调用 LLM → 解析工具调用 → 按序执行工具 → 结果返回 LLM → 继续循环直到 pi-coding-agent(SDK 层) 提供 OpenClaw 在 Pi 之上包了六部分,让它从一个通用 agent 框架变成多渠道 AI 助手: 一条消息从进入系统到收到回复,经过这样的流水线: 两个值得注意的设计: WhatsApp 有"已读回执",Telegram 有"群组管理 API",Discord 有"权限体系",Signal 几乎什么管理接口都没有——每个平台的能力完全不同。 OpenClaw 的做法不是设计一个大而全的接口让每个通道都实现,而是拆成 10 种细粒度 Adapter,每个通道只实现它需要的子集: 社区开发新渠道插件(比如飞书、LINE)时,用 Plugin SDK 实现同样的接口即可接入,不需要改动 OpenClaw 核心代码。 你在 WhatsApp 里说"帮我看看屏幕上是什么",AI 就能截屏、理解画面内容、告诉你答案。你说"点击登录按钮",它就能找到按钮并点击。你说"打开 Safari 访问某个网址",它能启动应用、导航页面、在输入框里打字。 这背后是 Peekaboo——一个 macOS 桌面自动化工具,让 AI 拥有"眼睛"和"手": 典型工作流是:截屏标注 → AI 识别元素 ID → 点击/输入 → 再截屏确认结果,全程在聊天窗口完成。 Peekaboo 内部分为五层: 几个关键设计: Bridge 权限代理:macOS 的屏幕录制和辅助功能权限是按应用授予的,但 AI agent 调用的是命令行工具 元素检测与编号: 内置 Agent 模式:Peekaboo 自带基于 Tachikoma 的 agent 循环(支持 OpenAI / Anthropic / Ollama 等模型),可以独立执行多步桌面任务——不经过 OpenClaw,直接 Skill 注入:Peekaboo 在 OpenClaw 中不是代码依赖,而是一个 Skill——通过声明文件标注"仅限 macOS、需要 peekaboo 命令",运行时按需注入到 AI 的 system prompt 中。非 macOS 用户完全不会感知到它的存在。 OpenClaw 的定时任务不是简单的 大模型有上下文窗口限制(比如 200K token),聊久了上下文就超出。Pi SDK 提供了底层的两步上下文管线( 默认实现用 token 计数 + LLM 摘要来压缩历史对话。但整个 Context Engine 是可插拔的——社区可以写一个完全不同的实现(比如基于向量检索的长期记忆),替换进去不需要改一行核心代码。 阿瑟·克拉克在《2001:太空漫游》里写过一个场景:猿人月亮观察者捡起一块石头,第一次意识到自己的手可以延伸。从那一刻起,工具就不再是身体之外的东西——它是意志的投射。 我们今天拆解的这些——Gateway、Adapter、Bridge、Agent Loop——本质上都是同一件事的不同切面:让意图穿透介质。用户在 WhatsApp 里打一行字,意图穿过消息协议、穿过归一化流水线、穿过 LLM 的概率空间、穿过工具调用,最终变成屏幕上的一次点击、磁盘上的一个文件、终端里的一行输出。中间的每一层抽象,都是为了让这条路径上的摩擦再少一点。 这让人想起维纳在《控制论》里的判断:智能的本质不是计算,而是与环境之间有效的信息交换。OpenClaw 做的事情,与其说是"让 AI 用工具",不如说是在缩短人的意图与世界的状态之间的距离。结构决定功能,历史揭示设计。本文从用户视角出发,向底层追问"它是怎么做到的"。
OpenClaw 是什么?

演化史
Warelay:"一条管道"
warelay = WA Relay(WhatsApp 中继)。用户通过 WhatsApp 或短信给 AI 发消息,收到文字回复。没有 Gateway、没有 Agent、没有会话管理——就是一个 webhook 脚本。
Clawdis:最关键的跃迁
Clawdbot → OpenClaw:生产化与平台化
插件系统:Plugin SDK + jiti
register(api) 函数即可声明能力——可注册的类型包括:registerChannel)—— 接入新的消息平台registerTool)—— 给 AI 新的操作能力registerHook)—— 在消息流水线的特定节点插入逻辑本地记忆:sqlite-vec
技能市场:ClawHub
clawhub install <slug>核心子系统拆解
Pi Agent Runtime:OpenClaw 的大脑

stream(model, context) 调用。每个供应商实现一个 StreamFunction,把各家私有的流式响应转成标准事件序列(text_delta、thinking_delta、toolcall_start/end)。模型注册表是自动生成的,包含每个模型的成本、上下文窗口、支持的输入类型(文本/图片)和推理能力。end_turn。工具用 TypeBox 定义参数 schema,运行时自动校验。。createAgentSession() 工厂方法,一次性组装工具集、上下文钩子和会话存储。SessionManager 用 JSONL 文件存储对话树(每条消息有 id + parentId),支持分支、恢复和压缩。上下文管线分两步:transformContext() 在 AgentMessage 层面裁剪/注入(比如删掉过旧的消息),convertToLlm() 再把自定义消息类型转成 LLM 能理解的标准格式。
消息全链路:从收到到回复

session.steer() 把新消息实时注入当前 agent 运行,AI 会立刻调整回复方向——就像你跟人说话时补了一句"等等,我改主意了"。通道适配器:如何统一 20+ 种渠道

Peekaboo Bridge:让 AI 看见并操控 macOS 桌面

peekaboo。解决方案是 Bridge 架构——CLI 通过 UNIX Socket 连接到 OpenClaw.app 内的 BridgeHost 进程,BridgeHost 先验证调用方的代码签名和 Team ID,通过后才借出 app 已获得的权限执行操作。用户只需在系统设置里授权一次 OpenClaw.app。see 命令截屏时同步遍历 Accessibility 树(通过 AXorcist 封装),把每个可交互元素按类型编号——按钮 B1、B2,输入框 T1、T2。遍历有严格限制(深度 8 层、子节点 200 个、150ms 超时),检测结果缓存 1.5 秒避免重复遍历。后续 click B1 就能直接定位到目标元素。peekaboo agent "打开备忘录写一条待办" 就能截屏→分析→点击→输入→确认,循环直到完成。Cron 调度器:不只是定时器
setInterval,而是一个生产级调度系统:systemEvent(把消息注入主会话,像用户发了一条消息)和 agentTurn(启动独立的 agent 运行,互不干扰)Context Engine:长对话不丢记忆
transformContext 裁剪 + convertToLlm 格式转换),OpenClaw 在此基础上实现了自己的 Context Engine,定义了 5 个生命周期钩子:bootstrap(初始化)→ ingest(新消息进入)→ assemble(组装发给模型的上下文)→ compact(上下文太长时压缩)→ afterTurn(一轮对话结束后清理)结语
2Libra 现在引入了 Pro 与站内推广功能。具体的介绍入口为: https://2libra.com/pro/about ,或可在页脚处看到这个入口。
2Libra Pro 现在可以通过 Ko‑fi 赞助手动开通:你可以在 Ko‑fi 页面进行一次性或多次赞助,满足门槛后,2Libra 会为你的账号标记 Pro 身份。
Pro 会员可以在 2Libra 通过自助推广系统,用更温和、可控的方式,把自己的产品、项目或内容长期展示给用户。
你可以为同一个作品创建多种不同风格的展示卡片,然后系统会按推广权重在页面右侧的专属位置展示。
每一位 Pro 会员在过去 365 天内的赞助金额,会被折算成「推广权重」。同一会员可以创建多个活动,系统会把 TA 的总权重平均分配到这些活动上,再与全站所有 Pro 会员的权重一起参与轮播。
后续会补充一些 Pro 独有的功能,若各位觉得 2Libra 不错的话,赞助支持一下最好了 ,目前的第一个目标是升级服务器配置
,目前的第一个目标是升级服务器配置 。
。


牛马刚到公司没帖子刷
大家好,我是良许。 最近在做一个智能监控项目时,我遇到了一个有趣的问题:摄像头采集的视频数据如果全部上传到云端处理,网络带宽根本扛不住,延迟也高得离谱。 但如果完全在本地处理,设备的算力又不够。 这让我深刻体会到,边缘计算和云计算并不是非此即彼的关系,而是需要巧妙结合才能发挥最大价值。 今天就和大家聊聊这个话题。 云计算大家都不陌生,简单来说就是把数据和计算任务都扔到远程的数据中心去处理。 就像我们用的百度网盘、阿里云服务器,数据存储和处理都在云端完成。 云计算的优势很明显:算力强大、存储容量几乎无限、可以随时扩展资源。 但问题也很突出。 我之前做过一个工业设备监控系统,传感器每秒产生几百 KB 的数据,如果全部实时上传到云端,光网络费用一个月就要好几千块。 更要命的是,从设备采集数据到云端处理再返回结果,整个过程可能需要几百毫秒甚至更长,对于需要实时响应的场景根本不适用。 边缘计算则是把计算能力下沉到数据产生的地方,也就是网络的"边缘"。 比如在工厂车间部署一台边缘服务器,或者在智能摄像头里集成 AI 芯片,数据产生后立即在本地处理,只把必要的结果上传到云端。 我在做汽车电子项目时,车载系统就是典型的边缘计算场景。 车辆行驶过程中,各种传感器每秒产生海量数据,如果都传到云端处理,等云端返回指令时车可能已经撞上去了。 所以像自动驾驶、紧急制动这些功能,必须在车载 ECU(电子控制单元)上实时完成计算和决策。 云计算和边缘计算就像大脑和神经系统的关系。 大脑负责复杂的思考和决策,神经系统负责快速的反射动作。 有些任务需要强大的算力和海量数据支持,适合在云端处理;有些任务需要毫秒级响应,必须在边缘完成。 两者结合才能构建一个高效的计算体系。 在实际项目中,我们通常采用三层架构来实现边云协同: 2.1.1 设备层(终端层) 这是最底层,包括各种传感器、摄像头、工控设备等。 这些设备负责数据采集,有些智能设备还能做简单的预处理。 比如我用 STM32 做的一个温湿度监控节点,就在设备层完成了数据采集和初步过滤: 这段代码展示了在设备层做数据预处理的思路。 通过在 MCU 上完成数据有效性检查和滤波,可以大大减少需要上传的无效数据量。 2.1.2 边缘层(边缘服务器/网关) 边缘层是整个架构的关键。 它通常是一台具备一定算力的服务器或者工业网关,部署在靠近数据源的位置。 我在工厂项目中用的是一台搭载 ARM 处理器的边缘服务器,运行嵌入式 Linux 系统。 边缘层的主要职责包括: 举个例子,在智能工厂场景中,边缘服务器可以实时监控设备运行状态,一旦发现异常立即触发报警,而不需要等待云端响应。 同时,它会把设备的运行数据定期汇总上传到云端,用于长期分析和优化。 这段代码展示了边缘层的智能决策能力。 通过在边缘端进行实时分析和判断,可以实现毫秒级的响应速度,同时大幅减少需要上传云端的数据量。 2.1.3 云层(云端数据中心) 云端负责那些需要强大算力和海量数据支持的任务,比如: 在边云协同架构中,数据的流动是双向的: 2.2.1 上行数据流(边缘到云端) 边缘端会根据策略选择性地上传数据。 比如在我做的视频监控项目中,边缘端的 AI 芯片会实时分析视频流,只有检测到异常事件时才上传关键帧到云端,平时只上传一些统计信息。 这样可以把带宽占用降低到原来的 1/100。 2.2.2 下行数据流(云端到边缘) 云端会把训练好的 AI 模型、更新的配置参数、优化的控制策略下发到边缘端。 比如云端通过分析大量历史数据,发现某个设备在特定工况下容易出故障,就会更新边缘端的预警阈值,让边缘端能更准确地预判故障。 在智能工厂中,边云协同发挥着巨大作用。 我参与过一个数控机床监控项目,就是典型的边云结合案例。 边缘端部署在车间的工控机上,实时采集机床的振动、温度、电流等数据,通过预装的算法模型实时判断机床运行状态。 一旦检测到异常振动或者刀具磨损,立即触发报警并自动调整加工参数,整个过程不超过 50 毫秒。 同时,边缘端会把机床的运行数据定期上传到云端。 云端基于所有机床的历史数据进行深度学习,不断优化预测模型,然后把更新的模型下发到边缘端。 这样整个系统就形成了一个自我进化的闭环。 自动驾驶是边云协同的另一个典型场景。 车载系统作为边缘节点,需要实时处理摄像头、激光雷达、毫米波雷达等传感器的数据,做出驾驶决策,这些都必须在车上完成,延迟要求在毫秒级。 但是,高精地图更新、路况信息共享、车辆调度优化这些任务,则需要云端的强大算力和全局视角。 比如云端可以汇总所有车辆上报的路况信息,实时生成最优路线推荐给每辆车。 我之前在汽车电子公司工作时,参与开发过车载网关系统。 车载网关就是一个边缘计算节点,它连接车内的各个 ECU,实时处理 CAN 总线上的数据,同时通过 4G/5G 模块与云端通信。 智能家居也是边云协同的好例子。像智能音箱,唤醒词识别必须在本地完成,不然每次说话都要传到云端,延迟太高体验很差。 但是复杂的语义理解和对话生成,则需要云端的强大 AI 能力。 我自己家里用的智能家居系统,就是这样设计的。 每个房间有一个基于树莓派的边缘控制器,负责控制灯光、空调等设备,响应速度很快。 同时这些边缘控制器会把用户的使用习惯数据上传到云端,云端分析后生成个性化的自动化场景,再下发到边缘端执行。 在工业物联网场景中,边云协同更是不可或缺。 我做过一个油田设备监控项目,油井分布在野外,网络条件很差。 如果完全依赖云端,网络一断就瞎了。 所以我们在每个油井旁边部署了一个边缘网关,运行嵌入式 Linux 系统。 边缘网关实时采集油井的压力、流量、温度等数据,在本地完成异常检测和报警。 即使网络中断,边缘网关也能独立运行,保证油井的安全。 当网络恢复时,边缘网关会把缓存的数据上传到云端。 云端基于所有油井的数据进行大数据分析,优化开采策略,然后下发到各个边缘网关执行。 边缘端和云端的数据同步是个大问题。 网络不稳定时,可能导致数据丢失或者不一致。 我的解决方案是在边缘端实现一个本地数据库,采用消息队列机制。 这种机制保证了即使网络中断,数据也不会丢失,网络恢复后会自动同步到云端。 边缘设备的计算能力、存储空间、功耗都有限制。 我们需要在边缘端部署轻量级的算法模型。 比如在做图像识别时,云端训练一个大型的深度学习模型,然后通过模型压缩、量化等技术,生成一个轻量级版本部署到边缘端。 我在 STM32H7 上部署过一个简单的神经网络模型,用于识别设备的运行模式。 虽然精度比云端的完整模型低一些,但是速度快,功耗低,完全满足边缘端的实时性要求。 边缘设备通常部署在物理安全性较差的环境中,容易被攻击。 我们需要在边缘端实现数据加密、身份认证、安全启动等机制。 同时,边缘端和云端的通信也需要加密。 我在项目中使用 TLS/SSL 协议加密通信,使用证书进行双向认证,确保数据传输的安全性。 云端训练的模型需要定期下发到边缘端更新。 这就涉及到版本管理、灰度发布、回滚等问题。 我的做法是在边缘端实现一个 OTA(Over-The-Air)升级机制,支持增量更新和断点续传。 5G 网络的大带宽、低延迟特性,会让边云协同更加高效。 我最近在关注 5G+ 边缘计算的应用,比如在 5G 基站侧部署边缘服务器,可以实现超低延迟的应用场景,像远程手术、工业控制等。 随着 AI 芯片的发展,越来越多的边缘设备具备了 AI 推理能力。 像英伟达的 Jetson 系列、谷歌的 Coral 系列,都是专门为边缘 AI 设计的。 未来会有更多的 AI 任务下沉到边缘端,云端主要负责模型训练和全局优化。 未来的趋势是云边端一体化,形成一个统一的计算架构。 开发者不需要关心任务是在云端还是边缘端执行,系统会根据任务特点、网络状况、设备能力自动调度。 这需要一个强大的编排系统,像 Kubernetes 已经开始支持边缘节点的管理。 目前边缘计算还缺乏统一的标准,各家厂商的方案都不一样。 未来随着边缘计算联盟(ECC)、工业互联网联盟(IIC)等组织的推动,会逐步形成统一的标准和规范,让边云协同更加容易实现。 边缘计算和云计算的结合,不是简单的技术叠加,而是一种架构上的创新。 通过合理的任务划分和数据流动机制,可以同时获得边缘计算的实时性和云计算的强大能力。 从我多年的嵌入式开发经验来看,边云协同是未来物联网、工业互联网、智能制造等领域的必然选择。 作为嵌入式工程师,我们需要掌握从底层硬件到云端应用的全栈技术,才能更好地设计和实现边云协同系统。 在实际项目中,我们要根据具体场景选择合适的架构。 对于实时性要求高的任务,尽量在边缘端完成;对于需要大量计算和存储的任务,交给云端处理。 同时要考虑网络状况、设备能力、成本等因素,找到最优的平衡点。 边云协同不是终点,而是一个持续演进的过程。 随着技术的发展,会有更多创新的应用场景出现。 我们要保持学习和探索的态度,不断提升自己的技术能力,才能在这个快速变化的时代保持竞争力。 更多编程学习资源1. 边缘计算与云计算的本质区别
1.1 云计算:集中式的算力中心
1.2 边缘计算:就近处理的智能节点
1.3 两者的互补关系
2. 边缘计算与云计算结合的典型架构
2.1 三层架构模型
// STM32 HAL库实现的传感器数据采集
typedef struct {
float temperature;
float humidity;
uint32_t timestamp;
uint8_t status;
} SensorData_t;
// 数据采集和预处理
HAL_StatusTypeDef CollectSensorData(SensorData_t *data)
{
float temp_raw, humi_raw;
// 读取DHT22传感器数据
if (DHT22_Read(&temp_raw, &humi_raw) != HAL_OK) {
return HAL_ERROR;
}
// 边缘端预处理:数据有效性检查
if (temp_raw < -40.0f || temp_raw > 80.0f) {
data->status = STATUS_INVALID;
return HAL_ERROR;
}
// 边缘端预处理:数据平滑滤波
static float temp_buffer[5] = {0};
static uint8_t buffer_index = 0;
temp_buffer[buffer_index] = temp_raw;
buffer_index = (buffer_index + 1) % 5;
// 计算移动平均值
float temp_sum = 0;
for (int i = 0; i < 5; i++) {
temp_sum += temp_buffer[i];
}
data->temperature = temp_sum / 5.0f;
data->humidity = humi_raw;
data->timestamp = HAL_GetTick();
data->status = STATUS_VALID;
return HAL_OK;
}// 边缘服务器的数据处理逻辑示例(Linux C)
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <pthread.h>
#include <time.h>
#define MAX_DEVICES 100
#define ALERT_THRESHOLD 75.0
typedef struct {
int device_id;
float value;
time_t timestamp;
int need_upload; // 是否需要上传云端
} EdgeData_t;
// 边缘计算:实时数据分析
void* edge_processing_thread(void *arg)
{
EdgeData_t *data = (EdgeData_t *)arg;
// 本地实时判断
if (data->value > ALERT_THRESHOLD) {
// 触发本地报警,无需等待云端
printf("[Edge Alert] Device %d: Value %.2f exceeds threshold!\n",
data->device_id, data->value);
// 立即执行本地控制逻辑
local_emergency_control(data->device_id);
// 标记需要上传云端记录
data->need_upload = 1;
} else {
// 正常数据,每10条上传一次
static int counter = 0;
counter++;
data->need_upload = (counter % 10 == 0) ? 1 : 0;
}
return NULL;
}
// 数据上传决策
int should_upload_to_cloud(EdgeData_t *data)
{
// 边缘智能:只上传有价值的数据
if (data->need_upload) {
return 1;
}
// 定时上传统计数据
static time_t last_upload = 0;
time_t now = time(NULL);
if (now - last_upload > 300) { // 每5分钟上传一次
last_upload = now;
return 1;
}
return 0;
}2.2 数据流动机制
3. 边云协同的实际应用场景
3.1 智能制造
3.2 智慧交通
// 车载网关的数据处理示例
#include <linux/can.h>
#include <linux/can/raw.h>
#define CAN_FRAME_BUFFER_SIZE 1000
typedef struct {
uint32_t can_id;
uint8_t data[8];
uint8_t len;
uint32_t timestamp;
} CANFrame_t;
// 边缘端实时处理CAN数据
void process_can_data_on_edge(CANFrame_t *frame)
{
// 实时安全检查(必须在边缘完成)
if (frame->can_id == 0x123) { // 制动系统CAN ID
uint16_t brake_pressure = (frame->data[0] << 8) | frame->data[1];
if (brake_pressure > 5000) {
// 紧急情况,立即本地处理
trigger_emergency_brake_assist();
log_emergency_event(frame);
}
}
// 数据聚合(定期上传云端)
static CANFrame_t upload_buffer[CAN_FRAME_BUFFER_SIZE];
static int buffer_count = 0;
// 选择性缓存数据
if (is_important_frame(frame)) {
upload_buffer[buffer_count++] = *frame;
if (buffer_count >= CAN_FRAME_BUFFER_SIZE) {
// 批量上传到云端进行深度分析
upload_to_cloud(upload_buffer, buffer_count);
buffer_count = 0;
}
}
}
// 云端下发的优化参数
void apply_cloud_optimization(void)
{
// 从云端获取最新的驾驶策略
DrivingStrategy_t strategy;
if (fetch_strategy_from_cloud(&strategy) == 0) {
// 更新边缘端的控制参数
update_local_control_params(&strategy);
printf("Applied new strategy from cloud\n");
}
}3.3 智能家居
3.4 工业物联网
4. 边云协同的技术挑战与解决方案
4.1 数据同步与一致性
// 边缘端数据缓存与同步机制
#include <sqlite3.h>
#include <pthread.h>
typedef struct {
int id;
char data[256];
int uploaded;
time_t timestamp;
} DataRecord_t;
// 本地数据库缓存
sqlite3 *local_db;
// 数据上传线程
void* data_sync_thread(void *arg)
{
while (1) {
// 查询未上传的数据
sqlite3_stmt *stmt;
const char *sql = "SELECT * FROM sensor_data WHERE uploaded = 0 ORDER BY timestamp LIMIT 100";
if (sqlite3_prepare_v2(local_db, sql, -1, &stmt, NULL) == SQLITE_OK) {
while (sqlite3_step(stmt) == SQLITE_ROW) {
DataRecord_t record;
record.id = sqlite3_column_int(stmt, 0);
strcpy(record.data, (const char*)sqlite3_column_text(stmt, 1));
// 尝试上传到云端
if (upload_to_cloud_with_retry(&record) == 0) {
// 上传成功,标记为已上传
mark_as_uploaded(record.id);
} else {
// 上传失败,保留在本地,下次重试
break;
}
}
sqlite3_finalize(stmt);
}
sleep(10); // 每10秒尝试一次同步
}
return NULL;
}4.2 边缘设备的资源限制
4.3 安全性问题
4.4 模型更新与版本管理
// 边缘端模型更新机制
typedef struct {
char model_version[32];
uint32_t model_size;
uint32_t model_crc;
char download_url[256];
} ModelUpdateInfo_t;
int update_edge_model(ModelUpdateInfo_t *info)
{
char current_version[32];
get_current_model_version(current_version);
// 检查版本
if (strcmp(current_version, info->model_version) == 0) {
printf("Model is already up to date\n");
return 0;
}
// 下载新模型
printf("Downloading new model version %s...\n", info->model_version);
if (download_model_from_cloud(info->download_url, "/tmp/new_model.dat") != 0) {
printf("Failed to download model\n");
return -1;
}
// 校验完整性
uint32_t crc = calculate_crc("/tmp/new_model.dat");
if (crc != info->model_crc) {
printf("Model CRC check failed\n");
return -1;
}
// 备份旧模型
system("cp /opt/model/current.dat /opt/model/backup.dat");
// 安装新模型
system("mv /tmp/new_model.dat /opt/model/current.dat");
// 重启推理引擎
restart_inference_engine();
printf("Model updated successfully to version %s\n", info->model_version);
return 0;
}5. 边云协同的未来发展趋势
5.1 5G 网络的推动作用
5.2 边缘 AI 的普及
5.3 云边端一体化
5.4 边缘计算的标准化
6. 总结
vLLM 是一款专为大语言模型推理加速而设计的框架,实现了 KV 缓存内存几乎零浪费,解决了内存管理瓶颈问题。 更多 vLLM 中文文档及教程可访问 →https://go.hyper.ai/Wa62f 源码 examples/offline_inference/vision_language.py"""
本示例演示如何使用 vLLM 执行离线推理,在视觉语言模型上
采用正确的提示格式进行文本生成。
对于大多数模型,提示格式应参照 HuggingFace 模型库中
对应的示例格式。
"""
import os
import random
from dataclasses import asdict
from typing import NamedTuple, Optional
from huggingface_hub import snapshot_download
from transformers import AutoTokenizer
from vllm import LLM, EngineArgs, SamplingParams
from vllm.assets.image import ImageAsset
from vllm.assets.video import VideoAsset
from vllm.lora.request import LoRARequest
from vllm.utils import FlexibleArgumentParser
class ModelRequestData(NamedTuple):
engine_args: EngineArgs
prompts: list[str]
stop_token_ids: Optional[list[int]] = None
lora_requests: Optional[list[LoRARequest]] = None
# 注意:默认的 `max_num_seqs` 和 `max_model_len` 可能会导致低端 GPU 出现 OOM(内存溢出)。
# 除非另有说明,这些设置已在单张 L4 GPU 上经过测试可正常运行。
# Aria
def run_aria(questions: list[str], modality: str) -> ModelRequestData:
assert modality == "image"
model_name = "rhymes-ai/Aria"
# 注意:需要 L40 (或同等) 以避免 OOM
engine_args = EngineArgs(
model=model_name,
max_model_len=4096,
max_num_seqs=2,
dtype="bfloat16",
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
prompts = [(f"<|im_start|>user\n<fim_prefix><|img|><fim_suffix>{question}"
"<|im_end|>\n<|im_start|>assistant\n")
for question in questions]
stop_token_ids = [93532, 93653, 944, 93421, 1019, 93653, 93519]
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
stop_token_ids=stop_token_ids,
)
# BLIP-2
def run_blip2(questions: list[str], modality: str) -> ModelRequestData:
assert modality == "image"
# BLIP-2 prompt format is inaccurate on HuggingFace model repository.
# See https://huggingface.co/Salesforce/blip2-opt-2.7b/discussions/15#64ff02f3f8cf9e4f5b038262 #noqa
# Blip-2提示格式在 HuggingFace 模型存储库上不准确。
# 请参阅 https://huggingface.co/salesforce/blip2-opt-2.7b/discussions/15#64ff02f3f3f3f8cf8cf9e4f5b038262
prompts = [f"Question: {question} Answer:" for question in questions]
engine_args = EngineArgs(
model="Salesforce/blip2-opt-2.7b",
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
)
# Chameleon
def run_chameleon(questions: list[str], modality: str) -> ModelRequestData:
assert modality == "image"
prompts = [f"{question}<image>" for question in questions]
engine_args = EngineArgs(
model="facebook/chameleon-7b",
max_model_len=4096,
max_num_seqs=2,
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
)
# Deepseek-VL2
def run_deepseek_vl2(questions: list[str], modality: str) -> ModelRequestData:
assert modality == "image"
model_name = "deepseek-ai/deepseek-vl2-tiny"
engine_args = EngineArgs(
model=model_name,
max_model_len=4096,
max_num_seqs=2,
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
hf_overrides={"architectures": ["DeepseekVLV2ForCausalLM"]},
)
prompts = [
f"<|User|>: <image>\n{question}\n\n<|Assistant|>:"
for question in questions
]
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
)
# Florence2
def run_florence2(questions: list[str], modality: str) -> ModelRequestData:
assert modality == "image"
engine_args = EngineArgs(
model="microsoft/Florence-2-large",
tokenizer="facebook/bart-large",
max_num_seqs=8,
trust_remote_code=True,
dtype="bfloat16",
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
prompts = ["<MORE_DETAILED_CAPTION>" for _ in questions]
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
)
# Fuyu
def run_fuyu(questions: list[str], modality: str) -> ModelRequestData:
assert modality == "image"
prompts = [f"{question}\n" for question in questions]
engine_args = EngineArgs(
model="adept/fuyu-8b",
max_model_len=2048,
max_num_seqs=2,
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
)
# Gemma 3
def run_gemma3(questions: list[str], modality: str) -> ModelRequestData:
assert modality == "image"
model_name = "google/gemma-3-4b-it"
engine_args = EngineArgs(
model=model_name,
max_model_len=2048,
max_num_seqs=2,
mm_processor_kwargs={"do_pan_and_scan": True},
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
prompts = [("<bos><start_of_turn>user\n"
f"<start_of_image>{question}<end_of_turn>\n"
"<start_of_turn>model\n") for question in questions]
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
)
# GLM-4v
def run_glm4v(questions: list[str], modality: str) -> ModelRequestData:
assert modality == "image"
model_name = "THUDM/glm-4v-9b"
engine_args = EngineArgs(
model=model_name,
max_model_len=2048,
max_num_seqs=2,
trust_remote_code=True,
enforce_eager=True,
hf_overrides={"architectures": ["GLM4VForCausalLM"]},
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
prompts = [
f"<|user|>\n<|begin_of_image|><|endoftext|><|end_of_image|>\
{question}<|assistant|>" for question in questions
]
stop_token_ids = [151329, 151336, 151338]
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
stop_token_ids=stop_token_ids,
)
# H2OVL-Mississippi
def run_h2ovl(questions: list[str], modality: str) -> ModelRequestData:
assert modality == "image"
model_name = "h2oai/h2ovl-mississippi-800m"
engine_args = EngineArgs(
model=model_name,
trust_remote_code=True,
max_model_len=8192,
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
tokenizer = AutoTokenizer.from_pretrained(model_name,
trust_remote_code=True)
messages = [[{
'role': 'user',
'content': f"<image>\n{question}"
}] for question in questions]
prompts = tokenizer.apply_chat_template(messages,
tokenize=False,
add_generation_prompt=True)
# Stop tokens for H2OVL-Mississippi
# https://huggingface.co/h2oai/h2ovl-mississippi-800m
# 停止 h2ovl-mississippi 的 token
# https://huggingface.co/h2oai/h2ovl-mississippi-800m
stop_token_ids = [tokenizer.eos_token_id]
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
stop_token_ids=stop_token_ids,
)
# Idefics3-8B-Llama3
def run_idefics3(questions: list[str], modality: str) -> ModelRequestData:
assert modality == "image"
model_name = "HuggingFaceM4/Idefics3-8B-Llama3"
engine_args = EngineArgs(
model=model_name,
max_model_len=8192,
max_num_seqs=2,
enforce_eager=True,
# if you are running out of memory, you can reduce the "longest_edge".
# see: https://huggingface.co/HuggingFaceM4/Idefics3-8B-Llama3#model-optimizations
# 如果您的内存不足,则可以减少 "LINGEST_EDDE"。
# 请参阅:https://huggingface.co/huggingfacem4/idefics3-8b-llama3#model-optimization
mm_processor_kwargs={
"size": {
"longest_edge": 3 * 364
},
},
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
prompts = [(
f"<|begin_of_text|>User:<image>{question}<end_of_utterance>\nAssistant:"
) for question in questions]
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
)
# InternVL
def run_internvl(questions: list[str], modality: str) -> ModelRequestData:
assert modality == "image"
model_name = "OpenGVLab/InternVL2-2B"
engine_args = EngineArgs(
model=model_name,
trust_remote_code=True,
max_model_len=4096,
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
tokenizer = AutoTokenizer.from_pretrained(model_name,
trust_remote_code=True)
messages = [[{
'role': 'user',
'content': f"<image>\n{question}"
}] for question in questions]
prompts = tokenizer.apply_chat_template(messages,
tokenize=False,
add_generation_prompt=True)
# Stop tokens for InternVL
# models variants may have different stop tokens
# please refer to the model card for the correct "stop words":
# https://huggingface.co/OpenGVLab/InternVL2-2B/blob/main/conversation.py
# 停止 token 进行 Internvl
# 型号变体可能具有不同的停止 token
# 请参考正确的"停止词"的模型卡:
# https://huggingface.co/opengvlab/internvl2-2b/blob/main/conversation.py
stop_tokens = ["<|endoftext|>", "<|im_start|>", "<|im_end|>", "<|end|>"]
stop_token_ids = [tokenizer.convert_tokens_to_ids(i) for i in stop_tokens]
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
stop_token_ids=stop_token_ids,
)
# LLaVA-1.5
def run_llava(questions: list[str], modality: str) -> ModelRequestData:
assert modality == "image"
prompts = [
f"USER: <image>\n{question}\nASSISTANT:" for question in questions
]
engine_args = EngineArgs(
model="llava-hf/llava-1.5-7b-hf",
max_model_len=4096,
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
)
# LLaVA-1.6/LLaVA-NeXT
def run_llava_next(questions: list[str], modality: str) -> ModelRequestData:
assert modality == "image"
prompts = [f"[INST] <image>\n{question} [/INST]" for question in questions]
engine_args = EngineArgs(
model="llava-hf/llava-v1.6-mistral-7b-hf",
max_model_len=8192,
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
)
# LlaVA-NeXT-Video
# Currently only support for video input
# 目前仅支持视频输入
def run_llava_next_video(questions: list[str],
modality: str) -> ModelRequestData:
assert modality == "video"
prompts = [
f"USER: <video>\n{question} ASSISTANT:" for question in questions
]
engine_args = EngineArgs(
model="llava-hf/LLaVA-NeXT-Video-7B-hf",
max_model_len=8192,
max_num_seqs=2,
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
)
# LLaVA-OneVision
def run_llava_onevision(questions: list[str],
modality: str) -> ModelRequestData:
if modality == "video":
prompts = [
f"<|im_start|>user <video>\n{question}<|im_end|> \
<|im_start|>assistant\n" for question in questions
]
elif modality == "image":
prompts = [
f"<|im_start|>user <image>\n{question}<|im_end|> \
<|im_start|>assistant\n" for question in questions
]
engine_args = EngineArgs(
model="llava-hf/llava-onevision-qwen2-7b-ov-hf",
max_model_len=16384,
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
)
# Mantis
def run_mantis(questions: list[str], modality: str) -> ModelRequestData:
assert modality == "image"
llama3_template = '<|start_header_id|>user<|end_header_id|>\n\n{}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n' # noqa: E501
prompts = [
llama3_template.format(f"{question}\n<image>")
for question in questions
]
engine_args = EngineArgs(
model="TIGER-Lab/Mantis-8B-siglip-llama3",
max_model_len=4096,
hf_overrides={"architectures": ["MantisForConditionalGeneration"]},
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
stop_token_ids = [128009]
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
stop_token_ids=stop_token_ids,
)
# MiniCPM-V
def run_minicpmv_base(questions: list[str], modality: str, model_name):
assert modality in ["image", "video"]
# If you want to use `MiniCPM-o-2_6` with audio inputs, check `audio_language.py` # noqa
# 如果您想与音频输入一起使用 `MiniCPM-O-2_6`,请检查 `audio_language.py`# noqa
# 2.0
# The official repo doesn't work yet, so we need to use a fork for now
# For more details, please see: See: https://github.com/vllm-project/vllm/pull/4087#issuecomment-2250397630 # noqa
# model_name = "HwwwH/MiniCPM-V-2"
# 2.0
# 官方存储库尚不正常,所以我们现在需要使用分支
# 有关更多详细信息,请参见:https://github.com/vllm-project/vllm/pull/4087#issuecomment-2250397630# NOQA
# model_name = "hwwwh/minicpm-v-2"
# 2.5
# model_name = "OpenBMB/minicpm-llama3-V-2_5"
# 2.6
# model_name = "openbmb/MiniCPM-V-2_6"
# o2.6
# modality supports
# 2.0: image
# 2.5: image
# 2.6: image, video
# o2.6: image, video, audio
# model_name = "openbmb/MiniCPM-o-2_6"
# 模式支持
# 2.0:图像
# 2.5:图像
# 2.6:图像,视频
# o2.6:图像,视频,音频
# model_name = "openbmb/MiniCPM-o-2_6"
tokenizer = AutoTokenizer.from_pretrained(model_name,
trust_remote_code=True)
engine_args = EngineArgs(
model=model_name,
max_model_len=4096,
max_num_seqs=2,
trust_remote_code=True,
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
# NOTE The stop_token_ids are different for various versions of MiniCPM-V
# 请注意,对于各种版本的 minicpm-v,stop_token_ids 不同
# 2.0
# stop_token_ids = [tokenizer.eos_id]
# 2.5
# stop_token_ids = [tokenizer.eos_id, tokenizer.eot_id]
# 2.6 / o2.6
stop_tokens = ['<|im_end|>', '<|endoftext|>']
stop_token_ids = [tokenizer.convert_tokens_to_ids(i) for i in stop_tokens]
modality_placeholder = {
"image": "(<image>./</image>)",
"video": "(<video>./</video>)",
}
prompts = [
tokenizer.apply_chat_template(
[{
'role': 'user',
'content': f"{modality_placeholder[modality]}\n{question}"
}],
tokenize=False,
add_generation_prompt=True) for question in questions
]
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
stop_token_ids=stop_token_ids,
)
def run_minicpmo(questions: list[str], modality: str) -> ModelRequestData:
return run_minicpmv_base(questions, modality, "openbmb/MiniCPM-o-2_6")
def run_minicpmv(questions: list[str], modality: str) -> ModelRequestData:
return run_minicpmv_base(questions, modality, "openbmb/MiniCPM-V-2_6")
# LLama 3.2
def run_mllama(questions: list[str], modality: str) -> ModelRequestData:
assert modality == "image"
model_name = "meta-llama/Llama-3.2-11B-Vision-Instruct"
# Note: The default setting of max_num_seqs (256) and
# max_model_len (131072) for this model may cause OOM.
# You may lower either to run this example on lower-end GPUs.
# 注意:此模型的 max_num_seqs (256) 和 Max_model_len (131072)
# 可能会导致 OOM。
# 您可以降低或者在低端 GPU 上运行此示例。
# The configuration below has been confirmed to launch on a single L40 GPU.
# 以下配置已确认可以在单个 L40 GPU 上启动。
engine_args = EngineArgs(
model=model_name,
max_model_len=4096,
max_num_seqs=16,
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
messages = [[{
"role":
"user",
"content": [{
"type": "image"
}, {
"type": "text",
"text": question
}]
}] for question in questions]
prompts = tokenizer.apply_chat_template(messages,
add_generation_prompt=True,
tokenize=False)
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
)
# Molmo
def run_molmo(questions: list[str], modality: str) -> ModelRequestData:
assert modality == "image"
model_name = "allenai/Molmo-7B-D-0924"
engine_args = EngineArgs(
model=model_name,
trust_remote_code=True,
dtype="bfloat16",
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
prompts = [
f"<|im_start|>user <image>\n{question}<|im_end|> \
<|im_start|>assistant\n" for question in questions
]
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
)
# NVLM-D
def run_nvlm_d(questions: list[str], modality: str) -> ModelRequestData:
assert modality == "image"
model_name = "nvidia/NVLM-D-72B"
# Adjust this as necessary to fit in GPU
# 根据需要进行调整以适合 GPU
engine_args = EngineArgs(
model=model_name,
trust_remote_code=True,
max_model_len=4096,
tensor_parallel_size=4,
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
tokenizer = AutoTokenizer.from_pretrained(model_name,
trust_remote_code=True)
messages = [[{
'role': 'user',
'content': f"<image>\n{question}"
}] for question in questions]
prompts = tokenizer.apply_chat_template(messages,
tokenize=False,
add_generation_prompt=True)
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
)
# PaliGemma
def run_paligemma(questions: list[str], modality: str) -> ModelRequestData:
assert modality == "image"
# PaliGemma has special prompt format for VQA
# PaliGemma 模型针对视觉问答(VQA)任务使用特殊的提示格式
prompts = ["caption en" for _ in questions]
engine_args = EngineArgs(
model="google/paligemma-3b-mix-224",
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache)
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
)
# PaliGemma 2
def run_paligemma2(questions: list[str], modality: str) -> ModelRequestData:
assert modality == "image"
# PaliGemma 2 has special prompt format for VQA
# PaliGemma 2 模型针对视觉问答(VQA)任务使用特殊的提示格式
prompts = ["caption en" for _ in questions]
engine_args = EngineArgs(
model="google/paligemma2-3b-ft-docci-448",
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache)
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
)
# Phi-3-Vision
def run_phi3v(questions: list[str], modality: str) -> ModelRequestData:
assert modality == "image"
prompts = [
f"<|user|>\n<|image_1|>\n{question}<|end|>\n<|assistant|>\n"
for question in questions
]
# num_crops is an override kwarg to the multimodal image processor;
# For some models, e.g., Phi-3.5-vision-instruct, it is recommended
# to use 16 for single frame scenarios, and 4 for multi-frame.
#
# Generally speaking, a larger value for num_crops results in more
# tokens per image instance, because it may scale the image more in
# the image preprocessing. Some references in the model docs and the
# formula for image tokens after the preprocessing
# transform can be found below.
# num_crops 是多模态图像处理器的覆盖参数
# 对某些模型(如 Phi-3.5-vision-instruct)建议:
# 单帧场景使用 16,多帧场景使用 4
#
# 通常来说,num_crops 值越大,每个图像实例生成的 token 越多
# 因为在图像预处理阶段可能进行更多缩放操作
# 模型文档中的相关说明及预处理后的图像 token 计算公式如下
#
# https://huggingface.co/microsoft/Phi-3.5-vision-instruct#loading-the-model-locally
# https://huggingface.co/microsoft/Phi-3.5-vision-instruct/blob/main/processing_phi3_v.py#L194
engine_args = EngineArgs(
model="microsoft/Phi-3.5-vision-instruct",
trust_remote_code=True,
max_model_len=4096,
max_num_seqs=2,
# Note - mm_processor_kwargs can also be passed to generate/chat calls
# 注意 - mm_processor_kwargs 参数也可传递给 generate/chat 调用
mm_processor_kwargs={"num_crops": 16},
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
)
# Phi-4-multimodal-instruct
def run_phi4mm(questions: list[str], modality: str) -> ModelRequestData:
"""
Phi-4-multimodal-instruct supports both image and audio inputs. Here, we
show how to process image inputs.
"""
assert modality == "image"
model_path = snapshot_download("microsoft/Phi-4-multimodal-instruct")
# Since the vision-lora and speech-lora co-exist with the base model,
# we have to manually specify the path of the lora weights.
# 由于 vision-lora 和 speech-lora 与基本模型共存,所以
# 我们必须手动指定 Lora 权重的路径。
vision_lora_path = os.path.join(model_path, "vision-lora")
prompts = [
f"<|user|><|image_1|>{question}<|end|><|assistant|>"
for question in questions
]
engine_args = EngineArgs(
model=model_path,
trust_remote_code=True,
max_model_len=4096,
max_num_seqs=2,
enable_lora=True,
max_lora_rank=320,
)
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
lora_requests=[LoRARequest("vision", 1, vision_lora_path)],
)
# Pixtral HF-format
def run_pixtral_hf(questions: list[str], modality: str) -> ModelRequestData:
assert modality == "image"
model_name = "mistral-community/pixtral-12b"
# NOTE: Need L40 (or equivalent) to avoid OOM
# 注意: 需要 L40 (或同等) 以避免 OOM
engine_args = EngineArgs(
model=model_name,
max_model_len=8192,
max_num_seqs=2,
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
prompts = [f"<s>[INST]{question}\n[IMG][/INST]" for question in questions]
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
)
# Qwen
def run_qwen_vl(questions: list[str], modality: str) -> ModelRequestData:
assert modality == "image"
engine_args = EngineArgs(
model="Qwen/Qwen-VL",
trust_remote_code=True,
max_model_len=1024,
max_num_seqs=2,
hf_overrides={"architectures": ["QwenVLForConditionalGeneration"]},
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
prompts = [f"{question}Picture 1: <img></img>\n" for question in questions]
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
)
# Qwen2-VL
def run_qwen2_vl(questions: list[str], modality: str) -> ModelRequestData:
model_name = "Qwen/Qwen2-VL-7B-Instruct"
engine_args = EngineArgs(
model=model_name,
max_model_len=4096,
max_num_seqs=5,
# Note - mm_processor_kwargs can also be passed to generate/chat calls
# 注意 - mm_processor_kwargs 参数也可传递给 generate/chat 调用
mm_processor_kwargs={
"min_pixels": 28 * 28,
"max_pixels": 1280 * 28 * 28,
},
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
if modality == "image":
placeholder = "<|image_pad|>"
elif modality == "video":
placeholder = "<|video_pad|>"
prompts = [
("<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n"
f"<|im_start|>user\n<|vision_start|>{placeholder}<|vision_end|>"
f"{question}<|im_end|>\n"
"<|im_start|>assistant\n") for question in questions
]
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
)
# Qwen2.5-VL
def run_qwen2_5_vl(questions: list[str], modality: str) -> ModelRequestData:
model_name = "Qwen/Qwen2.5-VL-3B-Instruct"
engine_args = EngineArgs(
model=model_name,
max_model_len=4096,
max_num_seqs=5,
mm_processor_kwargs={
"min_pixels": 28 * 28,
"max_pixels": 1280 * 28 * 28,
"fps": 1,
},
disable_mm_preprocessor_cache=args.disable_mm_preprocessor_cache,
)
if modality == "image":
placeholder = "<|image_pad|>"
elif modality == "video":
placeholder = "<|video_pad|>"
prompts = [
("<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n"
f"<|im_start|>user\n<|vision_start|>{placeholder}<|vision_end|>"
f"{question}<|im_end|>\n"
"<|im_start|>assistant\n") for question in questions
]
return ModelRequestData(
engine_args=engine_args,
prompts=prompts,
)
model_example_map = {
"aria": run_aria,
"blip-2": run_blip2,
"chameleon": run_chameleon,
"deepseek_vl_v2": run_deepseek_vl2,
"florence2": run_florence2,
"fuyu": run_fuyu,
"gemma3": run_gemma3,
"glm4v": run_glm4v,
"h2ovl_chat": run_h2ovl,
"idefics3": run_idefics3,
"internvl_chat": run_internvl,
"llava": run_llava,
"llava-next": run_llava_next,
"llava-next-video": run_llava_next_video,
"llava-onevision": run_llava_onevision,
"mantis": run_mantis,
"minicpmo": run_minicpmo,
"minicpmv": run_minicpmv,
"mllama": run_mllama,
"molmo": run_molmo,
"NVLM_D": run_nvlm_d,
"paligemma": run_paligemma,
"paligemma2": run_paligemma2,
"phi3_v": run_phi3v,
"phi4_mm": run_phi4mm,
"pixtral_hf": run_pixtral_hf,
"qwen_vl": run_qwen_vl,
"qwen2_vl": run_qwen2_vl,
"qwen2_5_vl": run_qwen2_5_vl,
}
def get_multi_modal_input(args):
"""
return {
"data": image or video,
"question": question,
}
"""
if args.modality == "image":
# Input image and question
# 输入图像和问题
image = ImageAsset("cherry_blossom") \
.pil_image.convert("RGB")
img_questions = [
"What is the content of this image?",
"Describe the content of this image in detail.",
"What's in the image?",
"Where is this image taken?",
]
return {
"data": image,
"questions": img_questions,
}
if args.modality == "video":
# Input video and question
# 输入视频和问题
video = VideoAsset(name="sample_demo_1.mp4",
num_frames=args.num_frames).np_ndarrays
vid_questions = ["Why is this video funny?"]
return {
"data": video,
"questions": vid_questions,
}
msg = f"Modality {args.modality} is not supported."
raise ValueError(msg)
def apply_image_repeat(image_repeat_prob, num_prompts, data,
prompts: list[str], modality):
"""Repeats images with provided probability of "image_repeat_prob".
Used to simulate hit/miss for the MM preprocessor cache.
"""
assert (image_repeat_prob <= 1.0 and image_repeat_prob >= 0)
no_yes = [0, 1]
probs = [1.0 - image_repeat_prob, image_repeat_prob]
inputs = []
cur_image = data
for i in range(num_prompts):
if image_repeat_prob is not None:
res = random.choices(no_yes, probs)[0]
if res == 0:
# No repeat => Modify one pixel
# 不重复 => 修改一个像素
cur_image = cur_image.copy()
new_val = (i // 256 // 256, i // 256, i % 256)
cur_image.putpixel((0, 0), new_val)
inputs.append({
"prompt": prompts[i % len(prompts)],
"multi_modal_data": {
modality: cur_image
}
})
return inputs
def main(args):
model = args.model_type
if model not in model_example_map:
raise ValueError(f"Model type {model} is not supported.")
modality = args.modality
mm_input = get_multi_modal_input(args)
data = mm_input["data"]
questions = mm_input["questions"]
req_data = model_example_map[model](questions, modality)
engine_args = asdict(req_data.engine_args) | {"seed": args.seed}
llm = LLM(**engine_args)
# To maintain code compatibility in this script, we add LoRA here.
# You can also add LoRA using:
# 要维护此脚本中的代码兼容性,我们在此处添加 Lora。
# 您还可以使用:
# llm.generate(prompts, lora_request=lora_request,...)
if req_data.lora_requests:
for lora_request in req_data.lora_requests:
llm.llm_engine.add_lora(lora_request=lora_request)
# Don't want to check the flag multiple times, so just hijack `prompts`.
# 不想多次检查标志,所以只是劫持"提示"。
prompts = req_data.prompts if args.use_different_prompt_per_request else [
req_data.prompts[0]
]
# We set temperature to 0.2 so that outputs can be different
# even when all prompts are identical when running batch inference.
# 我们将温度设置为 0.2,以便输出可能不同
# 即使在运行批处理推理时所有提示都相同。
sampling_params = SamplingParams(temperature=0.2,
max_tokens=64,
stop_token_ids=req_data.stop_token_ids)
assert args.num_prompts > 0
if args.num_prompts == 1:
# Single inference
# 单个推理
inputs = {
"prompt": prompts[0],
"multi_modal_data": {
modality: data
},
}
else:
# Batch inference
# 批次推理
if args.image_repeat_prob is not None:
# Repeat images with specified probability of "image_repeat_prob"
# 重复图像,具有 "Image_repeat_prob"的指定概率
inputs = apply_image_repeat(args.image_repeat_prob,
args.num_prompts, data, prompts,
modality)
else:
# Use the same image for all prompts
# 为所有提示使用相同的图像
inputs = [{
"prompt": prompts[i % len(prompts)],
"multi_modal_data": {
modality: data
},
} for i in range(args.num_prompts)]
if args.time_generate:
import time
start_time = time.time()
outputs = llm.generate(inputs, sampling_params=sampling_params)
elapsed_time = time.time() - start_time
print("-- generate time = {}".format(elapsed_time))
else:
outputs = llm.generate(inputs, sampling_params=sampling_params)
for o in outputs:
generated_text = o.outputs[0].text
print(generated_text)
if __name__ == "__main__":
parser = FlexibleArgumentParser(
description='Demo on using vLLM for offline inference with '
'vision language models for text generation')
parser.add_argument('--model-type',
'-m',
type=str,
default="llava",
choices=model_example_map.keys(),
help='Huggingface "model_type".')
parser.add_argument('--num-prompts',
type=int,
default=4,
help='Number of prompts to run.')
parser.add_argument('--modality',
type=str,
default="image",
choices=['image', 'video'],
help='Modality of the input.')
parser.add_argument('--num-frames',
type=int,
default=16,
help='Number of frames to extract from the video.')
parser.add_argument("--seed",
type=int,
default=None,
help="Set the seed when initializing `vllm.LLM`.")
parser.add_argument(
'--image-repeat-prob',
type=float,
default=None,
help='Simulates the hit-ratio for multi-modal preprocessor cache'
' (if enabled)')
parser.add_argument(
'--disable-mm-preprocessor-cache',
action='store_true',
help='If True, disables caching of multi-modal preprocessor/mapper.')
parser.add_argument(
'--time-generate',
action='store_true',
help='If True, then print the total generate() call time')
parser.add_argument(
'--use-different-prompt-per-request',
action='store_true',
help='If True, then use different prompt (with the same multi-modal '
'data) for each request.')
args = parser.parse_args()
main(args)
在网上看到一个关于龙虾的暴论,v 友们怎么看?

2026年,全球SSL证书行业迎来重大变革:国际主流CA机构(如DigiCert)将免费证书有效期从90天缩短至200天,且需通过订阅服务自动续期。这一调整虽降低了运维频率,但长期成本和管理复杂度仍高于一年期证书。与此同时,中国《密码法》《等保2.0》等法规要求政务、金融、教育等关键领域必须采用国密算法(SM2/SM3/SM4) ,推动国产SSL证书市场快速增长。 在此背景下,免费SSL证书呈现两大分化趋势: 传统国密证书价格高昂,但JoySSL在2026年仍为政务及教育单位提供一年期免费国密证书,支持以下特性: 在注册页面填写邀请码“230959” ,即可解锁以下权益:一、行业背景:免费证书的“有效期缩短”与“国密合规”双重压力

二、国密算法:免费证书的“安全升级”与“合规刚需”
1. 国密算法的核心优势
2. 国密证书的适用场景
3. 免费国密证书的突破
三、免费证书申请全流程:以JoySSL为例
1. 注册账号与解锁权益
2. 申请证书
gov.example.com或edu.example.com)。3. 验证域名所有权
_acme-challenge.example.com的TXT值)。4. 人工审核与签发
.crt和.key文件)。5. 安装证书
nginx
server {
listen 443 ssl;
server_name example.com;
ssl_certificate /etc/nginx/ssl/example.com.crt;
ssl_certificate_key /etc/nginx/ssl/example.com.key;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers 'ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256';
}
systemctl restart nginx。四、免费证书的“隐藏价值”:长期运维支持
1. 自动续期与到期提醒
2. 技术支持与故障排查
五、未来展望:国密证书的普及与免费化的平衡
1. 政策驱动市场增长
2. 技术突破降低成本
3. 免费证书的“合规转型”
我有一个朋友,真·朋友,不是我,用的是一加手机 Ace5 ,他不是程序员,就是普通人,应该能代表大多数普通用户
我用这个一加手机打开自带音乐 app ,首次进入是正常的,返回主屏幕再进入音乐就有一个弹窗广告,右上角有关闭,我不知道是没点到关闭还是摇晃了手机,就跳转广告了
最后我是在跳转到淘宝后,再从底部的多任务按钮结束了广告才恢复正常
一时之间不知道是该喷一加还是喷安卓还是喷这个强大的广告
发帖时 日韩股市暴跌 6% 原油大涨 20%
/
中东战争长期化,推高能源/原物料/保险成本,消费品基础定价调升
资产价格下跌,蓄水池功能弱化,资金流出,消费品波动定价上限调升
郭嘉层面原来就不爱通缩,劝阻'价格战'等各种策略只会趁机大力
/
希望能给穷人定向补贴,比如 罗森 大米先生 滴滴 宜家 优衣库 大润发 等穷人友好商户,应该成为定向消费券目标
在这场即将到来的海啸中,传统的SaaS逻辑将被彻底撕裂,连当红炸子鸡Cursor都面临淘汰,而英伟达的无敌铁幕也已经出现了裂痕。 在Murdock最近接触的众多真正具备AI原生思维的初创公司中,大家达成了一个令人毛骨悚然的共识:Cursor的产品已经过时了。 像E2B、Eventual等使用OpenClaw或NanoClaw构建自主智能体系统的初创公司,仅仅花了2到6周的时间,就将完全自主的编程智能体投入了实际运行。它们不需要人类在键盘前一行行审查、回车,而是直接自主完成代码生成与部署。 传统的软件采购流程是怎样的?销售人员请客吃饭、制作精美的PPT、展示炫酷的用户界面(UI),最后由人类高管签字买单。 但在Murdock的预判中,这一切即将作废。未来的软件和技术服务,不再是由人类采购,而是由企业雇佣的“自主智能体”进行自动评估、试用和决策。 智能体没有喜好,不吃画饼,它们会在毫秒级的时间内开启几万个沙箱环境,直接测试哪家软件的API响应最快、成本最低。比如E2B响应仅需70毫秒,智能体会毫不犹豫地抛弃那些响应需要400毫秒的传统巨头。 在这场智能体革命中,底层算力的格局也将被重写。Murdock指出,未来的智能体将形成一个“编排层”(类似当年的LAMP架构)。它们会极其精明地分发工作流:复杂的推理丢给昂贵的闭源模型(如Claude),而大量的基础任务则分配给开源模型(如DeepSeek、Llama)。 这种精准的算力分发,将极大地刺激ASIC(专用集成电路)芯片的爆发。因为ASIC在处理特定工作负载时,成本远低于英伟达昂贵的通用GPU。Meta等巨头敢于对黄仁勋说“不”,正是因为他们将赌注压在了ASIC芯片上。 Murdock抛出了一个极度刺耳的现实:企业会先砍掉“下一个准备招的人”。任何向系统中输入数据的工作、行政、营销甚至初级程序员,都将被自主智能体取代。这并非天方夜谭,小微企业将率先开始这场冷酷的替换,因为AI不需要事假、病假,更没有千禧一代过剩的自我意识。 未来十年,“十亿美元估值、只有一名人类员工”的超级个体公司将不再是神话,而是常态。而随之而来的,是劳动力市场的剧烈震荡,全民基本收入(UBI)将在未来两到三年内被迫摆上大选的谈判桌。 👇 欢迎关注我的公众号 在 AI 爆发的深水区,我们一起探索真正能穿越周期的技术价值。 欢迎关注【睿见新世界】
在这个所有人都以为大模型就是终局的狂热时刻,管理着超900亿美元资产的Insight Partners联合创始人Jerry Murdock,却向科技界泼下了一盆极其刺骨的冷水:不要再把AI当成辅助人类的工具,真正的海啸是“自主智能体(Autonomous Agents)”。一、 估值270亿的Cursor,可能已经是一只“恐龙”
【笔者观点】
“人类在环(Human-in-the-loop)”的工具,注定只是过渡期的安慰剂。
当下的科技圈对Cursor顶礼膜拜,却忽略了一个致命的反常识:如果你的AI工具还需要人类去充当“点击器”和“决策者”,那它就无法实现真正的指数级爆发。Cursor如果不能在短期内迅速斩断对“人类开发者”的依赖,全面拥抱自主智能体,它高达270亿美元的估值将迅速沦为虚幻的泡沫。二、 B2B已死,未来是B2A(Business-to-Agent)的天下
【笔者观点】
软件行业的“颜值时代”宣告终结,极致的底层效率将成为唯一通行证。
这意味着全球数百万的SaaS销售、UI/UX设计师将面临灭顶之灾。当你未来的客户是一个不懂人情世故、只看重并行计算能力和Token性价比的AI时,你所有的营销话术都将沦为废话。企业如果不立刻转向“为智能体开发软件(B2A)”,最多一年半后,连留在牌桌上的资格都没有。三、 英伟达的护城河,并非坚不可摧
【笔者观点】
天下苦“算力霸权”久矣,智能体将成为瓦解英伟达垄断的第一把尖刀。
AI绝不会为品牌溢价买单。当自主智能体掌控了模型调度权,它们会像最苛刻的精算师一样榨干每一滴算力性价比。英伟达收购Groq是在拼命修补护城河,但芯片硬件被“商品化”、“管道化”的历史宿命,或许连黄仁勋也无法彻底逆转。四、 员工数量,正在从“资产”沦为“负债”
【笔者观点】
一场没有硝烟的“白领大清洗”已经鸣枪。
过去,庞大的团队规模是企业实力的象征,而在AI时代,庞大的人类团队意味着低效、高廉、决策迟缓,是纯粹的“负债”。当智能体正式挂上工牌成为你的“新同事”时,不要问它能帮你做什么,而要问自己:在它眼里,你还有什么不可替代的价值?如果你只会做“流程的搬运工”,那么你的职业倒计时,现在已经开始了。
微信搜索 【睿见新世界】 或扫描下方二维码,获取每周硬核技术推文:
Standard IO是对字节流的读写,在进行IO之前,首先创建一个流对象,流对象进行读写操作都是按字节 ,一个字节一个字节的来读或写。而NIO把IO抽象成块,类似磁盘的读写,每次IO操作的单位都是一个块,块被读入内存之后就是一个byte[],NIO一次可以读或写多个字节。 I/O 与 NIO 最重要的区别是数据打包和传输的方式,I/O 以流的方式处理数据,而 NIO 以块的方式处理数据。 面向流的 I/O 一次处理一个字节数据: 一个输入流产生一个字节数据,一个输出流消费一个字节数据。为流式数据创建过滤器非常容易,链接几个过滤器,以便每个过滤器只负责复杂处理机制的一部分。不利的一面是,面向流的 I/O 通常相当慢。 面向块的 I/O 一次处理一个数据块,按块处理数据比按流处理数据要快得多。但是面向块的 I/O 缺少一些面向流的 I/O 所具有的优雅性和简单性。 I/O 包和 NIO 已经很好地集成了, NIO 常常被叫做非阻塞 IO,主要是因为 NIO 在网络通信中的非阻塞特性被广泛使用。但其实应该叫new IO,是相较于传统IO来说的。 Java NIO 中的 关于触发模式 关于水平触发和边缘触发的区别可以看这篇文章,总结一下: 因此,如果在 Linux 上使用 Java NIO 的 被建立的一个应用程序和操作系统交互事件、传递内容的渠道(注意是连接到操作系统)。一个通道会有一个专属的文件状态描述符。那么既然是和操作系统进行内容的传递,那么说明应用程序可以通过通道读取数据,也可以通过通道向操作系统写数据。 通道 Channel 是对原 I/O 包中的流的模拟,可以通过它读取和写入数据。通道与流的不同之处在于,流只能在一个方向上移动(一个流必须是 InputStream 或者 OutputStream 的子类),而通道是双向的,可以用于读、写或者同时用于读写。 JAVA NIO 框架中,自有的Channel通道包括: 所有被Selector(选择器)注册的通道,只能是继承了SelectableChannel类的子类。如上图所示 FileChannel 是磁盘IO的通道,后三个是网络IO的通道。并且FileChannel不能切换为非阻塞模式,因此FileChannel不适合Selector。 数据缓存区: 在JAVA NIO 框架中,为了保证每个通道的数据读写速度JAVA NIO 框架为每一种需要支持数据读写的通道集成了Buffer的支持。用于读取或写入数据到通道。 这句话怎么理解呢? 例如ServerSocketChannel通道它只支持对OP_ACCEPT事件的监听,所以它是不能直接进行网络数据内容的读写的。所以ServerSocketChannel是没有集成Buffer的。 Buffer有两种工作模式: 写模式和读模式。在读模式下,应用程序只能从Buffer中读取数据,不能进行写操作。但是在写模式下,应用程序是可以进行读操作的,这就表示可能会出现脏读的情况。所以一旦您决定要从Buffer中读取数据,一定要将Buffer的状态改为读模式。 发送给一个通道的所有数据都必须首先放到缓冲区中,同样地,从通道中读取的任何数据都要先读到缓冲区中。也就是说,不会直接对通道进行读写数据,而是要先经过缓冲区。 缓冲区实质上是一个数组,但它不仅仅是一个数组。缓冲区提供了对数据的结构化访问,而且还可以跟踪系统的读/写进程。 缓冲区包括以下类型: ByteBuffer 大小分配: ByteBuffer 不能太大,比如一个 ByteBuffer 1Mb 的话,要支持百万连接就要 1Tb 内存,因此需要设计大小可变的 ByteBuffer 状态变量的改变过程举例: ① 新建一个大小为 8 个字节的缓冲区,此时 position 为 0,而 limit = capacity = 8。capacity 变量不会改变,下面的讨论会忽略它。 ② 从输入通道中读取 5 个字节数据写入缓冲区中,此时 position 移动设置为 5,limit 保持不变。 ③ 在将缓冲区的数据写到输出通道之前,需要先调用 flip() 方法,这个方法将 limit 设置为当前 position,并将 position 设置为 0。 ④ 从缓冲区中取 4 个字节到输出缓冲中,此时 position 设为 4。 ⑤ 最后需要调用 clear() 方法来清空缓冲区,此时 position 和 limit 都被设置为最初位置。 ⑥ compact 方法,是把未读完的部分向前压缩,然后切换至写模式 以下展示了使用 NIO 快速复制文件的实例: Selector (选择器,多路复用器)是JavaNIO 中能够检测一到多个NIO通道,是否为诸如读写事件做好准备的组件。这样,一个单独的线程可以管理多个channel,从而管理多个网络连接。 NIO 实现了 IO 多路复用中的 多Reactor多进程/线程 模型,一个线程 Thread 使用一个选择器 Selector 通过轮询的方式去监听多个通道 Channel 上的事件,从而让一个线程就可以处理多个事件。通过配置监听的通道 Channel 为非阻塞,那么当 Channel 上的 IO 事件还未到达时,就不会进入阻塞状态一直等待,而是继续轮询其它 Channel,找到 IO 事件已经到达的 Channel 执行。 因为创建和切换线程的开销很大,因此使用一个线程来处理多个事件而不是一个线程处理一个事件具有更好的性能。 selector 的作用就是配合一个线程来管理多个 channel,获取这些 channel 上发生的事件,这些 channel 工作在非阻塞模式下,不会让线程吊死在一个 channel 上。适合连接数特别多,但流量低的场景(low traffic) 也称之为注册事件,绑定的事件 selector 才会关心 Channel必须配置为非阻塞模式,否则使用选择器就没有任何意义了,因为如果通道在某个事件上被阻塞,那么服务器就不能响应其它事件,必须等待这个事件处理完毕才能去处理其它事件,显然这和选择器的作用背道而驰。 在将通道注册到选择器上时,还需要指定要注册的具体事件,主要有以下几类: 它们在 SelectionKey 的定义如下: 可以看出每个事件可以被当成一个位域,从而组成事件集整数。例如: 使用 select() 来监听到达的事件,它会一直阻塞直到有至少一个事件到达。 那 select 何时不阻塞: 事件发生时 事件发生后,能否不处理? 这里为什么要 keyIterator.remove() 操作? cancel 的作用? cancel 会取消注册在 selector 上的 channel,并从 keys 集合中删除 key 后续不会再监听事件 split 方法 用 selector 监听所有 channel 的可写事件,每个 channel 都需要一个 key 来跟踪 buffer,但这样又会导致占用内存过多,就有两阶段策略 客户端 FileChannel 只能工作在阻塞模式下,没有非阻塞模式 获取FileChannel 时,不能直接打开 FileChannel,必须通过 FileInputStream、FileOutputStream 或者 RandomAccessFile 来获取 FileChannel,它们都有 getChannel 方法 实际传输一个超大文件 FileChannel.map()方法其实就是采用了操作系统中的内存映射方式,将内核缓冲区的内存和用户缓冲区的内存做了一个地址映射。它解决数据从磁盘读取到内核缓冲区,然后内核缓冲区的数据复制移动到用户空间缓冲区。程序还是需要从用户态切换到内核态,然后再进行操作系统调用,并且数据移动和复制了两次。 transferTo方法则是使用了sendfile的方式,来分析一下其中原理: 具体细节可以看这篇文章 网络编程 - NIO的零拷贝实现 多路复用IO技术是操作系统的内核实现。在不同的操作系统,甚至同一系列操作系统的版本中所实现的多路复用IO技术都是不一样的。那么作为跨平台的JAVA JVM来说如何适应多种多样的多路复用IO技术实现呢? 面向对象的威力就显现出来了: 无论使用哪种实现方式,他们都会有“选择器”、“通道”、“缓存”这几个操作要素,那么可以为不同的多路复用IO技术创建一个统一的抽象组,并且为不同的操作系统进行具体的实现。JAVA NIO中对各种多路复用IO的支持,主要的基础是java.nio.channels.spi.SelectorProvider抽象类,其中的几个主要抽象方法包括: 由于JAVA NIO框架的整个设计是很大的,所以我们只能还原一部分我们关心的问题。这里我们以JAVA NIO框架中对于不同多路复用IO技术的选择器 进行实例化创建的方式作为例子,以点窥豹观全局: 很明显,不同的SelectorProvider实现对应了不同的 选择器。由具体的SelectorProvider实现进行创建。另外说明一下,实际上netty底层也是通过这个设计获得具体使用的NIO模型。以下代码是Netty 4.0中NioServerSocketChannel进行实例化时的核心代码片段: 前面的代码只有一个选择器,没有充分利用多核 cpu。而现在都是多核 cpu,设计时要充分考虑别让 cpu 的力量被白白浪费 分两组选择器 首先启动服务器端 运行客户端 最初在认识上有这样的误区,认为只有在 netty,nio 这样的多路复用 IO 模型时,读写才不会相互阻塞,才可以实现高效的双向通信,但实际上,Java Socket 是全双工的:在任意时刻,线路上存在 服务端: 客户端: 使用 Java 原生 NIO 来编写服务器应用,代码一般类似:流与块
java.io.* 已经以 NIO 为基础重新实现了,所以现在它可以利用 NIO 的一些特性。例如,java.io.* 包中的一些类包含以块的形式读写数据的方法,这使得即使在面向流的系统中,处理速度也会更快。Java对IO多路复用的支持

Selector 类是基于操作系统提供的 I/O 多路复用机制实现的,而在 Linux 上,这个机制就是 epoll。Selector 默认使用的是水平触发模式(Level-Triggered, LT)。这意味着当一个文件描述符(在 Java 中通常是 SocketChannel 或 ServerSocketChannel)变得可读或可写时,Selector 会持续通知,直到该文件描述符上的事件被处理。这与 epoll 的水平触发模式是一致的。epoll 也支持边缘触发模式(Edge-Triggered, ET),但 Java NIO 的 Selector 并没有直接提供对边缘触发模式的支持。如果需要使用边缘触发模式,通常需要直接使用底层的系统调用(如通过 JNI 调用 epoll 的边缘触发模式),但这超出了标准 Java NIO 库的范围。epoll 作为底层的 I/O 多路复用机制。Selector 默认使用 epoll 的水平触发模式。epoll 的边缘触发模式,需要通过其他方式实现。Selector,它使用的是 epoll 的水平触发模式。三大组件
通道

缓冲区
ByteBuffer 正确使用姿势
缓冲区状态变量


写到输出通道,意味着要从buffer中读出,才能写入channelpublic Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}



文件 NIO 实例
public static void fastCopy(String src, String dist) throws IOException {
// 获得源文件的输入字节流
FileInputStream fin = new FileInputStream(src);
// 获取输入字节流的文件通道
FileChannel fcin = fin.getChannel();
// 获取目标文件的输出字节流
FileOutputStream fout = new FileOutputStream(dist);
// 获取输出字节流的通道
FileChannel fcout = fout.getChannel();
// 为缓冲区分配 1024 个字节
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
while (true) {
// 从输入通道中读取数据到缓冲区中
int r = fcin.read(buffer);//对于buffer来说,这是写入的过程
// read() 返回 -1 表示 EOF
if (r == -1) {
break;
}
// 切换读写
buffer.flip();
// 把缓冲区的内容写入输出文件中
fcout.write(buffer);//对于buffer来说,这是读取的过程
// 清空缓冲区
buffer.clear();
}
}选择器
// Initial capacity of the poll array
private final int INIT_CAP = 8;
// Maximum number of sockets for select().
// Should be INIT_CAP times a power of 2
private final static int MAX_SELECTABLE_FDS = 1024;
// The list of SelectableChannels serviced by this Selector. Every mod
// MAX_SELECTABLE_FDS entry is bogus, to align this array with the poll
// array, where the corresponding entry is occupied by the wakeupSocket
private SelectionKeyImpl[] channelArray = new SelectionKeyImpl[INIT_CAP];


创建选择器
Selector selector = Selector.open();绑定 Channel 事件
ServerSocketChannel ssChannel = ServerSocketChannel.open();
ssChannel.configureBlocking(false);
ssChannel.register(selector, SelectionKey.OP_ACCEPT);public static final int OP_READ = 1 << 0;
public static final int OP_WRITE = 1 << 2;
public static final int OP_CONNECT = 1 << 3;
public static final int OP_ACCEPT = 1 << 4;int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;监听事件
int count = selector.select();int count = selector.select(long timeout);int count = selector.selectNow();处理accept事件
// 获取所有事件
Set<SelectionKey> keys = selector.selectedKeys();
// 遍历所有事件,逐一处理
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
// 判断事件类型
if (key.isAcceptable()) {
ServerSocketChannel c = (ServerSocketChannel) key.channel();
// 必须处理
SocketChannel sc = c.accept();
sc.configureBlocking(false);
sc.register(selector, SelectionKey.OP_READ);
// ...
}
// 处理完毕,必须将事件移除
keyIterator.remove();
}
不能,事件发生后,要么处理,要么取消(cancel),不能什么都不做,否则下次该事件仍会触发,这是因为 nio 底层使用的是水平触发
因为 select 在事件发生后,就会将相关的 key 放入 selectedKeys 集合,但不会在处理完后从 selectedKeys 集合中移除,需要我们自己编码删除。例如处理 read 事件
// 获取所有事件
Set<SelectionKey> keys = selector.selectedKeys();
// 遍历所有事件,逐一处理
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
// 判断事件类型
if (key.isAcceptable()) {
ServerSocketChannel c = (ServerSocketChannel) key.channel();
// 必须处理
SocketChannel sc = c.accept();
sc.configureBlocking(false);
sc.register(selector, SelectionKey.OP_READ);
// ...
} else if (key.isReadable()) {
SocketChannel sc = (SocketChannel) key.channel();
//实际使用中,不会一次给buffer缓冲区分配太多空间,因此可能存在粘包的问题
ByteBuffer buffer = ByteBuffer.allocate(128);
int read = sc.read(buffer);
if(read == -1) {
key.cancel();
sc.close();
} else {
buffer.flip();
}
}
// 处理完毕,必须将事件移除
keyIterator.remove();
}处理消息的边界
// 获取所有事件
Set<SelectionKey> keys = selector.selectedKeys();
// 遍历所有事件,逐一处理
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
// 判断事件类型
if (key.isAcceptable()) {
ServerSocketChannel c = (ServerSocketChannel) key.channel();
// 必须处理
SocketChannel sc = c.accept();
sc.configureBlocking(false);
ByteBuffer buffer = ByteBuffer.allocate(16); // attachment
// 将一个 byteBuffer 作为附件关联到 selectionKey 上
SelectionKey scKey = sc.register(selector, 0, buffer);
scKey.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) { // 如果是 read
try {
SocketChannel sc = (SocketChannel) key.channel();
// 获取 selectionKey 上关联的附件
ByteBuffer buffer = (ByteBuffer) key.attachment();
int read = sc.read(buffer);
if(read == -1) {
key.cancel();
} else {
split(buffer);
// 需要扩容
if (buffer.position() == buffer.limit()) {
ByteBuffer newBuffer = ByteBuffer.allocate(buffer.capacity() * 2);
buffer.flip();
newBuffer.put(buffer); // 0123456789abcdef3333\n
key.attach(newBuffer);
}
} catch (IOException e) {
e.printStackTrace();
key.cancel(); // 因为客户端断开了,因此需要将 key 取消(从 selector 的 keys 集合中真正删除 key)
}
}
// 处理完毕,必须将事件移除
keyIterator.remove();
}private static void split(ByteBuffer source) {
source.flip();
for (int i = 0; i < source.limit(); i++) {
// 找到一条完整消息
if (source.get(i) == '\n') {
int length = i + 1 - source.position();
// 把这条完整消息存入新的 ByteBuffer
ByteBuffer target = ByteBuffer.allocate(length);
// 从 source 读,向 target 写
for (int j = 0; j < length; j++) {
target.put(source.get());
}
debugAll(target);
}
}
source.compact(); // 0123456789abcdef position 16 limit 16
}处理 write 事件
一次无法写完的例子
public class WriteServer {
public static void main(String[] args) throws IOException {
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false);
ssc.bind(new InetSocketAddress(8080));
Selector selector = Selector.open();
ssc.register(selector, SelectionKey.OP_ACCEPT);
while(true) {
selector.select();
Iterator<SelectionKey> iter = selector.selectedKeys().iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
iter.remove();
if (key.isAcceptable()) {
SocketChannel sc = ssc.accept();
sc.configureBlocking(false);
SelectionKey sckey = sc.register(selector, SelectionKey.OP_READ);
// 1. 向客户端发送内容
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 3000000; i++) {
sb.append("a");
}
ByteBuffer buffer = Charset.defaultCharset().encode(sb.toString());
int write = sc.write(buffer);
// 3. write 表示实际写了多少字节
System.out.println("实际写入字节:" + write);
// 4. 如果有剩余未读字节,才需要关注写事件
if (buffer.hasRemaining()) {
// read 1 write 4
// 在原有关注事件的基础上,多关注 写事件
//key.interestOps() 表示原有关注的时间,+ SelectionKey.OP_WRITE 写事件
sckey.interestOps(sckey.interestOps() + SelectionKey.OP_WRITE);
// 把 buffer 作为附件加入 sckey
sckey.attach(buffer);
}
} else if (key.isWritable()) {
ByteBuffer buffer = (ByteBuffer) key.attachment();
SocketChannel sc = (SocketChannel) key.channel();
int write = sc.write(buffer);
System.out.println("实际写入字节:" + write);
if (!buffer.hasRemaining()) { // 写完了
// 为什么要取消关注 写事件
// 只要向 channel 发送数据时,socket 缓冲可写,这个事件会频繁触发,因此应当只在 socket 缓冲区写不下时再关注可写事件,数据写完之后应该取消关注
key.interestOps(key.interestOps() - SelectionKey.OP_WRITE);
key.attach(null);
}
}
}
}
}
}public class WriteClient {
public static void main(String[] args) throws IOException {
Selector selector = Selector.open();
SocketChannel sc = SocketChannel.open();
sc.configureBlocking(false);
sc.register(selector, SelectionKey.OP_CONNECT | SelectionKey.OP_READ);
sc.connect(new InetSocketAddress("localhost", 8080));
int count = 0;
while (true) {
selector.select();
Iterator<SelectionKey> iter = selector.selectedKeys().iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
iter.remove();
if (key.isConnectable()) {
System.out.println(sc.finishConnect());
} else if (key.isReadable()) {
ByteBuffer buffer = ByteBuffer.allocate(1024 * 1024);
count += sc.read(buffer);
buffer.clear();
System.out.println(count);
}
}
}
}
}文件编程 FileChannel
两个 Channel 传输数据
String FROM = "helloword/data.txt";
String TO = "helloword/to.txt";
long start = System.nanoTime();
try (FileChannel from = new FileInputStream(FROM).getChannel();
FileChannel to = new FileOutputStream(TO).getChannel();
) {
from.transferTo(0, from.size(), to);
} catch (IOException e) {
e.printStackTrace();
}
long end = System.nanoTime();
System.out.println("transferTo 用时:" + (end - start) / 1000_000.0);//transferTo 用时:8.2011超过 2g 大小的文件传输
public class TestFileChannelTransferTo {
public static void main(String[] args) {
try (
FileChannel from = new FileInputStream("data.txt").getChannel();
FileChannel to = new FileOutputStream("to.txt").getChannel();
) {
// 效率高,底层会利用操作系统的零拷贝进行优化
long size = from.size();
// left 变量代表还剩余多少字节
for (long left = size; left > 0; ) {
System.out.println("position:" + (size - left) + " left:" + left);
left -= from.transferTo((size - left), left, to);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}position:0 left:7769948160
position:2147483647 left:5622464513
position:4294967294 left:3474980866
position:6442450941 left:1327497219网络编程
JAVA NIO 框架简要设计分析

private static ServerSocketChannel newSocket(SelectorProvider provider) {
try {
/**
* Use the {@link SelectorProvider} to open {@link SocketChannel} and so remove condition in
* {@link SelectorProvider#provider()} which is called by each ServerSocketChannel.open() otherwise.
*
* See <a href="See https://github.com/netty/netty/issues/2308">#2308</a>.
*/
return provider.openServerSocketChannel();
} catch (IOException e) {
throw new ChannelException(
"Failed to open a server socket.", e);
}
}
JAVA实例 - 利用多线程优化
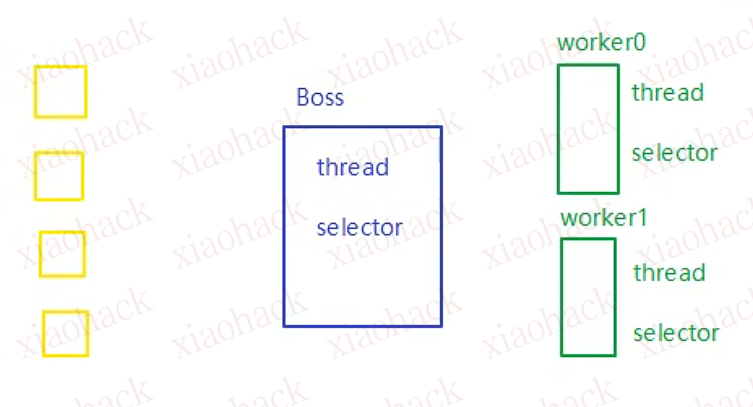
public class ChannelDemo7 {
public static void main(String[] args) throws IOException {
new BossEventLoop().register();
}
@Slf4j
static class BossEventLoop implements Runnable {
private Selector boss;//只负责建立连接
private WorkerEventLoop[] workers;//负责处理业务能力
private volatile boolean start = false;
AtomicInteger index = new AtomicInteger();
public void register() throws IOException {
if (!start) {
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.bind(new InetSocketAddress(8080));
ssc.configureBlocking(false);
//获取 boss 的选择器
boss = Selector.open();
//将ssc 绑定到boss的选择器
SelectionKey ssckey = ssc.register(boss, 0, null);
ssckey.interestOps(SelectionKey.OP_ACCEPT);
workers = initEventLoops();
//启动boss线程,接收accept事件
new Thread(this, "boss").start();
log.debug("boss start...");
start = true;
}
}
public WorkerEventLoop[] initEventLoops() {
//Runtime.getRuntime().availableProcessors(可以拿到 cpu 个数
//但是如果工作在 docker 容器下,因为容器不是物理隔离的,会拿到物理 cpu 个数,而不是容器申请时的个数
// 这个问题直到 jdk 10 才修复,使用 jvm 参数 UseContainerSupport 配置, 默认开启
// EventLoop[] eventLoops = new EventLoop[Runtime.getRuntime().availableProcessors()];
//创建处理业务的线程
WorkerEventLoop[] workerEventLoops = new WorkerEventLoop[2];
for (int i = 0; i < workerEventLoops.length; i++) {
workerEventLoops[i] = new WorkerEventLoop(i);
}
return workerEventLoops;
}
@Override
public void run() {
while (true) {
try {
boss.select();
Iterator<SelectionKey> iter = boss.selectedKeys().iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
iter.remove();
if (key.isAcceptable()) {
ServerSocketChannel c = (ServerSocketChannel) key.channel();
SocketChannel sc = c.accept();
sc.configureBlocking(false);
log.debug("{} connected", sc.getRemoteAddress());
//选择哪个线程来注册这个 accept事件
workers[index.getAndIncrement() % workers.length].register(sc);
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
@Slf4j
static class WorkerEventLoop implements Runnable {
private Selector worker;
private volatile boolean start = false;
private int index;
private final ConcurrentLinkedQueue<Runnable> tasks = new ConcurrentLinkedQueue<>();
public WorkerEventLoop(int index) {
this.index = index;
}
public void register(SocketChannel sc) throws IOException {
if (!start) {
worker = Selector.open();
new Thread(this, "worker-" + index).start();
start = true;
}
tasks.add(() -> {
try {
SelectionKey sckey = sc.register(worker, 0, null);
//关注读事件
sckey.interestOps(SelectionKey.OP_READ);
worker.selectNow();
} catch (IOException e) {
e.printStackTrace();
}
});
worker.wakeup();
}
@Override
public void run() {
while (true) {
try {
worker.select();
Runnable task = tasks.poll();
if (task != null) {
task.run();
}
Set<SelectionKey> keys = worker.selectedKeys();
Iterator<SelectionKey> iter = keys.iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
//只需要关注 读事件
if (key.isReadable()) {
SocketChannel sc = (SocketChannel) key.channel();
ByteBuffer buffer = ByteBuffer.allocate(128);
try {
// 这里没再关注 粘包半包 的问题了
int read = sc.read(buffer);
if (read == -1) {
key.cancel();
sc.close();
} else {
buffer.flip();
log.debug("{} message:", sc.getRemoteAddress());
//... 处理业务
}
} catch (IOException e) {
e.printStackTrace();
key.cancel();
sc.close();
}
}
iter.remove();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}UDP
public class UdpServer {
public static void main(String[] args) {
try (DatagramChannel channel = DatagramChannel.open()) {
channel.socket().bind(new InetSocketAddress(9999));
System.out.println("waiting...");
ByteBuffer buffer = ByteBuffer.allocate(32);
channel.receive(buffer);
buffer.flip();
//业务处理
} catch (IOException e) {
e.printStackTrace();
}
}
}public class UdpClient {
public static void main(String[] args) {
try (DatagramChannel channel = DatagramChannel.open()) {
ByteBuffer buffer = StandardCharsets.UTF_8.encode("hello");
InetSocketAddress address = new InetSocketAddress("localhost", 9999);
channel.send(buffer, address);
} catch (Exception e) {
e.printStackTrace();
}
}
}多路复用IO的优缺点
存在的误区
A 到 B 和 B 到 A 的双向信号传输。即使是阻塞 IO,读和写是可以同时进行的,只要分别采用读线程和写线程即可,读不会阻塞写、写也不会阻塞读public class TestServer {
public static void main(String[] args) throws IOException {
ServerSocket ss = new ServerSocket(8888);
Socket s = ss.accept();
new Thread(() -> {
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(s.getInputStream()));
while (true) {
System.out.println(reader.readLine());
}
} catch (IOException e) {
e.printStackTrace();
}
}).start();
new Thread(() -> {
try {
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(s.getOutputStream()));
// 例如在这个位置加入 thread 级别断点,可以发现即使不写入数据,也不妨碍前面线程读取客户端数据
for (int i = 0; i < 100; i++) {
writer.write(String.valueOf(i));
writer.newLine();
writer.flush();
}
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
}public class TestClient {
public static void main(String[] args) throws IOException {
Socket s = new Socket("localhost", 8888);
new Thread(() -> {
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(s.getInputStream()));
while (true) {
System.out.println(reader.readLine());
}
} catch (IOException e) {
e.printStackTrace();
}
}).start();
new Thread(() -> {
try {
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(s.getOutputStream()));
for (int i = 0; i < 100; i++) {
writer.write(String.valueOf(i));
writer.newLine();
writer.flush();
}
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
}JavaNIO的缺陷
// 创建、配置 ServerSocketChannel
ServerSocketChannel serverChannel = ServerSocketChannel.open();
serverChannel.socket().bind(new InetSocketAddress(9998));
serverChannel.configureBlocking(false);
// 创建 Selector
Selector selector = Selector.open();
// 注册
serverChannel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
selector.select(); // select 可能在无就绪事件时异常返回!
Set<SelectionKey> readyKeys = selector.selectedKeys();
Iterator<SelectionKey> it = readyKeys.iterator();
while (it.hasNext()) {
SelectionKey key = it.next();
... // 处理事件
it.remove();
}
}selector.select() 应该 一直阻塞,直到有就绪事件到达,但很遗憾,由于 Java NIO 实现上存在 bug,select() 可能在 没有 任何就绪事件的情况下返回,从而导致 while(true) 被不断执行,最后导致某个 CPU 核心的利用率飙升到 100%,这就是臭名昭著的 Java NIO 的 epoll bug。实际上,这是 Linux 系统下 poll/epoll 实现导致的 bug,但 Java NIO 并未完善处理它,所以也可以说是 Java NIO 的 bug。
该问题最早在 Java 6 发现,随后很多版本声称解决了该问题,但实际上只是降低了该 bug 的出现频率,起码从网上搜索看,Java 8 还是存在该问题。



最近出了一个 K60 澎湃 3 未解锁 bl 给爱回收,已经退出了谷歌账号,但是现象是重置系统后依然无法安装 apk ,提示需要登陆绑定的谷歌账号,商店装应用不影响,做了以下一些措施,最终是成功退出了但是不确定是哪个步骤成功的,在这里记录下:
1 、再次登录谷歌账号,这时候安装 apk 是 ok 的,退出账号,重置系统,再次尝试安装 apk ,失败
2 、再次登录谷歌账号,打开/关闭 oem 解锁开关,保证最终是关闭状态,重启,退出账号,重置系统,再次尝试安装 apk ,失败
3 、再次登录谷歌账号,确保 oem 解锁开关关闭,退出谷歌账号,等待 5 分钟,关闭谷歌框架开关,退出账号,重置系统,尝试安装 apk ,成功
最终结论猜测是退出账号后可能需要一些时间同步到谷歌或者小米,希望有帮助。
在传统前端开发中,表单页面是这样写的: 每个 要解决这个问题,前端必须与业务逻辑完全解耦:前端只提供原子化的组件和布局容器,页面的拓扑形态完全由后端下发的一份 JSON 元数据(Schema)动态决定。 这种架构在 Salesforce 中被称为 FlexiPage 和 Layout 体系。 在动手写前端代码之前,我们需要与后端确立一套接口规范。前端发起请求: 后端返回如下结构: 注意那个关键的 首先,将底层 UI 库的组件封装为符合 Meta 规范的原子组件: 同理封装 核心魔法是 Vue 的内置 这套代码中最精妙的一笔是 我们完全不用操心有多少个字段、什么嵌套结构。点击"提交"时, 整个流程分为 4 步:MetaForm 低代码引擎系列 · 第 2 篇
技术栈:Vue.js 3 + Composition API + 动态组件一、前端硬编码的终结
<!-- 硬编码的噩梦 -->
<el-form>
<el-input v-model="form.name" placeholder="姓名" />
<el-select v-model="form.gender">
<el-option label="男" value="male" />
<el-option label="女" value="female" />
</el-select>
<el-date-picker v-model="form.birthday" />
</el-form><input>、每个 <select> 都硬编码在 .vue 文件中。这种做法在低代码系统中无法存活:二、定义 Layout Schema 协议
GET /api/layout/{form_id}{
"layout_id": "lay_1001",
"title": "入职申请表",
"action_url": "/api/data/frm_1001",
"sections": [
{
"section_id": "sec_basic",
"section_title": "基础信息",
"columns": [
{
"items": [
{
"field_name": "employee_name",
"field_type": "string",
"component_type": "MetaInput",
"label": "姓名",
"required": true,
"max_length": 50,
"placeholder": "请输入真实姓名"
}
]
},
{
"items": [
{
"field_name": "gender",
"field_type": "string",
"component_type": "MetaSelect",
"label": "性别",
"required": false,
"options": ["男", "女"]
}
]
}
]
},
{
"section_id": "sec_detail",
"section_title": "详细信息",
"columns": [
{
"items": [
{
"field_name": "join_date",
"field_type": "date",
"component_type": "MetaDate",
"label": "入职日期"
}
]
}
]
}
]
}component_type 字段——它将指导 Vue 引擎进行组件的动态装载。三、Vue 3 动态渲染引擎实现
3.1 原子组件封装
<!-- MetaInput.vue -->
<template>
<!-- 动态读取 schema 中的 rules,转化为底层 UI 库的属性 -->
<el-form-item :label="schema.label" :required="schema.required">
<el-input
v-model="internalValue"
:placeholder="schema.placeholder"
:maxlength="schema.max_length"
:show-word-limit="!!schema.max_length"
/>
</el-form-item>
</template>
<script setup>
import { computed } from "vue";
const props = defineProps({
schema: Object,
modelValue: [String, Number],
});
const emit = defineEmits(["update:modelValue"]);
const internalValue = computed({
get: () => props.modelValue,
set: (val) => emit("update:modelValue", val),
});
</script>MetaSelect.vue、MetaDate.vue 等原子组件。架构师提示(关于动态校验规则下发):底层的原子组件不仅负责渲染 UI,更需要忠实地继承 Layout Schema 中定义的业务规则。如上面的
MetaInput,通过直接读取 JSON 中的 required 和 max_length 属性,并绑定到 <el-input> 上,前端无需硬编码任何繁复的校验逻辑,便自然拥有了浏览器和 UI 库提供的表单拦截能力。3.2 动态 Component Factory 解析器
<component> 指令,结合 is 属性:<!-- DynamicFormParser.vue -->
<template>
<div class="dynamic-form" v-if="layoutSchema">
<h2>{{ layoutSchema.title }}</h2>
<div
v-for="section in layoutSchema.sections"
:key="section.section_id"
class="form-section"
>
<h3>{{ section.section_title }}</h3>
<!-- 细化层级结构:遍历列 (Column) -->
<div class="section-layout" style="display: flex; gap: 24px;">
<div
v-for="(col, colIdx) in section.columns"
:key="colIdx"
class="layout-column"
style="flex: 1;"
>
<!-- 引擎核心:<component :is> 动态加载该列中的 items -->
<component
v-for="item in col.items"
:key="item.field_name"
:is="getComponent(item.component_type)"
:schema="item"
v-model="formData[item.field_name]"
/>
</div>
</div>
</div>
<el-button type="primary" @click="submitData">提交表单</el-button>
</div>
</template>
<script setup>
import { ref, onMounted } from "vue";
import axios from "axios";
import MetaInput from "./components/MetaInput.vue";
import MetaSelect from "./components/MetaSelect.vue";
import MetaDate from "./components/MetaDate.vue";
const props = defineProps({ formId: String });
const layoutSchema = ref(null);
const formData = ref({}); // 核心:所有动态组件的数据归宿
const componentMap = { MetaInput, MetaSelect, MetaDate };
const getComponent = (typeStr) => componentMap[typeStr] || MetaInput;
onMounted(async () => {
const { data } = await axios.get(`/api/layout/${props.formId}`);
layoutSchema.value = data;
});
const submitData = async () => {
// formData.value 就是完美的 JSON Payload
await axios.post(layoutSchema.value.action_url, formData.value);
};
</script>
<style scoped>
.grid {
display: grid;
gap: 16px;
}
.form-section {
margin-bottom: 24px;
}
</style>四、双向绑定的精髓
v-model="formData[item.field_name]"。formData 是一个初始化为空的 ref({}) 对象。当 Vue 渲染包含 field_name: "employee_name" 的组件时,它会自动在 formData 中创建键值 formData.employee_name,并通过 update:modelValue 事件实现双向绑定。formData.value 里就是一份完美的、准备好塞给后端 JSONB payload 的数据体。五、Schema 驱动渲染管线图解

<component :is="..."> 解析器读取 JSON 并进行路由分发v-model 双向绑定到集中的 JSON Payload State 中小结
formData 统一收集所有组件的值,与后端 DML 引擎无缝对接下一篇预告:前端收集好了
formData,这份 JSON Payload 如何安全地经过类型转换、规范化编码后落入 PostgreSQL 的 JSONB 堆表?请看第 3 篇《运行时数据引擎 —— DML 拦截与 JSONB 检索》。
上一篇中,Vue 前端收集到了一份 如果直接把这段未经处理的 JSON 塞入 由于我们放弃了关系型数据库原生的强类型列( 前端的 Raw JSON 进入运行时引擎后,引擎从 UDD 缓存中拉取 我们设计 整个流程:加载元数据 → 类型转换 → 组装 JSONB → SQL Insert,一气呵成。 数据落地后,更具挑战的是取出来。 假设前端请求:"查询年龄大于 18 岁的记录": 运行时引擎充当查询翻译器 (Query Builder): 前端的 API 请求被 Query Builder 引擎结合元数据翻译为底层 SQL,关键在于 JSONB 之所以能在生产环境立足,是因为 GIN (Generalized Inverted Index) 倒排索引: PostgreSQL 会将 JSONB 文档内所有键值组合索引化。使用 为了彻底解决 Schema-Free 宽表范围检索的性能瓶颈,Salesforce 在其底层架构中设计了复杂的 对于那些在业务上被高频用于范围检索(大于、小于、区间等)的数字或日期字段,系统可以在后台自动静默建立一个强类型的表达式索引: 一旦建立了这个索引,PGSQL 的查询优化器(Planner)会非常聪明地在执行 MetaForm 低代码引擎系列 · 第 3 篇 基于 JSONB 函数索引的高性能 DML 落地指南
技术栈:Python FastAPI + PostgreSQL JSONB + GIN 索引一、规范化格式 (Canonical Format) 的必要性
JSON Payload:{
"employee_name": "张三",
"age": "25",
"join_date": "2024年1月1日"
}data_heap.payload,会埋下两颗定时炸弹:age: "25" 是字符串,字符串的 "100" 在字典序中排在 "25" 前面(因为首字符 1 < 9)。数值比较将完全错误。int, timestamp),就必须在应用层用代码将类型安全补回来。这个过程叫做数据规范化 (Normalization) 与强制转换 (Type Cast)。数据入库拦截器

meta_fields 进行对比,将字符型的 "18" 转换为整型 18,日期格式化为 ISO 8601,最终以 Formatted JSONB 落入 data_heap 物理表。二、通用 DML 写入接口实现
POST /api/data/{form_id} 作为所有数据的唯一入口:from fastapi import APIRouter, Depends, HTTPException, BackgroundTasks
from sqlalchemy.orm import Session
from datetime import datetime
import json, uuid
router = APIRouter(prefix="/api/data")
def canonical_encode(value, field_type: str):
"""根据元数据类型,强制格式化数据"""
if value is None:
return None
if field_type == "number":
return float(value)
elif field_type == "date":
# 支持多种输入格式,统一输出 ISO 8601
if isinstance(value, str):
for fmt in ["%Y-%m-%d", "%Y年%m月%d日", "%Y/%m/%d"]:
try:
return datetime.strptime(value, fmt).isoformat()
except ValueError:
continue
return str(value)
elif field_type == "boolean":
return bool(value)
else:
return str(value)
@router.post("/{form_id}")
def insert_record(form_id: str, payload: dict, db: Session = Depends(get_db)):
# 1. 加载元数据蓝图(通常走 Redis/LRU Cache)
fields_meta = db.execute(
"SELECT field_name, field_type, is_required FROM meta_fields WHERE form_id = :fid",
{"fid": form_id}
).fetchall()
# 2. 运行时类型转换与校验
canonical_payload = {}
for meta in fields_meta:
raw_val = payload.get(meta.field_name)
# 必填校验拦截
if meta.is_required and raw_val is None:
raise HTTPException(422, f"字段 '{meta.field_name}' 为必填项")
if raw_val is not None:
canonical_payload[meta.field_name] = canonical_encode(raw_val, meta.field_type)
# 3. 组装 JSONB 并写入堆表
record_id = str(uuid.uuid4())
db.execute(
"""INSERT INTO data_heap (id, org_id, form_id, payload)
VALUES (:id, :org_id, :form_id, :payload::jsonb)""",
{
"id": record_id,
"org_id": "tenant-001",
"form_id": form_id,
"payload": json.dumps(canonical_payload, ensure_ascii=False)
}
)
db.commit()
return {"status": "ok", "id": record_id}三、动态 SQL 与 JSONB 查询
GET /api/data/frm_1001?age__gt=18age,操作符 __gt (Greater Than)meta_fields 缓存得知 age 是 Number 类型->>,附加显式类型转换 ::numericJSONB 查询翻译器

->> 操作符和 ::numeric 类型强转:SELECT id, payload
FROM data_heap
WHERE form_id = 'frm_1001'
AND (payload->>'age')::numeric > 18;@router.get("/{form_id}")
def query_records(form_id: str, request: Request, db: Session = Depends(get_db)):
# 解析查询参数如 age__gt=18, name__contains=张
filters = []
params = {"fid": form_id}
for key, value in request.query_params.items():
if "__" in key:
field_name, operator = key.rsplit("__", 1)
# 从元数据获取字段类型
field_meta = get_field_type(db, form_id, field_name)
if operator == "gt":
cast = "::numeric" if field_meta == "number" else ""
filters.append(f"(payload->>'{field_name}'){cast} > :val_{field_name}")
params[f"val_{field_name}"] = value
elif operator == "eq":
filters.append(f"payload->>'{field_name}' = :val_{field_name}")
params[f"val_{field_name}"] = value
where_clause = " AND ".join(filters) if filters else "1=1"
results = db.execute(
f"SELECT id, payload FROM data_heap WHERE form_id = :fid AND {where_clause}",
params
).fetchall()
return [{"id": r.id, "data": r.payload} for r in results]四、性能进阶:索引策略
4.1 GIN 倒排索引
-- 为整个 JSONB payload 建立 GIN 索引
CREATE INDEX idx_heap_payload ON data_heap USING GIN (payload jsonb_path_ops);@> (包含) 操作符时,数据库直接走倒排索引,速度与普通 B-Tree 索引差距极小。-- 精确匹配查询(走 GIN 索引)
SELECT * FROM data_heap
WHERE payload @> '{"status": "active"}'::jsonb;4.2 性能核弹:函数/表达式索引 (Functional Indexes)
架构师提示(解决全表扫描的终极杀器):在我们上面的查询翻译器中,出现了
(payload->>'age')::numeric > 18 这样的条件。
必须警惕:在千万级数据量下,每次查询都做显式的 ::numeric 类型转换是无法命中普通 GIN 索引的,这必定会导致极其缓慢的全表扫描。MT_Indexes(索引透视表)。而在现代 PostgreSQL 中,我们拥有更优雅的原生武器:函数索引(表达式索引)。-- 为高频检索的数值字段 age 创建"提纯"的表达式 B-Tree 索引
CREATE INDEX idx_heap_age_numeric
ON data_heap USING BTREE (((payload->>'age')::numeric));(payload->>'age')::numeric > 18 查询时,自动感知并直接命中这个原生的强类型 B-Tree 索引,完全跳过全表扫描。这让 JSONB 的范围过滤拥有了与原生独立物理数据库列极度接近的极限查询性能!小结
下一篇预告:数据能正确落库了,但如何在写入前自动执行业务校验规则(如"分数不能为负")?
在传统的软件开发模式中,我们的潜意识里有一条不可动摇的黄金定律:一个业务对象,就必然对应数据库里的一张物理表。 比如我们要开发一个问卷系统,很自然地会建立 但是,现代企业级 SaaS(比如低代码平台、灵活的 CRM 系统)面临的核心挑战是:极端的个性化诉求规模化。 设想一下,你的平台服务了成百上千个企业客户(租户): 如果坚持"一对象一表"的传统架构,灾难接踵而至: 面对这些困难,业界诞生了一个近乎"离经叛道"的核心选择:彻底放弃让应用层直接操作数据库 Schema。 数据库退化为纯粹的数据仓库,它不关心也不知道具体的业务模型长什么样。至于"系统里有哪些表、表里有哪些字段"这种工作,被"上架"到了应用层来管理。 这就是元数据驱动架构(Metadata-Driven Architecture)的起点。 元数据 (Metadata),简单来说就是"描述数据的数据"。 如果说普通的业务数据记录的是"张三考了 95 分",那么元数据记录的就是"系统里有一个叫『问卷』的表,它有一列叫『分数』"。 管理这些元数据的系统,我们称之为 通用数据字典 (Universal Data Dictionary, UDD)。 核心思想是:既然底层数据库不让自由建表了,那就拿两张固定的表当"户口本",把用户想要的表结构"登记"在册。 当你在低代码后台点击"新建表单"并命名为"问卷调查"时,底层不会执行 每当你在页面上拖拽生成一个"问卷标题"的输入框,系统就在 传统架构中,每个业务对象(User、Order、Survey)都有自己独立的物理表,每次结构变更都需要 结构定义好了,实际的业务数据存哪里? Salesforce 早期使用了 弹性宽表 (Flex Table) 方案:建一张超级大的宽表,包含 虽然实现了 Schema-Free,但痛点极多: 在现代技术栈下,我们选择 PostgreSQL + JSONB 作为底层底座。这是一种降维打击: 上方 了解了物理底座后,来看后端的 API 接口。整个平台只需要几个元数据管理接口: 调用 元数据驱动的核心并不是消灭了结构,而是做了一次巧妙的维度提升。 我们将传统数据库赖以生存的 Schema 从底层剥离,搬到了更高一层的"应用层数据字典"中。 在这个世界里,无论租户有多少,无论他们定义怎样千奇百怪的表单,底层物理依然是一张纹丝不动、便于统一治理和灾备的 JSONB 堆表。MetaForm 低代码引擎系列 · 第 1 篇
技术栈:PostgreSQL (JSONB) + Python FastAPI + Vue.js一、痛点引入:无限建表的 DDL 灾难
Survey(问卷表)、Question(题目表)、Response(答卷表)。表里定义好具体的列:title 是 VARCHAR,score 是 INT,created_at 是 TIMESTAMP。各司其职,结构清晰。ALTER TABLE ADD COLUMN 语句。DDL 操作会锁表(Metadata Lock),在高并发的生产数据库中等同于自杀。if-else 的泥潭。二、核心理念:通用数据字典 (UDD)
meta_forms(登记"有什么表")CREATE TABLE。系统只是在 meta_forms 中插入一行记录。meta_fields(登记"表里有什么列")meta_fields 表里加上一行。理解关键点:在这个体系里,修改系统结构不再是高危的数据库操作(DDL),而变成了最简单的增删改查(CRUD)。
三、架构对比图解

ALTER TABLE。而在 MetaForm 的元数据架构中,只有两张配置表 meta_forms 和 meta_fields 负责定义结构,所有业务数据统一落入 data_heap 的 JSONB payload 字段中。四、技术抉择:为什么是 PGSQL + JSONB
Value0 到 Value500 共 500 个 VARCHAR(255) 列。元数据字典记录某个字段存入了哪个具体的 Slot(例如"手机号"存入 Value3)。CREATE TABLE data_heap (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
org_id VARCHAR(64) NOT NULL, -- 租户隔离
form_id VARCHAR(64) NOT NULL, -- 关联 meta_forms(⚠️ 绝对的隔离条件)
payload JSONB NOT NULL, -- 核心:所有业务数据打包在此
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- GIN 索引:加速 JSONB 内部的键值检索
CREATE INDEX idx_data_heap_payload ON data_heap USING GIN (payload jsonb_path_ops);架构师提示(关于数据隔离的底线):由于所有的表单数据都在
data_heap 这个“大通铺”里,哪怕在单租户架构下,查询时 WHERE form_id = 'xxx' 也是绝对不可或缺的隔离条件。这就如同给数据分区,必须在后端底层DAO层强行统一带上 form_id,防止业务数据产生灾难级的越界。
### JSONB 的核心优势与 Key 映射规则
1. **天然 Schema-Free**:无论前端提交多少动态字段,直接打包成 JSON 塞进 `payload` 字段,彻底免除了维护 Slot Mapping 的痛苦。
* ** 架构提示(关于 Key 的映射)**:在设计 `meta_fields` 时,强烈建议区分**显示名 (Label)** 和 **内部标识名 (DeveloperName / API Name, 如 `age__c`)**。JSONB 内部的 Key **必须**使用不可变的 `field_api_name`,而不是可能会被业务人员随时修改的中文显示名,以此保证底层物理数据的稳定性。
2. **极速数据定位**:通过 PGSQL 的 JSONB 操作符(如 `->>`、`#>>`),可以轻松查询深层结构:
```sql
SELECT payload->>'phone_number' FROM data_heap WHERE form_id = 'frm_1001';payload 建立一个 GIN 倒排索引,就能自动加速所有基于 JSON Key/Value 的检索,碾压传统的逐列 B-Tree 索引。JSONB 存储映射透视

meta_fields 定义了字段名(如 Age、Name)和类型,下方 data_heap 的 payload 列中,这些字段名直接作为 JSON 的 Key 存储。元数据定义了 JSON 内部的结构。五、 API 设计
from fastapi import APIRouter, Depends, HTTPException
from sqlalchemy.orm import Session
from pydantic import BaseModel
from typing import List
import uuid
router = APIRouter(prefix="/api/meta")
class FieldCreate(BaseModel):
field_name: str
field_type: str # 'string', 'number', 'boolean', 'date'
is_required: bool = False
class FormCreate(BaseModel):
name: str
description: str = ""
fields: List[FieldCreate]
@router.post("/forms")
def create_dynamic_form(body: FormCreate, db: Session = Depends(get_db)):
"""
新建动态表单:操作元数据字典,而非 DDL 建表。
"""
form_id = f"frm_{uuid.uuid4().hex[:8]}"
# 1. 在 meta_forms 中登记"虚拟表"
db.execute(
"INSERT INTO meta_forms (form_id, name, description) VALUES (:fid, :name, :desc)",
{"fid": form_id, "name": body.name, "desc": body.description}
)
# 2. 批量登记字段定义到 meta_fields
for field in body.fields:
db.execute(
"""INSERT INTO meta_fields (field_id, form_id, field_name, field_type, is_required)
VALUES (:fld_id, :fid, :fname, :ftype, :req)""",
{
"fld_id": f"fld_{uuid.uuid4().hex[:8]}",
"fid": form_id,
"fname": field.field_name,
"ftype": field.field_type,
"req": field.is_required,
}
)
db.commit()
return {"status": "success", "form_id": form_id}
@router.get("/forms/{form_id}")
def get_form_meta(form_id: str, db: Session = Depends(get_db)):
"""
获取表单的完整元数据蓝图,前端据此渲染 UI。
"""
form = db.execute(
"SELECT * FROM meta_forms WHERE form_id = :fid", {"fid": form_id}
).fetchone()
if not form:
raise HTTPException(404, "Form not found")
fields = db.execute(
"SELECT field_name, field_type, is_required FROM meta_fields WHERE form_id = :fid",
{"fid": form_id}
).fetchall()
return {
"form_id": form.form_id,
"name": form.name,
"fields": [dict(f._mapping) for f in fields]
}POST /api/meta/forms 时,虽然在业务概念上我们"新建"了一张表,但数据库底层仅仅发生了普通的事务性 INSERT。没有任何表结构被改动,也没有触发锁。小结
下一篇预告:后端有了"JSON 蓝图",前端 Vue.js 是如何像搭积木一样将它们动态渲染成生动、可交互、带双向绑定的表单界面的?