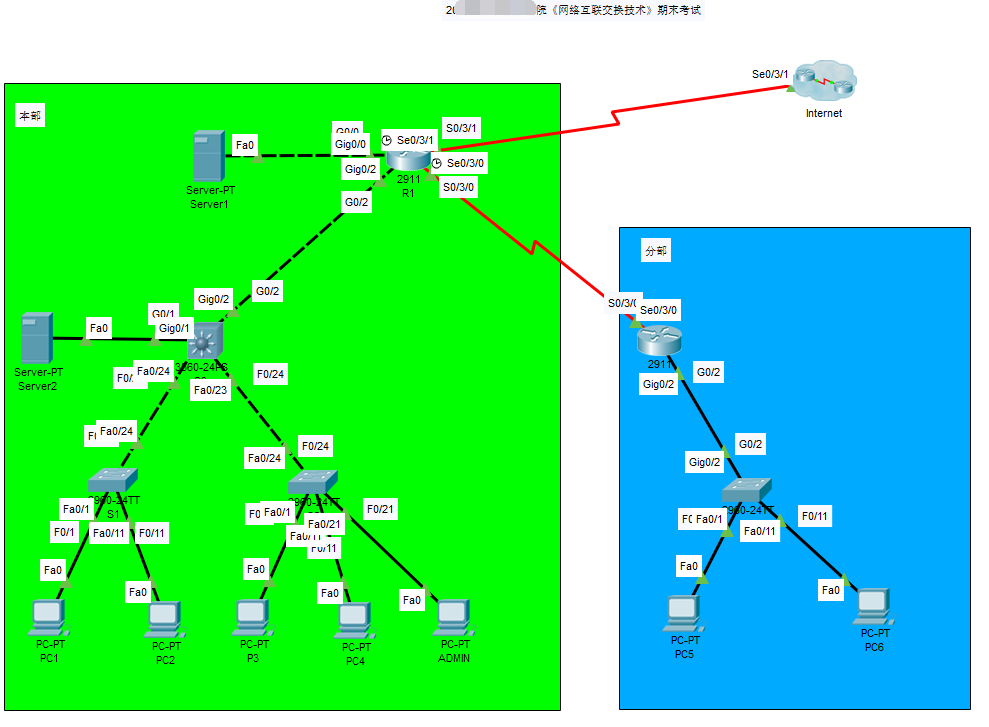
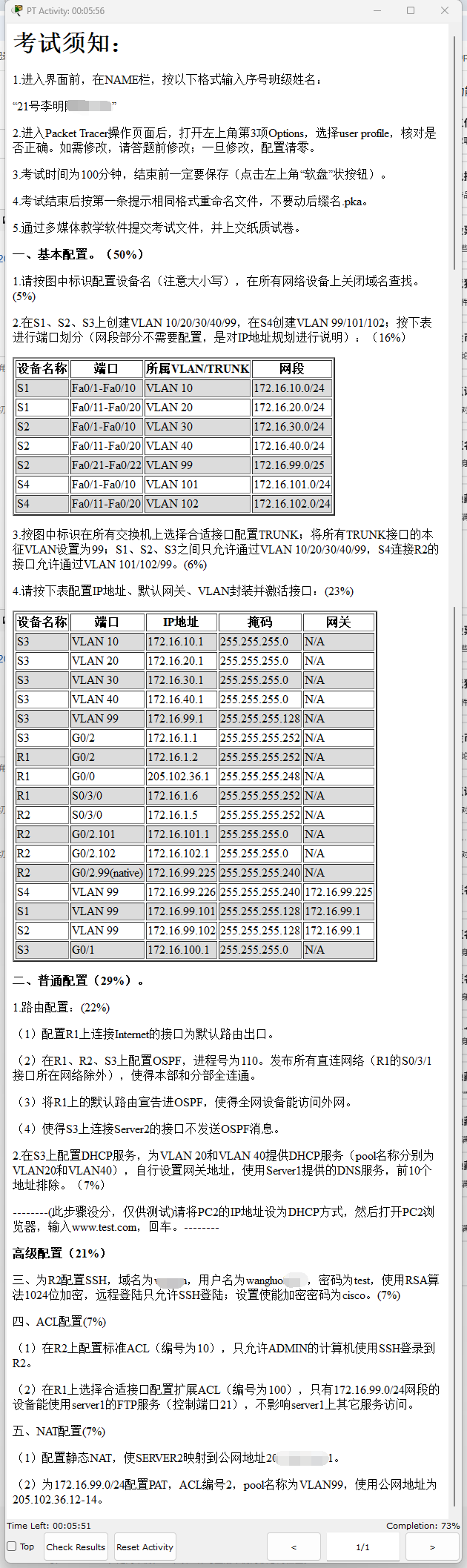
在企业 IT 环境中,特权账户是指拥有超出普通用户权限的身份账户。这类账户具备更高的系统控制能力,可以在企业基础设施中执行影响重大的操作,例如:
修改目录对象
管理身份验证策略
更改 组策略对象(GPO)
将计算机加入域
访问敏感数据
管理服务器或关键系统资源
由于这些账户拥有强大的控制能力,一旦被滥用或遭到攻击,可能对整个 IT 环境造成严重影响。因此,识别、监控和管理特权账户是 Active Directory 安全管理中的核心任务之一。
一、AD 中常见的特权账户类型
在Active Directory中,特权账户通常分为几类。
内置的管理账户:如域管理员和企业管理员,拥有对域的完全控制权。这些是最敏感且最严密保护的身份。
委派管理账户:用于处理特定操作任务,如密码重置、用户配置或组织单元管理。虽然范围比域名管理员更广泛,但他们仍然拥有有意义的权威。
服务账户:是另一个关键类别。这些非人类身份运行应用程序和调度任务,通常拥有更高权限。由于它们在幕后运作,常常在评审中被忽视。
本地管理员账户:则面临不同的风险。即使域级权限受到严格控制,跨机器重复使用的本地管理员凭证也能在被攻破后实现横向移动。
遗留账户:是为过去的项目或临时需求创建的,通常在其目的结束后仍保持活跃,保留不必要的高层访问权限。
在大多数组织中,特权账户是根据运营责任分配的。域管理员仅限于高级基础设施管理员。帮助台团队获得授权的权利。服务器管理员负责管理特定的层级。应用团队使用服务账户来管理工作负载。
从理论上看,这种结构是可行的。访问权限与工作职能相符。但环境会变化。临时访问权不会被撤销。角色变更并不总是触发访问审查。服务账户获得更广泛的权限以避免重复失败。嵌套的群体成员数量不断增长。
随着时间推移,能见度下降。特权会被分布在群组、组织单元和委托层之间。这就是合理访问逐渐变成过度特权,扩大攻击面而无人察觉的原因。
三、如何在 AD 中识别过度特权账户
特权膨胀是通过操作捷径和角色变更逐步积累。识别Active Directory中过度特权的账户需要同时检查直接和间接的权限路径。
直接特权通过域管理员或类似高级组的组成员身份可见。间接特权则更为微妙。它可以源自嵌套的组层级结构、OU的委托权限,或敏感对象继承的ACL。
为了正确识别权限过高的账户,管理员应评估有效权限,而不仅仅是群组名称。他们应该审查那些长期积累了多个管理员会员的账户。他们应审查拥有广泛目录权限的服务账户,并标记没有多重身份验证或密码过时的特权账户。
非活跃但特权账户值得特别关注。如果账户几个月未使用但保留了高额权利,则属于不必要的风险。定期报告、访问审查和分析攻击路径是预防攻击的方法。
四、特权账户管理
控制特权只是问题的一半。管理特权账户同样重要。
在Active Directory中,高风险事件包括特权组成员资格的更改、委托修改、GPO编辑、管理员账户密码重置以及域级设置的更改。如果没有集中可视性,这些变化可能被忽视。
管理特权账户需要同时跟踪认证和活动。成功的管理员登录并不一定意味着安全。行为异常、异常登录时间或权限快速升级往往是更深层问题的信号。能够生成结构化、可审计的特权活动报告,对于安全运营和合规要求都至关重要。
五、特权账户最佳实践
Active Directory 环境中强特权账户的最佳实践通常围绕几个关键原则展开。
(1)执行最小特权
过多权限扩大了攻击面,并在账户被攻破时更容易横向移动。
这包括限制域级权限,并避免像域名管理员这样的广泛组成员,除非必要。存在的高级身份越少,入侵时的爆炸半径就越小。
(2)独立的管理和用户身份
特权账户绝不应用于日常任务。将日常活动与管理权限混淆,增加了通过钓鱼或恶意软件导致凭证泄露的可能性。这种分离降低了风险暴露并限制了凭证盗窃的风险。即使标准账户被攻破,管理控制依然孤立。
(3)定期审查访问权限
群组成员资格和授权权限必须持续审查,因为特权膨胀是渐进且常常无意的。它还能确保休眠的访问能够及时消除。
(4)要求多因素认证
多因素认证增加了额外的验证层,如硬件令牌、生物识别验证或一次性密码。即使凭证被攻破,攻击者也无法在没有第二个因素的情况下进行身份验证。对于特权账户,MFA不应是可选的。这应该是强制性的、执行的,并且受到监督。
(5)使用特权会话管理
特权会话管理确保所有管理会话均被监控、记录并可审计。会话日志创建了详细的审计跟踪,在调查过程中变得至关重要。如果发生安全事件,团队可以重建活动,确定具体发生了哪些变化。
六、管理特权账户的软件
随着 AD 环境的扩大,手动权限审查变得不切实际。
用于管理特权账户的软件支持集中式发现、报告、访问审查自动化以及结构化委托的执行。
这些工具有助于识别高影响力群组中的账户,跟踪特权会员的变化,审查嵌套群暴露情况,并检测权限过剩的服务账户。
其价值不仅在于可见性,更在于运营效率。管理员无需在审计时运行临时的PowerShell查询,几分钟内即可生成报告。
七、使用ADManager Plus进行特权账户管理
ADManager Plus 提供 Active Directory 中特权账户的集中可视化。它使管理员能够识别高影响力群组成员,扩展嵌套成员,审查委托权限,并生成关于特权账户的详细报告。

核心能力:
集中可视性内置 200 + 用户与组报表,可实时查看关键管理员组成员,支持自动定时发送。
闲置特权账户检测快速识别仍在敏感组中的闲置账户,消除休眠高风险身份。
委派权限报表分析 OU 级别的权限分配,清晰掌握哪些用户或组拥有委派控制权。
定期权限评审通过定时报表与结构化工作流,持续开展权限认证,确保权限合理。
审批流程管控为特权访问申请建立审批机制,在授权前落实监督。
风险暴露管理通过攻击路径分析识别风险,批量修复过度特权账户。
合规审计报表一键生成可直接用于审计的特权账户报表,满足等保、行业法规与内部合规要求。