AIGC 类的 App 是否很难上架?国内
最近给我女儿 vibe 了一个 AI 讲故事的一个应用,她很喜欢,我老婆也觉得喜欢。主要就是在 APP 里,用户使用 AI 生成一些指定主题的故事,可以讲给孩子听。
其实也算是 vibe 快结束了,然后突然想到,这类属于 AIGC 应用了吧,好像个人是很难上架国内 Android 的,是这样么?
苹果不知道有没有类似的限制。
我问了一下 AI,个人超难,几乎不太可能。注册公司的话,得去申请一大堆东西好像,成本感觉有点高。不是很想注册公司
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
最近给我女儿 vibe 了一个 AI 讲故事的一个应用,她很喜欢,我老婆也觉得喜欢。主要就是在 APP 里,用户使用 AI 生成一些指定主题的故事,可以讲给孩子听。
其实也算是 vibe 快结束了,然后突然想到,这类属于 AIGC 应用了吧,好像个人是很难上架国内 Android 的,是这样么?
苹果不知道有没有类似的限制。
我问了一下 AI,个人超难,几乎不太可能。注册公司的话,得去申请一大堆东西好像,成本感觉有点高。不是很想注册公司
这篇文章只讲本项目里“OCR文字识别”工具的功能 JS 实现。页面层用 Vue 负责挂载和交互,真正的识别链路由前端脚本完成:上传图片、可选预处理、创建 OCR worker、执行识别、输出文本结果。 核心流程可以概括成一条线: 这个工具不是简单的“上传后立即识别”,它还要处理语言切换、识别进度、结果复制、结果下载和 worker 生命周期,所以一开始就把核心状态收拢到了 这里最关键的几项是: 这样做的好处是,上传、识别、切换语言、清空结果这些动作都能围绕同一份状态工作,不容易出现界面和内部状态不一致的问题。 工具同时支持点击上传和拖拽上传,但最终都会进入同一套处理函数。文件进来后先判断是不是图片,再检查大小,符合条件才继续读取。 读取方式用的是 上传成功后,工具会同步重置旧结果,避免新图片沿用上一次的识别文本。 这个工具提供了一个可选预处理开关,目的很明确:在识别前先把图片转换成更适合 OCR 的形式。 实现方式是把图片绘制到 处理完成后,再导出成新的 PNG DataURL 交给 OCR 引擎。这样可以让识别阶段拿到更干净的图像数据,尤其适合文字和背景对比比较明显的场景。 识别引擎基于 这一步的意义不是“把库跑起来”这么简单,而是把识别工作放到独立线程里执行,避免主线程在 OCR 过程中完全卡住。页面上还能继续更新进度、按钮状态和提示信息。 工具没有把所有语言一次性全部初始化,而是按当前所选语言创建 worker,这样功能逻辑更清晰,也更符合实际使用路径。 OCR 工具和普通文本工具不一样,第一次识别前通常要先准备语言数据。如果每次点击“开始识别”才从头加载,交互会显得很钝。 所以这里单独做了 其中 真正点击识别后,主流程会按顺序做这些事: 这里比较关键的一点是:识别用的 worker 和预加载用的 worker 是分开的。预加载只负责把语言资源准备好,正式识别时再创建当前任务自己的 worker。这样任务边界更清楚,结束时也更容易完整释放。 工具里的进度展示并不是写死几个延时动画,而是直接读取 Tesseract logger 回调里的状态。 实现里会根据不同阶段的状态文本更新进度,例如: 前几个阶段使用固定百分比区间,进入 识别成功后,工具不会只把文本塞进文本框里就结束,而是立刻补齐几项结果信息: 其中字符数和行数来自结果文本本身:字符数直接取长度,行数则按换行拆分并过滤空白行。这样结果区既能作为复制出口,也能给用户一个快速判断识别质量的依据。 识别结果出来后,工具提供两个常用动作:复制和下载。 复制优先走 这两个动作都不依赖额外服务,结果一旦识别完成,就可以立刻在浏览器侧完成后续处理。 这个 OCR 工具的关键不只是把图片送进识别引擎,而是把一次识别任务从开始到结束完整串起来:图片读取、语言预热、预处理、识别、进度反馈、结果统计、复制下载、worker 释放。 从功能 JS 的角度看,它本质上是一条比较清晰的前端任务流水线,而 Vue 在这里主要负责承接交互和挂载,让整套 OCR 功能可以稳定地运行在页面里。在线工具网址:https://see-tool.com/ocr-text-recognition
工具截图:选择图片 -> 读取为 DataURL -> 可选 Canvas 预处理 -> 创建 Tesseract Worker -> 识别文字 -> 输出文本与统计信息1)先把功能状态集中到一个对象里
state 里。imageDataUrl:当前待识别图片selectedLanguage:当前语言isProcessing:是否正在识别activeWorker:当前识别任务对应的 workerpreloadedLanguages:已经预加载过的语言preloadTasks:正在进行中的语言加载任务2)上传入口统一走图片校验和 DataURL 读取
FileReader.readAsDataURL。这么做有两个直接好处:3)预处理不是独立服务,而是前端 Canvas 直接完成
canvas,取出像素数据后做两步处理:4)OCR 引擎的关键是 Worker 化
Tesseract.createWorker。每次创建 worker 时,会同时指定三类资源:5)语言预加载解决的是“首次识别前的等待感”
preloadLanguage。它负责三件事:preloadedLanguages 用来记忆“这个语言已经准备好”,preloadTasks 用来避免同一种语言被重复并发加载。这样切换语言时可以提前准备,真正开始识别时就不会重复走整套加载流程。6)识别主流程围绕一次任务展开
setParameters 写入 tessedit_pageseg_moderecognize 开始识别7)进度条不是本地估算,而是跟着 Tesseract 的 logger 走
recognizing text 后,再根据回调里的 progress 动态推进到 100%。这样用户看到的不是“假进度”,而是和识别过程同步的真实状态。8)结果区不只展示文本,还会同步生成统计信息
9)复制和下载都围绕结果文本本身展开
navigator.clipboard.writeText,如果浏览器环境不支持,再退回到隐藏 textarea 加 execCommand('copy') 的兼容写法。下载则是把文本内容包装成 Blob,再生成对象 URL 触发保存。10)这套核心 JS 的重点,其实是“任务生命周期完整”












行色 APP 好用
hy2 协议间歇性断开 得过一会自动恢复
而且部分 vps 的 ip 比如日本 akari 即便不是 hy2 协议也会间接断开 不知道是不是互联有问题还是什么
各位有遇到过这种情况吗
很多人都会遇到这样的场景:想把截图里的文字、拍照的资料、纸质文件内容快速变成可复制文本,但又不想安装软件。这个时候,直接用在线 OCR 文字识别工具会更省事。 我做的这款 OCR 文字识别工具,主要面向普通用户,适合处理截图、笔记、表单、图片资料等内容。打开网页,上传图片,识别完成后就能直接复制或下载文字结果。 如果图片里的字比较小、倾斜明显,或者背景太杂,识别效果可能会受影响。实际使用时,尽量上传清晰、端正的图片,结果会更好。 这个工具是我用 Vue 开发的,重点放在操作简单和反馈清晰上。上传后能直接看到预览,识别过程有进度提示,结果出来后可以马上复制使用,尽量让没有技术背景的用户也能轻松上手。 如果你经常需要把图片转成文字,这个工具会比手动敲字省下很多时间。在线工具网址:https://see-tool.com/ocr-text-recognition
工具截图:怎么使用
这个工具适合谁
你有没有想过这个问题:当你和 Claude Code 聊了一个小时后,它是怎么记得你之前的需求?当你第二天打开同一个项目时,它为什么还能"认识"你? 这不是简单的"存下来"就能搞定的事。这背后是一套精妙的记忆系统设计。 今天我们就来拆解 Claude Code 的 Memory 架构,顺便聊聊记忆系统的本质设计。 很多人觉得,记忆嘛,不就是"存数据"吗? 如果把历史对话都存下来,每次原封不动传给 AI,很快就会遇到两个问题: 所以光存没用,得看能不能影响 AI 的决策。 换个说法:历史要能改变 AI 的行为,才算有记忆。 举个例子:你上次告诉 Claude Code "不要在测试里 mock 数据库",下次它就不再 mock 了。这才是记忆。 按这个思路,一个记忆系统需要三个东西: 账本 —— 记录存了什么、什么时候存的,不能糊里糊涂 索引 —— 光有账本查起来太慢,得能快速找到相关内容 策略 —— 决定什么时候该记住、什么时候该忘记。这点最容易被忽略,但最关键 没有账本就是一笔糊涂账;没有索引存了也查不到;没有策略,系统就会乱套。 能不能把所有能力都塞进一个模型?理论上可以——通过反复训练,让模型权重"学会"记忆。 但这条路有几个问题: 通用能力会退化。不断用"记住用户偏好"这类任务来微调模型,模型的其他能力可能会被稀释。就像让一个人同时学十种技能,结果每种都学不精。 无法审计和回滚。一旦能力"固化"到权重里,出了问题没法排查。 无法实时更新。用户偏好会变、项目会变,但重新训练模型的成本太高。 所以可行的方案是:把记忆能力从模型里抽出来,单独做一个系统。 这就是 System 1 + System 2 的架构: 简单说:System 1 负责"回答问题",System 2 负责"准备回答问题需要的背景"。 关键原因是:记忆能力和通用推理能力是独立的。 怎么证明?可以看三点: 结构上——整个系统可以写成 优化上——可以在不改变推理模型的情况下,单独改进记忆策略;反过来也可以只优化模型,不动记忆系统。 经验上——同一个基础模型,换不同的记忆系统,长程任务表现差异很大;同一套记忆系统,套在不同的模型上,也能工作。 既然独立,就可以牺牲一点理论上限,换取大量工程好处: 把记忆放到外部系统,会面临三个问题: 注入带宽有限 再多的记忆,一次只能往上下文里塞有限的内容。Token 限制摆在那。 检索不精准 索引是近似的,查到的可能不相关,没查到的可能正好需要。检索噪声会误导 AI 推理。 策略设计很难 什么时候该记、什么时候该查、查到后该怎么用——这些策略如果设计得不好,记忆反而帮倒忙。写多了污染环境,写少了学不到。 很多系统的失败不是因为存得不够多,而是策略太蠢。 Claude Code 的记忆系统分成了六个层级: 优先级:项目配置 > 用户配置 > 全局配置。 这是 Claude Code 最核心的记忆系统。它的特点是:AI 自己能从对话中提取值得记住的信息。 写入有两条路: 一是用户明确要求记住。你说"Claude,记住我喜欢用 tabs 缩进",AI 直接写文件。 二是AI 主动提取。每轮对话结束后,后台会跑一个子代理,分析这一轮对话有没有值得跨会话保留的信息。比如你提到"这个项目的认证模块要重写",AI 就会默默记下来。 写入的内容分成四类: 读取是主动召回的机制: 每次你发消息,AI 都会主动去记忆库看看有没有相关的。 流程是:扫描记忆目录(最多 200 个文件)→ 排除之前展示过的 → 让小模型打分选出最相关的 5 个 → 读取内容注入上下文 → 加上时间提示。 Claude Code 会根据记忆的"年龄"给出不同待遇: 对话一长,上下文就会满。Claude Code 的解决方案是压缩。 当 Token 使用到 92% 时,会触发压缩:调用 AI 把对话历史浓缩成结构化摘要,检查质量,通过则替换原历史。整个过程会显示进度给你看。 Claude Code 不会等到 92% 才告诉你: 旧信息可能已经过时了。 比如你三个月前告诉 AI "我在负责 X 项目",但现在你早就不负责了。如果 AI 不知道这条信息已经过期,它就会用旧信息做错误的决策。 所以"时间"不是附加字段,而是架构层面的设计。 Claude Code 的做法是:检索时默认只看"当前有效"的信息;给记忆打时间戳,区分"曾经为真"和"现在为真";旧信息不会直接删除,而是标记为过期。 前面的记忆都是"知识"——"这是什么"、"之前怎么样"。 但有时候更重要的是"怎么做"。 比如 AI 学会了"怎么排查 Redis 连接问题"——不是一条知识点,而是一套可复用的解决流程。这种记忆叫程序性记忆。 Claude Code 通过把成功经验固化成技能(Skill) 来实现这一点。一个技能就是一段可执行的"套路",下次遇到类似问题直接复用。 外部记忆怎么接入 AI 的脑子? 最简单的方式是拼接到 prompt 里。但这种方式有代价:每次都要把文字转成 token,AI 再重新理解一遍。 前沿研究在尝试跳过文本中间层,直接把记忆压缩成 AI 更容易理解的"潜层表示",直接注入到注意力计算里。目前还在探索阶段。 真正智能的记忆,不在于记住多少,而在于管理得有多精细。深入解析 AI Agent 的记忆系统设计
1. 记忆到底是什么?
2. 为什么需要两个"大脑"?
为什么这个拆分是合理的?
f(M(C), C) 的形式,C 是通用推理能力,M 是记忆系统,它们是独立的模块。分开有什么好处?
3. 非参数化路线有什么挑战?
4. Claude Code 怎么实现的?
六层记忆架构
层级 名字 作用 6 Agent Memory 子代理的专属记忆 5 Auto Memory AI 自己管理的长期记忆 4 Local Memory 项目私有配置 3 Project Memory 项目级指令(比如 CLAUDE.md) 2 User Memory 用户全局偏好 1 Managed Memory 管理员策略 Auto Memory 的工作方式
记忆会过期
上下文满了怎么办?
三级预警
使用率 提示 60% "记忆使用量较高" 80% "建议手动整理,或者开新对话" 92% "正在整理记忆..." 5. 时间在记忆系统里有多重要?
6. 从"知道什么"到"会做什么"
7. 记忆怎么"喂"给 AI?
8. 总结
15,000 条 heavy-OR 规则,200,000 条文档,同一台机器:Easysearch 在线规则引擎全流程 11.68 秒,Percolate Query 仅搜索阶段就跑了 254.30 秒——慢了 21.8 倍。 在"规则先存、文档后到"这类场景下,Percolate Query 的延迟会随规则数量和复杂度的增长快速恶化。规则涨到数千条后,每批文档匹配的耗时可以从秒级攀升至几分钟。这类问题换索引参数、调批次大小、精简 DSL,都治标不治本,根子在执行模型本身。 本文通过一组 heavy-OR 基准测试,量化两种方案的实际差距。 测试在同一台主机上运行,使用同一套规则文本和文档样本。Percolate Query 的查询条件由相同规则翻译而来,保证两侧规则语义一致。 具体指标: 规则匹配会对写入链路产生多少额外开销,是评估在线规则引擎可行性的重要指标之一。 与之对比,Percolate Query 仅搜索阶段就需要 上一组数据(11.68s vs 254.30s)包含了 Easysearch 的在线写入、bulk 解析和索引处理等通用开销。为了单独衡量规则匹配引擎自身的性能,我们用 Java 直调 JNI 做了一次离线 match,绕过写入链路,只跑规则匹配逻辑。 这组数据说明两点:Easysearch 的性能优势并非来自写入链路的整合效率,即便剔除通用写入成本,规则匹配引擎本体与 Percolate Query 之间依然存在约 50 倍的差距。 根因在执行模型,OR 条件多只是放大器。 每批文档到达时,Percolate Query 都要走完这套流程: 以本次测试为例,各阶段耗时分布如下: 搜索阶段是每批文档都必须重新支付的代价。 Heavy-OR 规则在这套流程里两头放大:规则覆盖面广,候选集更难剪掉;单条规则条件多,逐条验证也更重。 Easysearch 规则引擎把规则提前编译好,文档到达后直接匹配,不走这套每批重建的流程,差距就在这里。 以下场景对规则匹配的吞吐和延迟要求较高,是 Easysearch 在线规则引擎的典型适用范围: 在本次 heavy-OR 基准测试中: 如果你的业务已经有 Percolate Query 延迟随规则增长持续上升的问题,不用看 demo 数据——把你线上最重的那批规则拿出来,跑一次就知道差距在哪。测试配置
参数 值 规则总数 15,000 文档总数 200,000 批次大小 10,000 / 批 重规则数量 2,500 条大 OR 热点规则 单条大 OR 规模 随机 50 ~ 500 个 OR 条件 测试结果
路径 用时 纯写入 plain_bulk6.025535s在线规则引擎 rules_only11.684568sPercolate Query 搜索阶段254.304583s11.68s254.30s242.62s21.76 倍0.49s,Percolate Query 约 12.69s开启规则引擎的增量成本
254.30s。换言之,Easysearch 在线规则引擎把规则匹配叠加进写入流程,新增成本约为 Percolate Query 搜索耗时的 1/44.9。只看匹配引擎本体
路径 用时 Easysearch 纯匹配(JNI 离线) 5.046934sPercolate Query 搜索阶段 254.304583s为什么 Percolate Query 会慢
9.560294s7.451857s254.304583s适用场景
小结
刚过完万物复苏,动物交配的季节,杭州的天气也跟着热起来了,这个时候吃一点生蚝,无疑是对体力的补充,但是作为一个 I 人不愿意一个人去饭店吃,并且价格也不菲,点外卖呢,到家里也不好吃,那肯定会考虑自己做。。打开山姆 app ,发现没有生蚝。。。幸好其他超市有。。看到了永辉超市的乳山生蚝,立马入手,一个 8 块,250-300g 一只很大。先来 8 只,再来一份打折排骨。20 分钟后。。到了。真的大。。先将生蚝的外封装带剪掉,用刷子刷一下,再用清水冲洗。(这个时候将排骨,放入清水泡一下,放点面粉),蒸锅添水,将生蚝放入,并放入姜片,大火烧起。。待上汽 3 分钟后关火。排骨:洗净以后直接放入砂锅,取少许家里的老蘑菇洗净放入,并放入一勺盐,烧锅中小火煮,等到血沫煮出来,撇净,转小火继续煮 20 分钟。生蚝好了,拿出(不要一直闷在锅里),调出蘸料,辣根配香醋,蒜、耗油等。。生蚝壳很紧,用羹匙儿撬开,非常新鲜,配合辣根直接上头入魂。8 个生蚝全部干掉,体力值回复 55%,这时候排骨应该也快好了,简单收拾一下厨房,拿出排骨。蘑菇的香味扑鼻了,先尝一口蘑菇,熟了。。继续吃排骨,软嫩入味。。小猫儿也来凑热闹,分它一块肉吃。最后的汤才是重点,像极了港剧,每次有人生病住院,就煮汤的场景。直接拿砂锅把汤一饮而尽,看见小猫端着我的碗也喝了起来。战斗结束,一身汗。。。最后将所有工具放入洗碗机,喝水漱口,结束今天的晚饭。总共花费 80 元,比自己去饭店强。。。很能恢复体力。。不说了 我去打游戏了。。
这是一个开源超轻量绘图画布 cli (纯 rust 实现,仅几百 KB 大小),提供了 SKILL.md
核心解决的问题:让 AI Agent 很方便地调用来画图,不调用生图的 API ,直接本地生成 PNG 图片!

Github 地址: https://github.com/echosoar/canvas-rs
已打包成一个二进制文件(支持 Windows/Linux/MacOS 平台),完全不用安装各种乱八七糟的 libxxx 依赖,下载就能用,支持通过文本描述的形式输出 png 图片(或输出 dataUrl )
支持 ctx.fill_text 绘制文字(默认是阿里普惠体),通过 ctx.set_text_align 设置对齐方式,还有 set_font 、set_fill_style 等方法
支持 ctx.create_linear_gradient 创建线性和 ctx.create_radial_gradient 径向渐变
支持 ctx.begin_path / move_to / line_to / arc / close_path 画各种形状,还有 set_line_width 设置粗细,fill_rect 和 stroke_rect 来填充形状
支持 ctx.draw_image 绘制图片到画布上
相对于其他文件转发不同的是:不用注册(使用 2Libra 登录)、不需要手机号、不限制文件类型(遇到不支持的找我添加就行了)、部分文件支持预览、不需要在同一局域网。
测试文件
提取地址: https://file.mxpy.cn/download?code=9KqIkb7L
提取码:9KqIkb7L
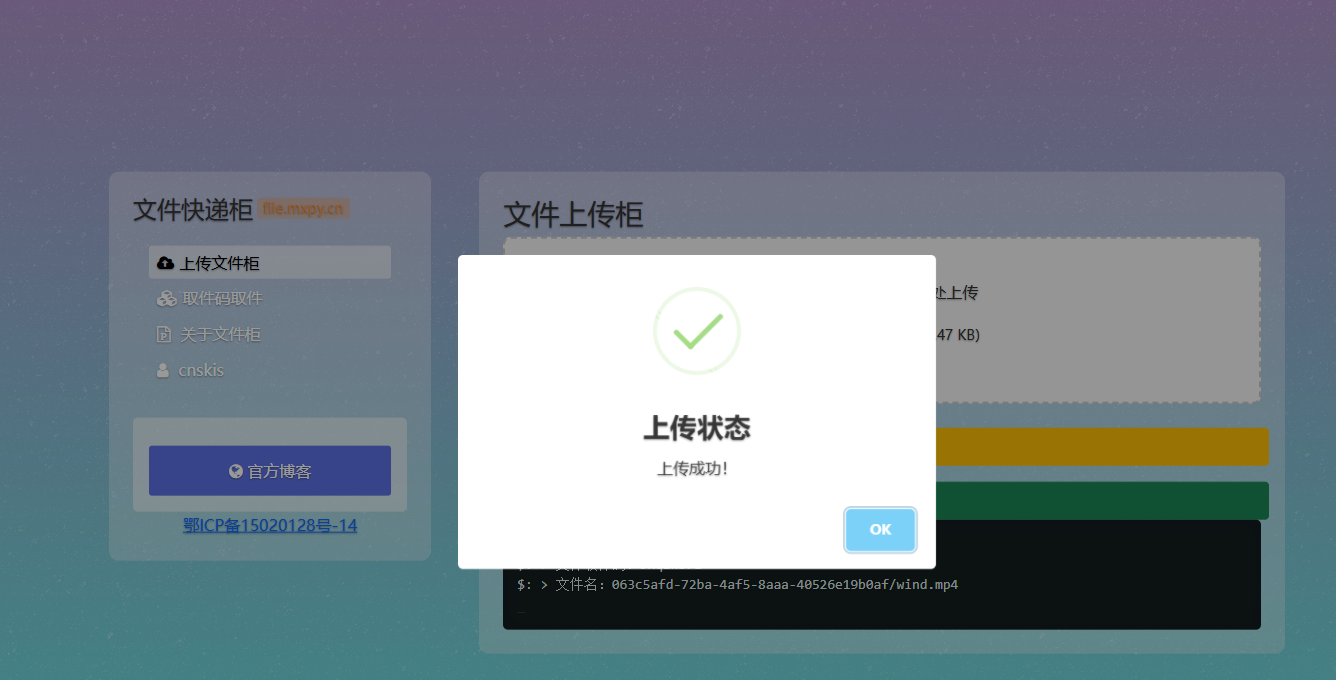
支持各种类型文件上传,(目前限制 100M,临时转发够用了)
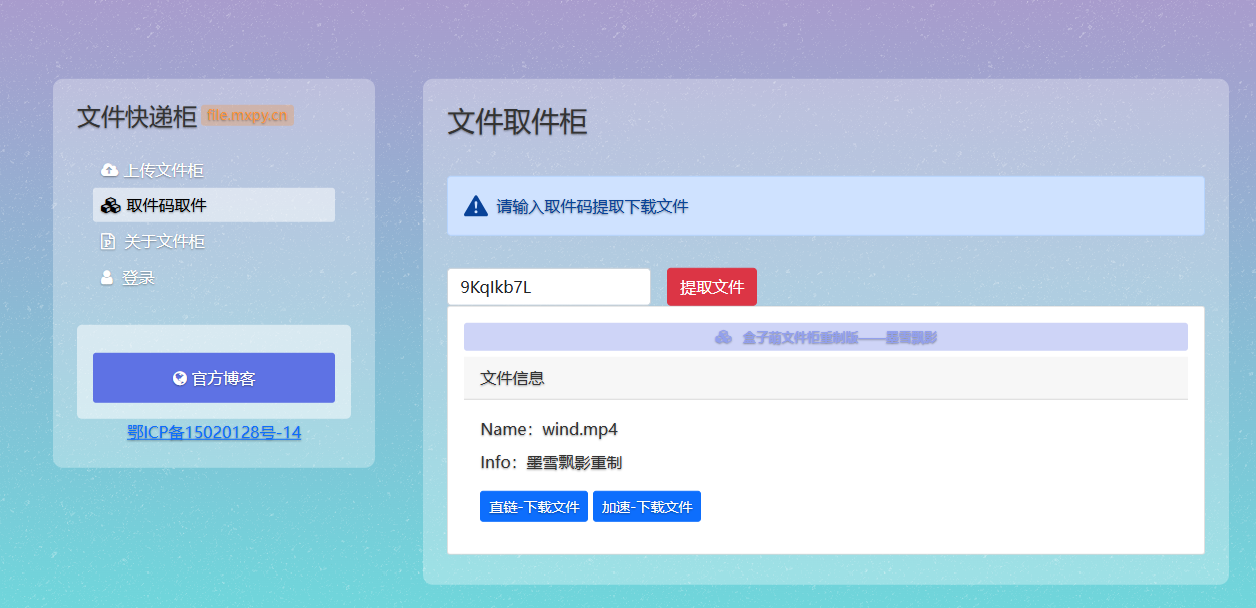
使用提取码提取文件
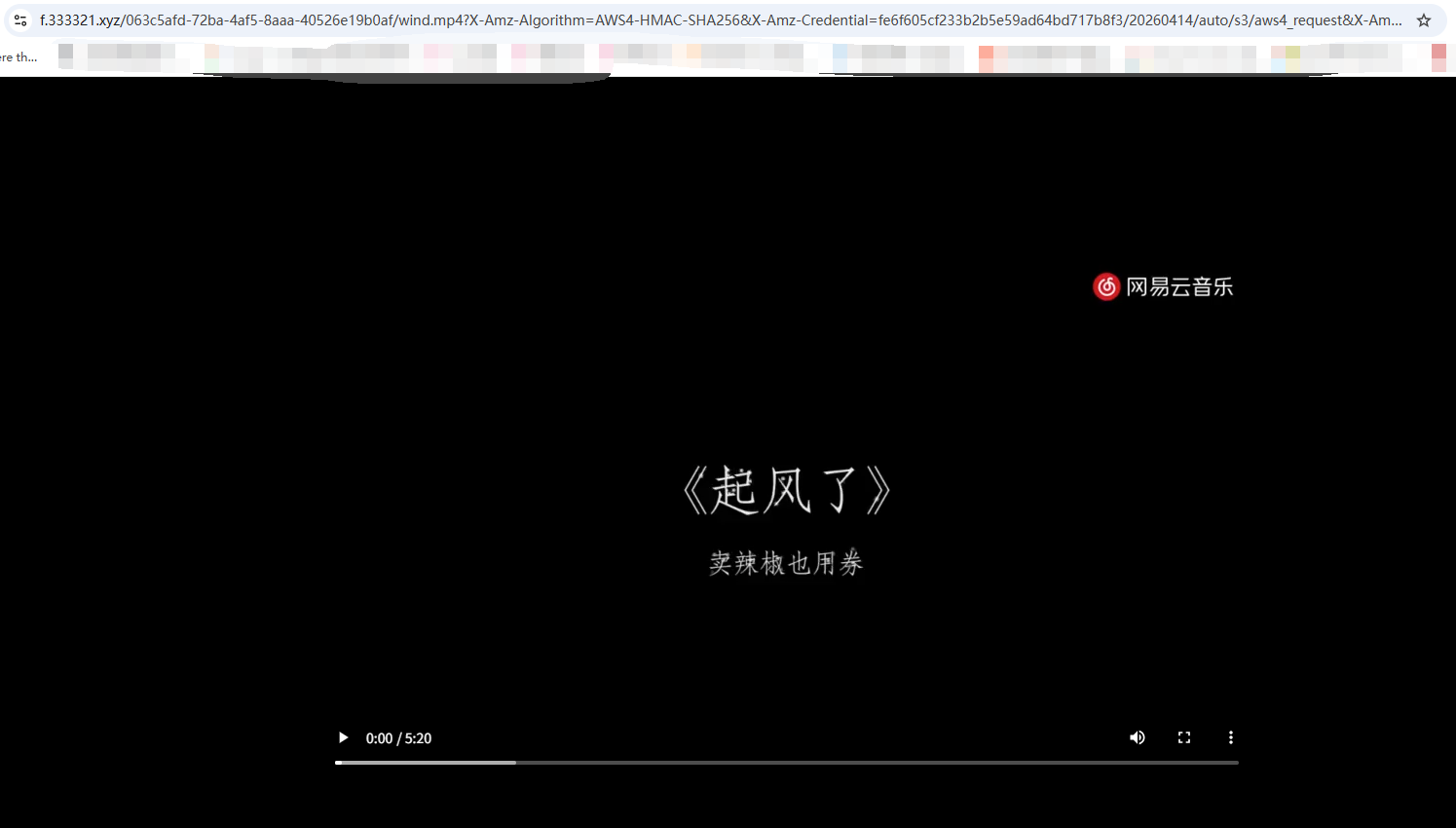
部分文件支持在线预览
点击用户名支持修改已上传的文件提取码
由于缓存原因,修改提取码后可能显示还是旧的(文件管理还有其他 bug,目前只用于临时转发文件,所以没做那么完美)
墨雪飘影图床: https://pic.mxpy.cn
图床介绍: https://2libra.com/post/tools-sharing/oLYDmMl
就一个马年签到徽章,看好多 2 友都有其他的徽章,都是怎么来的?
买了质谱的 coding plan ,用了两个月,一直感觉不错,直到前几天,说我是多人使用,一直不让我用。
我一个人用,说我是多人使用,无理由封锁服务,多次!客服没有证据,没有退款。315 投诉估计没用。
北京互联网法院有攻略么?直接起诉退款吧。

今天看到 trae 闪烁这个广告。999 ,是写错小数点了吗? 不应该是 9.99 吗?
不知道是不是因为身份识别的缘故,晚上用 cc 感觉突然换了个 ai 一样
最近在做一个动漫圣地巡礼规划网站:Anime Seichi Planner
起因很简单。
平时看动漫、电影或者日剧,真想去线下走一遍的时候,会发现信息特别散:
有的点位在博客里,有的在地图里,有的只有截图没有坐标,真要自己排路线也很麻烦。
所以我想做一个更偏“巡礼执行”而不是纯内容展示的东西,
把地点、地图、路线规划和分享放到一个入口里。
现在已经做了这些:
线上地址:
https://anime-seichi-planner.malu.moe
目前还不完善的地方也直说:
👍(点赞)这条帖子或我下面的评论,留言随机打赏!
还是加上金币池,给你们触发幸运儿!
不知道现在活跃人数能不能凑到 200 点赞







