作者 | Tina
采访嘉宾 | 沈浪、茹炳晟、吴娟、方汉
编辑 | 蔡芳芳
“我不明白,AI 的发展为什么不是让我们能 5 点下班,而是让更多人被裁员,其他人继续工作到 10 点。”
“两年前,我们工作的节奏还可以,但 AI 到来之后,这个状态不存在了。节奏一下子被拉快了,因为管理层觉得 AI 可以极大提升效率,以前还能按正常周期推进的事情,现在都默认你应该更快给结果。”
“现在我们内部的考核,其实已经慢慢往 AI 那边偏了。最直接的就是代码量,我们有一个排行榜,谁发了多少行代码,一刷就能看到。组里有个别人几乎全靠 AI 在写,代码量和 PR 数量一下子拉得特别高,慢慢大家就都被拿去跟这种人对标。慢慢就有点变味了,一开始是比代码量,后来开始比谁用 AI 用得多,再往后连 Token 都开始被看。这些东西其实没有写进绩效,但你心里都清楚,什么是会被看到的。”
从这三个程序员的讲述里,能明显感觉到,行业里的气氛在变,大家都在被迫提速。
与此同时,业界也不断传出各种收紧人力的消息,真假交织。国外亚马逊、Meta 在调整岗位结构,国内也不断传出网易等大厂压缩外包、用 AI 接手基础工作的消息,连“裁员一定要快”都成了热梗。
AI 的发展,开始和一种残酷的判断绑在了一起:既然有些活已经明显变快,那人是不是可以少一点?于是,越来越多人心里开始冒出一丝不安:当效率被不断量化、不断比较之后,下一个被算掉的,会不会就是自己?
提效这阵风,没人能站在风外
过去一年,大家讨论 AI,已经从“要不要用(adoption)”转向“到底能不能提速(speed)”,感觉像是“成熟度”的潘多拉魔盒一下子被打开了。毕竟,AI 在软件开发里的角色变化太快了,从最早的代码补全,到对话式生成,再到 agent,甚至多智能体协同,它介入研发流程的深度已经和以前很不一样了。
也正因为变化太快,市场上越来越多人开始把这类能力看得近乎神乎其神,甚至开始有意无意地传播一种更浮躁而激进的想法:AI 时代的软件工程已经和过去完全不同了,好像原来那套工程实践都可以被抛开,不需要懂 Kubernetes,不需要理解系统架构,只要会用模型,就够了。Agent 也仿佛成了什么都能包办的“万能外包”。而其中的代表 Claude Code,不知不觉间已经成了部分人的“技术信仰”。
对不少企业负责人来说,这确实是一个疯狂又不可思议的时期。
尤其是对于那些本来就只有二三十人的小公司,或者现在很流行的 OPC、“一人公司”来说,大模型带来的提效几乎是一眼就能看到的,很多活就是比过去纯靠人手写快得多。也正因为这样,这类公司的负责人最容易被那些炫技产品打动,尤其是 Design to Code 这种从 Figma 直接生成前端代码的演示。
这种效率上的提升,同样也吸引了互联网企业。
互联网公司最后还是要看数字。比如腾讯就在去年底发过一组数据:九成员工使用编程助手,将编码时间缩短了 40%,整体提升 20%。
快手则把生产力提升的北极星指标直接放在了“需求交付周期”上。按照他们向 InfoQ 提供的最新数据,L1 阶段的团队,AI 主要还是代码补全工具,提升通常在 15% 到 25% 之间;而到了 L2、L3 阶段,AI 开始更深地进入交付过程,甚至能自主完成更多任务,人主要做需求定义和质量审核,提效幅度会更大一些。“我们标杆团队,L2/L3 需求占比超过 20% 的,交付周期下降了 58%。”
昆仑万维 CEO 方汉也对 InfoQ 提到,公司使用 AI 后,“项目平均交付时间大幅缩短了”。他在接受《中国企业家》采访时也进一步披露了背后的投入和效果:公司已经不再把 AI 支出看作 Token 补贴,而是纳入统一的 IT 采购。按他的说法,公司现在每个月消耗的 Token 大概在 10000 亿到 12000 亿之间,分摊到员工身上,大约是每人每月 700 元。按 2024 年底约 1500 名研发技术人员来算,公司一个月在 Token 上的支出大约是 105 万元,一年最少 1200 万元。
方汉认为这笔投入“太值了”。因为每月百万元左右的投入,差不多相当于 20 个员工的成本。更重要的是,实施一个月后,研发速度提升了 50% 以上,尤其是架构师和 Team Leader 这类岗位,提升最明显,几乎能达到 3 到 5 倍。
金融行业要求稳、安全、合规,AI 落地没法一蹴而就。
神州信息做的是银行核心软件系统。跟互联网公司不一样,金融领域对技术方案的引入持更为审慎的态度:不关心这技术有多“炫酷”,而是能否与现有技术体系实现无缝衔接。具体来说,这涵盖代码质量的可控性、复杂任务的拆解能力、功能需求的完整覆盖、需求定位的精准程度,以及与既有系统架构、开发规范和工程流程的适配程度。简言之,评判标准不仅是“能否生成代码”,更是“能否在现有系统内生成符合工程质量要求的代码”。
所以 2025 年之前,神州信息试过用 AI 做文档补全、代码-文档一致性治理这些事,但那时模型能力和工具都跟不上,试下来效果不怎么样,内部结论是“还不能用在生产上”。
到 2025 年前后,情况变了。大模型强了,配套工具也更完善了,神州信息又重新开始系统性地验证 AI 能力,逐步确认了 AI 技术已初步具备进入银行软件这类高可靠性要求场景的条件。
那金融行业到底有没有提效?具体到一些单点环节,提效已经很明显了。以测试用例编写为例:此前单个功能模块的测试用例编写工作通常需要 5 人团队耗时一个月完成;引入 AI 辅助后,该流程已转变为 1 人审核 AI 生成结果的轻量化模式,且 AI 在异常场景覆盖方面往往表现出更优的全面性。在文档维护场景中,以往需要投入 10 人月方能完成的文档补全工作,如今借助 AI 从代码逆向生成设计文档的方式,可在 3 至 5 人月内完成,效率提升幅度达 50%以上。
AI 时代的“效率悖论”:明明让人变快了,但提效却断在中间
这轮“提效”风里,AI 真把人变快了,对此现在已经没人怀疑了。但一线开发者感受到的却是另一回事。
有开发者对 InfoQ 形容,AI 出现之前,开发这件事其实是有节奏的。写代码、调试、验证,一步一步往前走。可到了 2025 年中,随着 AI 编程工具大规模普及,周围几乎已经没人再老老实实一行行手写代码了。AI 写代码当然更快,但人并没有因此轻松下来,反而比以前更忙了。因为“老板也懂了 AI 能提效”,预期被迅速抬高,很多原本按正常周期推进的事情,一下子都被要求更快交付结果。
问题不在“快”,而在快的那一段,只发生在局部。需求还要对齐,测试还要走,联调、上线、问题处理,一样都没少,甚至因为 AI 的引入,多了一层新的复杂性。于是就出现一种很别扭的状态:编码提速了,但整体节奏没跟上,被压掉的时间,最后还是得靠人自己补上。
从企业披露的数据里也能看到这种“错位”:编码这一段确实更快了,但整体提效大多仍然停留在 15%~25%。
腾讯研究院特约研究员茹炳晟,对这种落差并不意外。在他看来,很多人都把“编码提速”看得太重了。
在企业级研发里,真正写代码的时间,通常只占 20%~30%。剩下的大头,都在沟通、对齐、评审、测试和各种临时事务上。AI 提升的,主要是这 20%~30% 的环节,自然很难直接拉动全局。“局部的提升,我认为很容易做到。”茹炳晟说,“难的是把效率真正拉通到端到端的全流程。这对推动改进的人要求很高:你要看得清瓶颈在哪,敢不敢动流程,也要有能力做取舍。”
按他的判断,至少在大型软件系统里,目前还没有看到特别显著的整体提升,尤其是那些大型、复杂、历史包袱重、同时质量要求又极高的系统,比如银行核心交易系统、工业软件等。
这类系统往往一个产品就有五六百人参与维护,多的甚至达到上千人。在这样的规模下,AI 可以带来局部提速,但还很难撬动整体交付效率。
也正是在这种“局部快、整体不动”的结构里,快手研发效能负责人沈浪说,他们花了一年多才摸到一个关键判断:AI 工具、个人提效和组织提效,从来不是一回事,他们自己一开始也踩过这个坑。AI 代码率上去了,看起来很不错,但回头看整体交付周期,改善其实有限。
因为大公司里,从个人提效到组织提效之间常常隔着两道鸿沟:第一个是从个人到团队,你个人写代码是快了,但代码评审还得排队,测试环境也得等,这些卡点会一点点把效率吃回去;第二个是从团队到组织,就算团队交付更快了,只要需求、测试、发布这些流程还是瓶颈,整个组织的交付周期照样快不起来。(延伸阅读:“3年、1万人,快手技术团队首次系统披露AI研发范式升级历程”、“生成率从8%到60%:快手智能测试用例生成系统的四阶进化”)
更麻烦的是,有些速度其实是“借”来的。茹炳晟提到,现在行业里一个很大的误区,就是太喜欢用交付速度来衡量 AI 的价值。短期看当然会更快,功能先跑通,代码先交上去,效果立刻就能看到。但这种快,往往是把代价往后挪了。
AI 生成的代码,未必符合原有的架构风格,也可能把本来不该重复实现的东西又写了一遍。眼前看是提速了,后面却可能留下维护税和技术债。这些账不会当场爆出来,但会一直跟着代码和系统走,到了后续维护、变更、扩展的时候,影响才会越来越明显。
什么样的企业,敢把提效直接置换成裁员?
这也是为什么,那种小型、轻量的软件开发看起来 AI 提效效果最“炸”。
尤其是那种由三五十人以下小团队负责的一个 IT 系统、一个小应用,系统不复杂,协作链条也短,大模型一接进去,很容易就跑出“一个人顶一个小团队”的效果。
问题是,这类项目很多活得不久。可能做一年就结束了,维护压力、技术债、架构混乱这些真正的后遗症,还没来得及爆发,项目先没了。老板看到的就只剩下一件事:人可以再少一点,活照样能干完。
AI 被拿来当裁员依据,往往就是从这里开始的:没做过大型复杂项目的人,最容易把 AI 神化;把软件工程误读成“写代码”的人,则最容易把小应用里的局部提效,错当成所有团队都该接受的裁员信号。
但金融企业不是这样。
金融行业系统本身非常复杂,AI 在代码生成环节的起效远没有外界想的那么高。像复杂账务、事务一致性、7×24 小时银行机制支撑这类代码,靠的是人长期积累下来的经验。AI 在简单查询和增删改查上当然快,但一碰到这些复杂场景,提效自然就放缓了——天花板就在那里。
除此之外,合规判断、数据安全边界、监管问责时的责任承担,最终还是得由人来扛。知识传递一旦断档,系统稳定性就会受影响。所以银行不会像小企业那样,一看到 AI 快了就急着裁人。所以有金融行业技术负责人认为:把 AI 省出来的人力直接砍掉,那是危险的误判。
怎么衡量开发者的生产力
AI 的出现,首先放大了组织之间的差异。沈浪打了个比方:AI 像一面透镜,基础扎实的组织,长板被放得更长;本来就有问题的组织,短板也暴露得更彻底。与此同时,AI 也把个人之间的差异拉得更开了。资深工程师对需求理解深、任务拆解能力强、能识别 AI 幻觉,AI 就成了判断力的放大器;初级工程师执行速度快了,但判断失误也跟着快了。这放大了不同层级工程师之间的差距。
这种差异一旦被看见,人就忍不住要比。程序员之间开始暗暗较劲,你用了多少 token,我写了多少行代码。有些是隐形的,同事间嘴上不说心里有数;有些干脆摆到明面上,成了榜单。比如 Meta 内部,有人搭了个叫 Claudeonomics 的排行榜,8.5 万名员工比谁烧的 token 多,前三名能拿徽章、头衔,甚至有人专门让 AI Agent 跑几小时任务就为了刷数据。
还有那个更古老的指标——代码行数,虽然老掉牙,但从来没人真的忘了它。当 AI 把“写代码”这件事变得廉价之后,衡量一个开发者的生产力到底该看什么,成了一个更棘手的问题。
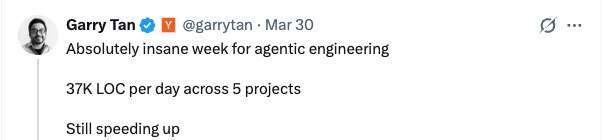
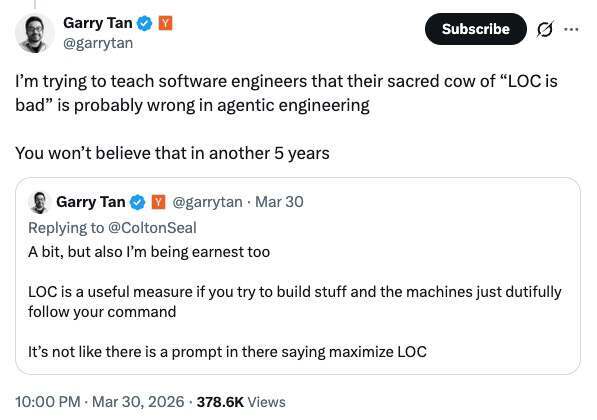
“同时推进 5 个项目,现在平均一天能产出 3.7 万行代码......我最近一直在试着让软件工程师接受一件事:你们一直奉为圭臬的那句‘代码行数没意义’,到了 agentic engineering 时代,可能没那么对了。再过 5 年,你们大概不会相信自己当年真这么想过。”
这其实是一个老问题。
几十年来,怎么衡量开发者的生产力,在软件行业里争议不断。十年前,Martin Fowler 甚至认为,开发者的生产力是无法真正被衡量的。

后来《Accelerate》问世,把软件交付拆成了几百个可测量的指标——部署频率、变更前置时间、平均恢复时间等等,行业总算有了一套相对成体系的参照系。
沈浪观察到,这套框架其实一直在变。十年里,从 DORA 到 GSM 到 SPACE 到 DevEx 到 DX Core 4,表面上是度量方法在进步,背后则是“开发者是什么”这个定义在变。DORA 时代,开发者是生产线上的工人,看产出速度;SPACE 时代,开发者是有情感、需协作的多维个体;到了 AI 时代,开发者变成了与 AI 协同的决策者。
如今 AI 来了之后,情况也变得更复杂了。写代码这件事也变得前所未有地快,组织自然想用新的尺子去量“AI 时代的生产力”。问题在于,这套尺子很快就走偏了——最典型的例子,就是代码行数这个早该被淘汰的指标,堂而皇之地杀了回来。
代码行数之所以重新流行,原因很简单:它最容易测量,结果也最显眼。你不需要复杂的遥测系统,也不需要成熟的指标框架,只要统计一下就行。然而,低投入的改动可能写出很多行代码,高投入的改动却可能只有寥寥几行——这个指标天然就不稳定。到了 AI 时代,问题只会更严重。同样一个程序,AI 生成的代码,本就倾向于写得更“膨胀”,行数更大。
但现实就是这么离谱,代码行数这个噪音极大的指标,正和 Meta 的 token 排行榜一样,成为衡量“谁更努力”的显性标尺。那么如果不看代码行数,不看 token 消耗量,那到底该看什么?
旧尺子量新世界:尺子没变,刻度变了
讽刺的是,DORA 和 SPACE 这类传统框架并没有被冲垮,反而在 AI 时代站得更稳了。
茹炳晟认为,软件研发的本质问题没有变。人月神话里那些关于复杂度、一致性、协作、沟通的属性,并没有因为大语言模型的出现而发生任何的改变,所以度量体系的底层逻辑也就不该变。
不过,他也指出,DORA 和 SPACE 的核心虽然有效,但标杆需要重新校正。其中,DORA 的四个指标——部署频率、变更前置时间、变更失败率、平均恢复时间——依然是稳定的核心选项。但基准变了。以前追求每日部署,现在 AI 让每小时部署都成为可能,原来的绝对值失去了意义。更合理的做法是:同一个团队,对比引入 AI 前后的变化——能不能在不牺牲稳定性和质量的前提下,把业务价值交付的节奏提上去。
SPACE 框架的维度——满意度、绩效、活动、沟通协作、效率——同样重要,但内涵发生了根本变化。以前衡量人,现在衡量人与 AI 的协同。满意度不再只看开发者对工具满不满意,更要看他是否信任 AI 的输出、是否对代码有掌控感;效率不再是“代码写得快不快”,而是认知负担有没有减轻;沟通协作从人与人的交互,扩展到人跟 AI 的交互、甚至 Agent 与 Agent 的交互。因此,可以引入一些新指标:比如完成一个任务需要与 AI 交互多少次,需求清晰与不清晰时分别调用 AI 多少次,生成内容被采纳与被驳回的比例。
代码行数不是完全没用,它可以作为过程指标,比如观察开发者的活跃度或 AI 使用频次。真正该看的,是 AI 代码采纳率、单位 token 产出,以及认知负担——高职级工程师原本并行 1.7 个项目,AI 帮忙后能升到 2.5 甚至 2.8。
快手也遵循了同样的逻辑。沈浪说,他们没有抛弃 DORA,而是在它之上加了一层 AI 维度:保留交付周期和变更失败率作为质量锚点,把人均产出从“代码行”换成“交付需求数”,新增 AI 代码率(逐行比对)、L2/L3 需求占比、研发 NPS。并且摒弃了最容易被刷也更危险的的 PR 数量和提交频率。
具体到代码行,正确的用法是衡量 AI 工具覆盖深度——AI 生成代码行占总代码行的比例。但用它衡量个人生产力就是错误用法。快手改用“人均有效代码行”:只算进入生产环境、通过质量门控的净增有效代码。这个数字从 134 行提升到 213 行每人天,涨幅 59%。
怎么给 Agent 算时薪,怎么给人算成本
前文提到的 Meta 排行榜,排名第一的人一个月烧掉 2810 亿 token,折合数百万美元。公司 30 天总消耗甚至突破了 60 万亿 token。另一个例子,Sigrid Jin,25 岁,去年 Anthropic 的榜一大哥,一年在 Claude Code 上烧掉 250 亿 token,约 17.5 万美元。
很多企业都是不设限的鼓励大家使用。方汉的原话是:“token 数大多数情况比人力便宜,如果考虑开发速度的提升,就更加正向了,限制开发者合理支出没有任何意义。”
方汉的观点代表了很多互联网公司的做法。而在对信息安全有严格要求的金融行业,神州信息则展现了另一种逻辑。
神州信息软件工艺创新部负责人提到,出于信息安全和监管合规要求,金融行业在应用 AI 时,普遍更倾向于私有化部署,而不是直接依赖公有云。通常的做法是自建 GPU 算力集群,并将大模型部署在本地,以支撑实际业务需求。在这样的前提下,GPU 算力虽然是 AI 应用中的一项主要成本,但放到企业整体技术投入中看,该项支出占比相对有限,"属于可接受的范围"。
也正因为如此,神州信息一直支持内部开发者使用 AI 工具。相比单纯控制资源消耗,他们更看重把 AI 真正用起来。神州信息软件工艺创新部负责人表示:“我们鼓励开发者积极探索 AI 能力的边界,用好了就是最有力的证明。”
但不管怎么用,token 烧掉的都是真金白银。大厂工程师薪酬很高,但他消耗的 token 成本,占薪酬的比例可能非常低。你甚至会觉得,跟他靠这些 token 多做出来的事情相比,这点钱几乎可以忽略。所以大厂可以“不计代价”。小公司则完全不一样。 员工薪酬绝对值没那么高,如果某个人的 token 消耗可能都快赶上他一半工资了,那么对公司来说,token 成本是真实刺痛的成本,不能忽略。
更根本的变化在于:过去算“人工小时”,现在算“token 成本”。今年 3 月阿里蔡崇信还表示,智能体本质上就是虚拟白领,是一种知识型员工。既是员工,就该算时薪——过去给人算时薪,现在也该给 Agent 算一算:它到底是不是一支高效、回报率高的劳动力?
沈浪提醒,Agent 模式不能跟 L1、L2 混用同一套指标。
L1 辅助形式,如 IDE 代码补全,效率单位是“人的产出”,消耗低、转化率高,基本上直接变成代码。L2 协同模式,如代码审查辅助和单测生成,中等消耗,转化率也不错,效率单位变成“团队的交付”。L3 自主模式,Agentic 任务执行消耗最高,但产出价值也最高,只是失败率也相应更高。随意问答探索价值最低,很难量化。
一个开发者几分钟内就可能消耗数千美元,在 Agentic 模式下尤其常见。企业如果没有预算管理机制,很容易出现“效率提升了,但成本也失控了”的局面。
另一方面,当生产力的最小单位从“人”变成了“人 + Agent 组合”,单评估“人”肯定不够,所以,目前快手探索的框架是把输入侧和输出侧分开来看。输入侧,人贡献的是需求定义、架构判断、质量审核的时间,Agent 消耗的是 Token、执行时间、工具调用次数。输出侧,看的是交付的需求数量、需求质量(一次通过率、线上 Bug 率)和交付周期。综合 ROI 就是输出价值除以人力成本加 Agent 成本。
另外在场景上,标准化、可验证的活——CRUD 代码、单测生成、写文档——ROI 高。模糊、要人拍脑袋的活——复杂业务逻辑、架构决策、安全审查——用 AI 可能省下来的时间还不够验证错没错,ROI 低。
最终价值是把 token 消耗和工程产出绑在一起。用掉多少 token,除以省下来的工程师工时,得到一个“token 效率比”。再折算成成本对比,看 ROI 是否为正。同时按场景和级别设预算,超了告警——不截断,但得让人心里有数。
写在最后
今年 2 月,谷歌将 AI 使用情况正式通过 GRAD 系统与员工绩效挂钩。同月,亚马逊被曝用内部系统 Clarity 追踪员工 AI 调用次数——AI 用得够不够,直接决定你能不能晋升。微软更早一步,将 AI 工具使用纳入全员绩效考核。国外三大厂殊途同归:AI 不再是可选项,而是考核的一部分。
国内也不遑多让。昆仑万维从普通开发到技术线 CTO,无一豁免,AI 编程能力直接纳入绩效考核,开发效率要提升至少 50%,并与末位淘汰绑定。
但我们也该明白,提效有天花板。复杂软件的地位,不会被动摇。那些动辄几百人维护的大型系统,靠的不是 Token 堆砌,是经验沉淀、是背责制度、是对稳定性的敬畏。
AI 省出来的人效,目的是承接更多项目、覆盖更多场景,而不是把做事的人变少。
未来,当 Token 计价器不断滚动、上下文成本不断雪球化,人类这种“看起来更慢”的大脑,会不会反而变成一种高端奢侈品?一个工程师可以花 5 个小时认真看复杂架构、深入思考问题,而不会像 AI 那样不断累积惊人的计算费用。在企业预算里,这种“慢速的人脑”,反而可能成为终极的固定成本资产。人的价值,恰恰藏在那些算不出 Token 的地方。





