【agent 测评】背景与挑战以及机遇
背景
从 24 年开始,LLM 从简单的文本对话向具备感知、规划、工具使用和自主行动能力的方向发展(关键词 React、Plan And Action),测试的核心痛点是模型的不确定性、技能的稳定性、行为的可控性。由于各种模型幻觉、rag 检索、工具使用、CoT 质量等等 span 的划分,传统的测试方法面临失效(注意 Tool、Mcp 的开发不在失效范围内)。在这种背景下应运而生一种全新职业,Agent 测评工程师。
测试崩塌
传统测试
在过去我们工作经验中,测试是质量保障,建立在确定性的基础上。无论是我们的单元测试、集成测试,都是输入 A 出 B 才适合功能正常,任何其他输出都是 Bug。但是 Ai Agent 的大脑 llm 天生就是概率性的系统。
这就导致传统测试以下问题:
- 非确定性的输出,不是输入 A(Prompt)就会出现 B,而是可能出现完全不同的推理路径,比如输入 hello,传统就是 hello xxx。但是 agent 可能推理用户什么输入 hello,他想干什么,从而输出 hello,或者 hello 我是 xxxx(自我介绍)
- 测试覆盖度,传统的软件空间是有限的,你可以使用脚本或者人力枚举所有的测试案例,但是面对 agent 输入的是自然语言,输入就是无穷的。
- 任务失败归因,当你的 agent 没有按照你的预期完成任务的时候,正常人是很难判定到底是模型能力不行、Rag 不行、Prompt 不行还是中间出现了异常情况 (网络、磁盘、工具等等)
信任问题
当 agent 出现一次离谱的操作的时候,你就会对其产生极度的不信任感,这种不信任感来自于对信息输入源、加工过程的黑盒问题,以及人类自身的能力边界,无法证伪但是我觉得不对。
简述
Agent 测评工作就是讲不确定性转变为可度量、可量化、可反馈的可靠性工程。
Agent 测试
测试集
代码
SWE-Bench 不容置疑,都用这个来跑 code agent 的能力,也是权威的测试基准之一。他不是建的算法题、一个功能实现,而是从 github 上的流行仓库中去收录 issue 和 pr。
测试方法通常包括:
issue(人类提出的问题)
pr(修复代码,金标答案)
test(fail to pass 测试用例)
测试过程:
注入 Prompt - llm - reasoning - plan - tool - llm 循环,过程中需要对每个节点继续观测,例如时间、轮数、决策、工具调用、Cot、结果。最后调用 test 用例测试修复效效果。
高阶一点的还要回归验证,如果太多还要通过 ast 找到代码修改后影响的功能,只对影响的进行回归。这里 pass@10 说一下,测试十次有一次通过就算通过,测试的是上限能力、探索能力、自我修正潜力,难度较低。
输出:
测试报告,dpo、sft 数据集(辅助 agent、模型成长)
通用
GAIA 测试的是 agent 的解决现实世界的能力,例如去淘宝买个低价 key。对于人来说很简单,但是对于 agent 来说需要复杂的工具使用、多模态理解和步骤规划。
测试方法:
Prompt(概念简单但步骤复杂,现实问题)
Mock (可以理解为一个测试淘宝站点,你不可能让 agent 真去买)
测试过程:
同代码雷同,但是这里会产生非结构化数据,比如录屏、截图(判断哪个步骤失败关键证据),最后以结果为导向,比如 mock 的数据库中数量 - 1(而不是 agent 说购买成功就行的)
输出:
同上
综合
AgentBench,涵盖 OS、DB、KG、卡牌游戏等不同的环境。
垂直
BFCL 专门测试模型函数调用的准确性,主要测试参数提取、格式对齐等能力。测试可以不真正调用,只要比对调用 json 与说明文档是否一致(不能多也不能少,还得对)
跑分
经过上面的说明,应该可以悟道为什么分高能低了吧。什么你不知道?
当指标成为目标
- 数据污染,由于上面说的测试集是公开集,那么模型训练数据甚至微调数据中可能就包含了测试题答案。那么这就是开卷考试了直接背答案而不是推理。那么遇见真是场景要推理的时候,完犊子了
- 针对性特训,为了刷榜写特定的 Prompt 或者启发式规则来迎合测试。
测试环境与现实的错误
- 基准测试都是在温室里面进行的,环境干净、网络稳定、权限全开,但是真实环境充满了,不稳定的 api、复杂的权限、屎山的各种奇怪约束

- 现实问题往往都是机械的多步的复杂的,误差会出现累积现象,每一个步骤都是 98% 成功,那么 50 个步骤呢?只有区区的 36%
评估的局限性
- 许多基准只看最终结果,例如我刚刚说的 swe-bench 你修好了一个 bug,引入了 10 个 bug,然后原来的功能凉了。还有例如,τ-bench 的评估脚本存在漏洞,导致一个 “什么都不做” 的 Agent 竟然能获得 38% 的通过率,仅仅因为测试脚本未能正确检测空操作。
- 缺乏过程监控,上面的测试集我都提到了,一个功能消耗 100k token 和 10 轮解决,与消耗 20k 和 15 轮解决你选哪个?还有为了解决 bug 把功能删了是不是修好了?
- 还有的甚至都不开发 mock,就像我上面说的,直接信任 agent 输出。
职责、框架、标准
这一篇不讲评测平台架构设计、模块开发、三高实现
初、中级
关键字:数据清洗、脚本、Case
执行评测任务,维护评测数据集,编写自动化测评脚本,对 bad case 继续标注归因分析。
高级、专家
构建平台体系,搭建评测框架,仿真环境搭建、过程数据采集(平台级别)、算法优化、红队测试(安全不要遗忘)
核心技能树
- Ai 与大模型原理(不掌握就找不到问题,只知道不行)
- 代码工程能力(python)
- 数据分析(统计学、归因)
- 评估框架与工具掌握(实现、原理、使用)
晋升
纵向
测试 - 测开 - 转型(+AI)- 工程师 - 架构师 / 专家
横向
Agent Ops/MLOps、Ai 安全专家
未来
- 人评到智评,会出现 Agent 判官作为专家辅助测评。可能测评工程师后面就是 "训练裁判",而不是亲自当裁判。
- 生成式社会模拟,把被测 agent 直接扔到一个 agent 社会里面,多智能体的高度延伸
- 安全与合规,目前从我的角度来看,都是裸奔没有什么安全可言。所以 Ai 安全专家也是安全转行的一个点(目前感觉都还在摸索 AI 安全的方向),Agent 跑不出软件的概念,传统安全可以涵盖但不是 AI 安全我认为。
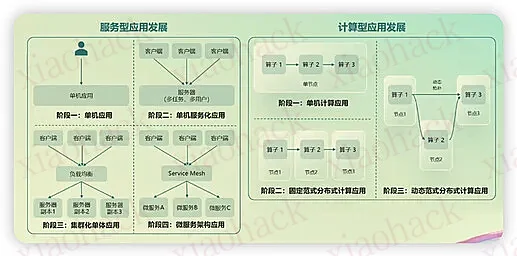
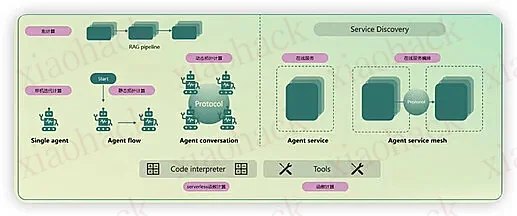
目前各个企业都还是热衷于搞自己的 agent,虽然社会上已经有这么多的 agent。Agent 不断的发展也会带来测评的改变,引用 2 张图:
结束
仅供扫盲,讲讲一些通俗易懂的点