请教各位,想回归技术,如何系统学习 Agent?
前全栈工程师,离开技术岗三四年。现在想重回技术,看了下目前很多 JD 招 Agent 工程师,想了解该如何学起
目前对 LLM 了解个大概,能用龙虾能写 skill 。能否像以前一样找专栏或 blog 啃文章系统来学习?搜了下主流社媒网站都是卖课的
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
前全栈工程师,离开技术岗三四年。现在想重回技术,看了下目前很多 JD 招 Agent 工程师,想了解该如何学起
目前对 LLM 了解个大概,能用龙虾能写 skill 。能否像以前一样找专栏或 blog 啃文章系统来学习?搜了下主流社媒网站都是卖课的
95 年的,马上 31 了
3月26日,Eclipse基金会生态系统发展副总裁Michael Plagge到访开放原子开源基金会,双方就开源生态发展、项目合作等议题进行了交流。开放原子开源基金会秘书长助理李博参加会议。
会上,Eclipse基金会介绍了其近期在全球开源生态中的发展情况,分享了Open VSX项目进展以及在汽车软件领域的生态布局。在项目协同方面,以开源鸿蒙和Oniro项目为代表的“姐妹项目”模式,通过在国内外分别设立项目、建立同步机制,实现了技术协同与生态联动,为跨国开源项目协作提供了有益探索。Plagge表示,该模式正受到越来越多国际开源组织及中国头部企业、机构的关注。
开放原子开源基金会介绍了开源鸿蒙、开源欧拉等项目的发展态势,以及开放原子开源生态大会、开发者大会等活动规划。李博表示,当前中国开源生态发展迅速,企业和开发者的开源意识不断提升,开源发展与国际合作得到广泛支持,为中外开源组织交流互鉴创造了良好环境。开放原子愿与Eclipse基金会保持密切沟通,探索更多务实合作方向。
双方就建立常态化沟通机制、加强活动交流等达成共识,并表示将保持密切沟通,共同推动中欧开源生态的协同发展。
比如这几行粘贴之后只会显示最后几行,不知道是为什么
然后 wsl 下粘贴则一切正常
难道是终端的问题吗?请问大家 Windows 环境下一般使用哪个终端去运行 Claude Code 的呢?
{
"code": 200,
"data": [
{
"clubId": 1,
"content": "xxx",
"endTime": "2026-04-19 00:00:00",
"id": 1251786757,
"name": "领养日",
"position": "xxx",
"startTime": "2026-04-18 00:00:00"
},
{
"clubId": 1,
"content": "线下摆点,欢迎来看看我校的猫猫周边,所得收益全部用于校内猫狗 TNR 绝育计划。",
"endTime": "2026-04-19 00:00:00",
"id": 1251786758,
"name": "线下摆点",
"position": "xx",
"startTime": "2026-04-17 00:00:00"
},
{
"clubId": 1,
"content": "我是一个示例,我是一个示例",
"endTime": "2026-04-26 00:00:00",
"id": 1251786760,
"name": "我是一个示例",
"position": "我是一个示例",
"startTime": "2026-04-24 00:00:00"
}
],
"message": "操作成功"
}
2025 年 12 月 13 日,VeloxCon China 2025 在北京成功举办。作为 Velox 项目首次在中国举办的线下技术大会,汇聚了来自Meta、IBM、蚂蚁集团、阿里云、腾讯、小米、小红书等企业的数十位核心贡献者与一线工程师。 大会通过 18 场演讲将 Velox 置于真实业务场景之中,系统展示了其在架构演进、AI 数据处理、湖仓加速、流批融合等方向的最新实践。这些分享不仅直面性能、稳定性与兼容性等落地挑战,也反应了开发者社区对构建可靠、可扩展、可协同的数据基础设施的共同探索,彰显了中国开发者在全球高性能分析生态中的工程深度与协作广度。 夯实底座,突破能力边界 在明确了社区与架构演进的总体方向后,大会议题迅速深入到如何利用 Velox 构建高性能计算引擎的具体实践中。阿里云 EMR Serverless Spark 技术负责人周克勇系统阐述了“可组合性”在数据计算领域的实践。他详细解析了阿里云如何深度集成并贡献于 Apache Celeborn、Paimon、Velox 及 Gluten 等开源组件,通过模块化组装构建出高性能湖仓一体引擎。他指出,基于该架构,阿里云 EMR Serverless Spark 成功创造了 TPC-DS 100TB 规模性能测试的世界新纪录,实现性能翻倍与性价比大幅提升。 接着,Meta 软件工程师 Masha Basmanova 阐述了现有查询引擎在跨语言通信、优化器能力与开发体验上面临的挑战,并介绍了基于 C++ 的统一前端框架 Axiom。该框架将 SQL 解析、逻辑优化与物理执行融为一体,通过内置的强大优化器与 Velox 运行时无缝对接,能够实现更高效、可扩展的查询处理。演讲最后,她积极展示了 Axiom 的开源路线图,并欢迎全球开发者加入,共同推动该项目的演进。 强大的执行框架,最终需要服务于极具挑战性的数据场景,特别是爆发式增长的 AI 数据。Meta 软件工程师孟晓烜则在之后的演讲中,深入阐述了应对AI训练数据规模激增与成本挑战的解决方案。他重点介绍了 Meta 如何通过数据归一化技术剥离重复特征,并构建可索引的序列存储系统。依托 Velox 技术栈,团队在训练数据的加载、生成与探索三大环节实现了端到端优化,显著提升了处理效率与资源利用率。 在 Meta 多位工程师从框架演进、可组合架构、数据标准化等角度深入分享后,蚂蚁集团高级技术专家黄叶伟也从企业落地实践层面分享了基于 Velox 的 Spark 加速实践。他重点介绍了基于 Gluten 与 Velox 构建的向量化引擎如何通过任务级 Fallback、Spill 优化、Shuffle 优化等关键技术,在混合部署场景下显著提升 Spark 性能与稳定性。他表示,该方案目前已实现日均数十万任务覆盖,平均节省资源超30%,并将在算子优化与架构扩展方面持续演进。 作为连接 Spark 生态与原生加速的关键中间层,Apache Gluten 的进展同样备受关注。来自 IBM 的莫芮与周渊聚焦 Apache Gluten与 Velox 的深度集成,阐述了其如何在大数据分析中驱动创新。他们介绍,Gluten 在保持对 Spark/Flink 作业透明加速能力的同时,正逐步增强对多后端引擎和复杂业务场景的适配能力。目前,该方案已在 Pinterest、顺丰科技及多个内部集群完成规模化验证,有效支撑了从日志分析到物流调度等多样化负载的性能提升与成本优化。 随着向量化加速在通用场景日趋成熟,针对特定存储格式的深度优化成为新的效能突破口。腾讯大数据开发工程师陈锦海分享了微信基于 Velox 加速 lceberg 湖仓分析的优化与实践,重点介绍了原生分桶方案。据他介绍,该方案通过动态识别表元信息自动设置分区数,能有效缓解 AQE 引发的写入倾斜,结合空闲资源灰度发布策略,可保障大规模作业的稳定上线。 扎根场景,释放协同效能 面对海量数据挑战,全球科技公司也在探索相似的演进路径。Meta 软件工程经理 Stanley Yao 在演讲中分享了公司基于 Velox 推进 Spark 向量化改造的整体策略。他表示,团队通过从定制化方案到开源架构的持续演进,已实现关键业务管线向 Gluten(Flare)的平稳迁移,并获得显著的效率提升。未来,Meta 计划进一步扩大该架构的应用规模。 在 CPU 向量化趋于普及的同时,利用异构硬件挖掘更高性能成为新的前沿。IBM 研究院资深软件工程师 Zoltán Arnold Nagy 展示了基于 Velox 与 Presto 的 GPU 加速数据处理方案。他介绍道,Velox 通过与 cuDF 集成,可在 GPU 上高效执行算⼦,并针对多 GPU 分布式场景优化通信与数据交换。此外,为突破 I/O 瓶颈,团队正在探索结合 GPUDirect 存储与缓存层的加速策略。 对性能与稳定性的追求,也驱动着查询引擎架构本身的融合与创新。Meta 软件工程师谭家梁与大家分享了 Native Presto-on-Spark 的规模化应用。该架构以 Presto 查询优化、Spark 资源调度与容错机制以及 Velox 原生向量化执行为核心,实现了性能与可靠性的显著提升。他表示,目前该方案已在生产环境中取得成效,并将在未来持续推进全栈原生化演进。 对于国内庞大的云上业务,Velox 同样在支撑着关键数据服务平台。 阿里云高级工程师王彬与范阿冬系统介绍了Velox在阿里云日志服务中的深度集成与应用。他们指出,基于 Velox 构建的高性能查询引擎,通过混合执行、表达式下推、自动增量物化视图及免 Schema 分析等核心技术,可显著提升平台在处理海量实时数据时的查询效率与资源利用率。他们还强调,该架构不仅为日志分析、智能运维等场景提供了稳定支撑,也为面向 AI 的云原生数据平台演进奠定了坚实基础。 除了通用的日志与湖仓分析,Velox 也在向更垂直的时序数据场景渗透。腾讯高级工程师李兆龙分享了基于 Velox 构建云原生时序数据库的落地经验。他表示,通过在 Velox 中实现时序数据去重优化与存储写入增强,系统在应对高频写入与实时查询场景时,可显著提升吞吐效率与响应性能。目前该方案已有效支持物联网、实时监控等业务场景,未来还将进一步完善缓存与压缩机制,持续优化时序数据处理的整体效能。 IBM 软件工程师刘平接着分享了 Velox 在 Iceberg 数据写入能力上的突破性进展。他表示,目前 Velox 对 Iceberg 的支持以读取为主,其写入功能的完善将填补该方向的关键能力空白,为基于 Presto 与 Spark 的数据湖架构提供更统一、高效的数据摄入层。这一进展也标志着 Velox 正从查询加速向数据全链路处理拓展。 接着,来自阿里云的毕岩与周滔分享了 Velox 与 Apache Paimon 深度集成的解决方案,为提升引擎与存储的协同效率提供了另一种集成思路。在他们看来,现有方案存在表类型支持受限、缺乏可移植性等瓶颈, 但可以建立 C++ 原生 Paimon 库,通过其统一的数据协议与插件化设计,使 Paimon 能够被 Velox、StarRocks 等多种计算引擎直接高效调用,从而提升数据读写性能,并为湖仓格式的跨引擎协同提供新的基础支撑。 在批处理场景之外,流计算框架的向量化也正成为新的热点。蚂蚁集团技术专家刘勇介绍了基于 Velox 为 Flink 构建的统一向量化执行引擎 Flex。他表示,Flink 作为流批一体架构的核心,其原生向量化能力的补足至关重要。Flex 通过将 Velox 的高性能算子能力引入 Flink,同时结合自动化验证、可视化计划与精细化回退机制,现已实现了作业性能的显著提升,并支撑多条核心业务链路平稳运行。 随着 Velox 赋能的应用场景日益广泛和复杂,确保其在不同引擎和版本间的整体质量与可靠性变得至关重要。Meta 软件工程师 Eric Liu 阐述了在 AI 数据基础架构下,保障 Velox 多引擎版本可靠性的系统化方法。他指出,面对不同引擎与存储格式交织带来的复杂性,关键在于建立跨引擎测试框架与合成数据工厂。这一实践能有效提前发现全栈潜在问题,从而确保底层变更在大规模生产环境中的稳定与高效。 针对向量化引擎中窗口运算符内存溢出的典型难题,来自英特尔的贾柯分享了她的见解。她认为,通过为 Velox 引入流式窗口处理机制,可使计算随数据到达逐步执行并即时释放内存,从而从架构层面化解多数场景下的内存风险,显著提升复杂查询的稳定性。 最后,小红书 Native Engine 团队技术负责人魏秀利也分享了向量化引擎在公司业务中规模化落地的经验。据他介绍,通过将写入异步化并构建原生 Avro 读取能力,小红书在不增加业务复杂度的前提下,成功缓解了端到端延迟,印证了“执行与存储协同优化”在湖仓场景中的关键价值。 从底层执行引擎的持续创新,到日志分析、湖仓写入、流批融合等复杂场景的稳定运行,在本届 VeloxCon China 上,我们看到 Velox 的技术价值已在真实业务中不断被验证和拓展。同时我们也很高兴看到中国开发者成为这一进程的重要推动者。期待未来有更多志同道合者加入 Velox 开源社区,共建高性能分析基础设施。weibo.com/ttarticle/p/show?id=2309405288632583061579 weibo.com/ttarticle/p/show?id=2309405288632960548872 weibo.com/ttarticle/p/show?id=2309405288633334104143 weibo.com/ttarticle/p/show?id=2309405288633816187157 weibo.com/ttarticle/p/show?id=2309405288634198130792 weibo.com/ttarticle/p/show?id=2309405288634579812521 weibo.com/ttarticle/p/show?id=2309405288634974076937 weibo.com/ttarticle/p/show?id=2309405288635355758612 weibo.com/ttarticle/p/show?id=2309405288635850424385 个
会议伊始,Velox 项目联合发起人 Pedro 发表开幕致辞。他回顾了 Velox 开源项目的发展历程,从项目启动、开源发布到建立技术治理结构,展示了 Axiom 架构、GPU 支持、PyVelox 等关键进展,强调了社区协作与工程严谨性是项目持续演进的核心动力。他特别提到,Velox 已建立了正式的技术治理机制,并迎来来自 IBM、Intel、NVIDIA、Microsoft 等多家企业的新增维护者,标志着项目正迈向更加开放和可持续的阶段。
午餐后的议程更加聚焦 Velox 在真实业务中的集成深度与生产韧性,回应了开发者们对兼容性、稳定性与端到端效能等规模化落地的核心关切。
小米计算平台计算引擎负责人王胜杰分享了公司在 Spark 向量化升级中的规模化落地经验。面对业务迁移中的兼容性与稳定性挑战,他表示,小米通过自动兼容校验、双跑结果比对及内存异常感知的三级资源升级机制,已成功推动向量化改造在数十万作业中平稳落地。
@ 九边 Pro: 这两天 “崩老头” 的视频大家看了吧,说的就是一些拼多多版的捞女,给一些中年人发暧昧信息,然后每次也不多要,要个一二十块,积少成多。主打一个便宜、量大、走下沉市场。
这个事已经存在了很多年了,这两年估计是太多了,慢慢被拿出来放到阳光下了。其实那些男的都知道精神小妹们就是逢场作戏,但太过性压抑了,毕竟整个人生当中从没有异性认真对待过自己,没被提供过任何情绪价值,于是也就无所谓了,花小钱养着一个精神小妹给自己提供点平多多情绪价值。
很多精神小妹不上班,每天就是混,她们的钱就是这么来的。
@ 拾人牙慧: 我培训的时候,教授说过一句话:当今社会快乐是一种生产力!
@ 用魔法打败魔法试试: 四五十岁中年妇女,通过广场舞,小公园等吊着那些六十到八十的男性(城市拆迁户,高退休金人群)。这个赛道也很热闹。
@ 星驰骋: 确实,绝大多数普通男人,年轻的时候无钱无势无背景,才能平平运气平平,优质美妙的性资源从未曾青睐于他们,也就是九边老师所说的 “人生当中从未被异性认真对待过”。待手里有一点点闲钱了,或多或少是要弥补这个缺憾了。
@ 调料架子鼓: 前一段时间一连忙了好几天,那天晚上九点多的时候已经非常疲惫了。突然手机显示了一条提醒,天晚了该回家了。突然,眼睛就湿了。崩老头这事儿必定能行。
@ 小勋奇: 这一行是这样的,精神小妹的日常就是崩老头,然后用崩老头的钱养精神小伙,精神小伙的日常就是泡吧,泡妹,相互转换
@ 语文不太好: 支持内经济周转,年轻人喜欢吃喝玩乐,钱留在那些老头身上会长毛的
@ 森罗万象: 现在都是花钱买情绪价值,所以能提供情绪价值也是一种能力,所以越来越魔幻了
@IDEC: 为什么 KTV 一波接着一波:就是因为毕竟整个人生当中从没有异性认真对待过自己,没被提供过任何情绪价值,于是也就无所谓了,花小钱养着一个精神小妹给自己提供点平多多情绪价值。
@ 云下江南: “下沉版情感杀猪盘”!本质上是用极低成本的情绪价值,收割极度缺爱的中年男性群体。
@ 磐石健身爱财经: 这钱不比打赏直播强多了么,情绪价值和实际陪伴拉的满满的
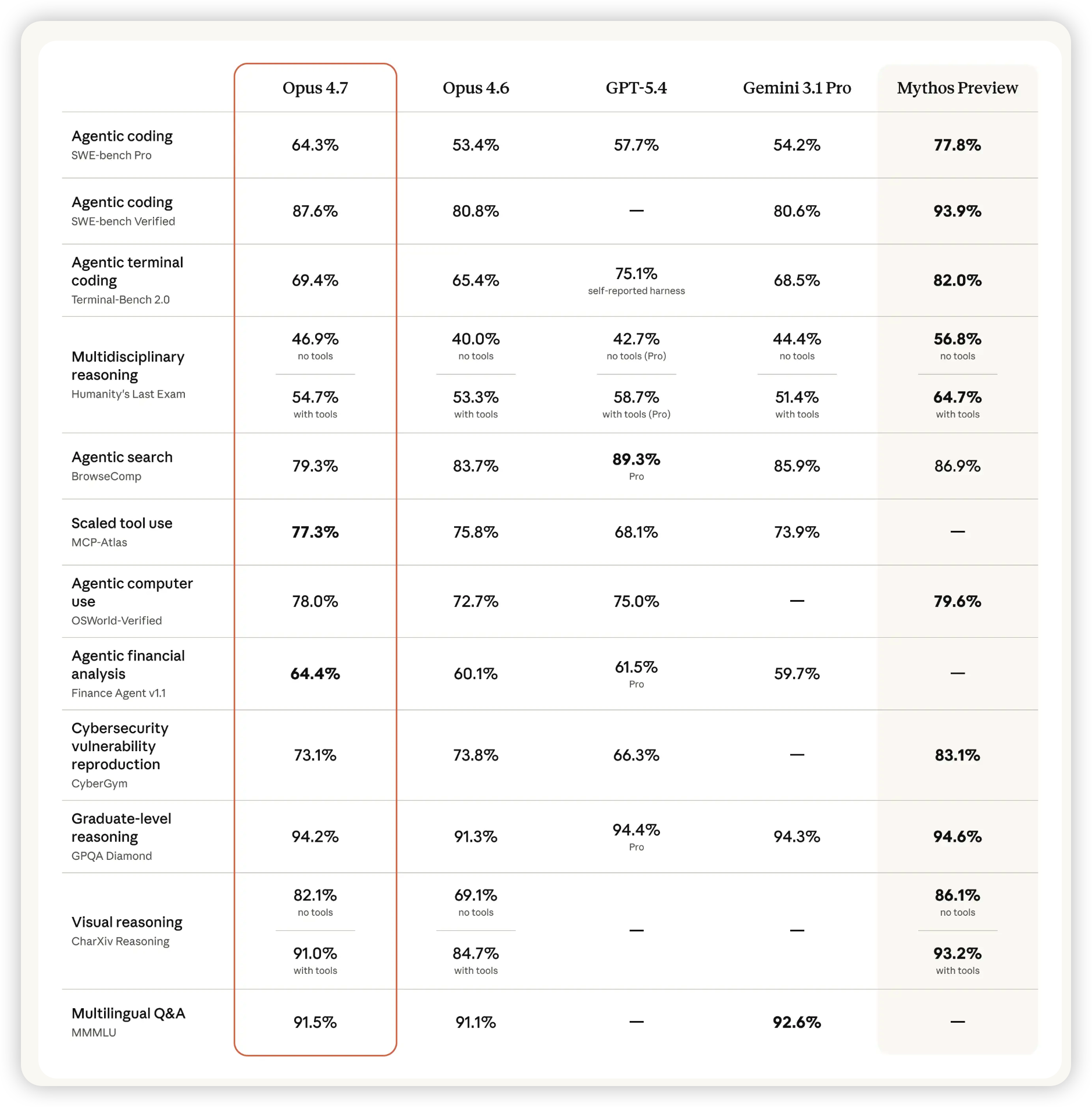
OpenAI 今天带来了多项重磅更新:Codex 现在能直接控制 macOS 应用,支持超过 90 款插件,还能在工作流中生成和编辑图片,任务执行也更加智能。同时,OpenAI 还推出了专为生命科学领域设计的 GPT-Rosalind 模型。另一边,Anthropic 也发布了更强大的 Claude Opus 4.7,处理复杂任务和遵循指令的能力都有显著提升。此外,Anthropic 共同撰写的一项关于 LLM 潜在偏差的学术研究也登上了《自然》杂志。
OpenAI 发布了全新的 GPT-Rosalind 系列模型,专为生命科学领域优化。它在蛋白质和化学推理、基因组分析、生物化学知识以及科学工具使用方面表现更强。
为什么重要: 这个模型旨在加速生物学研究、药物发现和转化医学的进程,有望将目前平均 10-15 年的新药研发周期大幅缩短。
OpenAI 对 Codex 进行了多项重大更新,它现在能通过“看、点、打字”的方式直接在 macOS 上操作任何应用,在后台运行而无需占用桌面。此外,Codex 新增了对 90 多款插件的支持,可以更好地获取上下文并跨工具执行操作。它还能在同一线程中运行自动化任务,保持上下文,并自动调度和继续长期工作。
为什么重要: 这意味着 Codex 不再局限于 API 交互,能够更深入地融入用户的桌面工作流,处理前端开发、应用测试等复杂任务,极大提升了开发者的生产力。
现在,用户可以在 Codex 中直接利用 gpt-image-1.5 生成和迭代图像,用于创建前端设计、模型图或游戏素材,无需离开当前工作流。此功能已包含在 ChatGPT 账户中,无需额外的 API Key。
为什么重要: 这将图像创作无缝融入开发流程,让开发者能更高效地进行视觉资产的迭代和管理。
Anthropic 介绍了最新、能力最强的 Claude Opus 4.7 模型。它在处理长时间任务时更加严谨,能更精确地遵循指令,并在报告结果前自行验证输出。
为什么重要: 用户可以将更困难、更复杂的任务放心地交给它,减少人工监督,提升工作效率和结果的可靠性。
OpenAI 详细说明了其 ChatGPT Pro $100 和 $200 套餐的实际用量,并指出由于定价页面表述不清造成了用户困惑。目前 $100 Pro 套餐提供至少 10 倍于 Plus 的用量,而 $200 Pro 套餐提供至少 20 倍于 Plus 的用量,这些优惠均持续到 5 月 31 日。
为什么重要: 透明化用量说明有助于用户更清晰地了解其订阅价值,避免误解。
重要性分析: Vas Narasimhan 的加入,预计将为 Anthropic 在医疗健康、生物制药等关键领域的 AI 应用带来宝贵的行业洞察和战略指导,特别是考虑到 AI 在药物研发等领域的巨大潜力。
2025 年 12 月 13 日,VeloxCon China 2025 在北京成功举办。作为 Velox 项目首次在中国举办的线下技术大会,汇聚了来自Meta、IBM、蚂蚁集团、阿里云、腾讯、小米、小红书等企业的数十位核心贡献者与一线工程师。 大会通过 18 场演讲将 Velox 置于真实业务场景之中,系统展示了其在架构演进、AI 数据处理、湖仓加速、流批融合等方向的最新实践。这些分享不仅直面性能、稳定性与兼容性等落地挑战,也反应了开发者社区对构建可靠、可扩展、可协同的数据基础设施的共同探索,彰显了中国开发者在全球高性能分析生态中的工程深度与协作广度。 夯实底座,突破能力边界 在明确了社区与架构演进的总体方向后,大会议题迅速深入到如何利用 Velox 构建高性能计算引擎的具体实践中。阿里云 EMR Serverless Spark 技术负责人周克勇系统阐述了“可组合性”在数据计算领域的实践。他详细解析了阿里云如何深度集成并贡献于 Apache Celeborn、Paimon、Velox 及 Gluten 等开源组件,通过模块化组装构建出高性能湖仓一体引擎。他指出,基于该架构,阿里云 EMR Serverless Spark 成功创造了 TPC-DS 100TB 规模性能测试的世界新纪录,实现性能翻倍与性价比大幅提升。 接着,Meta 软件工程师 Masha Basmanova 阐述了现有查询引擎在跨语言通信、优化器能力与开发体验上面临的挑战,并介绍了基于 C++ 的统一前端框架 Axiom。该框架将 SQL 解析、逻辑优化与物理执行融为一体,通过内置的强大优化器与 Velox 运行时无缝对接,能够实现更高效、可扩展的查询处理。演讲最后,她积极展示了 Axiom 的开源路线图,并欢迎全球开发者加入,共同推动该项目的演进。 强大的执行框架,最终需要服务于极具挑战性的数据场景,特别是爆发式增长的 AI 数据。Meta 软件工程师孟晓烜则在之后的演讲中,深入阐述了应对AI训练数据规模激增与成本挑战的解决方案。他重点介绍了 Meta 如何通过数据归一化技术剥离重复特征,并构建可索引的序列存储系统。依托 Velox 技术栈,团队在训练数据的加载、生成与探索三大环节实现了端到端优化,显著提升了处理效率与资源利用率。 在 Meta 多位工程师从框架演进、可组合架构、数据标准化等角度深入分享后,蚂蚁集团高级技术专家黄叶伟也从企业落地实践层面分享了基于 Velox 的 Spark 加速实践。他重点介绍了基于 Gluten 与 Velox 构建的向量化引擎如何通过任务级 Fallback、Spill 优化、Shuffle 优化等关键技术,在混合部署场景下显著提升 Spark 性能与稳定性。他表示,该方案目前已实现日均数十万任务覆盖,平均节省资源超30%,并将在算子优化与架构扩展方面持续演进。 作为连接 Spark 生态与原生加速的关键中间层,Apache Gluten 的进展同样备受关注。来自 IBM 的莫芮与周渊聚焦 Apache Gluten与 Velox 的深度集成,阐述了其如何在大数据分析中驱动创新。他们介绍,Gluten 在保持对 Spark/Flink 作业透明加速能力的同时,正逐步增强对多后端引擎和复杂业务场景的适配能力。目前,该方案已在 Pinterest、顺丰科技及多个内部集群完成规模化验证,有效支撑了从日志分析到物流调度等多样化负载的性能提升与成本优化。 随着向量化加速在通用场景日趋成熟,针对特定存储格式的深度优化成为新的效能突破口。腾讯大数据开发工程师陈锦海分享了微信基于 Velox 加速 lceberg 湖仓分析的优化与实践,重点介绍了原生分桶方案。据他介绍,该方案通过动态识别表元信息自动设置分区数,能有效缓解 AQE 引发的写入倾斜,结合空闲资源灰度发布策略,可保障大规模作业的稳定上线。 扎根场景,释放协同效能 面对海量数据挑战,全球科技公司也在探索相似的演进路径。Meta 软件工程经理 Stanley Yao 在演讲中分享了公司基于 Velox 推进 Spark 向量化改造的整体策略。他表示,团队通过从定制化方案到开源架构的持续演进,已实现关键业务管线向 Gluten(Flare)的平稳迁移,并获得显著的效率提升。未来,Meta 计划进一步扩大该架构的应用规模。 在 CPU 向量化趋于普及的同时,利用异构硬件挖掘更高性能成为新的前沿。IBM 研究院资深软件工程师 Zoltán Arnold Nagy 展示了基于 Velox 与 Presto 的 GPU 加速数据处理方案。他介绍道,Velox 通过与 cuDF 集成,可在 GPU 上高效执行算⼦,并针对多 GPU 分布式场景优化通信与数据交换。此外,为突破 I/O 瓶颈,团队正在探索结合 GPUDirect 存储与缓存层的加速策略。 对性能与稳定性的追求,也驱动着查询引擎架构本身的融合与创新。Meta 软件工程师谭家梁与大家分享了 Native Presto-on-Spark 的规模化应用。该架构以 Presto 查询优化、Spark 资源调度与容错机制以及 Velox 原生向量化执行为核心,实现了性能与可靠性的显著提升。他表示,目前该方案已在生产环境中取得成效,并将在未来持续推进全栈原生化演进。 对于国内庞大的云上业务,Velox 同样在支撑着关键数据服务平台。 阿里云高级工程师王彬与范阿冬系统介绍了Velox在阿里云日志服务中的深度集成与应用。他们指出,基于 Velox 构建的高性能查询引擎,通过混合执行、表达式下推、自动增量物化视图及免 Schema 分析等核心技术,可显著提升平台在处理海量实时数据时的查询效率与资源利用率。他们还强调,该架构不仅为日志分析、智能运维等场景提供了稳定支撑,也为面向 AI 的云原生数据平台演进奠定了坚实基础。 除了通用的日志与湖仓分析,Velox 也在向更垂直的时序数据场景渗透。腾讯高级工程师李兆龙分享了基于 Velox 构建云原生时序数据库的落地经验。他表示,通过在 Velox 中实现时序数据去重优化与存储写入增强,系统在应对高频写入与实时查询场景时,可显著提升吞吐效率与响应性能。目前该方案已有效支持物联网、实时监控等业务场景,未来还将进一步完善缓存与压缩机制,持续优化时序数据处理的整体效能。 IBM 软件工程师刘平接着分享了 Velox 在 Iceberg 数据写入能力上的突破性进展。他表示,目前 Velox 对 Iceberg 的支持以读取为主,其写入功能的完善将填补该方向的关键能力空白,为基于 Presto 与 Spark 的数据湖架构提供更统一、高效的数据摄入层。这一进展也标志着 Velox 正从查询加速向数据全链路处理拓展。 接着,来自阿里云的毕岩与周滔分享了 Velox 与 Apache Paimon 深度集成的解决方案,为提升引擎与存储的协同效率提供了另一种集成思路。在他们看来,现有方案存在表类型支持受限、缺乏可移植性等瓶颈, 但可以建立 C++ 原生 Paimon 库,通过其统一的数据协议与插件化设计,使 Paimon 能够被 Velox、StarRocks 等多种计算引擎直接高效调用,从而提升数据读写性能,并为湖仓格式的跨引擎协同提供新的基础支撑。 在批处理场景之外,流计算框架的向量化也正成为新的热点。蚂蚁集团技术专家刘勇介绍了基于 Velox 为 Flink 构建的统一向量化执行引擎 Flex。他表示,Flink 作为流批一体架构的核心,其原生向量化能力的补足至关重要。Flex 通过将 Velox 的高性能算子能力引入 Flink,同时结合自动化验证、可视化计划与精细化回退机制,现已实现了作业性能的显著提升,并支撑多条核心业务链路平稳运行。 随着 Velox 赋能的应用场景日益广泛和复杂,确保其在不同引擎和版本间的整体质量与可靠性变得至关重要。Meta 软件工程师 Eric Liu 阐述了在 AI 数据基础架构下,保障 Velox 多引擎版本可靠性的系统化方法。他指出,面对不同引擎与存储格式交织带来的复杂性,关键在于建立跨引擎测试框架与合成数据工厂。这一实践能有效提前发现全栈潜在问题,从而确保底层变更在大规模生产环境中的稳定与高效。 针对向量化引擎中窗口运算符内存溢出的典型难题,来自英特尔的贾柯分享了她的见解。她认为,通过为 Velox 引入流式窗口处理机制,可使计算随数据到达逐步执行并即时释放内存,从而从架构层面化解多数场景下的内存风险,显著提升复杂查询的稳定性。 最后,小红书 Native Engine 团队技术负责人魏秀利也分享了向量化引擎在公司业务中规模化落地的经验。据他介绍,通过将写入异步化并构建原生 Avro 读取能力,小红书在不增加业务复杂度的前提下,成功缓解了端到端延迟,印证了“执行与存储协同优化”在湖仓场景中的关键价值。 从底层执行引擎的持续创新,到日志分析、湖仓写入、流批融合等复杂场景的稳定运行,在本届 VeloxCon China 上,我们看到 Velox 的技术价值已在真实业务中不断被验证和拓展。同时我们也很高兴看到中国开发者成为这一进程的重要推动者。期待未来有更多志同道合者加入 Velox 开源社区,共建高性能分析基础设施。个weibo.com/ttarticle/p/show?id=2309405288628946600037 weibo.com/ttarticle/p/show?id=2309405288629319893010 weibo.com/ttarticle/p/show?id=2309405288629831598215 weibo.com/ttarticle/p/show?id=2309405288630209085541 weibo.com/ttarticle/p/show?id=2309405288630578184323 weibo.com/ttarticle/p/show?id=2309405288630951739522 weibo.com/ttarticle/p/show?id=2309405288631325032675 weibo.com/ttarticle/p/show?id=2309405288631815503912 weibo.com/ttarticle/p/show?id=2309405288632189059115
会议伊始,Velox 项目联合发起人 Pedro 发表开幕致辞。他回顾了 Velox 开源项目的发展历程,从项目启动、开源发布到建立技术治理结构,展示了 Axiom 架构、GPU 支持、PyVelox 等关键进展,强调了社区协作与工程严谨性是项目持续演进的核心动力。他特别提到,Velox 已建立了正式的技术治理机制,并迎来来自 IBM、Intel、NVIDIA、Microsoft 等多家企业的新增维护者,标志着项目正迈向更加开放和可持续的阶段。
午餐后的议程更加聚焦 Velox 在真实业务中的集成深度与生产韧性,回应了开发者们对兼容性、稳定性与端到端效能等规模化落地的核心关切。
小米计算平台计算引擎负责人王胜杰分享了公司在 Spark 向量化升级中的规模化落地经验。面对业务迁移中的兼容性与稳定性挑战,他表示,小米通过自动兼容校验、双跑结果比对及内存异常感知的三级资源升级机制,已成功推动向量化改造在数十万作业中平稳落地。
4 月 21 - 22 日,GenAICon 2026丨2026 中国生成式 AI 大会(北京站)将在北京富力万丽酒店正式举行。中国生成式 AI 大会已成功举办四届,现已成为国内人工智能领域最具影响力的产业峰会之一。 本次大会由智一科技旗下智东西联合智猩猩发起主办,为期两天,由开幕式 + 专题论坛 + 研讨会 + 交流晚宴 + 展览区组成,将以“奔赴 AGI 重塑未来”为主题,邀请 70+ 位重量级嘉宾与会带来致辞、报告、演讲和对话。 本次大会,阿里云高级技术专家沈林受邀出席,将在 4 月 22 日下午主会场的「AI 智能体专题论坛」带来演讲,主题为《Agent 开发范式演进:从环境工程出发,“简化”多源实时上下文》。 Part 1 嘉宾介绍 沈林,Apache RocketMQ PMC,阿里云高级技术专家、阿里云 EventBridge 和 EventHouse 负责人,深耕于消息中间件、事件驱动、Agent 上下文生态集成领域。目前,致力于赋能 Agent 开发者,让 AI 深入各行各业,真正实现 AI 普惠和平权。 Part 2 演讲主题 《Agent 开发范式演进:从环境工程出发,“简化”多源实时上下文》 Part 3 演讲概要 “简单”和“可靠”是 AI 普惠的关键。然而,企业数据碎片化、Schema 多变、Context-Rot、语义冲突等难题,正成为 Agent 迈向生产级的“深水区”。 本次分享从环境工程出发,“简化”多源实时上下文:打破传统知识库不断“辛勤”打补丁的方式,通过内置的一键集成、状态机、闭环反馈,将原本散乱在各处的数据,“快速”变成真正有效的知识,提升 Agent 的感知能力。以统一的、一键集成的、Serverless 的上下文服务,助力开发者轻松搭建生产级的 Agent。
2025 年 12 月 13 日,VeloxCon China 2025 在北京成功举办。作为 Velox 项目首次在中国举办的线下技术大会,汇聚了来自Meta、IBM、蚂蚁集团、阿里云、腾讯、小米、小红书等企业的数十位核心贡献者与一线工程师。 大会通过 18 场演讲将 Velox 置于真实业务场景之中,系统展示了其在架构演进、AI 数据处理、湖仓加速、流批融合等方向的最新实践。这些分享不仅直面性能、稳定性与兼容性等落地挑战,也反应了开发者社区对构建可靠、可扩展、可协同的数据基础设施的共同探索,彰显了中国开发者在全球高性能分析生态中的工程深度与协作广度。 夯实底座,突破能力边界 在明确了社区与架构演进的总体方向后,大会议题迅速深入到如何利用 Velox 构建高性能计算引擎的具体实践中。阿里云 EMR Serverless Spark 技术负责人周克勇系统阐述了“可组合性”在数据计算领域的实践。他详细解析了阿里云如何深度集成并贡献于 Apache Celeborn、Paimon、Velox 及 Gluten 等开源组件,通过模块化组装构建出高性能湖仓一体引擎。他指出,基于该架构,阿里云 EMR Serverless Spark 成功创造了 TPC-DS 100TB 规模性能测试的世界新纪录,实现性能翻倍与性价比大幅提升。 接着,Meta 软件工程师 Masha Basmanova 阐述了现有查询引擎在跨语言通信、优化器能力与开发体验上面临的挑战,并介绍了基于 C++ 的统一前端框架 Axiom。该框架将 SQL 解析、逻辑优化与物理执行融为一体,通过内置的强大优化器与 Velox 运行时无缝对接,能够实现更高效、可扩展的查询处理。演讲最后,她积极展示了 Axiom 的开源路线图,并欢迎全球开发者加入,共同推动该项目的演进。 强大的执行框架,最终需要服务于极具挑战性的数据场景,特别是爆发式增长的 AI 数据。Meta 软件工程师孟晓烜则在之后的演讲中,深入阐述了应对AI训练数据规模激增与成本挑战的解决方案。他重点介绍了 Meta 如何通过数据归一化技术剥离重复特征,并构建可索引的序列存储系统。依托 Velox 技术栈,团队在训练数据的加载、生成与探索三大环节实现了端到端优化,显著提升了处理效率与资源利用率。 在 Meta 多位工程师从框架演进、可组合架构、数据标准化等角度深入分享后,蚂蚁集团高级技术专家黄叶伟也从企业落地实践层面分享了基于 Velox 的 Spark 加速实践。他重点介绍了基于 Gluten 与 Velox 构建的向量化引擎如何通过任务级 Fallback、Spill 优化、Shuffle 优化等关键技术,在混合部署场景下显著提升 Spark 性能与稳定性。他表示,该方案目前已实现日均数十万任务覆盖,平均节省资源超30%,并将在算子优化与架构扩展方面持续演进。 作为连接 Spark 生态与原生加速的关键中间层,Apache Gluten 的进展同样备受关注。来自 IBM 的莫芮与周渊聚焦 Apache Gluten与 Velox 的深度集成,阐述了其如何在大数据分析中驱动创新。他们介绍,Gluten 在保持对 Spark/Flink 作业透明加速能力的同时,正逐步增强对多后端引擎和复杂业务场景的适配能力。目前,该方案已在 Pinterest、顺丰科技及多个内部集群完成规模化验证,有效支撑了从日志分析到物流调度等多样化负载的性能提升与成本优化。 随着向量化加速在通用场景日趋成熟,针对特定存储格式的深度优化成为新的效能突破口。腾讯大数据开发工程师陈锦海分享了微信基于 Velox 加速 lceberg 湖仓分析的优化与实践,重点介绍了原生分桶方案。据他介绍,该方案通过动态识别表元信息自动设置分区数,能有效缓解 AQE 引发的写入倾斜,结合空闲资源灰度发布策略,可保障大规模作业的稳定上线。 扎根场景,释放协同效能 面对海量数据挑战,全球科技公司也在探索相似的演进路径。Meta 软件工程经理 Stanley Yao 在演讲中分享了公司基于 Velox 推进 Spark 向量化改造的整体策略。他表示,团队通过从定制化方案到开源架构的持续演进,已实现关键业务管线向 Gluten(Flare)的平稳迁移,并获得显著的效率提升。未来,Meta 计划进一步扩大该架构的应用规模。 在 CPU 向量化趋于普及的同时,利用异构硬件挖掘更高性能成为新的前沿。IBM 研究院资深软件工程师 Zoltán Arnold Nagy 展示了基于 Velox 与 Presto 的 GPU 加速数据处理方案。他介绍道,Velox 通过与 cuDF 集成,可在 GPU 上高效执行算⼦,并针对多 GPU 分布式场景优化通信与数据交换。此外,为突破 I/O 瓶颈,团队正在探索结合 GPUDirect 存储与缓存层的加速策略。 对性能与稳定性的追求,也驱动着查询引擎架构本身的融合与创新。Meta 软件工程师谭家梁与大家分享了 Native Presto-on-Spark 的规模化应用。该架构以 Presto 查询优化、Spark 资源调度与容错机制以及 Velox 原生向量化执行为核心,实现了性能与可靠性的显著提升。他表示,目前该方案已在生产环境中取得成效,并将在未来持续推进全栈原生化演进。 对于国内庞大的云上业务,Velox 同样在支撑着关键数据服务平台。 阿里云高级工程师王彬与范阿冬系统介绍了Velox在阿里云日志服务中的深度集成与应用。他们指出,基于 Velox 构建的高性能查询引擎,通过混合执行、表达式下推、自动增量物化视图及免 Schema 分析等核心技术,可显著提升平台在处理海量实时数据时的查询效率与资源利用率。他们还强调,该架构不仅为日志分析、智能运维等场景提供了稳定支撑,也为面向 AI 的云原生数据平台演进奠定了坚实基础。 除了通用的日志与湖仓分析,Velox 也在向更垂直的时序数据场景渗透。腾讯高级工程师李兆龙分享了基于 Velox 构建云原生时序数据库的落地经验。他表示,通过在 Velox 中实现时序数据去重优化与存储写入增强,系统在应对高频写入与实时查询场景时,可显著提升吞吐效率与响应性能。目前该方案已有效支持物联网、实时监控等业务场景,未来还将进一步完善缓存与压缩机制,持续优化时序数据处理的整体效能。 IBM 软件工程师刘平接着分享了 Velox 在 Iceberg 数据写入能力上的突破性进展。他表示,目前 Velox 对 Iceberg 的支持以读取为主,其写入功能的完善将填补该方向的关键能力空白,为基于 Presto 与 Spark 的数据湖架构提供更统一、高效的数据摄入层。这一进展也标志着 Velox 正从查询加速向数据全链路处理拓展。 接着,来自阿里云的毕岩与周滔分享了 Velox 与 Apache Paimon 深度集成的解决方案,为提升引擎与存储的协同效率提供了另一种集成思路。在他们看来,现有方案存在表类型支持受限、缺乏可移植性等瓶颈, 但可以建立 C++ 原生 Paimon 库,通过其统一的数据协议与插件化设计,使 Paimon 能够被 Velox、StarRocks 等多种计算引擎直接高效调用,从而提升数据读写性能,并为湖仓格式的跨引擎协同提供新的基础支撑。 在批处理场景之外,流计算框架的向量化也正成为新的热点。蚂蚁集团技术专家刘勇介绍了基于 Velox 为 Flink 构建的统一向量化执行引擎 Flex。他表示,Flink 作为流批一体架构的核心,其原生向量化能力的补足至关重要。Flex 通过将 Velox 的高性能算子能力引入 Flink,同时结合自动化验证、可视化计划与精细化回退机制,现已实现了作业性能的显著提升,并支撑多条核心业务链路平稳运行。 随着 Velox 赋能的应用场景日益广泛和复杂,确保其在不同引擎和版本间的整体质量与可靠性变得至关重要。Meta 软件工程师 Eric Liu 阐述了在 AI 数据基础架构下,保障 Velox 多引擎版本可靠性的系统化方法。他指出,面对不同引擎与存储格式交织带来的复杂性,关键在于建立跨引擎测试框架与合成数据工厂。这一实践能有效提前发现全栈潜在问题,从而确保底层变更在大规模生产环境中的稳定与高效。 针对向量化引擎中窗口运算符内存溢出的典型难题,来自英特尔的贾柯分享了她的见解。她认为,通过为 Velox 引入流式窗口处理机制,可使计算随数据到达逐步执行并即时释放内存,从而从架构层面化解多数场景下的内存风险,显著提升复杂查询的稳定性。 最后,小红书 Native Engine 团队技术负责人魏秀利也分享了向量化引擎在公司业务中规模化落地的经验。据他介绍,通过将写入异步化并构建原生 Avro 读取能力,小红书在不增加业务复杂度的前提下,成功缓解了端到端延迟,印证了“执行与存储协同优化”在湖仓场景中的关键价值。 从底层执行引擎的持续创新,到日志分析、湖仓写入、流批融合等复杂场景的稳定运行,在本届 VeloxCon China 上,我们看到 Velox 的技术价值已在真实业务中不断被验证和拓展。同时我们也很高兴看到中国开发者成为这一进程的重要推动者。期待未来有更多志同道合者加入 Velox 开源社区,共建高性能分析基础设施。个weibo.com/ttarticle/p/show?id=2309405288618326884486 weibo.com/ttarticle/p/show?id=2309405288618691526861 weibo.com/ttarticle/p/show?id=2309405288619056693322 weibo.com/ttarticle/p/show?id=2309405288619417141392 weibo.com/ttarticle/p/show?id=2309405288619920719906 weibo.com/ttarticle/p/show?id=2309405288620285624488 weibo.com/ttarticle/p/show?id=2309405288620658655237 weibo.com/ttarticle/p/show?id=2309405288621023821879 weibo.com/ttarticle/p/show?id=2309405288621380075666
会议伊始,Velox 项目联合发起人 Pedro 发表开幕致辞。他回顾了 Velox 开源项目的发展历程,从项目启动、开源发布到建立技术治理结构,展示了 Axiom 架构、GPU 支持、PyVelox 等关键进展,强调了社区协作与工程严谨性是项目持续演进的核心动力。他特别提到,Velox 已建立了正式的技术治理机制,并迎来来自 IBM、Intel、NVIDIA、Microsoft 等多家企业的新增维护者,标志着项目正迈向更加开放和可持续的阶段。
午餐后的议程更加聚焦 Velox 在真实业务中的集成深度与生产韧性,回应了开发者们对兼容性、稳定性与端到端效能等规模化落地的核心关切。
小米计算平台计算引擎负责人王胜杰分享了公司在 Spark 向量化升级中的规模化落地经验。面对业务迁移中的兼容性与稳定性挑战,他表示,小米通过自动兼容校验、双跑结果比对及内存异常感知的三级资源升级机制,已成功推动向量化改造在数十万作业中平稳落地。
然后同等价格额度少一半
然后担心受怕被封号
就这样,大家还是挤破头想去订阅 claude code (包括我)
有人能讲下是为什么吗?难道是越得不到的越想要?
经常看到有 V 友在站上求 Linux 桌面环境或 WM ,也算月经贴了。
在家里和公司用的都是 Linux 系统(公司早期不管,就自己安装了),导致后面出现了一件搞笑的事情:
网管: “麻烦安装下 XX 软件。”
我: “我 Linux 系统。”
下面分享下我的配置以及原因。声明:适合自己的才是最好的!
.deb 包(例如:钉钉、微信、WPS )。
Alt + 数字键:切换桌面Alt + Tab:切换应用mpd + mpc,写代码时常听的一些离线音乐。fcitx)、截图软件 (flameshot) 等。Alt + 鼠标左键拖动:移动窗口Alt + 鼠标右键拖动:缩放窗口
当需要安装新软件时,我的尝试顺序:
现在用的 TPLINK AX3000 ,最近半个月两三次断网,需要手动重启。
2025 年 12 月 13 日,VeloxCon China 2025 在北京成功举办。作为 Velox 项目首次在中国举办的线下技术大会,汇聚了来自Meta、IBM、蚂蚁集团、阿里云、腾讯、小米、小红书等企业的数十位核心贡献者与一线工程师。 大会通过 18 场演讲将 Velox 置于真实业务场景之中,系统展示了其在架构演进、AI 数据处理、湖仓加速、流批融合等方向的最新实践。这些分享不仅直面性能、稳定性与兼容性等落地挑战,也反应了开发者社区对构建可靠、可扩展、可协同的数据基础设施的共同探索,彰显了中国开发者在全球高性能分析生态中的工程深度与协作广度。 夯实底座,突破能力边界 在明确了社区与架构演进的总体方向后,大会议题迅速深入到如何利用 Velox 构建高性能计算引擎的具体实践中。阿里云 EMR Serverless Spark 技术负责人周克勇系统阐述了“可组合性”在数据计算领域的实践。他详细解析了阿里云如何深度集成并贡献于 Apache Celeborn、Paimon、Velox 及 Gluten 等开源组件,通过模块化组装构建出高性能湖仓一体引擎。他指出,基于该架构,阿里云 EMR Serverless Spark 成功创造了 TPC-DS 100TB 规模性能测试的世界新纪录,实现性能翻倍与性价比大幅提升。 接着,Meta 软件工程师 Masha Basmanova 阐述了现有查询引擎在跨语言通信、优化器能力与开发体验上面临的挑战,并介绍了基于 C++ 的统一前端框架 Axiom。该框架将 SQL 解析、逻辑优化与物理执行融为一体,通过内置的强大优化器与 Velox 运行时无缝对接,能够实现更高效、可扩展的查询处理。演讲最后,她积极展示了 Axiom 的开源路线图,并欢迎全球开发者加入,共同推动该项目的演进。 强大的执行框架,最终需要服务于极具挑战性的数据场景,特别是爆发式增长的 AI 数据。Meta 软件工程师孟晓烜则在之后的演讲中,深入阐述了应对AI训练数据规模激增与成本挑战的解决方案。他重点介绍了 Meta 如何通过数据归一化技术剥离重复特征,并构建可索引的序列存储系统。依托 Velox 技术栈,团队在训练数据的加载、生成与探索三大环节实现了端到端优化,显著提升了处理效率与资源利用率。 在 Meta 多位工程师从框架演进、可组合架构、数据标准化等角度深入分享后,蚂蚁集团高级技术专家黄叶伟也从企业落地实践层面分享了基于 Velox 的 Spark 加速实践。他重点介绍了基于 Gluten 与 Velox 构建的向量化引擎如何通过任务级 Fallback、Spill 优化、Shuffle 优化等关键技术,在混合部署场景下显著提升 Spark 性能与稳定性。他表示,该方案目前已实现日均数十万任务覆盖,平均节省资源超30%,并将在算子优化与架构扩展方面持续演进。 作为连接 Spark 生态与原生加速的关键中间层,Apache Gluten 的进展同样备受关注。来自 IBM 的莫芮与周渊聚焦 Apache Gluten与 Velox 的深度集成,阐述了其如何在大数据分析中驱动创新。他们介绍,Gluten 在保持对 Spark/Flink 作业透明加速能力的同时,正逐步增强对多后端引擎和复杂业务场景的适配能力。目前,该方案已在 Pinterest、顺丰科技及多个内部集群完成规模化验证,有效支撑了从日志分析到物流调度等多样化负载的性能提升与成本优化。 随着向量化加速在通用场景日趋成熟,针对特定存储格式的深度优化成为新的效能突破口。腾讯大数据开发工程师陈锦海分享了微信基于 Velox 加速 lceberg 湖仓分析的优化与实践,重点介绍了原生分桶方案。据他介绍,该方案通过动态识别表元信息自动设置分区数,能有效缓解 AQE 引发的写入倾斜,结合空闲资源灰度发布策略,可保障大规模作业的稳定上线。 扎根场景,释放协同效能 面对海量数据挑战,全球科技公司也在探索相似的演进路径。Meta 软件工程经理 Stanley Yao 在演讲中分享了公司基于 Velox 推进 Spark 向量化改造的整体策略。他表示,团队通过从定制化方案到开源架构的持续演进,已实现关键业务管线向 Gluten(Flare)的平稳迁移,并获得显著的效率提升。未来,Meta 计划进一步扩大该架构的应用规模。 在 CPU 向量化趋于普及的同时,利用异构硬件挖掘更高性能成为新的前沿。IBM 研究院资深软件工程师 Zoltán Arnold Nagy 展示了基于 Velox 与 Presto 的 GPU 加速数据处理方案。他介绍道,Velox 通过与 cuDF 集成,可在 GPU 上高效执行算⼦,并针对多 GPU 分布式场景优化通信与数据交换。此外,为突破 I/O 瓶颈,团队正在探索结合 GPUDirect 存储与缓存层的加速策略。 对性能与稳定性的追求,也驱动着查询引擎架构本身的融合与创新。Meta 软件工程师谭家梁与大家分享了 Native Presto-on-Spark 的规模化应用。该架构以 Presto 查询优化、Spark 资源调度与容错机制以及 Velox 原生向量化执行为核心,实现了性能与可靠性的显著提升。他表示,目前该方案已在生产环境中取得成效,并将在未来持续推进全栈原生化演进。 对于国内庞大的云上业务,Velox 同样在支撑着关键数据服务平台。 阿里云高级工程师王彬与范阿冬系统介绍了Velox在阿里云日志服务中的深度集成与应用。他们指出,基于 Velox 构建的高性能查询引擎,通过混合执行、表达式下推、自动增量物化视图及免 Schema 分析等核心技术,可显著提升平台在处理海量实时数据时的查询效率与资源利用率。他们还强调,该架构不仅为日志分析、智能运维等场景提供了稳定支撑,也为面向 AI 的云原生数据平台演进奠定了坚实基础。 除了通用的日志与湖仓分析,Velox 也在向更垂直的时序数据场景渗透。腾讯高级工程师李兆龙分享了基于 Velox 构建云原生时序数据库的落地经验。他表示,通过在 Velox 中实现时序数据去重优化与存储写入增强,系统在应对高频写入与实时查询场景时,可显著提升吞吐效率与响应性能。目前该方案已有效支持物联网、实时监控等业务场景,未来还将进一步完善缓存与压缩机制,持续优化时序数据处理的整体效能。 IBM 软件工程师刘平接着分享了 Velox 在 Iceberg 数据写入能力上的突破性进展。他表示,目前 Velox 对 Iceberg 的支持以读取为主,其写入功能的完善将填补该方向的关键能力空白,为基于 Presto 与 Spark 的数据湖架构提供更统一、高效的数据摄入层。这一进展也标志着 Velox 正从查询加速向数据全链路处理拓展。 接着,来自阿里云的毕岩与周滔分享了 Velox 与 Apache Paimon 深度集成的解决方案,为提升引擎与存储的协同效率提供了另一种集成思路。在他们看来,现有方案存在表类型支持受限、缺乏可移植性等瓶颈, 但可以建立 C++ 原生 Paimon 库,通过其统一的数据协议与插件化设计,使 Paimon 能够被 Velox、StarRocks 等多种计算引擎直接高效调用,从而提升数据读写性能,并为湖仓格式的跨引擎协同提供新的基础支撑。 在批处理场景之外,流计算框架的向量化也正成为新的热点。蚂蚁集团技术专家刘勇介绍了基于 Velox 为 Flink 构建的统一向量化执行引擎 Flex。他表示,Flink 作为流批一体架构的核心,其原生向量化能力的补足至关重要。Flex 通过将 Velox 的高性能算子能力引入 Flink,同时结合自动化验证、可视化计划与精细化回退机制,现已实现了作业性能的显著提升,并支撑多条核心业务链路平稳运行。 随着 Velox 赋能的应用场景日益广泛和复杂,确保其在不同引擎和版本间的整体质量与可靠性变得至关重要。Meta 软件工程师 Eric Liu 阐述了在 AI 数据基础架构下,保障 Velox 多引擎版本可靠性的系统化方法。他指出,面对不同引擎与存储格式交织带来的复杂性,关键在于建立跨引擎测试框架与合成数据工厂。这一实践能有效提前发现全栈潜在问题,从而确保底层变更在大规模生产环境中的稳定与高效。 针对向量化引擎中窗口运算符内存溢出的典型难题,来自英特尔的贾柯分享了她的见解。她认为,通过为 Velox 引入流式窗口处理机制,可使计算随数据到达逐步执行并即时释放内存,从而从架构层面化解多数场景下的内存风险,显著提升复杂查询的稳定性。 最后,小红书 Native Engine 团队技术负责人魏秀利也分享了向量化引擎在公司业务中规模化落地的经验。据他介绍,通过将写入异步化并构建原生 Avro 读取能力,小红书在不增加业务复杂度的前提下,成功缓解了端到端延迟,印证了“执行与存储协同优化”在湖仓场景中的关键价值。 从底层执行引擎的持续创新,到日志分析、湖仓写入、流批融合等复杂场景的稳定运行,在本届 VeloxCon China 上,我们看到 Velox 的技术价值已在真实业务中不断被验证和拓展。同时我们也很高兴看到中国开发者成为这一进程的重要推动者。期待未来有更多志同道合者加入 Velox 开源社区,共建高性能分析基础设施。个weibo.com/ttarticle/p/show?id=2309405288500232060990 weibo.com/ttarticle/p/show?id=2309405288500689240152 weibo.com/ttarticle/p/show?id=2309405288501054144520 weibo.com/ttarticle/p/show?id=2309405288501406466081 weibo.com/ttarticle/p/show?id=2309405288501779497011 weibo.com/ttarticle/p/show?id=2309405288502136012842 weibo.com/ttarticle/p/show?id=2309405288502609969177 weibo.com/ttarticle/p/show?id=2309405288502966747147 weibo.com/ttarticle/p/show?id=2309405288503323000845
会议伊始,Velox 项目联合发起人 Pedro 发表开幕致辞。他回顾了 Velox 开源项目的发展历程,从项目启动、开源发布到建立技术治理结构,展示了 Axiom 架构、GPU 支持、PyVelox 等关键进展,强调了社区协作与工程严谨性是项目持续演进的核心动力。他特别提到,Velox 已建立了正式的技术治理机制,并迎来来自 IBM、Intel、NVIDIA、Microsoft 等多家企业的新增维护者,标志着项目正迈向更加开放和可持续的阶段。
午餐后的议程更加聚焦 Velox 在真实业务中的集成深度与生产韧性,回应了开发者们对兼容性、稳定性与端到端效能等规模化落地的核心关切。
小米计算平台计算引擎负责人王胜杰分享了公司在 Spark 向量化升级中的规模化落地经验。面对业务迁移中的兼容性与稳定性挑战,他表示,小米通过自动兼容校验、双跑结果比对及内存异常感知的三级资源升级机制,已成功推动向量化改造在数十万作业中平稳落地。
大家好我是 iztro 开源库的作者,仓库好不容易有 3.6k 的 star 了,昨天突然被标记了,导致账号和仓库都 404 了。尝试申诉渠道,但是现在的问题是,申述页面登录后需要短信验证,现在不支持+86 的手机号,找了个朋友的手机验证又显示达到 requests limit ,发邮件给 github 官方也发不出去。
被标记的原因应该是因为我前天晚上在 About Me 的页面里加了一个用 iztro 库开发的一个产品的链接: https://app.ziwei.pro/register?ref=TPgWxvwH
现在我已经删除那个链接了,求各位大佬指点怎么恢复账号?
最近 MCP 协议挺火的,Claude Desktop 、Cursor 、Kiro 都支持了。但 Go 生态里现有的库( mcp-go 、官方 SDK )都是 SDK 级别的,写个 Tool 要一堆样板代码。
所以做了个框架叫 GoMCP ,核心卖点:
最实用的场景:你已经有个 Gin 项目,想让 AI 能调接口:
adapter.ImportGin(s, ginRouter, adapter.ImportOptions{
IncludePaths: []string{"/api/v1/"},
})
就这样,所有路由自动变成 MCP Tool 。
GitHub: https://github.com/zhangpanda/gomcp ( https://github.com/zhangpanda/gomcp)
欢迎试用,有问题随时提 issue 。
平时会频繁用到 JSON 、时间戳、Diff 、还有一些简单的图片处理这类小工具。
但网页工具一直有两个问题:一是分散,要来回切页面;二是有些内容也不太想往线上贴。后来想了想,就自己慢慢捣鼓了一个。
结果越搞越多,也把自己平时的一些想法都一点点塞了进去。
AirTools 的定位其实很简单,就是一个本地优先、跨平台的开发者工具箱。我更想把它做成那种常驻电脑、随手就能打开的小工具集合,而不是一次性网页。
市面上已经有 it-tools 、DevToys 这类产品,我自己也用过。AirTools 不是想重复造一个“更多工具列表”,而是希望做一个更偏本地优先、桌面常驻、能慢慢进入日常工作流的版本。
目前一些比较常用的场景,大概像这些:
下载地址:
AirTools (一些工具)
如果你愿意试一下,欢迎直接提意见或者挑刺。
有问题或者建议都欢迎说,求轻喷。
另外准备了 20 个激活码,一个激活码只能绑定一个邮箱。
AT-R794M-7A2PE-AUDTY-Q6LN7
AT-NWEQ9-V9B2H-AJZU9-VNVL5
AT-A3PTK-3ZGSD-8CSCK-48WFR
AT-DRC7P-7KHV2-ZHB3P-559RW
AT-TGXBW-XUDKP-JWTTL-5D5S2
AT-ZF39N-MS8SM-TF9XZ-GZF4V
AT-97XUY-B8FMB-B8T49-DXT33
AT-TD988-TVKJ4-TRB9K-9NL2L
AT-2XH5L-L3XD3-QDBJG-9U78D
AT-VJREB-29CAQ-Z84B2-B9FVP
AT-CZZD2-D2EW9-8UZWL-DJDQL
AT-P9KHH-WJ37D-D4A8Q-7NDQV
AT-XN9CJ-4Y8H3-5MT92-VPRLG
AT-ZUHVS-Y769P-JTYU4-GWUGD
AT-UAX7L-DURRR-L3D6W-X7V3M
AT-RNJMF-CNJDN-8YZQE-TWLL7
AT-KLCVS-8TSBN-J6SPM-BQK9Q
AT-KZK2F-9V3RY-TVKG2-J43YL
AT-BP3XN-NLMU8-7AP3E-V3W3H
AT-FXHAZ-HNDHS-SH4BB-J5N8G
如果你觉得这个工具确实对你有帮助,也可以付费支持一下。
首发优惠码:FIRST90
原价 $8.99 ,折后 $1.44
如果用了之后愿意回来提点意见,就更感谢了。
2025 年 12 月 13 日,VeloxCon China 2025 在北京成功举办。作为 Velox 项目首次在中国举办的线下技术大会,汇聚了来自Meta、IBM、蚂蚁集团、阿里云、腾讯、小米、小红书等企业的数十位核心贡献者与一线工程师。 大会通过 18 场演讲将 Velox 置于真实业务场景之中,系统展示了其在架构演进、AI 数据处理、湖仓加速、流批融合等方向的最新实践。这些分享不仅直面性能、稳定性与兼容性等落地挑战,也反应了开发者社区对构建可靠、可扩展、可协同的数据基础设施的共同探索,彰显了中国开发者在全球高性能分析生态中的工程深度与协作广度。 夯实底座,突破能力边界 在明确了社区与架构演进的总体方向后,大会议题迅速深入到如何利用 Velox 构建高性能计算引擎的具体实践中。阿里云 EMR Serverless Spark 技术负责人周克勇系统阐述了“可组合性”在数据计算领域的实践。他详细解析了阿里云如何深度集成并贡献于 Apache Celeborn、Paimon、Velox 及 Gluten 等开源组件,通过模块化组装构建出高性能湖仓一体引擎。他指出,基于该架构,阿里云 EMR Serverless Spark 成功创造了 TPC-DS 100TB 规模性能测试的世界新纪录,实现性能翻倍与性价比大幅提升。 接着,Meta 软件工程师 Masha Basmanova 阐述了现有查询引擎在跨语言通信、优化器能力与开发体验上面临的挑战,并介绍了基于 C++ 的统一前端框架 Axiom。该框架将 SQL 解析、逻辑优化与物理执行融为一体,通过内置的强大优化器与 Velox 运行时无缝对接,能够实现更高效、可扩展的查询处理。演讲最后,她积极展示了 Axiom 的开源路线图,并欢迎全球开发者加入,共同推动该项目的演进。 强大的执行框架,最终需要服务于极具挑战性的数据场景,特别是爆发式增长的 AI 数据。Meta 软件工程师孟晓烜则在之后的演讲中,深入阐述了应对AI训练数据规模激增与成本挑战的解决方案。他重点介绍了 Meta 如何通过数据归一化技术剥离重复特征,并构建可索引的序列存储系统。依托 Velox 技术栈,团队在训练数据的加载、生成与探索三大环节实现了端到端优化,显著提升了处理效率与资源利用率。 在 Meta 多位工程师从框架演进、可组合架构、数据标准化等角度深入分享后,蚂蚁集团高级技术专家黄叶伟也从企业落地实践层面分享了基于 Velox 的 Spark 加速实践。他重点介绍了基于 Gluten 与 Velox 构建的向量化引擎如何通过任务级 Fallback、Spill 优化、Shuffle 优化等关键技术,在混合部署场景下显著提升 Spark 性能与稳定性。他表示,该方案目前已实现日均数十万任务覆盖,平均节省资源超30%,并将在算子优化与架构扩展方面持续演进。 作为连接 Spark 生态与原生加速的关键中间层,Apache Gluten 的进展同样备受关注。来自 IBM 的莫芮与周渊聚焦 Apache Gluten与 Velox 的深度集成,阐述了其如何在大数据分析中驱动创新。他们介绍,Gluten 在保持对 Spark/Flink 作业透明加速能力的同时,正逐步增强对多后端引擎和复杂业务场景的适配能力。目前,该方案已在 Pinterest、顺丰科技及多个内部集群完成规模化验证,有效支撑了从日志分析到物流调度等多样化负载的性能提升与成本优化。 随着向量化加速在通用场景日趋成熟,针对特定存储格式的深度优化成为新的效能突破口。腾讯大数据开发工程师陈锦海分享了微信基于 Velox 加速 lceberg 湖仓分析的优化与实践,重点介绍了原生分桶方案。据他介绍,该方案通过动态识别表元信息自动设置分区数,能有效缓解 AQE 引发的写入倾斜,结合空闲资源灰度发布策略,可保障大规模作业的稳定上线。 扎根场景,释放协同效能 面对海量数据挑战,全球科技公司也在探索相似的演进路径。Meta 软件工程经理 Stanley Yao 在演讲中分享了公司基于 Velox 推进 Spark 向量化改造的整体策略。他表示,团队通过从定制化方案到开源架构的持续演进,已实现关键业务管线向 Gluten(Flare)的平稳迁移,并获得显著的效率提升。未来,Meta 计划进一步扩大该架构的应用规模。 在 CPU 向量化趋于普及的同时,利用异构硬件挖掘更高性能成为新的前沿。IBM 研究院资深软件工程师 Zoltán Arnold Nagy 展示了基于 Velox 与 Presto 的 GPU 加速数据处理方案。他介绍道,Velox 通过与 cuDF 集成,可在 GPU 上高效执行算⼦,并针对多 GPU 分布式场景优化通信与数据交换。此外,为突破 I/O 瓶颈,团队正在探索结合 GPUDirect 存储与缓存层的加速策略。 对性能与稳定性的追求,也驱动着查询引擎架构本身的融合与创新。Meta 软件工程师谭家梁与大家分享了 Native Presto-on-Spark 的规模化应用。该架构以 Presto 查询优化、Spark 资源调度与容错机制以及 Velox 原生向量化执行为核心,实现了性能与可靠性的显著提升。他表示,目前该方案已在生产环境中取得成效,并将在未来持续推进全栈原生化演进。 对于国内庞大的云上业务,Velox 同样在支撑着关键数据服务平台。 阿里云高级工程师王彬与范阿冬系统介绍了Velox在阿里云日志服务中的深度集成与应用。他们指出,基于 Velox 构建的高性能查询引擎,通过混合执行、表达式下推、自动增量物化视图及免 Schema 分析等核心技术,可显著提升平台在处理海量实时数据时的查询效率与资源利用率。他们还强调,该架构不仅为日志分析、智能运维等场景提供了稳定支撑,也为面向 AI 的云原生数据平台演进奠定了坚实基础。 除了通用的日志与湖仓分析,Velox 也在向更垂直的时序数据场景渗透。腾讯高级工程师李兆龙分享了基于 Velox 构建云原生时序数据库的落地经验。他表示,通过在 Velox 中实现时序数据去重优化与存储写入增强,系统在应对高频写入与实时查询场景时,可显著提升吞吐效率与响应性能。目前该方案已有效支持物联网、实时监控等业务场景,未来还将进一步完善缓存与压缩机制,持续优化时序数据处理的整体效能。 IBM 软件工程师刘平接着分享了 Velox 在 Iceberg 数据写入能力上的突破性进展。他表示,目前 Velox 对 Iceberg 的支持以读取为主,其写入功能的完善将填补该方向的关键能力空白,为基于 Presto 与 Spark 的数据湖架构提供更统一、高效的数据摄入层。这一进展也标志着 Velox 正从查询加速向数据全链路处理拓展。 接着,来自阿里云的毕岩与周滔分享了 Velox 与 Apache Paimon 深度集成的解决方案,为提升引擎与存储的协同效率提供了另一种集成思路。在他们看来,现有方案存在表类型支持受限、缺乏可移植性等瓶颈, 但可以建立 C++ 原生 Paimon 库,通过其统一的数据协议与插件化设计,使 Paimon 能够被 Velox、StarRocks 等多种计算引擎直接高效调用,从而提升数据读写性能,并为湖仓格式的跨引擎协同提供新的基础支撑。 在批处理场景之外,流计算框架的向量化也正成为新的热点。蚂蚁集团技术专家刘勇介绍了基于 Velox 为 Flink 构建的统一向量化执行引擎 Flex。他表示,Flink 作为流批一体架构的核心,其原生向量化能力的补足至关重要。Flex 通过将 Velox 的高性能算子能力引入 Flink,同时结合自动化验证、可视化计划与精细化回退机制,现已实现了作业性能的显著提升,并支撑多条核心业务链路平稳运行。 随着 Velox 赋能的应用场景日益广泛和复杂,确保其在不同引擎和版本间的整体质量与可靠性变得至关重要。Meta 软件工程师 Eric Liu 阐述了在 AI 数据基础架构下,保障 Velox 多引擎版本可靠性的系统化方法。他指出,面对不同引擎与存储格式交织带来的复杂性,关键在于建立跨引擎测试框架与合成数据工厂。这一实践能有效提前发现全栈潜在问题,从而确保底层变更在大规模生产环境中的稳定与高效。 针对向量化引擎中窗口运算符内存溢出的典型难题,来自英特尔的贾柯分享了她的见解。她认为,通过为 Velox 引入流式窗口处理机制,可使计算随数据到达逐步执行并即时释放内存,从而从架构层面化解多数场景下的内存风险,显著提升复杂查询的稳定性。 最后,小红书 Native Engine 团队技术负责人魏秀利也分享了向量化引擎在公司业务中规模化落地的经验。据他介绍,通过将写入异步化并构建原生 Avro 读取能力,小红书在不增加业务复杂度的前提下,成功缓解了端到端延迟,印证了“执行与存储协同优化”在湖仓场景中的关键价值。 从底层执行引擎的持续创新,到日志分析、湖仓写入、流批融合等复杂场景的稳定运行,在本届 VeloxCon China 上,我们看到 Velox 的技术价值已在真实业务中不断被验证和拓展。同时我们也很高兴看到中国开发者成为这一进程的重要推动者。期待未来有更多志同道合者加入 Velox 开源社区,共建高性能分析基础设施。weibo.com/ttarticle/p/show?id=2309405288490241228973 weibo.com/ttarticle/p/show?id=2309405288490585161890 weibo.com/ttarticle/p/show?id=2309405288490924900457 weibo.com/ttarticle/p/show?id=2309405288491373691166 weibo.com/ttarticle/p/show?id=2309405288491742789763 weibo.com/ttarticle/p/show?id=2309405288492086460460 weibo.com/ttarticle/p/show?id=2309405288492430393423 weibo.com/ttarticle/p/show?id=2309405288492774326341 weibo.com/ttarticle/p/show?id=2309405288493227311213 个
会议伊始,Velox 项目联合发起人 Pedro 发表开幕致辞。他回顾了 Velox 开源项目的发展历程,从项目启动、开源发布到建立技术治理结构,展示了 Axiom 架构、GPU 支持、PyVelox 等关键进展,强调了社区协作与工程严谨性是项目持续演进的核心动力。他特别提到,Velox 已建立了正式的技术治理机制,并迎来来自 IBM、Intel、NVIDIA、Microsoft 等多家企业的新增维护者,标志着项目正迈向更加开放和可持续的阶段。
午餐后的议程更加聚焦 Velox 在真实业务中的集成深度与生产韧性,回应了开发者们对兼容性、稳定性与端到端效能等规模化落地的核心关切。
小米计算平台计算引擎负责人王胜杰分享了公司在 Spark 向量化升级中的规模化落地经验。面对业务迁移中的兼容性与稳定性挑战,他表示,小米通过自动兼容校验、双跑结果比对及内存异常感知的三级资源升级机制,已成功推动向量化改造在数十万作业中平稳落地。
为什么你的网站必须安装SSL证书?从业者揭秘HTTPS背后的安全逻辑 作为长期深耕网络安全与证书服务的从业者,经常被开发者、运维同行问:“我的网站只是个测试环境/个人博客,没必要装SSL证书吧?” 答案很明确:现在没有任何一个网站可以“例外” 。无论是生产环境、内网系统,还是个人Demo、小程序接口,SSL证书早已不是“加分项”,而是必须落地的基础安全基建。 今天不堆空洞概念,从技术底层拆解HTTPS的安全逻辑,讲透“为什么必须装SSL证书”,以及开发者最容易踩的证书坑。 很多开发者只知道“HTTPS有小锁,HTTP没有”,却没搞懂底层逻辑,这也是踩坑的根源。 简单说:HTTP是明文传输,HTTPS = HTTP + TLS/SSL加密 + 身份认证,两者的安全等级天差地别。 从技术实现上,HTTPS核心解决了HTTP的三大致命缺陷: 对开发者而言,这不是“额外工作量”,而是规避后续安全事故的第一道防线。 很多开发者抱有侥幸心理:“我的网站没敏感数据,裸奔也没事”。但实际落地中,这些问题会直接导致项目停摆、用户流失。 Chrome、Edge、Safari等主流浏览器早已全面禁用HTTP:未安装SSL证书的站点,地址栏会醒目标红“不安全”,部分版本直接拦截访问,用户需手动跳过才能进入——对用户而言,这和“恶意网站”几乎没有区别,留存率直接归零。 即使是个人博客、测试环境,只要涉及用户登录、表单提交,HTTP明文传输就会导致: 亲身经历过一个项目:测试环境未装证书,被内网抓包篡改接口数据,导致测试用例全部失效,浪费了3天排查时间。 这是最直接的影响,也是开发者最头疼的问题: HTTP明文传输的另一个常见问题:运营商、路由器可随意劫持页面,植入弹窗广告、恶意跳转,不仅影响用户体验,还会损害品牌形象——即使是内网系统,也可能被内网设备劫持篡改。 很多开发者以为SSL证书只是“生成一个文件部署到服务器”,其实背后是一套完整的PKI公钥基础设施,核心价值远不止加密。 正规SSL证书默认采用:2048/4096位RSA算法(或更高效的ECC椭圆曲线加密),搭配256位AES对称加密——这种加密强度,依靠现有算力几乎无法暴力破解,能有效抵御监听、重放、中间人攻击。 这里提醒一句:自签名证书虽然能实现加密,但没有CA机构背书,浏览器不认可,等于“自欺欺人”。 SSL证书不是“一刀切”,不同场景对应不同等级,避免过度配置或安全不足: 从1年→398天→200天,SSL证书有效期不断收紧,很多开发者抱怨“续期麻烦”,但从安全角度看,这是必然趋势: 有效期越短,证书被盗用、伪造的风险窗口就越小,同时强制网站定期更新身份核验,对抗日益增强的黑客攻击能力——这不是“麻烦”,而是行业对安全的基本要求。 很多开发者为了省事,用自签名证书或不知名免费证书,结果踩坑不断: 结论:真正可用、稳定的HTTPS,必须依靠权威CA签发的正规SSL证书。 HTTPS早已不是“可选项”,而是网站的基础基建。对开发者而言,提前部署SSL证书,不是“增加工作量”,而是规避后续安全事故、项目上线受阻的最优解。 尤其是在证书有效期全面收紧、安全规范不断升级的今天,选择一套标准化、稳定可靠的证书服务,能节省大量排查、续期、兼容的时间,把精力放回核心业务上。 毕竟,对开发者而言,“少踩坑、省时间、保安全”,才是最核心的需求。一、先理清核心:HTTP与HTTPS的本质差异(开发者必懂)
二、不装SSL证书,你要面对的4个致命问题(实测踩坑总结)
1. 浏览器拦截 + 信任崩塌
2. 数据泄露风险(开发者最易忽视)
3. 平台限制,项目无法上线
4. 网页劫持、广告植入
三、从业者揭秘:SSL证书的安全逻辑,不止“加个锁”
1. 加密强度的底层逻辑
2. 证书等级的适配逻辑(开发者必看)
3. 有效期缩短的底层逻辑(别嫌麻烦)
四、开发者避坑:别再用自签名、野路子免费证书
五、最后:对开发者、运维的一点建议
内网 HTTP 明文传输、浏览器持续告警、等保审计不通过、自签名证书管理混乱…… 在内网 OA、ERP、堡垒机、BMC、K8s 集群、IoT 设备等大量仅用静态内网 IP提供服务的场景中,这些问题长期困扰运维与安全团队。内网 IP SSL 证书,专为私有 IP 环境设计,无需公网域名、无需自建 CA,即可实现可信 HTTPS 加密与身份校验,是企业内网安全升级的标准方案。 内网 IP SSL 证书由合规 CA 直接签发,绑定内网静态 IP(如 192.168.x.x、10.x.x.x、172.16.x.x),基于 TLS 1.2/1.3 构建加密通道,端到端防窃听、防篡改、防重放。相比自签名证书,它无需逐台导入根证,浏览器与系统默认信任,彻底消除 “不安全” 提示;相比私有 CA,它省去搭建、维护、续期、吊销的复杂成本,即开即用。 支持RSA/SM2 双算法,兼容国密与国际标准,对称加密采用 AES-256/SM4-GCM,密钥交换使用 ECDHE/SM2,满足金融、政务、能源等高安全要求。证书支持 SAN 多 IP 绑定,单张可覆盖集群与多节点,适配负载均衡与微服务架构。 满足《网络安全法》《数据安全法》对传输加密的强制要求,直接匹配等保 2.0 三级及以上 “通信传输安全” 测评项。证书包含企业身份信息,支持OV/IV 认证,可审计、可追溯、可快速吊销,杜绝非法接入与伪造站点。 提供自动化部署与续期对接,兼容 Nginx、Apache、IIS、Tomcat 及 K8s cert-manager,支持 API 批量签发,降低人工运维与过期故障风险。 IP证书获取办法:打开JoySSL官网,填写注册码230970,获得大额优惠。 内网不是安全盲区,HTTPS 不是公网专属。一张内网 IP SSL 证书,以最小成本解决内网加密、身份可信、合规审计三大核心问题,让内网通信从 “裸奔” 变 “密传”。 我们提供内网 IP 证书咨询、选型、签发与部署一站式服务,支持测试签发与技术对接,帮你快速完成内网 HTTPS 全覆盖。一、核心技术价值:解决内网明文与信任难题
二、典型应用场景:全覆盖内网关键系统
三、合规与管理:等保 2.0 与审计轻松过
四、为什么选择专业内网 IP 证书
结语



