老电视出了投屏,还有没有其他办法解决影视播放问题?
Android 5 ,6 的系统,飞牛、极空间这些 app 都无法安装。
投屏经常失败,除了购买一个投屏神器或者盒子,还有其他办法吗?
投屏经常失败,除了购买一个投屏神器或者盒子,还有其他办法吗?
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
为什么你的网站必须安装SSL证书?从业者揭秘HTTPS背后的安全逻辑 作为长期深耕网络安全与证书服务的从业者,经常被开发者、运维同行问:“我的网站只是个测试环境/个人博客,没必要装SSL证书吧?” 答案很明确:现在没有任何一个网站可以“例外” 。无论是生产环境、内网系统,还是个人Demo、小程序接口,SSL证书早已不是“加分项”,而是必须落地的基础安全基建。 今天不堆空洞概念,从技术底层拆解HTTPS的安全逻辑,讲透“为什么必须装SSL证书”,以及开发者最容易踩的证书坑。 很多开发者只知道“HTTPS有小锁,HTTP没有”,却没搞懂底层逻辑,这也是踩坑的根源。 简单说:HTTP是明文传输,HTTPS = HTTP + TLS/SSL加密 + 身份认证,两者的安全等级天差地别。 从技术实现上,HTTPS核心解决了HTTP的三大致命缺陷: 对开发者而言,这不是“额外工作量”,而是规避后续安全事故的第一道防线。 很多开发者抱有侥幸心理:“我的网站没敏感数据,裸奔也没事”。但实际落地中,这些问题会直接导致项目停摆、用户流失。 Chrome、Edge、Safari等主流浏览器早已全面禁用HTTP:未安装SSL证书的站点,地址栏会醒目标红“不安全”,部分版本直接拦截访问,用户需手动跳过才能进入——对用户而言,这和“恶意网站”几乎没有区别,留存率直接归零。 即使是个人博客、测试环境,只要涉及用户登录、表单提交,HTTP明文传输就会导致: 亲身经历过一个项目:测试环境未装证书,被内网抓包篡改接口数据,导致测试用例全部失效,浪费了3天排查时间。 这是最直接的影响,也是开发者最头疼的问题: HTTP明文传输的另一个常见问题:运营商、路由器可随意劫持页面,植入弹窗广告、恶意跳转,不仅影响用户体验,还会损害品牌形象——即使是内网系统,也可能被内网设备劫持篡改。 很多开发者以为SSL证书只是“生成一个文件部署到服务器”,其实背后是一套完整的PKI公钥基础设施,核心价值远不止加密。 正规SSL证书默认采用:2048/4096位RSA算法(或更高效的ECC椭圆曲线加密),搭配256位AES对称加密——这种加密强度,依靠现有算力几乎无法暴力破解,能有效抵御监听、重放、中间人攻击。 这里提醒一句:自签名证书虽然能实现加密,但没有CA机构背书,浏览器不认可,等于“自欺欺人”。 SSL证书不是“一刀切”,不同场景对应不同等级,避免过度配置或安全不足: 从1年→398天→200天,SSL证书有效期不断收紧,很多开发者抱怨“续期麻烦”,但从安全角度看,这是必然趋势: 有效期越短,证书被盗用、伪造的风险窗口就越小,同时强制网站定期更新身份核验,对抗日益增强的黑客攻击能力——这不是“麻烦”,而是行业对安全的基本要求。 很多开发者为了省事,用自签名证书或不知名免费证书,结果踩坑不断: 结论:真正可用、稳定的HTTPS,必须依靠权威CA签发的正规SSL证书。 HTTPS早已不是“可选项”,而是网站的基础基建。对开发者而言,提前部署SSL证书,不是“增加工作量”,而是规避后续安全事故、项目上线受阻的最优解。 尤其是在证书有效期全面收紧、安全规范不断升级的今天,选择一套标准化、稳定可靠的证书服务,能节省大量排查、续期、兼容的时间,把精力放回核心业务上。 毕竟,对开发者而言,“少踩坑、省时间、保安全”,才是最核心的需求。一、先理清核心:HTTP与HTTPS的本质差异(开发者必懂)
二、不装SSL证书,你要面对的4个致命问题(实测踩坑总结)
1. 浏览器拦截 + 信任崩塌
2. 数据泄露风险(开发者最易忽视)
3. 平台限制,项目无法上线
4. 网页劫持、广告植入
三、从业者揭秘:SSL证书的安全逻辑,不止“加个锁”
1. 加密强度的底层逻辑
2. 证书等级的适配逻辑(开发者必看)
3. 有效期缩短的底层逻辑(别嫌麻烦)
四、开发者避坑:别再用自签名、野路子免费证书
五、最后:对开发者、运维的一点建议
内网 HTTP 明文传输、浏览器持续告警、等保审计不通过、自签名证书管理混乱…… 在内网 OA、ERP、堡垒机、BMC、K8s 集群、IoT 设备等大量仅用静态内网 IP提供服务的场景中,这些问题长期困扰运维与安全团队。内网 IP SSL 证书,专为私有 IP 环境设计,无需公网域名、无需自建 CA,即可实现可信 HTTPS 加密与身份校验,是企业内网安全升级的标准方案。 内网 IP SSL 证书由合规 CA 直接签发,绑定内网静态 IP(如 192.168.x.x、10.x.x.x、172.16.x.x),基于 TLS 1.2/1.3 构建加密通道,端到端防窃听、防篡改、防重放。相比自签名证书,它无需逐台导入根证,浏览器与系统默认信任,彻底消除 “不安全” 提示;相比私有 CA,它省去搭建、维护、续期、吊销的复杂成本,即开即用。 支持RSA/SM2 双算法,兼容国密与国际标准,对称加密采用 AES-256/SM4-GCM,密钥交换使用 ECDHE/SM2,满足金融、政务、能源等高安全要求。证书支持 SAN 多 IP 绑定,单张可覆盖集群与多节点,适配负载均衡与微服务架构。 满足《网络安全法》《数据安全法》对传输加密的强制要求,直接匹配等保 2.0 三级及以上 “通信传输安全” 测评项。证书包含企业身份信息,支持OV/IV 认证,可审计、可追溯、可快速吊销,杜绝非法接入与伪造站点。 提供自动化部署与续期对接,兼容 Nginx、Apache、IIS、Tomcat 及 K8s cert-manager,支持 API 批量签发,降低人工运维与过期故障风险。 IP证书获取办法:打开JoySSL官网,填写注册码230970,获得大额优惠。 内网不是安全盲区,HTTPS 不是公网专属。一张内网 IP SSL 证书,以最小成本解决内网加密、身份可信、合规审计三大核心问题,让内网通信从 “裸奔” 变 “密传”。 我们提供内网 IP 证书咨询、选型、签发与部署一站式服务,支持测试签发与技术对接,帮你快速完成内网 HTTPS 全覆盖。一、核心技术价值:解决内网明文与信任难题
二、典型应用场景:全覆盖内网关键系统
三、合规与管理:等保 2.0 与审计轻松过
四、为什么选择专业内网 IP 证书
结语
2025 年 12 月 13 日,VeloxCon China 2025 在北京成功举办。作为 Velox 项目首次在中国举办的线下技术大会,汇聚了来自Meta、IBM、蚂蚁集团、阿里云、腾讯、小米、小红书等企业的数十位核心贡献者与一线工程师。 大会通过 18 场演讲将 Velox 置于真实业务场景之中,系统展示了其在架构演进、AI 数据处理、湖仓加速、流批融合等方向的最新实践。这些分享不仅直面性能、稳定性与兼容性等落地挑战,也反应了开发者社区对构建可靠、可扩展、可协同的数据基础设施的共同探索,彰显了中国开发者在全球高性能分析生态中的工程深度与协作广度。 夯实底座,突破能力边界 在明确了社区与架构演进的总体方向后,大会议题迅速深入到如何利用 Velox 构建高性能计算引擎的具体实践中。阿里云 EMR Serverless Spark 技术负责人周克勇系统阐述了“可组合性”在数据计算领域的实践。他详细解析了阿里云如何深度集成并贡献于 Apache Celeborn、Paimon、Velox 及 Gluten 等开源组件,通过模块化组装构建出高性能湖仓一体引擎。他指出,基于该架构,阿里云 EMR Serverless Spark 成功创造了 TPC-DS 100TB 规模性能测试的世界新纪录,实现性能翻倍与性价比大幅提升。 接着,Meta 软件工程师 Masha Basmanova 阐述了现有查询引擎在跨语言通信、优化器能力与开发体验上面临的挑战,并介绍了基于 C++ 的统一前端框架 Axiom。该框架将 SQL 解析、逻辑优化与物理执行融为一体,通过内置的强大优化器与 Velox 运行时无缝对接,能够实现更高效、可扩展的查询处理。演讲最后,她积极展示了 Axiom 的开源路线图,并欢迎全球开发者加入,共同推动该项目的演进。 强大的执行框架,最终需要服务于极具挑战性的数据场景,特别是爆发式增长的 AI 数据。Meta 软件工程师孟晓烜则在之后的演讲中,深入阐述了应对AI训练数据规模激增与成本挑战的解决方案。他重点介绍了 Meta 如何通过数据归一化技术剥离重复特征,并构建可索引的序列存储系统。依托 Velox 技术栈,团队在训练数据的加载、生成与探索三大环节实现了端到端优化,显著提升了处理效率与资源利用率。 在 Meta 多位工程师从框架演进、可组合架构、数据标准化等角度深入分享后,蚂蚁集团高级技术专家黄叶伟也从企业落地实践层面分享了基于 Velox 的 Spark 加速实践。他重点介绍了基于 Gluten 与 Velox 构建的向量化引擎如何通过任务级 Fallback、Spill 优化、Shuffle 优化等关键技术,在混合部署场景下显著提升 Spark 性能与稳定性。他表示,该方案目前已实现日均数十万任务覆盖,平均节省资源超30%,并将在算子优化与架构扩展方面持续演进。 作为连接 Spark 生态与原生加速的关键中间层,Apache Gluten 的进展同样备受关注。来自 IBM 的莫芮与周渊聚焦 Apache Gluten与 Velox 的深度集成,阐述了其如何在大数据分析中驱动创新。他们介绍,Gluten 在保持对 Spark/Flink 作业透明加速能力的同时,正逐步增强对多后端引擎和复杂业务场景的适配能力。目前,该方案已在 Pinterest、顺丰科技及多个内部集群完成规模化验证,有效支撑了从日志分析到物流调度等多样化负载的性能提升与成本优化。 随着向量化加速在通用场景日趋成熟,针对特定存储格式的深度优化成为新的效能突破口。腾讯大数据开发工程师陈锦海分享了微信基于 Velox 加速 lceberg 湖仓分析的优化与实践,重点介绍了原生分桶方案。据他介绍,该方案通过动态识别表元信息自动设置分区数,能有效缓解 AQE 引发的写入倾斜,结合空闲资源灰度发布策略,可保障大规模作业的稳定上线。 扎根场景,释放协同效能 面对海量数据挑战,全球科技公司也在探索相似的演进路径。Meta 软件工程经理 Stanley Yao 在演讲中分享了公司基于 Velox 推进 Spark 向量化改造的整体策略。他表示,团队通过从定制化方案到开源架构的持续演进,已实现关键业务管线向 Gluten(Flare)的平稳迁移,并获得显著的效率提升。未来,Meta 计划进一步扩大该架构的应用规模。 在 CPU 向量化趋于普及的同时,利用异构硬件挖掘更高性能成为新的前沿。IBM 研究院资深软件工程师 Zoltán Arnold Nagy 展示了基于 Velox 与 Presto 的 GPU 加速数据处理方案。他介绍道,Velox 通过与 cuDF 集成,可在 GPU 上高效执行算⼦,并针对多 GPU 分布式场景优化通信与数据交换。此外,为突破 I/O 瓶颈,团队正在探索结合 GPUDirect 存储与缓存层的加速策略。 对性能与稳定性的追求,也驱动着查询引擎架构本身的融合与创新。Meta 软件工程师谭家梁与大家分享了 Native Presto-on-Spark 的规模化应用。该架构以 Presto 查询优化、Spark 资源调度与容错机制以及 Velox 原生向量化执行为核心,实现了性能与可靠性的显著提升。他表示,目前该方案已在生产环境中取得成效,并将在未来持续推进全栈原生化演进。 对于国内庞大的云上业务,Velox 同样在支撑着关键数据服务平台。 阿里云高级工程师王彬与范阿冬系统介绍了Velox在阿里云日志服务中的深度集成与应用。他们指出,基于 Velox 构建的高性能查询引擎,通过混合执行、表达式下推、自动增量物化视图及免 Schema 分析等核心技术,可显著提升平台在处理海量实时数据时的查询效率与资源利用率。他们还强调,该架构不仅为日志分析、智能运维等场景提供了稳定支撑,也为面向 AI 的云原生数据平台演进奠定了坚实基础。 除了通用的日志与湖仓分析,Velox 也在向更垂直的时序数据场景渗透。腾讯高级工程师李兆龙分享了基于 Velox 构建云原生时序数据库的落地经验。他表示,通过在 Velox 中实现时序数据去重优化与存储写入增强,系统在应对高频写入与实时查询场景时,可显著提升吞吐效率与响应性能。目前该方案已有效支持物联网、实时监控等业务场景,未来还将进一步完善缓存与压缩机制,持续优化时序数据处理的整体效能。 IBM 软件工程师刘平接着分享了 Velox 在 Iceberg 数据写入能力上的突破性进展。他表示,目前 Velox 对 Iceberg 的支持以读取为主,其写入功能的完善将填补该方向的关键能力空白,为基于 Presto 与 Spark 的数据湖架构提供更统一、高效的数据摄入层。这一进展也标志着 Velox 正从查询加速向数据全链路处理拓展。 接着,来自阿里云的毕岩与周滔分享了 Velox 与 Apache Paimon 深度集成的解决方案,为提升引擎与存储的协同效率提供了另一种集成思路。在他们看来,现有方案存在表类型支持受限、缺乏可移植性等瓶颈, 但可以建立 C++ 原生 Paimon 库,通过其统一的数据协议与插件化设计,使 Paimon 能够被 Velox、StarRocks 等多种计算引擎直接高效调用,从而提升数据读写性能,并为湖仓格式的跨引擎协同提供新的基础支撑。 在批处理场景之外,流计算框架的向量化也正成为新的热点。蚂蚁集团技术专家刘勇介绍了基于 Velox 为 Flink 构建的统一向量化执行引擎 Flex。他表示,Flink 作为流批一体架构的核心,其原生向量化能力的补足至关重要。Flex 通过将 Velox 的高性能算子能力引入 Flink,同时结合自动化验证、可视化计划与精细化回退机制,现已实现了作业性能的显著提升,并支撑多条核心业务链路平稳运行。 随着 Velox 赋能的应用场景日益广泛和复杂,确保其在不同引擎和版本间的整体质量与可靠性变得至关重要。Meta 软件工程师 Eric Liu 阐述了在 AI 数据基础架构下,保障 Velox 多引擎版本可靠性的系统化方法。他指出,面对不同引擎与存储格式交织带来的复杂性,关键在于建立跨引擎测试框架与合成数据工厂。这一实践能有效提前发现全栈潜在问题,从而确保底层变更在大规模生产环境中的稳定与高效。 针对向量化引擎中窗口运算符内存溢出的典型难题,来自英特尔的贾柯分享了她的见解。她认为,通过为 Velox 引入流式窗口处理机制,可使计算随数据到达逐步执行并即时释放内存,从而从架构层面化解多数场景下的内存风险,显著提升复杂查询的稳定性。 最后,小红书 Native Engine 团队技术负责人魏秀利也分享了向量化引擎在公司业务中规模化落地的经验。据他介绍,通过将写入异步化并构建原生 Avro 读取能力,小红书在不增加业务复杂度的前提下,成功缓解了端到端延迟,印证了“执行与存储协同优化”在湖仓场景中的关键价值。 从底层执行引擎的持续创新,到日志分析、湖仓写入、流批融合等复杂场景的稳定运行,在本届 VeloxCon China 上,我们看到 Velox 的技术价值已在真实业务中不断被验证和拓展。同时我们也很高兴看到中国开发者成为这一进程的重要推动者。期待未来有更多志同道合者加入 Velox 开源社区,共建高性能分析基础设施。weibo.com/ttarticle/p/show?id=2309405288480426557959 weibo.com/ttarticle/p/show?id=2309405288480766034510 weibo.com/ttarticle/p/show?id=2309405288481110229125 weibo.com/ttarticle/p/show?id=2309405288481458356355 weibo.com/ttarticle/p/show?id=2309405288481806483864 weibo.com/ttarticle/p/show?id=2309405288482259206188 weibo.com/ttarticle/p/show?id=2309405288482595012644 weibo.com/ttarticle/p/show?id=2309405288482930557213 weibo.com/ttarticle/p/show?id=2309405288483270295767
会议伊始,Velox 项目联合发起人 Pedro 发表开幕致辞。他回顾了 Velox 开源项目的发展历程,从项目启动、开源发布到建立技术治理结构,展示了 Axiom 架构、GPU 支持、PyVelox 等关键进展,强调了社区协作与工程严谨性是项目持续演进的核心动力。他特别提到,Velox 已建立了正式的技术治理机制,并迎来来自 IBM、Intel、NVIDIA、Microsoft 等多家企业的新增维护者,标志着项目正迈向更加开放和可持续的阶段。
午餐后的议程更加聚焦 Velox 在真实业务中的集成深度与生产韧性,回应了开发者们对兼容性、稳定性与端到端效能等规模化落地的核心关切。
小米计算平台计算引擎负责人王胜杰分享了公司在 Spark 向量化升级中的规模化落地经验。面对业务迁移中的兼容性与稳定性挑战,他表示,小米通过自动兼容校验、双跑结果比对及内存异常感知的三级资源升级机制,已成功推动向量化改造在数十万作业中平稳落地。
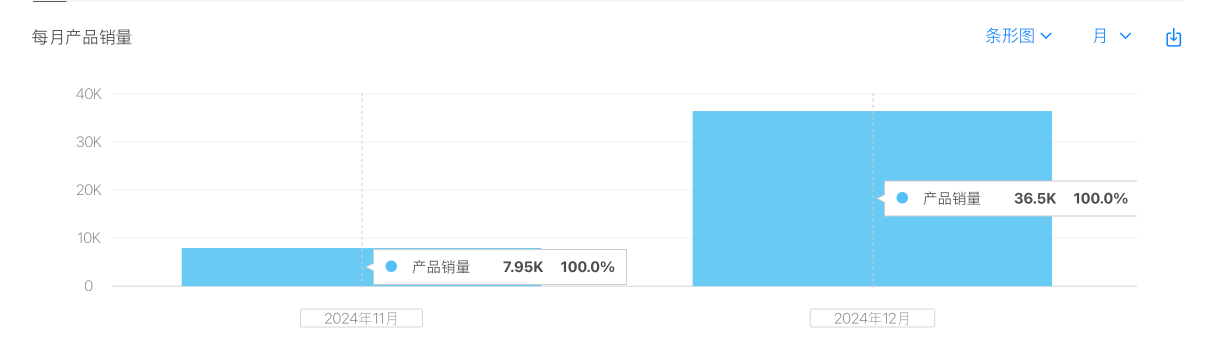
11 月我这个 App 下载 7.95K ,12 月做了一轮 ASO 之后变成 36.5K 。
就改了三样:关键词、标题副标题、描述。
最近把这套流程做成了工具: https://topstore.000ooo.ooo/
丢一个 App Store 链接进去,一键生成可以直接粘回 App Store Connect 的那三样。
还在补关键词库,做 App 或者搞 ASO 的朋友欢迎试试。
网上很多靠漏洞,8r 到 15r 能官方直冲 GPT plus 版本的,还能充值到自己账号上。
我目前用的是站上网友推荐的海鲜市场 team,也很便宜,10r 一个月也能搞定。
这都是小钱,只是好奇哪种方式更安全一点?别到时用着用着自己的号没了
最近在研究净水器,纠结点比较明确:要不要自己组装一套 RO 净水器。
我目前的需求是:
之所以倾向 DIY ,是因为看了一些方案,比如这个 21 年的帖子:
https://post.smzdm.com/p/aqxpeqex/
感觉思路是:通用滤瓶 + 通用滤芯( PP 棉、活性炭、RO 膜),后期换芯成本确实低很多。
但也有点担心几个问题:
所以现在有点纠结:是不是直接买成品更省心?
如果买成品的话,希望满足:
想问下大家:
邮件签名证书(S/MIME 证书) 核心作用:证明你是你、邮件没被改、内容别人看不了、发了不能赖。它是邮箱的 “电子身份证 + 安全锁 + 法律签名”,解决传统邮件身份伪造、内容篡改、信息泄露、事后抵赖四大死穴。 ↓ 邮件签名证书:https://www.joyssl.com/certificate/select/free.html?nid=7 ↑ 邮件签名证书 = 身份防伪 + 内容防改 + 传输加密 + 法律有效。日常商务、敏感信息、正式往来强烈建议用;普通闲聊可不用。一、核心四大作用(最实用)
1. 身份认证:防钓鱼、防冒充(最关键)
2. 防篡改:内容 100% 完整
3. 邮件加密:内容只有收件人能看
4. 法律效力:不可否认、可当证据
二、额外价值(企业 / 商务必看)
三、一句话总结
Zendesk 最近提出,生成式 AI 改变了软件交付的核心制约因素——从编写代码转变为所谓的“吸收能力”。所谓吸收能力是指组织清晰界定问题、将各类变更融入整体系统、验证功能行为正确性并将落地成果转化为稳定可靠价值的综合能力。在 Zendesk 的论述框架下,当代码供给变得充足,核心挑战便不再是快速产出代码,而是要避免快速生成的内容与架构一致性、评审能力及交付流程脱节。 在 Zendesk Engineering 的一篇博文中,Bence A. Tóth 用农业与制造业的类比阐述了这一观点。他认为,若系统中仍存在其他约束条件,仅优化某一环节未必能提升整体吞吐量。他在文中写道,在软件领域,生成式 AI 已大幅降低代码生产成本,实现环节不再是最大瓶颈。 回看 Margaret Hamilton 那张标志性的阿波罗登月软件照片,当时代码编写仍是软件交付的主要制约因素(来源) Tóth 提出的 “吸收能力” 这一概念涵盖了将生成式代码转化为可靠成果所需的各项工作,包括明确要构建的内容、让实现方案与整体架构保持一致、通过验证确保可靠性,以及判断最终变更是否切实提升了客户价值。 文章提出了四项务实应对措施。首先,问题定义应成为产品与工程团队的共同责任,而非单向交接,因为模糊的需求可能导致看似合理、实则偏离目标的实现。其次,团队应通过完善验证闭环来降低试错成本,包括 CI 检测、静态分析、安全检查、可观测性建设、分阶段发布,以及部署后的快速产品反馈。 第三,架构与工程规范应作为 AI 辅助交付的支撑框架,包括清晰的边界划分、统一的命名规范、通用模板、轻量级的架构决策记录(ADR),以及在 CI 流程中强制落地的防护机制。最后,团队应衡量整体交付效能而非单纯产出量,优先关注前置时间、评审队列耗时、变更失败率、回滚频次及事件负载等指标,而非代码行数、PR 数量或词元数量。 他认为,AI 会放大代码库与交付流程中已有的结构性问题。在模块边界清晰、不变量有文档说明、实现路径少且易于理解的系统中,AI 能够提升研发效率,同时也更容易进行引导与校验。而在规范模糊或存在架构漂移的系统中,同样的加速效果反而会加剧不一致性、加重评审负担,并降低对代码变更的可信度——这些变更在局部看似合理,却可能在更大范围内对系统造成损害。 在 InfoQ 近期一篇关于 Agoda 对 AI 编码工具看法的报道中,Agoda 同样认为,编码从来都不是真正的瓶颈。随着实现速度加快,规范与验证的重要性愈发凸显。Zendesk 则进一步深化了这一观点,明确指出了新的制约因素,并将其定义为组织设计问题:如何在不影响架构稳定性与交付质量的前提下提升团队吸收快速变更的能力。 对于架构师和工程负责人而言,这意味着真正的优势并不属于生成代码最多的团队,而是属于能够安全、高效地吸收更多有价值变更的团队。 【声明:本文由 InfoQ 翻译,未经许可禁止转载。】 查看英文原文:https://www.infoq.com/news/2026/04/zendesk-absorption-capacity/
2026 年 2 月,Nous Research 发布了 Hermes Agent,一个"会自我进化"的开源 AI Agent 框架。不到两个月,GitHub 星标突破 35k,成为 AI Agent 赛道增长最快的项目之一。和 OpenClaw 那种"做完就走"的无状态模式不同,Hermes 的核心理念是 "the agent that grows with you"——越用越懂你,用得越久能力越强。 但说实话,很多中文用户装完之后会发现:官方文档全是英文,网上的教程要么太浅要么太散,真正能指导日常使用的高阶技巧几乎找不到。这篇文章就是想把这个缺口补上。我会从实际使用场景出发,把 Hermes Agent 最值得掌握的功能——上下文文件、记忆系统、技能体系、定时任务、安全沙箱——逐个拆开讲,同时在关键位置穿插和 OpenClaw 的对比,帮你看清两者的本质区别。 很多文章喜欢用表格列一堆功能做对比,但看完还是不知道怎么选。我用一句话总结它们的根本区别: 具体来说,差异体现在五个核心维度: 1. 记忆机制 OpenClaw 的记忆依赖 Markdown 文件(SOUL.md、AGENTS.md),高级能力如向量检索需要额外装插件,本质上是"你让 AI 记什么,它才记什么"。Hermes Agent 则内置了多层原生记忆架构: 这两套记忆文件在每次会话启动时自动注入上下文,所以你不用每次重新解释"我的项目用 FastAPI、测试用 pytest、不要提交 .env"这类东西——Hermes 已经记住了。 2. 技能体系 OpenClaw 的技能完全依赖人工编写或从 ClawHub 社区下载,目前有 13729+ 个扩展插件,生态确实庞大。但技能不会自己变多,能力边界由你装了多少插件决定。 Hermes Agent 的技能系统走的是另一条路。每当 Agent 完成一个复杂任务——特别是中间出过错然后自己修了、走了非显而易见但有效的路径、或者你做了纠正——它会自动触发学习循环,在 说得直白一点:OpenClaw 是用现成技能,Hermes 是自己造技能。 3. 安全设计 这个维度差距特别明显。OpenClaw 没有默认内置安全沙箱,ClawHub 上的插件质量参差不齐——根据安全研究机构的报告,高达 36.8% 的插件被查出存在严重漏洞或被投毒。"ClawHavoc"攻击事件中,恶意插件甚至直接扫荡了用户的本地目录,窃取聊天记录和钱包私钥。 Hermes Agent 从第一天起就内建了五层安全防线: 截至 2026 年 4 月,Hermes Agent 没有公开记录的任何 CVE 漏洞。 4. 成本控制 OpenClaw 默认全量加载所有已安装技能,技能越多,每次请求携带的技能定义文本就越大,token 消耗自然就高。Hermes Agent 用了渐进式加载(Progressive Disclosure):先只加载技能列表(约 3k token),等 Agent 真正需要某个技能时才加载完整内容。简单任务用便宜模型,复杂任务切到强模型, 5. 消息平台覆盖 Hermes 走的是国际主流加密通讯平台的路线,对国内社交渠道的支持在 v0.9.0 之后快速补齐。OpenClaw 在国内平台生态上积淀更深,覆盖也更成熟。值得一提的是,Hermes 官方在宣布支持微信时专门用中文发推、用中文回复社区留言,这个细节在中文圈刷了不少好感度。 选型建议一句话版: Hermes Agent 有三个关键上下文文件,理解了它们,你就掌握了让 Agent 快速进入状态的方法。 在项目根目录放一个 一个典型的 AGENTS.md 长这样: 这个机制和 Claude Code 的 CLAUDE.md、Cursor 的 .cursorrules 是同一个思路——Hermes 的 Issue #681 也明确提到,这是研究 30+ AI Agent 界面后发现的最普遍的 UX 模式。如果你已经在用 Cursor,现有的 这个文件控制的是"Agent 怎么说话"而不是"Agent 做什么"。如果你觉得 Agent 太啰嗦,或者回复风格不对胃口,改这个文件比每次在对话里纠正效率高得多。 如果你是 Cursor 用户,不用担心配置迁移的问题。Hermes 会自动检测并读取以下位置的文件: 不需要额外配置,也不用复制粘贴。这个兼容性设计对从 Cursor IDE 切换过来的开发者特别友好。 很多人把 Hermes 的记忆简单理解为"聊天记录存盘",其实远不止于此。它的记忆是一个分层体系,每一层有不同用途和不同时间跨度: 关键点在于"Agent 自主维护"这几个字。MEMORY.md 和 USER.md 的内容不是你手动写的,而是 Agent 根据对话模式自己决定存什么。2,200 字符的上限看起来很小,但这个限制反而迫使 Agent 只保留最重要的信息——相当于一种自动的信息压缩机制。 如果你想扩大记忆容量,可以接入 Honcho 作为外部记忆提供者,支持无限量的跨会话用户建模和语义搜索。截至 2026 年 4 月,Hermes 已支持 8 种外部记忆提供者插件,同一时间只能激活一个 alongside 内置记忆。 实际使用技巧: Hermes 的 CLI 设计得相当完善,支持多行编辑、斜杠命令补全和历史搜索。除了基本的 这三个命令解决了一个高频痛点:你昨天跟 Agent 聊了一半的调试任务,今天想接着来。不用重新描述上下文,直接 在 CLI 或消息平台里输入 LLM 的 API 定价里有一个容易被忽略的细节:如果连续请求的系统提示(system prompt)完全相同,很多模型提供商会自动命中缓存,缓存命中的 input token 价格通常比正常便宜 50% 以上。 Hermes Agent 的系统提示由固定的框架结构 + 动态的上下文文件 + 记忆文件 + 工具定义组成。要想最大化缓存命中率: 所有技能存放在 这是 Hermes 技能系统最精巧的设计之一。技能不是一次性全部塞进上下文的,而是按需加载: Agent 先拿到技能列表(Level 0,约 3k token),判断需要哪个技能后才加载完整内容(Level 1)。如果技能还引用了外部文件(比如模板或脚本),再按需加载(Level 2)。这比 OpenClaw 全量加载所有技能省 token 多了。 技能可以根据当前可用的工具自动显示或隐藏。一个实际例子:内置的 这个机制的好处是:你可以给同一类任务准备"高级方案"和"备选方案",不用手动切换。 技能可以在 SKILL.md 里声明所需的环境变量: 当缺少对应值时,Hermes 只在本地 CLI 安全地询问你(消息平台不会在聊天里问敏感信息)。一旦设置好,这些环境变量会自动传递给 Hermes 内置了 cron 调度器,不需要额外装任何东西。下面用一个真实场景演示完整流程:每天早上 8 点,自动搜索 AI 新闻并发送到 Telegram。 两种方式都行: 方式一:用斜杠命令 方式二:用自然语言 Agent 会自动解析你的意图并创建 cron job。 定时任务在独立的会话中运行,无法访问当前对话的上下文。所以 cron 任务的 prompt 必须是自包含的(self-contained),把所有必要信息都写在 prompt 里,不要依赖"Agent 应该知道我之前说过什么"。 例如,不要这样写: 应该这样写: 如果你从 Telegram 创建了 cron job,结果会自动发回同一个 Telegram 聊天。你也可以在创建时指定投递平台: 如果定时任务需要同时做几件独立的事情,可以用 Hermes 会把三个子任务分配给隔离运行的子 Agent,并行执行后合并结果。 Hermes 支持六种终端后端,安全级别从低到高: 配置 Docker 后端: Docker 模式下,Hermes 采用"容器硬化"策略:只读根文件系统、最小权限、命名空间隔离。文件系统操作默认限定在挂载的工作目录内。 当 Agent 要执行可能危险的操作时(比如 如果你完全信任 Agent(比如在沙箱环境里),可以用 接入 Telegram 或企业微信时,建议配置用户白名单: 这样只有指定用户才能跟 Agent 对话。Hermes 还支持私聊配对机制:用户通过特定的配对码注册身份,未注册的用户发送的消息会被忽略。 Hermes 会扫描 AGENTS.md、SOUL.md 等上下文文件中是否包含 prompt injection 攻击向量。这是一个经常被忽略但至关重要的安全层——如果你的项目中有第三方贡献者提交的 AGENTS.md,这个扫描可以防止恶意指令被注入到 Agent 的系统提示中。 如果你之前在用 OpenClaw,Hermes 提供了一键迁移工具: 这个命令会检测 迁移完成后,原来的 OpenClaw 配置不会被删除,所以你可以两个都留着对比使用。agentskills.io 格式的技能文件在两个平台之间是互通的。 Hermes Agent 的官方文档虽然是英文的,但中文社区已经相当活跃: 如果你是刚开始接触 Hermes Agent,建议的路线是:先看中文社区的快速入门指南装起来 → 配好模型 → 试着用 CLI 聊几轮 → 接一个消息平台(推荐 Telegram 或飞书)→ 设置第一个 cron 定时任务 → 等待 Agent 自动生成第一个 Skill。整个流程大约 1-2 小时就能走完。 最后的建议:Hermes Agent 最大的价值不在于某个单一功能,而在于"时间复利"。第一天用和第三十天用,体验是完全不同的——因为 Agent 在这段时间里积累了你的工作习惯、项目上下文、常用操作模式,并且把这些全部转化为了可复用的技能。这种"越用越强"的特性,是 OpenClaw 的"做完就走"模式做不到的。 如果你已经决定试试,hermesagent.org.cn 是最好的中文起点。 本文由mdnice多平台发布如果你还在犹豫选 OpenClaw 还是 Hermes Agent,或者已经装了 Hermes 但不知道怎么用好它——这篇文章应该能帮到你。
一、先说选择:Hermes Agent vs OpenClaw,到底差在哪?
OpenClaw 是"拿来主义"——有 13000+ 社区技能直接装,接上就能干活;Hermes Agent 是"自我进化"——技能是自己长出来的,用两个月后你会发现它比你更了解你的工作流程。
~/.hermes/skills/ 目录下生成一个标准的 SKILL.md 文件,包含完整的步骤、陷阱和验证方法。格式兼容 agentskills.io 开放标准,理论上可以和 OpenClaw 生态互通。hermes model 命令可以随时切换。很多社区用户反馈"Hermes Agent 比 OpenClaw 便宜"。平台 Hermes Agent OpenClaw Telegram ✅ ✅ Discord ✅ ✅ Slack ✅ ✅ WhatsApp ✅ ✅ Signal ✅ ✅ 企业微信 ✅(v0.9.0 原生支持) ✅ 飞书 ✅ ✅ 钉钉 ✅ ✅ 微信 ✅(腾讯 Bot API) ✅ iMessage ❌ ✅ hermes claw migrate 一键迁移命令二、上下文文件:让 Agent 一进项目就"懂行"
2.1 AGENTS.md —— 项目规则,自动注入
AGENTS.md 文件(也兼容 .cursorrules 和 .cursor/rules/*.mdc),Hermes 启动会话时会自动读取并注入系统提示。你不用每次都跟它解释"这个项目用 Python、测试用 pytest、别碰 main 分支"。# 项目上下文
- 这是一个 FastAPI 后端项目,使用 SQLAlchemy ORM
- 所有数据库操作必须使用 async/await
- 测试文件放在 tests/ 目录下,使用 pytest-asyncio
- 禁止提交 .env 文件
- API 路由统一使用 /api/v1/ 前缀
- Git commit message 遵循 Conventional Commits 规范.cursorrules 文件不用改,Hermes 直接就能读。2.2 SOUL.md —— 人格配置,定义 Agent 的"性格"
~/.hermes/SOUL.md 是全局人格文件,定义了 Agent 在所有项目中的行为风格。和 AGENTS.md 不同的是,SOUL.md 不是项目级的,而是跟着你走的。# 灵魂
You are a senior backend engineer. Be terse and direct.
Skip explanations unless asked. Prefer one-liners over verbose solutions.
Always consider error handling and edge cases.2.3 .cursorrules 兼容
.cursorrules(项目根目录).cursor/rules/*.mdc(Cursor 规则目录)三、记忆系统:不是"记住对话",而是"理解你"
记忆类型 工作方式 持久性 最适合存储 MEMORY.md Agent 自主维护的笔记,~2,200 字符上限 永久(磁盘) 项目细节、偏好、环境备注 USER.md Agent 自主维护的用户画像,~1,375 字符上限 永久(磁盘) 角色、技术栈、沟通风格 会话历史 SQLite + FTS5 全文索引 永久(磁盘) 回溯历史对话、搜索上下文 Honcho 结论 辩证推理推导的用户洞察 永久(云/自托管) 深度用户建模、偏好模式 技能(过程记忆) 从经验中提取的可复用能力 永久(磁盘) 学到的工作流、任务流程 工作上下文 当前会话的对话窗口 仅当次会话 当前任务、进行中的工作 hermes memory search "关键词" 可以快速搜索历史记忆hermes sessions 可以浏览、导出、清理过去的会话记录~/.hermes 挂载为 volume,否则容器重建会丢失记忆四、CLI 进阶技巧:那些文档里不太提但很好用的命令
hermes、hermes setup、hermes gateway 之外,这些命令特别值得记住:4.1 会话管理
hermes -c # 恢复最近一次会话(continue)
hermes -c "部署" # 恢复标题包含"部署"的最近会话
hermes -r "fix-auth" # 按标题精确恢复某个会话(resume by title)-c 就能无缝续接。4.2 斜杠命令速查
/ 可以看到所有可用命令。最实用的几个:命令 作用 场景 /compress手动压缩对话上下文 对话变长、token 快用完时 /verbose切换工具执行进度显示 调试 Agent 行为时开到 verbose /model claude-sonnet-4实时切换模型 简单任务切便宜模型,复杂任务切强的 /model provider:model跨供应商切换 从 OpenRouter 切到本地 Ollama /usage查看 token 消耗和成本 控制预算 /title 我的调试会话给当前会话命名 方便以后用 -r 恢复/bg <prompt>后台执行任务 不阻塞当前对话,完成后弹出结果 /btw <question>临时提问(不入历史) 快速确认一个小问题,不污染对话流 /branch 分支名分叉当前会话 想同时探索两个方案时 /plan <需求>先生成计划不执行 复杂任务先看看 Agent 的思路对不对 /rollback [n]文件系统回滚 Agent 改坏了东西,一键还原 4.3 Context Caching 省钱技巧
/compress:在上下文快到上限之前主动压缩,而不是等到被迫截断五、技能系统详解:从零创建一个自定义 Skill
5.1 目录结构
~/.hermes/skills/ 目录下,这是唯一的技能来源。安装时自带一批 bundled skills,Hub 安装的和 Agent 自动创建的也放在这里。~/.hermes/skills/ # 技能根目录
├── mlops/ # 分类目录
│ ├── axolotl/
│ │ ├── SKILL.md # 技能主文件(必需)
│ │ ├── references/ # 参考文档
│ │ ├── templates/ # 模板文件
│ │ └── scripts/ # 脚本文件
│ └── training-monitor/
│ └── SKILL.md
└── my-category/
└── my-skill/
├── SKILL.md
└── config.yaml5.2 SKILL.md 格式
---
name: my-skill
description: 简述这个技能做什么
version: 1.0.0
platforms: [macos, linux] # 可选:限制平台
metadata:
hermes:
tags: [python, automation]
category: devops
fallback_for_toolsets: [web] # 仅在 web 工具集不可用时显示
requires_toolsets: [terminal] # 仅在 terminal 工具集可用时显示
config: # 可选:非敏感配置项
- key: wiki.path
description: "Wiki 目录路径"
default: "~/wiki"
prompt: "请输入 Wiki 目录路径"
---
# 技能标题
## When to Use
触发条件——什么场景下应该用这个技能。
## Procedure
1. 第一步:做什么
2. 第二步:做什么
## Pitfalls
- 已知的失败模式和修复方法
## Verification
怎么确认技能执行成功了。5.3 渐进式加载(Progressive Disclosure)
Level 0: skills_list() → [{name, description, category}, ...] (~3k tokens)
Level 1: skill_view(name) → 完整内容 + 元数据 (不定)
Level 2: skill_view(name, path) → 加载特定的参考文件 (不定)5.4 条件激活(Fallback Skills)
duckduckgo-search 技能设置了 fallback_for_toolsets: [web]。如果你配了 FIRECRAWL_API_KEY,web 工具集可用,Agent 用 web_search 做搜索,DuckDuckGo 技能自动隐藏。如果 API Key 没配,web 工具集不可用,DuckDuckGo 技能就自动冒出来作为替代方案。5.5 安全的环境变量管理
required_environment_variables:
- name: TENOR_API_KEY
prompt: Tenor API key
help: 从 https://developers.google.com/tenor 获取
required_for: full functionalityexecute_code 和 terminal 沙箱,技能脚本可以直接用 $TENOR_API_KEY。六、定时任务实战:搭建一个每日 AI 新闻简报机器人
6.1 启动调度器
hermes cron start6.2 创建定时任务
/cron add "0 8 * * *" "搜索今天最重要的 AI 新闻,总结为 5 条要点,用中文回复"每天早上 8 点给我发一份 AI 新闻简报6.3 其他常用操作
hermes cron list # 查看所有定时任务
hermes cron status # 查看调度器状态和下次执行时间
/cron pause <id> # 暂停某个任务
/cron resume <id> # 恢复暂停的任务
/cron run <id> # 立即执行一次(测试用)
/cron remove <id> # 删除任务6.4 进阶:工作日 standup 报告
/cron add "45 8 * * 1-5" "Review my git log for the last 24 hours and draft a standup update: what I did yesterday, what I'm doing today, any blockers."1-5 表示只在周一到周五执行。6.5 重要注意事项:Cron 任务的"自包含"原则
帮我整理昨天讨论的那个 bug 的进展查看 ~/projects/myapp 目录下最近 24 小时的 git log,
总结代码变更和 bug 修复进展,生成 standup 报告。6.6 平台投递
/cron add "0 7 * * *" "生成天气简报并发送到我的 Telegram"6.7 子 Agent 委派:并行处理复杂任务
delegate_task 创建子 Agent 并行处理:每天早上 8 点,同时做三件事:
1. 搜索 AI 新闻并总结
2. 检查我的 GitHub 仓库有没有新的 issue
3. 查看今天的日程安排
把结果合并成一份早报发给我七、安全实践:让 Agent 跑起来但不"跑偏"
7.1 终端后端选择
后端 安全级别 适用场景 local低(直接执行) 个人开发机,信任环境 docker中(容器隔离) 推荐大多数用户使用 ssh中(远程隔离) VPS 或远程服务器 daytona高(无服务器持久化) 企业级,空闲自动休眠 singularity高(HPC 场景) 超算集群 modal高(无服务器) 弹性计算 # .env 或 hermes setup 中配置
TERMINAL_BACKEND=docker
TERMINAL_DOCKER_IMAGE=hermes-sandbox:latest7.2 危险命令审批
rm -rf、sudo、修改系统文件),Hermes 会弹出审批提示,提供四种策略:--yolo 参数或 /yolo 命令跳过所有审批,但不建议在生产环境这么做。7.3 消息平台安全
# .env
TELEGRAM_ALLOWED_USERS=123456789,9876543217.4 上下文文件注入扫描
八、从 OpenClaw 迁移:三步搞定
hermes claw migrate~/.openclaw 目录,把你的技能、上下文文件、工作流配置全部迁移过来。Hermes 首次安装时也会自动检测 OpenClaw 的存在并提示迁移。九、中文社区资源
PureMac - 免费开源的 macOS 应用管理器和系统清理器。 彻底卸载应用,清除遗留文件与系统垃圾。 公 众z 号: 精准识别应用及全部残留文件,支持多级清理。 缓存、日志、大文件、Xcode / Brew 垃圾一键清理。 系统级保护 + 自动化扫描,干净、不误删。
无订阅,无遥测,不收集任何数据。安装
方式一:Homebrew(推荐)
brew install --cask puremac方式二:安装包
BugShare发送PureMac获取安装包文件。功能
一键卸载,彻底干净
全面清理,释放空间
原生安全,智能无忧
平时对 ai 敏感度不高,但是昨晚做的这个梦,感觉太奇特了,都不知道怎么产生这么奇妙的想法。
梦到和同学学习,这个同学家里就很有钱。日常学习获取知识,是通过消耗类似于我们现在的 token 。
梦里并没有出现电脑之类的产品,获取到的信息仿佛是神经元一样电信号直接传送到大脑中,由你去决定消耗多少 token 来获取想要的领域或者词条对应的知识。
通过 token 获取到的信息是经过整理、抽象过后的,人仿佛不用进行学习和思考,直接能消化得到这部分知识一样。在梦里我也意识到了这个问题,下意识的想到,小时候买课外辅导资料,课本上的知识只是基础,每次考试都会出超出范围或者来回变换让你没见过的题。但是辅导里都会把考题的套路全总结进去。
在梦里,人如果没有 token ,取到的信息和课本一样,都是最基础的,得通过大量的思考和做题一样,才能转换为抽象化经过整理的知识。但是有个想法,人通过思考学习花费大量时间和直接灌输知识,两者会有什么本质的差异吗,对于现在来说肯定是有的,小时候家长老说某个小孩学习很踏实,某个小孩愚笨智力不行,只知道死记硬背根本理解不了。我就从小纳闷,踏实到底代表了什么,对知识的理解能力和深度吗?
如果未来,真可以出现这种灌输知识的能力,是不是可以解决现在学习知识繁重,知识领域需要花费大量时间深耕才能达到顶尖水平的问题。是不是就没了这种问题。
醒来后,还清楚记得这个梦,不知道未来会如何发展,还挺有趣的。


在企业级集成中,有些场景比较棘手,如:如何在保持内网应用物理隔离的同时,无缝对接企业微信的身份认证体系? 关键步骤: 步骤二:企业微信上创建自有应用 步骤三:ZeroNews用户控制台,创建应用访问隧道 步骤四:部署ZeroNews IAM并完成配置 在IAM平台,创建基于应用的访问连接器,并可以同步企微的通讯录,并根据角色控制访问权限。 便捷性:企业维护成本怎样? 员工体验:员工无需安装访问客户端 实现逻辑 ZeroNews 企业网关方案最大的优点是轻量,体验好,管理成本低,如果你的企业也有类似场景痛点,不妨体验一下。
本期我们将关注一种轻量级应用边缘网络访问方案-ZeroNews企业网关,在企业微信集成中的使用实践。
ZeroNews 企业网关+企业微信
ZeroNews 的解决方案理念是 "零接触"。通过企业安全网关+应用级隧道和解耦的 IAM 架构,在保障安全的前提下,实现了简单的接入体验。更重要的时,不需要所有人额外安装客户端。
步骤一:注册ZeroNews 企业账号,并添加企业域名
ZeroNews用户控制中心--自有域名,此处可以提交企业自己的域名
登录企业微信管理后台--应用管理--创建应用,此步骤最关键的是要完成应用域名的校验。因为企微对自建应用的域名,必须满足可信域名的要求,即使用的域名,必须是认证企业自己域名,或关联企业的域名。
步骤二完成域名审核后,即可在平台创建应用的安全隧道,并成功获取隧道访问地址。
在配置中,也可以设置在浏览器,企业微信扫码登录访问。
配置时,会涉及到企微的一些信息,如Corp ID,应用的AgentID等。
步骤五:测试访问
可以针对不同角色添加授权,测试从企业微信里面访问应用,和浏览器扫码访问应用,看是否允许或被拒。
方案要点
安全性:数据安全如何得到保障?
除了隧道本身的加密外,ZeroNews提供了端到端的TLS方案,私钥可以部署在上游应用端,这样便不用担心数据泄密问题。IAM服务部署在企业自己的服务器,企业通讯录也不会外泄。
这套方案的优势,就是轻量化,基于应用,对企业现有网络零侵入。
同时,所有配置操作都是可视化管理,几乎不涉及纯技术,即使产品经理,也可以一人完成配置,极大的降低了企业维护的门槛和成本。
所有访问应用的用户,无需安装任何 APK 或证书。只需在企微中点击应用,网关会自动处理基于 SNI 的路径匹配与身份重定向。被授权的访问用户,在企微里感受不到任何多余步骤。
身份映射: 将企微的 OAuth2.0 回调地址映射到 ZeroNews 提供的 CNAME 域名。
流量管理: 在边缘网关层配置访问策略,仅允许来自企业微信 IP 段或持有特定 JWT 令牌的请求进入隧道。
QoS 管理: 可以为不同的内部应用,分配独立的带宽配额,确保关键业务的体验不受干扰。
Matrix 首页推荐
Matrix 是少数派的写作社区,我们主张分享真实的产品体验,有实用价值的经验与思考。我们会不定期挑选 Matrix 最优质的文章,展示来自用户的最真实的体验和观点。
文章代表作者个人观点,少数派仅对标题和排版略作修改。
上周久违地去正经剪了个头,不是往常10块钱10分钟的快剪。理发师一层层修,洗头洗了两遍,全程将近一小时,慢得我差点睡着。走出店门那刻,头发是顺的,人精神了不少。
这让我想起咖啡。从速溶喝到胶囊,再折腾到手冲。喝得越多,越觉得手冲就像那次精剪——不追求效率,但每个步骤都有交代。一套器具摆出来,烧水、磨豆、注水,过程折磨也迷人。最后那杯下肚,人跟着清醒过来。
少数派上关于咖啡的好文章已经不少。老林老师(@老林还年少)那些《家用咖啡手册》,从豆种、处理法、烘焙法讲到器材和冲煮攻略,体系完整,是很多人的入坑必读。我也是认真拜读过的——当你需要系统了解咖啡这件事的时候,这就是最好的地图。
但作为一个喝了几年、踩过不少坑的普通人,我的体会是:新手入坑手冲,最需要的反而不是知识,是信心。
什么是信心?就是冲出一杯不翻车的咖啡,喝完觉得「诶,还不错,好喝哎」,瞬间有了成就感,然后愿意明天再冲一杯。很多人放弃手冲,不是因为学不会,是因为头几杯太难喝,觉得自己不行。
今天这篇,就想聊聊这件事:怎么用最低的成本建立手冲的信心。我把这几年控制变量法试出来的经验,从好喝、好用(包括好看)、不翻车三个维度整理出来。希望能帮你少走点弯路。喝到第一杯不翻车的咖啡,信心就有了。
另外,为什么是手冲?入门成本最低、空间占用最小,或许就是最主要的原因:

我爸妈不理解我为什么喝咖啡,我老婆也不理解。
他们的理由很一致:苦了吧唧的,喝完心跳加速,有什么好喝的。我妈天天看我冲咖啡,有一次突然说了句:「年纪轻轻的,别老喝这些提神的东西,对心脏不好。」
我说这杯特甜的,有果酸,有回甘。她不信。
这事儿不怪她。大多数中国人对咖啡的第一印象,就是速溶,味如中药,喝完心脏突突跳。这印象刻得很深。
问题出在豆子上。传统速溶为了压低成本,多数用的是罗布斯塔豆。罗豆咖啡因含量是阿拉比卡的两倍,风味单薄,只有傻苦味。喝完心慌手抖,这不是咖啡的错,是罗豆的错。

现在的精品咖啡多数用的是阿拉比卡豆(当然我也见过拼配罗豆的,美其名曰复古怀旧)。种植的条件更加严苛,但是整体产业链更加完善完备,而且咖啡因相对低,风味丰富——浅烘的有花香果酸,深烘的有坚果黑巧。

所以新手入坑手冲,第一件事不是买器具,而是应该要找对豆子。在我的认知里,豆子选对了,整一杯咖啡都不会太差;豆子不行,再贵的器具、再好的手法也救不回来。(也就是俗话说的八分靠豆子)
我的建议很直接:试试看辛鹿的「糖心宇宙」混合装(不是广告)。
原因很简单,它帮你把变量中最关键的一个——豆子风味——给控制了。

而且辛鹿的独立包装真的很方便,一条16克(也有18克的,看清楚),每次不用上称,直接往手磨里面一倒就行。
而且每种豆子都有2-3包,够你用控制变量法尝试不同的冲煮法、研磨度了。品质不错,这个价格可以拿下瑰夏,和巴拿马的没法比,但是确实可以喝出一些酸酸甜甜的感觉了。价格也友好,100左右一斤,对于建立信心的成本来说,我觉得是可以接受。
后续明确了自己喜欢的烘焙度、处理法之后可以逐步进阶,我现在喝的是辛鹿的雷莉达庄园的瑰夏,这真不是辛鹿的广告,一是支持下云南品牌,二是它有着比较完善的供应链、相对比较合理的价格,没人愿意和(省)钱过不去吧?

我们先捋一下一次完整的手冲需要怎么样的过程:
手冲另一半的乐趣在器具,这话没错。
手冲讲究的是仪式感和成就感并重。一套顺手的壶、磨、滤杯摆在那,本身就是一种驱动力——让你每天早上愿意花那十五分钟。所以选器具的时候,好用和好看同等重要。
但有一点得先说清楚:咖啡器具不存在或者说不应该「一步到位」。
这不是配电脑,加钱就能换性能。以滤杯为例,锥形和平底,萃取逻辑不同,没有谁绝对更好。以磨豆机为例,有手磨有电磨,统一了类型的价差能到十倍,但最终那杯咖啡的风味提升,远没有价格差距那么大。
经济学里这叫边际效应递减——过了某个临界点,每多花一块钱,你能感知到的提升越来越小。
所以入门的策略不是「一步到位」,是选一个稳定、适合自己当前阶段的配置。等手艺上去了,舌头也刁了,再考虑升级。
下面按优先级,聊聊我的入门配置。
手冲壶的核心变量是控流。新手最怕水流忽大忽小,一抖就冲出一个坑,萃取不均匀。
贵的壶(比如Brewista、Fellow)好在哪?壶颈设计合理,出水口开得讲究,水流垂直稳定。便宜的壶,颈部设计敷衍,出水口斜切角度不对,水出来带着倾角,想垂直落到粉层上得靠手感找补。
但入门不一定要上贵的。经过一番研究,我发现一个方案:一把够用的不锈钢壶+一个引流片,完全可行。

去任意电商平台搜「不锈钢咖啡壶」,带温度计的最好,长得像传统细嘴壶那种就行,三四十块。再花几块钱买个不锈钢引流嘴,卡在壶嘴下面。引流片的作用是把偏掉的水流「掰」回来,帮便宜壶补上设计短板。

这套组合,控流效果对入门来说足够用了。
当然,我现在用的是泰摩鱼Smart。它把烧水、温控、注水一体化了,方便省心。但入门阶段,三四百一把壶对我来说太贵了。先把基础手感练出来,再考虑升级不迟。
磨是风味的上限变量。新手最容易踩的坑,就是在这个变量上过度投资。
有些朋友咖啡还没冲明白,C40已经下单了。C40好不好?好。手摇的baseline,业界公认。但一千多的售价,意味着你花大价钱去提升一个现阶段舌头还分辨不出的变量。我的体验是:借朋友的C40用过一周,手感比我两百块的巫师丝滑,冲出来的咖啡更均衡,风味铺的更开,但也就那样(而且磨出来的细粉甚至更多,怀疑更多的风味、更高的萃取率可能来自于这些细粉)。
后来出于好奇,我买了把恶作剧家的M40——结构和C40几乎一样,价格只要六分之一。算是个有趣的参照物。

结论:先入一台国产中端,巫师、栗子、汉匠都行。 国产手磨有多卷大家都知道,两三百块的研磨均匀度已经足够入门。先固定住这个底线,等舌头能分辨出更细微的差异时,再考虑升级不迟。
新手直接上V60,二三十块那个。好看、好用。

为什么是它?因为它保留了最多的变量让你去感受。V60是锥形滤杯,粉层深,对注水手法敏感。用V60冲咖啡像读一本厚书,每个变量都会影响结果。等你用它练出手感、练出理解了,再换到平底滤杯(比如我现在常用的Solo、冰瞳B75,还有经典的Origami),你会发现一切都变简单了。这个过程,就是所谓的「先读厚,再读薄」。
当然,如果真的入坑了以后,滤杯应该是买得停不下来的,这里只是我的几个滤杯,还不包括被我儿子打碎了的Origami和聪明杯……

电子秤买个能精准到0.1g的,香山的就行,二三十块。别搜「咖啡秤」,价格会翻倍。有了秤,你才能量化「粉水比」这个关键基础变量。

清洁手磨,花三块钱买个吹气球。它比刷子更快、更干净。同样,别带咖啡二字!忠告啊忠告
其他东西,暂时都别买。手冲支架、分享壶、筛粉器、闻香杯、布粉针……这些东西不是智商税,但对现阶段的你来说,用不上。
先把基础三件套玩熟。等哪天你冲咖啡时觉得「诶,这里好像缺个什么」,那才是该买的时候。
我知道,不是每个人都想拆解所有变量。如果你觉得手冲的变量太多,与你追求便利的本能相悖,我有两条很实在的退路(也许是直接退烧之路):
聪明杯的原理是浸泡式萃取。它直接把「注水手法」这个最难的变量给封装了。

你只需要控制粉水比、研磨度、水温和时间这四个量化参数,中间拿个小勺子适时扒拉一下,其余不用管。配合一个带温控的小米烧水壶,几十块搞定,翻车概率几乎为零。工具是手段,喝到好咖啡才是目的。
2016 年世界咖啡冲煮大赛(WBrC)冠军粕谷哲就是Hario 聪明杯的忠实使用者。

冠军说的能有错吗?
写到这里,我想认真聊一下xBloom。
我主观上真的觉得这是个好东西。
xBloom Studio是两位前苹果设计师创的品牌,2021年成立于硅谷,拿过iF金奖、红点、CES创新奖,设计语言一看就是那种「苹果系」的克制和精致——阳极氧化铝机身、极简塔型结构、黑白两色,摆在厨房里不像是咖啡机,更像是件工业设计作品。

但让我真正喜欢它的不是外观,是它把「自动化」这件事做得很彻底。研磨、称重、注水、萃取,全塞进一台机器里。内置的48毫米七角锥形磨盘,80档研磨调节,研磨均匀度能打。注水手臂是动态的,中心、绕圈、螺旋三种模式,模拟的就是人手冲时的注水曲线。配方可以存进App,一次调好,之后一键出杯。
你只需要把豆子倒进去,按下开始,三分钟后一杯出品稳定的手冲就出来了。

当然,贵(这可能是我的问题)。Studio国内大概三四千。鲜豆胶囊也比普通咖啡胶囊贵一些,豆子选择目前不算多(虽然和很多主理人品牌有合作)——不过它支持用自己的豆子和Kalita 155滤纸。
值不值?看你怎么算这笔账。如果你每天早上能省出十五分钟,不用调参数、不用控水流,还能喝到一杯比自己手冲更稳的咖啡,三千多块摊到每一天,可能还真是有些性价比。
最后送你两个零成本优化体验的方法,这同样符合控制变量法——在不改变任何器具和豆子的前提下,只改变饮用方式,就能获得更好的体验。
首先是,放凉了再喝。只改变温度这个变量。人的舌头在高温下不灵敏。手冲冲好别急着入口,等它凉到50度左右,果酸和甜感会自己显现。这不是玄学,是科学。
还有一点是,嘬一口喝。只改变入口方式这个变量。试着像喝热汤那样,把咖啡「呲」地吸进嘴里,目的是让液体布满整个口腔,舌头的不同部位。你会发现,风味层次比大口喝时丰富得多。
有孩子后,我每天属于自己的时间,大概就只剩下早上冲咖啡这十五分钟。磨豆、烧水、注水,看着液体一滴滴落下——这个过程能让我从一个赶时间的「爸爸」,变回一个不着急的「我」。这十五分钟,就是我的精剪时刻。
如果你也想试试,希望这篇指北能帮你把力气花在刀刃上。
选对豆子,稳住变量,一杯好咖啡没那么玄。
祝你入坑愉快。
> 关注 少数派小红书,感受精彩数字生活 🍃
> 实用、好用的 正版软件,少数派为你呈现 🚀
如果你还把 AI 编程工具当作"锦上添花"的辅助品,那你可能已经落后了。2026 年,终端里的 AI Agent 早已超越了"聪明的自动补全"这一定位——它们能通读整个代码仓库、自主规划并执行多步骤任务、生成测试、完成大规模重构、提交 PR,甚至直接对接 CI/CD 流水线。 然而,面对市面上层出不穷的工具,很多开发者陷入了选择困难。本文将从实际使用体验出发,对 Claude Code、Cursor CLI、Gemini CLI、Codex CLI、Copilot CLI 五款主流工具进行全方位横评,帮你厘清它们各自的核心优势和短板,找到最适合你工作流的那一款——或者那几款。 在深入对比之前,先来看一眼这五款工具的基本定位: 有意思的是,五款工具的价格带从免费到 $20/月不等,而定价高低和实际能力之间并非简单的线性关系。接下来,我们逐项拆解。 SWE-bench Verified 是目前最权威的编码 Agent 评测标准,任务是自动修复真实的 GitHub Issue。各工具的表现如下: Particula Tech 团队用一个完整的 Express.js 项目重构作为测试任务,结果: 时间差异看似不大,但放到日常开发中,一天处理多个类似任务的话,累积差距相当可观。 下面这张表比较全面地展示了五款工具在不同维度上的表现差异: 可以看到,没有哪款工具在所有维度都占优。Claude Code 在重构和代码质量上领跑,Cursor 在 IDE 集成和实时补全上无敌,Gemini CLI 有免费的 1M 上下文和 Google 搜索,Codex CLI 主打 Token 效率和沙盒安全,Copilot CLI 胜在生态广泛和低价。 这是一个容易被忽略但实际影响很大的维度。以 Codex CLI 为基准 1×: 实际使用中,Claude Code 虽然 Token 消耗最大,但因为首次通过率高,很少需要多轮修补,综合成本未必最高。这就像买东西——便宜的用三次,贵的用一次,算下来可能差不多。 2026 年 AI 编码领域最有意义的变化之一,就是 SKILL.md 成为跨工具通用标准。 简单来说,Skills 就是给 AI Agent 的"专属操作手册"——一个 Markdown 文件,告诉 Agent 在特定任务场景下该怎么做。可以通过 一个典型的 Skill 长这样: 从性能角度看,每个技能在元数据扫描阶段仅消耗约 100 Token,激活时加载不超过 5K Token,非常轻量——不会对你的上下文窗口造成压力。 这才是 SKILL.md 标准的真正威力——跨工具互通。你在 Claude Code 上开发的一个 Skill,不用做任何修改就能在 Cursor、Gemini CLI、Codex CLI 和 Copilot CLI 上运行。 目前最大的跨工具技能库包括: 安装起来也很简单: 理论数据看完了,来聊点实际的。根据不同开发场景,我的推荐如下: 首选 Claude Code,备选 Cursor。 Claude Code 的 SWE-bench 得分和首次通过率均为业界最高。当你面对一个涉及十几个文件、多个模块的重构任务时,Claude Code 的"一把过"能力特别省心——不用来回纠错,不用手动修补遗漏。 首选 Gemini CLI(免费),备选 Claude Code(质量更高)。 两者均支持 1M Token 的超大上下文窗口。Gemini CLI 每天免费提供 1,000 次请求,非常适合前期的代码探索和架构理解阶段;等到要动手改代码时,再切换到 Claude Code 获得更高质量的输出。 首选 Cursor,备选 Codex CLI。 Cursor 的实时 Tab 补全响应时间低于 100ms,配合视觉反馈,在前端开发中几乎是降维打击。另外,如果你经常需要把设计稿截图转成代码,Codex CLI 支持截图转代码的能力是 Claude Code 和 Gemini CLI 目前没有的。 首选 Codex CLI,备选 Copilot CLI。 Codex CLI 的内核级沙盒和脚本化设计就是为自动化流水线量身打造的;而如果你已经重度依赖 GitHub Actions,Copilot CLI 的原生集成会让你更顺手。 首选 Cursor,备选 Copilot。 Cursor 的 Tab 补全速度和 IDE 集成深度目前无人能及;Copilot 的优势在于跨 IDE 覆盖面最广——VS Code、JetBrains、Neovim、Xcode 等几乎所有主流编辑器都支持。 首选 Claude Code,其余工具共享同一套技能库。 Claude Code 作为 SKILL.md 标准的发起者,社区生态最成熟,安全审核最完善。但得益于跨工具互通,你在 Claude Code 上积累的技能资产可以无缝迁移到其他任何工具。 不同工具会读取不同的配置文件来获取项目上下文,搞清楚这个很重要: 实践建议:维护一份不超过 100 行的 数据显示,2026 年平均每位开发者使用 2.3 个 AI 编码工具。一个经过验证的高效组合是: 不同工具的优势互补,远比单押一个更高效。 2026 年的 AI 编码工具格局,最让人兴奋的不是某一款工具有多强,而是 SKILL.md 标准的跨工具互通——写一次技能定义,全生态通用。这意味着你的 AI 工作流投资不会被锁定在某个特定工具上,可以随时根据任务需要灵活切换。 选工具的核心逻辑也很简单:不要追求"最好的",要追求"最适合你当前任务的"。最佳实践是选 2-3 款工具组合使用,让每款工具发挥它最擅长的那个维度。 数据来源:Particula Tech 基准测试(2026)、SWE-bench Verified 官方榜单、各工具官方文档及社区报告。部分数据(Cursor、Gemini CLI SWE-bench 成绩)为基于底层模型的估算值。JEECG低代码 AI编程工具研究 | 从编程能力到 Skills 生态,五款主流 AI 编码 CLI 横评与选型指南
引言:AI 编码工具已是基础设施
五大选手速览
工具 出品方 核心定位 起步价格 Claude Code Anthropic 高自主度终端 Agent $20/月 Cursor CLI Anysphere AI 原生 IDE + CLI $20/月 Gemini CLI Google 开源终端 Agent 免费 Codex CLI OpenAI 轻量终端 Agent $20/月 (ChatGPT Plus) Copilot CLI GitHub/Microsoft GitHub 原生 CLI $10/月 硬核指标:谁的编程能力最强?
SWE-bench 基准跑分
真实项目实测
工具 完成时间 是否一次通过 Claude Code 1 小时 17 分钟 ✓ Codex CLI 1 小时 41 分钟 ✓ Gemini CLI 2 小时 04 分钟 ✓ 各维度能力细项
能力维度 Claude Code Cursor Gemini CLI Codex CLI Copilot CLI 多文件复杂重构 ✅ 最强 ✅ 强 ⚠️ 中等 ⚠️ 中等 ❌ 弱 超大代码库理解 ✅ 1M 上下文 ⚠️ 200K ✅ 1M 上下文 ✅ 1M (Pro) ❌ ~128K 实时 Tab 补全 ❌ 不支持 ✅ <100ms ❌ 不支持 ❌ 不支持 ✅ 截图转代码 ❌ ✅ ❌ ✅ ❌ 实时网络搜索 ❌ ❌ ✅ Google 搜索 ❌ ⚠️ 部分 多 Agent 协作 ✅ Agent Teams ⚠️ 有限 ❌ ✅ 并行容器 ❌ 规划中 测试生成 ✅ 强 ✅ 强 ⚠️ 中等 ✅ 强 ✅ CI/CD 自动化 ⚠️ 间接支持 ✅ Actions ⚠️ 间接支持 ✅ 原生 ✅ 原生 Plan 模式 ⚠️ 部分 ✅ ✅ 2026.3 新增 ✅ ✅ 沙盒安全执行 ⚠️ 部分 ✅ 容器隔离 ❌ ✅ 内核级沙盒 ✅ 代码风格一致性 ✅ 优秀 ✅ 强 ⚠️ 中等 ⚠️ 中等 ⚠️ 中等 主动提问澄清 ✅ 习惯性提问 ⚠️ 有时 ⚠️ 有时 ⚠️ 有时 ⚠️ 有时 关于 Token 消耗
工具 Token 消耗倍率 点评 Codex CLI 1× 最省,Rust 重写后优化显著 Gemini CLI ~2× 性价比不错,毕竟免费 Cursor ~3× IDE 体验好,代价是 Token 用得多 Claude Code ~4× 质量最高,但确实"烧钱" Skills 生态:2026 年最值得关注的变化
SKILL.md 是什么?
/skill-name 命令手动调用,也可以根据上下文自动触发。---
name: frontend-design
description: 当用户要求创建前端组件或页面时,遵循高质量设计规范
---
# Frontend Design Skill
## 设计原则
1. 禁止使用 Inter、Roboto 等过度使用的字体
2. 在写任何代码前,先确定一个独特的设计方向...各工具 Skills 生态对比
维度 Claude Code Cursor Gemini CLI Codex CLI Copilot CLI 格式标准 SKILL.md(原创者) SKILL.md + .cursorrules SKILL.md 兼容 SKILL.md 兼容 SKILL.md(采用者) 官方技能包 Anthropic 官方维护 无专属 极少 ~35 个精选 dotnet/skills(.NET 为主) 社区规模 最大 中等 成长中 中等 早期 发现平台 Agensi + skills.sh cursor.directory 无专属平台 仅 GitHub VS 2026 内置 安全审核 ✅ 有 ❌ 无 ❌ 无 ❌ 无 ⚠️ 部分 激活方式 自动 + /命令 /skill-name GEMINI.md 上下文 $skill-name 自动识别 一份技能,五个工具都能用
# 安装单个官方技能(以 frontend-design 为例)
npx skills add anthropics/claude-code --skill frontend-design
# 一次安装 1,234+ 个社区技能
npx antigravity-awesome-skills --claude # Claude Code
npx antigravity-awesome-skills --cursor # Cursor
npx antigravity-awesome-skills --gemini # Gemini CLI实战选型:不同场景该选谁?
场景一:复杂多文件重构
场景二:超大代码库分析
场景三:前端 / React 开发
场景四:CI/CD 自动化
场景五:日常 IDE 内编码
场景六:Skills 扩展需求
上下文配置文件速查
文件 作用 哪些工具会读取 SKILL.md任务专属操作手册,按需加载 全部五款 AGENTS.md项目持久上下文,每次对话自动注入 Claude Code、Codex、Gemini、Copilot CLAUDE.mdClaude 专属配置 仅 Claude Code .cursorrulesCursor 专属规则文件 仅 Cursor GEMINI.mdGemini 上下文配置 仅 Gemini CLI AGENTS.md 作为跨工具通用上下文,把具体的工作流程封装成独立的 SKILL.md 文件让 Agent 按需加载。这样既能保证上下文信息充足,又不会撑爆 Token 预算。终极选型建议
只选一款的话
组合使用(2026 年主流做法)
日常 IDE 编码 → Cursor(Tab 补全 + 视觉反馈)
复杂重构 / 深度任务 → Claude Code(最高质量 + Agent Teams)
大仓库探索 → Gemini CLI(1M Token + 免费额度)
CI/CD 自动化 → Codex CLI / Copilot CLI写在最后
请注意 YouTube 需简单配置后使用。点击左上角更多 > 设置 > 位置 > 添加 ptube.app ,之后返回主页点击切换热门 > YouTube 即可 。
请确保网络环境可以正常访问 YouTube
默认热门国家是美国,也可以在设置>语言>首选热门国家/地区中设置为其他地区,如香港或日本
下次启动后,SponsorBlock 会自动启用
主页的 tab 也可以在外观设置中自定义

Rinox 所有核心功能都是免费的,我个人非常讨厌付费去广告的模式所以也没有任何广告。
为确保服务稳定性,免费用户可以创建的播放列表数,订阅的频道数有一定限制,同时限制了每天的下载数。
如果 Rinox 帮到了你,欢迎开通会员。
截止到 4 月 25 日,每一位留下邮箱(可以用 base64 )的 v 友都可以获赠一枚 Rinox 的月度会员激活码,我每天都会把激活码发到大家的邮箱里。
*会员结束后会自动取消,不会扣费
















