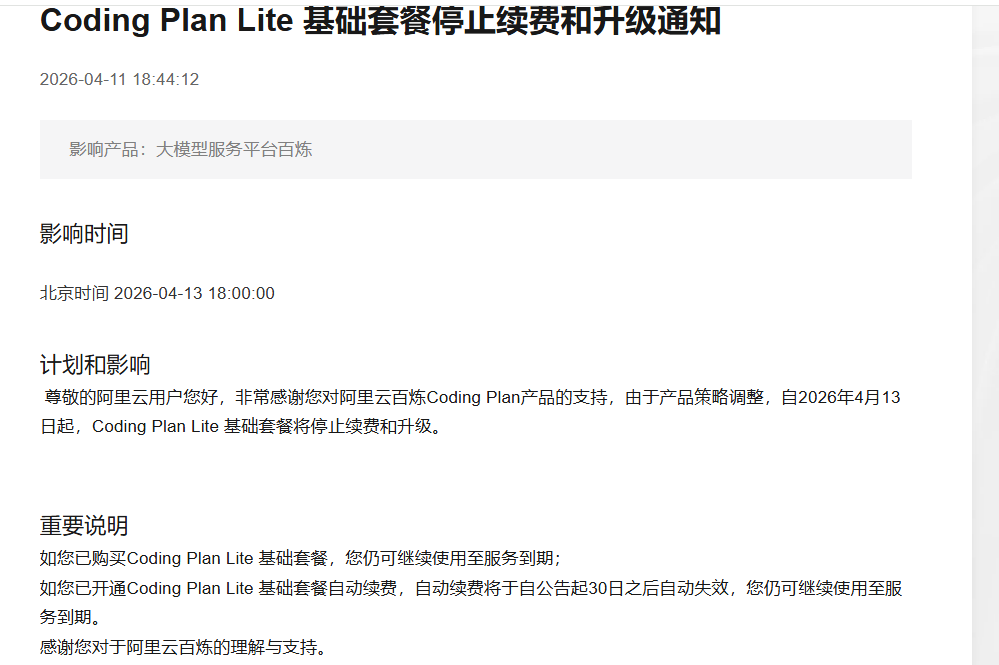
简介
在 .NET 异步里,如果你顺着这条线往下学:
TaskValueTaskIValueTaskSource
会发现难度是明显跳跃的。
Task 还是大多数业务代码的默认答案。
ValueTask 已经开始涉及“减少分配、减少状态对象”的优化。
到了 ValueTaskSource,就基本进入了 .NET 异步底层设施这一层。
这个知识点最容易被写得很玄:
- “零分配异步”
- “高性能神器”
- “Kestrel 同款”
这些说法不算错,但如果只停在这里,其实没什么用。
这篇文章更想把几件真正重要的事讲清楚:
ValueTaskSource 到底是什么;- 它为什么会出现;
- 它和
Task、ValueTask 是什么关系; - 怎么自己写一个最小 demo 跑起来;
ManualResetValueTaskSourceCore<T> 到底解决什么问题;- 为什么普通业务代码通常不该直接使用它。
一句话先给结论:
IValueTaskSource 是 ValueTask 异步路径上的低层承载接口,核心价值是让异步操作的状态对象可以复用,从而减少甚至避免额外分配。
为什么会有 ValueTaskSource?
先从 Task 说起。
大多数异步 API 最开始都是这样:
Task<int> ReadAsync(...)
这类 API 最大的优点是简单、通用、心智负担低。
但它有一个很现实的问题:
Task 是引用类型- 一旦异步操作不能直接同步完成,通常就要有一个状态对象来承载这次操作
在普通业务里,这点成本通常完全可以接受。
但在这些场景里,问题会变得明显:
- 高吞吐网络库
SocketPipelinesKestrel- 高频 I/O 循环
因为这里的异步操作不是偶发,而是每秒几十万、上百万次地发生。
这时,光是“为每次异步操作分配一个状态对象”,就可能成为热点成本。
于是有了第一步优化:
ValueTask<int>
ValueTask<T> 的价值在于:
- 如果结果已经同步可得,可以直接把结果放进值类型里
- 不一定每次都需要分配一个
Task<T>
但问题并没有完全结束。
因为一旦操作真的异步挂起,后面还是得有一个对象来保存:
- 当前状态
- continuation
- 完成结果
- 异常或取消
IValueTaskSource 就是在这里出现的。
它解决的是更深一层的问题:
异步路径上的状态对象,能不能不是“一次性 Task”,而是一个可复用的承载体?
ValueTaskSource 到底是什么?
更准确地说,这里说的通常是:
IValueTaskSource
IValueTaskSource<TResult>
它们位于:
System.Threading.Tasks.Sources
接口成员看起来不多,但都很底层:
public interface IValueTaskSource<out TResult>
{
ValueTaskSourceStatus GetStatus(short token);
void OnCompleted(Action<object?> continuation, object? state, short token, ValueTaskSourceOnCompletedFlags flags);
TResult GetResult(short token);
}
这几个方法如果只看名字,很容易觉得抽象。
把它翻成人话,大概就是:
GetStatus:这次异步操作现在完成没?OnCompleted:如果还没完成,把 continuation 挂进来GetResult:完成后把结果、异常或取消状态取出来
所以它本质上是在做这件事:
提供一个可以被 ValueTask 包装的“异步结果来源”。
它和 Task、ValueTask 的关系怎么理解?
这几个类型最好分层理解。
1. Task
- 最通用
- 最容易用
- 一次异步操作通常对应一个独立的任务对象
2. ValueTask
- 是一个结构体
- 可以直接承载同步结果
- 也可以包一个
Task - 还可以包一个
IValueTaskSource
所以 ValueTask 不是 Task 的简单替代品,而更像是:
3. IValueTaskSource
它不是给业务方直接 await 用的“常规 API 类型”,而是:
- 给框架、基础设施、高性能组件用来承载
ValueTask 异步状态的底层接口
更直白一点说:
Task 更像“现成成品”ValueTask 更像“包装壳”IValueTaskSource 更像“你自己提供的底层发动机”
安装
这个点和很多库不太一样。
如果你用的是现代 .NET,例如:
通常不需要额外安装专门的 NuGet 包,命名空间就在运行时库里:
using System.Threading.Tasks.Sources;
如果你是较老的目标框架,或者做一些兼容性场景,文档里会看到这些类型也出现在:
Microsoft.Bcl.AsyncInterfaces
但如果你只是想在当前主流 .NET 版本里写 demo,通常直接可用,不需要额外加包。
怎么自己建一个最小 demo 跑起来?
先建一个控制台项目:
dotnet new console -n ValueTaskSourceDemo
cd ValueTaskSourceDemo
然后把 Program.cs 改成下面这样。
先准备一个最小的 IValueTaskSource<int> 实现:
using System.Threading.Tasks.Sources;
public sealed class SimpleValueTaskSource : IValueTaskSource<int>
{
private ManualResetValueTaskSourceCore<int> _core;
public SimpleValueTaskSource()
{
_core.RunContinuationsAsynchronously = true;
}
public ValueTask<int> StartAsync()
{
_core.Reset();
_ = Task.Run(async () =>
{
await Task.Delay(100);
_core.SetResult(42);
});
return new ValueTask<int>(this, _core.Version);
}
public int GetResult(short token) => _core.GetResult(token);
public ValueTaskSourceStatus GetStatus(short token) => _core.GetStatus(token);
public void OnCompleted(
Action<object?> continuation,
object? state,
short token,
ValueTaskSourceOnCompletedFlags flags)
=> _core.OnCompleted(continuation, state, token, flags);
}
再在 Main 里这样调用:
var source = new SimpleValueTaskSource();
var result = await source.StartAsync();
Console.WriteLine(result);
最后执行:
dotnet run
如果终端输出:
42
就说明这个最小链路已经跑通了。
这个 demo 不复杂,但已经能说明最关键的一点:
ValueTask<int> 的底层不一定是 Task<int>- 它也可以包装你自己的
IValueTaskSource<int>
为什么示例里几乎都要配 ManualResetValueTaskSourceCore<T>?
因为手写 IValueTaskSource<T> 的成本其实不低。
你真正要自己处理的东西包括:
- 状态流转
- continuation 注册
- 结果设置
- 异常设置
- 取消处理
- 版本控制
- 并发竞态
这已经不是“写三个接口方法”那么简单了。
官方给出的务实做法就是:
ManualResetValueTaskSourceCore<T>
它可以理解成:
一个帮你实现大部分 IValueTaskSource<T> 生命周期管理逻辑的核心组件。
所以真实使用里,更常见的模式是:
- 你自己实现
IValueTaskSource<T> - 但真正的底层逻辑委托给
_core
也就是示例里这种写法:
private ManualResetValueTaskSourceCore<int> _core;
ManualResetValueTaskSourceCore<T> 到底帮你做了什么?
最核心的是三件事:
1. 管状态
异步操作至少会经历这些状态:
PendingSucceededFaultedCanceled
这部分它已经帮你管理好了。
2. 管 continuation
await 的本质并不是魔法,而是:
- 如果没完成,就注册 continuation
- 等完成时再把 continuation 调起来
OnCompleted 这一整套逻辑,_core 也帮你处理了。
3. 管版本号
这点特别关键。
token / Version 是干什么的?
你会看到示例里有这句:
return new ValueTask<int>(this, _core.Version);
这里的 Version 不是装饰字段,而是很重要的保护机制。
因为 IValueTaskSource 这套东西经常会和“复用对象”一起出现。
也就是说,同一个 source 实例,未来可能会承载:
这时候如果没有版本号,调用方就可能把:
混在一起。
所以 token / Version 的作用就是:
- 区分“这是第几次操作”
- 防止错误复用
- 防止旧 await 读取到新状态
这也是为什么 GetStatus、OnCompleted、GetResult 都要带 token。
GetStatus / OnCompleted / GetResult 的调用链到底是什么?
如果只背接口定义,这三个方法会很抽象。
但一旦放回 await 的真实流程里,它们就顺了很多。
你可以把一次典型调用粗略理解成这条链:
调用方拿到 ValueTask
-> await 开始检查它是否已完成
-> ValueTask 去问 IValueTaskSource.GetStatus(token)
-> 如果还没完成,就调用 OnCompleted(...) 注册 continuation
-> 异步操作真正完成时,source 内部执行 SetResult / SetException / SetCanceled
-> continuation 被调起
-> await 恢复执行
-> ValueTask 再调用 GetResult(token) 取结果或抛异常
这里最关键的是角色分工:
GetStatus:告诉 await 当前是不是还在 PendingOnCompleted:把“后续恢复逻辑”挂进去GetResult:在完成后统一取结果
所以不要把这三个方法看成三个孤立 API。
它们其实是在共同完成一件事:
- 让
ValueTask 能像等待 Task 一样去等待你这个自定义异步源
为什么 GetResult 不只是“返回结果”?
这一点很容易低估。
GetResult(token) 不只是负责:
它还负责:
- 如果这次操作失败,就在这里重新抛出异常
- 如果这次操作被取消,就在这里把取消语义抛出来
也就是说,从 await 调用者角度看:
最后都会统一落到 GetResult 这一步来收口。
这也是为什么很多最小 demo 看起来只像“return 结果”,但真实实现里这一步其实承担了更完整的语义边界。
OnCompleted 里的 flags 到底在控制什么?
这也是面试和源码阅读里很容易被问到的一点。
OnCompleted 的第四个参数是:
ValueTaskSourceOnCompletedFlags
它的价值不在于“多了一个枚举”,而在于:
await 在注册 continuation 时,不只是把一个委托交给你- 还会把“这个 continuation 应该怎么跑”的一部分上下文要求带过来
最值得关心的通常是两类语义:
ExecutionContextSynchronizationContext
ExecutionContext 和 SynchronizationContext 分别是什么语境?
这两个词经常一起出现,但不是一个东西。
1. ExecutionContext
它更偏逻辑执行上下文,比如:
当 continuation 需要捕获和恢复这类上下文时,相关 flag 会体现在 OnCompleted 调用里。
2. SynchronizationContext
它更偏“恢复到哪个调度环境”,最典型的语境是:
也就是说,一个 continuation 不只是要不要执行,还涉及:
这就是这些 flags 存在的意义。
为什么这类 flags 很重要?
因为 IValueTaskSource 已经不是纯业务 API,它在和编译器 / awaiter 协议直接打交道。
如果这一层处理不对,影响的不是一两个字段,而是:
- continuation 恢复位置不对
- 上下文流动不符合预期
- 某些
AsyncLocal 数据丢失 - 某些回调调度时机异常
所以更稳妥的做法通常不是自己重写一套 continuation 机制,而是:
- 尽量把这部分交给
ManualResetValueTaskSourceCore<T> 处理
也就是前面示例里的:
_core.OnCompleted(continuation, state, token, flags);
这不是偷懒,而是减少自己踩协议细节坑的概率。
对象池复用模型到底该怎么理解?
前面提到它通常和对象池一起出现,但这里要再讲透一点。
比较典型的复用模型通常是这样:
从池中取出一个 source 对象
-> Reset,准备承载这一次异步操作
-> 返回一个包装了该 source + version 的 ValueTask
-> 异步操作完成
-> 调用方 await 结束,结果已消费
-> source 解除本次状态绑定
-> 归还到对象池
这里最重要的不是“用了池”,而是:
- 同一个 source 在任意时刻只能归属于一次正在进行的操作
也就是说,真正的关键约束是:
- 借出前必须是空闲的
- 归还前必须确认本次操作已经彻底结束
这也是为什么复用模型如果写错,会比普通 Task 更难排查。
因为出错后常见现象不是直接编译报错,而是:
- continuation 串了
- 旧 token 访问到了新状态
- 上一次异常污染了下一次操作
一个更贴近真实实现的池化心智模型
你可以把一个池化的 IValueTaskSource 实例想成:
- 它本身不是“某次异步操作”
- 它只是“某次异步操作的可复用承载槽位”
所以真正的生命周期不是:
而是:
- 借出一个槽位
- 绑定到这次操作
- 完成并清理
- 再让下一次操作复用这个槽位
理解到这一层,就会更容易明白为什么:
Version 必须存在Reset 必须小心- 并发复用绝对危险
它和编译器生成的 async ValueTask 状态机边界是什么?
这是另一个很容易混的点。
很多人会想:
- 既然
async ValueTask 也返回 ValueTask - 那它是不是天然就等于
IValueTaskSource
答案通常是否定的。
这里要把两层东西拆开:
1. 语言层的 async ValueTask
如果你写:
public async ValueTask<int> GetAsync()
{
await Task.Delay(100);
return 42;
}
编译器会为这个方法生成:
- 状态机
- builder
- continuation 恢复逻辑
也就是说,编译器已经替你把异步状态机搭好了。
2. IValueTaskSource
它解决的是:
- 当你不想让异步路径每次都走一次性状态对象时
- 怎么自己提供一个低层可复用的异步结果来源
所以两者的边界可以这样记:
async ValueTask:编译器帮你生成状态机IValueTaskSource:你自己提供状态承载体给 ValueTask
为什么说它们不是一回事?
因为“返回类型一样”不代表“底层实现一样”。
ValueTask<T> 只是一个外壳,它底层可能来自:
- 直接结果
Task<T>IValueTaskSource<T>
编译器生成的 async ValueTask<T> 更多是在处理:
而 IValueTaskSource<T> 更偏:
- 某次异步操作的结果载体和 continuation 协议怎么承载
这就是它们的边界。
什么时候该优先看 async ValueTask,什么时候才该看 IValueTaskSource?
如果你的问题还是这些:
- 一个异步方法该怎么写
- 返回
Task 还是 ValueTask await 为什么会恢复
那重点应该还在:
只有当你的问题已经进一步变成:
- 异步路径上的状态对象能不能复用
- continuation 承载开销能不能继续压
- 高吞吐基础设施还能不能再少一点分配
这时 IValueTaskSource 才会成为主角。
为什么它通常和对象池一起出现?
如果 IValueTaskSource 每次都 new 一个新的 source 对象,那它的价值就会打折。
因为它真正想优化的是:
所以在真实高性能组件里,常见模式通常是:
- 从对象池里取出一个 source 对象
- 发起一次异步操作
- 完成后把对象重置
- 再还回池中
也就是说,它和 ObjectPool 常常不是偶然搭配,而是天然能配起来的一组工具。
它和 TaskCompletionSource<T> 是什么关系?
这个对比很值得看。
TaskCompletionSource<T>
它的定位是:
比如:
SetResultSetExceptionSetCanceled
这套模型很好理解,也很常用。
但它的底层结果仍然是:
IValueTaskSource<T>
它更进一步,解决的是:
- 手动控制异步完成
- 但不想每次都落回一次性的
Task<T> 对象
所以如果只用一句话区分:
TaskCompletionSource<T>:给你一个手动完成的 Task<T>IValueTaskSource<T>:给你一个可被 ValueTask<T> 包装、且更适合复用的低层异步来源
一个更贴近实际的例子:成功、异常、取消
前面的 demo 只演示了成功路径。
但真实实现里,通常至少还要考虑异常路径。
例如:
public ValueTask<int> StartAsync(bool fail)
{
_core.Reset();
_ = Task.Run(async () =>
{
await Task.Delay(100);
if (fail)
{
_core.SetException(new InvalidOperationException("failed"));
return;
}
_core.SetResult(42);
});
return new ValueTask<int>(this, _core.Version);
}
调用:
try
{
var result = await source.StartAsync(fail: true);
}
catch (InvalidOperationException ex)
{
Console.WriteLine(ex.Message);
}
这说明它在能力上和 Task 一样,也要完整承载:
只不过承载方式更底层。
使用它时最容易踩的坑
这部分比 demo 更重要。
1. 同一个 ValueTask 被多次 await
普通 Task 通常可以被多次 await。
但 ValueTask 尤其是背后挂了 IValueTaskSource 时,语义没有这么宽松。
如果你把它当成普通 Task 那样随便重复消费,很容易出问题。
所以要先记住一个工程化原则:
来自 IValueTaskSource 的 ValueTask,默认按“一次性消费”来理解更安全。
2. 在上一次操作没结束时就 Reset
这个错误很致命。
因为 Reset() 的含义是:
如果上一次操作还没彻底结束,你就 reset 了,同一个 source 实例里的状态就会被覆盖。
3. 并发复用同一个 source
示例里的 SimpleValueTaskSource 其实就有一个默认前提:
也就是说:
如果你想做真正的池化复用,就得保证:
4. 忘记设置 RunContinuationsAsynchronously
这不是绝对必须,但在很多场景里是非常值得显式设置的:
_core.RunContinuationsAsynchronously = true;
原因在于 continuation 是否同步内联执行,会影响:
对大多数手写 demo 和基础设施代码来说,把它设成 true 更稳妥。
5. 把它用到普通业务代码里
这是最常见的误用。
很多人学完会本能地想:
- 那以后是不是都该用
ValueTaskSource?
答案通常是否定的。
因为你引入的复杂度非常真实:
- 生命周期要自己管
- 版本号要自己理解
- 复用边界要自己保证
- 竞态问题要自己扛
如果你的场景不是明确的高频热点,这套复杂度大概率不值。
它适合什么场景?
- 自己在写底层高性能库
- 每秒异步调用次数非常高
- 分配已经被性能分析证明确实是瓶颈
- 愿意接受更复杂的生命周期管理
- 对象池化和复用模型已经设计清楚
典型例子包括:
它不适合什么场景?
1. 普通 Web 业务代码
绝大多数业务服务、控制器、应用层逻辑,没有必要手写这一层。
2. 异步频率不高的场景
如果吞吐量并没有高到让分配成为热点,那你只是把代码写复杂了。
3. 团队还没把 ValueTask 用明白
如果 ValueTask 自身的使用边界都还没形成稳定认知,就不该继续往下跳到 IValueTaskSource。
一个比较务实的学习顺序
- 先彻底理解
Task 和 async/await - 再理解
ValueTask 为什么存在 - 再理解
TaskCompletionSource<T> 的手动完成模型 - 最后再看
IValueTaskSource<T> 和 ManualResetValueTaskSourceCore<T>
因为它不是孤立知识点,而是站在前面这些东西之上的。
总结
ValueTaskSource 最值得理解的,不是接口长什么样,而是它为什么存在:
Task 很好用,但有分配成本ValueTask 先优化了同步路径IValueTaskSource 再把异步路径的状态对象复用问题也纳入优化范围
所以它真正适合的是:
一句话收尾:
IValueTaskSource 不是“更高级的 Task”,而是给高性能基础设施准备的异步状态承载接口。