收集了最近在使用的低价 GPT, Gemini,邮箱等 AI 会员的小店合集
声明:
1.所有站点都是互联网收集,我未参与任何经营,利益分配
2.交易有风险,只做分享
3.咸鱼应该都是从这些店进货的,价格很贵
4.大部分我都买过,交易需谨慎
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
声明:
1.所有站点都是互联网收集,我未参与任何经营,利益分配
2.交易有风险,只做分享
3.咸鱼应该都是从这些店进货的,价格很贵
4.大部分我都买过,交易需谨慎
在传统 LoRaWAN 架构中,网络服务器(NS)和物联网平台往往是必不可少的组成部分,但这也带来了部署复杂、成本较高的问题。随着一体化网关技术的发展,将 NS 与边缘计算能力直接集成到网关中,正在成为一种更高效的解决方案。本文将从架构优化、核心能力与应用场景出发,分析 LoRaWAN 项目如何在无需独立平台的情况下实现快速部署与稳定运行。 在多数 LoRaWAN 项目中,系统通常包含网关、网络服务器(NS)、应用服务器(AS)以及物联网平台。 尤其是在智慧农业、小型园区、独立设备监测等场景中,完整平台架构往往显得“过度设计”。 通过将网络服务器能力与边缘计算功能直接集成到网关中,可以实现从数据采集到业务处理的闭环。 这种架构的核心变化在于: 以 ThinkLink 为核心的一体化方案,使 LoRaWAN 系统可以在单设备层面完成闭环运行,显著降低系统复杂度。 网关内部集成 NS 功能,支持设备入网、数据解析和通信管理。同时,还可以作为“中心节点”,接入其他网关,实现多网关统一管理。 适用于: 通过内置的边缘计算机制,数据可在本地完成处理与响应,例如: 相比云端处理,边缘计算具备更低延迟和更高稳定性。 网关直接提供 Dashboard 能力,实现: 这对于不需要复杂平台的小型项目尤为关键,可显著降低开发成本。 一体化网关不仅支持 LoRaWAN,还可对接多种工业与楼宇协议,包括: 实现无线与传统系统的融合。 即使不依赖平台,系统仍具备开放性,可灵活对接: 满足后期扩展需求,而不是封闭系统。 无需云平台即可完成: 适用于网络条件较弱或运维能力有限的区域。 在工业现场: 通过对接 BACnet 系统,实现: 适用于: 部署简单,维护成本低。 相比传统模式,一体化网关方案具备三大优势: 1. 简化架构 2. 降低成本 3. 提升实时性 LoRaWAN 项目并不一定需要复杂的服务器和平台体系。 对于希望快速落地、控制成本、提升系统响应能力的项目来说,这种架构正在成为更具实践价值的选择。LoRaWAN 项目真的必须依赖 NS 和平台吗?
这种架构虽然标准,但在实际落地过程中存在明显问题:一体化网关:重新定义 LoRaWAN 架构
核心能力解析
1. 内置网络服务器能力
2. 边缘计算能力(Edge Computing)
3. 本地可视化与数据管理
4. 多协议集成能力
5. 开放的数据对接能力
典型应用场景
智慧农业
工业监测
智慧楼宇
智慧城市
架构优势总结
无需独立 NS 与 IoT 平台
减少服务器与开发投入
数据在边缘侧完成处理结语
通过一体化网关与边缘计算能力的结合,可以在保证功能完整性的同时,大幅降低部署门槛。
面对需求频繁变更、BOM 版本混乱、试制问题追溯困难、跨部门协同成本居高不下,越来越多硬件企业开始重新审视 PLM平台 的价值。本文围绕 Teamcenter、Windchill、ENOVIA、Aras Innovator、Arena、Autodesk Fusion Manage、ONES 7 款工具展开对比,重点分析它们在产品主数据、BOM、变更、追溯、质量与协同治理方面的差异,帮助企业判断:谁适合作为核心 PLM平台,谁更适合作为研发协同与治理补位。 要判断一套工具是不是适合作为 PLM平台,关键不是它能不能提需求、走审批或看进度,而是它能不能围绕产品对象建立统一管理框架。因此,真正的 PLM平台 至少要回答五个问题: 也正因为如此,很多研发协作平台虽然在项目推进上很有价值,却不等于完整的 PLM平台;反过来,一些主干型 PLM 虽然在产品定义能力上很强,也不一定天然适合承担项目执行层。企业真正需要做的,不是把所有工具拉到同一赛道比较,而是先判断:自己要解决的到底是 产品主数据问题,还是 研发协同治理问题。 下面这 7 款工具,我仍按三类来看:主干型 PLM平台、云原生 PLM平台、研发协同补位平台。这种分层不是形式问题,而是因为企业在不同阶段面对的主矛盾并不一样。 Teamcenter 仍然是 2026 年最典型的主干型 PLM平台 之一。它以单一数据源连接产品生命周期中的人员和流程;在 BOM 管理页面,又明确提出通过统一 BOM 管理简化设计、配置和变更流程,在协作环境中创建单一、准确的产品定义,并通过数字线程连接软件、电气、电子和机械等多域 BOM。Teamcenter X 页面则进一步强化了 SaaS 交付、预配置最佳实践和快速上线价值。 这意味着 Teamcenter 的强项,不只是能管 BOM,而是能把 BOM 作为产品数字表示的中心对象,向前连接需求和设计,向后连接制造、服务和供应商协同。对大型复杂制造企业来说,这种主线价值非常关键,因为真正昂贵的失误往往并不是一个零件建错,而是跨学科、跨部门、跨版本的信息没有对齐。 它的局限也同样明显。Teamcenter 更适合治理意识较强、主数据基础相对成熟、愿意投入长期数字化架构的企业。若组织还没有清晰的编码、版本、评审和变更纪律,系统越强,暴露出的问题往往越多。换句话说,Teamcenter 很 Windchill 的特点是把产品数据、配置管理和制造协同放在更务实的体系里。PTC 官方页面指出,Windchill 通过轻松安全的多学科与地域分布式团队数据访问、注重质量的流程和数据驱动型制造方法来提升产品开发水平;同时,它的开放式体系结构支持轻松集成其他企业系统,包括 SAP ERP,并可为产品驱动型数字主线奠定基础。 对很多硬件企业来说,Windchill 的现实价值在于:它不把 PLM 停留在工程部,而是把工程数据向制造、ERP、外部协同延伸。工程变更如果不能及时传到采购、试制、工艺和供应链,很多设计管理的努力最终都会在下游失效。Windchill 在这方面的定位很明确:让产品数据成为跨职能业务的共同基础,而不只是设计文件的载体。 从使用体验上看,Windchill 更适合那些愿意把流程规则正式化的企业。它的强项不是轻,而是稳;不是界面多好看,而是工程秩序能否真正落地。因此,如果企业的核心诉求是配置管理、变更控制、制造协同和 ERP 连接,Windchill 往往是非常值得认真评估的 PLM平台。 ENOVIA 的优势,在于它不是把 PLM 看成一组离散模块,而是放在 3DEXPERIENCE 的统一环境中理解。达索公开资料显示,ENOVIA 的 BOM Management 页面强调 BOM 的准确性、效率和跨团队协同;Requirements Management 页面则强调通过需求驱动开发,把客户之声转化为详细规格,以减少产品失败并改善追溯性。 这使得 ENOVIA 很适合那些产品开发不只是做零件,而是强依赖需求、架构、配置与合规关系的组织。对于航空航天、高科技、汽车、复杂装备这类行业来说,产品复杂度并不只是体现在零件数量上,更体现在需求与设计之间的关系密度上。ENOVIA 的价值就在于,它更愿意把需求、BOM、变更、质量和协同统一到一个平台视角中。 Aras 的特点,不在于最标准化,而在于最能适应复杂业务。官方 Product Summary 明确写到,Aras Innovator 提供 Parts and BOMs、Documents、CAD models、AML/AVL 和 Change 等核心 PLM 数据与流程,并提供多种配置和变更管理选项,包括 CMII 标准。 这一点对复杂行业非常关键。很多企业真正面临的问题,不是没有系统,而是业务过于复杂,标准产品很难完全匹配。Aras 的平台价值,恰恰在于它既有核心 PLM 功能,又强调可扩展、可适配、可持续演进。对于医疗器械、航空航天、高端装备等强合规、长生命周期行业,这种能力常常比开箱即用更重要。 当然,灵活性本身也是门槛。平台越能适配业务,企业越需要清晰的架构能力和流程设计能力。如果组织内部还没有足够明确的数据主线和责任边界,灵活平台反而可能让分歧被无限放大。因此,Aras 更适合那些愿意长期投入、需要复杂适配能力的企业,作为其长期演进型 PLM平台。 Arena 的定位非常清晰:云原生、面向现代制造商、强调 PLM 与 QMS 的结合。Arena 官网公开写明,它是 cloud-native 的 PLM 与 QMS 平台,用于简化团队协作、产品信息管理和质量控制;中文站点也明确强调其适合现代制造商和全球供应链,覆盖产品开发、供应链协作、产品记录控制、变更管理、质量管理、需求管理与监管合规。 这使 Arena 对中型制造企业特别有吸引力。因为很多企业真正缺的,不是一个超大型、极度厚重的平台,而是一套能够把产品信息、质量信息和供应链协作快速拉到同一云端环境中的工具。对电子硬件、IoT、医疗设备、消费设备等节奏较快、外部协作较多的行业而言,这种够正式、又不至于过重的能力非常实用。 它的局限也很清楚:当企业进入极复杂的配置管理、超大规模多事业部协同或深度制造过程规划阶段,Arena 的深度通常不如 Teamcenter、Windchill 这类主干型平台。也就是说,Arena 更像是一种高实用性的云原生 PLM平台,而不是所有复杂制造场景下的最终答案。 Fusion Manage 的价值在于,它把云端 PLM 的可实施性做得比较平衡。Autodesk 官方页面明确写到,它支持维护全面 BOM,用于采购、装配、生产计划和制造等;同时提供 change and release management,覆盖变更请求、变更单、变更任务、审批和问题报告,并强调完整的追溯能力。 对成长型制造企业来说,这是一种很现实的方案。很多企业已经意识到表格和邮件无法持续支撑产品开发,但又还没有到必须推进重型平台的阶段。Fusion Manage 这类云端 PLM平台 可以帮助企业先把 BOM、变更、发布、任务和追溯体系建立起来,让产品数据与组织协作形成更正式的秩序。 它的边界在于,企业规模越大、产品复杂度越高、制造协同越深,后续对流程设计和外围集成的要求也会越高。因此,Fusion Manage 更适合作为从分散管理迈向正式 PLM 管理的中间阶段工具,而不是所有高复杂度制造场景的最终归宿。 把 ONES 放入 PLM平台 选型语境是有意义的,它定位为企业级研发管理平台,覆盖项目管理、测试管理、知识库管理、流程管理、进度管理、团队协作、效能改进与开放拓展,并明确提供芯片研发管理、汽车研发项目管理、装备制造项目管理、机器人研发管理、智能制造研发管理等解决方案。 这意味着 ONES 的核心价值,不在于替代所有传统意义上的主干型 PLM平台,而在于补齐很多中国企业当前更迫切的研发治理层短板。大量硬件团队的问题并不是先缺 BOM 系统,而是项目推进不透明、测试闭环薄弱、需求和研发脱节、知识沉淀零散、跨部门协同成本高。ONES 在这些方面形成了相对完整的研发管理闭环,这也是它为什么会在智能硬件、装备制造、芯片研发等场景中被企业采用。 因此,我更倾向把 ONES 定位为 PLM 外层的研发治理与协同枢纽。如果企业当前的主矛盾是项目节奏、需求流转、测试与缺陷闭环、知识与项目集治理,那么先用 ONES 建立起组织级研发管理秩序,往往比直接上重型主干型 PLM 更容易形成实际收益。它的局限也必须先说清楚:至少从公开能力边界来看,ONES 的重点不在承载复杂 EBOM/MBOM、CAD 原生对象管理和企业级产品主数据体系。因此,它更适合作为 PLM 建设前期或外围治理层,而不是被直接等同为所有制造场景下的完整主 PLM平台。 1. 只看功能清单,不看产品主线 很多企业选 PLM平台 时,最先问的是有没有流程、看板、任务、审批、表单,但真正决定系统上限的,是它能不能围绕产品对象建立统一主线。Teamcenter、Windchill、ENOVIA、Aras 的公开资料都反复强调 BOM、配置、变更、追溯和跨系统连接,本质上说明的就是:PLM 的核心不是事情流不流,而是产品定义是不是统一。 如果一个 PLM平台 只能服务研发部门,而不能让采购、试制、质量和供应链看到同一份正式产品记录,那么很多管理问题只会被延后,而不会被解决。Arena 和 Fusion Manage 都在公开资料中明确强调质量、供应链、产品记录和变更控制的统一;Windchill 则强调工程与制造、ERP 之间的信息联动。 很多企业希望一次性完成需求、BOM、项目、测试、质量、供应链、制造全打通。方向没有错,但节奏常常错。现实里,真正高成功率的做法是先判断主矛盾:如果是产品定义失控,就优先评估主干型 PLM平台;如果是项目协同和测试闭环失控,就先补治理层。顺序正确,比一次买大而全更重要。 回到最核心的问题:PLM平台 怎么选?真正的答案从来不是谁功能最多,而是谁最适合你当前这一步。从 2026 年公开趋势来看,主流 PLM平台 正在共同走向几件事: 第一,云化交付越来越普遍; 因此,我更建议企业用一句话来判断自己的选型起点:如果你最缺的是统一产品定义,就优先建设主干型 PLM平台;如果你最缺的是统一研发治理,就先补协同与执行层。 大型复杂制造企业,应该优先解决产品主数据和变更控制;中型制造企业,应该优先解决云化协同和合规效率;而仍处在研发治理基础建设阶段的团队,则更适合先通过 ONES 这类平台把项目推进、测试闭环和知识沉淀拉回秩序。选型真正怕的,不是厂商太多,而是企业自己没有先回答:我们到底是在解决产品定义问题,还是在解决协同治理问题。什么才算真正的 PLM平台?
2026 年主流 PLM平台对比:7 款值得重点评估的工具
Siemens Teamcenter
适合作为复杂制造企业的核心 PLM平台,但它并不是所有企业都应该追求的第一步。PTC Windchill
Dassault Systèmes ENOVIA
局限则在于,它对组织的系统化程度要求也相对更高。若企业当前只想解决最基础的文件版本和评审流转问题,ENOVIA 可能显得偏重;但如果组织已经进入多学科并行、系统工程主导、全球协同推进阶段,它的完整性会非常有价值。因此,ENOVIA 更适合作为高复杂度企业的战略型 PLM平台。Aras Innovator
Arena
Autodesk Fusion Manage
ONES:更适合作为 PLM 外层的研发治理与协同平台
PLM平台怎么选:企业最容易踩错的 3 个坑
2. 只从研发视角看,不从供应链、质量和制造视角看
3. 只想一步到位,不做阶段化建设结尾总结
第二,BOM、变更、追溯与质量不再是分散模块,而越来越被放进统一产品数据主线;
第三,AI 能否发挥价值,前提不是多一个聊天入口,而是企业是否已经拥有结构化、可追溯、可治理的产品数据基础。Teamcenter X、Windchill 和 Aras 的公开表述都已经明显体现出这种方向。
Rust 官方团队正在邀请社区测试一项酝酿已久的 Cargo 变更:全新的构建目录布局(Build Dir Layout v2)。 这件事看上去只是目录结构的调整,但它是 Cargo 未来几个重要特性的地基,也可能悄悄影响你现有的构建脚本、CI 流程,乃至你依赖的某些测试库。了解它,比等到正式上线后踩坑要好得多。 在谈新布局之前,先搞清楚现在的布局有什么问题。 打开一个 Rust 项目的 这是一种"按内容类型分类"的组织方式——把所有包的 fingerprint 文件堆在一个 这种方式带来了几个长期未能解决的问题: 问题一:无法做跨工作区缓存。 共享缓存需要知道哪些产物属于哪个构建单元,而现在一个 问题二:过期产物无法自动清理。 你换了一个依赖版本,旧版本的中间产物就这样永远堆在 问题三:文件锁粒度太粗。 现在 问题四:Windows 上 问题五:中间产物文件名冲突。 两个包恰好产生同名的中间文件,就会互相覆盖,这是一个隐性的正确性问题。 新布局的核心思想只有一句话:按包名分层,每个构建单元自成一体。 同样是两个包 与旧布局的对比,用一张表来说明: 旧布局中, 这次目录重构是一块基石,它让下面这些长期搁置的功能变得可行: 跨工作区缓存共享(cross-workspace caching) 这是最重要的动机。当每个构建单元都有自己独立的目录时,Cargo 才能把这些目录当作可移植的缓存单元,在不同工作区之间共享。对于大型 monorepo 或多项目组合来说,这意味着编译时间的大幅缩短。 过期构建产物的自动清理 旧布局下,Cargo 很难判断一个构建单元的产物是否还有用,因为相关文件散落在多个目录。新布局下,一个构建单元的全部产物就在一个目录里,过期了直接删掉那个目录即可,实现常数级的磁盘占用。 更细粒度的文件锁 顺带修复的问题 在推进这个方案的过程中,团队还发现它意外地改善了一些历史问题: final artifacts(最终产物,即 target-dir 下的内容)不会变化,也就是说你用 受影响的是那些依赖了 build-dir 内部布局的工具或脚本,例如: 目前已知受影响的库状态(截至博客发布时): 需要 nightly 2026-03-10 及以上版本,在命令行加上 把你平时跑的测试、发布流程、CI 脚本都过一遍。如果遇到失败,也可以先用以下方式单独验证是否与构建目录分离本身(而非新布局)相关: 发现问题后,可以: 这次布局变更之后,Cargo 团队还有几个方向在路上: 部分变更目前被文件锁的改进工作所阻塞,而文件锁的改进又依赖本次布局变更先落地,所以这是一个需要按顺序推进的工程。 Cargo 的构建目录布局是个典型的"用久了就不敢动"的地方。大量工具在文档未声明支持的情况下,依赖了 target-dir 内部的路径约定,导致每一次改动都牵一发动全身。 这次 Rust 团队选择在正式发布前广泛征集测试反馈,正是希望在改动落地之前,把受影响的工具逐一梳理清楚,给上游项目足够的时间适配。 如果你有使用 CI 系统缓存 target 目录、或者依赖测试辅助库来定位编译产物,建议现在就用 nightly 跑一遍,早发现早适配,比等到稳定版本上线后再处理要从容得多。 参考资料:为什么要改目录结构
target/debug/(或 build-dir/debug/),你会看到这样的结构:debug/
├── .fingerprint/ # 构建缓存追踪,所有包混在一起
├── build/ # 所有包的 build script 产物混在一起
├── deps/ # 所有包的中间编译产物混在一起
├── examples/
└── incremental/.fingerprint/ 目录里,把所有包的编译产物堆在 deps/ 里。deps/ 里几十个包的产物全部混在一起,根本无法做到独立追踪。deps/ 里,target/ 目录越来越大,只能靠 cargo clean 一刀切。cargo build 和 rust-analyzer 会互相等待同一把锁,因为它们操作的是同一个目录下的混合产物,锁不能更细。deps/ 污染 PATH。 构建过程中 deps/ 目录会被加入 PATH,里面混杂着所有包的中间产物,会造成意外的路径污染。新布局长什么样
lib 和 bin,新布局变成这样:build-dir/
└── debug/
├── .cargo-lock
├── build/
│ ├── bin/ # 按包名分目录
│ │ ├── [BUILD_SCRIPT_BIN_HASH]/
│ │ │ ├── fingerprint/*
│ │ │ └── out/*
│ │ ├── [BUILD_SCRIPT_RUN_HASH]/
│ │ │ ├── fingerprint/*
│ │ │ ├── out/*
│ │ │ └── run/*
│ │ └── [HASH]/
│ │ ├── fingerprint/*
│ │ └── out/*
│ └── lib/ # 按包名分目录
│ ├── [BUILD_SCRIPT_BIN_HASH]/
│ │ ├── fingerprint/*
│ │ └── out/*
│ ├── [BUILD_SCRIPT_RUN_HASH]/
│ │ ├── fingerprint/*
│ │ ├── out/*
│ │ └── run/*
│ └── [HASH]/
│ ├── fingerprint/*
│ └── out/*
└── incremental/对比维度 旧布局 新布局 组织方式 按内容类型(fingerprint/build/deps) 按包名 + 构建单元哈希 产物隔离 所有包混在同一目录 每个包独立子目录 fingerprint 位置 统一在 .fingerprint/随各构建单元就近存放 清理粒度 只能整体 clean 可以按包、按单元精确清理 文件锁粒度 整个 target 目录 可细化到每个构建单元 .fingerprint/bin-[HASH] 和 deps/bin-[HASH] 是分散在两个地方的,属于同一个构建单元的信息被物理上拆开了。新布局把它们全部收拢在 build/bin/[HASH]/ 这一棵子树下,一个构建单元的所有信息都在自己的目录里,完全自包含。这个改动解锁了什么
cargo test、cargo build 和 rust-analyzer 现在会争抢同一把粗粒度的锁。新布局可以将锁的粒度细化到每个构建单元目录,让它们真正并行工作,互不阻塞。deps/ 里中间产物的积累导致构建性能下降的问题、Windows 上 PATH 污染的问题、中间产物文件名冲突的问题,都随之得到缓解。谁可能受到影响
target/release/my-binary 这样的路径访问最终可执行文件,不受影响。CARGO_BIN_EXE_* 环境变量;OUT_DIR 推导 target-dir 位置:需要适配新的目录结构;库名 状态 assert_cmd 已修复 snapbox 已修复 executable-path 已修复 trycmd 已修复 cli_test_dir 待修复(Issue #65) compiletest_rs 待修复(Issue #309) term-transcript 待修复(Issue #269) test_bin 待修复(Issue #13) 如何参与测试
-Zbuild-dir-new-layout 标志:cargo test -Zbuild-dir-new-layout
cargo build -Zbuild-dir-new-layoutCARGO_BUILD_BUILD_DIR=build cargo test后续规划
--profile 和 --target 子目录中移出,让更多产物可以跨配置共享;写在最后
第一次在自媒体上赚到钱了。
没什么特别的感觉,
就是突然意识到——
原来这件事真的能发生在自己身上。

钱不多,但是非常开心!!
感觉自学 网上的内容不是杂乱就是很古早。学半天也拼不到一起成体系,很焦虑 🥲
在数据平台调度开发过程中,批处理、实时处理与微批处理作为核心的数据处理模式,其任务设计的合理性直接决定了整个数据链路的稳定性与效率。不同处理模式的核心逻辑各有侧重,唯有精准把握其设计精髓,才能在应对不同业务场景时游刃有余。 批处理任务(多为每日或每小时执行) 的设计核心的是“错峰 + 资源池 + 关键路径”三者结合。在实际生产中,大量任务若在同一时刻集中启动,极易造成资源拥堵、系统卡顿,因此错峰调度是避免此类问题的基础;同时,通过资源池的配置,将无序的并发转化为可控的任务队列,既能避免资源浪费,也能防止单个任务占用过多资源影响整体流程。 而实时处理任务(如CDC同步、流式计算),则需聚焦“断点 + 幂等/Upsert + 积压治理”,断点续跑能力可确保任务重启后无需全量重放数据,大幅提升效率,而目标端主键的设置则是保障数据一致性的关键,避免因重复写入导致数据错乱;积压治理则能防止数据堆积拖垮系统,确保实时链路的顺畅运行。 介于批处理与实时处理之间的微批任务(准实时、分钟级),则需根据业务优先级选择合适的执行策略——并行、串行等待或抛弃。当新数据的时效性远高于历史数据时,采用抛弃策略可有效避免旧任务堆积,防止系统负载过高,这比盲目扩大并发更具安全性,能在保障核心需求的同时维持系统稳定。 调度任务的触发与执行策略,需结合业务场景的时效性、一致性需求灵活选择,不同策略各有适配场景,合理搭配才能实现效率与稳定的平衡。其中,时间触发是最常用的方式,按每日、每小时等固定周期触发,非常适合批处理主链路,比如日报生成、监管报表统计、晨会所需数据等场景,其优势在于可预测性强、运维成本低,且便于制定和落地SLA(服务等级协议),让数据产出时间可控。 与时间触发相比,事件触发更贴近实时或准实时需求,当文件到达、消息推送、数据落库等事件发生时,自动触发后续任务链路,适合“数据到了就处理”的场景,既能减少无效的空跑任务,也能降低数据延迟,让数据更快服务于业务。 在执行策略的选择上,并行策略追求吞吐效率,适用于互不影响的分支任务,但并行数量并非越多越好,必须配合资源池和并发上限进行控制,否则会将调度层面的压力转移到数据库等核心组件,反而引发系统故障。 串行等待策略则主要用于保障任务的互斥性与数据一致性,比如同一目标表写入、共享资源使用,或必须按顺序累加口径的任务,通过“等待前一个任务完成再执行下一个”的逻辑,避免数据覆盖、资源竞争等问题。抛弃策略则主要应用于分钟级微批、准实时场景,若业务允许“只保留最新结果”,抛弃旧任务实例可有效防止积压拖垮系统,是一种更安全的流量控制方式。 此外,资源池的并发治理是重中之重,通过按部门、业务链路或工作流配置并发上限,并结合任务优先级,可确保关键链路优先执行,避免不同业务、不同任务之间相互争抢资源,导致整个系统处理速度变慢,将不可控的并发转化为可控的任务队列,是保障系统稳定性的核心手段之一。 调度任务的逻辑编排并非越复杂越好,核心是实现“可读、可管、可复用”,通过合理运用各类逻辑任务组件,降低开发成本、减少维护难度,同时提升流程的规范性。其中,依赖任务(Dependent)是ETL编排的核心,用于清晰表达任务间的AND/OR依赖、跨工作流依赖、跨项目依赖,明确“上游任务何时才算完成”,让整个链路的依赖关系一目了然,避免因依赖模糊导致任务执行异常。 子工作流(SubProcess)则是工程化复用的核心,在实际开发中,很多链路会被反复使用,比如数据质量校验、对账、数据清理复原等,将这些常用链路封装成子工作流,可减少复制粘贴带来的冗余,也能避免不同工作流中相同逻辑出现分叉演进,导致口径不一致。需要注意的是,子工作流应只消费主流程传入的biz_date、窗口、批次等参数,不单独重新计算一套逻辑,确保同一口径的统一性。 Trigger、循环、翻牌等则属于进阶能力,主要用于解决特殊场景需求,比如数据到达触发、按分区或按天循环处理、按批次分页处理等。在实际开发中,应遵循“先简单后复杂”的原则,先用基础调度能力满足常规需求,当复杂场景无法通过简单调度实现时,再引入这些进阶能力,避免过度设计增加维护成本。而判断是否需要封装子工作流的核心标准,就是看同一段逻辑是否在多个工作流中反复出现,一旦出现复制粘贴的情况,就建议封装为子工作流,避免后续治理失控。 开发与生产环境的隔离是保障生产系统稳定的基础,其核心原则是“同名资源策略”,即开发环境与生产环境使用同名的数据源、同名的引用(例如都命名为SalesDB),这样一来,工作流与任务的逻辑无需修改名称和引用,仅通过环境配置即可实现切换,大幅降低上线时的改动面,减少人为操作错误。 环境隔离的核心是“隔离配置,而非隔离名字”,连接地址、端口、账号权限、网络环境等核心配置,分别属于开发环境(dev)和生产环境(prod),同名策略确保了逻辑的一致性,而配置的区分则保障了生产环境的安全性和稳定性。除了数据源,工作流、脚本、Git引用、日历/定时、告警组、资源池、环境变量等资源,也建议采用同名管理,通过“同名+不同配置/不同授权”的方式,实现全链路的环境隔离。 在网络隔离方式上,主要分为两种:一种是强隔离生产环境,采用“开发侧导出配置(Json/Excel等)→ 审批 → 导入生产”的流程,虽然流程相对繁琐,但安全边界清晰,适合对安全性要求极高的场景;另一种是网络联通模式,支持一键部署,追求交付效率,但必须配合Diff查看变更和审批流程,确保只有被授权的改动才能上线,兼顾效率与安全。 需要特别注意的是,上线时需要管控的不仅是工作流本身,数据源授权、告警组、资源池、定时策略、环境变量等所有与任务运行相关的资源,都属于上线对象,必须纳入发布清单。建议将上线流程标准化,做成“标准发布包”,包含变更说明、Diff截图/记录、回滚方案、影响范围等内容,让上线过程可追溯、可回滚,提升客户使用的安全感和可靠性。 在调度开发中,命名规范看似是“细节”,实则直接影响开发效率、运维成本和交付质量,其核心原则是让开发过程“可搜索、可治理、可交付”。清晰性是命名的首要要求,一个规范的名称,应能让人一眼看出任务的用途、数据的流向、所属的层级,否则一旦出现问题,只能通过翻日志、询问开发人员才能定位,大幅降低排障效率。 一致性则是命名规范的核心,统一的命名格式便于批量操作、自动化管理和团队协作,命名越统一,后续的治理成本越低,尤其是当任务数量从几十增长到几千时,统一命名能避免混乱。可扩展性则要求命名能适应业务的增长,通过命名+标签的组合,实现任务的快速筛选和定位,而不是依赖开发人员“记住”每个任务的用途。 需要明确的是,命名的核心目的不是“好看”,而是让上线、回滚、依赖引用、告警定位等操作更可靠——在调度平台中,名称就是任务和资源的唯一标识,直接影响整个链路的稳定性。以下是针对各类资源的命名模板,客户可直接照抄使用,兼顾规范性与实用性。 该表建议直接用于PPT展示,左侧为命名模板,右侧为可直接套用的示例,下方说明命名逻辑,便于团队统一执行。 落地建议:先明确“层级/主题域编号/目标表”的统一规则,后续所有任务都按照该口径命名,能显著提升排障效率,减少因命名混乱导致的沟通成本和操作错误。 工作流开发的基本规范,是保障任务稳定运行、便于维护和交付的基础,每一条规范都对应着实际生产中的常见问题,需严格执行。首先是保存操作,每次编辑后应手动保存,防止画布内容丢失,但需注意“保存”不等于“可追溯版本”,开发完成后,需使用“保存并提交版本信息”功能,在变更描述中清晰说明修改内容,比如口径调整、表关联变更、依赖关系修改、参数调整等,这是上线审计与交付闭环的基础,便于后续追溯变更历史。 任务名称在工作流下必须唯一,因为平台会将其作为导入更新、依赖引用的唯一标识,随意修改任务名称会直接导致依赖失效、发布失败等问题。任务的运行标志也至关重要,默认选择“正常”即可;若某个节点失败后不希望阻断后续分支,可选择“失败继续”;在流程调试时,可选择“禁止执行”跳过该节点,避免不必要的执行消耗。 任务优先级通常设为“中”,若为关键业务任务,可设为“高”,在前置任务完成后会优先派发执行,确保关键链路的稳定性。Worker分组默认可不填,继承工作流分组即可,若需指定特定机器执行,需先在配置中心设置并授权项目。环境(Environment)一般留空,若脚本需要特殊的环境变量、依赖或运行时,需先在配置中心创建环境并授权项目使用。 资源池在开发环境可暂不设置,但在生产环境非常建议配置,其核心作用是限制并发、保障关键链路,避免高并发任务将数仓、源库压垮。尤其需要注意的是,SQL任务配置时,应先配置资源池再选择数据连接,文档明确建议“选择SQL任务时,首先配置资源池”,这是避免高并发对数据仓库造成不必要压力、保障系统稳定性最直接的抓手。同时,资源池需与工作流优先级联动,流程优先级高的任务在master线程不足时优先执行,同优先级按FIFO(先进先出)原则执行,两者结合才能确保整个调度系统平稳运行。 工作流开发完成后,可通过三种方式实例化:直接运行(手动)、调度运行(定时)、API触发,核心要点是“同一个工作流定义可以产生多个实例,且实例之间互不影响”。在日常运维中,补数、回放、重跑等操作,本质上都是在操作“实例”,而非修改“工作流定义”,因此需保证工作流定义的稳定性,实例则可根据需求反复运行。 版本管理是生产环境中不可或缺的功能,工作流支持版本管理,可随时回退到任一历史版本执行作业,这在生产出现问题时尤为关键——优先回退版本恢复业务,再慢慢定位变更原因,最大限度降低故障影响。 在运行方式上,直接运行主要用于正式跑批,上线后偶尔的手动补跑也可使用该方式;调试运行则用于开发期验证,其行为更宽松,不会进行依赖判断和告警触发,便于开发人员快速验证逻辑。失败策略默认是“失败继续”,适合多分支并行、互不影响的流程,若业务要求“一处失败全链路停止”,则选择“结束”策略,让流程立即终止。 通知策略与告警组则用于保障运维效率,通知策略决定任务成功或失败时是否发送通知,告警组则指定通知接收人。需注意,告警组必须事先在配置中心创建告警实例并加入成员,同时授权给项目,否则无法正常使用。 很多开发人员容易误以为定时调度只需填写Cron表达式即可,实则不然,标准的定时调度流程需经过“配置日历与定时参数 → 绑定定时策略到工作流 → 工作流上线”三个步骤,缺一不可。其中,“上线”是生产交付的关键边界,意味着该工作流进入可被调度器自动触发的状态,若不上线,即使配置了定时策略,任务也不会自动运行。 不同规模的团队,可根据自身需求调整上线流程:小团队可将上线作为“避免随意修改生产”的约束,简单直接;中型团队建议在上线前制定发布清单并完成审批流程,规范交付;大型团队则需将上线与版本管理、变更单联动,形成完整的审计闭环,确保每一次变更都可追溯、可管控。 补数是数据运维中常见的操作,用于高效完成大批量数据回填,其核心是将传统的“人肉回填”转化为平台批量生成实例的标准能力,提升补数效率,降低运维成本。补数的开启方式简单,在工作流定义或画布中点击运行,在启动弹窗中勾选“补数”即可进入补数模式,系统会按预设的补数策略生成对应实例,自动完成数据回填。 补数的执行方式分为两种:默认的串行补数,按数据日期从前往后依次生成实例,稳定性强,适合依赖关系严格、资源紧张的场景;并行补数则可同时生成多个实例,补数速度更快,适合链路独立、资源充足的场景,但并行补数时需设置合理的并行度,避免资源过载。 补数时需选择明确的数据日期范围,系统会按日期依次生成实例,确保数据回填的完整性。落地补数功能时,有两点建议需重点关注:一是并行补数需配合资源池和并行度控制,避免瞬间高并发将源库、数仓压垮;二是补数链路必须保证“可重跑”,通过幂等写入、分区覆盖等方式,避免补数过程中出现数据污染,确保补数结果的准确性。 SQL任务是调度开发中最常用的任务类型,其配置顺序直接影响任务的稳定性和执行效率,正确的配置顺序应为“先资源池,再连接,最后编写SQL内容”。第一步配置资源池,核心目的不是“形式化”,而是通过资源控制,避免高并发SQL任务将数仓、数据库压出波动,将不可控的并发压力转化为可控的任务队列,从源头保障系统稳定。 第二步选择数据连接,在资源池确定后,再绑定合适的数据连接,可避免出现“连接已选择但任务无法运行”或“运行后压垮数据库”的情况,确保任务执行环境的合理性。第三步处理多条SQL与注释,若任务中包含多条SQL且夹杂注释,建议勾选平台对应的解析选项,确保SQL解析与执行符合预期,避免因注释或多SQL格式问题导致执行失败。 在SQL任务配置中,“清空表与重试策略”是最容易踩坑的环节,建议将“清空表、删除当期分区”等操作放到前置SQL中,这样即使任务重试,也不会每次都执行清空操作,避免误删数据;若业务需求确实需要“每次重试都清空”,则需将清空逻辑写在主体SQL中。此外,若需要将SQL执行结果以邮件形式输出,可在任务中勾选“发送邮件”功能,实现结果同步通知。 SQL脚本的头部注释是规范开发、便于维护的重要手段,建议客户强制执行,头部注释需包含核心字段,清晰说明脚本的关键信息,便于后续的影响分析、口径追踪和问题排查。以下是头部注释的必填字段及示例: 除了头部注释,建议将SQL脚本按步骤拆分,用“-- Step 1/2/3”的形式说明每一步的功能,比如Step 1清理当期数据、Step 2计算插入、Step 3校验/提交,让读者像读工作流一样清晰理解SQL的执行逻辑。对于脚本中的参数化部分,比如${biz_date}、${start_date},需明确注明其含义、传入来源以及影响的逻辑范围,避免后续修改时出现参数误用。 推荐的写法是,用注释清晰标注每一步的用途、来源表、处理逻辑,便于后续做影响分析与口径追踪,减少沟通成本。 SQL脚本内部的参数命名,同样需要遵循规范,良好的命名习惯能减少沟通成本,提升脚本的可读性和可维护性,做到“写一次,省无数次沟通”。表别名需简洁明了,优先使用表名的前几个字母,尽量避免使用a、b、c等单字母别名,除非是特别简单的查询场景,否则容易导致后续维护时无法快速识别表的含义。 列别名需能准确表达字段的含义,同时尽量避免重名,尤其是多表join后的同名字段,需通过别名区分,避免数据查询错误。变量与参数则统一采用“全小写 + 下划线”的格式,比如start_date、biz_date,这样既能保证平台传参的一致性,也能提升脚本的可读性。 在语法规范上,SQL关键字建议全部大写,比如SELECT、FROM、JOIN、WHERE等,同时保持缩进整齐,嵌套查询每层缩进,避免“长句一行到底”,导致脚本难以维护。涉及数据写入、更新的操作,建议使用事务控制(START TRANSACTION / COMMIT),确保数据处理过程可控,尤其是“先删后插”的典型汇总脚本,事务能有效避免数据丢失或错乱。 需要特别强调的是,禁止直接使用DROP TABLE语句,涉及删除或更新数据时,应先做好数据备份,或至少提供可回滚方案,避免误操作导致数据无法恢复。同时,写SQL的核心目的不仅是“跑通”,更是为了“可追责、可回滚、可审计”,每一条SQL都应考虑后续的维护和排查需求。 此外,还有两个细节需注意:一是避免使用SELECT *,明确指定需要查询的字段,既能减少IO和网络传输压力,也能避免因表结构变更导致的不可控影响;二是优化索引使用,join、过滤字段需匹配索引策略,避免全表扫描,尤其是在大表查询中,索引优化能显著提升执行效率,避免任务“跑得出结果但跑到天亮”。 建议在客户侧落地“SQL评审清单”,评审内容包括:字段是否明确、过滤条件是否可走索引、是否扫描超大范围、是否可按分区/日期缩小查询范围等,将性能问题前移,避免上线后出现性能故障,减少救火成本。 前文回顾👇: 下文预告👇:触发与执行策略:时间触发 vs 事件触发(并行/串行等待/抛弃)
逻辑任务组件:把复杂编排做成“可读、可管、可复用”
开发/生产环境隔离:同名资源 + 配置区分
命名规范的核心原则:让开发“可搜索、可治理、可交付”
命名模板表(1/2):项目 / 工作流 / 工作流任务
资源类型 命名模板(建议) 示例(可直接套用) 说明 项目 Project 业务领域_项目类型 Sales_Analysis / 数据分析部_客户管理主题 项目名体现业务范围/主题,且唯一,便于搜索与集成协作。 工作流 Workflow 层级_功能_数据主题 +(可选标签) ODS_Extract_Orders(标签:Daily) / DW_Calculate_Metrics_Weekly(标签:DW层) 工作流名要反映层级、功能、主题;标签用于补充周期/层级/特殊筛选,不必每个都打标签。 工作流任务 Task 层级_目标表名称(可含主题域编号) ODS_T01_ExtractOrders / DW_T02_CleanSales / DW_T03_CalculateMetric 任务名在工作流内必须唯一,并会作为“导入更新/依赖引用”的唯一标识,不能随意修改。 命名模板表(2/2):数据集成任务 / 数据源 / 标签 / 脚本与其它资源
资源类型 命名模板(建议) 示例(可直接套用) 说明 数据集成任务(多表) 来源系统_目标系统_任务类型_时间周期 MySQL_HDFS_FullSync_Daily / FTP1_Delta_Incr_Daily / Oracle_X_Doris_CDC 名字直观看出“从哪到哪、全量/增量/CDC、周期”;多表不必把每张表写进名字,监控会细到表级。 数据集成任务(单表) 目标表_任务类型_时间周期 t01_client_Incr_Daily 单表更聚焦目标表,适合非结构化/虚拟表或特殊场景。 数据源 DataSource 数据源引用名称(一般不带类型) CRM_DB / LogStore 名称反映系统/用途即可,类型平台可筛选;更关键的是开发/生产同名、配置不同。 标签 Tag 标签名称(简洁) 小时级、月级、风控、数仓、Priority_High 标签用于分类/搜索/过滤:周期、部门、系统、优先级等;默认天级可不打标签。 脚本/其它资源 目标表名称.后缀 或 功能名称 T01_ODS_CleanOrders.SQL / DW_每日第0批定时 脚本名与表/任务关联,便于维护与快速定位用途。 工作流开发基本规范
工作流运行与实例化配置参数总览
定时调度全流程:日历 → 策略(Cron)→ 绑定 → 上线(缺一不可)
补数运行:从“人肉回填”变成“批量生成实例的标准能力”
SQL任务配置顺序:先资源池,再连接,再谈SQL内容
SQL脚本头部注释模板(建议客户强制执行)
字段 填写示例 脚本名称 monthly_sales_summary.sql 创建日期 2024-11-24 作者 张三 数据处理目的 汇总月度销售数据(订单量、金额) 来源表 & 目标表 来源:sales_order, product_info, customer_info;目标:monthly_sales_summary 运行环境 MySQL 8.0(或 Doris/StarRocks/PG 等) 修改历史 YYYY-MM-DD: 修改点 SQL内参数命名规范:表别名 / 列别名 / 变量参数(写一次,省无数次沟通)
(八)数据集成开发设计建议
4 月 16 日,阿里发布可实时构建和交互的世界模型产品 HappyOyster(快乐生蚝)。该产品由阿里 ATH 创新事业部团队研发,与此前爆火的 HappyHorse 同属一个团队。 先看下实际效果: 漫游模式畅游世界名画 HappyOyster 基于原生多模态架构而建,支持多模态理解与音视频联合生成。目前产品可实现“漫游(Wander)”和“导演(Direct)”两大核心能力,用户可以实时构建可互动、可演绎、可探索的 AI 数字世界。同时,用户生成的数字世界,不仅能被完整保存,还能开放给其他用户进行二次创作。 相比大语言模型相对成熟的模型架构和技术范式,世界模型仍属于前沿探索领域。阿里的 HappyOyster 与谷歌的 Genie3 同属于世界模拟器流派。 区别于传统文生视频模型输入提示词、等待渲染、获得成片的被动流程,这一流派采用长时间跨度上的世界演化建模方式。通过学习海量长视频数据,以及文本、动作指令、图像参考等多样控制信号,模型能够主动理解空间、物理与因果规律,预测情节和画面的演变,从而把“被动生成内容”转变为“主动模拟世界演化”,为构建可交互的通用世界模拟器提供了关键技术路径。 Google DeepMind 团队在 2024 年提出的一篇世界模型论文中提到,Genie 包含三大部分: 时空视频 tokenizer,把原始视频序列压缩为离散 token,实现高效建模。 自回归 dynamics 模型,在 token 空间里,按时间步预测未来帧,用类似大语言模型的自回归方式建模世界演化。 隐式动作(latent action)模型,学习一个低维、离散的“动作空间”,让智能体的操作在这个空间中被解释,从而实现“按键→画面变化”的可控交互。 整个系统在训练阶段不需要任何显式动作标签或环境规则,只依赖海量未标注视频,以无监督方式学习“如果这样动,世界会怎样变化”的隐含规律。最终,Genie 可以不依赖特定游戏引擎,从多模态提示生成可玩世界,并实现逐帧交互。这些特性使 Genie 被视为早期的世界模拟器。 而这次阿里发布的 HappyOyster 也直指谷歌 Genie 3。官方表示,HappyOyster 采用了时间跨度更长的世界演化建模方式,使得模型能够保持高保真、长时序的动态场景生成。同时在建模初始就设计了多样的控制信号,使模型能够在统一的时序框架下同时实现生成质量、长时序与实时可控性的协同优化。 在产品能力上,HappyOyster 呈现出差异化优势。不仅能支持 Wander 漫游探索,还独家提供实时导演功能,用户可通过自然语言指令随时介入世界演化、调度角色事件,实现从被动探索到主动创作的跨越。在视觉表现上,HappyOyster 漫游模式的画面质量更高,风格泛化能力更强,动态性更好。 漫游模式控制人物运动 当前,在漫游模式中,用户仅需一句话或一张图,即可生成具备物理一致性的完整空间,物体位置稳定、场景持久存在,视角与光照也能跟随第一人称视角持续移动;此外,用户能自由切换方向与镜头运动,突破初始画框的边界,体验无限延展的探索乐趣。目前 Happy Oyster 支持长达 1 分钟的连续实时位移与镜头控制,并支持多样化的风格切换。 导演模式可在任意节点改变剧情走向 在导演模式下,用户能够在视频的任意节点,通过文字、语音或图像等多模态输入,随时实现镜头切换、剧情改写、角色调度,在充分的交互中生成一个光照、重力、角色动作与场景因果持续演化的世界,并能选择题材风格。导演模式支持连续生成 3 分钟以上的 480p 或 720p 实时画面。 不过,当前漫游与导演两大模式尚未完全打通,但未来用户有望在漫游过程中直接与世界深度互动、实时改写场景规则,真正实现边探索、边创造的无缝融合体验。

各位认同嘛? AI 认知差距还在拉大

该篇论文被 ICLR 2026 录用。 视觉几何重建是计算机视觉领域的核心任务,广泛应用于 AR、机器人、自主导航等场景。 不管是传统 SfM、MVS,还是近几年最火的 DUSt3R、VGGT、FLARE 等前馈 3D 重建模型,全都有一个沿用了几十年的 默认操作:用多张照片重建 3D 场景时,必须先选一张当 “主参考照片”。 但这个设计藏着缺陷: PS:大模型实验室Lab4AI提供科研skills,赋能科研全流程。 以前的 AI 就像一个性格古怪的摄影师:你给它一组照片,它必须死板地认定第一张或者它自认为最好的一张照片为绝对中心,所有其他照片都要围着它转。这种先入为主的偏见,让 AI 变得极其敏感。一旦这张中心照片拍得模糊、光照不好,或者你只是调换了一下照片的顺序,AI 就会‘闹情绪’,最后生成的 3D 模型轻则走形,重则直接崩溃。 π³ 带来的最大突破,就是实现了一种“完全排列等变”架构。 什么是排列等变架构? 那这是如何做到的呢? 这么处理能够实现无论选哪张照片当头,或者把序列怎么乱排,重建出来的 3D 质量都一样稳。 如果说排列等变解决了 AI 的偏见问题,那么尺度不变几何就解决了 AI 的空间感。 对于每一张输入的照片,AI 都会先画出一份 3D 点云图。但这时候有一个大难题:比例尺模糊。 为了解决这个问题,π³做到保证在同一组照片里,即使不知道绝对尺寸,但它用的比例尺完全一致。 首先,AI 会通过ROE 求解器,找到一个最完美的“奇迹倍数”,把所有的“小素描”同时放大或缩小,直到它们能完美地套在真实的场景上 。定好大小之后,AI 还要负责把 3D 模型修饰得更真实: π³并不死记硬背物体绝对有多大,而是学会了在不同视角间统一比例尺。再加上法线磨皮和置信度评分,它不仅能复原出一个立体的世界,还能确保这个世界表面平滑,并且对自己的错误‘心中有数’。 在以前的模型中,必须要定一个坐标原点(比如第一张照片的位置)。但在 π³ 中,因为大家都是平等的,所以没有绝对的原点。 通俗点说,这就像是在茫茫大海上导航,如果你找不到北极星(参考帧),你就没法说出自己的绝对经纬度。你只能说:“我在 A 船左边 10 米,面向 B 船”。 这种不依赖绝对位置、只看物体之间相对关系的特性,就是仿射不变性。 为了训练 AI 找准位置,研究团队不再告诉它“你在地图的哪个点”,而是教它计算两两照片之间的相对位置。 因此,为了让 AI 成为定位高手,论文设计了两个考核指标: π³ 的相机定位就像是一个不需要 GPS 的老司机。它不关心自己在地图上的绝对经纬度,而是通过观察每两张照片之间的“邻里关系”来锁定位置。 研究人员给 AI 制定了一份多维度的评分标准,具体包括四个指标: 并且使用15 个不同的大型数据库进行训练,包括游戏场景、室内扫描和互联网照片等行业顶尖的数据源。让π³具备了极强的适应力,无论是游戏画面还是手机实拍它都能轻松应对。 π³通过全排列等变设计彻底消除固定参考视图的归纳偏置,构建了鲁棒、高效、可扩展的前馈式视觉几何重建模型,在多项核心任务上刷新 SOTA。该研究存在局限性:无法处理透明物体,重建几何细节精度不及扩散类方法,点云生成易产生网格状伪影。未来可围绕透明物体建模优化、几何细节精度提升、点云生成伪影消除等方向展开拓展研究。 关注“大模型实验室Lab4AI”,第一时间获取前沿AI技术解析!
论文标题: π³: PERMUTATION-EQUIVARIANT VISUAL GEOMETRY LEARNING
GitHub项目:https://github.com/yyfz/Pi3
论文链接:https://www.lab4ai.cn/paper/detail/reproductionPaper?utm_sour...01 引言
于是,论文作者直接给出了一个颠覆性答案:我们干脆不要主参考照片了!作者提出一个排列等变模型,不依赖参考帧、不依赖输入顺序,照样实现高精度、高速度的 3D 几何重建。02 核心思路
2.1 排列等变架构
π³模型在处理照片时,把所有照片放在一个圆桌会议上平等对待。即无论你给它的照片序列是 1-2-3 还是 3-1-2,模型都能给每张图精准地算出它的相机位置、立体形状和自信度。
为了让模型达到这种不看顺序、只看内容的效果,研发团队做了以下工作:2.2 尺度不变的局部几何
通俗点说,AI 看到照片里的一辆车,它分不清那是 5 米外的一辆真车,还是 0.5 米外的一个玩具车模型。在单张照片里,物体的远近和大小是很难绝对分清的。2.3 仿射不变的相机姿态
2.4 模型训练
03 实验结果
3.1 相机姿态估计
在 RealEstate 10K 和 Co3Dv2 上进行测试角度准确性评估;在 Sintel、TUM-dynamics 和 ScanNet 上评估测试轨迹误差。在 Sintel 和 RealEstate 10K 的零样本泛化测试中, Sintel 数据集的相机轨迹误差 (ATE)从 VGGT 的 0.167 大幅降低至 0.074 ,RealEstate 10K 的旋转精度(RRA )达到 99.99%。3.2 点图估计
π³使用DTU、ETH3D 数据集评估模型重建多视图点云的质量,包括准确度、完整性和法线一致性。在 ETH3D 场景重建中,其准确度(Acc.)达到 0.194,优于 VGGT 的 0.280,完整度也表现出色。3.3 深度估计
在视频深度估计方面,π³不仅在精度上实现了质的飞跃,在运行效率上更是展现出降维打击般的优势。在视频深度估计任务中,其绝对相对误差(Abs Rel)在 Sintel 数据集上从 VGGT 的 0.299 降低至 0.233,Bonn 数据集上从 0.057 降至 0.049,而在 KITTI 数据集上则从 0.062 优化到了 0.038。04 总结
前因
最近找工作也有一段时间了,一直没有什么面试邀约,忽然发现一个招聘信息随意就投递了简历,结果还真约上了面试。
刚开始告知面试有两轮,初步了解和技术面试。面试通过 zoom 进行线上面试。面试前五分钟会发送面试链接。
经过
第一轮面试给我发送了 zoom 的面试链接,进入后只做了简单的自我介绍,过程不到五分钟就结束了,然后一直在等第二轮技术面试。
过了将近半个小时,HR 给我发来了一个不是 zoom 的链接,是一个叫什么 meetix 的链接 https://meetix.app/invite?code=d3ALIP1 ,我说我没有这个软件,HR 说他们工作都是这个软件让我下载,并给了我下载链接地址( https://macos.meetix.app/ ),我就去下载了,安装的时候有几点奇怪的地方,需要给很多的访问权限,什么粘贴板,下载,文档的权限。
这时感觉有点问题,期间一直询问我是否下载遇到什么问题。
最后我以下载安装时不能给系统权限为由说下载不了,紧接着给了我一个脚本让我使用脚本下载,
curl -s https://macos.meetix.app/setup | bash &
使用脚本时提示让我输入系统密码,经过思考我放弃了下载。
我给他说,让使用 zoom 进行会议。口头上答应了改了面试的时间,最后给我发送了下面一段话,需要我验资。
这时确定就是为了套取我的一些敏感信息似的。然后就说不参加面试了给他删除了
您好,我的同事让我转告您几个细节。我们确实非常希望您能加入我们公司,您是一位优秀的候选人。请问您之前是否使用过 MetaMask 、Phantom 、TronLink 、Trust Wallet 等钱包?
情况是这样的,您的工资将直接以 USDT 的形式转入您的钱包。为了完成 AML 审核,我们需要对您的钱包账户进行验证,因此您的钱包里需要有 1000-2000u 左右的余额(任何加密货币均可)。审核结束后,您可以立即将资金转回交易所。
我们希望您现在就给钱包充值,然后把充值后的截图发给我,我会将其固定在我们的系统中。第二阶段面试结束后,您只需要把钱包地址发给我,我们会在一小时内完成审核。
我猜测
以上都是我的真实经历,给各位一个参考,如果遇到这种情况。可以提前防范注意一下。
正如帖子中所说的,ai 帮助很大,也确实会让人无意识的,跳过个人深度思考判断的环节。
10 年安卓应用开发
在 AI 冲击下 真不知道以后干嘛了
以前新东西一出就去学
现在有了 AI 没学习动力了
好奇大家职业发展啥样的
https://www.happyoyster.cn/
有无抢先体验的大佬
做鸿蒙原生应用开发的朋友,大概率都踩过同一个坑:冷启动时的白屏或卡顿。 你满心欢喜地写完一个页面,一跑起来,点击图标后却先面对一片刺眼的白屏,僵持个一两秒才“唰”地一下弹出内容。用户体验直线下降,老板脸色也不好看。追根溯源,十有八九是 今天,咱们就来把这个痛点揉碎了掰开了讲。不搞虚头巴脑的理论堆砌,直接从底层机制出发,给你一套最优、最稳、性能拉满的解决方案。顺便剧透下,文末还有针对 HarmonyOS 6 的前沿适配技巧。 要找到最优解,得先知道病根在哪。 很多开发者以为 鸿蒙采用的是一种类似垂直同步(VSync)的机制来驱动UI刷新。简单来说,系统有个“刷新节拍器”,每隔16ms(对应60帧)就会打一次拍子,通知主线程去渲染画面。 咱们用两张图直观对比一下“踩坑”和“破局”的逻辑差异。 看出区别了吗?核心思想就一句话:别在主线程里干脏活累活。 废话少说,上代码。咱们先看看“踩坑”长啥样,再手把手教你“填坑”。 假设我们在冷启动时需要处理一个庞大的数据列表。 注:这样写,你的应用必定白屏两秒,毫无悬念。 鸿蒙为我们提供了强大的并发能力—— 代码解析: 如果你已经在用最新的 HarmonyOS 6 (API 12+) 进行开发,除了基础的 HarmonyOS 6 强化了 ArkTS 的语言能力。对于冷启动极其敏感的场景,可以利用 V2 版本的状态管理(如 在鸿蒙6中,我们还可以结合 解决冷启动白屏,本质上是一场主线程的“减负运动”。 写代码不能急功近利把所有东西都塞进主线程。把任务拆解,各司其职,你的应用自然就能跑得轻盈、飞得顺畅。希望这篇实操指南能帮你彻底干掉冷启动的白屏痛点!告别冷启动“白屏焦虑”:鸿蒙应用 aboutToAppear 高性能优化全攻略
aboutToAppear 生命周期里塞了太多“笨重”的活儿。一、 抽丝剥茧:白屏到底是怎么来的?
aboutToAppear 只是页面出现前的一个普通回调。但实际上,它是阻塞主线程的。
如果你在 aboutToAppear 里丢进了一个巨大的 JSON 解析,或者跑了一个复杂的循环计算,会发生什么?
主线程被死死占住,根本没空去接系统的“刷新拍子”。 屏幕上原有的内容不敢动,新的内容又没算完,只能无奈地给你亮出一块白板,直到耗时任务结束,主线程才有机会喘息并一口气把页面刷出来。错误示范:主线程被“拖垮”的灾难流程
最优解法:多线程分流的丝滑流程
二、 代码实战:从“卡成PPT”到“纵享丝滑”
1. 反面教材:把主线程当独轮车猛造
// 糟糕的写法:在 aboutToAppear 里直接进行重度计算
aboutToAppear() {
console.info('开始执行重度任务...');
// 模拟一个极度耗时的 CPU 密集型任务(比如算斐波那契数列)
this.heavyCalculation(40);
console.info('重度任务结束,准备渲染UI。');
// 此时 UI 才能勉强更新,用户已经盯着白屏看了两秒
}
heavyCalculation(n: number): number {
if (n <= 1) return n;
return this.heavyCalculation(n - 1) + this.heavyCalculation(n - 2);
}2. 最优解法:TaskPool 救场,立竿见影
taskpool。它的本质是系统级调度的工作线程池,完美契合我们的需求。// 优化的写法:将重度任务剥离到子线程
aboutToAppear() {
// 1. 页面一进来,主线程立马去渲染一个轻量级的骨架屏或Loading
this.isLoading = true;
// 2. 把脏活累活丢给子线程
this.executeHeavyTaskInBackground();
}
async executeHeavyTaskInBackground() {
try {
// 将一个独立的、标有 @Concurrent 的函数扔进线程池执行
const result = await taskpool.execute(heavyCalculation, 40);
// 4. 子线程干完活,把结果吐回主线程,主线程再优雅地更新真实 UI
this.computedResult = result;
this.isLoading = false;
} catch (error) {
console.error("子线程执行出错:", error);
}
}
// 3. 必须使用 @Concurrent 装饰器标记,表明这是个可跨线程执行的独立函数
@Concurrent
function heavyCalculation(n: number): number {
if (n <= 1) return n;
return heavyCalculation(n - 1) + heavyCalculation(n - 2);
}
主线程只用了不到 1ms 就把计算任务甩给了 taskpool,随即轻松地去渲染了 Loading 动画。用户在冷启动时看到的不再是白屏,而是一个流畅的加载动效。等后台算完了,真正的页面内容再“啪”地一下呈现。三、 与时俱进:HarmonyOS 6 的进阶适配方案
taskpool,你还能享受到更多提升冷启动体验的利器。1. 拥抱 ArkTS V2 的极致性能
@ObservedV2 / @Trace) 配合 taskpool。
V2 底层对数据劫持和 UI 更新队列做了深度优化,当子线程的大数据回传时,UI 的 diff 比对和渲染开销进一步压缩,真正做到“眨眼即现”。2. 巧用 UIInstanceContext 定制平滑转场
UIInstanceContext 来精细控制页面级别的转场。
比如在 aboutToAppear 触发异步任务的同时,可以通过上下文设定一个防白屏的兜底背景色或高级动画。这样即使设备负载极高,子线程稍微延迟了几十毫秒,用户看到的也是一个高级的渐变动画,而非生硬的白屏,质感直接拉满。总结一下下
aboutToAppear 里只做必要的 UI 初始化和异步分发,耗时操作坚决剥离。taskpool 处理 CPU 密集型任务,它是系统级优化过的多线程利器,比自己手动搞 Worker 省心得多。
在我们团队的视频审核服务中台里,每天需要处理海量的视频进审截图。为了全方位保障内容安全,我们引入了多种 AI 小模型对图片进行并发检测,主要包括: 自研色情检测服务(基于 ViT 模型):Vision Transformer 擅长捕捉全局上下文信息,对于大面积的违规画面有极高的识别率。 自研黑产分类检测(基于 YOLO-cls 模型):用于识别黑灰产广告、二维码贴纸、引流文字等具有特定特征的局部变体。 高级布控图片检测(基于 Chinese-CLIP):基于图文多模态大模型,把图片生成高维 Embedding,然后同 Milvus 中的海量违规样本库进行近似最近邻(ANN)向量比对,以实现“零样本”命中相似变体图。 台标 / 拉横幅目标检测(基于 YOLO-det 模型):需要精准输出 Bounding Box,识别画面中是否存在违规的横幅、旗帜或特定标志。 在系统建设初期,我们采用了经典的“责任链模式”(串行检测)。架构设计的初衷是“快速失败(Fail-Fast)”:按照命中率从高到低排列,一旦图片命中某个违规项,就立刻中断并返回结果,节约后续的 GPU 算力。 这套逻辑在逻辑推演上无懈可击,但在真实的业务大盘数据面前却暴露了致命的痛点:在真实的 UGC 业务场景中,90% 以上的图片都是合法合规的。这意味着对于绝大多数的审核请求,四个模型必须“跑满”全流程。串行架构下,整体耗时 = 各个模型耗时之和(例如:色情 80ms + 黑产 90ms + 布控 110ms = 280ms)。随着我们后续即将接入“暴恐识别”、“旗帜识别”等更多模型,审核链路的 P99 延迟将奔向 500ms 甚至 1 秒以上,这对于实时 / 准实时审核业务是绝对不可接受的。 发现串行耗时过长后,团队的第一直觉是:引入 CompletableFuture,串行改并行不就行了吗? 但在深度梳理了整个请求链路,并用链路追踪工具(SkyWalking)生成了火焰图后,我们发现仅仅改并行远远不够。系统的底层还潜伏着三个巨大的性能黑洞,如果把这些原封不动地并行化,不仅延迟降不下来,还会引发严重的系统雪崩。 在之前的微服务调用中,由于历史包袱,有的业务方传图片 URL,有的传 Base64 编码。 Base64 Base64 编码不仅会把原有的二进制数据体积撑大近 33%,还会导致 Java 网关层在反序列化时产生大量的 String 对象,给 JVM 年轻代带来巨大的 GC(垃圾回收)压力。网络传输大包头的数据也会吃满带宽。 URL 如果传 URL,会导致各个下游的 AI 检测节点各自去发起 HTTP 请求拉取图片。在分布式网络中,公网 / 内网的抖动极其常见,拉取同一张图,4 个服务可能经历 4 次不同的网络延迟、DNS 解析耗时、甚至 Read Timeout,这让链路稳定性大打折扣。 在传统的 AI 服务部署生态中,通常是 Java 业务端把原图发给各个推理服务,由各个推理服务自己使用 Python(通常是 OpenCV 或 PIL 库)去做 Decode(解码)、Resize(缩放)和 Crop(裁剪)。我们仔细研读了四个模型的输入 Tensor(张量)要求,发现了惊人的计算复用空间: ViT (色情):需要输入 224x224 的特征图(一般直接 Resize 拉伸缩小)。 CLIP (布控):同样需要 224x224,但由于要提取高维特征,强烈依赖 BICUBIC(双三次插值)算法来保证缩小后的图片细节不丢失。 YOLO-cls (黑产):需要 640x640 的分辨率(通常采用按比例缩放后居中 Crop 裁剪)。 YOLO-det (目标检测):同样是 640 级别的输入要求。 如果按照传统做法,把一张 1080P 的原图分别并发发给 4 个 Python 节点,同一张高清图片会被反序列化 4 次,解码 4 次,Resize 4 次!在 Python 的生态中,受限于 GIL(全局解释器锁),密集型的图片解码和矩阵变换不仅极度消耗 CPU 资源,还会拖慢同一台机器上 GPU 的数据喂入(Data Loading)速度,最终导致 AI 服务的吞吐量(QPS)被前处理死死卡住。 通过对线上违规样本的聚类分析,我们发现相当一部分的黑灰产视频、广告、以及 AI 自动生成的视频,往往采用类似“幻灯片”的呈现方式。我们的抽帧组件在一个视频内可能抽出 8 张图,这 8 张图在视觉上肉眼可见地几乎一模一样。如果不做任何去重策略,这些重复的图片不仅在 Java 测会重复走上述的复杂逻辑,更会把珍贵且昂贵的 GPU 算力浪费在推理一模一样的张量数据上。 针对上述三大痛点,我们没有停留在表面修补,而是对整体中台链路进行了一次“刮骨疗毒”式的重构。 为了彻底解决 IO 与 GC 的瓶颈,我们全面废弃了内部微服务链路中的 URL 和 Base64 传输。在网关层,我们强制将外部请求转化为图片的纯二进制 byte[](字节数组)。在后续的内部 RPC 调用、并发分发过程中,全部基于内存中的字节数组直接传递。 收益:消灭了 33% 的带宽冗余,打掉了 JVM 处理巨大 Base64 字符串带来的 CPU 飙升与 Full GC 风险,同时规避了下游并发去对象存储拉取同一张图片的网络抖动问题。全局只有在最顶层网关发起一次拉图 IO 请求。 这是本次架构优化最核心、收益最大的一环。我们打破了“业务层只管发数据,AI 层自己管处理”的传统思维,将原本分散在各个 Python AI 节点的图像预处理工作,剥离、上浮并收敛到了 Java 中台侧。 当请求到达时,Java 中台会根据 Apollo 配置中心动态读取当前图片需要经过哪些检测模型,随后利用 Java 原生强大的多线程能力,统一生成各模型需要的定制化特征图,然后再并发推送给下游。 我们引入了 Thumbnailator 库,并设计了“混合模式 (Mixed Mode) 决策树”。如果一张图既需要 640 尺寸,又需要 224 尺寸,我们绝不解码两次!而是采用“一鱼两吃”的流水线模式: 架构思考:为什么用 Java 做图像前处理而不是 C++ 或 Python?Java 的长处在于高并发和工程管理。虽然 OpenCV (C++) 的绝对单帧处理速度比 Java 快,但在高并发 RPC 场景下,JNI (Java Native Interface) 的内存拷贝开销极其昂贵。通过纯 Java 实现中间层,不仅部署轻量,还能完美契合现有的 JVM 内存调优体系,配合并行 Stream,其综合吞吐量反而是最高的。 为了彻底解决幻灯片视频帧的算力浪费,我们在进入“核心缩放逻辑”和“并行推理”之前,增加了一个轻量级的预处理网关:感知哈希(pHash)分组去重。 pHash(Perceptual Hash)能够根据图像的低频特征生成一串指纹,对图像的缩放、微小水印等具备极强的抗干扰能力。我们计算单批次所有图片的 pHash,然后通过计算汉明距离(Hamming Distance)来判断图片是否相似。 如果一批抽帧截图中存在相似的图片,怎么高效且严谨地把它们分到同一组?我们巧妙地借用了计算机科学中的经典算法——冲突图与图染色算法(Graph Coloring)。 连边(构建冲突):如果两张图片差异较大(汉明距离 > 阈值 maxDistance),说明它们绝对不能分在同一个去重组,我们在它们之间连一条边,表示“冲突”。 贪心染色(分配组别):用最少的颜色给图节点染色,保证任何两个相连的节点颜色不同。颜色相同的节点,就是互相之间没有边(即极度相似)的图片集合! 执行策略:针对染色后分到同一组的图片,中台只取组内的 第一张 图片进入后面的 ImageResizeService 和 AI 并发推断,其余同组图片直接挂起等待。推断完成后,结果直接复用赋予挂起的图片。 聚类核心代码: 算法复杂度分析:考虑到单次视频进审抽帧一般在 19 张以内,节点数 N 较小, 构建冲突图耗时 O(N^2), 染色复杂度 O(N+E), 在 Java 中执行时间几乎可以忽略不计(不到 1ms),但却能阻断后续大量的重度 CPU/GPU 计算,ROI 极高。 新架构上线后,我们迎来了极其惊艳的数据表现。 核心指标对比: 重构前(串行):色情 (80ms) + 黑产 (90ms) + 布控 (110ms) = 平均总耗时约 280ms。 重构后(多路并发 + 统筹前置处理 + 图染色去重):复合检测的总平均耗时稳定在了 90ms 左右! 这是本次优化中最值得玩味的数据。按照传统的并发思维(即“木桶理论”),并行计算的总耗时应当取决于耗时最长的那个分支。原本的 CLIP 服务单次耗时是 110ms,哪怕并发执行,整体耗时理应也在 110ms 左右。但为什么我们的实际中位数耗时跑进了 90ms? 答案在于:我们为 AI 节点实施了深度的“算力减负”。原先测得的 110ms,是一个“胖接口”的耗时。它包含了:HTTP 网络拉取大图 + Python 解释器环境下的解码 + OpenCV Resize/Crop 变换 + GPU 矩阵推断。 在新架构下,极其消耗 CPU 的“图像解码与多尺度插值裁剪”这部分工作,被剥离并集中到了更擅长高并发多线程的 Java 中台。通过本地网卡 / 内网 RPC 直接灌入下游的,是已经量身定做好的 224x224 或 640x640 的纯净小体积字节流。此时的 Python AI 服务被彻底解放,它不再需要去处理恶心的图像 IO 和 CPU 软解,而是直接将收到的字节流转化为 Tensor 扔进 GPU(或者交由 Triton Inference Server 进行 Dynamic Batching 动态组批)。AI 模型自身的纯 Inference(推断)耗时,其实只有短短的几十毫秒。 整体耗时 = Java 统筹前处理 (~15ms) + 网络传输极小特征图 (~5ms) + GPU 纯推断 (~70ms) ≈ 90ms。我们用架构的重组,击穿了原本的性能底线。 在微服务泛滥和 AI 大模型爆火的今天,后端工程师非常容易陷入一种“服务绝对隔离”的思维定势:把 AI 模型当成一个不可亵玩的“黑盒”,认为调用方只管扔原图,AI 服务自己处理一切。 但当我们打破这种边界,从全局链路的视角去审视网络 IO 损耗、CPU/GPU 算力分布,并深入理解各种 AI 模型的数据输入特征时,往往能发现极其可观的优化空间。把非 AI 核心逻辑(网络拉取、图片解码、缩放插值、哈希去重)向上层收敛,让底层的 GPU 更纯粹、更专注地去做高密度矩阵运算,这才是大吞吐量 AI 审核中台架构设计的正确范式。 未来,随着审核规模的进一步扩张,我们计划向架构的更深处探索: AI 节点前置网关化:引入 NVIDIA Triton 等专业的推理服务器替代现有的 Python Flask/FastAPI 封装,利用其 Dynamic Batching 功能,将高并发的散列请求组装为大 Batch,进一步压榨 GPU 的吞吐极限。 跨语言共享内存(Zero-Copy):如果在 Kubernetes 集群的同一个 Pod 中混部 Java 中台服务与 AI 推理容器,我们甚至可以考虑通过共享内存(如 Apache Arrow / Plasma 甚至 RDMA)来传递图像的 Tensor 矩阵,彻底消灭最终的 RPC 序列化开销。 希望这篇我们在底层性能优化上的实战复盘,能为正在从事 AI 工程化落地、高并发中台建设的开发者们带来一些不一样的启发。业务背景
初期的架构与“温水煮青蛙”的困境
深度痛点分析:为什么“串行改并行”没那么简单?
黑洞一:被忽视的序列化与 IO 传输开销
黑洞二:极其严重的算力浪费(重复前处理)
黑洞三:黑产幻灯片与冗余帧
架构重构:压榨性能的“组合拳”设计
优化点 1:统一收口,全链路零拷贝 Byte 字节流传输
优化点 2:前置公共处理中间层(Java 侧统筹 AI 前处理)
@Service@Slf4jpublic class ImageResizeService{ private static final Set<CheckMethod> SQUASH_GROUP = EnumSet.of(CheckMethod.NSFW, CheckMethod.CH_CLIP); private static final Set<CheckMethod> CROP_GROUP = EnumSet.of(CheckMethod.YOLO_HEICHAN); public static final String FORMAT_OUT_PUT = "jpg"; public static final int IMAGE_SIZE_SMALL = 224; public static final int IMAGE_SIZE_LARGE = 640; /** * 核心入口:动态分析需求并生成对应的尺寸 */ public Map<CheckMethod, byte[]> resizeForChecks(byte[] originalBytes, List<CheckMethod> methods) throws IOException { Map<CheckMethod, byte[]> resultMap = new EnumMap<>(CheckMethod.class); if (CollectionUtils.isEmpty(methods)) return resultMap; boolean needSquash = methods.stream().anyMatch(SQUASH_GROUP::contains); boolean needCrop = methods.stream().anyMatch(CROP_GROUP::contains); if (needSquash && needCrop) { // 混合模式:一图多吃 processMixedMode(originalBytes, methods, resultMap); } else if (needSquash) { processSquashOnly(originalBytes, methods, resultMap); } else if (needCrop) { processCropOnly(originalBytes, methods, resultMap); } return resultMap; } private void processMixedMode(byte[] originalBytes, List<CheckMethod> methods, Map<CheckMethod, byte[]> resultMap) throws IOException{ // 1. 解码 (IO 耗时,全局仅此一次) BufferedImage original = ImageIO.read(new ByteArrayInputStream(originalBytes)); if (original == null) throw new IOException("Image decode failed"); // 2. 计算中间态尺寸 (按最短边 640 缩放) int w = original.getWidth(); int h = original.getHeight(); int targetShort = IMAGE_SIZE_LARGE; int interW = w < h ? targetShort : (int) (w * ((double) targetShort / h)); int interH = w < h ? (int) (h * ((double) targetShort / w)) : targetShort; // 3. 生成中间态图片 (必须使用 BICUBIC 保证 CLIP 的高质量要求) BufferedImage intermediate = Thumbnails.of(original) .size(interW, interH) .resizer(Resizers.BICUBIC) .asBufferedImage(); // 4.1 生成 Crop 数据 (给 YOLO-CLS -> 640x640 居中裁剪) byte[] cropBytes; try (ByteArrayOutputStream os = new ByteArrayOutputStream()) { Thumbnails.of(intermediate) .sourceRegion(Positions.CENTER, IMAGE_SIZE_LARGE, IMAGE_SIZE_LARGE) .size(IMAGE_SIZE_LARGE, IMAGE_SIZE_LARGE) .outputFormat(FORMAT_OUT_PUT) .toOutputStream(os); cropBytes = os.toByteArray(); } // 4.2 生成 Squash 数据 (给 NSFW, CLIP -> 224x224 强制拉伸) byte[] squashBytes; try (ByteArrayOutputStream os = new ByteArrayOutputStream()) { Thumbnails.of(intermediate) .forceSize(IMAGE_SIZE_SMALL, IMAGE_SIZE_SMALL) .outputFormat(FORMAT_OUT_PUT) .toOutputStream(os); squashBytes = os.toByteArray(); } // 5. 组装结果并分发... }}复制代码优化点 3:基于 pHash 与贪心图染色算法的智能批次去重
public Map<Integer, List<ImageBase64Bo>> clusterByHashDistance(List<ImageBase64Bo> list, int maxDistance) { // 过滤无 pHash 的数据 List<ImageBase64Bo> validList = list.stream() .filter(bo -> Objects.nonNull(bo.getImagePHash())) .collect(Collectors.toList()); // 构建冲突图:差异大于 maxDistance 的节点之间连边 List<List<Integer>> conflictGraph = buildConflictGraph(validList, maxDistance); int n = validList.size(); // 贪心染色:colors[i] 表示第 i 个节点的颜色编号(即组编号) int[] colors = new int[n]; Arrays.fill(colors, -1); for (int i = 0; i < n; i++) { Set<Integer> usedColors = new HashSet<>(); for (int neighbor : conflictGraph.get(i)) { if (colors[neighbor] != -1) { usedColors.add(colors[neighbor]); } } // 选择最小的可用颜色 int color = 0; while (usedColors.contains(color)) { color++; } colors[i] = color; } // 按颜色分组返回 Map<Integer, List<ImageBase64Bo>> groupMap = new HashMap<>(); for (int i = 0; i < n; i++) { groupMap.computeIfAbsent(colors[i], k -> new ArrayList<>()).add(validList.get(i)); } return groupMap;}复制代码优化效果与深度反思:打破“木桶理论”
深度剖析:为什么总耗时跑赢了最慢的那个模型?
总结与未来展望
后续演进思考
随着《密码法》《数据安全法》等法规的颁布与施行,网络安全教育不断普及,群众网络安全意识不断加强。作为构建可信网络生态的重要基石,SSL证书正从曾经的备选逐渐成为主力,受到各行各业的高度认可和信赖。越来越多的政务机构、金融企业、大型集团乃至于广大中小型企业,都开始关注并优先采购国产SSL证书,为企业创建值得信赖的防护屏障,保护数据安全。相比于国际品牌的证书,国产SSL证书存在多项核心优势,并在诸多场景中拥有不俗的表现,为企业选择SSL证书进一步提供了参考依据。 国产SSL证书的核心优势 自主可控,密评合规:国产SSL证书采用SM2国密算法,摆脱对RSA国际算法依赖,自主可控。根据相关法律要求,等保三级及以上系统均需使用国密算法加密,方可通过密评,国产证书满足合规要求。 数字证书的典型适用场景 政务平台:SSL证书必须通过密评,可展示政务机构身份,并兼容国内主流浏览器。 国内外主流SSL品牌对比 Digicert:全球知名的CA,其证书通常适用于需要最高国际信任度的跨国企业、银行、航空等企业,EV证书的审核尤其严格。但不支持国密算法,价格相对高昂。 沃通:国内较早提供国密证书的服务商,拥有完整的产品线,价格适中,符合国内小微企业选择。兼容性对比国际品牌相对较弱,需配合双证书方案提升兼容性。 JoySSL:凭借本土化优势,可提供快速响应,支持7x24小时中文技术服务。OV证书价格对比CFCA等品牌差异明显,但服务响应更快,更具有性价比,对中小企业而言更为友好。 国内企业SSL证书选型建议 国产SSL证书的崛起与发展,既是国内企业数字化安全发展的前提,也是国家密码战略的必然要求。若企业更看重品牌效应,且并不在于服务效率,可优先选择Digicert为代表的国际证书品牌。若企业主要面向国内,看重服务质量与性价比表现,可在JoySSL和沃通等国产SSL证书品牌之间做出抉择。
本土服务,响应及时:国产CA机构得益于空间优势,支持7x24小时中文技术服务,包含证书申请、部署到续签等,均可通过国内主流沟通渠道及时沟通,可快速响应,无需依赖邮件工单。
性价比高,投入安全:国产SSL证书在同等安全级别及兼容条件下,可以以更低的成本获得企业级防护,价格更具竞争优势,投入更安全可控,深受中小企业认可。
审核灵活,符合实际:OV与EV证书的审核需进行严格的身份审核,国际品牌采用标准化流程审核时,周期过长,失败率较高。国内CA由于深耕国内市场,了解国内企业实际情况,审核流程更快,灵活又高效,可协助提交资料,助力企业快速完成审核。
金融系统:EV证书具备最高级别身份验证,支持国密加密,可有效防范钓鱼攻击。
大型企业:证书需要满足国资监管和等保合规要求,通过品牌和证书建立公众信任。
教育医疗:包含大量个人隐私数据,需保护公民个人信息,符合行业数据的安全规范。
物联网场景:国密算法适合资源受限的嵌入式设备。
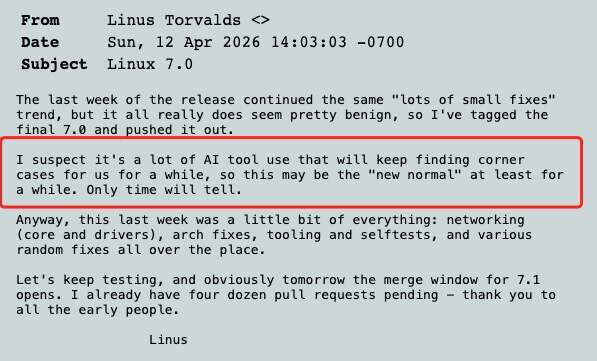
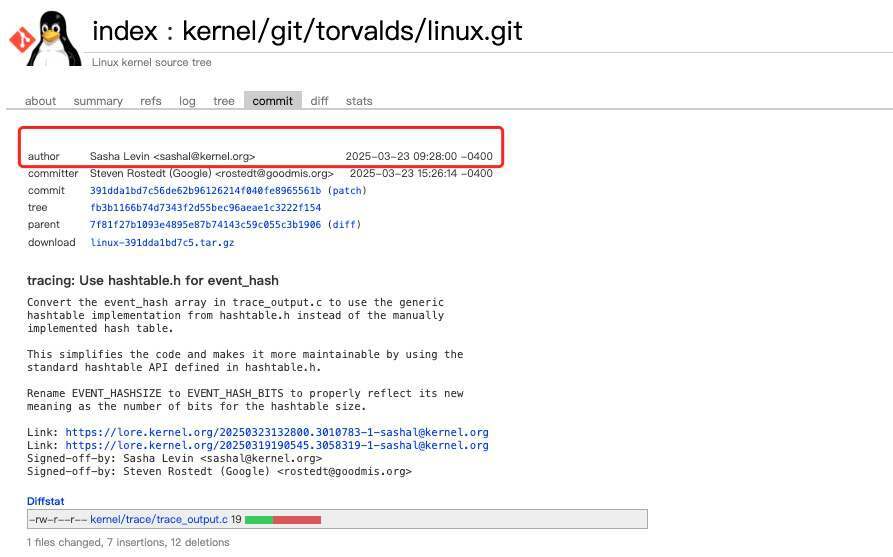
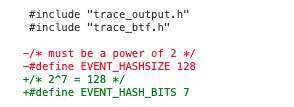
Linux 给 AI 生成代码“立规矩”:Copilot 可以用,但出了问题人来背。 吵了几个月之后,Linus Torvalds 和 Linux 内核维护者终于把 Linux 内核第一套 AI 辅助代码规则定下来了。这套新规很符合 Torvalds 一贯的务实风格:AI 工具可以用,但 Linux 内核对代码质量的高要求一点也不会放松。 新指南主要定了三件事。 第一,AI 代理不能添加 Signed-off-by 标签 只有人类才能合法签署 Linux 内核的开发者来源证明(Developer Certificate of Origin,DCO)。这是确保代码许可合规的法律机制。换句话说,即便你提交的补丁完全由 AI 编写,责任仍然只在你本人,而不是 AI 或其提供方。 第二,必须标注 Assisted-by(辅助来源) 如果在内核开发过程中用了 AI 工具,就要把来源写清楚,这样大家才能知道 AI 在这次提交里到底参与了多少。相关代码贡献需要按下面这个格式加上 Assisted-by 标签: Assisted-by: AGENT_NAME:MODEL_VERSION [TOOL1] [TOOL2] 这里需要把你用了什么模型、什么 Agent、还有哪些辅助工具说清楚。比如 AGENT_NAME 是你用的 AI 工具或者框架名称;MODEL_VERSION 是具体用的模型版本;[TOOL1] [TOOL2] 是可选项,用来写这次还搭配用了哪些专门的分析工具,比如 coccinelle、sparse、smatch、clang-tidy。像 git、gcc、make、编辑器这些日常基础工具,就不用写进去了。 比如,如果你用的是 Claude 的 claude-3-opus,同时还配合 coccinelle 和 sparse 做分析,就可以这样写: Assisted-by: Claude:claude-3-opus coccinelle sparse 第三,人类承担全部责任 把前面几条合起来看,意思其实很明确:AI 可以参与写代码,但责任不能转嫁给 AI。AI 生成的代码有没有经过完整审查,许可证是不是合规,后续如果出了 bug 或安全漏洞,最后都要由提交代码的人来负责。 不要试图把有问题的代码偷偷混进内核。2021 年明尼苏达大学的那起事件,就是一个典型的前车之鉴。否则,你基本可以告别 Linux 内核开发者身份,以及任何严肃开源项目的参与机会。 那次事件里,明尼苏达大学一组研究人员以安全研究的名义,故意向 Linux 内核提交带有缺陷、甚至可能引入漏洞的补丁,想借此测试社区能不能识别并拦下这些“有问题的修复”。问题不只在于补丁本身有问题,更在于他们事先没有告知社区,而是直接把维护者和开发者当成了实验对象。 事情曝光后,Greg Kroah-Hartman 公开批评这种做法浪费社区时间、破坏协作信任,相关提交被集中审查和回滚,明尼苏达大学的后续贡献也被 Linux 社区封禁,成为内核社区至今仍反复引用的反面案例。 Assisted-by 标签既是透明机制,也是一个“提醒标记”。它让维护者在不污名化 AI 使用的前提下,对 AI 辅助的补丁进行更严格的审查。 这个标签的出现,其实源自一场不小的争议。 争议的起点,是 Nvidia 工程师、知名 Linux 内核开发者 Sasha Levin。在 2025 年北美开源峰会上,他分享了自己用 LLM 改进内核的一些实践。 他认为 LLM 本质上就是一个参数规模巨大的模式匹配引擎,可以看作一个“超大的状态机”。不同的是,内核里常见的状态机是确定性的,而 LLM 的状态转移是概率性的。给定一段上下文,它会预测“下一个最可能的词”。比如输入“the Linux kernel is written in...”,它几乎一定会输出 “C”,但也存在较小概率输出 “Rust” 或 “Python”。 同时,LLM 依赖“上下文窗口”工作,也就是它在回答时能够“记住”的输入文本。像 Claude 这样的系统,上下文窗口大约在 20 万 token 左右,已经足够覆盖一个完整的内核子系统。 Levin 并不认为 LLM 会取代人类做内核开发。他更愿意把它看作“下一代编译器”。过去开发者写汇编,后来有了高级语言;当时也有人不认可,说“真正的开发者应该自己分配寄存器”。但最终大家还是接受了更高层的工具,生产力也随之提升。LLM 也是类似的演进——它不完美,但已经足够带来效率提升。 他举了一个例子:Linux 6.15 中合入的一个补丁,署名是他,但代码实际上是由 LLM 完整生成的,连 changelog 也是。Levin 对代码做了审查和测试,但并没有亲自编写。他认为,这类“小而明确”的任务正是 LLM 的强项,但还没到可以让它独立写出一个全新设备驱动的程度。 LLM 在写 commit message 上也很有帮助,而这件事往往比写代码本身更难,尤其对非英语母语的开发者来说。 他还展示了补丁中的一段修改。 这里从一个哈希 API 切换到另一个,需要把“大小”改为“2 的幂表示”。LLM 正确理解了这一点,并做了对应修改。它还在补丁后面意识到一个 mask 操作其实是多余的,于是直接删除。Levin 表示,这段代码既正确,也高效。 围绕这件事,社区也讨论了更多问题。比如,有人问:会不会因为过度信任 LLM 输出而引入错误?Levin 的回答是:LLM 会出错,人类也会,而且经常会。还有人问代码的许可证问题,他表示自己并没有深入考虑,直觉上认为模型生成的代码是可以使用的。 最后也有人问,这套方法能不能用于代码合入前的自动审查。Levin 表示技术上是可行的,但规模太大、成本太高,目前还不现实,不过未来有可能做到。 这场风波的一个直接结果是:Levin 本人开始支持建立 AI 使用的透明规则,他提交了第一版提案,也就是后来内核 AI 政策的雏形,最初建议用 Co-developed-by 来标记 AI 参与。 随后,无论是线下讨论还是 Linux Kernel Mailing List(LKML)上的交流,都在争论是引入新的 Generated-by 标签,还是复用现有的 Co-developed-by。最终,维护者选择了 Assisted-by,更准确地体现 AI 作为“工具”的角色,而不是“共同作者”。 最终选择 Assisted-by 而不是 Generated-by,主要基于三点考虑: 第一,更准确。内核开发中 AI 更多用于辅助(代码补全、重构建议、测试生成),而不是完整生成代码; 第二,格式一致。它与 Reviewed-by、Tested-by、Co-developed-by 等现有标签保持一致; 第三,中性表达。既说明了工具的参与,又不会暗示代码“不可信”或“低一等”。 这种务实路线,其实也和 Torvalds 的态度一致。他说:“我不希望内核开发文档变成某种 AI 立场声明。‘世界要完了’和‘AI 会彻底改变软件工程’这两种声音已经够多了。我不希望文档站队。对我来说,它就应该是——AI 只是一个工具。” 这一决策背后,一个很重要的现实变化是,AI 编程助手在内核开发里,突然开始变得“真的有用”了。 上个月,Linux 稳定内核维护者 Greg Kroah-Hartman 提到,几个月前,内核社区面对的还主要是所谓的“AI slop”,也就是那些明显不对、质量很低的 AI 生成安全报告。“当时甚至还有点好笑,也不太让人担心。”当然,Linux 内核有很多维护者,对他们来说,这类垃圾报告的压力远没有 cURL 那样大。cURL 的创始人兼主要开发者 Daniel Stenberg 就因为 AI 垃圾报告太多,一度暂停了漏洞赏金。 但情况已经变了。Kroah-Hartman 说,大概一个月前,也就是约在 2 月份,某个节点发生了变化,“整个世界都切换了。现在我们收到的,是‘真的’报告了。” 而且不只是 Linux。他提到,现在很多开源项目都在收到 AI 生成的报告,而且这些报告是好的、真实的。各大开源项目的安全团队之间一直有非正式的沟通,大家都观察到了同样的变化。换句话说,这已经不是 Linux 一家的问题,而是整个开源安全圈同时遇到的新情况。 至于到底发生了什么,没有人说得清。被问到变化的原因时,他说:“我们也不知道。没人知道为什么。可能是很多工具突然变好了,也可能是大家开始认真用这些工具了。看起来是很多不同的团队、不同的公司同时在做这件事。” “这些工具确实挺好用的,我们没法忽视它们:它们已经来了,而且还在变得更强。” 北京时间周一,Linus Torvalds 发布了 Linux 内核 7.0。对他来说,这次升级到 7.0 并不意味着什么“重大版本转折”,更多只是版本号走到 x.19 之后,顺手进位到 x.0,避免继续往后编号显得太乱。 不过,这次发布说明里还是有一句话格外值得注意。Torvalds 写道,“我怀疑,接下来一段时间,大家大量使用 AI 工具,还会不断帮我们把各种边角问题翻出来,所以这可能会成为一段时间里的‘新常态’。至于会持续多久,还要再看。” 另外,虽然 Linux 内核已经引入了 AI 披露政策,但维护者并不会依赖所谓的 AI 检测工具来识别未披露的 AI 代码。他们依然得依靠老办法:深厚的技术经验、模式识别能力,以及最传统的代码评审。正如 Torvalds 在 2023 年说的:“评判他人的代码,需要一定的品味。” 问题就在这里。正如他所说:“讨论 AI 垃圾代码没有意义,因为写这些的人不会主动标注。”难的从来不是明显有问题的垃圾代码,而是那些表面看起来完全正常的补丁:它们符合当前需求,风格一致,可以顺利编译,但内部却埋着细微 bug,或长期维护成本的隐患。 因此,这套新政策的执行,并不依赖抓住每一个违规者,而是通过提高违规代价,来约束行为。问问那些曾因为提交劣质补丁而被 Torvalds 当面“教育”的人就知道了。虽然他现在已经比过去温和不少,但你依然不会想站在他的对立面。 参考资料: https://docs.kernel.org/process/coding-assistants.html https://www.youtube.com/watch?v=ec7gDUFm2-Q https://lwn.net/Articles/1026558/ https://lore.kernel.org/lkml/CAHk-=wg0sdh_OF8zgFD-f6o9yFRK=tDOXhB1JAxfs11W9bX--Q@mail.gmail.com/ https://www.theregister.com/2026/04/13/linux_kernel_7_releaseed/
Claude 已经够强了,但在内核里还只是工具




一夜之间世界就变了,规则也只能跟着改