直到现在还不想换 MacOS 的原因, 只剩下 Win+ V & Everything 了
MacOS 上面的 Paste 是收费的, 而 Windows 的 Win+V 是自带的.
Spotlight 能用, 但是不如 Everything 好用.
比如我要找一个带日期时间戳的 .xlsx 文件, 用 everything 简单把 MMDD xlsx 输进去, Everything 搜索结果清单大概率在 top 5 给列出来. Spotlight 就不能这么跳序地把结果给搜索出来
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
MacOS 上面的 Paste 是收费的, 而 Windows 的 Win+V 是自带的.
Spotlight 能用, 但是不如 Everything 好用.
比如我要找一个带日期时间戳的 .xlsx 文件, 用 everything 简单把 MMDD xlsx 输进去, Everything 搜索结果清单大概率在 top 5 给列出来. Spotlight 就不能这么跳序地把结果给搜索出来
Java Agent 是 Java 提供的一种在 JVM 启动时或运行时动态修改字节码的强大机制,广泛应用于 APM 监控(如 SkyWalking、Pinpoint)、热部署(如 JRebel)、代码覆盖率(JaCoCo)、故障注入、安全审计等场景。一、Java Agent 的两种模式模式加载时机典型用途Premain AgentJVM 启动时(-javaagent)APM 探针、性能监控、字节码增强Attach AgentJVM 运行时动态 attach线上诊断(如 Arthas)、动态开关二、核心原理:InstrumentationAgent 通过 java.lang.instrument.Instrumentation 接口实现:retransformClasses():重新转换已加载的类(需类支持 retransformation)redefineClasses():直接替换类的字节码(限制多,不常用)addTransformer():注册 ClassFileTransformer,在类加载时修改字节码三、快速入门:编写一个简单 Agent步骤 1:创建 Agent 入口类package com.example; import com.example.transformer.RestTemplateTraceAdvice; import java.lang.instrument.Instrumentation; import static net.bytebuddy.matcher.ElementMatchers.isAnnotatedWith; public class TraceAgent { // builder.method(any()).intercept(MethodDelegation.to(NoOpInterceptor.class)) }步骤 2:实现 TraceAdvicepackage com.example.transformer; import com.fasterxml.jackson.core.JsonProcessingException; import javax.servlet.http.HttpServletRequest; import static com.example.transformer.TraceContextHolder.PARENT_APP_ID; public class TraceAdvice { // TraceContextHolder.setTraceContext(traceContext); }步骤 3:用于跟踪调用链的上下文在 src/main/resources/META-INF/MANIFEST.MF 中声明:// com/example/transformer/TraceContextHolder.java public class TraceContextHolder { }步骤 4:打包 & 使用如果用 Maven,可通过 maven-jar-plugin 自动生成:<?xml version="1.0" encoding="UTF-8"?> </project>四、创建两个web应用验证trace到调用生命周期 import org.springframework.context.annotation.Bean; @Configuration } import org.slf4j.Logger; import javax.annotation.Resource; @RestController }2、web- app1package com.example.demo.controller; import org.slf4j.Logger; @RestController }从上面可以看到我们在web-app的应用中的hell接口中调用了web-app1的shopping接口,且web-app的接入方式是无代码入侵形式的RestTemplate,主要是依赖agent对asm对增强能实现对trace调用透传
import com.example.transformer.TraceAdvice;
import com.fasterxml.jackson.databind.ObjectMapper;
import net.bytebuddy.agent.builder.AgentBuilder;
import net.bytebuddy.asm.Advice;
import net.bytebuddy.description.method.MethodDescription;
import net.bytebuddy.matcher.ElementMatcher;
import java.util.Arrays;
import java.util.HashSet;
import java.util.Set;
import static net.bytebuddy.matcher.ElementMatchers.named;
import static net.bytebuddy.matcher.ElementMatchers.takesArguments;private final static String appId ;
private static final Set<String> REQUEST_MAPPING_ANNOTATIONS = new HashSet<>(Arrays.asList(
"org.springframework.web.bind.annotation.RequestMapping",
"org.springframework.web.bind.annotation.GetMapping",
"org.springframework.web.bind.annotation.PostMapping",
"org.springframework.web.bind.annotation.PutMapping",
"org.springframework.web.bind.annotation.DeleteMapping"
));
private static CustomAgentListener customListener;
static {
appId = System.getProperty("appId");
}
public static void premain(String agentArgs, Instrumentation inst) {
install(inst);
}
public static void agentmain(String agentArgs, Instrumentation inst) {
install(inst);
}
private static void install(Instrumentation inst) {
// 创建自定义监听器,输出到指定文件,只记录指定包的类
customListener = new CustomAgentListener(
"/Users/dsy/code/agent-demo/logs/"+appId+"-bytebuddy-agent.log", // 日志文件路径
"com.example" // 只记录 com.example 包下的类
);
new AgentBuilder.Default()
.with(customListener) // 👈 关键:输出匹配详情
.disableClassFormatChanges()
.with(AgentBuilder.RedefinitionStrategy.RETRANSFORMATION)
.with(AgentBuilder.InitializationStrategy.NoOp.INSTANCE)
.with(AgentBuilder.TypeStrategy.Default.REDEFINE)
.with(AgentBuilder.DescriptionStrategy.Default.POOL_ONLY) // 👈 启用完整类型解析
.type(
isAnnotatedWith(named("org.springframework.stereotype.Controller"))
.or(isAnnotatedWith(named("org.springframework.web.bind.annotation.RestController")))
)
.transform((builder, typeDescription, classLoader, module) ->
builder.visit(Advice.to(TraceAdvice.class)
.on(anyMethodAnnotatedWithRequestMapping())) )
.type(named("org.springframework.web.client.RestTemplate"))
.transform((builder, td, cl, module) ->
builder.visit(Advice.to(RestTemplateTraceAdvice.class)
.on(named("exchange")
.and(takesArguments(4))
.or(takesArguments(5))
.or(takesArguments(6))))
)
.installOn(inst);
System.out.println("[Agent] Controller tracing agent installed.");
}
private static ElementMatcher.Junction<MethodDescription> anyMethodAnnotatedWithRequestMapping() {
return isAnnotatedWith(named("org.springframework.web.bind.annotation.RequestMapping"))
.or(isAnnotatedWith(named("org.springframework.web.bind.annotation.GetMapping")))
.or(isAnnotatedWith(named("org.springframework.web.bind.annotation.PostMapping")))
.or(isAnnotatedWith(named("org.springframework.web.bind.annotation.PutMapping")))
.or(isAnnotatedWith(named("org.springframework.web.bind.annotation.DeleteMapping")));
}
// 添加关闭方法,用于清理资源
public static void shutdown() {
if (customListener != null) {
customListener.close();
}
}
import com.fasterxml.jackson.databind.ObjectMapper;
import net.bytebuddy.asm.Advice;
import java.util.Arrays;
import java.util.UUID;
import static com.example.transformer.TraceContextHolder.X_TRACE_ID;public final static String appId ;
public final static ObjectMapper objectMapper;
static {
appId = System.getProperty("appId");
objectMapper = new ObjectMapper();
}
@Advice.OnMethodEnter
public static void enter(@Advice.AllArguments Object[] args) {
TraceContextHolder.TraceContext traceContext = TraceContextHolder.traceContext();
// 尝试从参数中提取 HttpServletRequest
HttpServletRequest request = null;
for (Object arg : args) {
if (arg instanceof HttpServletRequest) {
request = (HttpServletRequest) arg;
break;
}
}
String traceId = null;
String parentAppId = null;
if (request != null) {
// 优先从 Header 中获取 traceId(例如:X-Trace-Id)
traceId = request.getHeader(X_TRACE_ID);
parentAppId = request.getHeader(PARENT_APP_ID);
}
if (traceId == null || traceId.trim().isEmpty()) {
// 未传入,则生成新 traceId(建议用 UUID 或 Snowflake)
traceId = "trace-" + UUID.randomUUID().toString().replace("-", "").substring(0, 32);
}
if (parentAppId == null || parentAppId.trim().isEmpty()){
parentAppId = "0" ;
}
traceContext.setTraceId(traceId);
traceContext.setArgs(args.toString());
traceContext.setAppId(appId);
traceContext.setParentAppId(parentAppId);
traceContext.setTraceSpanStartTime(System.currentTimeMillis());
// 绑定到当前线程 System.err.println(">>> Entering method with args: " + Arrays.toString(args));
}
@Advice.OnMethodExit
public static void exit(@Advice.Return Object result) {
TraceContextHolder.TraceContext traceContext = TraceContextHolder.traceContext();
traceContext.setTraceSpanEndTime(System.currentTimeMillis());
try {
traceContext.setResult(objectMapper.writeValueAsString(result));
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
System.err.println("<<< Exiting method, returned: " + traceContext.toSting());
}
package com.example.transformer;public final static String X_TRACE_ID = "X-Trace-Id";
public final static String PARENT_APP_ID = "X-Parent-APP-Id";
static String FORMAT = "traceId:%s,parentAppId:%s,appId:%s,traceSpanStartTime:%d,traceSpanEndTime:%d,args:%s,result:%s";
private static final ThreadLocal<TraceContext> TRACE = new ThreadLocal<>();
public static void setTraceContext(TraceContext traceContext) {
TRACE.set(traceContext);
}
public static void clear() {
TRACE.remove();
}
public static TraceContext traceContext() {
TraceContext object;
if (TRACE.get() != null) {
object = TRACE.get();
} else {
object = new TraceContext();
TRACE.set(object);
}
return object;
}
public static class TraceContext{
private String traceId;
private String parentAppId;
private String appId;
private Long traceSpanStartTime;
private Long traceSpanEndTime;
private String args;
private String result;
public String getTraceId() {
return traceId;
}
public void setTraceId(String traceId) {
this.traceId = traceId;
}
public String getParentAppId() {
return parentAppId;
}
public void setParentAppId(String parentAppId) {
this.parentAppId = parentAppId;
}
public String getAppId() {
return appId;
}
public void setAppId(String appId) {
this.appId = appId;
}
public Long getTraceSpanStartTime() {
return traceSpanStartTime;
}
public void setTraceSpanStartTime(Long traceSpanStartTime) {
this.traceSpanStartTime = traceSpanStartTime;
}
public Long getTraceSpanEndTime() {
return traceSpanEndTime;
}
public void setTraceSpanEndTime(Long traceSpanEndTime) {
this.traceSpanEndTime = traceSpanEndTime;
}
public String getArgs() {
return args;
}
public void setArgs(String args) {
this.args = args;
}
public String getResult() {
return result;
}
public void setResult(String result) {
this.result = result;
}
public String toSting(){
return String.format(FORMAT,traceId,parentAppId,appId,traceSpanStartTime,traceSpanEndTime,args,result);
}
}
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.example</groupId>
<artifactId>agent-demo</artifactId>
<version>1.0-SNAPSHOT</version>
</parent>
<artifactId>agent3</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- ByteBuddy 核心 -->
<dependency>
<groupId>net.bytebuddy</groupId>
<artifactId>byte-buddy</artifactId>
<version>1.12.10</version>
</dependency>
<dependency>
<groupId>net.bytebuddy</groupId>
<artifactId>byte-buddy-agent</artifactId>
<version>1.12.10</version>
</dependency>
<!-- Spring Web(仅用于类型判断,非强制) -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-web</artifactId>
<version>5.3.31</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>4.0.1</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.36</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.17.0</version> <!-- 使用最新稳定版 -->
</dependency>
</dependencies>
<build>
<plugins>
<!-- 使用 shade plugin 打包 fat jar -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.5.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<manifestEntries>
<Premain-Class>com.example.TraceAgent2</Premain-Class>
<Agent-Class>com.example.TraceAgent2</Agent-Class>
<Can-Redefine-Classes>true</Can-Redefine-Classes>
<Can-Retransform-Classes>true</Can-Retransform-Classes>
</manifestEntries>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
1、web-apppackage com.example.demo.conf;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate;
public class BeanConfig {@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
package com.example.demo.controller;
import org.slf4j.LoggerFactory;
import org.springframework.http.HttpMethod;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
public class HelloController {private static final Logger logger = LoggerFactory.getLogger(HelloController.class);
@Resource
private RestTemplate restTemplate;
@GetMapping("/hello")
public String hello(@RequestParam(defaultValue = "World") String name) {
logger.info("Processing hello request for: {}", name);
String url = "http://localhost:8081/shopping?commodity=香蕉";
String r = restTemplate.exchange(url, HttpMethod.GET,null,String.class).getBody();
return "Hello, " + name + "!" + " commodity = " + r;
}
@PostMapping("/user")
public String createUser(@RequestBody String userData) {
logger.info("Creating user with data: {}", userData);
return "User created: " + userData;
}
@GetMapping("/error")
public String error() {
logger.info("Triggering error");
throw new RuntimeException("Test exception");
}
import org.slf4j.LoggerFactory;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
public class ShoppController {private static final Logger logger = LoggerFactory.getLogger(ShoppController.class);
@GetMapping("/shopping")
public String hello(@RequestParam(defaultValue = "苹果") String commodity) {
logger.info("Processing hello request for: {}", commodity);
return "commodity, " + commodity + "!";
}
@PostMapping("/user")
public String createUser(@RequestBody String userData) {
logger.info("Creating user with data: {}", userData);
return "User created: " + userData;
}
@GetMapping("/error")
public String error() {
logger.info("Triggering error");
throw new RuntimeException("Test exception");
}
且web-app和web-app1两个进程起来时要通过-javaagent方式将agent的探针无入侵的方式接入应用中而-DappId时接入的应用id,用于跟踪tarce所在的应用和构建应用的拓扑图
五、验证触发接口


至此可以通过Agent的探针实现对应用无入侵式,实现调用链的APM 监控、构建应用的拓扑图,并切基于Agent Advice 的增强方式可以进一步实现对中间件的跟踪和观测,如接入DB的观测。
kt新增功能点 离线环境部署增强。常用国际和国产操作系统依赖,内置到安装包中。已适配芯片和操作系统如下 支持开启防火墙,只暴露 kt版本更新和下载地址 服务器基本信息 操作系统不需要安装docker,不需要设置selinux,swap等操作,全新的操作系统即可。 将离线制品、配置文件、kt和sh脚本上传至服务器其中一个节点(本文以master为例),后续在该节点操作创建集群。本文使用kt: 根据实际服务器信息,配置到生成的 解压 该命令 此命令会在 <font style="background-color:rgb(255,245,235);">说明:</font> <font style="background-color:rgb(255,245,235);">Harbor 管理员账号:</font><font style="background-color:rgb(255,245,235);">admin</font><font style="background-color:rgb(255,245,235);">,密码:</font><font style="background-color:rgb(255,245,235);">Harbor@123</font><font style="background-color:rgb(255,245,235);">。密码同步使用配置文件中的对应password</font> <font style="background-color:rgb(255,245,235);">harbor 安装文件在 </font> 创建 Harbor 项目 此命令kt会自动将离线制品中的镜像推送到 执行后会有如下提示,输入 等待一段时间,直至出现熟悉的等待安装完成的小箭头>>---> 期间可以另开一个窗口用以下命令查看部署日志 继续等待一段时间最终可以看到安装成功的消息 登录页面 集群管理 监控告警 配置文件默认只安装了监控,如果需要安装其他组件,可以自行在自定义资源中开启Centos虽然已经停止维护了,而且内核也非常低,耐不住国内大环境很多公司还是一直在用它。时不时见到有人想要在centos上面部署k8s1.23版本,本文将以centos 7为例,从0开始搭建k8s+ks集群。1.说明
关于kt
kt是基于kk二次开发的产物,具备kk的所有功能。二开主要为适配信创国产化环境、简化arm部署过程和国产化环境离线部署。支持arm64和amd64架构国产操作系统,已适配芯片+操作系统 如下。./kt init-os 一条命令完成操作系统依赖安装和初始化操作。30000-32767端口,其他k8s端口添加到节点白名单。./kt firewall 一条命令自动获取节点信息开白名单和防火墙。2.环境准备

主机名 架构 OS 配置 IP all-in-one x86_64 Centos 7 4核8G 192.168.85.164 2.1 上传离线制品
3.1.12-centos版本
2.2 修改配置文件
config-sample.yaml中kind: Cluster
metadata:
name: sample
spec:
hosts:
- {name: node1, address: 192.168.85.164, internalAddress: 192.168.85.164, user: root, password: "123123"}
roleGroups:
etcd:
- node1
control-plane:
- node1
worker:
- node1
# 如需使用 kk 自动部署镜像仓库,请设置该主机组 (建议仓库与集群分离部署,减少相互影响)
# 如果需要部署 harbor 并且 containerManager 为 containerd 时,由于部署 harbor 依赖 docker,建议单独节点部署 harbor
registry:
- node1
controlPlaneEndpoint:
## Internal loadbalancer for apiservers
internalLoadbalancer: haproxy
domain: lb.kubesphere.local
address: ""
port: 6443
kubernetes:
version: v1.23.17
clusterName: cluster.local
autoRenewCerts: true
containerManager: docker
etcd:
type: kubekey
network:
plugin: calico
kubePodsCIDR: 10.233.64.0/18
kubeServiceCIDR: 10.233.0.0/18
## multus support. https://github.com/k8snetworkplumbingwg/multus-cni
multusCNI:
enabled: false
registry:
type: harbor
registryMirrors: []
insecureRegistries: []
privateRegistry: "dockerhub.kubekey.local"
namespaceOverride: "kubesphereio"
auths: # if docker add by `docker login`, if containerd append to `/etc/containerd/config.toml`
"dockerhub.kubekey.local":
username: "admin"
password: Harbor@123 # 此处可自定义,kk3.1.8新特性
skipTLSVerify: true # Allow contacting registries over HTTPS with failed TLS verification.
plainHTTP: false # Allow contacting registries over HTTP.
certsPath: "/etc/docker/certs.d/dockerhub.kubekey.local"
addons: []
---2.3 系统初始化
kt-centos.tar.gz文件后执行./kt init-os -f config-sample.yaml 已适配操作系统和架构见1.说明kt会根据配置文件自动判断操作系统和架构以完成所有节点的初始化配置和依赖安装。
3 创建 Harbor私有仓库
3.1 创建镜像仓库
./kt init registry -f config-sample.yaml -a artifact-x86-k8s12317-ks3.4.1.tar.gzharbor节点自动安装docker和docker-compose

3.2 创建harbor项目
<font style="background-color:rgb(255,245,235);">/opt/harbor</font><font style="background-color:rgb(255,245,235);"> 目录下,可在该目录下对 harbor 进行运维。</font>chmod +x create_project_harbor.sh && ./create_project_harbor.sh
4 创建k8s和KubeSphere
./kt create cluster -f config-sample.yaml -a artifact-x86-k8s12317-ks3.4.1.tar.gzharbor 私有仓库yes/y继续执行

kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l 'app in (ks-install, ks-installer)' -o jsonpath='{.items[0].metadata.name}') -f
5 验证




开发者朋友们大家好: 这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的技术」、「有亮点的产品」、「有思考的文章」、「有态度的观点」、「有看点的活动」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。 本期编辑:@瓒an、@鲍勃 1、Vibecraft 发布:Claude Code 的 3D 可视化工具,数据纯本地运行 开发者 @nearcyan 近日发布了「Vibecraft」,这是一款专为 Claude Code 打造的 3D 可视化应用程序。它支持用户通过全新的六边形网格布局,实时查看并管理 Claude 实例。 为了保障数据安全,该应用采取了严格的本地化运行模式,直接与用户计算机上的 Claude Code 实例同步。这意味着所有的文件与代码数据均完全保留在本地,不会被发送至任何网络服务器,从而确保了开发过程的隐私安全。 体验链接: ( @nearcyan@X) 2、智谱 GLM-4.7-Flash 模型发布并开源,可免费调用 智谱 GLM-4.7-Flash 模型今日正式发布并开源。 GLM-4.7-Flash 是一个混合思考模型,总参数量为30B,激活参数量为3B,作为同级别 SOTA 模型,为轻量化部署提供了一个兼顾性能与效率的新选择。 即日起,GLM-4.7-Flash 将替代 GLM-4.5-Flash,在智谱开放平台 BigModel.cn 上线,并供免费调用。 在 SWE-bench Verified、τ²-Bench 等主流基准测试中,GLM-4.7-Flash 的综合表现超过 gpt-oss-20b、Qwen3-30B-A3B-Thinking-2507,在相同和近似尺寸模型系列中取得开源 SOTA 分数。 在内部的编程实测中,GLM-4.7-Flash 在前、后端任务上表现出色。在编程场景之外,官方也推荐用户在中文写作、翻译、长文本、情感 / 角色扮演等通用场景中体验 GLM-4.7-Flash。 需要注意的是,上一代免费语言模型 GLM-4.5-Flash 将于 2026 年 1 月 30 日下线,用户需要及时将模型编码更新为最新版本。GLM-4.5-Flash 正式下线后,相关请求将会自动路由至 GLM-4.7-Flash。 Hugging Face: 魔搭社区: https://modelscope.cn/models/ZhipuAI/GLM-4.7-Flash (@智谱) 3、华为云发布 CodeArts Doer 代码智能体:个人版免费开放,开启「编码自动驾驶」 2026 年 1 月 16 日,华为云正式发布代码智能体「CodeArts Doer」。这款产品深度集成了 AI IDE、Code Agent 及 Codebase 代码仓深度理解能力,旨在通过「人+AI+工具」的协同模式,为开发者开启「编码自动驾驶」体验。 为了重构传统的开发工作流,CodeArts Doer 以 AI 原生为起点构建了 AI IDE。它不再局限于单一的代码补全,而是能够支持从需求描述、任务拆解到代码落地的全流程闭环。这种设计让开发者可以专注于业务判断与关键决策,将高频重复的工程化工作交由 AI 处理,从而解决了以往需要在多窗口间频繁切换寻找工具的痛点。 在具体的编码执行层面,CodeArts Doer 提供了两种差异化模式以适应不同诉求。「探索模式」侧重人机协同与创造力,开发者通过自然语言即可规划项目任务并生成项目级代码,适合快速将想法转化为可运行版本;而「规范模式」则更强调质量与一致性,在代码生成过程中严格对齐标准流程与安全校验,确保交付的稳定性。 针对 AI 编码在生产环境中常遇到的「看似正确实则不适配」难题,产品特别强化了 Codebase 能力。通过支持百万行级代码索引与知识图谱构建,它能够准确理解代码仓结构、依赖关系及演化历史。这使得 AI 即使在复杂的业务边界内,也能提供贴合项目现实的建议,帮助新老成员快速定位与上手。 目前,CodeArts Doer 代码智能体个人版已正式面向开发者开放免费体验,覆盖了项目级代码生成、研发知识问答及单元测试生成等核心场景。 相关链接: (@华为云开发者联盟) 1、OpenAI 或正测试新产品、首款硬件设备计划今年下半年亮相 据 BleepingComputer 报道,OpenAI 近日被发现启用了以「sonata」为域名前缀的新子域名,外界推测这可能对应一项正在测试中的 ChatGPT 新功能或新产品。 相关记录显示,sonata.openai.com 于 1 月 16 日首次出现,sonata.api.openai.com 则在 1 月 15 日被发现,意味着 OpenAI 已在主站与 API 体系中同步启用该前缀,通常指向内部测试中的新服务或面向用户的网页工具。 报道指出,OpenAI 新增域名往往对应尚未公开的产品页面、内部工具或 Web 应用。尽管「sonata」一词本身常用于指代多乐章器乐作品,但其含义并不限定于音乐领域,因此目前尚无法据此判断功能方向。 除新域名外,OpenAI 近期也在持续更新 ChatGPT 的现有能力,包括「引用聊天记录」功能,当用户开启后,ChatGPT 在检索旧对话细节时将更为可靠,并会在回答中标注引用来源,便于用户回溯上下文。 此外,据 Axios 报道,OpenAI 全球事务负责人 Chris Lehane 今天在达沃斯的 Axios House 活动上表示,OpenAI 正按计划推进其首款硬件设备,目标是在今年下半年亮相。 这也是继去年收购前苹果设计主管 Jony Ive 创办的公司后,OpenAI 首次给出更明确的时间窗口。 Lehane 将「设备」列为 OpenAI 今年的重点方向之一,但并未透露任何外观、形态或交互方式。此前多份报道提到,OpenAI 正在测试无屏幕的小型原型机,可能以可穿戴方式与用户互动。 Sam Altman 曾表示,这款设备将比智能手机更「平和」,并以极简设计为核心。 Ive 团队在去年被收购时发布的宣传视频中也曾暗示 2026 年的发布节点,称「我们期待明年与大家分享我们的工作」。 Lehane 在活动中补充称,OpenAI 正「考虑在今年后段推出某些东西」,但仍保留调整空间,强调最终时间取决于研发进展。他并未承诺设备会在今年正式开售。 ( @APPSO) 2、字节跳动旗下扣子 2.0 正式发布,全球首发 AI Agent 技能商店 昨天,字节跳动旗下智能体平台「扣子(Coze)」发布 2.0 版本重大升级,并同步推出全球首个面向普通用户的 AI 技能商店(Coze Skills)。 此次更新围绕 Agent Skills、Agent Plan、Agent Office、Agent Coding 四大能力展开,旨在让 AI 从被动回答工具,进一步进化为可长期协作的职场伙伴。 扣子方面称,2.0 版本的目标是让 AI 不仅能帮你做,更能替你做完。随着技能、长期任务与开发平台的整合,扣子希望推动 AI 在职场场景中承担更多执行与分析工作,让用户将精力集中在策略与创造上。 ( @APPSO) 3、「自然选择」融资 3000 万美元,阿里、蚂蚁布局 AI 陪伴 据「暗涌 Waves」独家获悉,AI 陪伴公司「自然选择」(Nature Select)已于近期完成超 3000 万美元的新一轮融资。本轮投资阵容豪华,由阿里巴巴、蚂蚁集团、启明创投、五源资本、创世伙伴创投及云时资本联合投资,星涵资本担任独家财务顾问。 在 AI 陪伴赛道上半年一度遇冷的背景下,「自然选择」凭借核心产品《EVE》呈现的全新形态突围。不同于传统 C.ai 类产品的被动响应,《EVE》强调具备独立意志的「主动发起」,并通过引入 3D 视觉与游戏化设计极大地提升了沉浸感。这种破次元 Agent 甚至能在达到一定亲密度后,直接在现实中为用户点奶茶。据暗涌 Waves 了解,这类打破虚拟与现实边界的体验,或许是阿里等投资方共同入局的原因之一。 为了实现这种双商兼具的拟人体验,团队采取了独特的技术路径。他们不仅设立了情感交互设计师岗位,还发布了首个情感大模型 Echo-N1,首次将强化学习应用于主观情感领域。针对关键的记忆难题,团队将早期的动态记忆槽位的长时记忆方案升级为多维 graphRAG,创始人 Tristan 直言 「记忆系统的本质是推荐系统」,并据此构建了更符合人类直觉的回忆与遗忘机制。 2025 年中以来,AI 陪伴赛道愈发拥挤,而「自然选择」目前看来呈现的核心优势在于:既为 AI 公司,有完整的 post-training 团队和长期记忆之类的专家系统;也有游戏公司背景,能做 3D 视觉和恋爱游戏化设计。但每个人类个体对于情感都有不尽相同的需求,这场瞄准最人类部分的 AI 商业大战,也只是刚刚开始。 基于此,Tristan 将公司的终极目标设定为「迎接硅基生命降临,并创造一个人与 AI 共存的世界」。 (@暗涌 Waves) 4、小米 AI 眼镜新版本内测:支持录音中按键拍照,蚂蚁阿福上线 1 月 19 日消息,小米社区今日开启小米 AI 眼镜新版本内测招募,特邀 200 名米粉,预计在 2026 年 1 月 21 号统一审核。 升级内容: (@极客公园) 5、Listen Labs 完成 6900 万美元 B 轮融资:AI 智能体自动化执行深度客户访谈 「Listen Labs」近日宣布完成6900 万美元 B 轮融资,由 Ribbit Capital 领投,估值达 5 亿美元。在短短 9 个月内,该公司将年化收入提升了 15 倍。其核心突破在于利用 AI 智能体自动化执行深度客户访谈,有效解决了传统问卷调查太浅与人工访谈太慢的两难困境。 为了实现定性调研深度与定量规模的结合,Listen Labs 推出了具备「追问能力」的视频访谈智能体。不同于僵化的选择题问卷,该 AI 能与受访者进行开放式视频对话,并根据回答实时生成追问以挖掘真实想法。针对行业普遍存在的刷单现象,其「Quality Guard」系统结合 LinkedIn API 身份校验与视频逻辑检测,成功帮助合作方 Emeritus 将调研中的虚假及低质量数据比例从 20% 降至接近 0。 这种技术带来的效率提升在实际应用中得到了验证。微软利用该平台,将原本耗时 6-8 周的用户故事收集工作缩短至 24 小时内;水杯品牌 Simple Modern 也在 4.5 小时内完成了 120 人的新产品概念测试。目前,平台已向企业用户开放,采用 B2B 订阅或项目制计费,服务客户涵盖 Microsoft、Sweetgreen 和 Chubbies 等。 支撑这一技术体系的是一支拥有极高「含码量」的团队——公司 30% 的工程师为国际信息学奥赛(IOI)奖牌得主,且即便是市场运营岗位也优先录用工程师,旨在用技术逻辑重构业务流程。 本轮融资后,团队计划从 40 人扩充至 150 人,重点研发「合成用户」功能,即基于历史数据构建数字孪生受访者,从而实现 「自动写代码-自动访谈-自动迭代」的自动化闭环。 ( @VentureBeat) 1、Shopify CEO:别把创业者「放进创始人托儿所」 据《商业内幕》报道 ,Shopify CEO Tobi Lütke 近日在播客节目《Founder's Podcast》中表示,许多公司在收购后往往低估创业者的经验价值,将他们边缘化,甚至形容这种做法像是把创始人「放进创始人托儿所」。 Lütke 指出,创业者通常具备独特的思维方式与解决问题的能力,但不少企业会将他们安排到组织边缘,或分配到所谓的「skunk work team」(秘密工作小组)。 他直言,这种做法是在「把最能指出问题的人隔离起来」,并强调「你不能把他们放进创始人托儿所」。 他提到,这种情况在 Shopify 于疫情期间的收购整合中曾出现。意识到问题后,他主动提升被收购公司创始人在组织内的存在感,甚至让他们在管理层级中拥有更高的影响力。 他还透露,自己与这些创始人保持一个 Slack 频道,用于交流产品与业务问题。 Shopify 近年来的收购包括 2022 年的物流公司 Deliverr、同年的网红营销平台 Dovetale,以及 2024 年的企业沟通平台 Threads。 报道指出,Dovetale 与 Threads 的创始人目前仍在 Shopify 担任产品相关角色,而 Deliverr 的 CEO 则在加入一年后离开,重新创办物流创业公司。 在节目中,Lütke 还提到,他在招聘时会特别询问候选人「你是否创办过公司」,因为这能帮助他判断对方在危机情境中的适应能力与执行力。 ( @APPSO) 阅读更多 Voice Agent 学习笔记:了解最懂 AI 语音的头脑都在思考什么 写在最后: 我们欢迎更多的小伙伴参与 「RTE 开发者日报」 内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。 对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。 作者提示:个人观点,仅供参考
01 有话题的技术

https://huggingface.co/zai-org/GLM-4.7-Flash

https://www.huaweicloud.com/product/codeartside/snap.html02 有亮点的产品




03 有态度的观点




大家好我是地鼠哥。 如果你也是从 但其实,Go语言的设计虽然崇尚简洁,却在细节中隐藏了很多巧思。从经典的Go 1.11到最新的Go 1.26,它一直在稳步进化,引入了很多实用的特性和设计模式。用好它们,不仅能让代码更清晰,还能在同事面前展示你的专业能力。 下面就聊几个在实际工作中非常实用的技巧,看看你是否都在使用。 在业务代码里,我们经常用 比如下面这个函数: 为了解决这个问题,我们可以利用Go的自定义类型特性,给ID加一层身份验证。这在编译阶段就能帮我们发现错误。 这个简单的改动,几乎零成本地消除了ID混用的隐患。 在Java中如果你需要创建一个复杂的对象,可能会用Builder模式。而在Go中,我们经常遇到初始化一个服务或组件时,有几十个配置项,但大部分都用默认值的情况。 如果写一个包含所有参数的 这时候,函数选项模式就是最佳选择。 这种模式让初始化的代码变得非常灵活,而且未来增加新的配置项时,不需要修改现有的调用代码,兼容性极好。 在代码中拼接SQL语句或者JSON字符串时,使用双引号往往需要大量的转义字符 Go语言原生支持反引号 这在编写内嵌的SQL、HTML模板或者测试用的JSON数据时非常有用。 Go语言标准库非常推崇表格驱动测试。如果你还在写大量的 通过定义一个包含输入和期望输出的结构体切片,我们可以用一个循环覆盖所有的测试用例。 新增测试用例只需要在列表中加一行数据,逻辑与数据分离,非常易于维护。 Go的 它能自动处理 看到这里,你可能意识到,Go的版本更新也非常快。从Go 1.11引入Module,到Go 1.18引入泛型,再到Go 1.22修复循环变量问题,每个版本都有重要的变化。在实际工作中,我们经常面临这样的场景: 在本地同时管理多个Go版本,配置 所以,这时候就需要ServBay。 虽然它常被认为是Web开发工具,但它对Go语言的支持也非常出色。最让我满意的是,它可以一键安装和管理多个Go版本。你可以同时安装Go 1.20、1.23、1.26等多个版本,它们之间完全隔离,互不干扰。 而且,你可以为不同的项目指定使用不同的Go版本。比如,设置项目A使用Go 1.20,项目B使用Go 1.25。这样一来,在切换项目时,根本不用担心版本不兼容的问题,ServBay会自动处理好环境变量。 对于Go开发者来说,这意味着可以把更多精力放在架构设计和代码逻辑上,而不是被环境配置这些琐事消耗时间。 Go语言虽然以简单著称,但写出地道的Go代码(Idiomatic Go)依然需要不断的积累。掌握这些技巧,可以让你的代码更加健壮、优雅。而借助像ServBay这样的工具,又能帮你轻松搞定环境管理,让你专注于创造价值。 你还有什么Go语言的开发技巧吗?欢迎在评论区分享交流。 如果你也对Go语言感兴趣,欢迎关注并私信我领取pdf面经资料,保证完全免费!fmt.Println("Hello, World!") 和 if err != nil 开始Go语言生涯的,那说明你已经是个成熟的Go开发者了。在日常的业务开发中,我们每天都在写着各种各样的结构体和接口,有时候会觉得Go的语法过于简单,写起来甚至有点繁琐。用自定义类型(Defined Types)提升安全性
int64 或 string 来表示各种ID,比如 UserID, OrderID, ProductID。直接使用基础类型的一个主要风险是,方法的参数很容易传混。// 很容易写错的调用
func ProcessOrder(userID int64, orderID int64) {
// ...
}
// 调用时可能不小心把两个ID搞反
var uid int64 = 1001
var oid int64 = 9527
ProcessOrder(oid, uid) // 编译器不会报错,但逻辑全错了type UserID int64
type OrderID int64
func ProcessOrder(uid UserID, oid OrderID) {
fmt.Printf("处理用户 %d 的订单 %d\n", uid, oid)
}
func main() {
var uid UserID = 1001
var oid OrderID = 9527
ProcessOrder(uid, oid) // 正确
// ProcessOrder(oid, uid) // 编译错误:cannot use oid (variable of type OrderID) as type UserID
}用函数选项模式(Functional Options)优化配置
NewServer 函数,调用起来会非常麻烦;如果传入一个配置结构体,又需要定义一个很大的Struct。type Server struct {
Host string
Port int
Timeout time.Duration
}
type Option func(*Server)
func WithHost(h string) Option {
return func(s *Server) {
s.Host = h
}
}
func WithPort(p int) Option {
return func(s *Server) {
s.Port = p
}
}
func NewServer(opts ...Option) *Server {
// 默认配置
server := &Server{
Host: "localhost",
Port: 8080,
Timeout: 30 * time.Second,
}
// 应用选项
for _, opt := range opts {
opt(server)
}
return server
}
func main() {
// 使用默认配置
s1 := NewServer()
// 只修改端口
s2 := NewServer(WithPort(9090))
// 修改多个配置,清晰直观
s3 := NewServer(WithHost("127.0.0.1"), WithPort(8888))
}用反引号(Raw String Literals)优雅处理多行文本
\,写起来麻烦,读起来也费劲。 ` 来定义原生字符串,所见即所得。func main() {
// 以前的方式,难以阅读
jsonStr := "{\n" +
" \"name\": \"Alice\",\n" +
" \"age\": 30\n" +
"}"
// 使用反引号,清晰明了
jsonNew := `
{
"name": "Alice",
"age": 30
}
`
fmt.Println(jsonNew)
}用表格驱动测试(Table-Driven Tests)简化测试代码
if-else 或者重复的测试逻辑,是时候改变一下了。func Add(a, b int) int {
return a + b
}
func TestAdd(t *testing.T) {
tests := []struct {
name string
a int
b int
want int
}{
{"正数相加", 1, 2, 3},
{"负数相加", -1, -1, -2},
{"零相加", 0, 0, 0},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
if got := Add(tt.a, tt.b); got != tt.want {
t.Errorf("Add() = %v, want %v", got, tt.want)
}
})
}
}用 ErrGroup 并发处理任务
go 关键字让并发变得很容易,但协调多个并发任务并处理错误却不简单。手动使用 sync.WaitGroup 和 channel 来收集错误会写出很多样板代码。errgroup 包(golang.org/x/sync/errgroup)能完美解决这个问题。import (
"context"
"fmt"
"golang.org/x/sync/errgroup"
)
func main() {
g, _ := errgroup.WithContext(context.Background())
urls := []string{"http://www.google.com", "http://www.bing.com"}
for _, url := range urls {
url := url // 注意闭包捕获问题(Go 1.22之前需要)
g.Go(func() error {
// 模拟请求
fmt.Printf("Fetching %s\n", url)
return nil // 或者返回错误
})
}
// 等待所有任务完成,如果有任何一个返回错误,这里会返回那个错误
if err := g.Wait(); err != nil {
fmt.Println("出错了:", err)
} else {
fmt.Println("所有任务完成")
}
}WaitGroup 的计数,并且一旦有一个任务出错,可以取消其他任务(配合 Context),是处理并发任务的有效工具。管理好Go环境,才能高效开发
GOROOT, GOPATH,修改环境变量,是一件非常繁琐的事情。总结
https://www.bilibili.com/video/BV1QLkTBCEEk/?aid=115903282814... NVIDIA RTX PRO™ 2000 Blackwell 是节能高效、外形小巧的解决方案,能够加速专业的图形和 AI 工作负载。采用突破性的 Blackwell 架构 和 16 GB 超高速 GDDR7 显存,那么对比上一代 NVIDIA RTX™ 2000 Ada 具体性能有哪些提升?本文将从核心参数、跑分测试、渲染性能以及主流工业设计软件表现多个维度,进行一次全面的对比分析,供大家参考。 1.参数对比 2.测试数据测试环境 测试内容 图形性能 1、SPECviewperf 2020 v3.0 SPECviewperf是一个专业级、符合工业标准的OpenGL图形显卡效能测试分析软件,使用C语言编写,用于测量运行在OpenGL应用程序接口之下硬件的3D图形性能。其中包含了 3ds max、catia、creo、energy、maya、medical、snx、solidworks 共8款软件的性能测试。 2、3D Mark 3DMark是一个由UL开发的智能设备性能评测软件,可用于评测设备的3D图形渲染能力。我们主要测试了 Port Royal 和 Speed Way 两个场景。 在 Port Royal 场景中,RTX PRO 2000 相较 RTX 2000 Ada 提升约 56%;在 Speed Way 场景中,RTX PRO 2000 相较 RTX 2000 Ada 提升约 45%; 3、V-Ray Benchmark 6.00.01 V-Ray Benchmark 是一款免费的独立渲染速度测试软件,用于测试计算机的渲染速度。 RTX PRO 2000 相较 RTX 2000 Ada 提升约 63%。4、OctaneBenchOctaneBench 是一种专有基准测试工具(也是当今最流行的GPU渲染基准测试),用于测量以每小时OctaneBench 点数(OBh)表示的GPU渲染速度,用于标准化和基准测试GPU性能。 渲染性能 1、Blender 2、Houdini 3、Maya 4、UE5 5、NVIDIA Omniverse™ AI 性能 1、Stable Diffusion 2、ComfyUI 测试项目:Hunyuan3D 模型生成 工业软件性能 为确保评测结果的可量化与可比性,本次测试明确以下核心指标: 1、UG NX 应用测试 UG NX 作为面向高端制造的三维设计软件,在复杂装配体设计、多物理场仿真等场景中应用广泛,本次选取五类模型,从简单到复杂覆盖不同负载需求,详细测试内容见下表: 2、Solidworks 性能测试 Solidworks 以易用性与兼容性著称,广泛应用于通用机械、模具设计等领域,本次测试选取两款模型,贴合不同用户的实际应用场景。 申请显卡测试https://my.feishu.cn/share/base/form/shrcnEmbNj6oRKsQ58SNldkb...



从测试结果来看:RTX PRO 2000 相较 RTX 2000 Ada 综合提升约 37%。


RTX PRO 2000 相较 RTX 2000 Ada 提升约 52%。
RTX PRO 2000 相较 RTX 2000 Ada 提升约 35%。
RTX PRO 2000 相较 RTX 2000 Ada 提升约 120%。
RTX PRO 2000 相较 RTX 2000 Ada 提升约 34%。
RTX PRO 2000 相较 RTX 2000 Ada 提升约 20%。
RTX PRO 2000 相较 RTX 2000 Ada 提升约 96%。
测试项目:FLUX 文生图
生成尺寸:1024*1280
RTX PRO 2000 相较 RTX 2000 Ada 提升约 35%。
测试项目:FLUX 文生图
生成尺寸:1280*720
RTX PRO 2000 相较 RTX 2000 Ada 提升约 46%。
RTX PRO 2000 相较 RTX 2000 Ada 提升约 30%。测试项目:Wan2.2 图生视频
RTX PRO 2000 相较 RTX 2000 Ada 提升约 59%。
测试结果:
在中小模型场景测试中,两款显卡均能很好地满足设计需求,RTX PRO 2000 和 RTX 2000 Ada在载入速度与操作流畅度方面差异较,性能差异在10%以内,RTX PRO 2000 略占优。
测试结果:
在中小模型场景中,两张显卡均表现出色,编辑、旋转、缩放等操作非常流畅,RTX PRO 2000 和 RTX 2000 Ada 性能差距较小,在高保真渲染操作中,RTX PRO 2000 比 RTX 2000 Ada 要快8秒,且整个过程流畅、无报错或卡顿现象。
*与 NVIDIA 产品相关的图片或视频(完整或部分)的版权均归 NVIDIA Corporation 所有。
Redis 已超越“单纯内存 KV 缓存”的角色,成为企业级、可扩展的高速缓存与实时数据平台。通过多种缓存模式(cache-aside、read/write-through、write-behind、prefetch 等)、企业级特性(Active-Active/CRDT、Redis on Flash、持久化与 SLA)、以及模块化生态(RedisGears、RediSearch、RedisJSON、RedisBloom 等),Redis 能在低延迟(sub-millisecond)同时支撑大规模流量与复杂一致性需求,是现代“systems of engagement”架构中的核心组件。 为什么需要企业级缓存 Read/Write-Through 与 Write-Behind(Inline / 背写) 小结
现代应用趋向“系统参与”(systems of engagement),对实时性、可伸缩性与高可用性的要求远高于传统系统;缓存把慢速系统(磁盘、传统 RDB)常用数据“移到近端”,以实现亚毫秒响应。对于企业级应用,单纯开源 Redis + 自研运维往往难以满足跨地域高可用、数据持久化、成本可控(大数据集内存成本)等需求;Redis Enterprise 提供扩展(线性扩容)、99.999% SLA、以及分层存储(RAM + Flash)以降低成本。
核心缓存模式(Patterns)
Cache-aside
应用先查缓存(Redis),若 miss 则去后端读取并回写缓存。适用于读多写少、可容忍偶发缓存不一致的场景(例如商品详情、配置、用户画像片段)。实现简单、延展性好,但一致性由应用负责。
伪代码val = redis.get(key)if not val:
val = db.read(key)
redis.set(key, val, ex=ttl)return val
Write-through:写操作同步经缓存到后端数据库(保证一致性,但写时延增加)。
Write-behind(Write-back):写先写缓存,然后后台异步落库以提升写性能,但存在短期不一致/丢失风险,需可靠的异步机制与重试策略(例如使用 Redis Streams + 后台 worker)。RedisGears/rgsync 提供了可用的 write-behind / write-through recipe,方便把 Redis 中的变化可靠写入关系型数据库。
Query Caching(SQL/查询结果缓存)对重复执行的 SQL 或昂贵查询缓存完整结果集或经过序列化的结果(注意分页、权限、排序等变化)。适合“相同查询多次”场景,常配合 cache-aside。
Prefetch / Cache Warming(主动预热)对于“读多写少”的仪表盘、前端账户总览等场景,建议把热点数据按策略提前写入缓存(比如定时任务、事件驱动同步),以避免冷启动或突发流量造成后端压力。移动银行示例中常用此策略把账户总览、余额等读多数据预先放入 Redis。
典型用例实践
金融行业缓存应用
在金融行业,特别是银行系统中,Redis缓存已成为支撑高并发业务的核心组件。江苏省联社在新一代移动金融综合服务平台中,使用Redis中间件进行热点数据缓存,显著降低了数据库访问压力,提升了应用吞吐量。该平台整合了个人手机银行、企业手机银行和各类生活服务应用,通过Redis缓存支撑了转账汇款、贷款理财、生活缴费等高并发业务场景。
中原银行则基于Redis构建了分布式缓存平台,创新性地实现了多租户机制,允许多个微服务系统使用同一套Redis集群而数据互不影响。这种设计既节省了服务器资源,又简化了集群管理。此外,中原银行还基于Redis实现了分布式锁功能,支持自动续约机制,避免了因业务执行时间过长引发的锁冲突问题。
分布式会话管理
在分布式系统架构中,Redis提供了可靠的分布式会话管理能力。通过将会话数据存储在Redis集群中,不同应用实例可以共享用户状态,实现真正的无状态应用架构。实践中,通常会自定义SessionManager,支持通过HTTP头部token传递sessionId,实现前后端分离架构下的会话管理:public class ShiroSessionManager extends DefaultWebSessionManager {
public final static String HEADER_TOKEN_NAME = "token";
@Override
protected Serializable getSessionId(ServletRequest request, ServletResponse response) {
// 从Header中获取sessionId
String id = WebUtils.toHttp(request).getHeader(HEADER_TOKEN_NAME);
if (!StringUtils.isEmpty(id)) {
request.setAttribute(ShiroHttpServletRequest.REFERENCED_SESSION_ID, id);
request.setAttribute(ShiroHttpServletRequest.REFERENCED_SESSION_ID_IS_VALID, Boolean.TRUE);
return id;
}
return super.getSessionId(request, response);
}
}
Redis作为一种多功能的内存数据存储,在现代应用架构中提供了多样化的缓存解决方案。从基础的全页面缓存到复杂的延迟消息队列,从简单的会话存储到企业级的分布式缓存平台,Redis展现了其卓越的性能和灵活性。
通过合理的架构设计、监控管理和优化策略,Redis缓存能够显著提升应用性能,降低后端数据库压力,为高并发、低延迟的业务场景提供有力支撑。随着云原生和微服务架构的普及,Redis在缓存领域的重要性将进一步提升,成为构建高性能应用不可或缺的基础组件。
做量化交易系统的后端开发,最怕的不是算法太难,而是数据源“太脏”或者粒度不够。 作为开发者,你一定遇到过这种情况:前端图表展示用K线绰绰有余,但后端撮合引擎如果也只用K线数据,那简直就是灾难。因为K线丢失了时间维度的时序性。 从工程角度看Tick数据的必要性 Tick(逐笔成交)数据,本质上是时间序列数据库里最基础的原子单位。在系统架构设计中,引入历史Tick数据主要为了解决两个工程痛点: 如何优雅地获取并“消费”Tick数据? 很多同学拿到Tick数据的第一反应是存起来再算。其实更高效的做法是流式处理或切片回放。这就要求上游接口必须足够稳定且结构规范。 这就涉及到接口选型的问题。如果每个交易所的API你都要写一套解析脚本,维护成本会极高。在工程实践中,推荐使用那些已经做过“归一化”处理的聚合接口,比如 AllTick API 这类服务,它直接返回标准化的JSON结构,能让你把精力集中在策略逻辑(Business Logic)上,而不是消耗在ETL(数据清洗)上。 数据消费建议 代码跑通后,建议大家把重点放在数据落地上。不要一上来就搞复杂的各种因子计算。先试着把Tick数据可视化,观察一下在极短时间窗口内的价格跳动逻辑。你会发现,很多K线上看似合理的支撑位,在Tick级别其实是脆弱不堪的。import requests
import pandas as pd
API_KEY = "YOUR_API_KEY"
symbol = "AAPL.US"
url = "https://apis.alltick.co/stock/historical/tick"
params = {
"symbol": symbol,
"limit": 500
}
headers = {
"Authorization": f"Bearer {API_KEY}"
}
resp = requests.get(url, headers=headers, params=params)
ticks = resp.json().get("ticks", [])
df = pd.DataFrame(ticks)
df["time"] = pd.to_datetime(df["time"])
print(df.head())

作者:中国联通软件研究院 · 计费结算中心 张兴宇 整理排版:蚂蚁密算 曾辉 在数据要素流通全面提速的背景下,我们在一线工程实践中越来越清晰地感受到:数据安全已经不再只是“合规约束”,而正在直接决定业务是否还能继续发展。 过去很多跨域协作的方式,本质上是把“数据怎么拿到一起”作为默认前提:先汇聚、再计算、最后补合规。但随着监管要求、数据安全责任、以及跨主体协作复杂度同步提升,这条路径越来越难走——尤其是在通信行业这种数据粒度细、规模大、敏感字段多、跨主体协作频繁的场景里。 因此,“原始数据不出域、可用不可见”并不是一个愿景口号,而是在通信行业中,被真实业务一步步推到了工程实现与生产落地阶段。更重要的是,它不是“加一层安全能力”这么简单,而是在重新定义协作方式:从“拿到数据再处理”,转向“在不拿到数据的前提下完成协作”。 从宏观层面看,这一变化并非偶然,而是由多重因素共同驱动: 当这些因素叠加到通信行业,问题被进一步放大:亿级数据规模 + 跨域协作刚需 + 合规红线不可突破,使得传统集中式技术路径开始系统性失效。 在通信行业,跨运营商协作并不是“要不要做”的问题,而是长期存在、无法回避的业务事实。 例如网间详单级对账、跨域核验与监管支撑,本质上都依赖多方数据协同完成。它们的共同点是: 但现实约束同样非常清晰,而且是工程层面的硬约束: 这直接导致一个结果:大量在实验室或PoC阶段“跑得通”的技术路线,在运营级业务中根本撑不住。 能“算出来”只是起点,真正的门槛是能否长期稳定地跑、能否支撑规则变化、能否可运维、可审计、可回溯、可复制。 正因为如此,我们在技术选型阶段,并没有把问题定义为“用不用隐私计算”,而是明确了一条更严格的原则:不是“能不能用”,而是“能不能长期跑在运营级业务中”。 这里的“运营级”,意味着它必须同时满足一组工程特征: 稳定性(可长期运行)、时效性(窗口内闭环)、可运维(可定位可回溯)、可扩展(规模上得去)、可治理(规则可控可审计)。 围绕这一目标,我们从工程视角对主流技术路线进行了系统评估,核心维度包括: 在详单级、亿级规模的密态对账场景中,我们最终选择了隐语SecretFlow,原因是它在真实业务约束下,在工程可演进性与场景贴合度上更接近可持续落地路径——尤其适配规则型密态计算与结构化数据协作的工程需求。 回顾整个建设过程,这并不是一蹴而就的体系设计,而是一条伴随业务演进不断调整的工程路径: 这条路径背后的关键词只有一个:即从小场景、可验证边界切入,用标准和规则把复杂度压缩到可控范围内,再逐步扩大规模与覆盖范围。 在这个过程中,我们并没有一开始就设计一个宏大的“总体架构”。 随着场景逐步稳定,一套可以被复用和推广的方法体系逐渐清晰,也就是现在对外呈现的 中国联通“113N”可信数据空间体系蓝图。 这套体系的出发点不是“平台建设”,而是可信协作如何真正落地: 目标并不只是“搭一个系统”,而是通过真实场景把工程能力跑顺、把规则跑稳,形成可复制、可持续的协作模式。 随着实践深入,我们逐渐意识到一个关键问题:可信协作不是一个系统能力,而是一种结构性能力。 如果把可信协作只落在单一系统里,短期看似集中统一,但一旦参与方变多、场景变多、规则变多,就会面临治理边界不清、责任难划分、扩展成本高的问题。 因此,在工程实现中,我们没有将所有能力集中到单一平台,而是将协作拆解到不同层次、不同类型的可信数据空间中: 这种方式的好处在于:参与方无需大规模改造现有系统、无需暴露原始数据,就可以在统一规则下持续协作,同时治理边界更清晰、扩展更自然。 在技术架构层面,我们始终坚持三条不可妥协的原则: 以隐语SecretFlow为核心,结合Kuscia等组件,支撑跨域联合作业、精密分析与账单核算。这不是“为了用隐私计算而用隐私计算”,而是业务约束下的工程选择。 从工程视角看,跨运营商对账的核心,是将传统集中式对账流程,拆解为一条可以在密态环境下长期稳定运行的计算流水线。 整体思路是:各参与方仍然在本地结算系统中生成详单数据,在进入计算前完成字段标准化与规则映射,确保计算语义一致;进入隐私计算阶段后,原始数据不出域,通过SecretFlow承载的密态计算能力执行规则驱动的对账逻辑。 关键工程特性包括: 这不是算法展示型方案,而是围绕高并发、规则复杂、长期运行场景做过充分工程约束的生产级实现。 在工程设计上,我们将跨运营商对账定义为双向对等、可验证的协同执行过程,而不是单向“算完给结果”。 发起方与审核方各自在本地运行隐私计算节点,执行同一套对账规则。系统输出可校验的对账报告与差异摘要,并通过链上机制固化关键结果,确保任何一方都无法事后篡改关键结论。 如存在差异,可在密态下进行定位、复核与调整,而不是重新全量重跑。 针对不同敏感等级的数据,我们采用分级协作策略: 各运营商在本地可信数据空间内部署隐私计算节点,跨域协作通过专线网络和统一安全接入区完成。 工程上强调“最小暴露面”: 系统仅开放标准协议接口(如gRPC、HTTPS),确保原始数据与计算逻辑始终不出域,同时满足合规要求、运行稳定性与可运维性。 在业务层面,对账与结算效率发生质变:对账周期从周级、月级压缩至天级,自动化覆盖接近全量,异常更早暴露、更快定位。 在人力与成本层面,大量依赖人工核对、反复沟通的工作被规则化、系统化协作替代,人力投入明显下降,长期成本持续可控,同时资金周转效率同步提升。 更重要的是,这套能力不再局限于单点场景:推动行业从“点对点对账”走向可复制、可推广的数据协同模式,为后续联合分析、联合运营与生态协同打开空间。 实践中我们深刻体会到:技术不是最大难点,真正的难点在于跨主体长期协作。 因此,我们优先建设可信数据空间的规则底座,通过统一规范,将隐私计算能力固化为可复用、可审计、可监管的协作方式,服务于长期运营。 换句话说,我们要解决的不是“某一次对账能跑通”,而是让协作成为一种长期可运行的机制:规则怎么变、版本怎么管、争议怎么裁、审计怎么做、责任怎么划分,都需要在工程体系内被吸收。 总结来看,我们走出了一条可持续落地路径: 可以概括为:从共识开始,用标准落地,靠规则运行,以经验放大。 我们更愿意将这些成果视为一次行业与社区协同探索的阶段性结果,而不是某一个系统建设的终点。 在整个实践过程中,隐语(SecretFlow)对我们来说不仅是一个“能跑算法的框架”,更像是一套能够承载真实业务约束、支撑工程演进的技术底座:它让隐私计算从“概念可行”走向“工程可用”,也让我们能够在高敏感、高规模、高稳定性要求的生产环境中把协作真正跑起来。 与此同时,真实生产场景也天然会暴露出大量“只有落地才会遇到”的问题:比如规则型计算在密态下如何组织与复用、亿级规模下的任务拆分与并行策略、失败恢复与回溯机制如何设计、跨主体协作的审计与存证如何做到既可信又可运营……这些问题无法靠单次PoC解决,只能在持续运行中逐步打磨。 因此,我们更愿意把“社区共建”理解为一种双向循环: 我们相信,可信协作的成熟并不是靠某一次“选型成功”完成的,而是在真实生产场景中一步一步验证: 什么是可执行、可运维、可持续的工程能力;什么样的规则体系能够长期运行;什么样的协作模式能够被复制推广。 面向未来,我们期待与更多行业伙伴和社区开发者一起,把生产实践中沉淀出的经验转化为社区可复用的能力:让更多参与方能够在统一的可信协作框架下参与协作、持续演进,并最终让“数据可用不可见”的理念真正走向——好用、常用、可复制、可持续。本文整理自隐语第三届嘉年华现场演讲,中国联通软件研究院基于隐语,从最初的对账试点出发,打造了一套可复制、可监管的跨域协作体系。详细介绍了对等组网、数据分级计算、规则上链存证等工程实现细节,并总结了实际推进中最难解决的部分:不是技术,而是多方协作。最终,这不仅是一套系统架构,更是一种行业共建的新模式。

行业技术背景
行业技术痛点

协作主体多、协作频次高、规则变化快、且必须在规定窗口内完成闭环。技术选型

项目演进里程碑
平台总体架构
相反,所有能力都是在真实业务中不断试错、修正、打磨后沉淀下来的。
空间治理架构

技术架构

技术方案——跨运营商详单级对账


最终形成原始数据不出域、结果可验证、过程可追溯的对账闭环,也使其能够在运营级场景中长期稳定运行。关键技术能力——面向不同数据敏感等级的跨域协作实现方式

生产部署架构与跨域互联方式

业务成效与行业意义

构建标准体系

实践方法论

结语
GitLab 18.8 带来多项新功能,包括 GitLab Duo Planner Agent、GitLab Duo Security Analyst Agent、自动忽略不相关漏洞等。随着本次发布,用于帮助组织统一编排 AI 代理的 GitLab Duo Agent Platform 正式达到全面可用(General Availability,GA)状态。 GitLab 表示,GitLab Duo Agent Platform 能够帮助团队在软件开发的各个阶段协同 AI 代理,从规划、构建到安全防护和最终交付。GitLab 认为,如果 AI 只停留在写代码阶段,价值依然有限。Duo Agent Platform 的思路,是让 AI 参与到整个研发流程中,帮助团队应对代码评审积压、安全漏洞、合规检查以及后续修复等现实问题。 为实现这一目标,GitLab Duo Agent Platform 将代理式聊天(agentic chat)、面向具体任务的代理、工作流自动化以及企业级管控能力整合在一起,使组织能够在整个软件开发生命周期中部署和管理 AI。 该平台提供了一个集中的 AI Catalog,团队可以在其中发现、管理并在组织内部共享各类代理和流程。内置的基础代理(如 Planner、Security Analyst 和 Data Analyst)可在关键决策节点处理结构化工作;同时,可定制的流程能够在开发工作流中自动执行多步骤的代理任务,覆盖从 Issue 到 Merge Request、CI/CD 迁移、流水线故障排查以及代码评审等多个场景。 开发者可以使用 Planner Agent 来创建、更新和分析 GitLab 中的工作项,例如进行待办事项分析、基于 RICE 或 MoSCoW 等框架进行优先级排序,并识别哪些问题需要人工直接介入。 Security Analyst Agent 将漏洞管理从仪表盘和脚本中“解放”出来,工程师只需在 GitLab Duo Agentic Chat 中进行对话,就能完成漏洞分流、评估以及修复指导等工作。 通过漏洞管理策略,安全团队可以自动忽略那些并不适用于自身组织的漏洞,从而减少噪音,让开发者专注于真正的安全风险。被自动忽略的漏洞会在 Merge Request 中被明确标注,并在漏洞报告中记录,以满足审计需求。 除了上述由 AI 驱动的新能力之外,GitLab 18.8 还包含多项其他改进,例如升级后的 GitLab Runner、多容器扫描、集中式凭据管理 API 等。更多细节可参考 GitLab 官方发布公告。 需要指出的是,GitLab Duo Agent Platform 并非市场上唯一的代理编排平台,其竞争对手还包括 Copilot Workspace、Google Gemini Enterprise、Microsoft Agent 365 等产品。 原文链接: https://www.infoq.com/news/2026/01/gitlab-18-8-duo-agent-platform/
Google 正式发布 Universal Commerce Protocol(UCP,通用商业协议),这是一项开放标准,旨在支持“代理式商业”,也就是由 AI 驱动的购物代理可完成从商品发现、下单结算到售后管理的全流程任务。UCP 同时兼顾零售商与消费者需求,在整个购物旅程中始终以“客户关系”为核心,从最初的商品发现到购买决策乃至购买之后。 UCP 在美国全国零售联合会(National Retail Federation,NRF)年度大会上正式公布。该协议为 AI 代理与商业生态中的后台系统建立了一种安全、标准化的连接方式。企业可以通过 UCP 对外暴露自身能力,并在此基础上扩展诸如折扣等功能;AI 代理则可以通过企业资料动态发现可用服务与支付选项。 在支付设计上,UCP 将支付工具与支付处理方进行解耦,支持多个支付服务提供商。通信层面,协议支持标准 API、Agent2Agent 以及 Model Context Protocol 绑定。Google 还提供了示例实现,包括一个 Python 服务器以及包含商品数据的软件开发工具包,用于展示 AI 代理如何发现商业能力并执行结算流程。 American Express 在 LinkedIn 上发文,强调了该协议在简化商业流程方面的潜力: Google 推出的 Universal Commerce Protocol(UCP)是一项面向代理式商业的全新开放标准,想减少支离破碎的购物体验,帮零售商与消费者建立更顺畅的连接。UCP 很快将为 Google 搜索的 AI Mode 以及 Gemini 应用中的全新结算体验提供支持。像这样的开放标准,对于构建更安全、更可信的商业体系至关重要。 正如 Google 在一篇深入解析的技术博客中所介绍的,UCP 定义了一系列核心商业能力,包括商品发现、购物车管理、结算流程以及售后工作流。AI 代理可通过查询企业资料来识别可用服务并协商支持的功能,从而减少定制化集成的需求。这种方式既能让企业继续掌控价格、库存和履约逻辑,又能让 AI 代理实现更高程度的自主运行。 UCP 高层架构示意图 在安全架构方面,UCP 通过凭证提供方对支付和身份信息进行令牌化处理,而具体的交易处理则由支付服务提供商完成。这种分离设计使 AI 代理在无需接触原始支付信息或个人数据的情况下即可完成交易。 此外,UCP 具备传输层无关性,既支持标准 API 交互,也支持面向代理的绑定形式,适用于对话式界面、AI 助手和自动化工作流。目前,UCP 的早期实现已出现在 AI 驱动的搜索与助理平台中,符合条件的零售商可以在不跳转至外部网站的情况下,直接向用户提供结算体验。 基于 AI 代理的购买流程演示 UCP 由 Google 与 Shopify、Etsy、Wayfair、Target、Walmart 共同开发,并获得了来自商业生态中 20 多家合作伙伴的支持与背书,其中包括 Adyen、American Express、Best Buy、Flipkart、Macy’s、Mastercard、Stripe、The Home Depot、Visa 以及 Zalando。 在未来规划方面,UCP 的路线图着眼于构建一个覆盖全球、超越单笔交易的统一商业标准。相关计划包括多商品结算、购物车管理、会员与忠诚度计划、订单后流程,以及个性化的交叉销售与追加销售能力,同时继续确保核心商业逻辑掌握在企业自身手中。 目前,UCP 的早期版本已支持美国部分符合条件的零售商在 Google 产品界面内直接完成结算。接下来,该协议还将拓展至印度、印度尼西亚以及拉丁美洲等市场。Google 与合作伙伴也正在广泛征求反馈,以不断完善这一协议,共同塑造可互操作、由 AI 驱动的未来商业形态。 原文链接: https://www.infoq.com/news/2026/01/google-agentic-commerce-ucp/ 相关报道: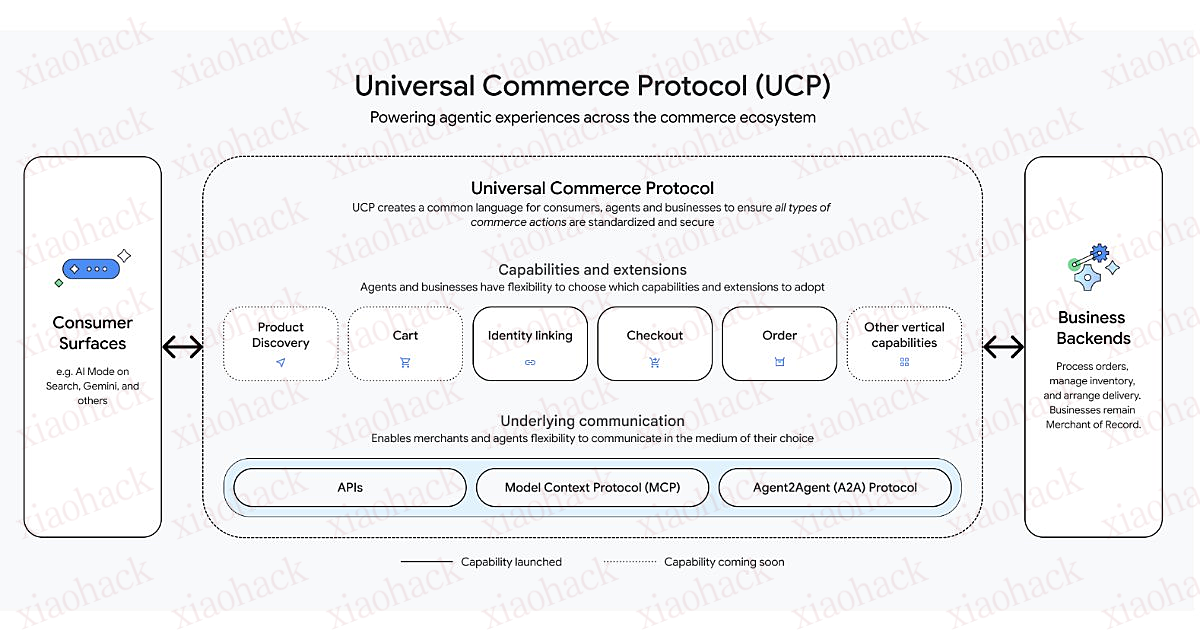

作者:子葵 配置中心和注册中心是微服务架构的核心基础设施,承担着关键的配置管理和注册发现职责。然而在实际生产中,部分企业的注册配置中心可能面临安全风险:如权限管理粒度不足、操作审计缺失,这可能导致未授权访问或误操作,进而影响业务的稳定运行。 你是否也曾遇到以下常见痛点? 为了有效应对这些挑战,MSE Nacos 推出基于 RAM 的精细化鉴权与审计方案。我们致力于在保障安全性的同时,提供平滑的过渡和直观的可视化能力。 告别过去手写复杂 JSON 策略、计算密码 Hash 的繁琐时代。MSE Nacos 与阿里云 RAM(访问控制)深度集成,实现了真正的企业级权限隔离。 精细隔离: 支持 Namespace(命名空间)、Group 甚至 Service/DataId 粒度的权限控制。你可以轻松实现: 针对存量系统开启鉴权可能引发的兼容性风险,我们提供了灰度鉴权功能,确保从“无鉴权”到“有鉴权”的平滑过渡。 无感升级路径: 安全不仅要具备防护能力,更需要具备可视化的监控能力。我们提供了全方位的鉴权审计大盘,让每一次访问都有据可查。 精准定位: 简单五步,即可完成从“零鉴权”到“安全闭环”的平滑升级: 客户端适配发布: 在客户端配置鉴权信息(AccessKey/SecretKey)并发布应用。详细配置过程可以参考文档: 为 Nacos 实例开启鉴权并配置客户端访问凭证:https://help.aliyun.com/zh/mse/user-guide/access-authenticati... MSE Nacos 鉴权审计方案,旨在为企业提供一套开箱即用、平滑过渡、可视可控的安全基础设施。 通过 MSE Nacos,您可以轻松构建企业级零信任安全体系,在保障业务灵活性的同时,彻底解决权限管理粗放与操作溯源难的痛点。
三大核心能力,提升 Nacos 安全性

1. 极简运维:RAM 深度集成,权限管理白屏化

2. 平滑开启鉴权:支持灰度鉴权,保障业务连续性
3. 全景监控:鉴权可观测大盘,提升运维透明度

核心操作流程
总结

当 AI 长出身体,从能听会说到能看会动!Agora Convo AI World 拉斯维加斯之夜活动回顾 主笔:周森 审校:小炫 编辑:陈述 AI 不再仅仅是屏幕里的对话框,从能感知情绪的陪护机器人,到具备实时翻译能力的智能眼镜,AI 硬件化成为 CES 2026 呈现的重要趋势。 然而,在 AI 硬件热潮背后,行业也在迫切寻找一个答案:当 AI 试图长出「身体」,它需要怎样的底层架构与交互逻辑? 1 月 9 日晚,Agora(声网兄弟公司)联合 RiseLink(博通集成)在拉斯维加斯 The LOFT at Cabo Wabo Cantina 举办了 Convo AI World 论坛活动。 这场吸引了近 300 位全球科技精英参与的盛会,意在为这股 AI 硬件热潮指引风向。 两家企业不仅联合发布了基于 BK7259 芯片的 R2 全场景 AI 机器人开发套件,更首次系统性地提出了「物理 AI 的蓝图」。 △ 活动现场 当前,行业正处于从文本模型、语音助手,迈向具备长期记忆、情绪理解与陪伴能力的 AI 伙伴的早期阶段。 Physical AI,本质上是具身智能(Embodied AI) 在消费级市场的落地呈现。AI 硬件不再是冰冷的电子零件,而是一种正在形成的数字生命形态。 由 Agora 与 RiseLink 联合提出的 Physical AI 蓝图,则试图为下一阶段的具身智能发展提供一套以体验为核心的设计方法论。 Tony Wang 在演讲中强调,Physical AI 的关键不在于堆砌硬件参数,而在于对话体验,即在复杂环境中理解语境、识别说话者并感知情绪的能力。 未来,AI 的核心语言将从单向的「指令」彻底转变为双向的「对话」,其商业模式也将从硬件单次销售,转向以订阅制为核心的长期服务。 张鹏飞博士进一步阐述道,Physical AI 时代的竞争已演变为协同效率的竞争。想要成为或持续保持第一,前提是与各自领域中已经处于领先位置的伙伴深度协作。 RiseLink 将通信、算力与功耗管理深度整合,配合 Agora 的 RTC 实时互动能力,构成了 Physical AI 的基础引擎:以低延迟保障交互的自然性,以高能效支撑长时间的在线陪伴。 △ 发言嘉宾:张鹏飞博士,RiseLink(博通集成) CEO 当 AI 跨越数字边界、从云端软件形态进入物理硬件,底层的技术架构不应该只是「模型 + 数据 + 算力」,而需要从「原子」到「比特」实现闭环。 在论坛环节,嘉宾们探讨和回答了什么是「真实的 AI 堆栈」并达成共识:AI 是否好用,取决于设备能否通过物理感知快速理解语境并做出即时反应。 △ Panel: The Real AI Stack 圆桌主持人:Rin Yunis 博士,RiseLink 开发者体验负责人 (中) 圆桌嘉宾: (自左向右) 在架构选择上,边缘(Edge)与云端(Cloud)的分工不再是二选一,而是基于延迟、隐私和成本的精密平衡 。对实时性和隐私敏感的能力更适合本地运行,而需要持续迭代、受成本约束的功能则更适合放在云端,工程实践应从验证出发,再逐步优化边云分配。 在消费级场景中,成本是最硬的约束条件。无论技术听起来多么具有颠覆性,如果缺乏可持续的单位经济模型(Unit Economics),产品终究无法走出实验室成为长期的生意。 同时,嘉宾们达成了一个感性却深刻的共识:AI 必须具备稳定的记忆和一致的行为 。一个今天热情、明天健忘的 AI 硬件,是无法真正建立起用户信任的。 △ 圆桌嘉宾:Max Fillin, WOWcube CEO(左) 这种信任的建立,在家庭与健康等强私密场景下尤为微妙。品牌的真实投入与清晰的价值传递,远比罗列一堆天衣无缝的安全技术术语更有效。 用户对 Physical AI 的接受度,往往并不取决于你背书了多少项加密协议,而取决于极其直观的交互体感,即:反馈要即时(低延迟)、过程要透明(可解释)、底线要有人守(人类参与)。 △ 圆桌嘉宾:Lin Chen 博士, Wyze 首席科学家 Physical AI 最令人兴奋的特质在于它的多模态能力,以及在各个场景的迅速渗透。 △ WOWcube(左):将经典的 2x2 魔方形态与 24 个高分辨率屏幕相结合,通过扭转、倾斜和触觉交互,让玩家在立体的物理空间中体验沉浸式的游戏与应用。 △ Wyze(右上): 新款户外安防摄像头采用贴纸式安装方式固定在窗户上,可从室内进行户外录像 △ Nanit Pro(右下): 全功能婴儿监控系统,新增用于记录宝宝成长发育的功能 在医疗与健康领域,Physical AI 的价值在于它能实时处理复杂的生理信号,并以人类能理解、能接受的方式进行交互,从而在专业性与亲和力之间找到平衡。 Blake Margraff 指出,AI 在医疗中的落地绝非简单的自动化,而是要实现「自动化的患者监测与干预」。 △ 圆桌嘉宾:Blake Margraff,Healthcare Technology 创始人 Amir Eitan 则从育儿与家庭监测的角度补充道,真正的信任来自于 AI 能在特定场景下提供「可解释的反馈」。 △ 圆桌嘉宾:Amir Eitan,Nanit CPO 在 AI 陪伴的主题论坛中,各位嘉宾围绕 AI 陪伴产品在儿童与家庭场景中的实际落地展开话题。 △ Panel:Where AI Companionship Comes to Life 圆桌主持人:Patrick Ferriter,Agora 产品与市场高级副总裁(左下) 圆桌嘉宾: 稳定性和一致性是影响儿童用户对 AI 硬件接受度的关键因素。无论是故事内容、角色设定还是互动方式,一旦发生变化,都会显著影响使用体验。 低延迟是实时陪伴场景中的基本要求,是建立用户与产品情感连接的底线,响应过慢会直接削弱互动的自然感。 长期留存更具挑战性。吸引用户首次尝试与长期留存两者的差异性需要引起重视,长期留存更具挑战性,需要 AI 在持续使用中形成稳定的互动节奏和情感连接,而不仅是单次回应。 安全与责任方面需要引入多层防护思路,包括年龄匹配内容、实时干预机制、以及对儿童隐私的明确告知与限制。当 AI 承担陪伴角色时,如何在维持互动亲密性的同时设立清晰边界,仍是行业需要持续面对的问题。 △ Fuzozo 芙崽(左上):面向 Z 世代的 AI 养成系潮玩 △ Luka AI Cube(右上):灵宇宙小方机,儿童 AI 学伴 △ Lgenie (左下):小匠宠物陪伴小车 & 四足桌面机器人 △ 海马爸比(右下): AI 智能婴儿看护器 在产品演示环节,Diana Zhu 博士主持发布了 Choochoo AI 教育机器人。她提到,Choochoo 能够实现流畅的视觉与动作反馈,核心在于集成了 RiseLink 的高集成度 SoC 方案。该芯片在单颗硅片上整合了 Wi-Fi 连接、音视频处理与 AI 加速引擎,使得开发者能够绕过复杂的底层硬件调优,直接在 R2 套件上通过简单的 API 调用,实现原本需要高性能服务器才能支撑的「视觉-语言-动作」协同。 △ 发言嘉宾:Diana Zhu 博士,RiseLink 美国负责人 作为首款由 RiseLink 芯片与 Agora 对话式 AI 引擎深度驱动的教育机器人,Choochoo 不仅能听懂孩子的提问,更能通过视觉传感器「看」到周围的环境与孩子的动作,并做出相应的物理反馈。 △ Choochoo / 延伸阅读:对话式 AI 升级,不仅能看还能动 值得一提的是,作为 R2 全场景 AI 机器人开发套件标杆案例,陆吾智能旗下的桌面机器人「陆卡卡」也同步亮相。现场,陆卡卡展示了如何在紧凑的形态下实现高频、低延迟的 AI 交互。 △ 陆卡卡 / 延伸阅读:桌宠陆卡卡,一只「兵蚁」从二次元走进现实 在两款极具代表性的具身智能产品身上,我们看到,当 AI 拥有了强大的「大脑」(大模型)与灵敏的「身体」后,交互的边界已彻底被打破。两款产品的发布,共同定义了 AI 硬件的新高度,同时也标志着基于 Agora 与 RiseLink 合作的 AI 方案已经完全成熟。 在快闪分享环节,Joey Jiang 分享了打造 AI 原生硬件的最短路径,强调了模块化硬件对快速实现概念落地的意义。他指出,AI 原生硬件的开发不应再遵循「从零打样」的旧逻辑。通过 Seeed Studio 提供的模块化感知节点(如传感器、视觉模块)与 RiseLink 方案的即插即用式结合,硬件原型的验证周期可以从数月缩短至几周。这种「搭积木」式的开发模式,正是初创团队在 Physical AI 浪潮中抢占市场窗口期的最短路径。 Kim Jin 分享了打造糯宝 AI 机器人的背后故事。在研发背后,团队耗费大量精力对用户意图的深度理解。通过多模态感知,敏锐地捕捉视觉、触觉与语音背后的感性信息,实现拟人化的回复。这种交互不只是指令的执行,而是基于对用户意图的精准洞察,让机器人产生真实的「情感共鸣」。这标志着 Physical AI 真正跨越了工具属性,进化为懂得用户灵魂的情感伴侣。 △ Pophie (机器灵动) 产品负责人 Kim Jin △ Maxevis(左):迈威儿童拍学机 △ Pophie 糯宝(右):桌面级情感陪伴机器人 随着环境式 AI(Ambient AI)走向「始终在线」,隐私与信任已不再是合规问题,而是产品体验本身。用户真正担心的并非模型出错,而是设备在「不被察觉的情况下」收集和使用数据。 △ Panel:When AI Is Everywhere: Redefining Data Privacy, Consent, and Trust 圆桌主持人:Ramana Kapavarapu,Agora 首席信息安全官 (CISO) & IT 运营负责人(中) 圆桌嘉宾:(自左向右) △ 成立于 2021 年底的 MiniMax 刚刚宣布港股上市,成为从成立到 IPO 用时最短的 AI 公司。大家首先向 MiniMax 的 Gibran Mourani 道贺。 围绕隐私实践,嘉宾们形成了一个明确共识:说到做到、做到可见。 透明性: 相比冗长的隐私条款,产品应在交互层面清晰呈现系统是否在监听、收集了什么数据,以及用户如何即时控制这些行为。透明性体现在硬件指示、软件状态和使用流程中,比如用物理指示灯直观地告诉用户系统是否在监听。 边缘保护: 通过边缘计算最小化数据流动,让原始语音和视觉数据停留在本地,是保护隐私的最有效路径。对多数场景而言,无需上传云端、本地处理并仅传递必要信号,既有助于隐私保护,也降低了系统暴露面。 响应机制: 谈及安全事件响应,需要成熟、结构化的应对机制,而非临时决策。快速隔离、明确影响、及时修复与复盘改进,比短期业务考量更重要。过往大型数据泄露案例反复证明,延迟或回避只会放大长期损失。 真正可规模化的信任,来自硬件与软件的一致设计以及可实时验证的控制能力。认证和合规是基础,但只有当系统行为与承诺持续一致,用户对「无处不在的 AI」才会产生长期接受度。 △ 活动现场 纵观整场活动,我们可以从三个层面理解这场关于 Physical AI 的深刻变革: 技术本质: 从「挂载」到「具身」。 AI 不再是硬件外挂的一个功能,而是通过专用芯片和实时通讯协议,深度融合进硬件的神经系统。 交互范式: 从「指令」到「共生」。 当 AI 能够理解语境、感知情绪并拥有长期记忆,它就从一个「好用的工具」进化为一个「理解你的物种」。对话不再是手段,而是其存在的形式。 商业本质: 从「买断」到「订阅」。 物理 AI 的核心价值在于其随时间不断进化的能力。厂商卖出的不再是零件,而是长期的服务与情感陪伴。 在 Agora 和 Riselink 两家公司和来自人工智能、芯片和硬件、AI 算法,以及数字健康、家居安防、AI 陪伴和教育等领域的数十家 AI 软硬件企业代表和顶尖专家的背书下,AI 将跳出单纯的数字世界,开始在物理世界中,真正长出它的身体。■ 阅读更多 Voice Agent 学习笔记:了解最懂 AI 语音的头脑都在思考什么


具身 AI 的蓝图:从「工具」到「生命形态」

△ 发言嘉宾:Tony Wang,Agora 联合创始人兼 CRO

真实的 AI 堆栈:重构技术底层




应用与具身落地:AI 硬件的场景爆发









△ 发言嘉宾:Joey Jiang,Seeed Studio 销售副总裁


隐私、授权与信任:环境式 AI 的底线




AI 具身化不可挡!



程序一、基础工程资料规划建档: 一个制造产业能否透过实施ERP全面电算化整合信息管理系统,而使企业能够具备:明确化、合理化、高效化、规范化、精细化、自动化的优质管理体系,第一个关键性的问题就是要对整个产业的基础工程做正确而合理的规划。 因为一个产业的基础工程规划建立就有如一栋大楼的地基规划建立一样重要,没有良好稳固的基础,就不可能建立一个具备高效而优质管理体系的企业。 一个制造产业在实施ERP全面电算化整合信息管理系统时必须先规划建立的基础工程包括哪些项目? 我们分别先列示如下,并且一一加以详细说明: 1、集团公司组织规划建档: 当一个企业已经发展成为集团企业之时,规模越大者或跨国际经营者,其经营管理体系的复杂度远比单一公司要超过十倍以上。面对这种大型集团企业的ERP全面电算化整合信息管理系统的规划实施,首先就要把整个集团公司的母子公司组织关系规划建档完成,包括:每个公司的代码、名称(本国名称/英文名称)、资本额、持股比率、公司所在地区/国家、地址、网址、ERP数据库的网址、重要主管资料、使用系统代码、产生单据代码等,并且可以从公司组织表查看到每一家公司的从属关系。 将来整个集团公司的运筹管理资料数据彙总,都会透过这份公司组织表建立的相关数据做为依据,包括:财务运筹管理、营业运筹管理、存货运筹管理、采购运筹管理、人力资源运筹管理、产品研发运筹管理等体系。 通常一个集团企业可以发展到100个母子公司以上已经不多见了,像荷兰的Philips飞利浦集团或美国的GE通用集团,子公司号称超过1000家,在母子公司编码的技术上,都还不会产生重大困扰。我们建议对于关系企业的公司编码上,和客户编码/厂商编码采用相同的编码规则,这样是一劳永逸的办法。即: (a)、对于国内使用中文的公司,直接以公司名称的前四个中文字的罗马拼音的第一码,4码以后则用流水码,可避免前4码重复。至于流水码要用几码,要看往来客户和厂商的家数多少来决定,最多可以用到4个流水码。 (b)、对于国外非使用中文名称的公司,则直接使用其英文名称的前四码,再加上流水码,将来就可以简单的进行查询的作业。 2、厂别/营所规划建档: 厂别/营所/分公司和母子公司的关系完全不同,母子公司是指两者都同时具备独立的法人资格,都必须独立向政府的税务机关报税的不同公司。而厂别/营所/分公司是指:在同一个公司名称法人之下,有多个制造工厂,多个营业所,或多个分公司,在申报企业之营利事业财务报表和所得税时,必须合并所有厂别/营所/分公司的数据,再统一向总公司所在地点的税捐机关申报。 对于每一个工厂/营所/分公司,都必须分别编定一个代码加以区别,因为厂别/营所/分公司和部门组织和部门代码并不相同,如果公司需要获得每一个厂别/营所/分公司经营的损益分析,就必须把厂别/营所/分公司加以编码管理。 厂别/营所/分公司的编码规则,最好就直接使用2码地区码,加上厂别流水码及属性即可。例如:昆山一厂:KS01F,东莞二厂:DG02F,其中“F”代表工厂(Factory);上海营一所(或分公司):SH01B,大连营二所(或分公司):DL02B,其中“B”代表营业所或分公司(Branch)。如果营业所超过1000家,就用4位流水码,肯定够用。 3、事业部别代码规划建档: 当一个企业跨产业经营的时候,就会用到事业部的管理技术和观念。事业部的观念和母子公司不同,也和厂别/营所的观念不同,事业部是以不同的产业做为区分的依据,例如:通讯事业部、计算机事业部、家电事业部、纺织事业部、包装事业部、化工事业部、家具事业部、汽车事业部等。对于相同的产业事业部可以再以不同的产品类别加以区分管理:例如:家电事业部之下,还可以再分为:洗衣机类、冰箱类、果汁机类、暖气机类、冷气机类、电视机类等产品类别。相同的产品类别再区分为不同的机型,或不同的产品型号,最底层则是每一项产品编号,即,一种产品型号可以依据客户的要求而衍生成为多项不同的产品编号。 部分企业因为规模并没有大到跨越多种产业别,而是以不同的产品类别当做一个事业部来规划管理,当然也可以。万一有一天企业突然快速发展之时,再来重新规划新的管理模式,还是可以透过企业改造来加以调整,只是要多花一点钱而已! 4、部门代号规划建档: 部门代号的编码是最简单的工作,但是也是最麻烦的工作,主要原因是:每一家企业的部门组织表都经常改变,增加(扩编)部门,减少(缩编)部门,部门归属调整重组,几乎每一个企业都必须面对部门组织经常变更的问题。 当公司调整部门组织时,一方面要能够建立新的组织表,同时还要确保每个部门先前发生的营收和费用不会消失,或是无法连贯,部门组织规划就必须要设计成为可以弹性组合的方式,随时可以把一个部门的上级部门修改为另一个部门,却不须要修改部门代号和名称。万一有一个部门必须要取消掉,只要输入该部门的失效日期就可以,从该部门失效的日期开始,任何新增的单据资料都不能选用该部门代码。在数据库中却不须要急着删除该部门的资料。 至于部门代码要如何编制,首先把部门区分属性并编定代码2码,例如:管理性质(MN)、营业性质(SA)、服务性质(SV)、财务性质(FN)、制造性质(MF)、品管性质(QC)、研发性质(RD)、生管性质(PC)、物控性质(MC)、采购性质(PR)、生技性质(TL)、人力资源性质(HR)、法务性质(LW)等,属性代码使用数字也可以。然后按照部门级数从0级、1级、2级、3级、4级到9级,使用1码应该足够。相同属性而且又同个级数的部门,可以用01、02、03、04、05、06、07到99加以编码,或从001、002、003、004、005、006、007到999加以编码,即,使用2或3码。若集团企业需要把公司代码加到部门代码上的话,就在最后的两码或三码拿来当做公司代码即可。 5、生产线代码规划建档: 生产线/工作中心(Work center)和部门组织具有完全不同的属性,生产线/工作中心是指具备生产机能的单位,部门组织则是指在企业经营管理组织中行政运作的机能单位。 生产线/工作中心的规划编码,必须以生产管制部门的角度来规划。若生管人员安排生管排程到每一个机台,则每一个机台就是一条生产线(工作中心)。若生管人员安排生管排程到同型的整个机群,而每一个机台要生产甚么产品(工令单)是由车间现场主管决定,则整个机群就是一条生产线(工作中心)。 一条生产线(工作中心)的产能依据可能是以机器设备为主,或是以人工为主,或是以人/机同时配合为主。对于不同产业,生产线(工作中心)的产能依据都必须依据实际状况决定如何正确的加以规划。 生产线的代号最多可以使用8码,前2或3码为生产线的性质,后面的流水码则依据同型生产线的数量决定长度,可用1码、2码、3码、4码、或5码。例如:ZS01,ZS02,ZS03,表示成型注塑机01、02、03三条生产线。ZK01,ZK02,ZK03,ZK04,ZK05表示钻孔机01、02、03、04、05五条生产线。 6、仓库类别代码规划建档: 仓库的分类规划非常重要,因为仓库是存放存货的地方,为了要提高存货周转率,提高空间利用率,降低存货报废率,降低存货的存置成本,达到先进先出目标,同时还要能够符合政府合同核销海关保税帐务的相关法令规定。 仓库类别主要可以分为:一般存货仓、IQC进料检验仓、FQC完工待验仓、海关保税仓、车间线边仓、客户寄售仓、代送货仓、营销发货仓、海外发货仓、售服维修仓、厂商寄库仓、储槽存货仓、研发备品仓、冷冻仓、冷藏仓、AS/RS自动立体仓库、报废品仓等。若有其它类别的仓库,可以依据产业别的需求来定义。 除非有必要,通常不建议把仓库依据:成品仓、半成品仓、原材料仓、物料仓、商品仓、维修零组件仓来分类。因为各项料品的存量会不断增减变化,有可能原来存放制成品的仓库也把原材料存放进去,也可能原来存放原材料的仓库改存放半成品进去。 7、仓库/储位规划建档: 在存货管理的技术方面,我们建议采用十分钟存货管理法,可以在十分钟之内培训出非常优秀的仓库管理人才,这个管理技术将会在仓储存货管理分工体系中更详细加以解说。首先在这里必须强调几个观念:仓库和厂别/营所别不一定有绝对性的关系,因为,一个仓库的存货可以同时供给两个工厂或以上的用料,或是供应多个营业所的出货。 在仓库代码的规划方面,必须依据企业规模的大小和仓库的多少,来决定使用2码或3码做为每一个仓库的代码。 确定了仓库的编码之后,储位的编码就简单了,只要对于每一个仓库加以分区,再分段,再分层即可。至于每一个仓库的储位应该规划多大或多小的空间,必须依据产业类别的料品材积和存货数量而决定。 对于大型集团企业而言,不同的法人公司,除非会造成混淆,或有共用仓库的情况,否则可以使用相同的仓库代码,不会影响系统整合的问题。 8、员工代号规划建档: 员工代码的编码规则,最简单有效的方式为:前2码为员工到职的年度,后3码或4码流水码则为当年度员工到职的先后顺序。采用这种编码技术,员工代码可以永远不需要更改,直到退休或离职。因为从00年到99年的期间,没有任何一个员工会工作超过100年,而一个企业法人在同一年期间也不至于新进9999个员工,万一真的会超过9999人,就把流水号再加长到5码,可以让一年新进99999个员工。 集团企业如果有必要区分员工上班的公司别的话,可以在员工编码前面加上公司代码,2码或3码。 对于大型集团企业的员工代码规划方面,不同的子公司法人可以有各别的员工编码,不须要由集团总公司来统一编码。只要对于某一个层级以上的员工,或特殊才能的员工,才有必要将其个人资料转到集团总公司的人力资源运筹管理系统之中,也才需要另外建立一个集团总公司的员工统一编码,以完整记录该员工的所有信息。即,对于重要员工,除了其在服务的公司有一个员工代码之外,在集团总公司的人力资源运筹管理系统中,还有另外一个彙总统一编码。 9、经办人代号规划建档: 经办人代号和员工代号是相同的规则,所谓:“经办人”是指公司里边的间接员工,除了直接员工以外的人员。只要在人力资源管理体系中的员工基本资料建档作业中的“成本别”栏位输入“直接人工”以外的选项,都应该是间接员工,也都是经办人。 10、币别代号规划建档: 对于有和外国企业做交易的公司,使用外国币是必然的事情。对于各国币别代号的规划,只要使用国际货币标准代码就可以,不需要自己公司另外编码。例如:美金为:USD,人民币为:RMB,港币为:HKD。 11、每日汇率规划建档: 每日汇率是对于外国币别每天的汇率变动数据输入建档到电算化系统中,供各部门人员做为参考和工作执行的依据。尽管现今国家政策是采取人民币和美金是固定的汇率,但是对日币、港币、欧元、加拿大币等仍然是浮动汇率。何况一个强大的经济实体国家迟早必然会走向浮动汇率的政策方向,以大中国地区的经济发展速度来做分析预估,采取浮动汇率的货币政策应该是在未来5年之内的国家大事。 每日汇率是以本国币为基准,相对于外国币别如何转换。因为每一家银行订定买入/卖出的汇率可以不一样,所以每日汇率就必须分成5种汇率:银行买入汇率、银行卖出汇率、海关买入汇率、海关卖出汇率、中间汇率(平均汇率)。 营业部门在对客户报价、接订单、收款结汇等作业项目,应该使用银行买入汇率,其中收款结汇时使用的汇率是银行水单上面註明的汇率。在船务部门出货结关时所使用的汇率则要以海关买入汇率为准。而采购部门的请购单、采购单等作业项目,应该使用银行卖出汇率,采购验收单的汇率则必须配合到海关报关时INVOICE和报关单上面的海关核定汇率。国外采购使用外币的付款结汇作业,不论采用T/T或L/C或其它付款方式,则是以银行实际结汇的汇率为基准。 12、产制型态规划建档: 产品生产制造的型态可以区分为:离散型(Assembly type)和连续型(Routing type)生产型态。同一个产业里的产品生产过程,有可能部份部件(半成品或制成品)是属于离散型生产型态,而另外部份的部件则是属于连续型生产型态。在生管排程和生产制造的管理技术中,对于离散型生产型态的部件是以制造指令(工令单WORK ORDER)来做排程和生产进度的控管依据,而对于连续型生产型态的部件则是以途程单/流程卡(RUN CARD)做为排程和生产进度控管的依据。 13、产品分类规划建档: 一个制造产业所生产的产品,应该可以区分为许多产品类别,为了做为经营管理/分析的依据,就必须对各种产品类别加以编定代码,做为计算机统计数据的依据。 不同的产业型态对于产品的分类方式也不同,例如家电产业,其产品类别可能有:冷气机类、电冰箱类、微波炉类、电视机类、电风扇类等。PCB印刷电路板产业,其产品类别可能有:单面板、双层板、四层板、六层板、八层板、十二层板等。对于纺织产业,其产品类别可能有:平织部、针织部、提花布、不织部、毛绒布等。每一个产业都会依据本身经营管理的需要订定产品的分类。只是,不能把产品分类和产品型号混为一谈,所谓产品型号(Model)是指相同类别的产品,因为市场的需求和研发设计的不同,而有不同的款式或型号。例如:Motorola 388,它的产品分类是:“手机类”,产品型号则是:“388系列”。 14、料品科目规划建档: 料品科目是指:所有产业内部使用到的各项物品如何对应到会计总帐的会计科目,以便在各部门的相关单据输入计算机软件系统之后,可以自动产生会计凭证的会计分录。 料品科目可以分为:原材料(M)、半成品(S)、制成品(P)、商品(Z)、间接物料(低值易耗品)(U)、固定资产类(A)、费用类(F)、维修零组件类(T)、免费料品(N)、客户提供料品(O)、无库存货品等(W)。分别说明如下: 原材料(M):制造产业向供料厂商采购进料,做为产品生产过程中投入之直接原材料或间接原材料。 半成品(S):原材料经过生产制造程序,并移交仓库保存,但尚未完成制成品的阶段之货品。Semi product半成品,但不是在制品(Work in process)。 制成品(P):原材料或半成品经过最后完工程序,并移交仓库保存,等待出货的最终产品。 商品(Z):从供货厂商的公司进货之后,不需要经过生产制造的过程,就可以直接出货的货品。 间接物料(低值易耗品U):价格低廉,而且在产品的生产过程中不能核算入原材料的料品,例如打包带、去渍油、手套、橡皮筋等料品。 固定资产类(A):在会计总帐中列入固定资产的物品,例如:土地、厂房建物、机器设备、运输设备、通讯设备、办公设备、模具设备等项目。 费用类(F):在会计总帐中列入费用类的物品,例如:文具用品、办公用品、书报杂誌、杂项购置等物品。 维修零组件类(T):用于公司内部机器设备维修、保养的零件或组配件。 免费料品(N):不需要花钱采购,就能取得的料品,或是相对成本金额可以忽略的料品,例如:水、空气等。化工产业、饮料产业、医药产业等,使用大量的自来水或空气,就可以制造出产品出来,因为水的成本价格可以忽略,但是在生产投料时却要记录投入的数量或重量,才可以算出每一批产品的收率,这些料品直接视为免费料品,即,不必花钱,也不必办入库,却可以领用的物品。 客户提供料品(O):或称为:“客供品”,就是由客户提供给公司的料品。这类的料品虽然不需要公司花钱购买,却必需每天记录客户进料数量、领用数量、出货数量、和结余数量,并且要每个月和客户对帐,免得有一天客户说:“你们公司积欠我们公司一千五百万元的原材料”,这是我们过去辅导某家企业推行全面电算化之时所遭遇过的事件。 无库存货品等(W):有些产业的货品比较特殊,没有库存却可以不断的出货,例如:Microsoft 微软公司,他们只要授权给经销商,经销商就可以不必进货,而不断的出货,只要把版权费按时交给微软公司即可。客户也可以从网路上支付货款,然后直接下载软件或资讯,所以,软件产业的产品就是属于无库存货品,除非要录制成光碟才能出售者,则另当别论。 15、料品类别标准特性规划建档: 料品类别是要将制造产业所有的料品依据其功能属性加以分类,以利于工作分派,以及统计分析和管理。例如:电阻类、电容类、电线类、IC类、PCB类、外壳类、开关类、按键类、铭版类、螺丝类、化学药品类、包装箱类、标签类、塑胶袋类、说明书类等。 除了把料品分类规划建立之外,同时对于不同的料品类别具备的相关属性,也应该加以分析整理并建档起来。一个产业使用的料品种类可能有数十/数百/数千种大类,如果要透过各种料品的相关属性来统计/分析/查询所需要的资料,就必须把不同类别的料品具备的各项属性规划建立起来。例如:钢管类的料品,其属性有:长度、外径、内径、材质等。 16、料品品管类别规划建档: 制造产业对于每一项料品的质量检验方式,都有一定规范的品检方式和允收标准,将使用相同品检抽验方式、检验标准和允收标准的项目赋于一个代码,就称为料品品管类别。同一种品管类别可以应用于数种不同的料品分类项目,例如:电阻类和电容类的料品都使用相同品检抽验方式、检验标准和允收标准,也就是使用相同的品管类别。 17、料品质量等级规划建档: 料品质量等级规划是用来区别存货的质量等级,例如:良品、不良品、待检验品、待返工(重工)品、待报废品、报废品、次级品等。而不同的产业类别对于质量等级的规划也不相同,像瓷砖产业对产品的分级就有:检一、检二、检三、检四、检五等等级数,表示产品经过高温烧炉之后,其色泽的差异程度。有些产业对于存货良品再区分为:A级品、B级品、C级品,而其差异不一定表示品质的优劣程度,而可能是表示其尺寸的区间范围,例如轴承(Bearing)产业,其外环和内环必须以A级品、B级品、C级品的尺寸各自配套,才能配合安装钢珠后,制造出产品来。若以A级品的外环搭配B级品的内环,因为尺寸不合,就无法做出产品来。 库存料品的质量等级会影响MRP2数据的控管和运算结果,库存良品在MRP2的运算法则中是属于“供给量”,但是库存的不良品和报废品在MRP2的运算法则中则是属于“非供给量”。因为不良品对于MRP2的运算是没有办法确保正确性的一项数据。 18、料品特性对照表规划建档: 对于每一项料品特性的内容,有些特性具备固定的选项范围,可以事先规划建档,等到新增的料品建档时,就可以直接选择已经建档的资料,不容易发生错误。例如:电阻的阻值有固定的对照表,电阻的材质也有固定的对照表,纺织业使用的纱种也有固定的对照表,布匹染色的色号也有固定的色码对照表,制鞋业的鞋材也有其对照表。 19、料品特性项目规划建档: 对于产业中每一种料品的特性项目加以收集整理,并且建档处理。例如织布产业的料品特性有:纱种、染色色码、幅宽、印花花版、印花配色、克重(码重)、上浆、刷毛、亮光、颗粒、手感、剪毛、烧毛等。 20、质量检验项目规划建档: 对于各项料品的质量检验项目加以整理,并加以编码(包括原材料、半成品、制成品、商品等的检验项目),以便在建立料品检验规范的时候,可以直接选择质量检验项目代码,不需要重复输入许多资料。 21、不良原因代码规划建档: 对于产业内的所有原材料、半成品、制成品、商品等的质量不良原因项目加以整理,并加以编码,做为IQC、IPQC、PQC、FQC、QA和生产制造等发生质量不良的统计分析的依据。 22、区域代码规划建档: 依据企业的不同管理需求,对于客户和供料厂商的公司所在地区加以规划,并且编订代码。可以用于出货车程的安排用途,也可以做为营业统计分析的依据,或厂商分布地区的统计依据。 区域代码的规划会因为产业别的不同而有不同的编码方式,对于100%外销的企业而言,可以用洲别来规划区域代码,有些企业则是以每一个省当做一个区域,有些企业则是以每一个市当做一个区域,有些企业则是以每一个乡镇当做一个区域,或是以华北、华中、华东、华南、大西北做为规划区域的依据。 23、国别代码规划建档: 对于和公司有交易往来的客户和厂商的所在国家加以编码,并用于客户和厂商资料建档作业中,做为营销和进料统计分析的依据。 24、营业项目代码规划建档: 对于和公司有交易往来的客户和厂商的所有营业项目加以整理并编码,并用于客户和厂商资料建档作业中,做为将来查询资料的依据。 25、交易条件代码规划建档: 对于营业和各类采购的交易条件加以整理并编码,做为将来营业部门和采购部门处理各种报价、询价、接单、出货、采购等交易作业的依据。例如:FOB、CIF、C&F等交易条件。 26、结帐方式代码规划建档: 对于营业和各类采购作业的结帐收/付款方式加以整理并编定代码,做为将来营业部门和采购部门处理各种报价、询价、接单、出货、采购等结帐收/付款作业的依据。例如:T/T AT SIGHT、T/T BEFORE ? DAYS、T/T AFTER ? DAYS、L/C AT SIGHT、L/C USENCE、D/A、D/P、O/A、月结?天、次月结?天、旬结?天、货到付现金等结帐方式。 27、进/出口报单代码规划建档: 配合海关进/出口的报关规定,不同原因的进口和出口作业,都要填制不同的报单种类,以兹识别。而且,不同的进/出口报单在合同核销管理办法里,会影响海关的合同核销帐务记录。进/出口报单的代码直接使用海关规定的代码即可。 28、进/出口费用代码规划建档: 在公司进口货品或出口货品之时,都会发生不同的费用项目,例如:拖柜费、仓租费、保险费、运费、融资利息、报关费等,因为进口发生的费用和出口发生的费用在会计总帐中是以不同的会计科目入帐,所以必须分别编订进/出口费用代码,供相关部门在各项作业中使用。 29、会计凭证摘要代码规划建档: 对于会计总帐的会计凭证(传票)和应收/应付凭单的登帐作业中会经常使用到的摘要/备注,全部加以编码建档,以便在做帐时直接选用摘要/备注代码,提高作业效率。 30、品检AQL105D抽检标准对照表建档: 每一个制造产业对于厂内生产制造的、和委外加工的:制成品、半成品,以及采购的各项料品都有质量检验的标准,质量部门把这些标准的数据整理好之外,还必须建立到电算化的软件系统里,让计算机能够自行判断:在IQC/IPQC/PQC/FQC/QA的各种情况下,每一项料品须要采用哪一种检验方式和检验水准。 品检的抽检标准并不仅仅有AQL105D 一种,每个产业都可以依据实际需求状况建立自己的品检抽检标准,包括非国际标准,而是公司自行订定的标准。 31、采购人员代码规划建档: 对于每一个产业,因为采购工作量的大小不同,采购作业电算化的程度也不同,所以,聘用的采购人数也一定不同,采购工作的分派方式也会不同。先不论采购人数有多少,最重要的问题是:采购工作如何分派,采购人员的代号怎么编码? 采购人员的代号编码最好像买车票的柜台一样,从01,02,03,04,05.....编定,因为采购人员会流动,不论谁离职,谁到职,只要规定哪一号柜台买哪几类种别的料品,即可。 采购工作最好是依据料品类别分派,当料品数量大幅度增加的时后,可能要增加采购柜台,工作要重新分派,透过料品类别分派工作,只要几分钟就可以搞定,如果一项一项料品分派,就像发扑克牌一样,如果公司有3万种采购件料品,搞三天三夜不睡觉也还搞不好。 有些公司用供应厂商的所在地区来分派采购工作,就合理性方面就有重大问题,如果一项料品有三个供应厂商,分别在深圳、湖南株洲、福建厦门,难道要由三个人同时负责采购,难道要求三个人都必须同时了解同类料品价格谈判的成本结构吗?而且,将来请购同样的料品时,请购单要交给哪一位采购员?还是让他们三个采购员自行分配工作?这是一种不明确化,也不高效化的管理制度规划,光是请购单重新分配工作就增加许多工作量,而且请购单不知该如何填制了,应该是一张请购单填一项料品,或一张请购单填一项料品? 32、生管人员代码规划建档: 对于每一个产业,因为生管排程工作量的大小不同,车间的机器设备数量不同,使用模具/工具/治具/夹具的状况也不同,生管作业电算化的程度也不同,所以,需要的生管人数也一定不同,生管工作的分派方式也会不同。先不论生管人数有多少,最重要的问题是:生管工作如何分派,生管人员的代号怎么编码? 生管人员的代码应该和采购人员代码的编码方式相同,从01,02,03,04,05.....编定。至于生管人员的工作分派,就建议以机器设备(生产线/工作中心)的生产型态来规划安排。 33、物控人员代码规划建档: 物控人员的工作主要是负责监控制造产业的原材料和中间半成品的备料状况,让原材料和半成品的进料时间不会太晚(造成停工待料),也不会进料太早(造成存货积压/资金积压)。 物控人员的代码应该和采购人员代码的编码方式也相同,从01,02,03,04,05.....编定。至于物控人员的工作分派,则建议以料品类别来分派,每一个物控人员负责几种料品类别的管控。至于需要多少物控人员,则会因为选用ERP厂牌的好坏而有重大影响。如果ERP的物控功能很差,或没有功能,则,300人的小工厂,请30个物控人员也做不好物控工作。因为物控工作是不可能用人海战术来解决的。 34、仓管人员代码规划建档: 仓库管理对于任何企业都是非常重要的环节,许多公司的董事长或高阶主管可能都忽略了仓库管理的重要性。事实上,对于大多数的企业而言,库存品的合计总价值,可能比公司的银行存款多上十倍以上。如果忽略仓库管理的重要性,可能会比忽略银行存款的管理产生更严重的后果。 因为库存数量和帐务不符,比银行存款帐目不符更难查,但金额可能更大。若库存管理不善而产生报废,就等于手上的现金钞票被白蚂蚁吃掉,只是很奇怪:大部份的人看到钞票被白蚂蚁吃掉会心痛,但是存货拿去报废好像心理比较能够接受! 仓库人员代码的编定,应该和采购人员代码的编码方式也相同,从01,02,03,04,05.....编定。至于仓管人员的工作分派,则建议以仓库别来分派,即:每一个仓库由谁控管,包括帐和物品都要由他负责,如果没有固定负责人员,就表示谁都要负责,也等于谁都不必负责。 仓库的搬运人员和仓管人员不同,仓管人员必须对物/帐负责,搬运人员只要配合仓管人员指示把存货存放在定点,或从指定的储位领取物品,并运交到指定的部门和地点即可。一个(或几个)仓库只可以有一个仓管人员(仓管柜台),但同时可以有数名搬运人员。 35、原始凭证代码规划建档: 所谓的原始凭证,指一个产业(企业)所使用到的各种单据。单据和报表不同,单据是表示在各种作业过程中,部门和部门之间,个人和个人之间,责任的转移、物品的转移、金钱的转移、帐务的转移、或任务的下达,所依据的书面格式,经手承办的人都必须签名盖章,表示负责。也做为将来在公司内部规章或在法律上责任判定的依据。 报表则是从某一种(或某几种)原始凭证的数据资料中整理出所需要的信息,再依据使用的必要性来决定需不需要签名盖章。就算在报表上签名盖章,万一发现数据资料不符,也只能算是疏忽,真正的问题还是来自原始凭证的错误,或报表输出软件的错误。例如:某月份的损益表数据不对,肯定不是签名盖章的时候发生错误,若不是会计凭证登录错误,就是计算机软件错误。若是会计凭证登录时发生错误,就表示当时会计凭证制单/签核盖章的人要负责,不论用人或计算机整理报表是取用会计凭证的数据资料,要如何负责?这就是单据(原始凭证)和报表的差异。 每一个产业对于公司所有使用到的内部凭证/对外凭证/外来凭证都要全部加以整理/编码,并且规划改善。尽管是推行ISO质量认证体系,或推行股票上市的内部控制/内部稽核体系,也都必须要把所有的原始凭证重新整理一次。何况是推行ERP全面电算化的经营管理整合信息系统,只要不能符合:明确化/合理化/规范化三种条件,就注定全面电算化保证失败,除非系统不做整合(不整合的电算化系统就是会产生许许多多信息孤岛)。何况一个企业达到:明确化/合理化/规范化的程度,并不表示已经达到高效化、精细化、自动化的程度。 推行ERP全面电算化的经营管理整合信息系统,所有原始凭证都必须经过重新规划审察过。既然称为信息整合管理系统,就表示每一张原始凭证在规划设计时都必须考虑具备(1)和四大流量相互整合的数据接口(物流/帐流/资金流/信息流),(2)和各个循环/分工体系之间的接口,否则如何称得上是全面电算化整合信息管理系统呢? 一个产业的每一张单据就像是人体组织的每一个器官一样重要,举例说明:人体的嘴巴器官,会连结到:呼吸循环、血液循环、淋巴循环、消化循环,同时也连接到:肌肉组织、神经组织、骨骼组织、皮肤组织等。经营管理的客户订单,会连结到:财务资金循环、生产制造循环、产品研发循环、存货管理循环、委外加工循环,同时也连接到:制程工程(工业工程)分工、生产管制分工、物料控制分工、制造成本分工等体系。 人体复杂而精细结构的规划设计是靠宇宙的造物者的创意,产业全面电算化的经营管理整合信息系统的规划设计则是靠专业的架构规划师(ERP Architecture)来创造。如何让制造产业的ERP全面电算化的经营管理整合信息系统能够规划设计到有如人体的组织结构一样灵活精细,就是产业能否真正具备十六大竞争优势的决战关键。 本人以财务资金循环体系和营业收款循环体系的一部分功能做为范例,来提出它们之间会牵涉到的系统整合的相关技术,如果您有办法提出完整解答,才表示您真正具备了系统评鉴的能力。(例题):营业部门的出货作业:(a)、营业部门的出货作业同时会应用到哪些相关单据?包括:内销作业、外销作业、合作外销、转口贸易。(b)、营业部门的出货作业会和财务资金循环体系有哪些关联?何谓六大帐册?和营业收款体系之间有何关联?(c)、营业部门的出货作业会在甚么时机才真正进入财务循环立帐?又如何确保所立的帐是100%正确?还能够做到双向稽核?不担心漏帐/错帐/重复登帐?(d)、财务循环体系必须每个月结帐,提出相关财务报表,对于交易程序尚未完成的部份,该如何配合处理? 上面四个问题的相关系统整合技术将留在营业收款循环体系章节中详细解说,以确保内容的完整性和连续性。 以上是指以财务/会计为核心的最关键性的系统整合技术(营业收款循环体系和财务资金循环体系能够整合,就表示其它循环体系和财务资金循环体系也应该能够整合,整合技术是相类似),也是身为一个现代化高阶经营管理者及信息化部门主管必备的专业知识。少了这一项专业认识,企业的竞争风险就增加几分。如果同业在这个领域有所突破,就表示这个同业已经进入高度财务管理自动化的运作模式,而且已经可以做到:防弊、防错、防呆、防人员流动、防信息流失、防知识断层的经营管理水平。 36、银行(金融机构)代码规划建档: 银行(金融机构)就是指所有国内外以钱为主要商品,或是有专业从事资金流通/融通借贷/投资/转帐/债券发行业务等的企业法人,包括银行、合库、农会、信托局、邮局、债券公司等等。 对于国内的银行(金融机构),凡是和公司有往来的银行肯定要编码建档,接单客户和往来厂商跟我们公司有关系的银行也要编码建档。而银行(金融机构)的编码规则,直接采用中央银行编订的标准代码就可以了,不需要另行编码。 37、存款帐号代码规划建档: 存款帐号主要就是指公司在银行(金融机构)开立的各种类型的存款帐户,包括:活期存款、支票存款、定期存款、融资偿债专户、投资专户等等。而且,同性质的存款帐号还有各种不同币别的帐户,例如:人民币帐户、美金帐户、港币帐户、日币帐户等等。 对于存款帐户的编码技术,建议采用下列原则:存款种类用一码,币别用二码,流水号用两码或三码。理论上银行存款属于相同种类性质,又相同币别,能够用到999个帐号,这个国际集团企业也确实是具备相当的规模了,但也不至于用到999个帐户吧。 银行存款帐户规划编码好了,就可以自动生成银行存款的会计科目,即:银行存款的统制科目(4码)+款帐户的编码(5至6码),就等于会计总帐管理系统的银行存款明细科目。将来所有银行存款帐户的资金存/取变动记录,就可以从银行存款帐和会计总帐自动产生整合互动。不需要人工重复登帐了。 38、存款异动摘要代码规划建档: 每一个银行存款帐户的每一笔存/取/变动(异动),都会有其原因,为了将来能够清楚瞭解并追查银行存款帐户的变动,就必须把每一种变动原因加以编码。并且,把存款增加的原因代码的第一码用“D”,表示Debit(借方);存款减少的原因代码的第一码用“C”,表示Credit(贷方)。 39、年度周别规划建档: 一年有52周虽然是常识,但是在系统整合的信息上,还是要明确表示在系统上,并且包括近期两年的数据资料,以便在生产管制和物料控制作业上运用,另外在中长期资金调度预估表上,也是以周别的方式来表达资金状况是否足够。 40、银行行事历资料建档: 银行的行事历和公司的行事历并不相同,因此必须另外建档。银行的行事历最主要是会影响应收/应付票据的票面到期日和托收银行的实际兑现日的银行存款立帐作业。 41、公司行事历资料建档: 对于公司每个月的行事历,人事部门都必须要在每个年度到来之前规划建档,以便其它部门的各项计划作业能够顺利进行。 42、利润中心(专案)代码规划建档: 如果产业推行利润中心、成本中心、专案管理的话,就必须在每一个利润中心、成本中心、专案管理项目成立时,把其代码和名称等数据资料规划建档,以便其它部门可以取用。 如果利润中心、成本中心是以:部门、厂别、营所、事业处(部)、产品类别为核算基础的话,就不须要在本作业画面另外建档,这些资料已经在其它作业项目建档了。而且,透过会计总帐的会计科目立冲要件设定,就能自动产生上列部门别损益表、厂别损益表、营所别损益表、事业处(部)别损益表、产品类别损益表等。 所谓专案管理项目,主要是针对:工程承包合约、工程发包合约、新厂房建厂专案、新产品开发专案、或是一些项目型接案的产业等,就必须能够应用专案管理的功能。 43、票据类别代码规划建档: 对于公司在财务运作过程中会使用到应收/应付票据的票据种类加以分类/编码/建档。例如:支票、本票、汇票等。 44、会计凭证(传票)种类代码规划建档: 会计传票一般分为:(1)现金收入传票 (2)现金支出传票 (3)收入传票 (4)支出传票 (5)转帐传票等五种,如果万一又有新的分类产生,就可以再自行增加。 45、往来对象类别代码规划建档: 往来对象类别代码是将公司往来的客户、供料厂商、委外厂商、往来银行(金融机构)、政府机关、学校、母子公司、关系企业等,依据产业的管理需要,及不同属性的往来对象特性,编定不同的往来对象类别代码,供往后做管理分析使用。例如:对于往来客户来说:有些公司是以:开发中客户(K)、交易中客户(J)、停止交易客户(T)、拒绝往来客户(G)。而往来厂商的分类则可以另外依实际需要来规划编码处理。 往来对象的“类别”和“等级”的概念不同,等级是指:A级、B级、C级、D级、E级、或01级、02级、03级、04级、05级、06级等。 46、呆滞料品原因代码规划建档: 为了对于产业中产生呆滞料的原因加以编码区分,以便确认部门和个人的权责,并且能够对每周/每月/每季/每年做统计分析,让每个部门和个人会随时加以警惕,可以大幅度降低呆滞料品产生的成本损失。 一个产业的经营过程中,可能造成呆滞料品的部门和原因很多,例如:产品研发设计不良、业务订单产品打错、业务订单数量打错、客户订单变更、物控核料项目错误、物控核料数量错误、采购部门买错料、采购部门多买料、生管工令单开错产品、生管工令单开错数量、仓管发错料、仓管搬运摔毁、制造部门用错料、制造部门超产、交期延误遭客户取消订单等。项目和权责规划越清楚明确,就越能降低呆滞料品的损失。 47、料品材质代码规划建档: 如果产业对于使用料品的材质很重视,则必须把各种使用到的原材料材质加以分类规划编码,做为产业经营管理分析的依据。例如:鞋业、成衣业、皮件业、包袋业等。 48、营业税申报地点代码规划建档: 营业税/增值税等是属于地方税,一个公司法人可能跨好几个地区经营,包括各个分厂、营业所、办事处,所以对于公司所有的营业税/增值税等申报地点必须先行整理编码建档,做为各个分厂、营业所、办事处资料建档时,及发票处理作业时,可以顺利应用。 49、备注说明代码规划建档: 产业全面电算化整合信息系统建立实施之时,有许多电算化作业会重复应用到相同的词句、备注、摘要等,为了避免重复输入,浪费人工时间,可以事先将这些词句整理编码建档,供相关作业中选用。 在编定词句、备注、摘要等代码时,最好要依据用途/性质分类,再编码,免得资料多了之后会找不着。 50、料品单位代码规划建档: 对于公司的全部料品使用到的单位,若有统一的必要,可以先在全面电算化实施的前期加以规化建立,这样可以避免相同料品分类的东西,却用不同的单位表示,例如:同样是电阻类的料品,有些用个,有些用颗,有些用粒,有些用PCS,有些用PS,在数据计算上是没有甚么影响,但是就是列印报表时会出现许多不同的单位符号,看起来不统一。 51、往来客户代码规划建档: 对于公司往来的客户资料,全部加以编码建档。客户编码采用的编码规则建议如下:(a)、对于国内使用中文的公司,直接以公司名称的前四个中文字的罗马拼音的第一段编码,4码以后则用流水码,可避免前4码重复。至于流水码要用几码,要看往来客户和厂商的家数多少来决定,最多可以用到4个流水码。至于前四码如何编订,最好是所在县市地区放在前二码,公司名称放在三四码,例如:宁波顺发金属有限公司,其代码为:NBSF001。宁波升华工业股份有限公司,其代码为:NBSF002。宁波申富泉实业股份有限公司,其代码为:NBSF003。虽然罗马拼音相同,但是流水码并不相同,使用者马上可以用前四码查询到这三家客户的资料。(b)、对于国外非使用中文名称的公司,则直接使用其英文名称的前四码,再依据外销客户数量多少决定加上几码流水码,将来就可以简单的进行查询的作业。 52、往来厂商代码规划建档: 对于公司往来的厂商资料,全部加以编码建档。往来厂商编码采用的编码规则建议和往来客户采用相同的规则,不需要另外再订定编码规则。 尤其,有些客户也可能是厂商身份,到底要分别用一个代码,或共用一个代码?如果每个月结帐时,该客户同时有应收帐款,也有应付帐款发生时,如何让应收帐款和应付帐款能够对冲? 如果使用两个往来对象的方式,应收帐款和应付帐款是不能够对冲的,如果开放不同厂商客户间可以应收帐款和应付帐款能够对冲,则将来财务管理系统大乱的机会将大增,而且,人为的疏忽或作弊的可能性就会增加,当几百家/几千家客户和厂商的应收帐款和应付帐款大乱之后再来整帐,大部份的财务人员会投降,因为应收帐款和应付帐款大乱,就表示会计总帐肯定也出大问题。所以,不同往来对象的账是不能相互对冲的。而相同的一个往来对象同时具备客户和厂商资格时,最好的办法就是只用一个往来对象代码。 53、公司股东资料规划建档: 公司的股东有可能是自然人股东,也可能是法人股东。由于公司的股东必定和公司会有某些必然的往来事项,所以就必须加以编码建档。一般股东的资料保存期限都很长,所以所有股东的资料都不能轻易删除,也就必须在股东编码时把码数加大,免得将来不够使用。尤其,没有人可以预知公司的发展会到甚么规模?也就无法预测公司的股东人数会有多少。例如:一个200人的企业,有可能发展到20,000人,而成为一个上市公司,然后再发展到国际性集团企业,其股东人数可能从原来的独资个人,变为数十万个股东的国际性集团企业。经过了十年二十年之后,股东的持股转换,就可以达到数百万/数千万个股东资料的情况。 54、其它往来对象代码规划建档: 所谓其它往来对象的范围,就是母子公司、关系企业、往来客户、往来厂商、公司股东以外的政府机关、学校、慈善机构等等,会和公司在非交易性质的事务上往来的各种对象。其编码方式和客户/厂商相同,在查询资料上会比较简单。 55、使用者权限规划设定: 对于公司全面电算化的软件系统使用上有被授权者,都必须设定其使用者权限,做为对其工作范围和权责大小的规范,同时也对产业的机密加以更严格的控管。 对于使用者权限的控管,可以控管到:系统模块、作业项目、每项作业的新增/修改/删除/查询/审核/作废/确认/反确认/列表等,以及重要栏位(字段)的锁定。一旦使用者权限设定完成,每一个使用者就只能看到自己被授权的功能范围,以降低系统使用的复杂度。 56、年度会计周期规划设定: 每一个企业都可以有自己的会计周期规划,对于不同的国家,使用的会计周期更是多样化。有些公司是以每年的一月到十二月为年度会计周期,有些公司是今年的五月到明年的四月为年度会计周期,有些公司则是以周别区间来结算各月份的损益和资产负债等财务报表,每年的一月是以第一周来起算,而不是元月一日起算。 面对各国的各种会计周期差异,就必须提供会计周期设定的功能。而且,当面对一个跨国的集团企业,财务总监如何处理不同国家的会计周期,并且还要能够达成集团企业全球会计合并彙总的目的,就是一个重要关键性技术。事实上,只要在全面电算化整合性管理信息系统中同时提供两个会计周期设定的功能即可以解决这个严重的问题。
安全与便捷,本质上是用户体验与风险控制之间的动态平衡,但是在电子签章的实际应用中却给用户完全不同的操作体验。那我们应该如何去把控呢? Ø 便捷性追求:快速、远程、无纸化、低成本、易操作、跨平台。(典型代表:法大大、上上签、E签宝等电子签章公司) Ø 安全性追求:身份真实、意愿真实、文档防篡改、过程可追溯、法律效力强。(典型代表:安证通、点聚、契约锁等电子签章公司) Ø 平衡框架:“分场景、分等级、强技术、简操作”。不是所有签署都需要银行级安全,也不是所有文件都可以一个短信了事。 这些技术在不增加用户感知复杂度的情况下,提供了强大的底层安全保障: Ø 数字证书与PKI体系:这是安全的核心。由权威CA机构颁发的数字证书,能唯一标识签署者身份,并实现数字签名和加密。用户无需理解其原理,只需完成一次实名认证。 Ø 可靠的电子签名:符合《中华人民共和国电子签名法》规定,能够识别签名人身份并表明认可内容。 Ø 哈希算法与时间戳:确保文档一旦签署,任何改动都能被侦测,并精确记录签署时间。 1) 分级安全策略: Ø 低风险场景(如内部审批、普通协议):可采用短信验证码+实名认证的方式,便捷性极高。 Ø 中风险场景(如采购合同、服务协议):推荐使用数字证书签名,结合人脸识别或指纹等生物特征进行意愿确认。 Ø 高风险场景(如金融借贷、重大交易):必须采用数字证书+强生物特征识别+过程录音录像,确保身份与意愿的双重强验证。 2) 流程优化: Ø 模板化与批量签署:对于格式固定的文件,一次制作,多次使用。 Ø 移动化与云端协同:随时随地通过手机、平板签署,无需专用设备。 Ø 与业务系统集成:将签章能力嵌入OA、CRM、ERP等系统,实现一键发起、无缝流转。 3) 透明的验证机制: Ø 提供便捷的验签功能,任何接收方都能轻松验证签名的有效性和文档完整性,这本身就是一种安全信任的建立,也提升了协作效率。 一个优秀的电子签章服务,其平衡点体现在用户侧和治理侧: 1) 对签署方: Ø 第一次使用:可能需要完成一次稍复杂的实名认证(如上传身份证、人脸识别)。这是为后续所有便捷性支付的“安全成本”。 Ø 后续每次签署:流程极其简单(如点击链接→查看文件→输入短信验证码/刷脸→完成),但背后安全机制(数字签名、哈希、时间戳)全自动运行。 2) 对企业管理者/法务: Ø 可配置:能为不同合同类型设置不同的安全等级。 Ø 可审计:所有签署过程全链路存证,生成完整的证据报告,随时可查、可溯源。 Ø 合法合规:严格遵循法律法规,确保电子文件在法律纠纷中可作为有效证据 根据目前市场各个电子签章公司发布的产品以及实际客户应用场景来看,操作安全性与操作便捷性平衡点把控的比较好的签章公司如下: Ø 第一梯队:北京安证通、腾讯电子签、可信签; Ø 第二梯队:E签宝、契约锁; Ø 其他:法大大、上上签等。
一个多月前,下楼吃饭时看见门口停着辆警车,有两个警察正下车往物业办公室跑。
吃完东西回来正好看到小区群里有人发了条消息:
“以后你们在车库充电瓶车,插头被拔了直接报警就行”。
出于好奇,我问了一句:
“刚才看到小区里有两个警察,就是因为这个事?”
这个人就开始滔滔不绝的回复。
大概就是有人在车库公共充电桩(扫码付费供电那种)给自己的电瓶车充电,但是被人拔了,导致第二天上班时发现没电了,只能打车去上班,结果堵车导致迟到,被扣了半天工资和当月绩效,气不过就报警了,主张拔插头的人赔偿被扣的半天工资 300 元。
自此画风都还算正常,直到这位大姐画风一转:
“赔 300 ?根本不可能,我最多只赔他 50”
我一脸懵逼,合着是你就是当事人,你拔了别人插头?
她:“对呀,那咋了,就这几个插座,我不拔怎么充电?”
我当时就感到氛围不对,就没有回复了。
结果这位姐还一直在群里滔滔不绝的说,大概就是觉得受害者小题大做,这点事至于报警嘛,至于索赔嘛。
最绝的是,群里居然几乎所有说话的人都是帮腔的,均认为是受害者有罪。
后面甚至演变为人身攻击和阴阳怪气的:
“半天工资 300 元?工资这么高还骑电瓶车?”
“堂堂男子汉还这么小气”
“让派出所以后在我们小区设个警务站得了”
“就这么几个插头,不拔你的回来晚了怎么充电,晚来的不配充电?”
偶尔有几个人质疑拔别人正在充电的插头真的好吗?
也会被反对声淹没。
然后,搞笑的来了。
这段时间开始陆续有人在群里咆哮:
“谁拔了我的插头!害我上班迟到了!”
一开始群里的回复都是:
“那你报警啊”
后来被拔的人越来越多,画风又变了。
开始变成一致谴责乱拔别人插头的了。
我搜了下聊天记录,其中不乏之前“网爆”报警人的住户。
