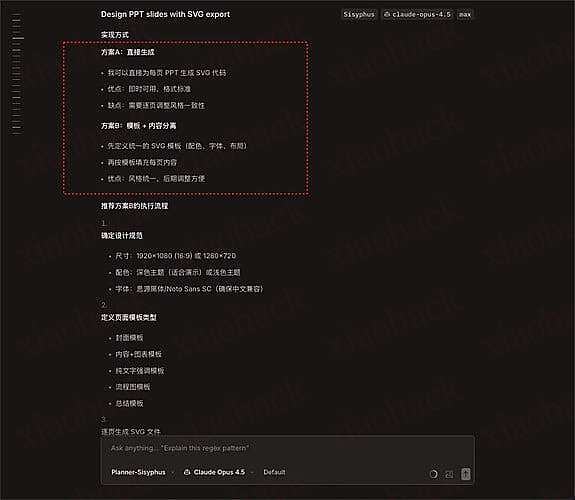
普通人该如何学习智能体
本文为普通人设计了从认知到应用、无代码到有代码、单一到复杂的智能体渐进式学习路径,分 8 个核心板块明确各阶段学习目标、实操方法、工具资源与避坑要点,同时通过高频 QA 解答零基础适配、学习时间投入、场景化学习重点等关键疑问,搭配可直接落地的 12 周学习计划,让不同基础、不同学习场景的学习者都能以 “先实践后理论” 为核心,从搭建简单智能体逐步进阶到开发落地化、甚至商业化的智能体系统,核心学习逻辑为以真实问题驱动实践,按需补充理论知识,快速积累可落地的智能体开发能力。 普通人学习智能体,应遵循 “从认知到应用、从无代码到有代码、从单一到复杂” 的渐进路径,先明确概念与应用场景,再通过零代码平台快速上手,逐步掌握核心技术并进阶实战,最终形成可落地的能力与作品。以下是分阶段的详细指南: 误区:一上来就啃底层算法(如深度学习、强化学习数学推导)。 误区:忽视提示词工程,过度依赖模型能力。 建议:提示词是智能体的 “灵魂”,花时间优化指令,比盲目换模型更有效。 误区:追求 “大而全”,忽略落地场景。 建议:从解决小问题(如 “每日邮件总结”)入手,逐步扩展功能,避免半途而废。 A:完全可以。目前主流的零代码平台(如扣子、CrewAI)已实现可视化拖拽操作,无需编写代码就能搭建简单智能体。建议先从这类平台入手,完成 “个人助理”“知识库问答” 等基础项目,积累实战经验后,再根据需求决定是否学习编程进阶。学习的核心是 “解决问题”,而非必须掌握编程技能。 A:无需一开始就深入学习复杂数学和深度学习。入门阶段(零代码 + 基础 API 调用)几乎不需要数学知识;代码进阶阶段,掌握基础的线性代数、概率论即可理解核心逻辑;只有向 “算法优化”“模型微调” 方向进阶时,才需要深入学习深度学习、强化学习的数学推导。普通人优先聚焦 “应用落地”,数学知识按需补充即可。 A:需结合场景精准定位:① 办公场景:重点学零代码平台、提示词工程、办公软件插件集成,目标是实现日程管理、文档总结等自动化需求;② 科研场景:侧重文献检索、数据处理、多智能体协作工具(如 AutoGen),提升科研效率;③ 创业 / 商业化场景:除技术能力外,需额外关注垂直领域需求调研、数据安全合规、产品部署与迭代,优先开发能解决行业痛点的落地产品。 A:按文中渐进路径,每周投入 5-8 小时,2-4 周就能做出第一个零代码智能体(如个人日程助手);4-8 周可完成基础代码开发,做出 API 调用型工具;12 周左右能开发复杂多智能体系统。关键是 “持续实战”,避免只学理论不落地,哪怕每周只完成一个小功能,也能逐步积累成果。 A:免费资源完全能满足入门到进阶需求。免费资源包括:零代码平台的官方文档(扣子、CrewAI 文档)、GitHub 开源项目(LangChain、AutoGen)、吴恩达等学者的免费课程、知乎 / B 站的入门教程。仅当需要 “系统化课程指导”“专属答疑服务” 或 “企业级工具部署” 时,才考虑付费,新手不建议盲目购买高价课程。 A:核心原则是贴合自身需求与现有资源。如果是职场人,优先从办公自动化切入,解决自己的日常工作痛点(如报表制作、信息汇总);如果是学生 / 科研人员,从文献分析、论文写作等科研辅助方向入手;如果想往开发方向发展,从 Python+LangChain 基础 API 调用开始;如果只是兴趣尝试,直接用零代码平台搭建趣味小工具(如智能问答、任务提醒)即可,切入点越贴近自身生活,越容易坚持并获得成就感。 A:多智能体协作并非入门必学,单智能体的应用场景依然非常广泛。单智能体能很好地解决单一、标准化的自动化需求,比如个人日程管理、单文档问答、简单数据处理等,这类需求在日常办公、个人使用中占比极高,掌握单智能体开发已能满足大部分普通人的需求。多智能体协作主要用于解决复杂、多步骤、跨领域的任务(如项目管理、行业报告撰写),适合有进阶开发需求或特定场景(如科研、企业级应用)的学习者,可在单智能体掌握扎实后再学习。 普通人学习智能体的关键在于先实践后理论,通过解决真实问题驱动学习,逐步建立技术栈与作品集。建议从最贴近自身需求的场景(如办公自动化)开始,快速获得成就感,再向更复杂的方向进阶。摘要
一、认知筑基(1-2 周):先懂 “是什么” 再动手
1. 核心概念理解
2. 资源推荐
二、零代码实践(2-4 周):快速做出第一个智能体
1. 平台选择(从易到难)
平台 特点 适合场景 推荐指数 扣子(Coze) 国内主流,可视化流程,插件丰富 办公助手、知识库问答 ★★★★★ CrewAI 无代码搭建多智能体,协作流程简单 团队任务分工、项目管理 ★★★★☆ LangGraph 社区活跃,灵活度高,支持复杂工作流 进阶开发、自定义逻辑 ★★★★☆ Dify 开源低代码,支持本地部署 企业级应用、数据隐私需求 ★★★☆☆ 2. 实战项目(从简到繁)
3. 核心技能
三、代码入门(4-8 周):从调用 API 到自定义开发
1. 技术栈准备
2. 实战项目(代码驱动)
3. 避坑指南
四、进阶深化(8-12 周):掌握核心技术与多智能体协作
1. 核心技术突破
2. 多智能体系统实战
3. 资源推荐
五、工程化与落地(12 周 +):从原型到产品
1. 工程能力建设
2. 商业化方向
六、常见误区与避坑建议
建议:先通过零代码平台做出可用产品,再按需补数学与算法知识。七、QA 问答:解决学习中的高频疑问
Q1:零基础、不懂编程,能学会智能体吗?
Q2:学习智能体需要掌握哪些数学知识?必须深入学深度学习吗?
Q3:不同学习场景(办公 / 科研 / 创业),学习重点有什么区别?
Q4:学习智能体需要投入多少时间?多久能做出可用的作品?
Q5:免费资源足够学习吗?需要付费购买课程或工具吗?
Q6:如何选择适合自己的智能体学习切入点?
Q7:多智能体协作是必学的吗?单智能体的应用场景多吗?
八、每周学习计划(示例)
周次 核心任务 工具 / 资源 输出成果 1 概念学习 + 扣子平台入门 扣子文档、吴恩达课程 理解智能体核心逻辑 2 搭建个人日程助手 扣子 + 日历插件 可自动管理日程的智能体 3-4 学习 Python+API 调用 《Python 入门》+OpenAI API 文档分析工具(代码版) 5-6 多智能体协作实战 CrewAI+LangGraph 团队任务管理系统 7-8 强化学习小项目 OpenAI Gym+PyTorch CartPole 平衡智能体 9-12 复杂系统开发 + 部署 Docker + 阿里云 企业级知识库智能体