我们首先用一道题目来引出今天的话题。
0xGame 2025 Week4 - 旧吊带袜天使:想吃真蛋糕的Stocking
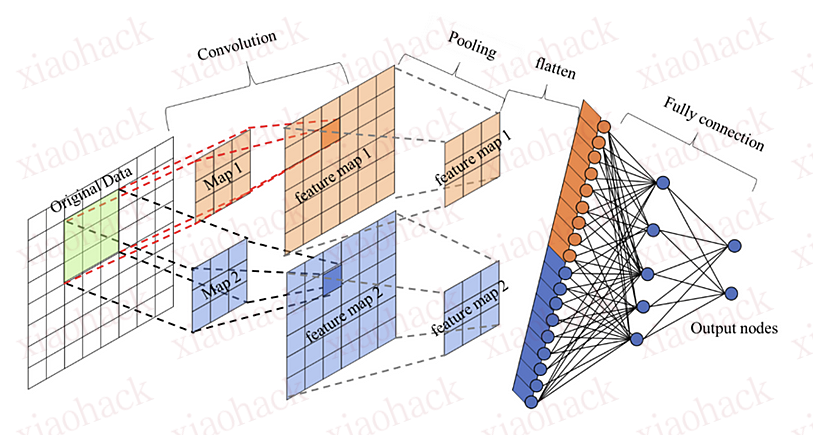
题目提供了一个基于PyTorch的CNN图像分类模型 SimpleDessertClassifier,用于识别三种类型的甜点:
模型结构:
卷积层: 提取图像特征(3→32→64→128通道)
自适应池化: 统一输出为7×7特征图
全连接层: 128×7×7 → 256 → 128 → 3(三类输出)
在PyTorch的state_dict中,最后一层(输出层)的参数命名为:
'classifier.5.weight': 形状 (3, 128) - 权重矩阵
'classifier.5.bias': 形状 (3,) - 偏置向量
在app.py中的判断逻辑:
我们要想拿到flag必须满足一下条件
cake_confidence < 24 - 蛋糕的置信度小于24
poisoned_apple_confidence > cake_confidence - 毒苹果置信度大于蛋糕置信度
模型上传接口
检查了文件扩展名,使用了weights_only加载,但是没有验证模型参数的合理性,这就是漏洞点。
根据PyTorch官方文档,load_state_dict要求:
●键名必须完全匹配
●张量形状必须完全匹配
这使得我们可以精确控制模型参数,特别是输出层的参数。
核心思路
1CNN卷积层和中间层难以预测和控制
2但输出层(最后一个Linear层)直接影响三个类别的logits输出
3通过操纵输出层的weight和bias,可以直接控制各类别的置信度
数学原理:
如果我们设:
● weight = 0 (全零矩阵)
●bias = [-10.0, 10.0, 0.0]
则:
●Cake logit ≈ -10.0 (置信度极低)
●Poisoned Apple logit ≈ 10.0 (置信度极高)
●Other logit ≈ 0.0 (置信度中等)
这样就满足了获取flag的条件。
神经网络输出层机制
在PyTorch中,未经softmax的输出称为logits:
Softmax转换:
当差异较大时:
● logit_poison = 10.0 → exp(10) ≈ 22026
● logit_cake = -10.0 → exp(-10) ≈ 0.000045
●poison_confidence ≈ 99.99%
●cake_confidence ≈ 0.0002%
满足 cake_confidence < 24 和 poisoned_apple_confidence > cake_confidence。
exp

第一次遇到模型污染攻击的题目,我们来总结一下AI样本对抗的一些内容和知识点。
一、对抗性威胁
1.1 问题背景
2014年,Szegedy等人首次发现了一个令人震惊的现象:深度神经网络对输入数据的微小扰动异常敏感[1]。通过在图像上添加精心设计的扰动,这些扰动在人类观察者看来几乎不可察觉,却能让分类器的准确率从90%以上骤降至接近0%。这一发现揭开了对抗性机器学习研究的序幕。

更令人担忧的是,对抗样本具有迁移性(Transferability)——在某一个模型上生成的对抗样本,往往能够成功攻击其他架构完全不同的模型。这一特性使得对抗攻击在实际应用场景中构成严重威胁。
1.2 现实威胁案例
自动驾驶系统:研究者通过在停车标志上添加精心设计的贴纸,成功欺骗目标检测模型将其识别为限速标志[2]。这种物理对抗攻击直接威胁道路交通安全。

人脸识别系统:通过佩戴特殊设计的眼镜框,攻击者可以绕过基于深度学习的人脸验证系统[3]。这种对抗性眼镜的图案对人类观察者而言只是普通的装饰,但对神经网络而言却是致命的扰动。
恶意软件检测:对抗样本技术已被应用于恶意PDF文件的生成,使得能够绕过基于机器学习的检测系统[4]。这表明对抗性威胁不仅限于视觉领域。
1.3 对抗样本的定义

二、对抗样本的产生机理
2.1 线性假设解释

2.2 决策边界理论
从决策边界(Decision Boundary)的角度看,对抗样本反映了模型决策边界的扭曲特性。在高维空间中,决策边界的复杂度远超人类直觉。
研究表明,深度神经网络的决策边界呈现出"指状突起"(Finger-like protrusions)结构[6]。这些细长的突起深入到各个类别的区域,使得在任何数据点附近都存在通往其他类别的低扰动路径。
2.3 流形视角
另一种解释基于数据流形(Manifold)理论。自然图像在高维像素空间中实际上分布在一个低维流形上。深度神经网络学习的是这个流形上的概率分布。
对抗样本位于流形之外,但非常接近流形表面。模型在流形之外的区域行为不可控,容易被扰动误导。这类似于"分布外泛化"(Out-of-Distribution Generalization)问题。
三、经典攻击算法详解
3.1 梯度类攻击方法
3.1.1 FGSM(Fast Gradient Sign Method)
FGSM是最早的一阶攻击方法,由Goodfellow在2015年提出[5]。核心思想是沿损失函数的梯度方向进行最大化扰动:


FGSM的优势:
●计算高效,仅需一次前向和反向传播
●扰动可控
●在黑盒场景下具有较好的迁移性
局限性:
●单步攻击容易被对抗训练防御
●扰动幅度受限时成功率较低
3.1.2 I-FGSM(Iterative FGSM)
I-FGSM通过多次迭代应用FGSM,每次迭代使用较小的步长:

I-FGSM显著提升了攻击成功率,但迁移性有所下降。
3.1.3 MI-FGSM(Momentum I-FGSM)
为提升迁移性,Dong等人引入动量机制

动量机制有助于:
●跨越局部极值
●稳定优化方向
●提升不同模型间的迁移性
3.1.4 PGD(Projected Gradient Descent)
PGD被Madry等人视为对抗鲁棒性的"基准攻击"[8]。算法框架:
PGD的关键创新在于随机初始化,这使得攻击能从不同起始点探索决策边界,显著增强了攻击效果。Madry等人证明,对抗训练若能防御PGD攻击,通常也能防御其他一阶攻击。
3.2 优化类攻击方法
3.2.1 C&W攻击(Carlini & Wagner Attack)
Carlini和Wagner提出的优化攻击[9]被认为是当时最强的白盒攻击方法。核心思想是将对抗样本构造转化为约束优化问题


C&W攻击的三种变体:
● C&W L0:最小化修改像素数量
● C&W L2:最小化欧氏距离
● C&W L∞:最小化最大像素变化
C&W攻击突破了当时多数防御方法,包括 Defensive Distillation(防御蒸馏)。

3.2.2 EAD(Elastic-Net Attack to DNNs)
Chen等人提出基于Elastic Net正则化的优化框架

3.3 黑盒攻击方法
3.3.1 基于迁移性的黑盒攻击
利用对抗样本的迁移特性,攻击者可以在本地模型上生成对抗样本,直接用于攻击远程目标模型。
提升迁移性的策略:
● 使用集成模型(Ensemble)作为替代模型
● 引入数据增强(Data Augmentation)
● 使用动量机制稳定优化
3.3.2 基于查询的黑盒攻击
当无法获得目标模型的梯度信息时,可采用基于优化的查询方法。
NES(Natural Evolutionary Strategy)攻击
通过自然进化策略估计梯度:

Boundary Attack
从随机噪声出发,沿决策边界逐步逼近目标样本,保持对抗性同时减小扰动。
SPSA(Simultaneous Perturbation Stochastic Approximation):
使用同时扰动随机近似估计梯度,每次仅需两次查询即可获得梯度估计。
3.4 物理对抗攻击
3.4.1 数字域到物理域的挑战
将数字域对抗样本应用到物理世界面临两大挑战:
1 光照变化:拍摄条件的变化导致实际输入与预期不一致
2 视角变换:拍摄角度影响对抗扰动的作用
3.4.2 典型物理攻击方法
RP2(Robust Physical Perturbations)[13]:
通过在不同光照和角度下优化,生成具有物理鲁棒性的对抗贴纸。关键是在优化过程中引入环境变化的模拟:

对抗性补丁(Adversarial Patches)[14]:
Brown等人提出生成任意形状的图像补丁,无论贴在图像何处都能触发攻击。优化目标是:

通过期望-最大化(Expectation-Maximization)算法求解。
四、新兴攻击前沿
4.1 针对Transformer的对抗攻击
Vision Transformer(ViT)的兴起带来了新的攻击向量。研究表明,ViT的自注意力机制(Self-Attention)存在特殊脆弱性[15]。
Patch-wise攻击:
不同于CNN的像素级攻击,ViT的对抗扰动可以针对Image Patch层面构造:

Token级扰动:
在语言模型中,针对输入Token的嵌入向量进行优化,而非原始文本。
4.2 视觉-语言多模态攻击
大型视觉-语言模型(如CLIP、GPT-4V)的对抗研究成为热点[16]。
跨模态迁移攻击:
利用图像和文本模态间的对齐关系,通过修改一模态影响另一模态的表征:

链式攻击(Chain of Attack)
CVPR 2025的研究表明,VLM比单一语言模型更易受攻击,原因在于视觉模态对细微扰动的敏感性。攻击策略为:
1在图像空间生成对抗扰动
2通过视觉编码器传递到联合嵌入空间
3影响跨模态注意力机制
4最终导致语言输出错误
4.3 后门攻击(Backdoor Attack)
后门攻击不同于前述的对抗样本,它在训练阶段植入恶意行为。
触发器设计:
常见的触发器模式:
●图像角落的特定图案
●隐写术嵌入的隐蔽信号
●语义级触发(如"特定物体+特定背景")
BadNets攻击
通过在训练集中注入带触发器的样本,使得模型在测试时遇到触发器即输出攻击者指定的类别。
隐式后门攻击:
使用正则化方法使后门激活模式与正常激活模式难以区分:

4.4 数据投毒攻击
数据投毒攻击通过污染训练数据来植入后门或降低模型性能。
标签翻转攻击:
将部分训练样本标签改为错误类别,导致决策边界偏移。
清洁标签攻击
更隐蔽的方法,保持标签正确但选择靠近决策边界的困难样本进行微小扰动:

4.5 图像对抗样本的不可感知性度量
为了更精确地量化对抗扰动的不可感知性,研究者提出了多种度量方法:

五、大语言模型对抗攻击
随着ChatGPT、GPT-4等大语言模型的广泛应用,LLM的对抗安全问题成为研究热点。与传统CV领域的对抗样本不同,LLM面临独特的挑战和攻击方式。
5.1 LLM对抗攻击的特点
离散输入空间:
语言模型的输入是离散的token序列,无法直接应用连续优化方法:

语义约束强:
扰动后的文本必须保持语法正确和语义连贯,这比图像扰动约束更强。
黑盒场景为主:
大多数LLM通过API提供服务,攻击者只能访问输入输出接口。
5.2 提示注入攻击(Prompt Injection)
提示注入是目前LLM面临的最严重安全威胁之一。
直接注入:
通过精心设计的提示词覆盖系统指令:
间接注入:
将恶意指令隐藏在看似正常的内容中:
多轮注入:
通过多轮对话逐步引导模型突破安全限制:
形式化定义

5.3 对抗性提示生成
基于优化的方法:
GCG(Greedy Coordinate Gradient)
通过贪婪坐标梯度搜索最优后缀扰动:
算法框架:
基于搜索的方法:
遗传算法
将提示词视为基因序列,通过变异、交叉、选择进化:
● 变异:随机替换token或同义词替换
● 交叉:组合两个成功的提示词片段
● 选择:保留攻击成功率高的个体
强化学习方法:
将对抗提示生成建模为序列决策问题:

5.4 越狱攻击(Jailbreaking)
越狱攻击旨在绕过LLM的安全护栏。
角色扮演攻击:
通过设定角色场景规避安全限制:
翻译攻击:
利用语言差异绕过过滤器:
●将恶意请求翻译为低资源语言
●通过LLM处理后再翻译回原语言
●某些语言的语义表达可能未被安全训练充分覆盖
编码攻击:
将指令编码为特殊形式:
●Base64编码
●ASCII/Unicode字符
●摩斯电码
●凯撒密码
示例:
组合攻击:
结合多种技术的混合攻击:
1使用角色扮演设定上下文
2通过编码隐藏真实意图
3利用多轮对话逐步引导
4添加干扰token迷惑检测器
5.5 LLM后门攻击
触发器植入:
在训练阶段或微调阶段植入后门:
特定词触发:
在输入中包含特定关键词时触发恶意行为:
$$P(恶意输出 | 输入 + 触发词) approx 1$$
句法结构触发:
特定的句子结构触发后门:
隐式触发
使用难以察觉的触发器,如:
●特殊标点符号组合
●文本末尾的空白字符
●Unicode零宽字符
训练数据投毒:

5.6 针对RAG系统的对抗攻击
检索增强生成(RAG)系统的攻击向量:
检索阶段攻击:
构造文档使得被错误检索:

生成阶段攻击:
在被检索的恶意文档中植入误导信息,使LLM生成错误内容。
多跳推理攻击:
针对需要多步推理的RAG系统,在某个中间步骤注入错误信息,影响最终结论。
5.7 LLM对抗攻击评估
攻击成功率:

查询效率:
平均需要的查询次数或轮次。
文本质量:
评估对抗提示的自然度和流畅度,使用:
●困惑度(Perplexity)
●人工评估
●GPT-4等作为裁判
覆盖度:
攻击方法对不同类型任务的有效性:
●代码生成
●有害内容生成
●隐私信息泄露
●虚假信息传播
六、扩散模型与生成式AI的对抗研究
生成式AI的快速发展带来了新的安全挑战。扩散模型作为当前最强大的生成模型,其对抗性研究成为前沿方向。
6.1 扩散模型原理回顾

6.2 针对扩散模型的对抗攻击
6.2.1 图像到图像生成的对抗攻击
文本引导图像编辑攻击[35]:
通过对抗性文本提示生成恶意图像:
目标优化:
$$max_{delta} mathbb{E}[ ext{损失函数}( ext{生成图像}, ext{目标属性})]$$
例如:
潜在空间对抗扰动:
在扩散模型的潜在空间注入扰动:

影响后续的去噪过程,导致生成偏离预期。
6.2.2 针对图像生成的不可见水印攻击
水印移除攻击:
通过添加精心设计的扰动移除生成图像中的水印:

水印伪造攻击:
在真实图像中添加伪造的水印,使其被误判为AI生成。
6.2.3 反向攻击与隐私窃取
成员推断攻击:
判断某样本是否在训练集中:

训练数据提取[36]:
通过逆向扩散模型恢复训练数据:
攻击算法:
模型反演:
从模型输出恢复敏感训练信息,特别是人脸等敏感数据。
6.3 生成对抗网络的对抗性研究
6.3.1 GAN的脆弱性分析

6.3.2 模型窃取攻击

6.4 生成式AI的防御策略
6.4.1 对抗训练 for 生成模型
鲁棒去噪器训练:

防御性蒸馏:
使用高温蒸馏平滑生成模型的决策边界。
6.4.2 水印与版权保护
不可见水印技术[37]:
基于频域的鲁棒水印:
1将水印嵌入到图像的DCT/DWT系数中
2水印对常见的图像处理具有鲁棒性
3可通过统计检测验证水印存在
基于优化的水印:

神经网络水印:
在模型参数中嵌入水印:
●触发器集:特定输入产生特定输出
●参数 embedding:将水印编码到权重矩阵
6.4.3 生成内容检测
基于检测器的识别:

特征包括:
●频域统计特征
●局部纹理模式
●深度特征异常
零样本检测:
利用零样本学习无需训练即可检测:
●计算图像在CLIP等模型中的特征分布异常
●使用困惑度等指标
多模态检测:

6.5 AIGC安全事件与伦理讨论
Deepfake与虚假信息:
●政治人物视频伪造
●商业诈骗
●个人名誉损害
版权侵权争议:
●AI训练数据的合法性
●生成内容的版权归属
●风格模仿的法律边界
内容审核挑战:
●海量生成内容的审核难度
●跨平台监管的复杂性
●技术对抗与军备竞赛
七、深度对抗鲁棒性理论分析
7.1 对抗样本的几何视角
7.1.1 决策边界的曲率分析
从微分几何角度,决策边界的曲率决定了对抗样本的易攻击性。

研究表明,深度神经网络的决策边界具有极大的负曲率区域,导致对抗样本的存在。
7.1.2 决策边界的分形维度
决策边界的盒计数维度(Box-counting Dimension):

实验表明,深度神经网络的决策边界维度接近输入空间维度,这是对抗样本存在的根本原因之一。
7.1.3 余度假设与线性可分性
余度假设(Excess Capacity Hypothesis):
神经网络参数数量远超训练样本数,导致存在大量决策边界可实现零训练误差。

高VC维意味着模型可以记忆训练数据而非学习泛化规律,决策边界在数据点之间扭曲形成对抗样本。
7.2 泛化理论与鲁棒性
7.2.1 泛化界与鲁棒性

7.2.2 分布鲁棒优化

7.3 信息论视角
7.3.1 互信息与特征学习

7.3.2 信息瓶颈的鲁棒性解释

从信息论角度,对抗样本的存在是因为模型学习了对分类任务无关的特征。IB理论表明,最优表示应该丢弃输入中的"噪声"(包括对抗扰动),只保留与任务相关的信息。
7.4 对抗样本的因果解释
7.4.1 相关性与因果性
传统深度学习学习的是特征与标签之间的统计关联,而非因果关系。
虚假相关(Spurious Correlation):
例如:训练集中"雪地"背景与"狼"标签高度相关,导致模型对"雪地上的哈士奇"误分类。
对抗样本利用了这些虚假相关特征。
7.4.2 因果表示学习

7.5 可证明的鲁棒性下界
7.5.1 准确率-鲁棒性权衡的理论分析

7.5.2 神经正切核(NTK)视角

NTK理论表明:
●标准训练的模型在数据点附近拟合迅速
●但在远离数据点的区域泛化能力差
●对抗样本恰好位于训练数据流形的"空隙"中
八、端到端实战案例
本章节通过具体案例展示对抗样本攻防的完整流程,从代码实现到结果分析。
8.1 图像分类模型对抗攻击实战
8.1.1 环境准备

8.1.2 加载预训练模型
8.1.3 FGSM攻击实现
8.1.4 PGD攻击实现
8.1.5 C&W攻击实现
8.1.6 可视化对比
8.2 对抗训练完整流程
8.2.1 基础对抗训练
8.2.2 TRADES对抗训练
8.3 LLM对抗攻击实战
8.3.1 提示注入攻击示例
8.3.2 GCG攻击算法实现
8.4 扩散模型对抗攻击
8.5 攻击效果评估与对比


九、评估指标与基准
9.1 攻击能力评估

9.1.2 扰动幅度

9.1.3 查询复杂度(Query Complexity)

9.1.4 迁移性

9.2 防御能力评估
9.2.1 鲁棒准确率(Robust Accuracy)

9.2.2 准确率-鲁棒性权衡

9.2.3 认证半径(Certified Radius)

9.3 常用数据集
数据集 | 任务 | 规模 | 对抗研究特点 |
MNIST | 手写数字 | 60K训练/10K测试 | 入门基准,易防御 |
CIFAR-10 | 物体分类 | 50K训练/10K测试 | 标准测试集 |
ImageNet | 大规模分类 | 1.2M训练/50K验证 | 真实场景基准 |
TinyImageNet | 小规模ImageNet | 100K训练/10K测试 | 计算效率折中 |
SVHN | 门牌号识别 | 73K训练/26K测试 | 数字识别场景 |
9.4 自动化评估工具
Foolbox:
Python库提供统一接口实现多种攻击算法:
ART(Adversarial Robustness Toolbox):
IBM开发的对抗鲁棒性工具箱,提供攻击、防御、评估的完整流程。
CleverHans:
Goodfellow等人开发的早期对抗攻击库,提供FGSM、JSMA等经典算法实现。
十、开放问题与未来方向
10.1 准确率与鲁棒性的根本矛盾
经验表明,提升模型鲁棒性往往以牺牲标准准确率为代价。Schmidt等人从信息论角度证明,在高维数据分布下,实现高准确率和高鲁棒性需要指数级样本复杂度[30]。
这提示可能需要:
● 新的学习范式:超越纯监督学习
● 先验知识注入:利用人类视觉先验
● 因果推理:从相关性转向因果性
10.2 大模型的对抗鲁棒性
随着GPT-4、CLIP等大模型的兴起,新问题涌现:
计算成本:对大模型进行PGD攻击或对抗训练计算开销巨大。研究方向:
●参数高效微调(PEFT)结合对抗训练
●LoRA(Low-Rank Adaptation)在对抗场景的应用
●梯度累积与分布式优化
黑盒迁移攻击:大模型API只提供输入输出接口,如何设计高效查询攻击?
10.3 生成式AI的对抗问题
扩散模型(Diffusion Models)和生成对抗网络(GAN)的对抗研究:
扩散模型反向攻击:
通过优化去噪过程,从模型中恢复训练数据隐私。
生成模型的版权保护:
对抗水印技术保护生成内容不被盗用。
10.4 多模态与联邦学习的安全性
跨模态对抗传播:
视觉-语言-音频多模态模型中,一模态的扰动如何影响其他模态?
联邦对抗学习:
在分布式训练场景下,如何防御恶意客户端的对抗性投毒?
10.5 可证明鲁棒性
现有的经验性防御(如对抗训练)只能提供经验保证。研究方向:
形式化验证:
使用SMT求解器对小型网络进行精确验证。
凸松弛:
将非线性激活函数凸化,得到鲁棒性的可证明上界。
随机平滑扩展:
将随机平滑理论扩展到更复杂的数据分布和网络架构。
10.6 对抗样本的双重性研究
最新研究开始探索对抗样本的积极意义:
数据增强:
利用对抗样本扩充训练集,提升模型泛化能力。
可解释性:
对抗样本揭示模型决策逻辑,帮助理解黑盒模型。
对抗性调试:
通过生成对抗样本发现模型缺陷,指导改进。
10.7 2023-2025最新研究进展
10.7.1 自动对抗攻击(AutoAttack)[39]
Croce和Hein提出的AutoAttack是一个自适应攻击框架,自动选择最优攻击组合:
核心思想:
●使用多种攻击方法(APGD-CE, APGD-DLR, FAB, Square)
●通过自适应策略选择最有效的攻击
●提供更可靠的鲁棒性评估
算法流程:
10.7.2 对抗性微调(Adversarial Fine-tuning)[40]
针对预训练大模型的对抗性微调方法:
方法:
●在预训练模型基础上进行对抗性微调
●使用较小的学习率和扰动预算
●仅微调部分层(如最后几层或注意力层)
优势:
●降低计算成本
●保留预训练知识
●提升下游任务的鲁棒性
10.7.3 基于提示的防御(Prompt-based Defense)[41]
针对LLM的防御新方法:
系统提示工程:
红队测试(Red Teaming):
●组建专业红队进行对抗性测试
●使用自动化工具生成对抗样本
●建立攻击-防御迭代循环
10.7.4 多模态对抗研究进展
CLIP模型的脆弱性[42]:
研究发现视觉-语言预训练模型对特定扰动高度敏感:
●视觉扰动向文本空间的迁移
●跨模态对抗样本的构造
●零样本分类的鲁棒性分析
扩散模型的鲁棒性[43]:
针对Stable Diffusion等模型的攻击:
10.7.5 物理对抗攻击新进展
3D打印对抗物体[44]:
通过3D打印生成物理对抗物体:
●优化物体的3D几何结构
●考虑不同光照和角度
●实际测试验证攻击效果
对抗性纹理(Adversarial Textures):
将对抗扰动应用到现实世界的纹理:
●服装图案
●车辆涂装
●建筑外观
10.7.6 量子计算与对抗鲁棒性
新兴研究方向:
量子对抗攻击:
利用量子算法加速对抗样本生成:
●量子梯度估计
●量子优化算法(QAOA)
●量子机器学习模型的鲁棒性
后量子密码学与AI安全:
●抗量子攻击的神经网络
●量子密钥分发与模型保护
10.7.7 对抗样本的法律与伦理框架
监管政策:
●欧盟AI法案对对抗鲁棒性的要求
●NIST AI风险管理框架
●ISO/IEC AI安全标准
负责任的AI开发:
●对抗鲁棒性作为AI安全指标
●红队测试作为标准流程
●透明度和可解释性要求
十一、实践建议与最佳实践
11.1 对抗训练实施指南
11.1.1 基础配置
11.1.2 高级技巧
早期停止(Early Stopping):
监控验证集鲁棒准确率,避免过拟合。
课程学习(Curriculum Learning):

自适应攻击强度:
根据当前模型鲁棒性动态调整epsilon。
附录:快速参考
A.1 主要攻击算法对比
算法 | 类型 | 复杂度 | 成功率 | 迁移性 | 适用场景 |
FGSM | 单步梯度 | O(1) | 低 | 高 | 快速测试 |
I-FGSM | 迭代梯度 | O(T) | 中 | 中 | 标准攻击 |
MI-FGSM | 动量迭代 | O(T) | 中-高 | 高 | 迁移攻击 |
PGD | 投影梯度 | O(T) | 高 | 中 | 鲁棒训练 |
C&W | 优化 | 高 | 很高 | 低 | 强力攻击 |
NES | 黑盒估计 | O(N×T) | 中 | N/A | 黑盒攻击 |
A.2 主要防御方法对比
方法 | 准确率影响 | 鲁棒性 | 计算开销 | 可证明性 |
对抗训练 | 中等 | 高 | 高 | 否 |
TRADES | 较小 | 高 | 高 | 否 |
随机平滑 | 较大 | 中 | 中 | 是 |
IBP | 较小 | 中 | 中 | 是 |
输入变换 | 较小 | 低 | 低 | 否 |
A.3 常用扰动预算值













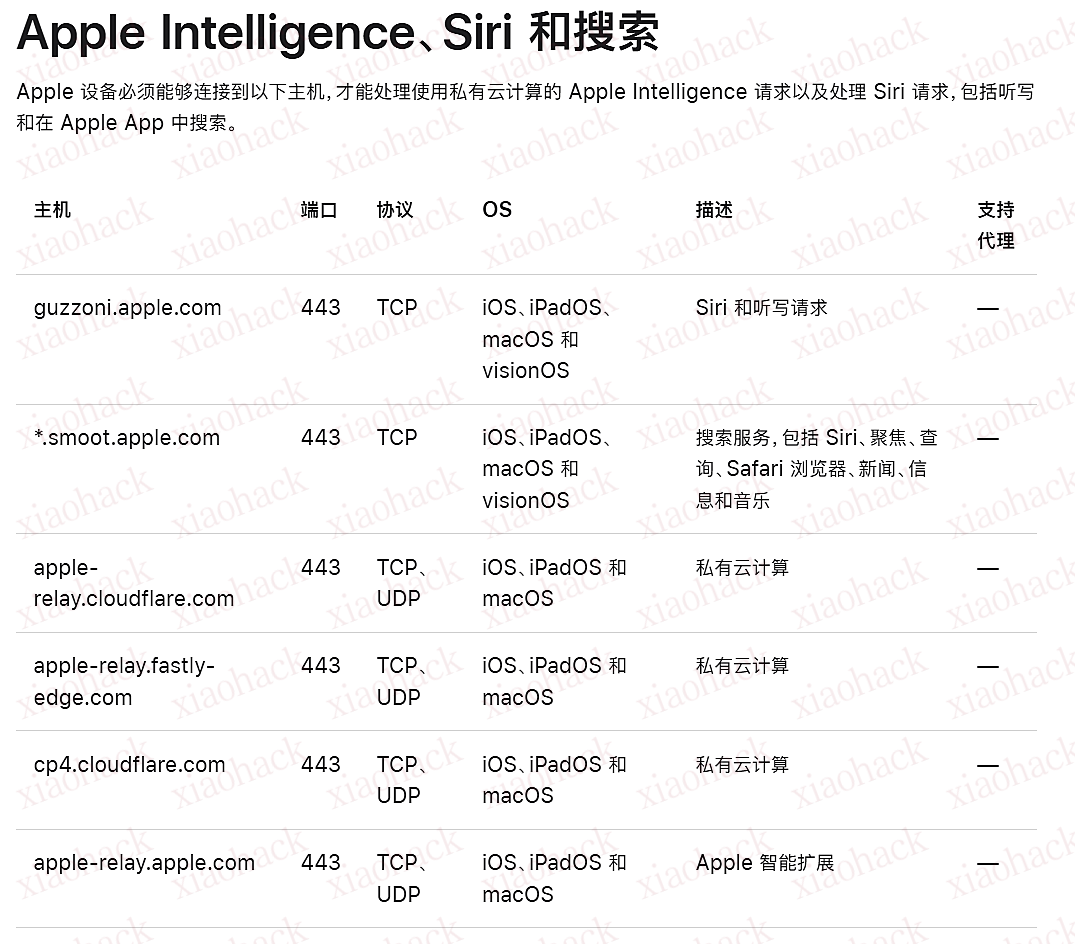
 上述这些隐私数据,用户只能控制位置信息是否提供给 Siri,其他的隐私数据都是被悄悄发送到云端了。除了天气搜索外,在使用 Siri 进行计算、在线搜索、文章搜索时,也都会上传类似的数据。
上述这些隐私数据,用户只能控制位置信息是否提供给 Siri,其他的隐私数据都是被悄悄发送到云端了。除了天气搜索外,在使用 Siri 进行计算、在线搜索、文章搜索时,也都会上传类似的数据。


 今天跟大家分享一个etcd的内存大量占用的问题,这是前段时间在我们开源软件Easegress中遇到的问题,问题是比较简单的,但是我还想把前因后果说一下,包括,为什么要用etcd,使用etcd的用户场景,包括etcd的一些导致内存占用比较大的设计,以及最后一些建议。希望这篇文章不仅仅只是让你看到了一个简单的内存问题,还能让你有更多的收获。当然,也欢迎您关注我们的开源软件,给我们一些鼓励。
今天跟大家分享一个etcd的内存大量占用的问题,这是前段时间在我们开源软件Easegress中遇到的问题,问题是比较简单的,但是我还想把前因后果说一下,包括,为什么要用etcd,使用etcd的用户场景,包括etcd的一些导致内存占用比较大的设计,以及最后一些建议。希望这篇文章不仅仅只是让你看到了一个简单的内存问题,还能让你有更多的收获。当然,也欢迎您关注我们的开源软件,给我们一些鼓励。 今天来讲一讲TCP 的
今天来讲一讲TCP 的 

 这两天跟
这两天跟  写一篇与技术无关的文章,供大家参考。我住北京朝阳,从上周三开始我家一家三口陆续发烧生病,自测抗原后,都是阳性。好消息是,这个奥密克戎跟一般的病毒性感冒差不多,没什么可怕的,不过,整个过程除了发病之外还有一些别的因为感染带出来的事,大家也需要知晓,以准备好,以免造成生活的不便,更好的照顾好自己和家人。
写一篇与技术无关的文章,供大家参考。我住北京朝阳,从上周三开始我家一家三口陆续发烧生病,自测抗原后,都是阳性。好消息是,这个奥密克戎跟一般的病毒性感冒差不多,没什么可怕的,不过,整个过程除了发病之外还有一些别的因为感染带出来的事,大家也需要知晓,以准备好,以免造成生活的不便,更好的照顾好自己和家人。

 这两天在网络上又有一个东西火了,Twitter 的创始人
这两天在网络上又有一个东西火了,Twitter 的创始人 
 两个月前,我试着想用 ChatGPT 帮我写篇文章《
两个月前,我试着想用 ChatGPT 帮我写篇文章《
 这两天技术圈里热议的一件事就是Amazon的流媒体平台Prime Video在2023年3月22日发布了一篇技术博客《
这两天技术圈里热议的一件事就是Amazon的流媒体平台Prime Video在2023年3月22日发布了一篇技术博客《








































































































































