导语
随着 DevSecOps 的不断推进,应用安全已被广泛纳入SDLC的各个阶段。然而,在代码扫描、依赖分析、漏洞检测等能力逐步成熟的同时,一个长期存在却难以解决的问题始终横亘在安全工程实践中:安全工具“能发现问题”,却难以判断问题是否真实、是否可利用、是否值得优先处理。大量规则驱动的扫描结果不仅带来了高误报率,也持续消耗着研发与安全团队的精力。
近年来随着大语言模型(LLM)的快速发展,为这一困境提供了新的可能。不同于传统规则或静态特征匹配,LLM 在语义理解、上下文推理和条件组合分析方面展现出独特优势,使其具备参与安全“判断层”的潜力。将 LLM 引入 SDLC,不再只是生成代码或辅助文档,而是尝试参与到安全结果的理解、验证与决策之中。
本文结合实际应用安全建设经验,围绕 LLM 在 SDLC 中的落地实践展开,重点探讨其在硬编码、SCA、漏洞挖掘等场景中的应用方式与工程化思路。
SDLC 应用安全流程

SDLC名词解释
- SAST(静态应用安全测试)通过对源代码或编译产物进行静态分析,在不运行系统的情况下发现潜在的安全缺陷,如 SQL 注入、XSS、不安全函数调用和硬编码敏感信息等,适合在开发阶段提前发现问题。
- SCA(软件成分分析)聚焦于项目中使用的第三方开源组件,识别依赖库及其传递依赖中已知的安全漏洞、风险版本和许可证问题,帮助团队降低因外部组件引入的安全风险。
- DAST(动态应用安全测试)在系统运行状态下,从攻击者视角对应用进行测试,通过捕获流量包修改参数重放,模拟真实攻击行为验证系统是否存在可被实际利用的漏洞,如注入攻击、未授权访问等
- 硬编码(Hard Coding),是指在程序中直接把固定的值写死在源码里,而不是通过配置文件、环境变量等方式获取,比如下面这些情况,都属于硬编码:用户名、密码、token或加密密钥等
为什么我们需要SDLC?
产品一句话需求 → 开发自己理解 → 按照个人习惯去开发 → 功能上线后出现大量漏洞 → 被外部利用造成损失
而SDLC要做的就是把漏洞扼杀于摇篮之中,而不是靠后期凭经验渗透测试发现。
但目前传统的SDLC存在大量告警/误报,推送大量工单给研发会导致业务间摩擦度增加,因此理想情况是把真正需要修复的工单交给研发处理
硬编码规则下引入AI判断,减少误报
问题背景:目前硬编码扫描是根据规则的正则匹配,存在一定的局限性和误报

整体流程
结合硬编码规则 + AI 判断保留高召回,同时降低误报率

硬编码规则先行
使用固定规则(正则、逻辑判断)先筛掉明显非风险项,让 AI 只处理模糊/不确定案例
AI 判断做辅助
只对硬编码规则未覆盖、可疑的候选项输出风险判断,输出结果可附置信度或分类标签
置信度 + 白名单控制
AI 输出带置信度,低于阈值直接忽略,对常见合法值、默认值设置白名单
提示词 promot
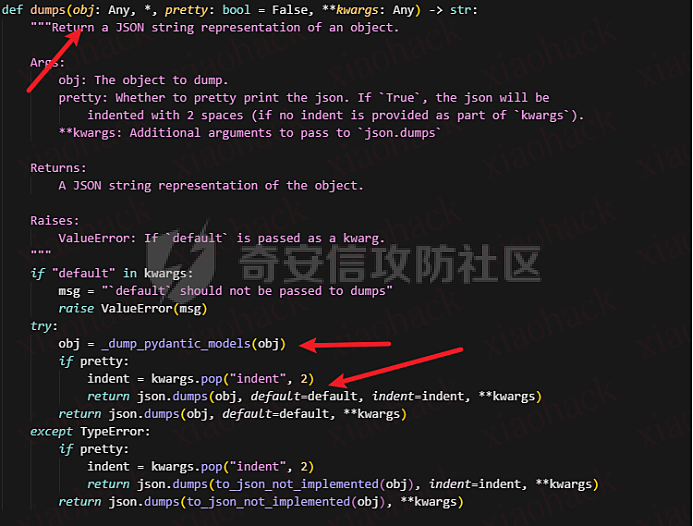
通过定位文件的位置,结合上下文判断实际风险等级,把AI分析结果输出
你是一个资深应用安全专家,精通代码安全、凭证泄露、真实攻击利用分析。
现在给你一个【疑似硬编码凭证】的扫描结果,请你进行【可利用性研判】。
输入信息如下(JSON):
%s
请严格按以下维度进行分析:
1. 该硬编码是否为真实敏感凭证
2. 是否存在被外部攻击者利用的可能
3. 是否依赖运行环境
4. 泄露后的安全影响
5. 修复建议
请以 JSON 格式输出分析结果
模型输入字段释义
|
|
| 字段 |
释义 |
| match |
匹配到的硬编码内容(部分脱敏显示) |
| rule |
key类型 |
| path |
硬编码所在的完整文件路径 |
| branch |
分支 |
| code |
上下5行代码 |
增加输出长度,避免截断
"extra_body": map[string]interface{}{
"think_mode": true,
"max_output_tokens": 1024,
实现效果

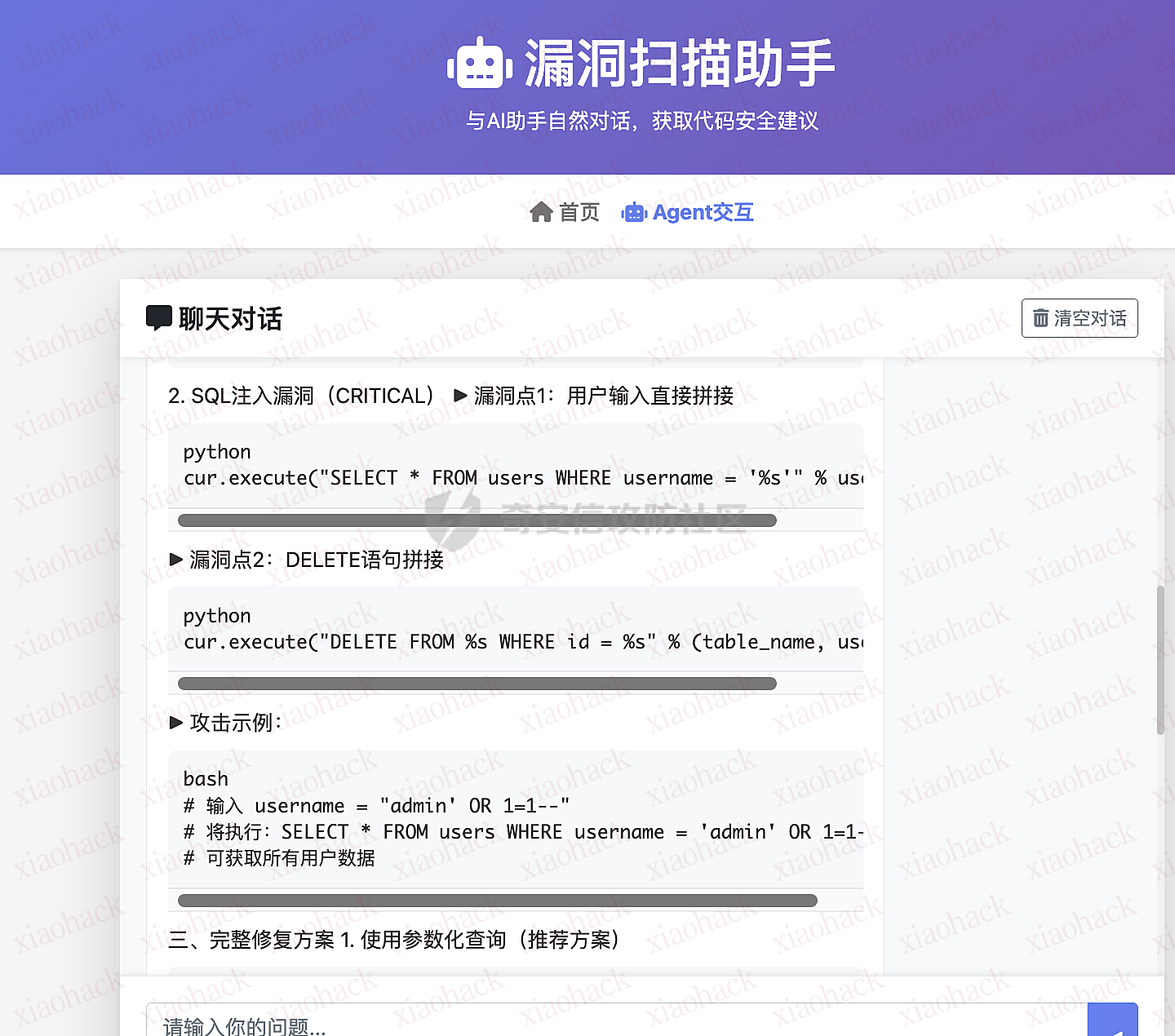
如果是走正常的流程,secret_value会被 generic-api-key规则名字标记严重程度为medium

开启AI分析选项后,通过定位文件的位置,结合上下文交给ai分析,AI判断实际危害程度为低
在代码中发现硬编码的敏感信息'DEMO_SECRET',其值为'secret_value'。根据规则'generic-api-key',这可能是一个API密钥或其他类型的敏感凭证。该变量位于'E:\SDLC平台\backend\uploads\demo.py_scan\demo.txt'文件中,并且注释表明它看起来像一个Key,但无实际用途。由于这是一个测试环境中的示例代码,风险相对较低。

掩码输出硬编码片段

代码中存在:
const apiKey = "sk_live_9f83a0b7..."
AI分析后会直接原样输出,给出完整的佐证片段,这样是不符合数据安全合规要求的,就会产生 二次扩散风险。
正确掩码后的做法,AI 只需知道这是一个硬编码密钥
const apiKey = "*MASKED_SECRET*"
实现效果
通过 AI 研判对硬编码、潜在风险及非生产路径问题进行自动识别与筛选,各产品待修复量平均下降约52.8%

价值体现:在保证安全覆盖率的前提下,AI 自动化研判显著提升效率,降低人工排查压力,推动安全研判进入智能化阶段
- AI 判断为 False:AI 判定为误报,可直接关闭
- AI 判断为 True 但 NonLive:问题真实但不在生产路径,可降低风险等级处理
- AI 研判后待修复:确认真实且影响生产,需进入修复流程
SCA可利用性与真实风险判断
从官方文档 https://react.dev/blog/2025/12/03/critical-security-vulnerability-in-react-server-components 描述可看到,涉及版本都需要更新到对应补丁

但从甲方安全运营的角度会存在以下这些问题:
1.大版本的更新会存在项目兼容性问题,不好推进
2.涉及仓库数量较多,如果全部同时进行整改将会是极大的工作量
如果我们深入分析后会发现,并不是在版本范围内就存在漏洞,还需要额外的条件满足才能利用
客户端请求 Server Action
↓
执行 Server Action (接收用户输入)
↓
react-server-dom-webpack 序列化响应
↓
【漏洞点】反序列化时未正确验证输入
↓
恶意 payload 被执行 → RCE
必要利用条件
| 条件 |
是否必须 |
说明 |
| App Router |
✅ 必须 |
提供 RSC / Flight 机制 |
| Server Actions |
✅ 必须 |
提供反序列化入口 |
| 用户可控输入 |
✅ 必须 |
构造恶意 payload |
整体流程
- 核心思路:证明SCA漏洞代码是否被业务代码真实调用,如果不可达那么这个SCA漏洞在该仓库就不可利用
- 调用链路:业务代码中是否存在外部可控输入→ 漏洞组件危险函数的真实可达路径

HTTP 请求 (scaHandler) -- 输入CVE编号
↓
CVE 分析 (runSCACVEAnalysis)
├─ 步骤 2.1: Google 搜索受影响版本
├─ 步骤 2.2: Qwen 识别依赖组件搜索官网信息
├─ 步骤 2.3: 搜索引擎寻找对应PoC
├─ 步骤 2.4: Qwen 提取结构化信息
└─ 步骤 2.5: Claude 最终安全分析
↓
仓库分析(可选)
├─ 方法一: 依赖分析 (analyzeRepositoryVulnerability)
└─ 方法二: 锚点分析 (analyzeRepositoryWithAnchor)
google搜索引擎调用
调用google进行联网搜索,局限性 key限制每天100个
https://console.cloud.google.com/apis/credentials
凭证-创建凭证

启用custom search api

https://programmablesearchengine.google.com/controlpanel/create
在这个地方可以定义调用的搜索引擎

优化阶段1:多个源进行信息整合导致出错
初步阶段测试发现,Qwen去重整理逻辑导致结果出现缺失

因此后续直接选用官方源,保证结果数据的准确性
官方情报来源
优化阶段2:未关联间接受影响组件导致结果不准
在漏洞受影响的范围很多都只提及了react组件,但是有其他间接依赖组件如next也会受到影响,因此在爬取网站内容需要把这部分信息也整理进来
虽然应用使用了受影响的 React 版本(19.0.0)并启用了 React Server Components 功能,但 React Server Components 的漏洞版本范围是 19.0.0-19.2.0,而当前仓库使用的是 react-server-dom-webpack 19.0.0。关键问题是该仓库使用的是 Next.js 16.0.6,而 CVE-2025-55182 主要影响独立的 React Server Components 实现,Next.js 有自己的 Server Components 实现机制,不直接受此 CVE 影响。条件1不满足,因此漏洞不可利用

优化阶段3:规范性提示词输入
这里有三个关键点:
将「CVE 知识」作为输入,而不是让 LLM 自行理解
- 不依赖模型对 CVE 的主观理解或记忆
- 由安全侧明确提供:漏洞成因和可利用条件链(Exploit Preconditions)
- 避免模型自由发挥导致的误报或信息污染
在目标代码仓库中,验证漏洞可利用条件是否成立
- 不做漏洞解读
- 不做风险定级臆断
- 不基于版本号直接下结论
将每个 CVE 拆解为一组必须同时满足的利用条件
- 逐条在仓库中进行验证:任一关键条件不满足 → 漏洞不可达,不构成真实风险
- 代码结构、依赖使用情况及配置与对外暴露面
最终提示词
你是一名资深应用安全分析师。请基于我提供的 SCA 扫描结果,对发现的第三方组件漏洞进行【汇总型安全分析输出】,输出需包含以下部分(使用简体中文):
1. 漏洞基本信息
- 受影响组件 / 编程语言 / 版本
- CVE 编号
- 漏洞类型
2. 漏洞原理说明
- 从安全分析视角解释漏洞成因
- 重点描述漏洞触发机制(如反序列化、解析、路由处理等)
- 对未公开的内部实现需明确说明"细节未披露",避免推测
3. 影响评估
- 可造成的安全影响(如拒绝服务、信息泄露等)
- 对业务连续性、系统稳定性和可用性的潜在影响
4. 攻击前置条件
- 环境条件(框架、运行模式、功能开启情况等)
- 依赖条件(受影响的第三方组件)
- 攻击者权限要求(是否需要认证、是否可远程触发)
5. 涉及模块或组件范围
- 受影响的框架模块或依赖包名称
- 若具体函数或代码位置未公开,需明确说明
- **必须列出所有依赖关系**:如果漏洞影响底层组件,必须说明哪些上层框架/库可能间接受影响,包括具体的组件名称和受影响版本范围
6. 可利用性与 EXP 情况说明
- 是否存在已公开的 PoC / EXP
- EXP 的公开来源类型(如 GitHub、安全研究博客等)
- 利用复杂度与稳定性评估(概念验证 / 可重复利用 / 条件受限)
- 输出poc/exp
7. 修复与缓解建议
- 官方推荐的修复方式(安全版本升级 / 官方补丁)
- 可选的临时缓解措施(如限制接口访问、WAF、防护策略等)
8. 验证与复现说明(高层级)
- 给出验证思路而非攻击步骤
- 描述在存在漏洞情况下的典型现象(如服务挂起、资源异常)
9. 信息来源说明
- 明确标注信息来源类型(NVD、官方博客、安全公告、PoC 仓库等)
- 不编造或推测来源
- **重要**:references 字段必须包含完整的 URL(以 http:// 或 https:// 开头),例如:
- 正确:https://github.com/msanft/CVE-2025-55182
- 错误:github: msanft/CVE-2025-55182 或 github.com/msanft/CVE-2025-55182
- 如果搜索结果中有链接,必须提取完整的 URL 格式
输出风格要求:
- 安全评估报告风格
- 用词克制、客观、中立
- 不渲染攻击效果,不放大风险,不自主推测
- 优先使用官方来源信息,避免"未确认"或"可疑"的评估
漏洞分析示例1:CVE-2025-55182
受影响的系统情况
app-router-vulnerable/app/api/action/route.ts
'use server'
export async function testAction(formData: FormData) {
const data = Object.fromEntries(formData)
return {
message: 'Server action executed',
data: data
}
}
使用 App Router 并启用了 Server Actions 的应用系统,受CVE-2025-55182影响
- ✅ 使用
app/ 目录(App Router 结构)
- ✅ 接收
FormData 作为参数
- ✅ 使用
react-server-dom-webpack 进行序列化/反序列化

不受影响的系统情况
- ❌使用
pages/ 目录(Pages Router 结构)
- ❌不使用
Server Actions
- ❌不依赖
React Flight Protocol 序列化
使用 Pages Router 的 Next.js 应用,即使引入同样处于受影响范围内的版本,也不受 CVE-2025-55184 漏洞影响,ai分析结果符合预期

漏洞分析示例2:CVE-2021-44228
受影响的系统情况
环境情况:
- Log4j 版本:2.14.1 (漏洞影响范围内)⚠️
- JNDI:✅ 允许
- 网络:✅ 可访问 LDAP / RMI
综上所述,满足漏洞触发条件,因此AI研判该仓库受影响

不受影响的系统情况
环境情况:
- Log4j 版本:2.14.1(漏洞影响范围内)⚠️
- JNDI:❌ 被禁用
- 网络:❌ 无法访问外部 LDAP
虽然在漏洞版本内,但是-Dcom.sun.jndi.ldap.object.trustURLCodebase=false ,因为${jndi:...} 被禁用不会被解析

AI 分析判断仓库不受影响,符合预期

模型费用对比及选择
根据官方获取定价数据:
https://platform.claude.com/docs/en/about-claude/pricing?utm_source=chatgpt.com
在选择前首先我们要定义模型好坏的标准,从数据表现出发而不是个人主观经验判断
如果追求 准确率 可以选择claude-sonnet-4@20250514,追求 性价比 但又有不错的准确率可以选择gemini-2.5-flash
| 项目 |
3 |
5 |
6 |
7 |
8 |
| 使用模型 |
gemini-2.5-pro |
claude-sonnet-4@20250514 |
claude-haiku-4-5 |
Qwen2.5-Coder-14B |
gemini-2.5-flash |
| 准确率 |
95% |
100% |
87.50% |
75% |
87.50% |
| 单个 CVE 分析平均费用(USD) |
0.33 |
0.69 |
0.19 |
-- |
0.08 |
白盒代码审计
存在的难点
- 代码文件很长
- 需要多文件上下文结合分析
- 需要精确定位行号、变量流、调用链
上述这些问题都会导致大量的token消耗,其他chat型大多数每一轮 = 重新塞一堆代码进 prompt
模型选择
Cursor 最大优势:通过索引 + 增量上下文,节约 token 消耗,适合多轮、持续审计
最关键的一点是,他是按照提问次数来计费的,它把一次提问变成了一次完整的白盒审计任务执行
| 维度 / AI |
ChatGPT (Web/API) |
Claude |
Gemini |
GitHub Copilot |
Cursor |
| 上下文获取方式 |
手动粘贴文件 |
手动粘贴 / 长上下文 |
手动粘贴 |
IDE 补全 |
自动索引 + AST |
| 重复 token 消耗 |
高 |
高 |
中 |
中 |
极低 |
| 多轮审计成本 |
指数级上升 |
高 |
高 |
中 |
平稳 / 增量消耗 |
| 跨文件调用分析 |
手动复制 |
手动复制 |
中 |
弱 |
自动关联 |
| 白盒审计推荐度 |
⭐⭐⭐ |
⭐⭐⭐ |
⭐⭐ |
⭐ |
⭐⭐⭐⭐⭐ |
提示词promot
明确任务定位
让 LLM 清楚自己在做什么,而不是默认行为(如写总结、生成报告),避免 LLM 自动归纳/总结导致丢失重要信息差异。
你不是在写安全报告,而是在做“证据整理(evidence collection)”。
你的目标是保留信息差异,而不是消除差异。
使用“反总结”指令
通常 LLM 会倾向总结、归纳,在 prompt 中明确要求保留原始信息、对比差异、不要归类。
请逐条保留所有原始输入中的差异信息,不要合并或总结条目。
每条信息保持独立输出。
明确输出结构
指定输出格式,避免每次输出不统一,便于后续自动化分析/汇总。
请按照以下 JSON 格式输出:
[
{"source": "文件A", "line": 23, "content": "..."},
{"source": "文件B", "line": 45, "content": "..."}
]
强化“证据导向”
提示 LLM 输出时只保留事实,不做主观判断。
只提取事实性内容,不要加入主观评论或判断。
标明来源和行号。
分步任务处理
对于复杂信息,分步任务处理比一次性要求总结更稳妥,避免分析中断停止,输出更结构化、更精确
第一步:提取每个输入文件的独立事件。
第二步:标记事件的时间戳和来源。
第三步:保留所有差异,不进行合并。
根据框架语言输入前置知识
不同的语言审计的方法和思路不一样,在让AI分析代码时候需要提供一些前置知识,这能让 AI 更精确地聚焦在“可能的风险点”,而不是泛泛地猜测
像SQL注入,不同语言的sink点也不完全相同
| 语言 |
方法 / 函数 |
示例代码 / SQL |
| Golang |
(*gorm.io/gorm).Where |
db.Where(StringData).First(&data) |
| Golang |
(*github.com/jmoiron/sqlx.DB).Queryx |
db.Queryx(query, params) |
| Java |
mybatis like |
select * from users where username like '%${name}%' |
| Java |
mybatis order by |
select * from users order by ${orderby} |
| Java |
mybatis-plus apply |
wrapper.eq("id", id).apply("username=" + name); |
| Python |
pymysql execute |
sql = "select * from users where username = '%s'" % (name) |
| Node.js |
mysql query |
sql = "select * from users where username = ${name}" |
在Shiro和Spring Security中,可以配置哪些API不需要进行权限校验
- 在Shiro中,可以使用Shiro的过滤器链(Filter Chain)来配置不需要进行权限校验的API
- 在Spring Security中,可通过继承WebSecurityConfigurerAdapter类并重写其中的configure()方法,配置不需要进行权限校验的API

像上述的内容可作为前置知识给AI输入,增加其分析的准确性
1. web.xml / Spring 配置分析
找出其中配置的可直接前台访问的 .jsp、.do、.action、.html、.json、.servlet 等接口路径。
指明配置项与访问路径的对应关系:
web.xml → <servlet-mapping>、<url-pattern>
@Controller、@RestController、@RequestMapping 等注解标注的接口
检查是否存在匿名访问的接口(无登录/权限验证拦截)。
检查 Filter、Interceptor、SecurityConfig、WebSecurityConfigurerAdapter 等中是否存在鉴权绕过配置。
2. classes / lib / jar 源码分析
对比 WEB-INF/classes 下的 .class 文件与反编译后的 .java 文件。
对 lib 下的 .jar 文件进行反编译,检查是否包含业务逻辑代码。
逐一分析对应的 Controller、Service、DAO、Repository 层实现:
对应的请求路径(前台/后台)
涉及的外部依赖或第三方库(如 HttpClient、JdbcTemplate、Hibernate 等)
标注潜在的高危点:未校验的用户输入、外部命令调用、文件上传写入、动态 SQL 拼接等。
3. 识别调用链路
标识所有暴露给前端或外部调用者的接口(如 REST API、RPC Endpoint、Controller 方法、Servlet)。
确定入口函数是否为用户完全可控(如 request.getParameter()、@RequestParam、@RequestBody)。
检查系统是否已接入统一认证(如 Spring Security / JWT / OAuth2 / Session)。
深入分析完整调用链:
Controller → Service → Repository → 外部系统
判断入口是否存在强约束:
用户归属验证
签名、时间戳、防重放机制
输出是否可以绕过认证或越权。
4. 重点模块审计(前台与后台分开)
重点排查以下常见的漏洞类型:
漏洞类型 漏洞Sink点(常见函数 / 类) 审计描述
SQL 注入 Statement.executeQuery(), Statement.executeUpdate(), JdbcTemplate.queryForList(), createNativeQuery(), EntityManager.createQuery() 检查点:SQL 是否通过字符串拼接、+、String.format、concat 等方式插入用户输入(如 Request 参数)。优先关注 MyBatis 自定义 SQL 与原生 JDBC 使用场景。
命令执行(RCE) Runtime.getRuntime().exec(), ProcessBuilder.start(), ShellUtils.exec() 检查点:是否拼接用户输入到命令中,或允许上传执行脚本。
文件上传 / 任意文件写入 MultipartFile.transferTo(), FileOutputStream.write(), Files.write(), FileUtils.copyInputStreamToFile() 检查点:是否校验扩展名、MIME、目录路径;是否防止 .jsp、.jspx、.java 等脚本文件上传。
反序列化 ObjectInputStream.readObject(), JSON.parseObject(), Yaml.load(), XStream.fromXML() 检查点:是否对外部输入执行反序列化;是否使用存在漏洞的库(如 fastjson < 1.2.83, Jackson 未加白名单)。
任意文件读取 Files.readAllBytes(), FileInputStream, IOUtils.toString(), response.getOutputStream().write() 检查点:是否直接读取用户指定路径;是否存在目录遍历绕过。
路径遍历 new File(), Paths.get(), ServletContext.getRealPath(), File.delete() 检查点:是否存在 ../ 等拼接导致目录逃逸。
XXE(XML 外部实体) DocumentBuilderFactory.newInstance(), SAXParserFactory.newInstance(), XmlMapper.readValue() 检查点:是否关闭外部实体解析;是否解析来自不可信来源的 XML。
SSRF HttpURLConnection, HttpClient.get(), RestTemplate.getForObject(), URL.openConnection() 检查点:是否允许用户指定 URL 并由服务器发请求;是否存在内网访问风险。
XSS response.getWriter().write(), 模板引擎输出 (<%= ... %>, Thymeleaf, Freemarker) 检查点:是否未进行 HTML/JS 输出转义。
认证绕过 / 越权 缺少 @PreAuthorize、@Secured、Session 检查或过滤器逻辑错误 检查点:检查接口访问控制逻辑,是否能直接调用他人资源。
5. 输出结构(每个发现需包含以下部分)
每个发现必须包含以下字段:
风险点名称
漏洞类型 + 影响接口 + 文件路径
漏洞成因
简述代码逻辑错误或输入未过滤的原因。
在net系统中,首先对dll进行反编译,然后让AI去关联路由和实现方法

### 审计和输出要求:
1. **web.config 分析**
- 找出其中配置的可直接前台访问的 `.ashx``.aspx` asmx ascx 文件。
- 指明配置项与访问路径的对应关系。
2. **bin 目录源码分析**
- 逐一对应 `bin` 下的 `.dll` 与其反编译出来的 `.cs` 文件。
- 分析对应的 `.ashx` 或 `.aspx` 、ascx asmx方法实现。
- 如果代码中存在潜在的高危点,需要重点标注
3. 识别调用链路
* (本文件内的路由/XXX 根据情况调整) 函数是暴露给前端或外部调用者的接口(如 API/RPC/Controller),其 request 对象是完全用户可控的
* 当前系统默认已接入统一认证中间件(如 JWT / Session / OAuth2),调用该函数的用户通常已登录
* 需要分析完整的调用链路,包括所有被调用的 Service 层、Repository 层和外部依赖
* 需要判断入口处有强约束(如强校验 user 归属/租户隔离/签名+时效+重放防护)
分析接口是通过什么鉴权的,尝试进行绕过,深入分析所有前台可访问的文件并挖掘漏洞
在项目中搜索所有 ASMX 接口,重点关注是否可匿名调用的未授权端点,并给出利用的wsdl方式和数据包
4.漏洞Sink点
| 漏洞类型 | 漏洞Sink点 | 审计描述 |
| ------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
| **SQL 注入** | `ExecuteNonQuery()`, `ExecuteReader()`, `ExecuteScalar()`, `SqlDataAdapter.Fill()`, `ExecuteSqlCommand()`, `ExecuteSqlRaw()`, `CreateSQLQuery()`, `connection.Query()` | **检查点**:查找 SQL 语句是否通过字符串拼接或格式化(`+`, `String.Format`, `$""`)将 `Request/Query/Form/Cookie` 等直接插入。 |
| **命令执行(RCE)** | `Process.Start()`, `ProcessStartInfo.FileName`, `ProcessStartInfo.Arguments` | **检查点**:是否把用户输入拼接到命令或传给 shell/PowerShell, `FileName` 与 `Arguments` 是否来自外部 |
| **文件上传 / 任意文件写入** | `SaveAs()`, `WriteAllBytes()`, `WriteAllText()`, `FileStream.Write()` | **检查点**:是否校验扩展名、MIME、内容类型、文件名(路径分隔符)、以及保存目录权限;是否防止覆盖已有文件,上传可执行脚本(`.aspx`/`.ashx`)getshell |
| **反序列化** | `BinaryFormatter.Deserialize()`, `SoapFormatter.Deserialize()`, `JsonConvert.DeserializeObject()`, `LosFormatter.Deserialize()` | **检查点**:反序列化是否对不可信输入(Request、Cookie、ViewState、文件等)执行;是否使用不安全的序列化库(BinaryFormatter、SoapFormatter) |
| **任意文件读取** | `File.ReadAllBytes()`, `File.ReadAllText()`, `Response.WriteFile()`, `Response.TransmitFile()`, `File()` | **检查点**:是否将用户参数直接作为文件路径输出或读取;是否存在未做路径合法化的文件下载接口。 |
| **路径遍历** | `Server.MapPath()`, `Path.Combine()`, `File.Delete()`, `Directory.GetFiles()` | **检查点**:路径拼接是否包含未过滤的用户输入;`Path.Combine` 后是否做规范化校验。 |
| **XXE(XML External Entity)** | `XmlDocument.LoadXml()`, `XmlDocument.Load()`, `XmlReader.Create()`, `DataSet.ReadXml()` | **检查点**:XML 解析是否启用了外部实体解析(DTD);是否解析来自不受信任来源的 XML。 |
| **SSRF**/远程文件下载 | `WebClient.DownloadString()`, `HttpClient.GetAsync()`, `WebRequest.Create()`, `HttpClient.PostAsync()` WebClient.DownloadFile()、HttpClient.GetStreamAsync()、HttpClient.GetByteArrayAsync()、WebRequest.GetResponseStream() | **检查点**:是否允许用户指定 URL 并由服务器发起请求;是否对目标地址做白名单或内部地址检测。 |
5. **输出结构**(每个发现都要包含以下部分)
- 风险点名称
- 漏洞成因(为什么可能触发)
- 攻击面分析(攻击者可能会怎么尝试)
- 关键代码片段(只展示相关函数或方法)
黑盒漏洞挖掘
个人观点
目前市面上大量工具打着AI 自动化漏洞挖掘、智能分析攻击链路的旗号,看似很酷炫但本质上是在用通用 Agent 架构包装传统扫描器。大多数通过 MCP 将模型与各类工具(发包、爬虫、指纹识别等)连接起来,试图让 AI 自主探索、组合工具、推导攻击路径,看起来“智能”“自动化”,但在真实黑盒安全场景中,这条路线存在根本性的工程与成本问题。MCP会不断尝试调用工具,然后根据结果修正答案,这样的操作会导致token消耗爆炸产生高额的费用,整体ROI其实为负
因此我认为,AI 在黑盒场景下的正确打开方式,不是无限制 Agent + MCP 调工具,而是针对场景去挖掘漏洞
目前对于SSRF、SQL注入这些探测已经很成熟了,因此我觉得未来方向应该着重于逻辑漏洞挖掘
1.黑盒安全不是“探索型问题”,而是“验证型问题”
黑盒漏洞挖掘的核心并不在于“能不能想到攻击手法”,而在于:
- 请求是否真实命中业务路径
- 返回数据是否具备越权或敏感属性
- 漏洞是否可稳定复现、可被证明成立
2.MCP 在黑盒场景下看起来智能,后期成本指数级失控,最终只能靠人工兜底
很多黑盒 MCP 服务在 Demo 中看起来效果不错,但问题往往出现在规模化运行之后:
- 请求数不可预测,模型为了提高“理解度”,会自然倾向于多次发包、多角度验证,但每一次都是真实成本。
- 工具调用链不可收敛, MCP 允许模型自由组合工具,但攻击链并不等于漏洞成立,复杂路径只会带来更多误报。
- 误报无法自动止损, AI 很容易给出“疑似漏洞”的判断,而这些“疑似”最终都需要人工复现,成本极高。
3.黑盒 AI 必须是“场景化裁判”,而不是“自由探索者”
真正可落地的黑盒 AI,不是让模型“自己决定下一步做什么”,而是先由人或规则系统把问题压缩成一个最小可验证场景。
也就是说:
- 场景先被定义(如 IDOR、越权、未授权访问、信息泄露)
- 输入、对照条件、请求模板全部固定
- 模型只负责判断结果是否成立
IDOR越权
流程设计
目前对于IDOR越权需要对多个参数进行构造和分析,会耗费大量的时间精力,因此我觉得AI赋能这个场景具有比较大的可塑性

实现效果
1.处理成标准的输入格式,burp导出数据包,右键选择save items

自动解析处理成规范输入格式,在demo目录生成随机文件夹用于后续分析

2.根据数据包中参数让ai判断是否存在可遍历性,可遍历性参数生成测试用例
【AI分析判定规则】
✔ 认为“可遍历”的参数:
- 纯数字:1、12、12345
- 明显自增 ID:orderId、userId、uid、id、page
- 数字 + 简单前缀后缀(如:10001、20002)
✘ 认为“不可遍历”的参数:
- 高随机字符串
- 明显 UUID / hash / token
- 大小写字母 + 数字混合、长度较长的字符串
例如:hjk2bvadn、A9xPqL0Zk
仅对“可遍历参数”继续后续步骤。

3.调用net/http库进行发包

根据PII、参数分析等规则划分为高中低风险

4.结束在前端展示,输出消耗token费用和耗时

输出风险参数及测试用例数据包

promot提示词
你是一名专业的 Web 安全测试与越权漏洞挖掘专家,请严格按照以下步骤对给定的数据包列表进行越权分析,不要跳步,不要假设结果。
【输入】
我将提供一批 HTTP 数据包(GET / POST 请求),每个数据包包含:
- 请求方法
- URL
- 请求参数(GET 参数或 POST body)
- 原始响应状态码
- 原始响应内容长度
【分析目标】
判断接口是否可能存在 越权漏洞(IDOR / BOLA / 水平越权 / 垂直越权)。
--------------------------------------------------
【分析步骤】
第一步:参数提取
1. 如果是 GET 请求:
- 提取 URL 中的所有参数,例如:
/api/xxx?aaa=1&bbb=abc
2. 如果是 POST 请求:
- 提取 body 中的参数,例如:
ccc=1&ddd=3
- JSON、form、x-www-form-urlencoded 均需解析
--------------------------------------------------
第二步:参数可遍历性判断
对每一个参数的值进行可遍历性分析:
【判定规则】
✔ 认为“可遍历”的参数:
- 纯数字:1、12、12345
- 明显自增 ID:orderId、userId、uid、id、page
- 数字 + 简单前缀后缀(如:10001、20002)
✘ 认为“不可遍历”的参数:
- 高随机字符串
- 明显 UUID / hash / token
- 大小写字母 + 数字混合、长度较长的字符串
例如:hjk2bvadn、A9xPqL0Zk
仅对“可遍历参数”继续后续步骤。
--------------------------------------------------
第三步:控制变量法修改参数
对每一个可遍历参数,单独进行修改,其他参数保持完全不变。
修改每一个参数生成一个测试用例,与原数据包进行对比
【修改规则】
- 数字参数:+1 或 -1
例如:
12345 → 12346
- 每次只修改一个参数
- 不同时修改多个参数
--------------------------------------------------
第四步:响应对比分析
对比【原始请求】与【修改参数后的请求】的响应:
重点关注:
1. HTTP 状态码
2. 响应内容长度
3. 响应语义是否发生变化
--------------------------------------------------
第五步:越权判定逻辑(核心)
【疑似存在越权漏洞】
满足以下所有条件:
- 修改参数后返回 HTTP 状态码为 200
- 响应内容长度发生明显变化
- 未命中任何权限拒绝关键字
→ 判定为:⚠️ 疑似存在越权漏洞(需要人工进一步确认)
【判定为不存在越权漏洞】
满足任意一个条件:
- 返回 HTTP 状态码为 403
- 或响应内容命中以下任一权限拒绝关键字(大小写不敏感):
(?i)permission\s*denied
(?i)access\s*denied
(?i)\bforbidden\b
(?i)unauthorized
(?i)not\s*authorized
(?i)not\s*allowed
(?i)no\s*permission
(?i)permission\s*required
(?i)insufficient\s*permission
(?i)insufficient\s*permissions
(?i)insufficient\s*privilege
(?i)insufficient\s*privileges
(?i)authentication\s*failed
(?i)authentication\s*required
(?i)login\s*required
(?i)not\s*logged\s*in
(?i)session\s*expired
(?i)invalid\s*session
(?i)invalid\s*token
(?i)token\s*expired
(?i)token\s*invalid
(?i)missing\s*token
(?i)jwt\s*expired
(?i)jwt\s*invalid
(?i)role\s*not\s*allowed
(?i)role\s*denied
(?i)authorization\s*failed
(?i)permission\s*check\s*failed
(?i)access\s*control\s*deny
(?i)rbac\s*deny
(?i)policy\s*denied
(?i)policy\s*reject
(?i)resource\s*access\s*denied
(?i)resource\s*not\s*owned
(?i)not\s*your\s*resource
(?i)resource\s*not\s*(found|exist)
(?i)record\s*not\s*(found|exist)
(?i)request\s*blocked
(?i)request\s*denied
(?i)security\s*policy\s*violation
(?i)access\s*blocked
(?i)\b403\b
→ 判定为:✅ 当前参数未发现越权漏洞
--------------------------------------------------
第六步:结果输出格式(必须遵守)
对每一个接口输出以下内容:
- 接口路径
- 请求方法
- 可遍历参数列表
- 被修改的参数及修改方式
- 原始响应状态码 / 长度
- 修改后响应状态码 / 长度
- 判定结论:
- 「疑似越权漏洞」
- 或「未发现越权」
如无法判断,明确说明原因,不要猜测。
模型费用对比及选择
通过多轮测试,在生成测试样例和判断PII数据准确率方面,各模型性能差异性不大,因此优先选择价格更便宜的模型model
测试下来,gpt-4.1-nano兼顾速度和费用优先选择,小任务可以选择Qwen
| 模型 |
描述 |
单接口消耗(USD) |
单接口消耗(RMB) |
推荐指数 |
| gpt-5-nano |
付费最便宜,主要是慢,一个请求需要等待3-5秒,不建议 |
$0.82 美分 |
$0.057 人民币 |
⭐⭐ |
| gpt-4.1-nano |
成本略高于 5-nano,但判断更稳,速度快,推荐 |
$0.91 美分 |
0.064元人民币 |
⭐⭐⭐⭐⭐ |
| Qwen |
免费,速度快,但是限频1分钟60次,容易429超时,数量少可选择 |
— |
— |
⭐⭐⭐ |
浏览插件自动化点击触发API
现在基于API测试越权已经实现了,要想实现全自动化挖洞还需要尽可能全的数据包,在甲方场景我们可以通过捕获流量重放去实现
在渗透攻防的场景下,如果需要人工一个个点击显得有点呆了,因此决定开发一个浏览器插件自动化触发button事件点击和提交表单
https://github.com/Pizz33/Xiadian_browser

智能元素识别
通过 isElementVisible() 函数进行识别button等点击元素
function findClickableElements() {
const selectors = [
'button:not([disabled])',
'a[href]:not([href="#"]):not([href="javascript:void(0)"])',
'input[type="submit"]:not([disabled])',
'input[type="button"]:not([disabled])',
'[role="button"]:not([disabled])',
'[onclick]',
'.btn:not([disabled])',
'.button:not([disabled])',
'[class*="button"]:not([disabled])',
'[class*="btn"]:not([disabled])'
]
动态内容监听
const observer = new MutationObserver(() => {
if (isRunning) {
}
})
observer.observe(document.body, {
childList: true, // 监听子节点变化
subtree: true
})
脚本注入与消息传递
- 延迟等待机制,确保脚本完全加载后再发送消息
- 通过
chrome.tabs.sendMessage 实现跨模块通信
startBtn.addEventListener('click', async () => {
const value = parseInt(inputValue.value) || 1
console.log('[Popup] 开始按钮被点击,输入值:', value)
// 重置统计
updateStats(0, 0)
// 保存状态
if (chrome.storage && chrome.storage.local) {
chrome.storage.local.set({
isRunning: true,
inputValue: value
})
}
主处理流程
- 定时执行机制:使用
setInterval 每 2 秒执行一次,控制操作频率
- 去重处理:使用
Set 数据结构记录已处理元素,避免重复操作
- 逐个处理按钮:每次只处理一个可点击元素,避免操作过快导致页面异常
function processPage() {
if (!isRunning) {
console.log('[自动点击助手] 未运行,跳过处理')
return
}
// 1. 查找所有可点击的元素
const clickableElements = findClickableElements()
// 2. 查找所有输入框
const inputElements = findInputElements()
console.log('[自动点击助手] 找到输入框:', inputElements.length, '个')
// 3. 处理输入框(遍历所有未处理的)
inputElements.forEach((input, index) => {
if (!processedElements.has(input)) {
console.log(`[自动点击助手] 处理输入框 ${index + 1}:`, input)
fillInput(input)
processedElements.add(input)
filledCount++
updateStats()
}
})
// 4. 处理可点击元素(每次只点击一个,避免过快)
if (clickableElements.length > 0) {
const unprocessedElements = clickableElements.filter(el => !processedElements.has(el))
if (unprocessedElements.length > 0) {
const element = unprocessedElements[0]
console.log('[自动点击助手] 准备点击元素:', element)
clickElement(element)
processedElements.add(element)
clickedCount++
updateStats()
}
}
}
流程设计优化
在满足我们的需求后,我们还可以对流程进行调整节省消耗
- 每个文件夹独立调用AI分析 ---> 统一收集所有参数,一次性AI分析
- AI调用次数 = API文件夹数量 ---> AI调用次数 = 1(参数分析)+ N(PII命中时的响应分析)
- 测试用例生成 ---> AI测试用例直接生成(+1/-1),不调用AI
- 处理顺序:串行处理每个文件夹 ---> 处理顺序:并行处理多个文件夹

详细对比
| 阶段 |
旧流程耗时 |
新流程耗时 |
优化比例 |
| 参数收集 |
10秒 |
8秒 |
20%↓ |
| AI参数分析 |
100秒(100次调用) |
3秒(1次调用) |
97%↓ |
| 测试用例生成 |
50秒(AI生成) |
1秒(直接生成) |
98%↓ |
| 测试用例验证 |
120秒 |
100秒 |
17%↓ |
| AI响应分析 |
20秒(50次调用) |
8秒(20次调用) |
60%↓ |
| 总计 |
300秒 |
120秒 |
60%↓ |
Token消耗对比
| 类型 |
旧流程 |
新流程 |
节省 |
| 参数分析Token |
150K |
2K |
98.7%↓ |
| 响应分析Token |
50K |
20K |
60%↓ |
| 总计 |
200K |
22K |
89%↓ |