将 AI 生成的内容改写得更自然、更像人类书写的文本 的 工具
再推荐一个项目:Humanizer-zh 。
一个用于去除文本中 AI 生成痕迹的工具,帮助你将 AI 生成的内容改写得更自然、更像人类书写的文本。
本项目适用于:
编辑和审阅 AI 生成的内容
提升文章的人性化程度
学习识别 AI 写作的常见模式
资源
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
再推荐一个项目:Humanizer-zh 。
一个用于去除文本中 AI 生成痕迹的工具,帮助你将 AI 生成的内容改写得更自然、更像人类书写的文本。
本项目适用于:
编辑和审阅 AI 生成的内容
提升文章的人性化程度
学习识别 AI 写作的常见模式
资源
把以前写的饭否 iOS 客户端开饭使用 AI 重写了,感觉很不错了,很多功能我以前根本不会写,我只能说 AI 真的太强了
更新日志:
更流畅的体验
转发、回复交互逻辑修改
支持语音输入
支持 ocr 输入
拍照支持多种滤镜
iPad 上支持分屏界面
支持自定义 tab 栏
支持自定义字体
支持分享图片、复制图片
使用本机数据库存储 节省流量更流畅
主题只保留黑色、白色和跟随系统
增加一些动画效果
下载链接
https://apps.apple.com/hk/app/开饭-饭否客户端/id1189449526
以前的我:
这个我不会,这页面好卡,这里怎么闪退了
现在有了 AI 的我:
我现在强得可怕

allowed-tools 配置不能限制工具的使用。agent 字段只有配合 context: fork 才会生效context: fork:Skill 在主 agent 上下文执行,继承主 agent 全部工具,agent 和 allowed-tools 字段被忽略context: fork:Skill 在独立子代理执行,agent 字段生效,限制工具集为该 agent 类型的固有工具agent 优先于 allowed-tools:当同时指定时,agent 类型决定工具集,allowed-tools 无法扩展name: test-agent-tools
description: 测试 agent 字段和 allowed-tools 的优先级关系
version: 1.0.0
agent: Bash
allowed-tools: Bash, Read
user-invocable: true agent 字段被忽略,Skill 在主 agent 上下文执行,继承全部工具name: test-agent-tools description: 测试 agent 字段和 allowed-tools 的优先级关系 version: 1.0.0 agent: Bash allowed-tools: Bash, Read user-invocable: true context: fork agent: Bash 生效,限制工具集为 Bash agent 的工具| 配置 | Bash | Read | Write |
|---|---|---|---|
无 context: fork | |||
有 context: fork |
大佬们好,我最近花了几个月的时间做了一个英雄联盟云顶之弈自动挂机的软件,初衷是为了全自动刷通行证和宝典。
Github 地址:Tft-Hextech-Helper

具体的方案是纯粹的视觉识别:OCR+模版匹配。不涉及任何的内存读取,操作则控制鼠标进行点击。同时使用了 LOL 官方公开的 API 接口来实现自动排队,自动接收对局等,目前可以做到全流程打通,挂一整天完全不用手动。我高强度挂机了两天,从青铜打到了白银三,期间没有被封过。
这里想跟各位大佬交流一下,这种完全不读取内存的方案,存在被封号的可能性吗?会不会检查玩家的鼠标移动是否平滑之类的?希望大佬们积极解答,也欢迎使用和 star 。
把以前写的饭否 iOS 客户端开饭使用 AI 重写了,感觉很不错了,很多功能我以前根本不会写,我只能说 AI 真的太强了
更新日志:
更流畅的体验
转发、回复交互逻辑修改
支持语音输入
支持 ocr 输入
拍照支持多种滤镜
iPad 上支持分屏界面
支持自定义 tab 栏
支持自定义字体
支持分享图片、复制图片
使用本机数据库存储 节省流量更流畅
主题只保留黑色、白色和跟随系统
增加一些动画效果
下载链接
https://apps.apple.com/hk/app/开饭-饭否客户端/id1189449526
以前的我:
这个我不会,这页面好卡,这里怎么闪退了
现在有了 AI 的我:
我现在强得可怕

大佬们好,我最近花了几个月的时间做了一个英雄联盟云顶之弈自动挂机的软件,初衷是为了全自动刷通行证和宝典。
Github 地址:Tft-Hextech-Helper

具体的方案是纯粹的视觉识别:OCR+模版匹配。不涉及任何的内存读取,操作则控制鼠标进行点击。同时使用了 LOL 官方公开的 API 接口来实现自动排队,自动接收对局等,目前可以做到全流程打通,挂一整天完全不用手动。我高强度挂机了两天,从青铜打到了白银三,期间没有被封过。
这里想跟各位大佬交流一下,这种完全不读取内存的方案,存在被封号的可能性吗?会不会检查玩家的鼠标移动是否平滑之类的?希望大佬们积极解答,也欢迎使用和 star 。
可以单纯作为 YouTube 下载器的备用软件。
PS: 如果在使用基于 yt-dlp 的软件时出现没法正常下载的情况,基本都是节点不行,需要更换可用节点
我大概用了两周的 coding agent 工作流:Superpowers(obra/superpowers)。今天看到它出现在 claude-plugins-official 列表里(我这边 /plugin 能看到 source),顺便分享下它的工作流思路。
来源:
Reddit 讨论:https://www.reddit.com/r/ClaudeCode/comments/1qgkupf/superpowers_is_now_on_the_official_claude/
它有一套最近大家在聊的很火的 skills,用来把 agent 拉回 “先想清楚、再动手、再验证” 的节奏,核心链路大概是:
brainstorming(/superpowers:brainstorm):任何 “要开始写 / 改功能” 之前先用它,把需求 / 约束 / 成功标准摸清楚,先出设计再实现(分段确认)
writing-plans(/superpowers:write-plan):把实现拆成很小、可验证的 steps,避免一口气写一大坨
executing-plans(/superpowers:execute-plan):按批次执行计划,每批做一次 review/checkpoint
test-driven-development:强调 red/green/refactor(先失败的测试,再最小实现)
verification-before-completion + systematic-debugging:先验证再宣称 “修好了”,遇到 bug 用更系统的方法追根因
安装我就不复读了:README 里 Claude Code/Codex/OpenCode 都有对应的入口和指令。我个人感觉最有用的是先从 brainstorming 那套问答 / 设计确认开始。
我也在不断熟悉这套工作流中,感觉它就是我想要的 coding agent 工作流。


看了其他佬友的,正常是 2 年,也有 5 年
4 年是什么原理?已有佬友在评论区展现 us 区 + Gpay,欢迎大家分享经验!
注意注意,先领取普通版 365,再去尝试 Premium 团队版 365!
分享下我的踩坑流程,希望能给大家带来帮助

1. 我先在 tw 区的链接,edu 的认证什么的都很顺利,但是卡在了绑卡上,试了 PayPal 和直接输入卡号都不行
https://checkout.microsoft365.com/acquire/purchase?language=zh-TW&market=TW&requestedDuration=Month&scenario=microsoft-365-student&client=poc&campaign=StudentFree12M
2. 于是换成 us 区,还是用之前的 edu(之前屯的 tw 的 edu)使用以下链接 https://checkout.microsoft365.com/acquire/purchase?language=en-US&market=US&requestedDuration=Month&scenario=microsoft-365-student&client=poc&campaign=StudentFree12M
这次还是卡在绑卡上,发现可以使用 Gpay,绑定,顺利通过!
3. 领取普通版本的 365 之后,尝试领取 Premium 版本的 365,也是 us 区,使用如下链接
https://checkout.microsoft365.com/acquire/purchase?language=en-US&market=US&requestedDuration=Month&scenario=microsoft-365-premium&client=poc&campaign=StudentPremiumFree12M
4. 它会一直显示错误,刷新也错误,本来我听别人说封车了,但是不要放弃!在不断尝试刷新、隐私网页再登陆领取,最后和之前一样的流程,绑定 Gpay 之后领取成功了
5. 最后在这里查看订阅时长:https://account.microsoft.com/services/
30 年 2 月 17 日到期,总共领取 4 年!
不清楚为什么和其他人不同,可能和地区或者邮箱有关吧,但是我个人用的是 us 区 + tw 的 edu,这种混搭感觉也不是很靠谱,佬友们参考看看吧
领到的佬友们记得取消自动续期哦
又到年终汇报时间,又要搞 word 格式,又要 ppt 形式述职,下面总结一下经验可以给佬们参考。
先根据每个月的月总按照公司模板生成年总需要填写的内容,这里我用的 Google AI Studio - Gemini 3 pro。没有月总的可以看看自己 Git 提交记录找找今年做了什么。
使用 Z.ai 生成 PPT。
![[工具] AI 生成的 PPT 导出 PDF 转 PPTX 解决样式丢失 | 附年终述职的思路1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/19/20260119175220_696dfed401563.png!mark)
![[工具] AI 生成的 PPT 导出 PDF 转 PPTX 解决样式丢失 | 附年终述职的思路2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/19/20260119175222_696dfed61bb4c.png!mark)
这里导出的 PPTX 打开后,会发现样式有变化。
可以使用先导出 PDF,之后使用 Python 脚本将 PDF 转为图片,图片再转为 PPTX,这样就解决样式变化的问题了。
pip install pymupdf python-pptx
pdf2pptx.py,内容:import fitz # PyMuPDF
from pptx import Presentation
from pptx.util import Inches
import io
import os
def pdf_to_pptx(pdf_path, pptx_path, dpi=300):
"""
将 PDF 转换为 PPTX(每一页作为一张全屏图片)
:param pdf_path: 输入 PDF 文件路径
:param pptx_path: 输出 PPTX 文件路径
:param dpi: 渲染清晰度,300 已经非常清晰,如果文件太大可以降到 200
"""
# 1. 打开 PDF
pdf_doc = fitz.open(pdf_path)
prs = Presentation()
# 2. 获取 PDF 第一页的尺寸,并设置为 PPT 的幻灯片尺寸
# PDF 默认单位是点 (points), 1 inch = 72 points
first_page = pdf_doc[0]
width_pts, height_pts = first_page.rect.width, first_page.rect.height
prs.slide_width = Inches(width_pts / 72)
prs.slide_height = Inches(height_pts / 72)
print(f"开始转换: {pdf_path}")
print(f"总页数: {len(pdf_doc)}")
# 3. 逐页处理
for page_num in range(len(pdf_doc)):
page = pdf_doc.load_page(page_num)
# 渲染页面为图片 (设置缩放倍数以提高清晰度)
zoom = dpi / 72
mat = fitz.Matrix(zoom, zoom)
pix = page.get_pixmap(matrix=mat, alpha=False)
# 将图片存入内存流中,避免产生临时文件
img_stream = io.BytesIO(pix.tobytes("png"))
# 添加一张空白幻灯片 (6 是空白布局)
slide_layout = prs.slide_layouts[6]
slide = prs.slides.add_slide(slide_layout)
# 将图片插入幻灯片,铺满全屏
slide.shapes.add_picture(img_stream, 0, 0, width=prs.slide_width, height=prs.slide_height)
print(f"正在处理第 {page_num + 1} 页...")
# 4. 保存文件
prs.save(pptx_path)
pdf_doc.close()
print(f"转换完成!已保存至: {pptx_path}")
if __name__ == "__main__":
# === 使用说明 ===
# 将下面的文件名替换为你实际的文件名
input_pdf = "input.pdf"
output_pptx = "output.pptx"
if os.path.exists(input_pdf):
pdf_to_pptx(input_pdf, output_pptx)
else:
print(f"错误:找不到文件 {input_pdf}")
input.pdf,然后执行:python pdf2pptx.py
![[工具] AI 生成的 PPT 导出 PDF 转 PPTX 解决样式丢失 | 附年终述职的思路3](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/19/20260119175227_696dfedb4692e.png!mark)
output.pptx。可以再让 AI 帮你输出一份口述草稿配合起来就行了。有尝试过在线 ILovePDF 网站去转,但是样式还是有问题。
试过 NotebookLM 生成 PPT,效果一般般,没想到 Z.ai 生成的效果还挺好看的
概述
使用 postgresql + etcd + patroni + haproxy + keepalived 可以实现 PG 的高可用集群,其中,以 postgresql 做数据库,Patroni 监控本地的 PostgreSQL 状态,并将本地 PostgreSQL 信息 / 状态写入 etcd 来存储集群状态,所以,patroni 与 etcd 结合可以实现数据库集群故障切换(自动或手动切换),而 haproxy 可以实现数据库读写分离 + 读负载均衡(通过不同端口实现),keepalived 实现 VIP 跳转,对 haproxy 提供了高可用,防止 haproxy 宕机。
Patroni 是一个基于 Python 的用于实现 PostgreSQL HA 解决方案的框架。为了最大程度的兼容性,它支持多种分布式配置存储,包括 ZooKeeper、etcd、Consul 或 Kubernetes。旨在帮助数据库工程师、DBA、DevOps 工程师和 SRE 快速部署数据中心(或任何地方)的 HA PostgreSQL 环境。
当前支持的 PostgreSQL 版本从 9.3 到 16。支持自动化故障转移、物理复制和逻辑复制、提供 RESTful API 接口,允许外部应用或运维工具直接操作 PostgreSQL 集群,进行如启停、迁移等操作,与 Linux watchdog 集成,以避免脑裂现象。
etcd 是一个分布式键值存储数据库,支持跨平台,拥有强大的社区。etcd 的 Raft 算法,提供了可靠的方式存储分布式集群涉及的数据。etcd 广泛应用在微服务架构和 Kubernates 集群中,不仅可以作为服务注册与发现,还可以作为键值对存储的中间件。从业务系统 Web 到 Kubernetes 集群,都可以很方便地从 etcd 中读取、写入数据。
etcd 完整的 cluster(集群)至少有三台,这样才能选举出一个 master 节点,两个 slave 节点。如果小于 3 台则无法进行选举,造成集群不可用。Etcd 使用 2379 和 2380 端口。
2379 端口:提供 HTTP API 服务,和 etcdctl 交互
2380 端口:集群中节点间通讯
项目地址:[[GitHub - etcd-io/etcd: Distributed reliable key-value store for the most critical data of a distributed system]]
| 服务器名 | ip 地址 | os | 数据库读写端口 | 只读端口 | 组件 | 组件端口 |
|---|---|---|---|---|---|---|
| k8s-mater01 | 192.168.28.11 | ubuntu 24.10 | 15433 | 25433 | PostgreSQL,Patroni、Etcd,haproxy、keepalived | 8008 |
| k8s-mater02 | 192.168.28.12 | ubuntu 24.10 | 15433 | 25433 | PostgreSQL,Patroni、Etcd,haproxy、keepalived | 8008 |
| k8s-mater01 | 192.168.28.13 | ubuntu 24.10 | 15433 | 25433 | PostgreSQL,Patroni、Etcd,haproxy、keepalived | 8008 |
| vip | 192.168.28.10 | PostgreSQL,Patroni、Etcd,haproxy、keepalived | 8008 |
| 软件名 | 版本 |
|---|---|
| Patroni | 4.0.6 |
| Etcd | 3.5.16 |
| Keepalived | 2.3.1 |
| Haproxy | 2.9.10-1ubuntu1.2 |
| PostgreSQL | 16.9 |
| watchdog | 5.16 |
| python | 3.12.7 |

这个架构中,PostgreSQL 提供数据服务,Patroni 负责主从切换,etcd 提供一致性存储,HAProxy 提供访问路由,Keepalived 提供网络 VIP 高可用,Watchdog 提供节点存活及脑裂防护机制。 六者协同组成一个企业级高可用数据库集群
关闭防火墙 (相对简单,但是不安全)
放行对应的端口(安全)
sudo apt install curl ca-certificates
sudo install -d /usr/share/postgresql-common/pgdg
sudo curl -o /usr/share/postgresql-common/pgdg/apt.postgresql.org.asc --fail https://www.postgresql.org/media/keys/ACCC4CF8.asc
. /etc/os-release
sudo sh -c "echo 'deb [signed-by=/usr/share/postgresql-common/pgdg/apt.postgresql.org.asc] https://apt.postgresql.org/pub/repos/apt $VERSION_CODENAME-pgdg main' > /etc/apt/sources.list.d/pgdg.list" sudo apt update
sudo apt -y install postgresql
mkdir -p /data/postgresql/pgdata/
mkdir -p /data/postgresql/pg_archive/
chown -R postgres:postgres /data/postgresql/
mkdir -p /home/postgres/
chown -R postgres:postgres /home/postgres/
vim /etc/passwd
#修改postgres 家目录为/home/postgres postgres:x:114:113:PostgreSQL administrator,,,:/home/postgres:/bin/bash vim /home/postgres/.bashrc
[ -f /etc/profile ] && source /etc/profile
export PATH=/usr/lib/postgresql/16/bin:$PATH # If you want to customize your settings, # Use the file below. This is not overridden # by the RPMS.
[ -f /var/lib/pgsql/.pgsql_profile ] && source /var/lib/pgsql/.pgsql_profile
vim /etc/sudoers
#行末新增
postgres ALL=(ALL) NOPASSWD: ALL wget https://github.com/etcd-io/etcd/releases/download/v3.6.4/etcd-v3.6.4-linux-amd64.tar.gz
tar -xf etcd-v3.6.4-linux-amd64.tar.gz --strip-components=1 -C /usr/local/bin etcd-v3.6.4-linux-amd64/etcd etcd-v3.6.4-linux-amd64/etcdctl
mkdir -p /etc/etcd/
mkdir -p /data/etcd/
touch /etc/etcd/etcd-pg.config.yml
#节点1配置文件
vim /etc/etcd/etcd-pg.config.yml
#节点名
name: pg-etcd01
#数据目录
data-dir: /data/etcd
snapshot-count: 5000
#选举和心跳参数
heartbeat-interval: 100
election-timeout: 1000
#存储新能优化
quota-backend-bytes: 8589934592
max-request-bytes: 10485760
max-concurrent-requests: 5000
#自动压缩与碎片整理
auto-compaction-mode: periodic
auto-compaction-retention: "2h"
#集群通信配置
listen-peer-urls: "http://192.168.28.11:12380"
listen-client-urls: "http://192.168.28.11:12379,http://127.0.0.1:12379"
max-snapshots: 3
max-wals: 5
cors:
initial-advertise-peer-urls: "http://192.168.28.11:12380"
advertise-client-urls: "http://192.168.28.11:12379"
discovery:
discovery-fallback: 'proxy'
discovery-proxy:
discovery-srv:
initial-cluster: "pg-etcd01=http://k8s-etcd01:12380,pg-etcd02=http://k8s-etcd02:12380,pg-etcd03=http://k8s-etcd03:12380"
initial-cluster-token: 'etcd-cluster-pg'
initial-cluster-state: 'new'
strict-reconfig-check: false
enable-v2: true
enable-pprof: true
proxy: 'off'
proxy-failure-wait: 5000
proxy-refresh-interval: 30000
proxy-dial-timeout: 1000
proxy-write-timeout: 5000
proxy-read-timeout: 0
#节点2配置文件
name: pg-etcd02
data-dir: /data/etcd
snapshot-count: 5000
#选举和心跳参数
heartbeat-interval: 100
election-timeout: 1000
#存储新能优化
quota-backend-bytes: 8589934592
max-request-bytes: 10485760
max-concurrent-requests: 5000
#自动压缩与碎片整理
auto-compaction-mode: periodic
auto-compaction-retention: "2h"
#集群通信配置
listen-peer-urls: "http://192.168.28.12:12380"
listen-client-urls: "http://192.168.28.12:12379,http://127.0.0.1:12379"
max-snapshots: 3
max-wals: 5
cors:
initial-advertise-peer-urls: "http://192.168.28.12:12380"
advertise-client-urls: "http://192.168.28.12:12379"
discovery:
discovery-fallback: 'proxy'
discovery-proxy:
discovery-srv:
initial-cluster: "pg-etcd01=http://k8s-etcd01:12380,pg-etcd02=http://k8s-etcd02:12380,pg-etcd03=http://k8s-etcd03:12380"
initial-cluster-token: 'etcd-cluster-pg'
initial-cluster-state: 'new'
strict-reconfig-check: false
enable-v2: true
enable-pprof: true
proxy: 'off'
proxy-failure-wait: 5000
proxy-refresh-interval: 30000
proxy-dial-timeout: 1000
proxy-write-timeout: 5000
proxy-read-timeout: 0
#节点3配置文件
name: pg-etcd03
data-dir: /data/etcd
snapshot-count: 5000
#选举和心跳参数
heartbeat-interval: 100
election-timeout: 1000
#存储新能优化
quota-backend-bytes: 8589934592
max-request-bytes: 10485760
max-concurrent-requests: 5000
#自动压缩与碎片整理
auto-compaction-mode: periodic
auto-compaction-retention: "2h"
#集群通信配置
listen-peer-urls: "http://192.168.28.13:12380"
listen-client-urls: "http://192.168.28.13:12379,http://127.0.0.1:12379"
max-snapshots: 3
max-wals: 5
cors:
initial-advertise-peer-urls: "http://192.168.28.13:12380"
advertise-client-urls: "http://192.168.28.13:12379"
discovery:
discovery-fallback: 'proxy'
discovery-proxy:
discovery-srv:
initial-cluster: "pg-etcd01=http://k8s-etcd01:12380,pg-etcd02=http://k8s-etcd02:12380,pg-etcd03=http://k8s-etcd03:12380"
initial-cluster-token: 'etcd-cluster-pg'
initial-cluster-state: 'new'
strict-reconfig-check: false
enable-v2: true
enable-pprof: true
proxy: 'off'
proxy-failure-wait: 5000
proxy-refresh-interval: 30000
proxy-dial-timeout: 1000
proxy-write-timeout: 5000
proxy-read-timeout: 0
vim /etc/systemd/system/etcd-pg.service
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=notify
ExecStart=/usr/local/bin/etcd --config-file=/etc/etcd/etcd-pg.config.yml
Restart=on-failure
RestartSec=5
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
启动 etcd-pg 服务
systemctl daemon-reload
systemctl start etcd-pg.service
systemctl enable etcd-pg.service
root@k8s-master01:~# etcdctl --endpoints="k8s-etcd01:12379,k8s-etcd02:12379,k8s-etcd03:12379" member list -w=table
+------------------+---------+-----------+-------------------------+----------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+-----------+-------------------------+----------------------------+------------+
| 2bb79737c88dd84d | started | pg-etcd03 | http://k8s-etcd03:12380 | http://192.168.28.13:12379 | false |
| 354b7a6aa8551f4a | started | pg-etcd02 | http://k8s-etcd02:12380 | http://192.168.28.12:12379 | false |
| 84101e54de967367 | started | pg-etcd01 | http://k8s-etcd01:12380 | http://192.168.28.11:12379为了简化命令,可以通过 alisa 配置
cd ~
vim .profile
alias etcdctlpg="etcdctl --endpoints="k8s-etcd01:12379,k8s-etcd02:12379,k8s-etcd03:12379" " source .profile
root@k8s-master01:~# etcdctlpg member list -w=table
+------------------+---------+-----------+-------------------------+----------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+-----------+-------------------------+----------------------------+------------+
| 2bb79737c88dd84d | started | pg-etcd03 | http://k8s-etcd03:12380 | http://192.168.28.13:12379 | false |
| 354b7a6aa8551f4a | started | pg-etcd02 | http://k8s-etcd02:12380 | http://192.168.28.12:12379 | false |
| 84101e54de967367 | started | pg-etcd01 | http://k8s-etcd01:12380 | http://192.168.28.11:12379 | false |
watchdog 防止脑裂。Patroni 支持通过 Linux 的 watchdog 监视 patroni 进程的运行,当 patroni 进程无法正常往 watchdog 设备写入心跳时,由 watchdog 触发 Linux 重启。
# 安装软件,linux内置功能 sudo apt install -y watchdog
# 初始化watchdog字符设备 sudo modprobe softdog
# 修改/dev/watchdog设备权限 sudo chmod 666 /dev/watchdog
sudo chown postgres:postgres /dev/watchdog
# 启动watchdog服务 sudo systemctl start watchdog
sudo systemctl enable watchdog
1. pip3 install --break-system-packages psycopg2-binary
2. pip3 install --break-system-packages patroni[etcd]
3. pip3 install --break-system-packages python-json-logger
4. mkdir -p /etc/patroni
cat /etc/systemd/system/patroni-5433.service
[Unit]
Description=Patroni high-availability PostgreSQL
After=syslog.target network.target etcd.service
Requires=etcd-pg.service
[Service]
Type=simple
User=postgres
Group=postgres
# 使用watchdog进行服务监控 ExecStartPre=-/usr/bin/sudo /sbin/modprobe softdog ExecStartPre=-/usr/bin/sudo /bin/chown postgres /dev/watchdog
PermissionsStartOnly=true
WorkingDirectory=/home/postgres/
ExecStart=/usr/local/bin/patroni /etc/patroni/patroni-5433.yaml
ExecReload=/bin/kill -HUP
KillMode=process
Restart=always
RestartSec=10
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
su postgres
cd ~
#备库从主库同步WAL日志使用,主备倒换后,主库降备库,新备库使用,所以备库也配置
touch .pgpass
vim .pgpass
192.168.28.11:5433:*:replica:replica 192.168.28.12:5433:*:replica:replica 192.168.28.13:5433:*:replica:replica sudo mkdir -p /var/log/patroni/
sudo chown -R postgres:postgres /var/log/patroni/
根据节点依次启动 Patroni
sudo systemctl daemon-reload
sudo systemctl restart patroni-5433.service
sudo systemctl enable patroni-5433.service
sudo systemctl status patroni-5433.service
查看服务状态,默认情况下,根据配置文件中,initdb 内容,Patroni 会自动对数据库进行初始化操作,并创建用户,配置文件,拉起数据库并建立主从关系及流复制
root@k8s-master01:~# patronictl -c /etc/patroni/patroni-5433.yaml list
+ Cluster: pg_patroni_etcd () ---+-----------+----+-----------+ | Member | Host | Role | State | TL | Lag in MB | + | pg_patroni_5433_01 | 192.168.28.11:5433 | Leader | running | 17 | | | pg_patroni_5433_02 | 192.168.28.12:5433 | Replica | streaming | 17 | 0 | | pg_patroni_5433_03 | 192.168.28.13:5433 | Replica | streaming | 17 | 0 | + 通过 alisa 设置简易命令
alias patr5433="patronictl -c /etc/patroni/patroni-5433.yaml" patronictl -c /etc/patroni/patroni-5433.yaml list
reinit 先是移除了整个 data 目录。然后选择正确的节点进行备份恢复。
patronictl -c /etc/patroni/patroni-5433.yaml reinit [nodename]
patronictl -c /etc/patroni/patroni-5433.yaml show-config
patronictl -c /etc/patroni/patroni-5433.yaml edit-config
#重载参数
patronictl -c /etc/patroni/patroni-5433.yaml reload [nodename]
patronictl -c /etc/patroni/patroni-5433.yaml restart [clustername] [nodename] patronictl -c /etc/patroni/patroni-5433.yaml restart [clustername] --pending patronictl -c /etc/patroni/patroni-5433.yaml restart [clustername]
patronictl pause 暂时将 Patroni 集群置于维护模式并禁用自动
在某些情况下,Patroni 需要暂时退出集群管理,同时仍然在 DCS 中保留集群状态。可能的用例是集群上不常见的活动,例如主要版本升级或损坏恢复。在这些活动期间,节点经常因为 Patroni 不知道的原因而启动和停止,有些节点甚至可以暂时提升,这违反了只运行一个主节点的假设。因此,Patroni 需要能够与正在运行的集群 “分离”,在 Pacemaker 中实现与维护模式相当的功能。
patronictl resume 将使 Patroni 集群退出维护模式,并重新启用自动故障转移。
自动拉起所有数据库
# Switchover
root@k8s-master01:~# patr5433 switchover
Current cluster topology
+ Cluster: pg_patroni_etcd (7540584003720074567) ---+-----------+----+-----------+
| Member | Host | Role | State | TL | Lag in MB |
+--------------------+--------------------+---------+-----------+----+-----------+
| pg_patroni_5433_01 | 192.168.28.11:5433 | Leader | running | 22 | |
| pg_patroni_5433_02 | 192.168.28.12:5433 | Replica | streaming | 22 | 0 |
| pg_patroni_5433_03 | 192.168.28.13:5433 | Replica | streaming | 22 | 0 |
+--------------------+--------------------+---------+-----------+----+-----------+
Primary [pg_patroni_5433_01]:
Candidate ['pg_patroni_5433_02', 'pg_patroni_5433_03'] []: pg_patroni_5433_02
When should the switchover take place (e.g. 2025-08-26T12:26 ) [now]: now
Are you sure you want to switchover cluster pg_patroni_etcd, demoting current leader pg_patroni_5433_01? [y/N]: y
2025-08-26 11:26:32.31189 Successfully switched over to "pg_patroni_5433_02"
+ Cluster: pg_patroni_etcd (7540584003720074567) ---+---------+----+-----------+
| Member | Host | Role | State | TL | Lag in MB |
+--------------------+--------------------+---------+---------+----+-----------+
| pg_patroni_5433_01 | 192.168.28.11:5433 | Replica | stopped | | unknown |
| pg_patroni_5433_02 | 192.168.28.12:5433 | Leader | running | 22 | |
| pg_patroni_5433_03 | 192.168.28.13:5433 | Replica | running | 22 | 0 |
+--------------------+--------------------+---------+---------+----+-----------+
root@k8s-master01:~# patr5433 list
+ Cluster: pg_patroni_etcd (7540584003720074567) ---+-----------+----+-----------+
| Member | Host | Role | State | TL | Lag in MB |
+--------------------+--------------------+---------+-----------+----+-----------+
| pg_patroni_5433_01 | 192.168.28.11:5433 | Replica | streaming | 23 | 0 |
| pg_patroni_5433_02 | 192.168.28.12:5433 | Leader | running | 23 | |
| pg_patroni_5433_03 | 192.168.28.13:5433 | Replica | streaming | 23 | 0 |
+--------------------+--------------------+---------+-----------+----+-----------+
数据库从 pg_patroni_5433_01 switchover 到 pg_patroni_5433_02
[root@pgtest1 ~]# curl -s http://192.168.28.11:8008/switchover -XPOST -d '{"leader":"pg_patroni_5433_01","candidate":"pg_patroni_5433_02"}'
Successfully switched over to "pg_patroni_5433_02" patronictl failover
# Failover
[postgres@pgtest1 ~]$ patronictl -c /etc/patroni/patroni-5433.yaml failover
Candidate ['pg_patroni_5433_01', 'pg_patroni_5433_02','pg_patroni_5433_03'] []: pg_patroni_5433_01
Current cluster topology
... ...
Are you sure you want to failover cluster pg_cluster, demoting current master pg_patroni_5433_02? [y/N]: y
2021-10-28 03:47:56.13486 Successfully failed over to "pg_patroni_5433_01"
... ...
root@k8s-master01:~# patronictl -c /etc/patroni/patroni-5433.yaml dsn
host=192.168.28.12 port=5433 sudo apt install haproxy
sudo vim /etc/haproxy/haproxy.cfg
global
maxconn 2000
ulimit-n 16384
log 127.0.0.1 local0 err
stats timeout 30s
defaults
log global
mode http
option httplog
timeout connect 5000
timeout client 50000
timeout server 50000
timeout http-request 15s
timeout http-keep-alive 15s
listen status_page
bind *:8888
stats enable
stats uri /haproxy-status
stats auth admin:admin
stats realm "Welcome to the haproxy load balancer status page of k8s-master"
frontend monitor-in
bind *:33305
mode http
option httplog
monitor-uri /monitor
# 主库读写端口
listen master
bind *:15433
mode tcp
option tcplog
balance roundrobin
option httpchk OPTIONS /master
http-check expect status 200
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
server pgtest1 192.168.28.11:5433 maxconn 1000 check port 8008 inter 5000 rise 2 fall 2
server pgtest2 192.168.28.12:5433 maxconn 1000 check port 8008 inter 5000 rise 2 fall 2
server pgtest3 192.168.28.13:5433 maxconn 1000 check port 8008 inter 5000 rise 2 fall 2
#从库读端口
listen replicas
bind *:25433
mode tcp
option tcplog
balance roundrobin
option httpchk OPTIONS /replica
http-check expect status 200
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
server pgtest1 192.168.28.11:5433 maxconn 1000 check port 8008 inter 5000 rise 2 fall 2
server pgtest2 192.168.28.12:5433 maxconn 1000 check port 8008 inter 5000 rise 2 fall 2
server pgtest3 192.168.28.13:5433 maxconn 1000 check port 8008 inter 5000 rise 2 fall 2
sudo systemctl enable haproxy
sudo systemctl start haproxy

登录地址:[[http://192.168.28.11:8888/haproxy-status]] (也可以通过各个节点 IP + 端口登录)
默认用户密码:admin/admin
sudo apt install -y keepalived
vim /etc/keepalived/keepalived.conf
global_defs {
router_id LVS_DEVEL00
script_user root
enable_script_security
}
vrrp_script check_haproxy {
script "/etc/keepalived/check_haproxy.sh" interval 2 weight 5 fall 3 rise 5 timeout 2
}
vrrp_instance VI_1 {
state Master interface ens18 virtual_router_id 80 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 12345 } virtual_ipaddress { 192.168.28.10/24 } track_script { check_haproxy }
}
vim /etc/keepalived/keepalived.conf
global_defs {
router_id LVS_DEVEL01
script_user root
enable_script_security
}
vrrp_script check_haproxy {
script "/etc/keepalived/check_haproxy.sh" interval 2 weight 5 fall 3 rise 5 timeout 2
}
vrrp_instance VI_1 {
state BACKUP interface ens18 virtual_router_id 80 priority 90 advert_int 1 authentication { auth_type PASS auth_pass 12345 } virtual_ipaddress { 192.168.28.10/24
}
track_script {
check_haproxy
}
}
vim /etc/keepalived/keepalived.conf
global_defs {
router_id LVS_DEVEL02
script_user root
enable_script_security
}
vrrp_script check_haproxy {
script "/etc/keepalived/check_haproxy.sh" interval 2 weight 5 fall 3 rise 5 timeout 2
}
vrrp_instance VI_1 {
state BACKUP interface ens18 virtual_router_id 80 priority 80 advert_int 1 authentication { auth_type PASS auth_pass 12345 } virtual_ipaddress { 192.168.24.15/24
}
track_script {
check_haproxy
}
}
vim /etc/keepalived/check_haproxy.sh
#!/bin/bash
count=`ps aux | grep -v grep | grep haproxy | wc -l`
if [ $count -eq 0 ]; then exit 1
else exit 0
fi 赋予执行权限
chmod +x /etc/keepalived/check_haproxy.sh
sudo systemctl start keepalived
sudo systemctl enable keepalived感谢 @elky 大佬开源此项目
大佬沉迷 coding ,更新了也不发贴
我近期也是疯狂的给大佬提需求 (偶尔提交几个 PR
更新说明: 本次更新距离上次版本已有较长时间,带来了多项功能新增和改进






pgBackRest 旨在提供一个简单可靠,容易纵向扩展的 PostgreSQL 备份恢复系统。pgBackRest 并不依赖像 tar 和 rsync 这样的传统备份工具,而是通过在内部实现所有备份功能,并使用自定义协议来与远程系统进行通信。 消除对 tar 和 rsync 的依赖可以更好地解决特定于数据库的备份问题。 自定义远程协议提供了更多的灵活性,并限制执行备份所需的连接类型,从而提高安全性。
pgBackRest 主页:http://pgbackrest.org
手册:pgBackRest User Guide - RHEL
pgBackRest
Github 主页:GitHub - pgbackrest/pgbackrest: Reliable PostgreSQL Backup & Restore
| ip | 软件 | 角色 |
|---|---|---|
| 192.168.1.11 | postgres,pgbackrest | primary |
| 192.168.1.12 | postgres,pgbackrest | standby |
| 192.168.1.13 | postgres, | standby |
| 192.168.1.16 | pgbackrest | 远程备份工具端 |
ubuntu (所有节点) :
sudo apt-get install pgbackrest
su - root
mkdir -p -m 770 /var/log/pgbackrest
chown postgres.postgres /var/log/pgbackrest/
chown postgres.postgres -R /etc/pgbackrest/
su postgres
vim /etc/pgbackrest.conf
[pg_5433]
pg1-port=5433
pg1-path=/data/postgresql/pgdata/pg-5433/
pg1-socket-path=/var/run/postgresql/
[global]
repo1-host=192.168.28.14
repo1-host-user=postgres
repo1-path=/var/lib/pgbackrest
repo1-retention-full=2
process-max=3
[global:archive-push]
compress-level=3 主库参数解释:
[pg_5433] 部分
这个 pg_5433 是备份集群的名字,多个备份集群可以添加 比如:[test-1],[test-2] 等等
pg1-path=/data/postgresql/pgdata/pg-5433/: 指定 PostgreSQL 数据库实例的数据目录路径。这是 pgBackRest 需要备份的主要内容所在的位置。
pg1-socket-path=/var/run/postgresql/: 指定 PostgreSQL 服务器的套接字文件(socket file)路径。pgBackRest 使用这个路径来通过 UNIX 套接字连接到数据库。
pg1-user=postgres: 定义 pgBackRest 连接到 PostgreSQL 实例时应该使用的用户名。这个用户需要有足够的权限来读取数据库文件和执行备份相关的操作。
[global] 部分
这部分的配置适用于 pgBackRest 的全局设置,影响所有备份和恢复操作。
repo1-host=192.168.28.14: 指定远程备份仓库的主机地址。这表明备份数据将被存储在指定 IP 地址的服务器上。pgBackRest 支持多个备份仓库,这里的 repo1 表示第一个仓库。
repo1-host-user=postgres: 定义访问远程备份仓库主机时使用的用户名。postgres 将以这个用户的身份在远程主机上执行操作。
log-level-file=detail: 设置文件日志记录的详细级别。detail 级别会记录更详细的操作信息,有助于故障排查和监控备份过程。
log-path=/var/log/pgbackrest: 指定日志文件的存储路径。pgBackRest 会将运行日志写入这个目录下,便于后续的日志分析和问题定位。
su postgres
vim /etc/pgbackrest.conf
[pg_5433]
pg1-path=/data/postgresql/pgdata/pg-5433/
pg1-port=5433
pg1-socket-path=/var/run/postgresql/
pg1-host-config=/etc/pgbackrest.conf
pg1-user=postgres
pg1-host=192.168.28.11
pg1-host-port=22
pg1-host-user=postgres
pg2-path=/data/postgresql/pgdata/pg-5433/
pg2-port=5433
pg2-socket-path=/var/run/postgresql/
pg2-host-config=/etc/pgbackrest.conf
pg2-user=postgres
pg2-host=192.168.28.12
pg2-host-port=22
pg2-host-user=postgres
pg3-path=/data/postgresql/pgdata/pg-5433/
pg3-port=5433
pg3-socket-path=/var/run/postgresql/
pg3-host-config=/etc/pgbackrest.conf
pg3-user=postgres
pg3-host=192.168.28.13
pg3-host-port=22
pg3-host-user=postgres
[global]
backup-standby=y
process-max=3
start-fast=y
repo1-path=/var/lib/pgbackrest
repo1-retention-full=2
backup-user=postgres
log-level-console=info
log-level-file=debug
buffer-size=16MiB
compress-type=gz
[global:archive-push]
compress-level=3 工具端参数解释
[pg_5433]
这个 pg_5433 是备份集群的名字,多个备份集群可以添加 比如:[test-1],[test-2] 等等
pg1-path :指定了数据库实例的数据目录路径。
pg1-port :定义了实例的端口号,通常 PostgreSQL 默认端口是 5432。
pg1-socket-path:指定了 UNIX 套接字文件的路径,用于本地连接。
pg1-user :定义 pgBackRest 连接到各个 PostgreSQL 实例时使用的用户名。
pg1-host-config-path :指定远程主机上 pgBackRest 配置文件的路径。
pg1-host:定义了各实例所在的主机地址。
pg1-host-port :指定了用于 SSH 连接的端口号,默认为 22。
pg1-host-user:定义了 SSH 连接时使用的用户名。
[global] 部分
这部分定义了全局备份策略和行为。
backup-standby=y:启用备份从备用服务器进行,这有助于减少对生产数据库的性能影响。
process-max=3:定义了 pgBackRest 同时执行任务的最大进程数。
start-fast=y:启用快速启动模式,尝试减少备份期间的停机时间。
repo1-path:指定了备份仓库的路径。
repo1-retention-full=2:定义了完整备份的保留数量,超过这个数量的旧备份将被删除。
backup-user:指定执行备份操作的用户。
log-level-console:设置控制台日志级别。
log-level-file:设置文件日志的详细级别。
buffer-size:定义了缓冲区大小,用于优化性能。
compress-type=gz:指定了压缩类型,这里使用的是 gzip。
[global:archive-push] 部分
这部分专门用于配置归档推送操作。
compress-level=3:定义了压缩级别,数值越高,压缩效果越好,但需要更多的 CPU 资源。
在各个服务器上,生成 postgres 的 ssh 密钥
su postgres
ssh-keygen -t rsa -b 4096 -f ~/.ssh/id_rsa -N "" 在主从服务器上 postgres 用户 配置备份服务器 postgres 的用户公钥
登录备份服务器 192.168.28.14
su postgres
cd ~
cat ./.ssh/id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAACAQDnvcOPSQgi2zKWqNHsFjKC0zp4X5+yG1eNf5fEr25r2+NlBGMRrBFh2pONh2pWSLiglbhOZA5Pr1ILpllwP34eiGNjxTp0ys0U1YjnOuvgY7iwwR+xkXJmywDb0g0ALSEi3TS0lu5z3u4mBcW03q4m/oS++Fi+7ieDinyQAZOXXOyvj8k7g7/NiUXzONN83do/+KC5htVm9Q77A2DrDmZWQGbypMKQYPY66RjcWvApPOVYbrUxHlndq3fU4IhHPOVwiAdpHm5bh8dyb9k1FWcIS9sxLVm4KsUbt99VeDC8ri7iglMKen+gcktIyo80rGRoIdzJrD6JPP8cTlhpTwV/uW42kWgS9lZ8I/Ahk7lWoDdiF/pVNkMiiTOgZ2/YGV88CE0khpOtRl3nPHFlUZHi1QLdfH9omI0FZWeLYAuQbKWBGZ8GgfAweKjEtMy/J43NO5qGK6JZ0KB2ve03JowCGbW65cmTuPQgz3Hwo5I0fv3YEy88LK9nVnLub44zunGqJ4JBAc2H/WrmSqLYtLtljo/5EuKmc34SS75WimY9wh1nTmhVPODuLzurXjz28zx245tkcLeImbn4C8Gge4I7TgtPj8VkWTXC6WlrTTLjebLuMjYR3qFfuGqfD2vuLEHU4CBGHAnpDCG51v96gBpw+m9Cman6f9KvA3iZRBOXHw== postgres@k8s-node01
在主从服务器上添加备份服务器的公钥
root@k8s-master01:~# su postgres
postgres@k8s-master01:/root$cd ~
postgres@k8s-master01:~$vim ./.ssh/authorized_keys
同样的在备份服务器的 postgres 的用户上配置主从服务器上 postgres 用户的公钥
在主库上修改 archive 归档
patronictl -c /etc/patroni/patroni-5433.yaml edit-config archive_mode = on archive_command = 'pgbackrest --stanza=pg_5433 archive-push %p'
max_wal_senders = 3 stanza 名需要和配置文件一致
修改完之后,通过 patronictl 重启所有数据库
patronictl -c /etc/patroni/patroni-5433.yaml restart pg_patroni_etcd pg_patroni_5433_01
patronictl -c /etc/patroni/patroni-5433.yaml restart pg_patroni_etcd pg_patroni_5433_02
patronictl -c /etc/patroni/patroni-5433.yaml restart pg_patroni_etcd pg_patroni_5433_03
在备份服务器上执行
su postgres
pgbackrest --stanza=pg_5433 --log-level-console=info stanza-create
#删除方式
pgbackrest --stanza=pg_5433 stop
pgbackrest --stanza=pg_5433 stanza-delete --force pgbackrest --stanza=pg_5433 --log-level-console=info check
#执行结果如下
postgres@k8s-node01:~$ pgbackrest --stanza=pg_5433 --log-level-console=info check
2025-10-27 15:40:57.655 P00 INFO: check command begin 2.50: --backup-standby --buffer-size=16MiB --exec-id=3943474-ea8cda56 --log-level-console=info --log-level-file=debug --pg1-host=192.168.28.25 --pg1-host-config=/etc/pgbackrest.conf --pg1-host-port=22 --pg1-host-user=postgres --pg1-path=/data/postgresql/pgdata/pg-5433/ --pg1-port=5433 --pg1-user=postgres --repo1-path=/var/lib/pgbackrest --stanza=pg_5433
WARN: option 'backup-standby' is enabled but standby is not properly configured
2025-10-27 15:41:00.980 P00 INFO: check repo1 configuration (primary)
2025-10-27 15:41:01.387 P00 INFO: check repo1 archive for WAL (primary)
2025-10-27 15:41:06.703 P00 INFO: WAL segment 000000230000000000000059 successfully archived to '/var/lib/pgbackrest/archive/pg_5433/16-1/0000002300000000/000000230000000000000059-0c80b7903193612ee31642ac12c2548bba36bc1b.gz' on repo1
2025-10-27 15:41:06.806 P00 INFO: check command end: completed successfully (9159ms)
在备份机上操作即可
pgbackrest --stanza=pg_5433 --log-level-console=info backup --type=full
pgbackrest pgbackrest --stanza=pg_5433 --log-level-console=info backup --type=incr
pgbackrest pgbackrest --stanza=pg_5433 --log-level-console=info backup --type=diff
这个恢复操作的一台新的 postgresql 主机上操作,并配置好 pgbackrest.conf 文件 和 备份机可以免密登陆 ssh 登陆
# 全量恢复
$ pgbackrest --stanza=pg_5433 restore --pg1-path=/data/postgresql/pgdata/pg-5433/
# 指定某个备份恢复
pgbackrest --stanza=pg_5433 --set=20251027-134949F restore
# 基于lsn恢复 # 指定备份策略,获取对应的lsn:lsn start/stop
pgbackrest --stanza=pg_5433 --set=20250713-195747F_20250713-195909I info
pgbackrest --stanza=pg_5433 --type=lsn --target="0/41000028" restore
# 基于时间点恢复
pgbackrest --stanza=pg_5433 --delta --type=time "--target=2025-10-27 14:11:02+08" restore
# 创建存储库
pgbackrest --stanza=pg_5433 stanza-create
# 删除存储库
pgbackrest --stanza=pg_5433 stanza-delete
# 更新存储库
pgbackrest --stanza=pg_5433 stanza-upgrade
# 启用备份
pgbackrest --stanza=pg_5433 start
# 停用备份
pgbackrest --stanza=pg_5433 stop
# 备份数据
pgbackrest --stanza=pg_5433 backup
# 恢复备份
pgbackrest --stanza=pg_5433 restore
# 查看备份
pgbackrest --stanza=pg_5433 info
# 检查备份是否过期
pgbackrest expire --stanza=pg_5433
pgbackrest expire --set=20250713-195747F_20250713-195909I --stanza=demo
# 检查配置
pgbackrest --stanza=pg_5433 check
# 获取存储库信息 # 疑似有bug,执行报错:ERROR: [032]: unable to determine cipher passphrase for ''
pgbackrest --stanza=pg_5433 --config=/pg14/pgbackrest/etc/pgbackrest.conf repo-get /pg14/pgbackrest/lib
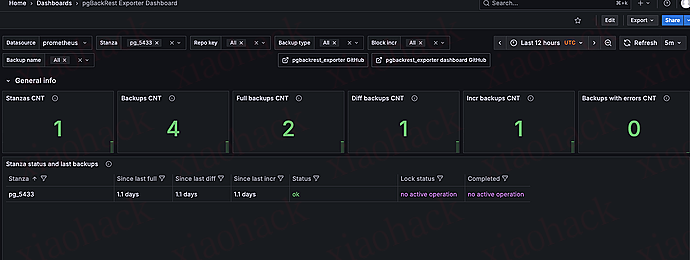
一般我们可以通过 pgbackrest info 去查看备份状态,但是这样并不直观
所以可以借助 exporter 获取 pgbackrest 的状态,从而及时监控到备份信息
安装 pgbackrest_exporter
pgbackrest_exporter 支持二进制运行,同时也支持 docker 运行,此处用二进制服务运行的方式
下载对应服务器版本的二进制包
wget https://ghfast.top/https://github.com/woblerr/pgbackrest_exporter/releases/download/v0.21.0/pgbackrest_exporter-0.21.0-linux-x86_64.tar.gz
tar -zxvf pgbackrest_exporter-0.21.0-linux-x86_64.tar.gz
mv pgbackrest_exporter-0.21.0-linux-x86_64/pgbackrest_exporter /usr/local/bin/pgbackrest_exporter
chown postgres:postgres /usr/local/bin/pgbackrest_exporter
创建 pgbackrest_exporter.service
touch /usr/lib/systemd/system/pgbackrest-exporter.service
vim /usr/lib/systemd/system/pgbackrest-exporter.service
[Unit]
Description=pgbackrest-exporter Service
After=network.target
[Service]
Type=simple
User=postgres
ExecStart=/usr/local/bin/pgbackrest_exporter --backrest.config=/etc/pgbackrest.conf
Restart=on-failure
RestartSec=10
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
Alias=pgbackrest-exporter.service
启动 pgbackrest_exporter.service
systemctl daemon-reload
systemctl start pgbackrest-exporter.service
systemctl enable pgbackrest-exporter.service
通过 grafana 展示页面
grafana id:17709
#!/usr/bin/env python3 """
Patroni钉钉通知脚本 - 增强诊断和错误修复版
主要解决:日志显示发送成功但实际未收到消息的问题
作者:资深SRE/数据库高可用架构师
""" import os
import string
import subprocess
import sys
import json
import logging
import requests
import socket
import traceback
from datetime import datetime
import time # 新增时间模块用于重试 import patroni
# 钉钉Webhook配置 - 添加详细的验证逻辑
DINGTALK_WEBHOOK = 'https://oapi.dingtalk.com/robot/send?access_token=********' if not DINGTALK_WEBHOOK:
print("错误:钉钉Webhook环境变量未设置,请配置 DINGTALK_WEBHOOK_URL", file=sys.stderr)
sys.exit(1)
# 高级日志配置 - 确保诊断信息完整
logger = logging.getLogger('patroni-dingtalk')
logger.setLevel(logging.DEBUG)
formatter = logging.Formatter('%(asctime)s [%(levelname)s] %(message)s')
# 文件日志
file_handler = logging.FileHandler("/var/log/patroni/dingtalk_diagnostic.log")
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
# 控制台日志
stdout_handler = logging.StreamHandler(sys.stdout)
stdout_handler.setFormatter(formatter)
logger.addHandler(stdout_handler)
def verify_dingtalk_network():
"""验证网络连通性到钉钉服务器"""
target_host = "oapi.dingtalk.com"
target_port = 443 try:
# 创建socket连接检查
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(3)
result = sock.connect_ex((target_host, target_port))
sock.close()
if result == 0:
logger.info(f"网络连通性检查: 可访问 {target_host}:{target_port}")
return True else:
logger.error(f"无法连接钉钉服务器 {target_host}:{target_port}, 错误代码: {result}")
return False except socket.gaierror:
logger.error("DNS解析故障 - 无法解析钉钉服务器地址")
return False except Exception as e:
logger.exception(f"网络检查异常: {str(e)}")
return False def send_with_retry(message_data):
"""带重试机制的消息发送函数 - 解决偶发网络问题"""
headers = {'Content-Type': 'application/json'}
max_retries = 3
retry_delay = 2 # seconds for attempt in range(max_retries):
try:
# 详细记录实际发送的内容
logger.debug(
f"发送请求 (尝试 #{attempt + 1}):\nURL: {DINGTALK_WEBHOOK}\nBody: {json.dumps(message_data, indent=2)}")
response = requests.post(
DINGTALK_WEBHOOK,
json=message_data,
headers=headers,
timeout=(3, 5) # 连接超时3秒,读取超时5秒
)
# 详细记录响应信息
logger.debug(f"钉钉响应状态码: {response.status_code}")
logger.debug(f"钉钉响应体: {response.text[:500]}...") # 只记录前500字符 # 钉钉成功响应格式: {"errcode":0,"errmsg":"ok"} if response.status_code == 200:
json_response = response.json()
if json_response.get('errcode') == 0:
logger.info(f"钉钉API确认消息已发送! (尝试#{attempt + 1})")
return True else:
# 钉钉API业务错误
logger.error(f"钉钉API错误: [{json_response.get('errcode')}] {json_response.get('errmsg')}")
# 特殊处理常见错误码 if json_response.get('errcode') == 130101:
logger.error("常见原因: 钉钉机器人关键词不匹配 - 检查消息中是否包含设置的keyword")
elif json_response.get('errcode') in [310000, 310001]:
logger.error("常见原因: 被钉钉限流 - 请降低通知频率或添加特殊关键词")
else:
logger.warning(f"HTTP错误码: {response.status_code}")
except requests.exceptions.RequestException as e:
logger.exception(f"网络请求异常 (尝试 #{attempt + 1}): {str(e)}")
except json.JSONDecodeError:
logger.error(f"响应JSON解析失败: {response.text[:200]}")
# 如果不是最后一次尝试则延时重试 if attempt < max_retries - 1:
logger.info(f"{retry_delay}秒后将重试...")
time.sleep(retry_delay)
return False def parse_event_args():
"""解析Patroni回调参数-增强容错""" if len(sys.argv) < 4:
logger.error(f"错误: 参数不足! 期望至少4个参数,实际收到 {len(sys.argv)}")
logger.info(f"完整参数列表: {sys.argv}")
return None try:
# 解析基础参数 ([0]=脚本路径, [1]=事件类型, [2]=角色, [3]=集群名)
PATRONI_LEADER=subprocess.run("/usr/local/bin/patronictl -c /etc/patroni/patroni-5433.yaml dsn -r leader", shell=True, capture_output=True, text=True).stdout.strip()
PATRONI_MEBERS=json.loads(subprocess.run("/usr/local/bin/patronictl -c /etc/patroni/patroni-5433.yaml list -f json", shell=True, capture_output=True, text=True).stdout.strip())
PATRONI_MEBERS_HOST=[]
for i in PATRONI_MEBERS:
PATRONI_MEBERS_HOST.append(i.get('Host'))
PATRONI_MEBERS_HOST=str(PATRONI_MEBERS_HOST)
len_members=len(PATRONI_MEBERS)
leader_num=0
replica_num=0 for i in PATRONI_MEBERS:
if i.get('Role')=="Leader":
i.get('State')=="running"
leader_num+=1 elif i.get('Role')=="Replica":
i.get('State')=="streaming"
replica_num+=1 else:
continue if len_members>=2 and leader_num==1 and replica_num==len_members:
PATRONI_HA_STATE='green' elif leader_num==1 and replica_num>=1 and replica_num < len_members:
PATRONI_HA_STATE='yellow' else:
PATRONI_HA_STATE='red'
event_info = {
'script_path': sys.argv[0],
'event_type': sys.argv[1],
'node_role': sys.argv[2],
'cluster_name': sys.argv[3],
'leader': PATRONI_LEADER,
'mebers': PATRONI_MEBERS_HOST,
'len_members': len_members,
'hostname': socket.gethostname(),
'ipaddress': socket.gethostbyname(socket.gethostname()),
'timestamp': datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
'ha_state': PATRONI_HA_STATE,
'old_role': os.getenv('PATRONI_OLD_ROLE', None) # 角色变更时存在
}
logger.debug(f"解析事件成功: {json.dumps(event_info, indent=2)}")
return event_info
except Exception as e:
logger.exception(f"参数解析错误: {str(e)}")
return None def build_safe_message(event):
"""构建安全的消息格式 - 兼容钉钉要求""" if not event:
logger.error("无法构建消息: 事件数据为空")
return None # 确保包含关键词 (避免钉钉关键词检查失败) # 根据事件类型设置不同的标题和颜色 if event['event_type'] in ['stop', 'failover']:
title= f"**<font color={'#FF0000'}>**🔴 Patroni故障事件**</font>**" elif event['event_type'] in ['start', 'promote']:
title = f"**<font color={'#008000'}>**🟢 Patroni恢复事件**</font>**" elif event['event_type'] in ['reload', 'restart']:
title = f"**<font color={'#FFA500'}>**🟡 Patroni维护事件**</font>**" else:
title = f"**<font color={'#0000FF'}>**🔔 Patroni状态变更**</font>**" # 使用最简单的markdown格式确保兼容性
message_content = f"""
### {title}
- **事件类型**: {event['event_type']}
- **集群名称**: {event['cluster_name']}
- **集群当前Leader**: {event['leader']}
- **集群当前成员**: {event['mebers']}
- **集群成员数量**: {len(event['mebers'].split(','))}
- **集群状态**: **<font color={'#008000' if event['ha_state'] == 'green' else '#FFFF00' if event['ha_state'] == 'yellow' else '#FF0000'}>{event['ha_state']}</font>**
- **当前节点角色**: {event['node_role']}
- **当前主机名称**: {event['hostname']}
- **当前主机IP**: {event['ipaddress']}
- **集群状态**: {event['ha_state']}
- **发生时间**: {event['timestamp']}
""" # 如果是角色变更事件,添加额外信息 if event.get('old_role'):
message_content += f"- **变更前角色**: {event['old_role']}\n" # 必须包含关键字"Patroni"两次以上避免误过滤
message_content += "\n> **Patroni数据库高可用系统**" return {
"msgtype": "markdown",
"markdown": {
"title": title,
"text": message_content
},
"at": {
"isAtAll": False # 不@所有人
}
}
if __name__ == "__main__":
logger.info("=" * 60)
logger.info("🚦 Patroni钉钉通知脚本启动 | 诊断模式开启")
logger.info(f"收到参数: {sys.argv}")
logger.info(f"环境变量 WEBHOOK={DINGTALK_WEBHOOK[:20]}...") # 部分展示避免泄露 # 步骤1: 网络连通性验证 if not verify_dingtalk_network():
logger.critical("网络诊断失败! 消息无法发送 - 请检查网络连接或防火墙设置")
sys.exit(10)
# 步骤2: 解析事件
event_data = parse_event_args()
if not event_data:
logger.error("无法解析事件数据,消息发送中止")
sys.exit(20)
# 步骤3: 构建消息(安全格式)
message_payload = build_safe_message(event_data)
if not message_payload:
logger.error("消息体构建失败")
sys.exit(30)
# 步骤4: 发送消息(带重试)
logger.info("尝试发送消息到钉钉...")
success = send_with_retry(message_payload)
if success:
logger.info("✅ 消息发送确认成功")
else:
logger.error("❌ 消息发送失败 - 请查看上述诊断信息")
logger.info("=" * 60)
sys.exit(0 if success else 40) # 非0退出码便于外部监控 
首先,教育邮箱的话,国内的看学校,有的学校可以有的不行,收不到邮件
国外的邮箱校友邮箱就可以,我的两个都是之前买的校友邮箱,一个美国的,一个英国的,实测都可以。没有的话去淘宝买,我之前买的大概 50-60 一个,完全个人控制的真实校友邮箱,第一个两年了没啥问题,固定 ip 全局隐私窗口登录就行。
其次,如果要五年的,必须美国 ip,支付方式的话选择 Google pay。实测 N26 和 dtcpay 的虚拟卡过不了 1 个月的那个验证,国内的 PayPal 我也没过。如果 1 个月高级的没有 Google pay 选项,换香港 ip 刷新后再换回美国 ip,就有了。
最后,链接的话都是用 @else 佬友贴子里的。详情看这个帖子 免费白嫖 2-5 年 Copilot(Microsoft365),可用 GPT-5.2 - 福利羊毛 / 福利羊毛,Lv1 - LINUX DO
最最后,如果只需要两年的,把网址里的 us 换成 hk,支付宝就行。1. 怎么切换香港区,第一个网址里面的 US 换成 Hk 2. 为什么教育邮箱受到邮件后点击链接登陆不了?你需要登录的不是教育邮箱,而是你订阅的邮箱 3. 第二个链接点开后为什么提示已经订阅,没资格? 同样需要把网址里的 us 换成 hk, 4. 第二个链接提示只有 1 个月? 没关系,订阅就完事,后面自己会升级的。

需求一个 EDU 邮箱(应该没啥要求我用的同济校友都能过),如果没有据说上传课程表也能过。
应该需要验证卡和地区是否匹配,选美区可以用 googlepay 和 paypal,左下角选香港可以使用支付宝支付,但是不知道影响不影响用 copilot
我使用美区 paypal 绑国内 visa 卡直接过
网络应该没要求,随便用的机场线路。
一定要按顺序点击,第一个过了再买第二个
第二个可能会提示只免费一个月不用管他,2 个链接都点完可以关闭续费
甚至只有这个情况可以突破 2 年,具体原因不明可能取决于账户
目前看来最少是 2 年,最多有到 2031 年。
点击第一个链接会获得 1 年个人版订阅

#第一个链接,修改market=US可以直接改国家
https://checkout.microsoft365.com/acquire/purchase?language=zh-TW&market=US&requestedDuration=Month&scenario=microsoft-365-student&client=poc&campaign=StudentFree12M
#第二个链接
https://checkout.microsoft365.com/acquire/purchase?language=zh-TW&market=US&requestedDuration=Month&scenario=microsoft-365-premium&client=poc&campaign=StudentPremiumFree12M


切港区直接用支付宝付,不是支付宝香港直接是支付宝


目录 先说一下背景,EaseProbe 是一个轻量独立的用来探活服务健康状况的小工具,支持http/tcp/shell/ssh/tls/host以及各种中间件的探活,然后,直接发送通知到主流的IM上,如:Slack/Telegram/Discrod/Email/Team,包括国内的企业微信/钉钉/飞书, 非常好用,用过的人都说好 😏。 这个探活工具在每次探活的时候,必须要从头开始建立整个网络链接,也就是说,需要从头开始进行DNS查询,建立TCP链接,然后进行通信,再关闭链接。这里,我们不会设置 TCP 的 KeepAlive 重用链接,因为探活工具除了要探活所远端的服务,还要探活整个网络的情况,所以,每次探活都需要从新来过,这样才能捕捉得到整个链路的情况。 但是,这样不断的新建链接和关闭链接,根据TCP的状态机,我们知道这会导致在探测端这边出现的 试想,如果我们以 10秒为周期探测10K的结点,如果TIME_WAIT的超时时间是120秒,那么在第60秒后,等着超时的 那么,为什么TCP在 以前写过篇比较宏观的《TCP的那些事》(上篇,下篇),这个访问在“上篇”里讲过,这里再说一次,TCP 断链接的时候,会有下面这个来来回回的过程。 我们来看主动断链接的最后一个状态 所以,我们只能等一个我们认为最大小时来解决两件个问题: 1) 为了 防止来自一个连接的延迟段被依赖于相同四元组(源地址、源端口、目标地址、目标端口)的稍后连接接受(被接受后,就会被马上断掉,TCP状态机紊乱)。虽然,可以通过指定 TCP 的 sequence number 一定范围内才能被接受。但这也只是让问题发生的概率低了一些,对于一个吞吐量大的的应用来说,依然能够出现问题,尤其是在具有大接收窗口的快速连接上。RFC 1337详细解释了当 2)另一个目的是确保远端已经关闭了连接。当最后一个ACK 丢失时,对端保持该 要解决这个问题,网上一般会有下面这些解法 对于服务器来说,上述的三个访问都不能解决服务器的 但是对于用于建立出站连接的探活的 EaseProbe来说,设置上 然后,过了几天后,我忽然想起来以前在《UNIX 网络编程》上有看到过一个Socket的参数,叫 这个东西在服务器端永远不要设置,不然,你的客户端就总是看到 TCP 链接错误 “connnection reset by peer”,但是这个参数对于 EaseProbe 的客户来说,简直是太完美了,当EaseProbe 探测完后,直接 reset connection, 即不会有功能上的问题,也不会影响服务器,更不会有烦人的 在 Golang的标准库代码里, 你需要把一个 但是对于Golang 的标准库中的 HTTP 对象来说,就有点麻烦了,Golang的 http 库把底层的这边连接对象全都包装成私有变量了,你在外面根本获取不到。这篇《How to Set Go net/http Socket Options – setsockopt() example 》中给出了下面的方法: 上面这个方法非常的低层,需要直接使用setsocketopt这样的系统调用,我其实,还是想使用 经过Golang http包的源码阅读和摸索,我使用了下面的方法: 然后,我找来了全球 T0p 100W的域名,然后在AWS上开了一台服务器,用脚本生成了 TOP 10K 和 20K 的网站来以5s, 10s, 30s, 60s的间隔进行探活,搞到Cloudflare 的 1.1.1.1 DNS 时不时就把我拉黑,最后的测试结果也非常不错,根本 没有 TIME_WAIT 的链接,相关的测试方法、测试数据和测试报告可以参看:Benchmark Report 下面是几点总结 最后强烈推荐阅读这篇文章 – Coping with the TCP TIME-WAIT state on busy Linux servers 今天来讲一讲TCP 的
今天来讲一讲TCP 的 TIME_WAIT 的问题。这个问题尽人皆知,不过,这次遇到的是不太一样的场景,前两天也解决了,正好写篇文章,顺便把 TIME_WAIT 的那些事都说一说。对了,这个场景,跟我开源的探活小工具 EaseProbe 有关,我先说说这个场景里的问题,然后,顺着这个场景跟大家好好说一下这个事。问题背景
TIME_WAIT 的 TCP 链接,根据 TCP 协议的定义,这个 TIME_WAIT 需要等待 2倍的MSL 时间,TCP 链接都会被系统回收,在回收之前,这个链接会占用系统的资源,主要是两个资源,一个是文件描述符,这个还好,可以调整,另一个则是端口号,这个是没法调整的,因为作为发起请求的client来说,在对同一个IP上理论上你只有64K的端口号号可用(实际上系统默认只有近30K,从32,768 到 60,999 一共 60999+1-32768=28,232,你可以通过 sysctl net.ipv4.ip_local_port_range 查看 ),如果 TIME_WAIT 过多,会导致TCP无法建立链接,还会因为资源消耗太多导致整个程序甚至整个系统异常。TIME_WAIT 我们就有可能把某个IP的端口基本用完了,就算还行,系统也有些问题。(注意:我们不仅仅只是TCP,还有HTTP协议,所以,大家不要觉得TCP的四元组只要目标地址不一样就好了,一方面,我们探的是域名,需要访问DNS服务,所以,DNS服务一般是一台服务器,还有,因为HTTPS一般是探API,而且会有网关代理API,所以链接会到同一个网关上。另外就算还可以建出站连接,但是本地程序会因为端口耗尽无法bind了。所以,现实情况并不会像理论情况那样只要四元组不冲突,端口就不会耗尽)为什么要 TIME_WAIT
TIME_WAIT 上要等待一个2MSL的时间?TIME_WAIT 后就不需要等待对端回 ack了,而是进入了超时状态。这主要是因为,在网络上,如果要知道我们发出的数据被对方收到了,那我们就需要对方发来一个确认的Ack信息,那问题来了,对方怎么知道自己发出去的ack,被收到了?难道还要再ack一下,这样ack来ack回的,那什么谁也不要玩了……是的,这就是比较著名的【两将军问题】——两个将军需要在一个不稳定的信道上达成对敌攻击时间的协商,A向B派出信鸽,我们明早8点进攻,A怎么知道B收到了信?那需要B向A派出信鸽,ack说我收到了,明早8点开干。但是,B怎么知道A会收到自己的确认信?是不是还要A再确认一下?这样无穷无尽的确认导致这个问题是没有完美解的(我们在《分布式事务》一文中说过这个问题,这里不再重述)TIME-WAIT状态不足时会发生什么。TIME-WAIT以下是如果不缩短状态可以避免的示例:
LAST-ACK状态。在没有TIME-WAIT状态的情况下,可以重新打开连接,而远程端仍然认为先前的连接有效。当它收到一个SYN段(并且序列号匹配)时,它将以RST应答,因为它不期望这样的段。新连接将因错误而中止:
TIME_WAIT 的这个超时时间的值如下所示:
sysctl net.inet.tcp | grep net.inet.tcp.mslcat /proc/sys/net/ipv4/tcp_fin_timeout解决方案
tcp_tw_reuse 。RFC 1323提出了一组 TCP 扩展来提高高带宽路径的性能。除其他外,它定义了一个新的 TCP 选项,带有两个四字节时间戳字段。第一个是发送选项的 TCP 时间戳的当前值,而第二个是从远程主机接收到的最新时间戳。如果新时间戳严格大于为前一个连接记录的最新时间戳。Linux 将重用该状态下的现有 TIME_WAIT 连接用于出站的链接。也就是说,这个参数对于入站连接是没有任何用图的。tcp_tw_recycle 。 这个参数同样依赖于时间戳选项,但会影响进站和出站链接。这个参数会影响NAT环境,也就是一个公司里的所有员工用一个IP地址访问外网的情况。在这种情况下,时间戳条件将禁止在这个公网IP后面的所有设备在一分钟内连接,因为它们不共享相同的时间戳时钟。毫无疑问,禁用此选项要好得多,因为它会导致 难以检测和诊断问题。(注:从 Linux 4.10 (commit 95a22caee396 ) 开始,Linux 将为每个连接随机化时间戳偏移量,从而使该选项完全失效,无论有无NAT。它已从 Linux 4.12中完全删除)TIME_WAIT 过多的问题,真正解决问题的就是——不作死就不会死,也就是说,服务器不要主动断链接,而设置上KeepAlive后,让客户端主动断链接,这样服务端只会有CLOSE_WAIT。tcp_tw_reuse 就可以重用 TIME_WAIT 了,但是这依然无法解决 TIME_WAIT 过多的问题。<code>SO_LINGER,我的编程生涯中从来没有使用过这个设置,这个参数主要是为了延尽关闭来用的,也就是说你应用调用 close()函数时,如果还有数据没有发送完成,则需要等一个延时时间来让数据发完,但是,如果你把延时设置为 0 时,Socket就丢弃数据,并向对方发送一个 RST 来终止连接,因为走的是 RST 包,所以就不会有 TIME_WAIT 了。 TIME_WAIT 问题。Go 实际操作
net.TCPConn 有个方法 SetLinger()可以完成这个事,使用起来也比较简单:conn, _ := net.DialTimeout("tcp", t.Host, t.Timeout())
if tcpCon, ok := conn.(*net.TCPConn); ok {
tcpCon.SetLinger(0)
}net.Conn 转型成 net.TCPConn,然后就可以调用方法了。dialer := &net.Dialer{
Control: func(network, address string, conn syscall.RawConn) error {
var operr error
if err := conn.Control(func(fd uintptr) {
operr = syscall.SetsockoptInt(int(fd), unix.SOL_SOCKET, unix.TCP_QUICKACK, 1)
}); err != nil {
return err
}
return operr
},
}
client := &http.Client{
Transport: &http.Transport{
DialContext: dialer.DialContext,
},
}TCPConn.SetLinger(0) 来完成这个事,即然都被封装好了,最好还是别破坏封闭性碰底层的东西。client := &http.Client{
Timeout: h.Timeout(),
Transport: &http.Transport{
TLSClientConfig: tls,
DisableKeepAlives: true,
DialContext: func(ctx context.Context, network, addr string) (net.Conn, error) {
d := net.Dialer{Timeout: h.Timeout()}
conn, err := d.DialContext(ctx, network, addr)
if err != nil {
return nil, err
}
tcpConn, ok := conn.(*net.TCPConn)
if ok {
tcpConn.SetLinger(0)
return tcpConn, nil
}
return conn, nil
},
},
}总结
TIME_WAIT 是一个TCP 协议完整性的手段,虽然会有一定的副作用,但是这个设计是非常关键的,最好不要妥协掉。tcp_tw_recycle ,这个参数是个巨龙,破坏力极大。SO_LINGER(0),而且使用 tcp_tw_reuse 对服务端意义不大,因为它只对出站流量有用。tcp_tw_reuse 和 SO_LINGER(0)。
目录 国内企业级在线交流工具主要有:企业微信、钉钉、飞书,国外的则是:Slack、Discord这两大IM工具,你会发现,他们有很多不一样的东西,其中有两个最大的不同,一个是企业管理,一个是企业文化。 Slack/Discrod 主要是通过建 Channel ,而国内的IM则主要是拉群。你可能会说,这不是一样的吗?其实是不一样的,很明显,Channel 的属性是相对持久的,而群的属性则是临时的,前者是可以是部门,可以是团队,可以是项目,可以是产品,可以是某种长期存在的职能(如:技术分享),而拉群则是相对来说临时起意的,有时候,同样的人群能被重复地拉出好几次,因为之前临时起意的事做完了,所以群就被人所遗忘了,后面再有事就再来。很明显,Channel 这种方式明显是有管理的属性的,而拉群则是没有管理的。 所以,在国内这种作坊式,野蛮粗放式的管理风格下,他们需要的就是想起一出是一出的 IM 工具,所以,拉群就是他们的工作习惯,因为没有科学的管理,所以没有章法,所以,他们不需要把工作内的信息结构化的工具。而国外则不然,国外的管理是精细化的,国外的公司还在重度使用 Email 的通讯方式,而 Email 是天生会给一个主题时行归类,而且 Email 天生不是碎片信息,所以,国外的 IM 需要跟 Email 竞争,因为像 Email 那样给邮件分类,把信息聚合在一个主题下的方式就能在 IM 上找到相关的影子。Channel 就是一个信息分类,相当于邮件分类,Slack 的 回复区和 Discord 的子区就像是把同一个主题信息时行聚合的功能。这明显是懂管理的人做的,而国内的拉群一看就是不懂管理的人干的,或者说是就是满足这些不懂管理的人的需求的。 团队协作和团队工作最大的基石是信任,如果有了信任,没有工具都会很爽,如果没有信任,什么工具都没用。信任是一种企业文化,这种文化不仅包括同级间的,还包括上下级间的。但是,因为国内的管理跟不上,所以,就导致了各种不信任的文化,而需要在这里不信任的文化中进行协同工作,国内的 IM 软件就会开发出如下在国外的 IM 中完全没有的功能: 而国外的 IM 则是,发出的信息可以修改/删除,没有已读标准,也不会监控员工。这种时候,我总是会对工作在这种不信任文化中人感到可怜……如果大家需要靠逼迫的方式把对方拉来跟我一起协作,我们还工作个什么劲啊。 所以,我们可以看到,畸形的企业管理和企业文化下,就会导致畸形的协同工具。最令人感到悲哀的是,有好多同学还觉得国内的钉钉非常之好,殊不知,你之所以感觉好用,是因为你所在的环境是如此的不堪。你看,人到了不同的环境就会有不同的认识,所以,找一个好一些的环境对一个人的成长有多重要。 给一些新入行的人的建议就是,一个环境对一个人的认知会有非常大的影响,找一个好的环境是非常重要,如果不知道什么 环境是好的,那就先从不使用钉钉为工作协同软件的公司开始吧…… 我们从上面可以得到,协同的前提条件是你需要有一个基于信任的企业文化,还需要有有结构化思维的科学的管理思维。没有这两个东西,给你的团队再多的工具都不可能有真正好有协同的,大家就是装模作样罢了。 假设我们的管理和文化都没有问题,那下面我们来谈谈协同工具的事。 我个人觉得 IM 这种工具包括会议都不是一种好的协同工具,因为这些工具都无法把信息做到真正的结构化和准确化,用 IM 或是开会上的信息大多都是碎片化严重,而且没有经过深度思考或是准备的,基本都是即兴出来的东西,不靠谱的概率非常大。 找人交流和开会不是有个话题就好的,还需要一个可以讨论的“议案”。在 Amazon 里开会,会前,组织方会把要讨论的方案打印出来给大家看,这个方案是深思过的,是验证过的,是有数据和证据或是引用支撑的,会议开始后,10 -15分钟是没有人说话的,大家都在看文档,然后就开始直接讨论或发表意见,支持还是不支持,还是有条件支持……会议效率就会很高。 但是这个议案其实是可以由大家一起来完成的,所以,连打印或是开会都不需要。试想一下,使用像 Google Doc 这样的协同文档工具,把大家拉到同一个文档里直接创作,不香吗?我在前段时间,在公网上组织大家来帮我完成一个《非常时期的囤货手册》,这篇文章的形成有数百个网友的加持,而我就是在做一个主编的工作,这种工作是 IM 工具无法完成的事。与之类似的协同工具还有大家一起写代码的 Github,大家一起做设计的 Figma……这样创作类的协同工具非常多。另外,好多这些工具都能实时展示别人的创作过程,这个简直是太爽了,你可以通过观看他人创作过程,学习到很多他人的思路和想法,这个在没有协同工具的时代是很难想像的。 好的协同工具是可以互相促进互相激励的,就像一个足球队一样,当你看到你的队友在勇敢地争抢,拼命地奔跑,你也会被感染到的。 所以,好的协同就是能够跟一帮志同道合,有共同目标,有想法,有能力的人一起做个什么事。所以,在我心中我最喜欢的协同工具从来都是创作类的,不是管理类的,更不是聊天类的。管理和聊天的协同软件会让你产生一种有产出的假象,但其实不同,这种工具无论做的有多好,都是支持性的工具,不是产出类的工具,不会提升生产力的。 另外,在创作类的协同工具上如果有一些智能小帮手,如:Github 发布的 Copilot。那简直是让人爽翻天了,所以,真正能提升生产力的工具都是在内容上帮得到你的。 我其实并不喜欢今天所有的 IM 工具,因为我觉得信息不是结构化的,信息是有因果关系和上下文的,是结构化的,是多维度的,不是今天这种线性的方式,我们想像一下“脑图”或是知识图,或是 wikipedia 的网关的关联,我们可能就能想像得到一个更好的 IM 应该是什么 样的…… 协同工作的想像空间实在是太大了,我觉得所有的桌面端的软件都会被协作版的重写,虽然,这种协作软件需要有网络的加持,但是协作软件的魅力和诱惑力实在的太大了,让人无法不从…… 未来的企业,那些管理类的工具一定会被边缘化的,聊天类的会被打成一个通知中心,而创作类的会大放异彩,让大家直接在要干的事上进行沟通、交互和分享。 这两天跟 Cali 和 Rather 做了一个线上的 Podcast – Ep.5 一起聊聊团队协同。主要是从 IM 工具扩展开来聊了一下团队的协同和相应的工具,但是聊天不是深度思考,有一些东西我没有讲透讲好,所以,我需要把我更多更完整更结构化的想法形成文字。(注:聊天聊地比较详细,本文只是想表达我的主要想法)
这两天跟 Cali 和 Rather 做了一个线上的 Podcast – Ep.5 一起聊聊团队协同。主要是从 IM 工具扩展开来聊了一下团队的协同和相应的工具,但是聊天不是深度思考,有一些东西我没有讲透讲好,所以,我需要把我更多更完整更结构化的想法形成文字。(注:聊天聊地比较详细,本文只是想表达我的主要想法)国内外的企业 IM 的本质差别
企业管理
企业文化
小结
什么是好的协同工具
结束语
目录 那么,这个协议是如何对抗网络审查的? 嗯,听起来很简单,整个网络是构建在一种 “社区式”的松散结构,完全可能会出现若干个 relay zone。这种架构就像是互联网的架构,没有中心化,比如 DNS服务器和Email服务器一样,只要你愿意,你完全可以发展出自己圈子里的“私服”。 其实,电子邮件是很难被封禁和审查的。我记得2003年中国非典的时候,我当时在北京,当时的卫生部部长说已经控制住了,才12个人感染,当局也在控制舆论和删除互联网上所有的真实信息。但是,大家都在用电子邮件传播信息,当时基本没有什么社交软件,大家分享信息都是通过邮件,尤其是外企工作的圈子,当时每天都要收很多的非典的群发邮件,大家还都是用公司的邮件服务器发……这种松散的,点对点的架构,让审查是基本不可能的。其实,我觉得 nostr 就是另外一个变种或是升级版的 email 的形式。 但是问题来了,如果不能删号封人的话,那么如何对抗那些制造Spam,骗子或是反人类的信息呢?nostr目前的解决方案是通过比特币闪电网络。比如有些客户端实现了如果对方没有follow 你,如果给他发私信,需要支付一点点btc ,或是relay要求你给btc才给你发信息(注:我不认为这是一个好的方法,因为:1)因为少数的坏人让大多数正常人也要跟着付出成本,这是个糟糕的治理方式,2)不鼓励那些生产内容的人,那么平台就没有任何价值了)。 不过,我觉得也有可以有下面的这些思路: 总之,还是有相应的方法的,但是一定没有完美解,email对抗了这么多年,你还是可以收到大量的垃圾邮件和钓鱼邮件,所以,我觉得 nostr 也不可能做到…… 最后,我们要明白的是,无论你用什么方法,审查是肯定需要的,所以,我觉得要完全干掉审查,最终的结果就是一个到处都垃圾内容的地方! 我理解的审查不应该是为权力或是个体服务的,而是为大众和人民服务的,所以,审查必然是要有一个开放和共同决策的流程,而不是独断的。 这点可以参考开源软件基金会的运作模式。 注意下面几点 如果审查是在这个框架下运作的话,虽然不完美,但至少会在一种公允的基础下运作,是透明公开的,也是集体决策的。 开源软件社区是一个很成功的示范,所以,我觉得只有技术而没有一个良性的可持续运作的社区,是不可能解决问题的,干净整齐的环境是一定要有人打扫和整理的。  这两天在网络上又有一个东西火了,Twitter 的创始人 @jack 新的社交 iOS App Damus 上苹果商店(第二天就因为违反中国法律在中国区下架了),这个软件是一个去中心化的 Twitter,使用到的是 nostr – Notes and Other Stuff Transmitted by Relays 的协议(协议简介,协议细节),协议简介中有很大的篇幅是在批评Twitter和其相类似的中心化的产品,如:Mastodon 和 Secure Scuttlebutt 。我顺着去看了一下这个协议,发现这个协议真是非常的简单,简单到几句话就可以讲清楚了。
这两天在网络上又有一个东西火了,Twitter 的创始人 @jack 新的社交 iOS App Damus 上苹果商店(第二天就因为违反中国法律在中国区下架了),这个软件是一个去中心化的 Twitter,使用到的是 nostr – Notes and Other Stuff Transmitted by Relays 的协议(协议简介,协议细节),协议简介中有很大的篇幅是在批评Twitter和其相类似的中心化的产品,如:Mastodon 和 Secure Scuttlebutt 。我顺着去看了一下这个协议,发现这个协议真是非常的简单,简单到几句话就可以讲清楚了。通讯过程
技术细节摘要
EVENT。发出事件,可以扩展出很多很多的动作来,比如:发信息,删信息,迁移信息,建 Channel ……扩展性很好。REQ。用于请求事件和订阅更新。收到REQ消息后,relay 会查询其内部数据库并返回与过滤器匹配的事件,然后存储该过滤器,并将其接收的所有未来事件再次发送到同一websocket,直到websocket关闭。CLOSE。用于停止被 REQ 请求的订阅。
EVENT。用于发送客户端请求的事件。NOTICE。用于向客户端发送人类可读的错误消息或其他信息EVENT 下面是几个常用的基本事件:
0: set_metadata:比如,用户名,用户头像,用户简介等这样的信息。1: text_note:用户要发的信息内容2: recommend_server:用户想要推荐给关注者的Relay的URL(例如wss://somerelay.com)如何对抗网络审查
如何对抗Spam和骗子
怎么理解审查

所以,基于上面这两个点认识,以发展的眼光来看问题,我觉得 ChatGPT 这类的 AI 可以成为一个小助理,他的确可以干掉那些初级的脑力工作者,但是,还干不掉专业的人士,这个我估计未来也很难,不过,这也很帅了,因为大量普通的工作的确也很让人费时间和精力,但是有个前提条件——就是ChatGPT所产生的内容必需是真实可靠的,没有这个前提条件的话,那就什么用也没有了。 今天,我想从另外一个角度来谈谈 ChatGPT,尤其是我在Youtube上看完了微软的发布会《Introducing your copilot for the web: AI-powered Bing and Microsoft Edge 》,才真正意识到Google 的市值为什么会掉了1000亿美元,是的,谷歌的搜索引擎的霸主位置受到了前所未有的挑战…… 我们先来分析一下搜索引擎解决了什么样的用户问题,在我看来搜索引擎解决了如下的问题: 基本上就是上面这几个,搜索引擎在上面这几件事上作的很好,但是,还是有一些东西搜索引擎做的并不好,如: 好了,我们知道,ChatGPT 这类的技术主要是用来根据用户的需求来按一定的套路来“生成内容”的,只是其中的内容并不怎么可靠,那么,如果把搜索引擎里靠谱的内容交给 ChatGPT 呢?那么,这会是一个多么强大的搜索引擎啊,完全就是下一代的搜索引擎,上面的那些问题完全都可以解决了: 一旦 ChatGPT 利用上了搜索引擎内容准确和靠谱的优势,那么,ChatGPT 的能力就完全被释放出来了,所以,带 ChatGPT 的搜索引擎,就是真正的“如虎添翼”! 因此,微软的 Bing + ChatGPT,成为了 Google 有史以来最大的挑战者,我感觉——所有跟信息或是文字处理相关的软件应用和服务,都会因为 ChatGPT 而且全部重新洗一次牌的,这应该会是新一轮的技术革命……Copilot 一定会成为下一代软件和应用的标配! 两个月前,我试着想用 ChatGPT 帮我写篇文章《eBPF 介绍》,结果错误百出,导致我又要从头改一遍,从那天我觉得 ChatGPT 生成的内容完全不靠谱,所以,从那天开始我说我不会再用 ChatGPT 来写文章(这篇文章不是由 ChatGPT 生成),因为,在试过一段时间后,我对 ChatGTP 有基于如下的认识:
两个月前,我试着想用 ChatGPT 帮我写篇文章《eBPF 介绍》,结果错误百出,导致我又要从头改一遍,从那天我觉得 ChatGPT 生成的内容完全不靠谱,所以,从那天开始我说我不会再用 ChatGPT 来写文章(这篇文章不是由 ChatGPT 生成),因为,在试过一段时间后,我对 ChatGTP 有基于如下的认识:

今天上午有好几个朋友在微信里转了三篇文章给我,如下所示: 看看这些标题就知道这些文章要的是流量而不是好好写篇文章。看到第二篇,你还真当 Prime Video 就是 Amazon 的全部么?然后,再看看这些文章后面的跟风评论,我觉得有 80%的人只看标题,而且是连原文都不看的。所以,我想我得写篇文章了…… 要认清这个问题首先是要认认真真读一读原文,Amazon Prime Video 技术团队的这篇文章并不难读,也没有太多的技术细节,但核心意思如下: 1)这个系统是一个监控系统,用于监控数据千条用户的点播视频流。主要是监控整个视频流运作的质量和效果(比如:视频损坏或是音频不同步等问题),这个监控主要是处理视频帧,所以,他们有一个微服务主要是用来把视频拆分成帧,并临时存在 S3 上,就是下图中的 Media Conversion 服务。 2)为了快速搭建系统,Prime Video团队使用了Serverless 架构,也就是著名的 AWS Lambda 和 AWS Step Functions。前置 Lambda 用来做用户请求的网关,Step Function 用来做监控(探测器),有问题后,就发 SNS 上,Step Function 从 S3 获取 Media Conversion 的数据,然后把运行结果再汇总给一个后置的 Lambda ,并存在 S3 上。 整个架构看上去非常简单 ,一点也不复杂,而且使用了 Serverless 的架构,一点服务器的影子都看不见。实话实说,这样的开发不香吗?我觉得很香啊,方便快捷,完全不理那些无聊的基础设施,直接把代码转成服务,然后用 AWS 的 Lamda + Step Function + SNS + S3 分分钟就搭出一个有模有样的监控系统了,哪里不好了?! 但是他们遇到了一个比较大的问题,就是 AWS Step Function 的伸缩问题,从文章中我看到了两个问题(注意前方高能): 注意,这里有两个关键点:1)帐户对 Step Function 有限制,2)Step Function 太贵了用不起。 然后,Prime Video 的团队开始解决问题,下面是解决的手段: 1) 把 Media Conversion 和 Step Function 全部写在一个程序里,Media Conversion 跟 Step Function 里的东西通过内存通信,不再走S3了。结果汇总到一个线程中,然后写到 S3. 2)把上面这个单体架构进行分布式部署,还是用之前的 AWS Lambda 来做入门调度。 EC2 的水平扩展没有限制,而且你想买多少 CPU/MEM 的机器由你说了算,而这些视频转码,监控分析的功能感觉就不复杂,本来就应该写在一起,这么做不更香吗?当然更香,比前面的 Serverless 的确更香,因为如下的几个原因: 好了,原文解读完了,你有自己的独立思考了吗?下面是我的独立思考,供你参考: 1)AWS 的 Serverless 也好, 微服务也好,单体也好,在合适的场景也都很香。这就跟汽车一样,跑车,货车,越野车各有各的场景,你用跑车拉货,还是用货车泡妞都不是一个很好的决定。 2)这篇文章中的这个例子中的业务太过简单了,本来就是一两个服务就可以干完的事。就是一个转码加分析的事,要分开的话,就两个微服务就好了(一个转码一个分析),做成流式的。如果不想分,合在一起也没问题了,这个粒度是微服务没毛病。微服务的划分有好些原则,我这里只罗列几个比较重要的原则: 3)Prime Video 遇到的问题不是技术问题,而是 AWS Step Function 处理能力不足,而且收费还很贵的问题。这个是 AWS 的产品问题,不是技术问题。或者说,这个是Prime Video滥用了Step Function的问题(本来这种大量的数据分析处理就不适合Step Function)。所以,大家不要用一个产品问题来得到微服务架构有问题的结论,这个没有因果关系。试问,如果 Step Funciton 可以无限扩展,性能也很好,而且白菜价,那么 Prime Video 团队还会有动力改成单体吗?他们不会反过来吹爆 Serverless 吗? 4)Prime Video 跟 AWS 是两个独立核算的公司,就像 Amazon 的电商和 AWS 一样,也是两个公司。Amazon 的电商和 AWS 对服务化或是微服务架构的理解和运维,我个人认为这个世界上再也找不到另外一家公司了,包括 Google 或 Microsoft。你有空可以看看本站以前的这篇文章《Steve Yegg对Amazon和Google平台的吐槽》你会了解的更多。 5)Prime Video 这个案例本质上是“下云”,下了 AWS Serverless 的云。云上的成本就是高,一个是费用问题,另一个是被锁定的问题。Prime Video 团队应该很庆幸这个监控系统并不复杂,重写起来也很快,所以,可以很快使用一个更传统的“服务化”+“云计算”的分布式架构,不然,就得像 DHH 那样咬牙下云——《Why We’re Leaving the Cloud》(他们的 SRE 的这篇博文 Our Cloud Spend in 2022说明了下云的困难和节约了多少成本) 最后让我做个我自己的广告。我在过去几年的创业中,帮助了很多公司解决了这些 分布式,微服务,云原生以及云计算成本的问题,如果你也有类似问题。欢迎,跟我联系:[email protected] 另外,我们今年发布了一个平台 MegaEase Cloud,就是想让用户在不失去云计算体验的同时,通过自建高可用基础架构的方式来获得更低的成本(至少降 50%的云计算成本)。目前可以降低成本的方式: 欢迎大家试用。 如何访问 注:这两个区完全独立,帐号不互通。因为网络的不可抗力,千万不要跨区使用。 产品演示 介绍文章  这两天技术圈里热议的一件事就是Amazon的流媒体平台Prime Video在2023年3月22日发布了一篇技术博客《规模化Prime Video的音视频监控服务,成本降低90%》,副标题:“从分布式微服务架构到单体应用程序的转变有助于实现更高的规模、弹性和降低成本”,有人把这篇文章在五一期间转到了reddit 和 hacker news 上,在Reddit上热议。这种话题与业内推崇的微服务架构形成了鲜明的对比。从“微服务架构”转“单体架构”,还是Amazon干的,这个话题足够劲爆。然后DHH在刚喷完Typescript后继续发文《即便是亚马逊也无法理解Servless或微服务》,继续抨击微服务架构,于是,瞬间引爆技术圈,登上技术圈热搜。
这两天技术圈里热议的一件事就是Amazon的流媒体平台Prime Video在2023年3月22日发布了一篇技术博客《规模化Prime Video的音视频监控服务,成本降低90%》,副标题:“从分布式微服务架构到单体应用程序的转变有助于实现更高的规模、弹性和降低成本”,有人把这篇文章在五一期间转到了reddit 和 hacker news 上,在Reddit上热议。这种话题与业内推崇的微服务架构形成了鲜明的对比。从“微服务架构”转“单体架构”,还是Amazon干的,这个话题足够劲爆。然后DHH在刚喷完Typescript后继续发文《即便是亚马逊也无法理解Servless或微服务》,继续抨击微服务架构,于是,瞬间引爆技术圈,登上技术圈热搜。原文解读

独立思考
后记
这里记录每周值得分享的科技内容,周五发布。([通知] 下周元旦假期,周刊休息。)
本杂志开源,欢迎投稿。另有《谁在招人》服务,发布程序员招聘信息。合作请邮件联系([email protected])。

哈尔滨19米大雪人,完工之前的样子。(via cgtn@instagram)
最近,我读了一本十年前的马斯克传记《硅谷钢铁侠》(中信出版社,2016)。

按理说,这本书已经过时了,这十年马斯克发生太多事情了。
我是睡觉前随手拿起来,翻了几页,看得津津有味,就读完了。
这本是马斯克的授权传记,他本人亲自接受了采访,还挺有料的。而且,因为我已经知道后续的发展,所以读到十年前的采访,反而有更多启发。
他的人生确实传奇,白手起家,家里给的最大帮助就是从南非移民到加拿大,后面都是自己奋斗出来的。
他创立了 Paypal,然后把卖掉它的钱拿来又创办了三家公司:特斯拉、SpaceX 和 SolarCity。
这太疯狂了,他一个外行同时进入了三个不同的行业----电动汽车、宇宙航天和太阳能----这些行业都刚萌芽,没有任何个人创业成功的先例。
更疯狂的是,他居然把这三家公司都做成了,而且都做到了世界第一(SolarCity 后并入特斯拉),他也因此变成了世界首富,你说神奇不神奇。
读完全书,我的最大感受是,还是要动手做事,没准真能做成。想他人不敢想,做他人不敢做。即使最狂野的梦想,只要全心投入,用力去做,也是有可能成功的。
下面就是我的一点摘录。
(1)
特斯拉最艰难的时候,非常接近于破产倒闭。
马斯克对外宣传,特斯拉是一家汽车公司,但实际上,他们只是一群年轻人租了一间大厂房,更像是在捣鼓汽车的大型实验室。
(2)
马斯克非常不理解,为什么有人设计了车灯开关。
他说:"真是多此一举。天黑时车灯自动打开,就这么简单。"
(3)
特斯拉的第一版设计稿,因为设计师没想好门把手的形状,就没画上去。
没想到马斯克很喜欢这个没有门把手的车型,就决定门把手应该在有需要的时候自动弹出。

(4)
马斯克认为,未来会有人口危机,主张多生孩子。
他认真考虑了,怎么在特斯拉后排安装婴儿座椅。传统的车门设计,使得把婴儿座椅和小孩安置在后排非常不方便,所以特斯特的车门设计采用了"鹰翼门"。

(5)
特斯拉的第一款车型是跑车,但没有大量生产。真正大量生产的第一款车型是 Model S,最初的名字是 Model Sedan。
Sedan 这个词的意思就是轿车,用来跟跑车相区别。但是马斯克认为这个词太平淡了。英国人习惯称轿车为 Saloon,这听上一样不伦不类。最后,就索性只保留第一个字母,称为 Model S。
(6)
马斯克对员工的要求是,全情投入你的工作,并把事情搞定。
不要等待上级的指导和详细指示,也不要等待别人的反馈意见,你要主动想办法把工作完成。
(7)
他认为,一个人独立工作,是最佳的工作状态。
一个人不需要开会、不需要与谁达成共识,也不需要在项目中帮助其他人。你一个人就可以持续地工作、工作、再工作。
(8)
特斯拉员工最害怕的事情,就是向马斯克申请额外的时间或者经费。
你一定要事先做好详细准备,跟他解释为什么必须招更多的人,以及需要追加的时间和资金预算。如果有招聘目标,还要准备那个人的简历。
(9)
如果你一上来就告诉马斯克,某件事情做不了,他会马上把你轰出办公室,甚至可能当场解雇你。
在马斯克看来,某件事办不成的唯一原因,就是违背了基本的物理原理。但是即使这样,你也必须做足了功课,深入每一个技术环节,向他解释为什么行不通。
(10)
马斯克要求员工,项目没完成之前,周六和周日依然要努力工作,并睡在桌子底下。
有些人反对,表示员工也需要休息,有时间陪陪家人。
马斯克说:"我们破产之后,你们会有大量时间陪家人。"
(11)
马斯克有自己计算时间价值的方法。他预期10年后,公司的日营收可以达到1000万美元,所以进度每拖延一天,就相当于多损失1000万美元。
(12)
马斯克的根本想法是改变这个世界,他总是喜欢谈论人类的生存问题。
早在他开始创业的时候,就已经得出了结论,那就是生命是短暂的。如果你真的意识到这一点,你就会知道,活着的时候工作越努力越好。
1、黑色圣诞卡
爱沙尼亚交通警察向800多名危险驾驶者,寄送了黑色圣诞卡,提醒他们新的一年必须安全驾驶。

这些人都是过去违反交通规则的司机,最常见的问题是超速和不系安全带。
圣诞卡上是一起交通事故的现场,黑漆漆的深夜,天空中有明亮的月亮,公路上有交通事故后的车辆残骸,远处还有车灯的亮光。

一个有趣的统计是,虽然人们常说女司机是"马路杀手",但是这800多个危险驾驶者里面,只有33名女性。
世界最大 CDN 服务商 Cloudflare,发布了《2025全球互联网报告》,公布了它的统计数据。

2025年,全球互联网流量上升19%,由于网民数量基本没变,所以多出来的流量来自 AI 爬虫。
流量最大的前10大互联网服务:谷歌、脸书、苹果......

移动流量中,苹果设备占35%,安卓设备占65%。
浏览器排行是,Chrome 66%,Safari 15.4%,Edge 7.4%。

3、违停巡逻车
上海警方启用无人驾驶的违章停车巡逻车。

这辆小车自动在马路上巡逻,对路面进行抓拍。
一旦发现违停车辆,它就会识别车牌,将其上传警务系统,系统后台会发送提醒短信给车主,要求在12分钟内驶离。
12分钟后,小车就会返回点位进行检查,将相关信息回传后台,并经民警审核后开罚单。

据报道,12月18日一天,它共发现违停车辆119辆次。
4、室内过山车
一家瑞典的创意工作室,在他们的办公室建造了世界唯一的室内过山车。

这个过山车途径办公室的各个角落,总长60米,最高的地方距离地面有3米。

坐上这个过山车,你就能游览一圈办公室,看到同事们在干什么。

工作室负责人说,建造它的目的是"促进员工之间的互动,以及打破常规,培养创造力。"

1、分布式架构的演化(英文)

本文将分布式架构分成三种:P2P、联邦式(比如 Mastodon)、中继式(比如 Nostr)。作者认为,对于大型分布式应用,中继式架构才是未来方向。
2、什么是 GitHub 自托管 Runner?(中文)

GitHub Actions 有一个 self-hosted runner 功能,让 action 运行在你自己的服务器。本文详细介绍它的概念、原理,并结合案例进行实践。(@luhuadong 投稿)
3、CSS Grid Lanes 布局(英文)

浏览器开始支持 CSS 的 Grid Lanes 布局了,大大方便了瀑布流的实现。
4、6502 指令集适用汇编语言初学者(英文)

6502 是一块诞生于1975年的 CPU,很多早期电脑(比如 Apple II)都使用它。作者解释,为什么你应该用它,作为学习汇编语言的第一个指令集。
5、你应该多用/tmp目录(英文)

作者提出,Linux 系统的/tmp目录用起来很方便,完全可以把它当作自己的临时性目录。
6、中国的清洁能源战略(英文)

《纽约时报》驻华记者的长文,体验当代中国的生活,比如无人驾驶、无人机送餐,他说"感觉像生活在未来"。
1、MADOLA

一种新的数学脚本语言,像编程一样写数学公式,可以编译成 HTML 格式作为文档,也可以编译成 C++ 或 WebAssembly 直接运行。(@AI4Engr 投稿)
2、CattoPic

一个基于 Cloudflare Worker 的图片托管服务,将图片上传到 Cloudflare 进行推过,支持自动格式转换、标签管理。(@Yuri-NagaSaki 投稿)
3、termdev
直接在终端,通过连接 Chrome Devtool 调试网页。(@taotao7 投稿)

为 Rust 语言的命令行项目添加一个横幅图案。(@coolbeevip 投稿)

macOS 菜单栏的资源监控工具,监控 CPU、内存、磁盘、网络和进程活动。(@nobbbbby 投稿)

C/C++ 代码的静态检查工具,可以接入 CI/CD 流程,简化代码质量管理。(@shenxianpeng 投稿)
7、Rote

开源的 Web 笔记软件,需要自己架设。(@Rabithua 投稿)

JS 的数据可视化框架,用于在网页生成各种信息图,内置200多种模板。(@Aarebecca 投稿)

天气时钟看板,适合老旧的电子设备再利用。(@teojs 投稿)
10、离线版问卷

开源 Web 应用,用来设计和托管调查问卷/报名表。(@chenbz777 投稿)
11、Xget

基于边缘计算(如 Cloudflare Workers/Vercel/Netlify)的加速引擎,可以加速程序员网站的访问速度,比如将github.com域名替换成xget.xi-xu.me/gh。(@xixu-me 投稿)
12、BoxLite

一个 Python 库,可以在脚本中运行一个微型虚拟机,提供硬件隔离。(@DorianZheng 投稿)
13、Green Wall

生成你的 GitHub 年度报告。(@Codennnn 投稿)

面向出海项目的 Next.js + Cloudflare 全栈项目模板,集成 Edge Runtime、D1 数据库、R2 存储。(@TangSY 投稿)
1、Chaterm

带有 AI 功能的智能终端工具,可以用自然语言完成命令行操作。(@zhouyu123666 投稿)
2、miniCC

网友开发的 AI 编程工具 Claude Code 替代品,主要用于学习目的。(@Disdjj 投稿)

一个开源的纯前端应用,通过 AI 翻译安卓资源文件,支持多语言同步、差异校验。(@huanfeng 投稿)
4、octopus

个人用户的大模型 API 聚合工具,支持接入多个模型供应商,提供负载均衡、分组名称、使用量统计等功能。(@bestruirui 投稿)
5、Vexor

一个 Python 工具,对当前目录的文件进行向量嵌入,用来语义搜索。(@scarletkc 投稿)
6、Tada

开源的任务管理应用,带有 AI 总结功能。(@Leaomato 投稿)
1、大模型原理(英文)

一篇相对好懂的大模型原理解释,文章不长,并且还有大量的互动图形,写得非常好,推荐阅读。
2、编程语言速度比较

这个网站使用不同的计算机语言,通过莱布尼茨公式计算 π 值,然后给出运行速度的排名,最快是 C++(clang++),最慢是 Python (CPython)。

这个网页提供三个 ZIP 炸弹文件的下载,其中最小一个只有 42KB,但是解压后的大小是 5.5GB。
《自然》杂志评选的一组2025年最佳科学图片。
两只争夺领地的青蛙。

南非废弃天文台长出的蘑菇。

2、帽子,乌龟和幽灵
2022年,一个业余数学家 David Smith 发现了一个有点像帽子的奇特形状。

这个形状的奇特之处在于,它可以无限不重复地铺满整个空间,且不形成周期性的重复图案。

不久后,他又发现了两种稍加变化的形状,称为乌龟和幽灵,也可以不重复地平铺平面。


下面就是这三种形状各自平铺的图案。

1、
我使用氛围编程会感到疲惫,AI 生成代码的速度太快了,我的大脑跟不上,无法及时完成代码验收或审查。我必须休息一段时间,才能重新开始。
-- 《氛围编程疲劳》
2、
制造汽车是非常困难的一件事。一辆车大约有3万个独立零部件,公司可能只会采购3000个,因为像车头灯这样的部件,是作为一个整体采购的,但它实际上包含很多组件。
里面的二级、三级、四级供应商提供的零部件,任何一个出现问题都可能导致整车的问题。
3、
数码世界的现状是,很多人(尤其是大多数老年人)已经放弃了抵抗,任由电子设备将他们带到任何地方。
因为一旦你想搞清楚电子设备的运作,就会发现,在便利的幌子下,一切都充满了敌意,暗箱操作无处不在,不可能完全理清。你想从它们手中夺回个人数据和隐私会非常艰苦,而且注定失败,最终只会带来更大的挫败感。
-- 《一切并非必然》
4、
现在的学生拥有前所未有的优质教育资源,但他们却陷入成千上万种选择中不知该学什么、该用什么资源的困境。拥有资源并不意味着就能找到方向。
-- 《不要关闭你的大脑》
5、
危险并非来自中国的崛起,而是美国的思维模式。如果把科学视为零和博弈,那么每一项中国专利看起来都像是美国的损失。但创意是非竞争性的:中国的科研突破不会让美国人变穷,而是会让世界变得更富有。多极化的科学世界意味着更快的增长、更大的财富和加速的技术进步。
-- 《中国的创新》
西蒙·威利森的年终总结,梁文锋的访谈(#332)
电动皮卡 Cybertruck 的 48V 供电(#282)
好用的平面设计软件(#232)
新人优惠的风险(#182)
(完)
这里记录每周值得分享的科技内容,周五发布。
本杂志开源,欢迎投稿。另有《谁在招人》服务,发布程序员招聘信息。合作请邮件联系([email protected])。

中法合作的一个艺术项目《挑战第841次》,让路过的行人在黄浦江边的一个玻璃亭子里,弹奏法国作曲家的一个钢琴作品。(via)
前两周,我跟大家说,美国现在最流行"预测市场"。我当时没有统计数字,现在有了。
2025年11月,美国前两大预测市场---- Polymarket 和 Kalshi ---- 一共成交了超过100亿美元。

看这个数字,大家可能没感觉。作为对比,美国全国的体育彩票,2024年的销售额是137亿美元。
这就是说,预测市场一个月的交易量,接近了体育彩票全年的销售额。要知道,这两个网站6年前都还不存在!
这么恐怖的增长速度,难怪美国各大公司现在都想挤入这个市场,分一杯羹。
预测市场就是变相的网络彩票,它的火爆只能说明一件事情,美国正出现疯狂的"彩票热"。

本周,我看到一篇文章(上图),一位风险投资家分析这个现象。我想分享他的观点,他认为,预测市场火爆的根本原因,是社会心态的焦虑和绝望。
(1)财富转移机制失效了,通过正常工作致富,越来越不可能。工资的增长速度,低于消费的增长速度,个人债务正在变多。
虽然资产的价格(比如股票、黄金、房产)也在上涨,但只是让那些拥有资产的人受益,对于没有这些资产的穷人,只是变得更贫穷。
(2)传统的人生模式也失效了。以前的模式是,找一家大公司,每天按时上班,努力工作,对公司忠心耿耿,坚持多年就会得到回报。你会收到公司的奖励,退休后还有养老金。
这种模式现在行不通了。公司的经营短期化,能存活20年的公司并不多,更不要说你的岗位了。一旦失去现在的工作,再次就业非常困难,以前的工作经验很可能用处不大。
(3)AI 的出现,加剧了前两种情况的发展速度。AI 让一切加速了,压缩了时间。以前,你有五年的时间奋斗,AI 让你感到必须在一年里拿到结果,否则就可能为时已晚。
(4)社交媒体则使得人们永远不会对现状满意。
以前,你的参照群体只是周围人群,现在的参照群体是全世界。你每天看到的都是收入高、赚钱容易、生活优渥的人群,永远会让你感到自己的生活不够好,而无论你已经取得了怎样的成就。
(5)结果就是,越来越多的人失去了耐心,不再相信长期投入,不再幻想长期的劳动积累会通往圆满的人生,社会也不奖励耐心。
为什么要苦苦奋斗20年,去争取10年后可能根本不存在的晋升机会?我要的是一条快速的道路,摆脱日常生活的困境,而且越快越好。
(6)这种心态下,人们的风险偏好发生了变化。为了快速摆脱困境,在风险更大的选项上放手一搏,成了合理的选择。
即使只有5%的希望,也比100%的停滞不前更有吸引力。这就是彩票在贫困社区更畅销的原因。
这在经济学上称为"不对称收益"(asymmetric returns),就是风险和收益不对称。失败的可能性很大,但只会损失一小笔钱,成功的可能性很小,但是一旦成功,就会获得巨大收益,简单说就是"小亏大赚"。
追求不对称收益,已经成了一种普遍的心态。它推动了前几年的加密货币和 NFT 的热潮,现在又推动了预测市场。
可以确定,凡是能够产生"不对称收益"的事情,今后都会迅速成为热点。
AI 编程工具,我用的是 Claude Code。以前推荐过,非常好用,功能很强。
我现在依然这样认为,但是必须说,Claude Code 不适合所有人,有使用门槛。
它要求用户熟悉命令行,而且 Windows 安装不方便,需要启用 Linux 子系统 WSL。另外,如果在外面,没有自己的计算机,临时想用一下,也很麻烦。
元旦的时候,我在广东听说,有人做了"云端 Claude Code 客户端",解决了这些痛点,就很感兴趣。

他们团队叫做 302.AI,我以前就有接触。他们做云端服务很多年了,现在专注于 AI 模型接入。大家可以去官网看一下,用他们的 API 能够接入几乎所有主流模型,数量有几百个。

他们跟我一样,也感到 Claude Code 的诸多不便,就想能不能再开发一个它的客户端,封装所有复杂性,提供最好用的 AI 编程体验。

(1)跨平台桌面应用。他们提供 Win/Mac/Linux 安装程序,通过桌面窗口去使用云端的 Claude Code。
(2)零配置的云端沙盒。云端的 Claude Code 预装在一个沙盒里,集成了 Node.js、Python、Git、CMake、build-essential 等开发工具,不需要任何本地环境配置,开箱即用。
同时,沙盒也保障了安全,跟本地电脑是隔离的,AI 就不会误删本地文件。
(3)对话界面。对于不习惯命令行的用户,他们提供对话式交互界面(Chat UI),以聊天方式完成编程。

(4)随意更换模型。Claude Code 更换底层模型,需要配置环境变量,他们的客户端不需要这么麻烦,只需要鼠标选中即可。
你可以直接用他们的 API,也可以配置自己的 API Key。
(5)一键部署。他们还提供了部署功能,AI 生成的结果可以一键发布到公网,直接访问,无需购买服务器或配置域名。

可以说,这个方案完全针对 Claude Code 的各种痛点,目标是打造新手最容易上手的 Vibe Coding 工具。
感兴趣的朋友可以去 studio.302.ai 下载,体验一下。(提醒:使用前需要注册/登录 302.AI 账号。)
1、乔布斯写的程序
乔布斯创立苹果公司之前,当过短时间的程序员。1975年,他20岁,从大学退学后,进入雅达利公司写电子游戏。
人们一直不知道,他的编程水平如何,现在终于曝光了。
本周,乔布斯的一些个人档案公开拍卖,其中就有当年他写的程序,打印纸上还有他的亲笔注释。

有人把这个程序还原出来,放到虚拟机上跑,终于让我们看到了乔布斯的软件作品。

这个程序叫做 AstroChart,跟星座有关。用户提供出生的时间地点,它会显示太阳系主要天体的位置。

从代码来看,乔布斯的编程水平可以,他使用三角函数计算行星位置,并且绕过当年硬件没有双精度浮点数的限制,用整数除法代替。
2、世界最大电动船
澳大利亚建造了世界最大的电力轮船,长度130米,里面的电池重达250吨。

这艘船将用作阿根廷与乌拉圭之间的轮渡,可以搭载多达2100名乘客和225辆汽车。

这艘船不仅是史上最大的电动船,可能也是史上最大的电动装置,一次可以携带超过4万度电。

3、最高过山车
2025年的最后一天,沙特阿拉伯在距离首都利雅得40分钟车程的地方,开张了一个乐园。

这个乐园有27个游乐设施,很多都是世界之最,其中就有目前世界最高的过山车。

这个过山车高达195米,相当于60层楼,比先前的世界纪录高出了55米。
整个过山车的长度是4.2公里,最高速度可以达到240公里/小时,全程只有3分多钟。

网上有很多这个过山车的视频,不要说坐在车上,就是看视频都觉得惊心动魄。
1、2025年大模型回顾(英文)

西蒙·威利森(Simon Willison)的 AI 年度回顾,过去一年的大事件基本都提及了,总结和评点得非常好,推荐阅读。
2、华为的 5nm 制程怎么样?(英文)

这是一家美国技术媒体对华为麒麟9030芯片(搭载于最新的 Mate 80 手机)的分析文章。
该文认为,该芯片比早先的 7nm 制程有提升,是大陆制造的最先进芯片,但从跑分看,还没达到台积电的 5nm 水平。文章有中文版。
3、Opus 4.5 将会改变一切(英文)

作者不相信 AI 会取代程序员,直到遇到 Anthropic 公司的 Opus 4.5 模型。本文是他的4个项目的编程体会,他现在确信程序员会被替代。
4、HTTP caching, a refresher(英文)

对于 HTTP 缓存机制的一个总体介绍,梳理浏览器缓存的处理逻辑。
5、Vitest 的浏览器模式介绍(英文)

JS 测试框架 Vitest 4.0 引入了浏览器模式,可以进行浏览器自动化,类似于 Playwright,进行 UI 测试,本文是一个简单介绍。
6、如何提高 JS 数组的读写速度(英文)

一篇 JavaScript 中级教程,介绍通过为 JS 数组分配连续内存,提高数组的读写速度。
1、ZenOps

一个命令行工具,在本地终端里查询阿里云/腾讯云等云平台的运行数据,并提供钉钉、飞书、企微机器人,进行自然语言查询。(@eryajf 投稿)
2、白虎面板

轻量级的服务器定时任务管理系统,适合低配置的服务器。(@engigu 投稿)

一个网页播放器,可以播放本地视频和云盘视频。(@13068240601 投稿)
4、gitstats

命令行工具,生成 Git 仓库的统计数据。(@shenxianpeng 投稿)
5、云图

一个极简风格的图床,可以搭建到自己的 NAS,提供灵活的 API。(@qazzxxx 投稿)
6、KeyStats

开源的 macOS 小工具,对按键行为进行统计。(@debugtheworldbot 投稿)
7、py2dist
这个工具可以将 Python 脚本编译成二进制模块,方便隐藏源码。(@xxnuo 投稿)

Chrome 浏览器开发者工具的一个扩展,用来调试服务器发送事件 (SSE) 和 Fetch 的流式连接。(@bywwcnll 投稿)
9、Zedis

Redis 的图形客户端,跨平台的桌面应用,不使用 Electron,而是使用 Rust + GPUI,性能更好。(@vicanso 投稿)
10、QDav

这个网站可以为夸克网盘加入 WebDAV 协议,从而挂载到网盘播放器来播放夸克网盘的视频。(@ZhouCai-bo 投稿)
11、XApi
开源的 Chrome 浏览器插件,自动捕获当前网页的 Fetch 与 XHR 网络请求,支持改写 Cookie、Origin、Referer 字段,方便开发调试。(@lustan 投稿)
12、PDFCraft

纯浏览器的 PDF 开源工具集,目前有80多个工具。(@pccprint 投稿)

智源公司的开源安卓应用,使用自然语言,让 AI 操作手机,进行手机自动化,可以接入各种模型,无需电脑端。(@Luokavin 投稿)
一个基于 Claude Code 的个人医疗数据中心,定义了一组自己的命令和技能,用 AI 分析个人医疗数据(体检报告、影像片子、处方单、出院小结)。(@huifer 投稿)
3、灵猫

免费的 AI 图片去水印网站,但只是去除视觉水印,嵌入的数字水印还在。(@pangxiaobin 投稿)

开源的 AI 应用,用自然语言驱动内置的 mermaid、echarts、mindmap、Draw.io 等绘图工具生成图表。(@twwch 投稿)
1、100万首页截图

这个网站收集了100万个热门网站的首页截图,将它们做在一个页面,可以放大查看。

各种老游戏机的经典游戏,通过模拟器免费在线游玩。(@SinanWang 投稿)
Mozilla 浏览器的新任 CEO 宣称,公司的发展方向是AI 浏览器。
这让 Mozilla 社区感到担忧,因为没人是为了 AI 而使用它。一位使用者就画了下面这张图。

Mozilla 的吉祥物----一只小狐狸拿着锯子,把自己正坐着的树枝锯断,旁边还有一只鸟,为它递上更锋利的电动锯子,上面写着"AI"。
这张图比喻 Mozilla 一直在自寻死路,全力转向 AI 只会死得更快。
1、外卖应用的秘密
我是一个大型外卖应用的开发者,受一项严格的保密协议约束。但是,我已经不在乎了,我昨天向公司递交了离职报告。
说实话,我希望公司能起诉我,这样一来,这些事情就会曝光。
我已经消极工作大约八个月了,只是看着代码被推送到生产环境。一想到自己参与了这台机器,我夜里都睡不着。
人们总怀疑算法对用户不利,现实比这更糟。我是一名后端工程师,每周参加产品会议,产品经理(PM)讨论如何才能挤出额外0.4%的利润,他们把用户当成有待开发的资源。
公司有一个"优先配送"服务,你多付2.99美元,就可以更快拿到外卖。这完全是个骗局,根本没有加快派送的速度,而是人为把非优先订单延迟5到10分钟,让你感觉优先订单更快。我们仅仅通过让标准服务变差,就赚取了数百万美元的纯利润,而不是真正改善服务。
最让我恶心的是"绝望分数",这是一个隐藏的外送员指标,根据外送员的行为判断他们多想赚钱。
如果外送员在晚上10点登录系统,毫不犹豫地立即接下每一个3美元的垃圾订单,算法会将他们标记为"高度绝望"。一旦被标记,系统就会停止向他们显示高价订单,理由是"既然我们知道他绝望到愿意接受3美元,为什么还要让他看到15美元的订单呢?"。系统把高价订单留给"休闲"外送员,即那些不愿接低价单的外送员,吸引他们接单,而全职外送员则被碾压成尘埃。
公司还会从用户的账单扣除一笔1.50美元的"外送员福利费",这个名字让用户感觉在帮助外送员。实际上,这笔钱流入了游说反对外送员成立工会的基金,这是公司用于"政策防御"的费用。用户实际上是在为那些高端律师付费,那些律师为削弱外送员的权益而工作。
最后,虽然公司不再从外送员的小费里面提成,因为被起诉过,但是使用其他方法窃取小费。
如果算法预测你是"可能支付小费的用户",而且你很可能会给10美元小费,那么公司只会给外送员可怜的2美元基本派送费。如果你给了0美元小费,公司会给外送员8美元的基本派送费。结果是用户的小费并没有奖励外送员,而是在补贴公司。用户给外送员付工资,这样我们就不用付了。
1、
在美国东海岸(纽约和华盛顿),人们会问:"中国是否就要失败了",而在西海岸(洛杉矶和旧金山),人们更倾向于问:"万一中国成功了会怎样?"
这一定程度上反映了硅谷的特点:更注重收益最大化,而非风险最小化。东海岸的问题也值得认真对待,但过分关注中国是否失败,会助长一种美国无需做出任何改变就能击败对手的论调,从而削弱美国改革的紧迫性。
2、
如果美国或中国在某个方面落后太多,落后者就会奋起直追。这将是未来数年甚至数十年世界变化的动力。
3、
程序员对待 AI 有两种态度:一种以结果为导向,渴望通过 AI 更快拿到结果;另一种以过程为导向,他们从工程本身获得意义,对于被剥夺这种体验感到不满。
4、
AI 数据中心的建设热潮,导致内存价格暴涨,进而产生一系列连锁反应。
手机和电脑厂商别无选择,只能提价。我们估计,2026年全球的手机市场和电脑市场都会萎缩。手机萎缩2.9%到5.2%,电脑萎缩4.9%到8.9%。
-- IDC 公司的预测
5、
eSIM 手机卡一旦更换就可能失效,相比之下,实体 SIM 卡可以随意插上插下,几乎不会出现故障。推广 eSIM 的后果就是,手机号丢失的事件会大大增多。
-- 《我后悔使用 eSIM》
一切都要支付两次(#333)
没有目的地,向前走(#283)
生活就像一个鱼缸(#233)
腾讯的员工退休福利(#183)
(完)