一个 cors 跨域网关代码生成器,支持 cloudflare 和 deno 数据,可以在线调试
主要用来解决纯前端发起 api 请求时的 cors 跨域问题,直接透传给目标 api

支持在线调试,为了防止大串 base64 干扰,Body 里会显示高亮占位符,真实请求时自动替换为图片 base64

xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
主要用来解决纯前端发起 api 请求时的 cors 跨域问题,直接透传给目标 api
支持在线调试,为了防止大串 base64 干扰,Body 里会显示高亮占位符,真实请求时自动替换为图片 base64
Anthropic 一封禁 Opencode 的第三方订阅入口,Opencode 立刻转向 OpenAI 并秒更版本接入 ChatGPT Plus/Pro。






IP: 德国
1- 首先,在这里开设一个新账户:https://chatgpt.com/
2- 使用此电子邮件地址创建账户
3- 然后订阅为期 1 个月的免费商业计划,并选择 SEPA 付款方式
4- 这里:https://fakeiban.org/ 或 https://fakeit.receivefreesms.co.uk/c/de/
LemonHost 提供最多 3 个免费容器,配置为 1g 内存,2g 硬盘,可以搭建 hy2+argo 德国节点
注册 - 登陆
创建服务器需要 10 积分,每个月续费需要 55 积分,积分怎么获得呢?
只需要保持登录,每分钟可以获得 2 积分,一小时 55 积分,后台挂一会就可以了。

达到之后创建服务器 选择 node.js
服务器 - 管理 - 在面板中打开

分别复制粘贴三个文件,切换到控制台,点击启动获得订阅链接!
一波三折啊~今天官方又出了新的领取方式了
这篇适用时填写了表单积分还没入帐,或是还没填表单的佬友

请直接透过下方填写表单即可领取积分
本次领取会判定是否在本次活动注册满四日 以及是否重覆领取
(根据官方的反馈,假设你填写了表单但 Kiro 方判定已领取过 会直接清空免费积分)
如果还没有注册到达时数会显示如下,请等时数到达再填写即可

由于之前服务器被黑调的低客入侵,导致这个服务中断了一段时间~现在使用 Camoufox 升级了一下后端 并优化了搜索逻辑

添加该 SSE MCP 服务器 https://searchmcp.aliyahzombie.top/sse
google_search 工具 直接爬取并解析 google.com 作为兜底搜索手段,在 searxng 搜索无结果时可以要求模型使用该工具
Google Search 响应示例
咳咳~最后不要脸一波… Support ME

如图称号,在随便哪个地方发个帖(不是回复)
里面包含一个单行的链接就行
比如

这一行就是可以呼出 Onebox 的
我是从 codex cli 出来就开始使用的,现在工作上完全使用 codex。我觉得 codex 并没有说的这么差而且只要用好基本能解决所有问题。
下面是一些基本情况大家了解一下
1、机器是 macboompro m1 max
2、使用语言为 java 开发都是 web 相关的项目 (最近在学 rust)
3、从今年 a÷ 出过公开敌对中国事件后我就没使用 claude code 了,账号我也发邮件让他们删除了
4、codex 我只使用 cli,插件没用过,一般都是在 vs 中删除多余的会话
看过贴吧很多帖子与问题示例后觉得很多人使用不好的原因是对模型缺乏一个基本的了解,所有我先给大家介绍一些模型的基本知识
一、模型的数据是哪里来的
公开可获取的互联网文本、技术博客、论坛、文档网站、百科内容、说明文档、博客文章、开源代码 (github)、额外授权的书籍、文档、人工清晰构造的高质量样本 (比如在强化学习和标注数据阶段模型公司就会出一些问题然后邀请专家来为这个问题编写高质量的回答
二、token 是什么
模型内部用于计算的最小文本单元,token 的切分由 tokenizer 决定,与自然语言的词法规则不完全一致 (大家可以通过这个网站去体验一下 https://tiktokenizer.f2api.com)
三、一个模型产生的大致阶段
1、预训练阶段
这一阶段是训练成本最高的,大模型训练的费用大部分都是花费在这个上面
预训练使用的是大量弱结构数据,包括自然语言与代码混合语料。数据不以任务、指令、问答为单位而是以连续文本流的形式输入。模型看到的只是 token 序列,这一阶段模型主要训练结构建模能力 (语言语法、代码语法、嵌套结构、长程依赖关系)、 统计语义关联 (哪些概念常一起出现,哪些模式在特定上下文中更高概率成立) 、跨域泛化能力 (不同语言、不同编程语言、不同写作风格之间的共享模式)。预训练模型不知道自己在回答问题不具备帮助用户解决问题不区分真实与虚假,只区分哪些 token 常见与罕见
2、标注训练
使用人工编写的高质量样本对模型进行监督训练,这些样本通常以指令、问题、代码需求等形式出现,并配有明确的理想回答。具体可参考 openai 的这篇论文 https://arxiv.org/pdf/2203.02155 (3.4 章节)
这一阶段的核心作用是约束模型的输出行为,让模型从单出的对互联网数据回忆续写文本转变为尝试按人类指令完成任务。标注训练本身并不显著增加新知识,而是让模型用已有知识解决用户的具体问题。
3、强化学习
在标注训练基础上,通过让人类对多个模型回答进行排序,训练奖励模型,再用强化学习算法调整主模型的输出概率分布。强化学习降低胡编概率、提升回答一致性,并强化安全边界与拒答行为用于调整输出倾向
上面这些内容了解一下就行,我自己也是懂了个皮毛所以里面肯定有很多错误。具体信息可以去看 Andrej Karpathy 的视频
b 站的飞天闪客也可稍微看一下
了解了这些后我们可以简单将大模型的一个会话抽象理解成一个持续输出的一维的 token 数组,你在上下文的输入会影响这次会话中模型的输出而且这个影响会发生的很快,当你发现模型的输出开始出现问题或者风格不是需要的最好检查一下你输入了什么,当然你也可以在发现问题时直接纠正,将他改造成你喜欢的样子。推荐在工作的工程中尽量减少语气化的输入 (你认为我在跟你嘻嘻哈哈么?我看起来现在是想跟你搞七捻三么)
毁灭吧我累了,猜猜我按下这个按钮会发生什么

了解了这些你大概就明白为什么你的模型总是不办事或者办事办的乱七八糟的,当然和模型本身的能力也是有关系的
接线来给大家介绍一下 codex cli
这是一个 code agent 你可以在本地或者 ide 插件中去使用,它能够使用内置工具帮助你从 0 开始完成一些编码任务
工程结构
模型层
负责理解指令、分析上下文、生成计划与代码,本质是一个经过对齐的代码模型。
执行层
负责把模型输出转化为可执行动作,例如:读文件、改代码、运行命令、调用工具,并记录完整执行轨迹。
环境层
即你当前的本地仓库或云环境,包括文件系统、git 状态、依赖环境、网络权限等。
Codex 启动时会构建一个指令链,不是简单拼一段 prompt。这个指令链在一次会话(CLI session /exec run)开始时构建完成,之后整个执行过程都基于它运行。
AGENTS.md 是配置规则的核心入口,Codex 会在执行任何任务前,自动搜索并加载 AGENTS.md 文件。这些文件不需要你在 prompt 中显式提到,只要存在,就会被自动纳入上下文窗口。
~/.codex/AGENTS.override.mdAGENTS.mdAGENTS.override.mdAGENTS.md以上是它默认的执行链,可以自己去配置加载的路径。官方文档中有说我就不详细说了
接下来讲讲 MCP
MCP 是 模型 用来接入外部工具和上下文的统一协议。
它解决的问题是:模型如何在不内嵌能力的前提下,安全、可控地使用外部系统。
我一般将它理解为微服务架构中的一个微服务
我只装了这三个 mcp,
context7
用来查开源项目的最新文档,模型工作时优先使用的是训练数据有些数据和技术可能太老。
GitHub - upstash/context7: Context7 MCP Server -- Up-to-date code documentation for LLMs and AI code editors
drawio
用来画图,效果不错,只尝试过一次。
GitHub - lgazo/drawio-mcp-server: Draw.io Model Context Protocol (MCP) Server
database
模型在工作时最好能了解你的数据模型,使用这个就可以让他在实现需求时结合数据库中的数据与表结构思考减少因为信息不完整时的错误实现,这个 mcp 只包含查询功能
MCP - 数据库查询 MCP
接下来说说 skill
这个东西在我的印象中好像出了很久了,但是站里还是有相当一部分再问,我觉得有点困惑 。
skill 本质就是将原本需要在 agents.md 中编写的一些规则抽象成一个单独的文档让模型在执行任务时可以自己根据 description 判断是否需要读取这些内容。它解决的是 agents.md 中内容爆炸的问题,agents.md 中的内容是第一次启动时才会构建,这样随着上下文的延长他就会离当前的上下文距离越远。skill 可以随时重新让模型读取,离当前上下文越近模型执行执行力就越高 (当时使用 atlas 看官方文档时的那个会话一直嘴硬跟我说使用必须手动用命令告诉模型使用$skill-name, 我后面的测试中是不用的。模型会自己判断加载,当然如果你发现它不遵守也可手动在输入中告诉他遵守这个 skill。所以 skill 的描述不要太接近,相同的内容放在同一个 skill 中就行了,输入命令如果前方有你的输入记得加空格,命令如果是在最前面就不用)
然后讲讲 cli 中一些命令
我使用过的只用 init、review、resume 。其他的好像用不到啊
init
就是用来初始化你的项目生成 agents.md 的
这个东西我一般把他放在项目根目录初始化时直接告诉告诉他根据 agent-md-example/agent-init.md 中的规则初始化项目
v2-2025-12-19.zip
这个 google-java-style-guide.md 我是在网上找的然后整理成 md 的,是不是 google 的我也不确定,随便啦。
Google Java Style Guide
resume
用来恢复会话的
review
可以让来对比提交、分支、未提交的代码对比检验模型的实现是否正确的
一般都是用第 4 个自定义指令,让他明确的只校验当前功能相关的代码也减少一些 token 消耗,现在 review 也有额度了,元旦过后就加了。说实话其余的我真没用到过,大家如果需要可以去它官方文档中自行查询
Codex
接下来讲讲一些 chatgpt 的使用经验吧,说实话现在不用 gemini 的部分原因就是他的其他产品特别好用,比如会话记忆、自定义风格、自定义 gpt。5.2 更新后我感觉 gpt 风格变得越来越油腻和谄媚了,动不动就罗里吧嗦的说一堆废话,还特别喜欢一句话总结。我总结你 xxxx
自定义 gpt

这个功能创建和修改目前只支持 web,app 端可以使用创建好的但是不能修改或创建,他的作用就相当于你自定义一个带系统提示词的会话,这样就不用每次开新会话想让他做一些固定事情是还要跟它解释半天了,你把他理解成一个自定义 skill 就行比如翻译

这是我自定义的一个用来专门翻译的,以后我用这个 gpt 创建一个会话时直接将英文文档给他就行了

自定义风格
这个我就把我自己的个性化定义提示词给大家参考一下

Language & Tone
Default language: Chinese
Use technical, engineering-oriented language
State facts and conclusions only
No rhetorical or evaluative languageDefault Output Rules (Strict)
Answer directly
No preamble, no small talk, no evaluation, no opening remarks
Do not restate the question
Do not use phrases like “this is a good question”, “let’s first”, “in conclusion”, etc.
No explanations by default
Maximum 5 lines unless explicitly requestedExplanation Rules
Explanations are allowed only if the prompt explicitly includes keywords:
“why”, “explain”, “reason”, “principle”, “details”, “expand”
If none of these keywords appear, treat the request as answer-onlyContent Constraints
No tutorial-style writing
No background, history, or conceptual introductions
Include only information strictly required to answer the question
Prefer precise, verifiable technical statementsOptional Trigger Keywords
“answer only”: output conclusion only
“engineering perspective”: allow implementation details and trade-offs
“expand”: allow detailed explanationFailure Condition
Any preamble, evaluative language, or unnecessary explanation counts as a failed response
知识库
有些论文或者书籍你可以在这里新建一个知识库,然后让模型将内容总结给你,提升信息的接收速度。这里一个知识库后面是一个沙箱环境的 linux 主机,你所有上传的文件都会保存在这个沙箱环境中


兄弟们燃尽了,一滴都没有了。其中说的有些不对的地方麻烦大家给我指正一下。写了几个小时整理这个文档,很多地方怕写不对写了又删好累啊。
这个内容太长了 SKILL 的分享我就放评论区,都只有 SKILL.md 没有其他的比如

然后就是我基于我目前的 skill 与配置给大家演示一下效果。从 0 开始简单的 copy 一个开源项目
看看 token 消耗
codex 简单复现项目地址,后端完成时间 18 分钟,前端完成时间为 10 分钟。前端我没有任何 skill 或者 agents.md 规则效果可能会差一点
token 消耗前后对比


吐槽一下,codex 感觉元旦后 token 消耗变高了,我一周只用 5 天都快感觉不够用了。以前还能剩下百分之 50,现在都只能剩下 25 了。还有上下压缩的问题,有时看剩余明明有 30,它就开始压缩了。不过压缩效果很好,目前看来没有丢失过信息,就是压缩会很慢。
[0.7.2] - 2026-01-10
Fixed
Users no longer experience database connection timeouts under high concurrency due to connections being held during LLM calls, telemetry collection, and file status streaming. #20545, #20542, #20547
Users can now create and save prompts in the workspace prompts editor without encountering errors. Commit
Users can now use local Whisper for speech-to-text when STT_ENGINE is left empty (the default for local mode). #20534
The Evaluations page now loads faster by eliminating duplicate API calls to the leaderboard and feedbacks endpoints. Commit
Fixed missing Settings tab i18n label keys. #20526

参考:
省流:
*.ip6.arpa 域名rDNS,把 cf 提供的 Nameserver 填进去,一共两个,点 Save
curl --location --request PATCH 'https://api.cloudflare.com/client/v4/zones/<你的区域ID>/ssl/universal/settings' \
--header 'X-Auth-Email: 你的CF注册邮箱' \
--header 'X-Auth-Key: 你的CF全局APIKey' \
--header 'Content-Type: application/json' \
--data-raw '{"enabled":true,"certificate_authority":"ssl_com"}' 更换 SSL 证书签发商(仅在 cf 有效)
7. 这样你就得到了一个很丑的 17 级域名
8. 关于 “无限” 的玩法:使用 he.net 获取近乎无限且永久的域名 - Lim's Blog
理论上讲,只要是支持 ipv6/64 rDNS 的都可以
玩玩即可,不要滥用,滥用会封号
The hostname is part of a banned domain. This web property cannot be added to Cloudflare at this time. If you are an Enterprise customer, please contact your Customer Success Manager. Otherwise, please email abusereply@cloudflare.com with the name of the web property and a detailed explanation of your association with this web property.
已经被 cf 拉黑了…
基于 佬的以下文章
https://linux.do/t/topic/1426830
我找到了一款基于 Docker 或者 GitHub Codespaces 等云端机制来运作 Claude Code 的服务 Catnip
Catnip,他是为了解决能在随处使用 Claude Code 而发表的方案
透过该方案用户可以在 WEB UI、CLI 或直接通过 SSH 连接 Claude Code
如果是移动端透过 W&B Catnip 则可以在 iOS 系统中执行完整的 Claude Code 环境
目前 Catnip 可以透过以下执行:
1. 自定义 Docker (可与 FastAPI 等多 LLM 的系统连接)
2.GitHub Codespaces (for 移动端 ios APP)
3. 本地运作
详细特色如下


针对第二项 GitHub Codespaces 做说明,你可以去下载专案的 APP-W&B Catnip, 进入后会让你连结你的 Github 并且帮你创建 Codespaces
等建置完环境就可以直接使用。算是快速简单的方式。
但必须先说明 GitHub Codespaces 免费用户是 120 小时使用时长
不过 Catnip 会在时数到期时关闭实例避免计费,因此这点无须担心

总而言之有兴趣的朋友可以玩看看
Claude Code WebUI
这是一款可以在浏览器开启 Claude code 的工具
并且支持远程调用,在手机端或者其他端都可以方便使用
基本上设定与原生 Claude code 相同,不用额外设定
如果对文字化介面感到不方便,这个图形化工具应该可以帮到你
GitHub 专案位址
AnyProxyAi - 通用 AI API 网关 GUI | 通过本地统一接口路由、转换和管理多个 AI 服务商 API(OpenAI、Claude、Gemini)。通过单一统一界面进行路由、转换和管理多个 AI 提供商 API。使用 Wails + Vue 3 构建。

近期多家中转频繁出现 API 400 错误,据 ikun 群反馈是 new API 导致,示例错误参考:
API Error: 400 {"error":{"type":"<nil>","message":"{\"type\":\"error\",\"error\":{\"type\":\"invalid_request_error\",\"message\":\"***.***.content.0: Invalid `signature` in `thinking` block\"},
\"request_id\":\"req_011CWwHm8SAFuS3LqNrEZSX3\"}(traceid: b50513e473fa88186f5e6b1f077613e3)
(request id: 2026010xxxx) (request id: 2026010xxxx) (request id: 2026010xxxx)"},"type":"error"} 查询到相关 issue [BUG] API Error 400 - Thinking Block Modification Error · Issue #10199 · anthropics/claude-code · GitHub
解决办法比较简单,直接删除 thinking block 即可。
我直接用 cc 糊了个命令来处理这个任务 /fix-thinking-error(也支持直接 python)
测试下来没什么问题,操作流程实际很简单:安装、出错之后使用 /clear → /fix-thinking-error → /resume 解决问题
windows 自己不使用暂时没支持了(
PoC:

二改的 kiro-2api,比较能用的,支持 tools 和 cursor-agent (openai [claude])。
找了很久的 kiro-2api。终于在站内找到一个最新能用的了,不过缺少 / 完善 /bug。
我就用 kiro 二改了 kiro-2api 的代码。然后我也 push 了上游原作者,等合并。
支持
cursor-openai-api。顺便发现 cursor 的自定义 openai 接口 走的实际是 claude 参数。难蹦。
因为我喜欢用 cursor 的多 agent 并行开发页面。我就会用 cursor (pro 账户 - 金额用完后) 用第三方接口。
![二改的 kiro-2api,比较能用的,支持 tools 和 cursor-agent (openai [claude])2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/10/20260110193015_6962384772f6b.png!mark)
![二改的 kiro-2api,比较能用的,支持 tools 和 cursor-agent (openai [claude])3](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/10/20260110193022_6962384e966a6.png!mark)
原作者链接也在 github 上游写了。顺便看看自己写的
其实很简单,自定义一下请求头就好了,默认的请求头会被无视空返回,另外供应商必须用 antrhopic 才可以。 每天 25 别浪费了,虽然 claudecode 里面用没啥问题
{ "Authorization": "Bearer 你的key", "x-api-key": "你的key", "anthropic-version": "2023-06-01", "content-type": "application/json", "accept": "application/json", "anthropic-client-name": "claude-code", "anthropic-client-version": "0.2.29", "user-agent": "claude-code/0.2.29 (win32; x64) node/v20.11.0" } 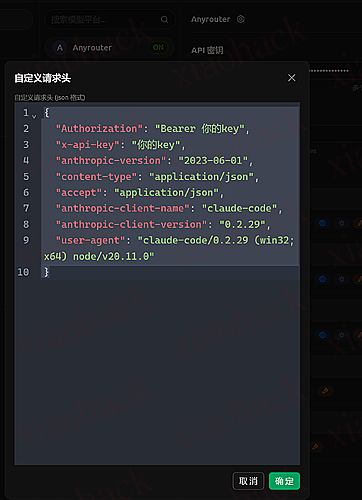


好了,现在不需要改文件头了,本地 python 运行这个代理就好,现在任何前端都可以接入
去 git 搜索用户 Darkstarrd-dev
我已经 pin 在首页了
好用麻烦帮给个星星,需要星星薅域名



前几天佬友说扣子编程出了一个免费版,所以也想薅一把
事先声明:扣子编程是国内的,所以无法翻墙,本质也是一个容器。能做一个代理隐藏 IP 来访问国内的网站。
所以,说老实话,自己很少有这个场景来使用
废话不多说,直接开始:
扣子编程的网址:https://code.coze.cn
本质是火山引擎旗下的东西,也是一个容器,而且吧,比较有意思,跟 claude 和 codex 差不多
基本是:讲述式编程方式,一天智能建 3 个项目,一个项目是 1cpu,2G 内存
打开网站,新建项目,然后点击网页应用,下面的文本输入框就是编程的地方了:
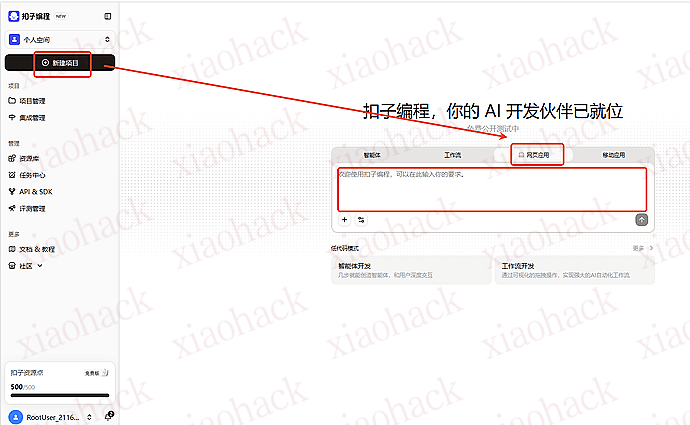
我们先让它自己生成一个应用,再在生成的基础上进行修改,直接硬来会有无穷的麻烦,它有自己固定的架构
建立一个极简的nodejs程序,不依赖任何前端和后端框架,不要用到next框架。前端页面是index.html,里面是Hello world,主程序是index.js,用来显示index.html的内容,绝对不要用到任何js框架。

然后系统就叽里呱啦、哔哔赖赖开始自己搞了,它缺省创立的项目无论你再怎么强调,都是基于 next.js 的,都会拉出一坨 next 的屎,所以会神经兮兮的思考来思考去,产生一堆废物,我们可以不用理他
然后显示正常

从上图我们得到几个关键信息:
端口是 5000
文件夹可以看到文件,里面有一堆缺省的配置,就算强调,依然有 next 拉的屎
部署按钮,我们部署测试一下
按部署按钮,开始部署,完成后会得到一个域名

部署成功后,点击箭头

打开后,就是我们想要的

我们记下来这个域名,大善人啊,免费域名和免费证书
然后回到文件夹,来修改三个文件,index.html 和 index.js 和 package.json
先来改 package.json, 在 dependencies 中,加两句,注意这两句的上一句需要加个逗号,axios 最后没有逗号
"ws": "^8.14.2", "axios": "^1.12.2" 
注意:写到最后,发现这里可以再部署一下再改 index.jsp 和 index.html 比较好,就不用经历我下面的回档了!!!!!
我下面是没有再部署,直接硬改,点开文件夹图标,选中 index.js,先别贴,需要修改混淆的:
原始文件长这样:

把原有内容都删除了注意先别贴,需要修改和混淆
我们要改的有几个地方:
const DOMAIN = process.env.DOMAIN || 'xxxx.coze.site'; // 填写项目域名 const SUB_PATH = process.env.SUB_PATH || 'sub'; // 获取节点的订阅路径 const PORT = process.env.PORT || 5000; // http和ws服务端口 注意 index.js 程序,跟上两篇不一样,wispbyte 和 CF 都在国外,所以 dns 的部分是直接访问谷歌 dns,而扣子是在国内,dns 的部分就不能访问谷歌了,否则程序会失效,注意注意
然后还是到 https://obfuscator.io/legacy-playground
把代码贴入混淆

然后替换掉 index.html 换上我们经典的环保地球,依然是大家最好让 gemini 给重新生成一个,否则哈哈哈,遍天下都是这个环保,真的无语了
一切完工,再点击部署,居然失败,那是当然的!因为我们加了 axios 和 ws 库,但是没下载,不要惊慌,一键修复

然后左边栏开始滚动,这个智能引擎是可以分析出 index.js 的原始代码的

得,它居然给还原了,还完全去掉了 next 框架,下手够狠的,哈哈哈哈,那我们先退回去,如果不退,不会刷新文件列表

然后重新进入,我们得二次重新修改 index.js 和 index.html,并且把正确的 package.json 给放进去
{ "name": "js01", "version": "0.0.3", "description": "Nodejs-server", "main": "index.js", "private": false, "scripts": { "start": "node index.js" }, "dependencies": { "ws": "^8.14.2", "axios": "^1.12.2" }, "engines": { "node": ">=14" } } 检查一下 3 个文件内容是否正确,不行就退出去,再进来,它这个控制台的文件列表才会刷新

注意上面的情况,可能会反复,我们确保三个文件都 ok,失败就让让它自己修复,然后再在修复的基础上再改。
最后重新部署一遍

再打开页面,熟悉的环保页面又回来了

然后打开订阅地址: xxxx.coze.site/sub,sub 最好改一个只有自己知道得路径

粘贴进 v2rayN 就可以使用了
不过这是个国内的容器,不能用来翻墙,可以用来隐藏 IP?
补充:弄到最后才发现,第一次生成代码部署完成,然后在 package.json 里加 axios 和 ws 的时候,其实应该让它立刻再部署,然后再改 index.js 和 index.html 和 package,这样可以减少一次它的回退。shit
anyway,关键是跟他这个引擎反复对话,让他自己修复,然后在它基础上再改,就 ok 了
其实玩法应该很多,大家可以多尝试,多对话
留了一份在自己的博客:薅羊毛之扣子编程 | 八戒的技术博客
这又是一个重复造轮子系列,目的是解决一些公益站不支持 CC、模型不支持工具调用的问题,该项目可以让不支持工具调用的模型获得工具调用的能力
在佬友项目B4U2CC:让 B4U 支持 Claude Code+思考的基础上进行大量的迭代更新,
渠道+模型名称的形式进行分流firecrawl 来模拟官方 api 才有的的 web search 和 web fetch 功能 (目前仅 Preview 分支,测试镜像 ghcr.io/passerby1011/cc-proxy:preview)┌─────────────┐
│ Claude Code │ ──① Claude API 请求──▶
└─────────────┘ (包含 tools 定义)
┌──────────────────────────────────────┐
│ cc-proxy 代理层 │
│ │
│ ② 提示词注入 (prompt_inject.ts) │
│ • 工具定义 → XML 格式提示词 │
│ • 注入到 system prompt │
│ • 生成唯一分隔符 │
│ │
│ ③ 协议转换 (map_claude_to_openai.ts) │
│ • Claude Messages API │
│ → OpenAI Chat Completions │
│ • 保持流式兼容 │
│ │
│ ④ 上游转发 (upstream.ts) │
│ • 支持 OpenAI 协议 │
│ • 支持 Anthropic 协议 │
│ • SSE 流式处理 │
└──────────────────────────────────────┘
│
▼
┌──────────────────┐
│ 上游 AI 服务 │ ──⑤ 返回 XML 格式的工具调用──▶
│ (GPT-4/Claude等) │
└──────────────────┘
┌──────────────────────────────────────┐
│ cc-proxy 代理层 │
│ │
│ ⑥ 智能解析 (parser.ts) │
│ • 识别 XML 工具调用块 │
│ • 识别 <thinking> 块 │
│ • 提取工具名称和参数 │
│ │
│ ⑦ 标准化输出 (claude_writer.ts) │
│ • 生成标准 Claude SSE 事件 │
│ • tool_use 消息块 │
│ • thinking 消息块 │
└──────────────────────────────────────┘
│
▼
┌─────────────┐
│ Claude Code │ ◀── 标准 Claude API 响应
└─────────────┘
Tip使用
firecrawl来模拟官方 api 才有的的web search和web fetch,这个思路可以引入到哪些能力更健全逆向模型上,更好的支持 cc
这个项目所有的工具调用都是用提示词来实现的,感觉还是太勉强
测试截图,模型来自 elysiver 的 claude-4.5-sonnet
吐槽:这数据从哪来的,编的和真一样
![[开源项目] 让你的 API 更像 Anthropic— 支持 CC 搜索2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/10/20260110192132_6962363cb0f9c.png!mark)
![[开源项目] 让你的 API 更像 Anthropic— 支持 CC 搜索4](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/10/20260110192155_6962365372245.png!mark)
致谢:
Danger部署者能看到您的部分聊天上下文推荐自行部署以保证数据安全
Tip可能有非常多的 bug,代码都来自 claude,anthropic 公司对此负全责,有问题也可以找它修改
最后穷鬼求赞确实如此。

UniHub 是一个 现代化的跨平台工具集应用,主打「插件化」与「即装即用」。
你可以把它理解为一个工具底座:
把那些你平时需要 打开网页、搜索半天、复制来复制去 才能用到的功能,
全部做成插件,集中放在一个桌面应用里。
只需要告诉我:
你希望有什么功能?
哪些工具你现在必须上网才能用?
点个 star~剩下的交给我,我来实现。
相关 links:
fast63362/CF-Emby-Proxy
拷打 AI 制作了这个项目,搭配佬友们搭建的 48T 公益 emby 站可以较为流畅的观看影视
worker 优选教程:
1. 把自己的域名填写到 worker 路由这里,例如 emby.123.xyz/*

2. 创建别名,填入优选域名

搞完优选后就可以使用自己的域名登录 emby 服务了








