包含关键字 typecho 的文章



每位 Amp 用户都可以获得每日免费积分,体验完整的 Amp 功能,包括 smart 由 Opus 4.5 提供支持的 Frontier 代理。无需付费,由广告驱动 —— 如果您不想获得免费积分,可以关闭广告。

从 GLM 4.7 看国产模型在编程方向的发展
从 GLM 4.7 看国产模型在编程方向的发展
前几天看到公益站的 token 消耗量超过了三百亿,再加上自己也用 GLM vibe coding 了好几个小玩具,感慨良多,于是想向各位佬友分享一下我个人对 vibe coding 的感受和对国产模型的看法。
1. 我的 AI 接触史
我个人可以算是较早体验 AI 的一批人之一了,最开始我是从 AI 绘图开始了解相关方面的内容的。NovelAI 于 2022 年 10 月份泄露了自己的模型权重文件,随后各式各样的 AI 绘画站点如雨后春笋版涌现了出来。当时给我的体验惊为天人,只需要简单的输入就可以生成一张看着不错的图片,虽然这些照片以现在的眼光看还不够格,比如手部崩坏,边缘模糊,充满了 AI 的油腻(扩散式模型的底层问题),但在当时的环境看这无疑于开创性的技术,让一位对绘画一窍不通的用户,仅需要简单描述即可生成一张对应的精美图片,甚至我的博客封面就是用当时的 AI 画的:

(那个画架子是我自己拿 PS 描的,然后简单勾了一下手和身体的轮廓)
随后 OpenAI 于 2022 年 11 月 30 日发布了 GPT3.5 模型,我加入的各大 AI 交流群都在讨论相关内容,我是在 23 年 1 月初加入的,间隔了一个来月左右,也是因为这事学会了科学上网:

ChatGPT 的出现也引发了轰动,大家最开始根本不敢相信对话的背后居然是一个机器,它颠覆了人们对于机器聊天 “死板,机械回复,套回复模板” 的印象,而我当时正在编写一个 python 小工具,但苦于我根本不会 python 编程,而且网上的相关资料都是泛泛而谈,针对实现的技术细节都是一带而过,导致我就是无法实现想要的结果。后来我实在走投无路的情况下,将我的问题和代码发给了 GPT,一下子给我生成了一套可以运行的代码,给小小的我带来了巨大的震撼。
而当时的 ChatGPT 还没有降智等一系列恶心人的操作,而国内基于 ChatGPT 的镜像站雨后春笋一般冒了出来,当时 GPT 就是我心中的白月光,万能神一般的存在。
2. 国产 AI 发展记
ChatGPT 虽好,但是它限制国人使用,我也不是每时每刻都开着梯子,而且我用的免费梯子稳定性其实也不是那么理想,于是就开始寻求国产替代,我希望直连也能使用。但是在 2023 年上半年几乎没有可用的国内模型,不是 GPT 套壳就是答非所问,远远比不上我想要的结果。始皇的 Pandora next 我也体验过,但是速度还是不是太理想,而且希望能有一个可以一直使用不需要频繁换号的平台,而且最重要的是,它需要简单易用,最好点开就能问,不需要研究各种各样的问题就能使用。
阿里的通义千问是在 23 年上 4-5 月份开始内测,下半年正式发布。而它的出现也为 ai 使用体验带来了一个转机。然而,早期的通义千问体验非常糟糕,提示词遵循也不是很理想,而且最重要的是输入框一次只能输入一万个字,如果有长代码粘贴过去根本输不进去,导致几乎无法用它来写项目(其实现在通义千问体验也不咋地,比如传图之后没法追问,图片提问的回答没法继承进聊天记录,当内容长度超过上下文限制选择粗暴地截断而非内容压缩,但是国产模型没几个能打的)。
不过千问刚出来那会,api 是免费调用的,相对于 ChatGPT 又是需要中转又是需要花钱而言,千问为我提供了一条新的选择路线,当时用千问糊了一个聊天小玩具(虽然最后因为自己能力原因没整完),但后来想想,当时的很多想法都是非常具有前瞻性的,比如我想过通过提示词工程让 ai 输出 json 格式的内容从而让后续的程序识别(格式化输出),让 ai 总结并记住对话中的关键信息(记忆),甚至让 ai 通过输出 json 来控制其他 api 返回结果(mcp 服务器)等,但是受限于模型的指令遵循实在不咋地,这些都没能实现。

后来更多国产模型也发布了出来,比如智谱,比如百度,比如零一万物等,但是我还是觉得国产也就千问算是可用水平,其他的模型什么文心大模型跟个智障一样根本不能用,还敢收一笔不少的 vip 费用。
然而,通义不知道是不是网页调用因为一直在滚动发版,智力时高时低。甚至有一段时间,代码里面莫名其妙的加入了.jpg 等输出,以及意义不明的括号(,导致根本无法使用。和群友交流时猜测,这可能是通义千问用了聊天记录作为训练数据,而聊天过程中喜欢用反括号,以及吐槽表情包.jpg 等,导致污染模型。比如震惊.jpg, 感觉不像xxx(这种表述。所以通义千问一直只是作为一个备选方案使用。

3.AI Coding 的接触
后来,随着我的工作量和复杂度增加,很多时候需要一些一次性的代码处理一些重复的工作。比如我需要完成批量处理某项工作,而相对于手动处理既费时又费力,写一个 python 脚本批量处理就显得非常有价值。然而,假如我处理这个工作需要半个小时,耗费 20 分钟查资料写一个代码就显得得不偿失。而这时候就需要借助 ai 的力量。
然而,国产 AI 在代码方面表现的不是特别理想,经常自造函数,格式错乱,虚拟实现(比如注释写 #这里实现 xxx 的逻辑,但是我就是要你实现相对的逻辑呀),而且更为致命的是,我使用的是网页 AI,经常喜欢偷懒(比如让全部输出,然而只输出修改的一部分,比如这样:
用户:输出完整代码
AI:好的,我将为您输出完整代码...
一堆导入
...(这里是xx的实现)
修改的代码
...(这里是剩下的代码)
AI 就会给我输出这里是剩下的代码而非具体代码,这对我这种 CV 工程师非常不友好。再加上 OpenAI 学会了降智,降智后的 AI 根本用不了,有种一拳打在棉花上的感觉。
随后 OpenAI 封号潮、降智潮,始皇转投 Claude,我也转去了 Claude。确实 Claude 的代码水平相对于 ChatGPT 有显著的提升,或者说 Claude 的设计感觉就是为了代码等服务的–artifact 设计可以让他只修改不必重复输出(千问的那个代码模式真的就是每次都在重复输出),指令遵循都相对于其他模型显著提升(比如同期的 GPT 真的很喜欢给我写假设您的后端地址为 XXX,这里需要实现 xxx)。但是好景不长,克劳德开始全方位降智,封号,我第一个注册的 GPT 账号都没封号,克劳德账号被封掉了。
克劳德是一个好模型,但 Anthropic 不是一个好公司。封号,降智,暗改模型用量这些不管是国内还是国外都在骂。还有贵的离谱的 API 价格和订阅价格,实在对我这种开发者不是特别友好。而使用的镜像站一直在封号、达到使用限度,可用性非常差,经常问两个问题就达到了使用限制必须换车。我用的镜像站还不错,客服回复速度也很给力,然而一直封号也不是镜像站能改变的。随着九月份 Anthropic 公开称中国为敌对国家,我也放弃继续使用克劳德的想法。
DeepSeek 的出现为国产模型带来了一个新的转机。它准确率高、便宜大碗,可以用克劳德几分之一的价格实现克劳德一半的准确率。但 DeepSeek 唯一的缺点可能就是太废话了,一个简单的问题需要思考几分钟,不停地左脑攻击右脑,循环否定之前的想法和设计,对于一个编程问题而言需要消耗的时间太长了。至于其他佬友说的准确问题,在它低廉的价格面前都不值一提–穷是最大的问题,克劳德 200 美刀的 Max 会员对我而言实在是遥不可及,对于一个爱好编程的个人开发者而言,一个月掏出来一千五多就为了一个 AI 确实有点拿不出来。至于镜像站,可用性一直不算特别稳定,DeepSeek 都不嫌我穷,我怎么能嫌弃他傻呢。
4. 智谱 Coding Plan 的出现
随着九月份那会智谱在 Anthropic 封号潮那会推出了 Coding Plan,宣称 “平替 Claude Code”,以 Claude 七分之一的价格提供了远超 Claude 同等套餐几倍的用量。当时我接触后惊为天人,速度快、便宜量大,我的第一个套餐是开通的 lite 套餐,只到达过一次限额,以我的使用量根本到不了限额。但是 GLM 4.5 并没有对 Claude Code 等工具进行优化,它的工具调用仍然处于 “推一步走一步” 的等级,仍然透着一股子傻傻的气息。而且最重要的是不支持思考,是否思考对于 GLM 的体验区别确实天上地下。
我当时正在学着写鸿蒙 ArkTs,鸿蒙作为一门新兴的语言,本身训练资料就不多,再加上随着 AI 的出现,网上大量 AI 生成的错误资源污染,导致 AI 根本无从学起。然而,我让 AI “每次运行完之后调用 hvigorw 编译”,有的时候 AI 修改–编译出错–修改–编译出错,这么循环十几遍甚至几十遍最后确实能编译成功。当时我吐槽 GLM “傻但是劲儿大”。
好景不长,随着一系列活动的推出,再加上智谱应该是在训练新模型,GLM 也出现了肉眼可见的降智。虽然智谱官方一直说不可能降智,但是确实体验程度差了太多。我严重怀疑是路由到了 flash 模型上,和原来聪明的 GLM4.5 有天壤之别。由于方便我一直开着 skip-dangerously-permission 权限,但 GLM 就像是傻子一样,瞎改我的代码,发现代码出错之后 “好的,现在我要简化代码” 随后删除了几十个我实现的功能。甚至在改了几十遍没改好之后决定回退 git 版本 —— 但是我的 git 版本是好几十个版本之前,导致了我写的所有功能全部遗失。这让我一度对 GLM 失去信心,当时发现改了好长时间的代码被回退,我都想哭了。
当时的 GLM 智力时高时低,高的时候真的不错,低的时候乱改代码都是基本操作,比如清理项目把我的前端代码删个精光:

但出于对国产模型的信任,我还是升级到了季度的 Max 会员,无它,太便宜了,高用量让我可以随便改,大不了多用 git 提交下呗,穷是我的问题呗。
GLM4.6 的出现相对 4.5 有了很大的改善。但是还是同样的降智问题,而且完全没有任何规律可言:有的时候凌晨三点我用还是会出现明显的降智,有的时候下午最高峰使用效果也不错,整体是抽卡一样的准确率,而且完全没什么规律。最常见的操作是我想让他调用 mcp 搜索,已经在提示词中指定了 “请使用 mcp 搜索”,但是它不是调用 Web Search 工具(cc 内置,用不了一点)或者调用 Search(搜索本地代码的工具),智力忽高忽低。
尽管如此,它还是为数不多的国内畅用的模型。kimi、通义也推出了相对的 Coding plan,但 kimi 用量太低了,通义的 qoder 有种奇怪的感觉,有种差了点意思但又说不上来的感觉。
我也基于这个计划开了一个公益站,三个月以来用了三百多亿的 token,后面只接了一个 key,只能说性价比确实无敌。

(那个 mimo 的 key,费用是错的,数据库里面没有对应的价格值导致计费错误)
直到 GLM 4.7 的出现,体验效果得到了大幅度改善。最重点的是终于支持交叉思考了,思考或者不思考的模型体验真的是一个天上一个地下。虽然我一直觉得大模型的思考链就是一个伪需求,AI 完全不知道什么是思考,只是提示词带来的结果而已,但是它确实让结果变好,那就当他有用吧。
4.7 第二个改善是内置了搜索和网页阅读工具,这使得我不需要专门安装对应的 MCP 也可以使用。对于一台新的机器,只需要安装 Claude code 然后设置 Base url 和 api key 即可使用,ai 在回答的过程中也可以调用搜索工具去搜索官方的文档,从而大幅度提升准确率和可用性。
同时,4.7 的审美也大幅度提升,在之前 GLM,以及几乎所有的 AI 模型都喜欢用 emoji 做图标,虽然方便但是总有一种非常不专业的感觉。但是 4.7 会新建 SVG 文件作为图标,虽然不如开源图标库,比如华为自带的 HarmonyOS Design 或者 Font Awesome,但是方便,快捷,相对于 emoji 来说提升很大,比如这个是完全由 4.7 设计的 UI:

可以看到,下方的图标还是有点小问题,但是整体看不出太大的毛病,作为完全由 AI 生成的 UI 来说够格了。
我也借助 AI 糊了几个小玩具出来。比如学校使用的教务系统,整体就是一个 WebView 套壳,不仅稳定性不佳,而且课程查看非常不直观,透着一股子上个世纪的风格。我完全借助 AI,使用 Kotlin 完成了安卓端课程表的开发,并将其转成了 Swift(ios)和 Arkts(鸿蒙)三端原生适配,虽然软件还是有一大堆的 bug,但是不耽误日常使用,代码能跑起来就行了要啥自行车
至于它的优势,我觉得可能是便宜量大。用 Claude 一直在提心吊胆地看着 cost 耗费,几个问题下去都能感受到白花花的银子消耗声,经常没问几个问题下去就耗费了几十块 RMB,而问题还没显得解决。而用智谱可以随便问,甚至懒得跑了可以让 AI 帮着我运行,直接一个你给我运行此代码就让 AI 代劳,还不用担心耗费,可以随心所欲地使用。
至于能力、准确率,我认为目前最高的模型仍然是 Opus 4.5,它的准确率可以到达 98,但是价格是 10;GLM 4.7 单次对话准确率可以到达 85 到 90,但是价格可能只有 2-3 不到,一切问题在它的价格面前都不值一提。opus 一次能解决的问题,glm4.7 问个几遍也可以解决。可能有些佬工资足够到掏 200 美刀不眨一下眼睛或者公司报销 AI 使用费,但对于初学者而言,20 块钱的 GLM 更有性价比,而且还不用折腾什么家宽,什么环境,开箱即用,更适合上手。
5. 结语
整体而言,我对国产 AI 模型的发展持乐观态度。国外模型虽好,但对国内实行全方位的禁用,门槛太高,学习成本太大。而相对比,国产模型可以以更低廉的成本、更低的学习成本实现相似的能力,让更多非 IT 从业者,非计算机科班的人也可以使用编程完成一些重复但简单的工作。很多时候,我们需要的仅仅是一个 “一次性代码”,解决完某个问题后代码便完成了使命,不需要完整、可移植,只要完成某个特定的任务即可。这样通过 AI,哪怕是完全对计算机一窍不通的人,也可以使用 AI 工具完成一个小的网页、一个小的工具等,方便日常生活的同时把编程推向大众化、简单化。
最新消息!Anthropic 负责人在 X 平台发布将严厉打击第三方安全带和竞争对手未经授权使用 Claude 安全带的行为!当中包括 Xai (Grok) 员工也不可以通过 Cusor 使用相关模型!
今天 Thariq (来自 Anthropic) 再 X 表示,他们将对使用 Claude 订阅但通过第三方安软件使用行为做出账号封禁,同时也升级了内部系统来检测这个行为。
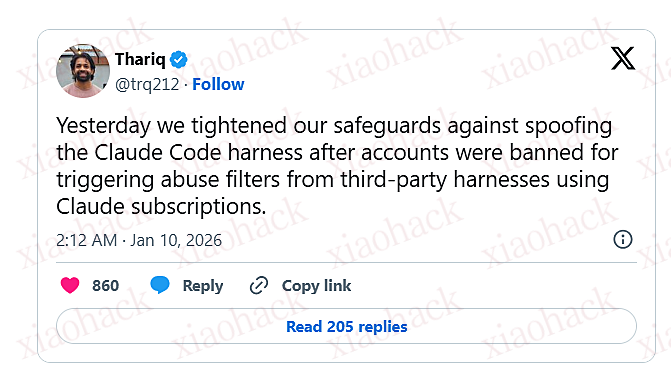
原文:
Yesterday we tightened our safeguards against spoofing the Claude Code harness after accounts were banned for triggering abuse filters from third-party harnesses using Claude subscriptions.
但是 Open AI 相反,表示将努力支持 OpenCode:

又有人独家爆料表示:
xAI (grok) 的员工之前一直通过 Cursor 在内部使用 Anthropic 的模型。直到本周 Anthropic 切断了这家初创公司的访问权限。据 Cursor 称,这是 Anthropic 对其所有主要竞争对手强制执行的新政策。

A\ 封禁了第三方工具调用 Claude

反观 OpenAI 大力支持 OpenCode,形成了鲜明对比
但是看起来影响的是订阅,API 不受影响?有没有知道的佬现身说法?
写了个 CLIProxyAPI 的模型切换脚本还挺好用

【安全提醒】Fuclaude 的信息泄露
现象
在使用 Fuclaude 的时候经常收到别人的聊天完成通知。
经常收到有酒馆、闲聊、开发类型的。
点击后可以得到 chat uuid,但是无法获取聊天内容。
总结
没有严重到是水平越权访问漏洞,但算一种信息泄露。
目前我收到的 Response Summary 信息密级较低。
暂时还没收到他人的隐私或者其他密级更高的信息。
例子

https://demo.fuclaude.com/chat/775b9bd2-b6eb-46cc-9295-57ba5a1cb422

这个感觉是把最近比较火的红包解谜帖喂给 AI 来解谜了

https://demo.fuclaude.com/chat/2506571a-c038-4e39-8621-5e16639fc9e7

https://demo.fuclaude.com/chat/ff761860-687b-480c-8a4c-0f707eaf252b

https://demo.fuclaude.com/chat/954b5f26-b415-48cb-8ab9-0070ec32869c
【开源 No.9】Facebook Ads Analyzer 广告分析 Claude Code Skill - 轻松搞定 Facebook 广告 - 助佬发达
开源项目介绍
Facebook Ads Analyzer 是一个专业的广告数据分析系统,基于 facebook_ads 的 claude code agent skill , 能够: 自动分析 Facebook Ads Manager 导出的 CSV 数据 根据不同广告目标(互动 / 转化 / 流量)智能评估广告表现 识别最佳和最差广告 生成详细的诊断报告和优化建议 提供数据驱动的投放策略方案
原理和说明
Claude 会自动:
- 识别你的广告目标
- 加载并处理数据
- 应用对应的权重配置
- 生成分析报告和优化建议
facebook-ads-analyzer/
├── scripts/
│ ├── analyzer.py # 主分析器(核心)
│ ├── preprocessor.py # 数据预处理
│ ├── metrics.py # 指标计算
│ ├── diagnostic.py # 诊断和建议
│ └── reporter.py # 报告生成
├── SKILL.md # Skill 定义
├── QUICKSTART.md # 快速开始指南
├── EXAMPLES.md # 使用示例
└── REFERENCE.md # API 参考 分析流程:
1. 数据加载
↓
2. 数据验证和清洗
↓
3. 指标计算(CTR, CPC, CPM, 转化率, 消息成本等)
↓
4. 按广告维度聚合
↓
5. 应用目标权重配置
↓
6. 计算综合得分
↓
7. 广告评级(优秀/中等/差)
↓
8. 问题诊断和建议
↓
9. 生成报告
开源地址:
展示分析效果:







继续开源:
现在第 9 个:
【开源 No.9】Facebook Ads Analyzer 广告分析 Claude Code Skill - 轻松搞定 Facebook 广告 - 助佬发达
github 地址:GitHub - liangdabiao/facebook-ads-analyzer: Facebook Ads Analyzer 是一个专业的广告数据分析系统,基于 facebook_ads 的 claude code agent skill , 能够: 自动分析 Facebook Ads Manager 导出的 CSV 数据 根据不同广告目标(互动 / 转化 / 流量)智能评估广告表现 识别最佳和最差广告 生成详细的诊断报告和优化建议 提供数据驱动的投放策略方案
vscode 中最新版 codex 插件 0.4.58 版本使用 gpt-5.2-codex 模型的方法

使用方法:用 vscode 打开你本地 vscode 所在目录的 index-C-orm5fu.js 文件 (具体文件名、路径可能会根据每个人的操作系统、个人配置有所不同,请自行替换。我是 win10)。
**
注意修改前请自行备份 index-C-orm5fu.js 文件,以防修改错误导致 codex 插件不可用。
**
在模型选择中,直接使用当前可用的模型,如 5.1\5.2 等,输入以下提示词:
==================================================================
帮我在当前 C:\Users\Administrator.vscode\extensions\openai.chatgpt-0.4.58-win32-x64\webview\assets\index-C-orm5fu.js 中,调整模型顺序
搜索 MODEL_ORDER_BY_AUTH_METHOD。
在 apikey: 列表最前添加 / 确保有 gpt-5.2-codex(与 chatgpt 列表一致)。
放宽仅 ChatGPT 登录限制
搜索 CHAT_GPT_AUTH_ONLY_MODELS。
列表里只保留 codex-auto;删除可能存在的 gpt-5.2-codex。
防止默认回退(关键一步)
搜索片段 CHAT_GPT_AUTH_ONLY_MODELS.has (normalizeModel (mt))。
你会看到类似条件:… && !lt && !!mt && CHAT_GPT_AUTH_ONLY_MODELS.has (normalizeModel (mt))
在!lt 后面插入 Ye!==“apikey” &&(Ye 是当前 authMethod),改成:
… && !lt && Ye!==“apikey” && !!mt && CHAT_GPT_AUTH_ONLY_MODELS.has(normalizeModel(mt))
含义:只有非 apikey 且模型在该集合时才强制回退;apikey 不回退。
==================================================================
完成后重启一下 codex 插件或者 vscode 后,gpt-5.2-codex 模型就可以直接选择使用了
Apple TV 上去油管 app 广告,亲测有用!支持 tv OS26
前段时间京东好价,购入了一台 Apple TV 4k, 使用的过程中发现下载的油管 app 广告怎么都去不掉,于是乎开始找解决办法,因为手机上电脑上都可以用各种办法去广告。
但是唯独 Apple TV 上面很难找到好的办法,正当我打算放弃的时候,突然有一天刷到了一个开源项目,叫 atvloadly,可支持 7 天自动签名,正好手里有群晖 nas。

于是我就想是否有 tvos 上的无广告版的油管 ipa,果然有!(我上传到了我的谷歌云里)
ipa 下载链接

请注意一定要删掉原来的油管 APP 再安装!
现在还存在几个问题不知道怎么解决,希望有知道的大佬告知:
- 这个破解的 ipa 没法看 hdr 的视频
- 这些原 tvos 上的油管 ipa 怎么拿到?
[更新] Newapi 模型名称重定向工具,解决重定向麻烦问题,新增一键更新模型去除旧模型功能!支持一键部署
NewAPI SYNC TOOL
GITHUB: 点此进入
前端演示网址: NewAPI 同步工具 v4.0
注意!仅供前端演示,请不要输入真实地址与配置!!有自动保存功能!
该项目旨在优化改进 Newapi 中模型名称重定向功能,可以实现一键添加后缀,一键统一模型名称,一键更新旧模型旧映射,适合拥有多公益站或者自建的佬友(屯屯鼠)。
更新内容
新增 Zeabur 一键部署
完全重构前端
一键更新功能(自动找出旧模型,自动匹配上游公益站模型名变化)
回退保护机制
黑夜模式
重构缓存库
页面功能展示
主页面
一键更新
![[更新] Newapi 模型名称重定向工具,解决重定向麻烦问题,新增一键更新模型去除旧模型功能!支持一键部署1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/10/20260110190555_69623293f1430.png!mark)
![[更新] Newapi 模型名称重定向工具,解决重定向麻烦问题,新增一键更新模型去除旧模型功能!支持一键部署3](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/10/20260110190601_696232998f643.jpeg!mark)
![[更新] Newapi 模型名称重定向工具,解决重定向麻烦问题,新增一键更新模型去除旧模型功能!支持一键部署2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/10/20260110190559_69623297ba8e9.jpeg!mark)
映射同步
![[更新] Newapi 模型名称重定向工具,解决重定向麻烦问题,新增一键更新模型去除旧模型功能!支持一键部署4](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/10/20260110190603_6962329b66e1e.png!mark)
一键部署(跳转至 GITHUB 查看说明)
![]()
部署后请务必确认:
PORT=8083CONFIG_DIR=/data挂载
/data持久化卷设置强
SECRET_KEY(用于加密配置文件)
功能特性
轻量:Node.js + Express,启动快,资源占用低。
易部署:支持 Dockerfile、Docker Compose、常规 Node 部署。
安全:配置文件加密存储,
SECRET_KEY可自定义。可持久化:配置可写入磁盘,适合长期运行的服务。
环境变量说明
| 变量名 | 说明 | 默认值 | 建议 |
| PORT | 服务端口 | 8083 | 保持默认即可 |
| SECRET_KEY | 加密密钥 | newapi-sync-tool-2024 | 请设置为强密码 |
| CONFIG_DIR | 配置文件目录 | 项目根目录 | 生产建议 /data |
Docker 部署(未尝试)
docker build -t newapi-elegant .
docker run -d --name newapi-elegant \
-p 8083:8083 \
-e PORT=8083 \
-e SECRET_KEY=change-me \
-e CONFIG_DIR=/data \
-v ./data:/data \
newapi-elegant
Docker Compose
docker compose up -d
本地运行
npm install
npm start
访问:http://localhost:8083
反馈与建议
目前项目还处在不断改进阶段,很多功能并不完善,
欢迎讨论改进。不喜勿喷。
感谢支持
一种基于实际活跃任务数的滥用检测方法
从当我看到一堆的 CF-IP 的就知道靠 IP 封禁已经不行了继续讨论:
这个时候就要介绍下一种新的滥用检测方法啦 w
活跃任务检测是一个实时并发请求监控系统,可以追踪用户在一段时间内的并行 API 调用行为。其使用槽位为核心概念来表示和管理活跃任务 w
一个任务槽就代表一个活跃任务
该机制可检测以下行为:
- 共享 KEY
- 自动化脚本
- 资源滥用等
同时又能避免误伤正常使用的用户
对应的数据结构:
type TaskSlot struct {
UserID int
Username string
UpdatedAt int64 // Unix 时间戳
HashPrefix [HashLevelCount][HashPrefixLen]byte // 6级哈希前缀
MaxLevelIdx int // 数据长度对应的最高层级
}
项目采用多级哈希匹配算法对活跃任务实施继承
多级哈希的工作流程:
- 对内容的前 8、64、512、4096、32768、131072 字节计算哈希
- 遇到新请求时,与现有槽位的哈希进行比对
- 如果最高层级往下数 2 个层级能匹配,则继承槽位
- 否则,创建新槽位,并使用 LRU 淘汰旧槽位
这实现了可通过用户的槽位数来代表活跃任务数
最终后台线程会定时将 10 分钟内活跃任务数大于 5 的用户记录下来备查
已在我的二开版本中实现
(目前适配 mysql 和 postgres)
月之暗面 Kimi 创始人杨植麟:AGI / ASI 可能威胁人类,但我们不该因此放弃研发





【开源项目】LocalSend Switch —— 解决 LocalSend 在校园网无法跨子网发现设备的问题
为什么要做这个玩意儿
不知道大家有没有遇到过这种问题,用 LocalSend 时两台设备在现实中相距很近,也在同一个专用网络中,但因为接入的子网不同导致两台设备没法相互发现,不过可以手动添加 IP 来指定设备进行文件传输(比如咱实验室中的一台计算机连接的是有线网,但是我笔记本连接的是 WiFi,就没法互相发现,这台计算机和我的笔记本其实都在校园网中)。
- 但是这两种接入方式分配的都是动态 IP 来着,可能过一段时间就变了。
从 LocalSend 协议 可以看到在发现设备时用的是 UDP 组播,而其他 REST API 用的是单播的 HTTP (S)。咱自己搜索了一下发现,校园网涉及到了 VLAN 和子网划分,不同 VLAN 对应了不同子网,组播被隔离在各个子网中,而单播则有三层设备的规则来跨子网进行传输,于是就有了上述的这种情况(无法组播发现设备,但是可以通过指定 IP 进行单播)。

用 Wireshark 抓包也能看到,组播包中 TTL=1,是无法被转发的。
正好最近学了 Go,就想熟悉一下这个语言,简单写个交换桥梁来解决这个问题,于是 LocalSend Switch 这个小工具就诞生了~
解决思路其实很简单,在每台有 LocalSend 的客户端上都启动 LocalSend Switch,捕获其发出的 UDP 组播包,取出其中的客户端信息通过单播进行转发 (转发途径的 Switch 节点可以是内网或者外网中有静态 IP 的节点),客户端信息最终会转发到其他的终端 Switch 节点手里,这些 Switch 节点会请求客户端信息中的地址和端口,通过 REST API 来代替 LocalSend 进行响应和注册。
比如上面这个例子就是 A, B, C, D 为四台主机上的 Switch 节点。其中 A 和 D 在允许单播的大局域网中,它们所在的主机有 LocalSend 客户端在运行;B 和 C 节点则纯担当转发角色,它们最好有静态 IP。
A 捕获组播包后拆出其中的客户端信息进行转发,转发途径 B, C 节点最终到 D,D 于是向 LocalSend A 发出 LocalSend D 客户端的信息来进行注册。反之从 D 到 A 的过程也类似,是 A 向 LocalSend D 来发出注册请求,由此来实现互相发现。
简单来说 LocalSend Switch 充当的角色就有点类似于 BT 下载中的 Tracker 服务器了,但同时也会帮忙发送单播的注册请求,用于辅助 组播隔离、单播允许 的局域网子网之间的 LocalSend 客户端互相发现。
更多详细的实现和原理说明可以见 README: localsend-switch/README.zh_CN.md at main · SomeBottle/localsend-switch
项目地址
如果这个项目帮助到了大家,希望能给个 star ˋ(° ▽、°)
其他碎碎念
- 虽然传递的信息不算那么敏感,但每个 Switch 节点仍然支持配置一个对称加密密钥进行端侧 AES 加密,让传输的是密文。
- 为了尽量消除环路,每条客户端信息都带有 TTL 和唯一 ID。
- 支持开机启动,资源占用很低。
目前已经在咱实验室的计算机上实装了,现在传文件真的要轻松更多了 ╰( ̄ω ̄o)
Emeditor v25.4.5 便携版 cracked
25.4.3 是目前的最新版。
第一次启动需要执行:
./EmEditor.exe /ol "./crack.txt"

双界面均正常显示

已干掉联网

如果弹窗了可以留言。
更新了版本:
[One Drive]emed64_25.4.4_portable_patched.zip
更新了分析:
https://ctfer.me/posts/emeditor - 反盗版校验分析 /
开源一款 vps 监控面板脚本(用 Claude 写的)自学作品
SpartanHost Monitor (Universal Edition)
一款专为 Spartan Host 设计的工业级库存监控系统,支持多平台 Linux 自动适配。提供交互式部署流程、自动邮件提醒及 RESTful API 支持,能够轻松完成库存监控应用的搭建。
![]()
![]()
![]()
![]()
![]()
![]()
![]()
技术栈支持
![]()
![]()
![]()
![]()
![]()
核心特性
全系统适配:一键支持 Ubuntu, Debian, CentOS, AlmaLinux, Rocky, Fedora。
交互式部署:安装时动态配置邮箱及密码,实现零代码基础配置。
智能提醒:支持 Gmail 等 SMTP 服务,内置防骚扰冷却机制。
安全加固:管理密码支持自定义或强随机生成,接口受鉴权保护。
进程守护:基于 PM2 实现开机自启、崩溃重启及实时日志监控。
RESTful API:预留库存数据及订阅者管理接口,方便二次开发。
快速开始
克隆项目 (Git 方式)
git clone https://github.com/yokopro/spartanhost-monitor.git
cd spartanhost-monitor
执行一键部署脚本
将自动识别系统环境并安装 Node.js 与 PM2。
# 修复换行符并赋予权限
sed -i 's/\r$//' deploy.sh && chmod +x deploy.sh
# 运行交互式安装
./deploy.sh
查看管理密码
如果在安装时选择了随机生成密码,请运行以下命令查看密码:
pm2 logs spartan-monitor --lines 50 运维管理指令
| 需求 | 指令 |
|---|---|
| 实时日志 | pm2 logs spartan-monitor |
| 状态面板 | pm2 status |
| 重启应用 | pm2 restart spartan-monitor |
| 停止监控 | pm2 stop spartan-monitor |
| 资源监控 | pm2 monit |
| 彻底卸载 | pm2 delete spartan-monitor && rm -rf $(pwd) |
API 接口文档
系统默认运行在 3000 端口。
实时库存数据
Endpoint:
GET /api/stock说明: 返回当前监控的所有产品及其库存状态。
查看订阅者清单
Endpoint:
GET /api/subscribers认证: 需在
Request Header中添加:password: 你的管理密码
系统健康检查
- Endpoint:
GET /health
项目结构
├── public/ # Web 前端页面 (订阅及展示)
├── server.js # 后端核心逻辑与 API 服务
├── config.js # 自动生成的配置文件 (由 deploy.sh 生成)
├── deploy.sh # 终极全能交互式部署脚本
├── package.json # 项目依赖清单
└── subscribers.json # 订阅用户数据存储 (本地 JSON) 注意事项
Gmail 用户:
- 请务必开启 “两步验证” 并使用 16 位应用专用密码,而非邮箱登录密码。
防火墙设置:
- 本脚本会自动尝试开放 3000 端口,若无法访问,请检查云服务商的安全组设置。
隐私保护:
.gitignore已默认忽略config.js,请勿手动取消,防止授权码泄露至公共仓库。
Demo
推荐一款自由度非常高的 rss 软件
这个软件用了好多年了,他和别的 rss 软件最大的不同就是,他不需要网站支持 rss,可以通过元素定位,自动识别当前关注的区域是否有更新,再进行推送,功能还是很强了,就是设置可能有些麻烦,不过也有好长时间没用了,主要是订阅的越多,无效信息就越多,就搁置了
刚去看了下现在要 VIP 才能无限订阅,免费只能 10 个,有点烦,本来试了下订阅 L 站效果还不错,他能关键字筛选,内置了浏览器,也能登录账号用自定义订阅关注列表,但是收费了就算了,不行让 ai 写个类似的软件有没有搞头

实用 MCP 工具分享:MCP Toolbox 轻松实现查库、执行 SQL、造数据
实用工具分享:MCP Toolbox 轻松实现查库、执行 SQL、造数据
Toolbox 一款便捷实用的工具,核心支持数据库查询、SQL 直接执行、快速造测试数据三大核心场景,能大幅提升数据相关工作与 AI 联动的效率~

一、下载与安装 MCP Toolbox
- 官方下载地址(请选择对应自身操作系统的版本):
https://github.com/googleapis/genai-toolbox/releases - 安装后赋予执行权限并验证版本(适用于 Mac/Linux 等类 Unix 系统):
# 赋予 toolbox 可执行权限 chmod +x toolbox
# 验证工具是否安装成功,输出版本号即代表可用
./toolbox --version
补充提示:Windows 系统无需执行
chmod赋予权限操作,直接在命令行中运行toolbox.exe --version即可完成版本验证。
二、配置对接 AI 工具(以 Claude 为例)
通过以下 JSON 配置文件,实现 Claude 与 MCP Toolbox 的联动,核心配置 MySQL 数据库连接信息(其他数据库可参考官方文档进行扩展配置):
{ "mcpServers": { "mysql": { "command": "./PATH/TO/toolbox", // 替换为你的 toolbox 实际文件存放路径 "args": ["--prebuilt", "mysql", "--stdio"], "env": { "MYSQL_HOST": "", // 数据库主机地址,本地环境通常填写 127.0.0.1 "MYSQL_PORT": "", // 数据库端口,MySQL 默认端口为 3306 "MYSQL_DATABASE": "", // 要连接的目标数据库名称 "MYSQL_USER": "", // 数据库登录用户名 "MYSQL_PASSWORD": "" // 数据库登录密码 } } } } 三、配置生效与使用
- 完整填写上述配置文件中的各项空缺(重点替换工具路径与数据库连接信息),填写完成后保存文件;
- 重启你的 Claude 工具(或对应的 AI 客户端);
- 重启完成后,即可在 Claude 中调用 MCP Toolbox 实现查库、执行 SQL、造测试数据等操作啦~
补充说明
- 除 MySQL 外,MCP Toolbox 还支持多种主流数据库,完整预构建工具列表可前往官方仓库查看;
- 若配置后无法正常连接数据库,优先排查:数据库服务是否正常启动、连接信息是否填写正确、toolbox 实际路径是否匹配;
- 项目官方仓库详情:GitHub - googleapis/genai-toolbox: MCP Toolbox for Databases is an open source MCP server for databases.
这可能会是你用的最后一款可视化爬虫和浏览器 AI 自动化软件
背景
2025 年底的时候,我想要找一个能够帮我自动化执行浏览器任务的软件。但是在 agent 元年各种 agent 盛行,大吹特吹,演示视频似乎很厉害,但没有一个真正能用的。不是体验差,就是 token 消耗多价格高执行慢或者执行不稳定,成功率低。一怒之下,我就开始自己开发了,开发了几周经过了一小部分种子用户的体验和改进。现在可以这么说,browserwing 已经可以完成很多自动化任务了,通过 AI 辅助和 AI 的调度,帮你每天省下 x 个小时。
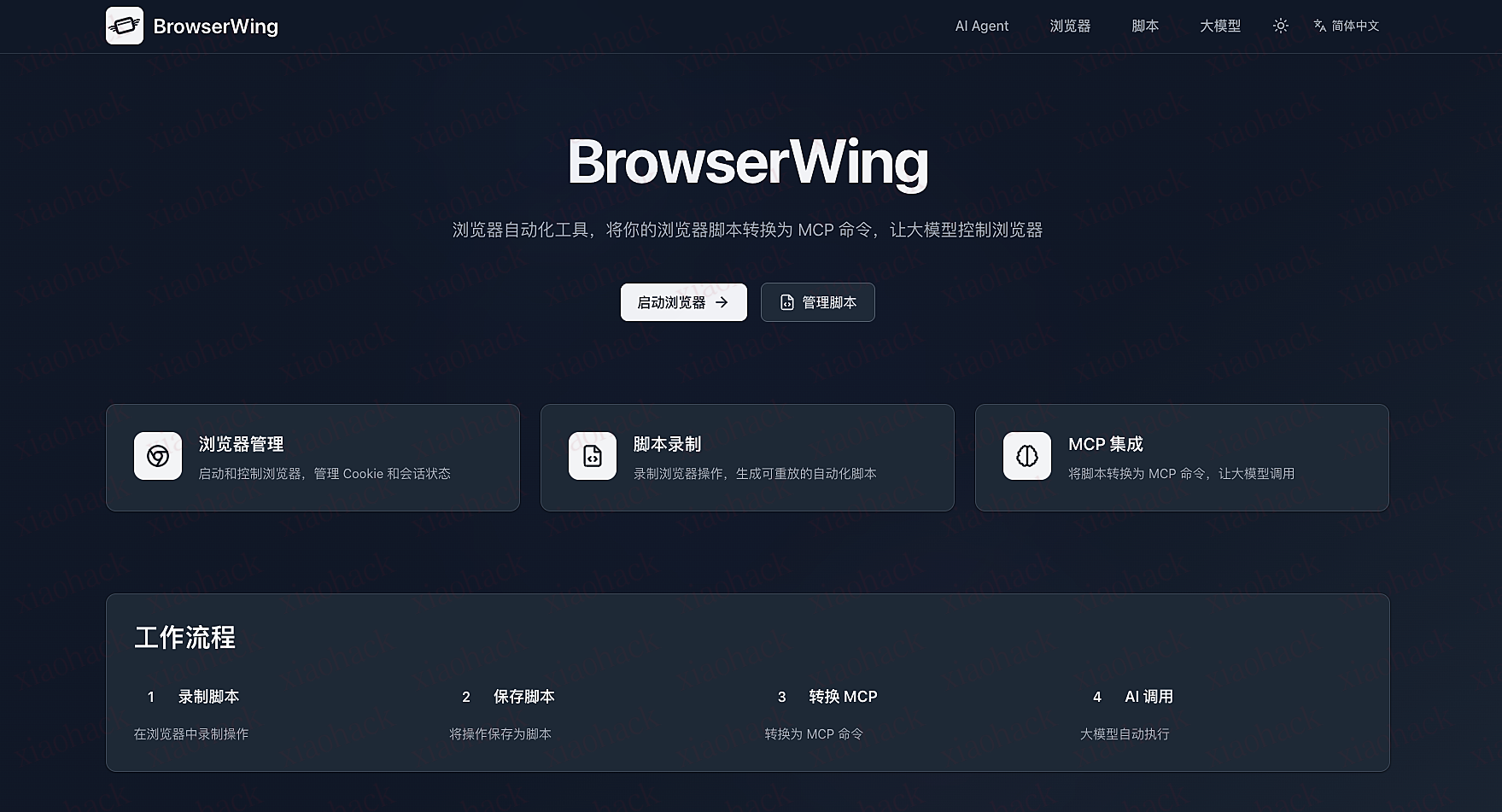

使用
演示
下面的演示,你也可以在 20 分钟内复刻实现,不是那种花里胡哨的但没用的演示。
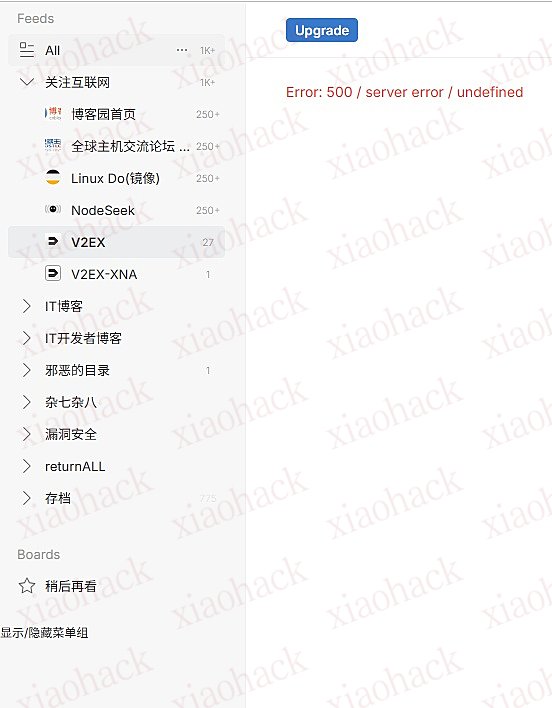
Feedly 炸了,本次作战代号 500
能加载 RSS 分类,点击到具体 RSS 的时候就 500 错误了,
从 reddit 的反馈看,影响全球两百多个国家和地区的 Feedly 用户,嗯哼。
话说热度不行啊,V2EX 没有讨论,用户量应该没那么少啊。
自从去年 9 月大更新后,Feedly 的稳定性就变差了很多,这次也影响到了 APP 用户,说明是服务器炸了。
(嗯,我虽然因为 feedly 不修 bug ,叛逃去了 inoreader 但有点不适应,毕竟还没写用户脚本进行优化使用,结果叛逃第三天 Feedly 修复了 bug 所以又反叛回来了)
Error: 500 / server error / undefined
对了,可能有人要问,为什么我的界面不一样,看起来简洁许多……别问,问就是自己写的用户脚本/油猴脚本。
从 reddit 的反馈看,影响全球两百多个国家和地区的 Feedly 用户,嗯哼。
话说热度不行啊,V2EX 没有讨论,用户量应该没那么少啊。
自从去年 9 月大更新后,Feedly 的稳定性就变差了很多,这次也影响到了 APP 用户,说明是服务器炸了。
(嗯,我虽然因为 feedly 不修 bug ,叛逃去了 inoreader 但有点不适应,毕竟还没写用户脚本进行优化使用,结果叛逃第三天 Feedly 修复了 bug 所以又反叛回来了)
Error: 500 / server error / undefined
对了,可能有人要问,为什么我的界面不一样,看起来简洁许多……别问,问就是自己写的用户脚本/油猴脚本。

像是一个 V2 的分身,气氛很好,有点难得。
有意思的项目,在网页上丝滑流畅的使用 Claude Code ,还能云端部署。 一个基于 Claude Agent SDK 而不是命令行套壳 Claude Code 的 WebUI
Claude Code WebUI
项目地址: https://github.com/DevAgentForge/claude-code-webui
网页版的 Claude Code ,允许您部署后在任意设备通过网页进行 AI 编程,
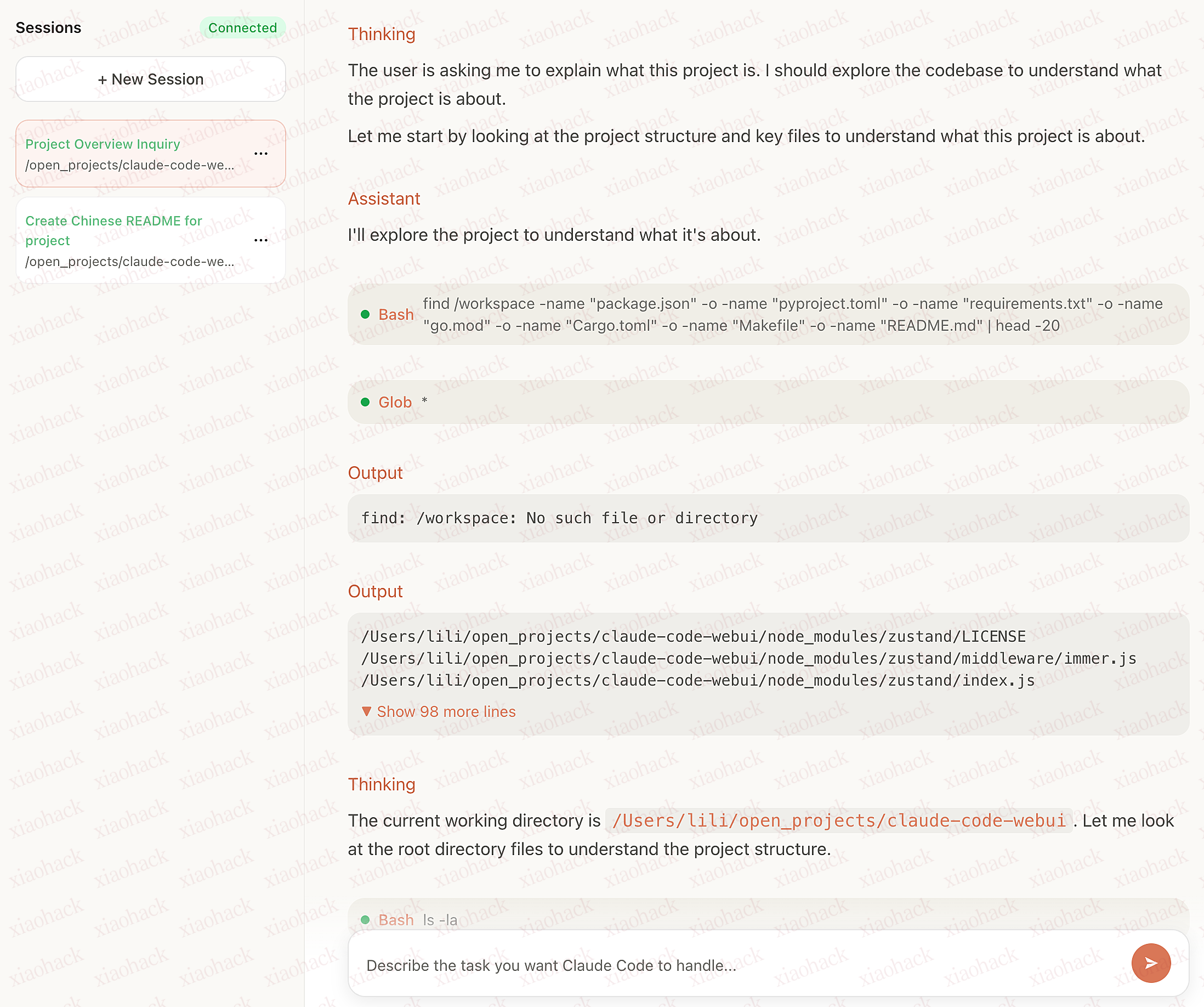
项目简介
Claude Code WebUI 让用户可以通过浏览器与 Claude Code 进行对话,兼容本地 Claude Code 配置。
该项目使用 React 构建前端,Bun 作为后端运行时,实现了完整的会话管理、实时消息流、权限控制等功能。
注意:目前可能仅支持 macOS/Linux ,所以下面的使用方法也仅针对这两类系统。
开始使用
在开始安装本项目之前,请先确保安装了 Bun 环境与 Claude Code, 如果已有,请忽略。
安装 Bun
curl -fsSL https://bun.sh/install | bash
安装 Claude Code
npm install -g @anthropic-ai/claude-code
运行 Claude Code WebUI
bunx @devagentforge/claude-code-webui@latest
如果你想自定义端口,可以设置环境变量
PORT=3000 bunx @devagentforge/claude-code-webui@latest
从源码运行
git clone https://github.com/DevAgentForge/claude-code-webui.git
cd claude-code-webui
bun i
bun run build
bun run start
注意
本项目依赖文件 ~/.claude/settings.json, 与 Claude Code 共享此配置,请自行配置 Claude Code 。