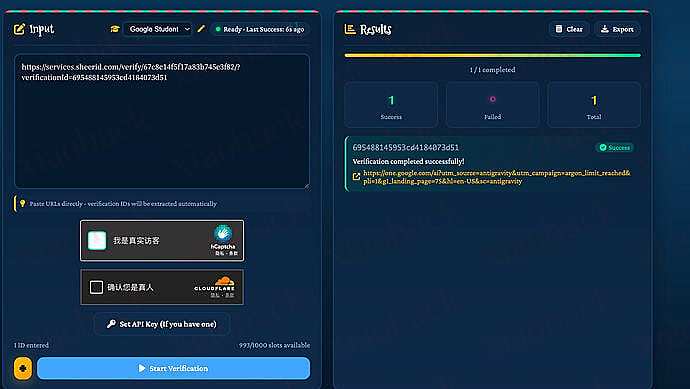
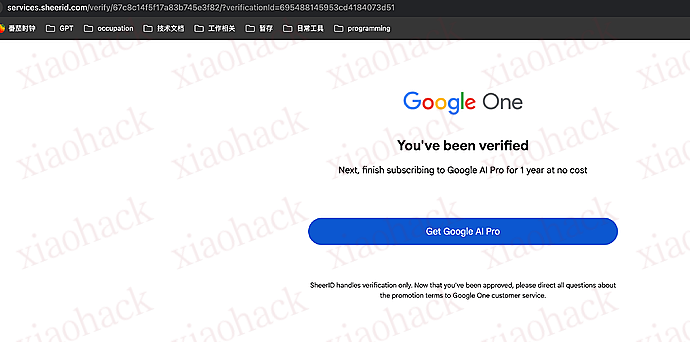
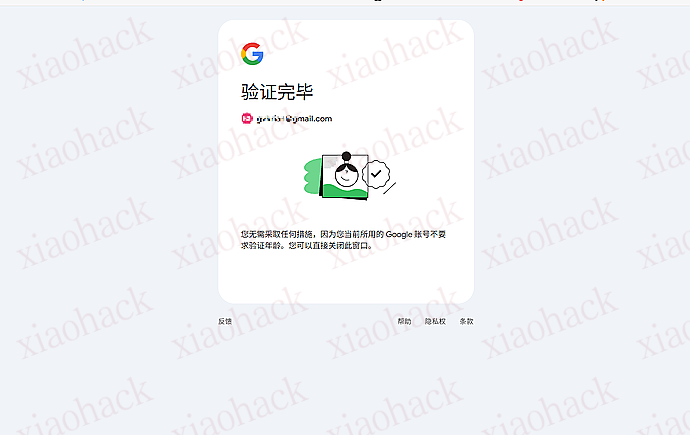
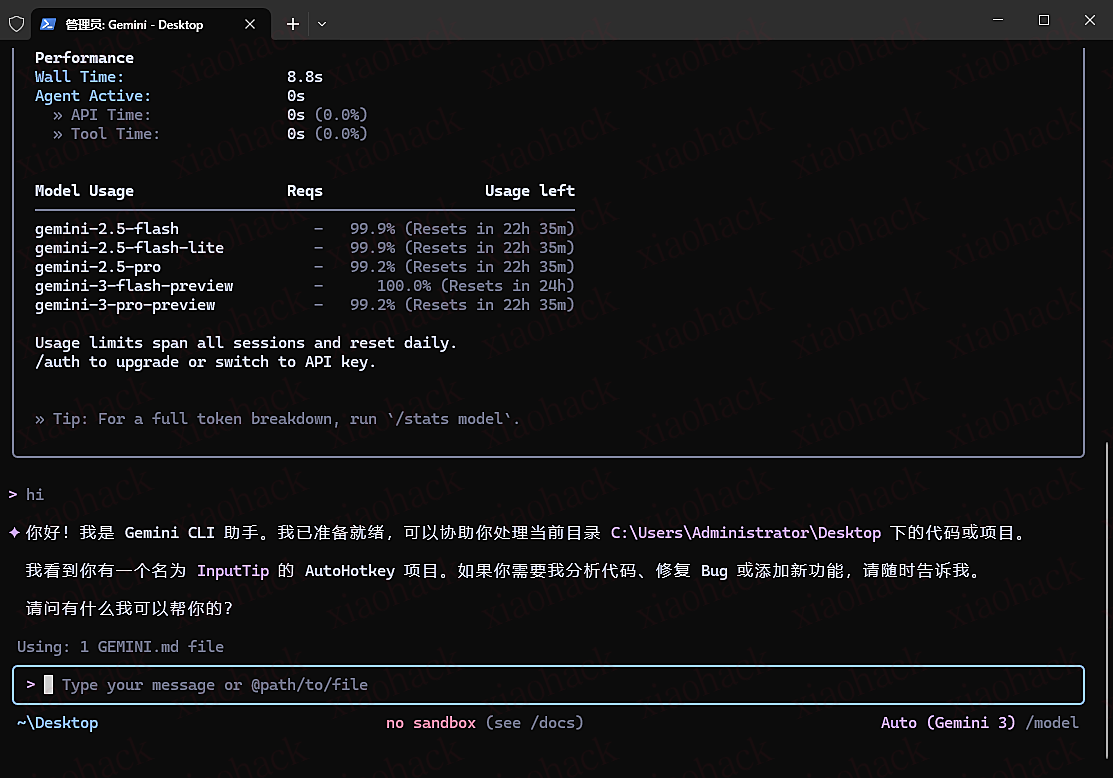
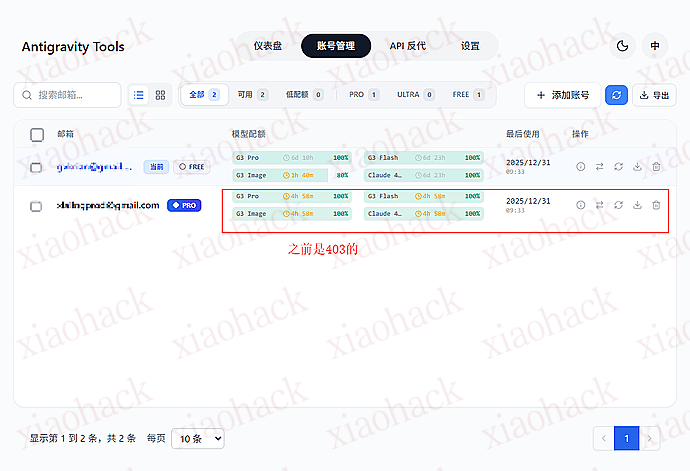
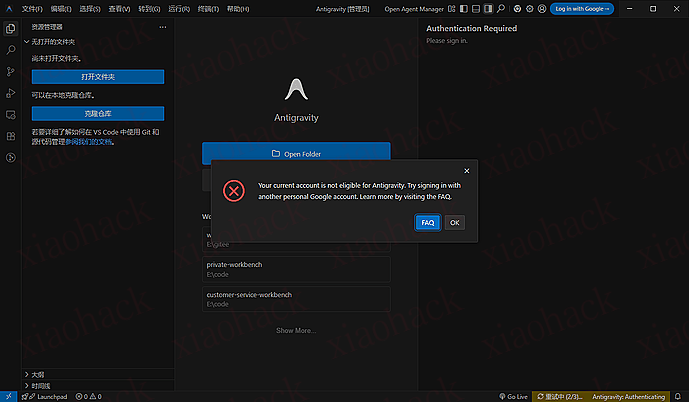
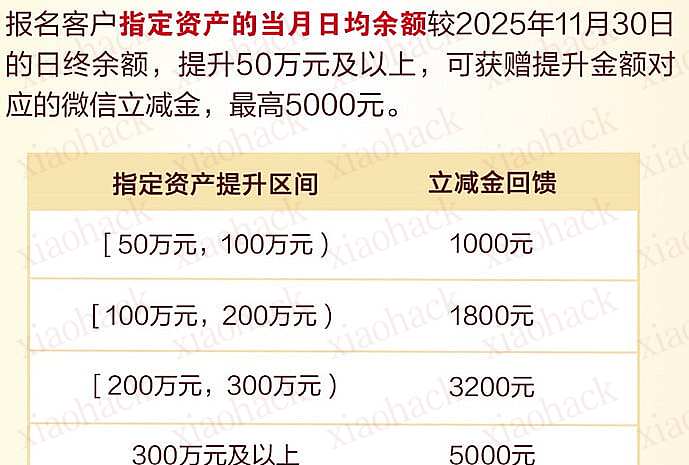
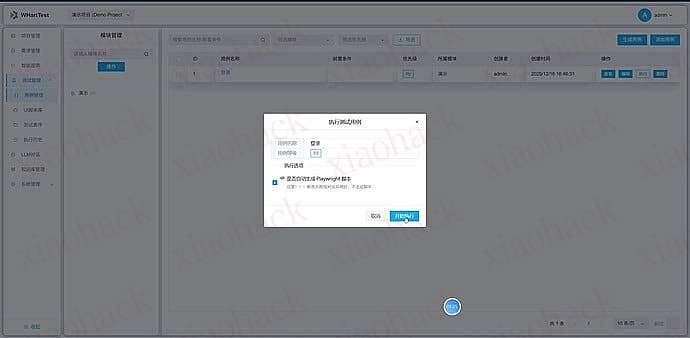
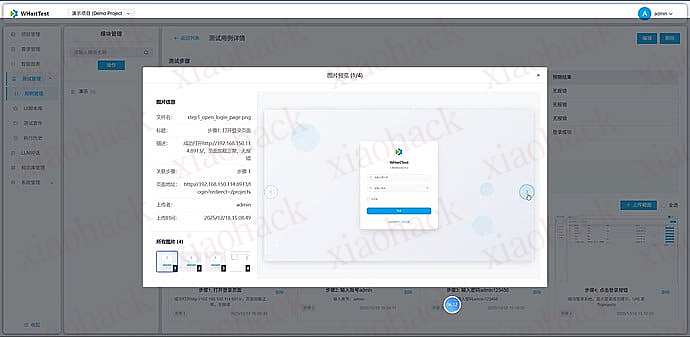
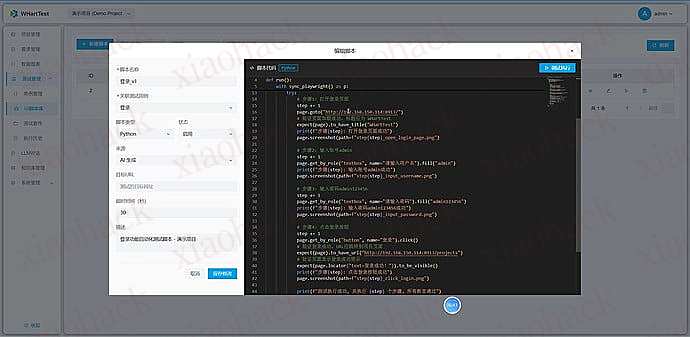
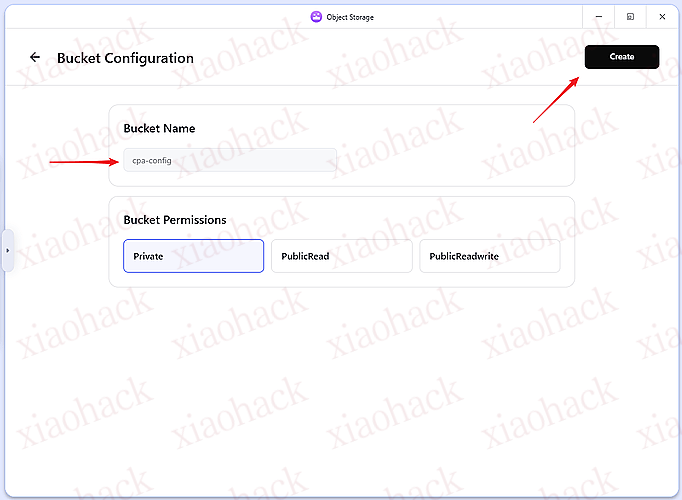
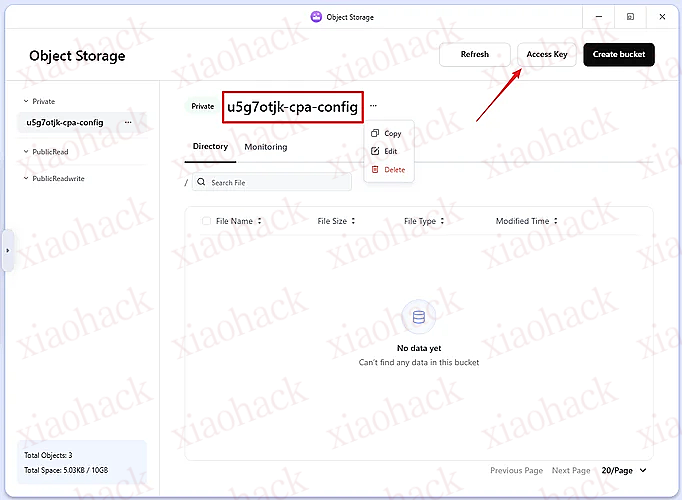
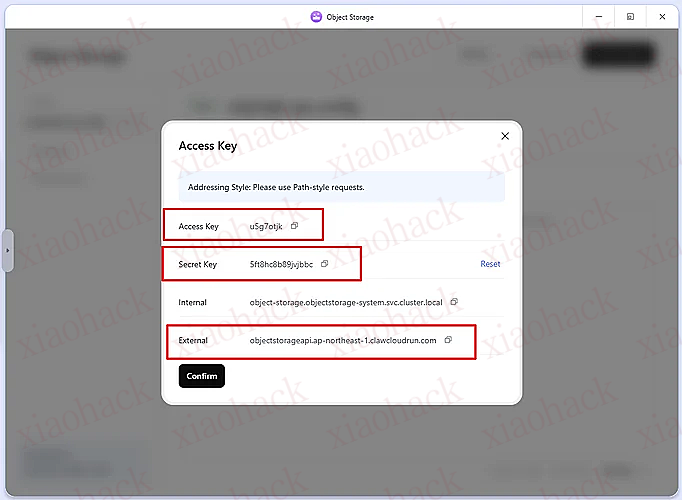
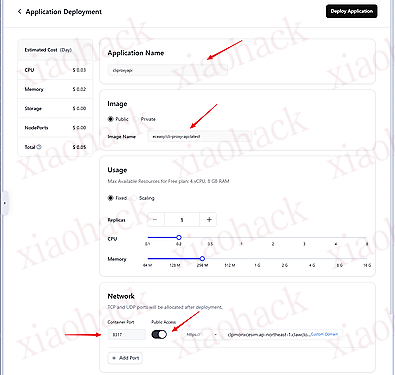
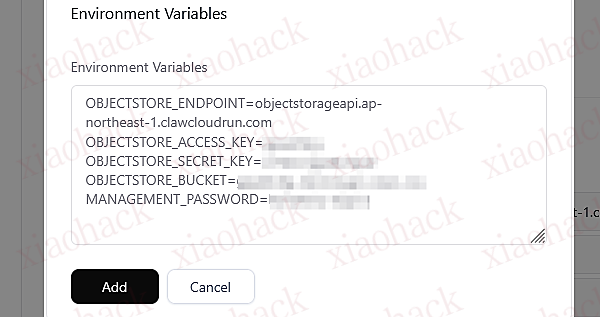
【新年快乐】$600 Codex
余额可在 https://crs.prismllm.tech/admin-next/api-stats 输入 api_key 查看。
~/.codex/config.toml:
model_provider = "crs" model = "gpt-5.2-codex" model_reasoning_effort = "xhigh" disable_response_storage = true preferred_auth_method = "apikey" [model_providers.crs] name = "crs" base_url = "https://crs.prismllm.tech/openai" wire_api = "responses" requires_openai_auth = true env_key = "CRS_OAI_KEY" ~/.codex/auth.json:
{ "OPENAI_API_KEY": null } export CRS_OAI_KEY=cr_ab8f442a747e9e5d591c54cfad8078c354993f5883e126d4c2c3310a8d37a980

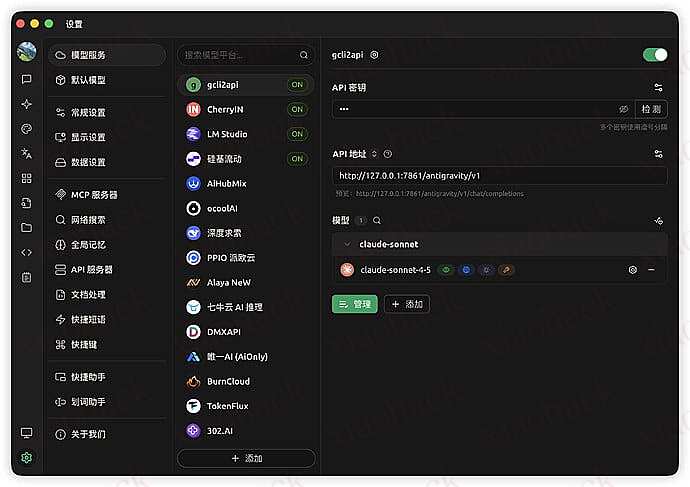
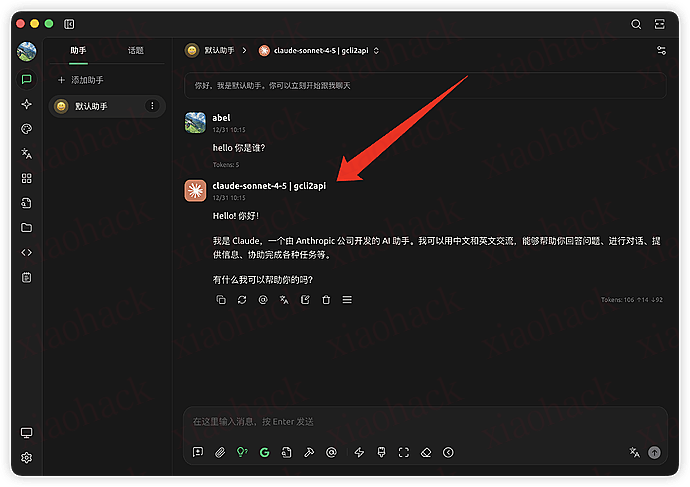

![[开源] PaperMate,让读论文看文档再优雅一点点3](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2025/12/31/20251231112821_695498552621e.gif!mark)
![[开源] PaperMate,让读论文看文档再优雅一点点2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2025/12/31/20251231112702_6954980698405.gif!mark)

![[开源] PaperMate,让读论文看文档再优雅一点点4](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2025/12/31/20251231112950_695498ae048f2.gif!mark)
![[开源] PaperMate,让读论文看文档再优雅一点点5](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2025/12/31/20251231113126_6954990e802e4.gif!mark)