2025年12月


Epic 喜加一 : 《取景器》
https://store.epicgames.com/zh-CN/p/viewfinder-61691c


使用一台拍立得相机,挑战你的认知、重新定义现实,并重塑周围的世界。《Viewfinder》是一款全新单人游戏,让玩家在数小时的有趣体验中揭开开遗留的谜团。
魔改 autojs 的魔改版 autox,添加 mcp 服务端,支持类似豆包手机的 ai 控制
看着佬友开源了基于智谱的手机助手的 Android 应用,感觉很高级,使用了一下,感觉还是不是我想的那种效果,想到以前的 autojs 就支持了类似的自动化,想着给它加上 mcp 服务端,不就是一个 ai 的自动化工具了吗。
说的做到
在驱动 codex-5_2 进行几轮对话后,就帮我集成了这个,通过 mcp 就能够驱动 autojs 来完成相应的

效果

期望
- 其他佬友们能够开发基于这个的 skills 支持更复杂的自动化开发
- 添加多模态支持,而不是 ocr,在复杂情况下 ocr 无法满足 ai 自动化的要求
已知问题
- 由于部分 Android(miui)的安全限制,无法操控微信等关键隐私 app
最后
源码地址: jinhan1414/AutoX: A UiAutomator on android, does not need root access (安卓平台上的 JavaScript 自动化工具)
文档: AutoX/docs/MCP_USAGE.md at setup-v7 · jinhan1414/AutoX
安装包: Release test · jinhan1414/AutoX
【开源自荐 Legado For Mac】适合 Mac 端的超轻量开源阅读工具,纯净无广,基于开源阅读。
——————事情又双叒是这样的——————
由于我本人想在 Mac 上爽看小说,但是苦于各大平台广告贼多,像类似于 Android 的开源阅读【Legado】在 Mac 端找不到相关的资源。于是,趁着手头上还有一些闲下来的时间,用 Swift 和 SwiftUI 自己写了一个在 Mac 端上运行的阅读 App【Legado for Mac】,基于原版 Andorid 的开源阅读。
最重要的书源、订阅,都可以平滑地从安卓中迁移过来,在【导入书源】后【解析】,基本实现了【在线找书】-> 【阅读】 → 【换源】 和 【订阅】 → 【解析】超方便的一体化工具链。并且在阅读逻辑上,基本保持了人类的阅读习惯。
下载地址:Release Legado for Mac v1.0.0 · Kequans/legado-for-mac-pub · GitHub
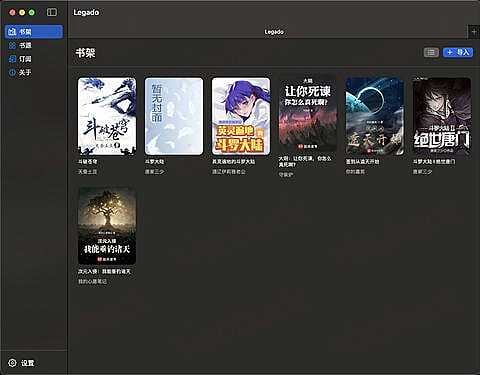
书架页面:书架 1
书架 2:
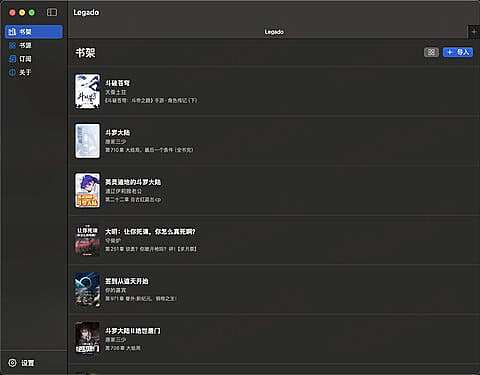
阅读页面:
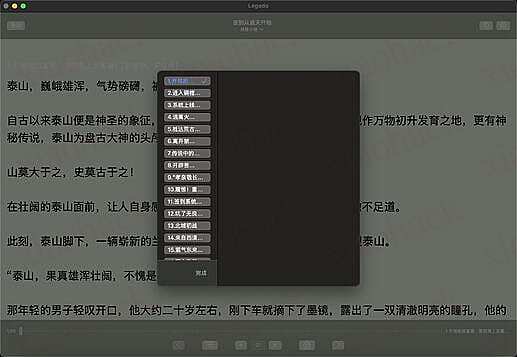
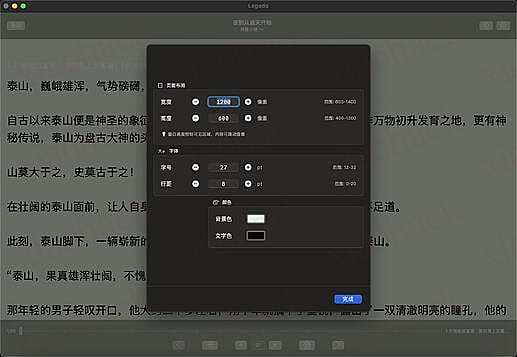
书籍搜索页面:

书源管理页面:
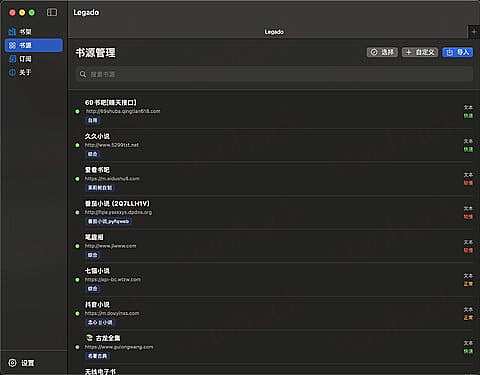
订阅管理页面:

关于页面:
项目简介Legado macOS 版本
这是 Legado(开源阅读)的 macOS 原生版本,使用 Swift 和 SwiftUI 构建。
功能特性
核心功能
- 自定义书源管理 - 支持导入、编辑、分组管理书源
- 本地 TXT/EPUB 阅读 - 支持多种格式本地书籍
- 在线书籍搜索和阅读 - 基于书源规则的网络书籍搜索
- 书架管理 - 书籍分组、排序、封面管理
- 阅读进度同步 - 章节索引和滚动位置的精确记忆
- 自定义阅读界面 - 字体、颜色、行距等可调
- 替换规则和净化功能 - 自定义文本替换和内容过滤
高级特性
- JavaScript 书源支持 - 部分支持书源中的 JS 脚本(java.ajax, java.get/put 等)
- 智能章节缓存 - 自动预加载后续章节,提升阅读体验
- 精确位置恢复 - 记住每本书的滚动位置,重新打开直达上次阅读处
- 并发网络请求 - 批量搜索和章节预加载的性能优化
- 自动过期清理 - 智能管理缓存空间,自动清理 30 天前的章节
系统要求
- macOS 13.0 或更高版本
使用方法用户安装步骤:
- 下载
Legado.app或Legado.dmg- 拖拽到「应用程序」文件夹
- 首次运行时在「系统偏好设置 > 隐私与安全性」中允许
后续代码会陆续开源。
(有 BUG,可以积极回帖反馈呀,虽然可能改不动 wuwuwu)
开源地址:
(因为目前一些拓展功能还在开发,所以暂时先把部分核心代码开源了,还有一些拓展功能后续再做…… 不知道有没有时间)
下载地址:Release Legado for Mac v1.0.0 · Kequans/legado-for-mac-pub · GitHub
觉得本项目不错的话,可以用 LDC 赞助一下帮帮我,Vibe coding 的额度要上天了,让我回回血呜呜呜 ~~~~||
————————————————————
-------------------- 附赞助链接:(LDC 打赏,最低 0.01,都是支持!)-----------------------
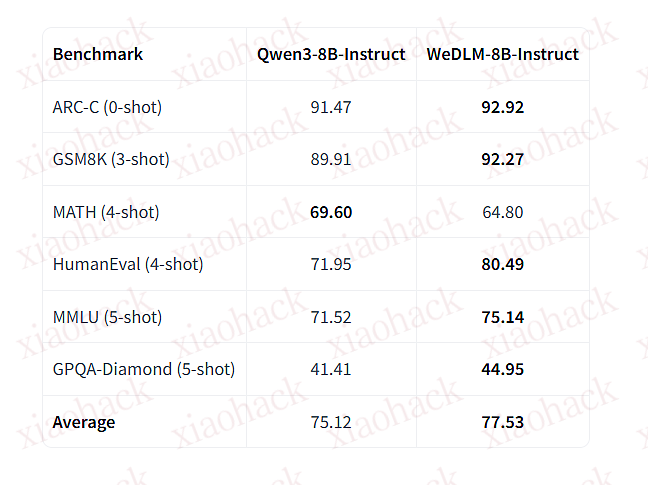
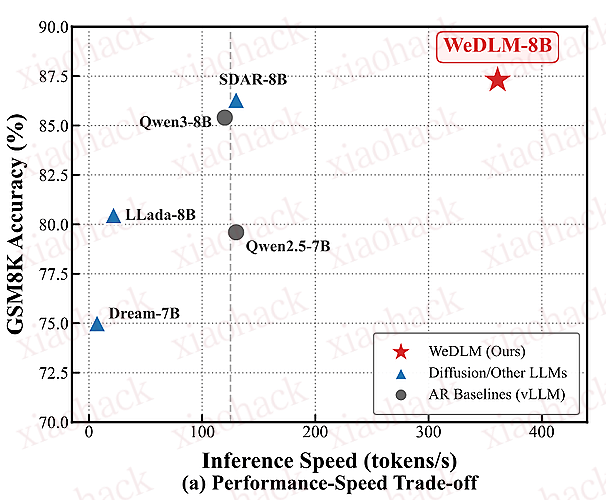
腾讯发布了首个 Diffusion 大语言模型 WeDLM-8B
在数学推理任务中,相比经 vLLM 优化的 Qwen3-8B,速度提升 3–6 倍
在大多数基准测试中,性能超越原始的 Qwen3-8B-Instruct
原生支持 KV Cache(兼容 FlashAttention、PagedAttention、CUDA Graphs)
【1038个书源】放个狠货,爱看小说的有福了
不管了,反正总会有人往外分享。
上传到Catbox了,链接看我心情失效,想导入的佬友抓紧导入。
导入方式:
打开 阅读APP
安卓: Releases · gedoor/legado · GitHub
ios: 阅读阅多 - 看小说电子书TXT书源阅读器 App - App Store进入 书源管理
点击右上角菜单 → 网络导入
粘贴链接(或者下载整个json文件,直接本地导入):
https://litter.catbox.moe/16xdzu.json
5. 最后别忘了点击启用所选书源
最最重要的是,感觉有用的可以给我点个赞哦。
或者打赏一下
终于用上反重力了!Mac 端完整配置指南
终于用上反重力了!Mac 端完整配置指南
前言
之前尝试过各种方法想用上反重力,但一直没能成功。今天终于借助 Antigravity-Manager 这个项目实现了,体验相当刺激!
配置步骤(Mac 版)
1. 下载与安装
前往 v3.2.0 Release 页面 下载适合 Mac 的安装包。
安装完成后,在终端执行以下命令解除系统的安全限制:
sudo xattr -rd com.apple.quarantine "/Applications/Antigravity Tools.app" 2. 登录配置
打开应用后,登录你的账号:
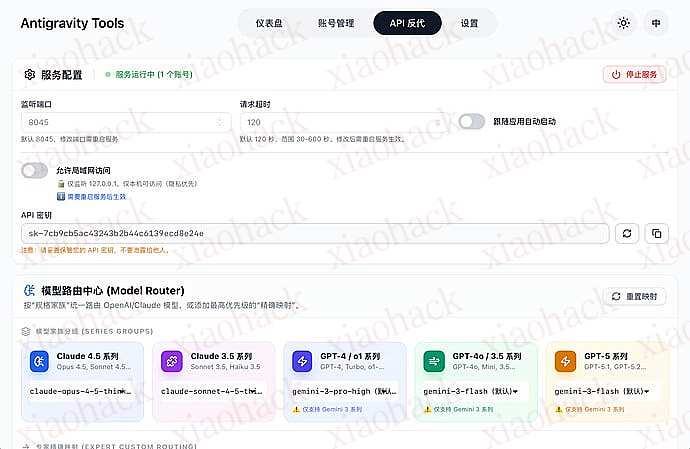
3. 启动 API 反代
进入 API 反代设置页面:
点击 "启动" 按钮:
实战测试
配置完成后,我测试了几个模型,效果不错。
测试 1:Claude Opus 4.5
使用 OpenAI SDK 调用 Claude Opus 4.5 模型:
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8045/v1",
api_key="sk-7cb9cb5ac43243b2b44c6139ecd8e24e"
)
response = client.chat.completions.create(
model="claude-opus-4-5-thinking",
messages=[{
"role": "user",
"content": "在白板上解:"一把钥匙开一把锁。现在有5把锁和相应的5把钥匙,但是全部放乱了,最多试几次,就可以打开全部的锁。",清晰地展示解题步骤"
}]
)
print(response.choices[0].message.content)
运行结果:

测试 2:Gemini 3 Pro Image(Banana Pro)
这个模型支持生成图像,可以通过 size 参数或模型后缀指定输出比例:
from openai import OpenAI
import base64
client = OpenAI(
base_url="http://127.0.0.1:8045/v1",
api_key="sk-7cb9cb5ac43243b2b44c6139ecd8e24e"
)
response = client.chat.completions.create(
model="gemini-3-pro-image",
# 方式 1: 使用 size 参数(推荐) # 方式 2: 使用模型后缀 # 例如: gemini-3-pro-image-16-9, gemini-3-pro-image-4-3 # model="gemini-3-pro-image-16-9",
messages=[{
"role": "user",
"content": "在白板上解:"一把钥匙开一把锁。现在有5把锁和相应的5把钥匙,但是全部放乱了,最多试几次,就可以打开全部的锁。",清晰地展示解题步骤"
}]
)
# 提取并保存图像
temp = response.choices[0].message.content
image_data = temp.split("[1][:-1]
with open("/Users/darbra/Downloads/result.jpg", 'wb') as f:
f.write(base64.b64decode(image_data))
生成的白板图:


总结
整个配置过程其实并不复杂,关键是找到靠谱的工具。Antigravity-Manager 这个项目维护得不错,Mac 端体验流畅。
正如那句话说的:“得不到的永远在骚动”—— 真正用上了之后,好像也就那么回事。不过既然成功了,分享出来给有需要的朋友。
美国著名科技杂志 Wired: 再见,GPT-5, 你好,qwen

Codanna 使用配置方法分享
本人是在 Windows 环境配合 vscode、cursor 使用。
1、下载 exe 文件,并把路径配置到系统环境变量 Path:
2、进入代码项目
执行 codanna init,这步会自动生成配置文件 settings.toml
3、调整 settings.toml, 比如嵌入模型、开启文档索引等
[semantic_search] enabled = true # Model to use for embeddings # Note: Changing models requires re-indexing (codanna index --force) # - AllMiniLML6V2: English-only, 384 dimensions (default) # - MultilingualE5Small: 94 languages including, 384 dimensions (recommended for multilingual) # - MultilingualE5Base: 94 languages, 768 dimensions (better quality) # - MultilingualE5Large: 94 languages, 1024 dimensions (best quality) # - BGESmallZHV15: Chinese-specialized, 512 dimensions # - See documentation for full list of available models model = "MultilingualE5Large" # Similarity threshold for search results (0.0 to 1.0) threshold = 0.6 [documents] enabled = true [documents.collections.docs] paths = ["."]
patterns = ["**/*.md", "**/*.txt"]
4、开始建立索引,这步会下载模型(首次),需要配置好网络,下载速度视网络情况决定
代码索引:
codanna index . --force
文档索引(文档编码需要是 utf-8 格式):
codanna documents index --progress
5、MCP 配置(我的样例,仅供参考)
Vscode:
{
"mcpServers": {
"codanna": {
"command": "D:\\soft\\codanna\\codanna.exe",
"args": [
"serve",
"--watch"
],
"alwaysAllow": [
"analyze_impact",
"find_callers",
"get_index_info",
"find_symbol",
"semantic_search_docs",
"semantic_search_with_context",
"search_symbols",
"get_calls",
"search_documents"
]
}
}
}
Cursor:
{
"mcpServers": {
"codanna": {
"command": "D:\\soft\\codanna\\codanna.exe",
"args": [
"--config",
"D:\\code\\xxx\\settings.toml",
"serve",
"--watch"
],
"alwaysAllow": [
"analyze_impact",
"find_callers",
"get_index_info",
"find_symbol",
"semantic_search_docs",
"semantic_search_with_context",
"search_symbols",
"get_calls",
"search_documents"
]
}
}
}
6、提示词加入:使用codanna mcp进行语义检索
【开源自荐】IDEA 版 Claude Code GUI 插件(v0.2)
前言说明
从原贴继续:IDEA 版 Claude Code GUI 插件 开发记录帖
本项目主要解决 IDEA 使用 Claude Code 没有可视化操作页面的问题
新帖原因
不知不觉已经开发一个多月了
以为老帖子已经无法修改编辑了,所以更换到本帖进行 v0.2 版本的开发记录
目前进度
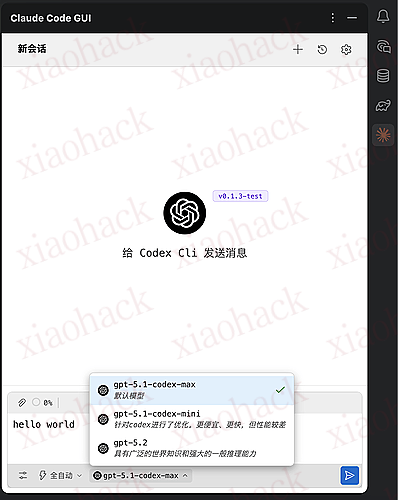
目前版本为 v0.1.3 版本(还未发布)
正在内测 Codex Cli 功能,预计本周三发商店版
以下均为实机演示,功能已经实现,正在内测中(内测两天找 BUG,静静期待)
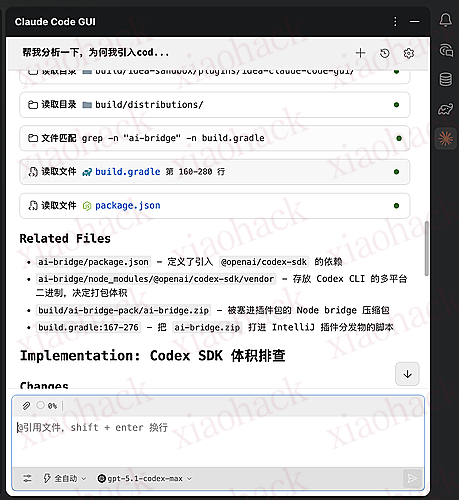
插件市场可下载
本插件已上架 Jetbrains 市场,搜索 claude code gui 安装即可
本项目后续不打算进行任何商业化行为,请放心食用
声明:政府部门,国企,学校 修改本项目代码,可遵循 MIT 协议,不需要遵守 AGPL-3.0 协议
致谢
感谢所有帮助 IDEA-Claude-Code-GUI 变得更好的贡献者!和感谢 L 站平台

本插件在极速更新中,每天预计发布 1 版,佬友们记得及时更新哦~
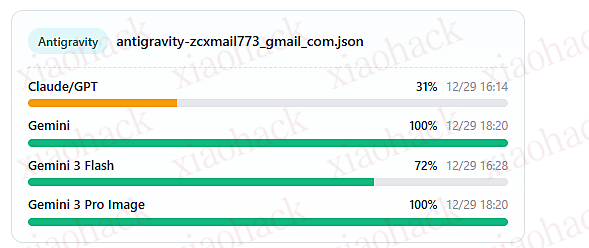
无限 claudecode 额度?太爽了
感谢这两个项目 + 谷歌的反重力额度,让我实现了无限的 claudecode 额度!!
【教程】AI 自动化测试 MCP
分享一个我最近开源的 API 测试框架,专门解决 AI 编程助手写测试代码的痛点。
背景
不知道大家有没有让 AI 写接口测试的经历?我之前用 Claude、Cursor 写测试,遇到了几个非常头疼的问题:
场景 1:重复劳动
每次让 AI 生成测试,都要重新描述项目结构、认证方式、断言风格。测 10 个接口,同样的 fixture 和 setup 代码能重复 10 遍。
场景 2:Token 黑洞
一个简单的登录接口测试,AI 生成 200 行代码。发现断言写错了,让它改,又生成 200 行。改 3 次,消耗 2000+ Token,最后还是自己手动改的。
场景 3:调试死循环
AI 生成的测试跑不通,报错信息贴给它,它改了一版还是不对。来回复 5 轮对话,问题还在,Token 已经烧了 5000+。
解决方案
传统方式:自然语言描述 → AI 生成完整代码 → 运行报错 → 贴报错 → AI 重新生成 → 循环…
本框架:自然语言描述 → AI 生成 YAML → 框架执行 → 直接定位问题 → 改 YAML 一行
这个框架的解决方案:
传统方式:自然语言描述 -> AI 生成完整代码 -> 运行报错 -> 贴报错 -> AI 重新生成 -> 循环...
本框架: 自然语言描述 -> AI 生成 YAML -> 框架执行 -> 直接定位问题 -> 改 YAML 一行
| 对比项 | 传统 AI 生成 | 本框架 |
|--------|-------------|--------|
| 测试 1 个接口 | ~200 行代码 | ~20 行 YAML |
| 修改断言逻辑 | 重新生成全部代码 | 改 1-2 行 YAML |
| 10 个接口测试 | 重复 setup 10 次 | 共享配置,0 重复 |
| 调试一个问题 | 平均 3-5 轮对话 | 通常 1 轮 |
核心特性
| 特性 | 说明 |
|------|------|
| YAML 声明式用例 | 测试逻辑与执行代码分离,AI 只需生成结构化数据 |
| MCP Server | 与 Claude/Cursor 等 AI 编辑器无缝集成 |
| 接口 Workflow 编排 | 单文件支持多步骤接口调用,步骤间数据传递与断言 |
| 变量解析引擎 | 支持步骤间数据传递、全局变量、动态函数调用 |
| 自动认证管理 | Token 获取和刷新由框架处理 |
| 数据工厂 | 无需 Java 依赖,内置 Mock 数据生成 |
| 多格式测试报告 | Allure(离线 / 在线)、pytest-html(独立 HTML,美化样式) |
| 多渠道通知 | 钉钉、飞书、企业微信 |
| 单元测试 | 支持 Python 代码单元测试,Mock 依赖自动注入 |
快速开始
安装
# 1. 安装 uv(如果没有)
curl -LsSf https://astral.sh/uv/install.sh | sh
# 2. 安装 MCP 服务器(推荐:安装为 tool)
uv tool install git+https://github.com/GalaxyXieyu/Api-Test-MCP.git
# 验证
api-auto-test-mcp --help # 管理工具
uv tool list
uv tool uninstall api-auto-test # 以 `uv tool list` 展示的 tool 名称为准 【爱词网开站】AI 提示词分享交流与管理,爆肝了半个月总算可以进入正式使用了。
日常使用中,发现,不管是工作流使用,还是在 Cherry studio 中使用,都不可避免的会用到很多提示词,而对这些提示词做管理,说简单也简单,但繁琐也真是繁琐。也看到了佬友的帖子的一些需求:
也看到了一些提示词管理的开源项目,但都不是特别符合,索性自己对 Wordpress 比较了解,因此结合 wp 开发出了这个网站,我称之为:” 爱词网 “
爱词网主要功能就是:提示词交流,分享与管理。
做起来其实不复杂,但真正复杂的是,如何做起来后更好用,更简便。因此整个站总是在不停打磨中,慢慢优化,或是 UI,或者增加些实用功能。直到现在,我觉得可以开放了。
说在前面的话:整个网站很多代码都是通过 vibe coding 实现,我虽然有进行审阅和测试,但是还是会不可避免的遇到各种问题,因此,反馈及意见将帮助良多。
站内主要实现了以下方便快捷的提示词管理功能:
功能详情,多图,注意流量
1、AI 提示词上传,给许多不知道如何去描述一个 “AI 提示词” 一个方便快捷的操作;
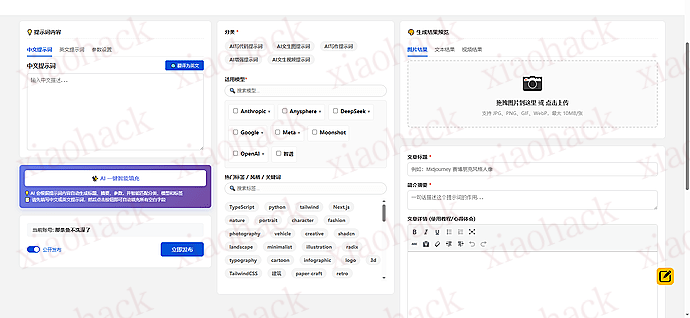
2、提示词快捷 fork, 很多别人的提示词,自己拿来直接用总是不太符合自己胃口,需要针对性的进行修改和二次调整优化,因此,我加入了一个类似于 GitHub 的 fork 功能。
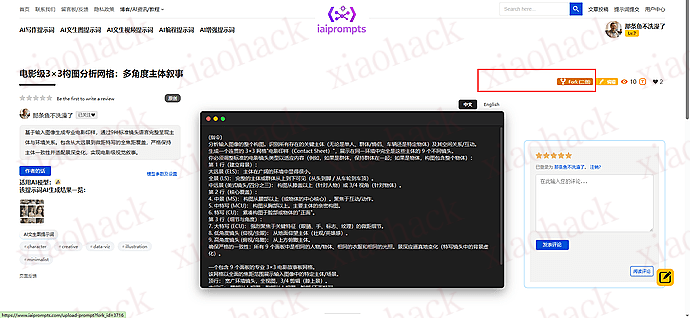
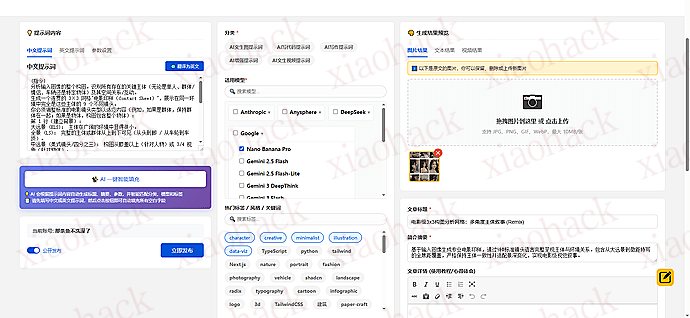
3、直观易懂的个人中心 实现了许多供交流和分享的用途,如用户名片(主要是为了间接实现关注作者功能,)收藏点赞,私信,评论评分,财富积分(暂时没什么用)…
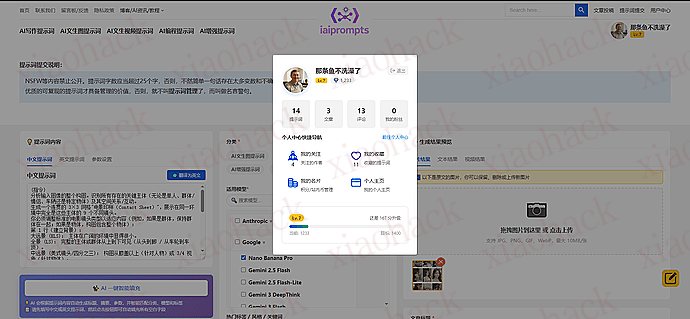
说在最后的话:
目前已接入 linuxdo 登录,同样的继承 l 站的等级,名称和头像。
主机只是个 1H1G 的服务器,但是线路很好,因此访问速度应该不错,但是还是有点慌,因为扛不住太高并发,当然,到时候,社区如果可以孵化支持下最好了。
正在 / 计划实现的一些其他功能
提示词的快捷使用:计划接入常用的各个 AI 客户端,实现,点击提示词即可在对应的客户端 / 网页自动置入并直接使用。
其他,还没想好…,欢迎佬友提交。
Verdent 获取试用绑卡链接脚本(无需安装 IDE,支持插件)
Verdent 本身是必须要 下载 IDE 才可以拿到付款链接去试用的,插件和网页控制台都是无法获取试用链接的。
脚本自取,喜欢的老友留个评论和赞~
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Verdent 获取付款链接工具
用于获取注册后的Stripe支付链接(绑卡链接)
"""
import httpx
import json
import sys
import time
import io
# 修复 Windows 控制台编码问题
if sys.platform == 'win32':
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8')
class VerdentPaymentLinkGetter:
"""Verdent 付款链接获取器"""
def __init__(self, token):
"""
初始化
token: Verdent 访问令牌
"""
self.token = token
self.base_url = "https://api.verdent.ai"
# 初始化 HTTP 客户端
self.client = httpx.Client(
timeout=30.0,
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36',
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Origin': 'https://www.verdent.ai',
'Referer': 'https://www.verdent.ai/',
'sec-ch-ua': '"Chromium";v="142", "Microsoft Edge";v="142", "Not_A Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
}
)
# Verdent 计划 ID
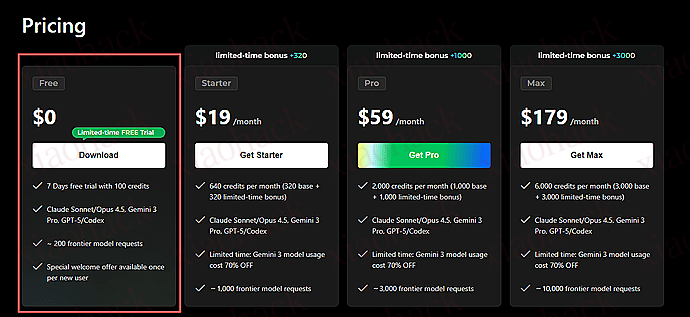
self.plan_ids = {
'Free': 'Pl1181733412181114881', # Free - 7天试用
'Starter': 'Pl1181727875814031360', # $19/月
'Pro': 'Pl1181727875813916672', # $59/月
'Max': 'Pl1181727875813818368', # $179/月
'PayAsYouGo_20': 'Pl1181727875813720064', # $20 一次性
'PayAsYouGo_60': 'Pl1181727875813588992', # $60 一次性
'PayAsYouGo_80': 'Pl1181727875813474304', # $80 一次性
'PayAsYouGo_100': 'Pl1181727875813376000', # $100 一次性
'PayAsYouGo_200': 'Pl1181727875813261312', # $200 一次性
}
def get_user_info(self):
"""获取用户信息(包含邮箱)"""
try:
print("📧 正在获取用户信息...")
# 添加 Cookie 头(包含 token)
headers = {
'Cookie': f'token={self.token}'
}
response = self.client.get(
f'{self.base_url}/verdent/user/info',
headers=headers
)
if response.status_code == 200:
data = response.json()
email = data.get('email', '')
print(f"✅ 用户邮箱: {email}")
return email
else:
print(f"⚠️ 获取用户信息失败: {response.status_code}")
print(f" 响应: {response.text}")
return None
except Exception as e:
print(f"❌ 获取用户信息出错: {e}")
return None
def create_subscription(self, plan_name='Free', user_email=None):
"""
创建订阅并获取支付链接
plan_name: 计划名称 (Free, Starter, Pro, Max, PayAsYouGo_20, 等)
user_email: 用户邮箱(如果不提供则自动获取)
"""
try:
# 获取 plan_id
plan_id = self.plan_ids.get(plan_name)
if not plan_id:
print(f"❌ 未知的计划名称: {plan_name}")
print(f" 支持的计划: {', '.join(self.plan_ids.keys())}")
return None
# 如果没有提供邮箱,尝试获取
if not user_email:
user_email = self.get_user_info()
if not user_email:
print("❌ 无法获取用户邮箱,请手动提供")
return None
print(f"\n💳 正在创建订阅...")
print(f" 计划: {plan_name}")
print(f" Plan ID: {plan_id}")
print(f" 邮箱: {user_email}")
# 添加 Cookie 头
headers = {
'Cookie': f'token={self.token}',
'Content-Type': 'application/json'
}
# 构造请求体
payload = {
'plan_id': plan_id,
'user_email': user_email,
'source': 'verdent'
}
# 发送请求
response = self.client.post(
f'{self.base_url}/verdent/subscription/create',
headers=headers,
json=payload
)
if response.status_code == 200:
data = response.json()
print(f"✅ 订阅创建成功!")
print(f"\n📋 完整响应:")
print(json.dumps(data, indent=2, ensure_ascii=False))
# 尝试提取支付链接
payment_url = None
# 常见的字段名
possible_keys = ['url', 'payment_url', 'checkout_url', 'stripe_url',
'redirect_url', 'session_url', 'link', 'checkout_session_url']
for key in possible_keys:
if key in data:
payment_url = data[key]
break
# 如果没有直接的URL字段,检查嵌套对象
if not payment_url:
if 'data' in data and isinstance(data['data'], dict):
for key in possible_keys:
if key in data['data']:
payment_url = data['data'][key]
break
if payment_url:
print(f"\n🔗 支付链接:")
print(payment_url)
return payment_url
else:
print(f"\n⚠️ 未在响应中找到支付链接,请查看完整响应")
return data
else:
print(f"❌ 创建订阅失败: {response.status_code}")
print(f" 响应: {response.text}")
return None
except Exception as e:
print(f"❌ 创建订阅出错: {e}")
import traceback
traceback.print_exc()
return None
def close(self):
"""关闭客户端"""
self.client.close()
def main():
"""主函数"""
print("=" * 60)
print("🌟 Verdent 付款链接获取工具")
print("=" * 60)
# 使用方式 1: 从命令行参数读取
if len(sys.argv) > 1:
token = sys.argv[1]
plan_name = sys.argv[2] if len(sys.argv) > 2 else 'Free'
user_email = sys.argv[3] if len(sys.argv) > 3 else None
else:
# 使用方式 2: 从 verdent_tokens.txt 读取
try:
with open('verdent_tokens.txt', 'r', encoding='utf-8') as f:
lines = [line.strip() for line in f if line.strip()]
if lines:
token = lines[0]
print(f"📄 从 verdent_tokens.txt 读取 token")
else:
print("❌ verdent_tokens.txt 为空")
print("\n使用方法:")
print(" python get_payment_link.py <token> [plan_name] [email]")
print("\n参数说明:")
print(" token: Verdent 访问令牌(必需)")
print(" plan_name: 计划名称(可选,默认: Free)")
print(" 支持: Free, Starter, Pro, Max, PayAsYouGo_20/60/80/100/200")
print(" email: 用户邮箱(可选,不提供则自动获取)")
return
except FileNotFoundError:
print("❌ 找不到 verdent_tokens.txt 文件")
print("\n使用方法:")
print(" python get_payment_link.py <token> [plan_name] [email]")
print("\n或创建 verdent_tokens.txt 文件并在第一行写入 token")
return
plan_name = 'Free' # 默认使用 Free 计划
user_email = None
print(f"\n🔐 Token: {token[:50]}...")
# 创建获取器
getter = VerdentPaymentLinkGetter(token)
try:
# 获取支付链接
result = getter.create_subscription(plan_name=plan_name, user_email=user_email)
if result:
print("\n" + "=" * 60)
print("✅ 成功!")
if isinstance(result, str) and result.startswith('http'):
print(f"🔗 复制此链接到浏览器即可绑卡:")
print(result)
print("=" * 60)
else:
print("\n" + "=" * 60)
print("❌ 获取失败,请检查 token 是否有效")
print("=" * 60)
finally:
getter.close()
if __name__ == "__main__":
main()
中国知网寒假账号分享
在吾爱看到有人分享账号,给佬友们也分享一下:
用户名: ccghxytsg01 ccghxytsg02 ccghxytsg03 ccghxytsg04
密 码: ccghxy02
请选择机构登录,且不要复制空格
[开源] ContextWeaver 本地代码库语义检索工具,目标是 ace 平替
augment code 的账号太难注册了,注册了就封,从海鲜市场买别人注册好的号也是几天就封了,augment context engine 又很好用,只能试试看能不能做一个平替了
项目使用方式
- 安装
# 全局安装
npm install -g @hsingjui/contextweaver
# 或使用 pnpm
pnpm add -g @hsingjui/contextweaver
- 配置
# 初始化
contextweaver init
# 或者简写
cw init
#修改 `~/.contextweaver/.env`
EMBEDDINGS_API_KEY=your-api-key-here
EMBEDDINGS_BASE_URL=https://api.siliconflow.cn/v1/embeddings
EMBEDDINGS_MODEL=BAAI/bge-m3
EMBEDDINGS_MAX_CONCURRENCY=10
EMBEDDINGS_DIMENSIONS=1024
RERANK_API_KEY=your-api-key-here
RERANK_BASE_URL=https://api.siliconflow.cn/v1/rerank
RERANK_MODEL=BAAI/bge-reranker-v2-m3
RERANK_TOP_N=20
这里 Embedding 和 Reranker 模型用的硅基流动免费的模型,用 Qwen/Qwen3-Embedding-8B 和 Qwen/Qwen3-Reranker-8B,效果好一些,但是速度会慢一点
- 索引代码库
#这一步不是必须的,使用mcp搜索的时候,如果没有索引代码库会自动索引 # 在代码库根目录执行
contextweaver index
# 指定路径
contextweaver index /path/to/your/project
# 强制重新索引
contextweaver index --force
- 使用 mcp
{
"mcpServers": {
"contextweaver": {
"command": "contextweaver",
"args": ["mcp"]
}
}
}
claude code 使用
claude mcp add contextweaver -- command contextweaver mcp
这是项目的工作流程
![[开源] ContextWeaver 本地代码库语义检索工具,目标是 ace 平替1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2025/12/29/20251229151024_6952296074562.png!mark)
下面是图一乐的用 claude code 在 new-api 的仓库对比 ace 和 ContextWeaver 的结果,仅供参考
使用的 prompt
任务:对比 Ace 和 ContextWeaver 在当前项目中的 Codebase Retrieval (代码库检索) 效果。
请执行以下步骤进行 A/B 测试:
设定三个测试问题:使用问题 "[请在此处填入具体的复杂技术问题,例如:如何修改鉴权逻辑以支持JWT?]" 作为基准。
分别检索:
场景 A (Ace):调用 Ace 的检索能力,列出其提取的关键文件和代码片段。
场景 B (ContextWeaver):调用 ContextWeaver 的检索能力,列出其提取的关键文件和代码片段。
对比分析:请基于以下维度创建一个对比表格:
相关性 (Precision):检索到的文件是否直接解决了问题?是否有核心文件遗漏?
噪音干扰 (Noise):是否包含了大量无关的测试文件或通用配置?
上下文完整度 (Context):是否提供了足够的上下文(如引用链路、类型定义)来理解代码?
结论:基于当前项目的代码结构,通过三个测试问题,指出哪一个工具的检索策略更优。
![[开源] ContextWeaver 本地代码库语义检索工具,目标是 ace 平替2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2025/12/29/20251229151026_695229626d279.png!mark)
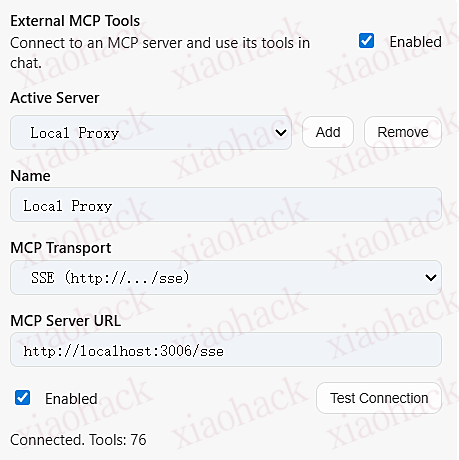
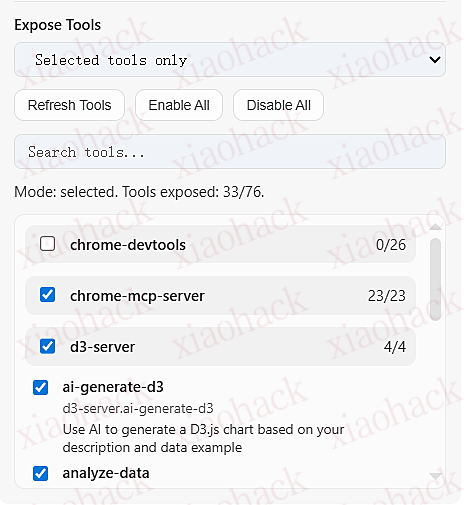
【开源】我给 Gemini Nexus 增加了外部 MCP 的支持

我的 claude code 和 skills 使用技巧.
Claude Code 官方文档https://code.claude.com/docs/zh-CN/overview
Claude Code 安装npm install -g @anthropic-ai/claude-code
之后在根目录下就会有 ./claude 文件夹,在命令行中输入 claude 后配置自己的账号后就可以使用了。
使用第三方的 api (屯屯鼠的乐趣)这里建议使用 ccr 或者 CCSwitch 或者 ccNexus.
https://github.com/musistudio/claude-code-router https://github.com/farion1231/cc-switch https://github.com/lich0821/ccNexus
Claude 技能增强包这里我使用 MyClaude 来一键安装。它预先设置了一系列的自定义命令,以方便使用
MyClaude 安装:
git clone https://github.com/username/myclaude.git
cd myclaude
执行命令
mac: python3 install.py --install-dir ~/.claude
win: python install.py --install-dir %USERPROFILE%\.claude
如果上面的命令不行试试下面的
python install.py
使用命令
# 核心开发命令
/dev # 完整开发流程
/code # 代码生成
/debug # 调试
/test # 测试生成
/review # 代码审查 # 辅助命令
/refactor # 重构代码
/optimize # 优化代码
/docs # 生成文档
/bugfix # 修复错误
/ask # 询问问题
/think # 思考分析
/enhance-prompt # 增强提示词 触发这些命令后 会调用 /agents 目录下的各种代理,使用 /skills 下的各种技能
简单理解:
Commands = 你说的话(用户界面)
Agents = 执行者(工作流程)
Skills = 工具箱(技能库)
查看当前有哪些命令工具
方式1:命令查看
python install.py --list-modules
方式2:查看目录
# Mac/Linux ls ~/.claude/commands/ # 查看所有命令 ls ~/.claude/skills/ # 查看所有技能 # Windows dir %USERPROFILE%\.claude\commands\
dir %USERPROFILE%\.claude\skills\
方式3:在 Claude Code 中查看
/help
或者直接问它:“列出所有可用命令”
这个项目的规则中已经配置了安全配置,就不用再单独增加了,如果需要可编辑 claude.md 文件
使用 skills.
skills 介绍
这里是官方文档, 简单理解就是预先设置了某个流程的步骤,AI 在使用时判断是否需要加载,如果加载就会按照预先设置的规则按序执行。
skills 为什么会节省 token 呢?
简单来讲就是预先设置了一系列规则后,AI 在遇到这样的逻辑后,从以前的全盘去找改为了根据各自 skills 中的规则去找,不用再读取全盘的数据,这样更快,也更减少 token 的消耗
本站里另一个佬的帖子很好,可以查看 实战 skills - 发票分类查询
自动生成任意网站 / 项目 / 文件且适合自己的 skills在配置了上面三点后,基本上对绝大多数的使用者的效率都有所提升。对于某个领域的效率提升,就需要自己在各自领域编写适合自己的 skills 了。 这里我使用的 Skill_Seekers 项目。
Skill_Seekers 项目介绍
Skill Seekers 是一个文档转 Claude AI 技能包的自动化工具。它能帮你去读取某个网站的 url, 然后帮你生成对应的 skills 文件:
- 输入:任何文档网站 URL(如 React、Django、Godot 官方文档)
- 处理:自动爬取、分类、增强、打包
- 输出:.zip 文件,可直接上传到 Claude AI
典型流程:
文档网站 → 爬取数据 → 生成 SKILL.md → 打包 .zip → 上传 Claude
使用配置:
安装: 方式1:
pip install skill-seekers
方式2:
uv tool install skill-seekers
这两种是最常用的,还有可以通过源码/脚本来安装,具体可以看github的项目页面.
skill-seekers 参数详解
它需要主命令 + 子命令 + 参数的形式去加载,这里列举几个简单的子命令
skill-seekers <command> [options]
| 子命令 | 数据源 | 处理方式 | 需要什么参数 |
|---|---|---|---|
| scrape | 文档网站 | 用 HTTP + BeautifulSoup 解析 HTML, 它是专门爬网页 | –url https://… |
| github | GitHub 仓库 | 用 GitHub API + PyGithub 获取仓库数据 | –repo owner/repo |
| PDF 文件 | 用 PyMuPDF 解析 PDF | –pdf /path/to/file.pdf | |
| unified | 多个源 | 组合上面三种 | –config xxx.json |
各自子命令的参数都不同 这里我折叠起来方法观看
子命令 scrape 参数
skill-seekers scrape [options]
| 参数 | 说明 | 示例 |
|---|---|---|
| –config | 配置文件路径 | –config configs/react.json |
| –name | 技能名称(快速模式) | –name myproject |
| –url | 文档 URL(快速模式) | –url https://docs.example.com/ |
| –description | 技能描述 | –description “React 开发框架” |
| –skip-scrape | 跳过爬取,使用缓存数据 | –skip-scrape |
| –enhance | API 增强(需 ANTHROPIC_API_KEY) | –enhance |
| –enhance-local | 本地增强(用 Claude Code,无需 API) | –enhance-local |
| –dry-run | 预览模式,不实际执行 | –dry-run |
| –async | 异步模式(2-3x 更快) | –async |
| –workers | 异步工作线程数 | –workers 8 |
典型用法:
使用配置文件skill-seekers scrape --config configs/react.json --enhance-local
快速模式(无需配置文件)skill-seekers scrape --name myproject --url https://docs.example.com/
使用缓存重建(秒级完成)skill-seekers scrape --config configs/react.json --skip-scrape
子命令 github 参数
skill-seekers github [options]
| 参数 | 说明 | 示例 |
|---|---|---|
| –config | 配置文件路径 | –config configs/react_github.json |
| –repo | GitHub 仓库(owner/repo) | –repo facebook/react |
| –name | 技能名称 | –name react-source |
| –description | 技能描述 | –description “React 源码分析” |
典型用法:
skill-seekers github --repo microsoft/TypeScript --name typescript
子命令 pdf 的参数
skill-seekers pdf [options]
| 参数 | 说明 | 示例 |
|---|---|---|
| –config | 配置文件路径 | –config configs/example_pdf.json |
| PDF 文件路径 | –pdf /path/to/doc.pdf | |
| –name | 技能名称 | –name my-manual |
| –description | 技能描述 | –description “产品手册” |
| –from-json | 从已提取的 JSON 构建 | –from-json output/my_data/ |
子命令 unified 参数 - 多源统一爬取
skill-seekers unified --config <config.json> [options]
| 参数 | 说明 | 示例 |
|---|---|---|
| –config | 必需 统一配置文件 | –config configs/react_unified.json |
| –merge-mode | 合并模式 | –merge-mode claude-enhanced |
| –dry-run | 预览模式 | –dry-run |
合并模式:
- rule-based:基于规则自动合并(默认)
- claude-enhanced:使用 Claude AI 智能合并
AI 增强命令 enhance
skill-seekers enhance <skill_directory>
| 参数 | 说明 | 示例 |
|---|---|---|
| skill_directory | 必需 技能目录路径 | output/react/ |
作用:将基础的 SKILL.md(~75 行)增强为专业指南(~500 行),包含:
- 真实代码示例
- 快速参考
- 使用场景建议
使用 --enhance-local, 不调用 API,而是启动本地 Claude Code 终端
skill-seekers scrape --config configs/react.json --enhance-local
这样可以使用你已配置的 Claude Code(包括自定义 API 设置)。
skill-seekers 参数加载方式
方式 1: 快速模式 直接在命令后面拼接参数
skill-seekers scrape --name myproject --url https://docs.example.com/方式 2: 交互模式(引导式)
这个模式我没测试,就是 工具会一步步问你哪些参数需要怎么配置skill-seekers scrape --interactive方式 3:使用 json 配置文件的方式
skill-seekers scrape --config configs/myproject.json方式 4: 加载的是 GitHub 仓库
需要提前在环境变量中设置 GITHUBTOKEN, 不然 github 会限制请求skill-seekers github --repo facebook/react --name react-code
在 AI 增强模块,我测试暂时不能使用本地模型,虽然文档说支持,但我测试下来提示找不到命令,已经给开发者提 bug 了,估计后续版本会修改吧.
当前三方汇总的 Claude skills第三方网站 (非推广)
如果觉得这篇文章对你有用,可否点个赞,评论有用。谢谢
ps: 实在不会好看的排版了 慢慢来吧
曝育碧惨遭史诗级数据泄露!近三十年项目源码被盗 (重发人工)
据推主 @Pirat_Nation 消息,黑客此行还窃取了数十 TB 内部源代码库,涵盖从上世纪 90 年代至当前项目的几乎所有游戏、工具、SDK 及服务。

这次攻击是利用了 MongoDB 数据库的漏洞,2025 年 12 月 27 日 - 28 日 <彩虹六号> 游戏中断数据库被篡改相关.
它允许未经身份验证的攻击者发送 专门构造的压缩网络数据包,让服务器的 zlib 解压缩模块直接泄露内部堆内存碎片,然后暴露出会话令牌或者密钥
这个漏洞编码是: CVE-2025-14847 漏洞编号连接
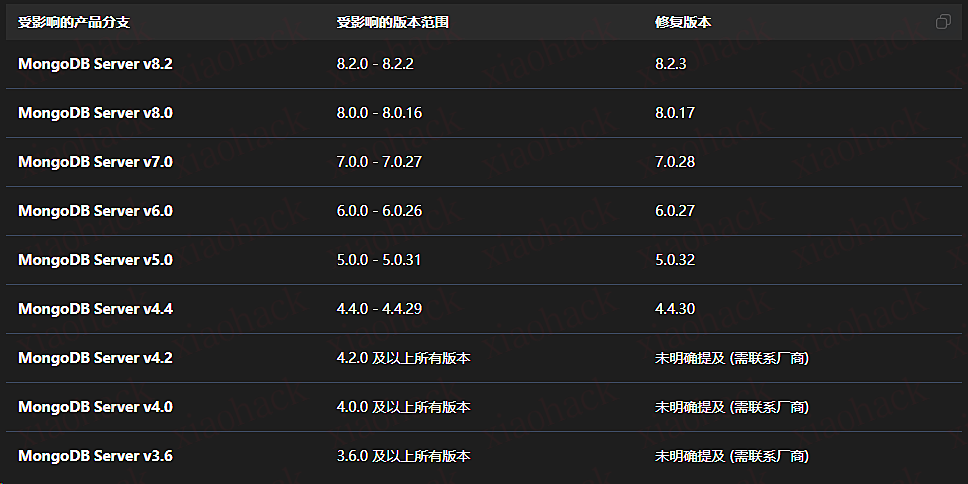
之前不知道经过润色是需要截图的,我心疼我的赞,此次人工了
[开源] ssrJSON: 比最快更快的 Python JSON 解析库
rt 我们基于 SIMD 技术写出了一个比目前最快的 orjson 还要更快的 Python JSON parser 。 支持 Python json 调用约定, github.com/Antares0982/ssrJSON, 以及对应的技术解析 文章
目前我们的速度基准测试结果:
![[开源] ssrJSON: 比最快更快的 Python JSON 解析库1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2025/12/29/20251229125108_695208bcb5693.svg!mark)
欢迎星标/PR!
[分享] 开发了个 100% 本地的身份证扫描工具,免费精准生成可打印文件,隐私不泄露
经常遇到需要提交身份证复印件的场景:要么找打印店排版收费,要么自己用 PS 裁剪调整,费时又麻烦;更担心的是,很多在线扫描工具需要上传照片,身份证信息有泄露风险。
LocalScan ,一款纯 Web 端的证件扫描件生成工具,核心优势就是「 100%本地计算」和「精准生成打印」,完全免费,不用下载任何软件。
🔗 直接能用: https://localscan.leavesc.cn/
核心功能(解决实际痛点)
- 📸 智能处理:上传手机拍的证件照,自动边缘检测、透视矫正,不用手动裁剪;还能 AI 去除背景、增强画质,文字更清晰。
- 📏 精准生成打印文件:等比例合成到 A4 画布,300DPI 标准,可直接打印,不用再调整缩放。
- 🔒 绝对隐私安全:基于 WASM/WebGPU 实现全本地计算,所有图像处理都在你的浏览器里完成,不上传任何数据到服务器,用着放心。
- ✍️ 自定义防伪水印:支持添加「仅供入职使用」「用于 XX 政务办理」这类水印,可调节透明度、旋转角度和密度,水印直接压在证件上,避免信息被滥用。
- 📑 双面合成:分别导入证件正反面,自动排列在同一张 A4 纸上(上方正向、下方反向),直接保存就能用。
使用场景
求职提交入职材料、学生办理学籍手续、居民办理政务/社保业务、小微企业 HR 批量处理员工证件,都能用到。不用装软件,打开浏览器上传照片,一步生成 PDF 或图片,直接打印。
技术说明
纯前端实现,基于 TensorFlow.js 的轻量 AI 模型做边缘检测和抠图,用 WASM 加速图像处理,确保在手机浏览器上也能流畅运行。没有后端服务器,所以完全不用考虑数据泄露问题。
pt 站点 BTSCHOOL 马上免费自由注册了。
马上 2026 年了,祝大家新年快乐!元旦快乐!
感谢大家一直对 BTSCHOOL 的支持,跨 2026 新年,网站活动如下:
2025.12.31 18 时至 2026.01.02 23 时, 限时开放自由注册。
2026.01.03~2026.01.06 全站种子 FREE 四天。
全站 24 小时 hr,不能下了就跑。要做种 24 小时。
最好有公网,要不然上传不好弄流量。