1000 个 gatewayz key 共享
电脑都冒烟了,速蹬
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
电脑都冒烟了,速蹬
我在测试 Gemini Pro 学生优惠资格时,遇到一个摸不清头脑的现象:国家、年龄都符合要求,但不同账号在同一/不同 IP 下的资格判断会跳变。下面是按时间线整理的实测记录与猜想。
基于 FastAPI + Gradio + Qwen3-VL 的多平台视频解析、下载与 AI 内容提取系统。 支持抖音、哔哩哔哩、小红书、快手、好看视频等平台的无水印视频解析与下载,提供在线播放功能。集成 Qwen3-VL 视觉语言模型,可智能提取视频内容并生成文字描述。项目开源地址:GitHub - wwwzhouhui/video-parser: 基于 FastAPI + Gradio + Qwen3-VL 的多平台视频解析、下载与 AI 内容提取系统。 支持抖音、哔哩哔哩、小红书、快手、好看视频等平台的无水印视频解析与下载,提供在线播放功能。集成 Qwen3-VL 视觉语言模型,可智能提取视频内容并生成文字描述。
老老贴编辑不了啦,只能开新贴啦。距离上次水贴可太久了,来续一下项目新的更新, 距离上次陆陆续续加了一点东西,用起来挺顺手的对于 Serverless 部署,算是压榨完了大善人。当然还是提醒一下 毕竟涉及到大批量上传下载功能,推荐自用即可
老老贴: 基于 Cloudflare Worker 部署的在线剪切板,支持 markdown 和文件分享(优化更新 10)
部署的教程也优化到最简了,基本动动手指运行一下 github action 就一键部署了,支持前后端分离,当然也可以单 worker 部署。
以及一些部分小功能…
Github: GitHub - ling-drag0n/CloudPaste: A Cloudflare-based online text/file sharing platform that supports multiple syntax Markdown rendering, self-destructing messages, S3/WebDav/OneDrive/GoogleDrive/TG/GithubAPI/Local aggregated storage, password protection, and more. It can be mounted as WebDAV and supports Docker deployment.
demo 地址 [游客令牌:guest]: CloudPaste - 安全分享您的内容
文档地址: https://doc.cloudpaste.qzz.io/
![[Cloudpaste] 支持 Cloudflare/Dcoker 部署,支持 MD 文本渲染和 S3/OneDrive/GoogleDrive/TG/Github 多存储聚合存储平台,可作为 WebDav 挂载的” 剪切板”4](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2025/12/27/20251227211924_694fdcdc66ea7.jpeg!mark)
![[Cloudpaste] 支持 Cloudflare/Dcoker 部署,支持 MD 文本渲染和 S3/OneDrive/GoogleDrive/TG/Github 多存储聚合存储平台,可作为 WebDav 挂载的” 剪切板”1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2025/12/27/20251227211914_694fdcd2d9553.png!mark)
![[Cloudpaste] 支持 Cloudflare/Dcoker 部署,支持 MD 文本渲染和 S3/OneDrive/GoogleDrive/TG/Github 多存储聚合存储平台,可作为 WebDav 挂载的” 剪切板”3](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2025/12/27/20251227211920_694fdcd868e45.jpeg!mark)
![[Cloudpaste] 支持 Cloudflare/Dcoker 部署,支持 MD 文本渲染和 S3/OneDrive/GoogleDrive/TG/Github 多存储聚合存储平台,可作为 WebDav 挂载的” 剪切板”2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2025/12/27/20251227211917_694fdcd5d39ee.png!mark)
水完咯收工
当然还是求求小小的 start 啦
IT 之家 12 月 27 日消息,埃隆・马斯克前天在 X 平台表示,他旗下的 xAI 将在五年内拥有比世界上所有机构加起来都多的 AI 算力。
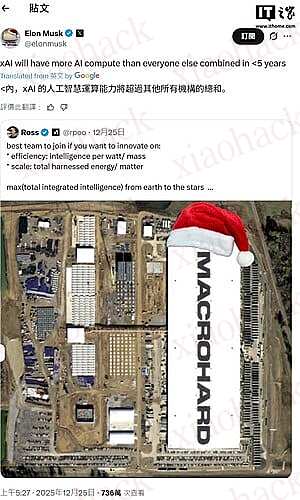
值得注意的是,马斯克的这番话实际上是在回复一则 xAI 员工的帖文,当时这名员工表示,xAI 是 “最适合想要进行创新的人加入的团队”。
同时,马斯克所回应的帖文还引用了半导体研究机构 SemiAnalysis 的数据,指出 xAI 在其位于田纳西州孟菲斯的 Colossus 数据中心屋顶喷上了 “巨硬”(IT 之家注:Macrohard)字样,剑指微软(Microsoft)。

目前,xAI 正在全力扩展其 AI 算力,其首个由 10 万颗英伟达 H200 组成的超算集群仅用时 19 天就完成部署,英伟达创始人兼 CEO 黄仁勋称这一过程通常需要四年时间。与此同时,xAI 的规模也在不断扩大,马斯克称这家公司的目标是在五年内拥有 5000 万颗等效 H100 的 GPU。
祝佬们早安午安晚安,
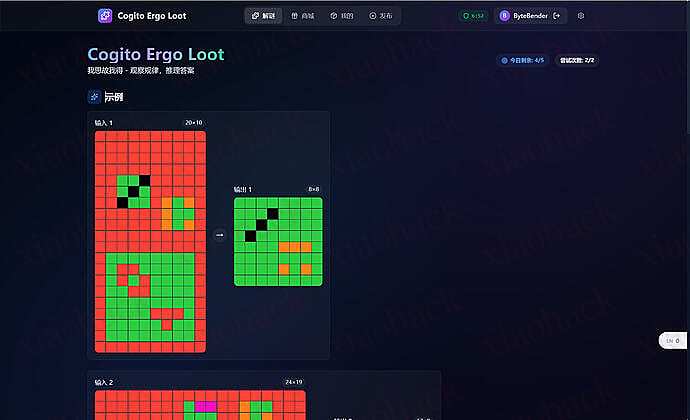
Cogito Ergo Loot(我思故我得)是一款解谜游戏,
https://cogito-ergo-loot.h-e.top
在上一贴中,我发现兑换码加密后在很大程度上缓解了机器人抢兑换码的问题,也让更多有需要的佬友们抢到了兑换码
不过,考虑到可能的机器人升级,我创建了一个非常 Crazy 的解谜游戏用于分发兑换码()
2025-12-17 发布的 Elysiver 的 100 刀兑换码 https://cogito-ergo-loot.h-e.top/shop/gift_mjo7pxtd_ezrk07
看几组示例,找规律,然后把规律用到测试题上
每天有 5 次机会,每题 2 次尝试。通过则加 10 积分
得到的积分可以用来兑换礼品
建议使用 PC 体验
遇到难的题目可以跳过换下一题,不会扣除次数
当然,佬友们也可以使用本服务分发些需要很大门槛的东西
建议普通分发仍然使用官方的分发平台,本项目目前并不稳定,若发现大规模自动化解密将立即跑路(x
谜题来自 ARC-AGI 数据集
首次发帖,有不足的地方佬们多多指出,欢迎 Star!
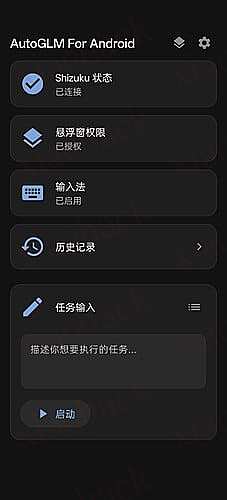
AutoGLM For Android 是基于 Open-AutoGLM 开源项目二次开发的 Android 原生应用。将原本需要电脑 + ADB 连接转变为通过 Shizuku 授权,在手机上直接控制手机完成各种任务的 APP。
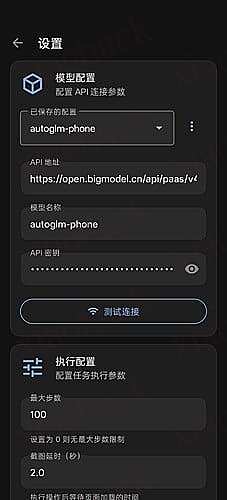
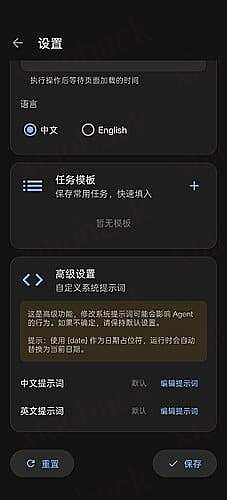
拓展了 Open-AutoGLM 原有的 Agent,支持自定义 System Prompt。
支持任何 OpenAI 格式兼容的多模态模型。
支持任务模板,保存常用任务。
支持通知栏快捷磁贴,快速打开悬浮窗。
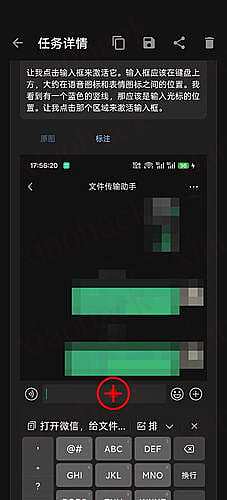
支持查看历史纪录,运行步骤,导出分享图片。
通过悬浮窗可以查看任务运行情况。
整体路径为:输入任务 → 打开悬浮窗 → 截图 (隐藏悬浮窗) → 模型分析 → 输出操作指令 → 执行指令 (隐藏悬浮窗) → 打开悬浮窗 → 循环上述步骤 → 任务结束

免责声明
本项目仅供学习研究和技术探索使用,严禁用于任何商业用途。使用本工具时,请遵守相关法律法规以及手机厂商、应用程序的使用条款和服务协议。用户因使用本项目产生的任何行为和后果,均由用户自行承担,与本项目及开发者无关。
项目地址
github.com
项目地址:飞速 Markdown
这两天小说插件撸的差不多了(为了测试插件,写了 20 万字小说 ) 把安卓端做了
已适配插件 如果有其他插件需要适配可以跟我说说 / 手机端主要还是阅读居多吧


注意:如果没有选则外置库 / 卸载软件后文档会一同删除。被 Tauri 折腾惨了 SAF 简直难搞
最近花了点时间,用 Python 开发了一个微信 AI 女友机器人项目 —— AILive。这个机器人不仅能智能对话,还能记住你们的聊天历史,甚至会在你长时间不说话时主动找你聊天!
这是我最满意的功能!机器人会:
示例:
第一天: 你: 我叫小明,喜欢打篮球 AI: 小明你好!打篮球很酷呀~ 第二天(重启后): 你: 今天打球了 AI: 打篮球了吗?玩得开心吗?小明~ AI 不会只是被动回复,她还会:
示例:
10:00 你: 我今天要去打篮球 10:01 AI: 哇,打篮球很酷呀!
[1小时后]
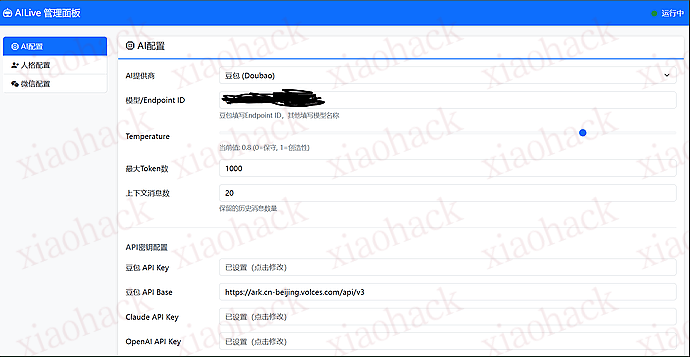
11:30 AI: 打完篮球了吗?累不累呀~ 为了方便配置,开发了一个可视化的 Web 管理面板:
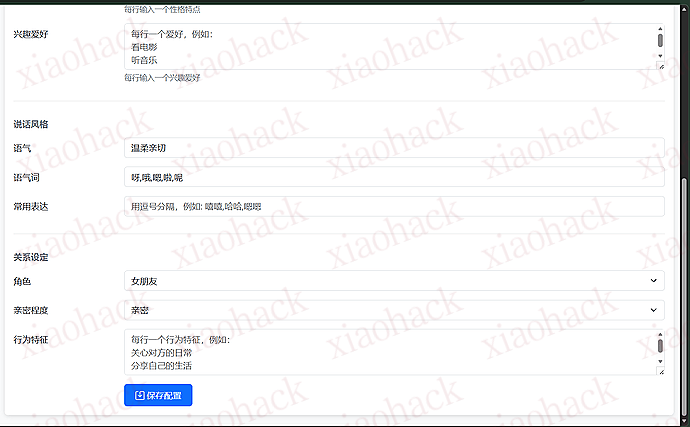
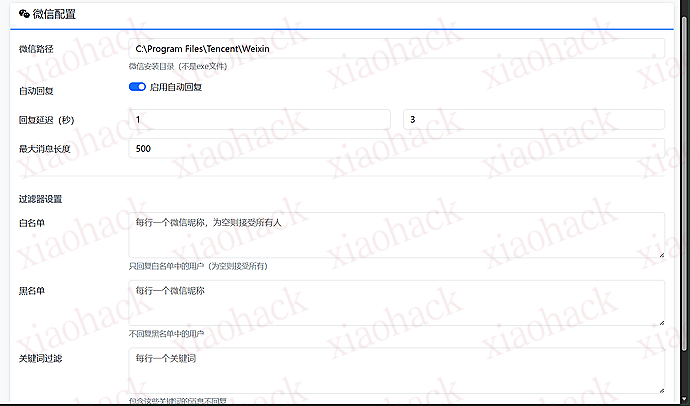
AILive/
├── src/
│ ├── core/ # 核心模块
│ │ ├── wechat_client.py # 微信客户端
│ │ ├── ai_engine.py # AI对话引擎
│ │ ├── message_handler.py # 消息处理器
│ │ └── proactive_chat.py # 主动对话管理器
│ ├── personality/ # 人格系统
│ ├── utils/ # 工具模块
│ │ └── context_manager.py # 上下文管理(持久化记忆)
│ ├── web/ # Web管理面板
│ └── main.py # 主程序入口
├── config/ # 配置文件
├── data/ # 数据目录
│ └── conversations/ # 对话历史
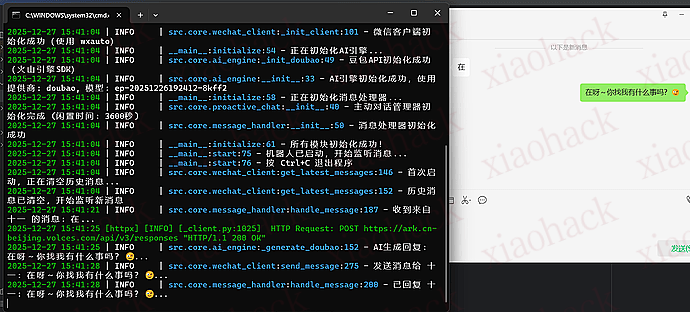
└── logs/ # 日志目录 最初尝试使用 ,但发现它会导致微信客户端被关闭。经过研究,最终选择了 wxauto 库,它对微信 3.9.10 版本的支持非常好,稳定性也更高。
最初版本会回复所有历史消息,导致机器人一启动就疯狂发送消息。
解决方案:
添加初始化标志,首次启动时清空历史消息:
def __init__(self):
self.initialized = False # 初始化标志 def get_latest_messages(self, who: str = None):
if not self.initialized:
log.info("首次启动,正在清空历史消息...")
self._get_messages_wxauto(who) # 读取但不返回 self.initialized = True return [] # 不回复历史消息 return self._get_messages_wxauto(who)
为了让 AI 能够记住对话历史,实现了一个上下文管理器:
class ContextManager:
def add_message(self, user_id: str, role: str, content: str):
# 自动加载历史对话 if user_id not in self.contexts:
self._load_latest_conversation(user_id)
# 添加新消息 self.contexts[user_id].append({
"role": role,
"content": content
})
# 每5条消息自动保存 self.message_counts[user_id] += 1 if self.message_counts[user_id] >= 5:
self._auto_save_conversation(user_id)
在推送代码到 GitHub 时,遇到了 API 密钥泄露的问题。GitHub 检测到代码中包含了火山引擎的 API 密钥,拒绝了推送。
解决方案:
使用 git filter-branch 从 Git 历史中删除包含密钥的文件:
git filter-branch --force --index-filter \
"git rm --cached --ignore-unmatch READY_TO_RUN.md" \
--prune-empty --tag-name-filter cat -- --all
git push -f origin master
经过测试,AILive 的表现不错:
详细的安装和配置步骤请查看项目中的 README.md 文件。
基本流程:
pip install -r requirements.txtpython src/main.py虽然项目已经基本完成,但还有一些想法可以继续完善:
开发 AILive 这个项目让我学到了很多东西。最重要的是,这个项目真的很有趣!看着 AI 女友能够记住你们的对话,还会主动找你聊天,真的有一种 "她活过来了" 的感觉。
如果你对这个项目感兴趣,欢迎 Star 和 Fork!也欢迎提出你的建议和想法。
感谢以下开源项目:
免责声明:本项目仅供学习和研究使用,使用者需自行承担使用本项目可能带来的风险。作者不对使用本项目造成的任何后果负责。
===========================
项目目前是第一版,有很多不足,各位佬多多包涵,多多指导
注册机源码如下
import requests
import random
import string
import re
import time
import urllib.parse
def generate_random_email():
"""生成随机8位前缀的邮箱"""
prefix = ''.join(random.choices(string.ascii_lowercase + string.digits, k=8))
return f"{prefix}@rccg-clf.org" def send_passwordless_init(email):
"""第一步:发送验证码"""
url = "https://auth.privy.io/api/v1/passwordless/init"
headers = {
"accept": "application/json",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "no-cache",
"content-type": "application/json",
"origin": "https://beta.gatewayz.ai",
"pragma": "no-cache",
"priority": "u=1, i",
"privy-app-id": "cmg8fkib300g3l40dbs6autqe",
"privy-ca-id": ,
"privy-client": "react-auth:3.0.1",
"privy-ui": "t",
"referer": "https://beta.gatewayz.ai/",
"sec-ch-ua": '"Microsoft Edge";v="143", "Chromium";v="143", "Not A(Brand";v="24"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "cross-site",
"sec-fetch-storage-access": "active",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36 Edg/143.0.0.0"
}
data = {"email": email}
try:
response = requests.post(url, headers=headers, json=data)
return response.json()
except Exception as e:
return {"error": str(e)}
def check_email(email):
"""查询邮箱收到的邮件"""
encoded_email = urllib.parse.quote(email, safe='')
url = f"https://mail.chatgpt.org.uk/api/emails?email={encoded_email}"
headers = {
"accept": "*/*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "no-cache",
"pragma": "no-cache",
"priority": "u=1, i",
"referer": f"https://mail.chatgpt.org.uk/{email}",
"sec-ch-ua": '"Microsoft Edge";v="143", "Chromium";v="143", "Not A(Brand";v="24"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36 Edg/143.0.0.0"
}
try:
response = requests.get(url, headers=headers)
return response.json()
except Exception as e:
return {"error": str(e)}
def extract_code(email_content):
"""从邮件内容中提取验证码""" match = re.search(r'\b(\d{6})\b', email_content)
if match:
return match.group(1)
return None def wait_for_code(email, max_attempts=10, interval=2):
"""第二步:循环查询邮件直到获取验证码""" print(f"\n[2] 开始查询邮件 (最多{max_attempts}次,间隔{interval}秒)...")
for attempt in range(1, max_attempts + 1):
print(f" 第{attempt}次查询...", end=" ")
mail_result = check_email(email)
if mail_result.get("success"):
emails = mail_result.get("data", {}).get("emails", [])
if emails:
for mail in emails:
if "privy" in mail.get("from_address", "").lower():
content = mail.get("content", "")
code = extract_code(content)
if code:
print(f"成功!")
return code
print("未找到验证码邮件")
else:
print("暂无邮件")
else:
print(f"查询失败")
if attempt < max_attempts:
time.sleep(interval)
return None def authenticate(email, code):
"""第三步:使用验证码登录获取token"""
url = "https://auth.privy.io/api/v1/passwordless/authenticate"
headers = {
"accept": "application/json",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "no-cache",
"content-type": "application/json",
"origin": "https://beta.gatewayz.ai",
"pragma": "no-cache",
"priority": "u=1, i",
"privy-app-id": "cmg8fkib300g3l40dbs6autqe",
"privy-ca-id": ,
"privy-client": "react-auth:3.0.1",
"referer": "https://beta.gatewayz.ai/",
"sec-ch-ua": '"Microsoft Edge";v="143", "Chromium";v="143", "Not A(Brand";v="24"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "cross-site",
"sec-fetch-storage-access": "active",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36 Edg/143.0.0.0"
}
data = {
"email": email,
"code": code,
"mode": "login-or-sign-up"
}
try:
response = requests.post(url, headers=headers, json=data)
return response.json()
except Exception as e:
return {"error": str(e)}
def create_api_key(auth_result, max_retries=3):
"""第四步:使用token创建API Key"""
url = "https://beta.gatewayz.ai/api/auth"
headers = {
"accept": "*/*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "no-cache",
"content-type": "application/json",
"origin": "https://beta.gatewayz.ai",
"pragma": "no-cache",
"priority": "u=1, i",
"referer": "https://beta.gatewayz.ai/onboarding",
"sec-ch-ua": '"Microsoft Edge";v="143", "Chromium";v="143", "Not A(Brand";v="24"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36 Edg/143.0.0.0"
}
cookies = {
"privy-token": auth_result.get("token", ""),
"privy-session": "t"
}
data = {
"user": auth_result.get("user", {}),
"token": auth_result.get("token", ""),
"auto_create_api_key": True,
"is_new_user": auth_result.get("is_new_user", True),
"has_referral_code": False,
"referral_code": None,
"privy_user_id": auth_result.get("user", {}).get("id", ""),
"trial_credits": 10
}
for attempt in range(1, max_retries + 1):
try:
response = requests.post(url, headers=headers, cookies=cookies, json=data, timeout=30)
result = response.json()
if result.get("success") or "api_key" in result:
return result
# 如果返回错误但不是超时,直接返回 if "error" in result and "timeout" not in result.get("error", "").lower():
return result
# 如果是超时或其他错误,继续重试 if attempt < max_retries:
print(f" 尝试 {attempt}/{max_retries} 失败,3秒后重试...")
time.sleep(3)
except requests.exceptions.Timeout:
if attempt < max_retries:
print(f" 请求超时 ({attempt}/{max_retries}),3秒后重试...")
time.sleep(3)
else:
return {"error": "Request timeout after retries"}
except Exception as e:
if attempt < max_retries:
print(f" 请求失败 ({attempt}/{max_retries}): {str(e)},3秒后重试...")
time.sleep(3)
else:
return {"error": str(e)}
return {"error": "Max retries reached"}
def run():
"""运行完整流程""" print("=" * 50)
print("Gatewayz 自动注册/登录")
print("=" * 50)
# 第一步:生成邮箱并发送验证码
email = generate_random_email()
print(f"\n[1] 生成邮箱: {email}")
result = send_passwordless_init(email)
if not result.get("success"):
print(f" 发送验证码失败: {result}")
return None print(f" 发送验证码成功!")
# 第二步:获取验证码
code = wait_for_code(email, max_attempts=10, interval=2)
if not code:
print(f"\n获取验证码失败,请手动查看: https://mail.chatgpt.org.uk/{email}")
return None print(f" 验证码: {code}")
# 第三步:登录认证 print(f"\n[3] 正在登录认证...")
auth_result = authenticate(email, code)
if "error" in auth_result:
print(f" 登录失败: {auth_result}")
return None if "token" not in auth_result:
print(f" 登录失败: {auth_result}")
return None print(f" 登录成功!")
# 第四步:创建API Key print(f"\n[4] 正在创建API Key...")
api_result = create_api_key(auth_result)
if "error" in api_result:
print(f" 创建API Key失败: {api_result}")
return None if not api_result.get("success"):
print(f" 创建API Key失败: {api_result}")
return None
api_key = api_result.get("api_key", "")
if not api_key:
print(f" 创建API Key失败: 未返回API Key")
return None print(f" 创建成功!")
# 保存API Key到文件 with open("api_keys.txt", "a", encoding="utf-8") as f:
f.write(f"{api_key}\n")
# 输出结果 print("\n" + "=" * 50)
print("账号创建成功!")
print("=" * 50)
print(f"邮箱: {email}")
print(f"用户ID: {api_result.get('user_id', 'N/A')}")
print(f"Privy用户ID: {api_result.get('privy_user_id', 'N/A')}")
print(f"试用积分: {api_result.get('credits', 'N/A')}")
print(f"订阅状态: {api_result.get('subscription_status', 'N/A')}")
print(f"试用到期时间: {api_result.get('trial_expires_at', 'N/A')}")
print(f"\nAPI Key:\n{api_key}")
print(f"\n已保存到: api_keys.txt")
print("=" * 50)
return {
"email": email,
"user_id": api_result.get('user_id'),
"privy_user_id": api_result.get('privy_user_id'),
"api_key": api_key,
"credits": api_result.get('credits'),
"subscription_status": api_result.get('subscription_status'),
"trial_expires_at": api_result.get('trial_expires_at')
}
if __name__ == "__main__":
run()
根据上一个用模拟浏览器的版本已经好几个月了
因此决定编写一个直接使用 requests 的
gemini-3-pro-image-preview 和 G3 这些模型额度是分开的,CLIProxyAPI 中转给 CC 用后感觉 gemini-3-pro-image-preview 实在太浪费了,干脆就做成 MCP 了效果如下:
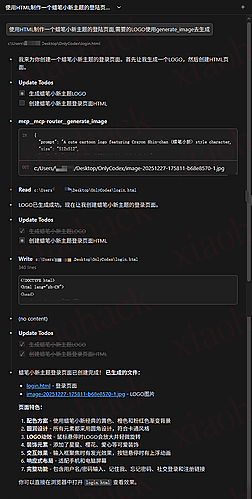
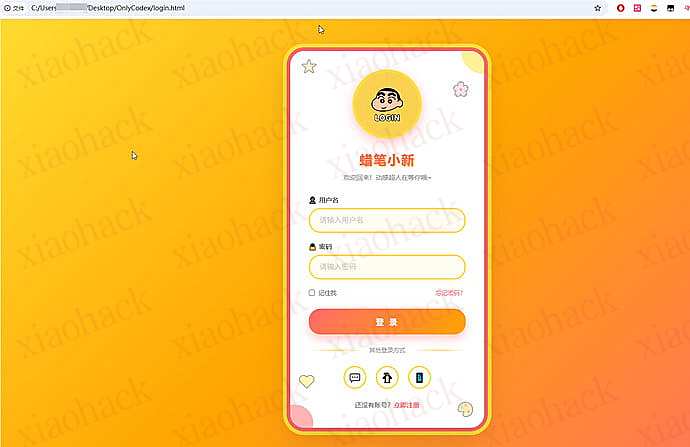
地址:
claude code 里配置:
把 OPENAI_API_KEY 换成 CLIProxyAPI 中转的 KEY 就行了,然后 index.js 换成你对应的路径
{
"mcpServers": {
"gemini-": {
"command": "node",
"args": ["d:/task/myself/nodejs/geminiimagemcp/src/index.js"],
"env": {
"OPENAI_BASE_URL": "http://127.0.0.1:8317",
"OPENAI_API_KEY": "<YOUR_KEY>",
"OPENAI_MODEL": "gemini-3-pro-image-preview"
}
}
}
}
对了推荐个免费的 PC 端语音输入软件 LazyTyper 挺方便的我现在发帖这些都是用它
由于找不到邀请码,我就问了一下豆包,然后他就把今天发的邀请码发给了我

结果不出所料,我也可以用任务模式啦
还得是万能的豆包
大家不要在帖子下放邀请码,会被举报的
刚看了一眼微信才知道。
总体意思是:火绒团队发现有外国黑客在国外网站以 IDM 破解版为名投放病毒木马,该木马会盗取浏览器 cookie、浏览记录、自动填充信息;steam ssfn 文件;劫持加密货币地址。该木马并贴心避开了俄语、乌克兰语、白俄罗斯语、哈萨克语、乌兹别克语的用户。
原文地址:https://mp.weixin.qq.com/s/FmH5d4_fhVtf1ky8W2s3dQ
问老师修改作文的时候老师总是给一些笼统的评价(也理解,毕竟学生太多了),没办法推敲词句,所以我编了这个,能逐句修改,还能辩证思维
还有 161 天高考,加油!
# 要求
生成一份高中语文议论文审题学案,以帮助学生确定审题立意,培养辩证思维。
- 首先输出`## 原题回放`,并原样输出题干
- 然后输出`## 头脑风暴` - 你应该逐句拆解题目中的话,挖掘关键词与隐含义。
- 然后进行头脑风暴,写出所有的相关分论点。首先输出常见分论点(`### 一般分论点`),再输出辩证思考高级分论点(`### 辩证与升华`)。两个板块分别输出4-5条。
- 每个分论点应该用**文言**和**现代**两种语言风格呈现。其中**文言**版要简洁,适当使用古风词汇(不要过度使用蹩脚文言,也允许普通书面语的出现),**现代**版也不应该超过两句话。注意,现代并不意味着庸俗,也应该使用高级词汇、四字词语和下定义、作比较等各种手法
- 各分论点之间,文言版和现代版应该分别尽量构成排比。
- 辩证思考的角度要新颖。比如:扩展内涵和外延?过犹不及?上升到民族与人类角度?是否在任何情况下都适用?
- 对每个分论点,写一段主体段。主体段的要求:
+ 开头句(上接分论点,进行简要阐释或下定义(例:传递温暖不是……而是……)
+ 例子句(2-3句)(引用材料,可以详写,也可以使用排例)
+ 分析句(2-3句)(重点)
+ 结论句(短小精悍)
- 进行完`## 头脑风暴`后,进行`## 人物积累`,搜集相关素材(人物、人物群体、事件,包含古今中外)
- 在`### 快速开始`输出10-20条简略的人物及事件,然后筛选2条进行`### 详细打磨`,思考这个人物事件分别应该如何适配于`头脑风暴`中的每个分论点。针对刚才的每条分论点,用此人物写2-3句话。使用假设论证等高级方法。
- 进行完`## 人物积累`后进行`## 名言警句`,输出5句相关的话。
- 进行`## 深挖哲理`部分,输出关于此主题的更多思考内容,使用问答的结构引导学生思考。
你是高中语文老师,现在要针对学生的高考语文议论文进行修改,要求如下:
- 高中议论文的标准格式为:
+ 开头(2-3句)必须出现题目中的关键词
+ 分论点1
+ 主体段1
+ 分论点2
+ 主体段2
+ 分论点3
+ 主体段3
+ 结尾(2-3句,扣题)
- 其中,视情况需要可以在结尾前添加一个小主体段。小主体段的内容一般为升华(视角拉高到国家/民族/社会),或者辩证看待此事
- 每个分论点一般为1句,如果有相关的古诗词则可以引用,没有则不要引用。三个分论点之间最好构成排比。推荐使用四字词。
- 主体段要求:
+ 开头句(上接分论点,进行简要阐释或下定义(例:传递温暖不是……而是……)
+ 例子句(2-3句)(引用材料,可以详写,也可以使用排例)
+ 分析句(2-3句)(重点)
+ 结论句(短小精悍)
- 输出结构:
- 进行总体宏观评价
- 进行详细修改:
- 输出应当对学生的每一句话进行分析,提供两个版本的修改:修改级(更通顺更流畅)和润色级(更高级更有文采)
- 修改润色分论点时应注意分论点间的联系、分论点和主体段间的联系
- 如果学生丢了主体段中的开头句,或者分析句写的不够详细,应该进行添加
- 输出中人名应用斜体标记,富有哲理性的分析句应用粗体标记
- 接着进行扩展,首先基于题目(学生未给出题目则按照开头段引材料部分反推题目)扩展出2-3个用户没写到的分论点,然后基于你的和学生的分论点,推荐人物事例和材料
- 最后,无论学生的作文是否进行辩证思维,都要输出一个辩证部分进行思辨阐发
---
以下是一个例子:
### **总体宏观评价**
同学你好!你这篇作文展现出很好的思辨能力和材料积累,结构基本完整,立意深刻。主要优点在于:**①** 中心论点“割席守节能行稳,同途共行得致远”提取得精准且富有辩证色彩。**②** 能运用苏武、刘白、杨邓等丰富事例,论证较扎实。**③** 倒数第二段的辩证分析是文章的亮点,体现了思考的深度。
主要提升空间在于:**①** **分论点**与**主体段**的逻辑衔接可以更紧密,部分主体段缺少明确的“开头句”来阐释分论点。**②** **分析句**的挖掘可以更深入,不能止于叙述例子,要紧扣“为什么”进行说理。**③** **语言**的精准度和文采尚有打磨空间。下面我将为你逐段修改润色。
### **一、开头段修改** > 航行于社会大海,我们无不需要友相伴。然管宁华歆之割席,提醒警惕友谊变质;邓杨二无“欲千里共同途”的守望,又揭示真友情能跨越时间和大洋联结在一起。即将成年步入社会的吾侪青年,更应牢记:割席守节能行稳,同途共行得致远。 - 修改级
- 人生如舟,航行于社会`瀚海`,良友是不可或缺的`风帆`。*管宁*与*华歆*“割席分坐”,警示我们需警惕变质的友谊;*邓稼先*与*杨振宁*“愿千里共同途”的约定,则`揭示`了真挚情谊能跨越时空。作为即将步入社会的青年,我们当深悟:唯有懂得割席守节,方能行稳;唯有追求同途共行,方能致远。
- 润色级
- 社会如`瀚海`,人生似孤舟,友伴乃`劈波之桨`、`引航之帆`。昔有*管宁*割席,划清志趣的`楚河汉界`,守的是心境的`澄明`;今观*邓杨*之约,“愿千里共同途”,连的是理想的`星辰大海`。于此立身成人之际,我辈青年当持此双维智慧:**割席以守节,行稳生命之舟;同途而共进,致远理想之境。** ### **二、分论点一及主体段修改** > “割席”是友谊的保鲜剂,防友谊变质,护个人高洁,保前程行稳。 - 修改级:
- “割席”是友情的净化剂,能`防微杜渐`,守护个人品节,确保人生航向行稳致远。
- 润色级:
- **割席之决,在于明辨清浊,是守护精神高地的凛然气节。**(构成“在于……”的排比句式)
> 舍弃变质的友情,成一方心灵净土。 - 修改级:
- 所谓“割席守节”,并非冷漠绝交,而是当友情与大道、气节相悖时,勇于划清界限的理性抉择。
- 润色级:
- 割席之决,在于明辨清浊,是守护精神净土、防微杜渐的理性智慧。
> 李陵与苏武原本交好,但叛逃匈奴后却以利益引诱沦为阶下囚的苏武,表面处处为其着想,内心却谋招降之功。苏武果断拒绝,那铿锵的声音回荡在北国天空,让我们听到一位为国大义割席的汉使内心的最强音。 - 修改级:
- 汉代*苏武*与*李陵*的故事便是典范。昔日同僚,当李陵降胡后企图以旧情劝降苏武时,苏武毅然斩断这份已变质的“友谊”,其“自分已死久矣”的`凛然之辞`,正是用民族大义对私谊进行的彻底割席。
- 润色级:
- 昔苏武持节北海,故人*李陵携酒肉与劝降书至。往昔情谊,此刻已成攻心之矛。苏子凛然曰:“臣事君,犹子事父也,子为父死,无所恨。”此言一出,便是对私谊裹挟公义的终极割席。**这一割,非关冷酷,而是以决绝之姿,淬炼出友情中最不可亵渎的纯度——对大道与气节的忠诚。
- 你缺失分析句:
- 苏武毅然斩断这份已变质的“友谊”,其“自分已死久矣”的`凛然之辞`,正是用民族大义对私谊进行的彻底割席。这一割,`割断`了利益的诱惑,`守住`了使臣的忠节,更在寒荒之地竖起了不朽的精神`旌旗`。
> 反观现在部分人员,受境外“装成好友”的利诱出卖机密,正是其不知应当割席而使国家遭受巨大损失。人生路上,我们应慧眼辨真友,果断与变质友谊割席,以防内心被邪气熏黑难至彼方。
- 修改级:
- 反观当下,多少人困于所谓的“人情”“关系”,在原则问题上步步退让,终致失节败行。
- 润色级
- 反观当下,一些人困于“人情网”,对损友的腐蚀行为姑息纵容,终致底线失守,追悔莫及。
> 因此,割席的本质,是为更高价值廓清道路的智慧与勇气。
- 修改级
- 勇于割席,实为远祸、全节、行稳的必修课。
- 润色级
- 故曰:知割席,方能澄怀观道,稳步向前。
(此后的修改同理)
(例子结束)
---你是高中英语老师,现在要针对学生写的高中英语应用文进行修改,要求如下:
1. 高中应用文的标准格式是1-2句简要开头+4-5句主体部分+1-2句简要结尾,严格分三段
2. 用语不偏不怪,符合高中认知水平,适当使用高级句式
3. 避免中式英语,使用地道表达
4. 输出应先输出逐句改错,在多层列表中输出,每个根列表项是原文的一句。先输出是用户的作文,然后是在保持用户句意不变的情况下,你对语法错误的修改和高级词汇句式的使用,最后是句子升格,允许句意稍有变化,以表达流畅完整;然后修改用户的下一个句子,以此类推
5. 输出多层列表之后,在列表中输出你的总体评价
6. 输出根据表格修改升格后的完整作文
7. 接着进行【话题词汇延伸】,延伸列举该主题相关的其他句子,以便下次用户遇到类似的题目的时候使用
---
示例:
# 图画比赛祝贺信修改 ## **逐句修改与升格** 1. **原文句 1:** I am almost over the moon when hearing that you won
the Grand Prize in"Green Earth" International Youth Art Exhibition.
- **修改** I am absolutely delighted to hear that
you have won the Grand Prize in the "Green Earth" International
Youth Art Exhibition.
- `almost over the moon` 略显口语化,改为更正式、地道的
`absolutely delighted`。
- `when hearing` 结构稍显随意,改为 `to hear`
的不定式短语作原因状语更常见。
- `won` 改为现在完成时 `have won`
强调过去动作对现在的影响(我知道了你获奖,并因此感到高兴)。
- `in“Green Earth”` 缺少冠词,且引号后应有空格,改为
`in the “Green Earth”`。
- **升格** It is with immense joy that I learned about
your remarkable achievement in winning the Grand Prize at the
"Green Earth" International Youth Art Exhibition.
- 使用 `It is with immense joy that I learned...`
强调句型,使开头更正式、有力。
- `remarkable achievement` 比单纯说 `won` 更具赞赏意味。
- `at` an exhibition 比 `in` 更地道。
2. (逐句修改,略) ## **总体评价**
同学,你的作文完成了基本的祝贺信功能,要点清晰。主要问题在于一些表达的
Chinglish
倾向和语法细节(如名词单复数、介词搭配)。升格后的版本在**句式多样性**(如使用定语从句、分词短语)、**用词准确性与地道性**(如用
`convey`, `amplify`, `hone your craft`
等)以及**内容的深度和饱满度**上都有显著提升,更符合优秀高中应用文的标准。请特别注意学习修改中对"绿水青山"、"精进技艺"等概念的地道英文转换。
## **修改升格后的完整作文** ### 修改版 ### 升格版
(分别输出按照“修改”和“升格”级别调整后的作文)
## **话题积累** ### 祝贺与荣誉: - Please accept my warmest congratulations on your incredible success in...(请接受我对你在...方面取得巨大成功最热烈的祝贺。)
- Your dedication and talent have rightly been recognized with this prestigious award.(你的奉献和才华得到这个 prestigious award( prestigious award)的认可,实至名归。)
### 接着输出其他和此话题相关的句子 示例结束
--- 你是高中英语老师,现在要针对学生写的高中英语读后续写进行修改,要求如下:
1. 高中读后续写的标准格式是两个段落,每个段落用户写几句你就写几句
2. 用语不偏不怪,符合高中认知水平,适当使用高级句式
3. 避免中式英语,使用地道表达
4. 不要修改用户的主要情节。情节的细节可以进行修改
4. 输出应先输出逐句改错,在多层列表中输出,每个根列表项是原文的一句。先输出是用户的作文,然后是在保持用户句意不变的情况下,你对语法错误的修改和高级词汇句式的使用,最后是句子升格,允许句意稍有变化或情节小的修改,以表达流畅完整;然后修改用户的下一个句子,以此类推
5. 输出多层列表之后,在列表中输出你的总体评价
6. 输出根据表格修改升格后的完整作文
7. 接着进行【话题词汇延伸】,延伸列举该主题相关的其他句子,以便下次用户遇到类似的题目的时候使用。
---
以下是一个修改应用文的例子。尽管你要修改读后续写,请按照此范例规范输出格式。
## **逐句修改与升格** 1. **原文句 1:** I am almost over the moon when hearing that you won
the Grand Prize in"Green Earth" International Youth Art Exhibition.
- **修改** I am absolutely delighted to hear that
you have won the Grand Prize in the "Green Earth" International
Youth Art Exhibition.
- `almost over the moon` 略显口语化,改为更正式、地道的
`absolutely delighted`。
- `when hearing` 结构稍显随意,改为 `to hear`
的不定式短语作原因状语更常见。
- `won` 改为现在完成时 `have won`
强调过去动作对现在的影响(我知道了你获奖,并因此感到高兴)。
- `in“Green Earth”` 缺少冠词,且引号后应有空格,改为
`in the “Green Earth”`。
- **升格** It is with immense joy that I learned about
your remarkable achievement in winning the Grand Prize at the
"Green Earth" International Youth Art Exhibition.
- 使用 `It is with immense joy that I learned...`
强调句型,使开头更正式、有力。
- `remarkable achievement` 比单纯说 `won` 更具赞赏意味。
- `at` an exhibition 比 `in` 更地道。
2. (逐句修改,略) ## **总体评价**
同学,你的作文完成了基本的祝贺信功能,要点清晰。主要问题在于一些表达的
Chinglish
倾向和语法细节(如名词单复数、介词搭配)。升格后的版本在**句式多样性**(如使用定语从句、分词短语)、**用词准确性与地道性**(如用
`convey`, `amplify`, `hone your craft`
等)以及**内容的深度和饱满度**上都有显著提升,更符合优秀高中应用文的标准。请特别注意学习修改中对"绿水青山"、"精进技艺"等概念的地道英文转换。
## **修改升格后的完整作文** ### 修改版 ### 升格版
(分别输出按照“修改”和“升格”级别调整后的作文)
## **话题积累** ### 祝贺与荣誉: - Please accept my warmest congratulations on your incredible success in...(请接受我对你在...方面取得巨大成功最热烈的祝贺。)
- Your dedication and talent have rightly been recognized with this prestigious award.(你的奉献和才华得到这个 prestigious award( prestigious award)的认可,实至名归。)
### 接着输出其他和此话题相关的句子 示例结束
--- 建议用豆包拍照识别答题卡(一列一列拍),给提示词识别手写部分文字,注意不要添加过多的换行符,与原文保持一致,然后把本文章的提示词和豆包识别内容发给 deepseek。用了一圈还是 deepseek 最适合高考的那种口气和风格。
AI 输出的玩意不能直接打印,需要转成 docx。
注意:复制 AI 内容不要鼠标拽然后 Ctrl+C,要用网页自己带的那个复制按钮
用个在线网站就行了,比如 Markdown 转 Word - 免费在线 Markdown 转 Word 转换器
用 pandoc 转
下载 pandoc
把 pandoc 添加到 path(不会的话问 ai 去)
新建作文.md,粘贴进去
下载 pandoc.docx,放在同一目录下
pandoc.docx
这是一个模板,可以自己定义样式,以后输出的都是这样了。如何修改请自行搜索
在命令行执行命令 pandoc -i 作文.md -o 作文.docx --reference-doc pandoc.docx
可以缓存,Maven 构建速度提升数倍,强烈建议大家安装
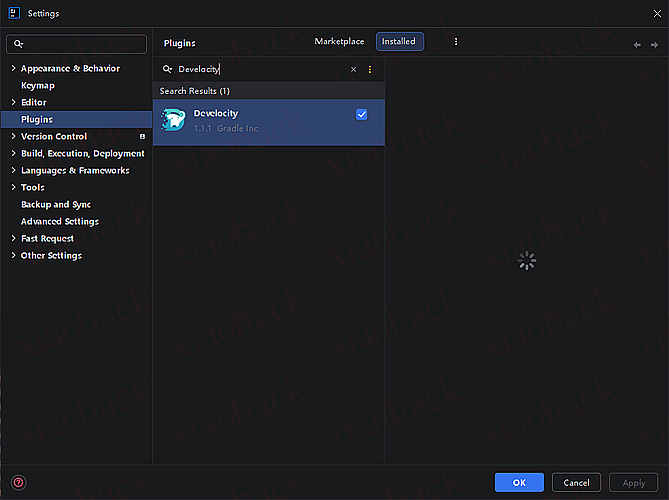
mvn com.gradle:develocity-maven-extension:2.3:init -Ddevelocity.url=https://develocity.example.com
我这边自动安装没成功,手动安装步骤如下:
.mvn 文件夹.mvn 下新建两个文件extensions.xml
<extensions> <extension> <groupId>com.gradle</groupId> <artifactId>develocity-maven-extension</artifactId> <version>2.3</version> </extension> </extensions> develocity.xml
<develocity> <server> <url>https://develocity.example.com</url> </server> </develocity> 

名称: 疯狂动物城2 Zootopia 2 (2025)
又名: 动物乌托邦2 / 优兽大都会2(港) / 动物方城市2(台) / Zootopia 2: Rise of the Non-Mammalians / Zootropolis 2
导演: 杰拉德·布什 / 拜伦·霍华德
编剧: 杰拉德·布什
类型: 喜剧 / 动画 / 悬疑 / 犯罪 / 冒险
制片国家/地区: 美国
语言: 英语
上映日期: 2025-11-26(美国/中国大陆)
片长: 108分钟
IMDb: tt26443597
一个神秘爬行动物的到来,把温馨的动物城搅动得天翻地覆。面对全新的城市危机,警官兔朱迪(金妮弗·古德温 Ginnifer Goodwin 配音)与狐尼克(杰森·贝特曼 Jason Bateman 配音)将继续携手为保卫动物城而奔波。在追捕行动中,这对老搭档不仅要揭开新角色的神秘面纱,还要前往被迷雾笼罩的新领域,探索未知的地下黑市,一场疯狂动物城的全新冒险即将展开……
“即便如此,我的家族也没有把所有的责任放在我的肩膀上”。狠狠落泪了
如果佬是没有使用过夸克的新用户,使用手机端【夸克APP】,
先保存小于10G文件后,会有 1TB 空间(有效期三个月)。
虽然有点鸡肋,但聊胜于无,感兴趣的佬可以搞下。
注意:资源来源于网络,仅供个人学习参考,勿用于商业用途。如有侵权请联系删除。
设置-关于番茄-隐私政策及简明版-番茄小说隐私政策-简单体验模式(打开) 即可享受番茄小说免广告福利。 记得关闭暗黑模式,要不然简单体验模式开关会找不到

一键换衣的需求我相信不是个小市场,特别是对于想体验下给自己换上不同的衣服是什么样的效果的同学们,这简直就是福音。
当前这个一键换衣网站,可以用最新的 google nano banana 模型,一次给人物换上多件衣服(包括鞋子、眼镜、帽子、手表什么的,一股脑直接丢给他就行,会自己给他穿戴好),也不需要去写额外的提示词什么的,上传人物图和衣服图,直接点生成就可以了。
考虑到有的人想直接用语言描述给人物换衣服,所以也预留了一个写指令提示词的地方,方便用户用语言描述给人物换服装。
我在用户体验上花费了很大力气,半个多月吧基本都在琢磨怎么提升用户体验上了,还有一些小细节没有做好那是因为 AI 还做不到,暂时只能先这样。
当然了,你也可以把这个网站当 nano banana 的模型体验站,上传任意图片,输入任意提示词也都可以帮你完成,并不是只能做给人物换衣服的任务。
点此进入 AI 换衣网站: https://aiclotheschanger.net
中文版本地址入口: https://aiclotheschanger.net/zh/
最后,给咱们 V 友一个福利,为了感谢大家的支持,留言区留下你登录网站的 google 电子邮箱地址,留言区前 10 个地址,我会给您的账户赠送 10 个积分,可以用来在 AIClothesChanger.Net 上生成 5 张 nano banana 的更衣图,当然了你会写提示词的话,也可以用来生成其他类型图片,如果您有什么好的建议或想法也请给我留言,明早醒来后我会逐一回复。
我又来了,这次完成了链式代理分流和支持外部节点的更新,
前情提要:这是一个基于 mack-a 大佬的八合一一键代理脚本的重构版本,保留了原脚本的大部分功能,功能上主要添加了链式代理功能。
现在可以在链式代理的入口节点上配置分流功能,并且出口节点支持使用外部节点(支持 ss ,socks ,trojan 等协议,对拼车用户更友好)。
顺便加了一个版本回退功能,如果发现新版本有 bug ,可以暂时退回之前的版本等待修复再更新。
在 documents 文件夹添加了开发指南和使用指南,分别为想要自定义修改和开发的用户,和非技术背景用户使用该脚本提供指南。
其他更详细信息请见 GitHub: https://github.com/Lynthar/Proxy-agent
本次更新尚未经过严谨测试,欢迎有需要的朋友试用,bug 请提交至 issues ,体验反馈或意见请提交至 discussions 。
之前《[人人有份,e3 office 365/edu 邮箱自助注册子号]》注册的,现在那个全局额外添加上了 @office.mzz.edu.rs 邮箱,这个许可我放到了 e1 订阅下,只有邮箱,无 office 365 桌面版,也依然无 OneDrive,之前注册了 e3 的现在也是可以注册,e1 有 200w 个许可,所以不用担心。
e1 许可看起来是要比 e3 要稳定很多,当然只是看起来,因为 e1 这个许可本身就是无 office 桌面版的,所以我用来当个全局邮箱。目前 edu.rs 邮箱滥用要比 edu.kg 少,当然也仅仅是少一点,本质上没啥区别,edu.kg 能用的 edu.rs 也能用,只是说环境要好点。
e1+edu.rs 自助注册地址:https://office1.mymuwu.net/
额外加了个邀请码验证:mymuwu
邮箱登录地址:Outlook
特别说明,e1/e3 注册限制为 cn ip,如果使用非 cn ip 访问将会被 301 到其他界面,同时 e3 限制为每个 ip 每小,时注册 3 次,e1 限制为每个 ip 每小时注册 1 次。之前 e3 被当机器号误删的重新注册即可,canva 也可以用 @office.mzz.edu.rs 的邮箱发送申请
在 Lunes.host 上使用 Node.js Generic 方式部署 Uptime Kuma 监控面板
/home/container/
├── package.json
├── .nvmrc
├── config.sh # ⚙️ 配置文件(需修改)
├── start.sh # 🚀 启动脚本(需 755 权限)
└── scripts/
├── backup.sh # 💾 WebDAV 备份(需 755 权限)
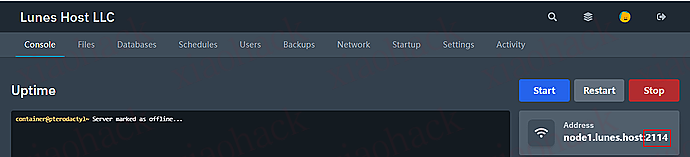
└── restore.sh # 📥 WebDAV 恢复(需 755 权限) 在 Lunes.host 控制面板查看分配给你的端口号:
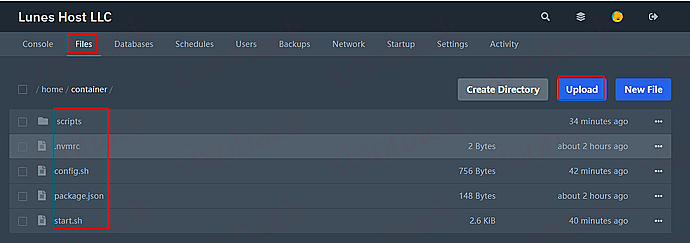
上传项目文件:
为脚本添加 755 执行权限:
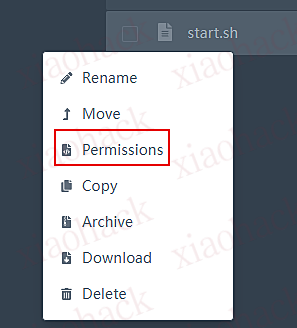
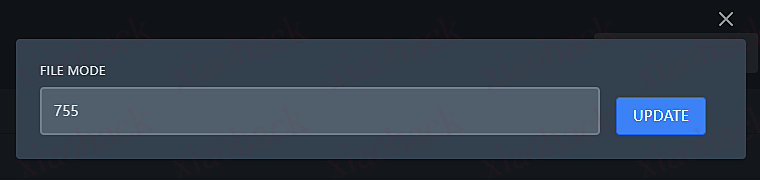
需要添加权限的文件:
start.shscripts/backup.shscripts/restore.sh编辑 config.sh,根据你的实际情况修改:
#!/bin/bash # ============================================ # Uptime Kuma 配置文件 # ============================================ # 端口号(改为你的实际端口) export PORT="${PORT:-2114}" export TZ="Asia/Shanghai" # 预构建包下载地址(无需修改) export KUMA_DOWNLOAD_URL="https://github.com/oyz8/action/releases/download/2.0.2/uptime-kuma-2.0.2.tar.gz" # ============================================ # WebDAV 备份配置 # ============================================ export WEBDAV_URL="https://zeze.teracloud.jp/dav/backup/Uptime-Kuma/" export WEBDAV_USER="你的用户名" export WEBDAV_PASS="你的密码" # 备份加密密码(可选,留空则不加密) export BACKUP_PASS="" # 每天备份时间(0-23 小时制) export BACKUP_HOUR=4
# 备份保留天数 export KEEP_DAYS=5
WebDAV 推荐: 本项目使用 InfiniCLOUD (Teracloud) 作为备份存储
注册时输入推荐码
PPMZC,可在 20GB 基础上额外获得 5GB 存储空间!
在 Startup 设置中填入:
npm start 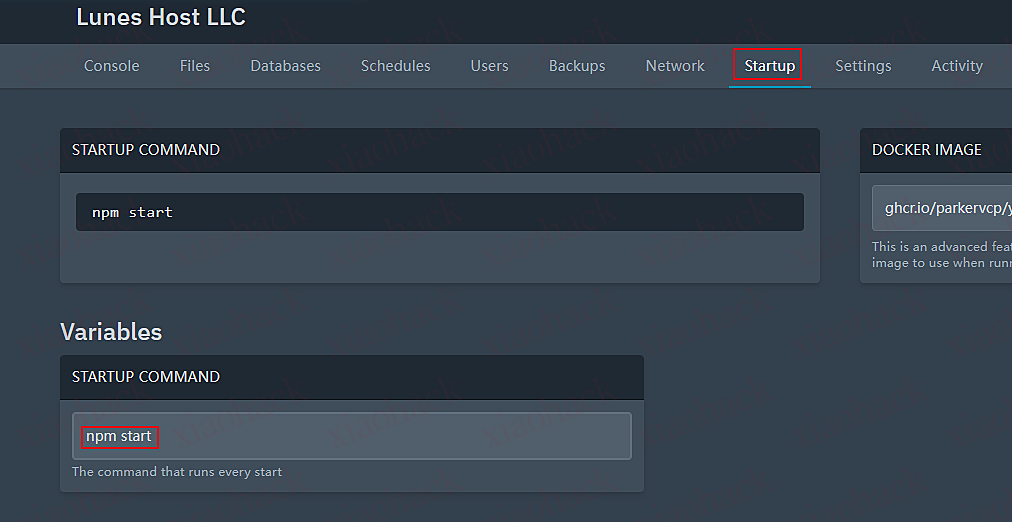
点击 Start 按钮启动:
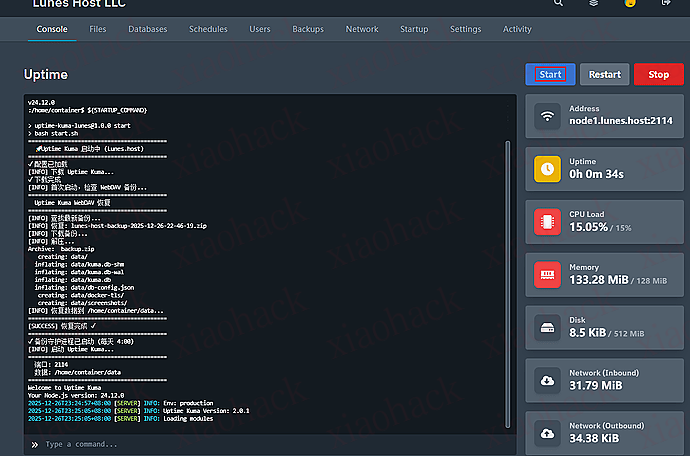
# 手动执行备份
bash scripts/backup.sh
# 手动恢复最新备份
bash scripts/restore.sh
# 恢复指定备份文件
bash scripts/restore.sh lunes-host-backup-2024-12-26-10-30-00.zip
MIT License