Finger - Burp Suite 自动化指纹识别与主动探测插件




xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
前些时间整了个备案域名,就想着把一些自建服务迁移回国内,原本我的 Bark 服务器是放在 Cloudflare Workers 上的,于是就想着看看能不能迁移到国内公有云的 Serverless 平台上。
选择 EdgeOne Pages 的原因也很简单,想着也许能够免费用,于是就遇到第一个问题:
我打开腾讯云的文档竟然发现完全没有描述 Pages KV 的计费规则,于是我提出售前工单询问计费规则,客服回复让我加微信群问技术支持……所以这个工单系统的作用是什么,电话总机吗?无奈还是加群问了下,技术支持表示是免费的。就算免费也得写一下吧……那好吧就用这个了,毕竟好像找不到第二个免费的……
设置环境变量为 0 表示禁用应该是挺常见的用法,一开始设置为 0 不行觉得可能是 JavaScript 0 == '' 的问题(后面一想那参数肯定是字符串啊),于是就试着设置成 "0",还是不行。在网页试了下可以设置,不过难道把环境变量设置为空字符串又是什么禁忌吗?
> npx edgeone pages env set EXAMPLE_KEY 0
[cli][✘] Variable name and value cannot be empty.
> npx edgeone pages env set EXAMPLE_KEY ""
[cli][✘] Variable name and value cannot be empty.
> npx edgeone pages env set EXAMPLE_KEY "0"
[cli][✘] Variable name and value cannot be empty.
这个文档里写了,但是没写能开多少次,我这边大概不到 20 次就触发日限额了(热重载不算,但是 Debug 的时候发现热重载不是很即时就反复开了下),只能等第二天。
这个开发环境似乎是远程在腾讯云那边起了三个 Worker ,而且对 KV 的读写会影响到生产环境(这要是真有人在重要生产环境用了怕不是会炸掉)……
最后的推送代码写好的时候,发现请求 APNs 服务器的时候连接会被断开,研究半天发现是 EdgeOne Pages Edge Functions Runtime 的 fetch() 不支持 HTTP/2 ,而 api.push.apple.com 是强制使用 HTTP/2 的。我问了下腾讯的员工,说是在规划中,本来我想着可能我是第一个发现的文档没有提示也不奇怪,后面发现似乎我不是第一个问这个的……
本来觉得又白干一天了,突然想起这个 Edge Pages 还有个 Node Functions 用的是 Node.js Runtime ,于是拿 Node Functions 写了个代理就勉强能用了。开发的过程中发现 Edge Functions 的 Catch-all 路由优先级是高于 Node Functions 所有路由的,只好把 Edge Functions 移动到了一个单独的目录下,当然这文档也没说明。
总而言之,头疼的体验主要来自文档不清晰,其次交流严重依赖 IM 而不是工单系统,最后是非常草台的设计。
视频会议国产化安全加密技术深度解析 在国产化视频会议系统的安全体系中,加密技术是保障数据不被窃取、篡改、泄露的核心支撑,其设计遵循全链路覆盖、国密标准合规、分级权限管控三大原则,从终端接入到数据传输、从会议信令到内容存储,构建起无死角的安全防护屏障。 一、 加密技术底座:国密算法的全面落地 国产化视频会议系统摒弃国外通用加密算法,全面采用符合《中华人民共和国密码法》要求的国密算法体系,核心算法包括SM2、SM3、SM4,分别承担身份认证、数据校验、内容加密的核心职能,实现算法层面的自主可控。 二、 全链路加密:从终端到存储的无缝防护 国产化视频会议系统的加密覆盖终端接入、信令传输、媒体流传输、数据存储四大环节,形成端到端的闭环防护,任一环节均不出现加密断点。 ◦ 信令数据采用“TLS 1.3 + SM4”双重加密,TLS协议保障信令传输链路安全,SM4算法对信令内容进行二次加密,即使链路被攻破,信令内容仍处于加密状态; ◦ 媒体流数据采用SRTP+SM4协议加密,SRTP协议为实时传输协议提供加密、认证、防重放保护,结合SM4算法的高强度加密,实现音视频流的安全传输。同时,系统支持加密参数动态更新,每10分钟自动生成新的会话密钥,进一步提升传输安全性。 三、 安全加固:防篡改、防重放、防攻击 除核心加密技术外,国产化视频会议系统还针对会议场景的典型安全威胁,部署多重防护机制,强化加密体系的抗攻击能力。 四、 权限管控:加密体系的精细化管理 加密技术的有效落地,离不开精细化的权限管控体系。国产化视频会议系统采用“管理员-主讲人-参会人”三级权限架构,将加密密钥、解密权限与用户角色绑定,实现“密钥不外露、权限不越界”。 • 管理员拥有最高权限,可配置加密算法参数、管理数字证书、分配用户权限,同时掌握硬件加密机的密钥调用权限; • 主讲人可控制会议加密状态,开启/关闭录制加密功能,指定可查看共享内容的参会人员; • 参会人仅拥有与其权限匹配的解密权限,普通参会人无法获取会议录制文件的解密密钥,也无法查看超出权限的共享内容。 权限变更操作全程记录于加密日志中,日志通过SM3算法校验,确保权限管理行为可追溯、可审计。
SM4算法以128位分组长度和密钥长度为基础,具备运算速度快、资源占用低的特性,完美适配视频会议音视频流的实时加密需求。在传输过程中,系统会将音视频数据切割为固定长度的数据块,通过SM4算法进行分组加密,加密后的数据流即使被截获,也无法通过暴力破解还原原始内容。相较于传统AES算法,SM4在国产芯片上的运行效率提升30%以上,可满足4K超高清视频流的低延迟加密需求。
针对会议终端接入认证、加密密钥协商等场景,系统采用SM2椭圆曲线公钥密码算法。会议发起前,服务器与终端会互相验证对方的SM2数字证书,确认终端身份合法性,杜绝非法设备接入会议;同时,通过SM2算法完成会话密钥的安全协商,避免密钥在传输过程中被窃取。SM2算法的密钥长度仅需256位,即可达到RSA算法2048位的安全强度,在提升安全性的同时,大幅降低密钥协商的计算开销。
为防止音视频流、会议信令在传输中被篡改,系统引入SM3密码哈希算法。发送端会为每一段数据生成对应的SM3哈希值,随数据一同传输;接收端收到数据后,会重新计算哈希值并与发送端数值比对,若数值不一致,则判定数据被篡改并自动丢弃。此外,SM3算法还用于会议日志、录制文件的完整性校验,确保会议全流程数据可追溯、不可篡改。
终端接入会议时,需通过“身份证书认证+权限令牌验证”双重关卡。终端内置的SM2数字证书由国产化CA认证中心签发,服务器通过校验证书有效性确认终端身份;同时,管理员为不同参会人员分配分级权限令牌,令牌通过SM4算法加密存储,确保只有授权人员才能加入会议。终端与服务器建立连接的瞬间,即刻启动TLS 1.3协议加密链路,所有接入请求数据均在加密链路中传输,防止接入信息被监听。
会议系统中的数据分为信令数据(会议预约、人员邀请、功能控制指令)和媒体流数据(音视频、屏幕共享内容),针对两类数据的不同特性,系统采用分层加密策略。
会议录制文件、签到日志、纪要等数据的存储环节,采用分级加密存储机制。涉密等级较高的会议内容,采用“SM4加密存储+硬件加密机密钥托管”的方式,加密密钥存储于国产化硬件加密机中,与存储数据物理隔离,只有授权人员通过身份认证后,才能调用密钥解密数据;普通会议内容则通过SM4算法加密后存储于国产化数据库中,数据库本身部署于国产服务器,遵循数据不出境的安全要求。此外,系统支持存储数据的透明加密,用户读取数据时自动解密,写入数据时自动加密,不影响用户操作体验。
为防止攻击者截取并重复发送合法的会议信令,系统为每一条信令添加时间戳+随机数标识。服务器接收信令时,会校验时间戳的有效性,超过有效期的信令直接丢弃;同时,通过随机数唯一性校验,拒绝重复的信令请求,确保每一条信令都是实时、合法的。
除SM3哈希校验外,系统还为关键信令和录制文件添加SM2数字签名。发送端使用私钥对数据签名,接收端通过公钥验证签名有效性,确认数据未被篡改且发送方身份合法,双重校验机制大幅提升数据完整性保障能力。
系统可与国产化防火墙、入侵检测系统(IDS)无缝联动,通过流量清洗、异常行为识别等技术,抵御针对会议服务器的DDoS攻击。针对视频会议的流量特性,防火墙可精准识别会议媒体流与信令流,优先保障合法会议流量的传输,避免攻击导致会议中断。
当我们审视人工智能的进化脉络时,一场颠覆性的智能变革正深刻重塑行业格局:人工智能正从执行特定指令的工具,蜕变成为能够理解复杂意图、规划执行路径并自主解决问题的自主智能体。 这一转变的关键动力,一方面来自大语言模型所提供的通用推理能力与广泛知识积累,另一方面也离不开高质量数据对模型性能的基础支撑。 曼孚科技作为一家从数据出发,以数据标注和数据管理为核心的 AI 平台型企业,致力于打造全球规模最大的数据处理平台与业界领先的端到端AI平台,通过一站式满足数据、算力、工具、管理、训练及推理等AI全链路需求,为大语言模型驱动的自主智能体发展奠定坚实基础。 这种依托大语言模型构建、由高质量数据赋能的智能体新形态,不仅重塑了人机协作的边界,更在本质上拓展了机器智能的疆域。 传统人工智能系统大多遵循 “输入 - 处理 - 输出” 的运作逻辑,无论是图像识别、机器翻译还是推荐系统,均在封闭的输入空间内执行预定义任务。这些系统缺乏对任务上下文的整体把控,更无法在动态环境中自主调整策略。 大语言模型驱动的智能体则呈现出全然不同的智能形态:它们具备任务理解、自主规划与动态调整的综合能力。 这种能力的基础,源于大语言模型已从 “文本预测器” 到 “世界模型”的进化,而支撑这一进化的核心前提,是海量高质量标注数据的训练与打磨。 通过标准化、精细化的数据标注与管理,模型不仅掌握了语言规则,更内化了关于世界运行规律的丰富知识。当这些知识与环境反馈相结合,智能体便能展现出令人惊讶的环境适应性。 在这一智能形态下,智能体的核心不再是单一算法模型,而是由感知、认知、决策、执行等多个模块构成的协同系统。 大语言模型充当系统的 “认知内核”,负责解读任务意图、分解复杂目标、制定行动策略并评估执行效果;外围模块则承担环境交互、反馈获取、工具调用与记忆存储的功能,形成完整的感知 - 行动闭环。 这种架构让智能体能够应对开放世界的复杂任务。例如,当被要求 “分析公司上个季度的销售数据并准备汇报 PPT” 时,传统 AI 需要多个独立系统协同完成 —— 数据分析工具、文档生成系统、演示软件等,且每个环节都依赖人工衔接。 而 LLM 驱动的智能体可自主规划完整流程:检索数据库获取销售数据,调用分析工具开展统计处理,基于分析结果生成文字总结,最终调用 PPT 生成模块创建演示文稿。整个过程中,智能体根据各步骤执行结果动态调整后续计划,展现出强大的任务管理能力。 而这一切能力的落地,离不开底层高质量数据的支撑。 曼孚科技深耕数据标注与管理领域,构建了一套覆盖项目全生命周期的内部质量管理体系,为大语言模型与自主智能体的训练提供了可靠的数据保障。 从新成员准入的严格筛选—→现有人员的常态化质量监督—→新场景新需求的规则培训与磨合,曼孚科技通过多轮数据质量检查、驳回修改的闭环流程,确保交付给客户的数据完全满足质量要求。 在标注人员培养层面,曼孚科技建立了系统化的培养体系: 1、针对所有标注人员开展全面的入职培训,内容涵盖标注平台使用方法、标注项目常见类型、标注质量要求等核心模块,帮助标注人员建立清晰的工作认知。 2、结合标注人员的水平差异与经验积累,制定分阶段、分层次的培训计划,精准匹配不同标注项目的需求。 3、创新性设立标注员培训师岗位,通过在线培训、面对面指导、视频教程等多元方式开展教学,并在项目启动前增加专项培训,助力标注员深度理解项目需求。 此外,曼孚科技高度重视培训效果评估,通过常态化测试与考核,及时发现标注人员的能力短板,给予针对性指导支持。 为了从机制上保障标注质量,曼孚科技搭建了全流程的标注质量管理机制: 1、通过随机抽取标注结果进行质量检查,确保标注数据的准确性与一致性,对发现的错误或低质量标注及时反馈指导,对严重违反规则的行为落实相应处罚。 2、建立以标注准确率、效率、工作态度为核心维度的绩效考核机制,以正向激励推动标注质量与效率双提升。 3、定期组织标注员培训,持续强化标注规则、工具使用与质量管理机制的认知;同时定期评估标注规则与数据集,及时调整更新不合理内容,保障标注质量的稳定性与可靠性。 在标注过程监督环节,曼孚科技更是构建了多维度的管控体系: 1、设立随机检查机制,抽取部分已标注数据进行核验,检查结果直接作为人员评估与培训的依据。 2、建立快速纠错机制,一旦发现标注错误立即修正,避免错误数据对后续模型训练与应用产生负面影响。 3、搭建实时反馈机制,帮助标注人员及时掌握自身工作质量,持续优化标注行为。 4、加强团队内部沟通协调,及时解决标注人员遇到的问题困难,避免因误解偏差影响标注质量一致性。 5、通过定期评估标注流程、引入自动化标注工具与算法、加入脚本及算法质检流程等方式,不断优化标注流程,减轻标注员工作负担,提升标注效率与准确性。 6、通过改善工作环境、完善奖励措施等途径,全方位提升标注员的工作效率与质量。 构建真正的 LLM 驱动智能体,需要一系列精心设计的组件协同运作,形成有机的认知 - 行动系统。 认知框架:从语言理解到任务规划 大语言模型作为认知核心,其能力已远超语言生成本身。借助思维链提示、自我反思与程序辅助推理等技术,LLM 能够将复杂问题拆解为逻辑步骤,逐步推演解决方案。 例如,面对 “帮助用户规划一次北京三日游” 这样的开放式任务时,智能体会先开展需求分析(明确预算、兴趣偏好、时间限制),再将任务分解为交通安排、住宿预订、景点选择等子目标,最终生成详细的日程计划。 更先进的智能体系统引入多专家协作框架,将单一 LLM 扩展为多个具备不同专长的 “认知专家”:有的擅长逻辑推理,有的专攻创意生成,还有的专注事实核查。 它们通过内部 “讨论机制” 协同决策,这一架构显著提升了智能体处理复杂多维度任务的能力。 记忆系统:从短时交互到持续学习 与传统对话系统仅维持短暂对话历史不同,现代智能体具备完善的多层记忆架构: 1、短期记忆:留存当前对话与任务的上下文信息。 2、长期记忆:以向量数据库或知识图谱形式,存储智能体长期运行中积累的经验、用户偏好及领域知识。 3、外部记忆:连接数据库、知识库与互联网,提供实时、准确的外部信息支撑。 记忆系统不仅承担信息存储功能,更支持复杂的记忆检索与关联推理。当智能体面对新任务时,可从长期记忆中检索相似案例、借鉴历史经验。 同时,持续将新获取的知识结构化存储,实现能力的持续迭代。这种记忆能力让智能体能够构建个性化用户模型,提供更精准的服务。 工具使用:从单一模型到能力扩展 纯粹的 LLM 存在明显能力边界 —— 无法获取实时信息、难以执行具体操作、精准计算能力薄弱。工具使用能力使智能体突破自身限制,将语言理解转化为实际行动。 智能体的工具集可涵盖: 1、信息工具:搜索引擎、数据库查询、API 调用。 2、操作工具:代码解释器、软件控制接口、机器人指令集。 3、专业工具:数学计算器、设计软件、专业分析平台。 智能体学习 “何时、如何选用何种工具” 的过程,被称为工具学习。 通过少量示例演示或强化学习,智能体能够根据任务需求自动选择适配工具,并以正确格式提供输入参数。 例如,需计算复杂统计指标时,会自动调用 Python 代码解释器而非尝试自主计算;需获取最新股票信息时,会调用金融数据 API 而非依赖训练数据中的陈旧信息。 行动策略:从确定性执行到适应性探索 在动态、不确定的环境中,智能体需根据环境反馈实时调整行动策略。这涉及强化学习与语言模型的多层次融合: 1、探索与利用的平衡:在已知有效策略与尝试创新方法之间找到平衡点,尤其面对未知环境时 2、分层强化学习:高层策略由 LLM 负责,处理抽象目标分解与计划制定;低层策略由专用控制器负责,处理具体动作执行 3、自我反思与修正:任务执行过程中持续评估进展,检测到目标偏离或障碍时,主动调整计划甚至重新规划整体任务 行动策略的优化,让智能体能够应对现实世界中充满变数的任务。 例如,自动化测试智能体发现某个按钮无法点击时,会尝试替代方案(如使用键盘快捷键或寻找其他入口),而非僵化等待按钮变为可用状态。 值得注意的是,大语言模型与自主智能体的产业化落地,往往面临垂类标注项目 “短频快” 的交付节奏挑战,而曼孚科技凭借成熟的风险管控体系,为项目平稳交付提供了坚实保障。 曼孚科技针对这类项目的核心风险控制目标明确:在保证数据质量和合规安全的前提下,通过流程优化与技术赋能,将项目的不确定性降至最低,实现稳定、可预测的交付输出。 实现这一目标的关键,在于曼孚科技创新性地将 “人的经验” 和 “规则的标准” 沉淀到 “系统的流程” 与 “智能的工具” 之中。 通过构建 “人机协同标注” 模式提升效率基线,依靠 “三角专业团队” 和 “闭环质量管理” 双轮驱动控制质量波动,并始终将合规安全作为不可逾越的红线。 这套风险管控体系,不仅解决了垂类标注项目的交付痛点,更为大语言模型驱动的自主智能体在各行业的规模化应用,扫清了数据层面的障碍。 尽管 LLM 驱动的智能体展现出巨大潜力,但要实现稳定可靠的自主智能,仍需攻克一系列重大技术难题。 幻觉与事实一致性问题 作为基于统计规律的语言模型,LLM 本质上是生成 “看似合理” 的文本,而非必然 “真实准确” 的答案。这导致智能体在任务规划或信息提供时,可能产生逻辑自洽但与事实不符的建议。 例如,规划旅行路线时,可能推荐不存在的交通方式或已关闭的景点。 解决这一问题需多维度协同:通过检索增强生成确保决策基于最新准确信息;建立自我验证机制,让智能体行动前核查计划可行性;优化不确定性校准,使智能体能够识别并表达对自身建议的信心程度。 前沿研究正探索符号推理与神经网络的融合,为智能体构建可验证的逻辑基础。而这一过程中,高质量的标注数据与严谨的质量管理体系,正是减少模型幻觉、提升事实一致性的核心前提 —— 这也正是曼孚科技的核心优势所在。 长期任务规划与执行一致性 人类能够围绕长期目标保持行动一致性,即便中途遭遇干扰或需调整计划。当前智能体在维持长期一致性方面仍存在短板,易在复杂任务中 “迷失方向” 或陷入执行循环。 应对这一挑战的前沿方向包括: 1、目标导向的层次记忆:构建从具体行动到抽象目标的多层关联,确保每一步执行都服务于最终目标 2、进展监控与里程碑管理:将大型任务分解为明确的里程碑,持续跟踪进展并适时调整策略 3、注意力机制优化:通过改进的注意力架构,让智能体在长时间跨度内保持对关键信息的聚焦 多模态情境理解与交互 真实世界任务往往涉及多种信息模态 —— 文本、图像、声音、界面状态等。智能体需具备真正的多模态理解能力,才能全面掌控环境状态。 最新的多模态大模型正推动这一领域突破。 例如,能够同时处理图像描述、文本指令与界面元素的智能体,可更精准地理解用户需求与环境限制。 当用户指着屏幕说 “把这个部分做得更突出些” 时,智能体需同时解读语言指令、视觉参照与界面编辑的可能性,这要求实现跨模态表征的深度融合学习。 而多模态数据的高质量标注,正是这类模型训练的关键支撑,曼孚科技的全流程数据管理能力,能够为多模态智能体的研发提供定制化的数据解决方案。 效率与可扩展性瓶颈 基于大型基础模型的智能体,面临显著的计算成本与响应延迟挑战。同时处理复杂规划、工具调用与环境交互,需要大量模型推理资源,在实时应用场景中可能难以适配。 解决效率瓶颈的创新方向包括: 1、模型专业化与分工:训练专用小型模型处理常规任务,仅将复杂问题交由大模型处理 2、预测与缓存机制:预判用户潜在需求并提前准备响应,降低实时计算压力 3、边缘 - 云协同架构:在边缘设备部署轻量级推理模块,复杂分析任务保留在云端执行 而曼孚科技打造的端到端 AI 平台,通过一站式整合数据、算力、工具等资源,能够有效优化模型训练与推理流程,帮助企业降低智能体研发与部署的成本,提升整体效率。 LLM 驱动智能体的未来发展,将循着从简单到复杂、从被动响应到主动协作、从单一运作到协同联动的路径持续演进。这一演进过程,将重新定义人类与数字系统的互动模式。 下一代智能体将不再局限于等待明确指令,而是能够解读用户的高层次目标,主动提出实施方案并寻求确认。 它们将具备更强的上下文感知能力,精准把握任务背景、约束条件与优先级,成为真正意义上的智能协作伙伴。 例如,当用户提出 “我们需要提高下季度的客户满意度” 时,智能体不仅会制定调研计划,还会主动建议改进措施并跟踪实施效果。 在通用能力方面,未来的智能体将突破单一应用或领域的限制,发展出通用的界面理解与操作能力。借助统一的环境表征学习与迁移学习方法,智能体可快速适配新软件界面、操作流程与领域知识,实现真正的通用智能。 这种能力将让智能体能够在整个数字生态中灵活 “穿梭”,完成涉及多平台、多工具的复杂工作流。而以全球最大数据处理平台为最终目标的曼孚科技,将不断为这类通用智能体提供覆盖多领域、多场景的高质量数据支撑。 可以说,LLM 驱动的智能体新形态,标志着人工智能正从 “模式识别” 时代迈向 “自主决策与行动” 时代。这一转变不仅是技术层面的突破,更是对智能本质的重新审视。 当机器能够解读复杂指令、制定合理计划并在动态环境中持续推进任务时,一种全新的智能形态已悄然形成。 而以曼孚科技为代表的 AI 平台型企业,正通过高质量的数据标注、全流程的质量管理与创新的风险管控体系,为这一智能形态的发展注入核心动力。 这种智能形态的发展,最终将助力我们构建出真正理解人类需求、尊重人类意图、增强人类能力的智能伙伴,开启人机协作的全新篇章。一、从 “工具” 到 “伙伴”


二、智能体系统的核心组件
三、大模型的“成长烦恼”
四、从“被动响应”到“主动协作”
1. 拿你喜欢的 ai 图,
我这里拿这位佬的现成的图打个样
(你也可以像我一样把这提示词做成 gem 或者 gpt 会更好用。)
把图上传到哈基米或者 chatgpt,输入以下提示词:
将此图像转换为 JSON 提示字符,包括尺寸和所有视觉细节

2, 拿到 json 后,就可以对 ai 提出要求,要修改的,随便你怎么发挥吧 (本文主要就是分享提取,下面的演示只是用法之一)
一般在上一步解析出来之后 ai 会友情提示

我比较直接 我对 ai 提出的要求如下:

3. 复制 ai 按你要求修改后的 json,咱们直接新建对话直接粘贴,记得开启 "大香蕉" 或 "创建图片"
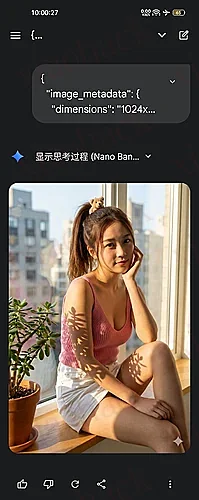
至此,艺术已成
over .
一句话就能分析数据?担心自己零基础,跟不上训练营节奏?别急!「瑶池 Data Agent 入门训练营」 第1节先导课来了! 点此报名参营,用 Data Agent 为你的业务按下加速键! 2026年1月21日-1月29日 (每个工作日下午17:00-17:30) 本次训练营所有课程内容将采取钉群线上直播方式,课程结束后每小节课后作业均在钉钉交流群内获取提交,这是你获得证书和奖品双重奖励的唯一通道。
Data Agent 是一款基于大模型的企业数据智能助手,提供免费版、个人版和企业版三种版本,分别满足个人用户的基础使用、进阶需求及企业的多用户协作、安全管控与独立部署等场景,支持通过自然语言对话完成数据查询、分析与处理,无需编写代码,助力各岗位用户高效实现数据驱动决策。这节课我们不讲复杂操作,只做一件事:帮你彻底搞懂 Data Agent 是什么、能帮你做什么。无论你是业务人员、管理者还是技术小白,都能在这里找到属于你的数据驱动起点。一、参营入口
二、参营时间
三、第一节课程介绍

四、超值奖励

五、如何参营
六、参考资料

之前的帖子 这可能是下一个周经帖:国产大模型哪个编程能力最顶?已经过去一段时间,现在不少模型都已经更新了,而且都支持方便的接入 claude code 等 cli 工具或者 cursor 这样的 ide 。那么,在众多的国产模型中,从你的实际体验出发,哪个国产模型才是最佳日常编码的口粮模型呢?量大管饱,能处理大多数场景的需求。
来吧,分享一下你的体验!
GLM-4.7:目前收集到的信息是,测试的时候效果还不错,能跟 sonet 4.0 有来有回,coding plan 也比较便宜,但是超售严重,订阅后降智严重
MiniMax M2.1:也推出了自己的 coding plan ,总的来说反馈还是不错
DeepSeek-V3.2:写代码还是不太行,听说 4.0 很强!
kimi-for-coding:听说比较蠢,具体请反馈
Doubao-Seed-Code:最近新出,还得到了阮一峰推荐 https://www.ruanyifeng.com/blog/2025/11/doubao-seed-code.html
微信支付完成后会有一个摇一摇领优惠。这点优惠聊胜于无,真不如支付宝每次减几毛。他还有音效,我支付完成后熄屏揣兜里还有音效。今天我决定把它关掉,去网上找了方法。这个开关的位置给我整笑了。
关闭方法如下:
我→服务→钱包→客服中心→消费者保护→隐私保护→
支付后摇一摇→开启支付后摇一摇
太有意思了

如图所示,今日处理注释任务的时候发现的真的是太棒了.
怀念免费使用 kiro 中 opus 每一天,kiro 的 claude 是真的快 但是一定要写好项目提示词有时候不是他降智了,是因为 kiro 的项目规则提示词太弱智了。

触发教程就是让他直接用子代理就行 嘿嘿 没想到的佬留个赞再走叭

日常问很多生活问题和一些小代码问题一般很喜欢用 Google Ai Studio,里面的回复也很不错,冬天的时候上了一个可以打开雪花特效的按钮,雪花特效挺好看的,但是每次都需要手动打开,刷新一下又没有了,让 AI 写了个脚本可以自动打开,每次刷新会自动打开,挺不错的
// ==UserScript==
// @name Google AI Studio - Auto Snow
// @namespace http://tampermonkey.net/
// @version 1.0
// @description 自动开启 Google AI Studio 的 Let it snow 特效
// @author You
// @match https://aistudio.google.com/*
// @icon https://www.google.com/s2/favicons?sz=64&domain=google.com
// @grant none
// ==/UserScript==
(function() {
'use strict';
// 定义检测器
const clickSnowButton = () => {
// 在页面中查找所有可能的按钮或菜单项
// 因为 Google 的类名经常变,我们直接找包含 "Let it snow" 文字的元素
// 或者查找特定的图标/按钮位置(这里使用最通用的文本匹配法)
const allElements = document.querySelectorAll('button, div[role="button"], span, li');
for (let el of allElements) {
// 忽略大小写,查找包含 Let it snow 的元素
if (el.textContent && el.textContent.toLowerCase().includes('let it snow')) {
// 找到后点击
console.log('Found Snow button, clicking...', el);
el.click();
// 只有点击成功后才清除定时器,防止元素还没加载出来
return true;
}
}
return false;
};
// 使用定时器循环检查,因为 AI Studio 是动态加载的,按钮可能不会一开始就出现
const checkInterval = setInterval(() => {
const success = clickSnowButton();
if (success) {
// 如果成功点击了,就停止检查,避免重复点击(导致又关掉了)
clearInterval(checkInterval);
}
}, 1000); // 每秒检查一次
// 设置一个超时,比如 30 秒后还没找到就停止,省点资源
setTimeout(() => {
clearInterval(checkInterval);
}, 30000);
})();
Antigravity 反代其实论坛里很多人都写过手把手教程,我前端时间也亲自跑通了,并且整理成了这篇从 0 到 1 的教程。
我还录了个视频教程发到 B 站,但可能涉及引流?就不发到这里了,需要的佬自行搜索标题获取吧。
我的这篇教程可以帮大家用默认配置从 0 到 1 先跑通流程,因为是默认设置会导致跑通后能用,但是比较粗糙。
然后大家可以继续学论坛中的详细配置和用法做到从 1 到 100,比如这个系列帖子:
你能成功的登录并使用 Antigravity,各种账号或网络问题你需要提前搞定。我个人是美国账号 + 美国 IP+TUN 模式。
当然新加坡或其他受支持的地区也行,看佬的自身情况。
直接下载最新的文件,解压后就能使用,如果有更新,也是从这个链接中查找就行。
比如写文章时的最新版为:CLIProxyAPI_6.6.84_windows_amd64.zip
https://github.com/router-for-me/CLIProxyAPI/releases
本教程中我解压到了 D:\Tools\CLIProxyAPI_6.6.84_windows_amd64 目录下,你可以解压到自己需要的目录,路径要全英文的,并且不能有空格。
使用一键脚本安装或升级,都用这个命令就行
curl -fsSL https://raw.githubusercontent.com/brokechubb/cliproxyapi-installer/refs/heads/master/cliproxyapi-installer | bash
使用 brew 安装命令
brew install cliproxyapi
后续升级命令
brew upgrade cliproxyapi
安装目录下把 config.example.yaml 复制一份,复制的改名为 config.yaml,然后修改里面的内容。
家 (Home) 目录下找 cliproxyapi/config.yaml,即 ~/cliproxyapi/config.yaml,然后修改里面的内容。
/opt/homebrew/etc 目录下找 cliproxyapi.conf,即绝对路径为:/opt/homebrew/etc/cliproxyapi.conf,然后修改里面的内容。
allow-remote: true secret-key: "my-password" ![[图文] 手把手教你 Antigravity 反代,全程不用敲代码,小白也能看懂的保姆教程1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/20/20260120104338_696eebda50e01.png!mark)
进入到刚才解压后的目录下直接 exe 执行就可以了,比如我刚才安装到了 D:\Tools\CLIProxyAPI_6.6.84_windows_amd64 下。
![[图文] 手把手教你 Antigravity 反代,全程不用敲代码,小白也能看懂的保姆教程4](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/20/20260120104345_696eebe1a2b0e.png!mark)
进入到 ~/cliproxyapi/ 目录后,启动。
cd ~/cliproxyapi/
./cli-proxy-api
不需要进入任何目录,直接启动即可。
brew services restart cliproxyapi
注意地址,本机的直接访问右边这个地址就行,首次登录密码是刚才设置的 my-password :http://localhost:8317/management.html
服务器的话要填服务器的地址或域名,比如你部署到了服务器的 ip 是 1.2.3.4,则访问:http://1.2.3.4:8317/management.html
![[图文] 手把手教你 Antigravity 反代,全程不用敲代码,小白也能看懂的保姆教程2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/20/20260120104340_696eebdcbb714.png!mark)
登录后台成功后,可以看到仪表盘。建议把使用统计打开,这样后面用模型我能能看到用了多少的 Tokens。
![[图文] 手把手教你 Antigravity 反代,全程不用敲代码,小白也能看懂的保姆教程3](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/20/20260120104343_696eebdf4ccc3.png!mark)
按照图示登录 Antigravity,并等待自动认证成功,认证成功后登录网页会自动关闭。
如果登录界面没有自动关闭 (如图),需要你手动把登录成功的网址复制粘贴回来,然后手动点击提交回调URL。
如果还登录不上,可以尝试重启机器,然后别的软件先别开,这时打开反代服务 + 开启 TUN 魔法 + 挂到美国 IP,再登录下试试。
![[图文] 手把手教你 Antigravity 反代,全程不用敲代码,小白也能看懂的保姆教程5](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/20/20260120104348_696eebe422ad4.png!mark)
你还可以登录 Gemini CLI ,这样就有更多的 Gemini 额度了。
![[图文] 手把手教你 Antigravity 反代,全程不用敲代码,小白也能看懂的保姆教程6](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/20/20260120104408_696eebf8ac330.png!mark)
登录认证成功后,后台就能看到认证信息了。我这里即反代了 Antigravity,也反代了 Gemini CLI, 如图:
![[图文] 手把手教你 Antigravity 反代,全程不用敲代码,小白也能看懂的保姆教程7](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/20/20260120104411_696eebfb53c62.png!mark)
反代出来的模型,可以在中心信息中查看到。后面使用模型时,需要来这里复制模型名,不能随便写模型名。
![[图文] 手把手教你 Antigravity 反代,全程不用敲代码,小白也能看懂的保姆教程8](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/20/20260120104413_696eebfdb55f5.png!mark)
注意 your-api-key-1 要配置成网页后台中的真正的 api key,我这里演示的是默认的。
模型的名称也要从网页后台拷贝,不要自己手写。
base url 填写为 "http://localhost:8317"
![[图文] 手把手教你 Antigravity 反代,全程不用敲代码,小白也能看懂的保姆教程9](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/20/20260120104416_696eec009767c.png!mark)
{ "env": { "ANTHROPIC_BASE_URL": "http://localhost:8317", "ANTHROPIC_AUTH_TOKEN": "your-api-key-1", "ANTHROPIC_DEFAULT_OPUS_MODEL": "gemini-claude-opus-4-5-thinking", "ANTHROPIC_DEFAULT_SONNET_MODEL": "gemini-claude-sonnet-4-5-thinking", "ANTHROPIC_DEFAULT_HAIKU_MODEL": "gemini-claude-sonnet-4-5", "ANTHROPIC_MODEL": "gemini-claude-opus-4-5-thinking" } } 注意!base url 要改为: http://localhost:8317/v1
api key 和模型名和刚才一样,从网页后台复制就行了。
vscode 中可以通过 oai 插件 (OAI Compatible Provider for Copilot) 来添加到 copilot 中。
正面回答是有风险,但我个人觉得风险更多的还是获取账号的渠道不合规,比如闲鱼买的成品号、各位佬薅羊毛的教育认证号等。。。我也没足够的统计数据,只能说不建议用自己的大号搞,因为确实逆向了有风险,建议用小号搞吧。
免费版的每周都有额度,但是额度很少,可以先试一下,把流程跑通了。付费会员或教育优惠会员,都是每 5 小时刷新额度,自己用一般是足够的,并且 Gemin Pro\Gemini Flash\Claude 这三组额度是独立的。
最快速的是把谷歌的 Gemini CLI 工具也反代了,这个工具中只有 Gemini 系列的模型,并且额度和 Antigravity 中的不互通,是独立的。
其次有个被社区称为升天的方法:其实就是家庭组,Pro 账号可以邀请最多 5 个人进入家庭 (算上自己共 6 人)。家庭里每个账号的 Antigravity 和 Gemini CLI 的额度是独立的,所以可以创建几个小号,来组建家庭后把小号也反代了。
最后,还是那句话,不建议用自己的主号这么搞,最好拿某鱼买的号来搞。
API KEY 在我们安装时,配置文件中会默认携带 2 个,你可以从网页上直接编辑 - 复制后使用。也可以在网页上把这两个 KEY 修改掉,或者自己新建后使用。
OAI 插件是搭配 vscode copilot 使用的,因为官方的 copilot 不支持自定义的模型和地址,所以需要这个插件来实现。
首次安装后可以按 Ctrl + Shift + P,然后输入 oai 关键字,点击 Open Configuration UI 进入。
大概率是地址配置错误,记得 OpenAI 格式的请求都需要加上 /v1 后缀,比如 http://10.126.12.162:8317/v1。
可能是关机了,或 CLIProxyAPI 被关掉了,然后反代的登录信息就失效了,下次开机或启动后,还需要重新登陆以下。
如果是在服务器上部署的,并且一直执行,是不会失效的,因为 CLIProxyAPI 会周期性的去刷新下登录信息,保持一直登陆的状态。
可以,添加这行参数可以绘制 4K 图像。
如图让 AI 总结的使用方法:
![[图文] 手把手教你 Antigravity 反代,全程不用敲代码,小白也能看懂的保姆教程10](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/20/20260120104419_696eec0330ed1.png!mark)

另外还有个日历节假日补充: https://fixcalendar.pages.dev/cn.ics


简单教程:
从需求收敛 → 规范固化 → 语料准备 → 换元骨架 → 类型校准 → Frankentexts 拼接 → 最小润色 → 多维质检 → 归档复用
同时给出 “小说改编” 和 “语料建库” 两条可插拔分支
1. 使用前准备(你需要提供的最少信息)
为了让 step1 输出的 project_config 足够可执行,建议至少准备:
目标题材 / 受众 / 风格:例如 “都市情感 + 身份反转 + 打脸”
总集数与单集字数:例如 “80 集;每集 500-700 字”
卡点与钩子口径:例如 “第 8-10 集付费卡点;免费集集末必有钩子”
源故事输入:小说全文 / 章节 / 梗概 / 旧剧本(至少一个)
语料来源:是否已有可用语料库(没有也能先做骨架,但无法完成高 Copy 率拼接)
2. 流程地图(你如何 “用到全部 step1-20”)
本体系的 “全量使用版” 通常是这样:
需求与规范层:step1 → step2 → step3
语料层(可选):step4 →(step5/step6 按素材类型增强)
改编层(按源文本体量分支):step6 → step7/8/9(小说改编路线)
换元骨架层(融合生成主路线):step10 → step11
市场校准层(可选):step19
生成与质检层(上线):step12 → step13 → step14 → step15 → step16 → step17 → step18
编排与复用层:step20(可在开始用,也可在结束做归档编排)
3. 标准执行规则
无论你在哪个大模型网页端执行,都遵守:
每一步只输出该 step 要求的 “预期输出格式”(通常 JSON);不要混入解释性文字.
上一步输出 JSON 必须原样粘贴给下一步(不要自然语言总结代替)
缺失信息用 null/待补充 占位,
格式规则以 step2 为准,特殊标注以 step3 为准;质检以 step14-18 为准
#step1:生成项目配置(ProjectConfig)
你给模型的输入(建议结构):
创作目标:
题材/元素:
总集数:
单集字数:
付费卡点:
钩子规则:
特殊标注要求(os/vo/闪回/互切):
是否使用Frankentexts(Copy率目标):
源故事输入(全文/章节/梗概/旧剧本):
语料库情况(有/无,来源说明):
你得到的输出:project_config JSON(后续所有步骤都引用它)
#step20(第一次使用):生成 “你该走的步骤链路”
把 step1 的 project_config 粘贴进去,让 step20 输出 step_sequence + io_mapping + checkpoint + rollback
你得到的输出:workflow JSON(告诉你下一步跑哪些 step、怎么传火,哪里要人审、哪里要返回查看)
#step2:固化剧本格式规则
把最终 “剧本长什么样” 固定成 format_rules
你得到的输出:format_rules JSON(后续生成正文与格式质检都依赖)
#step3:固化特殊场景标注策略
固定 os/vo/ 闪回 / 互切 的使用条件与格式
你得到的输出:special_scene_policy JSON(后续提取、骨架、拼接、专项质检都依赖)
#step4-6:准备语料库(没有语料库就先建)
如果你已经有高质量语料库:跳到 step10。
如果你没有语料库:建议至少跑 step4(再按素材类型跑 step5 或 step6)
##step4:通用语料提取
输入:
project_config、special_scene_policy
原始文本(一次一段 / 一章 / 一集)
source_reference
输出:corpus_chunks[](JSON 数组语料块)
#step5:剧本专项增强(如果语料来自剧本
输出增强点:
场景头、人物列表、卡点标注、对话密度等,用于提升检索精度
#step6:小说专项增强(如果语料来自小说)
输出增强点:
可视化潜力、可外化改编提示、章节 / 叙事视角等(把所有语料块 JSON 数组按文件归档,最终合并为一个 corpus.json,并确保每条有 source_reference。)
#step10:六源分析 + 核心动作程序抽取
对源故事做六源拆解(事件 / 结构 / 主体 / 背景 / 人物 / 道具)
抽取核心 “动作程序”(骨骼层)
给出哪些事件适合 os/vo/ 闪回 / 互切
输入:
project_config
special_scene_policy
源故事文本 / 梗概
输出:source_analysis JSON
#step11:换元方案 + 新剧本场次功能表(Framework)
选择一度置换 / 二度置换,产出 substitution_plan
把新剧本拆成 “每集每场” 的功能表 new_script_framework(含信息点 / 情绪 / 标注计划 / 钩子 / 卡点)
输入:
project_config(集数、字数、卡点、钩子口径)
special_scene_policy
source_analysis
输出:substitution_plan JSONnew_script_framework JSON
同时审核(是否符合题材定位与受众预期第 8-10 集是否有明确付费卡点策略每集末尾是否都有钩子
每场是否写清信息点与情绪目标(否则 step12 会乱拼))
#step19:类型库匹配校准
把 “骨架方向” 对齐市场趋势:主用模式 + 辅助模式 + 融合建议
给出关键场景、台词要点、情感触发点、推荐标注策略
输入:
project_config
source_analysis(可选)
substitution_plan + new_script_framework
输出:matched_patterns[] + adaptation_recommendations + creation_guidance
用法建议:
将其作为 step12 的检索排序偏好(例如优先召回 “打脸 / 身份揭示” 片段、控制 os 使用密度等)
#step12:Frankentexts 检索与拼接生成正文
按 new_script_framework 逐场检索候选片段、选择拼接
严格遵守 Copy 率目标与最小化修补
输出:选片记录、编辑日志、Copy 率估算、标注保真检查 + 标准格式剧本正文
输入:
project_config(Copy 率 / 禁用操作)
format_rules
special_scene_policy
corpus_json(语料库;来自 step4/5/6)
new_script_framework
(可选)step19 的创作指导作为检索偏好
输出:
场次级 JSON 结果
标准格式剧本正文(可直接给制作)
关键建议(避免一次跑崩):
按 “集” 为单位生成(例如先生成第 1-3 集),通过质检后再批量推进
#step13:最小润色与终稿准备
只做桥接 / 纠错 / 格式 / 归一 / 标注规范化
保持 Copy 率与原片段风格
输出:
终稿正文 + 润色日志 + 校验准备摘要
#step14-18 是质检线建议跑完
#step14:格式质检
#step15:逻辑一致性(因果 / 时间线 / 信息点覆盖)
#step16:风格一致性(声纹 / 语体 / 节奏 / 题材)
#step17:Copy 率校验(Frankentexts 指标)
#step18:特殊标注专项校验(os/vo/ 闪回 / 互切)
常用回退策略:
Copy 率不足:回退 step12 重选片段(不要继续润色)
格式问题:按 step14 修复后复检
逻辑漏洞:按 step15 给的 “最小修补策略” 修复,避免重写
标注问题:按 step18 规范化(补齐闪回起止 / 明确互切切换点)
#step20(第二次使用):归档复用与流程固化
一份可复用的 workflow JSON(你下一次可以直接照着跑)
分支流程:小说转剧本(step6 → step7/8/9)
step1 /step2 /step3(全局规范)
step6 小说专项语料提取(产出可外化与可标注提示)
按体量选择:
长篇:step7 主线提纯 → 得到分集结构 / 梗概
中篇:step8 节奏倍速 → 得到反转 / 爽点 / 钩子密度规划
短篇:先 step10+11 做扩充骨架,再 step9 落地分集结构
若需要正文:把改编结果转成 new_script_framework(可由 step11 生成或人工映射),再进入 step12/13/14-18(备注:step7-9 的主要产出是 “大纲与分集梗概”;若要可拍剧本正文,最终仍需进入 step12/13)
分支流程:语料建库(step4/5/6)
建库链路:step1 → step2 → step3 → step4(→ step5/6)→ corpus.json
生产链路:step10 → step11 → step19 → step12 → step13 → step14-18
特别感谢 @jianhuaguiyi
大概就是这样了 呵呵!
各位在日常运维或者学习过程中,应该遇到过这些痛点:
kubectl --help 或 docker --help 这类命令帮助文档时,面对满屏的英文参数看得头疼。用过 Openwrt 软路由的大概从 web 界面连接过终端,它的终端是由一个叫 ttyd 的小插件实现的。问一下 Gemini 方案确实可行。

大部分 Linux 发行版都可以直接安装:
# Ubuntu/Debian sudo apt install ttyd
# CentOS/RHEL sudo yum install ttyd
# macOS
brew install ttyd
运行以下命令开启一个 Web 终端(默认端口 7681):
ttyd -W bash
注:-W 参数允许在浏览器中进行写入操作(输入命令)或者 ttyd -p port bash。

打开浏览器,访问 http://your-ip:7681。你会看到一个熟悉的终端界面。

确保你安装了 沉浸式翻译 插件。

kubectl 帮助文档或者报错日志上。

为了方便使用,可以在 .bashrc 或 .zshrc 中添加一个别名:
# 自动获取本机 IP 并启动,限定端口防止冲突 alias webterm='ttyd -p 7681 -W bash' 如果你是在远程服务器上操作,建议配合 ssh -L 做端口转发,或者在前端加个 Nginx 反代并开启 Basic Auth,确保安全:
ttyd -c user:password -p 7681 bash
kubectl get pods --help,滚屏后直接点选大段的参数说明,中文释义紧随其后。Error from server (Forbidden): ... 等长难句时,一键翻译,秒懂权限缺失的具体原因。-c) 或配置防火墙。原插件 hard code 了路径为 mac os 的,fork 添加了选项设置路径
需要安装 rust-analyzerwhere rust-analyzer
的输出路径填到插件的设置选项即可 (需要重启插件)
不过正经人谁在 rider 中写 rust
fork 仓库
原插件:
原仓库:
原作者:
在中小企业数字化转型中,CRM(客户关系管理系统)已从“辅助工具”升级为“销售流程的中枢神经”——它既要解决“线索怎么来、跟进怎么顺”的前端问题,也要支撑“报价准、签约稳、订单可控”的后端闭环。 本文选取超兔一体云、Zendesk Sell、OKKICRM(原小满)、Highrise、Less Annoying CRM五大主流品牌,围绕跟单协作、销售跟踪、报价管理、签约管理、合同订单五大核心维度展开横向对比,结合“功能深度、场景适配性、性价比”三大选型关键,为中小企业提供决策参考。 优秀的CRM需覆盖“从线索到回款”的完整销售周期,核心评估点包括: 跟单是销售的“执行层核心”,考验CRM对不同业务场景的适配能力。 流程图:超兔一体云跟单协作逻辑 销售跟踪的核心是将“碎片化线索”转化为“可落地的客户” ,考验CRM的“获客-转化”能力。 脑图:超兔销售跟踪功能架构 报价是“签单的临门一脚”,需解决“快速生成+与订单联动”的问题。 签约的核心是控制信用风险,避免“签单易、回款难”。 合同订单是“销售的结果层”,考验CRM对多样业务模型的支持能力。 在中小企业CRM市场中,超兔一体云以“全场景覆盖、深度流程闭环”成为综合能力最强的选择——它不仅解决了“跟单怎么顺”的执行问题,更通过“客户生命周期、签约风险管控、合同财务联动”实现了“从线索到回款”的全链路价值。对于需要“精细化管理”的中小企业而言,超兔一体云的“场景化能力”与“闭环逻辑”,正是应对当前复杂市场环境的核心竞争力。 (注:文中功能相关描述均基于公开披露信息,具体功能服务与价格以厂商实际落地版本为准。)一、评估框架:CRM的“全流程价值链”
二、核心维度横向对比
(一)跟单协作:从“单点跟进”到“场景化协同”
品牌 核心能力 场景适配性 优势亮点 超兔一体云 1. 多模型支持(小单快单/商机跟单/多方项目); 2. 360°视图+跟单时间线+通信集成; 3. 分组隔离(多级客户汇总,如医院科室/高校院系) 全场景覆盖(小单到大型项目) 独有的“三一客”(小单快单)、“多方项目视图”(集成合同/采购/收支);支持复杂组织客户(如医院) Zendesk Sell 1. 任务分配+团队共享客户视图; 2. 邮件模板+自动提醒; 3. 与客服系统联动(查看售后反馈) 通用销售场景 客服联动是特色,销售可同步客户售后问题,提升跟进针对性 OKKICRM(原小满) 1. 外贸场景分级权限管理; 2. 国际订单与客户信息整合 跨境贸易场景 适配外贸团队“多角色、多地区”的协作需求,避免权限混乱 Highrise 1. 共享客户沟通记录; 2. 跟进提醒 轻量销售场景 适合“单一线索跟进”的小团队,功能简单但无场景适配 Less Annoying CRM 1. 任务+日历+联系人三模块联动; 2. 基础跟进提醒 微型企业场景 界面简洁,无需培训,但仅支持“基础任务跟踪” graph TD
A[业务需求] --> B{选择跟单模型}
B -->|小单快单| C[三一客(三定:定性/定级/定量+关键节点)]
B -->|商机跟单| D[阶段+预期日期优化中长单]
B -->|多方项目| E[项目组+合同+采购+收支全周期管控]
C --> F[360°视图+跟单时间线+通信数据集成]
D --> F
E --> F
F --> G[分组隔离(多级客户汇总到上级)]
G --> H[跟单完成](二)销售跟踪:从“线索散养”到“全链路可视化”
1. 超兔一体云:全渠道获客+客户生命周期管理
2. Zendesk Sell:销售管道+自动化跟进
3. OKKICRM:跨境线索整合
4. Highrise/Less Annoying CRM:基础跟踪
graph LR
A[销售跟踪] --> B[线索处理]
A --> C[客户管理]
A --> D[数据分析]
B --> B1[多渠道集客(百度/抖音/微信/会销)]
B --> B2[线索一键转化(客户/待办/订单)]
B --> B3[线索分配+短信提醒]
C --> C1[客户信息管理(查重+工商背景调查)]
C --> C2[客户生命周期(客池分类)]
C --> C3[工作流引擎(AI生成流程)]
D --> D1[数据统计(数字卡片+同比环比)]
D --> D2[KPI引擎(单日/周期目标)](三)报价管理:从“手动 excel”到“精准联动”
品牌 报价生成 与订单联动 特殊功能 超兔一体云 OpenCRM生成 自动关联 客户通过网页/小程序确认报价,一键转订单 Zendesk Sell 自定义审批 支持 需额外购买“自定义对象”许可证 OKKICRM(原小满) 外贸标准化模板 支持 多币种报价(适配跨境场景) Highrise 无明确支持 无 — Less Annoying CRM 无明确支持 无 — (四)签约管理:从“被动签约”到“风险管控”
超兔一体云:全链路风险管控
其他品牌:
(五)合同订单:从“纸质管理”到“全流程闭环”
品牌 业务模型支持 执行管理 财务管控 超兔一体云 服务型/实物型/特殊型(维修/租赁/套餐) 锁库+采购计划+供应商直发 应收/开票/回款三角联动,支持一票对多单 Zendesk Sell 通用订单 移动端同步 基础应收管理 OKKICRM(原小满) 国际订单(跨境物流联动) 国际物流跟踪 多币种财务整合 Highrise 无明确支持 无 无 Less Annoying CRM 无明确支持 无 无 三、综合能力雷达图(1-5分,5分为优)
品牌 跟单协作 销售跟踪 报价管理 签约管理 合同订单 总分 超兔一体云 5 5 4 5 5 24 Zendesk Sell 4 4 3 2 3 16 OKKICRM(原小满) 3 3 4 2 4 16 Highrise 2 2 1 1 1 7 Less Annoying CRM 2 2 1 1 1 7 四、选型建议:匹配需求优先级
五、结论

