2026年1月

Kiro 注册机以及可能不封号的方法
昨天看群里都在讨论 Kiro 闲着无聊我就研究一下了注册机
然后开发了一个脚本 全自动注册
但是我注册几个发现会封号呀
然后我就研究了半小时 我发现和邮箱无关 和 代理 ip 无关 只和环境有关
于是我手动注册了 10 个都没封 (不保证有效)
- 我打开 win 软件的 kiro

- 点击这个 awz 登录 会生成带参数一个 login?workflowStateHandle=a78fdd8f-9780-439f-8efa-be793967583a
- 然后使用域名邮箱注册 会提示授权 Kiro 点击拒绝 然后重复操作 这样手动的号居然没事
以上均为个人研究不保证可用 开源的注册机是会封号的(仅供学习思路)
DeepSeek 发布新论文:Conditional Memory via Scalable Lookup




[分享] 撸了一个全自动微信公众号发文 Workflow(n8n + DeepSeek + Gemini),顺便开源了 mdnice 转换工具
最近在折腾自动化内容产出,发现微信公众号的排版和发布流程非常割裂。虽然 mdnice 很好用,但它没有官方 API ,很难集成到自动化流里。
于是自己动手撸了一套方案,并把其中最关键的 Markdown 转微信排版 环节封装成工具开源了。
技术栈:
n8n:作为全流程自动化编排中心。
DeepSeek:负责高质量文本生成。
Gemini (Image Generation):根据内容自动生成配图作为头图。
自建 API (markdown2wechat):解析 mdnice 主题并将 MD 转换为适合微信预览的 HTML 格式。
全流程逻辑:
定时触发或 Webhook 触发。
调用 DeepSeek API 生成符合排版规范的 Markdown 。
调用 Gemini 生成文章封面图并自动上传。
通过我的工具接口,将 MD 自动套用 mdnice 主题模板并转换为 HTML 。
推送到草稿箱。
工具开源地址: https://github.com/koala9527/markdown2wechat
欢迎 V 友们拍砖,如果大家有更好的全自动发布 API 思路也欢迎交流。



于是自己动手撸了一套方案,并把其中最关键的 Markdown 转微信排版 环节封装成工具开源了。
技术栈:
n8n:作为全流程自动化编排中心。
DeepSeek:负责高质量文本生成。
Gemini (Image Generation):根据内容自动生成配图作为头图。
自建 API (markdown2wechat):解析 mdnice 主题并将 MD 转换为适合微信预览的 HTML 格式。
全流程逻辑:
定时触发或 Webhook 触发。
调用 DeepSeek API 生成符合排版规范的 Markdown 。
调用 Gemini 生成文章封面图并自动上传。
通过我的工具接口,将 MD 自动套用 mdnice 主题模板并转换为 HTML 。
推送到草稿箱。
工具开源地址: https://github.com/koala9527/markdown2wechat
欢迎 V 友们拍砖,如果大家有更好的全自动发布 API 思路也欢迎交流。



今晚的大羊毛,预约马年贺岁币/钞,大几百的羊毛记得必须搞下!(免费送辅助预约插件)
插件是网上看别人发的,我昨晚使用后有两个不错
TanStack 发布框架无关的 AI 工具包
TanStack是广受欢迎的 TypeScript 库(如TanStack Query和TanStack Table)背后的团队,该团队最近发布了TanStack AI的 alpha 版本。这是一个与框架无关的 AI 工具包,旨在消除供应商锁定,让开发者完全掌控自己的 AI 技术栈。 TanStack AI 引入了跨多个 AI 供应商的统一接口、多语言服务器支持以及开放式协议架构。该 alpha 版本提供了对 JavaScript/TypeScript、React 和 Solid 的支持,并内置了OpenAI、Anthropic、Gemini和Ollama的适配器。此次发布代表了一种全新的 AI 工具理念,即将自身定位为中立于供应商的基础设施,而非平台服务。 TanStack AI 的突出特性之一就是其同构(isomorphic)工具系统,允许开发者通过 工具模式有两种定义方式:推荐使用Zod Schemas,或者使用JSON Schema(适用于已有 JSON Schema 定义的项目)。该工具包还提供了模型粒度的类型安全性,使开发者能够针对每个模型获得完整的、针对特定供应商选项的类型提示。 客户端库包括原生 JavaScript、React 和 Solid,未来还将支持更多框架。alpha 版本还附带了同构的开发工具,可洞察大语言模型(LLM)在服务器端和客户端的行为,使开发者能使用熟悉的模式调试 AI 工作流。 该版本在开发者社区中获得了积极反响。开发者 Stanley Ulili 在 Better Stack 的一篇详细指南中这样写到: 虽然仍处于 alpha 阶段,但是它已经展现出了巨大的潜力。它注重清晰的架构、强大的 TypeScript 支持,并强调融入现有技术栈的自由,而非强制绑定特定框架或供应商。 在Reddit上,一些评论者对 SDK 的使用场景以及这个新库试图解决的问题提出了疑问,这促使 TanStack 生态系统的创始人 Tanner Linsley 作出了回应: 最近,我和 TanStack 的所有其他维护者都在深入探索 AI,我们发现 Vercel 的解决方案仍有足够的改进空间,因此决定自己打造一个更贴近我们产品原则的方案。 到目前为止,这带来了更好的类型安全性、更优的同构模式,坦白说,这也能够让我们自由地朝着自己想要的方向发展,而不必受制于其他团队。 竞争是好事,它能推动整体进步。 TanStack AI 将自己定位为 Vercel AI SDK 的直接替代品,后者目前是 JavaScript AI 工具领域的主导者。与 Vercel 的做法不同,TanStack AI 作为纯粹的开源基础设施,不包含服务层、不收取平台费用,也不存在供应商锁定。团队强调,开发者直接连接到自己选择的 AI 提供商,无需通过中间商。 由于这是新库的 alpha 版本,因此不存在从早期版本迁移的路径。开发者可通过 npm 安装核心包并开始使用: TanStack AI 是由 TanStack 团队开发和维护的开源项目。它延续了该团队在构建框架无关的开发者工具方面的良好声誉,目标是提供真正开放的工具,兼容任何技术栈,而非将开发者捆绑进专有的生态系统。 toolDefinition()一次性地定义工具,并通过.server()或.client()方法提供特定环境的实现。这种架构在整个应用中提供类型安全性,同时支持工具在服务器和客户端上下文中执行。npm install @tanstack/ai @tanstack/ai-react @tanstack/ai-openai。快速入门指南提供了创建聊天应用的分步说明,而工具指南则深入讲解了同构的工具系统。
64G 免费空间支持 webdav 的德国网盘
Hubu.cloud
网盘特点:
1. 免费空间 64G
2. 支持 webdav
3. 可以分享文件
4. 不限制上传大小,不限制文件类型
4. 无需代理,速度快
注意事项:
1. 未注册用户上传的文件保留 180 天,免费注册用户的文件永久保留
2. 经测试,视频文件存在压缩的情况,视频下载到本地不是原文件,是压缩过的版本
3. 邮箱注册收不到验证码,也可以登录使用
webdav 地址:
https://hubu.cloud/webdav
欢迎大家留言讨论,分享经验!
整理下 AI 大模型厂商和平台,能长期稳定提供免费额度的 API (非公益站)
现在 AI 的使用场景越来越多,公益站有时也不稳定,给大家整理一些能提供相对长期稳定大模型 api 的厂商和平台,作为备用或测试。
这里主要收集文本大模型,图片视频生成相关的大模型没有专门做整理。
tldr
- 国内大模型平台太卷了,免费额度真的很多,如果没有特殊需求,国内的 api 就够用了。
- 主力模型推荐:阿里 iflow, 字节火山引擎,阿里 modelscope 魔搭社区。
- 免费 vibe coding 推荐:腾讯 codebuddy, 快手 codeflicker, 阿里通义灵码 /qwen-code
最新渠道 (可能不稳定)
一些平台会不定期推出吸引用户的免费活动,适合测试,过期了的就评论下提醒我删掉。
20260109: cerebras 免费提供 glm-4.7, 注意每天免费 token 数为 100w,虽然少但速度快
- Rate Limits - Cerebras Inference: tpd-1M, rpm-10
20260105: minimax-m2.1 限免
- Cline 3.47.0 adds Background Edits and free MiniMax 2.1
kilo code 限时免费 minimax-m2.1RooCode 直接免费了 minimax-m2.1, 实测能用
20260103: NVIDIA NIM APIs 开始免费提供 glm-4.7, minimax-m2.1
- 因为才刚开始免费提供这些最新模型,所以资源紧张,速度可能较慢
- 虽然模型名没在官方页面列出,但实测已经可用了,可以用自己的 api key 试试
- api url: https://integrate.api.nvidia.com/v1
- 模型名: z-ai/glm4.7, minimaxai/minimax-m2.1
限免结束的历史渠道 (可以不定期检查下是否有新活动)
- AI Ping
- 20260109: 限时免费 Kimi-K2-0905
- 20251226:
限时免费 glm-4.7, minimax-m2.1
- AI Ping
模型限制相关说明
- rpm (Requests per minute): 每分钟请求次数
- rpd (Requests per
day ): 每天请求次数- tpm (Tokens per minute): 每分钟输入输出的 token 数
- tpd (Tokens per
day ): 每天输入输出的 token 数
Vibe Coding 免费代码工具
- 国内的 ai coding 太卷了,各家都提供了很大的免费额度
腾讯云代码助手 CodeBuddy, 独立 IDE
目前 (20251222) 免费使用 glm-4.6, deepseek-v3.1-terminus, huyuan-2.0
- 20251223: 免费提供最新的 glm-4.7
有佬友反馈可能碰到请求次数上限的问题
快手 CodeFlicker, 独立 IDE
- 目前 (20251222) 免费使用 kimi-k2-0905, deepseek-v3.2, glm-4.6, minimax-m2, kat-coder-pro
阿里 通义灵码, 独立 IDE
- 免费不限量使用 千问系列模型,但不可更换使用其他模型
阿里 qwen-code, cli 命令行
- free tier : use an OpenAI-compatible API, or sign in with Qwen OAuth to get 2,000 free requests/
day .
- rpd 每天 2000 次,免费额度很大,且长期稳定
Cline, vscode 扩展 /cli 命令行
- 提供多种使用方式,包括 vscode 里的扩展、独立的 cli
- vscode 的模型配置界面长期提供免费模型
- 20251223 免费: minimax-m2, devstral-2512, grok-code-fast, kat-coder-pro
Roo Code, vscode 扩展 / Cloud Agents
- 提供多种使用方式,包括 vscode 里的扩展、云端编程
- vscode 的模型配置界面长期提供免费模型
- Roo Code Cloud Models
- 20251223 免费: MiniMax-M2, Grok Code Fast 1
Kilo Code, vscode 扩展 /cli 命令行
- 提供多种使用方式,包括 vscode 里的扩展、独立的 cli
- vscode 的模型配置界面长期提供免费模型
- Models
- 20251223 免费: minimax-m2, devstral-2512, kat-coder-pro
- 20260105 免费: minimax-m2.1
OpenCode, cli 命令行
- 最近也提供了 OpenCode Desktop 的使用方式,长期提供免费模型
- Zen Models
- 20251223 免费: glm-4.7, minimax-m2.1, Grok Code Fast 1, Big Pickle
代码工具 Others
- 字节 TRAE, 独立 IDE
- 提供很多免费模型: GLM-4.7, MiniMax-M2.1, Kimi-K2-0905, DeepSeek-V3.1-Terminus, Qwen-3-Coder
- 还支持通过 API 密钥(API Key)接入其他平台的模型,但我没找到使用公益站 url 和 key 的方法,有知道的佬友可以指导下
- 注意小红书上有用户反馈使用最新模型时经常碰到要排队的情况,国际版和国内版都有排队的限制,而使用 auto 模型时系统很可能分配旧模型或豆包模型,此时排队的情况会少点
coding 工具说明
国内厂商或平台
阿里心流 iflow
- S 级推荐: 心流开放平台
- iflow-cli 是可以免费使用的 vibe coding 工具,对标 claude code
- 目前我所知的免费额度最大的平台,不限量,速度也很快
- 主要提供的模型:阿里千问系列模型较多, 还有 Kimi-K2-Instruct-0905, GLM-4.6, DeepSeek-V3.2-Exp, Qwen3-Coder-Plus
- 限流
- 每个用户最多只能 同时发起一个 请求,超出限制的请求会返回 429 错误码。
- iflow 社区反馈 api 可用的模型很久没更新了,官方似乎准备将更多资源投入 iflow-cli,
- iflow-cli 支持最新的 glm-4.7 / minimax-m2.1
- 通过开源转换工具如 CLIProxyAPI 可以将 iflow-cli 的免费模型转换成类似公益站的 api, 需要折腾一下,不过渠道真的很稳
字节火山方舟大模型
- 目前 每个模型 每天免费 250w token, 速度很快,体验很好,但单模型 token 不够用,经常切换模型我觉得麻烦
- 主要提供的模型:豆包系列模型较多,最新的 deepseek-v3.2, Kimi-K2-Instruct-0905
- 还提供文生图相关模型
- 免费推理额度
- rpm/tpm 各模型不同,一般 rpm 为 1000~10000, tpm 为 500w
阿里 modelscope 魔搭社区
- 每天允许进行 总数为 2000 次 的 API-Inference 调用,其中每单个模型不超过 500 次,具体每个模型的限制可能随时动态调整。
- 我不太喜欢阿里的 modelscope, 受欢迎的模型总是开放一段时间就下架,但提供的免费额度很稳定,千问系列模型很稳定
- 还提供文生图相关模型
- 限制
- 在每个模型每天不超过 500 次调用的基础上,平台可能对于部分模型再进行单独的限制,例如,deepseek-ai/DeepSeek-R1-0528,deepseek-ai/DeepSeek-V3.1 等规格较大模型,当前限制 单模型每天 200 次 调用额度。
- 在上述调用次数限制的基础上,不同模型允许的调用并发,会根据平台的压力进行动态的速率限制调整,原则上以保障开发者单并发正常使用为目标
- 在每个模型每天不超过 500 次调用的基础上,平台可能对于部分模型再进行单独的限制,例如,deepseek-ai/DeepSeek-R1-0528,deepseek-ai/DeepSeek-V3.1 等规格较大模型,当前限制 单模型每天 200 次 调用额度。
快手 KAT-Coder 系列模型
- KAT-Coder-Pro V1 和 KAT-Coder-Air 目前都提供免费使用,其中 KAT-Coder-Air 长期提供免费使用
- 我经常拿来做测试,速度很快,对结果要求不高可以试试
- KAT-Coder-Air V1 模型免费使用规则
- 高峰时段: 08:00-02:00(次日), 每 6 小时内您将可以发起 120 次 对话请求。
- 非高峰时段: 02:00-08:00, 每 6 小时内您将可以发起 200 次 对话请求
智谱 glm flash 系列模型
- 智谱 AI 开放平台 福利专区
- 少数的模型厂商自己提供免费模型 api,长期稳定,免费的都是小模型,但种类比较全
- 速度很快,但效果不好,适合用来测试
- 模型包括: GLM-4-Flash-250414, GLM-4.1V-Thinking-Flash, Cogview-3-Flash (文生图), CogVideoX-Flash (视频生成)
- 速率限制
- 限制的维度是请求 并发 数量(在途请求任务数量), GLM-4-Flash 为 200, GLM-4V-Flash 为 10
硅基流动 SiliconFlow
- 长期稳定提供免费的小模型,大多 7b/8b/9b 的小模型,速度快
- 不提供 32b 以上的免费模型,小模型质量较差,我平时用的少
- Rate Limits
- 大多都是 tpm-50k
国内 Others
上面都是我用的比较多的,下面是一些其他免费模型,大家也可以补充
美团 LongCat 系列模型
- LongCat API 开放平台
- 每个账号每天自动获得 500,000 Tokens 免费额度
- 单次请求限制 输出文本:最大 8K Tokens, 当触发限流时,API 将返回 HTTP 状态码 429
特别提及: 七牛 AI 大模型推理服务
- 这是我所知的国内仅有的大模型平台,官方能提供 OpenAI/Claude/Gemini 模型,不知道是不是 2API 的渠道
- 官方提供 300w 免费 token, 有效期一年,
- 速度很快,强烈推荐,能用各种模型
- AI 大模型推理服务 - 七牛云
- 官方虽然没在模型广场上写出 claude/gpt-5/gemini, 但领到资源包后,在控制台
订单管理 / 资源包管理 / 资源包明细界面 可查看具体适用范围和抵扣规则, 里面可以搜索到 claude/gpt, 实测可以在 cline/cherry-studio 这些工具里使用,并且速度可达 100+ token/s
国外厂商或平台
显卡一哥英伟达老黄的福利 - Nvidia NIM API
- 我觉得比 openrouter 更好用,似乎免费不限量
- 提供各种模型, 包括国外的模型: glm-4.7, minimax-m2.1, deepseek-v3.2, qwen3-coder-480b, kimi-k2-thinking, mistral-large, devstral
- 不支持:
- 还支持部分文生图模型,FLUX.1-dev 免费 25 requests, 可以试试
- Try NVIDIA NIM APIs
- 限制 rpm: 40
Cerebras Inference
- 我体验过的速度最快的大模型平台,速度可达 220+ token/s, S 级推荐
- 提供的免费模型较少,经常更换,现在包括: glm-4.6, qwen-3-235b-a22b-instruct-2507, gpt-oss-120b, …
- Rate Limits
- RPM: 10~30
- TPD: 1M , 每天 100w token 有点不够用,但爽就完事了
OpenRouter
- 长期稳定,模型丰富
- API Rate Limits
- 免费次数:不充钱的用户每天 50 rpd, 充了 10 刀的用户每天 1000 rpd, 在免费额度内使用不会扣费
- 注册了不需要绑卡和充钱就可以免费 50 次,只能使用模型名里面带 free 的,模型名不带 free 的不能免费使用
- 很多公益站都用了 OpenRouter 的渠道
Mistral
- 欧洲主流模型厂商,提供长期稳定的模型 api
- 我试过在官方聊天网站 Le Chat 体验的效果很差,远不如国内的模型,
- 我还试过在本地用 Ollama / LM Studio 跑 mistral/devstral 系列的模型也远不如国内的 qwen3-32b 内的模型,但 reddit 论坛很多人都在吹 mistral 系列的模型,我觉得就是老欧人的自嗨
- Rate Limits & Usage tiers
- 免费额度非常大,
- Tokens per Minute 500,000
- Tokens per Month 1,000,000,000,大约每天 rpd 是 3300w
- Codestral
- mistral 系列专注于 coding 的模型似乎有额外的免费额度,但我没用过,因为 coding 模型竞争太激烈了,有其他选择
国外 Others
groq
- 免费模型种类多,但大模型不多,大多是小模型, 免费额度较少
- 免费大模型包括: kimi-k2-instruct-0905, gpt-oss-120b, llama-4-maverick-17b-128e
- Rate Limits
- rpm - 10~60
- tokens per
day 是 100K~500K, 每天的 token 太少了,不够用
Poe
- poe 既不是模型研发厂商,也不是聚合平台,主要业务是方便用户通过 ui 创建 chat-bot 和自动化任务 bot,也提供了模型 api 供用户使用
- 免费用户每天发放 3000 points, 仅当日有效
- 官方文档提到了支持 claude-code, cline, cursor, continue
佬友 tips: 用之前建议一个个模型按费率和收费标准选一下,像 Grok-4.1-Fast 、Gemini Flash 系列、GPT-5-mini/GPT-5-nano 都不怎么耗积分
- 我个人不推荐使用这家的 api, 因为不支持结构化输出,这是 ai 非聊天类工具大多需要的基础功能
- Structured outputs are not supported
- The
strictparameter for function calling is ignored, which means the tool use JSON is not guaranteed to follow the supplied schema. - OpenAI Compatible API
ZenMux
- 目前提供了 4 个免费模型: gemini-3-flash-preview-free, xiaomi/mimo-v2-flash, kuaishou/kat-coder-pro-v1, z-ai/glm-4.6v-flash
- 测试时 gemini-3-flash 返回异常 429, xiaomi-mino 能用但速度一般
- 这个平台我看 25 年 8 月才开始运营,是不是长期稳定还要让子弹飞一会儿,以后会关注更新
- 目前提供了 4 个免费模型: gemini-3-flash-preview-free, xiaomi/mimo-v2-flash, kuaishou/kat-coder-pro-v1, z-ai/glm-4.6v-flash
Chutes- 目前限时免费的模型
有 4 个: GLM 4.5 Air, Gpt Oss 20b, Gemma 3 4b, Tongyi DeepResearch 30B- 免费的模型参数不够大,不如其他平台
- Chutes Free Models
- 目前测试注册就可以用,不需要充钱,只写了限时免费,没找到请求速度限制说明
- 不推荐使用这个平台,因为免费规则经常调整,在 25 年 7 月需要充 5 刀了才给 200rpd 免费额度
- 20251230: 已取消所有免费模型
- 目前限时免费的模型
国外平台我用的少,大家可以补充一些反馈和其他平台
其他
- 这么多免费大模型 api,不知道有没有什么好的统一管理的方法
DeepSeek-V4 技术架构提前曝光



Who Starred My Repo: 发现哪些 Star 了你仓库的大佬们
Who Starred My Repo
是否曾经好奇,在那些给你仓库点过 Star 的用户中,是否有隐藏的开源大佬?本项目来帮助你找到答案!
影响力排行: 基于多维度指标综合计算用户的「开源影响力」并进行排序
单维度排序: 同时也支持按单一指标排序:
- 🌟 Star 总数
- 📅 Star 日期
- 👥 粉丝 (Follower) 数量
- 📦 公开仓库数量
在线预览: Who Starred My Repo
(你可能会遇到 GitHub API 的速率限制导致请求失败,此时你可以 Clone 本项目并在本地使用自己的 GitHub Token 来运行,启动方法见 ReadMe )
开源地址: https://github.com/wy-luke/who-starred-my-repo 欢迎 Star ~

Anthropic 发布通用 AI 代理工具 “Cowork” 全场景自动化办公
Anthropic 宣布推出全新 AI 代理工具 “Cowork”。该工具旨在将此前专为开发者设计的 “Claude Code” 自动化能力扩展至通用办公领域。
Cowork 的诞生源于用户对自动化办公的强烈需求。Anthropic 发现,大量开发者在使用 Claude Code 处理编程任务的同时,已开始尝试将其应用于日常行政与数据处理。为此,Cowork 在沿用 Claude Code 底层架构的基础上,为非技术用户打造了更易上手的操作界面。目前,该功能已作为研究预览版(Research Preview)面向 macOS 端的 Claude Max 订阅用户开放。
与传统的 AI 聊天机器人不同,Cowork 具备显著的 “Agent 属性”。用户可授权其访问计算机上的特定文件夹,使其能够直接读取、编辑或创建文件。Cowork 不仅能自主完成整理下载目录、根据屏幕截图提取数据并生成电子表格等繁琐任务,还能基于散乱的笔记草拟完整报告。在执行过程中,Cowork 会根据指令制定详细计划并稳步推进,用户可实时查看进度并与之并行协作,无需等待任务结束即可提供反馈。
在功能扩展方面,Cowork 集成了 Claude 现有的数据连接器,并新增了一系列文档与演示文稿制作技能。通过与 Chrome 浏览器配合使用,Cowork 还能跨越本地与云端,处理需要网络访问权限的复杂任务,其交互体验更接近于与真实同事沟通协作。
针对 AI 代理的安全性,Anthropic 在 Cowork 中引入了严格的权限控制机制。系统仅能访问用户明确授权的资源,且在执行删除文件等关键操作前必须获得二次确认。此外,针对行业关注的 “提示词注入” 风险,Anthropic 已构建了多层安全防御体系,并建议用户在预览阶段加强对 AI 操作的监督。
Anthropic 表示,Cowork 目前仍处于快速迭代的研究阶段。公司计划在未来几个月内增加跨设备同步功能,并推出 Windows 版本。即日起,符合条件的订阅用户可通过更新 macOS 端应用体验 Cowork,其他用户可申请加入候补名单。
新的 Hackathon,由 Cloud9 跟 JetBrains 举办
看到一个新的 Hackathon,由 Cloud9 跟 JetBrains 举办
说实在的我第一次在编程圈看到 Cloud9
不过看到比赛项目又觉得挺合理的
第三项就是 B/P 助手跟预测,难道我大 C9 以后的分析师要失业了吗?!
说回活动 总奖金 25000 刀
各项活动优胜为 4000~6000 刀
截止日期是 2026 年 2 月 4 日 @ 3:00am GMT+8
有兴趣的可以参与一下,没打算参加评比也可以注册免费用 JetBrains 的 Agent-Junie


有玩守望先锋的佬友吗?做了一个守望先锋的准星分享网站,欢迎大家使用找找 bug


刚刚,DeepSeek 突发梁文峰署名新论文:V4 新架构提前曝光?
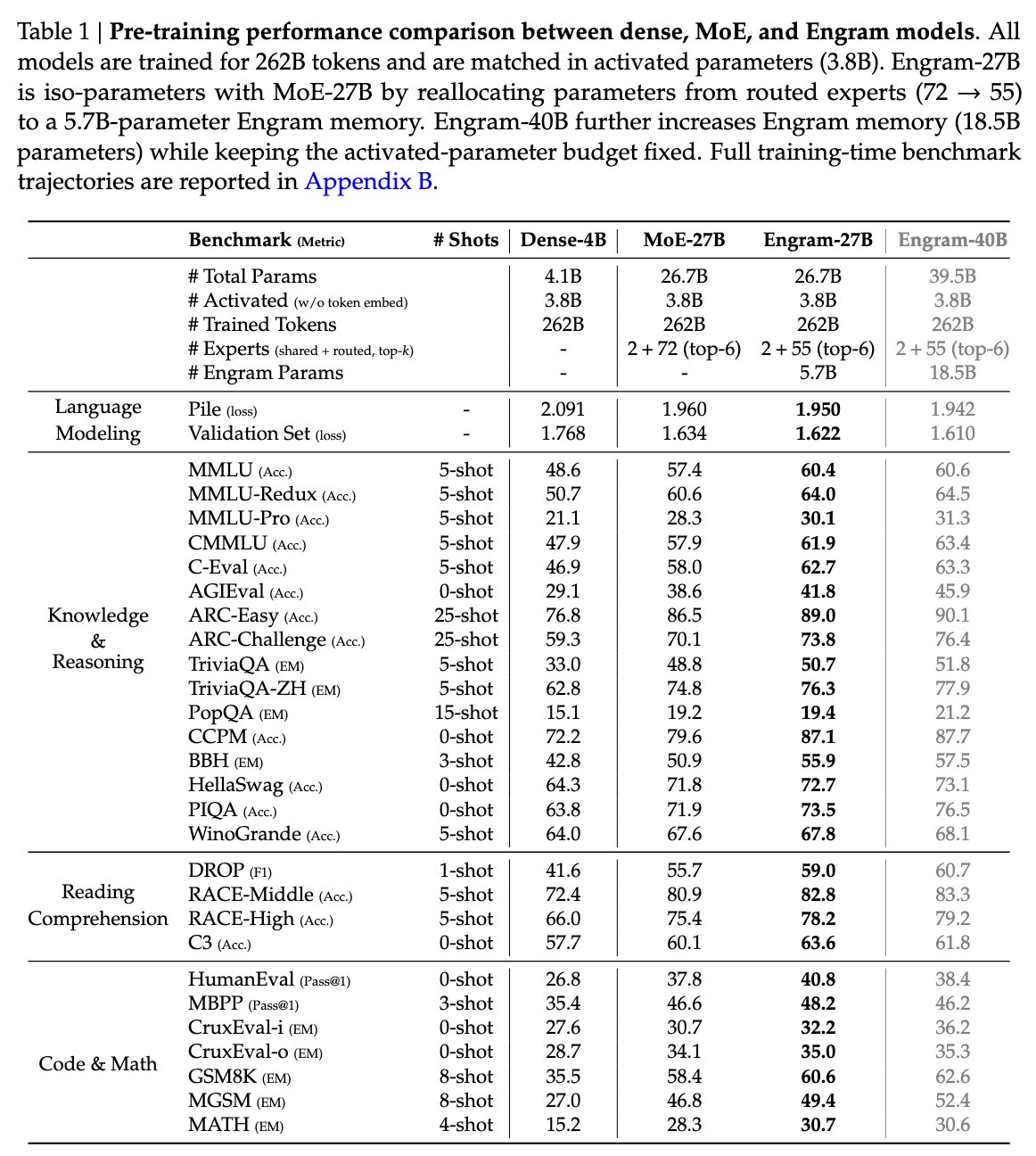
今天凌晨,喜欢闷声做大事的 DeepSeek 再次发布重大技术成果,在其 GitHub 官方仓库开源了新论文与模块Engram,论文题为“Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models”,梁文锋再次出现在合著者名单中。 与传统的大模型架构相比,该方法提出了一种新的“查—算分离”机制,通过引入可扩展的查找记忆结构,在等参数、等算力条件下显著提升模型在知识调用、推理、代码、数学等任务上的表现。代码与论文全文均已开源。 论文地址:https://github.com/deepseek-ai/Engram/blob/main/Engram_paper.pdf 代码地址:https://github.com/deepseek-ai/Engram 这种查和算分离的 Engram 新方法的整体架构如下图所示: 那么,我们为什么需要 Engram ? 目前主流的大语言模型架构依然基于 Transformer 和Mixture-of-Experts(MoE)结构。MoE 是目前推进参数规模和能力扩展的关键技术之一,通过动态路由机制,只激活部分参数以降低计算成本,同时在任务容量方面实现大规模扩展。DeepSeek 自家系列模型(如 DeepSeek V2、DeepSeek V3 等)也采用了先进的 MoE 方法进行扩展训练。 但在这些传统的 Transformer 架构(无论是 Dense 还是 MoE)中,模型的参数实际上承担着两种截然不同的角色: 事实性记忆(Memorization):存储海量的知识事实。例如,“法国的首都是哪里?”、“世界最高的山脉是哪座”等。这类信息相对死板,更多依赖于“查表”式的检索。 逻辑推理与计算(Calculation):负责复杂的逻辑链条、多步推理和情境理解。例如,“根据这段代码的逻辑推导可能的 Bug”、“解析一段复杂的哲学论证”。 目前的大语言模型倾向于将这两者混在一起。当你试图让模型记住更多知识时,你不得不增加参数量。而在传统的 Dense 模型中,参数量增加意味着前向传播时的计算量(FLOPs)也会同步激增。MoE 架构虽然通过稀疏激活解决了“算力随参数同步爆炸”的问题,但 DeepSeek 研究发现,MoE 专家在处理“死记硬背”的任务时依然不够高效。 神经网络本质上是连续的数学变换,用高昂的矩阵运算去模拟简单的“查表检索”,本身就是一种极大的浪费。DeepSeek 的 Engram 正是为了打破这一困境——“该查表的查表,该算的算”。 聚焦到问题本身,Engram 方法为什么能解决上述问题? “Engram”一词源自神经科学,意为“记忆痕迹”,它是一个可扩展、可查找的记忆模块,用于语言模型在推理过程中过去可能已经见过的模式或片段。 Engram 的核心技术之一是现代化的哈希 N-Gram 嵌入(Modernized Hashed N-gram Embeddings)。 传统方式:模型通过多层自注意力(Self-Attention)和 MLP 层的非线性变换,反复提取输入文本中的特征。 Engram 方式:它对输入的 Token 序列进行 N-Gram(连续 N 个词)切片,并利用哈希算法将这些片段映射到一个巨大的、可学习的查找表(Lookup Table)中。 由于采用哈希索引,这种查找是确定性且 O(1) 时间复杂度的。这意味着无论模型存储了多少万亿个记忆片段,检索的速度几乎是恒定的,且算力消耗极低。 O (1) 的含义是: 一次查找的耗时是常数级的,与 N-gram 表的规模无关。 也就是说,这种设计本质上将一部分“记忆职责”从深度神经计算中卸载出来(例如序列模式、固定知识段的识别与回填),使得模型既拥有活跃神经通道(例如 Transformer + MoE)处理复杂计算,也有静态记忆通道高效处理固定模式,这就是所谓的“稀疏性的新轴”(a new axis of sparsity)。 简单来说就是 MoE 负责:“计算密集”神经推理与复杂组合功能、Engram 负责:“记忆查找”固定模式以及模式重建,两者协同构成一个更高效的整体架构。 此外,它还具备条件记忆(Conditional Memory)。与简单的静态查找表不同,Engram 是“条件化”的。它会根据当前上下文的隐向量(Hidden States)来决定提取哪些记忆。 在架构设计上,Engram 模块位于 Transformer 层的早期阶段。它负责“模式重构(Pattern Reconstruction)”,即在计算层(MoE 或 Dense)开始干活之前,先把相关的背景事实和历史模式检索出来,作为“素材”喂给后续的逻辑层。 它与 MoE(Mixture of Experts)的关系是怎样的? 论文特别指出:Engram 提供了一个新的稀疏性轴,与 MoE 的条件计算不同,它通过条件查找提供静态记忆容量。下面图表中从目标、计算方式、优化方向和作用位置四个维度解释了 Engram 和 MoE 的区别。 最后,DeepSeek 将 Engram 与 MoE 结合,形成了一个双系统: Engram 模块:负责海量知识点的“存储与快速检索”。 MoE 专家:摆脱了沉重的记忆负担,全身心投入到“逻辑推理与合成”中。 这种分工极大地优化了参数效率。在 27B 的实验模型中,Engram 模块可以占用大量的参数用于记忆,但在实际推理时,它只消耗极少的计算量(FLOPs)。 在 Reddit、X 和其他平台的相关帖子中,Engram 的技术核心受到了不少用户的肯定和技术肯定。众多网友认为这个模块的特点在于让模型架构处理“记忆模式查找”和“神经计算推理”两块职责分离,从而开启了新的稀疏性方向。 在 Reddit 平台有用户评论说: “Engram 嵌入方法很有意思。大多数模型仅通过 MoE 进行扩展,但 Engram 增加了静态记忆作为补充的稀疏性轴,查找复杂度为 O(1)。他们发现 MoE 和 Engram 之间存在 U 形缩放规律,这指导着如何在两者之间分配容量。分析表明,这减轻了早期层级静态模式重建的压力,从而保留了用于复杂推理的深度。确定性寻址意味着它们可以将嵌入表卸载到主机内存中,而不会增加太多推理开销。” 同时,有用户对这种基于 n-gram lookup 的机制表达了直观兴趣,他评论道: “即便是在不依赖 GPU 的环境下也能实现这种 O(1) 查找方式,让不少开发者对本地部署这样的大模型功能有了更实际的期待。” 在部分技术性评论中,有人指出: 即从已有技术逻辑来看,在 LLM 中加入静态记忆查找似乎是“顺理成章”的发展方向。 这类观点反映了一个重要观点:专家群体开始从纯参数扩张思维转向更“智能”的架构设计,包括查表式模块和神经网络的协同。 不少高级开发者在讨论中进一步提到,这种设计在理念上类似于对传统 NLP 技术(如 n-gram embedding)的现代化转换,结合了高效寻址机制(deterministic addressing)和神经推理模块,这种组合在纸面上看具有较高的可行性和实用性(这一点正是 Engram 的核心贡献)。 另一条社区评论指出,Engram 很可能是DeepSeek 即将发布的 V4 模型的核心技术基础: 业内观察者认为 Engram 模块可能会成为 DeepSeek V4 的重要组成部分,并预示 DeepSeek 下一代模型会在记忆和推理协同上实现架构级提升。 在 X 平台,也有网友表达了同样的猜测,认为 V4 也将采用这种架构。 还有网友调侃,原本想抄袭下谷歌的技术,但现在要抄袭 DeepSeek 了,因为它比谷歌更好! 还有网友表示,其实 Meta 之前也有过类似想法,但用到的技术不同。 参考链接: https://x.com/scaling01/status/2010748516788777445 https://github.com/deepseek-ai/Engram/blob/main/Engram_paper.pdf
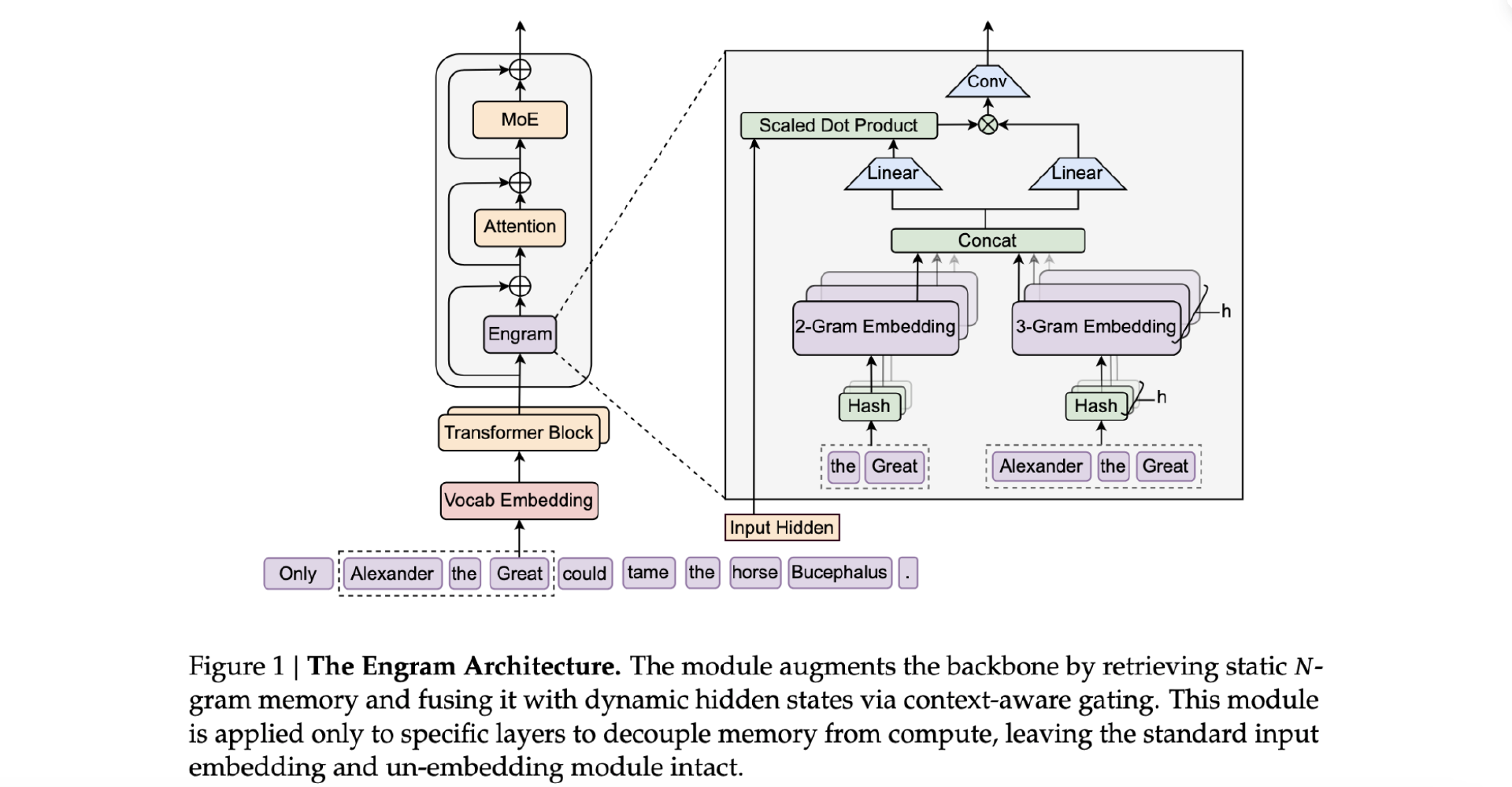
为什么需要 Engram?
Engram 的核心思想与架构
网友:V4 将采用这种架构

活久见!连 Linux 之父等“顽固派”大佬,都在用 AI 编程了
程序员中的超级“保守派”、Linux 之父Linus Torvalds,现在也用起了 AI 编程。 图源:GitHub 最近,Linus 在 GitHub 上悄悄上传了一个小项目。项目本身不大,但特别的是,它是他用一款谷歌系 AI 编程助手 进行 Vibe Coding 完成的。 这个仓库很快就被眼尖的网友挖了出来,目前已经收获了 1600+ 颗 Star。 Linus 缔造的 Linux,与 Windows、macOS 一起,构成了当今计算世界的三大通用操作系统阵营之一。 不过他曾直言:“在过去将近 20 年里,我并没有从事编程工作。”这并不是他远离技术,而是早就从亲手写代码的人,转变成了为整个系统长期演进负责的人。 在这种角色下,这位老哥过去对“AI 帮你写代码”这套叙事,一直保持高度警惕甚至是嗤之以鼻——他关注重点的不是代码写得快不快,而是代码在多年之后是否还能被理解、维护和演进。 而现在,Linus 对 AI 编程的态度可谓是“大转弯”:不仅开始亲自尝试 Vibe Coding,还公开表示自己对这种方式“相当积极”。 这些事情的冲击力并不在于“AI 又进步了”,而在于连最不吃 AI 编程这一套的人,也开始松动了。 在生成式 AI 席卷软件行业的当下,有这么一群特殊的 “顽固派”, 他们定义了现代计算机的技术基石,却曾长期对 AI 编程嗤之以鼻,甚至公开泼冷水。 比如 Linux 之父 Linus Torvalds、Java 之父 James Gosling、Redis 之父 antirez(Salvatore Sanfilippo),个个都是编程界的殿堂级人物。 但有意思的是,随着 AI 工具能力的突飞猛进,这群昔日的 “反 AI 先锋”,正以各自的方式重新划定 AI 的边界:有人有限度拥抱,有人批判中认可,还有人干脆彻底转身。 比如 Linus 老哥,之前对生成式 AI 一直保持观望的态度。 他并不否认 AI 的潜力,但极度厌恶围绕 AI 的过度炒作。在一次开源峰会上,他直言当前关于生成式 AI 的讨论“90% 是行销炒作,只有 10% 是现实”,并毫不掩饰自己的反感。正因为讨厌炒作,他选择在相当长一段时间内 主动忽略 AI 热潮。 Linus 之前一直没有使用各种 AI 编程工具。不过,这并不代表他对新范式抱有敌意。相反,他对 Vibe Coding 总体持正面态度,只是并未急于亲自下场。 而现在,随着工具逐渐成熟、噪音开始下降,Linus 也终于对 Vibe Coding 上手了。 他用上了谷歌的智能体优先开发平台 Antigravity,靠 Vibe Coding 搞定了项目里的 Python 音频采样可视化工具。 从最初的 “搜索 + 照猫画虎”,到后来直接让 AI 写代码,甚至自定义组件,最终效果比他手写的还要好。 面对内核社区里 AI 生成补丁泛滥的争议,他的立场很清醒:问题不在于 AI 本身,而在于维护者是否真正理解代码、承担责任。在他眼里,AI 可以当帮手,但不能当甩手掌柜。 而 Redis 创始人 Salvatore Sanfilippo(网名:antirez) 的转变更具戏剧性。 这位以 “简洁、可预测” 为信仰的系统级程序员,曾固执地坚持一行行手写代码,对自动化工具保持高度警惕。 但最近,他公开抛出了一句颠覆自己过往理念的话: “对于大多数项目而言,除非是为了娱乐,现在自己写代码已经不再明智了。” 让他改口的,是实打实的体验。 在使用 Claude Code 的过程中,他发现 AI 在极少人工干预的情况下,就能完成原本需要数周的系统级任务:修复 Redis 测试中的并发与时序问题、重写核心库、复现复杂的数据结构改动。 更夸张的是,他只提出需求,Claude Code 5 分钟就生成了一个 700 行的纯 C 库,用于 BERT 类嵌入模型推理,性能仅比 PyTorch 慢约 15%;而他耗时数周完成的 Redis Streams 内部改动,AI 根据设计文档,20 分钟便复刻完成。 他坦言,对抗浪潮没什么意义,不如主动拥抱: “忽略人工智能对你或你的职业生涯都没有好处。花几周时间仔细研究,而不是五分钟浅尝辄止。” 但 antirez 强调,这不是编程乐趣的终结,而是转移:“真正有趣的事情,已经从‘如何写代码’,变成了‘要做什么、为什么这样做’。” 当然,这位技术极客也没丢掉警惕性。他担忧 AI 技术的集中化风险。少数公司掌握核心能力,可能引发程序员失业、技术权力失衡等问题。 相比前两位,Java 之父 James Gosling 的态度要尖锐得多。他多次炮轰,当前的 AI 热潮 “基本上是一场骗局”,AI 已经沦为“自带误导属性的营销术语”。 在他看来,生成式 AI 编程的本质,不过是对已有代码和模式的重组,根本谈不上真正的创造力。那些看起来惊艳的演示,一旦碰上复杂项目就露馅:“刚开始接触氛围编程,会觉得它特别酷炫。可一旦项目变得稍微复杂一点,氛围编程就会很快耗尽开发者的脑力。” Gosling 的核心质疑点很明确:AI 只能复刻见过的代码,但专业软件开发的精髓,在于开拓性的创新 —— 这些内容从来不在现成的代码库里。 不过,他也没把话说死。他承认 AI 技术背后的数学与统计原理很复杂,也认可它的实用价值,不是取代程序员,而是 “生成没人愿意去写的文档”,或者解释现有代码的功能。说到底,AI 更像一个智能搜索引擎,而非编程大神。 他还不忘吐槽一把资本:“科技行业里骗子和炒作者的数量之多,令人难以置信。风险投资者只关心成功获利,而不是开发出真正有用的技术。” 他甚至预言,“绝大多数 AI 投资都会被烧个精光。” 说到底,这三位大佬的转变,都不是向 AI “投降”。 他们认可的,是 AI 在重复劳动上的效率;他们坚守的,是人类程序员不可替代的核心价值,对复杂系统的理解、对工程架构的判断、对长期维护的责任,以及开拓性的创新能力。 需要说明的是,虽然 Linus 现在对 Vibe Coding 的态度很积极,但他也直言称,这种方式 并不适用于 Linux 内核开发。 一个重要原因在于,今天的计算机系统早已比他学习编程的年代复杂得多。Linus 曾回忆,当年他接触的一些输入程序,甚至是从计算机杂志上照着敲下来的。 虽然他已经很久没有深度参与具体功能编程,长期为整个内核的演进负责。在他的“系统维护者”视角下,稳定性、安全性和可维护性,远比“写得快不快”更重要。 这一点,其实在他最近上传到 GitHub 的那个项目里有所体现:AI 主要写的只是对 Python 可视化工具部分,核心 C 语言部分(音频效果的数字信号处理等)还是他亲自写的。 在 Linus 看来,Vibe Coding 在小项目和探索性场景中确实优势明显:进入门槛低、反馈速度快,能迅速把模糊的想法变成可运行的程序,用来生成样板代码、辅助脚本,或者“先跑起来看看”,都非常合适。 但这种方式的短板同样明显——生成代码往往风格不稳定、抽象边界模糊、依赖隐性假设,短期能用,长期却很难维护。 而 Linux 内核,恰恰是一个对“可维护性”极端苛刻的系统:代码需要被不同年代、不同背景的维护者反复阅读、修改和重构,任何一次“看起来省事”的生成式决策,都可能变成未来十年的技术债。 不过话说回来,即便不能“全靠 AI 写代码”,“部分交给 AI”本身,就已经在重塑程序员的工作方式。 在另一条时间线上,有些工程师甚至已经开始用 AI 来开发 AI 本身。 比如 Boris Cherny。作为 Anthropic 工程师、也是 Claude Code 的创造者,他已经几乎不再以传统方式写代码了,而是把自己打造的 AI 编程工具玩儿出了花: 他让 Claude Code 自己参与开发自己,然后竟在一年内完成了 1096 提交。 这个工具已成为全球最受欢迎的 AI 编程工具之一,去年还给 Boris 带来了超过 10 亿美元(约合人民币 70 亿元) 的收入。 参考链接: https://github.com/torvalds/AudioNoise https://www.theregister.com/2025/11/18/linus\_torvalds\_vibe\_coding/ https://www.bnext.com.tw/article/81200/linus-torvalds-gen-ai-bubble
反 AI 编程的“顽固派”们,也开始接受 Vibe Coding 了

对 Linux 内核开发,Vibe Coding 还欠火候

Anthropic 深夜放出王炸!白领饭碗要被 AI 砸了?网友:不支持 Linux,差评
在开发者工具 Claude Code 推出之后,Anthropic 团队很快意识到一个出乎预料的现象:开发者并没有把它局限在“写代码”这件事上。相反,Claude Code 被迅速用于整理资料、撰写文档、生成报告、分析数据,甚至承担起类似“数字同事”的角色。 这种使用方式的外溢,最终促使 Anthropic 做出一个更激进的产品判断——如果大模型已经被当作工作伙伴使用,那么是否应该为“所有人”,而不仅仅是开发者,提供一种真正面向日常工作的智能协作形态? 于是今天,Anthropic 正式推出了 Cowork。 Anthropic 工程师、Claude Code 创建者 Boris Cherny 在 X 上发帖宣布了该消息。他写道: 自 Claude Code 发布以来,我们发现用户将其用于各种非编码工作:例如进行度假研究、制作幻灯片、清理电子邮件、取消订阅、从硬盘恢复婚礼照片、监测植物生长、控制烤箱等等。这些应用场景丰富多样,令人惊喜——原因在于底层 Claude Agent 是最佳代理,而 Opus 4.5 是最佳模型。 今天,我们非常激动地推出 Cowork,这是我们让 Claude Code 服务于所有非编码工作的第一步。该产品目前仍处于早期阶段,功能尚不完善,与 Claude Code 最初发布时的状态类似。Cowork 包含许多我们认为使其真正与众不同的创新用户体验和安全功能:内置虚拟机用于隔离、开箱即用的浏览器自动化支持、以及对所有非编码工作的支持。 据介绍,Cowork 是一款基于 Claude Code 底层架构构建的全新产品,目前以“研究预览版”的形式,率先面向 macOS 平台上的 Claude Max 订阅用户开放。与传统对话式 AI 不同,Cowork 的核心定位并非“聊天”,而是“协作”:它试图让 Claude 从一个被动响应指令的助手,转变为能够理解任务、制定计划、持续执行,并与用户保持协同关系的智能工作体。 长期以来,大模型产品的主流交互形态仍然是对话。用户输入问题,模型生成回答;用户提出修改,模型再次响应。这种模式在信息查询、文本生成等场景下行之有效,但在真实工作流中却暴露出明显局限——上下文需要反复提供,文件需要人工整理,输出结果往往还要用户自行转换为可用格式。 Cowork 试图解决的,正是这一断裂问题。 在 Cowork 模式下,用户可以直接授予 Claude 对本地指定文件夹的访问权限。需要强调的是,这种访问并非“全盘授权”,而是由用户明确选择、逐一控制的结果。Claude 只能看到、读取、编辑或创建那些被允许的文件和目录,而无法触及任何未授权内容。 一旦获得权限,Claude 的能力边界就发生了质变。它不再只是基于文本上下文“想象”文件内容,而是可以直接操作真实存在的工作材料。例如,它可以扫描一个杂乱无章的下载文件夹,按照文件类型、时间或用途进行分类和重命名;可以从大量截图中提取关键信息,自动生成一份结构化的费用清单;也可以将零散的会议笔记、草稿和片段,整理成一份逻辑清晰的报告初稿。 这种能力的本质,并不是简单的“更聪明”,而是 Claude 被嵌入进了用户的实际工作环境之中。 Anthropic 在产品说明中多次强调,Cowork 的体验更接近“给同事布置任务”,而不是与机器人来回对话。一旦任务被下达,Claude 会自行拆解步骤、规划执行路径,并在执行过程中持续向用户同步进展。用户无需等待任务完成即可插入新的反馈或补充想法,这些指令会被自动排队、并行处理。 这也是 Cowork 与普通对话模式最根本的差异之一:它默认假设用户的工作是多线程的,而不是线性的。 当然,“更自主”的能力,意味着更高的风险。 让 AI 进入文件系统,甚至具备修改、创建和删除文件的能力,无疑是一种能力跃迁,同时也是风险跃迁。Anthropic 并未回避这一点,反而在产品介绍中反复提醒用户保持警惕。 首先是操作层面的风险。如果收到明确指令,Claude 确实可以执行具有破坏性的操作,例如删除本地文件或批量修改内容。一旦指令本身存在歧义,或者模型误解了用户意图,后果可能是不可逆的。 因此,在 Cowork 中,Claude 在执行任何“重要操作”之前,都会主动征求用户确认。这种设计并非形式上的“弹窗提示”,而是希望用户在关键节点重新审视任务目标,必要时进行纠正或细化指令。Anthropic 也明确建议,在涉及高风险操作时,用户应提供尽可能清晰、具体的指示,而不是依赖模糊的自然语言。 另一类更复杂、也更具行业共性的风险,是“提示注入”(Prompt Injection)。 在 Cowork 的工作过程中,Claude 可能会接触来自互联网的内容,例如网页、文档或第三方信息源。如果这些内容中被恶意嵌入了指令,试图诱导模型偏离原本的任务计划,就可能引发安全问题。Anthropic 表示,他们已经构建了针对提示注入的多层防御机制,但也坦言,“代理安全”——即确保 AI 在现实世界中执行操作时的可控性——仍然是整个行业正在积极探索的前沿问题。 从这个角度看,Cowork 并不是一个“已经完全成熟”的产品,而更像是一次对未来工作方式的现实实验。 Anthropic 也明确指出,这些风险并非 Cowork 独有,而是所有具备“行动能力”的 AI 工具都会面临的问题。只是对许多用户来说,Cowork 可能是第一次接触到一个超越简单对话、真正能够影响本地环境的 AI,因此更需要建立正确的使用习惯和风险意识。 Cowork 目前被定义为“研究预览版”,这一定位本身就释放了明确信号:Anthropic 并不认为自己已经找到了最终形态,而是希望通过真实用户的使用反馈,加速产品迭代。 根据官方披露,Anthropic 计划在后续版本中引入多项重要改进。其中包括跨设备同步能力,使 Cowork 不再局限于单一终端;以及将其移植到 Windows 平台,从而覆盖更广泛的办公人群。同时,安全机制也将持续强化,尤其是在代理行为可解释性和可控性方面。 从产品路径上看,Cowork 与 Claude Code 之间存在清晰的继承关系。两者共享相同的底层架构,这意味着 Cowork 在能力上,理论上可以完成 Claude Code 已经证明可行的许多复杂任务。不同之处在于,Cowork 将这些能力重新封装为更偏向非技术用户的交互方式,降低了使用门槛。 如果说 Claude Code 面向的是“愿意为效率付出学习成本”的开发者群体,那么 Cowork 的目标人群显然更加广泛:内容创作者、产品经理、运营人员、行政人员,乃至任何需要与文件、资料和信息打交道的知识工作者。 在掌握 Cowork 的基本使用方式后,用户还可以进一步扩展 Claude 的能力边界。 首先是连接器。Claude 可以通过用户已有的连接器,访问外部信息源,从而将本地任务与外部数据打通。这使得 Cowork 不再只是一个“本地整理工具”,而是可以承担跨系统的信息整合角色。 其次是新增的一系列技能。这些技能专门用于提升 Claude 在创建文档、演示文稿以及其他常见办公文件时的表现,使其输出更加贴近真实工作场景的格式和标准。 此外,如果用户在 Chrome 浏览器中将 Cowork 与 Claude 配对使用,Claude 还可以完成需要访问浏览器的任务。这一步,实际上进一步模糊了“对话 AI”“自动化工具”和“数字员工”之间的界限。 从整体设计来看,Cowork 试图减少用户在“提供上下文”和“整理结果”上的认知负担。用户无需手动拼接背景信息,也无需将 Claude 的输出再加工成可用成果。更重要的是,用户不必为了等待 AI 完成某个任务而中断自己的工作节奏——任务可以被连续布置、并行执行。 Anthropic 在描述这种体验时,用了一个耐人寻味的比喻:这更像是给同事留言,而不是来回沟通。 在 Cowork 发布之后,迅速在开发者社区、AI 产品圈以及更广泛的知识工作者群体中引发讨论。与以往单纯围绕模型能力、跑分或价格的争论不同,这一次的焦点明显转向了一个更现实的问题:“AI 是否真的开始成为一个可以被信任、被授权的工作参与者?” 在 Reddit 上的最新讨论串里,有用户评论指出他们“很期待尝试这个功能”,认为 Anthropic 近来在产品和用户信任构建上做得不错。 **因为仅限 macOS 和订阅计划,部分用户感到遗憾。**在另一个 Reddit 讨论串中,有用户对 Cowork 的平台限制表达了不满或遗憾,评论集中在“只支持 macOS”这一点上。 此外,值得注意的是,有些评论虽然不是专门针对 Cowork,但有一些用户还是对 Anthropic 近期产品策略与沟通的不满,对 Cowork 的发布背景和用户关系具有间接关联语境。 在 Reddit 平台,有长期用户表示,自己已经从忠实支持者变成对 Anthropic 的信任下降甚至不满。该用户指出: “作为很早一批用户,我原本极力推荐 Claude,但最近几个月感觉 Anthropic 的产品质量沟通都变差了。” 参考链接: https://claude.com/blog/cowork-research-preview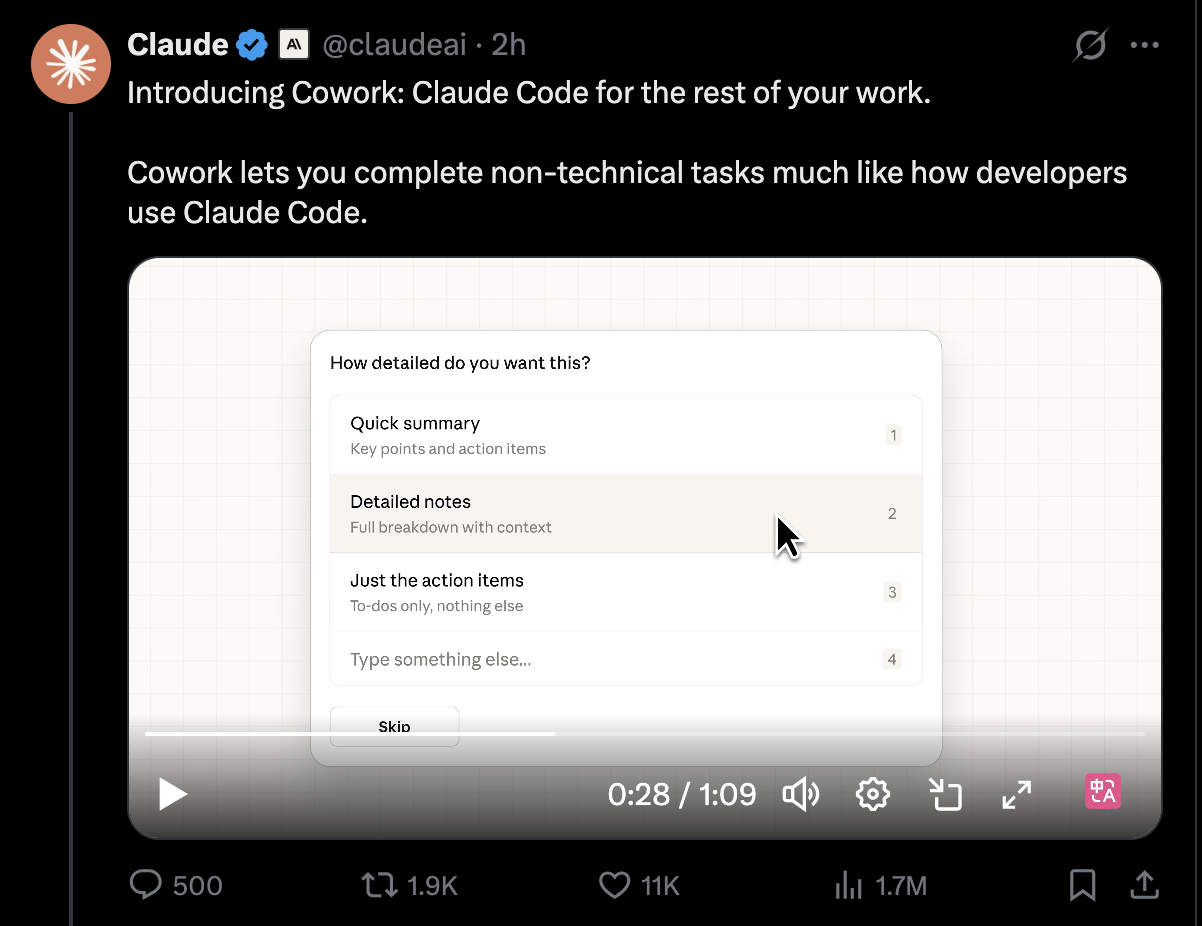
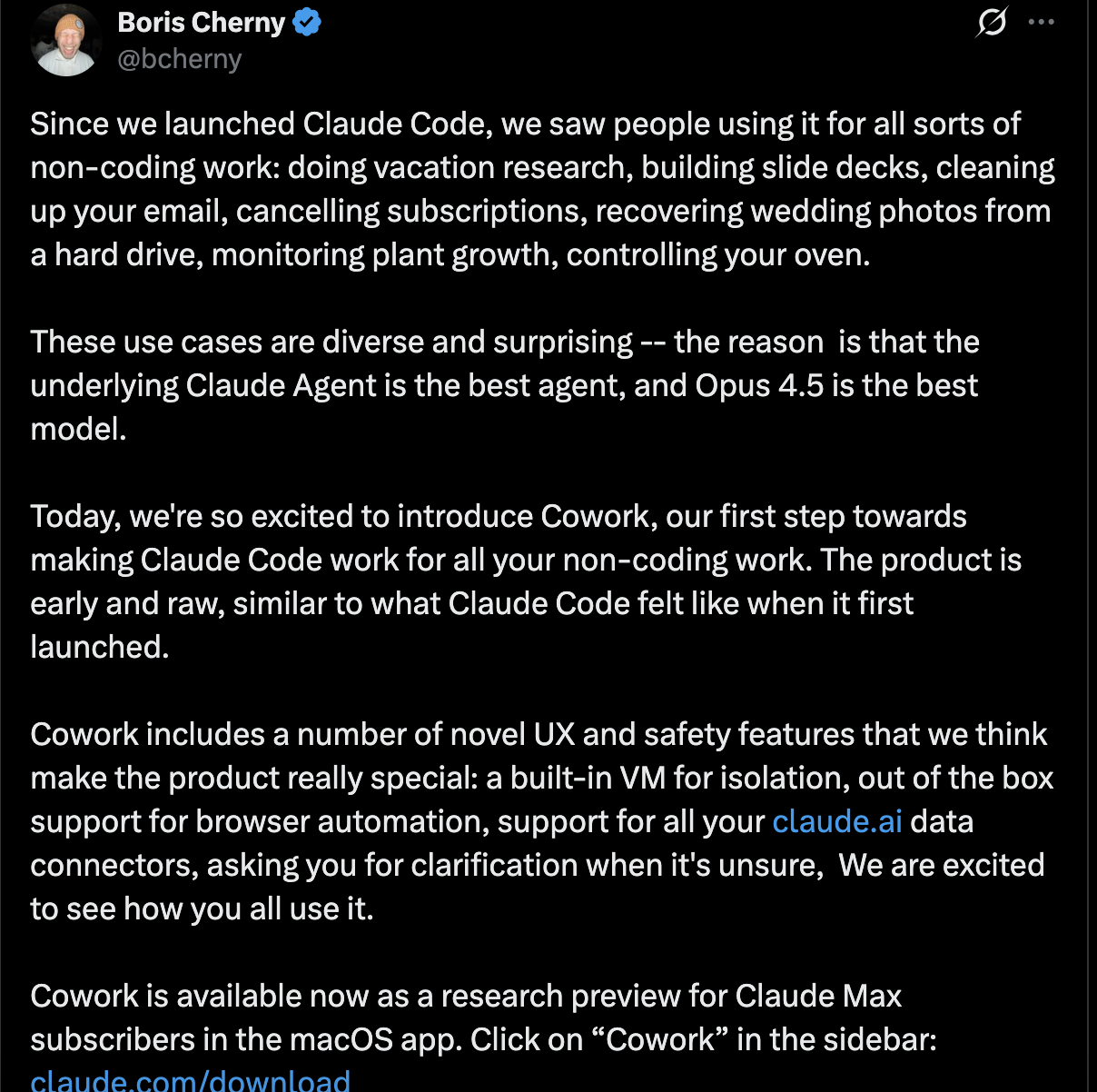
从“对话助手”到“数字同事”
研究预览版背后的产品逻辑
用户:没有 Linux 版本,差评!


各大 APP 换绑手机号体验经历参考
之前也注销过一次手机卡,基本就是换绑经常用的 APP ,线下一次跑遍所有银行。也没多麻烦。
高德地图,抖音 一个按钮自动更换,体验非常好👍。
大部分 APP 正常逻辑为先验证旧手机号,后验证新手机号,涨乐则相反。
BOSS 直聘,默默背单词,在验证原手机号后,新手机发验证码时提示操作太频繁。(发短信接口估计同一个,频繁操作)
银行系的,建行,工商,中行,浦发,光大 就巨麻烦,有些要人脸,身份证,卡号。就算线上改好了,有些还需要线下去。所以最好是线下一并弄好。招行,平安能直接改还是比较友好,但是卡关联的手机号估计还得线下。
云闪付比较反人类,验证了新手机号,旧手机号后,再验证 登录密码。不应该先验证登录密码吗?谁记得。
数币要换绑的话,有些银行卡预留的手机号也要改。
豆瓣的 toast 组件交互差,toast 显示半天等它消掉麻烦,有时 toast 又过早消掉,强烈建议互联网应用都去掉 toast 组件。
中国人寿,国家医保服务平台,修改的手机号需要是个人实名的。你说国家的没问题,但中国人寿作为保险公司这么谨慎?其他保险公司都能改。实名这个问题,主卡和副卡本人要一起去营业厅"过户"才能搞。
避雷一个机场,也是在 V 站看到有人发的
名字叫水下,域名 udwt.io
之前在某个求推荐机场的回帖里看到有人发的(没有讨伐的意思,我也没走 aff ),试用了一下 1 元套餐,发现延迟和稳定性非常棒,而且是符合我需求的按量付费,于是冲了最高档套餐,后面陆续用了一段时间后感觉速度明显不如试用的时候,还经常全部节点超时,刚开始发工单还算有人处理,也就凑合继续用了,后面越来越拉,上个月出现了一次流量统计异常,一天跑了几百个 G ,发工单说是 cf 故障导致的统计异常,给我恢复了,结果上周又出现了异常几百 G 的使用,这次发工单完全没人了,看了下 TG 频道也没人,TG 群也是全员禁言,怕是应该跑路了,气不过来这里发下避雷,在用的别续费了,没用的千万避开

之前在某个求推荐机场的回帖里看到有人发的(没有讨伐的意思,我也没走 aff ),试用了一下 1 元套餐,发现延迟和稳定性非常棒,而且是符合我需求的按量付费,于是冲了最高档套餐,后面陆续用了一段时间后感觉速度明显不如试用的时候,还经常全部节点超时,刚开始发工单还算有人处理,也就凑合继续用了,后面越来越拉,上个月出现了一次流量统计异常,一天跑了几百个 G ,发工单说是 cf 故障导致的统计异常,给我恢复了,结果上周又出现了异常几百 G 的使用,这次发工单完全没人了,看了下 TG 频道也没人,TG 群也是全员禁言,怕是应该跑路了,气不过来这里发下避雷,在用的别续费了,没用的千万避开
黑客因入侵鹿特丹和安特卫普港口获刑七年
阿姆斯特丹上诉法院判处一名44岁荷兰公民七年监禁,其罪名包括计算机黑客攻击和企图敲诈勒索。
该男子于2021年被捕,并于2022年由阿姆斯特丹地方法院定罪,但他以当局非法拦截其通信并获取定罪证据为由提出上诉。
这些通信发生在端到端加密聊天服务Sky ECC上。欧洲刑警组织于2021年"破解"了该服务,导致其首席执行官及多名用户被捕。此次行动的相关调查工作一直持续到去年。
关于执法部门获取Sky ECC信息的异议被驳回,因为辩护方未能证实其关于侵犯被告公平审判权的程序违规指控。
此人被指控入侵荷兰鹿特丹、巴伦德雷赫特和比利时安特卫普港口的服务器,以便秘密走私毒品。
法院声明指出:"他犯有协助计算机黑客攻击的罪行",并补充说明"其目的是通过入侵港口系统,实现毒品走私的隐蔽运输,从而为毒品贩运提供便利。"
该男子通过让员工插入含恶意软件的U盘,入侵了一家港口物流公司的IT系统。目前尚未明确这些员工是受欺骗还是被贿赂参与此事。
这使得黑客能够在内部系统植入远程访问工具,从数据库中窃取数据并拦截传输中的信息。
当局还提到,在2020年9月15日至2021年4月24日期间,该男子曾与他人合谋试图转售恶意软件及其使用教程。
最终,该男子因通过计算机黑客手段协助毒品贩运、在荷兰走私210公斤可卡因以及企图敲诈勒索等罪名,被判处七年监禁。
夏威夷大学癌症中心遭遇勒索软件攻击
夏威夷大学癌症中心遭遇勒索软件攻击
夏威夷大学表示,一个勒索软件团伙于2025年8月入侵了其癌症中心,窃取了研究参与者的数据,其中包括包含社会安全号码的1990年代文件。
夏威夷大学系统成立于1907年,目前包含3所大学和7所社区学院,以及在夏威夷群岛的10个校区及培训研究中心。其癌症中心位于檀香山的Kakaʻako区,拥有300多名教职员工以及额外的200名附属成员。
在一份提交给州立法机构的报告中,夏威夷大学表示,8月31日的事件影响了夏威夷大学癌症中心的单个研究项目,未影响临床运营或患者护理。
然而,因系统被加密造成的广泛损害,延迟了夏威夷大学的恢复工作和对攻击影响的调查。
"在8月下旬发现后,受影响系统立即被断开连接,我们聘请专家进行了全面调查,并通知了外部相关方,"夏威夷大学发言人告诉BleepingComputer。
"在此过程中,夏威夷大学做出了艰难的决定,与威胁行为者接触,以保护可能受影响的个人信息。涉及一组有限的研究文件(非医疗记录),其中包含一些历史个人信息。"
支付赎金以获取解密工具并删除被盗数据
夏威夷大学补充说,还与外部网络安全专家合作获取了解密工具,并"确保威胁行为者非法获取的信息被安全销毁",以"保护可能泄露敏感信息的个人"。
尽管大学尚未通知在勒索软件攻击中数据被盗的个人,但夏威夷大学告诉BleepingComputer,将在"确定联系方式后立即"通知他们。
为应对此次攻击,夏威夷大学还采取措施加强系统安全,防止进一步入侵,包括安装端点保护软件、更换受损系统、重置密码、更换防火墙软件,并对癌症中心进行第三方安全审计。
6月,夏威夷航空公司也披露了一起网络攻击,该攻击中断了对其部分IT系统的访问,但未影响飞行安全。
自10月下旬以来,美国其他几所大学也在语音钓鱼攻击中遭到入侵,普林斯顿大学、哈佛大学和宾夕法尼亚大学披露,其开发和校友活动系统被黑客入侵,以窃取捐赠者、教职员工、学生和校友的数据。
Clop勒索软件团伙还再次入侵了哈佛大学和宾夕法尼亚大学,在一次利用Oracle电子商务套件零日漏洞的数据窃取活动中,窃取了学生、教职员工和供应商的敏感个人及财务数据。
12月,贝克大学也披露了一起数据泄露事件,此前攻击者在去年入侵了其网络,窃取了超过53,000人的个人、健康和财务信息。
恶意攻击者在实时对战中劫持《Apex英雄》角色
上周末,《Apex英雄》玩家在实时对战中遭遇干扰,攻击者劫持了他们的游戏角色、强制断开连接并篡改了玩家昵称。
这款仍广受欢迎的大逃杀英雄射击游戏的发行商Respawn就此次安全事件发表公开声明,向玩家保证事件并非由漏洞利用或恶意软件感染导致。
截至2025年中,该游戏在全平台仍保持约50万的日均同时在线用户规模。
自上周五起,玩家开始报告相关问题,称有外部攻击者在游戏中操控其角色并试图将角色移出地图边界。他们还分享了记录异常行为的实时游戏画面。
周六,Respawn承认该问题并发布声明,描述"存在恶意攻击者能够远程操控《Apex英雄》中其他玩家输入指令的活跃安全事件"。该公司强调:"根据初步调查,未发现攻击者能像RCE或注入攻击那样安装或执行代码的证据。"
在Respawn寻求解决方案期间,玩家持续报告干扰事件,部分攻击行为甚至表现为强制断开客户端与服务器的连接以及游戏角色被劫持。有玩家根据观察指出:"攻击者获得了管理员权限",能够访问服务器调试系统并利用特权使用自瞄作弊器等漏洞利用工具。
多名玩家反映,被强制踢出队伍的队友昵称会被替换为"RSPN Admin"。Respawn表示:"反作弊是一场持续的攻防战,玩家的报告对我们及时掌握信息至关重要,今天的案例正是如此。"
BleepingComputer已联系游戏发行商以获取事件详情,收到回复后将更新本文内容。
去年,《Apex英雄》北美赛事曾发生类似干扰事件,黑客在比赛期间入侵了选手账户,导致电子艺界被迫推迟决赛,并动摇了玩家群体对游戏安全性的信任。
CISA要求联邦机构修补Gogs RCE漏洞,该漏洞已在零日攻击中被利用
美国网络安全和基础设施安全局(CISA)已下令各政府机构保护其系统,防范一个已在零日攻击中被利用的高危Gogs漏洞。
Gogs作为GitLab或GitHub Enterprise的替代方案而设计,使用Go语言编写,通常暴露在互联网上以支持远程协作。
该漏洞被追踪为CVE-2025-8110,是一个远程代码执行(RCE)安全漏洞,源于PutContents API中的路径遍历缺陷。它允许经过身份验证的攻击者通过符号链接覆盖仓库外的文件,从而绕过为先前已修补的RCE漏洞(CVE-2024-55947)实施的保护措施。
攻击者可以通过创建包含指向敏感系统文件的符号链接的仓库,然后利用PutContents API通过符号链接写入数据,覆盖仓库外的目标文件,从而滥用此漏洞。通过覆盖Git配置文件(特别是sshCommand设置),威胁行为者可以强制目标系统执行任意命令。
Wiz Research在7月份调查一起影响客户面向互联网的Gogs服务器的恶意软件感染事件时发现了该漏洞,并于7月17日向Gogs维护者报告了此缺陷。维护者在三个月后的10月30日确认了Wiz的报告,并于上周发布了针对CVE-2025-8110的补丁,该补丁在所有文件写入入口点增加了对符号链接的路径验证。
根据Wiz Research分享的披露时间线,在11月1日观察到了针对此漏洞的第二波零日攻击。
在调查这些攻击活动期间,Wiz研究人员发现了超过1,400台暴露在互联网上的Gogs服务器(其中1,250台目前仍处于暴露状态),以及超过700个实例显示出被入侵的迹象。
CISA现已确认Wiz的报告,并将此安全漏洞添加到其"野外被利用漏洞"清单中,命令联邦民事行政部门(FCEB)机构在三周内,即2026年2月2日之前完成修补。
FCEB机构是指美国的非军事行政部门,例如能源部、司法部、国土安全部和国务院。
CISA警告称:"此类漏洞是恶意网络行为者的常见攻击媒介,对联邦企业构成重大风险。请根据供应商说明实施缓解措施,遵循适用于云服务的BOD 22-01指南,如果无法实施缓解措施,则停止使用该产品。"
为了进一步减少攻击面,建议Gogs用户立即禁用默认的开放注册设置,并使用VPN或允许列表来限制服务器访问。
此外,希望检查其Gogs实例是否遭受入侵的管理员,应查找PutContents API的可疑使用情况,以及在两波攻击期间创建的具有随机八字符名称的仓库。