前言
比较碎碎念
几年前,在没有经过复杂的配置之前,我一开始使用的是某不知名 vpn,45 元包月的那种,虽然很稳定,但是一直上不去 openai , 于是我经过一番资料的查找,我选择了一家机场,一直用到现在,也就是 flowercloud, 配合 clash verge 进行链式代理上网.
这一步还不懂配置的朋友请先掌握 clash 和机场的订阅方法,很简单.
clash 我的个人使用习惯
建议
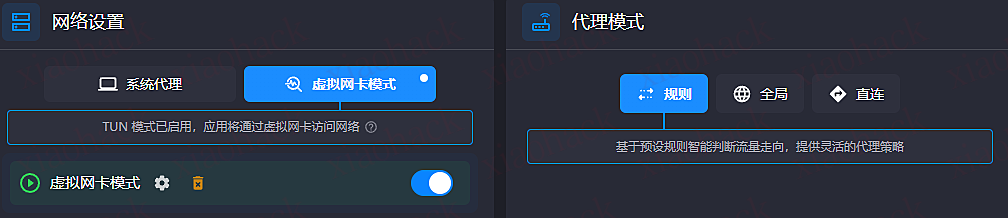
- 始终使用 Tun 模式 (虚拟网卡模式), 系统代理不需要开.
- 选择规则 rule 模式 (大机场的话会自己附带规则,基本上不需要自己手动修改,除非按这个帖子修改一点点内容), 这样的话访问国内网站不需要流量中转,不会工作微信收个图片也得先去日本跑一圈.
Then…
我终于访问 openai 了!然后就是紧跟时事了呗,每天喝喝咖啡看各种技术帖子,逛论坛什么的,深度思考一直用的不算多,直到我开始非常非常重度的使用 AI 来进行工作和学习.
发现降智是我第一次使用 openai 的 deep research 功能的时候,满怀期待的我,发现他在深度研究的时候访问的网站非常的奇怪且不入流,都是各种花边新闻,根本不是 gemini 的那股子干活劲儿,我就发现了 openai 的鸡贼之处.
经过一段时间的思考,我发现我的主力模型还是只能是 gpt, 于是我开始搜索防止降智的方法。经过好一番折腾后,总结最佳方法如下!
环境和软件要求
- clash + 机场 (非常常见的上网环境)
- 一个 https/http 的或者支持 socks5 连接的静态住宅代理
关于静态住宅代理和家宽到底是否有效支持 AI 降智的说法众说纷纭,我只能说,在我不想购买高额的家宽 (动辄几十美元) 也不想折腾 VPS (我也不懂) 的情况下,从各种 proxy 网站购买的一个月大概 5 刀的静态住宅代理绝对能满足我不想 openai 降智的刚需,要是有更好的做法也欢迎各位佬友讨论!
1. 第一步,购买一个静态住宅代理
随便买一个就可以,但是建议买美国的 (日本的也行), 我买了 60days 花了大概 10 刀,仔细找估计会有更有性价比的。一般来说服务会提供 socks5 或者 http 连接,端口不同而已,我们选择 socks 配置方法,在这里我使用了脱敏数据,操作更直观一些.
假设这就是你买到的服务啦
server: 104.21.55.2
port: 20086
type: socks5
username: user_8d9b877
password: pass_7c1ea5
第二步,打开你的 clash
1. 选择 tun 模式 (虚拟网卡模式), 开启 Rule 模式
(这一点都不奇怪对吧)
2. 跳转到订阅界面,右键你使用的订阅,点击编辑文件
之后大概是这个样子
第三步:开始配置
找到类似这部分的代码
proxies:
- {name: "Traffic: 108.45 GB | 400 GB", server: gzdata1.233netbest.com, port: 10011, type: ss, cipher: aes-128-gcm, password: Sj10bnYDe7w6V29E, plugin: obfs, plugin-opts: {mode: http, host: 28fc00eeca.m.ctrip.com}, udp: true}
- {name: "Expire: 2026-01-13", server: gzdata1.233netbest.com, port: 10011, type: ss, cipher: aes-128-gcm, password: Sj10bnYDe7w6V29E, plugin: obfs, plugin-opts: {mode: http, host: 28fc00eeca.m.ctrip.com}, udp: true}
- {name: 🇭🇰 香港实验性 IEPL 专线 1, server: gzdata1.233netbest.com, port: 10011, type: ss, cipher: aes-128-gcm, password: XXXXX, plugin: obfs, plugin-opts: {mode: http, host: 28fc00eeca.m.ctrip.com}, udp: true}
...
也就是以 proxies 开头的部分,在最下面填写你买好的静态住宅服务
proxies:
- {name: "Traffic: 108.45 GB | 400 GB", server: gzdata1.233netbest.com, port: 10011, type: ss, cipher: aes-128-gcm, password: Sj10bnYDe7w6V29E, plugin: obfs, plugin-opts: {mode: http, host: 28fc00eeca.m.ctrip.com}, udp: true}
- {name: "Expire: 2026-01-13", server: gzdata1.233netbest.com, port: 10011, type: ss, cipher: aes-128-gcm, password: Sj10bnYDe7w6V29E, plugin: obfs, plugin-opts: {mode: http, host: 28fc00eeca.m.ctrip.com}, udp: true}
- {name: 🇭🇰 香港实验性 IEPL 专线 1, server: gzdata1.233netbest.com, port: 10011, type: ss, cipher: aes-128-gcm, password: XXXXX, plugin: obfs, plugin-opts: {mode: http, host: 28fc00eeca.m.ctrip.com}, udp: true}
⬇️直接粘贴
- {name: 家宽落地, server: 104.21.55.2, port: 20086, type: socks5, username: user_8d9b877, password: pass_7c1ea5, dialer-proxy: 运载火箭}
dialer-proxy: 运载火箭的作用是声明这个是链式代理,也就是调用这个服务器之前,去运载火箭这个组里的服务器先溜一圈,这样即可以满足流量正常出境,也可以针对 openai 显示美国 / 日本静态住宅的身份,一举两得
继续下拉,找到 proxy-groups 那一栏,按照缩进把这个粘贴进去 (注意缩进在 proxy-groups 栏目的里面)
proxy-groups:
⬇️是你要粘贴进去的
- name: 运载火箭
type: select
proxies:
- 🇯🇵 日本高级 IEPL 专线 1
- 🇯🇵 日本高级 IEPL 专线 2
- 🇯🇵 日本高级 IEPL 专线 3
- 🇺🇸 美国高级 IEPL 专线 1
- 🇺🇸 美国高级 IEPL 专线 2
- 🇺🇸 美国高级 IEPL 专线 3
这里面局部的的 proxies: 如果您和我的不一样,就去找上文的 proxies 服务器,选择几个你最常用的,我这里选了几个,您任选就好.(这一步看不懂可以问 AI)
继续在 proxy-groups 下拉,找到 name 为 OpenAi 的选项,这样进行配置:
- name: OpenAI
type: select
proxies:
- 家宽
完成了
如何使用
关闭设置界面,和我一样操作
如果和您的配置文件差异较大,可以问 LLM, 他一看就懂.
📌 转载信息
转载时间:
2026/1/8 18:09:45






![[开源分享] 专为 nextjs 打造的 cc seo 优化神器1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/08/20260108180947_695f826b5b183.png!mark)