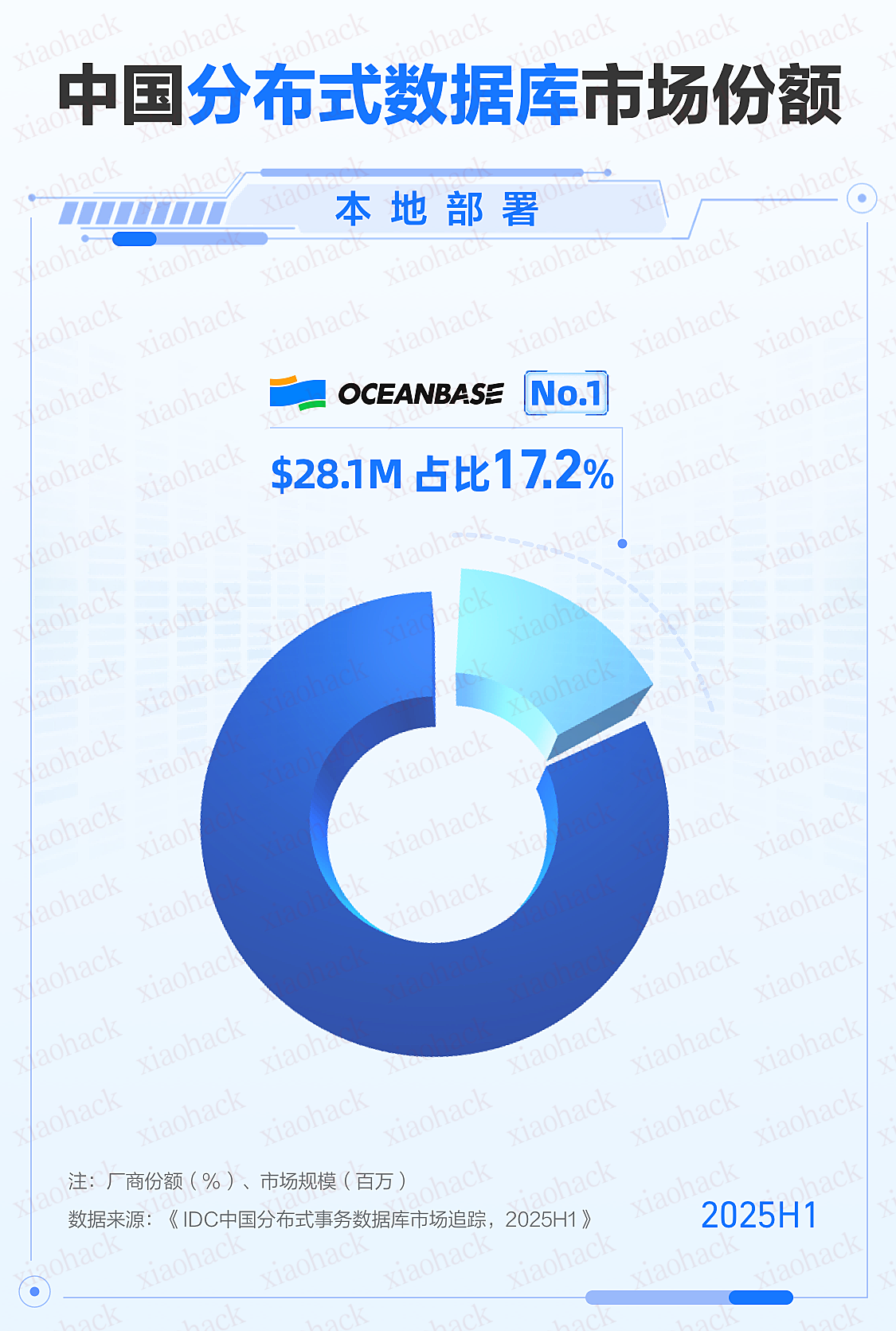
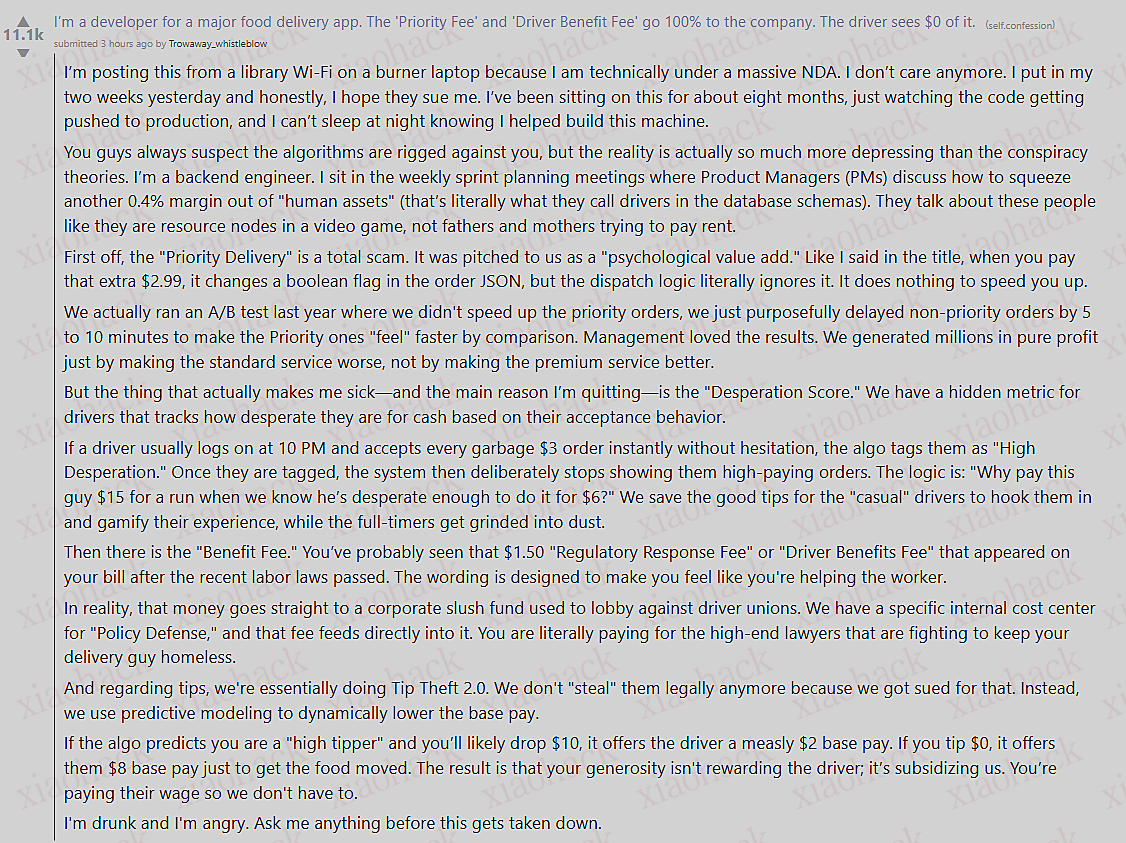
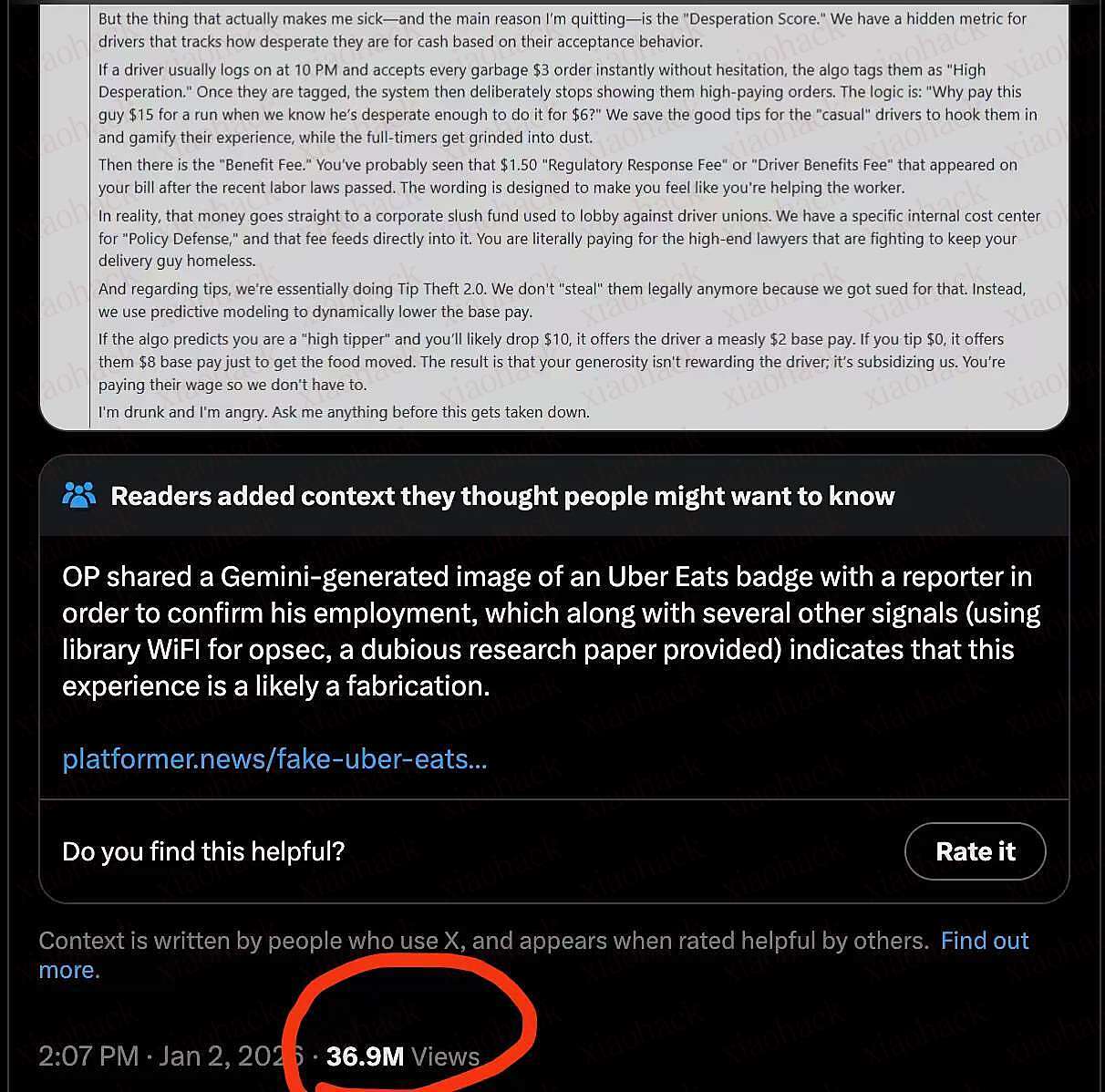
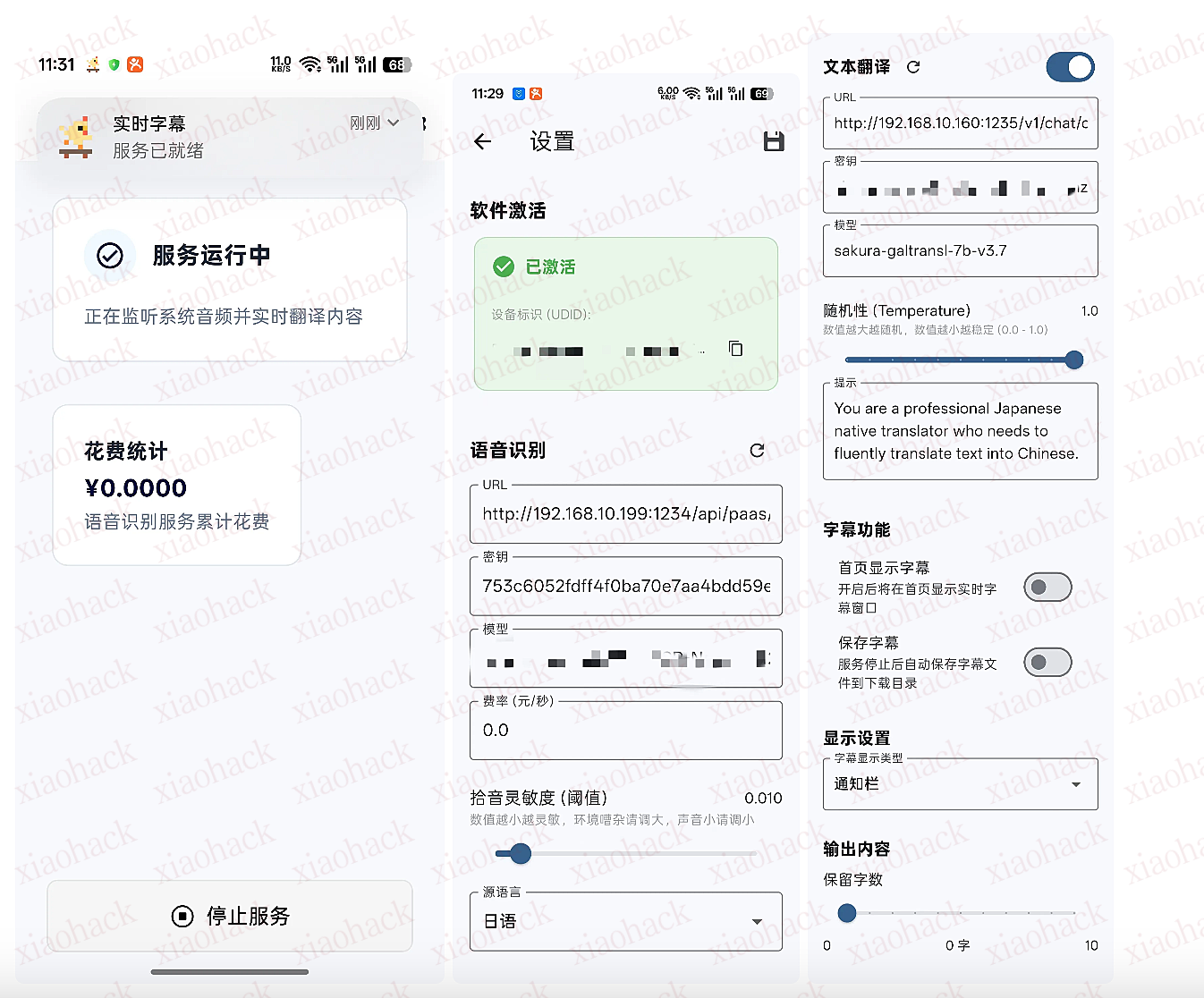
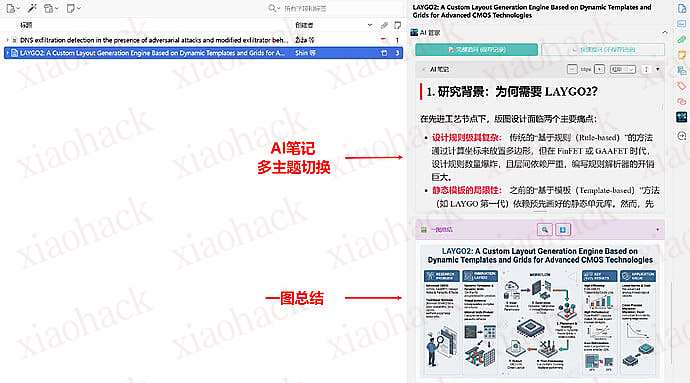
在 2025 年 9 月的云栖大会上,阿里巴巴集团 CEO 吴泳铭发表演讲认为实现 AGI 是个确定性事件,实现全面超越人类的 ASI 才是终局。
ASI 的概念起源,通常会追溯到统计学家 / 密码学家 I. J. Good 在 1965 年发表的文章: “Speculations Concerning the First Ultraintelligent Machine”,在性质上更接近学术随笔讨论。因此,排除所有面向资本市场的叙事后,如何准确理解 ASI ,某种程度上也决定了阿里云的去路和归处。
吴泳铭认为实现 ASI,需要满足两大核心条件:
AI 能获取真实世界的全量原始数据;
实现 “Self-learning(自主学习)”,即 AI 能为自身模型搭建训练基础设施、优化数据流程与升级架构;
两个条件的“基础设施味”都很重,再结合阿里广为人知的 3800 亿投资计划,导向已经十分明显:在一段时间内,阿里云都会是企业在 AI 时代的“隐形”支撑者、赋能者和陪跑者。相比于平台注册数据、公有云 Token 调用数据……客户数据 + 基础设施投产进度,是阿里云业务发展更重要的 KPI。
从市场份额增长到利润下降,二者之间的差值,或许就是寻找 ASI 的“路费”。抛开资本市场不谈,普通人很难理解这份“路费”的价值与合理性,大家更乐于见到“Manus 式”的 C 端产品上岸故事,而不是一家云计算公司如何帮助成千上万家实体企业做 AI 提效。
这也使得 2025 年的阿里云极具“反差感”:一方面,它是中国云计算市场的领头羊,决计要做全球领先的人工智能服务商;另一方面,在最热闹的 AI 营销大战中,它又似乎不那么性感。
阿里云的“反差感”之一: AI 不能只靠“热闹”赚钱
从 2025 年初到 2025 年底,国内的 AI 热度实际是由有限的几个 C 端应用串联而成的,包括了:DeepSeek、元宝、千问、豆包、夸克、蚂蚁阿福等。而 AI 原生 App 的月活,在这些应用的影响下,量级也来到了数以亿计。剩下一部分公共注意力,则被具身智能包揽。
AI ToC 应用的火爆,加速了 AI 的落地。
由于 C 端火热,全民对 AI 的前景抱有期待,让企业内部“要不要上 AI”更容易达成共识。此外大量 C 端产品的出现,造成了技术价值外溢,间接推动提示词工程、Agent 工作流、评测方法、开源工具带入企业。
最后,20% 的头部 ToC 产品瓜分了互联网 80% 的流量,作为数字世界入口,它们把 AI 做成默认功能,倒逼企业被动升级对接与治理策略(尤其是权限、数据边界、知识库)。
应该说,过去一年, AI ToC 实在太热闹了,以至于在 AI 时代,市场教育经常是不需要的。
如果将这些 C 端产品的北极星指标定为“用户价值 x 增长效率 x 商业化质量”,前两者看似已经完成了,独独商业化质量成为了“拦路虎”。
北美 AI ToC 类工具,无论是 Coding 工具,还是搜索工具,一般都是付费订阅的,最低档通常为 20 美元 / 月。而国内大部分 C 端 AI 工具,通常是免费的,没有订阅收入。换句话说,“用户愿付费的核心场景”还没找到。当 C 端竞争主要集中在渠道和入口问题上,这种从“热闹”到“留存 / 付费”的落差,成为了 2025 AI ToC 最大的结构性矛盾。
AI 在 B 端的进展,某种程度上要比 C 端的进展更为顺利。至少在业务的核心评估模型上,不存在明显短板。AI ToB 领域以云模式、项目制 / 交付制为主,目标主要包括:
从拜访结果来看,企业引入 AI 改善业务流程和产品的决心,要比 C 端消费者购买一个 AI 语音助手的决心要大得多。更关键的是,企业使用 AI 具有强连续性的。
在重工业制造领域,诸如 AI 顾问、设备维修助手、智能客服、财务助手、工艺标准 AI 助手、试验在线助手这些新兴事物正在形成的过程中,价值空间巨大。
在农牧业,比如国内两家最大的龙头集团,已实现猪兽医领域大模型"猪小新"、实现猪场猪只数量识别、猪死淘鉴定、后备猪筛选、猪异常行为识别等业务场景,通过体貌图片等数据,实时获取猪群健康信息,交由 AI 系统能够在后台快速完成初步诊断。即便是新手员工,也能凭借平台系统辅助,像经验丰富的养殖专家一样快速判断猪群的健康状况,并及时处置指导,降低了对资深专家经验的依赖。
值得我个人庆幸的是,我从没有把「写文章」作为 2025 年的目标,也从未把它优先放在这一年的计划里。偶尔有几次,我在制定短期计划的时候,以为自己有空,就把「写完某文章」顺手塞进去,作为一个优先级很低的项目。然后,在做完一些优先级更高的事之后,我发现自己用光了时间和精力,于是(第 N 次)搁置了这些低优先级项目。——也即,虽然没做,但是无所谓。
2025 年 1 月 1 日,我在自己全年的 Block Year Planner 上列出了这一年三个最重要的目标,以及相应的时间节点:
对代价的思考,是目标设定前期很重要的一项工作(Bird et al., 2024)。在现实层面上,这是一个很好的「确定优先级(Prioritization)」的问题。结合代价(或者说,目标达成的难度)以及潜在的获益两个维度,我们可以很好地回答「是否值得」的问题。如果实现一个目标收益极高,那么只要代价没高到无法接受,都可以考虑优先列入年度计划。反之,如果一个目标带来的收益不高,但代价却相当高,或许你就不该因为心血来潮把它丢进自己的「目标清单」。
Laborde, S., Kauschke, D., Hosang, T. J., Javelle, F., & Mosley, E. (2020). Performance habits: A framework proposal. Frontiers in Psychology, 11, Article 1815. https://doi.org/10.3389/fpsyg.2020.01815
Lally, P., van Jaarsveld, C. H. M., Potts, H. W. W., & Wardle, J. (2010). How are habits formed: Modelling habit formation in the real world. European Journal of Social Psychology, 40(6), 998–1009. https://doi.org/10.1002/ejsp.674
Matthew D. Bird, Christian Swann & Patricia C. Jackman (2024) The what, why, and how of goal setting: A review of the goal-setting process in applied sport psychology practice, Journal of Applied Sport Psychology, 36:1, 75-97, DOI: 10.1080/10413200.2023.2185699
Sebire, S. J., Standage, M., & Vansteenkiste, M. (2008). Development and validation of the goal content for exercise questionnaire. Journal of sport & exercise psychology, 30(4), 353–377. https://doi.org/10.1123/jsep.30.4.353
Prochaska, J. O., DiClemente, C. C., & Norcross, J. C. (1992). In search of how people change: Applications to addictive behaviors. American Psychologist, 47(9), 1102–1114. https://doi.org/10.1037/0003-066X.47.9.1102
https://linux.do/t/topic/1365022 今天看到一个佬的 X 上信息流筛选折腾感觉思路还不错,但是佬说都是一个一个手动操作的,我觉得还是太麻烦了,自己也折腾发现 grok fast api 也是可以获取的,只是数量获取的少,但是没事,用 grok2api 多个账号并发速度也不慢!
dependencies:flutter:sdk:flutterfreezed_annotation:^3.1.0json_annotation:^4.9.0# The following adds the Cupertino Icons font to your application.# Use with the CupertinoIcons class for iOS style icons.cupertino_icons:^1.0.8dev_dependencies:flutter_test:sdk:flutterflutter_lints:^6.0.0build_runner:^2.10.4freezed:^3.2.4json_serializable:^6.11.3