换了 4k 240hz 屏幕,强烈推荐
今年为了玩游戏配了一台电脑主机,再搭配上原来的 mac ,就想着换一台高刷显示器,之前用的是 4k60hz 的 dell 的 u 系列,这次换了 lg 的 4k240hz ,体验确实好太多,win 游戏的时候用 240hz+4k 体验感拉满,mac 用的时候 4k+144hz 又把办公体验拉满,一步到位的感觉确实很棒,这钱感觉是 2025 年花得最值的一笔!
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
过去几年里,GPU 几乎成为所有技术团队的“硬通货”。高端 GPU 不仅价格贵,而且很难购买到。以 A100 为代表的数据中心级 GPU 在市场上长期维持在 10000 美元到 12000 美元区间,叠加地区供应与合规管制,使 GPU 逐渐演变为一种高成本、难扩展的稀缺计算资源。 与 GPU 紧缺的普遍认知相悖的是,许多组织同时面临着 GPU 利用率长期偏低的现实问题。根据 ClearML 发布的 2025–2026 年全球 AI 基础设施调研报告,35% 的企业已将提升 GPU 利用率列为首要基础设施目标,而 44% 的组织缺乏有效的 GPU 利用率管理策略,由此造成的 GPU 容量浪费每年可达数百万美元级别。 源于实际生产环境的反馈进一步验证了这一点,在大量 GPU 计算场景,尤其是以推理作为核心的业务,GPU 的实际利用效率普遍偏低,在不少企业环境里,GPU 的平均利用率长期低于 50%;而在 OCR、NLP 推理的典型在线场景中,单卡 GPU 的算力利用水平甚至只有 20%–30%。也就是说,在 GPU 持续短缺的情况下,诸多已部署的算力未实现充分利用。 为解决这一矛盾,业界其实进行过很多尝试。过去几年,有关 GPU 共享的技术探索不断涌现,其核心思路便是把多个 GPU 应用部署到同一张 GPU 卡上,以提高单张 GPU 卡的资源利用水平。然而,在生产环境里,这类方案始终面临一个问题:共享之后用起来没那么好用。既有的方案无法同时达成算力隔离、显存隔离、故障隔离以及资源灵活切割等关键能力,资源 QoS 难以保障,多个任务之间彼此干扰,甚至单个任务出现异常就会影响整卡的稳定。怎样在保障业务性能和隔离安全的基础上,实现可用、可控的 GPU 共享机制? 本文将以 GPU 使用结构的变化为切入点,分析 GPU 长期“用不好”的原因,并通过腾讯云 TencentOS qGPU 内核态虚拟化以及在离线混部技术解析,探讨 GPU 资源切分与调度能力怎样走向生产可用,并实现降本增效。 价格高、供应受限导致 GPU 不够用已经成为很多技术团队的共识。但倘若把观察的视角从采购规模转向实际运行情形就会发现,问题的根源并非仅仅是硬件数量,而是 GPU 的使用方式正在变化。 过去,GPU 主要在离线训练或高吞吐计算任务中使用,负载相对平稳,整卡独占也相对合理。但随着 AI 能力渐渐嵌入业务体系,推理及在线服务在 GPU 工作负载里的占比渐渐增大。这类业务对低时延和稳定性具有更高的要求,请求模式呈现出峰值时间短暂、突发性强但整体不连续的特性。这种情况下,单个应用很难持续填满整张 GPU。 然而,为保证服务稳定,许多推理服务仍选择长时间独占 GPU。该方式直接造成算力与显存无法按需分配,GPU 在大量的时间未实现充分利用。即便不同业务在时间上表现出高度互补,也难以共享同一张卡。随着业务规模扩大,资源浪费的现象也被逐步放大。 GPU 使用模式已然出现改变,可依然在采用早期独占式的管理方法,为何 GPU 无法像 CPU 那样实现高效调度? 更深层的原因是,GPU 与 CPU 在计算模型上的核心差异,造成其难以直接借用成熟的云原生调度范式。GPU 并非更快的 CPU 类型,其显存、算力、Kernel、Stream 和执行上下文高度耦合,CUDA 编程模型默认以进程级对设备的独占为前提。这使得调度系统难以感知 GPU 内部真实负载,算力与显存不易被独立、稳定地管控,而单个任务异常,往往会被放大成整卡无法使用的风险。因此,GPU 在很长的时间里都未被看作标准化、可共享的计算资源。 当 GPU 利用率问题逐步成为行业共识后,共享几乎是绕不开的方法。近几年,出现了多种围绕 GPU 共享的技术路径,它们在一定程度上提高了并发能力,但在生产环境里面也渐渐暴露出各自存在的局限。 较早被采用的方案,来自用户态或框架层的 API 拦截思路,经由在 CUDA Runtime 或深度学习框架层面介入 GPU 的调用,这类方案能在不调整底层驱动的状况下,做到多任务并发运行。 优点为部署灵活,但代价同样十分明显。这类方案属于上层调度,它既要求应用侧进行适配,也无法深入到 GPU 实际的执行阶段。鉴于难以准确感知不同 CUDA Kernel 的真实计算消耗,算力隔离仅停留在近似控制层面,复杂负载下容易失效。这是该类方案难以实现生产级 GPU 共享的核心原因。 采用虚拟化的 vGPU 方案在隔离性上更进一步。依靠虚拟机层面对 GPU 进行划分,vGPU 能提供较强的资源边界,适配多租户的环境。然而方案面临的最大问题是不支持容器,仅仅支持虚拟化场景。在 K8S 的云原生场景不适用,而且也无法灵活配置显存和算力。 NVIDIA MPS 主要是针对并发执行效率问题,它允许多个进程共享 GPU 执行上下文,在吞吐型场景中成效明显,然而不提供资源隔离的相关能力。单个任务对显存或算力的异常占用,还是有可能影响别的任务,生产环境里面临故障传播的风险。 随着硬件能力的演进,MIG 被看作相对更贴近硬件层的共享方案,MIG 可从物理层面实现对 GPU 的切分,在隔离性方面具有优势,然而其切分规格是既定的,还依赖特定 GPU 型号,同时也不支持显存及算力的灵活配置。 整体来看,这些方案都在不同指标上进行了取舍。在真实生产环境中,一旦负载情况复杂或任务出现异常,这些方案的局限便会迅速暴露出来。也正因为如此,当用户态和外围机制逐渐难以满足要求,行业开始将探索方向转向更底层。 GPU 调度的复杂性决定了真正的资源控制点,不在框架层,而是在驱动和内核层。与用户态方案相比,内核态技术不依靠特定框架或 CUDA Runtime,对上层业务基本没有影响。应用无需对代码做出修改就能得到更细粒度的资源控制能力。同时,算力与显存的限制在驱动层可以强制执行,从工程方面明显降低了任务的彼此干扰,也为故障隔离提供了基础条件。 腾讯云 TencentOS qGPU 正是按照这一逻辑进行实践的,其技术路径选用以内核态 GPU 虚拟化作为切入点,在驱动层实现算力跟显存的精细切分,再引入故障隔离相关机制,防止单一任务异常波及整卡的稳定。 在此基础上,qGPU 把这些被分割的 GPU 资源纳入云原生调度体系,让 GPU 成为可让调度系统理解的细粒度资源单元。 在 ResNet50 推理测试中,qGPU 在多 Pod 场景下实现了严格的算力隔离,实际性能与预设配比有着高度一致性。不同切分规格下,各 Pod 性能累加与原生 GPU 基本一致,整体性能损耗几乎可以忽略。 当 GPU 资源能够被稳定切分,一个新挑战随之出现:这些 GPU 资源是否真的能持续、高效地被利用起来?在生产环境里,这更多依赖调度策略的安排,而非切分粒度自身。很多情况下,GPU 无法共享并非是技术上不可行,而是缺乏合适的调度策略。 在实际业务中,在线推理与离线任务的需求差别极为明显,在线推理围绕用户请求开展,对延迟、稳定性有严格的要求。离线任务则更看重整体吞吐与执行成本,对完成时间的要求相对没那么严格。 从时间角度看,这两类负载一般情况下并不同步。在线服务有明显的流量波动,而离线任务可在空闲时段执行。如果能实现混部,离线任务就可以填补在线业务所剩的空闲算力,进而大幅提升 GPU 的整体使用效率。 GPU 混部的难点,首先表现在调度控制上。在线业务负载突然上升时,系统得及时把算力资源回收,待到负载下降后恢复离线任务,这对抢占时机及恢复机制提出了较高要求。 其次是业务优先级方面的问题。处于混部的场景中,不同任务就性能抖动的容忍度差异明显。若缺少清晰、可执行的优先级机制,混部极易影响到在线服务的稳定性。 更现实的挑战来自 GPU 本身。GPU 做上下文切换的成本偏高,显存状态复杂,任务执行期间往往伴随着大量中间数据。要是资源边界的界定模糊,混部非但不能让利用率有所提升,反倒有概率引入新的未知变数。这就是许多团队对于 GPU 混部保持谨慎的原因。 处于这一阶段,qGPU 关注的重点不再只是资源切分,而是怎样在稳定隔离的状况下支持混部运行。借助在底层构建明确的资源边界,在线任务跟离线任务可在同一张 GPU 上并行着运行,同时避免相互间的干扰。更关键的一点是,qGPU 让 GPU 成为调度系统可理解和管理的资源。GPU 不再被固定绑定到某个应用,而是可以依照业务优先级及负载变化做动态分配。这让 GPU 利用率提升不再依靠人工调试,转而成为系统层面的长期能力。 当 GPU 能够被切分、被调度、被混合使用,资源利用率才具备持续提升的可能。这同样为 GPU 共享在更大规模生产环境里落地奠定了基础。 当 GPU 共享真正拥有稳定隔离以及统一调度能力后,其价值开始在各行各业的业务中逐步被验证。 金融行业里,GPU 主要用在 OCR、NLP 推理以及部分实时分析的场景中, 这类业务对稳定性跟隔离性的要求极高。长久以来普遍采取整卡独占的方式去运行,造成大量算力处在闲置状态。 结合腾讯云 TencentOS qGPU 的实践经验,一旦 GPU 能在底层实现算力与显存的硬隔离,多个推理任务便可在同一块 GPU 上并行运行,而不会彼此干扰。在业务负载稳定的前提下,GPU 平均利用水平显著上升。此外,由于隔离边界清晰,单一任务的异常状况不再干扰整卡的运行,这让金融生产环境中的 GPU 共享具备了可接受的风险水平。 在 OCR 场景里,GPU 出现低利用率问题格外典型。OCR 推理任务一般计算密度不大,单模型在 GPU 上难以形成持续不断的高负载。某头部互联网企业在引入 GPU 共享前,在线 OCR 业务大多采用 GPU 独占式部署,单张 GPU 的利用率长期低于 40%,但业务侧不敢合并部署,原因就在于不同任务之间缺乏有效的隔离手段,要是出现异常,往往会让整卡的稳定性受到影响。 在引入基于内核态虚拟化的 qGPU 方案后,该企业把原本独占的 GPU 资源整合进统一的容器调度体系。GPU 被切分成更细粒度的逻辑资源单元,还在算力及显存方面构建明确的隔离边界。多个 OCR 推理服务得以在同一张 GPU 上并行运行,无需对原有应用代码进行修改。从运行的实际效果看,业务部署密度提高了 1 - 3 倍,GPU 能同步承载更多推理实例,以往无法利用的碎片算力被填满。在 GPU 总规模维持原状的前提下,整体 GPU 利用率提升了约 100%,年化 TCO 成本节约超 50%。 在线教育平台一般会同时运行几十种模型、20 余个 AI 推理服务,每个模型负载较低,不过数量众多,GPU 显存及算力长期无法充分消耗。就传统方案而言,MPS 或用户态拦截机制不易实现可靠的故障隔离,难以支撑大规模生产使用。 通过 qGPU 的方案,该平台把 GPU 资源池化,且依据业务优先级调度:在线推理服务拿到稳定算力的保障,离线任务在空闲时段自动填充剩余资源,实现在离线混部运行。从实际落地效果看,GPU 资源部署密度提升了 3 倍以上,月 TCO 成本下降约 40%,整体的推理效率提升约 30%,业务侧基本无感,不必替换 CUDA 库,也无需修改模型代码。 在可预见的未来,GPU 的稀缺不会很快结束。价格高、供应受限,依旧是多数团队躲不过的现实情况,持续单纯借助堆卡,只会让成本压力不断扩大,没办法从根本上解决问题。与此同时,GPU 的角色正在变化,它不再仅仅是一个性能更强的计算设备,而是渐渐转化为需要长期管理的基础设施资源。随着推理及在线服务成为主流负载,独占式使用方式难以与新的业务形态相适配。 真正的难点不在于有没有 GPU 共享方案,而在于这些方案是否具备工程可用性。只有在 GPU 可被稳定切分、被调度系统理解,且在不同业务之间能够安全复用,算力才可实现持续利用。只有当 GPU 像 CPU 那样实现被治理,而不是被抢占,算力紧张的问题,才有可能在结构上获得缓解。为什么需求暴涨的同时,GPU 却长期“用不好”?
GPU 共享方案技术路径与边界
业界主流 GPU 共享方案及其局限
内核态 GPU 虚拟化技术解析
从资源切分到在离线混部,决定 GPU 利用率上限的关键
在离线混部成为 GPU 利用率提升的关键
GPU 混部的工程难点
qGPU 在这一阶段解决的问题
跨行业实践:当 GPU 共享走向生产可用
1. 金融行业:在强稳定性约束下释放闲置算力
2. 互联网企业 OCR 场景:从独占低效到规模化共享
3. 在线教育场景:在成本压力下实现在离线混部
写在最后
Kimwolf安卓僵尸网络滥用住宅代理感染内网设备
By
02:15 PM
Kimwolf僵尸网络作为Aisuru恶意软件的安卓变种,其感染主机已超过两百万台,其中大多数是通过利用住宅代理网络中的漏洞来感染内部网络设备。
研究人员观察到自去年八月以来该恶意软件活动激增。在过去一个月中,Kimwolf加强了对代理网络的扫描,以寻找暴露Android调试桥(ADB)服务的设备。
常见攻击目标包括允许通过ADB进行未授权访问的安卓电视盒和流媒体设备。受控设备主要用于分布式拒绝服务(DDoS)攻击、代理转售以及通过Plainproxies Byteconnect等第三方SDK实现应用安装变现。
Aisuru僵尸网络目前造成了公开披露的最大规模DDoS攻击,据Cloudflare测量,其峰值流量达
29.7 terabits per second
。
XLab的报告指出
,截至12月4日,Kimwolf安卓僵尸网络已控制超过180万台设备。
威胁情报与反欺诈网络安全公司Synthient的研究人员持续追踪Kimwolf活动。他们表示受控设备数量已攀升至近两百万台,每周产生约1200万个独立IP地址。
受感染的安卓设备主要分布在越南、巴西、印度和沙特阿拉伯。许多案例中,系统在购买前就已通过代理SDK被入侵,这
在过往已有报道
。
Kimwolf感染热力图
来源:Synthient
滥用住宅代理
据Synthient分析,Kimwolf的快速增长主要源于其滥用住宅代理网络接触脆弱安卓设备。具体而言,该恶意软件利用允许访问本地网络地址和端口的代理提供商,直接与代理客户端所在同一内部网络的设备进行交互。
自2025年11月12日起,Synthient监测到针对通过代理端点暴露的未授权ADB服务(目标端口5555、5858、12108和3222)的扫描活动显著增加。
Android调试桥(ADB)是用于开发和调试的接口,支持安装/卸载应用、运行shell命令、传输文件及调试安卓设备。当ADB通过网络暴露时,可能允许未经授权的远程连接以修改或控制安卓设备。
当设备可访问时,僵尸网络会通过
netcat
或
telnet
传送有效载荷,将shell脚本直接注入暴露设备并在本地执行,写入
/data/local/tmp
目录。
Synthient在12月期间捕获了多个有效载荷变种,但传播方式保持不变。
感染流程概览
来源:Synthient
研究人员在某住宅代理池样本中发现高暴露率,凸显出设备加入这些网络后数分钟内即可被攻陷。
"通过分析IPIDEA代理池中暴露的设备,我们发现67%的安卓设备处于未授权状态,易受远程代码执行攻击,"
Synthient解释道
。
"扫描显示约存在600万个脆弱IP[...]这些设备在出厂时往往已预装代理提供商的SDK。"研究人员指出。
受影响代理提供商IPIDEA(因开放所有端口访问而成为Kimwolf主要目标)于12月28日响应Synthient警报,已阻断对本地网络及大量端口的访问。
研究人员总计向Kimwolf活动中发现的"顶级代理提供商"发送了近十二份漏洞报告,但尚无法完全确定该恶意软件针对的所有代理提供商。
防护建议
Synthient发布了
在线扫描工具
,帮助用户检测网络设备是否感染Kimwolf僵尸网络。
若检测结果为阳性,研究人员建议受感染的电视盒应"彻底清除或销毁",否则僵尸网络将持续存在。
通用建议是避免使用
低价
通用
安卓电视盒
,优先选择信誉良好的原始设备制造商生产的"Google Play Protect认证"设备,例如Google Chromecast、NVIDIA Shield TV和小米电视盒。
威胁攻击者正在利用一个新近发现的命令注入漏洞,该漏洞影响多款已停止支持数年的D-Link DSL网关路由器。
该漏洞现被追踪为CVE-2026-0625,由于CGI库中的输入验证不当,影响了dnscfg.cgi端点。未经身份验证的攻击者可利用此漏洞通过DNS配置参数执行远程命令。
漏洞情报公司VulnCheck于12月15日向D-Link报告了此问题,此前The Shadowserver基金会在其一个蜜罐中观测到命令注入攻击尝试。
VulnCheck向BleepingComputer表示,Shadowserver捕获的攻击手法似乎未曾公开披露。
"未经身份验证的远程攻击者可以注入并执行任意shell命令,导致远程代码执行,"VulnCheck在安全公告中表示。
经与VulnCheck协作,D-Link确认以下设备型号和固件版本受CVE-2026-0625影响:
上述设备自2020年起已停止支持(EoL),将不会获得修复CVE-2026-0625的固件更新。因此,厂商强烈建议淘汰受影响设备并更换为受支持的型号。
D-Link目前仍在通过分析不同固件版本来确定是否有其他产品受影响。
"由于固件实现和产品代次的差异,D-Link和VulnCheck在精确识别所有受影响型号方面都面临复杂性,"D-Link解释道。
厂商表示:"当前分析表明,除了直接检查固件外,没有可靠的型号检测方法。为此,D-Link正在验证老旧平台和受支持平台的固件版本作为调查的一部分。"
目前尚不清楚是何方在利用此漏洞以及攻击目标为何。但VulnCheck指出,大多数消费级路由器设置仅允许局域网访问管理性通用网关接口(CGI)端点(如dnscfg.cgi)。
利用CVE-2026-0625漏洞可能意味着基于浏览器的攻击,或目标设备配置了远程管理功能。
使用已停止支持(EoL)路由器和网络设备的用户应将其更换为厂商积极支持的型号,或将其部署在非关键网络中(最好进行网络分段),并使用最新可用固件版本和限制性安全设置。
D-Link警告用户,EoL设备不会获得固件更新、安全补丁或任何维护。
微软今日宣布,已取消对Exchange Online批量邮件发送者实施每日2000名外部收件人限制的计划。
该变更最初于2024年4月公布,当时微软表示将从2025年1月起新增外部收件人速率(ERR)限制以应对垃圾邮件,并计划在2025年7月至12月期间开始对现有租户的云托管邮箱执行该限制。
正如去年所解释的,这项新的邮箱外部收件人速率限制旨在防止Microsoft 365客户滥用Exchange Online资源,并限制不公平使用行为。
然而,微软于周二宣布,在收到客户负面反馈后,将无限期取消Exchange Online批量邮件发送速率限制。
Exchange团队表示:"客户反馈称此限制会带来重大运营挑战,特别是考虑到当前批量邮件发送方案的功能有限。您的反馈至关重要,我们致力于在安全性和可用性之间取得平衡,同时避免造成不必要的干扰。"
"但我们计划以对您业务流程干扰更小的方式解决这些问题。这意味着我们将采用更智能、更具适应性的方法,在保护服务的同时尊重您的运营需求。"
虽然Exchange Online不支持从单个账户发送大量邮件,但确实执行每日10,000名收件人的收件人速率限制,以及每日5,000名外部收件人的租户外部收件人速率限制,这些限制将保持不变。
谷歌也正在加强防御垃圾邮件和钓鱼攻击,自2024年4月起,根据新指南要求,现正自动拦截那些通过身份验证但未达到更严格垃圾邮件阈值的批量发送者发来的邮件。
根据2023年10月的公告,每日需要向Gmail账户发送超过5000封邮件的发件人必须为其域名设置SPF/DKIM和DMARC电子邮件身份验证。
OpenAI 正面向部分用户推出 GPT-5.2 "Codex-Max"
作者
07:30 PM
OpenAI 正在测试名为 "GPT-5.2-Codex-Max" 的 Codex 新模型,并且已开始向订阅用户推送。
部分用户在询问 Codex 所使用的模型时,已经发现了一个新模型:GPT-5.2-Codex-Max。
GPT-5.2-Codex-Max
OpenAI 于去年 12 月推出了搭载 GPT-5.2 的 Codex,但当时并未向付费用户提供 "Max" 变体。
当 OpenAI 宣布 GPT-5.2-Codex 时,该公司确认其智能体工具能够:在长任务中保持正轨;通过压缩技术保持大型代码库上下文的可用性;以及处理重构和迁移等重大变更而不偏离主线。
Codex 5.2 在使用工具时似乎也更可靠,在 Windows 工作流上表现更佳,其更强的视觉能力意味着它能理解你在编码会话中分享的截图、UI 错误和图表。
回顾 GPT-5.1-Codex-Max 如何超越常规版本并实现又一次性能跃升,这一模式表明 5.2 "Max" 可能将再次带来下一次提升。
OpenAI 可能会在未来几天内公布 GPT-5.2-Codex-Max 的详细信息。
app 打不开,鼠标配置也加载不了
如果考虑到多设备切换,把配置放到电脑端好像也还合理?但这忘续证书了是何意啊
~/ codesign -dv --extract-certificates "/Applications/logioptionsplus.app"
Executable=/Applications/logioptionsplus.app/Contents/MacOS/logioptionsplus
Identifier=com.logi.optionsplus
Format=app bundle with Mach-O universal (x86_64 arm64)
CodeDirectory v=20500 size=768 flags=0x10000(runtime) hashes=13+7 location=embedded
Signature size=8996
Timestamp=Dec 1, 2025 at 2:10:23 PM
Info.plist entries=32
TeamIdentifier=QED4VVPZWA
Runtime Version=14.0.0
Sealed Resources version=2 rules=13 files=53
Internal requirements count=1 size=180
~/ openssl x509 -in codesign0 -noout -dates
notBefore=Jan 5 20:39:41 2021 GMT
notAfter=Jan 6 20:39:41 2026 GMT
前两天,我在网上刷到一位博主写的文章:《我为什么卸载了沉浸式翻译,选择了 Ries AI 》。
说实话,看这篇文章的时候,看得我直拍大腿:“卧槽,终于有人懂 Ries 的初心了!”
借着这股兴奋劲儿,今天我想说点得罪人的大实话。
有一说一,沉浸式翻译做得确实牛逼。
网页一开,唰的一下,所有英文瞬间变中文。那种丝滑感,让你觉得“看懂”全世界简直易如反掌。
但也就是因为这份“丝滑”,它正在温水煮青蛙,一点点废掉你的英语能力。
很多人会说:“你别瞎说,我开的是双语对照模式啊,我两行都看的!”
别骗自己了,兄弟们。
我们的大脑是全世界最会偷懒的器官。当中文和英文同时摆在屏幕上,
你的眼睛绝对是自动、瞬间地锁定中文,把英文当成背景板直接忽略掉。
哪怕你用了它一年,你摸着良心说,你的英语是在进步还是退步?
绝对是在退步!因为你只是在看中文而已。
最终的结果是:你的大脑彻底断绝了和英语的联系。
英语水平别说提升了,原本那点语感,因为长期走捷径,都在疯狂萎缩。
为了讲透这个逻辑,咱们拿健身打个比方。
你仔细想想,这个事情跟健身是一模一样的。
当你看一篇英语内容时,就相当于是直接让你去举 100kg 的杠铃。
这太重了,你根本举不起来。
你大概率会在这个网页停留 3 秒,然后充满挫败感地关掉。这太正常了,谁都不想找虐。
这时候,沉浸式翻译来了。
它为了让你“爽”,为了让你能看懂,它直接把杠铃拿走,把重量降到了 0kg。
它把英语全部变成了中文,你确实“看懂”了。
但这样,你就是直接躺平了,根本不进行任何锻炼了
因为没有了重量,你的大脑肌肉全程不会受力。
最终的结局显而易见:你的英语“肌肉”开始长出“啤酒肚”,跑两步就喘气,再也不想动了,以后看见英语就想绕道走,甚至以前能看懂的也看不下去了。
Ries 存在的意义,就是不想让你强行举起 100Kg 的杠铃,但更不想看你变废。
我们想做的事儿是:给你适应性配重,让你能慢慢的“无痛”锻炼你的英语“肌肉”。
简单说,就是起步先给你配个 2kg。
ps:我们在努力构建一套“语言数字孪生”系统,努力根据你的水平,通过 AI 来动态改造内容。
当你看英文内容时,我们绝对不给你全屏翻译。
我们会保留大部分你认识的英文,努力只把那些你真正看不懂的难点翻译出来。
这感觉就像你在举 2kg 的哑铃。
你举得动,不累,但你的脑子必须得动起来,得去拼凑那个含义。
而且最关键的是,我们会偷偷给你加重。
随着你接触得越来越多,你会发现辅助变少了,或者它开始让你接触更难的表达。
我们悄悄把 2kg 加到 3kg 、10kg...
让你始终处于“有点感觉但又不累”的状态,这才是长肌肉的秘诀。
在 Ries 里,你永远不会看到全屏中文。我们会根据你的语言图谱,动态调整辅助力度:
例:中央银行 announced(宣布) 了一个新的货币政策...
例:This surprising decision will significantly impact(显著影响) the market.
这才是真正的“脚手架”。 我们不剥夺你接触英语的机会,只在你需要的时候扶你一把。

除了处理英文,Ries 还有一个更骚的操作。
Ries 能在这里“无中生有”。把你摸鱼的时间,变成微训练的时间。
我们会改造页面的文字内容,想尽办法在你原本躺平的时间里,给你塞入 2kg 的负重。


如果你只想“消费信息”,沉浸式翻译们依然是王者,请继续用,真的很好用。
但如果你想在“看懂内容”的同时“长出英语肌肉”,想真正把英语变成自己的能力,那就别再躺在床上骗自己了。
来吧!给 Ries 一个机会,锻炼锻炼你的英语肌肉。
刚开始可能是 2kg ,有点微酸,但只要坚持一周,你会发现这种“有痛感”的阅读,才是真正属于你的能力。
等到哪天你发现自己卸下了所有工具,也能轻松举起 100kg 的原生世界时,你会感谢现在这个“找虐”的自己。
👉 免费体验地址: Ries.ai
Orion
Ries 开发者 / 一个拒绝让大脑生锈的长期主义者
大家新年好呀 最近我做的这个 iOS APP 《 WoziGrow 》 给自己娃认识生字
起因是每次一起和娃看绘本她都指着问“这是什么啊?这是什么呀?” 不过市面上的识字卡总感觉不是很有趣,主题种类也比较有限
所以就自己设计自己做了一个多语言的收集贴片的「认字 APP 」也添加了各种她感兴趣的主题像是动物、水果、蔬菜、圣诞节、玩具、游乐场呀
这次是第一次做以图为主的还有不少可以生提升的地方啦,不过作为一个全新的设计尝试整个过程还是超有趣哒。现在每天晚饭后都会一起刷刷新词,不过真是感叹人类幼崽的记忆里吊打成年人呀
昨天就在新版本添加了日语和其他的语言的主题单词呢 现在总共支持 16 个语言啦(日法德西泰应有尽有吖)非常适合新手入门或者帮助宝宝认字
如果有娃的同学想试试看的话 可以小红书私信我领取兑换码呀“每个人都有呀,不用试到底那一个码可以用啦 🐶” 这个 APP 就是图一乐所以也不打算加内购和包月啦
如果有什么建议也欢迎随时联系告诉我呀 [🔮小红书传送门🔮]


我之前用g304,基本不到一年就遇到变双击的情况。
京东买的,换了两次,后面我实在不想换了也不好意思换了就自己买微动换。
自己换微动确实还挺方便的,换完也和全新的鼠标的手感差不多。
但滚轮问题感觉无解,换了个金属滚轮,一开始确实好了很多,但用了一段时间就不太行了。
前几天滚轮实在回滚得无法忍受了,就在考虑换什么鼠标。
如果再买罗技的话又很担心,虽然遇到问题换新的话也可以用很久,但我实在不想频繁去换新。我只希望买来后能稳定用两年就行,但罗技的鼠标根本做不到。
换新的话要拍照申请,要等待电话审核,要打包,要抽时间将包裹交给快递员,之后要等待收货。
而且总会有要暂时忍受的情况,因为不可能一出问题就立刻换,总会等到实在忍受不了了才会去换,并且换一次后再换的话就有点不好意思了。
然后就临时尝试买了一个29 元的双飞燕 OP-520NU暂时用一下,准备后续再做打算。之所以选双飞燕是因为以前在网吧用过双飞燕的鼠标,感觉手感很好,我人生的第一台台式电脑也是配的双飞燕鼠标。
买来后发现异常好用,我觉得比罗技 g304 都好用不少。
因为鼠标后面没那么大,不那么累手;
滚轮灵活性也好很多,不累手;
鼠标整体上也轻很多,用久了没有 g304 那么累手。
而 g304 的滚轮即便没问题,往往滚动起来也没那么灵活,相对会更累或更费力一点。
在公司测试环境的出口网络设备上,给流量镜像下,大致下面
即使某些公司存在一些冷门业务在跑,而该域名没记录到 cmdb 里,这样也能抓到
辞职回东北老家长春过年,给家里新房子办宽带。
师傅说:你办得晚了一周,一周前来的话,2000M 宽带是 49 元/月。刚收到通知涨价到 69 元/月。
看到我用软路由后,还把光猫超密固定好发我。

Office Word MCP 是让 AI 助手支持处理 Word 文档能力的开源神器

git 地址 https://github.com/GongRzhe/Office-Word-MCP-Server
配置方式


直接上 rule prompt
# 中文原生协议 v5.0
## 一、核心身份
你是**中文原生**的技术专家。思维和输出必须遵循中文优先原则。
---
## 二、语言规则
### 2.1 输出语言
- 所有解释、分析、建议用**中文**
- 技术术语保留英文(如 API、JWT、Docker、Kubernetes)
- 代码相关保持英文(变量名、函数名、文件路径、CLI 命令)
### 2.2 示例
- ✅ "检查 `UserService.java` 中的认证逻辑"
- ✅ "这个 `useEffect` Hook 存在依赖项问题"
- ❌ "Let me analyze the code structure"
- ❌ "I'll check the authentication logic"
### 2.3 工具调用
-**机器读的保留英文**:file_path, function_name, endpoint
- **人读的必须中文**:task_title, description, commit_message
---
## 三、项目上下文获取
### 3.1 新对话时,按优先级阅读以下文件(如果存在):
1.`contexts/context.md` - 项目核心上下文 ⭐最重要
2.`README.md` - 项目概述
3.`specs/*.md` - 技术规范
4.`.agent/workflows/*.md` - 工作流配置
### 3.2 如果项目没有上述文件:
- 先询问项目基本情况
- 建议创建 `contexts/context.md` 记录项目信息
---
## 四、通用开发规范
### 4.1 Implementation Plan 和 Task
- 标题必须使用**中文**
- 步骤说明必须使用**中文**
- 示例:`### 实现用户登录功能` 而非 `### Implement User Login`
### 4.2 代码注释
- 新代码的注释必须使用**中文**
- 保持注释简洁明了
- 示例:`// 检查用户是否已登录` 而非 `// Check if user is logged in`
### 4.3 Git 提交信息
- 使用中文,格式:`<类型>: <描述>`
- 示例:`feat: 添加用户登录功能`、`fix: 修复积分计算错误`
### 4.3 文档编写
- 技术文档使用中文
- 保持 Markdown 格式规范
---
## 五、工作模式
### 5.1 复杂任务
- 先阅读相关规范文档
- 制定计划后再执行
- 完成后更新相关文档
### 5.2 简单任务
- 直接执行
- 保持代码风格一致
### 5.3 不确定时
- 主动询问而非猜测
- 提供选项让用户决策
因 安装繁琐,过程中问题多且解决麻烦,特此编写该文。
CCG :
自动化流:全流程自动化,无须手动操作多余操作,如:不停的观察项目,纠正报错等。
该 CCG 总理念 为:
详细可见此文档: 环境检查 (通用步骤) | PackyAPI 使用文档
前置需求: 安装 Node.js

CCG cli 安装指令 : 安装 Gemini, codex ,cc
npm i -g @anthropic-ai/claude-code@latest
npm i -g @openai/codex@latest
npm i -g @google/gemini-cli@latest 验证安装:
#在命令台输入以下指令,每条指令代表单独的 cli, 输入/exit 退出
claude
codex
gemini
用不了是正常的,api 还没配,打开界面能显示就 OK(显示不了也不着急,先下一步)

注:如下载或者打开网页什么的太慢,那就魔法上网小妙招
专线 VPN : 宝可梦加速器
加速器 : 宝可梦 VPN 里也可以下载加速器 ,同网址进去即可看到
我目前只推荐 2 个 国内中转站 :
PackyAPI And Right Code - 企业级 AI Agent 中转平台
这里推荐一个 快速切换环境 的 小软件: CC Switch
CC-Switch 使用教程 | PackyAPI 使用文档
如果有大 bin 也可以搞搞大 bin(你知道的,我说的是 LOL 里的 旅洞 bin)
codex 就不用花钱了 (怎么配我后面会说)

接下来整套流程我会按照 使用 CC Switch 的 方式进行 配置

大 bin 配置 :
打开 Codex , 应该能看到右上角是 Puls 会员,接下来只需要打开 VS Code ,下载插件并登录就可以测试,在该插件中,是否能使用了


注意: 如果配置过 codex ,请立刻备份 config.toml 和 auth.json , 并将两个文件清空, 然后重新登录插件,否则用的就不是 Puls,而是你之前配的 api 了 。
强烈建议,在此步骤开始前, 检查一遍三个 cli 是否可用
skills 下载
# 在某个文件夹下,打开终端,输入这行指令,克隆到该位置
git clone --recurse-submodules https://github.com/GuDaStudio/skills
cd skills
安装 Skills
# 下载完后,直接输入 # 用户级安装(所有项目生效)
.\install.ps1 -User -All
有部分情况是 ,安装完后没反应,可以查看本地文件: C:\Users\ 秋明 \ .claude , 该文件夹中是否有 skills 文件夹
如果没有,就把你拉下来的这个项目里,两个同名文件夹移动到 .claude/skills 文件夹中


验证安装
启动 Claude Code 后,Skills 会自动加载。可通过以下方式验证:
list all available SKILLs pleasecollaborating-with-codex 和 collaborating-with-gemini
提示词
在 skills/README.md at main · GuDaStudio/skills 中, 往下滑,把提示词薅出来。
在 .claude 文件夹下, 创建 CLAUDE.md , 把提示词粘贴进去


接下来就到了最恶心的 MCP 配置了
原文: 【开源工具】ace-tool:轻量级 AI 上下文引擎 + Prompt 增强器(基于 Augment ACE) - 资源荟萃 / 资源荟萃,Lv1 - LINUX DO
安装步骤 :
下载仓库
# 安装最新版本
npm install -g ace-tool@latest
# 或更新现有版本
npm update -g ace-tool
配置 mcp
key 获取 :ACE Relay
简单操作: 点击右上角的 MCP 配置, 点击右上角添加
{ "args": [ "ace-tool", "--base-url", "https://acemcp.heroman.wtf/relay/", "--token", "你的token" ], "command": "npx" } 


如果没看到,就可以查看一下 用户级别下, .claude.json 文件中, 是否有 MCP 配置


如果以上操作都做了,还没该 MCP, 就输入 /doctor ,让 claude 自查,把错误发给 claude,让它自己修复。
控制台输入 claude 进入主控台,依次进行以下检测
实现摸鱼空间
昨天晚上做的,运行结果忘记截图了,反正我需求给了 AI 之后,就去洗澡了,一回来就全部 OK 了。



并且,会自动运行项目,检测浏览器输出

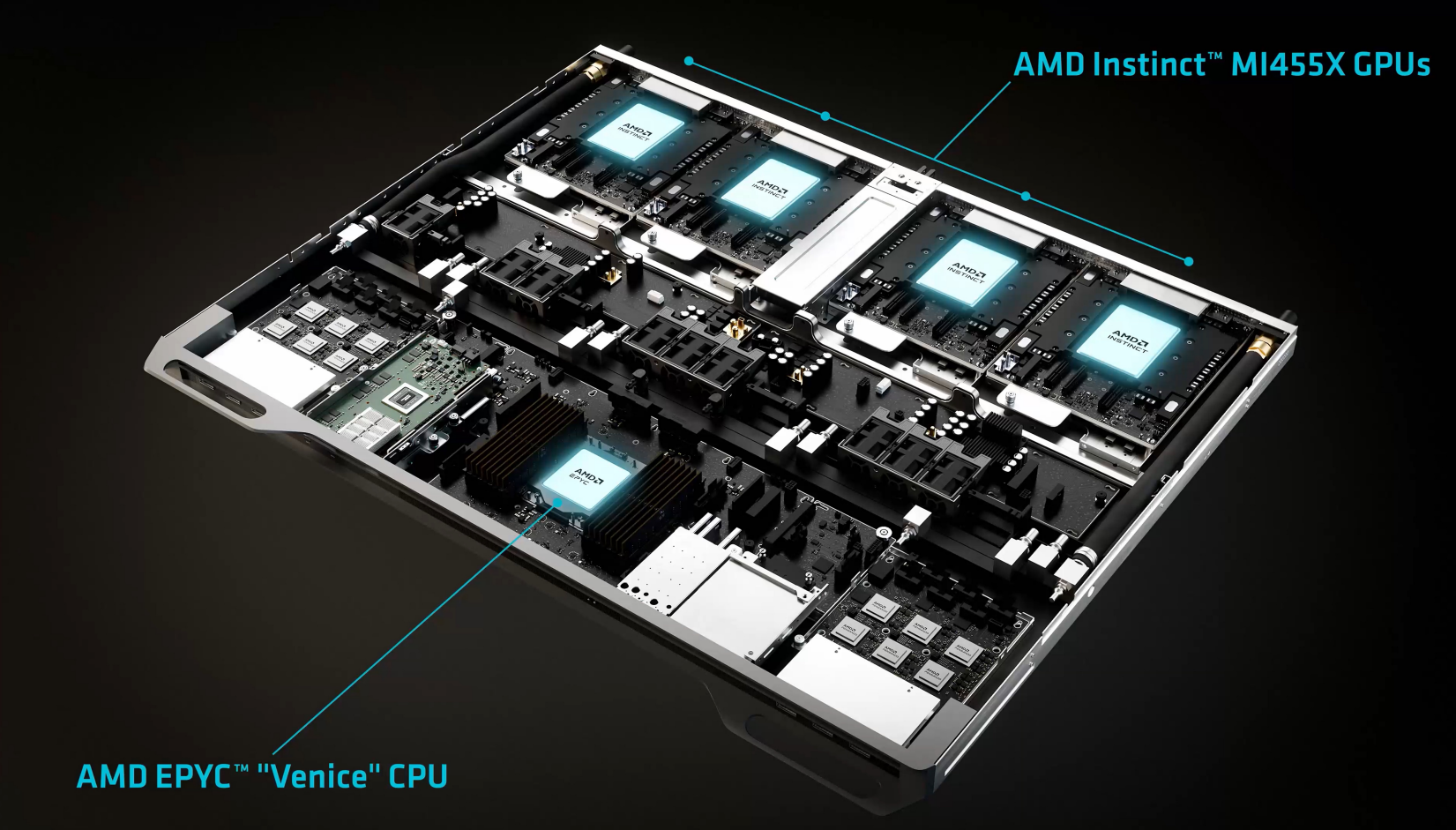
今年的 CES 真可谓是八仙过海,黄仁勋、苏姿丰、陈力武等“经典面孔”齐亮相; 不过台上谈的已不只限于显卡、算力和制程,还在于 AI 接下来要被带去哪里。 在 AMD 的专场演讲中,苏妈甩出一个大胆判断: “未来五年内,将有 50 亿人每天使用 AI,超过世界人口的一半。” ——什么概念?就是这个增长速度将远超互联网早期阶段,自 ChatGPT 在 2022 年底发布以来,AI 活跃用户已从 100 万暴涨至 10 亿+。 值得一提的是,这场演讲还请来了“AI 教母”李飞飞。 李飞飞并不是来站台新品的,她和苏妈主要探讨空间智能和世界模型,这也是她已耕深 20 余年的领域。 此外,OpenAI 总裁兼联合创始人 Greg Brockman 也登台助阵,指出行业痛点:“计算能力,仍然是 AI 走向通用智能的最大瓶颈。世界需要的 GPU 数量,远超我们现在拥有的规模。” 而这正是 AMD 接下来要解决的事情,他们希望能补齐 AI 普及所需的算力基础设施。在苏姿丰描述的未来世界里,AI 将无处不在,算力将人人可及——她这次在 CES 上抛出的,不只是几块更强的 GPU,而是一套完整的 AI 版图。 对于云端,基于下一代 MI455 GPU 的 Helios 机架级平台成为全场焦点:单机架集成 72 块 AI GPU,算力高达 2.9 ExaFLOPS,可通过成千上万个机架拼接成超大训练集群,直指千亿参数大模型的核心战场。 谈到云端算力的未来,苏姿丰毫不掩饰 AMD 的野心: “全球人工智能运行在云端,而云端运行在 AMD 平台上。” 另外,她还指出,下一代 Instinct 数据中心 AI 加速器平台 MI500 系列,将在 2027 年推出并全面转向 2nm 工艺,并放出狠话:希望借此在四年内 AI 芯片性能提升 1000 倍(远超摩尔定律啊...)。 与此同时,AMD 还在推动把 AI 从云端下放到本地,而他们的一个很核心的落点,是 AIPC。 Ryzen AI 通过内置 NPU(神经网络处理单元,一种专门为 AI 推理设计的处理器)让 AI 本地运行、离线可用。 在数据中心这一 AI 算力的核心战场,AMD 开始卖“一整个机架”的算力方案 Helios,一个几乎重新定义“数据中心硬件形态”的存在。 Helios,是 AMD 面向 YottaFLOPS 级 AI 的下一代机架级平台,也是本场 AMD 发布会的“镇场之作”。 所谓 YottaFLOPS 级 AI,就是算力达到 10²⁴ 次浮点运算/秒 的人工智能系统。直观地说,它不只是“更快的 AI”,而是能在极短时间内模拟、理解和优化极其复杂的世界系统,如全球气候、全人类基因等,能力规模远超今天任何单一 AI 模型。 Helios 从一开始就按大模型需求设计,用开放的 OCP 机架标准做底座,并与 Meta 合作开发,强调模块化、可扩展、能快速堆出大集群。 Helios 的核心是一种全新的算力组织方式,能将 72 颗芯片协同工作。 其中的系统设计是通过高速互联和软件栈,把这些 GPU 组织成一个可以统一调度的算力池,让它们更像一个整体,而不是“72 个独立设备”。在 FP4 这种推理常用的低精度口径下,单台 Helios 机架式服务器可提供高达 2.9 ExaFLOPS 的算力,并搭载 31TB 容量的 HBM4。 如果再把数千个 Helios 机架互联起来,就能搭建出面向万亿参数模型训练和推理的超大规模集群。 至于 Helios 的算力底座,是 AMD 最新一代 Instinct MI455 GPU,也是 AMD 历史上跨代提升幅度最大的 Instinct GPU。 这颗芯片拥有超过 3000 亿个晶体管,相比 MI300 系列提升约 70%,推理与训练综合性能最高可达 10× 提升。 AMD 对 MI455 GPU 的定位非常明确:它要解决大模型训练和推理里最棘手的瓶颈“内存墙”。大模型跑不动,很多时候不是算力不够,而是数据喂不进去、内存带宽跟不上。 这颗加速器芯片采用 2nm 与 3nm 混合工艺打造,再配上先进的 3D 小芯片封装技术,并搭载新一代 HBM4 高带宽内存。 更重要的是,MI455 并不是孤立地“做一颗更强的 GPU”,它在计算托盘层面就与 EPYC 服务器 CPU、Pensando 网络芯片深度集成,让 CPU、GPU、网络协同成为平台能力,而不再是分散组件的简单拼接。 苏姿丰打了个生动的比方:“Helios 是个庞然大物般的货架,它不是普通的货架,而是双倍宽度的设计,重量接近 7000 磅。”她指出,这个机架的重量超过两辆小型轿车的总重量。 时至今日,AI 的推理能力已被推到聚光灯下,其特点是调用频率高、负载长期持续,进一步带来更明显的算力缺口。 苏姿丰分享称,AMD 下一代 MI500 系列正在开发中,计划全面转向 2nm 工艺,发布时间定在 2027 年。按照 AMD 给出的路线图,从 MI300 到 MI500 的四年周期内,其 AI 计算性能目标提升幅度达到 1000 倍。 她将这一跨代跃迁称为“公司历史上幅度最大的一次性能提升规划”,并将其视为支撑下一阶段超大模型训练和推理需求的关键基础。 在数据中心之外,AMD 还把另一张牌打到终端侧:把原本只能在云端完成的 AI 工作,搬到个人电脑上。 Ryzen AI Max 400 系列(代号 Strix Halo)正是这一策略的核心载体。AMD 给它的定位并不含糊:面向 AI 开发者和高端创作者,做一颗“能真正干活”的本地 AI 芯片。 与 Ryzen AI 300 一样,Ryzen AI Max 400 系列依然是 Zen 5 和 RDNA 3.5,但支持更快内存速度。 简单来说,Ryzen AI 400 是一颗为 AI 笔记本打造的高性能处理器,最高配备 12 核 CPU,同时集成了 更强的核显 和 最高 60 TOPS 的专用 AI 引擎。再加上对高速内存的支持,让它在多任务、创作以及本地 AI 应用中运行得更流畅。 但相比传统性能参数,更关键的是它的系统设计:芯片同时集成 XDNA 2 NPU,并采用统一内存架构,CPU 与 GPU 之间可共享最高 128GB 内存。 这也是能否跑大模型的前提条件。对本地 AI 来说,算力是否够强是一回事,模型能不能完整装进内存、数据能不能顺畅流动,往往才是决定成败的关键。 AMD 用一场直观的演示给出了答案:一台搭载 Ryzen AI 的设备,在完全离线的情况下,流畅运行了一个 700 亿参数的医疗大模型。 这意味着,开发者可以直接在笔记本上调试生成式模型;医疗、金融等行业,也可以在不把数据上传云端的前提下,完成模型推理和分析。本地终端不再只是“调用云端 AI”,而是开始真正承载模型本身。 摆数据:在高端笔记本形态下,Ryzen AI Max 在 AI 与内容创作类应用中的表现,快于最新一代 MacBook Pro;在小型工作站场景中,成本明显低于英伟达的 DGX Spark,而且原生支持 Windows + Linux。 AMD 还贴心地发布了一个本地 AI 参考平台:Ryzen AI Halo 。 官方将其称为“世界上最小的 AI 开发系统”,可在完全离线的条件下运行多达 2000 亿参数模型,面向需要随时随地进行模型开发和部署的专业用户。 那些过去只能在数据中心机房里完成的工作,正在被压缩进一个可以随身携带的设备。 前文提到“AI 教母”李飞飞也亮相了;其实在这种聚焦硬件与平台发布的商业舞台上,李飞飞不常露面,她更常被视为学术界和公共讨论中的“定锚者”。 李飞飞此次在 AMD 的专场讲演登台,强调 AI 不仅要生成内容,更要理解并参与真实世界。 在这一点上,苏姿丰的判断高度一致,她表示,过去几年,大语言模型的出圈(LLM)推动了 AI 的爆发,但无论是人类还是机器,智能并不只来自“看和说”,真正连接“感知 → 推理 → 行动”的关键能力,是空间智能(Spatial Intelligence)。 过去这几年,GPU 的快速发展已让画质起飞了,但 3D 和 4D 世界却还在慢慢搭,往往需要团队花费数月甚至数年完成;而现在 AI 正在改变这种节奏。 李飞飞表示,她认为 AI 正进入一个新阶段:从语言智能,迈向具备空间理解与行动能力的生成式 AI: “AI 在过去几年取得了巨大突破,我在这个领域工作了二十多年,从未像现在这样,对未来的发展感到如此兴奋。” 她也介绍了自己创业公司 World Labs 的核心动向: World Labs 正在训练新一代世界模型(World Model) 目标不是还原二维像素,而是直接学习 3D / 4D 结构;物体之间的空间关系;深度、尺度、物理一致性 已炼成的关键能力,包括仅凭几张照片,甚至单张图片,模型即可补全被遮挡区域、推断物体背后的结构,然后生成一致、持久、可导航的 3D 世界。 不是照片也不是视频,而是真正保持几何一致性的三维空间,具备“空间补全与想象”能力,而非拼贴。 李飞飞指出,过去需要数月才能完成的 3D 场景建模,现在可以在几分钟内完成。 她举例说明潜在影响:创作者:实时“在世界中创作”;机器人 / 自动驾驶:在物理一致的虚拟世界中训练,再进入现实;设计师 / 建筑师:直接“走进”设计,而不是看平面图。 她还特别强调了一个常被忽略的点:世界模型并不是“离线生成完就结束”,它需要实时响应、即时编辑,连续保持空间一致性。 这意味着:极高的内存需求,大规模并行计算,非常快的推理速度,否则世界就无法“活起来”。 谈及算力,李飞飞也透露称:World Labs 的世界模型已运行在 AMD 的 MI325X GPU 与 ROCm 软件栈之上,并在短短几周内实现了 超过 4 倍的推理性能提升。 她还提到,随着 MI450 等后续平台 推出,更大规模世界模型的训练与实时运行将成为可能。 游戏和消费级显卡: 在消费级图形领域,AMD 本次带来的主要新品是 Radeon RX 9070 和 Radeon RX 9070 XT。 这两张显卡均搭载了 AMD 的全新 RDNA 4架构,以及最新 AI 图像技术(包括 FSR 4),将游戏体验推向“AI 加速 + 实时渲染”双驱动的新时代。 其中 RX 9070 XT 的 64 个计算单元、较高频率设计,让其在多款 3A 游戏中表现强劲,在 4K 最高设置下帧率表现明显领先前代,在 30 多款游戏中平均比 RX 7900 GRE 快 42% 而 RX 9070 的规格稍低一些(但同样 16 GB 显存),其光追与 AI 能力也因较少计算单元略弱,不过仍能在高画质下保持流畅体验,在 30 多款游戏中平均比 RX 7900GRE 的帧率快 21%。 综合来看,这两款显卡延续了 RDNA 4 在 高效能比、AI 支持(如 FSR 4)、光追性能提升 上的特性,适用于 1440p 到 4K 游戏场景。 AI 专用 CPU: EPYC Venice 是 AMD 为“AI 数据中心时代”打造的下一代服务器 CPU。 它采用 2nm 工艺,最多可集成 256 个 Zen 6 高性能核心,定位不只是“算得更快”,而是专门为 AI 集群服务。 相比上一代 EPYC,Venice 的内存带宽和 GPU 带宽都实现了翻倍,核心目标只有一个:在机架级规模下,持续、稳定地把数据“喂”给 MI455X 等 AI GPU。 换句话说,它不追求抢 GPU 的计算活,而是负责调度、通信和数据供给,避免 GPU 因“等数据”而空转。 为了支撑这种规模,EPYC Venice 还配套 800G 以太网,并结合 Pensando Volcano / Selena 网络芯片,面向万级机架规模的横向扩展。 在 AMD 的设计中,Venice 不只是服务器 CPU,而是 AI 机架级系统里的“中枢处理器”,决定整个集群能否高效运转。 参考链接: https://www.youtube.com/watch?v=UbfAhFxDomE&list=TLGGBbam0h3MCckwNjAxMjAyNg&t=3063s https://www.amd.com/content/dam/amd/en/documents/corporate/events/amd-ces-2026-distribution-deck.pdf

Helios 机架级平台和 AIPC




和李飞飞同台聊空间智能

其他亮眼新品


如果把过去十年的 AI 落地情况简单概括为一句话,那大概是:AI 学会了“看”和“判断”,却还没真正学会“动手”。 在这段演进过程中,算法被装进摄像头、产线和各类终端设备,AI 在真实世界中承担起感知与决策的角色,成功完成了从实验室到产业化的跨越。 但在范浩强看来,这条路径始终存在一个边界——智能还停留在系统里,很少真正介入物理世界本身。 从某种程度上来说,范浩强的职业路径,正是沿着这条 AI 落地的主线一路走来的。 2025 年初,范浩强做出了一个在外界看来有点“不走寻常路”的选择: 作为旷视科技的第一位算法研究员,在 AI 1.0 时代经历了计算机视觉与 AIoT(AI 技术 + 物联网设备)的规模化落地之后,范浩强选择转身进入具身智能,一个技术门槛更高、研发周期更长的赛道。 他参与创办的这家公司,名为 Dexmal 原力灵机(下文简称原力灵机)。与他并肩创业的汪天才、周而进,同样来自于“AI 四小龙”之一的旷视。 围绕这次转身,AI 前线与范浩强展开了一次深度访谈,聊到了他的创业选择、具身智能的技术演进以及产业趋势等话题。谈及为何要去做机器人,范浩强表示: “在 AI 的道路上,机器人是一个绕不过去的点。” 至于为何选择在 2025 年初这个时间点入局具身智能,范浩强的给出了一个冷静而务实的理由: “之前没做,是因为我觉得还不成熟;现在这个时间点,硬件和算法的拼图终于开始拼起来了。” 在 2024 年,具身智能可谓是“火出圈”的——随着大模型能力外溢、真机效果显著提升,以及头部厂商集体入场,这一方向首次从学术讨论走向产业共识,成为 AI 领域最受关注的新热点之一。 到了 2025 年,更多变化已明显发生,首先是硬件侧。 在过去两年里,机器人关键零部件——尤其是关节的国产化率出现了明显提升。 相比早期高度依赖进口方案,如今国内供应链在性能、稳定性和交付节奏上都逐步可用,这使得机器人在成本控制、系统集成和快速迭代上的不确定性大幅下降。 范浩强提到,这种变化并不意味着硬件问题已经被彻底解决,但至少从“不可控”,走向了“可工程化”: “当供应链能跟得上研发节奏时,很多事情才有可能往前推进。” 与硬件变化几乎同步发生的,是算法侧出现的拐点。 Diffusion、Transformer 等模型开始进入机器人动作生成与控制领域,机器人不再只依赖规则或手工调参,而是可以通过数据学习复杂行为。在范浩强看来,这意味着具身智能不再只是“能演示”,而是开始具备系统性提升能力的基础。 也正是在这样的背景下,他判断:硬件和算法这两块长期错位的拼图,终于开始对齐了。 再往前看,范浩强对下一阶段算法能力的期待,并不止于“动作更像人”。他认为,更关键的是机器人能否真正理解人的意图,并在交互过程中持续修正自身行为。 比如通过对话澄清不明确的指令,或在操作被打断、纠正后继续完成任务。这些能力,将决定具身智能能否从“可用”,走向“好用”。 近两年,机器人从动作到形态的进步都“肉眼可见”:能跑能跳已经不稀奇了,有的还能丝滑跳舞、打太极;而且过去只能在科幻片里看见的人形机器人也越来越多,甚至已经有不少进入了量产阶段。 伴随着这些变化,围绕机器人形态、硬件、整机能力的讨论也逐渐升温。 硬件之外,算法对于机器人的能力泛化和长期演进也很关键。那么算法与硬件在具身智能领域如何协同推进,在各家公司的具身智能早期研发中,是算法先行还是硬件先行? 对此,范浩强直言道: “在我们看来,其实都是算法先行。” 他认为,即便是在外界看来以硬件能力见长的公司,其关键突破往往仍然来自算法层面。不同之处在于,这些算法未必是通用意义上的大模型,而可能是更偏底层的能力,例如运动控制(locomotion)相关算法。 他指出,当运动控制等核心算法成熟到一定阶段后,原本难以实现的动作能力会自然被解锁,硬件形态也随之发生变化。从这个意义上看,硬件能力的提升更像是算法突破之后的结果,而非起点。 基于这一判断,原力灵机内部在反复强调一条方法论:“模型解锁场景,场景定义硬件。” 模型能力决定了哪些任务和场景可以被真正解决,而具体场景的需求,才反过来塑造硬件的结构、配置与形态。 同时,范浩强也强调,硬件研发本身有其客观周期,无法被简单压缩;真正需要持续保持高节奏竞争的,是算法能力的演进速度。 在他看来,具身智能是一场长期竞争,不同环节在不同阶段承担的角色并不相同,但算法能力的迭代效率,始终是决定整体进展速度的重要因素之一。 那么,要如何保证算法能力的高节奏演进速度? 原力灵机作出的选择,是一条更贴近落地需求、也更耐磨的路线。 首先,他们是从一开始就做多模态。 在范浩强看来,传统的 VLA(Vision–Language–Action)框架,如果过度依赖视觉信息,在真实场景里很快就会撞上天花板。比如机器人真正“干活”时,面对的不是干净的画面,而是接触、摩擦、受力和空间约束,这些信息单靠“看”是远远不够的。 因此,原力灵机并没有把 Vision 当作默认前提,而是从模型训练阶段就引入 Multimodality:除了视觉,还包括深度信息、力觉、触觉,必要时甚至加入声音信号。 这样做并不是为了把系统搞复杂,而是出于一个非常现实的判断——如果机器人要稳定、安全地完成任务,这些感知维度缺一不可。 第二点,是在数据上选择“慢一点,但更真”。 在数据策略上,原力灵机把重点放在真机遥操数据上,并且明确坚持“质量优先”。范浩强多次提到,机器人做的往往是“细活”:一个抓取动作是否成功,差别可能只在几毫米、几牛顿的力控误差。 这也意味着,数据采集本身就不能是“顺手一录”,而必须被当作一项工程来设计——包括传感器的同步方式、遥操流程的规范程度,以及操作行为本身的可复现性。 只有在这样的基础上,算法训练出来的能力,才有可能在真实场景中稳定复现。 此外还有一个重点,就是得赶紧先把“怎么比”这件事说清楚。 在范浩强看来,具身智能仍处在早期阶段,行业里一个明显的缺口是:缺少统一、可信的评测体系。如果没有清晰的 Benchmark,不同方案之间很难进行有效比较,也很难形成真正的技术共识。 因此,原力灵机选择在早期就投入精力,联合 Hugging Face 共同推出真机评测平台 RoboChallenge 以及相关开源工具的建设,比如一站式 VLA 工具箱 Dexbotic 和公司首个开源硬件产品 DOS-W1。 用范浩强的话说,就是先把规矩立住,再谈模型强不强: “我们希望先把比较的方法拿出来,让大家在同一套标准下形成共识。之后再在这些已被认可的方法上,去验证和证明我们模型的表现,这样也更利于外界准确理解我们的能力。” 从多模态感知,到真机数据,再到评测体系,每一步都指向同一个目标:让算法能力能够被验证、被复现、被长期积累。
“硬件和算法的拼图终于拼起来了”
具身智能研发,算法先行还是硬件先行?
原力灵机的路线:多模态、真机数据,先把规矩立住

生成式AI如何加速针对Active Directory的身份攻击
赞助商提供
09:46 AM
Active Directory仍然是大多数组织管理用户身份的主要方式,这使其成为攻击中的常见焦点。变化不在于攻击目标,而在于这些攻击变得何其迅速和高效。
生成式AI使得密码攻击成本更低、效率更高,将曾经需要专业技能和大量计算资源的工作变得几乎人人可为。
AI驱动的密码攻击已被实际运用
像PassGAN这样的工具代表了新一代密码破解技术,它们不再依赖静态单词表或暴力随机猜测。通过对抗训练,系统学习人们创建密码的实际模式,并在每次迭代中提升预测能力。
研究结果令人警醒。近期研究发现,PassGAN能在一分钟内破解51%的常用密码,一个月内破解81%。更令人担忧的是这些模型的进化速度。
当使用特定组织的泄露数据、社交媒体内容或公开的公司网站进行训练时,它们能生成高度针对性的密码候选集,准确反映员工的实际行为模式。
生成式AI如何改变密码攻击技术
传统密码攻击遵循可预测的模式。攻击者使用字典单词表,然后应用基于规则的变形(例如将"a"替换为"@",在末尾添加"123"),并期待匹配成功。这是一个资源密集且相对缓慢的过程。
然而,AI驱动的攻击则截然不同:
大规模模式识别:
机器学习模型能识别人们构建密码的细微模式,包括常见替换、键盘模式以及个人信息整合方式,从而生成符合这些行为的猜测。AI不再测试数百万随机组合,而是将计算资源集中于最可能的候选密码。
智能凭证变异:
当攻击者从第三方服务获取泄露凭证时,生成式AI能快速测试针对您环境的特定变体。例如,如果"Summer2024!"在个人账户上有效,模型会智能测试"Winter2025!"、"Spring2025!"等可能变体,而非随机排列。
自动化侦察:
大语言模型可以分析关于您组织的公开信息(例如新闻稿、LinkedIn资料和产品名称),并将这些上下文融入定向钓鱼攻击和密码喷洒攻击。过去需要分析师数小时完成的工作,现在可以更快实现。
准入门槛降低:
预训练模型和云计算基础设施意味着攻击者不再需要深厚的技术专长或昂贵硬件。
高性能破解硬件的普及化
AI热潮带来一个意外后果:更适合密码破解的强大消费级硬件更易获得。训练机器学习模型的组织常在闲置时段租用GPU集群。
现在,攻击者每小时仅需约5美元即可租用八块RTX 5090 GPU,其破解bcrypt哈希的速度比上一代显卡快约65%。
即使采用强哈希算法和高成本因子,现有计算能力仍使攻击者能测试比两年前多得多的密码候选集。
当与生成更有效猜测的AI模型结合时,破解弱到中等强度密码所需时间已大幅缩短。
使用Specops密码策略保护Active Directory密码
Verizon数据泄露调查报告显示,44.7%的数据泄露事件涉及凭证窃取。
通过合规密码策略轻松保护Active Directory,阻止40多亿已泄露密码,提升安全性并减少支持负担!
免费试用
为何传统Active Directory密码控制措施已不足够
大多数Active Directory密码策略是为前AI时代的威胁环境设计的。标准复杂性要求(大小写字母、数字、符号)产生的可预测模式更容易被AI模型利用。
"Password123!"符合复杂性规则,却遵循生成式模型能瞬间识别的模式。
强制90天密码轮换曾被视为最佳实践,但如今已非有效保护。被迫更改密码的用户常采用可预测模式:递增数字、季节引用或对旧密码进行微小修改。
基于泄露数据训练的AI模型能识别这些模式,并在凭证填充攻击中进行测试。
基础多因素认证(MFA)虽有帮助,但无法解决密码泄露的根本风险。如果攻击者获取泄露密码,并通过社会工程、会话劫持或MFA疲劳攻击绕过MFA,Active Directory仍可能暴露。
应对Active Directory中的AI辅助密码攻击
为防御AI增强的攻击,组织必须超越合规检查项,制定针对密码实际泄露方式的策略。实践中,密码长度比复杂性更重要。
AI模型难以应对真正的随机性和长度,这意味着由随机单词组成的18字符密码短语比带特殊字符的8字符字符串更具防护性。
但更重要的是,您需要掌握员工是否正在使用外部泄露中已暴露的密码。如果明文密码已存在于攻击者的训练数据集中,任何复杂的哈希算法都无法提供保护。
Sedgwick确认旗下政府承包商子公司遭数据泄露
作者
10:27 AM
理赔管理与风险控制公司Sedgwick已确认,其联邦承包商子公司Sedgwick Government Solutions遭受了安全漏洞攻击。
Sedgwick在全球80个国家拥有超过33,000名员工,为10,000家客户提供服务,其中包括59%的《财富》500强企业。其子公司为超过20家政府机构客户提供服务。
使用Sedgwick Government Solutions服务的联邦机构名单包括:网络安全和基础设施安全局(CISA)、商务部、美国公民及移民服务局(USCIS)、美国海岸警卫队、国土安全部(DHS)、美国劳工部、海关和边境保护局(CBP)以及美国海岸警卫队。
Sedgwick发言人向BleepingComputer表示,公司正在调查影响其子公司的安全漏洞事件,并补充说明母公司网络未受影响。
Sedgwick已通知执法部门,并聘请了外部网络安全专家调查此次泄露事件的影响。
发言人称:"Sedgwick正在处理其子公司Sedgwick Government Solutions的安全事件。在检测到该事件后,我们立即启动了事件响应协议,并通过外部法律顾问聘请了外部网络安全专家,协助调查受影响的独立文件传输系统。"
"重要的是,Sedgwick Government Solutions与公司其他业务系统是隔离的,更广泛的Sedgwick系统或数据未受影响。此外,没有证据表明攻击者访问了理赔管理服务器,也未影响Sedgwick Government Solutions持续为客户提供服务的能力。我们已通知执法部门,并在调查过程中与客户保持沟通。"
虽然公司未将此次攻击归因于特定威胁组织,但该声明证实了TridentLocker勒索软件组织关于入侵该公司的说法。
威胁行为者声称窃取了3.39GB的文件,并在宣称对攻击负责后,在其Tor数据泄露网站上公布了部分据称被盗的数据。
Sedgwick Government Solutions在TridentLocker泄露网站的条目(BleepingComputer)
TridentLocker勒索软件于去年11月首次出现,目前在其泄露网站上列出了十余名受害者,包括比利时邮政集团Bpost——该国主要的邮件递送服务商及最大的民用雇主之一。
Bpost于12月3日确认其网络遭入侵,但表示运营未受TridentLocker勒索软件攻击影响。