无需软件和密钥激活所有版本的 Windows 10 – 适合还在使用该系统的各位佬友们
免费激活 Windows 10,无需产品密钥。
步骤 1:将以下代码复制到一个新的文本文档中。
@echo off
title Activate Windows 10 ALL versions for FREE!&cls&echo ============================================================================&echo #Project: Activating Microsoft software products for FREE without software&echo ============================================================================&echo.&echo #Supported products:&echo - Windows 10 Home&echo - Windows 10 Home N&echo - Windows 10 Home Single Language&echo - Windows 10 Home Country Specific&echo - Windows 10 Professional&echo - Windows 10 Professional N&echo - Windows 10 Education N&echo - Windows 10 Education N&echo - Windows 10 Enterprise&echo - Windows 10 Enterprise N&echo - Windows 10 Enterprise LTSB&echo - Windows 10 Enterprise LTSB N&echo.&echo.&echo ============================================================================&echo Activating your Windows...&cscript //nologo slmgr.vbs /upk >nul&cscript //nologo slmgr.vbs /cpky >nul&set i=1&wmic os | findstr /I "enterprise" >nul
if %errorlevel% EQU 0 (cscript //nologo slmgr.vbs /ipk NPPR9-FWDCX-D2C8J-H872K-2YT43 >nul&cscript //nologo slmgr.vbs /ipk DPH2V-TTNVB-4X9Q3-TJR4H-KHJW4 >nul&cscript //nologo slmgr.vbs /ipk WNMTR-4C88C-JK8YV-HQ7T2-76DF9 >nul&cscript //nologo slmgr.vbs /ipk 2F77B-TNFGY-69QQF-B8YKP-D69TJ >nul&cscript //nologo slmgr.vbs /ipk DCPHK-NFMTC-H88MJ-PFHPY-QJ4BJ >nul&cscript //nologo slmgr.vbs /ipk QFFDN-GRT3P-VKWWX-X7T3R-8B639 >nul&goto server) else wmic os | findstr /I "home" >nul
if %errorlevel% EQU 0 (cscript //nologo slmgr.vbs /ipk TX9XD-98N7V-6WMQ6-BX7FG-H8Q99 >nul&cscript //nologo slmgr.vbs /ipk 3KHY7-WNT83-DGQKR-F7HPR-844BM >nul&cscript //nologo slmgr.vbs /ipk 7HNRX-D7KGG-3K4RQ-4WPJ4-YTDFH >nul&cscript //nologo slmgr.vbs /ipk PVMJN-6DFY6-9CCP6-7BKTT-D3WVR >nul&goto server) else wmic os | findstr /I "education" >nul
if %errorlevel% EQU 0 (cscript //nologo slmgr.vbs /ipk NW6C2-QMPVW-D7KKK-3GKT6-VCFB2 >nul&cscript //nologo slmgr.vbs /ipk 2WH4N-8QGBV-H22JP-CT43Q-MDWWJ >nul&goto server) else wmic os | findstr /I "10 pro" >nul
if %errorlevel% EQU 0 (cscript //nologo slmgr.vbs /ipk W269N-WFGWX-YVC9B-4J6C9-T83GX >nul&cscript //nologo slmgr.vbs /ipk MH37W-N47XK-V7XM9-C7227-GCQG9 >nul&goto server) else (goto notsupported)
:server
if %i%==1 set KMS_Sev=kms7.MSGuides.com
if %i%==2 set KMS_Sev=kms8.MSGuides.com
if %i%==3 set KMS_Sev=kms9.MSGuides.com
if %i%==4 goto notsupported
cscript //nologo slmgr.vbs /skms %KMS_Sev% >nul&echo ============================================================================&echo.&echo.
cscript //nologo slmgr.vbs /ato | find /i "successfully" && (echo.&echo ============================================================================&echo.&echo #My official blog: MSGuides.com&echo.&echo #How it works: bit.ly/kms-server&echo.&echo #Please feel free to contact me at msguides.com@gmail.com if you have any questions or concerns.&echo.&echo #Please consider supporting this project: donate.msguides.com&echo #Your support is helping me keep my servers running everyday!&echo.&echo ============================================================================&choice /n /c YN /m "Would you like to visit my blog [Y,N]?" & if errorlevel 2 exit) || (echo The connection to my KMS server failed! Trying to connect to another one... & echo Please wait... & echo. & echo. & set /a i+=1 & goto server)
explorer "http://MSGuides.com"&goto halt
:notsupported
echo ============================================================================&echo.&echo Sorry! Your version is not supported.&echo.
:halt
pause >nul
步骤 2:将代码粘贴到文本文件中。然后将其保存为名为 windows.cmd 的批处理文件
步骤 3:以管理员身份运行批处理文件。

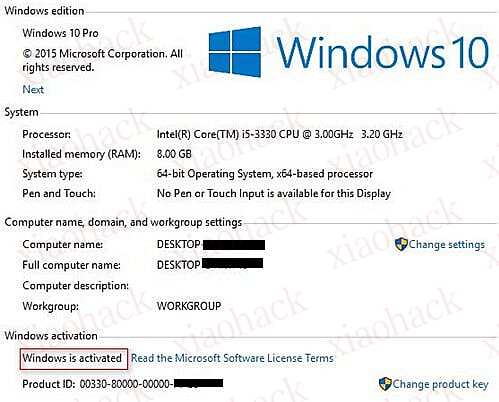
当你以管理员身份运行它时,你会看到一个像下面这样的新窗口 等待 5-10 分钟完成并见证奇迹











![[油猴脚本] 原生 CSS 实现所有网页添加盘古之白1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106184327_695ce74f63bd4.jpeg!mark)
![[油猴脚本] 原生 CSS 实现所有网页添加盘古之白2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106184330_695ce75215e91.png!mark)
![[油猴脚本] 原生 CSS 实现所有网页添加盘古之白3](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106184333_695ce755be55e.png!mark)