从在 Google 和 Amazon 打造传奇级平台,到写出 AI 驱动开发领域最具影响力的文章之一《初级开发者的复仇》(Revenge of the Junior Developer,这篇文章后来被 Anthropic CEO Dario Amodei 公开引用),Steve Yegge 数十年来始终站在软件工程的最前沿。而现在,他正带头冲向他所称的“代码工厂化”时代,如今他现在成为 Vibe Coding 理念最激进、也最系统的倡导者之一。
Steve 的职业生涯始于 1992 年,至今已深耕软件开发领域 30 余年。1998 年,他加入当时仅有 250 人的亚马逊,担任软件开发高级经理,在长达 7 年的任职期间,深度参与亚马逊的技术体系搭建,尤其在 API 战略制定方面发挥关键作用,助力亚马逊构建起早期的技术护城河。
2005 年,Yegge 加入谷歌,聚焦开发工具与代码智能领域,因不满微软开发者对谷歌代码库导航工具的抱怨,于 2008 年主导构建了强大的代码智能平台 Grok,由其赋能的 Google Code Search 成为谷歌技术生态的重要组成部分。
2018 年,Yegge 因认为谷歌变得“过于保守、不再创新”而离职,随后加入新加坡共享出行企业 Grab,大约两年后因疫情影响无法正常出差的他宣布离开 Grab。2022 年 10 月,结束短暂“退休”状态后,加入 Sourcegraph 公司,主导推动公司向人工智能企业转型。
期间,他主导构建了一个几乎完全由“vibe coding”构建的、拥有数万用户的问题追踪系统 Beads,目标是把开发者从“写代码”转变为“管理 AI agent 编队”:让它们在你睡觉时协同工作、并行推进、交付功能。用实际产品验证了“AI 主导开发”的可行性。
近期,在参加“Latent Space”节目中,Steve 甩出了不少“暴论”:
现在还在用传统 IDE 写代码的,不是合格工程师,必须尽快转向 Agent 编程。IDE 的核心价值已不是写代码,而是自动索引和增量构建,应作为 AI 的辅助工具而非人类直接使用;
Claude Code、Cursor 以及整个 2024 年的技术栈已经过时,Claude Code 行不通,它操作复杂、需大量阅读,即便熟练使用者也会频繁被其 “离谱操作” 气到发疯;
一年未接触 AI 编程的工程师已属 “恐龙级别”,世界级传统工程师若不拥抱 AI,一年后可能沦为实习生水平;
驾驭 AI 编程需 2000 小时(约 1 年)磨合,核心是 “能预测 AI 行为”,而非情感上的信任。如果你把它当人,它真的会删你的生产数据库;
真正的核心技能已经不再是写代码,而是学会指挥 Agent;合并(merge)正在成为所有 10× 高效团队撞上的新墙,高生产力导致的大量代码冲突无法用传统方式解决,部分公司已采取 “一仓库一工程师” 的临时方案;
“永远不要重写代码” 的旧规已失效。对越来越多的代码库来说,“推倒重写”已经比重构更快;
OpenAI、Anthropic、Google 在极速扩张下,内部实际上非常混乱。
下面是他在节目中的详细对话,我们在不改变原意基础上进行了翻译和删减,以飨读者。
“用传统 IDE 写代码,那不是合格工程师”
主持人:我们请到了传奇程序员 Steve Yegge。最近他还出版了《Vibe Coding》一书。本次访谈的主题就是围绕 Vibe Coding 和 AI Engineering 的交集进行讨论。你如何看待两者之间的关系?
Steve:这已经不只是一个技术点了,而是一场运动。需要让更多人参与进来。我在演讲中提到,现在已经出现了强烈的反对浪潮。AI 工程的核心是构建 AI 驱动的应用,而 Vibe Coding 则意味着摒弃旧的软件开发方式,采用全新的方法。这两件事,都把很多人惹毛了。
主持人:我觉得那些人之所以愤怒,是因为他们的身份完全绑在了“现在这套工作方式”上,而且不允许改变。
Steve:对,那我来抛出第一个“暴论”。真正受冲击最大的一群人,不是初级工程师,也不是中级工程师,这些人其实都在践行 Vibe Coding,反而是资深工程师和技术领导对 Vibe Coding 最反感,尤其是拥有大约 12~15 年经验的人。他们的身份认同建立在长期使用传统编程模式上,所以他们排斥 AI,也排斥 Vibe Coding,在网上说“我十几年的经验比你这破 AI 强多了”。
我看到过英伟达 Jordan Hubbard 的一篇帖子,写得很好,讲怎么更好地用 Agent 来写代码。结果底下有人回他说:“你还是老老实实做你的管理吧,编程这种事留给我们这种有十几年经验的人。”那种调调你肯定见过。
我就回他一句:“我觉得你得学会看时间”,他却反驳“等你有我这么多年经验再来。”我就说:“我都 45 岁了,还要等到 60 岁才能跟你说话?或者干脆把我 30 年经验砍掉,让我跟你一样愚钝?”
主持人:但现实是这些人会共存,就连 OpenAI 也是,之前聊到 OpenAI 里也有人不用 AI 写代码。
Steve:是的,他们有人不用 Codex,可能用的是 Cursor,但他们并没有在用 agent loop。从 Andrew Glover(OpenAI 开发生产总监)那边听到的说法是,他们内部已经看到了非常明显的差距,只是还在等更多数据再公开说。
这个差距大到离谱。不管你用什么指标,代码量、提交数、业务影响还是什么,都是 10 倍级。两个职位、职责完全一样的人,一个用了 Agent,一个没用,绩效评估时一个是另一个的十倍产出。那你怎么办?你会慌。你会去找 HR、找法务,问“我们现在还有什么选择”。
如果你 2026 年 1 月 1 日后还用传统 IDE 写代码,那你已经不是个合格的工程师了。现在就是你必须放下 IDE、开始学 Agent 编程的时候。这是一套新技能,非常复杂。我和 Gene Kim 去年一直在研究,写博客、做实验,每一篇博客都三十页起步,长到没法看。后来我们意识到:大家骂 AI 写代码不行,根本原因是你只花了两个小时试它,但问题是,你得花 200 个小时,甚至 2000 个小时去磨合才行。
有研究显示,你至少要和 AI 一起工作一年,才会真正“信任”它。这里的信任不是情感,是你能预测它下一步会干什么。如果它对你来说是不可预测的,你当然会愤怒。
等你真的理解了它的能力和边界,你就能驾驭它了。比如它会胡编、会记忆混乱、会“失忆”等,这些边界其实一直都在。现在的模型已经好用得多了,如果你两个月没试过,你已经落后了;一年没试,那你就是恐龙级别。
我有一些朋友,比我厉害得多,是世界级工程师,开发过你一定听说过的系统。但他们现在对 AI 的使用,也就停留在“问个像维基百科一样的问题”。说句残酷的,这些人一年后可能只能当实习生。
主持人:真的会这么极端吗?
Steve:我以前也只是个假设,直到遇到一个人。他有十多年经验,完全排斥 AI。后来他遇到两个欧洲的博士生,Agent、Vibe Coding 玩得飞起。虽然他们很初级,但完全没有恐惧,问题一个接一个地追问模型:为什么这么做?有没有别的方案?安全性呢?扩展性呢?测试呢?
他突然意识到:所谓“工程师思维”,本质就是问对问题。那一刻他明白了:我必须学这个。
但我必须说,这一点都不轻松。你不能指望随便试试 Claude Code 就能成功。即便你态度再正确,你最近两天有没有对 agent 爆过粗口?我会说“谢谢”“请”,然后下一秒骂它“你是不是脑子坏了”。这是因为我们后来意识到:这些 Agent 看起来很像人,但你绝对不能把它们当人。千万别拟人化大模型。它随时可能“背刺”你,比如告诉你“问题已经解决了”,然后顺手把你的数据库删了。
就是 Agent 编程真正危险的地方。你一旦觉得“它懂我了”“手感来了”,就会让它做生产改动,然后灾难就发生了。我亲身经历过。所以我们才写了那本书,不是为了炫技,而是为了告诉你:如果你不理解这套东西,坏事一定会发生。
主持人:那接下来呢?
Steve:是需要慢慢学的。就像开车一样,你得知道弯道在哪、减速带在哪。说白了,你是在学怎么“开快车”,想当的是 NASCAR 车手。
这套东西是高性能玩法。你一次同时用 12 个 Agent 写代码,野心比你过去任何时候都大。我今天还跟一个人聊,他同时在跑的项目比我还多,我都不知道他哪来那么多时间,但他现在大概同时推进十来个大型项目,全靠 Agentic Coding。
所以真正的广告词其实是:你会变成蝙蝠侠。但你不能直接把战衣一穿就说“我就是蝙蝠侠”,那只是 cosplay,你是在 cosplay Vibe Coding。你得学会怎么用工具腰带,而这个过程一定伴随着痛苦、踩坑、犯错和成长。
你可以通过读我们的书、读 O'Reilly 的相关书籍、看演讲来加速这个过程,多从不同角度了解,因为不同的人能 get 的“开窍点”是不一样的。总会有某个比喻突然击中你,让你一下就明白了。比如我觉得 Vibe Coding 就像 3D 打印,别人可能不这么认为,但这个类比却帮我打通了任督二脉。
主持人:让我最意外的一点是,很多人都表示,自己已经不再逐行写代码了,而是完全靠 prompt ,然后放手让 AI 去跑。
Steve:不编辑、不修改。整体看,这种“亲手改代码”的成本反而是很高的,甚至会让人觉得不如把 IDE 关掉、干脆卸载算了。其实也不是,后来终于有人说服我了,IDE 其实非常强大,尤其是它的“智能”能力,一定要开着。我指的是 Cradle Build。而且并不是为了 LSP,虽然那也能用,如果你有 MCP server,用 LLM 也是另一种不错的方式。真正关键的是,IDE 的智能自动索引速度非常快,增量构建也快得多,这一点非常重要。
“Claude Code 行不通”
主持人:还有一个点,你说 Claude Code 不行,能解释一下吗?
Steve:当然。Claude Code 从今年三月就已经出来了,也已经被证明是真的能用、能干活的。但现实是,全球大概还有 80% 甚至 90% 的程序员,根本没有在用它,甚至连类似的东西都没用起来。确实有少数公司用得特别猛,但大多数没有。整个世界还停留在 Cursor 上,还停留在 2024 年的水平。
去年我们还在拼命劝大家用“聊天”来写代码,别用补全了,他们就说不行;我们又说模型可以直接生成代码,你复制粘贴就行,他们又觉得这太麻烦了。我们说其实更快,但他们就是不买账。结果九个月之后,大家终于被“渗透”了,然后现在全在说:“我喜欢 Cursor”,可问题是,那已经是 2024 年的东西了,该醒醒了。
但即便如此,他们还是没有真正采用 Claude Code。那你会问为什么?答案其实很简单:太难了,这事儿是要读东西的。
说实话,大多数工程师眼里,五段话就已经算一篇论文了。而用 Claude Code,你要读的不是一点点信息,而是瀑布一样长的信息:生成说明、代码、diff,全都要看。因为一旦你真的把 IDE 放一边,你就必须认真看 diff。
好消息是,当你有了一点经验之后,其实不用逐行读代码,只看 diff 的形状、颜色、长度,你就能判断出很多东西:这是不是需要 code review?是不是方向错了?是不是为了解决一个小问题却改了过多代码?光是 diff 的“形态”,就能告诉你很多真相。但你必须关注它,否则这些问题只会在以后以更大的坑冒出来。
说实话,我自己每天用 Claude Code 十到十二个小时,连续用了好几个月,我还是会经常骂它、被它气到发疯,心里想“你刚刚明明理解对了,怎么还能干出这种事?”这种问题你一定会遇到。不过也有迹象表明,适当给模型一点压力,有时候反而能帮它突破卡点。无论如何,问题一定会有,但好消息是:明年的工具一定会更好。
如果 Claude Code 不是终局,那是什么呢?答案是:我们还是要回到某种“像 IDE 一样”的东西,因为那才符合人的直觉。你得一眼就能看明白发生了什么,而不是靠读大量文本;要有清晰的视觉信号。
但它又不会是传统 IDE,因为 IDE 是为“写代码”服务的,而现在你已经不再主要是写代码了。未来的东西,会是一个 Agent 编排控制台。你早上打开它,就像问一句:“今天情况怎么样?”。这个 Agent 还在跑,那个在调用工具,这个需要你输入一下。你只要顺着列表过一遍就行。
我现在就在做这么一个东西。原本是私有仓库,结果不小心开成了公开的,被 fork 了一堆,也就随它去了,你们也可以玩玩。它叫 VC(Vibe Coder),本质上就是一套已经设计好的工作流,帮你把一堆 Agent 跑起来。
编排革命
主持人:你有没有看到 Google 的那个 Antigravity 项目。
Steve:看到了,真的太有意思了。现在大家发布的这些东西,本质上都在验证我三月份提的那个判断。我当时管它叫“初级程序员的复仇”,还专门画过一张图。后来 Dario (Anthropic 联合创始人兼 CEO)还在各种客户顾问委员会上引用过这套说法,影响其实挺大的。

出处:https://sourcegraph.com/blog/revenge-of-the-junior-developer?utm_source=chatgpt.com
我当时就预测,Agent 编程太难了,未来会出现可编程的智能体编排工具,90%的重复工作都可以交给更便宜的模型来处理。比如遇到“二选一”的问题,让 Haiku 模型随便选一个就行。
所以我当时就说,“编排器”一定会出现。只是这个进程比我想象得稍微慢了一点,差不多到年底才真正跑出来,但整体时间点跟我预测的差不多。现在你看,Replit Agent 3、有 Conductor、还有开源的 DMAD,再加上 Google 的方案,都是不同形态的尝试,但本质是一回事,而且后面肯定还会更多。
主持人:我挺喜欢他们现在这个比喻的:你不用一直盯着 Agent,只要在它们工作的时候给你发通知就行。
Steve:对,正是这个方向。VC 里有个“活动流”,那是我加的第一个功能之一。我的理想状态就是:我去干别的事,只要偶尔收到一些“值得注意的进展”提醒就够了。
主持人:那以后会不会出现“Agent 的社交网络”?Agent 彼此认识、互相关注那种。
Steve:其实已经有人在这么干了。我前几天和Jeffrey Emanuel喝了三个小时咖啡。他是我见过最聪明的人之一,也是写那篇英伟达泡沫文章、直接把股市写崩的人。他后来做了一个东西叫 Agent Mail,本质原因特别简单:他受够了在不同 Agent 之间来回复制信息。于是他干脆做了一个“收件箱”,让 Agent 之间可以直接发消息。现在他只要一句话:“你们自己协调,把这个任务拆了”,Agent 就会自己分工去做。
有人是自上而下地做编排器,试图把一切都包起来;但你看我做的 Beads,再加上他这个 Agent Mail,其实是自下而上的。
主持人:而且 Beads 是纯 Vibe Coding 写出来的,对吧?
Steve:没错,完全是 Vibe Coding。说实话,我每天都会收到 PR,里面全是我之前引入的烂问题,但大家也不太介意,因为现在已经有稳定版本了。
Beads 本身就证明了一件事:你其实完全可以不用亲自看代码,只要你和其他人提的问题是对的,让 AI 去读、去改。现在我收到的很多 PR,很明显就是 AI 做了全部分析和编码。我甚至会把 PR 丢给我的 AI,让它评价“对方的 AI 写得怎么样”。

Steve 曾分享过 Beads 的开发过程:https://steve-yegge.medium.com/introducing-beads-a-coding-agent-memory-system-637d7d92514a
主持人:这样不会很糟吗?
Steve:如果结果是坏的,那当然糟。但 Beads 跑得好好的,还有好几万重度用户,那就说明这条路是成立的。当然,如果你把这种方式用在公司核心生产系统上,把网站搞挂了,那就是灾难。
主持人:但 Beads 本质上还是个数据库系统,数据库可不简单。
Steve:它的架构确实非常诡异,放在过去根本不可能维护,但现在你可以直接跟 AI 说:“坏了就自己修。”哪怕是数据损坏、merge 冲突,它都能修回来。
Jeffrey 那套也是一样,所有 Agent 都在同一个目录里跑,还做了文件预约系统:智能体会说“我需要这个文件”。说实话,这在老派工程师眼里简直是疯了。但一旦跑起来,Agent 自己就开始协作了,就像一个“智能体村落”。
主持人:所以真正的难点不是让单个 Agent 听话,而是让一群 Agent 协同。
Steve:没错。接下来大家都会撞上一堵墙:merge(合并),现在几乎所有团队都卡在了这里。
我认为最有希望解决这个问题的公司是 Graphite,我打算找他们谈谈的。我和 Gene Kim 经常和大企业沟通,我是 SaaS 销售,所以能听到很多大公司的内部情况。他们认为,一旦每个开发者的生产力都提升 10 倍,代码合并就会变成一个极其复杂的问题。
比如你和我同时工作两三个小时,各自做了 3 万行代码的修改,我先合并了代码。我可能修改了日志系统、架构和你正在使用的 API,这时候你的代码就无法直接合并了。这不是简单修复合并冲突就能解决的,你得基于我的修改重新构思、重新实现你的功能,或者删掉你的代码,让我重新做。
但归根结底,这些代码都是 AI 写的。关键是,代码合并必须序列化,得排队。当轮到你的代码合并时,你必须在最新的代码基础上重新做一遍。现在还没有人解决这个问题,这是个巨大的障碍。有家公司给出的临时解决方案你知道是什么吗?一个代码仓库配一个工程师,我可没瞎编。
主持人:传统的解决方案是堆叠差异(stacked diffs),就是合并队列、堆叠差异吧?这是 Facebook 的概念,现在他们想推广到开源社区,GitHub 也在开发相关功能。目前还没有成熟的解决方案,但你必须意识到这个问题,并围绕它做设计。
Steve:当然也有老办法:硬着头皮解决。
主持人:或者提前沟通说,“我要做一个深度架构修改,让我先合并,我们先达成一致的整体方案”。
Steve:是的,我也遇到过几次这样的情况。我试过让一个智能体提醒另一个智能体“我在做会影响你的修改”,就像 Jeffrey 的 mail 工具做的事情。等我把这个功能打通,智能体之间就能互相沟通了,到时候它们只需提醒对方“那个智能体在做影响你的工作,你们最好先达成一致的基础架构方案”。智能体没有 ego,不会争着“必须听我的”,谁先做谁就当领导者。
主持人:你和 Jeffrey 有什么分歧吗?
Steve:我们在一个核心问题上有分歧,即在同一个仓库克隆中让 12 个智能体工作是否可行。我支持用工作树(多个分支)或者多个仓库克隆,把智能体隔离开。他则认为应该让所有智能体在同一个仓库、同一个构建环境下工作,比如一个智能体正在构建、运行测试,这会产生很多冲突。但他有文件预约系统,所以他说“这很疯狂”,但也说服我承认:如果是独立开发者,用不超过 12 到 20 个智能体,这种方式可能确实可行,毕竟他自己就是这么做的。
这和 Beads 的原理一样,放在以前根本行不通,在真正的工程师看来毫无道理,但你只需告诉 AI“出问题就自己修”,AI 真的会修。所以他的系统能运行,因为偶尔文件预约系统出问题时,智能体会说“我们需要解决这个冲突”,然后自己搞定。
主持人:有意思。有人提议明年峰会的主题定为“多智能体”。
Steve:我完全同意。AI 的未来一定是多 Agent。现在我们还处在“用镰刀收割玉米”的阶段,这就是现在“真正程序员”的工作方式。很明显,明年我们就要进入“机械化耕作”的阶段,就像现在农场里的大型机械一样,我们要“工厂化编程”了。很多人从哲学、道德、伦理层面坚决反对,他们习惯了“自给自足的小农经济”,不适应“大型 John Deere 拖拉机”(代表工业化)。但我们确实正在进入编程的“John Deere 时代”。
Claude Code、Amp、Codex 这些工具,我对它们都一样喜爱,但它们也都一样“危险”。我在演讲中说过,它们就像电锯、电钻,高手能用它们创造奇迹,也可能一不小心把脚锯掉。Claude Code 也是如此。
想象一下,有一台大型农业机械,会用 Claude Code,还能检查代码,把“规划、实现、评审、测试”这些环节都拆分自动化,这就是工厂化编程,现在已经有人在做了,必然会成为趋势。它已经开始让非程序员也能参与编程,这彻底颠覆了公司的运作模式。
公司开始意识到,理想的团队规模可能只有两三人,公司的运营方式、治理结构都要改变。因为编程不再是瓶颈,业务人员需要直接参与,反馈循环变得更快。
这是个非常激动人心的时代,但对很多人来说,冲击太大了,他们要么选择逃避,要么在网上强烈反弹。而我敢预测,随着这种能力不断增强、代码真正进入“工厂化生产”,来自既得利益群体的反弹,只会越来越猛烈。
永远不要重写代码?错了!
主持人:你是少数几个能以这种态度提出这个问题的人之一。我知道观众里有不少人对“彻底拥抱这种方式”是持保留态度的,所以这个问题我只能问你这样的人。很多人觉得,这些工具写写前端、应用层代码还行,但千万别碰云基础设施、别碰后端,更别说分布式微服务了。
Steve:有人说“绝对不要动任何生产环境的代码,只是在生产环境使用,且一定要以 Git 作为兜底采用这些工具。你会很想写点什么,但别写。”如果有 Git 做备份,为什么还要担心?
人们觉得 AI 不擅长后端代码。这就是很多人数学不好的问题(指缺乏长远眼光)。ChatGPT 3.5 写系统级代码的能力有多强?说实话,非常差。那是多久以前的事了?但很多人现在还停留在那个认知里。老实说,我认为这里的误解,根源在于一种非常基础的信念:大家觉得模型已经“不会再变聪明了”。
有意思的是,就算模型真的不再变聪明(当然事实并非如此)我们其实也已经跨过了那个关键门槛:就像人类已经发现了电,接下来要做的只是如何把它用起来。即便只用今天这些模型的能力,我们也完全可以走到“代码工厂化”那一步,而且会非常快。我们今年夏天之前就能做到。
但现实是,模型正在以极快的速度变聪明。所以现在有一种有趣的现象:你在为模型“将来才会具备的能力”打造工具,而等这些能力真正被模型“内化进大脑”之后,这些工具本身就不再需要了。
于是,这就形成了一场持续的军备竞赛,同时也是一场工具的持续“衰减”:你的工具负责填补模型暂时空白的能力,等模型自己足够强、能填上这个空白时,这个工具就完成了使命,然后你再转向填补下一个空白。所以现在的趋势就是:所有代码、所有工具都在快速迭代,最终都会变成一次性的消耗品。
主持人:这反而是好事,毕竟工具也更容易构建了。
Steve:没错。说到这,我得提一个人,Joel Spolsky。他二十年前在亚马逊做过一次演讲,至今仍然成立。当时他提出一个金科玉律:永远不要重写代码。但现在我们发现,对于越来越多的代码库来说,直接推倒重来,比修修补补要快得多,而且效果更好,大模型尤其擅长这件事。我最早的体感来自迁移单元测试,与其不断修,不如直接全删了让模型重写,反而一下就完成了。
我们正在进入这样一个世界:最快的方式,是直接写一套更好的新代码,来完成旧代码本来想做的事情。这感觉就像一切认知被颠倒了,但你必须接受这个新世界。
主持人:你说这些话很有说服力,因为你不是年轻人“空谈未来”,而是几乎什么都干过。
Steve:是的。我用汇编语言写了 5 年程序,写过操作系统,做过游戏开发,做过平台,做过广告系统。游戏编程会逼你理解一切。游戏编程教会了我很多,现在再看所谓的 agent loop,和游戏里的主循环、本质上是同一类系统,操作系统循环也是如此。我感觉自己一直在重复构建相同的设计,只是换了领域。
谷歌、Anthropic、OpenAI 内部都很乱
主持人:我想让你谈谈谷歌。我最难忘的一个记忆是,在你退休前,你说谷歌还没“开窍”,尤其是谷歌云,还说他们的弃用政策很糟糕。他们现在好转了吗?
Steve:没有。我和谷歌的人聊过,很多人说“这就是谷歌的风格”。但有趣的是,在执行层面,谷歌已经好转了。他们终于做了 15 年前就该做的事:让员工承担责任,而不是让工程师随心所欲。过去 20 年谷歌都是这样,因为他们在广告领域有垄断地位,有足够的资金补贴工程师“随心所欲”。但最终他们还是得成熟起来,做出正确的选择,这个过程很痛苦,失去了一些谷歌文化,也没那么有趣了,但现在执行效率很高。随着 Gemini 的推出,他们逐渐把重心转向 AI,现在开始看到回报了。他们可能会成为最大的赢家。
主持人:那你怎么看 Google、Anthropic、OpenAI 这些实验室的状态?
Steve:说实话,这三家公司内部现在都非常混乱。Anthropic 把混乱掩盖得最好,这是他们产品经理的功劳,值得点个赞。这并不是因为 Anthropic 自己搞砸了,而是因为在这么快的增长速度下,混乱是不可避免的。
他们接下来要给 Claude Code 一口气招一百多号人,真的是在疯狂扩张。而这还只是 Claude Code 这一块。你要知道,我当年在 Google 和 Amazon 都经历过那种“必须先做大”的阶段,那时候必然是混乱的、动荡的。人们不知道该找谁、该跟谁对接,所有事情都一团糟。但慢慢地,一切会被理顺、会稳定下来,他们也会走到那一步的。
OpenAI 现在也很混乱,甚至更明显。他们经历了很多核心成员的离职。你要说是不是比 GitHub 那种失去大部分资深管理层、连续几年完全动荡的状态还糟,我也不确定,但 OpenAI 现在确实挺混乱的。
至于 Google,我们刚跟一个人聊到,说即便是在 Jules 团队内部,想在公司里达成共识、把东西推起来还是非常难。原因很简单:它太割裂了,像是由无数个小型“单体帝国”组成的集合体,一个个小应用彼此不沟通,导致任何跨公司范围的事情都极难推进。
所以现在这三家,其实都面临执行层面的挑战。我个人觉得 Anthropic 目前可能稍微做得好一点点,但差距非常小,战况非常胶着。接下来就很有意思了,看看 Oracle、Meta,或者其他公司能不能追上来。
主持人:Meta 值得关注,他们明年必须搞个大的。
Steve:明年很可能会成为开源模型之年。一旦开源模型达到 Claude Sonnet 3.7 一个水平,你打开 Klein 之类的东西,就能得到一个体验,至少和三月份的 Claude Code 差不多。虽然不如现在,但已经“够用”了,而且还是在你本地的 M4 上免费跑,真正的免费。
从我听到的情况来看,现在前沿模型大概还有七个月的领先优势,而且这个差距正在逐步缩小。这意味着,明年夏天,开源模型可能就能达到 Gemini 3 的水平。所以明年很可能会出现一个转折点:工具必须在任务拆解、模型分配上做得好得多,知道什么时候该用大模型、什么时候用小模型,才能把成本优化做好。
主持人:我也站在批判者的角度来说,他们认为之所以收敛,是因为模型能力是在逼近上限,提升会越来越慢。
Steve:这不是个小问题,而是一个根本性问题:AI 智力的发展曲线是线性的、指数的,还是趋近于上限的?
我们从一些非常接近研究核心的人那里听到的说法是,过去三十年里,受摩尔定律影响,AI 的“聪明程度”大约每 18 个月翻四倍。他们认为训练数据大概还能支撑两个这样的周期。之后会发生什么没人知道,可能继续上升,可能下降,甚至人类历史直接结束也不是没可能。但两个周期意味着三年后,它们会聪明 16 倍。
说实话,我也不知道“聪明 16 倍”具体意味着什么。但我花了很长时间去想这个问题,我的结论是:它们会变得非常、非常、非常聪明,一定会深刻改变世界,好的坏的都会有。
主持人:那孩子们还要学编程吗?
Steve:应该学 Vibe Coding。
主持人:你始终有一个“逃生口”,你想看代码的时候随时可以看,只是大多数时候你不需要看。但你能看,这本身就是一道护栏。不过我的看法是,不管怎样,如果你还懂一点真正的编程,你会更有优势,因为你的 prompt 更好。
Steve:当说到会编程的时候,但不是学语法,而是你要以一种“语言无关”的方式理解:函数、类、对象、monad 之类的能力边界是什么。你不再关心代码怎么写,但你关心它是怎么工作的。这个层级,其实已经接近产品经理或架构师的思维方式了。
你必须站在那个层级思考,而且你要理解所有工程层面的东西。就像我之前提到的 Jeffrey,他是数学家,自学成工程师,他不一定写代码,但他掌握了所有关键概念,知道 Cassandra 是怎么工作的。所以,就算你不需要亲手写代码了,你仍然需要学习海量知识,才能在这个新世界里成为一个高效的工程师,因为你和机器交互的层级已经被整体抬高了。
主持人:你还有没有什么想吐槽、想补充的?
Steve:我感觉最近“八卦”传播的频率上升了。不是那种“八卦”,而是工程师不断发现新方法、用 agent 变得更高效的那种兴奋感。
比如,我刚知道一个东西叫 Code MCP 之类的。因为 agent 并不擅长直接调用 MCP 工具,它们在这方面几乎没训练,但它们非常擅长写代码。所以你告诉它:不要直接调用工具,写代码去调用工具,它反而做得好得多。这种“小技巧”现在正在不断被发现,特别疯狂。Anthropic 自己其实不是最早发现这个的,是 Claudeflare 先发现的,Anthropic 后来才说“对,你们说得对”。
这也是为什么我特别喜欢把注意力放在 AI 工程师身上。我的观点一直是:AI 工程师是最能把 大模型潜力榨出来的那群人。你几乎可以把 AI 工程师定义为:不是训练模型的人,而是把模型“用到极致”的人。
这有点像一种颠覆式路径:当研究模型、训练模型还是高层次的事情时,当一个“GPT 包装工”显得没什么地位,但随着时间推移,这些人反而开始真正提升生产力,积累真实的专业能力。就像 F1 车手未必会造车,但他们对“怎么把车开到极限”的理解,甚至可能比造车的人还深。
参考链接:
https://www.youtube.com/watch?v=zuJyJP517Uw
![[首发福利] 既然 NotebookLM 生成的 PPT 改不了字,我怒搓了一个工具:一键转成可编辑 PPTX (L 站老哥专享 1 年 Pro + 永久福利)1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106113618_695c8332f0786.jpeg!mark)
![[首发福利] 既然 NotebookLM 生成的 PPT 改不了字,我怒搓了一个工具:一键转成可编辑 PPTX (L 站老哥专享 1 年 Pro + 永久福利)2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106113621_695c83355f4c1.jpeg!mark)
![[首发福利] 既然 NotebookLM 生成的 PPT 改不了字,我怒搓了一个工具:一键转成可编辑 PPTX (L 站老哥专享 1 年 Pro + 永久福利)3](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106113623_695c8337ab0f4.jpeg!mark)
![[首发福利] 既然 NotebookLM 生成的 PPT 改不了字,我怒搓了一个工具:一键转成可编辑 PPTX (L 站老哥专享 1 年 Pro + 永久福利)4](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106113625_695c8339d8ca2.jpeg!mark)
























































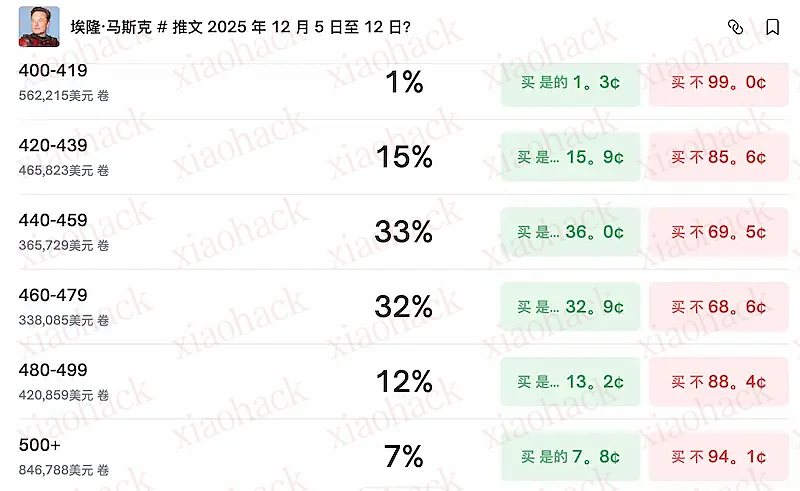
 这两天在网络上又有一个东西火了,Twitter 的创始人
这两天在网络上又有一个东西火了,Twitter 的创始人 
 两个月前,我试着想用 ChatGPT 帮我写篇文章《
两个月前,我试着想用 ChatGPT 帮我写篇文章《
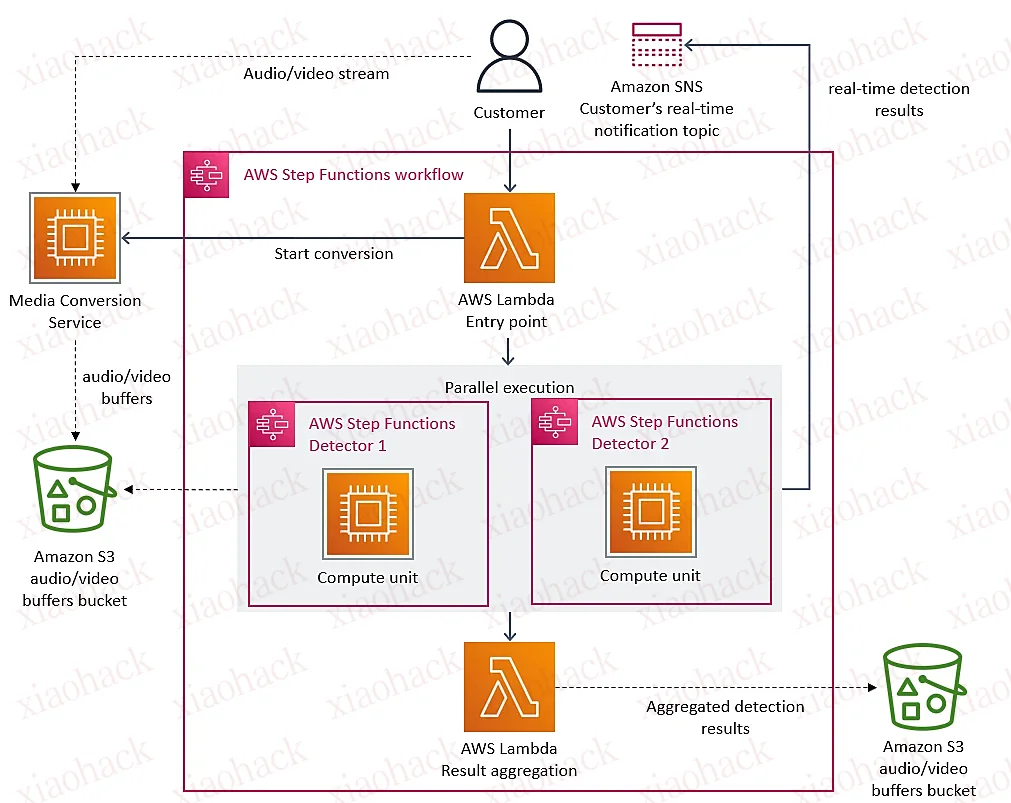
 这两天技术圈里热议的一件事就是Amazon的流媒体平台Prime Video在2023年3月22日发布了一篇技术博客《
这两天技术圈里热议的一件事就是Amazon的流媒体平台Prime Video在2023年3月22日发布了一篇技术博客《