农行信用卡刷卡金、积分
农业银行 AP - 搜 “旅游节”- 精彩盲盒,抽:0.6/66/666 元刷卡金、2 倍积分,月限 1 次,每周 3 万名额

xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
农业银行 AP - 搜 “旅游节”- 精彩盲盒,抽:0.6/66/666 元刷卡金、2 倍积分,月限 1 次,每周 3 万名额

发现站里有许多佬注册 aws 和完成任务得 200 刀乐的文章,但是这些刀乐怎么订阅 kiro pro + 没有一篇完整的教程。早上自己摸索了一下也算猜了一些坑,写一点自己的流程和踩过的坑与佬们分享
注册 aws 账号的过程请参考别的佬的文章,此处不赘述
首先注册完账号之后在控制台搜索 kiro,然后选择用户组
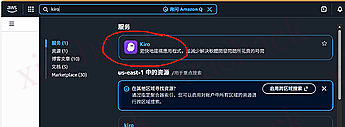

然后点击 add user,会发现咱们没有用户(我已经注册过了,假如第一次来是没有用户的),这时候点击页面里的链接转到 IAM


然后添加一个用户

在设置密码这里记得用默认的选项(就是用电子邮件设置用户密码的)
然后亚马逊就会给你发邮件,让你设置密码这一串的
最后回到 kiro 的控制台,add user,就能发现能搜出来咱们之前创建的账户了

最后就是下载 kiro 的 ide,然后选择最后一个选项登录(Sign in with AWS IAMldentity Center)
会出现一个让你填 start URL 的地方,复制 kiro 控制台此处的 URL 即可

(新人第一次写帖子,希望佬们多多包涵,如有错误希望佬们能指出)
项目官网:
原生安卓,相比较 Flutter 等框架,性能很强。
笔记私有,任务也是根据笔记获取的,可以使用 Webdav 等同步,我也搞了官方同步,后续用于文章分享等。


【完善中】OCR 功能,我选择了 Paddle OCR 本地,AI 可用于后续生成待办和文章。

【正在做】语音功能,可能会使用 whisper。
【正在做】绘图功能,使用 Excalidraw、 Xournal++ 等

项目:
斜杠命令,需要用户自己主动触发;本质是把重复的提示词存储起来,直接通过命令调用提示词。
使用方法: 用户可以通过在项目的 .claude/commands/ 目录下创建 Markdown 文件 (.md) 来定义自定义命令。
文件名:决定命令的触发词(例如 analyze.md 对应 /analyze)。
文件内容:包含你希望 Claude 执行的具体 Prompt(提示词)。
参数:支持使用 $1, $2 或 $ARGUMENTS 接收用户输入。
官方 / 社区示例:/security-review 这是一个常见的自定义命令,用于让 Claude 按特定标准审查代码安全。
文件路径:~/.claude/commands/security-review.md (全局命令) 或 .claude/commands/security-review.md (项目命令)
文件内容示例:
--- description: Review the current code for security vulnerabilities --- Please review the code in the current context for security vulnerabilities. Focus specifically on: 1. SQL injection risks 2. XSS vulnerabilities 3. Hardcoded secrets If you find issues, please suggest specific fixes. 如何使用:在终端输入 /security-review
Agent 本质上是拥有独立上下文和特定系统提示词(System Prompt) 的 Claude 实例
减小主流程上下文的占用,子代理上下文隔离,可以更好的聚焦任务;
使用方法: 你可以通过 CLI 交互式创建,或者通过配置文件定义。Agent 本质上是拥有独立上下文和特定系统提示词(System Prompt) 的 Claude 实例。
交互式创建:在 Claude Code 中输入 /agents,然后选择 “Create new agent”。
配置定义:通常定义在配置文件中,指定其 role(角色)、description(描述)和 tools(可用工具)。
官方示例:Code Reviewer (代码审查员) 这是官方文档中常用来演示如何通过子代理分担任务的例子。
配置逻辑(概念性描述):
名称:code-reviewer
角色描述:你是一位资深的代码审查专家,通过严格的标准审查代码变更。你只关注代码质量、可读性和潜在 bug,不要直接写代码,只提供建议。
工具权限:限制为 Read(只读)权限,防止它意外修改代码。
如何使用: 在对话中,主 Agent 可能会根据任务自动调用它,或者你可以显式指派任务(如果配置允许)。
“Please ask the code-reviewer to check my latest changes.”
按需加载,只有需要该技能的时候才会加载文件内容。
都可以对业务及开发流程进行规范
使用方法: Skill 是赋予 Claude 新能力的 “知识包”,通常由一个 SKILL.md 文件和相关的脚本 / 文档组成。
核心文件:SKILL.md。
原理:Claude 启动时会加载 Skill 的元数据(Metadata)。只有当它判断当前任务需要该技能时(例如用户要求 “处理 PDF”),它才会读取 SKILL.md 的完整内容并执行其中的步骤。
官方示例:PDF Processing Skill (PDF 处理技能) 这是 Anthropic 工程博客中介绍的一个经典案例,教 Claude 如何读取 PDF 表单。
目录结构示例:
skills/pdf-skill/
├── SKILL.md # 告诉 Claude 如何使用这个技能
├── extract.py # 实际执行提取工作的 Python 脚本
└── README.md
SKILL.md 内容摘要:
“When the user asks to extract data from a PDF, run the
extract.pyscript provided in this directory. Do not try to read the PDF raw bytes directly. Interpret the JSON output from the script.”
如何使用:用户无需显式调用。只需说 “Read the contract.pdf and tell me the date”,Claude 会自动激活 PDF Skill。
Plugin 是上述所有内容(Commands, Agents, Skills)的分发容器。
接下来说一下比较容易混淆的地方,commands,agents,skills 确实有功能重叠的地方,但是他们的侧重点是不一样的,只有明白了他们各自的侧重点之后才能更好的决定使用哪一个。
这是最容易混淆的一对。它们都可以用来封装一段 Prompt 或脚本。
重叠点:它们本质上都是 “预定义的指令 / 脚本”。
核心区别:谁掌握 “扳机”?
Command (命令) 是显式的。你(用户) 是控制者。你必须输入 /review,Claude 才会去审查。
Skill (技能) 是隐式的。Claude (模型) 是控制者。你只需要说 “帮我看看这代码咋样”,Claude 会自己判断:“哦,用户需要审查代码,我应该调用 CodeReviewSkill。”
例子:
如果你写了一个 Python 脚本 format_code.py。
做成 Command (
/fmt):你每次必须手动输入/fmt才能运行它。做成 Skill:当你对 Claude 说 “这代码太乱了” 时,Claude 会自动运行这个脚本。
这两者都涉及 “特定领域的专业能力”。
重叠点:都能让 Claude 变得更专业(例如都懂 SQL)。
核心区别:上下文是不是独立的?
Skill (技能) 是工具。它在当前对话中被加载。它就像给了当前的 Claude 一本《SQL 手册》,它现学现卖,但还是同一个 Claude 在跟你说话,上下文是混在一起的。
Agent (代理) 是分身。它拥有独立的上下文。当你调用 Agent 时,就像是 Claude 把任务转包给了坐在旁边的 “数据库专家”。这个专家有自己的记忆和设定,处理完后只把结果告诉主 Claude,避免了主对话窗口被大量的中间步骤污染。
Plugin 没有任何功能上的重叠,因为它不是功能本身,而是包装盒。
你不能把 Plugin 和 Command 并列比较。
Plugin 包含 Command、Skill 和 Agent。
就好比:Command 是苹果,Agent 是橙子,而 Plugin 是水果篮。
假设你想实现一个功能:“将代码翻译成中文文档”。你可以通过三种方式实现,侧重点不同:
| 方式 | 实现形态 | 交互体验 | 适用情况 |
|---|---|---|---|
| 方式 A: Command | 定义 /trans 命令 | 你输入 /trans file.py,Claude 立即执行翻译。 | 高频、确定性任务。你很清楚什么时候需要翻译,不需要 Claude 废话。 |
| 方式 B: Skill | 编写 TranslationSkill.md | 你说 “帮我把这文件弄得容易读一点”,Claude 自动识别并调用翻译技能。 | 模糊指令、智能化。你希望 Claude 像助手一样自动判断该做什么。 |
| 方式 C: Agent | 创建 TranslatorAgent | 你说 “开启翻译项目”,主 Claude 唤醒子代理。子代理独立运行,不打扰你,翻译了几百个文件后,只给你一个汇总报告。 | 复杂、耗时、多步骤任务。防止翻译几百个文件的过程刷屏,导致你之前的对话记忆被挤掉。 |
如果你在尝试扩展 Claude Code,可以用这个简单的决策树:
这个功能需要用户手动且精确地触发吗?
是 → Command (/foo)
否 → 下一步
这个任务是否非常复杂,需要大量步骤,且容易污染当前的聊天记录?
是 → Agent (独立的子脑)
否 → Skill (教会当前大脑新知识)
你想把这些功能打包发给同事用吗?
如果内容有误,欢迎指出
首先放上佬 的项目地址,有需要的可以给佬点下小星星

期间参考了佬 @user554 的部署教程,大部分都是一样的,
下面开始教程:
1. 注册 [TiDB Cloud] 创建免费的 mysql 数据库,点击 connet, 需要先设置好密码,然后把数据库连接参数保留好,后续忘记密码可以点击重置密码。
免费版本:5G 存储空间,完全够用了。






2. 打开 octopus 项目,fork 到自己的仓库。
3. 登录 Render,选择 Github 方式,创建 Web 服务,选择仓库里面的 octopus 项目,选择免费计划,注意免费计划需要绑定信用卡,预扣款 1 美元进行校验(我查了下 1 美元过一段时间会退款,即使不退款影响也不大)



4. 这里不要直接点击创建,要改一下默认参数,如果已经创建了可以重新编辑参数后在部署
Build Command 改为:
d web && npm install && npm run build && cp -r out/. ../static/out/ && cd .. && go build -tags netgo -ldflags '-s -w' -o app
Start Command 改为:
./app start

下面修改 docker 环境变量


特别需要注意的就是数据库配置,采用第一步注册的 TiDB 数据相关参数,格式为
用户名:密码@tcp(ip:端口)/数据库?tls=true&parseTime=true 然后部署或者重新启动就行,等到启动后,点击页面上的地址进行访问,默认的账号密码都是 admin


5. 目前已经能正常使用了,后续上游仓库更新后,只需要进入自己的 fork 仓库进行同步,Render 会检查到后会自动同步更新重部署。

6. 注意事项:
6.1. 后续不要点击这里进行升级,采用 github 同步代码或者提交自己的代码,你们部署出来可能版本号不一致请不要在意 ,版本号目前有处理方式,但是要多几步配置,懒得写了,不影响使用。

6.2.Render 使用的免费服务,如果超过 15 分钟后不使用,服务会休眠,当再次使用或者访问的时候需要等待一分钟左右,等服务激活,如果不想服务休眠,可以 uptimerobot 免费注册这个完整,设置 10 分钟自动检查一下服务状态,这样服务就不会进入休眠,


6.3. 后续如果数据库免费的 5G 空间满了,请清理日志表:relay_logs,正常使用估计能用一年。
感谢论坛里面的各个大佬的公益站,以及佬 @ByteBender 的公益站(本次部署全程使用):
https://linux.do/t/topic/1175087
提醒:如用本方式聚合公益站,请自己使用,不要二次分发!不要二次分发!不要二次分发!
划水这么久,第一次写教程贴,写得不好请见谅
(\ _ /)
( ・-・)
/ っ 依然是节气海报,因为就这个最没约束。唯一约束是要符合百货商场。
& 因为离赤道较近上头不准海报用雪元素。。
第①步¦随便想想,然后随手掏来桌面的废纸和笔随意划个大概。

第②步¦把 线稿 + Prompt 丢 AI 随缘炼金 原图保真参数用 low 效果更佳。

虽说 MJ 审美也许更高但给 gpt 写 Prompt 省脑细胞。
第③步¦也把选中的图喂给 AI 要文案

最后套上常规文字 LOGO 模板等即可。

(\ _ /)
( ・-・)
/ っ 然后放在一旁不要发送,该吃吃该摸摸,不要比还在传统素材网找素材的不会科学上网的同事更快交稿 / 等快到截稿期再交稿、但要预留上级想 DIY 文案的时间、但不要预留足够推翻整张图重新设计的时间。
重新优化的网格模式,以及部分细节的调整,将比之前更加清新美观
支持至多三列显示,多种布局多种配置等等
将很快推送更新,欢迎各位 star
双侧栏 - 网格
双侧栏 - 列表
单侧栏 - 列表
单侧栏 - 网格 2 列
单侧栏 - 网格 3 列
单双侧栏 - 网格瀑布







演示站: Firefly - Demo site
我的博客: 夏叶博客
使用文档: Firefly 博客模板文档
GitHub 地址: GitHub - CuteLeaf/Firefly: 流萤,这是一款清新美观的 Astro 博客主题模板 | a fresh and visually appealing Astro blog theme template, Secondary development based on Fuwari.
因为看了平行眼的视频,发现立体效果很好,我就想着能不能把 NSFW 也平行眼看,那岂不是很爽。所以简单糊了一个 worker.js 放在 cloudflare 上面部署即可。
/**
* 双屏同步视频播放器 - Cloudflare Workers
*
* 部署步骤:
* 1. 登录 Cloudflare Dashboard -> Workers & Pages
* 2. 创建新 Worker
* 3. 将此文件内容粘贴到编辑器
* 4. 点击 Deploy
*/
// 内嵌的HTML页面
const HTML_CONTENT = `<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>双屏同步视频播放器</title>
<style>
* { box-sizing: border-box; margin: 0; padding: 0; }
body {
font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, sans-serif;
background: linear-gradient(135deg, #1a1a2e 0%, #16213e 100%);
min-height: 100vh;
color: #fff;
}
/* 上传页面 */
.upload-container {
min-height: 100vh;
display: flex;
flex-direction: column;
align-items: center;
justify-content: center;
padding: 20px;
gap: 24px;
}
.title { font-size: 28px; text-align: center; }
.subtitle { color: #888; text-align: center; }
.drop-zone {
width: 100%;
max-width: 500px;
padding: 60px 40px;
border: 2px dashed #444;
border-radius: 16px;
background: rgba(255,255,255,0.02);
cursor: pointer;
text-align: center;
transition: all 0.3s;
}
.drop-zone:hover, .drop-zone.dragging {
border-color: #2563eb;
background: rgba(37,99,235,0.1);
}
.drop-zone input { display: none; }
.drop-icon { font-size: 48px; margin-bottom: 16px; }
.drop-text { color: #aaa; line-height: 1.8; }
.divider {
display: flex;
align-items: center;
width: 100%;
max-width: 500px;
gap: 16px;
color: #666;
}
.divider::before, .divider::after {
content: "";
flex: 1;
height: 1px;
background: #333;
}
.url-form {
display: flex;
width: 100%;
max-width: 500px;
gap: 12px;
}
.url-input {
flex: 1;
padding: 14px 16px;
border: 1px solid #333;
border-radius: 8px;
background: rgba(255,255,255,0.05);
color: #fff;
font-size: 14px;
outline: none;
}
.url-input:focus { border-color: #2563eb; }
.url-input::placeholder { color: #666; }
.btn {
padding: 14px 24px;
background: #2563eb;
color: #fff;
border: none;
border-radius: 8px;
font-weight: 600;
cursor: pointer;
transition: background 0.2s;
}
.btn:hover { background: #1d4ed8; }
.error { color: #ef4444; text-align: center; }
.tips { text-align: center; color: #666; font-size: 14px; }
.tips h3 { color: #888; margin-bottom: 8px; }
/* 播放器页面 */
.player-container {
display: none;
flex-direction: column;
height: 100vh;
}
.player-container.active { display: flex; }
.upload-container.hidden { display: none; }
.player-header {
display: flex;
align-items: center;
gap: 16px;
padding: 12px 16px;
background: #0f0f1a;
border-bottom: 1px solid #222;
}
.back-btn {
padding: 8px 16px;
background: transparent;
color: #fff;
border: 1px solid #444;
border-radius: 6px;
cursor: pointer;
}
.back-btn:hover { background: rgba(255,255,255,0.1); }
.source-name {
flex: 1;
color: #888;
font-size: 13px;
overflow: hidden;
text-overflow: ellipsis;
white-space: nowrap;
}
.dual-wrapper {
flex: 1;
display: flex;
background: #000;
}
.dual-wrapper video {
flex: 1;
width: 50%;
height: 100%;
object-fit: contain;
background: #000;
}
.video-left { border-right: 1px solid #333; }
.video-right { pointer-events: none; }
.video-right::-webkit-media-controls { display: none !important; }
.sync-hint {
text-align: center;
padding: 8px;
background: #1a1a2e;
color: #888;
font-size: 12px;
}
</style>
</head>
<body>
<!-- 上传页面 -->
<div class="upload-container" id="uploadPage">
<h1 class="title">双屏同步视频播放器</h1>
<p class="subtitle">上传本地视频或输入视频URL,两个播放器同步播放</p>
<div class="drop-zone" id="dropZone">
<input type="file" id="fileInput" accept="video/*">
<div class="drop-icon">📁</div>
<p class="drop-text">拖放视频文件到此处<br>或点击选择文件</p>
</div>
<div class="divider"><span>或</span></div>
<form class="url-form" id="urlForm">
<input type="text" class="url-input" id="urlInput" placeholder="输入视频URL地址">
<button type="submit" class="btn">加载视频</button>
</form>
<div class="error" id="error"></div>
<div class="tips">
<h3>支持的格式</h3>
<p>MP4, WebM, OGV 等浏览器原生支持的视频格式</p>
</div>
</div>
<!-- 播放器页面 -->
<div class="player-container" id="playerPage">
<div class="player-header">
<button class="back-btn" id="backBtn">← 返回</button>
<span class="source-name" id="sourceName"></span>
</div>
<div class="dual-wrapper">
<video id="videoLeft" class="video-left" controls playsinline></video>
<video id="videoRight" class="video-right" playsinline></video>
</div>
<div class="sync-hint">左侧播放器控制两个窗口同步播放</div>
</div>
<script>
const uploadPage = document.getElementById('uploadPage');
const playerPage = document.getElementById('playerPage');
const dropZone = document.getElementById('dropZone');
const fileInput = document.getElementById('fileInput');
const urlForm = document.getElementById('urlForm');
const urlInput = document.getElementById('urlInput');
const errorDiv = document.getElementById('error');
const backBtn = document.getElementById('backBtn');
const sourceName = document.getElementById('sourceName');
const videoLeft = document.getElementById('videoLeft');
const videoRight = document.getElementById('videoRight');
let objectUrl = null;
// 拖放处理
dropZone.addEventListener('click', () => fileInput.click());
dropZone.addEventListener('dragover', e => {
e.preventDefault();
dropZone.classList.add('dragging');
});
dropZone.addEventListener('dragleave', () => dropZone.classList.remove('dragging'));
dropZone.addEventListener('drop', e => {
e.preventDefault();
dropZone.classList.remove('dragging');
const file = e.dataTransfer.files[0];
if (file) handleFile(file);
});
fileInput.addEventListener('change', e => {
const file = e.target.files[0];
if (file) handleFile(file);
});
function handleFile(file) {
if (!file.type.startsWith('video/')) {
showError('请选择视频文件');
return;
}
cleanup();
objectUrl = URL.createObjectURL(file);
playVideo(objectUrl, file.name);
}
urlForm.addEventListener('submit', e => {
e.preventDefault();
const url = urlInput.value.trim();
if (!url) {
showError('请输入视频URL');
return;
}
try {
new URL(url);
} catch {
showError('请输入有效的URL地址');
return;
}
cleanup();
playVideo(url, url);
});
function playVideo(src, name) {
errorDiv.textContent = '';
videoLeft.src = src;
videoRight.src = src;
sourceName.textContent = name;
uploadPage.classList.add('hidden');
playerPage.classList.add('active');
// 同步逻辑
videoLeft.muted = true;
videoRight.muted = true;
videoLeft.addEventListener('play', () => videoRight.play());
videoLeft.addEventListener('pause', () => videoRight.pause());
videoLeft.addEventListener('seeking', () => videoRight.currentTime = videoLeft.currentTime);
videoLeft.addEventListener('ratechange', () => videoRight.playbackRate = videoLeft.playbackRate);
videoLeft.addEventListener('volumechange', () => {
videoRight.volume = videoLeft.volume;
videoRight.muted = videoLeft.muted;
});
// 时间同步
function syncTime() {
if (Math.abs(videoLeft.currentTime - videoRight.currentTime) > 0.05) {
videoRight.currentTime = videoLeft.currentTime;
}
requestAnimationFrame(syncTime);
}
syncTime();
videoLeft.addEventListener('canplay', () => videoLeft.play(), { once: true });
}
backBtn.addEventListener('click', () => {
cleanup();
videoLeft.src = '';
videoRight.src = '';
urlInput.value = '';
uploadPage.classList.remove('hidden');
playerPage.classList.remove('active');
});
function cleanup() {
if (objectUrl) {
URL.revokeObjectURL(objectUrl);
objectUrl = null;
}
}
function showError(msg) {
errorDiv.textContent = msg;
}
</script>
</body>
</html>`;
export default {
async fetch(request) {
return new Response(HTML_CONTENT, {
headers: {
'Content-Type': 'text/html;charset=UTF-8',
'Cache-Control': 'public, max-age=3600',
},
});
},
};


整理 | 华卫 1 月 1 日,百度旗下 AI 芯片子公司昆仑芯已于向香港联合交易所秘密递交上市申请,为分拆独立上市铺平了道路。 据称,IPO 规模和结构在内的细节尚未最终确定。知情人士透露,为数据中心服务器提供动力的芯片制造商昆仑芯的估值至少为 30 亿美元(约合 210 亿元人民币)。 百度表示,分拆上市能更好体现昆仑芯的价值,吸引专注于通用 AI 计算芯片及相关软硬件系统业务的投资者群体,提升其在客户、供应商及潜在战略合作伙伴中的形象,提高其协商及争取更多业务的地位。 昆仑芯仍将是百度旗下子公司。据报道,百度持有昆仑芯约 59%的股份。分拆还将使昆仑芯能在未来有需要时直接且独立地进入股权及债务资本市场,百度集团能更有效地配置财务资源等。 此举仍需获得包括中国证监会在内的监管机构批准。百度强调,分拆计划能否最终完成尚无保证。 Counterpoint Research 副总监 Brady Wang 表示,“在市场上,昆仑芯被视为中国最实用、应用最广泛的 AI 芯片之一。”他还补充说,这家芯片制造商的主要优势之一在于软件。“昆仑芯芯片不会强迫用户采用封闭系统,而是能够很好地与常见的 AI 框架兼容,从而更容易将工作负载从英伟达迁移过来。” 去年底,摩根大通分析师预测,昆仑芯的芯片销售额到 2026 年将增长六倍,达到 80 亿元人民币。 受此消息影响,百度集团港股当日大涨。
12 月 14-18 日,计算机图形学顶会 Siggraph Asia 2025 在香港召开。火山引擎多媒体实验室有多项工作入选,包括了拓扑变换的自适应建模、动态人体重建、人体重打光的三项成果进行汇报和展出。 多媒体实验室研究人员与来自德国马克思普朗克研究所、上海科技大学的团队进行深入合作,提出了应对体积视频中拓扑变换的自适应解决方案 TAOGS,针对视频制作过程中频繁出现的拓扑变化问题进行了长时序跟踪与自适应建模,在极具调整性的场景下也能进行高保真的渲染。 为了解决这个问题,研究人员提出了一种双层的动态高斯表示方法,利用运动高斯去自适应地处理新观测的出现与过时观测的消失,以及利用外观高斯来进行复杂纹理的表征。其核心思想是利用稀疏的拓扑感知高斯来表示底层场景运动,并在时空跟踪器与光度线索的引导下捕捉新出现的观测,融合这些观测,并持续更新局部形变图。在其生命周期内,每个运动高斯可以派生并激活多个高斯,以建模细粒度的视觉细节。该方法在保持训练高效与压缩友好的同时,支持稳健的跟踪与拓扑自适应。 该方案生成的拓扑感知的高斯表示,可以自然适配基于标准视频编解码的体积视频格式,支持在移动端进行快速的传输和推理,进行自由视点的高清渲染,呈现与真实世界相融合的沉浸式体验。 动态 3D 重建技术正面临一个核心矛盾:序列越长、动作越复杂,重建质量越难保持。现有方法要么因误差累积而失真,要么因关键帧切换而产生画面闪烁。 火山引擎多媒体实验室最新提出的 《EvolvingGS: Stable Volumetric Video via High-Fidelity Evolving 3D Guassian Reconstruction》,通过一种“先对齐,后生长修复”的两阶段协同范式,首次实现了在单个连续时间段内,对任意时长与复杂运动的鲁棒 4D 高斯重建,无需关键帧切换,彻底避免闪烁。 引入光流一致性损失指导形变场学习,确保高斯模型的运动趋势与实际场景严格一致,即使应对快速运动也保持稳定。 在形变对齐的基础上,允许模型在拟合不足的区域智能增减少量高斯点: 保留的“参考高斯点”维持外观不变,保障时序连贯性; 新增的“拓展高斯点”自由优化,赋予模型强大的细节拟合能力; 提出基于贡献度的删点策略,解耦删点策略对不透明度下降的依赖,防止模型无限膨胀。 这一设计使模型能自适应物体的出现/消失、服装剧烈飘动、拓扑结构变化等极端情况。 w/o v.s. w/ 修复阶段 (应对拓扑变化) w/o v.s. w/ 修复阶段 (应对局部细节拟合) EvolvingGS 不只是一个技术方案,更是一种建模理念的进化:我们让模型具备结构性对齐能力(形变阶段)与局部生长能力(修复阶段),使其像生命系统一样,在保持整体一致的前提下,灵活适应局部变化。这意味着,无论是复杂舞蹈、服装飘动、还是场景中物体的突然出现或消失,EvolvingGS 都能应对自如,为动态 3D 重建打开了“无限时长”的大门。 在 3D 高斯场建模中,几何与外观的深度纠缠,长久以来是一个被默认却充满代价的设定。当颜色与形状被迫共享同一套不透明度分布时,其结果往往是渲染质量与几何精度互相妥协,真实感重光照更是难以企及。 传统方法内生地将模型的外观和几何紧密捆绑 解耦外观和几何 引入耦合系数 火山引擎多媒体实验室的最新研究 《Disentangled Gaussian Splatting:High-Fidelity Relightable Volumetric Video through Geometry-Appearance Decoupling》 ,提出一种几何-外观解耦式高斯表征。它如同为 3D 重建赋予了“双重身份”:让几何结构精准独立,让外观细节自由表达,最终在渲染质量与几何精度上同时实现显著提升,为高保真、可重光照的容积视频开辟了新路径。 传统 3DGS 将颜色与几何属性捆绑优化,如同用同一把刻刀同时雕刻形状与上色。我们的方法进行了根本性革新: 双分支独立渲染:我们为每个高斯基元同时引入几何不透明度场与外观不透明度场。在渲染时,两者通过可学习的解耦因子β进行加权融合,实现像素级的精准对齐与独立控制; 协同优化与独立规制:几何分支专注于法向量、深度与可见性的重建;外观分支则负责建模视点相关的色彩与光照。两个分支通过 β 因子动态协作,既能互相促进优化,又允许我们对各自施加针对性的约束(如法向平滑、深度一致),最小化相互干扰; 智能生长策略:基于两个分支的梯度信息独立判断局部区域的欠拟合情况。当一处需要“生长”更多高斯点来细化几何时,另一分支会以最小化干扰的方式协同初始化,确保模型紧凑高效; 可以轻松与 EvolvingGS 结合,将其优点拓展到 4D 重建领域 12 月 18-19 日,在火山引擎 FORCE 原动力大会上,多媒体实验室也展示了全息通信的商业化技术。该项技术由实验室研发的实时 4D GS 重建及压缩技术驱动,能够在消费级带宽(<10mbps)下高清高保真实现全息通信,支持远程面对面互动。与行业内全息通信(e.g.,Google Starline/Beam)方案相比,该技术不仅支持普通摄像头实时生成 6DoF 视频,更将设备成本与带宽需求降低了一个数量级,降低了全息通信的门槛,将促进该技术的规模化应用。 该项技术通过创新性地采用前馈神经网络架构,仅使用少量相机采集画面,极大的降低了采集成本,同时在保证画质的前提下将计算量降低 70%,在 A10 显卡上以超过 30 FPS 的帧率实现实时的 3D 高斯泼溅重建。在传输层面,实验室展示了全链路能力:通过基于渲染重要性的低损耗压缩策略,LiveGS 将 3D 高斯数据的传输带宽从行业普遍的 60Mbps 压缩至 10Mbps 以下,并保持画质损失(PSNR)小于 3dB——这意味着全息通信可以无缝复用现有的视频传输链路。在渲染层面,结合混合渲染技术,在 iPhone 15 等设备上实现了 30FPS 流畅的视角旋转、缩放等交互操作,同时支持在 PC、VR 等多终端实现流畅分发。 随着硬件成本实现量级下降,火山引擎计划在 2026 年全面推进全息直播场景的落地。全方位重塑社交、互动直播及办公协同体验。在全息通信的赋能下,多个行业正迎来体验革命:远程医疗可实现更真实的微表情反馈,金融与奢侈品服务能通过线下面谈般的临场感建立信任,而企业协作中的全息沙盘则让异地专家实时标注三维模型成为现实。火山引擎通过区域化高斯裁剪与高效编码技术,解决了移动端算力瓶颈与传输难题,使空间视频在手机、PC、VR 等多终端实现流畅分发。随着空间视频落地节点的到来,全息通信将不再是科幻场景,而是提升用户留存与互动深度的商业利器。 火山引擎多媒体实验室将“拓扑自适应+动态演进+解耦表征”的创新思路应用于动态 3D 重建与 6DoF 视频任务中,在处理复杂拓扑变换、长序列稳定性以及高保真可重光照渲染等核心挑战上取得了突破性表现。 通过 TAOGS 的拓扑感知高斯优化、EvolvingGS 的“先对齐后生长”演进范式以及 Disentangled3DGS 的几何-外观解耦架构,该系列研究有效解决了传统动态重建中对模板依赖高、长时序闪烁及几何外观纠缠等痛点,显著提升了复杂动态场景下的渲染精度与建模鲁棒性。 更重要的是,这些前沿技术促进了全息通信的商业化方案形成,通过创新的实时 4D GS 重建与超低带宽压缩技术,在消费级带宽(<10Mbps)和移动端设备上实现了高清、流畅的 6DoF 沉浸式交互,将全息通信的设备成本与传输门槛降低了一个数量级。从学术顶会的算法突破到 2026 年全息直播的规模化落地蓝图,火山引擎正在通过技术迭代重塑社交、办公与远程协作的视听体验,为下一代空间计算与全息媒体产业的发展奠定了坚实的技术基石。 多媒体实验室是字节跳动旗下的研究团队,致力于探索多媒体领域的前沿技术,参与国际标准化工作,其众多创新算法及软硬件解决方案已经广泛应用在抖音、西瓜视频等产品的多媒体业务,并向火山引擎的企业级客户提供技术服务。实验室成立以来,多篇论文入选国际顶会和旗舰期刊,并获得数项国际级技术赛事冠军、行业创新奖及最佳论文奖。TAOGS:突破传统模板依赖的限制进行自由建模!拥有拓扑变换的自适应能力

EvolvingGS:告别基于关键帧的 GoP 切分,能够应对任意复杂动作的可进化 4D 高斯表征
方法核心:让模型学会“动态生长”

形变场粗对齐
修复阶段


Disentangled3DGS:画质与几何质量的双重飞跃,基于解耦 3D 高斯表征的可打光体积视频




核心思路:为每个高斯点赋予“双重松耦合的不透明度”
全息通信方案


总结
团队介绍
整理|华卫 去年这个时候,外界普遍传言:图灵奖得主、Meta 前首席科学家 Yann LeCun 将主动离开 Meta,寻求新的研究机会。如今,LeCun 也已官宣离职开启创业之路。 而刚刚公开的一场对 LeCun 的专访,却呈现了另一番截然不同的故事。这场对话长达三小时,期间 LeCun 曝出了不少 Meta 的猛料,并勾勒出了这一残酷现状:组织运转失灵、基准测试结果造假,以及一位拒绝为自己认定存在科学缺陷的方案背书的研究员的出走。 首先,LeCun 透露了一个 Meta 本不愿公之于众的惊人细节:Llama 4 的基准测试结果是人为操纵的。 “这些结果有几分掺假,”他解释道,工程师针对不同的基准测试采用了不同的模型变体,目的是优化分数,而非展示真实的能力。 这绝非一场单纯的产品失利。2022 年 11 月 ChatGPT 的问世打了 Meta 一个措手不及,公司领导层陷入慌乱。Meta 随即围绕生成式 AI 业务进行重组,相继推出了 Llama 2 和 Llama 3。Meta 将自身定位为开源领域的领军者,是对抗 OpenAI 封闭模式的一方。单看 Llama 3 的下载量和生态系统渗透率,Meta 的布局相当成功,这包含渠道分发、品牌塑造和生态引力所带来的效果。 这一系列势头最终促成了 2025 年 4 月 Llama 4 的发布。这款模型虽斩获亮眼的基准测试分数,却因实际表现问题饱受诟病。此前也有独立报道证实了 LeCun 所描述的“数据作弊”行为,针对不同测试,专门挑选对应的模型变体。 LeCun 在采访中表示,这一事件让 Mark Zuckerberg 对公司现有 AI 团队彻底失去了好感。 据称,这位首席执行官当时震怒不已,“基本上对所有参与此事的人都失去了信任”。“也正因为如此,整个生成式 AI 团队都被边缘化了。”LeCun 表示,“很多人已经离职,还有不少没走的人也即将离开。” 随后,Meta 针对 Llama 4 失利所做出的一系列应对举措,折射出其管理层当时的窘迫处境。据路透社报道,2025 年 6 月,该公司斥资约 150 亿美元收购了数据标注初创企业 Scale AI 的大量股份。与此同时,Meta 聘请了 Scale 年仅 28 岁的首席执行官 Alexandr Wang,牵头组建一个名为 TBD 实验室的全新研究部门,负责前沿 AI 模型的研发工作。 该公司还展开了声势浩大的挖人行动,据称向竞争对手旗下的顶尖研究员开出了 1 亿美元的签约奖金。 通常,健康的研究机构不会因为一次挫折就动辄斥资 150 亿美元收购初创企业的大量股份。这些举动,似乎亦在展露这家公司正面临战略押注摇摇欲坠的危机。 对 Wang 的任命,造成了公司架构上一次令人错愕的上下级反转。身为图灵奖得主、卷积神经网络发明者、深度学习革命联合发起人的 LeCun,如今竟要向一位主业为训练数据标注的人汇报工作。在任何一家研究机构,这样的身份倒置都堪称骇人。这位领域奠基人端坐会议桌前,听着一位年龄不及自己一半的后辈,为那些对方既未参与创造、也未完全理解的技术规划发展蓝图。 LeCun 在采访中直接表示,此人“毫无研究经验,既不懂研究该如何开展,也不知道研究该如何落地”。“他学得很快,也清楚自己的短板所在……但他毫无研究经验,既不懂研究该如何开展、如何落地,也不知道什么样的东西能吸引研究员,什么样的东西会让研究员反感。”LeCun 如此说道。 当就这一汇报层级向 LeCun 追问时,他的回应措辞谨慎却一针见血:“没人能对研究员指手画脚。尤其像我这样的研究员,更是绝无可能。”LeCun 表示,尽管在 Zuckerberg 主导的 AI 业务重组后,这位 28 岁的年轻人曾短暂担任自己的上司,但实际上并没有对他发号施令。 实际上,双方更深层的矛盾似乎并非源于层级,而是源于理念分歧。Wang 代表的是 Meta 押注语言模型规模化的战略方向,而 LeCun 则认为这一范式从根本上就误入了歧途。让奉行这一理念的人身居管理要职,让他的留任变得绝无可能。 “我敢肯定,Meta 内部有不少人,或许也包括 Alex,都巴不得我不要对外宣称,在通往超级智能的道路上,大语言模型本质上已是一条死胡同。”LeCun 强调,“但我不会因为某个家伙说我错了,就改变自己的想法。我没有错。作为一名科学家,我的职业操守不允许我做出这种违心之举。” 如今 Meta 的 AI 战略,核心是沿用 OpenAI 联合创始人声称已触及天花板的架构方案,与 OpenAI 展开竞争。 然而,作为这家公司最具声望的 AI 研究员,LeCun 认为,这种方案根本无法实现 Meta 宣称要追逐的智能目标。据其透露的内容,负责 Meta 旗舰模型的团队交出的成果可信度极低,致使管理层对整个团队都丧失了信任。 事实上,LeCun 对大型语言模型的批判,早已超越 Meta 此次的具体失利事件。LeCun 一直以来都在强调,大型语言模型的局限性过大,若要释放 AI 的真正潜力,必须另辟蹊径。 过去数年间,他在公开演讲与技术论文中阐释的核心论点,本质上是一个数学层面的结论:语言这一载体,对于培养真正的智能而言,存在着根本性的带宽不足问题。 参与 Lex Fridman 播客节目时,LeCun 曾测算过一组数据:若要通读互联网上的全部文本(体量约为 2×10¹³字节),人类需要耗费 17 万年的时间。而一个四岁孩童,单是通过视觉输入接收的信息体量就约达 10¹⁵字节。也就是说,在幼儿阶段,孩子吸收的信息量,就比大型语言模型从人类全部书面语料库中提取的内容多出 50 倍。 这一数据背后,潜藏着更为深刻的启示。训练大型语言模型,就如同试图通过阅读所有与木材相关的书籍来学习木工手艺:你自始至终都没有碰过一把锤子。诚然,你能掌握相关的专业词汇,但却无法真正理解背后的物理原理。LeCun 的判断很简单:要学好木工,你必须亲手挥起锤子。 这一点恰好解释了 AI 能力上长期存在的短板。青少年只需 20 小时就能学会开车,幼儿第一次尝试就能擦干净桌子,家猫能轻松穿梭于复杂的三维空间。然而,即便投入了数十亿美元的研究经费,在万亿级别的语料库上训练出来的 AI 系统,却在这些任务面前束手无策。 2025 年 11 月,OpenAI 前首席科学家、规模化范式的缔造者 Ilya Sutskever 在接受 Dwarkesh Patel 采访时也抛出了这样一个振聋发聩的观点。他表示,该领域正从“规模化时代”迈向“研究时代”,单纯依靠算力规模的扩张,只会产生边际效益递减的结果。 当这一范式的开创者都如此表态时,其分量不言而喻。ChatGPT 问世后形成的、围绕大语言模型规模化的行业共识正在瓦解。 在接受采访的午餐会上,LeCun 用一个具体的例子阐释了他提出的另一种技术路径。当他掐别人一下时,对方会感到疼痛,其心智模型随即发生更新,下次当他再抬手靠近时,对方会本能地退缩。这种基于预判产生的反应,以及随之触发的情绪,才构成了对因果关系的真正理解。而大型语言模型并不具备这样的机制。它们只是基于统计规律来预测语言符号,而非通过因果模型去判断行为会引发何种后果。 为此,LeCun 提出了一套名为联合嵌入预测架构(JEPA)的世界模型架构,以此弥补现有技术的缺陷。该架构通过对视频与空间数据进行训练,培养系统基于物理原理的认知能力。它让系统学习与行为相关的抽象表征,而非执着于符号层面的预测;同时,它还融入了能随经验不断进化的持久记忆,而非在每次对话时都重置记忆。 采访中,LeCun 给出了该架构的落地时间表:12 个月内推出雏形版本,数年内实现更大规模的部署应用。 据称,他创办的这家初创公司命名为“先进机器智能”,其技术路径正是他所主张的、比大型语言模型更具优势的方案。在这家新公司里,他将出任执行董事长,而非首席执行官。 “我是一名科学家,一个有远见的人。我能激励人们去做有趣的事情。我很擅长预测哪种技术会成功,哪种会失败。但我当不了 CEO。”LeCun 说,“我既太缺乏条理,也太老了!” 世界模型能否后来居上,目前尚无定论。LeCun 预测,具备动物级智能水平的 AI 将在五到七年内实现,而达到人类级智能则需要十年时间。 这位曾助力构建当前 AI 范式的领军人物,如今正孤注一掷地押注:要实现超越,必须依托截然不同的技术路径。绝非细枝末节的渐进式改良,而是彻底颠覆式的全新架构。 参考链接: https://www.ft.com/content/e3c4c2f6-4ea7-4adf-b945-e58495f836c2篡改模型测试结果后,小扎边缘化所有参与员工
LeCun 锐评 Alexandr Wang:毫无经验、休想对我指手画脚
“语言模型已经达到瓶颈”
新架构一年内有雏形?
作者按:本文最早发布于 2021 年。文章发表后,我收到了许多正面反馈,不少朋友都说是因为读到了这篇文章才知道了 ADHD,甚至走进医院,获得了医生的帮助和诊疗。
而在 2025 年的罗永浩科技创新发布会后,老罗发布了一条微博,表达了自己因为 ADHD 而拖延和患得患失,最终影响了直播效果的感慨。ADHD 因此再度登上微博热搜,又一次成为公众话题。
因此,我在补充了新信息、新内容后重推本文,希望你可以了解 ADHD,也希望能帮助更多疑似或已经确诊为 ADHD 的朋友们走出困境。
也许你在工作和生活中时常遇到这样的问题:精神不集中,很难长时间只做某项工作,非常容易分神;情绪不稳定,对于他人的行动没有耐心,易怒;严重拖延,经常踩着死线甚至跨过死线完成项目。如果你在分神、冲动或拖延的时候内心充满了自责与困扰,但就是无法控制自己的注意力和行动力,那你有可能和我一样,也是 ADHD 患者。
在 2016 年的「罗辑思维读书会」上,罗永浩分享了一本冷门书籍《分心不是我的错》,这是 ADHD 这个概念在国内声量最大的一次曝光和讨论。事实上,全球大约有 6% 到 8% 的儿童都或轻或重地患有 ADHD,其中一些可以在成长过程中自愈,另外一些则会带着疾病进入成年。ADHD 会给成年人的工作和生活都带来负面影响,造成粗心大意、过度拖延、无法持续重复劳动等问题。
大学毕业后一两年,我就意识到了自己患有 ADHD。过去的五六年中,我也一直尝试用各种方式和 ADHD 对抗,但始终因为拖延而没有走进医院接受正规治疗。直到 2020 年的末尾,在外界工作压力和我内心对自己的不断督促下,我终于决心走进精神科,接受大夫的诊断。在这篇文章中,我想结合自己接受诊疗的过程,把关于 ADHD 的相关知识和问诊经验分享给你。如果你也饱受分心和拖延的困扰,希望这篇文章能帮你找到脱困的捷径。
注:我在撰写这篇文章的过程中得到了播客《沒有主題的閑聊》主播 @LOSSES 老师的指点,他在 这期节目 里专门讲解了 ADHD 的知识和细节,推荐收听。如果你想更深入地了解 ADHD,也可以阅读节目 shownotes 中提供的参考链接。
建议搭配观看和收听——
如果你想更好地了解和保护专注力,可以阅读这篇《注意力使用不完全报告》。
ADHD 的全称是 Attention Deficit Hyperactivity Disorder,大陆通常译作「注意力缺陷多动障碍」,民间俗称「多动症」。ADHD 是一种精神疾病,人类目前尚未完全知晓此症的核心病理,普遍认为该病可能与遗传、发育、社会环境等因素有关。
ADHD 的核心症状是注意力缺失(Attention Deficit)和多动(Hyperactivity Disorder)。注意力缺失体现在对于自己不喜欢、不擅长的领域,或者从事重复性劳动时很难保持专注;多动体现在行为上的不安、冲动和破坏性,譬如频繁打断别人说话,或者听人讲话时总要东摸西看等。伴随 ADHD 而来的还有各种情绪问题,如急躁、焦虑、抑郁等,以及拖延、粗心马虎、常丢东西等表现。
造成这种病症的原因在于,ADHD 患者的多巴胺和去甲肾上腺素分泌不足,当需要调动注意力时,大脑无法给予足够的补偿机制。因此,许多患者在关注自己特别感兴趣的内容时依然可以非常专注,因为此时大脑会产生兴奋感,多巴胺也会大量分泌,进而让患者暂时脱离了注意力缺失的状态。
如果你感觉自己有类似上文提到的行为和心理状况,那就可以考虑检查自己是否有可能患有 ADHD。从简单的自查到接受专业医师的诊断,你可以通过以下步骤逐渐排查:
ADHD 大多始发于儿童时期(大约 6 到 12 岁),因此回顾自己童年的表现就成了自我检查时最为重要的一步。如果你小时候的整体状态还不错,没有明显、长期的注意力缺失或者多动症状,也不是造成课堂秩序混乱的源头,只是近期或步入社会后才有了拖延、多动等状况,那多半是枯燥的工作给你带来了压力。你可以考虑接受其它方面的心理疏导,并改善自己的工作方法,也大概率排除了患有 ADHD 的可能性。
在粗略判断自己是否有 ADHD 的可能之后,你可以在接下来做一套 ADHD 自测题来进一步自查。如果你曾做过心理测验题,那 ADHD 自测题的内容和答题方式会和心理测验类似——题目通常会询问你的身体和精神状况,譬如是否粗心犯错,遇到重复性工作是否难以完成等,你需要根据自己实际的严重程度给予评分。测试结束后,分值达到某个区间就可以怀疑自己患有 ADHD。
我目前比较推荐的两套 ADHD 测试题分别是:
注意,和第一步的自测一样,ADHD 自测题也只是粗略地帮你排查自己是否有罹患 ADHD 之可能,在社会环境和工作压力的作用下,任何人都有可能在某个时期特别符合自测题中的大部分情况。就我自己的经验来看,网上所有 ADHD 自测题都和精神科的医学测试完全不同,不能仅凭自测题成绩断定自己是否患病。
另外,《精神障碍诊断与疾病统计手册(第五版)》(DSM-V)还给出了「注意力不足」和「多动」类型的 ADHD 患者的症状标准,如果你在少儿时期的行为符合这两类的至少一类,也可以作为判定自己患病与否的参考。


如果你在前两步的自测中均发现自己有较为明确的 ADHD 症状,那就可以考虑接受来自专业医师的诊断了。具体的预约和诊断步骤我会在下文说明。
预约精神科医生并接受诊断和治疗的大体过程和你到医院看感冒发烧没有太大区别,但有些细节需要特别留意——
在我国,精神类疾病的整体受重视程度不如身体疾病,医疗资源也相对有限。很多三、四线城市没有独立的精神病医院,各大医院的精神科室所能诊断的疾病类型也不多。在此基础上,ADHD 更是一个极小的精神科分支,很多精神病医院都没有相应科室或诊断能力。所以,如果你所在的地方没有足够专业的精神医疗机构,要做好到省会城市或其它大城市就医的准备。
预约门诊的第一步就是要搜索你的所在地是否有 ADHD 诊疗机构,我推荐以下两种搜索方式:
以上搜寻只是搜索工作的第一步,目的是筛选出可以诊疗 ADHD 的医院。接下来,你还需要通过进一步验证以明确对方可以诊疗成人 ADHD。
二次验证也不复杂,到目标医院的网站查看是否有对应科室和诊疗资质即可,亦可尝试在该医院挂号,看看是否有对应科室。如果目标医院有电话号码,我建议致电询问。

二次验证这一步非常重要。国内针对 ADHD 的诊治主要面向儿童,没有专门的成人多动症科室,因此你在搜索时需要搜索和「小儿多动症」相关的关键字,并在找到信息后进一步向对方确认是否可以诊疗成人 ADHD。

预约和挂号完成后,你就可以按时接受初诊了。在这里,我想请你做好心理准备——如上文所言,目前治疗 ADHD 没有专门的成人科室,所以你诊断和治疗的全程身边都会有孩子们陪伴。也正因如此,电脑自动生成的参考报告里很多遣词造句都是针对儿童的,譬如「最近连最爱的动画片都没兴趣了」,把我笑死。
初诊的过程稍微有点长。大夫会首先询问你的基本情况,你需要向大夫大致描述你的症状和困扰程度。这个部分大夫询问的内容和之前你做过的 ADHD 自查非常相似,只要回答你的真实情况即可。
随后,你要参与多个精神测试项目,大体包含数套自我测评题、脑电波测试、各种反应测试等。其中,自我测评题会和 ADHD 自测题在形式上相近;脑电波测试则是你常在电影、电视中见到的——脑袋上戴着奇怪帽子和电线的——测试方法;各种反应测试很像小游戏或智力测验,你要借助电脑完成一系列操作。

为了不给你任何暗示,我就不描述测试的具体细节和内容了。但有一点可以提醒:由于 ADHD 的测试系统大多是为儿童多动症设计的,所以很多题目对成人来说非常简单,但你在做的时候不用担心「这么简单的题目会不会测不出我的真实情况呀?」,尽可能保持专注完成测试并相信大夫的专业和判断就好。
完成全部测试大概需要半天时间,完毕后就可以进一步接受大夫的诊断和治疗。
在深圳,成人 ADHD 的诊断(包含测试)费用是一千块左右,据我了解,全国应该相差不多。深圳可以使用医保支付诊断费,但确诊后的医药费需要自付(18 岁以下可以使用医保)。我不确定这项政策是否全国通行,你可以根据自己所在地的情况酌情选择支付方式。
通常来说,在完成初诊之后,大夫会根据你的测试结果给出治疗方案。目前主流的治疗方案是服药和行为治疗,遗憾的是,成人已经错过了行为治疗的最佳阶段(这项治疗主要针对儿童有效,市面上已经有了针对 ADHD 儿童的辅导班,部分幼儿园还引进了相关项目),所以大部分患者都需要通过服药来克服疾病。
国内治疗 ADHD 的主要药物是专注达和择思达等,其中又以专注达为多(我也服用的它)。专注达(成分为派甲酯)是一种中枢神经兴奋剂,其作用原理是阻断突触前神经元对去甲肾上腺素和多巴胺的再回收,进而提升两者浓度。
专注达是知名的「聪明药」,很多家长会通过灰色渠道购买进口药或同类药,帮孩子提升专注力,应对功课和高考,这是相当危险的做法。
再次强调,ADHD 是精神疾病,治疗药物也是精神类药物。如果你曾怀疑自己是 ADHD,请通过正规渠道治疗、购买并服药。我此前也尝试过通过其它渠道购买药物自己治疗,但请相信,这些药物和你通过医生诊断后获得的药物相比,从价格到疗效都有着天壤之别。我在接受正规治疗后从身体到心理的变化,以及伴随而来的、巨大的幸福感,正是驱动我写下这篇文章的直接原因。
一旦你确诊了 ADHD 并需要服药,那服药就是终身的。不过,专注达等药物的特点是可以按需服用——你不用每天都吃,只在工作日或需要调动注意力的时候服药即可。
如果服用某种药物没有疗效或者副作用很大,那就要及时停药并复诊。大夫会帮你换用其它药物或者采取其它治疗措施。另外,运动可以帮你改善 ADHD 的非药物治疗手段之一,多运动可以刺激多巴胺分泌,也能给你带来一副好身体,无论你是否需要服药都值得长期坚持。
另外,自 2025 年下半年起,国产的仿制药(立优加,由立方制药研发)已经上市,价格比原研药更便宜,剂量和规格也略有不同。盐酸哌甲酯这个核心成分并无技术壁垒,制药方也表示仿制药的缓释曲线可以做到与原研药相同,但因为新药上市不久,目前的使用反馈并不多,我本人也没用过。
考虑到其尚无大面积负评且价格更低,如果你想尝试未尝不可,只需要开药师跟大夫申明需要仿制药就行。
走到这一步,尽管你已经获得了医疗层面的治疗方案,但和 ADHD 的战斗其实还未结束。ADHD 所导致的拖延、急躁、马虎等状况会影响你的心理状态,这些都需要你及时调节。

《意志力》这本书中有个观点令我印象深刻:人在调动意志力全情投入某件事时会消耗体内的能量,所以在需要保持专注工作时把肚子填饱非常重要。就我实际体验来说,饿肚子前后的工作状态差别极大,我每天下午四五点就开始觉得饿,如果能吃一顿加餐,就能一路战斗到底。
另外,导致工作混乱、拖延的原因往往很复杂,除了 ADHD 之外,也要排查和改良自己的工作方法。关于如何管理时间、如何进行任务管理的文章我派已经堆积成山啦,善用搜索,找一套适合自己的方法吧。
在见到大夫的那一刻,我内心非常激动,因为我知道这场在我脑内拉锯了长达数年的战争就要结束了。
在遵医嘱服药之后,我在状态和专注度上的表现与之前判若两人。但我的「脱困」只是个例,即使按照最低 2% 的患病率来计算,如今的中国仍有着不可计数的 ADHD 患者。与此同时,大众对这项病症的认知度依然很低,还时常伴随着各种曲解和无视。相比于 ADHD 本身造成的问题,对患者来说,更痛苦的事情是不知道自己患有精神疾病,仍处于无尽的自责和纠结之中。
希望这篇文章可以让更多人看到,也希望每个患者都可以走出困境——迈入诊室,接受专业人士的诊疗和建议,恢复健康和宁静。
注:文章题图使用 AI 生成,并经过人工修改。
> 下载少数派 2.0 客户端、关注 少数派公众号,解锁全新阅读体验 📰
> 实用、好用的 正版软件,少数派为你呈现 🚀
50mm 是摄影中最经典,也最常被谈论的焦段之一。它没有 35mm 的广角张力,也没有 75mm 以上的空间压缩感,其视角平实,接近人眼所见,因此能够适应多种拍摄场景,是很多摄影爱好者不可或缺的一款镜头。
我一直偏爱 50mm 镜头。2018 年,我购买了当时备受关注的适马 50mm F1.4 DG HSM。它凭借出色的光学设计,显著提升了全开光圈下的画质,改变了当时「大光圈必须收缩使用」的普遍认知,给我带来了很大的震撼。
然而在那之后,我有很长一段时间没有再购入新镜头。尽管市场上不断有新镜头发布,但作为普通消费者,我感觉选择并没有变得更多。50mm 镜头的市场格局似乎已经固定:追求顶尖画质,就需要选择五千元以上的日系原厂镜头;如果预算有限,则只能考虑千元价位、主打轻便但需要在操控和做工上做些妥协的国产 F1.8 镜头。对于一个有两三千元预算、希望买到一支在画质、操控和做工上都较为均衡的镜头的用户来说,中间的选择几乎是一片空白。直到唯卓仕 AF 50mm F1.4 Pro FE 的出现,它让我重新找到了七年前第一次使用那支适马镜头时,眼前一亮的感觉,以至于让我觉得,也许这支镜头真的可以是年轻人的第一支 50mm F1.4。

要说明这支镜头为何特别,或许可以从它和原厂镜头的区别说起。几年前,国产自动镜头给人的印象通常是「平替」,在对焦、镀膜等体验上与原厂有明显差距,是不得已而为之的选择。但这款唯卓仕 50mm F1.4 Pro 的出现,显示出一种不同的思路:它不再只强调低价,而是在关键的画质和做工上,直接向索尼原厂的中高端产品看齐。
具体来看,它的竞争策略很清晰。比如在操控上,它配备了金属镜身、实体光圈环和自定义按钮,这些通常属于原厂高端镜头的配置,明显区别于那些采用塑料机身、简化操作的入门镜头(例如索尼原厂的 FE 50mm F1.8 或部分国产镜头)。实际握持手感扎实,操作反馈明确。其采用的自研双重 HyperVCM 对焦马达,在对焦的安静度、速度与果断性上,也明显优于 FE 50mm F1.8。
在最重要的成像上,尤其是在大光圈虚化方面,它做得相当不错。焦外过渡柔和,光斑干净,没有察觉到明显的「二线性」或「柠檬圈」。这一点让它和一些早期国产大光圈镜头,甚至部分原厂入门镜头拉开了差距,更接近高端镜头的表现。上述产品体验和表现将会在下文详细说明。
当然,和索尼 FE 50mm F1.4 GM 相比,它在对焦速度、品牌整合度上仍有差距,但价格也仅为前者的三成不到。它精准地找到了自己的位置:为那些不满足于入门 F1.8 镜头画质和手感,又觉得原厂 F1.4 旗舰价格过高的用户,提供了一个折中选择。它证明,国产镜头可以靠扎实的素质和准确的定位,而不仅仅是低价,来赢得摄影者的主动选择。
打开包装盒,它的设计语言与日系厂商相似,风格简洁,没有过多冗余信息。盒体三面印有英文品牌标识,两面展示了这款唯卓仕 50 Pro 的镜头图示、具体型号及对应卡口信息,底部贴有序列号与厂家联系方式。
镜头本体由厚实的海绵紧密包裹,随包装还附赠了一个质感不错的镜头保护套和遮光罩。
实际握在手中,镜身表面光滑,但经过我这个「手汗大户」的验证,并不容易残留指印。细看之下,表面带有细腻的手感,既提升了持握的稳定性,也降低了滑落的风险。镜头底部配备了一个光圈环,转动时反馈清晰,段落感明确。此外,接口处有一圈橙色的防泼溅密封圈,进一步增强了防护的可靠性。对于追求操作效率的用户,这支镜头也提供有操作按键,可按照使用习惯自行设置快捷键。

将镜头安装到索尼机身上,整体感很强。无论是所使用的材质、造型线条还是标识设计,都显得协调统一。如果不特意说明,其整体质感与国际大厂的产品相差无几。
镜头滤镜口径为 77mm。作为一支 50mm F1.4 规格的镜头,它体积确实稍微大了一些。但考虑到它提供的画质表现和对焦性能,我认为在体积上做出这点妥协是可以接受的。毕竟,对于许多用户而言,这是他们的「第一支F1.4自动标头」,这点小小的不便完全可以克服。
不过需要说明的是,上述的「协调感的欠缺」主要是基于像 A7C 这类没有军舰头的紧凑机身。如果安装在 A7M4、A7R5 等型号上,整体的比例相信会更加均衡。

| 项目 | 规格参数 |
| 焦距与画幅 | 50mm,全画幅 |
| 最大光圈 | F1.4 |
| 光学结构 | 11 组 15 片。含 3 片 ED(超低色散)镜片、1 片 UA(超高精度非球面)镜片及 8 片 HR(高折射率)镜片。 |
| 自动对焦 | 搭载自研双重 HyperVCM 马达,支持人脸/人眼追踪。 |
| 最近对焦距离 | 0.45 米 |
| 滤镜口径 | 77mm |
| 重量 | 约 800克(E-mount 版本) |
| 专业特性 | 具备防尘防溅结构、自定义Fn按钮、有级/无级光圈环以及 Type-C 固件升级接口。 |

从官方提供的 MTF 图表来看,这款镜头在最大光圈 F1.4 下表现十分出色,像场曲线平直,整体性能稳定。尤其在画面中心区域,其MTF值接近理论极限的 1,表现甚至优于 F8 光圈,展现了出色的分辨率。
随着像场向边缘过渡,在中心到约半幅的位置,最大光圈下的 MTF 值仍能保持在 0.8 以上。直至画面极边缘,全域 MTF 值也基本维持在 0.6 以上,说明其边缘画质的衰减控制得当。
同时值得注意的是,在最大光圈时,代表对比度的实线与代表锐度的虚线彼此贴近、走向一致。这表明镜头能够实现过渡自然、质感良好的虚化效果。关于其实际成像表现,我们将在后续的实拍环节中具体展示。
Q1: 为什么镜头在按下快门后老是按半拍或者干脆不响应?
A1: 根据说明书步骤检查是否已安装最新固件。我也经历过这个问题,后来更新了最新固件后基本解决,对焦的跟手感能够达到原厂镜头八成到八成五的水平,虽然仍有轻微迟滞,但因为我主要不拍摄运动类等对延迟要求极高的场景,所以整体可以接受。
Q2: 为什么缓慢晃动镜头时能听到镜筒内部有轻微声响?
A2: 该镜头采用唯卓仕自研的 HyperVCM 浮动对焦结构,在未通电时,内部镜组机构因不限位,会随晃动产生轻微声响,此为正常物理现象,与相机 CMOS 防抖组件在关机时的松动声响原理类似。镜头通电后,该声响即会消失。如在正常开机拍摄时仍听到明显马达异响,建议联系唯卓仕客服进行检测。
我分别测试了这款镜头在人像与人文纪实主题拍摄中的表现,希望能为大家提供有价值的参考。
人像拍摄:即使在最大光圈下,画面依然锐利,细节清晰,完全能满足 A7C 这类机身的传感器需求。我认为即便是面对 A7R5 等具备半亿像素的传感器,它也游刃有余。当将人物置于画面的三分之一处(如黄金分割构图)时,凭借镜头优秀的像场平整度,依然能获得扎实的成像效果,无需担心边缘画质下降。

这款镜头在不同对焦距离下的表现也令人满意。有些镜头在一米左右画质尚可,但在过近或过远的对焦距离下,画质就会「露怯」。这主要是因为镜头的光学设计是针对常用距离优化的,当进行极端近距离(近摄)或远距离对焦时,各类像差(如球差、场曲)的校正平衡会被打破,导致锐度下降。 而这支镜头无论拍摄面部特写还是远距离全身人像,主体始终清晰。


柔和焦外:在实际拍摄中,我能明显感受到其焦外光斑圆润、边缘过渡柔和,且几乎察觉不到生硬的「二线性」。这得益于镜头内那枚超高精度 UA 非球面镜片对球差和「洋葱圈」现象的有效抑制,同时,3 枚 ED 镜片的加入保证了焦外色彩的纯净,而 11 片圆形光圈叶片则让收缩光圈后的光斑依然能保持漂亮的圆形。即使是人偶玩具队列这种复杂的工况也能实现柔和的虚化过渡。可以说,唯卓仕在光学设计上对像差的综合平衡,让 F1.4 大光圈不仅意味着进光量,更代表了一种高质量的虚化表达。


夜景与弱光:F1.4 大光圈在夜晚展现出巨大优势。我可以为了画面纯净度而调低感光度,也可以为提高快门速度捕捉动态瞬间而控制噪点水平,这让创作空间更加自由。我十分认同某位 B 站 UP 主的观点:在创作中,唯一该限制你的是想象力。而这支镜头,正为我提供了探索更多可能的工具。




人文与风景:50mm 是一个「甜点焦段」。在实际拍摄中,我发现当我注意到某个主体并举起相机时,距离通常在 2-3 米左右。这个距离下,拍人物能捕捉半身并带入环境;拍建筑则能聚焦局部结构。使用 50mm 焦距拍风景或建筑,我反而不会执着于收纳整体(因为无法全部纳入),而是更专注于线条、结构与结构、结构与光影的呼应关系,这常常带来意想不到的视角。





逆光表现:在逆光环境下,得益于优秀的镀膜技术,镜头色散控制得很好。画面对比度和细节都保持在线,即便光源直接射入画面,边缘也未见明显紫边或色散,表现出色。

回顾与唯卓仕 AF 50mm F1.4 Pro FE 相伴的时光,它所带来的,远不止是令人满意的照片,更是一种久违的「恰到好处」的体验。
在 3000 元价位段,它精准地切入了一片长期空白的市场。它没有因「国产」或「高性价比」的标签而在核心体验上妥协,反而以 Pro 级的光学素质、专业的操控防护与成熟的设计语言,有力地证明了——国产镜头足以摆脱「廉价平替」的刻板印象,成为摄影爱好者们主动选择、并引以为傲的创作利器。


当然,我并非想要将它「捧上神坛」。在使用下来,我希望它能够在保持画质的情况下进一步控制体积,希望在固件方面的调教更加成熟。但是说一千道一万,如果忽视「预算」讲「性能」,或许正确,但也提供不了多少价值。对于一个刚刚入门的摄影爱好者,想要走进大光圈的世界,探索一层层镜片后埋藏的梦幻和美好,基本绕不开考虑这支「年轻人的第一支 50mm F1.4」。
这支镜头为预算有限的爱好者打开了一扇通往广阔创作空间的大门。在衡量一支镜头是否值得购买时,预算的意义并不仅仅在于数字本身。当你拥有一支素质优异、价格适宜的镜头,内心会自然而然地放松下来——你不必过分担心每次握持时手上的油脂是否会从细微的缝隙渗入镜身,也不必想象每一次与外物的触碰都可能为其埋下内部损伤的隐患……相反,你可以心无旁骛地投入创作,充分调动它的各项特性:柔美的虚化、细节丰富的主体刻画……一切都只为更好地记录你心中那个珍贵的瞬间。
它在有限的投入内,提供了近乎完整的专业体验与素质。对于正在寻找一支全能标准镜头的用户来说,无论是希望从套头进阶的新手,还是需要一款高画质备机的资深玩家,唯卓仕这款镜头都提供了一个无法忽视且极具说服力的选择。唯卓仕这支镜头的问世,清晰表明了:国产镜头的突围之路,不在于单纯堆料或一味低价,而在于在关键体验上正面抗衡,同时在价格上保持诚意。
对我而言,这支镜头更像是一个清晰的路标,标志着国产镜头终于跨过了「雄关漫道真如铁」的艰难探索,真正站在了「而今迈步从头越」的新起点上。从十年前的 SIGMA 50mm F1.4 DG HSM | Art 时,到这支 AF 50mm F1.4 Pro FE ,我很高兴能看到国产镜头的不断成长,逐渐摆脱「廉价」和「仿造」的标签,凭借自身的竞争力和素质在市场中取得一席之地。前路依然漫长,但有了这坚实的第一步,我们有理由相信,未来市场上会出现更多个性鲜明、素质优异且价格合理的产品,为用户提供真正丰富的选择。对于中国制造的明天,我们可以抱以更高的期待。
Matrix 首页推荐
Matrix 是少数派的写作社区,我们主张分享真实的产品体验,有实用价值的经验与思考。我们会不定期挑选 Matrix 最优质的文章,展示来自用户的最真实的体验和观点。
文章代表作者个人观点,少数派仅对标题和排版略作修改。
不久前刷到一条新闻说,富士已经免费开放了自家胶片风格 LUT 供所有用户下载,不管是摄影新手还是手机摄影爱好者,都能轻松将经典富士滤镜色调导入自己的设备。
我也试着用手里的小米 13 Ultra 拍摄 RAW 格式素材、通过达芬奇转换色彩空间,最后把富士原厂 LUT 导入到拍摄素材中,最终成片效果如下。

在进入具体操作分享之前,咱们得先搞清楚两个关键问题:什么是 LUT?富士画面风格又有哪些特别之处?

LUT 是 Lookup Table(查找表)的缩写,简单说就是一套「预设的色彩转换规则」—— 它就像给影像套上的「色彩模板」,能把原始素材的色彩数据快速映射成预设好的色调风格,不用手动调整白平衡、对比度、饱和度等一堆参数,就能一键出效果。
从专业角度来看,LUT 是一个包含色彩数值对应关系的文件,它的常见格式为.cube,也是富士官方提供的格式,本质上来说也是一份「输入色→输出色」 的快速对照表。比如富士原厂 LUT 就是把富士胶片的经典色彩曲线,比如胶片的色彩倾向、对比度、颗粒感,都做成了标准化文件,导入剪辑软件或设备后,就能让普通素材直接染上富士胶片机的质感。
富士的色彩科学灵感源自胶片摄影,「画面风格」 是由对比度、色调等复杂元素组合而成的美学效果。胶片模拟功能可提供多种多样的画面风格,同时保持整体的一致性。
富士胶片于 2004 年推出的胶片模拟技术,凝聚了自 1934 年公司成立以来的 70 年间、富士在胶片制造领域积累的丰富经验,这份历史底蕴和经验也体现在胶片模拟技术的品质上。如今,经过数字化精细调整,胶片模拟已经能够像传统胶片一样带来惊喜和无限可能,同时激发摄影师的拍摄创意。
就像在餐厅用餐时,经验丰富的厨师会精心把控每道菜的口味一样,胶片模拟功能让你无需深厚的摄影知识,也能享受到专业水准的影像效果。

和网上的第三方 LUT 不同,富士官方 LUT 基于自家胶片技术开发,比如 Provia、Velvia、Astia 等经典胶片配方,色彩还原更正宗,也适配了富士 G、X 系列等多款相机机型,下载后直接解压就能用,无需额外调整参数适配,对新手相当友好。更多详情可前往官网了解。

RAW 格式是相机未经过压缩的原始影像数据,保留了最多色彩细节;而达芬奇这类专业软件能精准读取 LUT 的色彩规则,先做色彩空间转换,让小米 13 Ultra 的 RAW 素材色彩更适配 LUT、再导入富士 LUT,最终效果会更接近富士胶片机的原生质感,不会出现色彩偏差或细节丢失。
打开小米 13 Ultra 手机的相机软件,打开专业模式并开启 Ultra Raw 拍摄,详细教程参考这里。

Ultra Raw 拍摄完成后,小米 13 Ultra 会生成 JPG 和 DNG 两种文件格式。这里所采用的 DNG 格式,也是数码相机生成原始数据文件时的公共存档格式 —— 它解决了不同型号相机的原始数据文件之间缺乏开放标准的问题,能最大程度保留拍摄时的色彩细节与动态范围,也为后续搭配富士 LUT 调色提供了充足的调整空间。

接着我们拷贝 DNG 格式文件到我们的电脑并且使用达芬奇软件导入。达芬奇软件请前往官网下载。

接着我们切换到达芬奇调色面板的 Camera Raw 页面,对 DNG 图片进行基础设置:核心是将解码模式改为「片段」,色彩空间设置为 P3 D60,伽马设为 「线性」;至于色温、锐度、色调、曝光等参数,大家可根据素材实际情况自行调整。

接着我们在达芬奇调色面板的节点面板中添加一个串行节点,用于色彩空间转换 —— 目的是将 RAW 文件素材转换为富士 LUT 可直接套用的 F-Log 或 F-Log2 格式。

色彩空间转换完成后,我们再添加一个串行节点,在达芬奇中直接导入从富士官网下载的 LUT 文件,套用后就能获得正宗的富士胶片风格色彩效果。

套用后就能得到不错的成片效果。对于想深入调色的朋友,还可以进一步微调其他参数,打造出更贴合自己预期的画面。以下是我用小米 13 Ultra 拍摄的 RAW 文件,套用富士官方 LUT 后的最终成片,大家可以参考看看。




大家如果感兴趣,也可以拿起自己手中的设备尝试拍摄,亲身感受富士胶片滤镜的独特魅力!我是狗空蓝,我们下篇文章见!
首页题图来自富士官网。
> 下载 少数派 2.0 客户端、关注 少数派公众号,解锁全新阅读体验 📰
> 实用、好用的 正版软件,少数派为你呈现 🚀
Matrix 首页推荐
Matrix 是少数派的写作社区,我们主张分享真实的产品体验,有实用价值的经验与思考。我们会不定期挑选 Matrix 最优质的文章,展示来自用户的最真实的体验和观点。
文章代表作者个人观点,少数派仅对标题和排版略作修改。
春节是农历新年的开始,小长假,是回家团聚的时刻,也是制定「新年计划」的高峰期。你过往是否会在这段时间里制定计划呢?如果是的话,这些计划通常关乎哪些生活领域、哪些个人议题?作为曾经的注册心理师、目前正在受训的运动心理学工作者,我想在这里先和各位聊聊「健康」这个领域内的计划。这些计划即使还没浮现,也与我们相距不远。

毕竟,在若干天的聚会、饮酒、投喂和吹牛之后,在回到正常工作、生活之前,照照镜子、低头看看,我们对身体的焦虑和愧疚很容易达到一个高峰。于是新一年的健康计划也就陆续浮出水面:增加运动时间,健康饮食,降低体重,增加肌肉,戒烟戒酒……——作为印证,春节之后的一段时间,往往也是健身办卡和购买私教课的旺季。不过,这个高峰能够持续多久,各位的「健康计划」能够持续多长时间?在下一个「健康计划季」来临之前,回顾过去一年的健康计划,其中又有多少得以实现?
人类在这方面的悲欢(以及无力)是共通的。根据 Statista 上的一组数据,2025 年,德国人的新年「立志(Resolution)」比例是这样的:

美国人,是这样的:

只看与健康相关的项目,除了「吃素」,其他的内容,是否让你感到似曾相识?这不就是许多人年复一年立志、年复一年失败的小计划、小目标吗?
无独有偶,我的老师在课上提到,德国的健身房在新年前后,通常也会迎来一个办卡和锻炼的高峰,但这个高峰到一月份的第三个周末,就会戛然而止。
这到底是为什么?我们有什么办法,能够令自己在新的一年里,更有把握地完成自己在健康方面的计划?——或者说,我们如何才能摆脱那个已经被用了很多年的烂梗,即「这一年的计划是完成若干年前计划了但没完成的计划」?
在讨论这一串问题之前,我们需要先区分四个不同的概念。
第一个是愿望(Wish)。它是来自大脑「想要」回路的声音。一个愿望可能相对明确,例如「减重十斤」,也可能相对模糊,例如「我要瘦下去」。但愿望不必然有现实依据,也不必然有基于行动的计划和反思。也就是说,愿望可以只停留在想象中。
第二个是目标(Goal)。目标是一个相对确定的、不同于当下处境的「状态」。改变现状、达到这个状态,能够满足我们的一些需求。也即,为了制定目标,你至少已经意识到现状令人不满,开始思考如何改变。
第三个是计划(Plan)。计划是从现状出发、达到目标所需的路径和时间。路径代表我达成目标所用的手段。时间节点对应了计划中的主要阶段。根据每个人的实际情况,可能的路径往往不止一条,而且在实践过程中可以随时调整。
第四个是日程(Schedule),也即具体的「任务」和「时间点」的对应关系。有一些日程是提前确定、很难变动的,例如奥运会和高考。另一些日程是相对自由的,可以在一定的范围内调整。

如果你所谓的「年度计划」只停留在愿望层面上,那么完成是随机的,完不成是必然的,严肃讨论也是没有太大意义的。另一方面,如果你已经越过愿望,开始认真构思自己新的一年想做什么,就不应该跳过中间的目标、直奔计划和日程。
以我自己为例。2023 年年底,我为 2024 年的自己设定了三个首要的年度目标:
(1)拿到德国大学的运动心理学硕士入学资格(最好是科隆体育大学)
(2)通过国际马伽术联盟(IKMF)G5 级别的考试
(3)完成三个新的桌游设计案
基于这些目标,我进一步制定了具体的计划。实际执行的结果就是前两个目标顺利达成、第三个目标超额完成,总体计划完成度超过 100%。我认为这里的关键不在于计划,而在于目标。很多计划之所以难以实现,就是因为我们没有清晰的、可行的、自己深刻认同的目标。如果目标是模糊的、实际不可行的、自己不够认同的,那么无论用什么「管理工具」、用怎样的「精神原子弹」死磕,结果都未必有保证。
只要你还对「新年计划」或「新年目标」有想法,请牢记下面这句话:
目标就是用来实现的。计划就是用来完成的。
如果憧憬目标、制定计划,只为了在三周之后就放弃,并在一年之后感到懊悔,这样的目标和计划不如没有。到了那个时候,再说「计划完不成,可能是好事」,就约等于「吃不着葡萄说葡萄酸」。
与其如此,不如在看到葡萄之初,就扪心自问:
吃葡萄能给我带来什么好处?
我为什么那么想吃葡萄?
我真正想要的,只是「吃到葡萄」那一瞬间的满足吗?
……
也即,在讨论计划之前,我们应该先妥善解决目标设定(Goal Setting)的问题。
自主意味着我们对自己的行为有足够的掌控和认同。例如,我们主动选择加入一个拳击俱乐部,每周定期参与三次训练,报名参加一次业余比赛,这些行为有助于满足自主需要。自主需要得不到满足或受挫,我们就会感到自己不像是一个「独立个体」,而是被外在力量或强迫性的要求所控制。
胜任意味着我们增进自身的能力、获得展示和实践能力的机会,并通过自己的行动获得想要的结果。例如,我们充分理解并掌握壶铃抓举(Snatch)的技术,完成了 5 分钟 100 个 Snatch 的挑战,这些行为有助于满足胜任需要。胜任需要如果得不到满足,或者也叫受挫(frustration),我们就会体验到失败,并对自身的效能感产生怀疑。
归属意味着我们充分感受到自身与他人的关系,以及与所处社会环境的关系。例如,我们得到了教练的赞许,受到了训练伙伴的尊重和欢迎,在训练和比赛中与其他人友好互动,这些行为有助于满足归属需要。归属需要得不到满足或受挫,我们就容易体验到孤独,或者感觉受了排斥。

在设定一个目标之初,我们可以首先思考,这个目标有助于满足上述哪一个(或哪些)基本的心理需要。你为什么想要减重、增肌、塑身或强化体能?你也许想要在「打工」之外找到一些自己喜欢做的事,并乐在其中,这就是自主需要。你也许想要自我挑战、变得更强,这就是胜任需要。你也许希望得到周遭人的好评,或者赢得伴侣的喜爱,这就是归属需要。
基本心理需要理论给我们的重要启发有两个。首先,一个目标与自身需要的关联越是广泛、越是深入、越是重要,这个目标的价值相应地也就越高,实现它的可能性也就越大。如果你只是产生了一个想法,经过仔细地思考,发现它和自己的需要相去甚远,那么不做也罢。
其次,我们要为自己创造一个更有利于探索、反思和追求这些基本需要的环境。仍然以运动为例。为了满足胜任需要,我们要找到合理的训练方式,学习正确的知识,促成进步,避免受伤。为了满足自主需要,我们要发展出自己内在的动机,明白自己为什么要运动。为了满足归属需要,我们最好找到志同道合的训练伙伴,以及具备支持性的、通情达理的教练。
训练环境、训练知识和人际关系都是外部因素,以后另文再谈。本文接下来要讨论的,是刚刚提到的「内在动机」。根据 SDT 的另一个子理论,「有机整合理论」,我们做一件事的动机强度,从弱到强,可以划分为六个不同的水平。
最低的水平是「没有动机」或「去动机」。最典型的去动机状态就是「我不知道我为什么需要运动」。去动机的个体会随机选择做或不做特定行为。如果你在运动、饮食、生活方式调整等议题上处在这个动机水平,你需要的就不是「制定计划」或「时间管理」,而是一个刺激你产生动机的契机。

这个契机可能是特定的外部要求。例如,某人由于严重肥胖,被医生勒令戒掉含糖饮料并开始运动。这种「我并不想运动,只是因为别人的要求才去运动」的心态,代表了次低的动机水平,即单纯的「外力驱动」。
如果我们对这样的外部要求多一些认同,就可能会因为达不到要求感到痛苦或内疚。为了避免这些负面的体验,我们从事了一些相应的行为。例如,某人受到社交媒体的影响,努力控制自己的体重和体型,以符合「双开门」或「白幼瘦」等特定的审美标准。这是第三个动机水平,即「内摄驱动」。
如果外部的要求变成了外在的威胁,我们的动机水平或许会进一步提高。例如,某中年男子经历心梗发作,为了避免自己死后无人养家,开始积极锻炼。此时特定的健康行为对个体而言有了某种重要的意义。这是第四个动机水平,基于认同(identification)的驱动。

你是否发自内心地认为,某种运动、饮食或生活习惯是自己的一部分?你是否认定「理想中的我,应该就是那种样子」?如果你能基于这样的心态从事某种活动,那么你就会进入更高的动机水平,基于整合(integration)的驱动。从这个阶段开始,你就逐渐脱离了外部动机的影响,脱离了所谓的「低级趣味」,逐渐进入以内部动机为主的状态。
但这还不是终点。如果你只是觉得「为了符合理想中的自我形象,我应该多吃蔬菜、每周训练两次」,说明你还在一定程度上忍受着痛苦——只是程度没那么高而已。若你这样做是因为自己真的喜欢,能够乐在其中,甚至因此感到骄傲和满足,那才是最高的动机水平,也即充分的内部动机。
六个动机水平从低到高,代表了我们行为的自主性水平逐渐增高。动机水平和自主性的增高意味着什么呢?一项针对肥胖患者的研究表明,2在出院 6 个月之后,大部分患者都不再保持运动习惯。也即,即使生命健康受到威胁,即使有外部动机驱使,人们仍然很难长期追求「健康」的生活目标。不过,具有高自主性的患者,保持运动习惯的比例显著更高——或者说,那些仍然保持运动习惯的患者,大部分都保持着高自主性的动机水平。

另外一项针对行为改变的荟萃分析发现了类似的趋势3。随着时间的推移,人们保持运动行为的趋势总是会减弱。也即,人类的天性让我们倾向于偷懒。不过,个体的动机水平越高、自主性越强,保持甚至增加运动行为的比例也相应提高。这个结果符合我们在本文开头看到的数据和现象。


健康行为的目标,包括但不限于维持体重、控制体脂、增肌、改善体态、增加体能、维系健康……统统都是长期目标,很难在短时间内实现。如果你真的想要达到这些目标,势必需要一个长期的计划。为了能够真的长期执行一个计划,我们需要给自己打造一个有利的环境,那么最好确保和提升自主动机的水平。如果你只追求三分钟热度,打算年后办张卡、上几次课,在两三周之后回归常态,那么你此刻的动机水平和自主性高低,就一点都不重要——反正很快就会放弃的!但,如果你发自内心地想要实现这些目标,从一开始就得做些不一样的事。
必须承认,从不知道自己为什么要「追求健康」,到半被迫地运动和注意饮食,再到形成自我认同的、乐在其中的生活方式,是一个长期的过程,并不是我们在思考目标之初就可以一蹴而就的。也即,我们不可能拍脑门就马上进入一个很高的动机水平、获得很高的自主性。不过,在考虑一个健康相关的目标之前,我们可以想象自己追求这个目标的过程,以及实现目标之后可能的体验。这个练习可以视为一种对动机和自主性的探索。
你可以尝试闭上眼睛,尽可能充分地视觉化(visualize)这个场景,并静下心来感受;你可以把它画下来或者写出来;你也可以联想文学作品、影视剧、动漫、纪录片……等媒介中的相似案例、进行类比。

这样的想象训练,可以帮助我们确定这个目标的长期意义,并有助于找到我们可能达到的最高动机水平。更高的动机水平和更高的自主性不仅更有利于长期执行计划、养成习惯,更有利于真实心理需要的满足。
除了与需要和动机水平的关联,我们还可以再次回到目标本身,思考这些目标的本质。SDT 的最后一个子理论,「成就目标理论」,将目标的本质分为三类:掌握型目标,表现型目标,以及结果型目标。

掌握型目标(Mastery Goal),也称为学习目标。这类目标的着眼点在于自身能力水平与特定任务要求或能力标准之间的比较。
结果型目标(Outcome Goal),也称为结果目标或自我(ego)目标。这类目标的着眼点是外在的能力展示,即与他人水平或他人评价标准之间的比较。
过程型目标(Process Goal)介于掌握型目标和结果型目标之间,关注自己在追求结果的途中是否完成了具体的、可控的任务或行为。
每一个目标可能都包含上述三种类型的要素。那么你的健康目标主要属于哪种类型呢?单纯以结果或自我为导向,我们就更容易在实践中偷懒、放弃或给自己找台阶,做出所谓的自我设限行为(self-handicapping)。这也许是很多人的「年度计划」屡立屡弃的一个重要原因。
一个最常见的例子莫过于许多人心心念念的「减肥」:从一开始,着眼点就是掉秤、照镜子/穿衣服好看、得到他人的认可、与他人比较;随着时间的推移,当节食、运动、改变生活方式造成的心理压力逐渐累积,当最初的外部动力逐渐消退,行为日益难以维系,数字量化的结果也越来越不如人意,终于以一次或多次的暴饮暴食和体重反弹收尾……直到下一次重来,或者干脆走上吃减肥代餐、把自己饿瘦的歧路。
一个目标中并非不能包含结果的成分,但是我们没必要也不应该仅仅着眼于结果。我们完全可以换一种方式思考:一个健康领域的结果,总是可以经由能力提升(掌握)随着时间累积(过程)得以实现。既然如此,我们完全可以向一个结果型为主的目标加入掌握型和过程型的成分,把控制点(即心理学上所谓的 locus of control)从单纯的外控转变为部分的内控。

例如,为了满足科隆体育大学的本科生入学要求,申请人必须在入学测试中表现出对应的运动能力,包括但不限于(男子要求) 100 米 13.4 秒,跳高 1.40 米,铅球 7.60 米,3000 米跑 13 分钟,100 米蛙泳 110 秒。这些数值是结果型目标,但对应的运动能力是掌握型目标,而且无法通过投机取巧的方式实现。为了提升运动能力、达到预期的要求,我们势必需要参与各项运动的技术训练和基础体能训练,这些参与就是过程型目标。因此,你当然可以把目标定为「通过考试」,但同时也可以将其本质重新界定为「在长时间内进行训练」「提高运动能力」。或者说,正是由于不断训练、提升了能力,你最终不但收获了考试通过的结果,而且增强了自己的效能感、有了更多积极的经验和感受。
在构思目标、制定计划的时候,你想要的也一定是这样多管齐下的「结果」罢?
制定计划,是一个关于自我探索的过程,而不仅仅是一次简单的愿望表达。既然是自我探索,我们可以容忍「失败」,但不应该在开始之前就用「失败也是好事」自我安慰。计划是用来完成的。目标是用来实现的。计划不能完成,一个重要原因是目标设置出了问题。若如此,我们需要的不是放弃计划,也不是自我安慰,而是重新思考自己的目标是否合理。
健康相关的目标或其他长期目标,都无法在短期内轻易实现。它们需要的,是一种既明确又灵活的规划,基于现实的调整,以及一颗始终向前的心。在新一年到来之际,不妨从一次对内心深处需求的认真思考开始,为真正可持续的改变奠定基础。
至于如何从目标发展到计划,从计划过渡到时间表,从时间表前进到执行……这是几个更大的话题。我会在之后的文章里继续讨论。这里就先祝大家新年能确定出新的目标来吧!
笔者目前就读于德国科隆体育大学运动心理学硕士项目。
> 关注 少数派小红书,感受精彩数字生活 🍃
> 实用、好用的 正版软件,少数派为你呈现 🚀
Matrix 首页推荐
Matrix 是少数派的写作社区,我们主张分享真实的产品体验,有实用价值的经验与思考。我们会不定期挑选 Matrix 最优质的文章,展示来自用户的最真实的体验和观点。
文章代表作者个人观点,少数派仅对标题和排版略作修改。
工作原因,我读过上百部讲「学习」或「认知」的书,既有哲学经典,也有网红畅销书。我把这些书分为大致四类:
讲完这些,我们就来看看学习类书籍里有哪些以讹传讹的错误观点。囿于篇幅,我会提供一些参考书籍,感兴趣的朋友可以自行找书来看。
前几年,「一万小时定律」的说法特别火,简直到了每本学习畅销书都要提一嘴的地步。这几年,有反思能力的作者都知道了这个说法源于误传,禁不住推敲。所以,如果有新出版的书还在提这个说法,可以直接一票否决。

这个讹传的源头,来自畅销书《异类》的作者格拉德威尔。他在写于 2008 年的书中讲到:「人们眼中的天才之所以卓越非凡,并非天资超人一等,而是付出了持续不断的努力。只要经过 1 万小时的锤炼,任何人都能从平凡变成超凡。」
实际上这个数字并无论据支持。心理学家艾利克森的《刻意练习》中文版推荐序里,详细介绍了这个观点的讹传路径:最早在 1973 年,后来的诺奖得主赫伯特·西蒙写了一篇关于国际象棋大师与新手的比较论文。西蒙推测,国际象棋大师能够在长时记忆系统中存储 5-10 万个棋局组块,获得这些专业知识大概需要 10 年。后来艾利克森参考西蒙论文的 10 年定律,积累了更多关于专业技能训练的数据。1993 年,艾利克森发表的一篇音乐学院学生的论文中提到一组数据,说到 20 岁的时候,卓越的演奏者已经平均练习了 1 万小时。就是这个数据,被格拉德威尔拿到书里误用,变成了一个通用的规则,还导致人家艾利克森为此背锅,备受心理学界的诟病。
「一万小时定律」的错误非常明显:它本身就是一个基于个例编造出来的学习规律,没有其他任何论据。而且它也是反学习规律的——不是凑够一万个小时,奇迹就会发生,这样只会导致无效重复。这就跟念一万遍 abandon、abandon 一样,是学不好英语的。

真正有价值的概念是艾利克森的「刻意练习」。这个理论强调,任何一个领域都需要持续反馈、不断纠错、建立心理表征1,这样才有可能取得杰出的成绩。
多说一句,《刻意练习》这本书值得一读,且一定要读原书。我读过好几遍,它是一本比较严谨的学术作品,里面让人觉得啰嗦的表述,大多是必要的科学论证。尤其是讲心理表征的章节,很有启发,值得反复阅读。
与「一万小时」同样有名的,恐怕要数「21 天养成一个新习惯」的说法了。

21 天这个数字,最早来自 1960 年一位整形外科医生,麦克斯韦·马尔茨的超级畅销书《心理控制术》。马尔茨医生在工作中观察到,截肢患者大约需要 21 天来消除幻肢感;整形患者大约需要 21 天来习惯镜子里那张新脸。后来各种励志演讲家、成功学作者进一步加工这个概念,大刀阔斧地把一个经验数据,变成了一个精准的规律:「只要 21 天,你就能养成任何习惯」。
因为 21 天听起来既不长,让人有盼头,又不短,显得有点挑战性,完美符合营销心理学。
2009 年,伦敦大学学院 (UCL) 的健康心理学家菲利帕·拉利做了一项关于习惯养成的研究。研究追踪了 96 名志愿者养成一个新习惯(比如午餐喝水、饭前跑步 15 分钟)的过程。结论是:平均时间是 66 天,而且个体差异巨大:最快的人用了 18 天,最慢的人用了 254 天,取决于习惯的难度和人的特质。我个人觉得,这个结论更符合生活的直觉:习惯这件事嘛,因人而异、可长可短,不是一个特定的数字能决定的。


所以,未来再去培养一个习惯,只要按照《掌控习惯》(AtomicHabits)或《福格行为模型》书中讲的方法,好好去实践,没有必要追求是 21 天还是 66 天。
重要的是培养习惯的过程,而不是追求数字、用打卡等手段感动自己。
所谓 XX 脑开发,是一个比较古早的说法,这几年说得少了。它基于一种简单粗暴的分类:「你是左脑型人(右撇子),擅长数学和逻辑;他是右脑型人(左撇子),擅长艺术和直觉。」
这种说法最早之所以流行,是因为它有诺贝尔生理学得主罗杰·斯佩里的实验背书。斯佩里研究的是「裂脑人」,这些患者为了治疗严重的癫痫,切断了连接左右大脑的桥梁,也就是一个叫胼胝体的地方。实验表明,如果把图像只投射给左眼(右脑负责处理),他们无法用语言(左脑负责处理)描述看到的东西,但能画出来。这证明了大脑确实存在功能上的划分,左半球确实主导语言,右半球确实在空间认知上更优势。
斯佩里的实验本身是很经典的,但它的对象是胼胝体被切断的病人。但对绝大多数人来说,左右脑之间有无数根神经连接,它们时刻在进行信息交换,前提就不成立。
其次,虽然左脑确实侧重语言,右脑侧重空间,但这并不意味着左脑不懂情感,或者右脑没有任何逻辑功能。脑成像技术早就表明:几乎所有复杂的认知活动,都是全脑协同的结果。很多个案发现,左脑(或右脑)严重受损的患者,通过后期训练,其他脑区可以接管原先属于受损脑区的部分功能,这说明人类的大脑是高度可塑的,并没有左右脑区分这么独断。

关于大脑功能区域的知识,强烈推荐看斯坦尼斯拉斯·迪昂的系列著作《精准学习》《脑与意识》《脑与阅读》《脑与数学》这几本书。尤其是后两本,就是在专题探讨阅读、数学这种复杂综合、高度文明化(原始人不用学)的知识,我们的大脑是如何习得的,非常权威。缺点是内容太扎实了,不太容易读,可以看看有没有可靠的讲书稿,或者让 AI 帮你一点点理清观点,慢慢研读。
至于如今还在打着「XX 脑开发」旗号的商家或文章,我个人认为基本可以视为营销号,就是想找个幌子招生、收割家长智商税的。毕竟左右脑开发这件事,我们普通人又摸不着、又控制不了,哪里擅长哪里不擅长,照样该学还是得学,对不对?与其花时间研究这些东西,不如让孩子多运动、多动脑,基于个人先天禀赋,只要健康成长,左右脑的发展都不会差的。
有一个教育学界特别流行的理论,叫:学习风格理论。它把学生分为 Visual(视觉型)、Auditory(听觉型)、Read/Write(读写型)、Kinesthetic(动觉型)四种不同的学习类型,每个人都各有所长、各有所短,简称 VARK 模型,类似的还有 VAR 模型等。
比如某学生不擅长读书,因为他是听觉型学习者,听课对他更有效;或者某某学生是动觉型的,别让他坐着看书,让他去动手操作。

这个理论不太出圈。起码我在进教育圈前根本没听过,但在教育行业,尤其是培训老师几乎人人在讲。它乍听起来很符合直觉,且相当有魅力:如果能优化教学方式,匹配学生的特定风格,学习效果就会突飞猛进。
遗憾的是,这又是一个听起来很美、实际上并无证据支持的伪科学。
最早提出 VARK 的是新西兰教师尼尔·弗莱明。上世纪八十年代,他为了设计一个问卷,帮助学生了解自己的偏好,提出了这几种学习风格。随后,这个分类被过度传播,逐渐演化成了一个「经典」的学习理论,影响力越来越大。
2008 年,四位顶级认知心理学家受美国心理科学协会委托,对「学习风格」进行了大量的文献审查。结论是几乎没有证据证明,根据学生的学习风格调整教学方式能提高学习成绩。
简单点说,一个自认为是听觉型的人,并不代表给他听录音就比让他看书学得更好。他可能只是更喜欢听录音而已。甚至还有研究得出了相反的结论:如果强行用学生偏好的方式教学,比如只给视觉型看图、看文字,反而可能害了他们,因为他们失去了锻炼短板,比如动手能力的机会。

关于这一点,欢迎大家去看认知科学家丹尼尔·威林厄姆的书《为什么学生不喜欢上学》。这本书里有专门的章节(第 7 章)在讨论学习风格的内容,并且非常明确地否定了 VARK 的科学性。
我觉得书里有一点讲的很对:教师的目的不是为了迎合孩子的学习风格,而是为了帮助孩子找出他们的学习能力(天赋、特长)所在,并且强化它们,变成孩子的独特优势。这或许才是教育更要关注的东西。

学习金字塔模型这几年比较出圈。尤其在「得到」风格的文章和书籍中,这个说法很常见。上述这个图就摘自周岭的《认知觉醒》,这本书里也推荐了金字塔模型。
最早提出这个模型的,是美国教育家埃德加·戴尔。1946 年,他提出了「经验之塔」,初衷是从抽象到具体,对不同的教学手段进行分类。比如说阅读最抽象,实地考察最具体。但是戴尔原本的图里,没有任何数字,也没有提到留存率或学习效率。
那么,这组看起来非常「科学」的数字是怎么来的呢?1960 年代,美国国家训练实验室 (NTL)在戴尔的原型图上强行加上了这组数字。很多年后,当研究人员向 NTL 索要数据的原始报告时,NTL 的回复是「原始数据已经丢失了。」所以,至今为止,没有任何人能找到这组数据背后的实证研究。
讲实话,这个图之前我也用过,因为它还挺符合直觉的。而且这个实验用脑子想想,其实不难设计。只要控制好变量,比如固定的学习时长、固定的时间间隔、标准的测试内容和评价标准,找几组被试,应该是比较好做出来的。但后来了解了背后的轶事后,我也觉得,NTL 有可能当年就没好好做这个实验,而是某个多事的研究者给了一个直观的数据,把一个经验性的思考模型,一下子变成了一个有理有据的学习规律,后来就跟上面所有的错误说法一样,越来越火,变成一个「经典理论」了。
关于学习金字塔模型(不带数字),我觉得它还是有启发性的。至于上面标的那些留存率,讲实话,当时研究者可能就没认真写,好在大多数人也不会认真追究——属于那种作者写上去,感觉很高大上;读者说出来,感觉自己懂很多的「社交谈资」,不必过度计较。

对学习效率感兴趣的朋友,建议参考认知科学家季清华提出的 ICAP 框架,这是 2014 年发表在顶级心理学期刊上的论文,也是目前学习科学界公认的标准。文章把学习分为四种类型:
从效果上看,I > C > A > P,也就是互动式最高效,建构式次之,主动和被动相对较差。比如书上画得花花绿绿,觉得自己很努力,但这种效果是最差的。而现在提得很多的「费曼学习法」,是一种互动式的学习方式,把知识讲出来,要求我们必须充分了解知识,并且对知识进行整合,还要用自己的语言表达出来,和对方互动交流,所以这种方法是最好的。
以上就是一些比较有趣的学习理论中的经典迷思。其中有一些是错误的,甚至是违背真正学习规律的,比如「一万小时理论」「学习风格理论」,有些则是以讹传讹,以偏概全,把一些具体的个体数据当成了绝对规律,比如「21 天习惯养成」。还有一些则是对经典实验或模型的不当延展,比如「全脑学习法」「学习金字塔模型」。
学习是一个很大的话题,我一直想写一个系列的主题,讲清楚和学习有关的迷思和经典观点。这篇文章主要在于破除错误认知,帮助大家避坑一些看似流行的说法。至于学习相关的认知科学、有效方法,如果有朋友感兴趣,以后再写文章做深入交流。
> 下载 少数派 2.0 客户端、关注 少数派公众号,解锁全新阅读体验 📰
> 实用、好用的 正版软件,少数派为你呈现 🚀
IT 之家 1 月 4 日消息,半导体与 AI 行业研究分析公司 SemiAnalysis 北京时间昨日表示,AI 企业 Anthropic 将直接从博通采购近 100 万颗 TPU v7p “Ironwood” AI 芯片,本地部署在其控制的数据中心中。
换句话说,博通将直接向 Anthropic 供应基于 TPU v7p 的机架级 AI 系统,“绕过” TPU 芯片的另一开发参与方谷歌。不过谷歌预计仍可从 Anthropic 同博通的交易中取得 IP 授权收入。

博通 CEO 陈福阳此前在 2025 年 12 月确认,Anthropic 已累计向博通下达了价值 210 亿美元的 AI 系统订单。
在 Anthropic 的自有 TPU 算力系统中,TeraWulf 等三家企业供应基础设施,Fluidstack 则将负责现场部署服务。
先上插件吧
ace-sidebar-0.1.0.zip
安装步骤
解压获得 vsix 文件
ctrl+shift+p>install extension from vsix 选择插件安装
点击侧边栏上的
首次使用需要配置 augment 的 api 地址 例如:


还有 mcp 端口提供给其他工具的 sse mcp (只在当前打开窗口有效 多开窗口会出现冲突)

然后就可以使用了

当前项目的提示词增强的上下文只支持以下
mcp 的话启动插件之后 可以在编辑器配置 sse 的 mcp 工具这个就不细讲了

代码自动索引,启动插件索引一次 保存代码也自动索引 添加了防抖机制
贴下 github 感兴趣的佬可以 fork 继续扩展
当前项目部分代码参考 ace-tool
https://linux.do/t/topic/1344562
感谢佬友 MistRipple 的无私分享
最近,我写了好几篇 AI 教程,就收到留言,要我谈谈我自己的 AI 编程。
今天就来分享我的 AI 编程,也就是大家说的"氛围编程"(vibe coding)。

声明一下,我只是 AI 初级用户,不是高手。除了不想藏私,更多是为了抛砖引玉,跟大家交流。
平时,我很少用 AI 生成新项目。因为每次看 AI 产出的代码,我总觉得那是别人的代码,不是我的。
如果整个项目都用 AI 生成,潜意识里,我感觉不到那是自己的项目。我的习惯是,更愿意自己写新项目的主体代码。
我主要把 AI 用在别人的项目和历史遗留代码,这可以避免读懂他人代码的巨大时间成本。
就拿历史遗留代码为例,(1)很多时候没有足够的文档,也没有作者的说明,(2)技术栈和工具库都过时了,读懂代码还要翻找以前的标准,(3)最极端的情况下,只有构建产物,没有源代码,根本无法着手。
AI 简直就是这类代码的救星,再古老的代码,它都能读懂和修改,甚至还能对构建产物进行逆向工程。
下面就是我怎么用 AI 处理历史遗留代码,平时我基本就是这样来 AI 编程。
我的 AI 编程工具是 Claude Code。因为命令行对我更方便,也容易跟其他工具集成。
我使用的 AI 模型,大部分时间是国产的 MiniMax M2。我测过它的功能,相当不错,能够满足需要,它的排名也很靠前。

另外,它有包月价(29元人民币),属于最便宜的编程模型之一,可以放心大量使用,反复试错。要是改用大家都趋之若鹜的 Claude 系列模型,20美元的 Pro 套餐不够用,200美元的 Max 套餐又太贵。
MiniMax 接入 Claude Code 的方法,参考我的这篇教程。
就在我写这篇文章的时候,MiniMax 本周进行了一次大升级,M2 模型升级到了 M2.1。

因为跟自己相关,我特别关注这次升级。
根据官方的发布声明,这次升级特别加强了"多语言编程能力",对于常用编程语言(Rust、Java、Golang、C++、Kotlin、Objective-C、TypeScript、JavaScript 等)有专门强化。
它的 WebDev 与 AppDev 开发能力因此有大幅提升,可以用来开发复杂的 Web 应用和 Android/iOS 的原生 App。
"在软件工程相关场景的核心榜单上,MiniMax M2.1 相比于 M2 有了显著的提升,尤其是在多语言场景上,超过 Claude Sonnet 4.5 和 Gemini 3 Pro,并接近 Claude Opus 4.5。"
根据上面这段介绍,它的编程能力,超出或接近了国外旗舰模型。
这个模型已经上线了,现在就能用。那么,这篇文章正好测一下,官方的介绍是否准确,它的 Web 开发能力到底有没有变强。
至于价格,跟原来一样。但是,官方表示"响应速度显著提升,Token 消耗明显下降",也算变相降价了。
M2.1 接入 Claude Code,我的参数如下。

我这次选择的历史遗留项目是 wechat-format,一个 Web 应用,将 Markdown 文本转为微信公众号的样式。

上图左侧的文本框输入 Markdown 文本,右侧立刻显示自动渲染的结果,可以直接复制到微信公众号的编辑器。
它非常好用,大家可以去试试看。我的公众号现在就用它做排版,效果不错(下图)。

问题是,原作者六年前就放弃了,这个项目不再更新了。我看过源码,它用的是老版本的 Vue.js 和 CodeMirror 编辑器,没有任何文档和说明,还经过了编译工具的处理,注释都删掉了。
如果不熟悉它的技术栈,想要修改这些代码是很困难的,可能要投入大量时间。
那么废话少说,直接让 AI 上场,把这些代码交给 MiniMax M2.1 模型。
接手老项目的第一步,是对项目进行一个总体的了解。
我首先会让 AI 生成项目概述。大家可以跟着一起做,跟我的结果相对照。
# 克隆代码库 $ git clone [email protected]:ruanyf/wechat-format.git # 进入项目目录 $ cd wechat-format # 启动 Claude Code $ claude-minimax
上面的claude-minimax是我的自定义命令,用来在 Claude Code 里面调用 MiniMax 模型(参见教程)。
输入"生成这个仓库的概述"。

AI 很快就给出了详细说明,包括项目的总体介绍、核心功能、技术栈和文件结构(下图)。

有了总体了解以后,我会让 AI 解释主要脚本文件的代码。
【提示词】解释 index.html 文件的代码

它会给出代码结构和页面布局(上图),然后是 JS 脚本加载顺序和 Vue 应用逻辑,甚至包括了流程图(下图),这可是我没想到的。


做完这一步,代码库的大致情况应该就相当了解了,而 AI 花费的时间不到一分钟。
既然这个模型号称有"多语言编程能力",我就让它把项目语言从 JavaScript 改成 TypeScript。
对于很多老项目来说,这也是常见需求,难度不低。

它先制定了迁移计划,然后生成了 tsconfig.json 和 types.d.ts,并逐个将 JS 文件转为对应的 TS 文件(下图)。

修改完成后,它试着运行这个应用,发现有报错(下图),于是又逐个解决错误。

最终,迁移完成,它给出了任务总结(下图)。

我在浏览器运行这个应用,遇到了两个报错:CodeMirror 和 FuriganaMD 未定义。
我把报错信息提交给模型,它很快修改了代码,这次就顺利在浏览器跑起来了。
至此,这个多年前的 JavaScript 应用就成功改成了 TypeScript 应用,并且所有内部对象都有了完整的类型定义。
你还可以接着添加单元测试,这里就省略了。
简单的测试就到此为止,我目前的 AI 编程大概就到这个程度,用 AI 来解释和修改代码。我也建议大家,以后遇到历史遗留代码,一律先交给 AI。
虽然这个测试比较简单,不足以考验 MiniMax M2.1 的能力上限,但如果人工来做上面这些事情,可能一个工作日还搞不定,但是它只需要十几分钟。
总体上,我对它的表现比较满意。大家都看到了,我的提示词很简单,就是一句话,但是它正确理解了意图,如果一次没有成功,最多再修改一两次就正确了。
而且,就像发布说明说的一样,它运行速度很快,思考过程和生成过程最多也就两三分钟,不像有的模型要等很久。
另外,不管什么操作,它都会给出详细的讲解和代码注释。
总之,就我测试的情况来看,这个模型的 Web 开发能力确实很不错,可以用于实际工作。
最后,说一点题外话。著名开发者 Simon Willison 最近说,评测大模型越来越困难,"我识别不出两个模型之间的实质性差异",因为主流的新模型都已经足够强大,足以解决常见任务,只有不断升级评测的难度,才能测出它们的强弱。
这意味着,对于普通程序员的常见编程任务,不同模型不会构成重大差异,没必要迷信国外的旗舰模型,国产模型就很好用。
(完)
据台媒《经济日报》及供应链消息透露,OpenAI 正在加速推进其首款个人 AI 硬件设备的研发进程。该项目在公司内部被称为 “Project Gumdrop”,标志着 OpenAI 正正式从纯软件服务向硬件领域跨界。
目前,该设备仍处于设计阶段,其具体形态尚未最终敲定,但大概率将以 “智能笔” 或 “便携式音频设备” 的形式呈现。
功能方面,该设备预计将配备麦克风与摄像头,核心卖点是能够让用户直接将手写笔记内容传输至 ChatGPT 进行处理。为了确保全球供应链的稳定性并避开特定地区的制造风险,OpenAI 已决定将代工订单从立讯精密转交给富士康,生产线预计将落地越南或美国。该专案最初计画由立讯代工,现已转向鸿海,主要考量制造地点,OpenAI 不希望新的 AI 装置在中国制造。
不过此前有报道指出,Project Gumdrop 曾面临软件漏洞、隐私合规以及云端基础设施不完善等技术挑战。
目前 OpenAI 的目标是在 2026 年或 2027 年正式发布该产品。届时,富士康不仅将负责终端设备的生产,还可能接手 OpenAI 相关的云端基础设施订单,双方的合作将覆盖从算力底座到消费电子的全产业链。而 Foxconn 将负责处理从云端基础设施到终端设备的全面生产。
直接导航——即在浏览器中手动输入域名访问网站的行为——正面临前所未有的风险:一项新研究发现,绝大多数"停放"域名(主要是过期或闲置域名,以及热门网站的常见拼写错误)现在都被配置为重定向访问者至传播诈骗和恶意软件的网站。
2025年10月,模仿FBI网络犯罪投诉中心网站的相似域名曾显示无威胁的停放页面(左图),而移动用户则被立即导向欺诈内容(右图)。图片来源:Infoblox。
当互联网用户尝试访问过期域名或意外导航至相似的"域名抢注"网站时,通常会被导向域名停放公司的占位页面。这些公司通过展示付费第三方网站的链接,试图从错误流量中获利。
十年前,访问这些停放域名后被重定向至恶意网站的概率相对较低:2014年研究人员发现(PDF),无论访问者是否点击停放页面上的链接,停放域名将用户重定向至恶意网站的概率不足5%。
但在过去几个月的系列实验中,安全公司Infoblox的研究人员表示,他们发现情况现已完全逆转,恶意内容目前已成为停放网站的常态。
"在大规模实验中,我们发现超过90%的情况下,停放域名的访问者会被导向非法内容、诈骗、恐吓软件和杀毒软件订阅服务或恶意软件。这是因为停放公司将'点击'出售给广告商,而广告商又经常将这些流量转售给第三方。"Infoblox研究人员在今日发布的论文中写道。
Infoblox发现,如果访问者使用虚拟专用网络(VPN)或非住宅IP地址访问停放网站,这些网站会显示正常内容。例如,Scotiabank.com客户若将域名误输为scotaibank[.]com,使用VPN时会看到正常停放页面,但使用住宅IP地址访问则会被重定向至试图传播诈骗、恶意软件或其他不良内容的网站。需要强调的是,仅需使用住宅IP地址的移动设备或台式电脑访问拼写错误的域名,就会触发这种重定向。
据Infoblox调查,scotaibank[.]com的所有者拥有近3000个仿冒域名组合,包括gmail[.]com——该域名已被证实配置了用于接收邮件的独立邮件服务器。这意味着如果您在发送邮件给Gmail用户时不小心遗漏了"gmail.com"中的字母"l",这封邮件不会消失或退回,而是直接落入诈骗者手中。报告指出,该域名近期还被用于多起商业邮件入侵攻击,通过附带木马恶意软件的"付款失败"诱饵进行欺诈。
Infoblox发现该特定域名持有者(通过公共DNS服务器torresdns[.]com暴露)针对数十个顶级网站建立了域名抢注页面,包括Craigslist、YouTube、Google、Wikipedia、Netflix、TripAdvisor、Yahoo、eBay和Microsoft。这些抢注域名的无害化列表可在此处查看(所列域名中的点号已替换为逗号)。
Infoblox威胁研究员David Brunsdon表示,停放页面会让访问者经历一系列重定向链,同时通过IP地理位置、设备指纹识别和Cookie持续分析用户系统,以确定最终重定向目标。
"通常在威胁到达前会存在重定向链——涉及停放公司外部的一到两个域名,"Brunsdon说。"每次交接时设备都会被反复分析,然后被传递到恶意域名,或者如果判定不值得攻击,则转向Amazon.com或Alibaba.com等诱饵页面。"
访问scotaibank.com时的重定向路径样本。每个分支包含观察到的系列域名,包括颜色编码的着陆页。图片来源:Infoblox。
Infoblox指出,另一个控制domaincntrol[.]com的威胁行为体(该域名与GoDaddy名称服务器仅差一个字符)长期利用DNS配置中的拼写错误将用户导向恶意网站。但最近几个月发现,这种恶意重定向仅发生在访问者使用Cloudflare DNS解析器(1.1.1.1)查询错误配置域名时,其他所有访问者只会收到拒绝加载的页面。
研究人员发现,甚至知名政府域名的变体也已成为恶意广告网络的目标。
"当我们有研究人员尝试向FBI网络犯罪投诉中心(IC3)举报犯罪时,他们意外访问了ic3[.]org而非ic3[.]gov,"报告指出。"他们的手机很快被重定向到虚假的'Drive订阅已过期'页面。他们还算幸运只遇到诈骗;根据我们的研究,他们同样可能轻易遭遇信息窃取程序或木马病毒。"
Infoblox报告强调,他们追踪的恶意活动无法归因于任何已知方,研究中提及的域名停放或广告平台与其记录的恶意广告行为无关。
但报告最终指出,尽管停放公司声称只与顶级广告商合作,但这些域名的流量经常被转售给联盟网络,经过多次倒手后,最终广告商与停放公司已不存在直接业务关系。