Claude Code 实战课程
最近刷到 Anthropic 官方的 **Claude Code 实战课程 **:
Claude Code in Action
在 reddit 有人完整学完后,把 ** 真正有用的要点 ** 整理了一遍。


xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
最近刷到 Anthropic 官方的 **Claude Code 实战课程 **:
Claude Code in Action
在 reddit 有人完整学完后,把 ** 真正有用的要点 ** 整理了一遍。
很多入职开发前的伙伴,可能或多或少接触过 git,
实际用的最多的命令也就是 git clone,git push,
以为 git 的流程也就这样,实则不然,实际上企业中的 git 流程,由五大分支构成

提示只有
main主分支和develop开发分支是贯穿项目生命周期本身,其他分支都会中途离场
所以也说main和develop是上二分支,其他分支是下三分支
主分支 (main/master): 项目的生产发布分支,始终保持稳定可发布状态
热修复分支 (hotfix/*): 从 main 分支创建,用于紧急修复线上 BUG, 修复后同时合并回 main 和 develop
开发分支 (develop): 日常开发的主分支,所有功能开发的集成分支
特性分支 (feature/*): 从 develop 创建,开发新功能,完成后合并回 develop
预发布分支 (release/*): 从 develop 创建,用于发布前的测试和最终调整,测试通过后合并回 main(打版本标签) 和 develop
feature/* → develop
develop → release/*
release/* → main + develop
hotfix/* → main + develop
作用:存放 稳定 , 可随时部署到生产环境的代码
特点:
分支上每一个提交对都应一个正式发布的版本
不允许在此分支直接开发
通常被打上版本标签 (如: v1.0.0 或 v20260101)
作用:存放 最新开发成果 的集成分支,是功能开发的集线器
特点:
当 develop 分支上的代码到达稳定状态并准备发布时,会合并到 main 分支 (如果有 release 分支,则合并到此分支)
所有功能的分支、发布分支都从 develop 分支拉取
来源: develop
合并目标: develop
命令惯例:feature/user-authentication,feature/payment-integration
作用: 开发新功能
生命周期:
从 develop 分支拉取
开发完成后,合并回 develop
合并后,该功能分支通常被删除
来源: develop
合并目标:develop 和 main
命名惯例:release/1.2.0,release/2026-spring
作用:为发布新版本做准备。在此分支上,只做 BUG 修复 , 生成版本号 , 整理文档 等发布准备工作,不再添加新功能
生命周期:
当 develop 分支的功能足够进行一次发布时,从 develop 拉出 release 分支
在此分支上进行最后的测试和修复
准备就绪后,将 release 分支合并到 main 分支 并打上版本标签
同时,必须合并回 develop 分支,因为 release 分支上修复的 BUG 可能 develop 分支上还没修复
来源:main
合并目标: main 和 develop
命名惯例:hotfix/critical-security-patch,hotfix/1.2.1
作用:快速修复生产环境 (main 分支) 上的紧急 BUG
生命周期:
从 main 分支上出现 BUG 的提交点 (通常是最近的标签) 拉取
修复完成后,合并回 main 分支并打上新的版本标签 (如:v1.0.1)
同时,必须合并回 develop 分支,确保修复在后续开发中也生效
恭喜你能看到这里,理论看起来确实是枯燥的,感谢你自己的坚持,
希望评论区就 gitflow 能展开相关讨论,而不是一味的刷 感谢分享 感谢大佬,
我分享文章也是希望有思想和经验上的交流碰撞
实际上,普通的开发入职后,如果有开发需求,一般都是从 develop 分支拉取代码后,
本地新建 feature/xxx 功能分支,在 feature/xxx 分支上进行开发的
功能开发到一定阶段后,比如一阶段完成了核心需求 (因为产品可能在开发内提出新需求,这很常见),
就可以合并到 develop 分支,develop 在积累了多个功能分支合并后,
就可以发布到 release 发布分支,这一分支不再接受新功能合并,只允许修补 BUG
这一过程就是提测,让测试工程师核验功能完整性,如果有 BUG 要及时修复
修复的时候拉取的是 release 分支,然后提交的时候也是推送到这个分支
在 release 分支准备完善 (修复了测试工程师检测到的 BUG), 就可以准备往主分支 (main) 发布了,
这就是一次完整的 git flow 发布流程,当然还有线上有 BUG, 需要做紧急修复
这个时候,就是直接拉取 main 分支并在本地创建热修复分支 hotfix,
在 BUG 被修复后,就可以合并回 main 分支 和 develop 分支了
是的,这里要注意,hotfix 要合并到 2 个分支里,
而不是 hotfix->main->develop 这是错误的做法 , 因为造成 develop 被 main 污染 (额外的标签记录以及其他)
大家有什么想法也可以在评论区里说一下,也可能有我没有讲到地方,大家也可以补充
wispbyte 的网址:https://wispbyte.com/
有佬友发了在 wispbyte 跑 sing-box 的方法,因为其实它是一个容器,资源非常有限。
跑多了必然被 oom 杀掉。那提供一个直接 js 的方法建 vless 和 trojan,这样资源能得到有效控制。而且代码混淆,不容易被封杀。
出一篇手把手教程:
wispbyte.com , 是欧洲的一个厂家
它可以免费建立一个 server,准确的来说是一个容器,并且暴露一个端口出来

那先 Create Server,Server Name 和 Server Description 就都写 god01 好了

Server Type 当然选 Free Plan 的,运行环境就选 NodeJS

选完就按最下面的创建即可。
建好了那就去到 server manage 管理界面,下面有个 Startup:

分析红框中那句启动命令,意思很简单,如果配了 git,就去拉代码,如果有存在 npm 的 package.json,就先 npm install 安装,最后,运行主程序 index.js
下面选项是 Docker Image,本来以为是可以随便引用别处的镜像,结果是不能,只能选固定的,那就选不太激进的 nodejs_22 ,保存好
然后就什么都不用动了
然后去到左边的 Files 选项,缺省路径会是 /home/container/

上面图是已经装好运行的,如果是新服务器,是空无一物,没有任何文件
我们只需要准备 5 个文件和一个域名:
域名去免费搞一个,然后证书用大善人的let's encrypt搞定
tls.crt 证书文件,用let’s encrypt申请
tls.key 密钥文件,用let’s encrypt申请
index.html 用来装饰的环保单页面,如果不加,就会显示 hello world,太假了,可以让 gemini 给你生成一个,代码如下,注意改名 index.html:
package.json 文件,index.js 运行时需要依赖的安装包文件,安装了 2 个包,axios 和 ws,注意改名 package.txt
package.txt (291 Bytes)
index.js 主文件,所有东西都在这里面,注意改名 index.js,上传的时候不知道为啥变成 indexjsp.txt 了
这样就齐活了,index.js 需要修改的地方
const DOMAIN = process.env.DOMAIN || '1234.abc.com'; // 填写域名 const SUB_PATH = process.env.SUB_PATH || 'sub'; // 获取节点的订阅路径 const PORT = process.env.PORT || 7860; // 端口 域名我们要填写自己的域名
路径要换掉,缺省是 sub,也就是订阅地址是 https://xxx.aaa.com/sub , 最好换成自己独特的地址
端口也选这个服务器给你开的端口,我的是 10407, 看下图

然后改好了,别急着贴进去
打开: https://obfuscator.io/legacy-playground
贴进去代码,混淆一下,弄成谁也认不得的模样,然后 Copy,再贴进去

最后运行

看到 Online 就好了
那域名解析到这个 IP,打开 https 看看:

那再打开 https://www.bbb.com/sub , 如果改了 sub,那就是设置的别的路径,会显示一堆 base64 加密的字符串

从 v2rayN 导入,有两个代理,一个是 vless,一个是 trojan,就可以用了
关键是这么做的原理,就是用 index.js 完整实现了 vless 和 trojan 的功能,加了证书,并且做了混淆和伪装
这样很自然,比在容器里直接 sing-box 安全占用资源少,不容易被扫描到
当然,这个网站的速度不太行,所以只是一个玩具,没有套大善人 Cloudflare 的 CDN
自己用的是 huggingface.co + CF worker,速度还是可以的。
代码放在: GitHub - zhangrr/js-server: nodejs server
大家自行取用吧
也放到博客了:wispbyte.com 薅羊毛记 | 八戒的技术博客
可以使用快捷指令实现
自定义闹钟 - 就寝版
自定义闹钟 - 常规版
- 点击「自定义闹钟 V3.0 - 常规版」下载添加,按照要求进行闹钟时间添加
- 手动运行一遍「自定义闹钟 V3.0 - 常规版」快捷指令,允许对应的权限请求
. 设定个人自动化:
- 特定时间 00:05
- 重复 每天
- 立即运行
- 选择「自定义闹钟 V3.0 - 常规版」快捷指令
原作者 微信公众号 [Jubal Moment]
1、把不好计算的积分制度换成对话次数。模型从 V3.2 换到了 Kimi 2T。之前是用完就没了,现在每周都会更新。我个人体感是,Kimi 比 V3.2 好用很多

2、新增加了图片生成,20 每周真的够了,我自己好像都用不完这个额度,使用的是即梦生成(真算不错了吧)

3、全方面的语言适配,中文率 90%,比起之前 50% 好很多了。支持最多五门语言(虽然不知道啥用,但反正是支持了)

以及修复了一堆 BUG 就不说了
总之就是大家登录就能体验到以上的更新了
之前帖子讲过,来 L 站之后想必各位佬友们都获得了不少的 AI 资源。如公益站 API、Cursor、反重力等等。一直希望能够整合一下,资源聚合,最好能够统一接口调用,于是总结了几个比较好用的工具。
这个工具我主要是用来配置 Gemini CLI、CodeX、Claude Code 的提示词、MCP、Skills 相关的内容的。
CLIProxyAPI 是一个为 CLI 提供 OpenAI/Gemini/Claude/Codex 兼容 API 接口的代理服务器。功能很强,官方介绍:
这是 CLIProxyAPI + 各类账户额度查询功能的 GUI 应用,和开发者交流了一下,提了建议,也支持了中文,感觉也很好用:
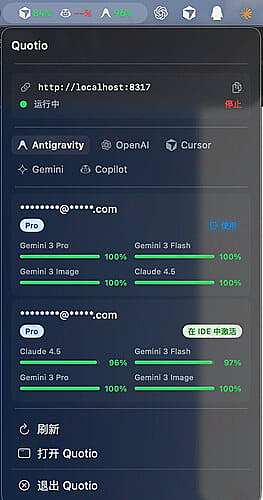
各位佬如果也有好用的产品,可以推荐推荐。
DataAgent 是一个基于 Spring AI Alibaba Graph 打造的企业级智能数据分析 Agent。它超越了传统的 Text-to-SQL 工具,进化为一个能够执行 Python 深度分析、生成 多维度图表报告 的 AI 智能数据分析师。
系统采用高度可扩展的架构设计,全面兼容 OpenAI 接口规范的对话模型与 Embedding 模型,并支持灵活挂载任意向量数据库。无论是私有化部署还是接入主流大模型服务(如 Qwen, Deepseek),都能轻松适配,为企业提供灵活、可控的数据洞察服务。
GitHub - spring-ai-alibaba/DataAgent: Spring AI Alibaba DataAgent 项目地址
大家可以去看看这个项目,我也算是里面的一个开发者了吧,项目的效果的话我感觉还不错,然后最近准备发布 1.0.0 正式版本了!大家感兴趣的可以去看看呀,可以去提 PR 或者去点点 Star。也可以作为工作流 Agent 的一个实现学习项目。
目前已经快 300star 了呀
目前 300star 了!!!!
你是否遇到过这样的场景?
Gflow 就是这样一个解决方案。
Gflow 是一个用 Rust 编写的轻量单节点作业调度器,专为管理和调度机器学习 / 深度学习任务而设计,特别是在具有多 GPU 资源的机器上。
他会帮你:
gflow 支持 cargo, conda 安装
conda install -c conda-forge gflow
# or
cargo install gflow
# 启动后端
gflowd up
# 提交需要 1 个 GPU 的训练任务
gbatch --gpus 1 python train.py
# 依赖上一个任务结束
gbatch --depends-on @~1 python evaluate.py
查看依赖关系树:
gqueue -t
# 输出:
JOBID NAME ST TIME TIMELIMIT
1 preprocess CD 00:02:15 00:20:00
└─ 2 train R 00:15:30 04:00:00
└─ 3 evaluate PD 00:00:00 00:10:00
搜索参数
gbatch -g 1 --param scale=2:0:-0.1 python train.py --model_id 0 --scale {scale}
自动探测 conda 环境
在默认情况下,gbatch 将会探测当前 shell 激活的环境,并作为脚本执行前激活的 conda 环境
conda activate lala
gbatch -g 1 --param scale=2:0:-0.1 python train.py --model_id 0 --scale {scale}
# or 手动设置
gbatch -c tran -g 1 --param scale=2:0:-0.1 python train.py --model_id 0 --scale {scale}
https://github.com/AndPuQing/gflow
1,部分重组后端,优化了 PAD 系统回传时带上模型思考原因
2,优化了日记向量化的模式,不再采用全篇向量,而是根据 highlight 进行日期 + 单个 highlight 的向量化处置,更易命中并且查找对应日记及历史记录
3,优化了 atri-self-review,改为便签,减少长尾效应
4,优化 working memory,改为两天全量对话记忆,更符合人类记忆模式
5,增加读取具体聊天记录的工具,可以让模型精确回答某个时间段的问题
注意,碰到带有思考签名的模型(如 Claude-opus-4-5-thinking),会显示无思考签名导致对话失败。所以,要么上游采用无思考签名的模型(或者过滤思考,只输出结果,如 sukaka-gcli2api 项目中的 opus-4-5),要么帮帮我提交个 pr,毕竟小白不是很懂如何去除这个
部署:
部署脚本在 scripts 中的那个 CF-deploy 脚本,可以按照要求一步一步来。就是先打开代理,然后设置你的 worker 名字,可以用默认名称,一路 enter,然后配置 URL,key ,记住自己的 worker 名称。如果 worker 名字被墙的话,要么魔法,要么挂一个自己的域名
我已经配置好了向量模型,是硅基流动的免费模型,可以在站内自行搜索免费硅基流动 key 进行填写,必填项目,否则日记无法发挥完整作用!向量模型也可以更改!
日记模型可以不填,用主对话模型(或者你选一个便宜一点的模型填上)后续可以进行 npm run deploy 同步更新(如果我仓库更新的话)
技术原理:
可以见我的 github 页:
原主贴:
SimTradeLab 内置:
SimTradeLab 的目标很简单:
做一个真正开源、可扩展、跨平台、系统级模拟的量化研究实验室,并且在兼容 pTrade 的同时,把速度提升一个数量级。同样的策略,同样的数据,SimTradeLab 回测速度比 pTrade 快 20–30 倍。
这不是 “理论值”,是实测。
回测结果 ≈ 实盘行为,而不是 “纸上富贵”。
SimTradeLab 的设计哲学是:
开源、可扩展、工程化、系统级、性能优先。
SimTradeLab = pTrade 兼容 + 20–30 倍速度 + 开源 + 系统级模拟 + 策略优化器。 这是一个为工程师和研究者打造的真正量化实验室。
可复用的量化交易机器学习框架
SimTradeML 是一个设计简洁、易于扩展的机器学习训练框架,专为量化交易场景设计。无缝集成 SimTradeLab,直接读取本地 h5 数据文件 SimTradeData 进行模型训练。
各位佬友们好,
不知道大家有没有过这种感觉:看着相册里那 “成千上万” 的数字,心里其实是恐惧的。每当存储空间告急,想要下定决心整理一下,却总是被翻不到头的照片流劝退。
我就是这种 “照片整理恐惧症” 的重度患者。为了自救,我开发了这款名为 PickPic 的软件。它不只是为了删除,更是为了让你在整理时不再感到 “累”。
这是我个人最看重的功能。传统的整理软件总是从最新或最旧开始排,翻两页就腻了。PickPic 会随机抽取照片和视频展示给你。
这种 “开盲盒” 式的整理方式,能让你在不经意间回顾往昔,极大地缓解了面对几千张连拍图时的那种枯燥感。
模仿卡片流的交互逻辑:
上滑:丢进待删列表。
下滑:保留这张回忆。
这种简单的二选一逻辑,不需要你在细碎的格子间点点选选。
视频清理最占空间。我把视频做成了类似短视频的沉浸流,你可以快速扫视视频内容,瞬间判断它的去留。
在设计之初,我深受 iOS 26 那种液态玻璃 (Liquid Glass) 美学的影响。那种通透、流动的质感非常迷人。
由于我并不是专业的 UI 设计师,光靠写代码去复刻那种顶级的视觉效果确实很有挑战。现在的成品虽然还远未达到那种 “完美” 的程度,但我依然通过 cc 来保留了这种尝试,比如纯黑的背景和带有阻尼感的水滴式 TabBar。希望在功能实用的基础上,能带给大家一点点视觉上的新鲜感。
由于我手头能测试的机型有限,目前在 MIUI/HyperOS 机型上发现了一个比较棘手的适配问题:
现象描述:
软件可以成功执行本地删除,但如果手机开启了 “小米云备份”,删除操作后回到系统相册,你会发现照片依然存在。
背后的逻辑:
这其实是系统自动从云端拉取了原图或缩略图。表现为照片看着还在,但点开时会模糊一下(正在重新下载)。
求助:
我不确定其他品牌的手机(如华为、OPPO、vivo)是否也有类似的云同步恢复情况。
如果有大佬知道如何通过 API 彻底同步触发云端删除,或者有相关的绕过思路,恳请在评论区指点迷津!
项目纯本地运行,不申请任何联网权限,隐私安全可以放心:
GitHub 项目地址:1Beyond1/PickPic
下载 APK (V0.1.1):GitHub Releases 页面
这算是我第一个正式成型的安卓开源小作。它还不完善,但它确实帮我清理掉了不少陈年废片。
如果你觉得这个思路有点意思,欢迎试用并赏个 Star 支持!
每一条评论我都会认真读,也期待能在评论区和大家讨论如何把这款 “碎纸机” 做得更趁手。
希望能陪你一起,清空相册,也清空焦虑。
音视频增强脚本(Taocrypt 魔改版):无极调速 | 长按倍速 | 快乐刷剧 | 视频下载 | 画面截图等「适用大部分网站」
本文系统梳理我对 h5player 脚本的 “魔改” 过程,重点在于将移动端 “长按倍速” 手势与 h5player 原有倍速逻辑进行深度桥接与共存。改造不仅保持了原脚本的全部功能,还在 DPlayer 等自定义播放器场景下通过全局捕获层实现了手势兼容,最终达成 “在绝大多数网站上稳定可用” 的目标。
h5player 是一个针对 H5 音视频网站的增强脚本,提供倍速控制、截图、画中画、网页全屏、画质调节、下载能力等丰富功能,覆盖 B 站、抖音、优酷、爱奇艺、YouTube、知乎、微博以及各类课程平台与网盘站点。其内部对 HTMLMediaElement 属性(如 playbackRate、volume、currentTime)进行了劫持与锁机制设计,以增强抗干扰能力,避免站点自行重置速度或音量。
与此同时,“手机长按倍速” 这一轻量手势逻辑在移动端场景非常自然:长按视频左半区以 1.0× 为基速,右半区以 2.0× 为基速;长按期间上滑加速、下滑减速,松手恢复原速。该脚本完全基于原生 API 编写,递归支持 Shadow DOM 与同源 iframe,并提供轻提示(右上角半透明倍速)与轻微振动反馈,体验上更贴合触屏设备。
在实际使用中,移动端手势与 h5player 的倍速管理可能产生冲突:站点脚本或 h5player 内部锁机制会在某些时刻 “回写” 速度,使得长按调速不生效。改造目标如下:
video 元素;将 “长按倍速” 脚本主体(IIFE 部分)追加到 h5player 代码末尾,避免多重 // ==UserScript== 头部冲突;保留并更新 @name/@description 多语言元数据,说明 “Taocrypt 魔改版” 的新增能力与兼容性;清理所有无意义的站点页面残留文本,使脚本自 // ==UserScript== 起始。
改造核心在于 兼容层:
function setPlaybackRateCompat(video, rate) {
// 优先获取 h5player 实例(window._h5Player 或常量 h5Player) const t = (window._h5Player && typeof window._h5Player.setPlaybackRate === 'function')
? window._h5Player
: (typeof h5Player !== 'undefined' ? h5Player : null);
if (t && typeof t.setPlaybackRate === 'function') {
// 将当前触发的 video 作为活动实例,并初始化其代理与锁 if (video && t.playerInstance !== video) {
t.playerInstance = video;
try { t.initPlayerInstance(false); } catch (e) {}
}
// 协同设置倍速:先解锁、再设置、再短锁,防止站点回写 try { t.unLockPlaybackRate(); } catch (e) {}
t.setPlaybackRate(rate, true);
try { t.lockPlaybackRate(800); } catch (e) {}
return;
}
// 无 h5player 时的事件协商与兜底 try {
const evt = new CustomEvent('h5player:requestSetPlaybackRate', { detail: { video, rate } });
document.dispatchEvent(evt);
} catch (e) {}
try {
video.playbackRate = rate;
try { video.dispatchEvent(new Event('ratechange')); } catch (e) {}
} catch (err) {
const desc = Object.getOwnPropertyDescriptor(HTMLMediaElement.prototype, 'playbackRate');
if (desc && typeof desc.set === 'function') {
desc.set.call(video, rate);
try { video.dispatchEvent(new Event('ratechange')); } catch (e) {}
}
}
}
该桥接使长按倍速直接走 h5player 的源逻辑,兼具解锁 / 短锁节奏,显著提高 “设定后不被回写” 的稳定性。
为减少与站点自定义控件的冲突,手势监听改为在捕获阶段执行:
touchstart/touchmove/touchend 采用 { passive: false, capture: true };stopImmediatePropagation() 调整为更温和的 stopPropagation(),降低与宿主脚本的事件冲突概率;preventDefault(),提升在覆盖层上的手势生效率。面对 DPlayer 这类 “控件层覆盖 video” 的场景,新增 全局捕获层:
document 捕获阶段监听触摸事件;video(含 Shadow DOM);video 时工作,避免无谓干扰。这一策略显著提升了在自定义播放器上的手势触发成功率,确保 “长按倍速” 在更多实际站点生效。
下表总结了本次改造后的核心特性与设计要点。
| 特性 | 设计要点 | 预期效果 |
|---|---|---|
| 源逻辑桥接 | 长按倍速走 h5player setPlaybackRate/lockPlaybackRate,含解锁 / 短锁节奏 | 设置更稳,不易被站点脚本改回 |
| 全局捕获层 | document 捕获 + 坐标命中 video,递归 Shadow DOM | DPlayer 等控件覆盖场景下依旧可触发长按 |
| 事件传播策略 | 捕获阶段监听、滑动阶段 preventDefault() + stopPropagation() | 减少冲突,提高手势有效性 |
| 深度扫描 | 初始高频扫描 + MutationObserver 持续监听 + iframe 递归 | 降低漏绑概率,适配动态加载 |
| 轻提示与振动 | 右上角倍速提示 + navigator.vibrate(设备支持) | 反馈清晰,手感良好 |
| 多语言元数据 | 更新 @name/@description(zh/zh-TW/ja/ko/ru/de/en) | 便于国际用户识别改造版 |
| 无冗余文本 | 清理脚本头部无意义页面残留 | 文件更干净,可直接安装 |
安装建议采用 “单脚本模式”:在脚本管理器(Tampermonkey / Violentmonkey)中新建脚本,将合并版代码整体粘贴并保存。为避免双重绑定导致提示重影或倍速冲突,请禁用或删除独立的 “手机长按倍速” 旧脚本,仅保留合并版。
移动端手势操作说明如下:
在绝大多数网站场景下,合并版脚本能稳定工作。但若个别站点对触摸事件做了强拦截或采用复杂的播放器封装(自定义组件、闭合 Shadow DOM、跨域 iframe 等),仍可能需要额外适配:
video(含全屏 / 网页全屏时的容器变化);Q1:桌面端是否需要长按倍速?
A:桌面端通常使用快捷键与菜单进行倍速控制,长按倍速主要面向移动端触屏场景。两者可在同一脚本中共存。
Q2:是否会影响 h5player 的其它功能?
A:不会。改造严格遵循 “保留原功能” 的原则,未删减任何原有能力。必要时通过桥接与短锁保障倍速生效。
Q3:为何新增了全局捕获层?
A:为解决自定义控件覆盖 video 的场景(如 DPlayer)。全局层在捕获阶段工作且仅在命中到 video 时启用,不会影响普通页面行为。
通过本次改造,移动端的 “长按倍速” 手势与 h5player 的倍速生态得以真正融合,既保留原有强大的增强能力,又赋予触屏设备更自然高效的操作方式。欢迎在更多站点上试用,并反馈兼容问题与改进建议,以进一步完善整体体验。
各位佬友好,最近在折腾 NoneBot2 机器人的时候,发现有时候 LLM 或者其他插件可能会输出一些不该说的 “违禁词”,导致账号风控或者刷屏炸群。 为了解决这个问题,我先找了插件商店但是没有类似的词汇黑名单插件,我弄了一个主动审查插件 nonebot-plugin-word-censor,主要用于拦截机器人发出的消息。
目前插件已经上传并申请发布,商店发布检查结果已经通过。
![[开源分享] NoneBot2 敏感词拦截插件:支持正则、实时热更1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/04/20260104100836_6959cba419e07.png!mark)
安装插件后,机器人的处理将变为:收到 QQ 消息 → Nonebot 其他插件 → nonebot-plugin-word-censor → 发送 QQ 消息。
测试效果如图
![[开源分享] NoneBot2 敏感词拦截插件:支持正则、实时热更2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/04/20260104100838_6959cba6d6ee6.png!mark)
![[开源分享] NoneBot2 敏感词拦截插件:支持正则、实时热更3](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/04/20260104100840_6959cba8e61ef.png!mark)
原理主要是利用了 NoneBot 的 Bot.call_api 钩子机制。在 API 调用前,检查 data['message'] 字段。如果命中黑名单,则直接 Raise 一个 Mock 异常,欺骗上层调用者 “API 调用已完成” 或者直接中断,从而阻止请求发送到 OneBot 端。
这个审查插件比较简陋,后续会不断优化它,欢迎佬友们提 Issue 并给予意见。
其实只是因为不是 23 岁就看不到好结局了


怎么会有人连开始游戏的成就都没有呢?奇怪捏

中文配音哦
Steam 免费开玩:
安卓用 4399 :

鉴赏家说:推荐
“没想到画师小姐真的是 23 岁的合法萝莉,我还以为是未成年来打童工了。” 这不仅是每个玩家刚开始游戏时最真实的想法,同样也是贯彻全作中苏幼晴遭受的隐形歧视:仅仅因为外表的幼小而找不到工作,其他人也会因为这点而瞧不起她,反而是在网络上装作强大的御姐大受欢迎。如果不是主角无微不至的关心与爱,她可能真的选择放弃自己的本真而强装成熟了。所幸 HE 中都未发生。另外,别错过音声特典哦~
评测员:三村绫野
来自朋友推荐~


我还没玩,有时间玩一下 官方说至少两个小时 w
[Edit - I’ve converted my post from English to Chinese for better understanding]
你好,
这是我的第一篇帖子,内容是关于创建令人惊艳的落地页。
如果你们需要一个令人惊艳的落地页,请告诉我你的具体需求,我至少可以在落地页方面帮助你,相信结果一定会让你感到惊喜。我会尽最大努力满足每一项要求。


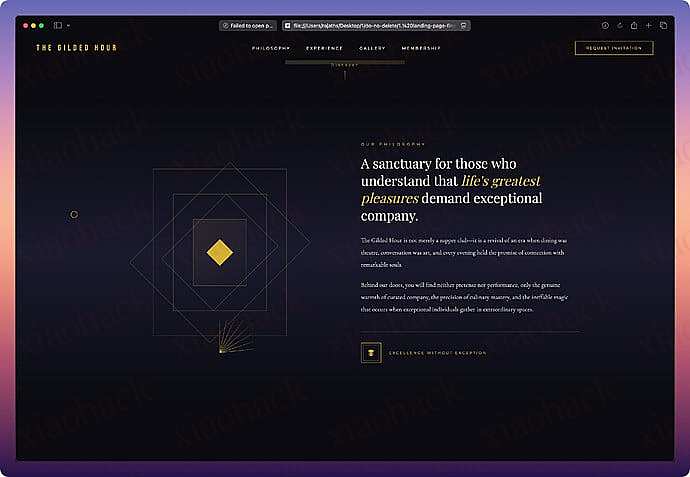


注意 - 这个提示词不是我个人创作的,我只是在研究时从 Reddit 上找到了几个提示词,这个是我测试过的所有提示词中表现最好的一个。
提示词在这里上传的 PDF 文件中。
我尝试上传创建的 HTML 文件的源代码,但在发帖时提示字符数超过了 64,000 的限制。因此,我以压缩格式直接上传 HTML 文件。请使用任何解压软件解压文件,你就能找到 HTML 文件。
The-Gilded-Hour-MembersOnly-Supper-Club.html.zip | 附件
感谢所有的开发者,感谢这个社区以及所有人所做的一切。我很高兴能够建立联系,如果有人需要我的帮助,我随时乐意提供协助。
 |  |
| 首页 | 管理员界面 |
 |  |
| 成绩录入界面 | 计时界面 |
 |  |
| 对阵表生成界面 | 排名表界面 |
很感慨,我从 2018 年开始参与 VEX 机器人比赛,到 2023 年进入世锦赛前 5,我对这个世界上最大的机器人比赛感情颇深。从 2023 年开始成为赛事伙伴(EP)。这个项目是我觉得官方的使用 Python 2(没错是 2)开发赛事管理器太难用,尤其是对于 GO 这个小学组赛段,于是开发了这个系统,稳定运行了 3 年。
随着官方的规则越来越复杂,上了大学后也很少有精力再去维护这个项目,索性把授权功能删掉,开源,以后估计还是继续在 EP 中担任技术支持。
如果有兴趣的佬友可以在符合 Apache License 的情况下拿去随便改,改成适合自己比赛的赛事管理器。在制作这个项目的期间,我学到了远超这个比赛可以带给我的知识,同时收获了金钱和赞许。我真的很快乐
纯 Vibe Coding 镇楼!!!
最近一直在用 cc 云 + GitHub Codespaces 做纯云开发,但踩了两个痛点。
发布 PR > 合并 PR > Codespaces 拉取代码 这套流程有点繁琐,而且手机操作不方便所以就因为这些原因我开发了这个项目:docker + cc + code-server
主要还是自用,但感觉功能还不够完善。
大家如果愿意当小白鼠的话可以尝试下 XDDDDDDDD
(白鼠哥们我写的不好千万轻喷我谢谢你们了)
关于 CC API / Key(重要说明)
具体的使用方案今天有点晚了,明天发个教程吧。
另外这个项目的配置有点蛮繁琐的,因为涉及到 code-server 代理的问题。
项目地址:GitHub - qinsehm1128/cloud_claude_code
SEO 优化页:https://ccc.qinshm1128.top
主要界面: