[开源自荐] 代码考古学家
可以使用自己的大模型去审查已经有的代码库主要有以下功能(第一次做代码相关的 Agent,佬们请指导
![[开源自荐] 代码考古学家1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/01/20260101155109_6956276d4b663.png!mark)
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
可以使用自己的大模型去审查已经有的代码库主要有以下功能(第一次做代码相关的 Agent,佬们请指导
Kamal 提供零停机部署、滚动重启、资源桥接、远程构建、附属服务管理,以及使用 Docker 在生产环境部署和管理 Web 应用所需的一切。最初为 Rails 应用打造,Kamal 适用于任何可容器化的 Web 应用。
美国 37signal 公司是一家 “小而美” 的公司,员工只有几十人但是每年有数百万利润。著名的项目管理工具 Basecamp、网络框架 Ruby on Rails 都出自他们。Kamal 也是他们的作品,用 Ruby 编写并集成到 Rails 的默认工具链中。
Kamal 的主要优势有二:一是与 Git 版本管理紧密结合,一次 commit 一个镜像,出什么问题可以立即回退;二是使用 kamal-proxy,从而带来健康检查与零停机部署,新版本实例正常上线前不会影响已有的实例。
前提条件如上所述,只要能被 Docker 打成镜像的 Web 应用都能用 Kamal 部署。同时因为 Kamal 有
Accessories的概念,事实上让 Kamal 占据了与 Docker Compose 一样的生态位。然而,你要部署的应用还要满足一些特殊条件:
- 你需要手动写一个 Dockerfile,使你的服务正常启动并向某个端口提供 HTTP 服务。
- 你需要添加
GET /up端点,该端点用于健康检查,如果应用状态正常则返回200 OK。(Kamal 最初是为 Rails 设计的,这个端点其实就是 Rails 的惯例。)对于部署目标 VPS 也有一定要求:
- 建议使用刚刚安装、仅配置好 SSH Key 远程连接的全新系统。
- 发行版建议为最新版本的 Ubuntu 或 Debian。
- SSH 开放在 22 端口且为
root账户登录。(显然 Kamal 的默认配置并不合安全的最佳实践,但是你会需要额外的配置,下文会说明)
下面准备了一个 Node.js 的例子,与一个 PHP+MySQL 的例子来说说它的基本用法。
请准备一个域名,并在 DNS 提供商中把域名解析事先设置到你的服务器上。
首先安装 Ruby 3.2+,如果你不知道怎么安装,可以用 rbenv。
然后运行:
$gem install kamal 把 Kamal 安装到本机上。
我已经准备了一个例子: GitHub - uqsme/app-size-comparison: App sizes comparison
切换到根目录,如你所见我已经写了 Dockerfile。本应用共有三个端点,根端点是一个 SPA,/api/files 是数据源,/up 是健康检查端点。
在根目录下执行:
$kamal init 此时会出现 config/deploy.yml,这就是 kamal 的配置文件。但是原配置过于冗长、注释繁琐,这里针对本例的简单应用,请直接清空然后复制粘贴以下内容:
service: app-size-comparison # 把kamal改成你Docker Hub的用户名,或你自定义registry的命名空间 kamal/app-size-comparison # 部署的目标服务器,即你ssh的IP或域名 servers: web: - 192.168.0.1 # 自动启用Let's Encrypt proxy: ssl: true # 换成你要部署的域名 host: lastname.uqs.me app_port: 8000 builder: arch: amd64 registry: password: KAMAL_REGISTRY_PASSWORD 再转到.kamal/secret:
# Secrets defined here are available for reference under registry/password, env/secret, builder/secrets, # and accessories/*/env/secret in config/deploy.yml. All secrets should be pulled from either # password manager, ENV, or a file. DO NOT ENTER RAW CREDENTIALS HERE! This file needs to be safe for git. # Option 1: Read secrets from the environment # KAMAL_REGISTRY_PASSWORD=$KAMAL_REGISTRY_PASSWORD # Option 2: Read secrets via a command # RAILS_MASTER_KEY=$(cat config/master.key) # Option 3: Read secrets via kamal secrets helpers # These will handle logging in and fetching the secrets in as few calls as possible # There are adapters for 1Password, LastPass + Bitwarden # # SECRETS=$(kamal secrets fetch --adapter 1password --account my-account --from MyVault/MyItem KAMAL_REGISTRY_PASSWORD RAILS_MASTER_KEY) # KAMAL_REGISTRY_PASSWORD=$(kamal secrets extract KAMAL_REGISTRY_PASSWORD $SECRETS) # RAILS_MASTER_KEY=$(kamal secrets extract RAILS_MASTER_KEY $SECRETS) Kamal 在这个文件中存储凭据的获取方式,注释说了不仅支持环境变量、文件,还适配了密码管理器(当然也包括明文),可以直接从管理器中的条目读取。这里你需要设置你的 Docker Hub 密码,添加以下内容
KAMAL_REGISTRY_PASSWORD=你的Docker Hub密码
然后针对你的特殊情况,展开对应的部分:
使用 ghcr.io、阿里云等三方 registry以阿里云仓库服务为例,在
config/deploy.yml添加以下内容:registry: # 把这两行添加回去 server: xxxx-xxxxxxxxxxxxxxx.cn-hangzhou.personal.cr.aliyuncs.com username: uqsme password: - KAMAL_REGISTRY_PASSWORD
ssh 使用非 22 端口在
config/deploy.yml添加:ssh: port: 12345
ssh 使用非 root 用户Kamal 无法自动在目标上安装 Docker。你需要手动安装 Docker 与 Git:
#curl -fsSL https://get.docker.com -o- | bash -然后,在
config/deploy.yml添加:ssh: user: your_username
一切配置完成后,运行 kamal setup。
这将:
- 通过 SSH 连接到服务器(默认使用 root,通过 SSH 密钥认证)。
- 在任何尚未安装 Docker 的服务器上安装 Docker(使用 get.docker.com):这需要通过 SSH 获取 root 权限。
- 在本地和远程登录镜像仓库。
- 使用应用根目录下的标准 Dockerfile 构建镜像。
- 将镜像推送到镜像仓库。
- 从镜像仓库拉取镜像到服务器。
- 确保 kamal-proxy 正在运行,并在 80 和 443 端口接收流量。
- 启动一个与当前 Git 版本哈希对应的应用版本的新容器。
- 告诉 kamal-proxy,一旦新容器对
GET /up返回200 OK,就将流量路由到该容器。- 停止运行旧版本应用的上一个容器。
- 清理未使用的镜像和已停止的容器,防止服务器磁盘被占满。
稍后访问你的域名,或者 lastname.uqs.me,你应该就能看到一张图表,证明我们的 SPA 启动成功了。

接下来,假设你又进行了开发,请转到 app/src/index.html,找到这两行注释:
<!-- <h1>Here it is!</h1>
<p>I just changed the content.<p> --> 选中,用 Ctrl+/ 组合键取消注释。
Kamal 对 Git 有很好的集成,所以如果你有什么更改,可以在 git 提交后就立马上线。下面请 git add --all .、git commit -m "changed something" 完成提交,然后使用 kamal deploy 命令。
$kamal deploy 完成后,刷新你的网站,你会发现标题与内容如期呈现了。
下面以异次元发卡系统为例。首先克隆源码:
$git clone https://github.com/lizhipay/acg-faka 然后初始化 Kamal
$cd acg-faka $kamal init 为了用 Docker 部署,编写 Dockerfile。由于有.htaccess,可以考虑用 fpm+apache 类型的,这里用 shinsenter 的:
FROM shinsenter/php:8.2-fpm-apache
COPY . /var/www/html/
WORKDIR /var/www/html
这里我还是直接提供完善的脚本 config/deploy.yml:
service: acg-faka # 把kamal改成你Docker Hub的用户名,或你自定义registry的命名空间 kamal/acg-faka # 部署的目标服务器,即你ssh的IP或域名 servers: web: - 192.168.0.1 # 自动启用Let's Encrypt proxy: ssl: true # 换成你要部署的域名 host: demo.uqs.me # fpm-apache脚本默认开80 app_port: 80 healthcheck: path: / builder: arch: amd64 registry: password: KAMAL_REGISTRY_PASSWORD accessories: db: mysql:8 # 假设是同一机器 host: 192.168.0.1 # 避免暴露公网 port: "127.0.0.1:3307:3306" # 要引入数据库容器的环境变量 # 都是mysql容器特有的设置 # 详见:https://hub.docker.com/_/mysql#environment-variables env: # 明文 clear: # 允许远程访问 MYSQL_ROOT_HOST: '%' # 库名 MYSQL_DATABASE: production # 需要保密的 secret: - MYSQL_ROOT_PASSWORD 首先要注意的是健康检查,上面说了 Kamal 要求 GET /up 返回 200 OK,但这只是 Rails 的惯例,往往其他应用就会 404,所以这里先把检查端点改成首页。
然后,发卡系统是一个数据库驱动的应用。一般情况下将网站与数据库同时部署,我们会考虑 Docker Compose,现在 Kamal 有 Accessories 机制,事实上就与前者等效了。
而且,Accessories 与主服务都在相同的 docker 网络下,可以直接用 <镜像名>-<accessory名> 代替 IP,来实现容器间的互通了。
在部署前,你仍要提供密码,不仅有 registry 的密码,还有你想让数据库使用的密码。.kamal/secret:
KAMAL_REGISTRY_PASSWORD=<你的registry密码>
MYSQL_ROOT_PASSWORD=mysql112233
配置完成后,提交一次 git commit,运行:
$git add --all . $git commit -m "setup kamal" $kamal setup 稍后,访问 demo.uqs.me,可以看到安装界面。在连接数据库时,可以这样写:

第一个字段是数据库所在主机,可以填 acg-faka-db,Docker 的域名解析就会转到数据库所在容器。第二个字段数据库名、第三个账户、第四个密码都是通过环境变量定义的。最后一个是表名前缀,但是 docker 部署的一个特点就是自带隔离,所以这个字段在这种部署模式下意义不大了。
最后看一下安装好的发卡网:

使用 kamal details 命令查看容器情况:

官网
kamal 加速 - Ruby China
Kamal 的讨论与问题汇总 - Ruby China
一些中转站的大香蕉支持 openai chat 和 gemini generateContent 的 api 调用
chat 可以在对话里直接说比例,但是图像分辨率不能指定(有些给了额外参数,有些没有)。
用 gemini 自己的 generateContent 不知道为什么一些在 cherrystudio 里用不会生图,只会回复文本。。。
(返回 token 才 184。。。就是没图了。。。)
但是调 api 却是好的.. 很神奇
写了个脚本,给大家参考一下.(脚本本身挺简单的,就是有几个参数要自己找下)。
依赖:
pnpm add @google/genai
pnpm add dotenv #直接写key 不需要用到.env不需要 文件名(这个工具类脚本项目里一开始就有。。用了就直接粘过来了):
src\utils\filename.ts
export function generateFilename(extension: string): string {
const now = new Date();
// Format date components const year = now.getFullYear();
const month = String(now.getMonth() + 1).padStart(2, "0");
const day = String(now.getDate()).padStart(2, "0");
const hours = String(now.getHours()).padStart(2, "0");
const minutes = String(now.getMinutes()).padStart(2, "0");
const seconds = String(now.getSeconds()).padStart(2, "0");
const milliseconds = String(now.getMilliseconds()).padStart(3, "0");
// Format: YYYYMMDD_HHMMSS_MS.ext return `${year}${month}${day }_${hours}${minutes}${seconds}_${milliseconds}.${extension}`;
}
export function generateFilenameWithPrefix(extension: string,
prefix?: string): string {
const timestamp = generateFilename(extension);
if (prefix) {
return `${prefix}_${timestamp}`;
}
return timestamp;
}
export function generateFilenameSimple(extension: string): string {
const now = new Date();
const year = now.getFullYear();
const month = String(now.getMonth() + 1).padStart(2, "0");
const day = String(now.getDate()).padStart(2, "0");
const hours = String(now.getHours()).padStart(2, "0");
const minutes = String(now.getMinutes()).padStart(2, "0");
const seconds = String(now.getSeconds()).padStart(2, "0");
return `${year}${month}${day }_${hours}${minutes}${seconds}.${extension}`;
}
export default {
generateFilename,
generateFilenameWithPrefix,
generateFilenameSimple,
};
src\paint\generate.ts
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
import dotenv from "dotenv";
import path from "path";
import { generateFilenameWithPrefix } from "../utils/filename.js";
// 不用.env这一行不需要
dotenv.config();
interface GenerateImageOptions {
textPrompt: string;
aspectRatio: string;
resolution: string;
referenceImage?: string[];
}
async function generateImage({ textPrompt, aspectRatio, resolution, referenceImage }: GenerateImageOptions,
resultDir: string) {
letif (referenceImage && referenceImage.length > 0) {
for (constof referenceImage) {
constreadFileSync(image);
const base64Image = imageData.toString("base64");
imageContents.push({
inlineData: {
data: base64Image,
mimeType: "image/png",
},
});
}
}
const ai = new GoogleGenAI({
httpOptions: {
// 换成你中转站的网址 不需要/v1beta baseUrl: "https://xxxx",
// 直接跑就把key直接写在里面 headers: { Authorization: "Bearer " + process.env.GOOGLE_API_KEY! },
},
});
const prompt = [
{
text: textPrompt,
},
...imageContents,
];
const response = await ai.models.generateContent({
model: "gemini-3-pro-image-preview",
contents: prompt,
config: {
responseModalities: ["TEXT", "IMAGE"],
: {
aspectRatio: aspectRatio,
: resolution,
},
},
});
if (!response.candidates) {
throw new Error("No candidates found");
}
const parts = response.candidates[0]?.content?.parts;
if (!parts) {
throw new Error("No parts found");
}
for (const part of parts) {
if (part.text) {
console.log(part.text);
} else if (part.inlineData) {
constinlineData.data;
if (!imageData) {
throw new Error("No image data found");
}
const buffer = Buffer.from(imageData, "base64");
const filePath = path.join(
resultDir,
generateFilenameWithPrefix("png", "gemini")
);
fs.writeFileSync(filePath, buffer);
console.log(`Image saved as ${filePath}`);
}
}
}
export default generateImage;
调用:
import path from "path";
import { fileURLToPath } from "url";
import generateImage from "./generate.js";
import { existsSync, mkdirSync } from "fs";
const __filename = fileURLToPath(import.meta.url);
const __dirname = path.dirname(__filename);
// 改成自己的目录 这里是相对跑的这个ts文件的位置 const resultDir = path.join(__dirname, "../../paint-result");
const aspectRatio = "16:9";
const resolution = "2K";
const textPrompt = `EVA中的明日香,凌波丽;凉宫春日系列中的长门有希;机动战舰中的星野琉璃(参考图片就是星野琉璃, 参考参考图画);Fate中的Saber。
她们并肩坐在草坪上,草地上有发光的萤火虫和五颜六色的花朵。身后是夜空,银河繁星闪烁,。
烟花在夜空中绽放。烟花的光芒映照在她们的脸庞上。
天空中用金色和红色的烟花轨迹写着"新年快乐"四个大字。
她们微笑着,面向镜头。草坪四周摆放着彩色的灯笼、礼物盒和香槟酒杯,充满新年气息。
画风参考参考图,精致细腻的动画画风。
`;
// 用String.raw因为windows下直接拖入vscode还是用的\ 懒得转了直接raw吧 // 不需要参考图 写 = []就行 const referenceImage: string[] = [
String.raw`c:\Users\ooo\Downloads\琉璃.jpg`,
];
existsSync(resultDir) || mkdirSync(resultDir, { recursive: true });
generateImage(
{
textPrompt,
aspectRatio,
resolution,
referenceImage,
},
resultDir
);
(想着本身就是复制谷歌文档里的 就只需要小改动没出动 ai 改 古法编程一个脚本改了快 20 分钟 哭死
祝佬们新年快乐~

原本注册不绑卡有这些可以用

kimi-k2-thinking / glm-4.7 / MiniMax-M2.1 / deepseek-v3.2 / llama-4-maverick / llama-4-scout
现在新年全系列开放免费使用
大家来尽量蹬吧

注意一下 base url 是这个
又找到一个不绑卡 可用免洗邮箱的站
虽然免费模型不多 但亮点是有小米可用
注册后直接拿 key 就可以了
API Key: YOUR_API_KEY
Base URL: https://api.askcodi.com/v1
Model:
xiaomi/mimo-v2-flash:free
qwen/qwen3-coder:free
kwaipilot/kat-coder-pro:free
mistral/devstral-2512:free
openai/gpt-oss-20b:free
zai/glm-4.5-air:free
有段时间没来水贴了,原因是尸体不太舒服:

放一下脚本的仓库链接:GitHub - ZipZhu/Flclash-scripts: A repository for Flclash scripts
相较于 scripts7,以下是我根据个人使用过程中遇到的问题,进行了一点点修改。
ChinaIp ChinaMedia GoogleCNProxyIP。优化了一下节点倍率识别。function main(config) {
const ICON_BASE = "https://cdn.jsdelivr.net/gh/Koolson/Qure@master/IconSet/Color/";
const RULE_BASE = "https://cdn.jsdelivr.net/gh/ACL4SSR/ACL4SSR@master/Clash/";
const maxRatio = 3.0;
const ratioRegex = /(\d+(?:\.\d+)?)\s*(?:x|X|×|倍)|(?:x|X|×|倍)\s*(\d+(?:\.\d+)?)/;
const filterKeywords = [
'群', '邀请', '返利', '官网', '官方', '网址', '订阅', '购买', '续费', '剩余',
'到期', '过期', '流量', '备用', '邮箱', '客服', '联系', '工单', '倒卖', '防止',
'节点', '代理', '梯子', 'tg', '发布', '重置', '测试'
];
const blackListRegex = new RegExp(filterKeywords.join('|'));
const originalProxies = config.proxies || [];
const filteredProxies = originalProxies.filter(proxy => {
if (blackListRegex.test(proxy.name)) return false;
const ratioMatch = proxy.name.match(ratioRegex);
if (ratioMatch) {
const ratio = parseFloat(ratioMatch[1] || ratioMatch[2]);
if (ratio > maxRatio) return false;
}
return true;
});
if (filteredProxies.length === 0) return config;
const REGIONS = [
{ name: "美国节点", pattern: "美|纽约|波特兰|达拉斯|俄勒冈|凤凰城|费利蒙|硅谷|拉斯维加斯|洛杉矶|圣何塞|圣克拉拉|西雅图|芝加哥|US|United States|SJC", icon: "United_States.png" },
{ name: "日本节点", pattern: "日本|东京|大阪|JP|Japan", icon: "Japan.png" },
{ name: "狮城节点", pattern: "新加坡|狮城|SG|Singapore|SIN", icon: "Singapore.png" },
{ name: "香港节点", pattern: "港|HK|Hong Kong", icon: "Hong_Kong.png" },
{ name: "台湾节点", pattern: "台|新北|彰化|TW|Taiwan", icon: "Taiwan.png" }
];
const validRegions = [];
for (const region of REGIONS) {
const regex = new RegExp(region.pattern);
if (filteredProxies.some(proxy => regex.test(proxy.name))) {
validRegions.push(region);
}
}
const validRegionNames = validRegions.map(r => r.name);
const proxyGroups = [];
proxyGroups.push({
name: "节点选择",
icon: `${ICON_BASE}Proxy.png`,
type: "select",
proxies: [...validRegionNames, "手动切换"]
});
for (const region of validRegions) {
proxyGroups.push({
name: region.name,
icon: `${ICON_BASE}${region.icon}`,
"include-all": true,
filter: region.pattern,
type: "url-test",
interval: 300,
tolerance: 50
});
}
proxyGroups.push({
name: "手动切换",
icon: `${ICON_BASE}Available.png`,
"include-all": true,
type: "select"
});
proxyGroups.push({
name: "GLOBAL",
icon: `${ICON_BASE}Global.png`,
type: "select",
proxies: ["节点选择", ...validRegionNames, "手动切换", "DIRECT"]
});
config["proxy-groups"] = proxyGroups;
config["rule-providers"] = {
LocalAreaNetwork: { url: `${RULE_BASE}LocalAreaNetwork.list`, path: "./ruleset/LocalAreaNetwork.list", behavior: "classical", interval: 86400, format: "text", type: "http" },
UnBan: { url: `${RULE_BASE}UnBan.list`, path: "./ruleset/UnBan.list", behavior: "classical", interval: 86400, format: "text", type: "http" },
BanAD: { url: `${RULE_BASE}BanAD.list`, path: "./ruleset/BanAD.list", behavior: "classical", interval: 86400, format: "text", type: "http" },
BanProgramAD: { url: `${RULE_BASE}BanProgramAD.list`, path: "./ruleset/BanProgramAD.list", behavior: "classical", interval: 86400, format: "text", type: "http" },
ProxyGFWlist: { url: `${RULE_BASE}ProxyGFWlist.list`, path: "./ruleset/ProxyGFWlist.list", behavior: "classical", interval: 86400, format: "text", type: "http" },
ChinaDomain: { url: `${RULE_BASE}ChinaDomain.list`, path: "./ruleset/ChinaDomain.list", behavior: "domain", interval: 86400, format: "text", type: "http" },
ChinaCompanyIp: { url: `${RULE_BASE}ChinaCompanyIp.list`, path: "./ruleset/ChinaCompanyIp.list", behavior: "classical", interval: 86400, format: "text", type: "http" },
ChinaIp: { url: `${RULE_BASE}ChinaIp.list`, path: "./ruleset/ChinaIp.list", behavior: "classical", interval: 86400, format: "text", type: "http" },
ChinaMedia: { url: `${RULE_BASE}ChinaMedia.list`, path: "./ruleset/ChinaMedia.list", behavior: "classical", interval: 86400, format: "text", type: "http" },
GoogleCNProxyIP: { url: `${RULE_BASE}Ruleset/GoogleCNProxyIP.list`, path: "./ruleset/GoogleCNProxyIP.list", behavior: "classical", interval: 86400, format: "text", type: "http" },
Download: { url: `${RULE_BASE}Download.list`, path: "./ruleset/Download.list", behavior: "classical", interval: 86400, format: "text", type: "http" }
};
config["rules"] = [
"RULE-SET,LocalAreaNetwork,DIRECT",
"RULE-SET,UnBan,DIRECT",
"RULE-SET,BanAD,REJECT",
"RULE-SET,BanProgramAD,REJECT",
"RULE-SET,GoogleCNProxyIP,节点选择",
"RULE-SET,ProxyGFWlist,节点选择",
"RULE-SET,ChinaMedia,DIRECT",
"RULE-SET,ChinaDomain,DIRECT",
"RULE-SET,ChinaCompanyIp,DIRECT",
"RULE-SET,ChinaIp,DIRECT",
"RULE-SET,Download,DIRECT",
"GEOIP,CN,DIRECT",
"MATCH,节点选择"
];
config.proxies = filteredProxies;
return config;
}
function main(config) {
const ICON_BASE = "https://cdn.jsdelivr.net/gh/Koolson/Qure@master/IconSet/Color/";
const RULE_BASE = "https://cdn.jsdelivr.net/gh/ACL4SSR/ACL4SSR@master/Clash/";
const maxRatio = 3.0;
const ratioRegex = /(?:\[(\d+(?:\.\d+)?)\s*(?:x|X|×)\]|(\d+(?:\.\d+)?)\s*(?:x|X|×|倍)|(?:x|X|×|倍)\s*(\d+(?:\.\d+)?))/i;
const filterKeywords = [
'群', '邀请', '返利', '官网', '官方', '网址', '订阅', '购买', '续费', '剩余',
'到期', '过期', '流量', '备用', '邮箱', '客服', '联系', '工单', '倒卖', '防止',
'节点', '代理', '梯子', 'tg', '发布', '重置', '测试'
];
const blackListRegex = new RegExp(filterKeywords.join('|'));
const originalProxies = config.proxies || [];
const filteredProxies = originalProxies.filter(proxy => {
if (blackListRegex.test(proxy.name)) return false;
const ratioMatch = proxy.name.match(ratioRegex);
if (ratioMatch) {
const ratio = parseFloat(ratioMatch[1] || ratioMatch[2] || ratioMatch[3]);
if (ratio > maxRatio) return false;
}
return true;
});
if (filteredProxies.length === 0 && originalProxies.length === 0) return config;
const REGIONS = [
{ name: "美国节点", pattern: "美|纽约|波特兰|达拉斯|俄勒冈|凤凰城|费利蒙|硅谷|拉斯维加斯|洛杉矶|圣何塞|圣克拉拉|西雅图|芝加哥|US|United States|SJC", icon: "United_States.png" },
{ name: "日本节点", pattern: "日本|东京|大阪|JP|Japan", icon: "Japan.png" },
{ name: "狮城节点", pattern: "新加坡|狮城|SG|Singapore|SIN", icon: "Singapore.png" },
{ name: "香港节点", pattern: "港|HK|Hong Kong", icon: "Hong_Kong.png" },
{ name: "台湾节点", pattern: "台|新北|彰化|TW|Taiwan", icon: "Taiwan.png" }
];
const validRegions = [];
for (const region of REGIONS) {
const regex = new RegExp(region.pattern);
if (filteredProxies.some(proxy => regex.test(proxy.name))) {
validRegions.push(region);
}
}
const validRegionNames = validRegions.map(r => r.name);
const proxyGroups = [];
proxyGroups.push({
name: "节点选择",
icon: `${ICON_BASE}Proxy.png`,
type: "select",
proxies: [...validRegionNames, "手动切换"]
});
for (const region of validRegions) {
const regex = new RegExp(region.pattern);
const regionProxies = filteredProxies
.filter(proxy => regex.test(proxy.name))
.map(proxy => proxy.name);
if (regionProxies.length > 0) {
proxyGroups.push({
name: region.name,
icon: `${ICON_BASE}${region.icon}`,
type: "url-test",
proxies: regionProxies,
interval: 300,
tolerance: 50
});
}
}
proxyGroups.push({
name: "手动切换",
icon: `${ICON_BASE}Available.png`,
"include-all": true,
type: "select"
});
proxyGroups.push({
name: "GLOBAL",
icon: `${ICON_BASE}Global.png`,
type: "select",
proxies: ["节点选择", ...validRegionNames, "手动切换", "DIRECT"]
});
config["proxy-groups"] = proxyGroups;
config["rule-providers"] = {
LocalAreaNetwork: { url: `${RULE_BASE}LocalAreaNetwork.list`, path: "./ruleset/LocalAreaNetwork.list", behavior: "classical", interval: 86400, format: "text", type: "http" },
UnBan: { url: `${RULE_BASE}UnBan.list`, path: "./ruleset/UnBan.list", behavior: "classical", interval: 86400, format: "text", type: "http" },
BanAD: { url: `${RULE_BASE}BanAD.list`, path: "./ruleset/BanAD.list", behavior: "classical", interval: 86400, format: "text", type: "http" },
BanProgramAD: { url: `${RULE_BASE}BanProgramAD.list`, path: "./ruleset/BanProgramAD.list", behavior: "classical", interval: 86400, format: "text", type: "http" },
ProxyGFWlist: { url: `${RULE_BASE}ProxyGFWlist.list`, path: "./ruleset/ProxyGFWlist.list", behavior: "classical", interval: 86400, format: "text", type: "http" },
ChinaDomain: { url: `${RULE_BASE}ChinaDomain.list`, path: "./ruleset/ChinaDomain.list", behavior: "domain", interval: 86400, format: "text", type: "http" },
ChinaCompanyIp: { url: `${RULE_BASE}ChinaCompanyIp.list`, path: "./ruleset/ChinaCompanyIp.list", behavior: "classical", interval: 86400, format: "text", type: "http" },
ChinaIp: { url: `${RULE_BASE}ChinaIp.list`, path: "./ruleset/ChinaIp.list", behavior: "classical", interval: 86400, format: "text", type: "http" },
ChinaMedia: { url: `${RULE_BASE}ChinaMedia.list`, path: "./ruleset/ChinaMedia.list", behavior: "classical", interval: 86400, format: "text", type: "http" },
GoogleCNProxyIP: { url: `${RULE_BASE}Ruleset/GoogleCNProxyIP.list`, path: "./ruleset/GoogleCNProxyIP.list", behavior: "classical", interval: 86400, format: "text", type: "http" },
Download: { url: `${RULE_BASE}Download.list`, path: "./ruleset/Download.list", behavior: "classical", interval: 86400, format: "text", type: "http" }
};
config["rules"] = [
"RULE-SET,LocalAreaNetwork,DIRECT",
"RULE-SET,UnBan,DIRECT",
"RULE-SET,BanAD,REJECT",
"RULE-SET,BanProgramAD,REJECT",
"RULE-SET,GoogleCNProxyIP,节点选择",
"RULE-SET,ProxyGFWlist,节点选择",
"RULE-SET,ChinaMedia,DIRECT",
"RULE-SET,ChinaDomain,DIRECT",
"RULE-SET,ChinaCompanyIp,DIRECT",
"RULE-SET,ChinaIp,DIRECT",
"RULE-SET,Download,DIRECT",
"GEOIP,CN,DIRECT",
"MATCH,节点选择"
];
config.proxies = originalProxies;
return config;
}
除了一些公开的规则列表,个人的附加规则例如:DOMAIN-SUFFIX,xn--ngstr-lra8j.com,MATCHDOMAIN-SUFFIX,services.googleapis.cn,MATCH
都没有写进脚本中,大家可以手动在 “进阶配置 - 附加规则” 里面添加。
如果你有什么个性化的需求,可以让 AI 帮你改:

还有 1 小时就是 2026 年了,21 世纪的 Q1 即将结束,祝大家睡个好觉,晚安。

想把 “行内补全” 做得好用,核心不是 “能生成”,而是生成后如何稳定落到光标处:不重复、不乱插、不无限循环、单行 / 多行行为符合预期。
prefix + suffix -> middle"FIM" 模型名对外提供)流程上分 6 段:预过滤 → 分类 → 模板 → 调用与过滤 → 后处理 → Diff(单行)
InlineCompletionProvider
-> 预过滤(跳过不该补全的场景)
-> 构建 prefix/suffix(HelperVars)
-> 单/多行分类
-> FIM 模板渲染
-> 调用 FIM API(非流式拿完整结果)
-> 过滤器管道处理(字符级/行级/后处理)
-> 单行:Diff 决定 range;多行:替换到行尾
-> 返回 InlineCompletionItem
<|fim_prefix|>{prefix}<|fim_suffix|>{suffix}<|fim_middle|>
"FIM"max_tokens:单行 64、多行 128(策略性限制 “胡乱续写” 概率)目的:便宜地跳过 “补全只会添乱” 的场景,减少无意义请求。
常见跳过项:
分类逻辑按优先级(越靠前越强):
即使是非流式输出,也可以把 “完整文本” 当成流来处理:逐步截断、跳过、清洗。
LLM 完整输出
-> 字符级过滤(stop token / suffix 重复 / 首字符换行)
-> 行级过滤(行数限制 / 重复行 / 相似行 / 空注释 / 双换行)
-> 后处理(空白、重复上一行、极端重复、去 markdown backticks)
-> 最终补全
典型能力:
典型能力:
//、# 这种空注释行直接丢弃典型规则:
FIM 模型对单行位置常见三种输出:
如果不处理,最常见的坏体验就是:多一个括号、多一段重复 token。
用 diffWords() 比较:
currentText:光标后到行尾的已有内容completion:模型给的最后一行补全然后根据 diff 模式判断:
range)range = undefined:在光标处插入range = { start: cursor, end: lineEnd }:先删除光标到行尾,再插入(用于清理重复后缀)多行补全的期望更像 “接管后续内容”,而不是 “精确对齐每个 token”。
选择 “替换到行尾” 的原因:
关键文件(按职责):
VvCompletionProvider.ts:主入口,串起 6 阶段流程vvCompletionStreamer.ts:API 调用管理(非流式)vvAutocompleteTemplate.ts:FIM 模板prefiltering.ts:预过滤multiline.ts:单 / 多行分类filters.ts:后处理processSingleLineCompletion.ts:单行 DiffstreamFilters/:字符级与行级过滤管道喜加一 | EPIC 限免(1.1)第十五弹
本期礼物
Chivalry 2「骑士精神 2」
注:游戏截止!1.2,00:00
新年快乐,我的佬友们!!!!
一个轻量、现代化的 LLM API 连通性测试与调试工具。
OmniProbe 为纯前端应用,帮助佬友快速验证 OpenAI 格式接口的可用性、延迟以及功能支持情况(如 Function Calling)。所有数据(API Key、聊天记录、设置)均存储在浏览器本地(LocalStorage & IndexedDB),不经过任何第三方服务器,确保隐私安全。支持 Vercel 一键部署。
API Check Demo:https://apicheck.96ai.top/
Github 开源地址:https://github.com/ssrsgaga/API-Check
![]()
![]()
![]()


选 nodejs

下载压缩包
https://nekoha.uk/usr/uploads/2026/01/1067276862.zip
在 Files 里解压开来

Startup 中的 Startup Command
chmod +x etc/sing-box/sing-box && ./etc/sing-box/sing-box run -C etc/sing-box/conf/

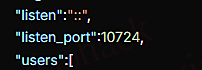
根据 Server Port 修改 13_tuic_inbounds.json 文件

运行
按照该链接导入
tuic://4727a44d-164b-47bd-b9cd-cd22bd28e1e2%3A4727a44d-164b-47bd-b9cd-cd22bd28e1e2@<你的主机>:<你的端口>?alpn=h3&congestion_control=bbr#60c346f3-0a04-4716-89f1-071a1acad756%20tuic
最近给哪吒面板弄一个随机 api, 然后之前一直想弄图床一直没有弄,就花时间找到这个叁月柒佬的项目,[CF 图床] 重磅更新!CloudFlare-ImgBed 现已支持 Cloudflare R2 上传方式! - #24,来自 MarSeventh 部署后我担心会用超 r2, 提了一个 pr, 询问能不能给容器增加容量限制,想问一下,存储桶能否添加最大容量限制,如果达到这个桶的阈值,就会停止这个桶新文件的存储・Issue #400・MarSeventh/CloudFlare-ImgBed・GitHub 但是我看见 iss 有这么多条,我觉得应该不难就自己让 ai 写了,跟佬讨论很多细节,然后实现了无额外写入次数实现容量限制 (cf 的 kv 写入次数每天只有 1000 次?), 第二天就叁月柒佬合并了,后面逛 iss 发现能否实现 Discord Bot api 实现图像托管・Issue #183・MarSeventh/CloudFlare-ImgBed・GitHub 问题支持 Discord Bot 实现类似电报机器人功能,我觉得这个应该也不难,就开始改,后面想着既然都加渠道了,Discord 实现好后,又尝试实现 HuggingFace 的支持,也是花了我一天的时间改代码
给叁月柒佬测试没有问题又合并了,到了这里基本上没有什么好改的了,然后我又看到了一个让我感兴趣的 iss, 能否添加访客模式・Issue #401・MarSeventh/CloudFlare-ImgBed・GitHub 我觉得这个功能很有必要,因为用户分享如果是简单的单个图片链接分享,这样不难很好扩展这个图库的价值,我希望好看的图片大家都能看到,就开始优化图库体验,前后改了百来次,大部分是手机端的操作体验,我很重视手机端的体验,因为手机端才是图库链接访问的大户,好的体验,会让用户喜欢,然后不断优化细节,让浏览图片和切换图片跟我的小米相册一样丝滑,是真的,我一直在小米相册琢磨每一个操作手势,(会有佬说你引入库呀,但是我不懂代码呀,我很多代码都是让 ai 完成的,我又不知道合适的库,我也没有精力阅读文档,一遍遍改操作.emmm
后面的效果我感觉还是不错的,这边放一下我 cf 部署的访问链接,有喜欢的佬可以点 star
随机图 api
https://image.ai6.me/random?type=img&dir=/1/landscape/
公开图床访问链接
图床上传地址
可以访问的文件夹路径
/portrait,/landscape,/anime,/1/landscape/,/2/landscape/,/1/portrait/,/2/portrait/,
landscape 是景观图,portrait 是肖像图
网页端图床访问效果
手机端图床访问效果
鄙人不才,如有建议可以在评论区留言,我看到会回复,最后值此元旦佳节,衷心祝愿大家:新年新气象,事业红红火火,身体健康,万事如意。
我们日常在画图形需要圆角时,经常使用 border-radius 来搞定,这样确实很方便,毕竟可以直接通知八个方向的角度。但是对于一些特殊需求或者是一些不规则的 border 而言,慢慢调整确实有些麻烦。今天就再给大家介绍一个新东西 corner-shape.

corner-shape 概念corner-shape 属于 CSS 背景与边框模块 Level 4 中的新特性,用来扩展原本只会画圆角的 border-radius 。 以前只能做圆圆的角,现在可以在同一块盒子上做出内凹、斜切甚至介于圆和方之间的 角 。
它是一个全新的属性,用来控制圆角区域的形状,配合 border-radius 可以非常方便地做出十字形、六边形、凹角卡片、对话气泡等复杂图形。
对有边框的盒子,简单理解为:
border-radius:控制圆角半径,即弧线的大小corner-shape:控制弧线的形状,是圆、斜切、凹口还是其他形状可以简单理解为:border-radius决定角有多大,corner-shape决定角长成什么样。
.box {
border: 4px solid #333;
border-radius: 20px;
corner-shape: round;
}
基本语法很简单,与 border-radius 搭配即可。
巧妇难为无米之炊必须要先有
border-radius,否则没有圆角区域可以改变形状。
在上述示例中,我们使用了 corner-shape: round,这里使用了 round 作为值。
其实 corner-shape 的可选值有多个,例如 round 、scoop 、bevel 、notch 、square、squircle。下面做一些简单说明:
round:默认圆角,和现在习惯的圆角一样。scoop:角被挖掉一块形成凹进去的四分之一椭圆。bevel:斜切角。notch:生成内凹的缺口角。square:强制角保持直角,等于取消圆角,即使 border-radius 不是 0。squircle:介于正方形和圆之间的平滑形状,可以理解为有点圆的方块。





我们可以像 border-radius 一样,自由的为每个角设置不一样的形状来完成更为复杂的需求,而不是全都一个样式。
我们主要有两种写法,一种是简写,一种是单独的方向控制。
和许多的属性一样,corner-shape 也可以简写来同时控制多个方向,最少一个值,最多可以设置四个值。
与 border-radius 一样, corner-shape 也有有 “方向版” 属性,如:corner-top-left-shape 、corner-top-right-shape 、corner-bottom-right-shape 、corner-bottom-left-shape 。
看名字就知道它们所代表的方向,这里就不细说了。
.card {
border-radius: 40px;
corner-top-right-shape: scoop;
}
superellipse()除了使用上述列举的关键字外,还可以使用数学函数 superellipse(K) 来精细控制角的曲率。
可以把 superellipse(K) 理解为:
bevel。.box1 {
border-radius: 40px;
corner-shape: superellipse(1); /* 接近圆角 */
}
.box2 {
border-radius: 40px;
corner-shape: superellipse(4); /* 更像正方形 */
}
.box3 {
border-radius: 40px;
corner-shape: superellipse(0); /* 斜切角 */
}
.box4 {
border-radius: 40px;
corner-shape: superellipse(-1.5); /* 内凹的角 */
}
其效果如下所示




一些关键词值其实可以看作superellipse(K)的别名:例如普通圆角round类似于superellipse(1),而square对应极大 K 值。
目前 corner-shape 仍然是非常新的属性,主要在新版 Chromium 内核浏览器里(如较新版本 Chrome)率先实现。 在较旧或不支持的浏览器里,这个属性会被忽略,最终表现就是普通的 border-radius 圆角。


为了保证兼容性:
border-radius 样式作为基础效果。corner-shape,支持的浏览器会增强显示,不支持的仍然是普通圆角。今天的分享就到这里了,后面我会增加几期实战效果,希望佬们喜欢
最后,元旦快乐!٩(‘ω’)و
点赞助力大鹅不摆烂

用 ClaudeCode+Antigravity 写的 ai 聊天软件
Github:TChat-wanxiaoT





各位佬友觉得咋样
Release 直达 github.com/wanxiaoT/TChat/releases/tag/1.1
WiNGPT-DocLoom 开源模型来袭!开源地址winninghealth/WiNGPT-DocLoom · Hugging Face
这款模型处理复杂 PDF 的多列、长文本、页眉页脚等场景都很亮眼,还针对医疗领域 PDF 处理做了性能增强~
它基于 Qwen3-VL 架构优化,支持 Transformers 和 vLLM 多种使用方式,单脚本就能高效处理多页 PDF,轻量化实现 PDF 结构化文本提取,能精准保留章节层级、表格、公式等关键结构信息。
在 olmOCR-Bench 上的综合得分达到了 78.8,超过 MinerU 等一众方案和基础模型。
测试结果如下:
| Arxiv | Old scans math | Tables | Old scans | Headers and footers | Multi columnn | Long tiny text | Base | Overall | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Marker 1.10.1 | -- | 83.8 | 66.8 | 72.9 | 33.5 | 86.6 | 80 | 85.7 | 99.3 | 76.1±1.1 |
| MinerU 2.5.4 | -- | 76.6 | 54.6 | 84.9 | 33.7 | 96.6 | 78.2 | 83.5 | 93.7 | 75.2±1.1 |
| DeepSeek-OCR | -- | 77.2 | 73.6 | 80.2 | 33.3 | 96.1 | 66.4 | 79.4 | 99.8 | 75.7±1.0 |
| Nanonts-OCR2-3B | 3B | 75.4 | 46.1 | 86.8 | 40.9 | 32.1 | 81.9 | 93 | 99.6 | 69.5±1.1 |
| Mistral OCR | -- | 77.2 | 67.5 | 60.6 | 29.3 | 93.6 | 71.3 | 77.1 | 99.4 | 72.0±1.1 |
| MonkeyOCR-pro-3B | 3B | 83.8 | 68.8 | 74.6 | 36.1 | 91.2 | 76.6 | 80.1 | 95.3 | 75.8±1.0 |
| Qwen3-VL-4B-Instruct | 4B | 83.1 | 74.5 | 83.9 | 40.5 | 35.5 | 81.7 | 88.7 | 99.3 | 73.4±1.0 |
| olmOCR pipeline v0.4.0 | 7B | 82.9 | 82.1 | 84.3 | 48.3 | 95.7 | 84.3 | 81.4 | 99.7 | 82.3±1.1 |
| DocLoom | 4B | 74.3 | 66.6 | 80.9 | 45.1 | 91.4 | 82.9 | 89.1 | 99.7 | 78.8±1.0 |
使用很简单,用 vllm 进行部署,用我们提供的脚本进行测试
python DocLoom_test.py <pdf_file_path>做文档解析、信息检索、数据挖掘的佬们这款工具值得一试!
登录后,来到这里新增一个 api key 就能用了
https://www.movementlabs.ai/api-keys
https://api.movementlabs.ai/v1/chat/completions
只限今日
无速率限制,还是免费有点离谱啦 (速度很快)
之前发了一个帖子,教大家用 wise 美元账户用 remitly 汇给自己英镑,可以免费赚 $25 美金新客户优惠。仅限推荐链接注册
然而 remitly 不只能通过美元账户付款,更提供的是其它地区的汇款,比如加拿大等等。注册时选择地区加拿大,汇款时折扣为 $30cad≈$21 美金,可汇到 wise 美元账户。此方法适用于开 wise 加区下卡的
新客户 gbp->usd 貌似仅折扣 10gbp,其它地区自测。
注意此为拉新教程请勿薅秃 remitly,勿谓言之不欲也~大额汇款可能会收到 1099-K 税表及强 kyc 参考 paypal
一个简单快捷的翻译软件,支持数十种语言互译。实时翻译,快捷高效。

macOS 15+
选中文本,快捷键(Command + Shift + E)打开软件翻译文本。
默认快捷键:Command + Shift + E
自定义快捷键:
系统设置 → 键盘 → 键盘快捷键
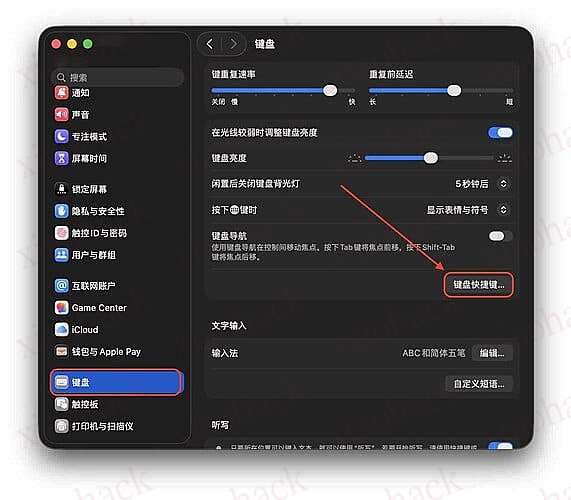
服务 → 文本 → iTranslation

注意: 因未使用开发者签名,首次运行会触发 macOS 安全提示。
前往 “系统设置> 隐私与安全性”,选择 “仍要打开”
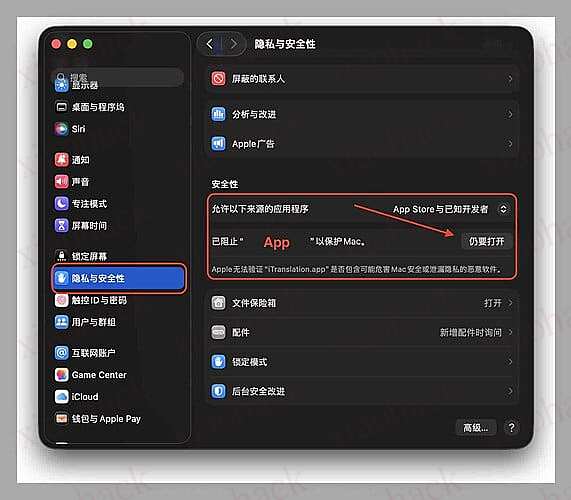
https://file.ichochy.com/iTranslation.zip
Blog: https://ichochy.com
Email:it.osx@icloud.com
GitHub: https://github.com/ichochy/iTranslation

Google 发布全新 FACTS 基准测试,专门用来检测 AI 是否产生不实内容,即使是自家 Gemini 3 Pro 正确率也低于 70%,凸显 AI 模型的内容问题。
随着生成式 AI (Generative AI) 应用日益普及,大型语言模型 (LLM) 最令人头痛的「幻觉」 (Hallucination) 问题 —— 即 AI 一本正经地胡说八道,始终是业界极力想解决的痛点。为了更精确量化 AI 到底「有多诚实」,Google 联合旗下的 Google DeepMind、Google Cloud 与 Kaggle 团队,发表一套名为 FACTS (Factuality Assessment for Contemporary Text Synthesis, 当代文本综合事实性评估) 的全新评估基准。
不同于传统仅针对文本生成的测试,FACTS 基准由四个针对不同能力的子测试组成,宛如一场全方位的 AI 体检:
・M-FACTS (多模态测试):考验 AI 的「眼力」与知识结合能力。例如给 AI 看一张特定型号的火车照片,不仅要能辨识型号,还要能回答该型号的制造年份等深层资讯,而非仅描述图片外观。
・P-FACTS (参数化测试):这是纯粹的「随堂考」。AI 必须在不联网的情况下,仅凭训练时内建的数据库回答困难问题。Google 特别采用「对抗性筛选」,只保留那些现有模型容易答错的题目,确保鉴别度。
・S-FACTS (搜寻测试):模拟 AI 作为代理人 (Agent) 的能力。AI 必须懂得自行拆解复杂问题 (例如:「某编剧最早发行的电影是哪部?」),执行多次搜寻,并且整合资讯。
・D-FACTS (文档理解测试):测验 AI 的「忠实度」。给定一份文件,AI 必须严格根据内容回答,严禁「脑补」添加文档中未提及的资讯。
评测结果:Gemini 3 Pro 险胜,GPT-5 展现「诚实的无知」
在导入双重自动评判机制 (由 AI 裁判员检查核心事实覆盖率与矛盾性) 后,测试结果显示目前市面上的顶级模型仍有约 30% 的错误率。
而 Google 自家的 Gemini 3 Pro 以 68.8% 的准确率位居榜首,其次是 Gemini 2.5 Pro (62.1%) 与 OpenAI 的 GPT-5 (61.8%)。
有趣的是,测试揭露了不同模型的「性格」差异。Gemini 系列倾向于提供详尽的资讯 (宁可多说),但在多模态测试中有时会因此夹杂不精确的内容;而 GPT-5 与 Claude 系列则表现出「精准至上」的特质,遇到不确定的问题倾向于承认「不知道」或拒绝回答。这种「诚实的无知」 (Honest Ignorance) 在某些专业场景下,反而比强行回答更有价值。
Fact 基准说明
详细排行
新闻原文
GitHub 开源链接加部署教程 https://github.com/htjtrh22-cpu/AppleIDsharingsystem/tree/main
开源寄语
本系统由全 JavaScript 代码驱动,追求轻量、高效与美感。适合作为个人公益站或技术研究使用。
开源寄语:本系统旨在提供一个高效、安全、美观的账号共享解决方案,欢迎各位佬们共同交流!演示网站 https://gx.880333.xyz
http://18.206.111.229/, sk-1234
http://115.120.28.33:8000,sk-1234
http://210.3.19.246:4000,sk-1234
总有人说 MoonTV 卡,其实我自己也觉得挺卡的,归根结底就是因为原版设计的存储结构有缺陷。
一个号有 80 条播放记录响应 10 秒才返回数据,能不慢吗,还有一些其他的问题就不多说了
现在优化到基本上返回都在 1s 以内,体验可谓是大幅提高,没更新的都建议更新一下,速度变快超多。
还加了不少功能,详情可以看 changelog
最近应该会暂时停更了,被某个二开抄袭,我上啥新功能他就抄啥
招行 App,我的,M 会员

数币返现券可以直接还信用卡 / 消费用掉,消费返现券充值余额宝 / 零钱通就行



