kiro1500额度明天到期,有需要的佬速用
用的是站里大佬的项目2api出来的https://linux.do/t/topic/1227895?u=zhizhang31415926-ops:
sk-2_u80BxkTnsNByeeFLWa20RCppWEUlRE0y-urWrMA3AnF6d2ZgK5dD2PUEp4zxce
api地址:https://api.mortis.edu.kg
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
用的是站里大佬的项目2api出来的https://linux.do/t/topic/1227895?u=zhizhang31415926-ops:
sk-2_u80BxkTnsNByeeFLWa20RCppWEUlRE0y-urWrMA3AnF6d2ZgK5dD2PUEp4zxce
api地址:https://api.mortis.edu.kg
省流:
自主备用免费节点,支持 hy2 和 argo, 无限流量,脚本一次性保活,娱乐项!

福利地址:https://www.hidencloud.com/service/free-server
申请账号后需要加入 Discord 才能创建成功,这就不啰嗦了自己搞定

下面选节点,我刚才注册的时候只有澳大利亚,就选了这个,你们自己看运气,随时会漏,运气好可以选到新加坡

进入后点击管理,去搭建节点

文件上传 github 上的脚本 3 个文件

切换到 console,点击运行即可,运行结束控制台会提示订阅链接,直接可以用
进入你的服务器续费界面
打开 F12 - 控制台
输入下面代码:
(async function() {
// === 配置区域 ===
const orderId = '87057';
const maxDaysPerRequest = 84; // 服务器允许的最大天数
const targetLoopCount = 1; // 你想循环多少次? (12次 * 84天 ≈ 1008天)
const delayMs = 1500;
// ================
const input = document.getElementById('renew-presets-input-' + orderId);
if (!input) return console.error('❌ 找不到输入框');
const form = input.closest('form');
// 延时函数
const sleep = (ms) => new Promise(r => setTimeout(r, ms));
console.log(`🚀 准备开始!计划执行 ${targetLoopCount} 次续费,每次 ${maxDaysPerRequest} 天。`);
for (let i = 1; i <= targetLoopCount; i++) {
console.log(`\n--- 正在执行第 ${i} / ${targetLoopCount} 次请求 ---`);
// 每次都需要重新构建 FormData,以防 token 过期或状态变化
const formData = new FormData(form);
formData.set('days', maxDaysPerRequest.toString());
formData.delete('custom_date');
try {
const response = await fetch(form.action, {
method: 'POST',
body: formData,
headers: { 'X-Requested-With': 'XMLHttpRequest' }
});
const text = await response.text();
console.log(`📡 第 ${i} 次状态码: ${response.status}`);
// 尝试解析结果
try {
const json = JSON.parse(text);
if (response.ok) {
console.log(`✅ 第 ${i} 次成功!`);
} else {
console.error(`❌ 第 ${i} 次失败:`, json.message || json.errors);
// 如果遇到错误(比如余额不足),通常应该停止脚本
if (response.status === 422 || response.status === 403) {
console.error('🛑 遇到严重错误,脚本停止执行。');
break;
}
}
} catch (e) {
console.log('📄 服务器响应:', text.substring(0, 50) + '...');
}
} catch (err) {
console.error(`❌ 网络请求出错:`, err);
}
if (i < targetLoopCount) {
console.log(`⏳ 等待 ${delayMs}ms ...`);
await sleep(delayMs);
}
}
console.log('\n🎉 所有任务执行完毕!去支付账单。');
})();
执行完毕后,刷新页面,你会在账单里面找到未支付账单,进去支付就行,0 元,然后,嗨呗!

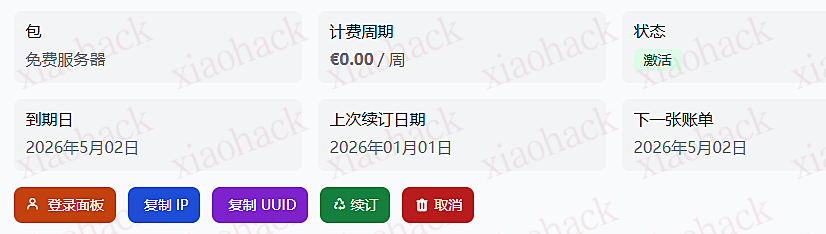
自己克制一点,续费太多自己找不痛快!!!
给你们看看娱乐测速:

有小伙伴对使用量没有概念,我分享下自己用的,统计每日 token 使用量的 statusline 插件,适用于官方标准输出结构,有些 2api 结构不符合标准,响应缺少 token 使用量的字段,会导致无法统计。
一个五小时周期差不多可以使用 15-20M 的总 token 数,算上读写缓存的计费方式,一个五小时周期差不多可以使用 8-12 刀的用量
文件路径以及文件名: ~/.claude/statusline-tokens.sh
#!/bin/bash
# Status line with daily token usage tracking for Claude Code
input=$(cat)
# Extract basic info
cwd=$(echo "$input" | jq -r '.workspace.current_dir')
transcript_path=$(echo "$input" | jq -r '.transcript_path')
base_dir=$(basename "$cwd")
# Git info
git_info=""
if git -C "$cwd" rev-parse --git-dir > /dev/null 2>&1; then
branch=$(git -C "$cwd" --no-optional-locks rev-parse --abbrev-ref HEAD 2>/dev/null)
if ! git -C "$cwd" --no-optional-locks diff --quiet 2>/dev/null || \
! git -C "$cwd" --no-optional-locks diff --cached --quiet 2>/dev/null; then
git_info=$(printf "\033[1;34mgit:(\033[0;31m%s\033[1;34m) \033[0;33m✗\033[0m " "$branch")
else
git_info=$(printf "\033[1;34mgit:(\033[0;31m%s\033[1;34m)\033[0m " "$branch")
fi
fi
# Daily token tracking file
DAILY_TOKENS_FILE="$HOME/.claude/daily_tokens.json"
TODAY=$(date +%Y-%m-%d)
# Initialize or load daily tokens data
if [ ! -f "$DAILY_TOKENS_FILE" ]; then
# Create initial structure
echo "{\"date\":\"$TODAY\",\"sessions\":{}}" > "$DAILY_TOKENS_FILE"
fi
# Check if we need to reset for a new day
stored_date=$(jq -r '.date // ""' "$DAILY_TOKENS_FILE" 2>/dev/null)
if [ "$stored_date" != "$TODAY" ]; then
# New day, reset the file
echo "{\"date\":\"$TODAY\",\"sessions\":{}}" > "$DAILY_TOKENS_FILE"
fi
# Token info - parse JSONL format
token_info=""
if [ -f "$transcript_path" ]; then
# Calculate tokens from current session's JSONL file - separate by type
session_input_tokens=$(jq -s '
[.[] | select(.type == "assistant") |
.message.usage.input_tokens // 0
] | add // 0
' "$transcript_path" 2>/dev/null)
session_cache_creation_tokens=$(jq -s '
[.[] | select(.type == "assistant") |
.message.usage.cache_creation_input_tokens // 0
] | add // 0
' "$transcript_path" 2>/dev/null)
session_cache_read_tokens=$(jq -s '
[.[] | select(.type == "assistant") |
.message.usage.cache_read_input_tokens // 0
] | add // 0
' "$transcript_path" 2>/dev/null)
session_output_tokens=$(jq -s '
[.[] | select(.type == "assistant") |
.message.usage.output_tokens // 0
] | add // 0
' "$transcript_path" 2>/dev/null)
# Update session tokens in the daily file (overwrite, not add)
if [ -n "$session_input_tokens" ] && [ -n "$session_output_tokens" ] && \
[ "$session_input_tokens" != "null" ] && [ "$session_output_tokens" != "null" ]; then
# Escape the transcript path for use as JSON key
escaped_path=$(echo "$transcript_path" | sed 's/\\/\\\\/g; s/"/\\"/g')
# Update the session data with all token types
jq --arg path "$escaped_path" \
--argjson inp "$session_input_tokens" \
--argjson cr "$session_cache_creation_tokens" \
--argjson rd "$session_cache_read_tokens" \
--argjson outp "$session_output_tokens" \
'.sessions[$path] = {"input": $inp, "cache_create": $cr, "cache_read": $rd, "output": $outp}' \
"$DAILY_TOKENS_FILE" > "${DAILY_TOKENS_FILE}.tmp" && \
mv "${DAILY_TOKENS_FILE}.tmp" "$DAILY_TOKENS_FILE"
# Calculate total from all sessions - separate by type
input_tokens=$(jq '[.sessions[].input] | add // 0' "$DAILY_TOKENS_FILE" 2>/dev/null)
cache_create_tokens=$(jq '[.sessions[].cache_create] | add // 0' "$DAILY_TOKENS_FILE" 2>/dev/null)
cache_read_tokens=$(jq '[.sessions[].cache_read] | add // 0' "$DAILY_TOKENS_FILE" 2>/dev/null)
output_tokens=$(jq '[.sessions[].output] | add // 0' "$DAILY_TOKENS_FILE" 2>/dev/null)
# Format and display if we have valid data
if [ "$input_tokens" != "0" ] || [ "$cache_create_tokens" != "0" ] || [ "$cache_read_tokens" != "0" ] || [ "$output_tokens" != "0" ]; then
total_tokens=$((input_tokens + cache_create_tokens + cache_read_tokens + output_tokens))
# Function to format number with K (thousands) and M (millions)
format_number() {
local num=$1
if [ "$num" -ge 1000000 ]; then
# Convert to M with 1 decimal place
local m_value=$(echo "scale=1; $num / 1000000" | bc | sed 's/\.0$//')
echo "${m_value}M"
elif [ "$num" -ge 1000 ]; then
# Convert to K with 1 decimal place
local k_value=$(echo "scale=1; $num / 1000" | bc | sed 's/\.0$//')
echo "${k_value}K"
else
echo "$num"
fi
}
# Format with K/M suffix for all token types
input_fmt=$(format_number $input_tokens)
cache_create_fmt=$(format_number $cache_create_tokens)
cache_read_fmt=$(format_number $cache_read_tokens)
output_fmt=$(format_number $output_tokens)
total_fmt=$(format_number $total_tokens)
token_info=$(printf "\033[0;35m[📊 今日用量 |\033[0m In:\033[0;36m%s\033[0m CW:\033[0;33m%s\033[0m CR:\033[0;32m%s\033[0m Out:\033[0;35m%s\033[0m Total:\033[1;32m%s\033[0;35m]\033[0m " \
"$input_fmt" "$cache_create_fmt" "$cache_read_fmt" "$output_fmt" "$total_fmt")
fi
fi
fi
# Output final status line
printf "\033[1;32m➜\033[0m \033[0;36m%s\033[0m %s\n%s" "$base_dir" "$git_info" "$token_info"
在 ~/.claude/settings.json 文件中添加以下配置:
{ "statusLine": { "type": "command", "command": "bash ~/.claude/statusline-tokens.sh" } } chmod +x ~/.claude/statusline-tokens.sh
配置完成后,重启 Claude Code 即可看到新的状态栏显示。
➜ 项目名称 git:(分支名)
[📊 今日用量 | In:12.5K CW:5K CR:8K Out:6.3K Total:31.8K]
| 部分 | 说明 | 示例 |
|---|---|---|
➜ | 命令提示符 | ➜ |
| 项目名称 | 当前工作目录名称 | my-project |
git:(分支名) | Git 分支信息(如果是 Git 仓库) | git:(main) |
📊 今日用量 | Token 统计标识 | 📊 今日用量 |
In:XXX | 输入 Token 数量(青色) | In:12.5K |
CW:XXX | 缓存写入 Token 数量(黄色) | CW:5K |
CR:XXX | 缓存读取 Token 数量(绿色) | CR:8K |
Out:XXX | 输出 Token 数量(紫色) | Out:6.3K |
Total:XXX | 总 Token 数量(亮绿色加粗) | Total:31.8K |
2026 新年快乐~
这次 V1.2 更新大幅加强了较弱模型的绘图能力,此前往往只有类似于 claude-sonnet 这样对 drawio 内容特殊训练的模型才能有效地绘制 drawio。这次更新引入了知识和主题的概念,同时重构了操作的工具来解决这个问题。
直接放一个使用 deepseek-chat(v3.2,非思考) 下展示下效果:

这一次的更新内容 electron/web 双端都能使用 详细介绍下这次更新内容:
可以在单次会话或在设置中指定要生成图标的整体风格和配色。同时也可以选择附加的 drawio 元素相关的知识,如在要绘制托管框架图时,勾选上 Azure 知识,这样提示词中就会自动附带 Azure 相关元素的使用说明了。

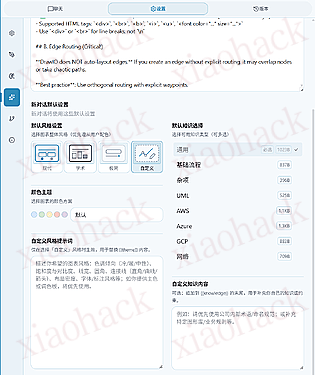
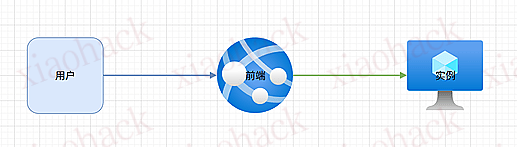
更多的画布增强功能,现在还支持进行布局检查,避免非视觉 LLM 对连接线位置理解不佳导致的线与元素重叠 (视觉 LLM 直接以视觉方式查看画布在做了 )

支持了自定义显示主题 / 编辑器服务地址 / URL 参数等更多自定义功能

支持了直接在 vercel 上部署:
或者可以直接访问 https://drawio2go.vercel.app/ 试用。所有 LLM 的配置都是直接保存到浏览器端的 (但是请求由于 CORS 的原因只能走服务端,不能从网页直接请求)。
欢迎各位佬友体验捉虫,感觉有意思或者未来可期的话顺手 star 一下吧
2026.1.1 日 发布新版本,能否被称为卷王
本项目基于 VocabMeld 深度改进的沉浸式语言学习插件,智能替换网页词汇,在阅读中自然习得外语
由于原项目存在一些问题,功能不够完善,且迭代更新较慢,提 pr 也不反馈,故自行 fork 进行维护和功能改进
这是本次更新的最大亮点。支持配置多个 API 节点,实现:

典型场景:
针对不同语言优化分词策略,避免错误切分:
用户可个性化自定义提示词:

魔搭社区(ModelScope)提供免费的 AI 推理服务,非常适合 Lingrove:
进阶玩法:申请多个魔搭账号,配置多节点轮询,叠加免费额度
许可证:MIT License
GitHub:Lingrove - 让语言学习融入日常浏览
原项目:VocabMeld by @lzskyline
欢迎 Star 和贡献代码!
前往 Releases 页面 下载最新版本
解压 zip 文件到本地目录
打开 Chrome,访问 chrome://extensions/
开启 "开发者模式"
点击 "加载已解压的扩展程序",选择解压后的文件夹
点击扩展图标 → 设置
选择预设服务(推荐魔搭社区)或自定义配置
填入 API 密钥,测试连接
开始享受沉浸式学习!
2025 年跨年之际,国内量化私募巨头九坤投资(Ubiquant)创始团队发起的 AI 研究机构 —— 至知研究院(IQuest Research)正式发布其首代开源代码大模型系列 IQuest-Coder-V1。该系列模型在多项权威编程评测中表现强劲,尤其在反映真实软件工程能力的 SWE-bench 指标上,以 81.4% 的成绩刷新了开源模型纪录。

至知研究院由九坤投资创始团队设立,是一个独立于量化交易业务的研究平台。继幻方量化旗下的 DeepSeek 在全球 AI 领域声名鹊起后,九坤背景的至知研究院此番动作被市场视为量化圈在 AGI 领域的又一次 “降维打击”。至知研究院表示,其目标是致力于原创性 AI 技术研究,加速 AI 在垂直领域的工业化落地。
技术突破:从 “静态代码” 到 “动态流”
IQuest-Coder-V1 放弃了传统的静态代码训练模式,转而采用创新的 Code-Flow 训练范式。该模型通过学习代码库的历史演变和 Commit 记录,掌握了软件开发的动态逻辑。此外,研究院同步推出了 “Thinking” 推理模型 与 “Loop” 循环架构 模型,前者通过强化学习模拟人类程序员的思考过程,后者则在有限的参数规模下实现了性能的跨越式提升。
目前,IQuest-Coder-V1 已在 GitHub 和 Hugging Face 平台全面开源,涵盖从 7B 到 40B 不同参数规模的版本。技术社区普遍认为,IQuest-Coder-V1 的发布将直接挑战 DeepSeek-Coder 在开源代码界的统治地位,为开发者提供更具竞争力的自主编程助手。
介绍页 demo
模型仓库
Upstage 发布了其专有的人工智慧 (AI) 模型 “Solar-Open-100B”,并表示它将建立 “最了解韩国文化甚至韩语细微差别的韩国人工智慧”。
Solar Open 是 Upstage 的旗舰型 102B 参数大规模语言模型,完全从零开始训练,并在 Solar-Apache 许可证 2.0(参见 LICENSE)下发布。作为一种专家混合(Mixture-of-Experts, MoE)架构,它在推理、指令遵循和代理能力方面提供企业级表现,同时优先考虑对开源社区的透明性和可定制性。
亮点
Upstage 首席执行官金成勋在 30 日于首尔三成洞 COEX 礼堂举行的独立人工智能基金会模式项目首次简报会上表示:“与大型企业不同,Upstage 在过去的五年里一直专注于一个目标:构建能够帮助每个人的人工智能。”
这次首发版本展示的 Solar-Open 模型是一个 1000 亿级(1000 亿)的大型语言模型(LLM)。 Kim 表示:“该模型已超越简单的实验阶段,并已完善到可以部署到实际服务和工作环境中的水平。” 他还补充道:“我们同时注重验证其性能和效率。”
Upstage 强调了 Solar-Open 基于高品质数据的韩语理解能力是其竞争优势。 Kim 表示:「我们的目标不仅是精通韩语,而是要建构能够理解语境、情感和细微差别的 AI。」他着重强调了敬语和非正式用语之间的区别、根据情境变化的表达方式,以及对需要逐步推理的问题的回答。
在训练过程中,资源效率和训练稳定性被认定为核心任务。 Kim 表示:“由于我们使用政府支持的 GPU 进行训练,因此我们优先考虑资源效率。” 他补充道:“通过自动故障检测和故障转移系统以及训练优化,即使在大规模 GPU 环境下,我们也显著缩短了整体训练时间。”
Upstage 也强调,该模式是透过联盟内部的角色分工来实现的。 Upstage 联盟是五支菁英团队中唯一完全由新创公司组成的团队。
Upstage 也公布了下一代模型的计划。明年,该模型将扩展到 2000 亿级语言学习模型 (LLM),使用 15 兆个代币进行训练,支援 25.6 万个上下文,并新增韩语、英语和日语三种语言。最终,该公司计划专注于模型的泛化能力和普及性,将模型扩展到 3000 亿级,同时扩大训练资料和上下文的范围。

金补充道:“我们的目标只有一个,” 他说,“我们将与众多联盟一起,利用太阳能 LLM 技术,帮助打造一个能够与谷歌和 OpenAI 竞争的全球人工智能三大巨头。”
明年 1 月,政府将对参与自主人工智慧基础模型计画的团队进行第一阶段评估,全面检视其表现和未来规划,并根据评估结果筛选出四支菁英团队。之后,每六个月进行一次评估,每次减少一支精英团队,最终在 2027 年选出两支球队。


图像生成:{“质量”:“照片级真实感,4K 分辨率,电影级光照,杰作”,“面部”:{“保留原始面部”:true,“参考匹配”:true},“主体”:{“描述”:“一位面容姣好的时尚女性,身穿优雅的白色露肩婚纱,婚纱上饰有精致的蕾丝纹理。”,“姿势”:“这位女性亲密地依偎在一只巨大的、栩栩如生的北极熊身上;他们像老朋友一样站在一起。”,“表情”:“这位女性脸上带着一丝调皮的微笑;北极熊则流露出一种深情、聪明、快乐的拟人化表情。”},“角色元素”:{“名称”:“逼真的可口可乐北极熊”,“细节”:[“真实的北极熊解剖结构,拥有浓密、乳白色半透明的皮毛”,“毛发清晰可见,皮毛呈现柔和自然的色泽”,“湿润的黑色鼻子和逼真深邃的眼睛,眼角带有细微的鱼尾纹”,“脖子上围着一条磨损的红色针织围巾,上面绣有复古的可口可乐标志和‘2026’字样”,“这只北极熊俏皮地模仿着这位女性的姿势,一只爪子轻轻地搭在她的肩膀附近”]},“环境”:{“背景”:“简约干净的灰蓝色工作室背景,柔和的体积光和地面阴影,上方摆放着巨大的雪雕,构成数字‘2026’。”,“渲染风格”:“国家地理野生动物肖像与高端时尚杂志风格相结合,皮毛具有次表面散射效果,浅景深”},“负面提示”:“3D 渲染、卡通、毛绒玩具、填充动物、玩偶、塑料纹理、低分辨率、CGI、动画、插图、假皮毛”}
今天刷微信公众号看到的
先安装官方的 skill-creator 的元 Skill:
然后在会话中,告诉 AI 自己要创建一个什么样的 Skill,它会自自动调用 skill-creator 来和你一起创建一个初稿出来。
但是,但是,不要把初稿当成终稿,要自己多调试、测试使用效果,把效果再反馈给 AI,让他帮忙迭代优化 Skill。

可以试试,刚部署的,也不确定好不好用:
API: https://cliproxyapi.ipacel.cc
API: https://cliproxyapi.ipacel.cc/v1/chat/completions
TOKEN: __IpacEL_CLIProxyAPI_API_TOKEN__

这个好像每天配额有限,不推荐用来做翻译之类的服务.
想象一下这样的场景:你正在和一个 AI 医疗助手聊天,它刚刚帮你记录了头痛的症状。第二天,你再次咨询时,它竟然完全忘记了你是谁,还要你重新介绍一遍病情…… 是不是很抓狂?这就是传统 AI 应用的 “金鱼记忆” 问题 —— 每次对话都是 “初次见面”,永远记不住历史信息。
今天,为大家介绍一款我最近开发的两款 AI 记忆存储产品 —— PowerMem + seekdb,一个让 AI 拥有 “超强记忆力” 的持久化记忆系统。
传统的 AI 对话系统每次会话都是 “失忆” 的。用户每次都需要重复说明自己的信息、偏好和历史,体验割裂、效率低下。开发者想要构建 “有记忆的 AI”,却面临数据持久化、智能提取、多模态支持、权限控制等诸多复杂问题,往往需要从零开始构建记忆系统,重复造轮子。
PowerMem 应运而生 —— 一款开源的 AI 记忆管理 SDK,致力于解决 80% 的 AI 记忆管理问题。我们相信,通过提供一套完整、易用、高性能的记忆管理解决方案,可以让开发者专注于业务创新,而不是重复造轮子。
PowerMem 建立在这样一个原则之上:AI 系统应该能够像人类一样随着时间积累知识和经验。这一理念驱动了 PowerMem 设计和实施的每个方面:
智能提取和保留:PowerMem 通过 LLM 模型进行记忆的提取,根据重要性和相关性确定哪些信息值得记住。
上下文理解:PowerMem 维护跨交互的上下文以实现有意义的个性化体验。
持续学习:PowerMem 使 AI 系统能够从每次交互中学习并随着时间的推移而改进。
自适应遗忘:像人类记忆一样,PowerMem 实现了自适应遗忘机制以防止信息过载。
PowerMem 的核心特性包括:
开发者友好:轻量级接入方式,提供简洁的 Python SDK / MCP 支持,让开发者快速集成到现有项目中
智能记忆管理:记忆的智能提取,通过 LLM 自动从对话中提取关键事实,智能检测重复、更新冲突信息并合并相关记忆,确保记忆库的准确性和一致性。举个例子:还记得上学时老师让你划重点吗?PowerMem 就是 AI 的学霸助手,不需要你手动标注,AI 自动帮你划重点。
# 用户说了一堆话
messages = [
{"role": "user", "content": "Hi, my name is Alice. I'm a software engineer at Google."},
{"role": "assistant", "content": "Nice to meet you, Alice!"},
{"role": "user", "content": "I love Python programming and machine learning."}
]
# PowerMem 自动提取关键事实
memory.add(messages=messages, user_id="alice", infer=True)
# 结果:自动提取出 4 条关键记忆 # 1. Name is Alice # 2. Is a software engineer at Google # 3. Loves Python programming # 4. Loves machine learning 艾宾浩斯遗忘曲线:基于认知科学的记忆遗忘规律,自动计算记忆保留率并实现时间衰减加权,优先返回最近且相关的记忆,让 AI 系统像人类一样自然 “遗忘” 过时信息。还记得那个著名的遗忘曲线吗?PowerMem 把它用在了 AI 记忆上,简单来说,就像人类大脑一样,重要的、最近的信息记得更牢。
最近的信息:权重高,优先召回
久远的信息:权重低,自然衰减
过时信息:自动清理,保持记忆库新鲜
多智能体支持:智能体共享 / 隔离记忆,为每个智能体提供独立的记忆空间,支持跨智能体记忆共享和协作,通过作用域控制实现灵活的权限管理。
多模态支持:不仅记得文字,还看得懂图片。文本、图像、语音记忆:自动将图像和音频转换为文本描述并存储,支持多模态混合内容(文本 + 图像 + 音频)的检索,让 AI 系统理解更丰富的上下文信息。
# 存储图片记忆
memory.add(
messages=[{"role": "user", "content": "这是我的X光片"}],
images=["xray_image.jpg"],
user_id="patient_001"
)
# 搜索时,文字 + 图片一起检索
results = memory.search("X光片结果", user_id="patient_001")
深度优化数据存储:支持子存储(Sub Stores),通过子存储实现数据的分区管理,支持自动路由查询,显著提升超大规模数据的查询性能和资源利用率。
混合检索:融合向量检索、全文搜索和图检索的多路召回能力,通过 LLM 构建知识图谱并支持多跳图遍历,精准检索复杂的记忆关联关系。
OceanBase seekdb 是 OceanBase 打造的一款开发者友好的 AI 原生数据库产品,专注于为 AI 应用提供高效的混合搜索能力,支持向量、文本、结构化与半结构化数据的统一存储与检索,并通过内置 AI Functions 支持数据嵌入、重排与库内实时推理。 seekdb 在继承 OceanBase 原核心引擎高性能优势与 MySQL 全面兼容特性的基础上,通过深度优化数据搜索架构,为开发者提供更符合 AI 应用数据处理需求的解决方案。

PowerMem 的架构旨在模块化、可扩展,包括如下层:
核心记忆引擎 (core):管理所有记忆操作,包括智能记忆处理器、分层记忆管理、全生命周期记忆管理模块
模型层:提供与流行 LLM 和嵌入模型的无缝集成
存储层:支持多种存储后端的灵活接口(特别地,我们在 seekdb /oceanbase 上做了深度适配,充分利用了 seekdb 的混搜能力)。
所以,PowerMem + seekdb 的组合不是简单的数据存储,而是一个真正智能的持久化记忆系统。
pip install powermem
from powermem import Memory, auto_config
# 自动从 .env 加载配置
memory = Memory(config=auto_config())
# 添加记忆(自动提取事实)
memory.add("用户喜欢喝咖啡", user_id="user123")
# 搜索记忆(智能检索)
results = memory.search("用户偏好", user_id="user123")
就这么简单!4 行代码,让你的 AI 拥有 "记忆力"!
还在为 AI 的 “金鱼记忆” 而烦恼吗?
还在为 Token 成本居高不下而头疼吗?
还在为检索准确率低而困扰吗?
是时候给 AI 装个 “外挂记忆” 了~
编辑器打开~/.antigravity/extensions/eamodio.gitlens-17.8.1-universal/dist/webviews/graph.js
全局查找
.webroot=${this.graphState.webroot}
在这行后面增加一行
style="display: none" 保存即可
相比于 8 月份发布的 Qwen-Image 基础模型,Qwen-Image-2512 进行了如下更新:
更真实的人物质感 相比于 Qwen-Image,Qwen-Image-2512 大幅度降低了生成图片的 AI 感,提升了图像真实性
更细腻的自然纹理 相比于 Qwen-Image,Qwen-Image-2512 在风景构图,动物毛发更加细腻。
更复杂的文字渲染 相比于 Qwen-Image,Qwen-Image-2512 提升了文字渲染的质量,图文混合渲染更准确,排版更好

模型地址:
Qwen/Qwen-Image-2512 · Hugging Face ,
博客介绍: Qwen
一些官方图:




地址:
release 已发布,可直接安装
在 arxiv,IEEE Xplore 网站上搜索论文的时候,怎么能一下子知道论文是否有阅读的价值呢?论文所在的期刊 / 会议的 CCF 分区是一个重要的指标。本 Script 可以在检索的时候在论文标题后面附一个 Badge,显示 CCF 分区,还会进行 DBLP 的查询,效果如图
![[自制开源脚本] 自动显示论文 CCF 分区,Arxiv,IEEEXplore3](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/01/20260101155754_69562902922dd.png!mark)
![[自制开源脚本] 自动显示论文 CCF 分区,Arxiv,IEEEXplore4](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/01/20260101155757_69562905dc0f8.png!mark)
可以选中分区进行高亮
![[自制开源脚本] 自动显示论文 CCF 分区,Arxiv,IEEEXplore2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/01/20260101155750_695628feeeff1.png!mark)
未来会尝试添加在 Google Scholar 上显示的功能
目前已知的问题:DBLP 查询可能会出 429
欢迎各位佬提 Issue,PR
Meeting Mind 是一个智能会议记录与分析系统,结合了实时语音识别(ASR)、说话人分离(Diarization)和本地大语言模型(LLM)智能分析功能。它能够实时转录会议内容,区分不同的发言者,并利用本地部署的 LLM 自动生成会议标题、总结、关键要点和行动项,确保数据隐私和安全。
| 功能 | 描述 |
|---|---|
| 实时语音转写 | 基于 FunASR (SenseVoiceSmall) 模型,提供高精度的实时语音转文字功能 |
| 本地 LLM 智能分析 | 集成 Transformers/vLLM,支持 Qwen2.5 等本地大模型,自动生成会议总结、要点和行动项 |
| 说话人分离 | 自动识别并区分会议中的不同发言人(基于 CAM++ 说话人识别模型) |
| 异步重新转写 | 支持对历史会议录音进行后台重新转写,优化转录质量 |
| 涉密模式切换 | 支持本地处理(涉密)与云端高精度转写(非涉密)两种模式 |
| 移动端适配 | 响应式设计,支持手机和平板访问 |
| 深色 / 浅色模式 | 提供舒适的 UI 体验,支持一键切换主题 |
京东超市 超市对暗号赢超市卡

【答案】运气好 8.88
第一轮:马
第二轮:炽热出发号
第三轮:王星越
第四轮:陶喆
第五轮:王心凌
第六轮:孟子义
最后一轮:倪萍
linux 系统下的这个学习版的 PDF 编辑工具,有需要的可以一块学习
适用环境:Debian 系
已测试环境:Ubuntu24.04/Xubuntu24.04
wget https://code-industry.net/public/master-pdf-editor-5.9.35-qt5.x86_64.deb
sudo apt install -y ./master-pdf-editor-5.9.35-qt5.x86_64.deb
# 在001b7b70处,将88替换成FE sudo perl -pi -e 's/(\xE8...\xFF)\x88(..\xBF\x30)/$1\xFE$2/g' /opt/master-pdf-editor-5/masterpdfeditor5
就可以见证奇迹了
明早我啥时候醒来啥时候就关
第一次下放 1 级的开放 key(三级也没开放过(Bushi
![[WindHub] 一点福利 无限并发的一些模型1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/01/20260101155148_695627946a477.png!mark)
元旦快乐呀!点点赞~


