花了两天啃完一篇 54 页的综述,Externalization in LLM Agents( LLM Agent 中的外化,arXiv 2604.08224 ),用认知科学的框架把 Memory 、Skills 、Protocols 、Harness 这几个看着各管各的工程趋势统一到一个逻辑下面解释,讲的是把能力从模型内部外化到运行环境中的发展过程。我自己这几个月在写一个 coding agent 用的 harness Chorus,所以对这篇综述很感兴趣。说实话 harness 这个词多少有点造词炒热度的味道,但这个先放一边,看看论文本身提了哪些实践。
写了篇完整的解读放博客了: https://chorus-ai.dev/zh/blog/externalization-in-llm-agents/ ,详细的逐页笔记在这: https://github.com/Chorus-AIDLC/Chorus/blob/main/docs/notes-externalization-llm-agents.md ,V2EX 篇幅有限这里简单聊聊,感兴趣可以去看全文。
TLDR: 外部工具不是让模型变强,是把难任务变成简单任务。
论文拿 Donald Norman 的"认知制品"理论做支点。Norman 有个很反直觉的观察:外部工具不是让你能力变强了,而是把任务变成了另一个任务。
拿购物清单举例,清单不是让你记忆力变好了,它做的事情是把"回忆要买什么"变成了"看一眼纸上写了什么"。任务性质变了,从回忆( recall )变成了识别( recognition ),识别比回忆简单太多了。
LLM Agent 的外化是同一回事。裸模型反复踩三个坑。上下文窗口有限,session 一断记忆就没了,有了外部 memory 之后回忆变成了检索。同一个 prompt 今天分五步做明天分三步后天跳过验证,有了 skill 之后从头发明变成了选择组合。每次调工具都得猜参数格式猜返回结构,有了 protocol (比如 MCP )之后临场猜变成了照着填。共同点就是模型被要求解决的问题变简单了。
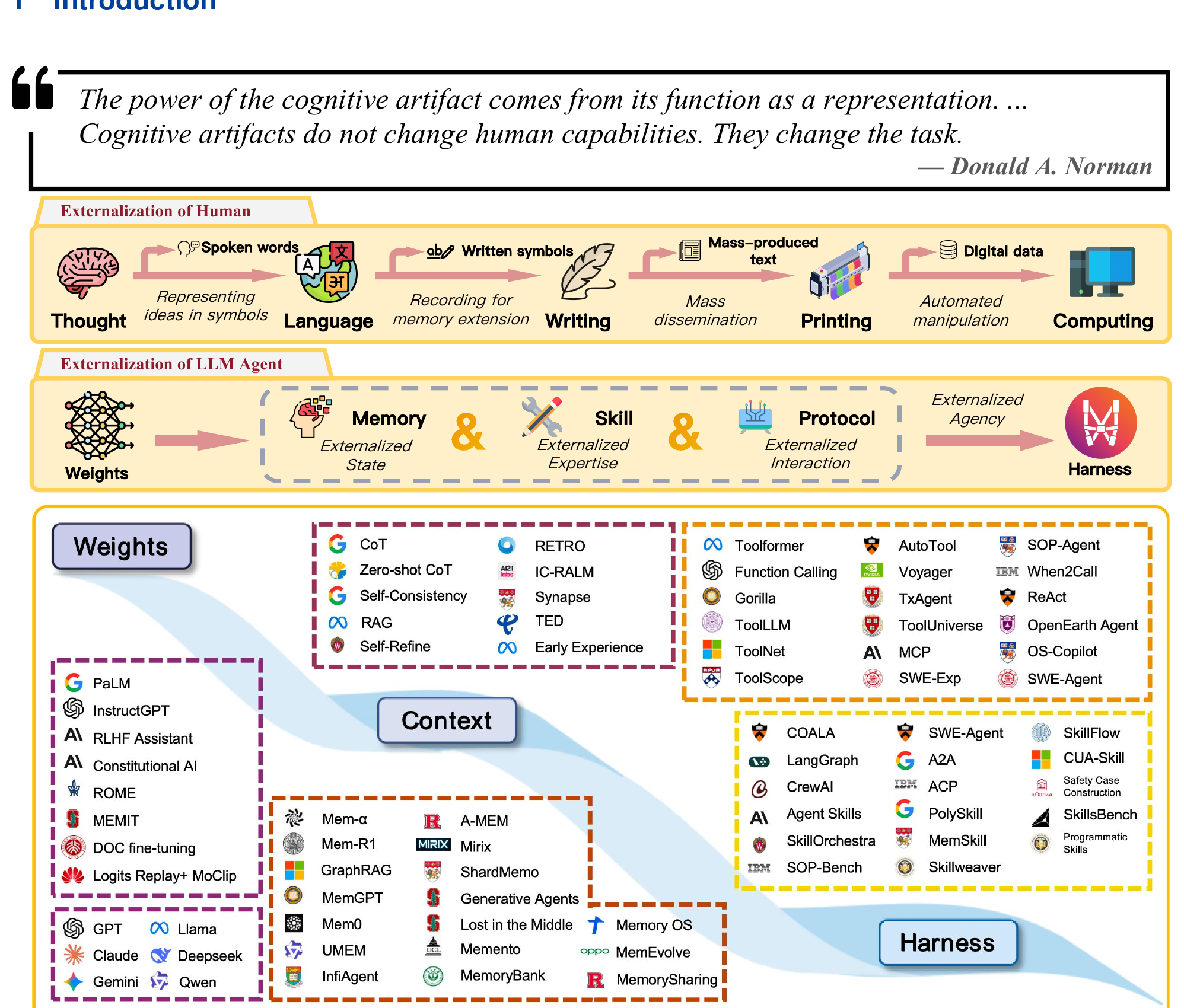
TLDR: Weights -> Context -> Harness ,开发者的精力从改模型转向改环境。
然后论文把 2022 到现在的演变分成三层,不是说前一层过时了,而是开发者把边际精力花的地方在转移。2022 年为主是 Weights 阶段,能力等于权重,更大模型更好训练更精对齐,好处是快和泛化强,坏处是想更新一个事实就得 retrain 。2023 到 2024 年是 Context 阶段,prompt engineering 、ReAct、RAG ,不动权重就能改行为,但窗口有限,每个新 session 都是部分失忆的开始。2025 年开始进入 Harness 阶段,从早期的 Auto-GPT 、BabyAGI 到后来的 SWE-Agent(最近还出了个 mini 版,核心 100 行 Python )、OpenHands、LangGraph,可靠性问题越来越多通过改环境解决,不是在 prompt 上修修补补,模型在什么环境里跑比模型本身聪不聪明更影响最终效果。
TLDR: 存多少不重要,检索出什么才重要。
来说说 memory ,这章大概是论文写得最扎实的部分。它把 memory 按"外化了什么负担"分成四层:工作上下文是当前任务的中间状态,不外化就随窗口重置没了;情景经验是之前跑过的决策和失败,能当先例用;语义知识是跨案例成立的抽象,项目惯例之类的;个性化记忆是用户偏好,不能混进通用存储。
memory 架构也经历了几代演进,从全塞 prompt 里的单体上下文,到带检索的外部存储( RAG ),到 MemGPT(现在已经被 Letta 收编了)那种热冷分离的分层管理,再到检索策略本身可以根据反馈演化的自适应系统。论文说存得多但检索弱的系统,给模型呈现的是错误的问题,memory 的成功标准不是"存了多少"而是"当前这一步的上下文是不是清晰可读"。
TLDR: 别让模型每次从头发明工作流,打包好让它选。
再说 skill 。模型可能"知道"怎么干一个活,但每次从头推导工作流的时候行为不稳定,跳步骤、停止条件飘忽、工具调用不一致。Skill 就是把验证过的工作流打包成可复用的东西。论文说一个完整的 skill 有三部分:操作过程(步骤骨架)、决策启发(分支处怎么选)、规范约束(什么条件下算合格),三个都指定了才真正可复用。演化路径也很清楚,先是 Toolformer 这种学会稳定调单个工具,然后 Gorilla、ToolLLM 解决工具多了之后选哪个的问题,最后到 Voyager 这种在 Minecraft 里自己探索产生不断增长的代码级 skill 库,能力的存在形式从散落的工具调用变成了可加载可复用的打包知识。
这里有个设计细节挺有意思的,叫渐进披露。找到一个 skill 不等于要把全部内容立刻塞进上下文,长上下文不能可靠转化为更好性能,详细指令反而可能变成噪声。所以分层加载,一开始只给名字和描述,需要的时候再逐步展开。Claude Code 的 skill 系统就是这么设计的。
TLDR: 不该让模型猜的东西就别让它猜。
然后是 protocol ,论文说在三种外化里 protocol 效果最猛,因为它直接把一整类问题从模型的思考负担里拿走了。没有协议的时候模型每调一个工具都在猜,参数叫什么、按什么顺序传、返回的东西长什么样,这些本来就不该靠猜。有了 MCP ,工具自己声明能做什么参数是什么返回什么,Agent 照着填就行。不过论文没提 MCP 吃 token 的问题,现在社区里 CLI wrapper 大有取代 MCP 的势头。
多 agent 协作方面论文也梳理了几个协议:Google 的 A2A( v1.0 今年 3 月刚发,已经移交 Linux Foundation 了)让 agent 之间互相发现能力和分配任务,IBM 的 ACP 走轻量 REST 路线降低接入门槛,不过 ACP 后来被 Cisco 的 AGNTCY 项目吸收捐给了 Linux Foundation ,独立存在感已经不太强了。论文还理清了一个容易搞混的边界:MCP 管"怎么调工具",不管"用这些工具该走什么流程"(那是 skill ),也不管"上次聊到哪了"(那是 memory )。
TLDR: Memory 、Skill 、Protocol 三个模块互相喂,正反馈也会放大错误。
最后聊聊模块之间的关系,三个模块不是各干各的,论文画了六条耦合流。
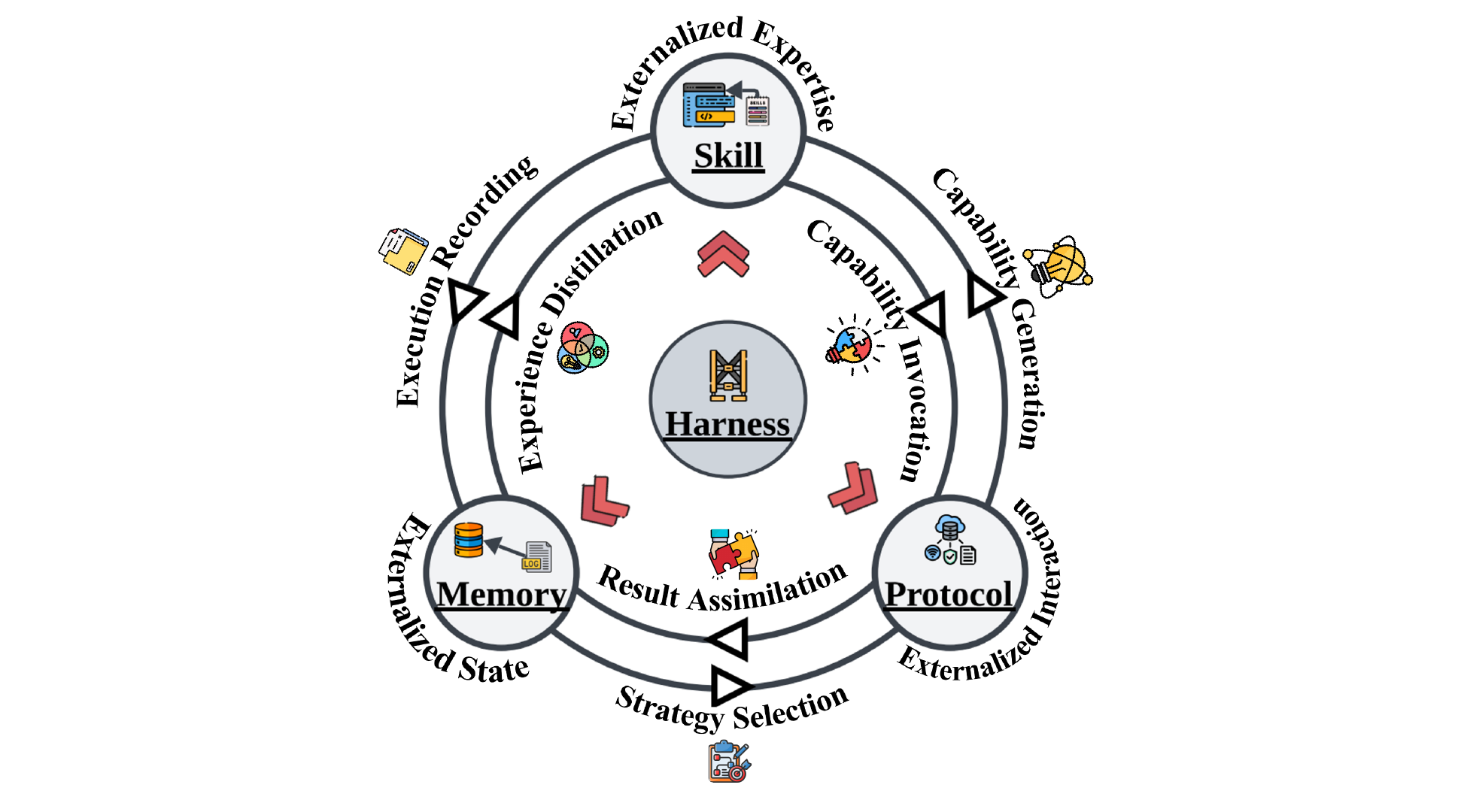
比较有意思的比如 Memory 到 Skill 的经验蒸馏,重复出现的成功路径被抽象成可复用流程。还有 Protocol 到 Skill 的能力生成,接口标准化之后写最佳实践变得容易很多,每个稳定的新接口都是一族新 skill 的种子。
论文还指出了一个自我强化循环:更好的 memory 带来更好的 skill 蒸馏,更好的 skill 产生更丰富的执行记录,进一步改善 memory 。正反馈加速增长,但也放大错误,有毒 memory 导致有缺陷的 skill ,级联下去单个模块控制不住,得靠 harness 级别的干预打断。
读完最大的收获就是一个思维框架吧,遇到 Agent 不靠谱的问题,先想想这个负担应该在模型里还是模型外面,别第一反应换更大的模型。模型擅长的事让模型干,灵活综合、对给定信息做推理。模型不擅长的事搬出去,长期记忆、流程一致性、跟外部系统打交道。
论文的结论也是我这段时间最大的体会:更好的 Agent 不是更好的推理器,是更好地组织的认知系统。
论文: https://arxiv.org/abs/2604.08224
完整解读: https://chorus-ai.dev/zh/blog/externalization-in-llm-agents/
逐页笔记: https://github.com/Chorus-AIDLC/Chorus/blob/main/docs/notes-externalization-llm-agents.md