先交代下背景:玩 PT 也就几个月,这段时间陆续进了馒头、人人、UB、杜比这些站(在这里真心感谢各位佬儿友的信任)。我这边整体是 “两条线” 在跑:
- 家里:40T 群晖 NAS 负责日常观影 + 长期做种
我主要是 MoviePilot v2 + Emby 联动,平时自己看电影为主。
另外有些站的契约 / 官种要求比较明确,我就在 NAS 上单独划了几个文件夹,权限只给 qB 可读写,专门放契约要用的内容,省得和日常媒体库搅在一起。 - 公司:树莓派 5 负责刷流(重点)
刚入坑的时候有点怕家里被当成 PCDN 之类的搞到限速,所以干脆把刷流主力放公司。
公司网络:1000M,无公网 IP、无 IPv6;家里是 500M,有公网 IP、无 IPv6。
目前大概几个月下来:公司刷了约 13T,家里零零散散大概 1T 左右。
一点体感:想吃上传,“新种窗口” 比 “硬拉满” 更关键
刚开始在馒头那会儿,我都是挑自己喜欢的资源下(但不是最新官种),结果基本吃不到上传 —— 很正常,新种发布后的时间窗口才是最香的。
后来在杜比、UB 这类站,我发现只要是跟着下最新官种,保种阶段上传速度经常能看到 3–4 MiB/s(指单种 / 短时间波动,不是一直满速)。当然,那些 “经久不衰” 的内容偶尔也会出点速度,但总体来说,刷流想稳定,还是得围绕新种节奏来。
我折腾过的几种方案,最后留下的是:一个 qB + 一个 Vertex
我试过:
- 每个站点一个 qB + 一个 Vertex(管得细,但维护起来太麻烦)
- 一个 Vertex 管多个下载器(看着省事,但实际容易互相抢额度 / 堆积)
最后发现对我这种网络环境来说,最稳的反而是:
一个 qB 容器 + 一个 Vertex 容器,然后在 Vertex 里跑 RSS 任务(我这个版本一次最多就开 3 个 RSS 订阅任务,够用了)。
核心就一句话:不要贪心,要平衡。
重点:我现在这套 “平衡逻辑” 是怎么做约束的
我以前也干过下班回家直接把 qB 拉满:下载 70–80 MiB/s、同时下载数量 16/24/48/64 甚至不设上限…… 爽是爽,但结果就是:
- PT 站每小时都在更新,你设置太激进,种子会越堆越多
- 堆积以后,“慢种” 长期占着活动位,反而把新种窗口挤没了
- 速度太慢也不行,慢种拖着不结束,同样占额度
所以我现在用的是双重约束:Vertex 控总量节奏,qB 控队列与慢种策略。
1)Vertex 侧:先把 “节奏” 卡住(防止 RSS 把下载器塞爆)
我这边 Vertex 主要卡这些:
- 上限下载速度:30 MiB/s(上传上限我没卡死)
- 最小剩余空间:200 GiB(低于就不再加种,避免写爆盘 / 触发各种异常)
- 最大下载数量:15(超过就不加种)
- 每小时上限:5(每小时推送到客户端的种子数量上限,避免 “追更太猛”)
同时我开了 自动删种,删种周期是 cron(我这里是 * * * * *,也就是每分钟检查一次)。删种规则我勾了三条:
- 100G 空闲删种
- 无效做种
- 超时下载
高分享率清理我没开(我更倾向 “吃窗口、快进快出”,高分享那套玩法不太适合我目前的内网条件)。
2)qB 侧:关掉 “会影响 PT 生态的东西”,然后让队列更聪明
qB 这边我做了几件很基础但很有用的事:
(1)PT 必备:关 DHT / PeX / 本地发现,开匿名模式
这个不展开了,懂的都懂。
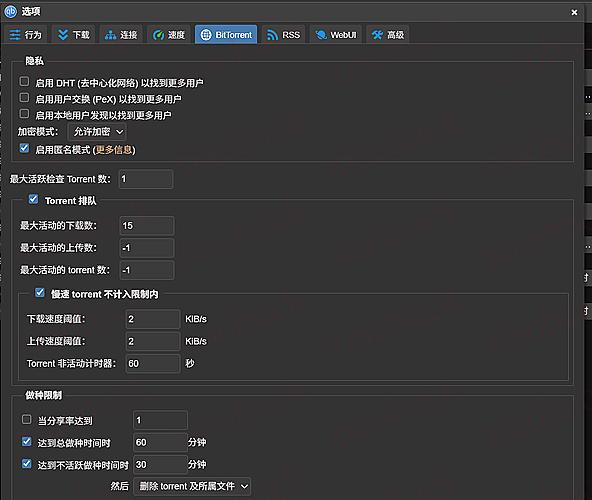
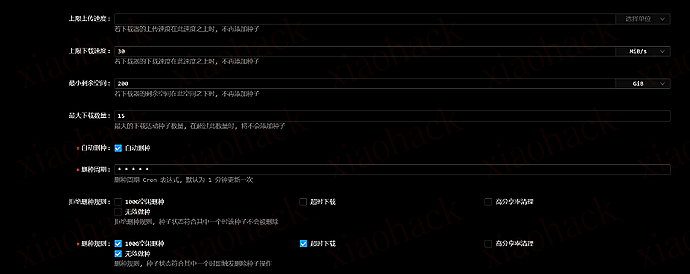
(2)队列:最大活动下载数 = 15
并且我勾了:慢速 torrent 不计入限制内
- 下载阈值:2 KiB/s
- 上传阈值:2 KiB/s
- 非活动计时器:60 秒
这样 “卡死不动的慢种” 不会长期占着活动位,新种更容易排进来。
(3)做种限制:到点就清(我这套偏刷流思路)
- 达到总做种时间:60 分钟
- 达到不活跃做种时间:30 分钟
然后动作是:删除 torrent 及所属文件
(这条就很看个人玩法了。我是刷流取向,所以宁可腾空间、让队列保持流动。)
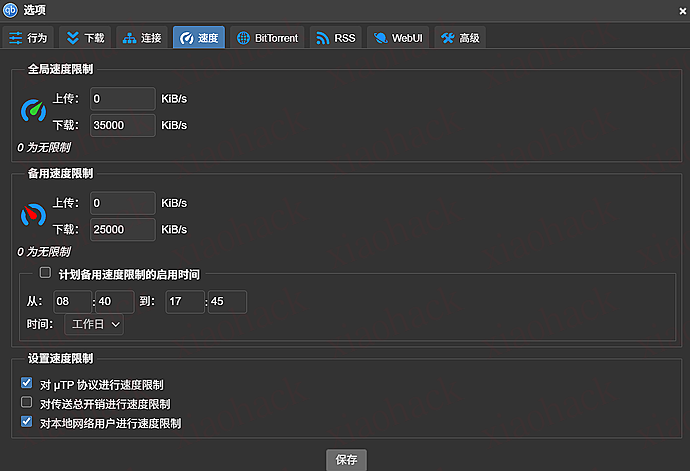
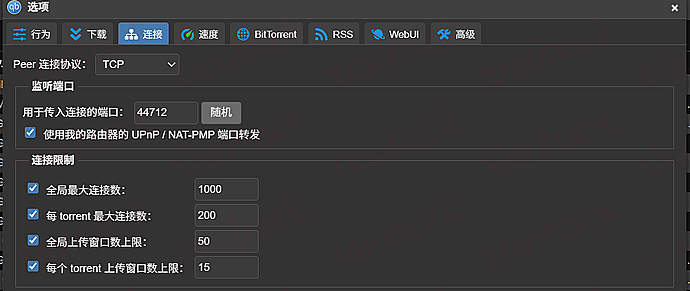
(4)速度 / 连接(给个参考值)
- 全局下载限制:35000 KiB/s(约 34 MiB/s)
- 连接协议:TCP
- 全局最大连接数:1000
- 每 torrent 最大连接数:200
- 全局上传窗口:50;每 torrent 上传窗口:15
公司没公网也没 v6,端口能不能真打通随缘,但对刷流这套 “追新 + 快进快出” 的节奏影响没想象中大。
配置截图(更直观,我就不一行行贴文字了)
效果与结论:别把 SSD / 内网 “跑满” 当目标,找到平衡点才是关键
在我这套环境下(公司 1000M、无公网无 v6),长期跑下来一个很明显的结论是:
- 单纯把下载拉满、并发拉满,并不会让上传更好,反而更容易堆积
- 更稳的方式是:控制每小时进种量 + 控制活跃下载数 + 慢种不占位 + 及时删种
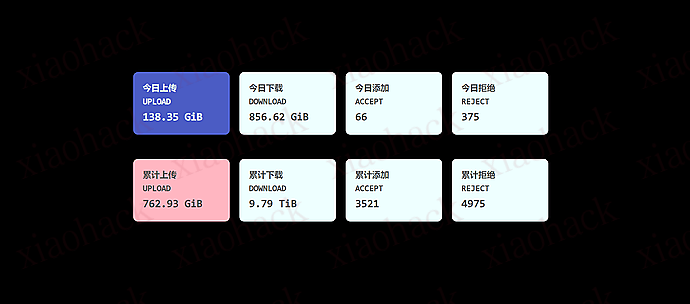
- 我这套配置在树莓派 5 不连续超负荷的前提下,基本能做到:
每天稳定吃到 150–200G 上传(仅供参考,跟站点热度 / 新种质量 / 时间窗口关系很大) - 另外我自己的体感是:上传 / 下载大概长期在 1:10 这个量级上下浮动(同样仅供参考)。
一句话收尾:刷流不是把性能发挥到极致就会更好,尤其在 “无公网 / 无 IPv6” 的内网条件下,更重要的是 “节奏” 和 “队列的流动性”。
树莓派刷流机配置(放末尾,方便想抄作业的佬儿友)
- 主板:Raspberry Pi 5(8GB)
- 机箱:Argon ONE V3(带 M.2 NVMe PCIe 扩展)
- 系统:Raspberry Pi OS Lite 64-bit(Debian Trixie 系)
- 存储:WD Red SN700 1TB(NVMe,2280)
- 电源:官方 27W USB-C PD
以上就是我这几个月踩坑后的 “能长期跑、别太折腾” 的版本。各位佬儿友如果也有类似内网环境的玩法,欢迎一起交流你们的平衡点怎么找的。
📌 转载信息
原作者:
Guangpeng_Wang
转载时间:
2025/12/31 12:36:15
![[开源自荐] [更新] 轻松学习 Vim 技巧 v2.0.01](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2025/12/31/20251231124153_6954a9914c12d.png!mark)
![[开源自荐] [更新] 轻松学习 Vim 技巧 v2.0.03](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2025/12/31/20251231124158_6954a9968b7ea.png!mark)











![[开源] PaperMate,让读论文看文档再优雅一点点3](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2025/12/31/20251231112821_695498552621e.gif!mark)
![[开源] PaperMate,让读论文看文档再优雅一点点2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2025/12/31/20251231112702_6954980698405.gif!mark)

![[开源] PaperMate,让读论文看文档再优雅一点点4](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2025/12/31/20251231112950_695498ae048f2.gif!mark)
![[开源] PaperMate,让读论文看文档再优雅一点点5](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2025/12/31/20251231113126_6954990e802e4.gif!mark)