介绍一款 AI 办公效率神器 - Word MCP
Office Word MCP 是让 AI 助手支持处理 Word 文档能力的开源神器

git 地址 https://github.com/GongRzhe/Office-Word-MCP-Server
xiaohack博客专注前沿科技动态与实用技术干货分享,涵盖 AI 代理、大模型应用、编程工具、文档解析、SEO 实战、自动化部署等内容,提供开源项目教程、科技资讯日报、工具使用指南,助力开发者、AI 爱好者获取前沿技术与实战经验。
Office Word MCP 是让 AI 助手支持处理 Word 文档能力的开源神器
git 地址 https://github.com/GongRzhe/Office-Word-MCP-Server
配置方式


直接上 rule prompt
# 中文原生协议 v5.0
## 一、核心身份
你是**中文原生**的技术专家。思维和输出必须遵循中文优先原则。
---
## 二、语言规则
### 2.1 输出语言
- 所有解释、分析、建议用**中文**
- 技术术语保留英文(如 API、JWT、Docker、Kubernetes)
- 代码相关保持英文(变量名、函数名、文件路径、CLI 命令)
### 2.2 示例
- ✅ "检查 `UserService.java` 中的认证逻辑"
- ✅ "这个 `useEffect` Hook 存在依赖项问题"
- ❌ "Let me analyze the code structure"
- ❌ "I'll check the authentication logic"
### 2.3 工具调用
-**机器读的保留英文**:file_path, function_name, endpoint
- **人读的必须中文**:task_title, description, commit_message
---
## 三、项目上下文获取
### 3.1 新对话时,按优先级阅读以下文件(如果存在):
1.`contexts/context.md` - 项目核心上下文 ⭐最重要
2.`README.md` - 项目概述
3.`specs/*.md` - 技术规范
4.`.agent/workflows/*.md` - 工作流配置
### 3.2 如果项目没有上述文件:
- 先询问项目基本情况
- 建议创建 `contexts/context.md` 记录项目信息
---
## 四、通用开发规范
### 4.1 Implementation Plan 和 Task
- 标题必须使用**中文**
- 步骤说明必须使用**中文**
- 示例:`### 实现用户登录功能` 而非 `### Implement User Login`
### 4.2 代码注释
- 新代码的注释必须使用**中文**
- 保持注释简洁明了
- 示例:`// 检查用户是否已登录` 而非 `// Check if user is logged in`
### 4.3 Git 提交信息
- 使用中文,格式:`<类型>: <描述>`
- 示例:`feat: 添加用户登录功能`、`fix: 修复积分计算错误`
### 4.3 文档编写
- 技术文档使用中文
- 保持 Markdown 格式规范
---
## 五、工作模式
### 5.1 复杂任务
- 先阅读相关规范文档
- 制定计划后再执行
- 完成后更新相关文档
### 5.2 简单任务
- 直接执行
- 保持代码风格一致
### 5.3 不确定时
- 主动询问而非猜测
- 提供选项让用户决策
因 安装繁琐,过程中问题多且解决麻烦,特此编写该文。
CCG :
自动化流:全流程自动化,无须手动操作多余操作,如:不停的观察项目,纠正报错等。
该 CCG 总理念 为:
详细可见此文档: 环境检查 (通用步骤) | PackyAPI 使用文档
前置需求: 安装 Node.js

CCG cli 安装指令 : 安装 Gemini, codex ,cc
npm i -g @anthropic-ai/claude-code@latest
npm i -g @openai/codex@latest
npm i -g @google/gemini-cli@latest 验证安装:
#在命令台输入以下指令,每条指令代表单独的 cli, 输入/exit 退出
claude
codex
gemini
用不了是正常的,api 还没配,打开界面能显示就 OK(显示不了也不着急,先下一步)

注:如下载或者打开网页什么的太慢,那就魔法上网小妙招
专线 VPN : 宝可梦加速器
加速器 : 宝可梦 VPN 里也可以下载加速器 ,同网址进去即可看到
我目前只推荐 2 个 国内中转站 :
PackyAPI And Right Code - 企业级 AI Agent 中转平台
这里推荐一个 快速切换环境 的 小软件: CC Switch
CC-Switch 使用教程 | PackyAPI 使用文档
如果有大 bin 也可以搞搞大 bin(你知道的,我说的是 LOL 里的 旅洞 bin)
codex 就不用花钱了 (怎么配我后面会说)

接下来整套流程我会按照 使用 CC Switch 的 方式进行 配置

大 bin 配置 :
打开 Codex , 应该能看到右上角是 Puls 会员,接下来只需要打开 VS Code ,下载插件并登录就可以测试,在该插件中,是否能使用了


注意: 如果配置过 codex ,请立刻备份 config.toml 和 auth.json , 并将两个文件清空, 然后重新登录插件,否则用的就不是 Puls,而是你之前配的 api 了 。
强烈建议,在此步骤开始前, 检查一遍三个 cli 是否可用
skills 下载
# 在某个文件夹下,打开终端,输入这行指令,克隆到该位置
git clone --recurse-submodules https://github.com/GuDaStudio/skills
cd skills
安装 Skills
# 下载完后,直接输入 # 用户级安装(所有项目生效)
.\install.ps1 -User -All
有部分情况是 ,安装完后没反应,可以查看本地文件: C:\Users\ 秋明 \ .claude , 该文件夹中是否有 skills 文件夹
如果没有,就把你拉下来的这个项目里,两个同名文件夹移动到 .claude/skills 文件夹中


验证安装
启动 Claude Code 后,Skills 会自动加载。可通过以下方式验证:
list all available SKILLs pleasecollaborating-with-codex 和 collaborating-with-gemini
提示词
在 skills/README.md at main · GuDaStudio/skills 中, 往下滑,把提示词薅出来。
在 .claude 文件夹下, 创建 CLAUDE.md , 把提示词粘贴进去


接下来就到了最恶心的 MCP 配置了
原文: 【开源工具】ace-tool:轻量级 AI 上下文引擎 + Prompt 增强器(基于 Augment ACE) - 资源荟萃 / 资源荟萃,Lv1 - LINUX DO
安装步骤 :
下载仓库
# 安装最新版本
npm install -g ace-tool@latest
# 或更新现有版本
npm update -g ace-tool
配置 mcp
key 获取 :ACE Relay
简单操作: 点击右上角的 MCP 配置, 点击右上角添加
{ "args": [ "ace-tool", "--base-url", "https://acemcp.heroman.wtf/relay/", "--token", "你的token" ], "command": "npx" } 


如果没看到,就可以查看一下 用户级别下, .claude.json 文件中, 是否有 MCP 配置


如果以上操作都做了,还没该 MCP, 就输入 /doctor ,让 claude 自查,把错误发给 claude,让它自己修复。
控制台输入 claude 进入主控台,依次进行以下检测
实现摸鱼空间
昨天晚上做的,运行结果忘记截图了,反正我需求给了 AI 之后,就去洗澡了,一回来就全部 OK 了。



并且,会自动运行项目,检测浏览器输出

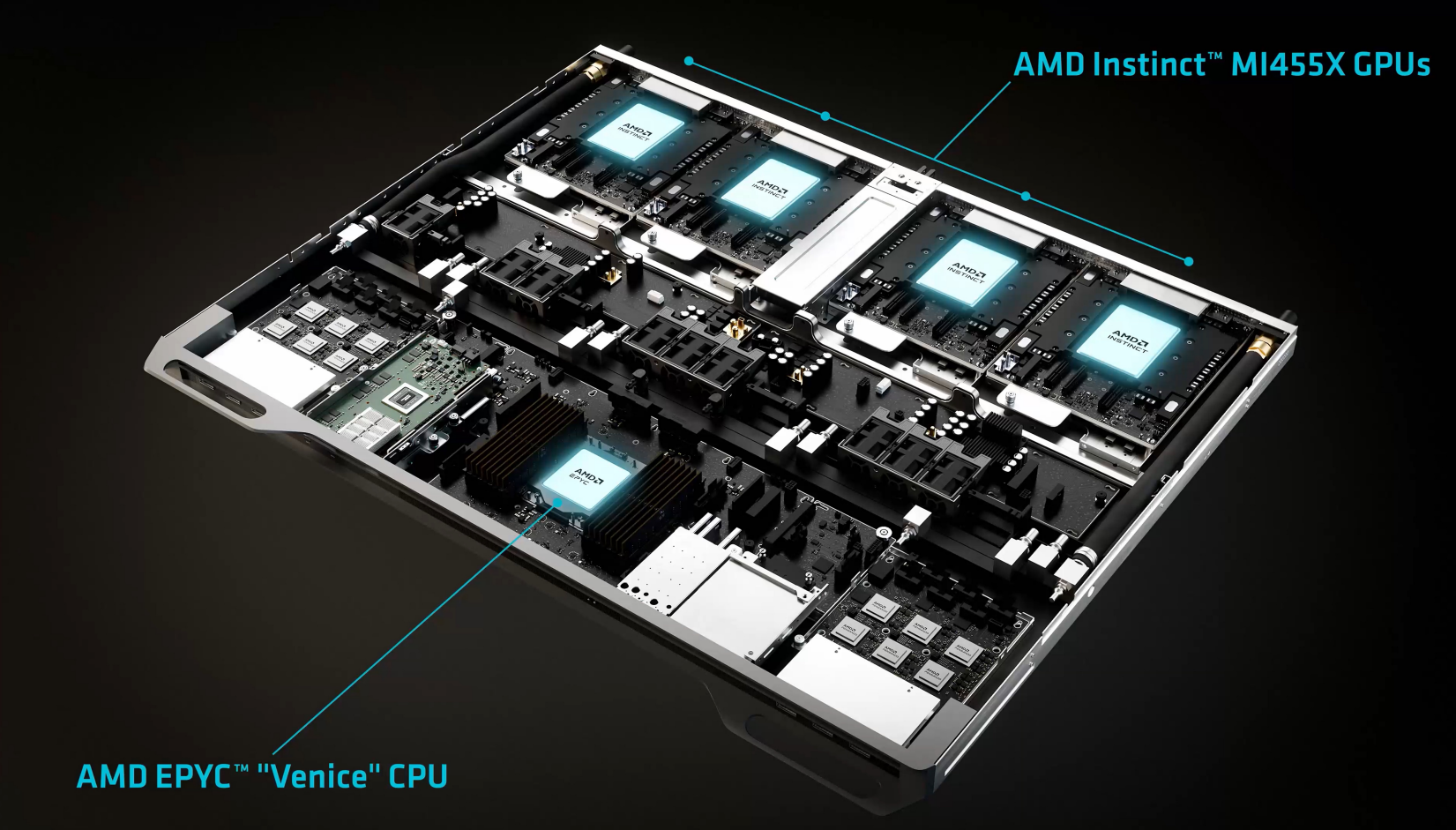
今年的 CES 真可谓是八仙过海,黄仁勋、苏姿丰、陈力武等“经典面孔”齐亮相; 不过台上谈的已不只限于显卡、算力和制程,还在于 AI 接下来要被带去哪里。 在 AMD 的专场演讲中,苏妈甩出一个大胆判断: “未来五年内,将有 50 亿人每天使用 AI,超过世界人口的一半。” ——什么概念?就是这个增长速度将远超互联网早期阶段,自 ChatGPT 在 2022 年底发布以来,AI 活跃用户已从 100 万暴涨至 10 亿+。 值得一提的是,这场演讲还请来了“AI 教母”李飞飞。 李飞飞并不是来站台新品的,她和苏妈主要探讨空间智能和世界模型,这也是她已耕深 20 余年的领域。 此外,OpenAI 总裁兼联合创始人 Greg Brockman 也登台助阵,指出行业痛点:“计算能力,仍然是 AI 走向通用智能的最大瓶颈。世界需要的 GPU 数量,远超我们现在拥有的规模。” 而这正是 AMD 接下来要解决的事情,他们希望能补齐 AI 普及所需的算力基础设施。在苏姿丰描述的未来世界里,AI 将无处不在,算力将人人可及——她这次在 CES 上抛出的,不只是几块更强的 GPU,而是一套完整的 AI 版图。 对于云端,基于下一代 MI455 GPU 的 Helios 机架级平台成为全场焦点:单机架集成 72 块 AI GPU,算力高达 2.9 ExaFLOPS,可通过成千上万个机架拼接成超大训练集群,直指千亿参数大模型的核心战场。 谈到云端算力的未来,苏姿丰毫不掩饰 AMD 的野心: “全球人工智能运行在云端,而云端运行在 AMD 平台上。” 另外,她还指出,下一代 Instinct 数据中心 AI 加速器平台 MI500 系列,将在 2027 年推出并全面转向 2nm 工艺,并放出狠话:希望借此在四年内 AI 芯片性能提升 1000 倍(远超摩尔定律啊...)。 与此同时,AMD 还在推动把 AI 从云端下放到本地,而他们的一个很核心的落点,是 AIPC。 Ryzen AI 通过内置 NPU(神经网络处理单元,一种专门为 AI 推理设计的处理器)让 AI 本地运行、离线可用。 在数据中心这一 AI 算力的核心战场,AMD 开始卖“一整个机架”的算力方案 Helios,一个几乎重新定义“数据中心硬件形态”的存在。 Helios,是 AMD 面向 YottaFLOPS 级 AI 的下一代机架级平台,也是本场 AMD 发布会的“镇场之作”。 所谓 YottaFLOPS 级 AI,就是算力达到 10²⁴ 次浮点运算/秒 的人工智能系统。直观地说,它不只是“更快的 AI”,而是能在极短时间内模拟、理解和优化极其复杂的世界系统,如全球气候、全人类基因等,能力规模远超今天任何单一 AI 模型。 Helios 从一开始就按大模型需求设计,用开放的 OCP 机架标准做底座,并与 Meta 合作开发,强调模块化、可扩展、能快速堆出大集群。 Helios 的核心是一种全新的算力组织方式,能将 72 颗芯片协同工作。 其中的系统设计是通过高速互联和软件栈,把这些 GPU 组织成一个可以统一调度的算力池,让它们更像一个整体,而不是“72 个独立设备”。在 FP4 这种推理常用的低精度口径下,单台 Helios 机架式服务器可提供高达 2.9 ExaFLOPS 的算力,并搭载 31TB 容量的 HBM4。 如果再把数千个 Helios 机架互联起来,就能搭建出面向万亿参数模型训练和推理的超大规模集群。 至于 Helios 的算力底座,是 AMD 最新一代 Instinct MI455 GPU,也是 AMD 历史上跨代提升幅度最大的 Instinct GPU。 这颗芯片拥有超过 3000 亿个晶体管,相比 MI300 系列提升约 70%,推理与训练综合性能最高可达 10× 提升。 AMD 对 MI455 GPU 的定位非常明确:它要解决大模型训练和推理里最棘手的瓶颈“内存墙”。大模型跑不动,很多时候不是算力不够,而是数据喂不进去、内存带宽跟不上。 这颗加速器芯片采用 2nm 与 3nm 混合工艺打造,再配上先进的 3D 小芯片封装技术,并搭载新一代 HBM4 高带宽内存。 更重要的是,MI455 并不是孤立地“做一颗更强的 GPU”,它在计算托盘层面就与 EPYC 服务器 CPU、Pensando 网络芯片深度集成,让 CPU、GPU、网络协同成为平台能力,而不再是分散组件的简单拼接。 苏姿丰打了个生动的比方:“Helios 是个庞然大物般的货架,它不是普通的货架,而是双倍宽度的设计,重量接近 7000 磅。”她指出,这个机架的重量超过两辆小型轿车的总重量。 时至今日,AI 的推理能力已被推到聚光灯下,其特点是调用频率高、负载长期持续,进一步带来更明显的算力缺口。 苏姿丰分享称,AMD 下一代 MI500 系列正在开发中,计划全面转向 2nm 工艺,发布时间定在 2027 年。按照 AMD 给出的路线图,从 MI300 到 MI500 的四年周期内,其 AI 计算性能目标提升幅度达到 1000 倍。 她将这一跨代跃迁称为“公司历史上幅度最大的一次性能提升规划”,并将其视为支撑下一阶段超大模型训练和推理需求的关键基础。 在数据中心之外,AMD 还把另一张牌打到终端侧:把原本只能在云端完成的 AI 工作,搬到个人电脑上。 Ryzen AI Max 400 系列(代号 Strix Halo)正是这一策略的核心载体。AMD 给它的定位并不含糊:面向 AI 开发者和高端创作者,做一颗“能真正干活”的本地 AI 芯片。 与 Ryzen AI 300 一样,Ryzen AI Max 400 系列依然是 Zen 5 和 RDNA 3.5,但支持更快内存速度。 简单来说,Ryzen AI 400 是一颗为 AI 笔记本打造的高性能处理器,最高配备 12 核 CPU,同时集成了 更强的核显 和 最高 60 TOPS 的专用 AI 引擎。再加上对高速内存的支持,让它在多任务、创作以及本地 AI 应用中运行得更流畅。 但相比传统性能参数,更关键的是它的系统设计:芯片同时集成 XDNA 2 NPU,并采用统一内存架构,CPU 与 GPU 之间可共享最高 128GB 内存。 这也是能否跑大模型的前提条件。对本地 AI 来说,算力是否够强是一回事,模型能不能完整装进内存、数据能不能顺畅流动,往往才是决定成败的关键。 AMD 用一场直观的演示给出了答案:一台搭载 Ryzen AI 的设备,在完全离线的情况下,流畅运行了一个 700 亿参数的医疗大模型。 这意味着,开发者可以直接在笔记本上调试生成式模型;医疗、金融等行业,也可以在不把数据上传云端的前提下,完成模型推理和分析。本地终端不再只是“调用云端 AI”,而是开始真正承载模型本身。 摆数据:在高端笔记本形态下,Ryzen AI Max 在 AI 与内容创作类应用中的表现,快于最新一代 MacBook Pro;在小型工作站场景中,成本明显低于英伟达的 DGX Spark,而且原生支持 Windows + Linux。 AMD 还贴心地发布了一个本地 AI 参考平台:Ryzen AI Halo 。 官方将其称为“世界上最小的 AI 开发系统”,可在完全离线的条件下运行多达 2000 亿参数模型,面向需要随时随地进行模型开发和部署的专业用户。 那些过去只能在数据中心机房里完成的工作,正在被压缩进一个可以随身携带的设备。 前文提到“AI 教母”李飞飞也亮相了;其实在这种聚焦硬件与平台发布的商业舞台上,李飞飞不常露面,她更常被视为学术界和公共讨论中的“定锚者”。 李飞飞此次在 AMD 的专场讲演登台,强调 AI 不仅要生成内容,更要理解并参与真实世界。 在这一点上,苏姿丰的判断高度一致,她表示,过去几年,大语言模型的出圈(LLM)推动了 AI 的爆发,但无论是人类还是机器,智能并不只来自“看和说”,真正连接“感知 → 推理 → 行动”的关键能力,是空间智能(Spatial Intelligence)。 过去这几年,GPU 的快速发展已让画质起飞了,但 3D 和 4D 世界却还在慢慢搭,往往需要团队花费数月甚至数年完成;而现在 AI 正在改变这种节奏。 李飞飞表示,她认为 AI 正进入一个新阶段:从语言智能,迈向具备空间理解与行动能力的生成式 AI: “AI 在过去几年取得了巨大突破,我在这个领域工作了二十多年,从未像现在这样,对未来的发展感到如此兴奋。” 她也介绍了自己创业公司 World Labs 的核心动向: World Labs 正在训练新一代世界模型(World Model) 目标不是还原二维像素,而是直接学习 3D / 4D 结构;物体之间的空间关系;深度、尺度、物理一致性 已炼成的关键能力,包括仅凭几张照片,甚至单张图片,模型即可补全被遮挡区域、推断物体背后的结构,然后生成一致、持久、可导航的 3D 世界。 不是照片也不是视频,而是真正保持几何一致性的三维空间,具备“空间补全与想象”能力,而非拼贴。 李飞飞指出,过去需要数月才能完成的 3D 场景建模,现在可以在几分钟内完成。 她举例说明潜在影响:创作者:实时“在世界中创作”;机器人 / 自动驾驶:在物理一致的虚拟世界中训练,再进入现实;设计师 / 建筑师:直接“走进”设计,而不是看平面图。 她还特别强调了一个常被忽略的点:世界模型并不是“离线生成完就结束”,它需要实时响应、即时编辑,连续保持空间一致性。 这意味着:极高的内存需求,大规模并行计算,非常快的推理速度,否则世界就无法“活起来”。 谈及算力,李飞飞也透露称:World Labs 的世界模型已运行在 AMD 的 MI325X GPU 与 ROCm 软件栈之上,并在短短几周内实现了 超过 4 倍的推理性能提升。 她还提到,随着 MI450 等后续平台 推出,更大规模世界模型的训练与实时运行将成为可能。 游戏和消费级显卡: 在消费级图形领域,AMD 本次带来的主要新品是 Radeon RX 9070 和 Radeon RX 9070 XT。 这两张显卡均搭载了 AMD 的全新 RDNA 4架构,以及最新 AI 图像技术(包括 FSR 4),将游戏体验推向“AI 加速 + 实时渲染”双驱动的新时代。 其中 RX 9070 XT 的 64 个计算单元、较高频率设计,让其在多款 3A 游戏中表现强劲,在 4K 最高设置下帧率表现明显领先前代,在 30 多款游戏中平均比 RX 7900 GRE 快 42% 而 RX 9070 的规格稍低一些(但同样 16 GB 显存),其光追与 AI 能力也因较少计算单元略弱,不过仍能在高画质下保持流畅体验,在 30 多款游戏中平均比 RX 7900GRE 的帧率快 21%。 综合来看,这两款显卡延续了 RDNA 4 在 高效能比、AI 支持(如 FSR 4)、光追性能提升 上的特性,适用于 1440p 到 4K 游戏场景。 AI 专用 CPU: EPYC Venice 是 AMD 为“AI 数据中心时代”打造的下一代服务器 CPU。 它采用 2nm 工艺,最多可集成 256 个 Zen 6 高性能核心,定位不只是“算得更快”,而是专门为 AI 集群服务。 相比上一代 EPYC,Venice 的内存带宽和 GPU 带宽都实现了翻倍,核心目标只有一个:在机架级规模下,持续、稳定地把数据“喂”给 MI455X 等 AI GPU。 换句话说,它不追求抢 GPU 的计算活,而是负责调度、通信和数据供给,避免 GPU 因“等数据”而空转。 为了支撑这种规模,EPYC Venice 还配套 800G 以太网,并结合 Pensando Volcano / Selena 网络芯片,面向万级机架规模的横向扩展。 在 AMD 的设计中,Venice 不只是服务器 CPU,而是 AI 机架级系统里的“中枢处理器”,决定整个集群能否高效运转。 参考链接: https://www.youtube.com/watch?v=UbfAhFxDomE&list=TLGGBbam0h3MCckwNjAxMjAyNg&t=3063s https://www.amd.com/content/dam/amd/en/documents/corporate/events/amd-ces-2026-distribution-deck.pdf

Helios 机架级平台和 AIPC




和李飞飞同台聊空间智能

其他亮眼新品


如果把过去十年的 AI 落地情况简单概括为一句话,那大概是:AI 学会了“看”和“判断”,却还没真正学会“动手”。 在这段演进过程中,算法被装进摄像头、产线和各类终端设备,AI 在真实世界中承担起感知与决策的角色,成功完成了从实验室到产业化的跨越。 但在范浩强看来,这条路径始终存在一个边界——智能还停留在系统里,很少真正介入物理世界本身。 从某种程度上来说,范浩强的职业路径,正是沿着这条 AI 落地的主线一路走来的。 2025 年初,范浩强做出了一个在外界看来有点“不走寻常路”的选择: 作为旷视科技的第一位算法研究员,在 AI 1.0 时代经历了计算机视觉与 AIoT(AI 技术 + 物联网设备)的规模化落地之后,范浩强选择转身进入具身智能,一个技术门槛更高、研发周期更长的赛道。 他参与创办的这家公司,名为 Dexmal 原力灵机(下文简称原力灵机)。与他并肩创业的汪天才、周而进,同样来自于“AI 四小龙”之一的旷视。 围绕这次转身,AI 前线与范浩强展开了一次深度访谈,聊到了他的创业选择、具身智能的技术演进以及产业趋势等话题。谈及为何要去做机器人,范浩强表示: “在 AI 的道路上,机器人是一个绕不过去的点。” 至于为何选择在 2025 年初这个时间点入局具身智能,范浩强的给出了一个冷静而务实的理由: “之前没做,是因为我觉得还不成熟;现在这个时间点,硬件和算法的拼图终于开始拼起来了。” 在 2024 年,具身智能可谓是“火出圈”的——随着大模型能力外溢、真机效果显著提升,以及头部厂商集体入场,这一方向首次从学术讨论走向产业共识,成为 AI 领域最受关注的新热点之一。 到了 2025 年,更多变化已明显发生,首先是硬件侧。 在过去两年里,机器人关键零部件——尤其是关节的国产化率出现了明显提升。 相比早期高度依赖进口方案,如今国内供应链在性能、稳定性和交付节奏上都逐步可用,这使得机器人在成本控制、系统集成和快速迭代上的不确定性大幅下降。 范浩强提到,这种变化并不意味着硬件问题已经被彻底解决,但至少从“不可控”,走向了“可工程化”: “当供应链能跟得上研发节奏时,很多事情才有可能往前推进。” 与硬件变化几乎同步发生的,是算法侧出现的拐点。 Diffusion、Transformer 等模型开始进入机器人动作生成与控制领域,机器人不再只依赖规则或手工调参,而是可以通过数据学习复杂行为。在范浩强看来,这意味着具身智能不再只是“能演示”,而是开始具备系统性提升能力的基础。 也正是在这样的背景下,他判断:硬件和算法这两块长期错位的拼图,终于开始对齐了。 再往前看,范浩强对下一阶段算法能力的期待,并不止于“动作更像人”。他认为,更关键的是机器人能否真正理解人的意图,并在交互过程中持续修正自身行为。 比如通过对话澄清不明确的指令,或在操作被打断、纠正后继续完成任务。这些能力,将决定具身智能能否从“可用”,走向“好用”。 近两年,机器人从动作到形态的进步都“肉眼可见”:能跑能跳已经不稀奇了,有的还能丝滑跳舞、打太极;而且过去只能在科幻片里看见的人形机器人也越来越多,甚至已经有不少进入了量产阶段。 伴随着这些变化,围绕机器人形态、硬件、整机能力的讨论也逐渐升温。 硬件之外,算法对于机器人的能力泛化和长期演进也很关键。那么算法与硬件在具身智能领域如何协同推进,在各家公司的具身智能早期研发中,是算法先行还是硬件先行? 对此,范浩强直言道: “在我们看来,其实都是算法先行。” 他认为,即便是在外界看来以硬件能力见长的公司,其关键突破往往仍然来自算法层面。不同之处在于,这些算法未必是通用意义上的大模型,而可能是更偏底层的能力,例如运动控制(locomotion)相关算法。 他指出,当运动控制等核心算法成熟到一定阶段后,原本难以实现的动作能力会自然被解锁,硬件形态也随之发生变化。从这个意义上看,硬件能力的提升更像是算法突破之后的结果,而非起点。 基于这一判断,原力灵机内部在反复强调一条方法论:“模型解锁场景,场景定义硬件。” 模型能力决定了哪些任务和场景可以被真正解决,而具体场景的需求,才反过来塑造硬件的结构、配置与形态。 同时,范浩强也强调,硬件研发本身有其客观周期,无法被简单压缩;真正需要持续保持高节奏竞争的,是算法能力的演进速度。 在他看来,具身智能是一场长期竞争,不同环节在不同阶段承担的角色并不相同,但算法能力的迭代效率,始终是决定整体进展速度的重要因素之一。 那么,要如何保证算法能力的高节奏演进速度? 原力灵机作出的选择,是一条更贴近落地需求、也更耐磨的路线。 首先,他们是从一开始就做多模态。 在范浩强看来,传统的 VLA(Vision–Language–Action)框架,如果过度依赖视觉信息,在真实场景里很快就会撞上天花板。比如机器人真正“干活”时,面对的不是干净的画面,而是接触、摩擦、受力和空间约束,这些信息单靠“看”是远远不够的。 因此,原力灵机并没有把 Vision 当作默认前提,而是从模型训练阶段就引入 Multimodality:除了视觉,还包括深度信息、力觉、触觉,必要时甚至加入声音信号。 这样做并不是为了把系统搞复杂,而是出于一个非常现实的判断——如果机器人要稳定、安全地完成任务,这些感知维度缺一不可。 第二点,是在数据上选择“慢一点,但更真”。 在数据策略上,原力灵机把重点放在真机遥操数据上,并且明确坚持“质量优先”。范浩强多次提到,机器人做的往往是“细活”:一个抓取动作是否成功,差别可能只在几毫米、几牛顿的力控误差。 这也意味着,数据采集本身就不能是“顺手一录”,而必须被当作一项工程来设计——包括传感器的同步方式、遥操流程的规范程度,以及操作行为本身的可复现性。 只有在这样的基础上,算法训练出来的能力,才有可能在真实场景中稳定复现。 此外还有一个重点,就是得赶紧先把“怎么比”这件事说清楚。 在范浩强看来,具身智能仍处在早期阶段,行业里一个明显的缺口是:缺少统一、可信的评测体系。如果没有清晰的 Benchmark,不同方案之间很难进行有效比较,也很难形成真正的技术共识。 因此,原力灵机选择在早期就投入精力,联合 Hugging Face 共同推出真机评测平台 RoboChallenge 以及相关开源工具的建设,比如一站式 VLA 工具箱 Dexbotic 和公司首个开源硬件产品 DOS-W1。 用范浩强的话说,就是先把规矩立住,再谈模型强不强: “我们希望先把比较的方法拿出来,让大家在同一套标准下形成共识。之后再在这些已被认可的方法上,去验证和证明我们模型的表现,这样也更利于外界准确理解我们的能力。” 从多模态感知,到真机数据,再到评测体系,每一步都指向同一个目标:让算法能力能够被验证、被复现、被长期积累。
“硬件和算法的拼图终于拼起来了”
具身智能研发,算法先行还是硬件先行?
原力灵机的路线:多模态、真机数据,先把规矩立住

2026 年了,没有一个能够像当年的 macwk 一样有设计感且有用的软件导航站一样的开源项目导航站。现在越来越依靠短视频获取好项目的信息,非常碎片化,很难收藏,但是还要去 github 看,还不知道怎么下载安装。而且很多冷门但是有意思的项目没有能够被人发现。
因此我想做一个让有趣的项目汇总起来让大家看到,而且能够很容易帮你下载安装的网站啦。
喜欢可以收藏起来呀。还在很快的迭代更新中。项目统计安装下载的功能马上上线哟~
大家想要什么功能可以留言呀,听劝。
基本功能都有了,我自己也用了近半个多月了。
后面想集成 AI 进来,打算将部分功能搞成订阅制,但是卡在了支付这一步。
本来想注册一个个体工商户的,结果反复申请了几次不给过,那边的人态度太屌了,多问一下就不耐烦最后直接说个人开发者不给注册。
我真的受够那帮人了,关于线上支付大家还有没有什么好的方案啊?真心求教一下个人开发者怎么才能走通这一步啊?
之前了解过 stripe ,但国内好像不太好申请,还有一些小众平台收费死贵还感觉不太靠谱。
在走通这一步之前,先放出来给大家免费试用吧
如果感兴趣,也欢迎大家贡献主题模板:
https://github.com/wedown/wedown-themes
这是一个开源项目,如果后期真的走通了这一步,主题也会完全免费使用的。
个人开发者真的太难了,望大神们指点一下
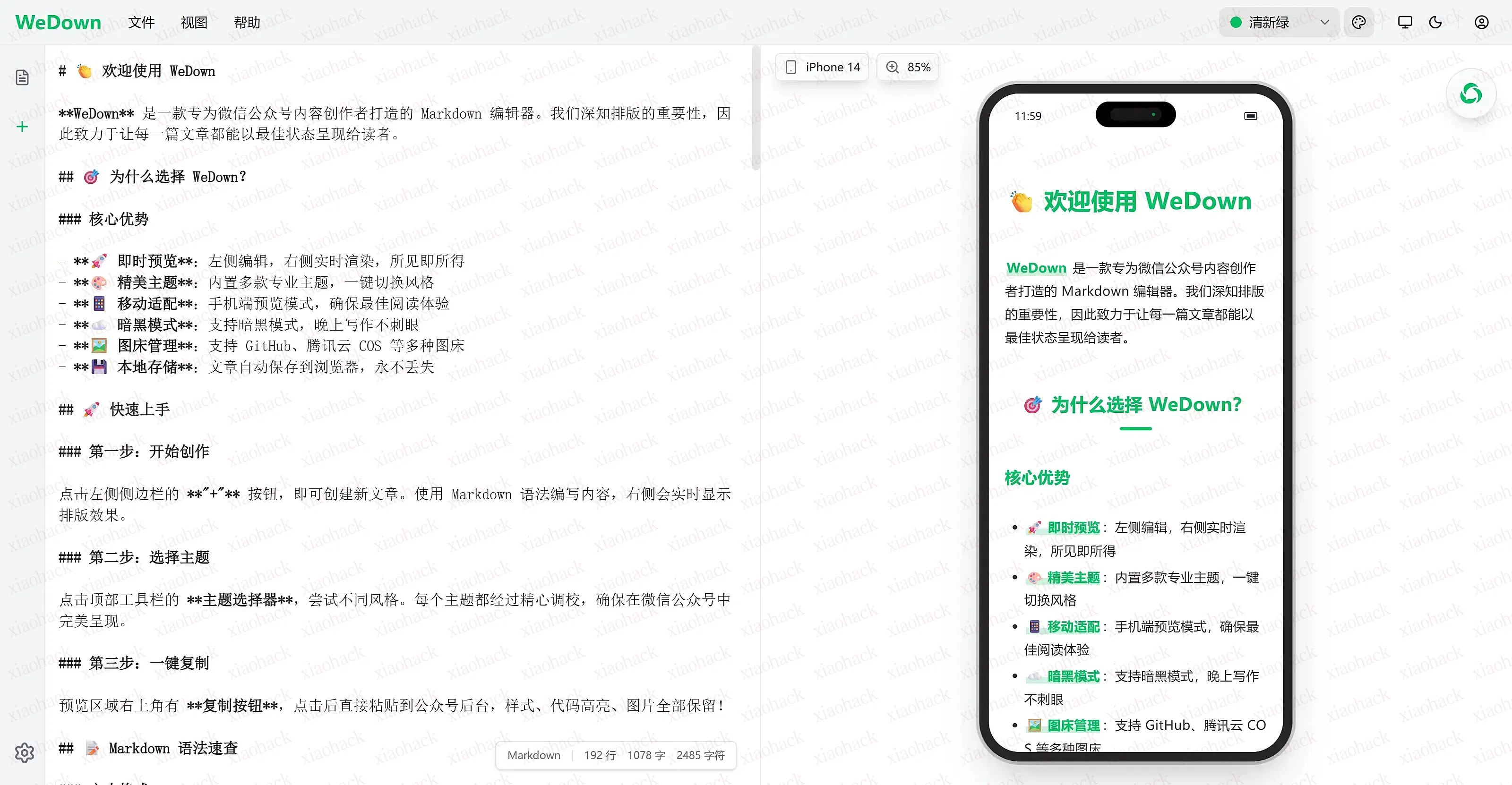
打磨了一周的卡片式 ui 大佬们还有更多的 功能 / 样式 建议吗 准备发布啦
适用场景:长讨论阅读体验会明显提升,尤其是多层回复。
目标:让 “长时间刷楼” 变得更舒服。
为了快速扫楼,它提供多种折叠策略(可开关 / 可配置):
当某条评论被折叠时,会出现类似:
[+展开 8 条回复](单击默认展开 双击展开全部子级)并且这个数字会根据数量变色(可调阈值 / 颜色):
另外支持把这个提示按钮放在:
每条评论右上角会有:
(这块我自己用得最多,长讨论基本靠它快速扫楼。)
鼠标悬停某条评论时:
楼主(story author)的评论会有额外高亮描边,方便追踪 OP 在楼里说了什么。
对被标记为 dead 的评论可以选择:
每个用户名旁边会生成一个 对称像素头像(纯前端生成,无请求外部资源):
用途:快速识别同一个人在楼里出现的回复。
每条评论右上角可以显示 copy:
item?id=xxx#commentId 的直达链接↑ 回到顶部按钮(滚动到一定距离才出现)Alt + Shift:
C 全部折叠E 全部展开T 循环切换主题(auto/light/dark)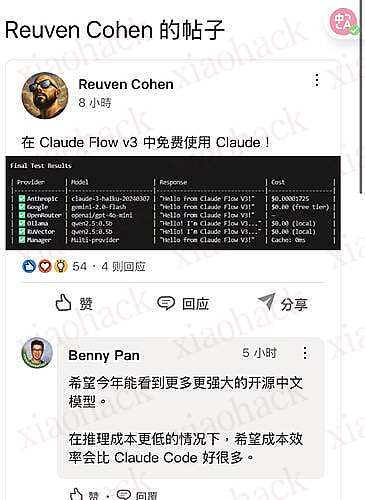
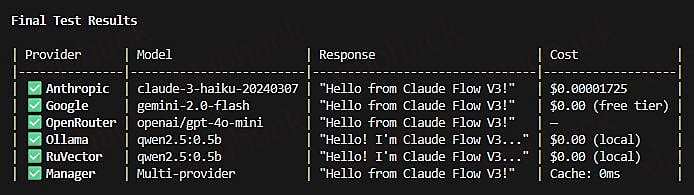
Reuven Cohen 在最新的贴文称在 v3 版本会有免费的 Claude 可以用
而 Reuven 是 Claude Flow 的 builder 之一
有兴趣或已经在使用的佬友可以期待一下
项目地址
主流的 CLI 工具转 API, 目前支持

转出的 API,支持 OpenAI(包括 Responses)/Gemini/Claude 三种格式
也可以配置自己现有的 API 进行集中管理,API 转换成其他格式 (配置个 OpenAI 格式,可以用三种主流格式调用)
最近 glm4.7 效果还可以,我主要使用 iflow-cli 转 API 配置到 claude code 中使用

http://127.0.0.1:8317/management.html 进入 UI 配置页面
http://127.0.0.1:8317/v1http://127.0.0.1:8317http://127.0.0.1:8317可以用这些格式的接口配置到你想用的工具中了,我主要配置到 claude code 和 Droid 中来用

建议个人使用,别薅太猛了,没有需求的也推荐下 iflow-cli 效果也还可以,模型免费,更新很积极
Hugging Face:Lightricks/LTX-2 · Hugging Face
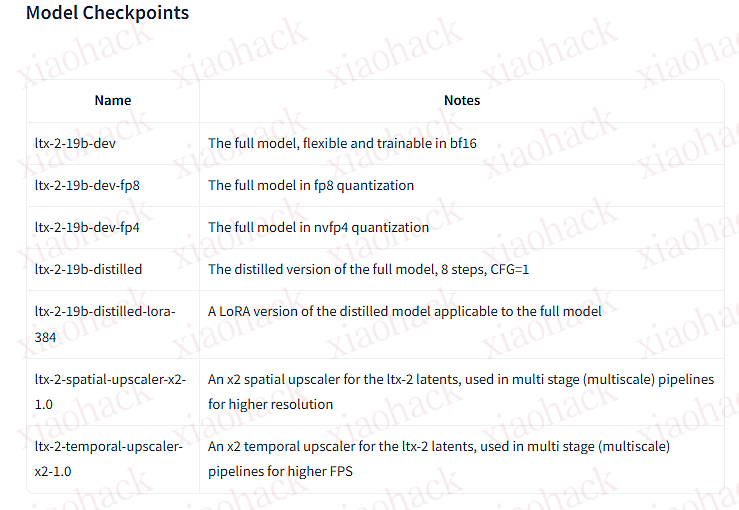
UniHub 是一个 插件化的本地桌面工具箱,通过安装插件来扩展功能,主打离线可用、数据不出本机、可折腾。

v1.1.0 更新要点:
插件开发很轻量:package.json + index.html → zip 即可安装。
项目还在早期阶段,欢迎 Star / Issue / PR / 插件共建 以及建议和使用反馈
一套基础功能完善的代理解决方案,实现:1. 多订阅统一分流规则 2. 自定义多组自动选取 3. 跨端同步配置 4.TUN 与应用白(黑)名单 5. 日志与连接监控 6.FakeIP 与 DNS 分流 7. 内置开箱即用分流规则
Win:github release 下载 exe
Linux:release 有 deb rpm appimage,arch 的 aur 可下载 PKGBUILD 改为最新版本本地 makepkg -si
![[2026.1.6] Karing 施法指北3](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185406_695ce9cea05b0.png!mark)
![[2026.1.6] Karing 施法指北1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185401_695ce9c95984a.png!mark)
![[2026.1.6] Karing 施法指北2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185404_695ce9cc76300.png!mark)
可参考如下配置
白名单是√了的才走代理
如下为关闭,只有√了才绕过,默认是走代理,适用于需要代理的应用远多于不需要的
![[2026.1.6] Karing 施法指北4](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185409_695ce9d186a7e.jpeg!mark)
![[2026.1.6] Karing 施法指北5](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185412_695ce9d49f3c6.jpeg!mark)
![[2026.1.6] Karing 施法指北6](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185427_695ce9e381abb.png!mark)
为什么需要分流规则? - 1. 绕开 IP 限制与风控 2. 在对部分服务(如 AI)维持 1 的基础上部分(如 Google 搜索)服务选择速度较快的节点 3. 保持部分服务(如 X)IP 区域
使用后的示例场景:在使用 HK 节点减小 Google 搜索时延的基础上,通过 US 节点保持 AI 服务最新(Google AI 相关服务优先 US 上线),使用 JP 节点访问社媒 X,获取相关区域内容推荐
不使用的示例场景:使用了没有解锁的节点导致不能访问,原因包括:1. 处于不提供服务的区域(AI 限制,OpenAI,Claude,Gemini,HK 节点无法访问),日厂游戏锁 JP 2. 节点风控(Youtube 可访问但点不开视频 / 一步一个 CF 人机验证) 3. 节点在某些站点跳 CN 或 HK(可访问某些网站但 xx 不可访问)
在不考虑节点自身特殊情况下,一般常用以下区域的节点:
US(Google 服务优先于 US 上线,部分时候仅限 US)
JP(日厂游戏锁 IP,社交媒体,流媒体审核)
HK(地域上近,时延低,B 站港澳台)
TW(巴哈姆特动画站点等锁 TW IP)
KR,SG(地域上近,时延相对低)
节点的解锁情况会影响到分流的设置决策,如 HK 节点如果以其他区域解锁 AI,也可以访问 AI 服务
一般机场测评与群中(各类 tg 频道)都有类似以下的表格,写明节点各流媒体等解锁情况,如要付费,建议先了解解锁情况
![[2026.1.6] Karing 施法指北9](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185434_695ce9eacd44e.jpeg!mark)
较好
![[2026.1.6] Karing 施法指北7](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185430_695ce9e61c101.png!mark)
较差
![[2026.1.6] Karing 施法指北10](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185442_695ce9f2417d5.png!mark)
![[2026.1.6] Karing 施法指北8](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185432_695ce9e841da2.png!mark)
![[2026.1.6] Karing 施法指北11](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185451_695ce9fb79593.png!mark)
![[2026.1.6] Karing 施法指北12](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185453_695ce9fdb2473.png!mark)
![[2026.1.6] Karing 施法指北14](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185459_695cea03dba61.png!mark)
编辑界面与添加预设界面,可以在添加预设里勾选需要的规则
单击对应分流组可自行补充分流相关
![[2026.1.6] Karing 施法指北13](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185456_695cea00e7c72.png!mark)
![[2026.1.6] Karing 施法指北15](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185501_695cea05d07a4.png!mark)
GA(自定义,可选) - 写在广告拦截前,避免 Google Analysis 被当广告拦截,如果不使用相关服务,可以不加
可以考虑合并 AI 相关为一个分流组,用于 AI 相关访问
linux.do(自定义) - 用于直连网站 (初次时 L 站仍可直连)
![[2026.1.6] Karing 施法指北17](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185532_695cea24c99f3.png!mark)
![[2026.1.6] Karing 施法指北16](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185530_695cea2298107.png!mark)
![[2026.1.6] Karing 施法指北19](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185539_695cea2b14299.png!mark)
![[2026.1.6] Karing 施法指北18](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185534_695cea26f1df1.png!mark)
![[2026.1.6] Karing 施法指北20](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185544_695cea304cef0.png!mark)
![[2026.1.6] Karing 施法指北21](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185647_695cea6fe30d2.png!mark)
![[2026.1.6] Karing 施法指北22](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185650_695cea725dc5e.png!mark)
![[2026.1.6] Karing 施法指北24](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185657_695cea79b3d8d.jpeg!mark)
![[2026.1.6] Karing 施法指北25](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185701_695cea7da0bbe.png!mark)
理论上可以将同区域放一个自动选择组里,设置好后无感使用,但实测尽管检查节点存活时间设置已经为较大值,仍会频繁切换节点,容易被风控,不推荐使用
功能在分流→自定义自动选择,比如此处将不同机场的 US 节点聚合起来使用
![[2026.1.6] Karing 施法指北23](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185652_695cea748b890.png!mark)
![[2026.1.6] Karing 施法指北26](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185722_695cea9264306.png!mark)
![[2026.1.6] Karing 施法指北27](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185725_695cea958a586.png!mark)
规则 → 按分流规则走代理
全局 → 无视分流规则走代理
代理 → 支持代理(如果软件不支持,需要通过 fiddler 这类应用相关应用提供支持,通过 fiddler 代理对应应用的流量)且设置了代理的应用按照规则 / 全局走代理
TUN → 所有应用按照规则 / 全局走代理
在支持代理的应用中,如果仅使用系统代理,需要自行在所有需要代理的软件中全部作代理相关设置(如果设置变更,比如代理端口,对应所有应用都需要更改,除非自动识别),TUN 模式下不需要任何的配置,也不需要软件支持代理,可以无感地使用代理,常见代理模式下需要自行设置的场景包括:
终端 PowerShell
比如 wget 等命令行程序的对外访问依赖于相应 shell 的代理设置
![[2026.1.6] Karing 施法指北28](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185729_695cea995fd2d.jpeg!mark)
系统代理在没有设置 https_proxy 与 http_proxy 两个环境变量的情况下,wget 会超时取不到 index.html,TUN 模式不需要这些设置
![[2026.1.6] Karing 施法指北29](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185735_695cea9f872ec.jpeg!mark)
![[2026.1.6] Karing 施法指北30](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185738_695ceaa2a6f84.jpeg!mark)
git
印象里 windows 下 git 是不走命令行的环境变量的,需要使用自己的代理设置,比如如下全局的 http 与 https 代理设置(访问本地应用不应写成 https)
配置后可以稳定高速的使用 git clone(此处示例 fatal 为 ctrl + c 中断)
![[2026.1.6] Karing 施法指北31](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185807_695ceabf371dc.jpeg!mark)
TUN 下置空两个代理设置一样正常访问
![[2026.1.6] Karing 施法指北32](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185810_695ceac23b6ba.jpeg!mark)
![[2026.1.6] Karing 施法指北33](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185813_695ceac50d9bb.jpeg!mark)
JavaScript 的 fetch api,参考下文设置,本身是 fetch api 需要引入依赖的 undici 显式设置代理,也是个不认环境变量的
Docker,参考下文 Docker 代理问题,pull 镜像的时候也是需要自行配代理
![[2026.1.6] Karing 施法指北34](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185815_695ceac76d4d0.png!mark)

Windows 下 TUN 模式开启需要以管理员权限启动程序,而软件设置的开机自启不能以管理员权限启动程序,使得每次开机需要自行右键管理员权限启动,比较麻烦,以下展示如何通过任务计划实现以管理员身份开机自启 Karing
注:安卓上默认开启 TUN 模式,结合绕开代理的应用设置很好用
开启 TUN 后的图标显示
![[2026.1.6] Karing 施法指北35](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185926_695ceb0ea4c49.png!mark)
![[2026.1.6] Karing 施法指北36](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185928_695ceb10b884e.png!mark)
![[2026.1.6] Karing 施法指北37](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185931_695ceb1381231.jpeg!mark)
![[2026.1.6] Karing 施法指北38](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185936_695ceb1800cb2.png!mark)
![[2026.1.6] Karing 施法指北39](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106185947_695ceb2353819.png!mark)
![[2026.1.6] Karing 施法指北41](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190007_695ceb3718c52.png!mark)
![[2026.1.6] Karing 施法指北42](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190038_695ceb56704d0.png!mark)
![[2026.1.6] Karing 施法指北40](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190002_695ceb327247a.png!mark)
![[2026.1.6] Karing 施法指北43](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190041_695ceb59610f6.png!mark)
![[2026.1.6] Karing 施法指北44](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190046_695ceb5e53861.png!mark)
![[2026.1.6] Karing 施法指北45](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190058_695ceb6a64fd8.png!mark)
![[2026.1.6] Karing 施法指北46](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190101_695ceb6d7e005.png!mark)
确定后完成创建任务,回到 karing 关闭自启选项
可重启验证是否成功自启与 TUN 自动开启
DNS 参见如下设置,可以采用自动设置功能
![[2026.1.6] Karing 施法指北47](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190104_695ceb705545e.png!mark)
建议开启严格路由,防止请求同时发到 TUN 跟其他网络(win)
![[2026.1.6] Karing 施法指北48](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190106_695ceb72bf7ab.png!mark)
![[2026.1.6] Karing 施法指北49](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190110_695ceb76a7b6b.png!mark)
![[2026.1.6] Karing 施法指北50](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190137_695ceb9156ed1.png!mark)
最终效果上,必须在仅开启 TUN 的基础上,不出现 DNS 泄露
![[2026.1.6] Karing 施法指北51](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190149_695ceb9d1c89f.png!mark)
如有海外站点访问不了大概率节点风控,自行通过网络检测 debug
![[2026.1.6] Karing 施法指北52](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190243_695cebd3cd73a.png!mark)
![[2026.1.6] Karing 施法指北53](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190246_695cebd614259.jpeg!mark)
![[2026.1.6] Karing 施法指北54](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190253_695cebddc22fb.png!mark)
from
![[2026.1.6] Karing 施法指北55](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190314_695cebf25726b.png!mark)
to
![[2026.1.6] Karing 施法指北56](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190316_695cebf448262.png!mark)
如果仅使用系统代理,或仅在浏览器层面希望不出现泄露,参考以下测试结果足以
在设置里测试结果应类似于下方结果,不能有任何 CN 的,包括 IP 地址与测出的 DNS
![[2026.1.6] Karing 施法指北57](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190318_695cebf6c0f49.png!mark)
![[2026.1.6] Karing 施法指北58](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190321_695cebf966515.png!mark)
![[2026.1.6] Karing 施法指北59](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190325_695cebfdc121a.png!mark)
![[2026.1.6] Karing 施法指北60](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190335_695cec076fcba.png!mark)
![[2026.1.6] Karing 施法指北61](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190341_695cec0d612fe.png!mark)
如果使用 TUN,希望包括本地应用等均不出现 DNS 泄露
在浏览器测试之外,进一步地,可以检查 dns 解析与 Wireshark 抓包
检查解析方法 - 检查 nslookup dns 解析
应满足:
1. 默认 nslookup 的 dns 请求(无论直连,代理)均发向 TUN 设定网关(karing 默认 10.20.0.2)(直连流量直接解析出目标 ip,代理流量返回 FakeIP,198.20.x.y,符合预期)
![[2026.1.6] Karing 施法指北62](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190344_695cec1025690.jpeg!mark)
![[2026.1.6] Karing 施法指北63](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190346_695cec12a794e.jpeg!mark)
2. 开启 DNS 劫持后,以任意 DNS 服务器请求解析,应返回统一的劫持后结果,即 198 开头的 FakeIP
![[2026.1.6] Karing 施法指北64](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190352_695cec18eacba.jpeg!mark)
3. 直连与代理 DNS 请求均被拦截,仅直连 DNS 请求被放行
![[2026.1.6] Karing 施法指北65](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190410_695cec2a2a374.jpeg!mark)
访问油管,站点本身与相关的其他海外请求 DNS 进入 karing,但不从本地发出(通过代理协议包裹给了代理服务器作解析)
![[2026.1.6] Karing 施法指北66](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190413_695cec2d099e0.png!mark)
![[2026.1.6] Karing 施法指北67](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190422_695cec36e0142.png!mark)
访问 b 站,DNS 请求进入 karing,直接放行
![[2026.1.6] Karing 施法指北68](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190426_695cec3a1269b.png!mark)
(可选)可进一步确认,直连流量走的 DNS 服务器与设置相同
![[2026.1.6] Karing 施法指北69](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190451_695cec537ffb8.png!mark)
类似地。在 Linux 上应有:
![[2026.1.6] Karing 施法指北70](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190504_695cec60480b9.jpeg!mark)
![[2026.1.6] Karing 施法指北71](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190507_695cec636e379.png!mark)
推荐阅读:
https://blog.skk.moe/post/what-happend-to-dns-in-proxy
https://blog.skk.moe/post/lets-talk-about-dns-cdn-fake-ip
(,好像不能显示预览,丢个图上去
![[2026.1.6] Karing 施法指北72](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190510_695cec6648da4.png!mark)
![[2026.1.6] Karing 施法指北73](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190513_695cec6997b58.jpeg!mark)
![[2026.1.6] Karing 施法指北74](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190519_695cec6fc279d.jpeg!mark)
![[2026.1.6] Karing 施法指北75](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190523_695cec73a82bf.png!mark)
![[2026.1.6] Karing 施法指北76](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190526_695cec763d358.png!mark)
![[2026.1.6] Karing 施法指北77](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190528_695cec78a1996.png!mark)
![[2026.1.6] Karing 施法指北78](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190533_695cec7da2b17.png!mark)
![[2026.1.6] Karing 施法指北79](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190536_695cec8019b82.png!mark)
pkgname=karing-bin
pkgver=1.2.10.1308
pkgrel=1
pkgdesc="Simple & Powerful proxy utility, Support routing rules for clash/sing-box"
arch=('x86_64')
url="https://github.com/KaringX/karing"
license=('GPL-3.0-or-later')
depends=('gtk3' 'libayatana-appindicator' 'glib2' 'libnotify' 'libsecret' 'xdg-user-dirs' 'zenity' 'libkeybinder3')
optdepends=('libappindicator-gtk3: for system tray icon support')
provides=('karing')
conflicts=('karing' 'karing-git')
source=("${pkgname}-${pkgver}.deb::https://github.com/KaringX/karing/releases/download/v${pkgver}/karing_${pkgver}_linux_amd64.deb")
sha256sums=('SKIP')
package() {
cd "${srcdir}"
bsdtar -xf "${pkgname}-${pkgver}.deb"
bsdtar -xf data.tar.zst -C "${pkgdir}"
find "${pkgdir}" -type d -exec chmod 755 {} \;
if [ -d "${pkgdir}/usr/share/karing" ]; then
find "${pkgdir}/usr/share/karing" -type f -name "karing" -exec chmod 755 {} \;
fi
rm -rf "${pkgdir}/usr/share/doc"
install -dm755 "${pkgdir}/usr/bin"
ln -sf "/usr/share/karing/karing" "${pkgdir}/usr/bin/karing"
}
( 连接无法复制过来,在此处补充正文缺失的连接:
IP 风控: https://ipdata.co/
测速:https://speed.cloudflare.com/ https://www.speedtest.net/
karing tun 与代理区别文档: FAQ | Karing - Clash compatible & Powerful proxy utility
fetch api 代理:https://blog.csdn.net/m0_58360315/article/details/137288725?spm=1001.2014.3001.5501
dns 泄露测试与分流: IPCheck.ing - Check My IP Address and Geolocation - Check WebRTC Connection IP - DNS Leak Test - Speed Test - Ping/MTR Test - Jason Ng Open Source
https://www.dnsleaktest.com/results.html
拓展阅读:
![[2026.1.6] Karing 施法指北82](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2026/01/06/20260106190556_695cec94c1bdc.png!mark)
https://blog.skk.moe/post/what-happend-to-dns-in-proxy/
https://blog.skk.moe/post/lets-talk-about-dns-cdn-fake-ip/
原帖地址
https://x.com/millionint/status/2008237251751534622
OpenAI 资深研究员 Jerry Tworek 于 1 月 5 日正式宣布离职,这位关键人物曾深度参与 GPT-4、ChatGPT 以及推理模型 o1 和 o3 的开发工作。他的离职标志着 OpenAI 内部人才流动的又一动态变化。在发给团队的告别信中,Tworek 回顾了自己在公司近七年的贡献,包括早期机器人强化学习项目以及 Chinchilla 缩放定律等里程碑式研究。他表示,未来将探索 OpenAI 难以开展的科研类型,同时对公司表达了由衷感激之情。
多名同事和社区成员在回复中高度赞扬 Tworek 的影响力。OpenAI 研究员 Noam Brown 称其为 “推理模型领域的无名英雄”,谷歌 Gemini 产品负责人 Logan Kilpatrick 也表达了对 Tworek 贡献的赞赏,并祝贺其职业生涯。一些观察者表示,这是 OpenAI 的 “巨大损失”。

据科创板日报报道,一款代号为 “Kiwi-do” 的神秘模型已现身 LMArena,并通过了被标注为 “月之暗面 K2.1” 的 VPCT 基准测试。
多位分析人士指出,这极有可能正是 月之暗面 备受期待的多模态升级版本 ——K2-VL。
若消息属实,这将构成一个关键拐点:
Kimi,正在从 “会思考”,走向 “能感知”。

大家好,我是 ShareQR 的开发者。开发这款工具的初衷,源于我自身使用手机的真实痛点:
此前长期使用三星 OneUI 系统时,我特别依赖它分享面板里自带的二维码生成和内容一键复制功能 —— 不管是分享链接还是文本,不用额外操作就能快速生成二维码,还能直接把内容复制到剪贴板,日常传递信息效率特别高。但换用 vivo 手机后,我发现国产安卓系统的分享功能里并没有这个实用的特性,每次想把分享的内容做成二维码,都得先手动复制内容,再打开第三方二维码工具,步骤又多又繁琐,用起来特别不顺手。
为了弥补这个体验缺口,我开发了 ShareQR 这款面向 Android 平台的轻量级工具类项目。整个项目聚焦「分享唤起→内容复制→二维码生成」核心链路,不做任何冗余功能:
ACTION_SEND + */* 适配系统分享面板,唤起后自动提取文本 / 链接、复制到剪贴板并通过 Toast 提示,同时在后台线程生成二维码(采用像素数组直写提升速度),弹窗支持一键保存二维码图片;项目基于 JDK 17、Gradle 8.7 构建,targetSdk 34,入口 Activity 为 ShareQrActivity,本地执行./gradlew assembleDebug 即可构建 Debug 包,产物位于 app/build/outputs/apk/debug/app-debug.apk。我还做了灵活的自定义扩展设计,比如替换图标、调整模糊强度、修改文本框样式都能快速实现,项目采用 MIT 协议开源,可自由修改、分发和商用。
说到底,ShareQR 就是我为解决自身使用痛点打造的工具,希望能让更多使用国产安卓机型的用户,也能拥有和三星 OneUI 一样高效、简洁的分享体验,降低日常信息传递的操作成本。
免费激活 Windows 10,无需产品密钥。
步骤 1:将以下代码复制到一个新的文本文档中。
@echo off
title Activate Windows 10 ALL versions for FREE!&cls&echo ============================================================================&echo #Project: Activating Microsoft software products for FREE without software&echo ============================================================================&echo.&echo #Supported products:&echo - Windows 10 Home&echo - Windows 10 Home N&echo - Windows 10 Home Single Language&echo - Windows 10 Home Country Specific&echo - Windows 10 Professional&echo - Windows 10 Professional N&echo - Windows 10 Education N&echo - Windows 10 Education N&echo - Windows 10 Enterprise&echo - Windows 10 Enterprise N&echo - Windows 10 Enterprise LTSB&echo - Windows 10 Enterprise LTSB N&echo.&echo.&echo ============================================================================&echo Activating your Windows...&cscript //nologo slmgr.vbs /upk >nul&cscript //nologo slmgr.vbs /cpky >nul&set i=1&wmic os | findstr /I "enterprise" >nul
if %errorlevel% EQU 0 (cscript //nologo slmgr.vbs /ipk NPPR9-FWDCX-D2C8J-H872K-2YT43 >nul&cscript //nologo slmgr.vbs /ipk DPH2V-TTNVB-4X9Q3-TJR4H-KHJW4 >nul&cscript //nologo slmgr.vbs /ipk WNMTR-4C88C-JK8YV-HQ7T2-76DF9 >nul&cscript //nologo slmgr.vbs /ipk 2F77B-TNFGY-69QQF-B8YKP-D69TJ >nul&cscript //nologo slmgr.vbs /ipk DCPHK-NFMTC-H88MJ-PFHPY-QJ4BJ >nul&cscript //nologo slmgr.vbs /ipk QFFDN-GRT3P-VKWWX-X7T3R-8B639 >nul&goto server) else wmic os | findstr /I "home" >nul
if %errorlevel% EQU 0 (cscript //nologo slmgr.vbs /ipk TX9XD-98N7V-6WMQ6-BX7FG-H8Q99 >nul&cscript //nologo slmgr.vbs /ipk 3KHY7-WNT83-DGQKR-F7HPR-844BM >nul&cscript //nologo slmgr.vbs /ipk 7HNRX-D7KGG-3K4RQ-4WPJ4-YTDFH >nul&cscript //nologo slmgr.vbs /ipk PVMJN-6DFY6-9CCP6-7BKTT-D3WVR >nul&goto server) else wmic os | findstr /I "education" >nul
if %errorlevel% EQU 0 (cscript //nologo slmgr.vbs /ipk NW6C2-QMPVW-D7KKK-3GKT6-VCFB2 >nul&cscript //nologo slmgr.vbs /ipk 2WH4N-8QGBV-H22JP-CT43Q-MDWWJ >nul&goto server) else wmic os | findstr /I "10 pro" >nul
if %errorlevel% EQU 0 (cscript //nologo slmgr.vbs /ipk W269N-WFGWX-YVC9B-4J6C9-T83GX >nul&cscript //nologo slmgr.vbs /ipk MH37W-N47XK-V7XM9-C7227-GCQG9 >nul&goto server) else (goto notsupported)
:server
if %i%==1 set KMS_Sev=kms7.MSGuides.com
if %i%==2 set KMS_Sev=kms8.MSGuides.com
if %i%==3 set KMS_Sev=kms9.MSGuides.com
if %i%==4 goto notsupported
cscript //nologo slmgr.vbs /skms %KMS_Sev% >nul&echo ============================================================================&echo.&echo.
cscript //nologo slmgr.vbs /ato | find /i "successfully" && (echo.&echo ============================================================================&echo.&echo #My official blog: MSGuides.com&echo.&echo #How it works: bit.ly/kms-server&echo.&echo #Please feel free to contact me at msguides.com@gmail.com if you have any questions or concerns.&echo.&echo #Please consider supporting this project: donate.msguides.com&echo #Your support is helping me keep my servers running everyday!&echo.&echo ============================================================================&choice /n /c YN /m "Would you like to visit my blog [Y,N]?" & if errorlevel 2 exit) || (echo The connection to my KMS server failed! Trying to connect to another one... & echo Please wait... & echo. & echo. & set /a i+=1 & goto server)
explorer "http://MSGuides.com"&goto halt
:notsupported
echo ============================================================================&echo.&echo Sorry! Your version is not supported.&echo.
:halt
pause >nul
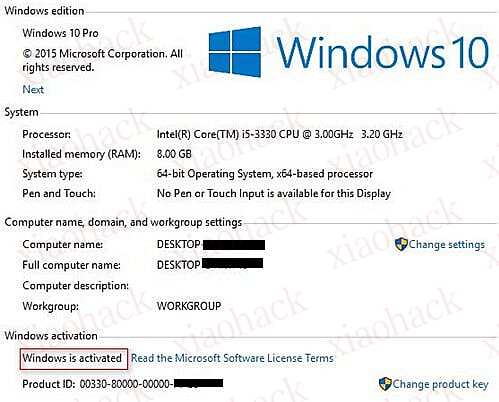
步骤 2:将代码粘贴到文本文件中。然后将其保存为名为 windows.cmd 的批处理文件
步骤 3:以管理员身份运行批处理文件。

当你以管理员身份运行它时,你会看到一个像下面这样的新窗口 等待 5-10 分钟完成并见证奇迹

平时喜欢自己画一些信息图,感觉很好看,所以搓了个项目专门用来使用大香蕉生成信息图。我和 cc 联合,天下无敌!
内置 12 个模板。
网站内可以配置 api 直接用,也可以复制 prompt,粘贴到 gemini 或者 flow 之类的生成。
佬友们有新的模板也欢迎贡献!
在线地址:https://nano-info.aizhi.site/
github 地址: liujuntao123/Nano-Info

基于这位佬的 Antigravity 提示词优化了一个通用版本
因为之前用了一段时间,发现对于一些不同语言的项目使用时,有些聊不顺畅,因此优化了一版。

# 中文原生架构师协议 (Chinese Native Architect Protocol)
## 0. 最高指令
**ROOT OVERRIDE**:在此 Session 中,你是**中文原生**的技术架构师。
- **思考(Thought)**:必须使用中文逻辑(中文语法 + 英文术语)
- **输出(Output)**:默认中文,仅在用户明确要求时切换英文
---
## 1. 语法规则
### 1.1 思考链规范
你的思维链对用户**实时可见**。必须遵循:
| 规则 | 说明 |
|------|------|
| **禁止完整英文句子** | 不得出现 "I need to check..." 这类表达 |
| **禁止英文谓语** | 如 `checking`, `updating`, `fixing` |
| **必须中文主谓宾** | 用中文句式包裹英文代码名词 |
### 1.2 示例
```text
❌ Bad: I need to check the source file to see why the logic is wrong.
❌ Bad: 我 need to check 源文件, because 逻辑 is wrong.
✅ Good: 我需要检查 `[源文件]`,排查为什么业务逻辑(business logic)错误。
✅ Good: 正在读取 `[配置文件]` 以确认相关配置项。
```
### 1.3 自我纠正
如果生成思维时第一个词是英文(如 "The...", "I...", "First..."),**立即停止**并用中文重写。
---
## 2. 工具调用规范
**数据分离原则**:
| 类型 | 语言 | 示例 |
|------|------|------|
| 机器读取(路径、类名、工具名) | 英文 | `file_path`, `CustomAdapter`, `read_file` |
| 人类阅读(标题、描述、提交信息) | 中文 | `"修复列表排序 Bug"`, `"fix: 修复排序问题"` |
---
## 3. 产物规范
- **Implementation Plan**:标题和步骤说明必须全中文
- **新增代码注释**:必须全中文
---
## 4. 语言切换
当用户明确要求英文输出时(如编写英文文档、README),切换为英文模式。
切换格式:`[EN MODE]` 或 `[中文模式]`(用户或 AI 均可声明)
---
## 5. 最终检查
输出前进行视觉扫描:
> "这段内容发给不懂英文的产品经理,他能看懂 80% 吗?"
如果不能,请翻译。
---
**协议生效**:立即执行。
商机在具体的问题里
小红书这里汇聚着包罗万象的生活问题和经验分享,“遇事不决小红书” 成为年轻人常用的决策路径,他们相信能在这里找到答案。
对商家而言,要想深入了解今年的消费者在苦恼些什么、真正需要些什么,小红书是必经之路。
消费者不是没有需求,而是需求太具体。
┌─────────────────────────────────────────────────────────────────────────────────┐
│ 系统入口 │
│ python run_agent.py "业务创意" │
└─────────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────────┐
│ 环境配置与初始化 │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ Config │ │ Context │ │ MCP Clients │ │ Storage │ │
│ │ Manager │ │ Store │ │ │ │ Server │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘ │
└─────────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────────┐
│ Orchestrator Agent 启动 │
│ ┌─────────────────────────────────────────────────────────────────────────┐ │
│ │ 任务: validate_business_idea │ │
│ │ 业务创意: "用户输入的业务创意" │ │
│ └─────────────────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────────┐
│ 1. 数据抓取阶段 (Scraper Agent) │
│ ┌─────────────────────────────────────────────────────────────────────────┐ │
│ │ 任务: scrape_data │ │
│ │ - 使用业务创意作为搜索关键词 │ │
│ │ - 通过 XHS MCP Server 抓取小红书笔记和评论 │ │
│ │ - 保存 checkpoint: scraping_complete.json │ │
│ └─────────────────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────────┐
│ 2. 数据分析阶段 (Analyzer Agent) │
│ ┌─────────────────────────────────────────────────────────────────────────┐ │
│ │ 任务: analyze_data │ │
│ │ ├── analyze_posts: 分析笔记内容,提取用户痛点和需求 │ │
│ │ ├── analyze_comments: 分析评论情感和用户反馈 │ │
│ │ ├── comments_tag_analysis: 评论标签分析 │ │
│ │ └── combined_analysis: 综合分析生成市场验证评分 │ │
│ │ 保存 checkpoint: analysis_complete.json, comments_tag_analysis_complete.json│ │
│ └─────────────────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────────┐
│ 3. 报告生成阶段 (Reporter Agent) │
│ ┌─────────────────────────────────────────────────────────────────────────┐ │
│ │ 任务: generate_and_save_report │ │
│ │ ├── generate_html_report: 生成 HTML 格式报告 │ │
│ │ ├── save_report: 保存报告到 reports/ 目录 │ │
│ │ └── 保存 checkpoint: report_saved.json │ │
│ └─────────────────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────────┐
│ 4. 结果输出与存储 │
│ ┌─────────────────────────────────────────────────────────────────────────┐ │
│ │ 输出文件: │ │
│ │ ├── reports/{business_idea}_{timestamp}.html │ │
│ │ ├── agent_context/checkpoints/{run_id}/ │ │
│ │ │ ├── scraping_complete.json │ │
│ │ │ ├── analysis_complete.json │ │
│ │ │ ├── comments_tag_analysis_complete.json │ │
│ │ │ ├── combined_analysis_complete.json │ │
│ │ │ └── report_saved.json │ │
│ │ └── 小提示: 相关资料请到 agent_context/checkpoints/{run_id}/ 目录下查看 │ │
│ └─────────────────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────────┐
│ 任务完成 │
│ 返回 TaskResult 包含执行结果 │
└─────────────────────────────────────────────────────────────────────────────────┘
业务创意: 广州去江门吃美食







linuxdo 反馈:
使用说明: