标签 开源项目 下的文章

开源自荐,MQTT 调试器,请大佬们帮忙看看
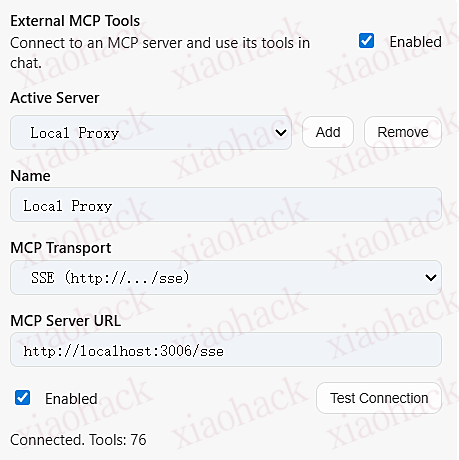
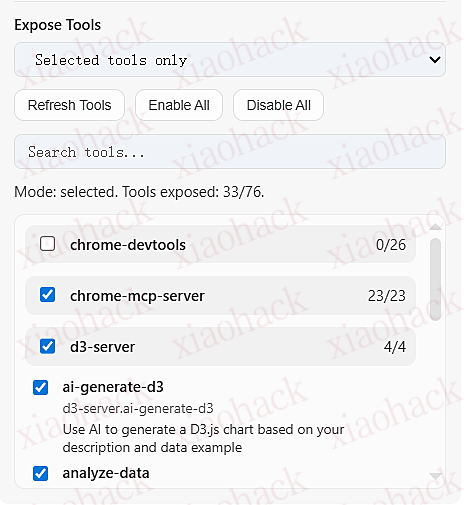
佬们好,最近在工作的时候需要使用 mqtt,然后调试的时候来回复制粘贴有点麻了,于是 vibe 了一个 mqtt 客户端,可以发送快捷指令,导入导出配置,方便多设备调试,这是我的第一个开源项目,大佬们多多包涵。
GitHub 项目地址:GitHub - HaxIOX/northrealm-mqtt: Northrealm (NR) — MQTT debugger / MQTT client (Web + Windows Desktop).
web 端:Northrealm MQTT
目前支持 Web 端 与 Windows 桌面端(Electron) ,后续计划扩展 移动端
亮点功能
- 配置导出 / 导入 :快速备份与迁移多套 Broker / 连接参数
- 快捷指令 :一键发送常用消息 / 主题组合,减少反复复制粘贴
- 排障友好日志与诊断提示 :连接过程更直观,便于定位认证 / ClientID / 协议等问题
演示图
开源一个高颜值壁纸站:干净无广告,支持 4K 下载,已上线!
标题
开源一个高颜值壁纸站:干净无广告,支持 4K 下载,已上线!
正文
大家好!最近做了一个自己日常在用的高清壁纸网站 —— Wallpaper Gallery,目前已部署上线,也已在 GitHub 开源,欢迎体验或 Star
在线访问:https://wallpaper.061129.xyz
GitHub 项目:https://github.com/IT-NuanxinPro/wallpaper-gallery
为什么值得试试?
市面上很多壁纸站充斥广告、加载慢、甚至无法下载原图。我希望能做一个 简洁、快速、尊重用户 的替代品 ——
- 真・4K 原图一键下载(无压缩、无水印)
- 智能适配设备:
- 电脑访问 → 展示 16:10 电脑壁纸 + 头像
- 手机访问 → 自动切换为 9:16 手机壁纸 + 头像
- 三种视图自由切换:网格 / 列表 / 瀑布流,切换时有流畅动画过渡
- 暗黑 / 亮色主题:自动跟随系统设置
- 每日精选推荐(PC 端首页)
- 完全静态站点,无广告、无追踪、加载快
所有图片均来自公开渠道整理,仅用于个人欣赏,版权归原作者所有。
如何支持?
如果你觉得这个小站还不错:
- 欢迎直接使用 https://wallpaper.061129.xyz
- 或去 GitHub 点个 Star 鼓励一下开源项目!
也欢迎提建议或贡献内容(比如推荐高质量壁纸源)~
感谢阅读,希望它也能成为你换壁纸的新选择
DeepAudit - 开源的代码审计智能体平台 ?♂️
让代码漏洞挖掘像呼吸一样简单,小白也能当黑客挖洞


? 界面预览
### ? Agent 审计入口
 *首页快速进入 Multi-Agent 深度审计*
*首页快速进入 Multi-Agent 深度审计*
*首页快速进入 Multi-Agent 深度审计*
? 审计流日志 实时查看 Agent 思考与执行过程 |
?️ 智能仪表盘 一眼掌握项目安全态势 |
⚡ 即时分析 粘贴代码 / 上传文件,秒出结果 |
?️ 项目管理 GitHub/GitLab 导入,多项目协同管理 |
### ? 专业报告
 *一键导出 PDF / Markdown / JSON*(图中为快速模式,非Agent模式报告)
? [查看Agent审计完整报告示例](https://lintsinghua.github.io/)
*一键导出 PDF / Markdown / JSON*(图中为快速模式,非Agent模式报告)
? [查看Agent审计完整报告示例](https://lintsinghua.github.io/)
*一键导出 PDF / Markdown / JSON*(图中为快速模式,非Agent模式报告)
? [查看Agent审计完整报告示例](https://lintsinghua.github.io/)
⚡ 项目概述
DeepAudit 是一个基于 Multi-Agent 协作架构的下一代代码安全审计平台。它不仅仅是一个静态扫描工具,而是模拟安全专家的思维模式,通过多个智能体(Orchestrator, Recon, Analysis, Verification)的自主协作,实现对代码的深度理解、漏洞挖掘和 自动化沙箱 PoC 验证。
我们致力于解决传统 SAST 工具的三大痛点:
- 误报率高 — 缺乏语义理解,大量误报消耗人力
- 业务逻辑盲点 — 无法理解跨文件调用和复杂逻辑
- 缺乏验证手段 — 不知道漏洞是否真实可利用
用户只需导入项目,DeepAudit 便全自动开始工作:识别技术栈 → 分析潜在风险 → 生成脚本 → 沙箱验证 → 生成报告,最终输出一份专业审计报告。
核心理念: 让 AI 像黑客一样攻击,像专家一样防御。
? 为什么选择 DeepAudit?
| ? 传统审计的痛点 | ? DeepAudit 解决方案 |
| :--- | :--- |
| **人工审计效率低**
跨不上 CI/CD 代码迭代速度,拖慢发布流程 | **? Multi-Agent 自主审计**
AI 自动编排审计策略,全天候自动化执行 | | **传统工具误报多**
缺乏语义理解,每天花费大量时间清洗噪音 | **? RAG 知识库增强**
结合代码语义与上下文,大幅降低误报率 | | **数据隐私担忧**
担心核心源码泄露给云端 AI,无法满足合规要求 | **? 支持 Ollama 本地部署**
数据不出内网,支持 Llama3/DeepSeek 等本地模型 | | **无法确认真实性**
外包项目漏洞多,不知道哪些漏洞真实可被利用 | **? 沙箱 PoC 验证**
自动生成并执行攻击脚本,确认漏洞真实危害 |
跨不上 CI/CD 代码迭代速度,拖慢发布流程 | **? Multi-Agent 自主审计**
AI 自动编排审计策略,全天候自动化执行 | | **传统工具误报多**
缺乏语义理解,每天花费大量时间清洗噪音 | **? RAG 知识库增强**
结合代码语义与上下文,大幅降低误报率 | | **数据隐私担忧**
担心核心源码泄露给云端 AI,无法满足合规要求 | **? 支持 Ollama 本地部署**
数据不出内网,支持 Llama3/DeepSeek 等本地模型 | | **无法确认真实性**
外包项目漏洞多,不知道哪些漏洞真实可被利用 | **? 沙箱 PoC 验证**
自动生成并执行攻击脚本,确认漏洞真实危害 |
?️ 系统架构
整体架构图
DeepAudit 采用微服务架构,核心由 Multi-Agent 引擎驱动。

? 审计工作流
| 步骤 | 阶段 | 负责 Agent | 主要动作 |
|---|---|---|---|
| 1 | 策略规划 | Orchestrator | 接收审计任务,分析项目类型,制定审计计划,下发任务给子 Agent |
| 2 | 信息收集 | Recon Agent | 扫描项目结构,识别框架/库/API,提取攻击面(Entry Points) |
| 3 | 漏洞挖掘 | Analysis Agent | 结合 RAG 知识库与 AST 分析,深度审查代码,发现潜在漏洞 |
| 4 | PoC 验证 | Verification Agent | (关键) 编写 PoC 脚本,在 Docker 沙箱中执行。如失败则自我修正重试 |
| 5 | 报告生成 | Orchestrator | 汇总所有发现,剔除被验证为误报的漏洞,生成最终报告 |
? 项目代码结构
DeepAudit/
├── backend/ # Python FastAPI 后端
│ ├── app/
│ │ ├── agents/ # Multi-Agent 核心逻辑
│ │ │ ├── orchestrator.py # 总指挥:任务编排
│ │ │ ├── recon.py # 侦察兵:资产识别
│ │ │ ├── analysis.py # 分析师:漏洞挖掘
│ │ │ └── verification.py # 验证者:沙箱 PoC
│ │ ├── core/ # 核心配置与沙箱接口
│ │ ├── models/ # 数据库模型
│ │ └── services/ # RAG, LLM 服务封装
│ └── tests/ # 单元测试
├── frontend/ # React + TypeScript 前端
│ ├── src/
│ │ ├── components/ # UI 组件库
│ │ ├── pages/ # 页面路由
│ │ └── stores/ # Zustand 状态管理
├── docker/ # Docker 部署配置
│ ├── sandbox/ # 安全沙箱镜像构建
│ └── postgres/ # 数据库初始化
└── docs/ # 详细文档? 快速开始 (Docker)
1. 启动项目
复制一份 backend/env.example 为 backend/.env,并按需配置 LLM API Key。
然后执行以下命令一键启动:
# 1. 准备配置文件
cp backend/env.example backend/.env
# 2. 构建沙箱镜像 (首次运行必须)
cd docker/sandbox && chmod +x build.sh && ./build.sh && cd ../..
# 3. 启动服务
docker compose up -d? 启动成功! 访问 http://localhost:3000 开始体验。
? 源码启动指南
适合开发者进行二次开发调试。
环境要求
- Python 3.10+
- Node.js 18+
- PostgreSQL 14+
- Docker (用于沙箱)
1. 后端启动
cd backend
# 激活虚拟环境 (推荐 uv/poetry)
source .venv/bin/activate
# 安装依赖
pip install -r requirements.txt
# 启动 API 服务
uvicorn app.main:app --reload2. 前端启动
cd frontend
npm install
npm run dev3. 沙箱环境
开发模式下,仍需通过 Docker 启动沙箱服务。
cd docker/sandbox
./build.sh? Multi-Agent 智能审计
支持的漏洞类型
| 漏洞类型 | 描述 |
|---|---|
sql_injection | SQL 注入 |
xss | 跨站脚本攻击 |
command_injection | 命令注入 |
path_traversal | 路径遍历 |
ssrf | 服务端请求伪造 |
xxe | XML 外部实体注入 |
| 漏洞类型 | 描述 |
|---|---|
insecure_deserialization | 不安全反序列化 |
hardcoded_secret | 硬编码密钥 |
weak_crypto | 弱加密算法 |
authentication_bypass | 认证绕过 |
authorization_bypass | 授权绕过 |
idor | 不安全直接对象引用 |
? 详细文档请查看 Agent 审计指南
? 支持的 LLM 平台
? 国际平台
OpenAI GPT-4o / GPT-4 |
?? 国内平台
通义千问 Qwen |
? 本地部署
Ollama |
? 支持 API 中转站,解决网络访问问题 | 详细配置 → LLM 平台支持
? 功能矩阵
| 功能 | 说明 | 模式 |
|---|---|---|
| ? Agent 深度审计 | Multi-Agent 协作,自主编排审计策略 | Agent |
| ? RAG 知识增强 | 代码语义理解,CWE/CVE 知识库检索 | Agent |
| ? 沙箱 PoC 验证 | Docker 隔离执行,验证漏洞有效性 | Agent |
| ?️ 项目管理 | GitHub/GitLab 导入,ZIP 上传,10+ 语言支持 | 通用 |
| ⚡ 即时分析 | 代码片段秒级分析,粘贴即用 | 通用 |
| ? 五维检测 | Bug · 安全 · 性能 · 风格 · 可维护性 | 通用 |
| ? What-Why-How | 精准定位 + 原因解释 + 修复建议 | 通用 |
| ? 审计规则 | 内置 OWASP Top 10,支持自定义规则集 | 通用 |
| ? 提示词模板 | 可视化管理,支持中英文双语 | 通用 |
| ? 报告导出 | PDF / Markdown / JSON 一键导出 | 通用 |
| ⚙️ 运行时配置 | 浏览器配置 LLM,无需重启服务 | 通用 |
? 发展路线图
我们正在持续演进,未来将支持更多语言和更强大的 Agent 能力。
- [x] v1.0: 基础静态分析,集成 Semgrep
- [x] v2.0: 引入 RAG 知识库,支持 Docker 安全沙箱
- [x] v3.0: Multi-Agent 协作架构 (Current)
- [ ] 支持更多漏洞验证 PoC 模板
- [ ] 支持更多语言
- [ ] 自动修复 (Auto-Fix): Agent 直接提交 PR 修复漏洞
- [ ] 增量PR审计: 持续跟踪 PR 变更,智能分析漏洞,并集成CI/CD流程
- [ ] 优化RAG: 支持自定义知识库
- [ ] 优化Agent: 支持自定义Agent
AI生成类项目
根据今日GitHub监控数据,整理出以下13个与AI视频制作、小说创作及有声书生成高度相关的开源项目。今日重点发现包括功能强大的电子书转有声书工具ebook2audiobook,以及多款视频生成与语音克隆的新兴工具。
1. 有声书制作与语音克隆
ebook2audiobook
- 项目介绍:一款功能强大的电子书转有声书转换器,支持CPU和GPU加速。
核心功能:
- 多引擎支持:集成XTTSv2、Bark、Vits等多种TTS引擎,支持超过1110种语言。
- 智能处理:支持按章节分割电子书,保留元数据,支持自定义语音克隆。
- 广泛兼容:支持.epub、.pdf、.mobi等多种输入格式及.m4b、.mp3等输出格式,提供Gradio Web界面和Docker部署。
- 项目地址:
https://github.com/DrewThomasson/ebook2audiobook
Dia-TTS-Server
- 项目介绍:Dia TTS模型的自托管服务器实现。
核心功能:
- API兼容:提供兼容OpenAI格式的API端点,易于集成。
- 高级特性:支持SafeTensors/BF16加速、语音克隆及多角色对话生成,配备用户友好的Web UI。
- 项目地址:
https://github.com/Gmzxdotzz/Dia-TTS-Server
ComfyUI-VoxCPM
- 项目介绍:专为ComfyUI设计的插件,用于生成高表现力的语音。
核心功能:
- 零样本克隆:支持在ComfyUI工作流中实现逼真的零样本语音克隆。
- 情感表达:能够将文本转换为具有丰富情感色彩的音频。
- 项目地址:
https://github.com/krishnasaivamsi/ComfyUI-VoxCPM
OpenVoice (VoltsyGM Fork)
- 项目介绍:基于MIT和MyShell技术的即时语音克隆应用。
核心功能:
- 风格控制:支持在克隆语音时精确控制说话的风格和语调。
- 项目地址:
https://github.com/VoltsyGM/OpenVoice
local-voice-cloning-app
- 项目介绍:一个轻量级的Python应用程序,用于本地语音克隆。
核心功能:
- 简易工作流:提供简单的界面和流程来合成和克隆语音。
- 项目地址:
https://github.com/Mohamedfat7i/local-voice-cloning-app
2. 视频创作与生成
MOBIUS
- 项目介绍:一个专门用于生成桌游教程视频的AI工具。
核心功能:
- 垂直领域生成:专注于将规则文本转化为直观的教学视频内容。
- 项目地址:
https://github.com/w9bikze8u4cbupc/MOBIUS
AI-course-generator
- 项目介绍:利用AI将长视频讲座转化为结构化在线课程的工具。
核心功能:
- 课程结构化:自动生成成绩单、模块划分、课程内容及测验题。集成OpenAI Whisper和GPT-4 Vision技术。
- 项目地址:
https://github.com/DavidFW27/AI-course-generator
VibeArt
- 项目介绍:一体化的图像与视频生成工具。
核心功能:
- 模型集成:结合开源与闭源模型,利用社区训练的LoRA优化特定风格的生成效果,降低提示词门槛。
- 项目地址:
https://github.com/vibeart-in/VibeArt
mulmocast-cli
- 项目介绍:AI驱动的播客与视频生成器。
核心功能:
- 脚本驱动:使用"MulmoScript"脚本语言生成多模态演示内容,集成OpenAI、Google、Anthropic等多家模型。
- 项目地址:
https://github.com/receptron/mulmocast-cli
Hollywood-Quality-UGC-Ad-Generator
- 项目介绍:利用单张产品照片生成好莱坞级视频广告的工具。
核心功能:
- 多模型协作:通过n8n编排,结合Sora 2、GPT-4o和Gemini 2.5 Pro实现高质量广告生成。
- 项目地址:
https://github.com/Saurabh22111998/Hollywood-Quality-UGC-Ad-Generator
AIQuoteClipGenerator
- 项目介绍:基于MCP的自动化名言视频生成器,面向Instagram/TikTok。
核心功能:
- 自动剪辑:自动生成包含名言的短视频片段,适合社交媒体快速传播。
- 项目地址:
https://github.com/mercyg/AIQuoteClipGenerator
3. 小说与故事创作
Ghost-Writer
- 项目介绍:一个AI驱动的故事创作引擎。
核心功能:
- 引导式写作:逐步引导用户完成小说创作过程,充当智能写作助手。
- 项目地址:
https://github.com/MAS-D-KING/Ghost-Writer
https://track.linso.ai/zh/execution/cmihfy83n07utl6945ke9i2yh
红墨 RedInk 小红书图文生成器开源

昨天就已经开源了,但是测试的时候智能使用官方接口,今天下午更新了,而且提供了docker版,部署更简单了,刚刚试了一下,已经成功生成图片了,就是使用起来账号积分如流水。
红墨 - 小红书AI图文生成器
让传播不再需要门槛,让创作从未如此简单
红墨首页

使用红墨生成的各类小红书封面 - AI驱动,风格统一,文字准确
写在前面
前段时间默子在 Linux.do 发了一个用 Nano banana Pro 做 PPT 的帖子,收获了 600 多个赞。很多人用?Nano banana Pro 去做产品宣传图、直接生成漫画等等。我就在想:为什么不拿?2来做点更功利、更刺激的事情?
于是就有了这个项目。一句话一张图片生成小红书图文
✨ 效果展示
输入一句话,就能生成完整的小红书图文
提示词:秋季显白美甲(暗广一个:默子牌美甲),图片 是我的小红书主页。符合我的风格生成
同时我还截图了我的小红书主页,包括我的头像,签名,背景,姓名什么的

然后等待10-20秒后,就会有每一页的大纲,大家可以根据的自己的需求去调整页面顺序(不建议),自定义每一个页面的内容(这个很建议)

首先生成的是封面页

然后稍等一会儿后,会生成后面的所有页面(这里是并发生成的所有页面(默认是15个),如果大家的API供应商无法支持高并发的话,记得要去改一下设置)

?️ 技术架构
后端
- 语言: Python 3.11+
- 框架: Flask
AI 模型:
- Gemini 3 (文案生成)
- ?Nano banana Pro (图片生成)
- 包管理: uv
前端
- 框架: Vue 3 + TypeScript
- 构建: Vite
- 状态管理: Pinia
? 如何自己部署
方式一:Docker 部署(推荐)
最简单的部署方式,一行命令即可启动:
docker run -d -p 12398:12398 -v ./output:/app/output histonemax/redink:latest访问 http://localhost:12398,在 Web 界面的设置页面配置你的 API Key 即可使用。
使用 docker-compose(可选):
下载 docker-compose.yml 后:
docker-compose up -dDocker 部署说明:
- 容器内不包含任何 API Key,需要在 Web 界面配置
- 使用
-v ./output:/app/output持久化生成的图片 - 可选:挂载自定义配置文件
-v ./text_providers.yaml:/app/text_providers.yaml
方式二:本地开发部署
前置要求:
- Python 3.11+
- Node.js 18+
- pnpm
- uv
1. 克隆项目
git clone https://github.com/HisMax/RedInk.git
cd RedInk2. 配置 API 服务
复制配置模板文件:
cp text_providers.yaml.example text_providers.yaml
cp image_providers.yaml.example image_providers.yaml编辑配置文件,填入你的 API Key 和服务配置。也可以启动后在 Web 界面的设置页面进行配置。
3. 安装后端依赖
uv sync4. 安装前端依赖
cd frontend
pnpm install5. 启动服务
启动后端:
uv run python -m backend.app启动前端:
cd frontend
pnpm dev? 使用指南
基础使用
- 输入主题: 在首页输入想要创作的主题,如"如何在家做拿铁"
- 生成大纲: AI 自动生成 6-9 页的内容大纲
- 编辑确认: 可以编辑和调整每一页的描述
- 生成图片: 点击生成,实时查看进度
- 下载使用: 一键下载所有图片
进阶使用
- 上传参考图片: 适合品牌方,保持品牌视觉风格
- 修改描述词: 精确控制每一页的内容和构图
- 重新生成: 对不满意的页面单独重新生成
? 配置说明
配置方式
项目支持两种配置方式:
- Web 界面配置(推荐):启动服务后,在设置页面可视化配置
- YAML 文件配置:直接编辑配置文件
文本生成配置
配置文件: text_providers.yaml
# 当前激活的服务商
active_provider: openai
providers:
# OpenAI 官方或兼容接口
openai:
type: openai_compatible
api_key: sk-xxxxxxxxxxxxxxxxxxxx
base_url: https://api.openai.com/v1
model: gpt-4o
# Google Gemini(原生接口)
gemini:
type: google_gemini
api_key: AIzaxxxxxxxxxxxxxxxxxxxxxxxxx
model: gemini-2.0-flash图片生成配置
配置文件: image_providers.yaml
# 当前激活的服务商
active_provider: gemini
providers:
# Google Gemini 图片生成
gemini:
type: google_genai
api_key: AIzaxxxxxxxxxxxxxxxxxxxxxxxxx
model: gemini-3-pro-image-preview
high_concurrency: false # 高并发模式
# OpenAI 兼容接口
openai_image:
type: image_api
api_key: sk-xxxxxxxxxxxxxxxxxxxx
base_url: https://your-api-endpoint.com
model: dall-e-3
high_concurrency: false高并发模式说明
- 关闭(默认):图片逐张生成,适合 GCP 300$ 试用账号或有速率限制的 API
- 开启:图片并行生成(最多15张同时),速度更快,但需要 API 支持高并发
⚠️ GCP 300$ 试用账号不建议启用高并发,可能会触发速率限制导致生成失败。
⚠️ 注意事项
API 配额限制:
- 注意 Gemini 和图片生成 API 的调用配额
- GCP 试用账号建议关闭高并发模式
生成时间:
- 图片生成需要时间,请耐心等待(不要离开页面)
? 参与贡献
欢迎提交 Issue 和 Pull Request!
如果这个项目对你有帮助,欢迎给个 Star ⭐
未来计划
- [ ] 支持更多图片格式,例如一句话生成一套PPT什么的
- [ ] 历史记录管理优化
- [ ] 导出为各种格式(PDF、长图等)
更新日志
v1.3.0 (2025-11-26)
- ✨ 新增 Docker 支持,一键部署
- ✨ 发布官方 Docker 镜像到 Docker Hub:
histonemax/redink - ? Flask 自动检测前端构建产物,支持单容器部署
- ? Docker 镜像内置空白配置模板,保护 API Key 安全
- ? 更新 README,添加 Docker 部署说明
v1.2.0 (2025-11-26)
- ✨ 新增版权信息展示,所有页面显示开源协议和项目链接
- ✨ 优化图片重新生成功能,支持单张图片重绘
- ✨ 重新生成图片时保持风格一致,传递完整上下文(封面图、大纲、用户输入)
- ✨ 修复图片缓存问题,重新生成的图片立即刷新显示
- ✨ 统一文本生成客户端接口,支持 Google Gemini 和 OpenAI 兼容接口自动切换
- ✨ 新增 Web 界面配置功能,可视化管理 API 服务商
- ✨ 新增高并发模式开关,适配不同 API 配额
- ✨ API Key 脱敏显示,保护密钥安全
- ✨ 配置自动保存,修改即时生效
- ? 调整默认 max_output_tokens 为 8000,兼容更多模型限制
- ? 优化前端路由和页面布局,提升用户体验
- ? 简化配置文件结构,移除冗余参数
- ? 优化历史记录图片显示,使用缩略图节省带宽
- ? 历史记录重新生成时自动从文件系统加载封面图作为参考
- ? 修复
store.updateImage方法缺失导致的重新生成失败问题 - ? 修复历史记录加载时图片 URL 拼接错误
- ? 修复下载功能中原图参数处理问题
- ? 修复图片加载 500 错误问题
交流讨论与赞助
- GitHub Issues: https://github.com/HisMax/RedInk/issues
联系作者
- Email: histonemax@gmail.com
- 微信: Histone2024(添加请注明来意)
- GitHub: @HisMax
用爱发电,如果可以,请默子喝一杯☕️咖啡吧

Star History
? 开源协议
个人使用 - CC BY-NC-SA 4.0
本项目采用 CC BY-NC-SA 4.0 协议进行开源
你可以自由地:
- ✅ 个人使用 - 用于学习、研究、个人项目
- ✅ 分享 - 在任何媒介以任何形式复制、发行本作品
- ✅ 修改 - 修改、转换或以本作品为基础进行创作
但需要遵守以下条款:
- ? 署名 - 必须给出适当的署名,提供指向本协议的链接,同时标明是否对原始作品作了修改
- ? 非商业性使用 - 不得将本作品用于商业目的
- ? 相同方式共享 - 如果你修改、转换或以本作品为基础进行创作,你必须以相同的协议分发你的作品
商业授权
如果你希望将本项目用于商业目的(包括但不限于):
- 提供付费服务
- 集成到商业产品
- 作为 SaaS 服务运营
- 其他盈利性用途
请联系作者获取商业授权:
- ? Email: histonemax@gmail.com
- ? 微信: Histone2024(请注明"商业授权咨询")
默子会根据你的具体使用场景提供灵活的商业授权方案。
免责声明
本软件按"原样"提供,不提供任何形式的明示或暗示担保,包括但不限于适销性、特定用途的适用性和非侵权性的担保。在任何情况下,作者或版权持有人均不对任何索赔、损害或其他责任负责。
? 致谢
- Google Gemini - 强大的文案生成能力
- 图片生成服务提供商 - 惊艳的图片生成效果
- Linux.do - 优秀的开发者社区
?? 作者
默子 (Histone) - AI 创业者 | Python & 深度学习
- ? 位置: 中国杭州
- ? 状态: 创业中
- ? 专注: Transformers、GANs、多模态AI
- ? Email: histonemax@gmail.com
- ? 微信: Histone2024
- ? GitHub: @HisMax
"让 AI 帮我们做更有创造力的事"
一个能够优化大模型流式传输质量的 API 网关项目,支持 Docker 部署
[bsgit user="2erTwo6"]Smooth-Gateway[/bsgit]
上游 API 提供商提供的流式传输可能是粗糙的、一大块一大块出现的,体感上不 “丝滑”
Gemini Balance 的流式传输优化功能就解决了这个痛点,在玩酒馆等需要流式传输的场景下,能够极大的提高体验,但是就如项目名那样,只能给 Gemini 用。
于是就有了这个项目,参考了 Gemini Balance 的思路,可以插入到任何一个 OpenAI 格式的 API 服务中间,对流式传输进行后处理,把粗糙的流切成细腻的流,再推送给最终的 AI 应用。
目前仅支持接入 OpenAI 格式的 API,推荐的使用方法是先接入 New API,再套一层这个
快速开始
前提: 您已安装 Docker。
克隆本仓库:
git clone https://github.com/2erTwo6/Smooth-Gateway.git cd Smooth-Gateway创建并编辑配置文件:
将模板文件复制为您的本地配置文件。cp .env.example .env然后使用您喜欢的编辑器(如 nano 或 vim)打开 .env 文件,并至少填入必需的 UPSTREAM_API_URL。
构建 Docker 镜像:
docker build -t smooth-gateway .运行容器:
使用 --env-file 参数,Docker 会自动加载您的 .env 文件。docker run -d \ --name my-smooth-gateway \ -p 3001:3001 \ --env-file .env \ --restart unless-stopped \ smooth-gateway现在,您的流式优化网关已根据您的 .env 文件配置,在 http://localhost:3001 上运行!
接下来,只需要在你的 AI 应用的 API URL 那里输入 http://localhost:3001 即可(假设你的 AI 应用和此 API 网关部署在同一机器?)
Stardew Server - Docker 一键部署星露谷物语开联机服务器
开源了一个基于 Docker 的星露谷物语服务器一键部署解决方案。
项目地址:
[bsgit user="truman-world"]puppy-stardew-server[/bsgit]
核心特性
这个项目最大的亮点是整合了几个自定义模组,带来了更好的多人游戏体验:
即时睡眠功能:任何一个玩家在床上选择睡觉,游戏会立刻为所有在线玩家存档并结束当天。再也不用互相等待离线或 AFK 的玩家。
24/7 专用服务器:基于 Docker 容器化,服务器可以 7x24 小时独立运行,房主无需在线。适合部署在 VPS 、云服务器或家用 NAS 上。
一键脚本部署:一条命令,3 分钟即可完成所有环境配置和启动。无需手动安装 SMAPI 、配置模组或设置环境。
跨平台联机:支持 PC 、Mac 、Linux ,以及 iOS 和 Android 玩家在同一个服务器中游戏。所有平台互通,无需复杂配置。
房主自动隐藏:主机玩家作为服务器运行,在游戏中自动隐身,不占用玩家名额,也不会干扰正常游戏。
存档自动加载:服务器重启后会自动加载最新的存档,无需手动操作。首次部署通过 VNC 创建存档后,之后完全自动化。
内置 VNC:首次创建世界时,可以通过浏览器或 VNC 客户端远程访问图形界面,操作简单。
自然技能升级( v1.0.58 新增):防止服务器强制房主升到 10 级,保持基于真实经验值的技能等级。玩家可以手动选择技能专精路线,保留游戏原有的成长乐趣。
一键启动
在任何一台安装了 Docker 的服务器上运行:
curl -sSL https://raw.githubusercontent.com/truman-world/puppy-stardew-server/main/quick-start.sh | bash脚本会自动完成环境检查、配置文件生成、目录创建、权限设置和容器启动。
手动部署
如果你更喜欢手动控制:
1. 创建 docker-compose.yml
version: '3.8'
services:
stardew-server:
image: truemanlive/puppy-stardew-server:latest
container_name: puppy-stardew
restart: unless-stopped
stdin_open: true
tty: true
environment:
- STEAM_USERNAME=your_steam_username
- STEAM_PASSWORD=your_steam_password
- ENABLE_VNC=true
- VNC_PASSWORD=stardew123
ports:
- "24642:24642/udp"
- "5900:5900/tcp"
volumes:
- ./data/saves:/home/steam/.config/StardewValley:rw
- ./data/game:/home/steam/stardewvalley:rw
- ./data/steam:/home/steam/Steam:rw
deploy:
resources:
limits:
cpus: '2.0'
memory: 2G2. 设置权限并启动
mkdir -p data/{saves,game,steam}
chown -R 1000:1000 data/
docker compose up -d3. 首次设置
使用 VNC 连接到 your-server-ip:5900(密码:stardew123),创建或导入存档。
4. 玩家连接
游戏中:Co-op → Join LAN Game → 输入 your-server-ip:24642
预装模组
- SMAPI 4.3.2 - 官方模组加载器
- Always On Server v1.20.3 - 无头服务器运行
- Skill Level Guard v1.4.0 - 防止强制升级,保持自然技能进度
- ServerAutoLoad v1.2.1 - 自动加载存档
- AutoHideHost v1.2.2 - 隐藏房主,即时睡眠
系统要求
服务器端:
- Docker 和 Docker Compose
- 2GB 内存( 4+ 玩家推荐 4GB )
- 2GB 磁盘空间
- Steam 账号(拥有星露谷物语)
客户端:
- 星露谷物语(任何平台)
- 与服务器相同的游戏版本
v1.0.58 更新
修复:
- Always On Server 自动启用问题(服务器现在可以自动暂停/恢复)
- 玩家技能专精选择问题(可以手动选择路线)
改进:
- 自然技能升级(基于真实经验值,不再强制 10 级)
- 服务器空闲时自动暂停(节省资源)
已解决的问题:
- 长时间空闲后无法连接
- 地震等特殊事件冻结游戏
- 无限等待其他玩家
- 无需邀请码(直接用 IP 连接)
文档与支持
- GitHub: https://github.com/truman-world/puppy-stardew-server
- Docker Hub: https://hub.docker.com/r/truemanlive/puppy-stardew-server
- 完整文档: README.md
- 中文文档: README_CN.md
- 问题反馈: GitHub Issues
许可证
- 项目: MIT License
- 游戏: 需合法拥有星露谷物语( Steam )
- SMAPI & Always On Server: GPL-3.0
- 自定义模组: MIT License
分享一些采集源
AI与科技动态日报 (2025-11-09):深海大模型发布与世界互联网大会看点
您好,这是过去24小时内最重要的人工智能与科技动态报告。
摘要
过去24小时,AI领域最引人注目的进展是中国发布了全球首个深海生境多模态大模型“DePTH-GPT”。同时,正在举行的2025世界互联网大会乌镇峰会成为科技公告的焦点,蚂蚁集团万卡国产算力集群的部署尤为突出。学术界和开源社区则持续关注AI Agent、RAG技术和模型可靠性。
模型发布 (Model Releases)
DePTH-GPT:全球首个深海生境多模态大模型
- 发布机构: 由中国大洋事务管理局指导,自然资源部第二海洋研究所、之江实验室联合国内外多家科研机构共同研发。
- 核心能力: 这是全球首个面向深海典型生境的多模态大模型,能够融合处理视频、地形、水动力、生物声学等多源异构数据,进行生境动态推演与智能决策支持。
- 意义: 标志着深海研究从传统定性分析向可解释、可预测的智能认知新阶段迈进。该模型将面向全球科研机构与国际组织开放使用。
- 来源: 来自gmw.cn网站。
最新论文 (New Papers)
研究焦点:AI Agent、可靠性与可持续性
- VeriCoT (arXiv:2511.04662): 提出一种神经符号方法,通过逻辑一致性检查来验证大模型的思维链(Chain-of-Thought)过程,以提升推理的可靠性。来自arxiv.org网站。
- DR. WELL (arXiv:2511.04646): 探索基于具身大语言模型(Embodied LLM)的多智能体协作,通过动态推理和学习来完成复杂任务。来自arxiv.org网站。
- Jr. AI Scientist (arXiv:2511.04583): 关注自主科学发现AI智能体及其风险评估,探讨AI在科研中的应用潜力与挑战。来自arxiv.org网站。
开源项目 (Open-Source Projects)
趋势:AI Agent工作流与本地化部署
- dify: 一个用于构建和部署AI Agent工作流的开源平台,持续在GitHub上保持热度,反映了市场对Agent应用的强烈需求。来自github.com网站。
- 微舆 (Wei Yu): 一个新晋热门项目,定位为“人人可用的多Agent舆情分析助手”,旨在通过多智能体协作还原舆情原貌,辅助决策。来自github.com网站。
- KTransformers: 近期备受关注的国产开源项目,通过与LLaMA-Factory联动,使消费级显卡也能进行超大语言模型的微调,大幅降低了AI技术的应用门槛。来自csdn.net网站。
重大公告与产品更新 (Major Announcements & Product Updates)
2025世界互联网大会乌镇峰会
- 蚂蚁集团部署万卡国产算力集群: 蚂蚁集团在会上透露,已部署万卡规模的国产算力集群,全面应用于安全风控等领域的大模型训练,训练任务稳定性超过98%。来自sina.com.cn网站。
- GLM大模型获领先科技奖: 清华大学与智谱华章的“GLM大模型关键技术及规模化应用”项目获奖,表彰其在预训练架构和规模化应用上的成就。来自tsinghua.edu.cn网站。
- 行业蓝皮书发布: 大会发布的报告指出,中国已成为全球人工智能专利最大拥有国,占比达60%,且“具身智能”成为全球主要经济体高度重视的方向。来自cctv.cn网站。
Linso AI & 科技动态日报 (2025-11-08)
早上好!这是为您整理的过去24小时内最重要的人工智能与科技动态,重点聚焦于新模型、论文及开源项目。
一、 模型发布与重要更新
- Drax Model (语音AI模型) 开源:初创公司aiOla发布了新型语音AI模型Drax,声称在嘈杂环境中比OpenAI的Whisper快32倍,词错误率更低。该模型已在GitHub开源。(来自zhiding.cn)
- 瞰海 (Kanhai) AI海洋大模型发布:我国发布首个“遥感—重构—预测”全链路的AI海洋大模型,能预测未来10天的海洋环境,对海洋科学研究和防灾减灾具有重要意义。(来自chinanews.com.cn)
- 华电智 (Huadian Zhi) 大模型发布:中国华电发布了电力能源领域的专用大模型,旨在推动全产业链的数智化转型。(来自hrbtv.net)
- 谷歌下一代模型 Gemini 3 传闻:有报道称谷歌正准备推出Gemini 3,主打代码生成和通用任务,其云平台Vertex AI上已出现相关模型名称,暗示可能在11月发布。(来自stcn.com)
- OpenAI ChatGPT 功能更新:ChatGPT的个性化设置和自定义指令现在将应用于所有对话(包括历史对话),以确保体验的一致性。(来自openai.com)
二、 最新AI论文速览 (来自arxiv.org)
- 过去24小时,arXiv上涌现了大量关于AI智能体、大型语言模型推理和伦理的论文。
- 智能体与多模态:一篇名为 DR. WELL 的论文 (arXiv:2511.04646) 提出了一个用于具身多智能体协作的动态推理和学习框架。
- LLM与推理:VeriCoT (arXiv:2511.04662) 提出了一种通过逻辑一致性检查来验证神经符号思维链的方法,以增强模型推理的可靠性。
- 伦理与对齐:一篇论文 (arXiv:2511.00379) 探讨了如何通过伦理推理,实现大型语言模型与多样化人类价值观的对齐。
三、 热门开源项目
- OpenEnv (by Meta & Hugging Face):Meta与Hugging Face联手推出开源项目OpenEnv,旨在为AI代理(Agent)的开发和部署提供一个标准化的运行环境,解决环境配置碎片化的问题。(来自huggingface.co)
- BettaFish (微舆):GitHub上的一个热门项目,是一个人人可用的多Agent舆情分析助手,旨在打破信息茧房,辅助决策。(来自github.com)
- strix:一个新兴的开源AI黑客工具,用于辅助应用程序开发。(来自github.com)
四、 科技行业重大公告
- 特斯拉股东批准马斯克万亿美元薪酬方案:特斯拉股东以超过75%的支持率,投票通过了CEO马斯克价值近1万亿美元的巨额薪酬方案。该方案与公司市值、汽车交付量、FSD订阅数等极具挑战性的目标挂钩,被视为股东对其将公司转型为AI和机器人巨头愿景的强力支持。(来自sina.cn)
- Meta宣布未来五年在美投入超6000亿美元:Meta宣布计划到2028年,将在美国投入超过6000亿美元,以支持其在人工智能、基础设施和员工队伍方面的扩展。(来自managertoday.com.tw)