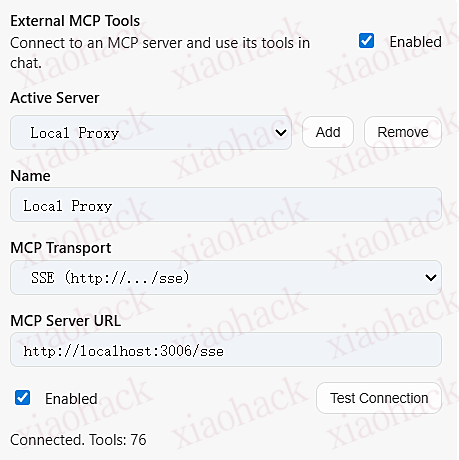
Verdent 本身是必须要 下载 IDE 才可以拿到付款链接去试用的,插件和网页控制台都是无法获取试用链接的。
脚本自取,喜欢的老友留个评论和赞~
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Verdent 获取付款链接工具
用于获取注册后的Stripe支付链接(绑卡链接)
"""
import httpx
import json
import sys
import time
import io
# 修复 Windows 控制台编码问题
if sys.platform == 'win32':
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8')
class VerdentPaymentLinkGetter:
"""Verdent 付款链接获取器"""
def __init__(self, token):
"""
初始化
token: Verdent 访问令牌
"""
self.token = token
self.base_url = "https://api.verdent.ai"
# 初始化 HTTP 客户端
self.client = httpx.Client(
timeout=30.0,
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36',
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Origin': 'https://www.verdent.ai',
'Referer': 'https://www.verdent.ai/',
'sec-ch-ua': '"Chromium";v="142", "Microsoft Edge";v="142", "Not_A Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
}
)
# Verdent 计划 ID
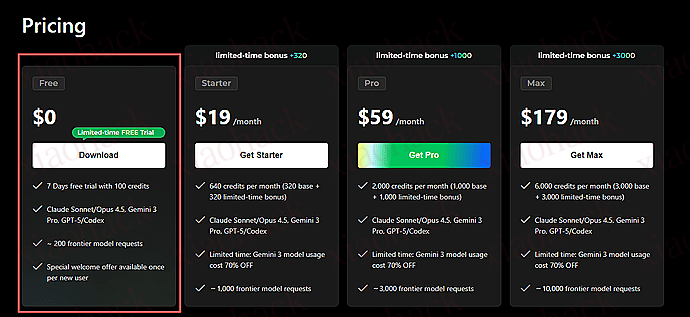
self.plan_ids = {
'Free': 'Pl1181733412181114881', # Free - 7天试用
'Starter': 'Pl1181727875814031360', # $19/月
'Pro': 'Pl1181727875813916672', # $59/月
'Max': 'Pl1181727875813818368', # $179/月
'PayAsYouGo_20': 'Pl1181727875813720064', # $20 一次性
'PayAsYouGo_60': 'Pl1181727875813588992', # $60 一次性
'PayAsYouGo_80': 'Pl1181727875813474304', # $80 一次性
'PayAsYouGo_100': 'Pl1181727875813376000', # $100 一次性
'PayAsYouGo_200': 'Pl1181727875813261312', # $200 一次性
}
def get_user_info(self):
"""获取用户信息(包含邮箱)"""
try:
print("📧 正在获取用户信息...")
# 添加 Cookie 头(包含 token)
headers = {
'Cookie': f'token={self.token}'
}
response = self.client.get(
f'{self.base_url}/verdent/user/info',
headers=headers
)
if response.status_code == 200:
data = response.json()
email = data.get('email', '')
print(f"✅ 用户邮箱: {email}")
return email
else:
print(f"⚠️ 获取用户信息失败: {response.status_code}")
print(f" 响应: {response.text}")
return None
except Exception as e:
print(f"❌ 获取用户信息出错: {e}")
return None
def create_subscription(self, plan_name='Free', user_email=None):
"""
创建订阅并获取支付链接
plan_name: 计划名称 (Free, Starter, Pro, Max, PayAsYouGo_20, 等)
user_email: 用户邮箱(如果不提供则自动获取)
"""
try:
# 获取 plan_id
plan_id = self.plan_ids.get(plan_name)
if not plan_id:
print(f"❌ 未知的计划名称: {plan_name}")
print(f" 支持的计划: {', '.join(self.plan_ids.keys())}")
return None
# 如果没有提供邮箱,尝试获取
if not user_email:
user_email = self.get_user_info()
if not user_email:
print("❌ 无法获取用户邮箱,请手动提供")
return None
print(f"\n💳 正在创建订阅...")
print(f" 计划: {plan_name}")
print(f" Plan ID: {plan_id}")
print(f" 邮箱: {user_email}")
# 添加 Cookie 头
headers = {
'Cookie': f'token={self.token}',
'Content-Type': 'application/json'
}
# 构造请求体
payload = {
'plan_id': plan_id,
'user_email': user_email,
'source': 'verdent'
}
# 发送请求
response = self.client.post(
f'{self.base_url}/verdent/subscription/create',
headers=headers,
json=payload
)
if response.status_code == 200:
data = response.json()
print(f"✅ 订阅创建成功!")
print(f"\n📋 完整响应:")
print(json.dumps(data, indent=2, ensure_ascii=False))
# 尝试提取支付链接
payment_url = None
# 常见的字段名
possible_keys = ['url', 'payment_url', 'checkout_url', 'stripe_url',
'redirect_url', 'session_url', 'link', 'checkout_session_url']
for key in possible_keys:
if key in data:
payment_url = data[key]
break
# 如果没有直接的URL字段,检查嵌套对象
if not payment_url:
if 'data' in data and isinstance(data['data'], dict):
for key in possible_keys:
if key in data['data']:
payment_url = data['data'][key]
break
if payment_url:
print(f"\n🔗 支付链接:")
print(payment_url)
return payment_url
else:
print(f"\n⚠️ 未在响应中找到支付链接,请查看完整响应")
return data
else:
print(f"❌ 创建订阅失败: {response.status_code}")
print(f" 响应: {response.text}")
return None
except Exception as e:
print(f"❌ 创建订阅出错: {e}")
import traceback
traceback.print_exc()
return None
def close(self):
"""关闭客户端"""
self.client.close()
def main():
"""主函数"""
print("=" * 60)
print("🌟 Verdent 付款链接获取工具")
print("=" * 60)
# 使用方式 1: 从命令行参数读取
if len(sys.argv) > 1:
token = sys.argv[1]
plan_name = sys.argv[2] if len(sys.argv) > 2 else 'Free'
user_email = sys.argv[3] if len(sys.argv) > 3 else None
else:
# 使用方式 2: 从 verdent_tokens.txt 读取
try:
with open('verdent_tokens.txt', 'r', encoding='utf-8') as f:
lines = [line.strip() for line in f if line.strip()]
if lines:
token = lines[0]
print(f"📄 从 verdent_tokens.txt 读取 token")
else:
print("❌ verdent_tokens.txt 为空")
print("\n使用方法:")
print(" python get_payment_link.py <token> [plan_name] [email]")
print("\n参数说明:")
print(" token: Verdent 访问令牌(必需)")
print(" plan_name: 计划名称(可选,默认: Free)")
print(" 支持: Free, Starter, Pro, Max, PayAsYouGo_20/60/80/100/200")
print(" email: 用户邮箱(可选,不提供则自动获取)")
return
except FileNotFoundError:
print("❌ 找不到 verdent_tokens.txt 文件")
print("\n使用方法:")
print(" python get_payment_link.py <token> [plan_name] [email]")
print("\n或创建 verdent_tokens.txt 文件并在第一行写入 token")
return
plan_name = 'Free' # 默认使用 Free 计划
user_email = None
print(f"\n🔐 Token: {token[:50]}...")
# 创建获取器
getter = VerdentPaymentLinkGetter(token)
try:
# 获取支付链接
result = getter.create_subscription(plan_name=plan_name, user_email=user_email)
if result:
print("\n" + "=" * 60)
print("✅ 成功!")
if isinstance(result, str) and result.startswith('http'):
print(f"🔗 复制此链接到浏览器即可绑卡:")
print(result)
print("=" * 60)
else:
print("\n" + "=" * 60)
print("❌ 获取失败,请检查 token 是否有效")
print("=" * 60)
finally:
getter.close()
if __name__ == "__main__":
main()
📌 转载信息
转载时间:
2025/12/29 15:28:36
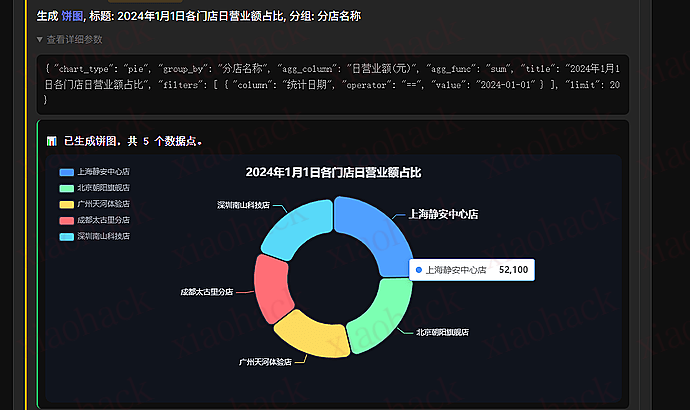
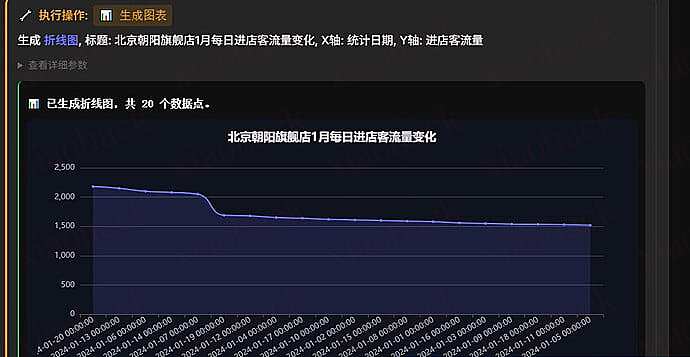
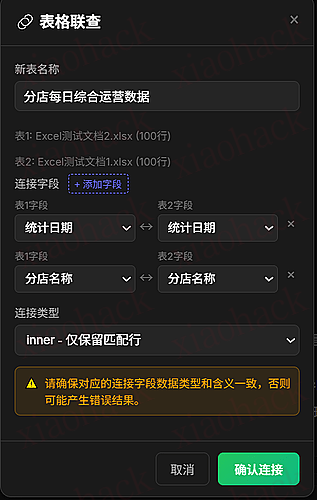
























![[开源] ContextWeaver 本地代码库语义检索工具,目标是 ace 平替1](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2025/12/29/20251229151024_6952296074562.png!mark)
![[开源] ContextWeaver 本地代码库语义检索工具,目标是 ace 平替2](https://xiaohack.oss-cn-zhangjiakou.aliyuncs.com/typecho/images/2025/12/29/20251229151026_695229626d279.png!mark)